Bu sayfada, makine öğrenimiyle ilgili temel terimlerin yer aldığı bir sözlük bulunmaktadır. Tüm sözlük terimleri için burayı tıklayın.
A
doğruluk
Doğru sınıflandırma tahminlerinin sayısının toplam tahmin sayısına bölünmesiyle elde edilir. Yani:
Örneğin, 40 doğru ve 10 yanlış tahminde bulunan bir modelin doğruluğu şu şekilde olur:
İkili sınıflandırma, doğru tahminler ve yanlış tahminler kategorileri için belirli adlar sağlar. Bu nedenle, ikili sınıflandırma için doğruluk formülü aşağıdaki gibidir:
Bu örnekte:
- TP, doğru pozitif (doğru tahminler) sayısıdır.
- TN, doğru negatiflerin (doğru tahminler) sayısıdır.
- FP, yanlış pozitiflerin (yanlış tahminler) sayısıdır.
- FN, yanlış negatiflerin (yanlış tahminler) sayısıdır.
Doğruluğu hassasiyet ve geri çağırma ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sınıflandırma: Doğruluk, geri çağırma, hassasiyet ve ilgili metrikler bölümüne bakın.
etkinleştirme işlevi
Nöral ağların özellikler ile etiket arasındaki doğrusal olmayan (karmaşık) ilişkileri öğrenmesini sağlayan bir işlevdir.
Popüler etkinleştirme işlevleri şunlardır:
Etkinleştirme fonksiyonlarının grafikleri hiçbir zaman tek bir düz çizgi değildir. Örneğin, ReLU etkinleştirme işlevinin grafiği iki düz çizgiden oluşur:

Sigmoid aktivasyon fonksiyonunun grafiği şu şekilde görünür:

Örnek görmek için simgeyi tıklayın.
Nöral ağlarda etkinleştirme işlevleri, bir nörona gelen tüm girişlerin ağırlıklı toplamını değiştirir. Nöron, ağırlıklı toplamı hesaplamak için ilgili değerlerin ve ağırlıkların çarpımlarını toplar. Örneğin, bir nöronla ilgili girişin aşağıdakilerden oluştuğunu varsayalım:
| giriş değeri | giriş ağırlığı |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
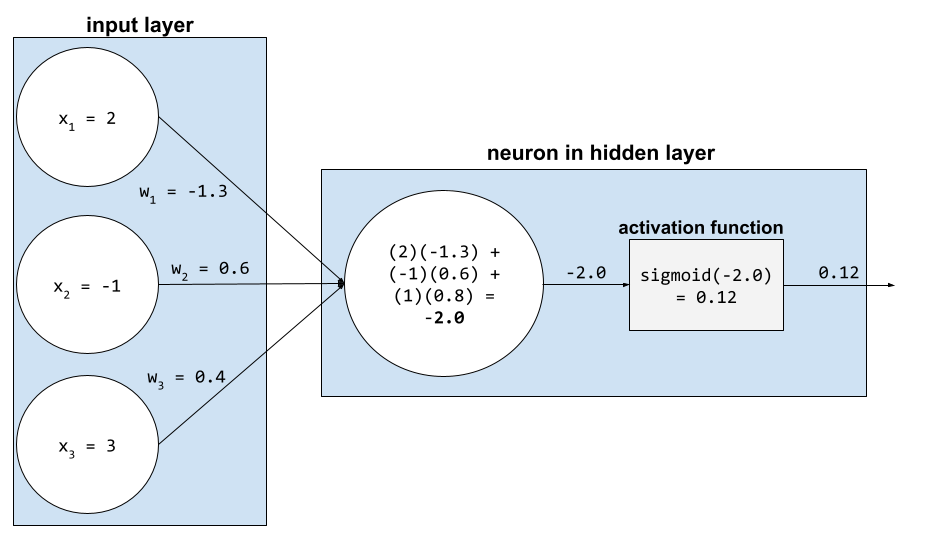
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sinir ağları: Etkinleştirme işlevleri başlıklı makaleyi inceleyin.
yapay zeka
Karmaşık görevleri çözebilen insan olmayan bir program veya model. Örneğin, metni çeviren bir program veya model ya da radyolojik görüntülerden hastalıkları tanımlayan bir program veya model yapay zeka gösterir.
Resmi olarak makine öğrenimi, yapay zekanın bir alt alanıdır. Ancak son yıllarda bazı kuruluşlar yapay zeka ve makine öğrenimi terimlerini birbirinin yerine kullanmaya başladı.
AUC (ROC eğrisinin altındaki alan)
İkili sınıflandırma modelinin pozitif sınıfları negatif sınıflardan ayırma becerisini gösteren 0,0 ile 1,0 arasında bir sayı. AUC değeri 1, 0'a ne kadar yakın olursa modelin sınıfları birbirinden ayırma yeteneği o kadar iyi olur.
Örneğin, aşağıdaki resimde pozitif sınıfları (yeşil oval) negatif sınıflardan (mor dikdörtgen) mükemmel şekilde ayıran bir sınıflandırma modeli gösterilmektedir. Bu gerçekçi olmayan mükemmel modelin AUC değeri 1,0'dır:

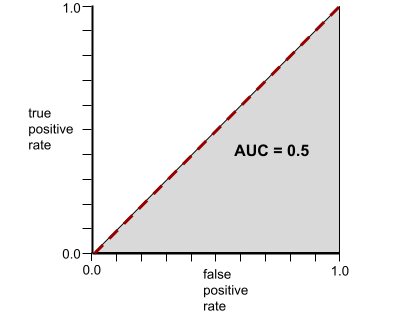
Buna karşılık, aşağıdaki resimde rastgele sonuçlar üreten bir sınıflandırma modelinin sonuçları gösterilmektedir. Bu modelin AUC değeri 0,5'tir:

Evet, önceki modelin AUC değeri 0,0 değil 0,5'tir.
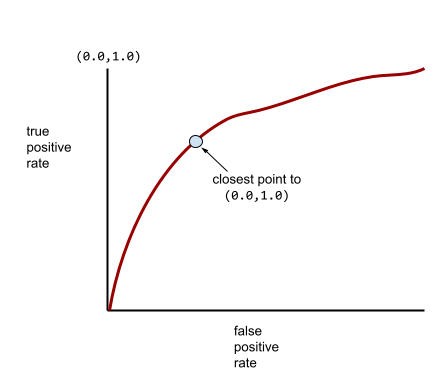
Çoğu model, iki uç nokta arasında bir yerdedir. Örneğin, aşağıdaki model pozitifleri negatiflerden biraz ayırır ve bu nedenle 0,5 ile 1,0 arasında bir AUC'ye sahiptir:

AUC, sınıflandırma eşiği için ayarladığınız tüm değerleri yoksayar. Bunun yerine AUC, olası tüm sınıflandırma eşiklerini dikkate alır.
AUC ve ROC eğrileri arasındaki ilişki hakkında bilgi edinmek için simgeyi tıklayın.
AUC, ROC eğrisinin altındaki alanı temsil eder. Örneğin, pozitifleri negatiflerden mükemmel şekilde ayıran bir modelin ROC eğrisi aşağıdaki gibi görünür:

AUC, önceki resimde gri bölgenin alanıdır. Bu alışılmadık durumda alan, gri bölgenin uzunluğu (1,0) ile gri bölgenin genişliğinin (1,0) çarpımıdır. Bu nedenle, 1,0 ve 1,0'ın çarpımı tam olarak 1,0 AUC değerini verir. Bu, mümkün olan en yüksek AUC puanıdır.
Buna karşılık, sınıfları hiç ayıramayan bir sınıflandırma modelinin ROC eğrisi aşağıdaki gibidir. Bu gri bölgenin alanı 0,5'tir.
Daha tipik bir ROC eğrisi yaklaşık olarak aşağıdaki gibi görünür:
Bu eğrinin altındaki alanı manuel olarak hesaplamak çok zahmetli bir iş olur. Bu nedenle, çoğu AUC değeri genellikle bir program tarafından hesaplanır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sınıflandırma: ROC ve AUC başlıklı makaleyi inceleyin.
B
geri yayılım
Nöral ağlarda gradyan inişini uygulayan algoritma.
Bir nöral ağı eğitmek için aşağıdaki iki geçişli döngünün birçok iterasyonu gerekir:
- İleri geçiş sırasında sistem, tahminler elde etmek için toplu örnekleri işler. Sistem, her tahmini her etiket değeriyle karşılaştırır. Tahmin ile etiket değeri arasındaki fark, söz konusu örnek için kayıptır. Sistem, mevcut toplu işin toplam kaybını hesaplamak için tüm örneklerin kayıplarını toplar.
- Geriye doğru geçiş (geri yayılım) sırasında sistem, tüm gizli katmanlardaki tüm nöronların ağırlıklarını ayarlayarak kaybı azaltır.
Nöral ağlar genellikle birçok gizli katmanda çok sayıda nöron içerir. Bu nöronların her biri, genel kayba farklı şekillerde katkıda bulunur. Geriye yayılım, belirli nöronlara uygulanan ağırlıkların artırılıp artırılmayacağını veya azaltılıp azaltılmayacağını belirler.
Öğrenme hızı, her bir geri geçişin her ağırlığı artırma veya azaltma derecesini kontrol eden bir çarpandır. Büyük bir öğrenme hızı, her ağırlığı küçük bir öğrenme hızına göre daha fazla artırır veya azaltır.
Kalkülüs açısından, geri yayılım, kalkülüsteki zincir kuralını uygular. Yani, geriye yayılım, her bir parametreye göre hatanın kısmi türevini hesaplar.
Yıllar önce makine öğrenimi uzmanları, geri yayılımı uygulamak için kod yazmak zorundaydı. Keras gibi modern makine öğrenimi API'leri artık sizin için geri yayılımı uygular. Bora
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Nöral ağlar bölümüne bakın.
grup
Bir eğitim iterasyonunda kullanılan örnekler kümesi. Grup boyutu, gruptaki örneklerin sayısını belirler.
Bir grubun dönemle nasıl ilişkili olduğuna dair açıklama için dönem başlıklı makaleyi inceleyin.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon: Hiperparametreler bölümüne bakın.
grup boyutu
Bir toplu işlemdeki örneklerin sayısı. Örneğin, grup boyutu 100 ise model, iterasyon başına 100 örnek işler.
Popüler grup boyutu stratejileri şunlardır:
- Stokastik Gradyan İnişi (SGD): Bu yöntemde grup boyutu 1'dir.
- Tam grup: Grup boyutu, eğitim kümesinin tamamındaki örneklerin sayısıdır. Örneğin, eğitim seti bir milyon örnek içeriyorsa grup boyutu bir milyon örnek olur. Tam toplu iş genellikle verimsiz bir stratejidir.
- Grup boyutunun genellikle 10 ile 1.000 arasında olduğu mini grup. Mini toplu iş genellikle en verimli stratejidir.
Daha fazla bilgi için aşağıdaki konulara bakın:
- Makine Öğrenimi Hızlandırılmış Kursu'ndaki Üretim ML sistemleri: Statik ve dinamik çıkarım.
- Derin Öğrenme Ayarlama Başucu Kitabı.
önyargı (etik/adalet)
1. Bazı şeylere, insanlara veya gruplara karşı diğerlerine kıyasla stereotip oluşturma, önyargı veya kayırma Bu önyargılar, verilerin toplanmasını ve yorumlanmasını, sistem tasarımını ve kullanıcıların sistemle etkileşim kurma şeklini etkileyebilir. Bu tür yanlılığın biçimleri şunlardır:
- otomasyon önyargısı
- doğrulama yanlılığı
- deneyci yanlılığı
- gruba atfetme önyargısı
- örtülü önyargı
- Grup içi önyargı
- grup dışı homojenlik önyargısı
2. Örnekleme veya raporlama prosedürüyle ortaya çıkan sistematik hata. Bu tür yanlılığın biçimleri şunlardır:
- kapsam yanlılığı (coverage bias)
- yanıt vermeme eğilimi (non-response bias)
- katılım önyargısı (participation bias)
- raporlama yanlılığı
- örnekleme yanlılığı
- seçim önyargısı
Makine öğrenimi modellerindeki bias terimi veya tahmin yanlılığı ile karıştırılmamalıdır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Adalet: Önyargı türleri bölümüne bakın.
önyargı (matematik) veya önyargı terimi
Bir başlangıç noktasından kesişme veya uzaklık. Önyargı, makine öğrenimi modellerindeki bir parametredir ve aşağıdakilerden biriyle sembolize edilir:
- b
- w0
Örneğin, aşağıdaki formülde b, yanlılığı ifade eder:
Basit bir iki boyutlu çizgide, önyargı yalnızca "y eksenini kesen nokta" anlamına gelir. Örneğin, aşağıdaki resimde çizginin eğimi 2'dir.
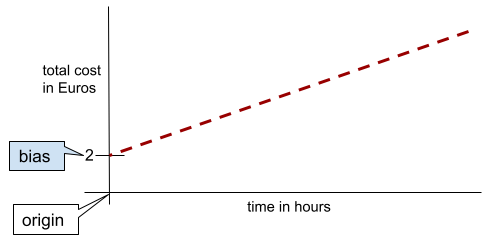
Tüm modeller başlangıç noktasından (0,0) başlamadığı için sapma vardır. Örneğin, bir eğlence parkına girişin 2 avro, müşterinin parkta kaldığı her saat için ise 0,5 avro ek ücret alındığını varsayalım. Bu nedenle, toplam maliyeti eşleyen bir modelde en düşük maliyet 2 Euro olduğundan 2 birimi kadar bir sapma vardır.
Önyargı, etik ve adalet alanındaki önyargı veya tahmin önyargısı ile karıştırılmamalıdır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal Regresyon bölümüne bakın.
ikili sınıflandırma
Bir sınıflandırma görevi türü. Birbiriyle bağdaşmayan iki sınıftan birini tahmin eder:
Örneğin, aşağıdaki iki makine öğrenimi modelinin her biri ikili sınıflandırma gerçekleştirir:
- E-posta iletilerinin spam (pozitif sınıf) veya spam değil (negatif sınıf) olup olmadığını belirleyen bir model.
- Bir kişinin belirli bir hastalığa (pozitif sınıf) sahip olup olmadığını veya bu hastalığa sahip olmadığını (negatif sınıf) belirlemek için tıbbi semptomları değerlendiren bir model.
Çok sınıflı sınıflandırma ile karşılaştırın.
Mantıksal regresyon ve sınıflandırma eşiği bölümlerini de inceleyin.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sınıflandırma bölümüne bakın.
gruplandırma
Tek bir özelliği, genellikle bir değer aralığına dayalı olarak paketler veya gruplar adı verilen birden fazla ikili özelliğe dönüştürme. Kırpma özelliği genellikle sürekli bir özelliktir.
Örneğin, sıcaklığı tek bir sürekli kayan nokta özelliği olarak temsil etmek yerine sıcaklık aralıklarını ayrı gruplara ayırabilirsiniz. Örneğin:
- Sıcaklığın 10 santigrat dereceden düşük olması "soğuk" kategorisine girer.
- 11-24 santigrat derece "ılıman" kategorisine girer.
- >= 25 santigrat derece "sıcak" grubu olur.
Model, aynı gruptaki her değeri aynı şekilde ele alır. Örneğin, 13 ve 22 değerleri ılıman aralığında olduğundan model, bu iki değeri aynı şekilde ele alır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sayısal veriler: Gruplandırma bölümüne bakın.
C
kategorik veriler
Belirli bir olası değerler grubuna sahip özellikler. Örneğin, yalnızca aşağıdaki üç olası değerden birine sahip olabilen traffic-light-state adlı kategorik bir özelliği ele alalım:
redyellowgreen
traffic-light-state kategorik bir özellik olarak temsil edildiğinde model, red, green ve yellow'nin sürücü davranışı üzerindeki farklı etkilerini öğrenebilir.
Kategorik özelliklere bazen ayrık özellikler de denir.
Sayısal verilerle karşılaştırın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Kategorik verilerle çalışma başlıklı makaleyi inceleyin.
sınıf
Etiketin ait olabileceği bir kategori. Örneğin:
- Spam'i algılayan bir ikili sınıflandırma modelinde iki sınıf spam ve spam değil olabilir.
- Köpek ırklarını tanımlayan bir çok sınıflı sınıflandırma modelinde sınıflar kaniş, beagle, pug vb. olabilir.
Sınıflandırma modeli bir sınıfı tahmin eder. Bunun aksine, regresyon modeli bir sınıf yerine bir sayı tahmin eder.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sınıflandırma bölümüne bakın.
sınıflandırma modeli
Tahmini sınıf olan model. Örneğin, aşağıdakilerin tümü sınıflandırma modelidir:
- Giriş cümlesinin dilini (Fransızca mı? İspanyolca mı? İtalyanca mı?).
- Ağaç türlerini tahmin eden bir model (Akçaağaç mı? Meşe? Baobab?).
- Belirli bir tıbbi durum için pozitif veya negatif sınıfı tahmin eden bir model.
Bunun aksine, regresyon modelleri sınıflar yerine sayıları tahmin eder.
Sık kullanılan iki sınıflandırma modeli türü şunlardır:
sınıflandırma eşiği
İkili sınıflandırmada, mantıksal regresyon modelinin ham çıkışını pozitif sınıf veya negatif sınıf tahminine dönüştüren 0 ile 1 arasında bir sayıdır. Sınıflandırma eşiğinin, model eğitimi tarafından seçilen bir değer değil, bir insan tarafından seçilen bir değer olduğunu unutmayın.
Mantıksal regresyon modeli, 0 ile 1 arasında bir ham değer çıkarır. Ardından:
- Bu ham değer, sınıflandırma eşiğinden büyükse pozitif sınıf tahmin edilir.
- Bu ham değer, sınıflandırma eşiğinden küçükse negatif sınıf tahmin edilir.
Örneğin, sınıflandırma eşiğinin 0,8 olduğunu varsayalım. Ham değer 0, 9 ise model pozitif sınıfı tahmin eder. Ham değer 0, 7 ise model negatif sınıfı tahmin eder.
Sınıflandırma eşiğinin seçimi, yanlış pozitif ve yanlış negatif sayısını büyük ölçüde etkiler.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Eşikler ve karmaşıklık matrisi bölümüne bakın.
sınıflandırıcı
Sınıflandırma modeli için kullanılan gündelik bir terimdir.
sınıf dengesizliği olan veri kümesi
Her bir sınıfın toplam etiket sayısının önemli ölçüde farklı olduğu bir sınıflandırma için veri kümesi. Örneğin, iki etiketi aşağıdaki gibi ayrılmış bir ikili sınıflandırma veri kümesini ele alalım:
- 1.000.000 negatif etiket
- 10 pozitif etiket
Olumsuz etiketlerin olumlu etiketlere oranı 100.000'e 1 olduğundan bu, sınıf dengesizliği olan bir veri kümesidir.
Buna karşılık, aşağıdaki veri kümesi sınıf dengelidir. Bunun nedeni, olumsuz etiketlerin olumlu etiketlere oranının 1'e nispeten yakın olmasıdır:
- 517 negatif etiket
- 483 pozitif etiket
Çok sınıflı veri kümelerinde de sınıf dengesizliği olabilir. Örneğin, aşağıdaki çok sınıflı sınıflandırma veri kümesi de sınıf dengesizdir. Bunun nedeni, bir etiketin diğer iki etikete kıyasla çok daha fazla örneğe sahip olmasıdır:
- "Yeşil" sınıfına ait 1.000.000 etiket
- "mor" sınıfına sahip 200 etiket
- "orange" sınıfına sahip 350 etiket
Sınıf dengesizliği olan veri kümelerini eğitmek özel zorluklar yaratabilir. Ayrıntılar için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Dengesiz veri kümeleri bölümüne bakın.
Entropi, çoğunluk sınıfı ve azınlık sınıfı bölümlerini de inceleyin.
kırpma
Aşağıdakilerden birini veya her ikisini birden yaparak aykırı değerleri işleme tekniği:
- Maksimum eşiği aşan özellik değerlerini bu maksimum eşiğe düşürme.
- Minimum eşiğin altındaki özellik değerlerini bu minimum eşiğe kadar artırır.
Örneğin, belirli bir özelliğin değerlerinin% 0,5'inden azının 40-60 aralığının dışında olduğunu varsayalım. Bu durumda şunları yapabilirsiniz:
- 60'tan (maksimum eşik) büyük tüm değerler tam olarak 60 olarak kırpılır.
- 40'ın (minimum eşik) altındaki tüm değerleri tam olarak 40 olacak şekilde kırpın.
Aykırı değerler modellere zarar verebilir ve bazen eğitim sırasında ağırlıkların taşmasına neden olabilir. Bazı aykırı değerler, doğruluk gibi metrikleri de önemli ölçüde etkileyebilir. Kırpma, hasarı sınırlamak için yaygın olarak kullanılan bir tekniktir.
Gradyan kırpma, eğitim sırasında gradyan değerlerini belirlenmiş bir aralıkta tutar.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sayısal veriler: Normalleştirme bölümüne bakın.
karışıklık matrisi
Sınıflandırma modelinin yaptığı doğru ve yanlış tahminlerin sayısını özetleyen NxN tablosu. Örneğin, bir ikili sınıflandırma modeli için aşağıdaki karmaşıklık matrisini inceleyin:
| Tümör (tahmini) | Non-Tumor (predicted) [Non-Tümör (tahmini)] | |
|---|---|---|
| Tümör (kesin referans) | 18 (TP) | 1 (FN) |
| Non-Tumor (ground truth) | 6 (FP) | 452 (TN) |
Yukarıdaki karışıklık matrisinde şunlar gösterilmektedir:
- Gerçek değerin tümör olduğu 19 tahminden 18'i doğru, 1'i ise yanlış sınıflandırıldı.
- Kesin referansın Non-Tumor olduğu 458 tahminden 452'si doğru, 6'sı ise yanlış sınıflandırıldı.
Çok sınıflı sınıflandırma sorununa ilişkin karışıklık matrisi, hata kalıplarını belirlemenize yardımcı olabilir. Örneğin, üç farklı iris türünü (Virginica, Versicolor ve Setosa) sınıflandıran 3 sınıflı çok sınıflı sınıflandırma modelinin aşağıdaki karmaşıklık matrisini ele alalım. Kesin referans Virginica olduğunda karmaşıklık matrisi, modelin Setosa'dan ziyade Versicolor'u yanlışlıkla tahmin etme olasılığının çok daha yüksek olduğunu gösteriyor:
| Setosa (tahmin edilen) | Versicolor (tahmini) | Virginica (tahmini) | |
|---|---|---|---|
| Setosa (kesin referans) | 88 | 12 | 0 |
| Versicolor (kesin referans) | 6 | 141 | 7 |
| Virginica (kesin referans) | 2 | 27 | 109 |
Başka bir örnek olarak, bir karmaşıklık matrisi, el yazısıyla yazılmış rakamları tanımak için eğitilmiş bir modelin 4 yerine yanlışlıkla 9'u veya 7 yerine yanlışlıkla 1'i tahmin etme eğiliminde olduğunu ortaya çıkarabilir.
Karmaşıklık matrisleri, kesinlik ve hatırlama dahil olmak üzere çeşitli performans metriklerini hesaplamak için yeterli bilgiyi içerir.
sürekli özellik
Sıcaklık veya ağırlık gibi sonsuz sayıda olası değere sahip kayan noktalı özellik.
Ayrık özellik ile karşılaştırma.
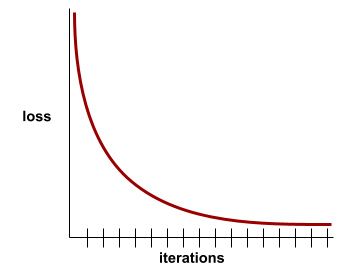
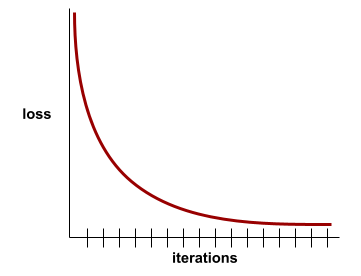
yakınsama
Kayıp değerlerinin her yinelemede çok az değiştiği veya hiç değişmediği durumda ulaşılan durum. Örneğin, aşağıdaki kayıp eğrisi, yaklaşık 700 yinelemede yakınsama olduğunu gösteriyor:
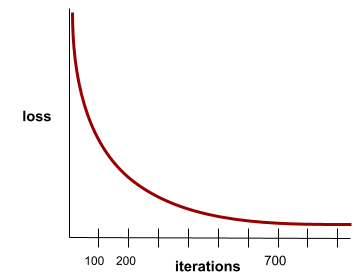
Ek eğitim modelin performansını artırmadığında model yakınsar.
Derin öğrenmede, kayıp değerleri sonunda düşmeden önce bazen birçok yineleme boyunca sabit kalır veya neredeyse sabit kalır. Uzun bir süre boyunca sabit kayıp değerleri olduğunda geçici olarak yanlış bir yakınsama hissi yaşayabilirsiniz.
Ayrıca erken durdurma başlıklı makaleyi de inceleyin.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Model yakınsama ve kayıp eğrileri bölümüne bakın.
D
DataFrame
Bellekteki veri kümelerini temsil etmek için kullanılan popüler bir pandas veri türü.
DataFrame, tabloya veya e-tabloya benzer. DataFrame'in her sütununun bir adı (başlık) vardır ve her satır benzersiz bir sayıyla tanımlanır.
DataFrame'deki her sütun, her sütuna kendi veri türü atanabilmesi dışında 2 boyutlu bir dizi gibi yapılandırılır.
Ayrıca resmi pandas.DataFrame referans sayfasını da inceleyin.
veri kümesi veya veri kümesi
Genellikle (ancak yalnızca değil) aşağıdaki biçimlerden birinde düzenlenen bir ham veri koleksiyonu:
- e-tablo
- CSV (virgülle ayrılmış değerler) biçiminde bir dosya
deep model
Birden fazla gizli katman içeren bir nöral ağ.
Derin model, derin nöral ağ olarak da adlandırılır.
Geniş model ile karşılaştırın.
yoğun özellik
Çoğu veya tüm değerlerin sıfır olmadığı bir özellik. Genellikle kayan nokta değerlerinden oluşan bir tensördür. Örneğin, aşağıdaki 10 öğeli tensör, değerlerinin 9'u sıfır olmayan değerler olduğundan yoğundur:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Seyrek özellik ile karşılaştırma.
derinlik
Nöral ağda aşağıdakilerin toplamı:
- Gizli katmanların sayısı
- Genellikle 1 olan çıkış katmanlarının sayısı
- Yerleştirme katmanlarının sayısı
Örneğin, beş gizli katmanı ve bir çıkış katmanı olan bir nöral ağın derinliği 6'dır.
Giriş katmanının derinliği etkilemediğini unutmayın.
ayrı özellik
Sınırlı sayıda olası değere sahip bir özellik. Örneğin, değerleri yalnızca hayvan, sebze veya mineral olabilen bir özellik, ayrı (veya kategorik) bir özelliktir.
Sürekli özellik ile karşılaştırma
dinamik
Sık sık veya sürekli olarak yapılan bir şey. Dinamik ve online terimleri, makine öğreniminde eş anlamlıdır. Aşağıda, makine öğreniminde dinamik ve çevrimiçi terimlerinin yaygın kullanım alanları verilmiştir:
- Dinamik model (veya online model), sık sık ya da sürekli olarak yeniden eğitilen bir modeldir.
- Dinamik eğitim (veya online eğitim), sık sık ya da sürekli olarak eğitim verme sürecidir.
- Dinamik çıkarım (veya online çıkarım), isteğe bağlı olarak tahmin oluşturma işlemidir.
dinamik model
Sık sık (hatta sürekli olarak) yeniden eğitilen bir model. Dinamik model, sürekli olarak gelişen verilere uyum sağlayan bir "hayat boyu öğrenen"dir. Dinamik model, çevrimiçi model olarak da bilinir.
Statik modelle karşılaştırma.
E
erken durdurma
Eğitim kaybı azalmayı bitirmeden eğitimi sonlandırmayı içeren bir normalleştirme yöntemidir. Erken durdurmada, doğrulama veri kümesindeki kayıp artmaya başladığında (yani genelleme performansı kötüleştiğinde) modeli eğitme işlemini kasıtlı olarak durdurursunuz.
Erken çıkış ile karşılaştırın.
yerleştirme katmanı
Yüksek boyutlu kategorik bir özellik üzerinde eğitim alarak düşük boyutlu bir yerleştirme vektörünü kademeli olarak öğrenen özel bir gizli katman. Yerleştirme katmanı, bir nöral ağın yalnızca yüksek boyutlu kategorik özellik üzerinde eğitim yapmaya kıyasla çok daha verimli bir şekilde eğitilmesini sağlar.
Örneğin, Earth şu anda yaklaşık 73.000 ağaç türünü desteklemektedir. Ağaç türünün modelinizde bir özellik olduğunu varsayalım. Bu durumda modelinizin giriş katmanı, 73.000 öğe uzunluğunda bir tek sıcak vektör içerir.
Örneğin, baobab sembolü şu şekilde gösterilebilir:

73.000 öğelik bir dizi çok uzundur. Modele yerleştirme katmanı eklemezseniz 72.999 sıfırın çarpılması nedeniyle eğitim çok zaman alır. Örneğin, yerleştirme katmanının 12 boyuttan oluşmasını seçebilirsiniz. Sonuç olarak, yerleştirme katmanı her ağaç türü için kademeli olarak yeni bir yerleştirme vektörü öğrenir.
Belirli durumlarda karma oluşturma, yerleştirme katmanına makul bir alternatiftir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Yerleştirme bölümüne bakın.
sıfır zaman
Her bir örneğin bir kez işlendiği, eğitim kümesinin tamamı üzerinde yapılan tam bir eğitim geçişi.
Bir dönem, N/grup boyutu eğitim iterasyonunu ifade eder. Burada N, toplam örnek sayısıdır.
Örneğin, aşağıdakileri varsayalım:
- Veri kümesi 1.000 örnekten oluşur.
- Grup boyutu 50 örnektir.
Bu nedenle, tek bir dönem için 20 yineleme gerekir:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon: Hiperparametreler bölümüne bakın.
örnek
Özellikler satırının değerleri ve muhtemelen bir etiket. Gözetimli öğrenme örnekleri iki genel kategoriye ayrılır:
- Etiketli örnek, bir veya daha fazla özellik ve bir etiketten oluşur. Eğitim sırasında etiketli örnekler kullanılır.
- Etiketsiz örnek, bir veya daha fazla özellikten oluşur ancak etiketi yoktur. Çıkarım sırasında etiketlenmemiş örnekler kullanılır.
Örneğin, hava koşullarının öğrencilerin sınav puanları üzerindeki etkisini belirlemek için bir model eğittiğinizi varsayalım. Aşağıda etiketlenmiş üç örnek verilmiştir:
| Özellikler | Şirket | ||
|---|---|---|---|
| Sıcaklık | Nem | Basınç | Test skoru |
| 15 | 47 | 998 | İyi |
| 19 | 34 | 1020 | Mükemmel |
| 18 | 92 | 1012 | Yetersiz |
Etiketlenmemiş üç örneği aşağıda bulabilirsiniz:
| Sıcaklık | Nem | Basınç | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Veri kümesinin satırı genellikle bir örnek için ham kaynaktır. Yani bir örnek genellikle veri kümesindeki sütunların bir alt kümesinden oluşur. Ayrıca, bir örnekteki özellikler özellik çarpımları gibi sentezlenmiş özellikleri de içerebilir.
Daha fazla bilgi için Makine Öğrenimine Giriş kursundaki Denetimli Öğrenme bölümüne bakın.
C
yanlış negatif (FN)
Modelin negatif sınıfı yanlışlıkla tahmin ettiği bir örnek. Örneğin, model belirli bir e-posta iletisinin spam olmadığını (negatif sınıf) tahmin ediyor ancak bu e-posta iletisi gerçekten spam.
yanlış pozitif (FP)
Modelin pozitif sınıfı yanlışlıkla tahmin ettiği bir örnek. Örneğin, model belirli bir e-posta iletisinin spam (pozitif sınıf) olduğunu tahmin eder ancak bu e-posta iletisi aslında spam değildir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Eşikler ve karmaşıklık matrisi bölümüne bakın.
yanlış pozitif oranı (FPR)
Modelin pozitif sınıfı yanlışlıkla tahmin ettiği gerçek negatif örneklerin oranı. Aşağıdaki formül, yanlış pozitif oranını hesaplar:
Yanlış pozitif oranı, ROC eğrisindeki x eksenidir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sınıflandırma: ROC ve AUC başlıklı makaleyi inceleyin.
özellik
Bir makine öğrenimi modelinin giriş değişkeni. Bir örnek bir veya daha fazla özellikten oluşur. Örneğin, hava koşullarının öğrencilerin sınav puanları üzerindeki etkisini belirlemek için bir model eğittiğinizi varsayalım. Aşağıdaki tabloda, her biri üç özellik ve bir etiket içeren üç örnek gösterilmektedir:
| Özellikler | Şirket | ||
|---|---|---|---|
| Sıcaklık | Nem | Basınç | Test skoru |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Etiketle kontrast.
Daha fazla bilgi için Makine Öğrenimine Giriş kursundaki Denetimli Öğrenme bölümüne bakın.
çapraz özellik
Kategorik veya gruplandırılmış özelliklerin "çaprazlanmasıyla" oluşturulan bir sentez özelliği.
Örneğin, sıcaklığı aşağıdaki dört gruptan birinde temsil eden bir "ruh hali tahmini" modelini ele alalım:
freezingchillytemperatewarm
Ayrıca rüzgar hızını aşağıdaki üç gruptan birinde gösterir:
stilllightwindy
Özellikler arası geçiş olmadan doğrusal model, önceki yedi farklı paketin her birinde bağımsız olarak eğitilir. Bu nedenle model, örneğin,
freezing üzerinde eğitilirken örneğin,
windy üzerinde eğitimden bağımsızdır.
Alternatif olarak, sıcaklık ve rüzgar hızının bir özellik kesişimini oluşturabilirsiniz. Bu yapay özellik aşağıdaki 12 olası değere sahip olacaktır:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Özellik kesişimleri sayesinde model, freezing-windy günü ile freezing-still günü arasındaki ruh hali farklılıklarını öğrenebilir.
Her biri çok sayıda farklı pakete sahip iki özellikten yapay bir özellik oluşturursanız ortaya çıkan özellik kesişimi çok sayıda olası kombinasyona sahip olur. Örneğin, bir özellikte 1.000 grup, diğer özellikte ise 2.000 grup varsa ortaya çıkan özellik kesişiminde 2.000.000 grup bulunur.
Resmi olarak, çarpım bir Kartezyen ürünüdür.
Özellik çaprazları çoğunlukla doğrusal modellerle kullanılır ve nöral ağlarla nadiren kullanılır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Kategorik veriler: Özellikler arası konusuna bakın.
özellik mühendisliği
Aşağıdaki adımları içeren bir süreç:
- Bir modeli eğitirken hangi özelliklerin faydalı olabileceğini belirleme.
- Veri kümesindeki ham verileri, bu özelliklerin etkili sürümlerine dönüştürme.
Örneğin, temperature özelliğinin faydalı olabileceğini belirleyebilirsiniz. Ardından, modelin farklı temperature aralıklarından neler öğrenebileceğini optimize etmek için gruplandırma ile denemeler yapabilirsiniz.
Özellik mühendisliğine bazen özellik çıkarma veya özellik oluşturma da denir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sayısal veriler: Bir model, özellik vektörlerini kullanarak verileri nasıl alır? başlıklı makaleyi inceleyin.
özellik grubu
Makine öğrenimi modelinizin üzerinde eğitildiği özellikler grubu. Örneğin, konut fiyatlarını tahmin eden bir model için basit bir özellik grubu; posta kodu, mülk boyutu ve mülkün durumundan oluşabilir.
özellik vektörü
Bir örneği oluşturan özellik değerleri dizisi. Özellik vektörü, eğitim ve çıkarım sırasında giriş olarak kullanılır. Örneğin, iki ayrı özelliği olan bir modelin özellik vektörü şu şekilde olabilir:
[0.92, 0.56]
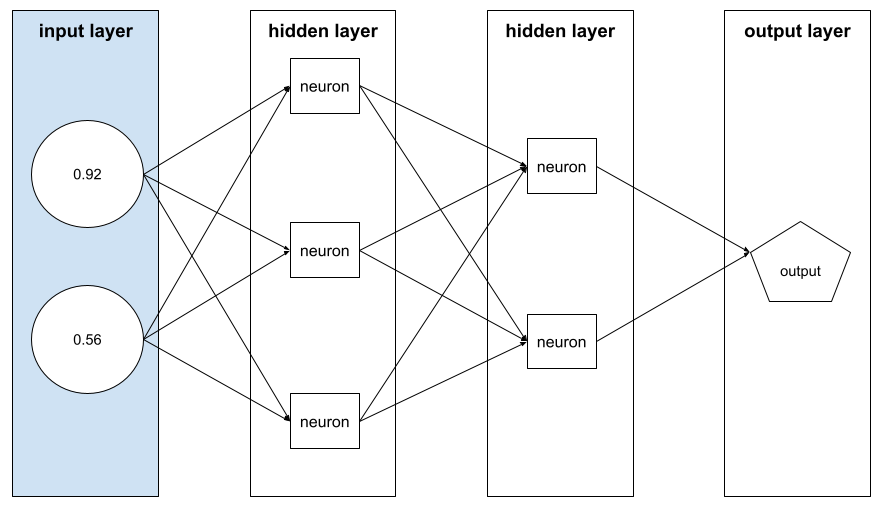
Her örnek, özellik vektörü için farklı değerler sağlar. Bu nedenle, sonraki örneğin özellik vektörü şu şekilde olabilir:
[0.73, 0.49]
Özellik mühendisliği, özelliklerin özellik vektöründe nasıl temsil edileceğini belirler. Örneğin, beş olası değeri olan ikili bir kategorik özellik, one-hot kodlama ile temsil edilebilir. Bu durumda, belirli bir örnek için özellik vektörünün bölümü dört sıfır ve üçüncü konumda tek bir 1, 0'dan oluşur:
[0.0, 0.0, 1.0, 0.0, 0.0]
Başka bir örnek olarak, modelinizin üç özellikten oluştuğunu varsayalım:
- Tek sıcaklık kodlamasıyla temsil edilen beş olası değere sahip ikili kategorik özellik; örneğin:
[0.0, 1.0, 0.0, 0.0, 0.0] - One-hot kodlamayla gösterilen üç olası değere sahip başka bir ikili kategorik özellik; örneğin:
[0.0, 0.0, 1.0] - Kayan nokta özelliği; örneğin:
8.3.
Bu durumda, her örnek için özellik vektörü dokuz değerle temsil edilir. Yukarıdaki listedeki örnek değerler göz önüne alındığında, özellik vektörü şu şekilde olur:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sayısal veriler: Bir model, özellik vektörlerini kullanarak verileri nasıl alır? başlıklı makaleyi inceleyin.
geri bildirim döngüsü
Makine öğreniminde, bir modelin tahminlerinin aynı modelin veya başka bir modelin eğitim verilerini etkilediği durum. Örneğin, film öneren bir model, kullanıcıların gördüğü filmleri etkiler. Bu da sonraki film önerisi modellerini etkiler.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Üretim ML sistemleri: Sorulması gereken sorular bölümüne bakın.
G
genelleştirme
Modelin yeni ve daha önce görülmemiş verilerle ilgili doğru tahminler yapabilme özelliği. Genelleme yapabilen bir model, fazla uyumlu bir modelin tam tersidir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Genelleştirme bölümüne bakın.
genelleştirme eğrisi
Eğitim kaybı ve doğrulama kaybının, iterasyon sayısının bir fonksiyonu olarak grafiği.
Genelleştirme eğrisi, olası aşırı uyumu tespit etmenize yardımcı olabilir. Örneğin, aşağıdaki genelleştirme eğrisi, doğrulama kaybı nihayetinde eğitim kaybından önemli ölçüde daha yüksek hale geldiği için aşırı uyumu gösterir.
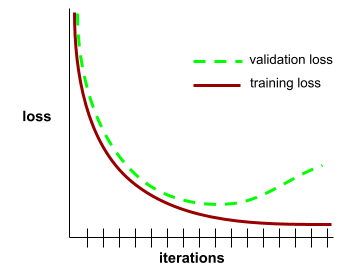
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Genelleştirme bölümüne bakın.
gradyan inişi
Kaybı en aza indirmek için kullanılan matematiksel bir teknik. Gradyan inişi, ağırlıkları ve önyargıları yinelemeli olarak ayarlar ve kaybı en aza indirmek için en iyi kombinasyonu yavaş yavaş bulur.
Gradyan inişi, makine öğreniminden çok daha eski bir yöntemdir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon: Gradyen inişi bölümüne bakın.
gerçek doğru
Gerçeklik.
Gerçekte olan şey.
Örneğin, üniversitenin ilk yılında olan bir öğrencinin altı yıl içinde mezun olup olmayacağını tahmin eden bir ikili sınıflandırma modelini ele alalım. Bu model için kesin referans, öğrencinin altı yıl içinde gerçekten mezun olup olmadığıdır.
H
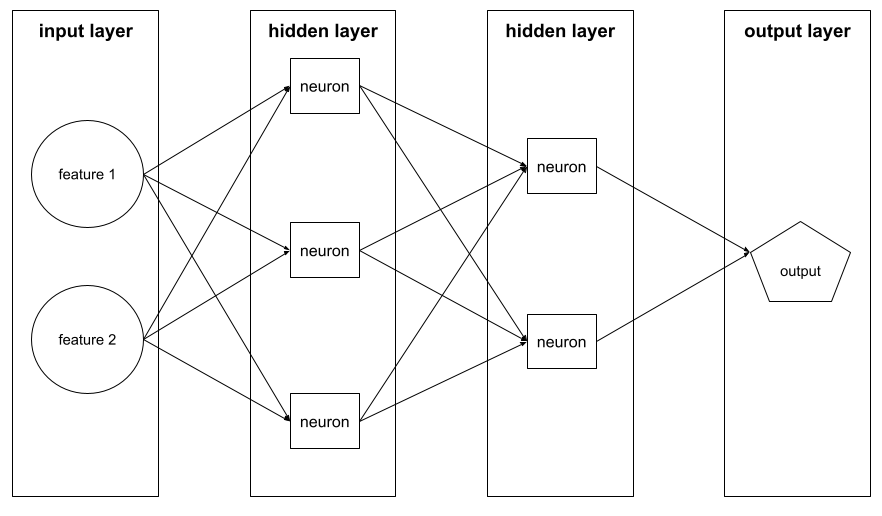
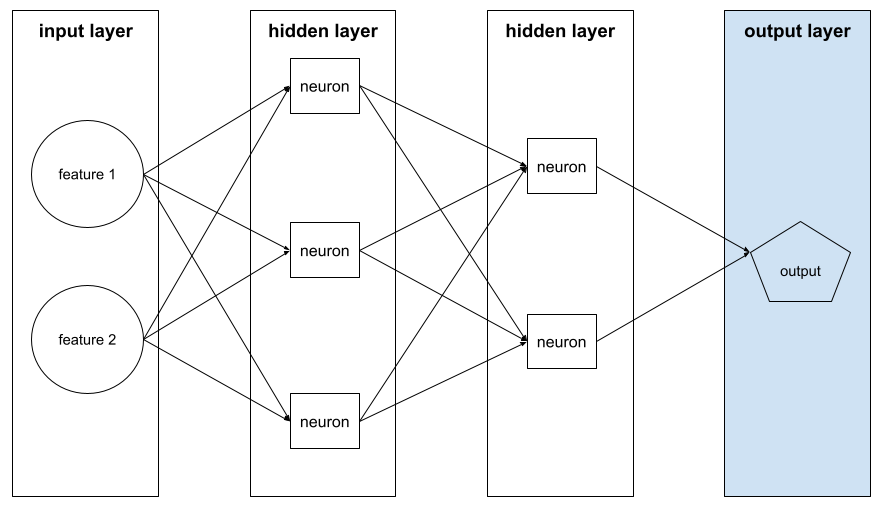
gizli katman
Giriş katmanı (özellikler) ile çıkış katmanı (tahmin) arasındaki sinir ağındaki bir katman. Her gizli katman bir veya daha fazla nöron içerir. Örneğin, aşağıdaki sinir ağında iki gizli katman vardır. Birincisinde üç nöron, ikincisinde ise iki nöron bulunur:
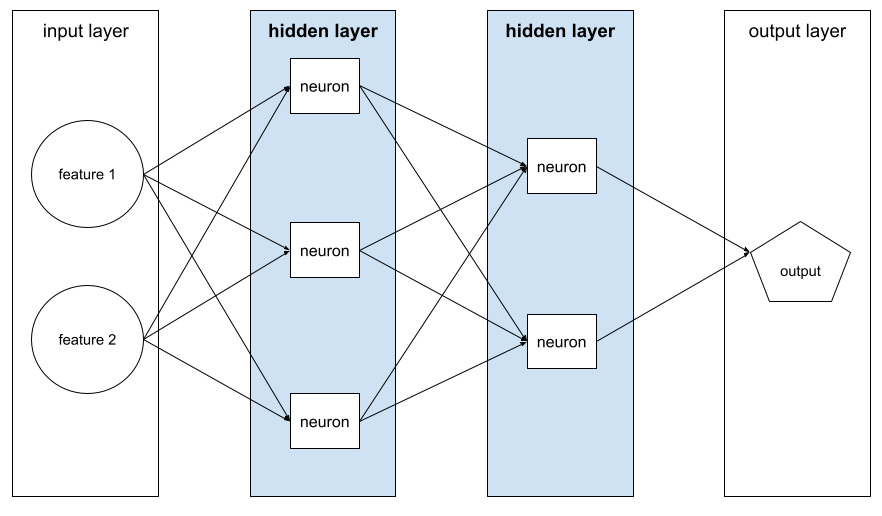
Derin nöral ağ, birden fazla gizli katman içerir. Örneğin, önceki resim bir derin sinir ağıdır çünkü model iki gizli katman içerir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sinir ağları: Düğümler ve gizli katmanlar bölümüne bakın.
hiperparametre
Sizin veya bir hiperparametre ayarlama hizmetinin bir modeli eğitmenin ardışık çalıştırmaları sırasında ayarladığı değişkenler. Örneğin, öğrenme hızı bir hiperparametredir. Bir eğitim oturumundan önce öğrenme hızını 0,01 olarak ayarlayabilirsiniz. 0,01 değerinin çok yüksek olduğunu düşünüyorsanız bir sonraki eğitim oturumunda öğrenme hızını 0,003 olarak ayarlayabilirsiniz.
Buna karşılık parametreler, modelin eğitim sırasında öğrendiği çeşitli ağırlıklar ve eğilimlerdir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon: Hiperparametreler bölümüne bakın.
I
bağımsız ve özdeş dağıtılmış (i.i.d)
Değişmeyen bir dağılımdan alınan ve alınan her değerin daha önce alınan değerlere bağlı olmadığı veriler. Bağımsız ve aynı dağılıma sahip (i.i.d.) kavramı, makine öğreniminin ideal gazıdır. Bu kavram, faydalı bir matematiksel yapı olsa da gerçek dünyada neredeyse hiçbir zaman tam olarak bulunmaz. Örneğin, bir web sayfasını ziyaret eden kullanıcıların dağılımı kısa bir süre boyunca i.i.d. olabilir. Yani dağılım, bu kısa süre boyunca değişmez ve bir kullanıcının ziyareti genellikle diğer kullanıcının ziyaretinden bağımsızdır. Ancak bu zaman aralığını genişletirseniz web sayfasının ziyaretçilerinde mevsimsel farklılıklar görülebilir.
Ayrıca durağan olmama konusuna da bakın.
çıkarım
Geleneksel makine öğreniminde, eğitilmiş bir modelin etiketlenmemiş örneklere uygulanarak tahminlerde bulunma süreci. Daha fazla bilgi edinmek için Makine Öğrenimine Giriş kursundaki Denetimli Öğrenme bölümüne bakın.
Büyük dil modellerinde çıkarım, eğitilmiş bir modelin giriş istemine yanıt oluşturmak için kullanılması sürecidir.
İstatistiklerde çıkarım biraz farklı bir anlama sahiptir. Ayrıntılar için istatistiksel çıkarım hakkındaki Wikipedia makalesine bakın.
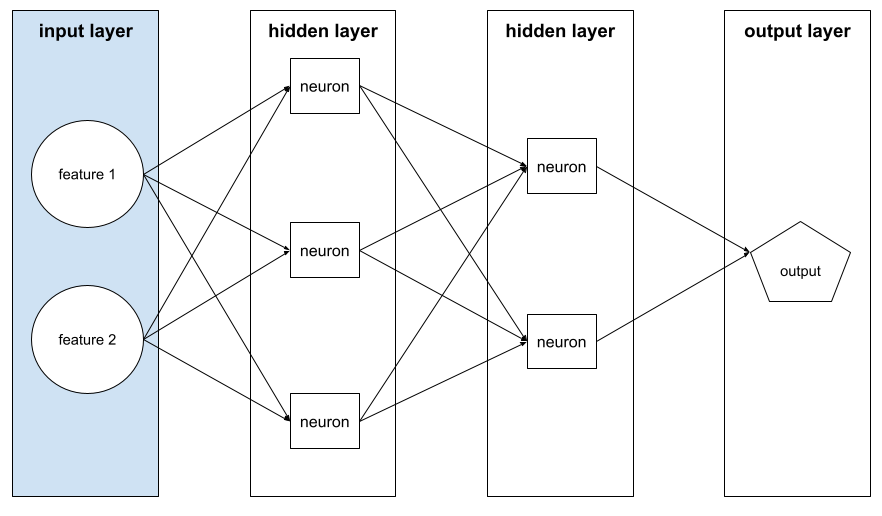
giriş katmanı
Özellik vektörünü tutan nöral ağın katmanı. Yani giriş katmanı, eğitim veya çıkarım için örnekler sağlar. Örneğin, aşağıdaki sinir ağındaki giriş katmanı iki özellikten oluşur:
yorumlanabilirlik
Bir makine öğrenimi modelinin muhakemesini bir insana anlaşılır bir şekilde açıklama veya sunma becerisi.
Örneğin, çoğu doğrusal regresyon modeli yüksek düzeyde yorumlanabilir. (Her bir özelliğin eğitilmiş ağırlıklarına bakmanız yeterlidir.) Karar ormanları da yüksek oranda yorumlanabilir. Ancak bazı modellerin yorumlanabilmesi için gelişmiş görselleştirmeler gerekir.
Makine öğrenimi modellerini yorumlamak için Learning Interpretability Tool'u (LIT) kullanabilirsiniz.
iterasyon
Modelin parametrelerinin (modelin ağırlıkları ve eğilimleri) eğitim sırasında tek bir kez güncellenmesi. Grup boyutu, modelin tek bir yinelemede kaç örnek işlediğini belirler. Örneğin, grup boyutu 20 ise model, parametreleri ayarlamadan önce 20 örnek işler.
Nöral ağ eğitilirken tek bir yineleme aşağıdaki iki geçişi içerir:
- Tek bir toplu işlemdeki kaybı değerlendirmek için iletme geçişi.
- Modelin parametrelerini kayba ve öğrenme hızına göre ayarlamak için geriye doğru geçiş (geri yayılım).
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Gradyen inişi bölümüne bakın.
L
L0 normalleştirmesi
Bir modeldeki sıfır olmayan ağırlıkların toplam sayısını cezalandıran bir normalleştirme türü. Örneğin, sıfır olmayan 11 ağırlığa sahip bir model, sıfır olmayan 10 ağırlığa sahip benzer bir modelden daha fazla ceza alır.
L0 normalleştirmesi bazen L0 normlu normalleştirme olarak adlandırılır.
L1 kaybı
Gerçek etiket değerleri ile modelin tahmin ettiği değerler arasındaki farkın mutlak değerini hesaplayan bir kayıp işlevi. Örneğin, beş örnekten oluşan bir toplu işlem için L1 kaybının hesaplanması aşağıda verilmiştir:
| Örneğin gerçek değeri | Modelin tahmini değeri | Delta'nın mutlak değeri |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 kaybı | ||
L1 kaybı, L2 kaybına göre aykırı değerlere karşı daha az hassastır.
Ortalama Mutlak Hata, örnek başına ortalama L1 kaybıdır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon: Kayıp bölümüne bakın.
L1 normalleştirmesi
Ağırlıkların mutlak değerinin toplamıyla orantılı olarak ağırlıklara ceza uygulayan bir normalleştirme türü. L1 normalleştirme, alakasız veya neredeyse alakasız özelliklerin ağırlıklarını tam olarak 0'a düşürmeye yardımcı olur. Ağırlığı 0 olan bir özellik, modelden etkili bir şekilde kaldırılır.
L2 normalleştirmesi ile karşılaştırın.
L2 kaybı
Gerçek etiket değerleri ile modelin tahmin ettiği değerler arasındaki farkın karesini hesaplayan bir kayıp işlevi. Örneğin, beş örnekten oluşan bir toplu işlem için L2 kaybının hesaplanması aşağıda verilmiştir:
| Örneğin gerçek değeri | Modelin tahmini değeri | Delta kare |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 kaybı | ||
Kare alma işlemi nedeniyle L2 kaybı, aykırı değerlerin etkisini artırır. Yani L2 kaybı, kötü tahminlere L1 kaybından daha güçlü tepki verir. Örneğin, önceki toplu iş için L1 kaybı 16 yerine 8 olur. 16 aykırı değerden 9'unun tek bir aykırı değerden kaynaklandığına dikkat edin.
Regresyon modelleri genellikle kayıp işlevi olarak L2 kaybını kullanır.
Ortalama karesel hata, örnek başına ortalama L2 kaybıdır. Kare kaybı, L2 kaybının diğer adıdır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Mantıksal regresyon: Kayıp ve düzenlileştirme bölümüne bakın.
L2 normalleştirme
Ağırlıkların karelerinin toplamıyla orantılı olarak ağırlıklara oran uygulayan bir normalleştirme türü. L2 normalleştirme, aykırı ağırlıkların (yüksek pozitif veya düşük negatif değerlere sahip olanlar) 0'a daha yakın olmasına yardımcı olur ancak tam olarak 0'a ulaşmaz. Değerleri 0'a çok yakın olan özellikler modelde kalır ancak modelin tahminini çok fazla etkilemez.
L2 düzenlileştirme, doğrusal modellerde her zaman genelleştirmeyi iyileştirir.
L1 normalleştirmesi ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Aşırı Uydurma: L2 düzenlileştirme bölümüne bakın.
etiket
Denetimli makine öğreniminde, bir örneğin "yanıt" veya "sonuç" kısmı.
Her etiketli örnek, bir veya daha fazla özellikten ve bir etiketten oluşur. Örneğin, bir spam algılama veri kümesinde etiket muhtemelen "spam" veya "spam değil" olur. Yağmur yağışı veri kümesinde etiket, belirli bir dönemde yağan yağmur miktarı olabilir.
Daha fazla bilgi için Makine Öğrenimine Giriş bölümündeki Denetimli Öğrenme konusuna bakın.
etiketli örnek
Bir veya daha fazla özellik ve bir etiket içeren bir örnek. Örneğin, aşağıdaki tabloda bir ev değerleme modelinden alınmış, her biri üç özelliğe ve bir etikete sahip üç etiketli örnek gösterilmektedir:
| Yatak odası sayısı | Banyo sayısı | Evin yaşı | Ev fiyatı (etiket) |
|---|---|---|---|
| 3 | 2 | 15 | 345.000 ABD doları |
| 2 | 1 | 72 | $179.000 |
| 4 | 2 | 34 | 392.000 ABD doları |
Gözetimli makine öğreniminde, modeller etiketli örnekler üzerinde eğitilir ve etiketsiz örnekler üzerinde tahminler yapar.
Etiketli örneği etiketsiz örneklerle karşılaştırın.
Daha fazla bilgi için Makine Öğrenimine Giriş bölümündeki Denetimli Öğrenme konusuna bakın.
lambda
Normalleştirme oranı ile eş anlamlıdır.
Lambda, aşırı yüklenmiş bir terimdir. Burada, terimin normalleştirme kapsamındaki tanımına odaklanıyoruz.
katman
Nöral ağdaki bir grup nöron. Sık kullanılan üç katman türü şunlardır:
- Tüm özellikler için değerler sağlayan giriş katmanı.
- Özellikler ile etiket arasındaki doğrusal olmayan ilişkileri bulan bir veya daha fazla gizli katman.
- Tahmini sağlayan çıkış katmanı.
Örneğin, aşağıdaki resimde bir giriş katmanı, iki gizli katman ve bir çıkış katmanı olan bir sinir ağı gösterilmektedir:
TensorFlow'da katmanlar, Tensor'ları ve yapılandırma seçeneklerini giriş olarak alan, çıkış olarak da başka tensorlar üreten Python işlevleridir.
öğrenme hızı
Gradyan inişi algoritmasına her iterasyonda ağırlıkların ve yanlılıkların ne kadar güçlü şekilde ayarlanacağını söyleyen bir kayan noktalı sayıdır. Örneğin, 0,3 öğrenme hızı, ağırlıkları ve yanlılıkları 0,1 öğrenme hızına kıyasla üç kat daha güçlü bir şekilde ayarlar.
Öğrenme hızı önemli bir hiperparametredir. Öğrenme oranını çok düşük ayarlarsanız eğitim çok uzun sürer. Öğrenme oranını çok yüksek ayarlarsanız gradyan inişi genellikle yakınsamaya ulaşmakta zorlanır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon: Hiperparametreler bölümüne bakın.
doğrusal
Yalnızca toplama ve çarpma işlemleriyle gösterilebilen iki veya daha fazla değişken arasındaki ilişki.
Doğrusal bir ilişkinin grafiği bir doğrudur.
Doğrusal olmayan ile karşılaştırma
doğrusal model
Tahmin yapmak için her bir özelliğe bir ağırlık atayan model. (Doğrusal modellerde yanlılık da bulunur.) Buna karşılık, derin modellerde özelliklerin tahminlerle ilişkisi genellikle doğrusal değildir.
Doğrusal modellerin eğitimi genellikle daha kolaydır ve derin modellere kıyasla daha yorumlanabilir. Ancak derin modeller, özellikler arasındaki karmaşık ilişkileri öğrenebilir.
Doğrusal regresyon ve mantıksal regresyon, iki tür doğrusal modeldir.
doğrusal regresyon
Aşağıdakilerin her ikisinin de geçerli olduğu bir makine öğrenimi modeli türü:
- Model, doğrusal bir modeldir.
- Tahmin, kayan nokta değeridir. (Bu, doğrusal regresyonun regresyon kısmıdır.)
Doğrusal regresyonu mantıksal regresyonla karşılaştırın. Ayrıca, regresyonu sınıflandırma ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon bölümüne bakın.
mantıksal regresyon
Bir olasılığı tahmin eden bir tür regresyon modeli. Mantıksal regresyon modelleri aşağıdaki özelliklere sahiptir:
- Etiket kategoriktir. Lojistik regresyon terimi genellikle ikili lojistik regresyonu, yani iki olası değere sahip etiketlerin olasılıklarını hesaplayan bir modeli ifade eder. Daha az yaygın bir varyant olan çok terimli mantıksal regresyon, ikiden fazla olası değere sahip etiketlerin olasılıklarını hesaplar.
- Eğitim sırasında kullanılan kayıp fonksiyonu Log Loss'tur. (İkiden fazla olası değeri olan etiketler için birden fazla Log Loss birimi paralel olarak yerleştirilebilir.)
- Model, derin sinir ağı değil, doğrusal bir mimariye sahiptir. Ancak bu tanımın geri kalanı, kategorik etiketlerin olasılıklarını tahmin eden derin modeller için de geçerlidir.
Örneğin, bir giriş e-postasının spam veya spam olmama olasılığını hesaplayan bir mantıksal regresyon modelini ele alalım. Çıkarım sırasında modelin 0, 72 tahmin ettiğini varsayalım. Bu nedenle, model şu tahminleri yapar:
- E-postanın spam olma olasılığı% 72.
- E-postanın spam olmama olasılığı% 28.
Mantıksal regresyon modeli, aşağıdaki iki adımlı mimariyi kullanır:
- Model, giriş özelliklerinin doğrusal bir fonksiyonunu uygulayarak ham bir tahmin (y') oluşturur.
- Model, bu ham tahmini sigmoid işlevine girdi olarak kullanır. Bu işlev, ham tahmini 0 ile 1 arasında (0 ve 1 hariç) bir değere dönüştürür.
Herhangi bir regresyon modeli gibi, mantıksal regresyon modeli de bir sayı tahmin eder. Ancak bu sayı genellikle aşağıdaki gibi ikili sınıflandırma modelinin bir parçası haline gelir:
- Tahmin edilen sayı sınıflandırma eşiğinden büyükse ikili sınıflandırma modeli pozitif sınıfı tahmin eder.
- Tahmin edilen sayı, sınıflandırma eşiğinden küçükse ikili sınıflandırma modeli negatif sınıfı tahmin eder.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki mantıksal regresyon bölümüne bakın.
Günlük Kaybı
İkili mantıksal regresyonda kullanılan kayıp fonksiyonu.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Mantıksal regresyon: Kayıp ve normalleştirme bölümüne bakın.
log-odds
Bazı olayların olasılık oranının logaritması.
mağlubiyetin ardından
Gözetimli bir modelin eğitimi sırasında, modelin tahmininin etiketinden ne kadar uzak olduğunu gösteren bir ölçü.
Kayıp işlevi, kaybı hesaplar.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon: Kayıp bölümüne bakın.
kayıp eğrisi
Eğitim iterasyonlarının sayısının bir fonksiyonu olarak kaybın grafiği. Aşağıdaki grafikte tipik bir kayıp eğrisi gösterilmektedir:
Kayıp eğrileri, modelinizin ne zaman yakınsadığını veya fazla uyumlu olduğunu belirlemenize yardımcı olabilir.
Kayıp eğrileri, aşağıdaki kayıp türlerinin tümünü çizebilir:
Ayrıca genelleştirme eğrisini de inceleyin.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Aşırı Uydurma: Kayıp eğrilerini yorumlama başlıklı makaleye bakın.
kayıp fonksiyonu
Eğitim veya test sırasında, bir örnek grubu üzerindeki kaybı hesaplayan matematiksel bir işlev. Bir kayıp işlevi, iyi tahminler yapan modeller için kötü tahminler yapan modellere göre daha düşük bir kayıp değeri döndürür.
Eğitimin amacı genellikle bir kayıp fonksiyonunun döndürdüğü kaybı en aza indirmektir.
Birçok farklı türde kayıp fonksiyonu vardır. Oluşturduğunuz model türü için uygun kayıp işlevini seçin. Örneğin:
- L2 kaybı (veya karesi alınmış ortalama hata), doğrusal regresyon için kayıp işlevidir.
- Log kaybı, mantıksal regresyonun kayıp işlevidir.
A
makine öğrenimi
Giriş verilerinden model eğiten bir program veya sistem. Eğitilmiş model, modeli eğitmek için kullanılan dağıtımla aynı dağıtımdan alınan yeni (daha önce hiç görülmemiş) verilerden yararlı tahminler oluşturabilir.
Makine öğrenimi, bu programlar veya sistemlerle ilgili çalışma alanını da ifade eder.
Daha fazla bilgi için Makine Öğrenimine Giriş kursuna bakın.
çoğunluk sınıfı
Sınıf dengesizliği olan bir veri kümesinde daha yaygın olan etiket. Örneğin, %99 negatif etiket ve% 1 pozitif etiket içeren bir veri kümesinde negatif etiketler çoğunluk sınıfıdır.
Azınlık sınıfı ile karşılaştırma
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Veri kümeleri: Dengesiz veri kümeleri bölümüne bakın.
mini toplu iş
Bir iterasyonda işlenen toplu işin küçük ve rastgele seçilmiş bir alt kümesi. Bir mini grubun grup boyutu genellikle 10 ile 1.000 örnek arasındadır.
Örneğin, tüm eğitim kümesinin (tam toplu iş) 1.000 örnekten oluştuğunu varsayalım. Ayrıca, her mini grubun grup boyutunu 20 olarak ayarladığınızı varsayalım. Bu nedenle, her yinelemede 1.000 örnekten rastgele seçilen 20 örnekteki kayıp belirlenir ve ardından ağırlıklar ve eğilimler buna göre ayarlanır.
Kaybı tam toplu işteki tüm örnekler üzerinden hesaplamak yerine mini toplu iş üzerinden hesaplamak çok daha verimlidir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon: Hiperparametreler bölümüne bakın.
azınlık sınıfı
Sınıf dengesizliği olan bir veri kümesindeki daha az yaygın etiket. Örneğin, %99 negatif etiket ve% 1 pozitif etiket içeren bir veri kümesinde pozitif etiketler azınlık sınıfıdır.
Çoğunluk sınıfıyla karşılaştırın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Veri kümeleri: Dengesiz veri kümeleri bölümüne bakın.
model
Genel olarak, giriş verilerini işleyen ve çıkış döndüren tüm matematiksel yapılar. Başka bir deyişle model, bir sistemin tahmin yapması için gereken parametreler ve yapı kümesidir. Gözetimli makine öğreniminde, bir model giriş olarak örnek alır ve çıkış olarak tahmin çıkarır. Gözetimli makine öğreniminde modeller biraz farklılık gösterir. Örneğin:
- Doğrusal regresyon modeli, bir dizi ağırlık ve bir önyargıdan oluşur.
- Nöral ağ modeli şunlardan oluşur:
- Her biri bir veya daha fazla nöron içeren bir dizi gizli katman.
- Her nöronla ilişkili ağırlıklar ve sapma.
- Karar ağacı modeli şunlardan oluşur:
- Ağacın şekli; yani koşulların ve yaprakların bağlanma şekli.
- Koşullar ve ayrılma
Modelleri kaydedebilir, geri yükleyebilir veya kopyalayabilirsiniz.
Gözetimsiz makine öğrenimi de modeller oluşturur. Bu modeller genellikle bir giriş örneğini en uygun kümeye eşleyebilen bir işlevdir.
çok sınıflı sınıflandırma
Denetimli öğrenmede, veri kümesinin ikiden fazla sınıf etiket içerdiği bir sınıflandırma problemi. Örneğin, Iris veri kümesindeki etiketler aşağıdaki üç sınıftan biri olmalıdır:
- Iris setosa
- Iris virginica
- Iris versicolor
Yeni örneklerde Iris türünü tahmin etmek için Iris veri kümesi üzerinde eğitilmiş bir model, çok sınıflı sınıflandırma gerçekleştiriyor.
Buna karşılık, tam olarak iki sınıf arasında ayrım yapan sınıflandırma sorunları ikili sınıflandırma modelleridir. Örneğin, spam veya spam değil olarak tahmin yapan bir e-posta modeli, ikili sınıflandırma modelidir.
Kümeleme sorunlarında çok sınıflı sınıflandırma, ikiden fazla kümeyi ifade eder.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Nöral ağlar: Çok sınıflı sınıflandırma başlıklı makaleyi inceleyin.
H
negatif sınıf
İkili sınıflandırmada bir sınıfa pozitif, diğerine ise negatif adı verilir. Pozitif sınıf, modelin test ettiği şey veya etkinliktir. Negatif sınıf ise diğer olasılıktır. Örneğin:
- Tıbbi bir testteki negatif sınıf "tümör yok" olabilir.
- Bir e-posta sınıflandırma modelindeki negatif sınıf "spam değil" olabilir.
Pozitif sınıfla karşılaştırın.
nöral ağ
En az bir gizli katman içeren bir model. Derin nöral ağ, birden fazla gizli katman içeren bir nöral ağ türüdür. Örneğin, aşağıdaki diyagramda iki gizli katman içeren derin bir sinir ağı gösterilmektedir.
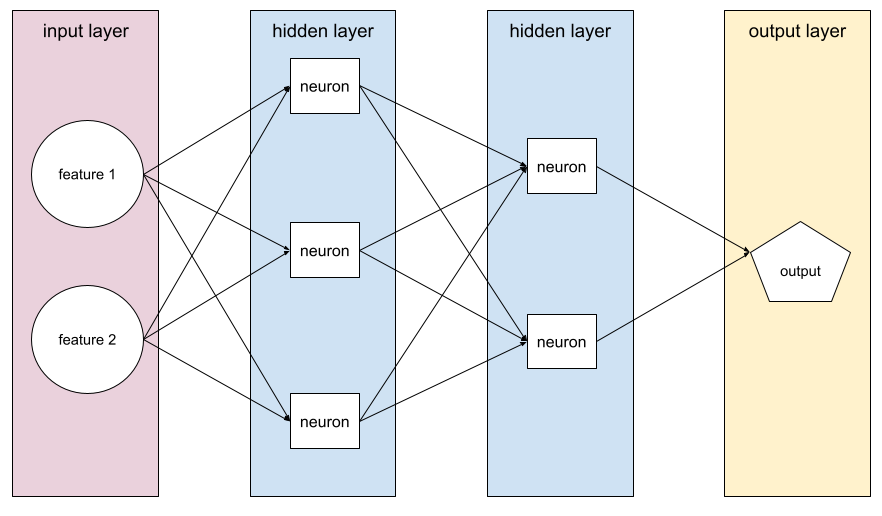
Nöral ağdaki her nöron, bir sonraki katmandaki tüm düğümlere bağlanır. Örneğin, önceki diyagramda ilk gizli katmandaki üç nöronun her birinin, ikinci gizli katmandaki iki nöronun her ikisine de ayrı ayrı bağlandığını görebilirsiniz.
Bilgisayarlarda uygulanan nöral ağlar, beyinlerde ve diğer sinir sistemlerinde bulunan nöral ağlardan ayırt etmek için bazen yapay nöral ağlar olarak adlandırılır.
Bazı sinir ağları, farklı özellikler ile etiket arasındaki son derece karmaşık doğrusal olmayan ilişkileri taklit edebilir.
Ayrıca evrişimli nöral ağ ve yinelemeli nöral ağ başlıklı makalelere de bakın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Nöral ağlar bölümüne bakın.
nöron
Makine öğreniminde, nöral ağın gizli katmanındaki ayrı bir birim. Her nöron aşağıdaki iki adımlı işlemi gerçekleştirir:
- Giriş değerlerinin, karşılık gelen ağırlıklarıyla çarpılmış ağırlıklı toplamını hesaplar.
- Ağırlıklı toplamı bir etkinleştirme işlevine giriş olarak iletir.
İlk gizli katmandaki bir nöron, giriş katmanındaki özellik değerlerinden girişleri kabul eder. İlk katmanın ötesindeki herhangi bir gizli katmanda bulunan bir nöron, önceki gizli katmandaki nöronlardan girişleri kabul eder. Örneğin, ikinci gizli katmandaki bir nöron, ilk gizli katmandaki nöronlardan giriş kabul eder.
Aşağıdaki resimde iki nöron ve bunların girişleri vurgulanmaktadır.

Nöral ağdaki bir nöron, beyinlerdeki ve sinir sistemlerinin diğer kısımlarındaki nöronların davranışını taklit eder.
düğüm (nöral ağ)
Gizli katmandaki bir nöron.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Nöral Ağlar bölümüne bakın.
doğrusal olmayan
Yalnızca toplama ve çarpma işlemleriyle gösterilemeyen iki veya daha fazla değişken arasındaki ilişki. Doğrusal bir ilişki çizgi olarak gösterilebilir. Doğrusal olmayan bir ilişki ise çizgi olarak gösterilemez. Örneğin, her biri tek bir özelliği tek bir etiketle ilişkilendiren iki modeli ele alalım. Soldaki model doğrusal, sağdaki model ise doğrusal değildir:

Farklı türde doğrusal olmayan işlevlerle denemeler yapmak için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Nöral ağlar: Düğümler ve gizli katmanlar bölümüne bakın.
durağan olmama
Değerleri bir veya daha fazla boyutta (genellikle zaman) değişen bir özellik. Örneğin, aşağıdaki durağan olmama örneklerini inceleyin:
- Belirli bir mağazada satılan mayoların sayısı mevsime göre değişir.
- Belirli bir bölgede hasat edilen belirli bir meyvenin miktarı yılın büyük bir bölümünde sıfır olsa da kısa bir süre boyunca yüksek olabilir.
- İklim değişikliği nedeniyle yıllık ortalama sıcaklıklar değişiyor.
Durağanlık ile karşılaştırın.
normalleştirme
Genel olarak, bir değişkenin gerçek değer aralığını standart bir değer aralığına dönüştürme süreci. Örneğin:
- -1 ile +1 arasında
- 0-1
- Z puanları (kabaca -3 ila +3)
Örneğin, belirli bir özelliğin gerçek değer aralığının 800 ila 2.400 olduğunu varsayalım. Özellik mühendisliği kapsamında, gerçek değerleri -1 ile +1 gibi standart bir aralığa normalleştirebilirsiniz.
Normalleştirme, özellik mühendisliğinde yaygın bir görevdir. Özellik vektöründeki her sayısal özellik yaklaşık olarak aynı aralığa sahip olduğunda modeller genellikle daha hızlı eğitilir (ve daha iyi tahminler üretir).
Ayrıca Z puanı normalleştirme konusuna da bakın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sayısal Veriler: Normalleştirme bölümüne bakın.
sayısal veriler
Tam sayılar veya gerçek değerli sayılar olarak gösterilen özellikler. Örneğin, bir ev değerleme modeli, evin büyüklüğünü (metrekare veya metrekare cinsinden) sayısal veri olarak temsil eder. Bir özelliği sayısal veri olarak temsil etmek, özelliğin değerlerinin etiketle matematiksel bir ilişkisi olduğunu gösterir. Yani bir evdeki metrekare sayısı muhtemelen evin değeriyle matematiksel bir ilişkiye sahiptir.
Tüm tam sayı verileri sayısal veri olarak gösterilmemelidir. Örneğin, dünyanın bazı bölgelerindeki posta kodları tam sayıdır ancak tam sayı posta kodları modellerde sayısal veri olarak gösterilmemelidir. Bunun nedeni, 20000 posta kodunun 10000 posta kodundan iki kat (veya yarısı) daha etkili olmamasıdır. Ayrıca, farklı posta kodları farklı emlak değerleriyle ilişkili olsa da 20000 posta kodundaki emlak değerlerinin 10000 posta kodundaki emlak değerlerinden iki kat daha değerli olduğunu varsayamayız.
Posta kodları bunun yerine kategorik veri olarak gösterilmelidir.
Sayısal özelliklere bazen sürekli özellikler de denir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sayısal verilerle çalışma bölümüne bakın.
O
çevrimdışı
Statik kelimesinin eş anlamlısı.
çevrimdışı çıkarım
Bir modelin toplu tahminler oluşturup bu tahminleri önbelleğe alma (kaydetme) süreci. Böylece uygulamalar, modeli yeniden çalıştırmak yerine önbellekteki çıkarılmış tahmine erişebilir.
Örneğin, dört saatte bir yerel hava durumu tahminleri (öngörüler) oluşturan bir modeli ele alalım. Sistem, her model çalıştırmasından sonra tüm yerel hava durumu tahminlerini önbelleğe alır. Hava durumu uygulamaları, tahminleri önbellekten alır.
Çevrimdışı çıkarıma statik çıkarım da denir.
Online çıkarım ile karşılaştırma Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Üretim ML sistemleri: Statik ve dinamik çıkarım bölümüne bakın.
tek sıcak kodlama
Kategorik verileri şu şekilde vektör olarak temsil etme:
- Bir öğe 1 olarak ayarlanır.
- Diğer tüm öğeler 0 olarak ayarlanır.
Tek sıcak kodlama, genellikle sınırlı sayıda olası değere sahip dizeleri veya tanımlayıcıları temsil etmek için kullanılır.
Örneğin, Scandinavia adlı belirli bir kategorik özelliğin beş olası değeri olduğunu varsayalım:
- "Danimarka"
- "İsveç"
- "Norveç"
- "Finland"
- "İzlanda"
Tek sıcak kodlama, beş değerin her birini aşağıdaki gibi temsil edebilir:
| Ülke | Vektör | ||||
|---|---|---|---|---|---|
| "Danimarka" | 1 | 0 | 0 | 0 | 0 |
| "İsveç" | 0 | 1 | 0 | 0 | 0 |
| "Norveç" | 0 | 0 | 1 | 0 | 0 |
| "Finland" | 0 | 0 | 0 | 1 | 0 |
| "İzlanda" | 0 | 0 | 0 | 0 | 1 |
Tek seferlik kodlama sayesinde bir model, beş ülkenin her birine göre farklı bağlantılar öğrenebilir.
Bir özelliği sayısal veri olarak temsil etmek, one-hot kodlamaya bir alternatiftir. Maalesef İskandinav ülkelerini sayısal olarak temsil etmek iyi bir seçim değildir. Örneğin, aşağıdaki sayısal gösterimi ele alalım:
- "Denmark" is 0
- "İsveç" 1
- "Norveç" 2
- "Finland" is 3
- "İzlanda" 4
Sayısal kodlamada model, ham sayıları matematiksel olarak yorumlar ve bu sayılar üzerinde eğitim almaya çalışır. Ancak İzlanda, Norveç'in iki katı (veya yarısı) olmadığından model bazı tuhaf sonuçlara varır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Kategorik veriler: Sözcük dağarcığı ve tek sıcak kodlama bölümüne bakın.
bire karşı tümü
N sınıflı bir sınıflandırma sorunu verildiğinde, N ayrı ikili program sınıflandırma modelinden oluşan bir çözüm (her olası sonuç için bir ikili program sınıflandırma modeli). Örneğin, örnekleri hayvan, bitki veya mineral olarak sınıflandıran bir model verildiğinde, bire karşı tüm çözüm aşağıdaki üç ayrı ikili sınıflandırma modelini sağlar:
- hayvan ve hayvan olmayan
- sebze ve sebze olmayan
- mineral ve mineral olmayan
online
Dinamik kelimesinin eş anlamlısı.
online çıkarım
İsteğe bağlı tahminler oluşturma. Örneğin, bir uygulamanın bir modele giriş ilettiğini ve tahmin isteğinde bulunduğunu varsayalım. Online çıkarım kullanan bir sistem, modeli çalıştırarak (ve tahmini uygulamaya döndürerek) isteğe yanıt verir.
Çevrimdışı çıkarım ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Üretim ML sistemleri: Statik ve dinamik çıkarım bölümüne bakın.
çıkış katmanı
Nöral ağın "son" katmanı. Çıkış katmanı tahmini içerir.
Aşağıdaki görselde, giriş katmanı, iki gizli katman ve çıkış katmanı içeren küçük bir derin sinir ağı gösterilmektedir:
fazla uyumlu
Modelin, eğitim verileriyle o kadar yakından eşleşmesi ki model, yeni verilerle ilgili doğru tahminler yapamaz.
Düzenlileştirme, aşırı uyumu azaltabilir. Büyük ve çeşitli bir eğitim kümesi üzerinde eğitim yapmak da aşırı uyumu azaltabilir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Aşırı Uydurma bölümüne bakın.
P
pandalar
numpy üzerine kurulu, sütun odaklı bir veri analizi API'si. TensorFlow da dahil olmak üzere birçok makine öğrenimi çerçevesi, giriş olarak pandas veri yapılarını destekler. Ayrıntılar için pandas belgelerine bakın.
parametre
Modelin eğitim sırasında öğrendiği ağırlıklar ve önyargılar. Örneğin, bir doğrusal regresyon modelinde parametreler, aşağıdaki formüldeki sapma (b) ve tüm ağırlıklardan (w1, w2 vb.) oluşur:
Buna karşılık, hiperparametreler, sizin (veya bir hiperparametre ayarlama hizmeti) modele sağladığınız değerlerdir. Örneğin, öğrenme hızı bir hiperparametredir.
pozitif sınıf
Test ettiğiniz sınıf.
Örneğin, bir kanser modelindeki pozitif sınıf "tümör" olabilir. Bir e-posta sınıflandırma modelindeki pozitif sınıf "spam" olabilir.
Negatif sınıfla karşılaştırın.
işleme sonrası
Model çalıştırıldıktan sonra modelin çıktısını ayarlama. Modellerin kendilerini değiştirmeden adalet kısıtlamalarını zorunlu kılmak için sonradan işleme kullanılabilir.
Örneğin, bir ikili sınıflandırma modeline, sınıflandırma eşiği ayarlanarak son işlem uygulanabilir. Bu sayede, gerçek pozitif oranının söz konusu özelliğin tüm değerleri için aynı olduğu kontrol edilerek bazı özellikler için fırsat eşitliği korunur.
precision
Aşağıdaki soruyu yanıtlayan sınıflandırma modelleri için bir metrik:
Model pozitif sınıfı tahmin ettiğinde tahminlerin yüzde kaçı doğruydu?
Formül şu şekildedir:
Bu örnekte:
- Gerçek pozitif, modelin pozitif sınıfı doğru tahmin ettiği anlamına gelir.
- Yanlış pozitif, modelin pozitif sınıfı yanlışlıkla tahmin ettiği anlamına gelir.
Örneğin, bir modelin 200 pozitif tahminde bulunduğunu varsayalım. Bu 200 pozitif tahminden:
- 150'si gerçek pozitifti.
- 50'si yanlış pozitif olarak değerlendirildi.
Bu durumda:
Doğruluk ve geri çağırma ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sınıflandırma: Doğruluk, geri çağırma, hassasiyet ve ilgili metrikler bölümüne bakın.
tahmin
Modelin çıktısı. Örneğin:
- İkili sınıflandırma modelinin tahmini, pozitif sınıf veya negatif sınıftır.
- Çok sınıflı sınıflandırma modelinin tahmini tek bir sınıftır.
- Doğrusal regresyon modelinin tahmini bir sayıdır.
proxy etiketleri
Bir veri kümesinde doğrudan kullanılamayan etiketleri tahmin etmek için kullanılan veriler.
Örneğin, çalışanların stres düzeyini tahmin etmek için bir modeli eğitmeniz gerektiğini varsayalım. Veri kümeniz çok sayıda tahmini özellik içeriyor ancak stres seviyesi adlı bir etiket içermiyor. Pes etmeyip stres seviyesi için proxy etiket olarak "iş yeri kazaları"nı seçiyorsunuz. Sonuçta, yüksek stres altındaki çalışanlar sakin çalışanlara göre daha fazla kaza yapar. Yoksa öyle mi? Belki de iş kazaları aslında birden fazla nedenden dolayı artıyor ve azalıyor.
İkinci bir örnek olarak, veri kümeniz için yağmur yağıyor mu? ifadesinin Boole etiketi olmasını istediğinizi ancak veri kümenizde yağmur verilerinin olmadığını varsayalım. Fotoğraflar varsa şemsiye taşıyan kişilerin resimlerini Yağmur yağıyor mu? için proxy etiketi olarak belirleyebilirsiniz. Bu iyi bir vekil etiketi mi? Olabilir ancak bazı kültürlerde insanlar yağmurdan ziyade güneşten korunmak için şemsiye taşıyor olabilir.
Proxy etiketleri genellikle kusurludur. Mümkün olduğunda, proxy etiketler yerine gerçek etiketleri seçin. Bununla birlikte, gerçek bir etiket olmadığında en az kötü olan vekil etiket adayını seçerek vekil etiketi çok dikkatli bir şekilde belirleyin.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Veri Kümeleri: Etiketler bölümüne bakın.
R
RAG
Almayla artırılmış üretim ifadesinin kısaltmasıdır.
puan veren kullanıcı
Örnekler için etiketler sağlayan kişi. "Açıklama Ekleyen", değerlendiricinin diğer adıdır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Kategorik veriler: Yaygın sorunlar başlıklı makaleye bakın.
hatırlanabilirlik
Aşağıdaki soruyu yanıtlayan sınıflandırma modelleri için bir metrik:
Kesin referans pozitif sınıf olduğunda model, tahminlerin yüzde kaçını doğru şekilde pozitif sınıf olarak tanımladı?
Formül şu şekildedir:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
Bu örnekte:
- Gerçek pozitif, modelin pozitif sınıfı doğru tahmin ettiği anlamına gelir.
- Yanlış negatif, modelin yanlışlıkla negatif sınıfı tahmin ettiği anlamına gelir.
Örneğin, modelinizin, temel doğrusu pozitif sınıf olan örnekler üzerinde 200 tahmin yaptığını varsayalım. Bu 200 tahminden:
- 180'i doğru pozitif olarak sınıflandırıldı.
- 20'si yanlış negatifti.
Bu durumda:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Daha fazla bilgi için Sınıflandırma: Doğruluk, geri çağırma, hassasiyet ve ilgili metrikler başlıklı makaleyi inceleyin.
Düzeltilmiş Doğrusal Birim (ReLU)
Aşağıdaki davranışa sahip bir etkinleştirme işlevi:
- Giriş negatif veya sıfırsa çıkış 0 olur.
- Giriş pozitifse çıkış girişe eşittir.
Örneğin:
- Giriş -3 ise çıkış 0 olur.
- Giriş +3 ise çıkış 3, 0 olur.
ReLU'nun grafiği:

ReLU, çok popüler bir etkinleştirme işlevidir. Basit davranışına rağmen ReLU, sinir ağının doğrusal olmayan ilişkileri özellikler ile etiket arasında öğrenmesini sağlar.
regresyon modeli
Gayri resmi olarak, sayısal tahmin oluşturan bir model. (Buna karşılık, sınıflandırma modeli bir sınıf tahmini oluşturur.) Örneğin, aşağıdakilerin tümü regresyon modelidir:
- Belirli bir evin değerini euro cinsinden tahmin eden bir model (ör. 423.000).
- Belirli bir ağacın ortalama yaşam süresini yıllar içinde tahmin eden bir model (ör.23,2).
- Belirli bir şehre önümüzdeki altı saat içinde düşecek yağmur miktarını inç cinsinden tahmin eden bir model (ör.0, 18).
Sık kullanılan iki tür regresyon modeli şunlardır:
- Etiket değerlerini özelliklere en iyi şekilde uyduran çizgiyi bulan doğrusal regresyon.
- Mantıksal regresyon: 0,0 ile 1,0 arasında bir olasılık oluşturur. Bu olasılık, sistem tarafından genellikle bir sınıf tahminiyle eşlenir.
Sayısal tahminler veren her model bir regresyon modeli değildir. Bazı durumlarda sayısal tahmin, sayısal sınıf adlarına sahip bir sınıflandırma modelidir. Örneğin, sayısal bir posta kodunu tahmin eden model regresyon modeli değil, sınıflandırma modelidir.
normalleştirme
Aşırı uyumu azaltan tüm mekanizmalar. Popüler düzenlileştirme türleri şunlardır:
- L1 normalleştirme
- L2 normalleştirme
- dropout regularization (dropout düzenlileştirme)
- erken durdurma (Bu, resmi bir düzenlileştirme yöntemi olmasa da aşırı uyumu etkili bir şekilde sınırlayabilir.)
Normalleştirme, bir modelin karmaşıklığına uygulanan ceza olarak da tanımlanabilir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Aşırı Uydurma: Model karmaşıklığı bölümüne bakın.
normalleştirme oranı
Eğitim sırasında normalleştirmenin göreli önemini belirten bir sayı. Düzenlileştirme oranını artırmak aşırı uyumu azaltır ancak modelin tahmin gücünü düşürebilir. Bunun tersine, düzenlileştirme oranının azaltılması veya atlanması aşırı uyumu artırır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Aşırı Uydurma: L2 düzenlileştirme bölümüne bakın.
ReLU
Rectified Linear Unit'in kısaltmasıdır.
veriyle artırılmış üretim (RAG)
Büyük dil modeli (LLM) çıkışının kalitesini, model eğitildikten sonra alınan bilgi kaynaklarıyla temellendirerek iyileştirmeye yönelik bir teknik. RAG, eğitilmiş LLM'ye güvenilir bilgi tabanlarından veya belgelerden alınan bilgilere erişim sağlayarak LLM yanıtlarının doğruluğunu artırır.
Almayla artırılmış üretimi kullanmanın yaygın nedenleri şunlardır:
- Modelin oluşturduğu yanıtların olgusal doğruluğunu artırma
- Modele, eğitilmediği bilgilere erişim izni verme
- Modelin kullandığı bilgileri değiştirme
- Modelin kaynakları alıntılamasını sağlama
Örneğin, bir kimya uygulamasının kullanıcı sorgularıyla ilgili özetler oluşturmak için PaLM API'yi kullandığını varsayalım. Uygulamanın arka ucu bir sorgu aldığında arka uç:
- Kullanıcının sorgusuyla alakalı verileri arar ("alır").
- İlgili kimya verilerini kullanıcının sorgusuna ekler ("artırır").
- LLM'ye, eklenen verilere dayalı bir özet oluşturması talimatı verilir.
ROC (alıcı çalışma özelliği) eğrisi
İkili sınıflandırmada farklı sınıflandırma eşikleri için gerçek pozitif oranı ile yanlış pozitif oranı arasındaki ilişkiyi gösteren grafik.
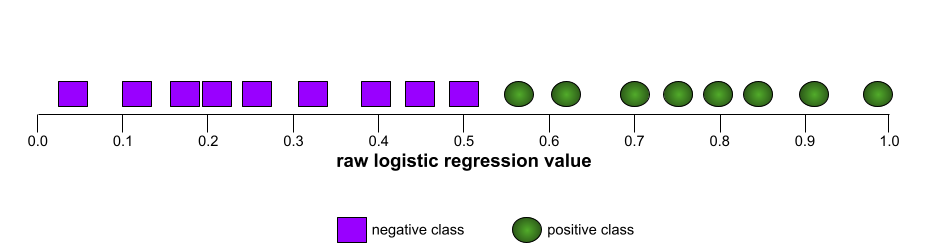
ROC eğrisinin şekli, ikili sınıflandırma modelinin pozitif sınıfları negatif sınıflardan ayırma yeteneğini gösterir. Örneğin, ikili sınıflandırma modelinin tüm negatif sınıfları tüm pozitif sınıflardan mükemmel şekilde ayırdığını varsayalım:
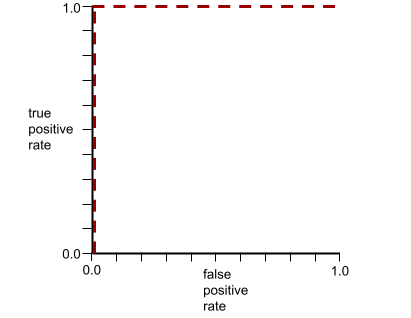
Önceki modelin ROC eğrisi aşağıdaki gibi görünür:
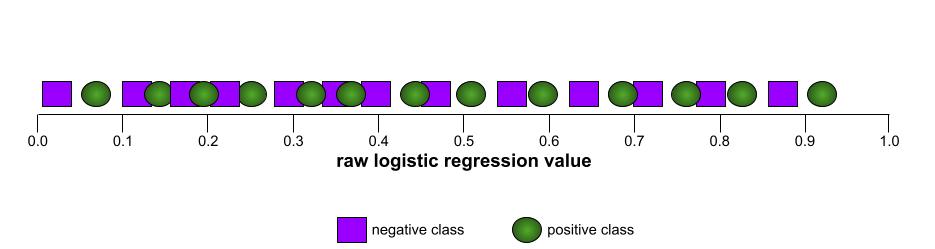
Buna karşılık, aşağıdaki resimde, negatif sınıfları pozitif sınıflardan hiç ayıramayan kötü bir modelin ham mantıksal regresyon değerleri grafik olarak gösterilmektedir:
Bu modelin ROC eğrisi aşağıdaki gibi görünür:
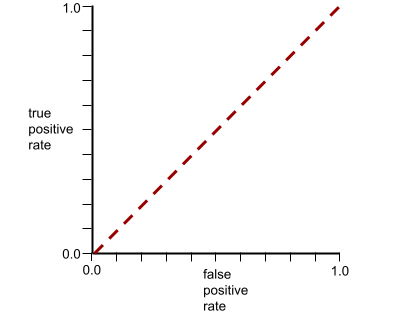
Bu arada, gerçek hayatta çoğu ikili sınıflandırma modeli pozitif ve negatif sınıfları bir dereceye kadar ayırır ancak genellikle mükemmel bir şekilde değil. Bu nedenle, tipik bir ROC eğrisi iki uç nokta arasında bir yerde bulunur:
Bir ROC eğrisinde (0.0,1.0) noktasına en yakın olan nokta, teorik olarak ideal sınıflandırma eşiğini tanımlar. Ancak ideal sınıflandırma eşiğinin seçilmesini etkileyen başka gerçek dünya sorunları da vardır. Örneğin, yanlış negatif sonuçlar, yanlış pozitif sonuçlardan çok daha fazla sorun yaratabilir.
AUC adı verilen sayısal bir metrik, ROC eğrisini tek bir kayan nokta değeriyle özetler.
Kök Ortalama Kare Hatası (RMSE)
Ortalama karesel hatanın karekökü.
G
sigmoid işlevi
Bir giriş değerini sınırlı bir aralığa (genellikle 0 ile 1 veya -1 ile +1) "sıkıştıran" matematiksel bir işlev. Yani, bir sigmoid fonksiyonuna herhangi bir sayı (iki, bir milyon, eksi bir milyar vb.) iletebilirsiniz ve çıkış yine de sınırlı aralıkta olur. Sigmoid aktivasyon fonksiyonunun grafiği şu şekilde görünür:
Sigmoid işlevinin makine öğreniminde çeşitli kullanım alanları vardır. Örneğin:
- Mantıksal regresyon veya çok terimli regresyon modelinin ham çıktısını olasılığa dönüştürme.
- Bazı sinir ağlarında etkinleştirme işlevi olarak çalışır.
softmax
Çok sınıflı sınıflandırma modelinde olası her sınıf için olasılıkları belirleyen bir işlev. Olasılıkların toplamı tam olarak 1,0'dır. Örneğin, aşağıdaki tabloda softmax'ın çeşitli olasılıkları nasıl dağıttığı gösterilmektedir:
| Resim bir... | Probability |
|---|---|
| köpek | 0,85 |
| Cat | 0,13 |
| at | 0,02 |
Softmax, tam softmax olarak da adlandırılır.
Aday örnekleme ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Nöral ağlar: Çok sınıflı sınıflandırma başlıklı makaleyi inceleyin.
seyrek özellik
Değerleri çoğunlukla sıfır veya boş olan bir özellik. Örneğin, tek bir 1 değeri ve bir milyon 0 değeri içeren bir özellik seyrek olur. Buna karşılık, yoğun bir özellik, çoğunlukla sıfır veya boş olmayan değerlere sahiptir.
Makine öğreniminde, şaşırtıcı sayıda özellik seyrek özelliklerdir. Kategorik özellikler genellikle seyrek özelliklerdir. Örneğin, bir ormanda olabilecek 300 ağaç türünden tek bir örnek yalnızca akçaağaç olarak tanımlanabilir. Alternatif olarak, bir video kitaplığındaki milyonlarca olası videodan tek bir örnek yalnızca "Casablanca"yı tanımlayabilir.
Bir modelde, seyrek özellikleri genellikle one-hot kodlama ile temsil edersiniz. Tek sıcak kodlama büyükse daha fazla verimlilik için tek sıcak kodlamanın üzerine bir gömme katmanı yerleştirebilirsiniz.
seyrek gösterim
Seyrek bir özellikte yalnızca sıfır olmayan öğelerin konumlarını saklama.
Örneğin, species adlı kategorik bir özelliğin belirli bir ormandaki 36 ağaç türünü tanımladığını varsayalım. Ayrıca her örneğin yalnızca tek bir türü tanımladığını varsayalım.
Her örnekteki ağaç türünü göstermek için tek sıcaklık vektörü kullanabilirsiniz.
Tek sıcaklık vektöründe tek bir 1 (örnekteki belirli ağaç türünü temsil etmek için) ve 35 0 (örnekteki 35 ağaç türünü temsil etmemek için) bulunur. Bu nedenle, maple öğesinin tek sıcaklık gösterimi aşağıdaki gibi olabilir:

Alternatif olarak, seyrek gösterim yalnızca belirli türlerin konumunu tanımlar. maple 24. konumdaysa maple öğesinin seyrek gösterimi şu şekilde olur:
24
Seyrek gösterimin, tek sıcak gösterimden çok daha kompakt olduğuna dikkat edin.
Biraz daha karmaşık bir örnek için simgeyi tıklayın.
Modelinizdeki her örneğin, İngilizce bir cümledeki kelimeleri (ancak bu kelimelerin sırasını değil) temsil etmesi gerektiğini varsayalım. İngilizce yaklaşık 170.000 kelimeden oluşur. Bu nedenle İngilizce, yaklaşık 170.000 öğeli kategorik bir özelliktir. İngilizce cümlelerin çoğunda bu 170.000 kelimenin çok küçük bir kısmı kullanılır. Bu nedenle, tek bir örnekteki kelime grubu neredeyse kesinlikle seyrek veriler olacaktır.
Aşağıdaki cümleyi ele alalım:
My dog is a great dog
Bu cümledeki kelimeleri temsil etmek için tek sıcak vektörün bir varyantını kullanabilirsiniz. Bu varyantta, vektördeki birden fazla hücre sıfır olmayan bir değer içerebilir. Ayrıca bu varyantta bir hücre, birden farklı bir tam sayı içerebilir. "Benim", "bir", "harika" ve "köpeğim" kelimeleri cümlede yalnızca bir kez geçse de "köpek" kelimesi iki kez geçiyor. Bu cümlede yer alan kelimeleri temsil etmek için tek sıcak vektörlerin bu varyantını kullandığımızda 170.000 öğeli aşağıdaki vektör elde edilir:

Aynı cümlenin seyrek gösterimi şu şekilde olur:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Kategorik verilerle çalışma başlıklı makaleyi inceleyin.
seyrek vektör
Değerleri çoğunlukla sıfır olan bir vektör. Ayrıca sparse feature ve sparsity konularına da bakın.
kare kaybı
L2 kaybı ile eş anlamlıdır.
statik
Sürekli olarak değil, bir kez yapılan bir şey. Statik ve çevrimdışı terimleri eş anlamlıdır. Makine öğreniminde statik ve çevrimdışı ile ilgili yaygın kullanım alanları şunlardır:
- Statik model (veya çevrimdışı model), bir kez eğitilen ve bir süre kullanılan modeldir.
- Statik eğitim (veya çevrimdışı eğitim), statik bir modeli eğitme sürecidir.
- Statik çıkarım (veya çevrimdışı çıkarım), bir modelin tek seferde bir grup tahmin oluşturduğu bir süreçtir.
Dinamik ile kontrast oluşturun.
statik çıkarım
Çevrimdışı çıkarım ile eş anlamlıdır.
durağanlık
Değerleri bir veya daha fazla boyutta (genellikle zaman) değişmeyen bir özellik. Örneğin, değerleri 2021 ve 2023'te yaklaşık olarak aynı görünen bir özellik durağanlık gösterir.
Gerçek dünyada çok az özellik durağanlık gösterir. Kararlılıkla eş anlamlı olan özellikler (ör. deniz seviyesi) bile zaman içinde değişir.
Durağansızlık ile karşılaştırın.
stokastik gradyan inişi (SGD)
Grup boyutunun bir olduğu gradyan inişi algoritması. Diğer bir deyişle SGD, eğitim setinden rastgele ve eşit şekilde seçilen tek bir örnek üzerinde eğitilir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon: Hiperparametreler başlıklı makaleyi inceleyin.
denetimli makine öğrenmesi
Özelliklerden ve bunlara karşılık gelen etiketlerden model eğitimi. Denetimli makine öğrenimi, bir dizi soruyu ve ilgili cevaplarını inceleyerek bir konuyu öğrenmeye benzer. Sorular ve cevaplar arasındaki eşlemeyi öğrendikten sonra, öğrenciler aynı konuyla ilgili yeni (daha önce hiç görülmemiş) soruları yanıtlayabilir.
Denetimsiz makine öğrenimi ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimine Giriş kursundaki Gözetimli Öğrenme bölümüne bakın.
yapay özellik
Giriş özellikleri arasında bulunmayan ancak bir veya daha fazla giriş özelliğinden oluşturulan bir özellik. Yapay özellikler oluşturma yöntemleri şunlardır:
- Sürekli bir özelliği aralık paketlerine paketleme.
- Özellikler arası geçiş oluşturma.
- Bir özellik değerini diğer özellik değerleriyle veya kendisiyle çarpma (ya da bölme). Örneğin,
avebgiriş özellikleri ise aşağıdaki özellikler sentetik özellik örnekleridir:- ab
- a2
- Bir özellik değerine aşkın fonksiyon uygulama. Örneğin,
cbir giriş özelliği ise aşağıdaki özellikler sentetik özellik örnekleridir:- sin(c)
- ln(c)
Yalnızca normalleştirme veya ölçeklendirme ile oluşturulan özellikler, sentetik özellik olarak kabul edilmez.
T
test kaybı
Bir modelin test kümesine karşı kaybını temsil eden bir metrik. Model oluştururken genellikle test kaybını en aza indirmeye çalışırsınız. Bunun nedeni, düşük test kaybının düşük eğitim kaybı veya düşük doğrulama kaybından daha güçlü bir kalite sinyali olmasıdır.
Test kaybı ile eğitim kaybı veya doğrulama kaybı arasında büyük bir fark olması bazen normalleştirme oranını artırmanız gerektiğini gösterir.
eğitim
Modeli oluşturan ideal parametreleri (ağırlıklar ve önyargılar) belirleme süreci. Eğitim sırasında bir sistem, örnekleri okur ve parametreleri kademeli olarak ayarlar. Eğitimde her örnek birkaç kezden milyarlarca kez kullanılabilir.
Daha fazla bilgi için Makine Öğrenimine Giriş kursundaki Gözetimli Öğrenme bölümüne bakın.
eğitim kaybı
Belirli bir eğitim yinelemesi sırasında modelin kaybını temsil eden bir metrik. Örneğin, kayıp işlevinin ortalama kare hatası olduğunu varsayalım. Örneğin, 10.yinelemede eğitim kaybı (ortalama kare hatası) 2,2 ve 100.yinelemede eğitim kaybı 1,9 olabilir.
Kayıp eğrisi, eğitim kaybını yineleme sayısına karşı çizer. Bir kayıp eğrisi, eğitimle ilgili aşağıdaki ipuçlarını sağlar:
- Aşağı doğru eğim, modelin iyileştiğini gösterir.
- Yukarı doğru eğim, modelin kötüleştiğini gösterir.
- Düz bir eğim, modelin yakınsama noktasına ulaştığını gösterir.
Örneğin, aşağıdaki biraz idealize edilmiş kayıp eğrisi şunları gösterir:
- İlk yinelemeler sırasında hızlı model iyileştirmesini ifade eden dik bir aşağı eğim.
- Eğitim sona erene kadar kademeli olarak düzleşen (ancak yine de aşağı doğru) bir eğim. Bu, ilk yinelemelerdeki hızdan biraz daha yavaş bir hızda modelin iyileşmeye devam ettiğini gösterir.
- Eğitimin sonuna doğru düzleşen bir eğim, yakınsamayı gösterir.
Eğitim kaybı önemli olsa da genelleme konusuna da göz atın.
eğitim ve sunma arası sapma
Bir modelin eğitim sırasındaki performansı ile aynı modelin sunma sırasındaki performansı arasındaki fark.
eğitim seti
Model eğitmek için kullanılan veri kümesinin alt kümesi.
Geleneksel olarak, veri kümesindeki örnekler aşağıdaki üç farklı alt kümeye ayrılır:
- eğitim seti
- Doğrulama kümesi
- test seti
İdeal olarak, veri kümesindeki her örnek yalnızca yukarıdaki alt kümelerden birine ait olmalıdır. Örneğin, tek bir örnek hem eğitim kümesine hem de doğrulama kümesine ait olmamalıdır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Veri kümeleri: Orijinal veri kümesini bölme başlıklı makaleyi inceleyin.
doğru negatif (TN)
Modelin negatif sınıfı doğru tahmin ettiği bir örnek. Örneğin, model belirli bir e-posta iletisinin spam olmadığını çıkarır ve bu e-posta iletisi gerçekten spam değildir.
Gerçek pozitif (TP)
Modelin pozitif sınıfı doğru tahmin ettiği bir örnek. Örneğin, model belirli bir e-posta iletisinin spam olduğunu çıkarımlıyor ve bu e-posta iletisi gerçekten spam oluyor.
Gerçek pozitif oranı (TPR)
Geri çağırma ile eş anlamlıdır. Yani:
Gerçek pozitif oranı, ROC eğrisindeki y eksenidir.
U
eksik uyum
Model, eğitim verilerinin karmaşıklığını tam olarak yakalamadığı için zayıf tahmin yeteneğine sahip bir model oluşturma. Aşağıdakiler de dahil olmak üzere birçok sorun, eksik uyuma neden olabilir:
- Yanlış özellikler kümesiyle eğitim yapılması.
- Çok az dönem için veya çok düşük bir öğrenme hızıyla eğitim.
- Çok yüksek bir normalleştirme oranıyla eğitim.
- Derin bir nöral ağda çok az gizli katman sağlamak.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Aşırı Uydurma bölümüne bakın.
etiketsiz örnek
Özellik içeren ancak etiket içermeyen bir örnek. Örneğin, aşağıdaki tabloda bir ev değerleme modelinden alınan üç etiketsiz örnek gösterilmektedir. Bu örneklerin her birinde üç özellik vardır ancak ev değeri yoktur:
| Yatak odası sayısı | Banyo sayısı | Evin yaşı |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
Gözetimli makine öğreniminde, modeller etiketli örnekler üzerinde eğitilir ve etiketsiz örnekler üzerinde tahminler yapar.
Yarı gözetimli ve denetimsiz öğrenmede eğitim sırasında etiketsiz örnekler kullanılır.
Etiketlenmemiş örneği etiketlenmiş örnekle karşılaştırın.
denetimsiz makine öğrenmesi
Bir veri kümesindeki (genellikle etiketlenmemiş bir veri kümesi) kalıpları bulmak için model eğitme.
Gözetimsiz makine öğreniminin en yaygın kullanım şekli, verileri benzer örnekler grupları halinde kümelemektir. Örneğin, gözetimsiz bir makine öğrenimi algoritması, şarkıları müziğin çeşitli özelliklerine göre gruplandırabilir. Elde edilen kümeler, diğer makine öğrenimi algoritmalarına (ör. müzik önerisi hizmeti) giriş olarak kullanılabilir. Kümeleme, faydalı etiketlerin az olduğu veya hiç olmadığı durumlarda yardımcı olabilir. Örneğin, kötüye kullanım ve sahtekarlıkla mücadele gibi alanlarda kümeler, insanların verileri daha iyi anlamasına yardımcı olabilir.
Denetimli makine öğrenimi ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimine Giriş kursundaki Makine öğrenimi nedir? başlıklı makaleyi inceleyin.
V
doğrulama
Bir modelin kalitesinin ilk değerlendirmesi. Doğrulama, bir modelin tahminlerinin kalitesini doğrulama kümesine göre kontrol eder.
Doğrulama seti, eğitim setinden farklı olduğundan doğrulama, aşırı uyum sorununu önlemeye yardımcı olur.
Modeli doğrulama kümesine göre değerlendirmeyi ilk test turu, modeli test kümesine göre değerlendirmeyi ise ikinci test turu olarak düşünebilirsiniz.
doğrulama kaybı
Eğitimin belirli bir iterasyonu sırasında doğrulama setindeki bir modelin kaybını temsil eden bir metrik.
Ayrıca genelleştirme eğrisini de inceleyin.
doğrulama seti
Eğitilmiş bir modele karşı ilk değerlendirmeyi yapan veri kümesinin alt kümesi. Genellikle, modeli test kümesine göre değerlendirmeden önce eğitilmiş modeli doğrulama kümesine göre birkaç kez değerlendirirsiniz.
Geleneksel olarak, veri kümesindeki örnekleri aşağıdaki üç farklı alt kümeye bölersiniz:
- eğitim seti
- doğrulama kümesi
- test seti
İdeal olarak, veri kümesindeki her örnek yalnızca yukarıdaki alt kümelerden birine ait olmalıdır. Örneğin, tek bir örnek hem eğitim kümesine hem de doğrulama kümesine ait olmamalıdır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Veri kümeleri: Orijinal veri kümesini bölme başlıklı makaleyi inceleyin.
W
ağırlık
Bir modelin başka bir değerle çarptığı değer. Eğitim, bir modelin ideal ağırlıklarını belirleme sürecidir. Çıkarım ise tahminlerde bulunmak için öğrenilen bu ağırlıkları kullanma sürecidir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Doğrusal regresyon bölümüne bakın.
ağırlıklı toplam
İlgili tüm giriş değerlerinin toplamının, karşılık gelen ağırlıklarıyla çarpılması. Örneğin, ilgili girişlerin aşağıdakilerden oluştuğunu varsayalım:
| giriş değeri | giriş ağırlığı |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
Bu nedenle, ağırlıklı toplam şu şekildedir:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Ağırlıklı toplam, bir etkinleştirme işlevinin giriş bağımsız değişkenidir.
Z
Z puanı normalleştirme
Ham özellik değerini, söz konusu özelliğin ortalamasından standart sapma sayısını temsil eden bir kayan nokta değeriyle değiştiren bir ölçeklendirme tekniği. Örneğin, ortalaması 800 ve standart sapması 100 olan bir özelliği ele alalım. Aşağıdaki tabloda, Z puanı normalleştirmenin ham değeri Z puanıyla nasıl eşleyeceği gösterilmektedir:
| İşlenmemiş değer | Z puanı |
|---|---|
| 800 | 0 |
| 950 | +1,5 |
| 575 | -2,25 |
Ardından makine öğrenimi modeli, ham değerler yerine bu özelliğin Z puanları üzerinde eğitilir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sayısal veriler: Normalleştirme bölümüne bakın.