Questa pagina contiene i termini del glossario dei concetti fondamentali dell'ML. Per tutti i termini del glossario, fai clic qui.
A
accuracy
Il numero di previsioni di classificazione corrette diviso per il numero totale di previsioni. Ossia:
Ad esempio, un modello che ha effettuato 40 previsioni corrette e 10 errate avrebbe un'accuratezza pari a:
La classificazione binaria fornisce nomi specifici per le diverse categorie di previsioni corrette e previsioni errate. Pertanto, la formula dell'accuratezza per la classificazione binaria è la seguente:
dove:
- TP è il numero di veri positivi (previsioni corrette).
- TN è il numero di veri negativi (previsioni corrette).
- FP è il numero di falsi positivi (previsioni errate).
- FN è il numero di falsi negativi (previsioni errate).
Confronta e metti a confronto l'accuratezza con la precisione e il richiamo.
Per saperne di più, consulta Classificazione: accuratezza, richiamo, precisione e metriche correlate in Machine Learning Crash Course.
funzione di attivazione
Una funzione che consente alle reti neurali di apprendere relazioni non lineari (complesse) tra le caratteristiche e l'etichetta.
Le funzioni di attivazione più comuni includono:
I grafici delle funzioni di attivazione non sono mai singole linee rette. Ad esempio, il grafico della funzione di attivazione ReLU è costituito da due linee rette:

Un grafico della funzione di attivazione sigmoide è il seguente:

Fai clic sull'icona per visualizzare un esempio.
In una rete neurale, le funzioni di attivazione manipolano la somma ponderata di tutti gli input di un neurone. Per calcolare una somma ponderata, il neurone somma i prodotti dei valori e dei pesi pertinenti. Ad esempio, supponiamo che l'input pertinente per un neurone sia costituito da quanto segue:
| valore di input | peso dell'input |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
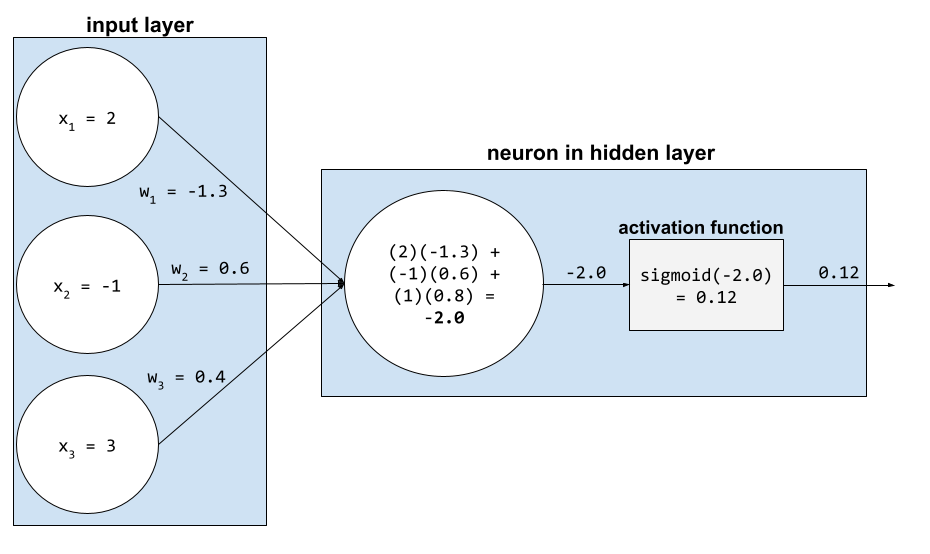
Per saperne di più, consulta Reti neurali: funzioni di attivazione in Machine Learning Crash Course.
intelligenza artificiale
Un programma o un modello non umano in grado di risolvere attività sofisticate. Ad esempio, un programma o un modello che traduce il testo o un programma o un modello che identifica le malattie dalle immagini radiologiche mostrano entrambi intelligenza artificiale.
Formalmente, il machine learning è un sottocampo dell'intelligenza artificiale. Tuttavia, negli ultimi anni, alcune organizzazioni hanno iniziato a utilizzare i termini intelligenza artificiale e machine learning in modo intercambiabile.
AUC (area sotto la curva ROC)
Un numero compreso tra 0,0 e 1,0 che rappresenta la capacità di un modello di classificazione binaria di separare le classi positive dalle classi negative. Più l'AUC è vicino a 1,0, migliore è la capacità del modello di separare le classi tra loro.
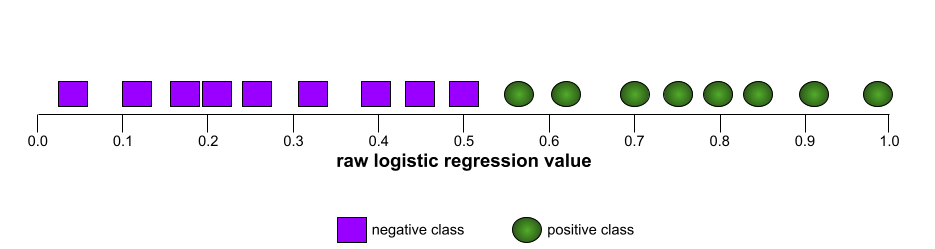
Ad esempio, la seguente illustrazione mostra un modello di classificazione che separa perfettamente le classi positive (ovali verdi) da quelle negative (rettangoli viola). Questo modello perfetto in modo non realistico ha un'AUC pari a 1,0:

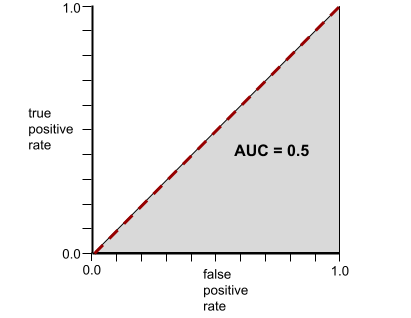
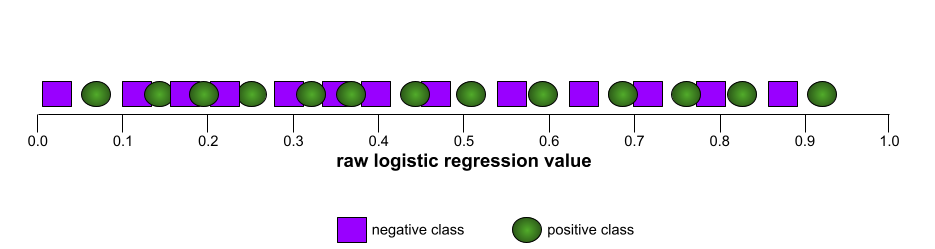
Al contrario, l'illustrazione seguente mostra i risultati per un modello di classificazione che ha generato risultati casuali. Questo modello ha un AUC di 0,5:

Sì, il modello precedente ha un'AUC di 0,5, non di 0.
La maggior parte dei modelli si trova a metà strada tra i due estremi. Ad esempio, il seguente modello separa in qualche modo i positivi dai negativi e pertanto ha un'AUC compresa tra 0,5 e 1,0:

L'AUC ignora qualsiasi valore impostato per la soglia di classificazione. L'AUC, invece, prende in considerazione tutte le possibili soglie di classificazione.
Fai clic sull'icona per scoprire la relazione tra le curve AUC e ROC.
L'AUC rappresenta l'area sotto una curva ROC. Ad esempio, la curva ROC per un modello che separa perfettamente i positivi dai negativi è la seguente:
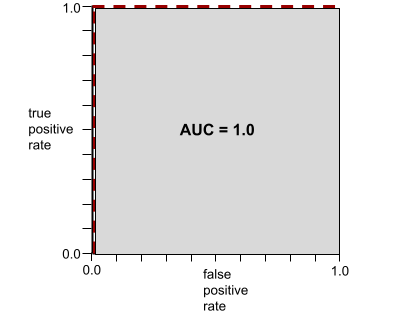
L'AUC è l'area della regione grigia nell'illustrazione precedente. In questo caso insolito, l'area è semplicemente la lunghezza della regione grigia (1.0) moltiplicata per la larghezza della regione grigia (1.0). Pertanto, il prodotto di 1,0 e 1,0 produce un AUC pari esattamente a 1,0, che è il punteggio AUC più alto possibile.
Al contrario, la curva ROC per un modello di classificazione che non può separare le classi è la seguente. L'area di questa regione grigia è 0,5.
Una curva ROC più tipica ha un aspetto simile al seguente:
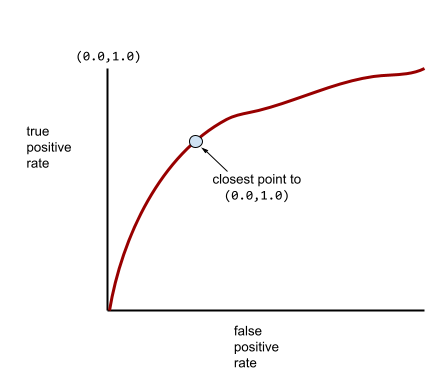
Calcolare manualmente l'area sotto questa curva sarebbe un'operazione laboriosa, motivo per cui in genere un programma calcola la maggior parte dei valori AUC.
Per saperne di più, consulta Classificazione: ROC e AUC in Machine Learning Crash Course.
B
backpropagation
L'algoritmo che implementa la discesa del gradiente nelle reti neurali.
L'addestramento di una rete neurale prevede molte iterazioni del seguente ciclo a due passaggi:
- Durante il passaggio in avanti, il sistema elabora un batch di esempi per generare una o più previsioni. Il sistema confronta ogni previsione con ogni valore dell'etichetta. La differenza tra la previsione e il valore dell'etichetta è la perdita per quell'esempio. Il sistema aggrega le perdite per tutti gli esempi per calcolare la perdita totale per il batch corrente.
- Durante il passaggio all'indietro (backpropagation), il sistema riduce la perdita modificando i pesi di tutti i neuroni in tutti gli strati nascosti.
Le reti neurali spesso contengono molti neuroni in molti strati nascosti. Ciascuno di questi neuroni contribuisce alla perdita complessiva in modi diversi. La retropropagazione determina se aumentare o diminuire i pesi applicati a particolari neuroni.
Il tasso di apprendimento è un moltiplicatore che controlla il grado in cui ogni passaggio all'indietro aumenta o diminuisce ogni peso. Un tasso di apprendimento elevato aumenterà o diminuirà ogni peso più di un tasso di apprendimento basso.
In termini di calcolo, la retropropagazione implementa la regola della catena del calcolo. ovvero la retropropagazione calcola la derivata parziale dell'errore rispetto a ogni parametro.
Anni fa, i professionisti del machine learning dovevano scrivere codice per implementare la backpropagation. Le moderne API ML come Keras ora implementano la backpropagation per te. Finalmente.
Per saperne di più, consulta la sezione Reti neurali di Machine Learning Crash Course.
batch
L'insieme di esempi utilizzati in un'iterazione di addestramento . La dimensione del batch determina il numero di esempi in un batch.
Per una spiegazione di come un batch si relaziona a un'epoca, consulta la sezione epoca.
Per saperne di più, consulta Regressione lineare: iperparametri in Machine Learning Crash Course.
dimensione del batch
Il numero di esempi in un batch. Ad esempio, se la dimensione del batch è 100, il modello elabora 100 esempi per iterazione.
Di seguito sono riportate le strategie più comuni per le dimensioni del batch:
- Discesa stocastica del gradiente (SGD), in cui la dimensione del batch è 1.
- Batch completo, in cui la dimensione del batch è il numero di esempi nell'intero set di addestramento. Ad esempio, se il set di addestramento contiene un milione di esempi, la dimensione del batch sarà di un milione di esempi. Il caricamento completo del batch è in genere una strategia inefficiente.
- Mini-batch in cui la dimensione del batch è generalmente compresa tra 10 e 1000. Il mini-batch è in genere la strategia più efficiente.
Per ulteriori informazioni, consulta le seguenti risorse:
- Sistemi ML di produzione: inferenza statica e dinamica in Machine Learning Crash Course.
- Guida pratica per l'ottimizzazione del deep learning.
bias (etica/equità)
1. Stereotipare, mostrare preconcetti o favoritismi verso determinate cose, persone o gruppi rispetto ad altri. Questi bias possono influire sulla raccolta e sull'interpretazione dei dati, sulla progettazione di un sistema e sul modo in cui gli utenti interagiscono con un sistema. Le forme di questo tipo di bias includono:
- bias di automazione
- Bias di conferma
- Bias dello sperimentatore
- bias di attribuzione di gruppo
- bias implicito
- Bias di affinità
- Bias di omogeneità del gruppo esterno
2. Errore sistematico introdotto da una procedura di campionamento o reporting. Le forme di questo tipo di bias includono:
- Bias di copertura
- Bias di mancata risposta
- Bias di partecipazione
- bias di segnalazione
- distorsione di campionamento
- Bias di selezione
Da non confondere con il termine di bias nei modelli di machine learning o con il bias di previsione.
Per saperne di più, consulta Equità: tipi di bias in Machine Learning Crash Course.
bias (matematica) o termine di bias
Un'intercettazione o un offset da un'origine. Il bias è un parametro nei modelli di machine learning, che è simboleggiato da uno dei seguenti:
- b
- w0
Ad esempio, il bias è il b nella seguente formula:
In una semplice retta bidimensionale, il bias indica semplicemente l'intercetta sull'asse y. Ad esempio, la pendenza della retta nell'illustrazione seguente è 2.

Il bias esiste perché non tutti i modelli iniziano dall'origine (0,0). Ad esempio, supponiamo che l'ingresso in un parco divertimenti costi 2 euro e che vengano addebitati 0,50 euro per ogni ora di permanenza di un cliente. Pertanto, un modello che mappa il costo totale ha una distorsione di 2 perché il costo più basso è di 2 euro.
Il bias non deve essere confuso con il bias in etica ed equità o con il bias di previsione.
Per saperne di più, consulta Regressione lineare in Machine Learning Crash Course.
classificazione binaria
Un tipo di attività di classificazione che prevede una delle due classi reciprocamente esclusive:
Ad esempio, i seguenti due modelli di machine learning eseguono ciascuno la classificazione binaria:
- Un modello che determina se i messaggi email sono spam (la classe positiva) o non spam (la classe negativa).
- Un modello che valuta i sintomi medici per determinare se una persona ha una determinata patologia (la classe positiva) o non ce l'ha (la classe negativa).
Contrasto con la classificazione multiclasse.
Vedi anche regressione logistica e soglia di classificazione.
Per saperne di più, consulta la sezione Classificazione del corso intensivo di machine learning.
il bucketing
Conversione di una singola caratteristica in più caratteristiche binarie chiamate bucket o bin, in genere in base a un intervallo di valori. La caratteristica troncata è in genere una caratteristica continua.
Ad esempio, anziché rappresentare la temperatura come una singola caratteristica continua in rappresentazione in virgola mobile, potresti dividere gli intervalli di temperature in bucket discreti, ad esempio:
- <= 10 gradi Celsius rientrerebbe nel bucket "freddo".
- 11-24 gradi Celsius rientrano nella categoria "temperato".
- >= 25 gradi Celsius rientrerebbe nel bucket "caldo".
Il modello tratterà ogni valore nello stesso bucket in modo identico. Ad esempio, i valori 13 e 22 si trovano entrambi nel bucket temperato, quindi il modello tratta i due valori in modo identico.
Per saperne di più, consulta la sezione Dati numerici: Binning in Machine Learning Crash Course.
C
dati categorici
Caratteristiche con un insieme specifico di valori possibili. Ad esempio,
considera una funzionalità categorica denominata traffic-light-state, che può
avere solo uno dei seguenti tre valori possibili:
redyellowgreen
Rappresentando traffic-light-state come una caratteristica categorica,
un modello può apprendere
i diversi impatti di red, green e yellow sul comportamento del conducente.
Le caratteristiche categoriche sono a volte chiamate caratteristiche discrete.
Contrasto con i dati numerici.
Per saperne di più, consulta la sezione Utilizzo dei dati categorici di Machine Learning Crash Course.
classe
Una categoria a cui può appartenere un'etichetta. Ad esempio:
- In un modello di classificazione binaria che rileva lo spam, le due classi potrebbero essere spam e non spam.
- In un modello di classificazione multi-classe che identifica le razze di cani, le classi potrebbero essere barboncino, beagle, carlino e così via.
Un modello di classificazione prevede una classe. Al contrario, un modello di regressione prevede un numero anziché una classe.
Per saperne di più, consulta la sezione Classificazione del corso intensivo di machine learning.
modello di classificazione
Un modello la cui previsione è una classe. Ad esempio, i seguenti sono tutti modelli di classificazione:
- Un modello che prevede la lingua di una frase di input (francese? Spagnolo? italiano?).
- Un modello che prevede le specie di alberi (acero? Quercia? Baobab?).
- Un modello che prevede la classe positiva o negativa per una particolare condizione medica.
Al contrario, i modelli di regressione prevedono numeri anziché classi.
Due tipi comuni di modelli di classificazione sono:
soglia di classificazione
In una classificazione binaria, un numero compreso tra 0 e 1 che converte l'output non elaborato di un modello di regressione logistica in una previsione della classe positiva o della classe negativa. Tieni presente che la soglia di classificazione è un valore scelto da un essere umano, non un valore scelto dall'addestramento del modello.
Un modello di regressione logistica restituisce un valore grezzo compreso tra 0 e 1. Quindi:
- Se questo valore grezzo è maggiore della soglia di classificazione, viene prevista la classe positiva.
- Se questo valore grezzo è inferiore alla soglia di classificazione, viene prevista la classe negativa.
Ad esempio, supponiamo che la soglia di classificazione sia 0,8. Se il valore non elaborato è 0,9, il modello prevede la classe positiva. Se il valore non elaborato è 0,7, il modello prevede la classe negativa.
La scelta della soglia di classificazione influisce notevolmente sul numero di falsi positivi e falsi negativi.
Per saperne di più, consulta Soglie e matrice di confusione in Machine Learning Crash Course.
classificatore
Un termine informale per un modello di classificazione.
set di dati sbilanciato
Un set di dati per una classificazione in cui il numero totale di etichette di ogni classe differisce in modo significativo. Ad esempio, considera un set di dati di classificazione binaria le cui due etichette sono suddivise come segue:
- 1.000.000 di etichette negative
- 10 etichette positive
Il rapporto tra etichette negative e positive è di 100.000 a 1, quindi si tratta di un set di dati con classi sbilanciate.
Al contrario, il seguente set di dati è bilanciato per classe perché il rapporto tra etichette negative ed etichette positive è relativamente vicino a 1:
- 517 etichette negative
- 483 etichette positive
Anche i set di dati multiclasse possono essere sbilanciati. Ad esempio, il seguente set di dati di classificazione multiclasse è anche sbilanciato perché un'etichetta ha molti più esempi rispetto alle altre due:
- 1.000.000 di etichette con la classe "verde"
- 200 etichette con la classe "viola"
- 350 etichette con la classe "arancione"
L'addestramento di set di dati con classi sbilanciate può presentare sfide particolari. Per maggiori dettagli, consulta Dataset sbilanciati in Machine Learning Crash Course.
Vedi anche entropia, classe maggioritaria e classe minoritaria.
clipping
Una tecnica per gestire gli outlier eseguendo una o entrambe le seguenti operazioni:
- Riduzione dei valori della funzionalità superiori a una soglia massima fino a tale soglia massima.
- Aumentando i valori delle funzionalità inferiori a una soglia minima fino a quella soglia minima.
Ad esempio, supponiamo che meno dello 0,5% dei valori di una determinata caratteristica rientri al di fuori dell'intervallo 40-60. In questo caso, puoi procedere come segue:
- Tronca tutti i valori superiori a 60 (la soglia massima) in modo che siano esattamente 60.
- Tronca tutti i valori inferiori a 40 (la soglia minima) in modo che siano esattamente 40.
Gli outlier possono danneggiare i modelli, a volte causando l'overflow dei pesi durante l'addestramento. Alcuni valori anomali possono anche rovinare drasticamente metriche come l'accuratezza. Il clipping è una tecnica comune per limitare i danni.
Il taglio del gradiente forza i valori del gradiente all'interno di un intervallo designato durante l'addestramento.
Per saperne di più, consulta Dati numerici: normalizzazione in Machine Learning Crash Course.
matrice di confusione
Una tabella NxN che riassume il numero di previsioni corrette e errate effettuate da un modello di classificazione. Ad esempio, considera la seguente matrice di confusione per un modello di classificazione binaria:
| Tumore (previsto) | Non tumorale (previsto) | |
|---|---|---|
| Tumore (dati di fatto) | 18 (VP) | 1 (FN) |
| Non-Tumor (ground truth) | 6 (FP) | 452 (TN) |
La matrice di confusione precedente mostra quanto segue:
- Delle 19 previsioni in cui la verità di base era Tumore, il modello ne ha classificate correttamente 18 e in modo errato 1.
- Delle 458 previsioni in cui la verità di base era Non-Tumor, il modello ne ha classificate correttamente 452 e in modo errato 6.
La matrice di confusione per un problema di classificazione multiclasse può aiutarti a identificare i pattern di errori. Ad esempio, considera la seguente matrice di confusione per un modello di classificazione multiclasse a tre classi che classifica tre diversi tipi di iris (Virginica, Versicolor e Setosa). Quando i dati empirici reali erano Virginica, la matrice di confusione mostra che il modello aveva molte più probabilità di prevedere erroneamente Versicolor rispetto a Setosa:
| Setosa (previsto) | Versicolor (previsto) | Virginica (previsto) | |
|---|---|---|---|
| Setosa (dati di fatto) | 88 | 12 | 0 |
| Versicolor (dati empirici reali) | 6 | 141 | 7 |
| Virginica (dati empirici reali) | 2 | 27 | 109 |
Come altro esempio, una matrice di confusione potrebbe rivelare che un modello addestrato a riconoscere le cifre scritte a mano tende a prevedere erroneamente 9 anziché 4 o 1 anziché 7.
Le matrici di confusione contengono informazioni sufficienti per calcolare una varietà di metriche di rendimento, tra cui precisione e richiamo.
funzionalità continua
Una rappresentazione in virgola mobile con un intervallo infinito di valori possibili, ad esempio temperatura o peso.
Contrasto con la funzionalità discreta.
convergenza
Uno stato raggiunto quando i valori di perdita cambiano molto poco o non cambiano affatto a ogni iterazione. Ad esempio, la seguente curva di perdita suggerisce la convergenza a circa 700 iterazioni:
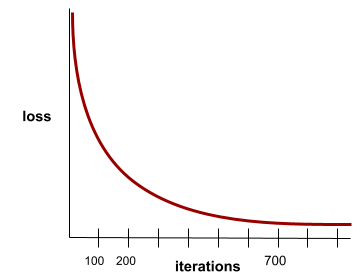
Un modello converge quando un ulteriore addestramento non migliora il modello.
Nell'deep learning, i valori di perdita a volte rimangono costanti o quasi per molte iterazioni prima di diminuire. Durante un lungo periodo di valori di perdita costanti, potresti avere temporaneamente una falsa sensazione di convergenza.
Vedi anche interruzione anticipata.
Per saperne di più, consulta Convergenza del modello e curve di perdita in Machine Learning Crash Course.
D
DataFrame
Un tipo di dati pandas popolare per rappresentare set di dati in memoria.
Un DataFrame è analogo a una tabella o a un foglio di lavoro. Ogni colonna di un DataFrame ha un nome (un'intestazione) e ogni riga è identificata da un numero univoco.
Ogni colonna di un DataFrame è strutturata come un array bidimensionale, tranne per il fatto che a ogni colonna può essere assegnato un proprio tipo di dati.
Consulta anche la pagina di riferimento di pandas.DataFrame ufficiale.
set di dati
Una raccolta di dati non elaborati, comunemente (ma non esclusivamente) organizzati in uno dei seguenti formati:
- un foglio di lavoro
- un file in formato CSV (valori separati da virgola)
modello profondo
Una rete neurale contenente più di un strato nascosto.
Un modello profondo è chiamato anche rete neurale profonda.
Contrasto con il modello ampio.
caratteristica densa
Una caratteristica in cui la maggior parte o tutti i valori sono diversi da zero, in genere un tensore di valori in rappresentazione in virgola mobile. Ad esempio, il seguente tensore di 10 elementi è denso perché 9 dei suoi valori sono diversi da zero:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Contrasto con la funzionalità sparsa.
profondità
La somma di quanto segue in una rete neurale:
- il numero di livelli nascosti
- il numero di livelli di output, che in genere è 1
- il numero di eventuali livelli di incorporamento
Ad esempio, una rete neurale con cinque strati nascosti e uno strato di output ha una profondità di 6.
Tieni presente che il livello di input non influisce sulla profondità.
funzionalità discreta
Una caratteristica con un insieme finito di valori possibili. Ad esempio, una caratteristica i cui valori possono essere solo animale, vegetale o minerale è una caratteristica discreta (o categorica).
Contrasta con la caratteristica continua.
dinamico
Qualcosa che viene fatto di frequente o in modo continuo. I termini dinamico e online sono sinonimi nel machine learning. Di seguito sono riportati gli utilizzi comuni di dinamico e online nel machine learning:
- Un modello dinamico (o modello online) è un modello che viene riaddestrato di frequente o in modo continuo.
- L'addestramento dinamico (o addestramento online) è il processo di addestramento frequente o continuo.
- L'inferenza dinamica (o inferenza online) è il processo di generazione di previsioni on demand.
modello dinamico
Un modello che viene riaddestrato frequentemente (forse anche in modo continuo). Un modello dinamico è un "apprendista permanente" che si adatta costantemente all'evoluzione dei dati. Un modello dinamico è noto anche come modello online.
Contrasta con il modello statico.
E
interruzione anticipata
Un metodo di regolarizzazione che prevede di terminare l'addestramento prima che la perdita di addestramento finisca di diminuire. Nell'interruzione anticipata, l'addestramento del modello viene interrotto intenzionalmente quando la perdita su un set di dati di convalida inizia ad aumentare, ovvero quando le prestazioni di generalizzazione peggiorano.
Contrasto con l'uscita anticipata.
livello di incorporamento
Uno strato nascosto speciale che viene addestrato su una caratteristica categorica ad alta dimensionalità per apprendere gradualmente un vettore di incorporamento a dimensionalità inferiore. Un livello di incorporamento consente a una rete neurale di eseguire l'addestramento in modo molto più efficiente rispetto all'addestramento basato solo sulla caratteristica categorica ad alta dimensionalità.
Ad esempio, Earth attualmente supporta circa 73.000 specie di alberi. Supponiamo che
la specie di albero sia una caratteristica del tuo modello, quindi il livello di input del modello
include un vettore one-hot lungo 73.000
elementi.
Ad esempio, forse baobab potrebbe essere rappresentato in questo modo:

Un array di 73.000 elementi è molto lungo. Se non aggiungi un livello di incorporamento al modello, l'addestramento richiederà molto tempo a causa della moltiplicazione di 72.999 zeri. Forse scegli che lo strato di incorporamento sia composto da 12 dimensioni. Di conseguenza, il livello di incorporamento imparerà gradualmente un nuovo vettore di incorporamento per ogni specie di albero.
In determinate situazioni, l'hashing è un'alternativa ragionevole a un livello di incorporamento.
Per saperne di più, consulta la sezione Incorporamenti di Machine Learning Crash Course.
periodo
Un passaggio di addestramento completo sull'intero set di addestramento in modo che ogni esempio sia stato elaborato una volta.
Un'epoca rappresenta N/dimensione del batch iterazioni di addestramento, dove N è il numero totale di esempi.
Ad esempio, supponiamo quanto segue:
- Il set di dati è composto da 1000 esempi.
- La dimensione del batch è di 50 esempi.
Pertanto, una singola epoca richiede 20 iterazioni:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Per saperne di più, consulta Regressione lineare: iperparametri in Machine Learning Crash Course.
esempio
I valori di una riga di caratteristiche ed eventualmente un'etichetta. Gli esempi di apprendimento supervisionato rientrano in due categorie generali:
- Un esempio etichettato è costituito da una o più funzionalità e da un'etichetta. Gli esempi etichettati vengono utilizzati durante l'addestramento.
- Un esempio senza etichetta è costituito da una o più funzionalità, ma nessuna etichetta. Gli esempi senza etichetta vengono utilizzati durante l'inferenza.
Ad esempio, supponiamo che tu stia addestrando un modello per determinare l'influenza delle condizioni meteorologiche sui punteggi dei test degli studenti. Ecco tre esempi etichettati:
| Funzionalità | Etichetta | ||
|---|---|---|---|
| Temperatura | Umidità | Pressione | Punteggio del test |
| 15 | 47 | 998 | Buono |
| 19 | 34 | 1020 | Eccellente |
| 18 | 92 | 1012 | Scadente |
Ecco tre esempi senza etichetta:
| Temperatura | Umidità | Pressione | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
La riga di un set di dati è in genere l'origine non elaborata di un esempio. ovvero un sottoinsieme delle colonne del set di dati. Inoltre, le caratteristiche di un esempio possono includere anche caratteristiche sintetiche, come incroci di caratteristiche.
Per saperne di più, consulta Apprendimento supervisionato nel corso Introduzione al machine learning.
V
falso negativo (FN)
Un esempio in cui il modello prevede erroneamente la classe negativa. Ad esempio, il modello prevede che un determinato messaggio email non sia spam (la classe negativa), ma che in realtà sia spam.
falso positivo (FP)
Un esempio in cui il modello prevede erroneamente la classe positiva. Ad esempio, il modello prevede che un determinato messaggio email sia spam (la classe positiva), ma che in realtà non lo sia.
Per saperne di più, consulta Soglie e matrice di confusione in Machine Learning Crash Course.
percentuale di falsi positivi (FPR)
La proporzione di esempi negativi effettivi per i quali il modello ha previsto erroneamente la classe positiva. La seguente formula calcola il tasso di falsi positivi:
La percentuale di falsi positivi è l'asse x di una curva ROC.
Per saperne di più, consulta Classificazione: ROC e AUC in Machine Learning Crash Course.
caratteristica
Una variabile di input per un modello di machine learning. Un esempio è composto da una o più funzionalità. Ad esempio, supponiamo di addestrare un modello per determinare l'influenza delle condizioni meteorologiche sui punteggi dei test degli studenti. La tabella seguente mostra tre esempi, ognuno dei quali contiene tre funzionalità e un'etichetta:
| Funzionalità | Etichetta | ||
|---|---|---|---|
| Temperatura | Umidità | Pressione | Punteggio del test |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Contrasto con l'etichetta.
Per saperne di più, consulta Apprendimento supervisionato nel corso Introduzione al machine learning.
incrocio di caratteristiche
Una caratteristica sintetica formata "incrociando" caratteristiche categoriche o raggruppate.
Ad esempio, considera un modello di "previsione dell'umore" che rappresenta la temperatura in uno dei seguenti quattro bucket:
freezingchillytemperatewarm
e rappresenta la velocità del vento in uno dei seguenti tre bucket:
stilllightwindy
Senza incroci di caratteristiche, il modello lineare viene addestrato in modo indipendente su ciascuno dei
sette bucket precedenti. Pertanto, il modello viene addestrato, ad esempio, su freezing indipendentemente dall'addestramento su, ad esempio, windy.
In alternativa, potresti creare un incrocio di caratteristiche di temperatura e velocità del vento. Questa funzionalità sintetica avrebbe i seguenti 12 valori possibili:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Grazie agli incroci di caratteristiche, il modello può apprendere le differenze di umore
tra un giorno freezing-windy e un giorno freezing-still.
Se crei una caratteristica sintetica da due caratteristiche che hanno molte bucket diversi, l'incrocio di caratteristiche risultante avrà un numero enorme di combinazioni possibili. Ad esempio, se una funzionalità ha 1000 bucket e l'altra ne ha 2000, il cross di funzionalità risultante ha 2.000.000 di bucket.
Formalmente, una croce è un prodotto cartesiano.
I cross di caratteristiche vengono utilizzati principalmente con i modelli lineari e raramente con le reti neurali.
Per saperne di più, consulta Dati categorici: combinazioni di caratteristiche in Machine Learning Crash Course.
e applicazione del feature engineering.
Un processo che prevede i seguenti passaggi:
- Determinare quali caratteristiche potrebbero essere utili per l'addestramento di un modello.
- Conversione dei dati non elaborati del set di dati in versioni efficienti di queste caratteristiche.
Ad esempio, potresti determinare che temperature potrebbe essere una funzionalità utile. Poi, potresti sperimentare il raggruppamento
per ottimizzare ciò che il modello può apprendere da diversi intervalli di temperature.
Il feature engineering è a volte chiamato estrazione delle funzionalità o featurizzazione.
Per saperne di più, consulta la sezione Dati numerici: come un modello acquisisce i dati utilizzando i vettori delle caratteristiche di Machine Learning Crash Course.
set di funzionalità
Il gruppo di funzionalità su cui viene addestrato il tuo modello di machine learning. Ad esempio, un semplice insieme di funzionalità per un modello che prevede i prezzi delle case potrebbe essere costituito da codice postale, dimensioni della proprietà e condizioni della proprietà.
vettore di caratteristiche
L'array di valori delle funzionalità che compongono un esempio. Il vettore di caratteristiche viene inserito durante l'addestramento e durante l'inferenza. Ad esempio, il vettore delle caratteristiche per un modello con due caratteristiche discrete potrebbe essere:
[0.92, 0.56]
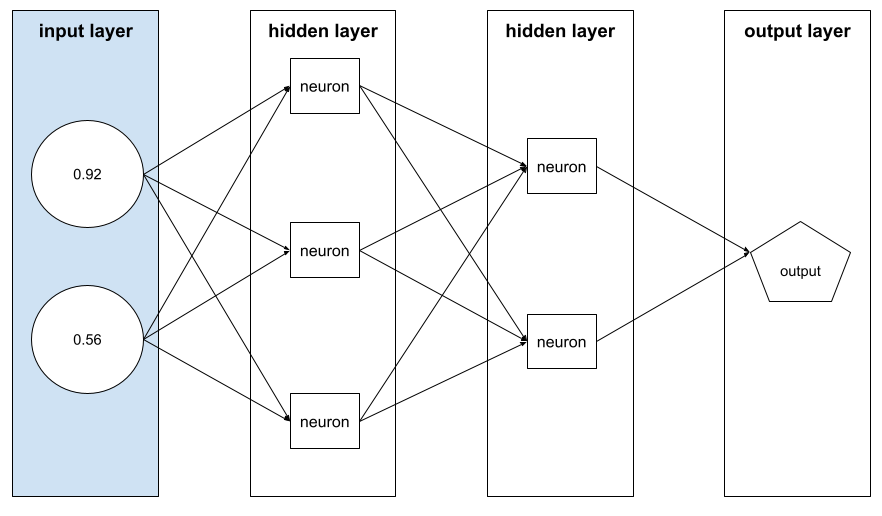
Ogni esempio fornisce valori diversi per il vettore delle caratteristiche, quindi il vettore delle caratteristiche per l'esempio successivo potrebbe essere simile a questo:
[0.73, 0.49]
Il feature engineering determina come rappresentare le caratteristiche nel vettore delle caratteristiche. Ad esempio, una caratteristica categorica binaria con cinque valori possibili potrebbe essere rappresentata con codifica one-hot. In questo caso, la porzione del vettore delle funzionalità per un particolare esempio sarebbe costituita da quattro zeri e un singolo 1.0 nella terza posizione, come segue:
[0.0, 0.0, 1.0, 0.0, 0.0]
Come altro esempio, supponiamo che il tuo modello sia composto da tre funzionalità:
- una caratteristica categorica binaria con cinque valori possibili rappresentati con la codifica one-hot; ad esempio:
[0.0, 1.0, 0.0, 0.0, 0.0] - un'altra caratteristica categorica binaria con tre valori possibili rappresentati
con la codifica one-hot; ad esempio:
[0.0, 0.0, 1.0] - una funzionalità in virgola mobile, ad esempio
8.3.
In questo caso, il vettore delle caratteristiche per ogni esempio sarebbe rappresentato da nove valori. Dati i valori di esempio nell'elenco precedente, il vettore delle funzionalità sarebbe:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Per saperne di più, consulta la sezione Dati numerici: come un modello acquisisce i dati utilizzando i vettori delle caratteristiche di Machine Learning Crash Course.
ciclo di feedback
Nel machine learning, una situazione in cui le previsioni di un modello influenzano i dati di addestramento per lo stesso modello o per un altro modello. Ad esempio, un modello che consiglia film influenzerà i film che le persone vedono, il che influenzerà a sua volta i modelli di consigli sui film successivi.
Per saperne di più, consulta Sistemi ML di produzione: domande da porre in Machine Learning Crash Course.
G
generalizzazione
La capacità di un modello di fare previsioni corrette su dati nuovi e mai visti prima. Un modello in grado di generalizzare è l'opposto di un modello che è overfitting.
Per saperne di più, consulta la sezione Generalizzazione in Machine Learning Crash Course.
curva di generalizzazione
Un grafico della perdita di addestramento e della perdita di convalida in funzione del numero di iterazioni.
Una curva di generalizzazione può aiutarti a rilevare un possibile overfitting. Ad esempio, la seguente curva di generalizzazione suggerisce un overfitting perché la perdita di convalida alla fine diventa significativamente superiore alla perdita di addestramento.
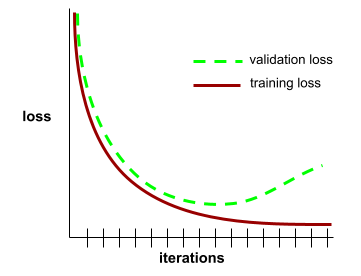
Per saperne di più, consulta la sezione Generalizzazione in Machine Learning Crash Course.
discesa del gradiente
Una tecnica matematica per ridurre al minimo la perdita. La discesa del gradiente regola in modo iterativo pesi e bias, trovando gradualmente la combinazione migliore per ridurre al minimo la perdita.
La discesa del gradiente è più vecchia, molto più vecchia, del machine learning.
Per saperne di più, consulta Regressione lineare: discesa del gradiente in Machine Learning Crash Course.
dati di fatto
Realtà.
La cosa che è effettivamente accaduta.
Ad esempio, considera un modello di classificazione binaria che prevede se uno studente del primo anno di università si laureerà entro sei anni. I dati di riferimento per questo modello sono se lo studente si è effettivamente laureato entro sei anni.
H
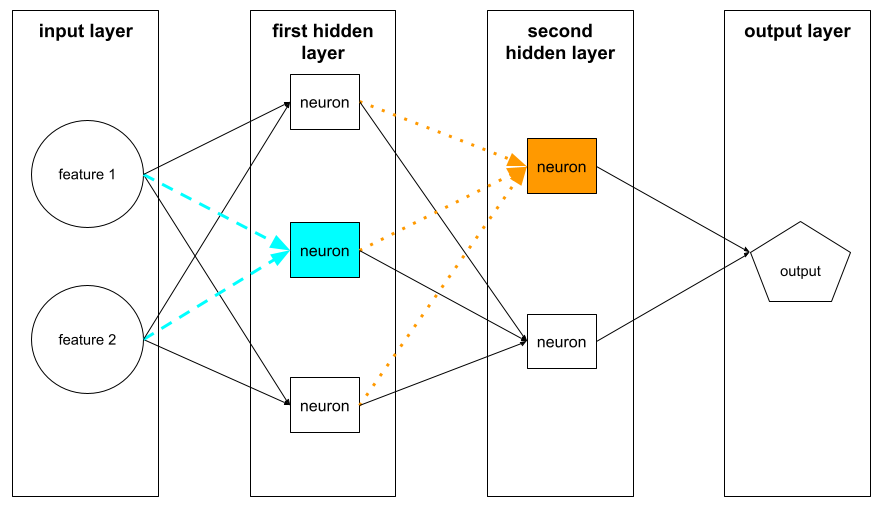
strato nascosto
Un livello in una rete neurale tra il livello di input (le funzionalità) e il livello di output (la previsione). Ogni strato nascosto è costituito da uno o più neuroni. Ad esempio, la seguente rete neurale contiene due strati nascosti, il primo con tre neuroni e il secondo con due neuroni:
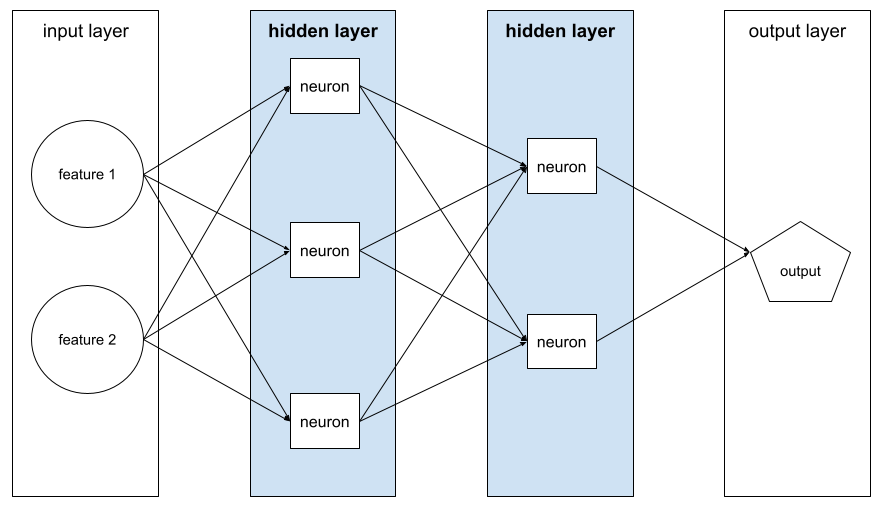
Una rete neurale profonda contiene più di uno strato nascosto. Ad esempio, l'illustrazione precedente è una rete neurale profonda perché il modello contiene due livelli nascosti.
Per saperne di più, consulta Reti neurali: nodi e livelli nascosti in Machine Learning Crash Course.
iperparametro
Le variabili che tu o un servizio di ottimizzazione degli iperparametri regolate durante le esecuzioni successive dell'addestramento di un modello. Ad esempio, il tasso di apprendimento è un iperparametro. Potresti impostare il tasso di apprendimento su 0,01 prima di una sessione di addestramento. Se determini che 0,01 è troppo alto, potresti impostare il tasso di apprendimento su 0,003 per la sessione di addestramento successiva.
Al contrario, i parametri sono i vari pesi e bias che il modello apprende durante l'addestramento.
Per saperne di più, consulta Regressione lineare: iperparametri in Machine Learning Crash Course.
I
indipendenti e identicamente distribuiti (i.i.d.)
Dati estratti da una distribuzione che non cambia e in cui ogni valore estratto non dipende dai valori estratti in precedenza. Una distribuzione i.i.d. è il gas ideale del machine learning, un costrutto matematico utile ma quasi mai trovato esattamente nel mondo reale. Ad esempio, la distribuzione dei visitatori di una pagina web potrebbe essere i.i.d. in un breve periodo di tempo, ovvero la distribuzione non cambia durante questo breve periodo e la visita di una persona è generalmente indipendente da quella di un'altra. Tuttavia, se espandi questo periodo di tempo, potrebbero comparire differenze stagionali nei visitatori della pagina web.
Vedi anche non stazionarietà.
inferenza
Nel machine learning tradizionale, il processo di fare previsioni applicando un modello addestrato a esempi non etichettati. Per saperne di più, consulta la sezione Apprendimento supervisionato del corso Introduzione al machine learning.
Nei modelli linguistici di grandi dimensioni, l'inferenza è il processo di utilizzo di un modello addestrato per generare una risposta a un prompt di input.
L'inferenza ha un significato leggermente diverso in statistica. Per maggiori dettagli, consulta l' articolo di Wikipedia sull'inferenza statistica.
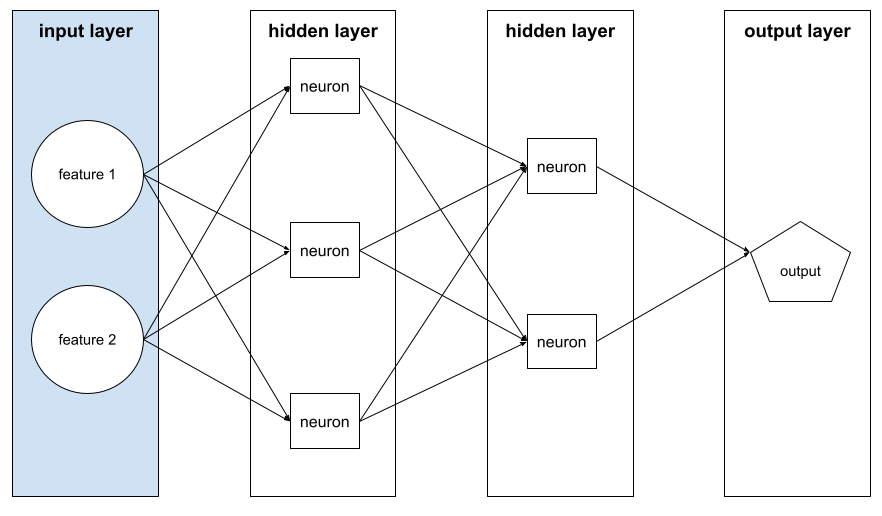
livello di input
Lo strato di una rete neurale che contiene il vettore di caratteristiche. ovvero il livello di input fornisce esempi per l'addestramento o l'inferenza. Ad esempio, il livello di input nella seguente rete neurale è costituito da due funzionalità:
interpretabilità
La capacità di spiegare o presentare il ragionamento di un modello di ML in termini comprensibili per un essere umano.
La maggior parte dei modelli di regressione lineare, ad esempio, sono altamente interpretabili. Basta controllare i pesi dell'addestramento di ogni caratteristica. Anche le foreste decisionali sono altamente interpretabili. Alcuni modelli, tuttavia, richiedono una visualizzazione sofisticata per poter essere interpretati.
Puoi utilizzare lo strumento di interpretabilità dell'apprendimento (LIT) per interpretare i modelli ML.
iteration
Un singolo aggiornamento dei parametri di un modello, ovvero i pesi e i bias del modello, durante l'addestramento. La dimensione del batch determina il numero di esempi che il modello elabora in una singola iterazione. Ad esempio, se la dimensione del batch è 20, il modello elabora 20 esempi prima di regolare i parametri.
Quando addestri una rete neurale, una singola iterazione prevede i seguenti due passaggi:
- Un passaggio in avanti per valutare la perdita su un singolo batch.
- Un passaggio all'indietro (retropropagazione) per regolare i parametri del modello in base alla perdita e al tasso di apprendimento.
Per saperne di più, consulta la sezione Discesa del gradiente in Machine Learning Crash Course.
L
Regolarizzazione L0
Un tipo di regolarizzazione che penalizza il numero totale di pesi diversi da zero in un modello. Ad esempio, un modello con 11 pesi diversi da zero verrebbe penalizzato più di un modello simile con 10 pesi diversi da zero.
La regolarizzazione L0 viene talvolta chiamata regolarizzazione della norma L0.
Perdita L1
Una funzione di perdita che calcola il valore assoluto della differenza tra i valori effettivi dell'etichetta e i valori previsti da un modello. Ad esempio, ecco il calcolo della perdita L1 per un batch di cinque esempi:
| Valore effettivo dell'esempio | Valore previsto del modello | Valore assoluto del delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 loss | ||
La perdita L1 è meno sensibile ai valori anomali rispetto alla perdita L2.
L'errore assoluto medio è la perdita L1 media per esempio.
Per saperne di più, consulta Regressione lineare: perdita in Machine Learning Crash Course.
Regolarizzazione L1
Un tipo di regolarizzazione che penalizza i pesi in proporzione alla somma del valore assoluto dei pesi. La regolarizzazione L1 contribuisce a portare i pesi delle caratteristiche irrilevanti o appena rilevanti a esattamente 0. Una caratteristica con un peso pari a 0 viene effettivamente rimossa dal modello.
Contrasto con la regolarizzazione L2.
Perdita L2
Una funzione di perdita che calcola il quadrato della differenza tra i valori effettivi dell'etichetta e i valori previsti da un modello. Ad esempio, ecco il calcolo della perdita L2 per un batch di cinque esempi:
| Valore effettivo dell'esempio | Valore previsto del modello | Quadrato del delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 loss | ||
A causa dell'elevazione al quadrato, la perdita L2 amplifica l'influenza degli outlier. ovvero la perdita L2 reagisce più fortemente alle previsioni errate rispetto alla perdita L1. Ad esempio, la perdita L1 per il batch precedente sarebbe 8 anziché 16. Nota che un singolo account anomalo rappresenta 9 dei 16.
I modelli di regressione in genere utilizzano la perdita L2 come funzione di perdita.
L'errore quadratico medio è la perdita L2 media per esempio. Perdita quadratica è un altro nome per la perdita L2.
Per saperne di più, consulta Regressione logistica: perdita e regolarizzazione in Machine Learning Crash Course.
Regolarizzazione L2
Un tipo di regolarizzazione che penalizza i pesi in proporzione alla somma dei quadrati dei pesi. La regolarizzazione L2 contribuisce a ridurre i pesi anomali (quelli con valori positivi elevati o negativi bassi) più vicini a 0, ma non esattamente a 0. Le caratteristiche con valori molto vicini a 0 rimangono nel modello, ma non influiscono molto sulla previsione del modello.
La regolarizzazione L2 migliora sempre la generalizzazione nei modelli lineari.
Contrasto con la regolarizzazione L1.
Per saperne di più, consulta Overfitting: regolarizzazione L2 in Machine Learning Crash Course.
etichetta
Nell'machine learning supervisionato, la parte "risposta" o "risultato" di un esempio.
Ogni esempio etichettato è costituito da una o più funzionalità e da un'etichetta. Ad esempio, in un set di dati per il rilevamento dello spam, l'etichetta sarebbe probabilmente "spam" o "non spam". In un set di dati sulle precipitazioni, l'etichetta potrebbe essere la quantità di pioggia caduta in un determinato periodo.
Per saperne di più, consulta Apprendimento supervisionato in Introduzione al machine learning.
esempio etichettato
Un esempio che contiene una o più caratteristiche e un'etichetta. Ad esempio, la seguente tabella mostra tre esempi etichettati di un modello di valutazione di una casa, ognuno con tre funzionalità e un'etichetta:
| Numero di camere | Numero di bagni | Età della casa | Prezzo della casa (etichetta) |
|---|---|---|---|
| 3 | 2 | 15 | $345.000 |
| 2 | 1 | 72 | $179.000 |
| 4 | 2 | 34 | $392.000 |
Nel machine learning supervisionato, i modelli vengono addestrati su esempi etichettati e fanno previsioni su esempi non etichettati.
Confronta l'esempio etichettato con quelli non etichettati.
Per saperne di più, consulta Apprendimento supervisionato in Introduzione al machine learning.
lambda
Sinonimo di tasso di regolarizzazione.
Lambda è un termine sovraccarico. Qui ci concentriamo sulla definizione del termine all'interno della regolarizzazione.
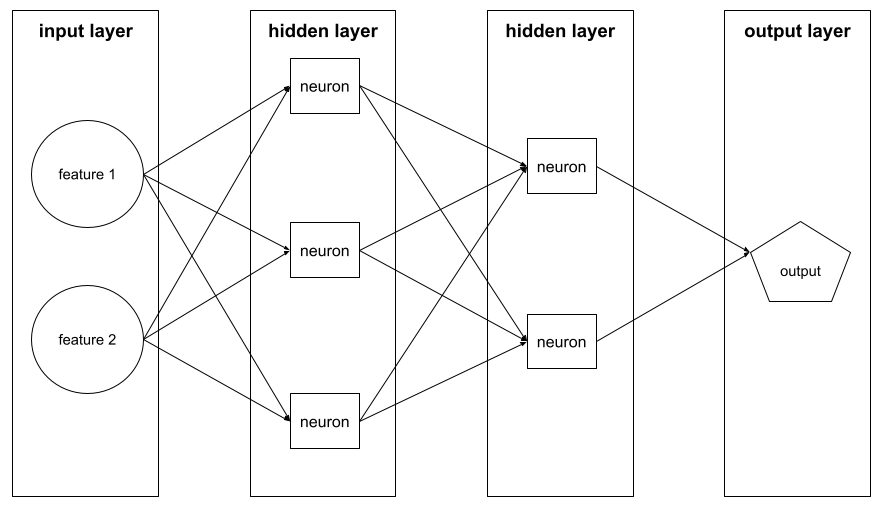
livello
Un insieme di neuroni in una rete neurale. Tre tipi comuni di livelli sono i seguenti:
- Il strato di input, che fornisce i valori per tutte le funzionalità.
- Uno o più livelli nascosti, che trovano relazioni non lineari tra le caratteristiche e l'etichetta.
- Il livello di output, che fornisce la previsione.
Ad esempio, la seguente illustrazione mostra una rete neurale con uno strato di input, due strati nascosti e uno strato di output:
In TensorFlow, i livelli sono anche funzioni Python che accettano tensori e opzioni di configurazione come input e producono altri tensori come output.
tasso di apprendimento
Un numero in virgola mobile che indica all'algoritmo di discesa del gradiente con quale intensità regolare i pesi e i bias in ogni iterazione. Ad esempio, un tasso di apprendimento di 0,3 modifica i pesi e i bias tre volte più intensamente di un tasso di apprendimento di 0,1.
Il tasso di apprendimento è un iperparametro fondamentale. Se imposti il tasso di apprendimento troppo basso, l'addestramento richiederà troppo tempo. Se imposti il tasso di apprendimento troppo alto, la discesa del gradiente spesso ha difficoltà a raggiungere la convergenza.
Per saperne di più, consulta Regressione lineare: iperparametri in Machine Learning Crash Course.
lineare
Una relazione tra due o più variabili che può essere rappresentata esclusivamente tramite addizione e moltiplicazione.
Il grafico di una relazione lineare è una retta.
Contrasto con non lineare.
modello lineare
Un modello che assegna un peso per caratteristica per fare previsioni. I modelli lineari incorporano anche un bias. Al contrario, la relazione tra le caratteristiche e le previsioni nei modelli deep è generalmente non lineare.
I modelli lineari sono in genere più facili da addestrare e più interpretabili rispetto ai modelli di deep learning. Tuttavia, i modelli profondi possono apprendere relazioni complesse tra le caratteristiche.
La regressione lineare e la regressione logistica sono due tipi di modelli lineari.
regressione lineare
Un tipo di modello di machine learning in cui sono vere entrambe le seguenti affermazioni:
- Il modello è un modello lineare.
- La previsione è un valore in virgola mobile. (Questa è la parte di regressione della regressione lineare.)
Confronta la regressione lineare con la regressione logistica. Inoltre, confronta la regressione con la classificazione.
Per saperne di più, consulta Regressione lineare in Machine Learning Crash Course.
regressione logistica
Un tipo di modello di regressione che prevede una probabilità. I modelli di regressione logistica hanno le seguenti caratteristiche:
- L'etichetta è categorica. Il termine regressione logistica si riferisce in genere alla regressione logistica binaria, ovvero a un modello che calcola le probabilità per le etichette con due valori possibili. Una variante meno comune, la regressione logistica multinomiale, calcola le probabilità per le etichette con più di due valori possibili.
- La funzione di perdita durante l'addestramento è Log Loss��. È possibile inserire più unità Log Loss in parallelo per le etichette con più di due valori possibili.
- Il modello ha un'architettura lineare, non una rete neurale profonda. Tuttavia, il resto di questa definizione si applica anche ai modelli di deep learning che prevedono probabilità per le etichette categoriche.
Ad esempio, considera un modello di regressione logistica che calcola la probabilità che un'email di input sia spam o meno. Durante l'inferenza, supponiamo che il modello preveda 0,72. Pertanto, il modello sta stimando:
- Una probabilità del 72% che l'email sia spam.
- Il 28% di probabilità che l'email non sia spam.
Un modello di regressione logistica utilizza la seguente architettura in due passaggi:
- Il modello genera una previsione non elaborata (y') applicando una funzione lineare delle caratteristiche di input.
- Il modello utilizza questa previsione non elaborata come input per una funzione sigmoide, che converte la previsione non elaborata in un valore compreso tra 0 e 1, esclusi.
Come qualsiasi modello di regressione, un modello di regressione logistica prevede un numero. Tuttavia, questo numero in genere diventa parte di un modello di classificazione binaria come segue:
- Se il numero previsto è maggiore della soglia di classificazione, il modello di classificazione binaria prevede la classe positiva.
- Se il numero previsto è inferiore alla soglia di classificazione, il modello di classificazione binaria prevede la classe negativa.
Per saperne di più, consulta Regressione logistica in Machine Learning Crash Course.
Log Loss
La funzione di perdita utilizzata nella regressione logistica binaria.
Per saperne di più, consulta Regressione logistica: perdita e regolarizzazione in Machine Learning Crash Course.
log-odds
Il logaritmo delle probabilità di un evento.
perdita
Durante l'addestramento di un modello supervisionato, una misura della distanza tra la previsione di un modello e la sua etichetta.
Una funzione di perdita calcola la perdita.
Per saperne di più, consulta Regressione lineare: perdita in Machine Learning Crash Course.
curva di perdita
Un grafico della perdita in funzione del numero di iterazioni di addestramento. Il seguente grafico mostra una tipica curva di perdita:
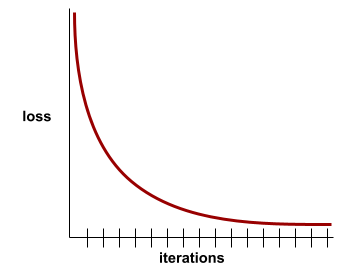
Le curve di perdita possono aiutarti a determinare quando il modello converge o quando si verifica l'overfitting.
Le curve di perdita possono tracciare tutti i seguenti tipi di perdita:
Vedi anche la curva di generalizzazione.
Per saperne di più, consulta Overfitting: interpretare le curve di perdita in Machine Learning Crash Course.
funzione di perdita
Durante l'addestramento o il test, una funzione matematica che calcola la perdita su un batch di esempi. Una funzione di perdita restituisce una perdita inferiore per i modelli che fanno buone previsioni rispetto a quelli che fanno previsioni errate.
L'obiettivo dell'addestramento è in genere quello di ridurre al minimo la perdita restituita da una funzione di perdita.
Esistono molti tipi diversi di funzioni di perdita. Scegli la funzione di perdita appropriata per il tipo di modello che stai creando. Ad esempio:
- La perdita L2 (o errore quadratico medio) è la funzione di perdita per la regressione lineare.
- La perdita logaritmica è la funzione di perdita per la regressione logistica.
M
machine learning
Un programma o sistema che addestra un modello a partire dai dati di input. Il modello addestrato può fare previsioni utili a partire da dati nuovi (mai visti prima) estratti dalla stessa distribuzione di quelli utilizzati per addestrare il modello.
Il machine learning si riferisce anche al campo di studio che si occupa di questi programmi o sistemi.
Per saperne di più, consulta il corso Introduzione al machine learning.
classe maggioritaria
L'etichetta più comune in un insieme di dati con sbilanciamento di classe. Ad esempio, dato un set di dati contenente il 99% di etichette negative e l'1% di etichette positive, le etichette negative sono la classe di maggioranza.
Contrasto con la classe di minoranza.
Per saperne di più, consulta Set di dati: set di dati non bilanciati in Machine Learning Crash Course.
mini-batch
Un piccolo sottoinsieme selezionato casualmente di un batch elaborato in un'iterazione. La dimensione del batch di un mini-batch è in genere compresa tra 10 e 1000 esempi.
Ad esempio, supponiamo che l'intero set di addestramento (l'intero batch) sia composto da 1000 esempi. Supponiamo inoltre di impostare la dimensione del batch di ogni mini-batch su 20. Pertanto, ogni iterazione determina la perdita su 20 esempi casuali dei 1000 e poi modifica di conseguenza i pesi e i bias.
È molto più efficiente calcolare la perdita su un mini-batch rispetto alla perdita su tutti gli esempi nel batch completo.
Per saperne di più, consulta Regressione lineare: iperparametri in Machine Learning Crash Course.
classe minoritaria
L'etichetta meno comune in un insieme di dati con sbilanciamento di classe. Ad esempio, dato un set di dati contenente il 99% di etichette negative e l'1% di etichette positive, le etichette positive sono la classe di minoranza.
Contrasto con la classe maggioritaria.
Per saperne di più, consulta Set di dati: set di dati non bilanciati in Machine Learning Crash Course.
modello
In generale, qualsiasi costrutto matematico che elabora i dati di input e restituisce l'output. In altre parole, un modello è l'insieme di parametri e della struttura necessari a un sistema per fare previsioni. Nel machine learning supervisionato, un modello prende un esempio come input e deduce una previsione come output. Nell'ambito del machine learning supervisionato, i modelli differiscono leggermente. Ad esempio:
- Un modello di regressione lineare è costituito da un insieme di pesi e da un bias.
- Un modello di rete neurale è costituito da:
- Un insieme di strati nascosti, ognuno contenente uno o più neuroni.
- I pesi e il bias associati a ogni neurone.
- Un modello ad albero decisionale è costituito da:
- La forma dell'albero, ovvero il pattern in cui sono collegate le condizioni e le foglie.
- Le condizioni e i permessi.
Puoi salvare, ripristinare o creare copie di un modello.
L'apprendimento automatico non supervisionato genera anche modelli, in genere una funzione che può mappare un esempio di input al cluster più appropriato.
classificazione multiclasse
Nell'apprendimento supervisionato, un problema di classificazione in cui il set di dati contiene più di due classi di etichette. Ad esempio, le etichette nel set di dati Iris devono appartenere a una delle seguenti tre classi:
- Iris setosa
- Iris virginica
- Iris versicolor
Un modello addestrato sul set di dati Iris che prevede il tipo di Iris su nuovi esempi esegue la classificazione multi-classe.
Al contrario, i problemi di classificazione che distinguono esattamente due classi sono modelli di classificazione binaria. Ad esempio, un modello di email che prevede spam o non spam è un modello di classificazione binaria.
Nei problemi di clustering, la classificazione multiclasse si riferisce a più di due cluster.
Per saperne di più, consulta la sezione Reti neurali: classificazione multiclasse di Machine Learning Crash Course.
No
classe negativa
Nella classificazione binaria, una classe è definita positiva e l'altra è definita negativa. La classe positiva è l'elemento o l'evento che il modello sta testando, mentre la classe negativa è l'altra possibilità. Ad esempio:
- La classe negativa in un test medico potrebbe essere "non tumore".
- La classe negativa in un modello di classificazione delle email potrebbe essere "non spam".
Contrasto con la classe positiva.
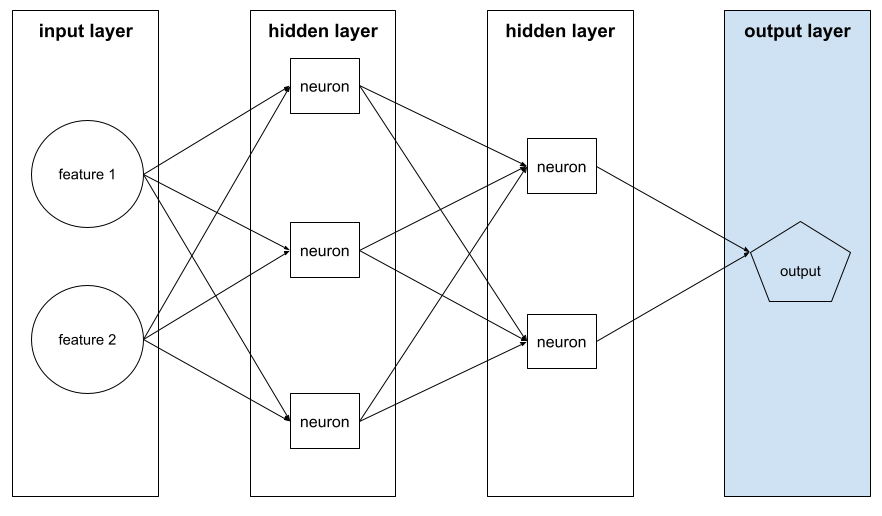
feed-forward
Un modello contenente almeno uno strato nascosto. Una rete neurale profonda è un tipo di rete neurale che contiene più di uno strato nascosto. Ad esempio, il seguente diagramma mostra una rete neurale profonda contenente due livelli nascosti.
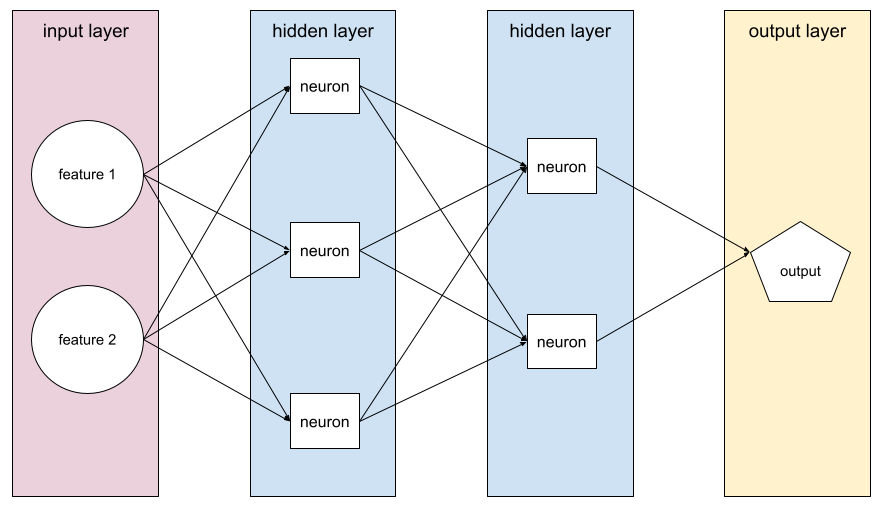
Ogni neurone di una rete neurale si connette a tutti i nodi del livello successivo. Ad esempio, nel diagramma precedente, nota che ciascuno dei tre neuroni nel primo strato nascosto si connette separatamente a entrambi i neuroni nel secondo strato nascosto.
Le reti neurali implementate sui computer sono a volte chiamate reti neurali artificiali per distinguerle dalle reti neurali presenti nel cervello e in altri sistemi nervosi.
Alcune reti neurali possono imitare relazioni non lineari estremamente complesse tra le diverse caratteristiche e l'etichetta.
Vedi anche rete neurale convoluzionale e rete neurale ricorrente.
Per saperne di più, consulta la sezione Reti neurali di Machine Learning Crash Course.
neurone
Nel machine learning, un'unità distinta all'interno di uno strato nascosto di una rete neurale. Ogni neurone esegue la seguente azione in due passaggi:
- Calcola la somma ponderata dei valori di input moltiplicati per i pesi corrispondenti.
- Passa la somma ponderata come input a una funzione di attivazione.
Un neurone del primo strato nascosto accetta gli input dai valori delle caratteristiche nello strato di input. Un neurone in qualsiasi strato nascosto oltre il primo accetta input dai neuroni dello strato nascosto precedente. Ad esempio, un neurone del secondo strato nascosto accetta input dai neuroni del primo strato nascosto.
La seguente illustrazione mette in evidenza due neuroni e i relativi input.
Un neurone in una rete neurale imita il comportamento dei neuroni nel cervello e in altre parti del sistema nervoso.
nodo (rete neurale)
Un neurone in uno strato nascosto.
Per ulteriori informazioni, consulta la sezione Reti neurali di Machine Learning Crash Course.
non lineare
Una relazione tra due o più variabili che non può essere rappresentata solo tramite addizione e moltiplicazione. Una relazione lineare può essere rappresentata come una linea, mentre una relazione non lineare non può essere rappresentata come una linea. Ad esempio, considera due modelli che mettono in relazione una singola funzionalità con una singola etichetta. Il modello a sinistra è lineare e quello a destra è non lineare:

Consulta la sezione Reti neurali: nodi e livelli nascosti del Machine Learning Crash Course per sperimentare diversi tipi di funzioni non lineari.
non stazionarietà
Una funzionalità i cui valori cambiano in una o più dimensioni, in genere il tempo. Ad esempio, considera i seguenti esempi di non stazionarietà:
- Il numero di costumi da bagno venduti in un determinato negozio varia in base alla stagione.
- La quantità di un determinato frutto raccolto in una regione specifica è pari a zero per gran parte dell'anno, ma elevata per un breve periodo.
- A causa dei cambiamenti climatici, le temperature medie annue stanno cambiando.
Contrasto con la stazionarietà.
normalizzazione
In generale, il processo di conversione dell'intervallo effettivo di valori di una variabile in un intervallo standard di valori, ad esempio:
- Da -1 a +1
- Da 0 a 1
- Punteggi z (approssimativamente da -3 a +3)
Ad esempio, supponiamo che l'intervallo effettivo di valori di una determinata caratteristica sia da 800 a 2400. Nell'ambito dell'ingegneria delle funzionalità, potresti normalizzare i valori effettivi in un intervallo standard, ad esempio da -1 a +1.
La normalizzazione è un'attività comune nell'ingegneria delle funzionalità. I modelli vengono addestrati più rapidamente (e producono previsioni migliori) quando ogni caratteristica numerica nel vettore delle caratteristiche ha all'incirca lo stesso intervallo.
Vedi anche Normalizzazione del punteggio Z.
Per saperne di più, consulta Dati numerici: normalizzazione in Machine Learning Crash Course.
dati numerici
Caratteristiche rappresentate come numeri interi o con valori reali. Ad esempio, un modello di valutazione di una casa rappresenterebbe probabilmente le dimensioni di una casa (in piedi quadrati o metri quadrati) come dati numerici. La rappresentazione di una caratteristica come dati numerici indica che i valori della caratteristica hanno una relazione matematica con l'etichetta. ovvero il numero di metri quadrati di una casa probabilmente ha una relazione matematica con il valore della casa.
Non tutti i dati interi devono essere rappresentati come dati numerici. Ad esempio,
i codici postali in alcune parti del mondo sono numeri interi; tuttavia, i codici postali
interi non devono essere rappresentati come dati numerici nei modelli. Questo perché un
codice postale di 20000 non è due volte (o la metà) più efficace di un codice postale di
10000. Inoltre, anche se codici postali diversi corrispondono a valori immobiliari diversi, non possiamo presumere che i valori immobiliari del codice postale 20000 siano il doppio di quelli del codice postale 10000.
I codici postali devono essere rappresentati come dati categorici.
Le caratteristiche numeriche sono a volte chiamate caratteristiche continue.
Per saperne di più, consulta la sezione Utilizzo dei dati numerici di Machine Learning Crash Course.
O
offline
Sinonimo di statico.
inferenza offline
Il processo di generazione di un batch di previsioni da parte di un modello e il successivo salvataggio nella cache. Le app possono quindi accedere alla previsione inferita dalla cache anziché eseguire nuovamente il modello.
Ad esempio, considera un modello che genera previsioni meteo locali (previsioni) una volta ogni quattro ore. Dopo ogni esecuzione del modello, il sistema memorizza nella cache tutte le previsioni meteo locali. Le app meteo recuperano le previsioni dalla cache.
L'inferenza offline è anche chiamata inferenza statica.
Contrasta con l'inferenza online. Per saperne di più, consulta la sezione Sistemi ML di produzione: inferenza statica e dinamica di Machine Learning Crash Course.
codifica one-hot
Rappresentazione dei dati categorici come un vettore in cui:
- Un elemento è impostato su 1.
- Tutti gli altri elementi sono impostati su 0.
La codifica one-hot è di uso comune per rappresentare stringhe o identificatori che
hanno un insieme finito di valori possibili.
Ad esempio, supponiamo che una determinata caratteristica categorica denominata
Scandinavia abbia cinque valori possibili:
- "Danimarca"
- "Sweden"
- "Norvegia"
- "Finlandia"
- "Islanda"
La codifica one-hot potrebbe rappresentare ciascuno dei cinque valori nel seguente modo:
| Paese | Vettoriale | ||||
|---|---|---|---|---|---|
| "Danimarca" | 1 | 0 | 0 | 0 | 0 |
| "Sweden" | 0 | 1 | 0 | 0 | 0 |
| "Norvegia" | 0 | 0 | 1 | 0 | 0 |
| "Finlandia" | 0 | 0 | 0 | 1 | 0 |
| "Islanda" | 0 | 0 | 0 | 0 | 1 |
Grazie alla codifica one-hot, un modello può apprendere connessioni diverse in base a ciascuno dei cinque paesi.
La rappresentazione di una caratteristica come dati numerici è un'alternativa alla codifica one-hot. Purtroppo, rappresentare i paesi scandinavi numericamente non è una buona scelta. Ad esempio, considera la seguente rappresentazione numerica:
- "Danimarca" è 0
- "Svezia" è 1
- "Norvegia" è 2
- "Finlandia" è 3
- "Islanda" è 4
Con la codifica numerica, un modello interpreterebbe i numeri grezzi matematicamente e tenterebbe di addestrarsi su questi numeri. Tuttavia, l'Islanda non è il doppio (o la metà) di qualcosa rispetto alla Norvegia, quindi il modello arriverebbe a conclusioni strane.
Per saperne di più, consulta Dati categorici: vocabolario e codifica one-hot in Machine Learning Crash Course.
one-vs.-all
Dato un problema di classificazione con N classi, una soluzione costituita da N modelli di classificazione binaria separati, uno per ogni possibile risultato. Ad esempio, dato un modello che classifica gli esempi come animale, vegetale o minerale, una soluzione uno contro tutti fornirebbe i seguenti tre modelli di classificazione binaria separati:
- animale o non animale
- verdura o non verdura
- minerale o non minerale
online
Sinonimo di dinamico.
inferenza online
Generazione di previsioni on demand. Ad esempio, supponiamo che un'app passi l'input a un modello ed emetta una richiesta di previsione. Un sistema che utilizza l'inferenza online risponde alla richiesta eseguendo il modello (e restituendo la previsione all'app).
Contrasto con l'inferenza offline.
Per saperne di più, consulta la sezione Sistemi ML di produzione: inferenza statica e dinamica di Machine Learning Crash Course.
strato di output
Lo strato "finale" di una rete neurale. Lo strato di output contiene la previsione.
La seguente illustrazione mostra una piccola rete neurale profonda con uno strato di input, due strati nascosti e uno strato di output:
overfitting
Creazione di un modello che corrisponde ai dati di addestramento in modo così preciso che il modello non riesce a fare previsioni corrette su nuovi dati.
La regolarizzazione può ridurre l'overfitting. L'addestramento su un set di addestramento ampio e diversificato può anche ridurre l'overfitting.
Per saperne di più, consulta la sezione Overfitting di Machine Learning Crash Course.
P
panda
Un'API per l'analisi dei dati orientata alle colonne basata su numpy. Molti framework di machine learning, tra cui TensorFlow, supportano le strutture di dati pandas come input. Per informazioni dettagliate, consulta la documentazione di pandas.
parametro
Le ponderazioni e i bias che un modello apprende durante l'addestramento. Ad esempio, in un modello di regressione lineare, i parametri sono costituiti dal bias (b) e da tutti i pesi (w1, w2 e così via) nella seguente formula:
Al contrario, gli iperparametri sono i valori che tu (o un servizio di ottimizzazione degli iperparametri) fornisci al modello. Ad esempio, il tasso di apprendimento è un iperparametro.
classe positiva
Il corso per cui stai eseguendo il test.
Ad esempio, la classe positiva in un modello per il cancro potrebbe essere "tumore". La classe positiva in un modello di classificazione delle email potrebbe essere "spam".
Contrasto con la classe negativa.
post-elaborazione
Modifica dell'output di un modello dopo l'esecuzione. Il post-processing può essere utilizzato per applicare vincoli di equità senza modificare i modelli stessi.
Ad esempio, è possibile applicare il post-processing a un modello di classificazione binaria impostando una soglia di classificazione in modo che l'uguaglianza delle opportunità venga mantenuta per un determinato attributo verificando che il tasso di veri positivi sia uguale per tutti i valori di quell'attributo.
precisione
Una metrica per i modelli di classificazione che risponde alla seguente domanda:
Quando il modello ha previsto la classe positiva, qual è stata la percentuale di previsioni corrette?
Ecco la formula:
dove:
- vero positivo significa che il modello ha previsto correttamente la classe positiva.
- Un falso positivo significa che il modello ha previsto erroneamente la classe positiva.
Ad esempio, supponiamo che un modello abbia effettuato 200 previsioni positive. Di queste 200 previsioni positive:
- 150 erano veri positivi.
- 50 erano falsi positivi.
In questo caso:
Contrasta con accuratezza e richiamo.
Per saperne di più, consulta Classificazione: accuratezza, richiamo, precisione e metriche correlate in Machine Learning Crash Course.
previsione
L'output di un modello. Ad esempio:
- La previsione di un modello di classificazione binaria è la classe positiva o la classe negativa.
- La previsione di un modello di classificazione multi-classe è una classe.
- La previsione di un modello di regressione lineare è un numero.
proxy labels
Dati utilizzati per approssimare le etichette non disponibili direttamente in un set di dati.
Ad esempio, supponiamo di dover addestrare un modello per prevedere il livello di stress dei dipendenti. Il tuo set di dati contiene molte funzionalità predittive, ma non contiene un'etichetta denominata livello di stress. Senza scoraggiarti, scegli "incidenti sul lavoro" come etichetta proxy per il livello di stress. Dopo tutto, i dipendenti sotto forte stress sono coinvolti in più incidenti rispetto a quelli tranquilli. O no? Forse gli incidenti sul lavoro aumentano e diminuiscono per diversi motivi.
Come secondo esempio, supponiamo che tu voglia che is it raining? sia un'etichetta booleana per il tuo set di dati, ma il tuo set di dati non contenga dati sulla pioggia. Se sono disponibili fotografie, potresti stabilire immagini di persone che portano ombrelli come etichetta proxy per sta piovendo? È un'etichetta proxy valida? Probabilmente, ma le persone di alcune culture potrebbero portare con sé l'ombrello più per proteggersi dal sole che dalla pioggia.
Le etichette proxy spesso non sono perfette. Se possibile, scegli etichette reali anziché etichette proxy. Detto questo, quando un'etichetta effettiva è assente, scegli l'etichetta proxy con molta attenzione, selezionando il candidato meno orribile.
Per saperne di più, consulta Set di dati: etichette in Machine Learning Crash Course.
R
RAG
Abbreviazione di retrieval-augmented generation.
rater
Una persona che fornisce etichette per gli esempi. "Annotatore" è un altro nome per valutatore.
Per saperne di più, consulta Dati categorici: problemi comuni in Machine Learning Crash Course.
richiamo
Una metrica per i modelli di classificazione che risponde alla seguente domanda:
Quando la verità di riferimento era la classe positiva, quale percentuale di previsioni il modello ha identificato correttamente come classe positiva?
Ecco la formula:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
dove:
- vero positivo significa che il modello ha previsto correttamente la classe positiva.
- Un falso negativo significa che il modello ha previsto erroneamente la classe negativa.
Ad esempio, supponiamo che il modello abbia effettuato 200 previsioni su esempi per i quali i dati empirici reali erano la classe positiva. Di queste 200 previsioni:
- 180 erano veri positivi.
- 20 erano falsi negativi.
In questo caso:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Per saperne di più, consulta Classificazione: accuratezza, richiamo, precisione e metriche correlate.
Unità lineare rettificata (ReLU)
Una funzione di attivazione con il seguente comportamento:
- Se l'input è negativo o zero, l'output è 0.
- Se l'input è positivo, l'output è uguale all'input.
Ad esempio:
- Se l'input è -3, l'output è 0.
- Se l'input è +3, l'output è 3.0.
Ecco un grafico della ReLU:

ReLU è una funzione di attivazione molto popolare. Nonostante il suo comportamento semplice, ReLU consente comunque a una rete neurale di apprendere relazioni non lineari tra le funzionalità e l'etichetta.
modello di regressione
Informalmente, un modello che genera una previsione numerica. Al contrario, un modello di classificazione genera una previsione di classe. Ad esempio, i seguenti sono tutti modelli di regressione:
- Un modello che prevede il valore di una determinata casa in euro, ad esempio 423.000.
- Un modello che prevede l'aspettativa di vita di un determinato albero in anni, ad esempio 23,2.
- Un modello che prevede la quantità di pioggia in pollici che cadrà in una determinata città nelle prossime sei ore, ad esempio 0,18.
Due tipi comuni di modelli di regressione sono:
- Regressione lineare, che trova la linea che meglio si adatta ai valori delle etichette alle caratteristiche.
- Regressione logistica, che genera una probabilità compresa tra 0.0 e 1.0 che un sistema in genere mappa a una previsione di classe.
Non tutti i modelli che restituiscono previsioni numeriche sono modelli di regressione. In alcuni casi, una previsione numerica è in realtà solo un modello di classificazione che ha nomi di classe numerici. Ad esempio, un modello che prevede un codice postale numerico è un modello di classificazione, non un modello di regressione.
regolarizzazione
Qualsiasi meccanismo che riduce l'overfitting. I tipi più comuni di regolarizzazione includono:
- Regolarizzazione L1
- Regolarizzazione L2
- Regolarizzazione dropout
- Interruzione anticipata (non è un metodo di regolarizzazione formale, ma può limitare efficacemente l'overfitting)
La regolarizzazione può anche essere definita come la penalità per la complessità di un modello.
Per saperne di più, consulta Overfitting: complessità del modello in Machine Learning Crash Course.
tasso di regolarizzazione
Un numero che specifica l'importanza relativa della regolarizzazione durante l'addestramento. L'aumento del tasso di regolarizzazione riduce l'overfitting, ma potrebbe ridurre il potere predittivo del modello. Al contrario, la riduzione o l'omissione del tasso di regolarizzazione aumenta l'overfitting.
Per saperne di più, consulta Overfitting: regolarizzazione L2 in Machine Learning Crash Course.
ReLU
Abbreviazione di Rectified Linear Unit.
Retrieval-augmented generation (RAG)
Una tecnica per migliorare la qualità dell'output di un modello linguistico di grandi dimensioni (LLM) basandolo su fonti di conoscenza recuperate dopo l'addestramento del modello. La RAG migliora l'accuratezza delle risposte dell'LLM fornendo all'LLM addestrato l'accesso alle informazioni recuperate da knowledge base o documenti attendibili.
I motivi più comuni per utilizzare la Retrieval Augmented Generation includono:
- Aumentare l'accuratezza oggettiva delle risposte generate da un modello.
- Consentire al modello di accedere a conoscenze su cui non è stato addestrato.
- Modifica delle conoscenze utilizzate dal modello.
- Consentire al modello di citare le fonti.
Ad esempio, supponiamo che un'app di chimica utilizzi l'API PaLM per generare riepiloghi relativi alle query degli utenti. Quando il backend dell'app riceve una query, esegue le seguenti operazioni:
- Cerca ("recupera") i dati pertinenti alla query dell'utente.
- Aggiunge ("aumenta") i dati chimici pertinenti alla query dell'utente.
- Indica al modello LLM di creare un riepilogo in base ai dati aggiunti.
Curva ROC (caratteristica operativa del ricevitore)
Un grafico della percentuale di veri positivi rispetto alla percentuale di falsi positivi per diverse soglie di classificazione nella classificazione binaria.
La forma di una curva ROC suggerisce la capacità di un modello di classificazione binaria di separare le classi positive da quelle negative. Supponiamo, ad esempio, che un modello di classificazione binaria separi perfettamente tutte le classi negative da tutte le classi positive:
La curva ROC per il modello precedente ha il seguente aspetto:

Al contrario, il grafico dell'illustrazione seguente mostra i valori grezzi della regressione logistica per un modello pessimo che non riesce a separare le classi negative da quelle positive:
La curva ROC per questo modello ha il seguente aspetto:
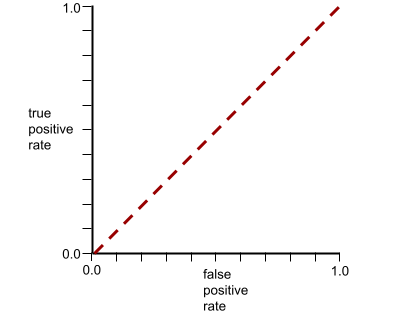
Nel frattempo, nel mondo reale, la maggior parte dei modelli di classificazione binaria separa le classi positive e negative in una certa misura, ma di solito non perfettamente. Pertanto, una curva ROC tipica si trova a metà strada tra i due estremi:
Il punto su una curva ROC più vicino a (0.0,1.0) identifica teoricamente la soglia di classificazione ideale. Tuttavia, diversi altri problemi del mondo reale influenzano la selezione della soglia di classificazione ideale. Ad esempio, forse i falsi negativi causano molto più dolore dei falsi positivi.
Una metrica numerica chiamata AUC riassume la curva ROC in un singolo valore in rappresentazione in virgola mobile.
Errore quadratico medio (RMSE)
La radice quadrata dell'errore quadratico medio.
S
funzione sigmoidea
Una funzione matematica che "comprime" un valore di input in un intervallo vincolato, in genere da 0 a 1 o da -1 a +1. ovvero puoi passare qualsiasi numero (2, un milione, un miliardo negativo, quello che vuoi) a una sigmoide e l'output sarà comunque nell'intervallo vincolato. Un grafico della funzione di attivazione sigmoide è il seguente:
La funzione sigmoide ha diversi utilizzi nel machine learning, tra cui:
- Conversione dell'output non elaborato di un modello di regressione logistica o di regressione multinomiale in una probabilità.
- che funge da funzione di attivazione in alcune reti neurali.
softmax
Una funzione che determina le probabilità per ogni classe possibile in un modello di classificazione multiclasse. La somma delle probabilità è esattamente 1.0. Ad esempio, la tabella seguente mostra come la funzione softmax distribuisce varie probabilità:
| L'immagine è un/una… | Probabilità |
|---|---|
| cane | 0,85 |
| gatto | ,13 |
| cavallo | .02 |
Softmax è anche chiamato softmax completo.
Contrasta con il campionamento dei candidati.
Per saperne di più, consulta la sezione Reti neurali: classificazione multiclasse di Machine Learning Crash Course.
caratteristica sparsa
Una caratteristica i cui valori sono prevalentemente zero o vuoti. Ad esempio, una caratteristica contenente un singolo valore 1 e un milione di valori 0 è scarsa. Al contrario, una caratteristica densa ha valori che non sono prevalentemente zero o vuoti.
Nel machine learning, un numero sorprendente di caratteristiche sono caratteristiche sparse. Le caratteristiche categoriche sono in genere caratteristiche sparse. Ad esempio, delle 300 specie di alberi possibili in una foresta, un singolo esempio potrebbe identificare solo un acero. Oppure, tra i milioni di video possibili in una raccolta video, un singolo esempio potrebbe identificare solo "Casablanca".
In un modello, in genere le caratteristiche sparse vengono rappresentate con la codifica one-hot. Se la codifica one-hot è grande, potresti inserire un livello di incorporamento sopra la codifica one-hot per una maggiore efficienza.
rappresentazione sparsa
Memorizzazione solo delle posizioni degli elementi diversi da zero in una funzionalità sparsa.
Ad esempio, supponiamo che una funzionalità categorica denominata species identifichi le 36
specie di alberi in una determinata foresta. Supponiamo inoltre che ogni
esempio identifichi una sola specie.
Potresti utilizzare un vettore one-hot per rappresentare le specie di alberi in ogni esempio.
Un vettore one-hot conterrebbe un singolo 1 (per rappresentare
la particolare specie di albero nell'esempio) e 35 0 (per rappresentare le
35 specie di alberi non presenti nell'esempio). Pertanto, la rappresentazione one-hot
di maple potrebbe avere un aspetto simile al seguente:

In alternativa, la rappresentazione sparsa identificherebbe semplicemente la posizione della
specie in questione. Se maple si trova nella posizione 24, la rappresentazione sparsa
di maple sarà semplicemente:
24
Tieni presente che la rappresentazione sparsa è molto più compatta di quella one-hot.
Fai clic sull'icona per un esempio leggermente più complesso.
Supponiamo che ogni esempio nel tuo modello debba rappresentare le parole, ma non l'ordine di queste parole, in una frase in inglese. L'inglese è composto da circa 170.000 parole, quindi è una funzionalità categorica con circa 170.000 elementi. La maggior parte delle frasi in inglese utilizza una piccolissima frazione di queste 170.000 parole, quindi l'insieme di parole in un singolo esempio sarà quasi certamente un insieme di dati sparsi.
Considera la seguente frase:
My dog is a great dog
Potresti utilizzare una variante del vettore one-hot per rappresentare le parole in questa frase. In questa variante, più celle del vettore possono contenere un valore diverso da zero. Inoltre, in questa variante, una cella può contenere un numero intero diverso da uno. Anche se le parole "il mio", "è", "un" e "grande" compaiono solo una volta nella frase, la parola "cane" compare due volte. L'utilizzo di questa variante di vettori one-hot per rappresentare le parole in questa frase produce il seguente vettore di 170.000 elementi:

Una rappresentazione sparsa della stessa frase sarebbe semplicemente:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Per saperne di più, consulta la sezione Lavorare con dati categorici in Machine Learning Crash Course.
vettore sparso
Un vettore i cui valori sono per lo più zeri. Vedi anche funzionalità sparse e sparsità.
perdita quadratica
Sinonimo di perdita L2.
static
Qualcosa fatto una volta anziché in modo continuo. I termini statico e offline sono sinonimi. Di seguito sono riportati gli utilizzi comuni di statico e offline nel machine learning:
- Un modello statico (o modello offline) è un modello addestrato una sola volta e poi utilizzato per un po' di tempo.
- L'addestramento statico (o addestramento offline) è il processo di addestramento di un modello statico.
- L'inferenza statica (o inferenza offline) è un processo in cui un modello genera un batch di previsioni alla volta.
Contrasto con dinamico.
inferenza statica
Sinonimo di inferenza offline.
stazionarietà
Una funzionalità i cui valori non cambiano in una o più dimensioni, in genere il tempo. Ad esempio, una caratteristica i cui valori appaiono più o meno uguali nel 2021 e nel 2023 mostra stazionarietà.
Nel mondo reale, pochissime caratteristiche mostrano stazionarietà. Anche le caratteristiche sinonimo di stabilità (come il livello del mare) cambiano nel tempo.
Contrasto con la non stazionarietà.
discesa stocastica del gradiente (SGD)
Un algoritmo di discesa del gradiente in cui la dimensione del batch è pari a uno. In altre parole, SGD esegue l'addestramento su un singolo esempio scelto in modo uniforme e casuale da un set di addestramento.
Per saperne di più, consulta Regressione lineare: iperparametri in Machine Learning Crash Course.
machine learning supervisionato
Addestramento di un modello a partire dalle caratteristiche e dalle relative etichette. Il machine learning supervisionato è analogo all'apprendimento di una materia studiando una serie di domande e le risposte corrispondenti. Dopo aver acquisito la mappatura tra domande e risposte, uno studente può fornire risposte a nuove domande (mai viste prima) sullo stesso argomento.
Confronta con machine learning non supervisionato.
Per saperne di più, consulta la sezione Apprendimento supervisionato del corso Introduzione al machine learning.
funzionalità sintetica
Una caratteristica non presente tra le caratteristiche di input, ma assemblata a partire da una o più di queste. I metodi per creare funzionalità sintetiche includono quanto segue:
- Suddivisione in bucket di una caratteristica continua in bin di intervallo.
- Creazione di un incrocio di caratteristiche.
- Moltiplicando (o dividendo) un valore di una caratteristica per altri valori di caratteristiche
o per se stesso. Ad esempio, se
aebsono caratteristiche di input, di seguito sono riportati alcuni esempi di caratteristiche sintetiche:- ab
- a2
- Applicazione di una funzione trascendentale a un valore della funzionalità. Ad esempio, se
cè una caratteristica di input, di seguito sono riportati alcuni esempi di caratteristiche sintetiche:- sin(c)
- ln(c)
Le caratteristiche create solo tramite normalizzazione o scalabilità non sono considerate caratteristiche sintetiche.
T
test loss
Una metrica che rappresenta la perdita di un modello rispetto al set di test. Quando crei un modello, in genere cerchi di ridurre al minimo la perdita di test. Questo perché una perdita dei dati di test bassa è un indicatore di qualità più forte rispetto a una perdita di addestramento bassa [training loss] o una perdita di convalida bassa [validation loss].
Un ampio divario tra la perdita di test e la perdita di addestramento o di convalida a volte suggerisce di aumentare il tasso di regolarizzazione.
formazione
Il processo di determinazione dei parametri (pesi e bias) ideali che compongono un modello. Durante l'addestramento, un sistema legge esempi e regola gradualmente i parametri. L'addestramento utilizza ogni esempio da poche volte a miliardi di volte.
Per saperne di più, consulta la sezione Apprendimento supervisionato del corso Introduzione al machine learning.
perdita di addestramento
Una metrica che rappresenta la perdita di un modello durante una particolare iterazione di addestramento. Ad esempio, supponiamo che la funzione di perdita sia l'errore quadratico medio. Forse la perdita di addestramento (l'errore quadratico medio) per la decima iterazione è 2,2 e la perdita di addestramento per la centesima iterazione è 1,9.
Una curva di perdita traccia la perdita di addestramento rispetto al numero di iterazioni. Una curva di perdita fornisce i seguenti suggerimenti sull'addestramento:
- Una pendenza verso il basso implica che il modello sta migliorando.
- Una pendenza verso l'alto implica che il modello sta peggiorando.
- Una pendenza piatta implica che il modello ha raggiunto la convergenza.
Ad esempio, la seguente curva di perdita un po' idealizzata mostra:
- Una pendenza ripida verso il basso durante le iterazioni iniziali, il che implica un rapido miglioramento del modello.
- Una pendenza che si appiattisce gradualmente (ma ancora verso il basso) fino quasi alla fine dell'addestramento, il che implica un miglioramento continuo del modello a un ritmo un po' più lento rispetto alle iterazioni iniziali.
- Una pendenza piatta verso la fine dell'addestramento, che suggerisce la convergenza.
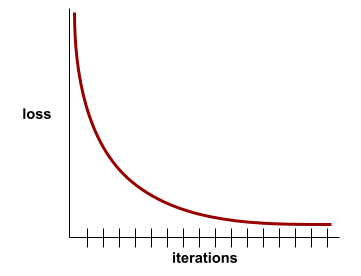
Sebbene la perdita per l'addestramento sia importante, consulta anche la generalizzazione.
disallineamento addestramento/produzione
La differenza tra il rendimento di un modello durante l'addestramento e quello dello stesso modello durante la produzione.
training set
Il sottoinsieme del set di dati utilizzato per addestrare un modello.
Tradizionalmente, gli esempi nel set di dati sono suddivisi nei seguenti tre sottoinsiemi distinti:
- un training set
- un set di validazione
- un test set
Idealmente, ogni esempio nel set di dati dovrebbe appartenere a uno solo dei sottoinsiemi precedenti. Ad esempio, un singolo esempio non deve appartenere sia al set di addestramento sia al set di validazione.
Per saperne di più, consulta Set di dati: divisione del set di dati originale in Machine Learning Crash Course.
vero negativo (VN)
Un esempio in cui il modello prevede correttamente la classe negativa. Ad esempio, il modello deduce che un determinato messaggio email non è spam e in effetti non lo è.
vero positivo (VP)
Un esempio in cui il modello prevede correttamente la classe positiva. Ad esempio, il modello deduce che un determinato messaggio email è spam e questo messaggio email è effettivamente spam.
tasso di veri positivi (TVP)
Sinonimo di richiamo. Ossia:
La percentuale di veri positivi è l'asse Y di una curva ROC.
U
underfitting
Produzione di un modello con scarsa capacità predittiva perché il modello non ha acquisito completamente la complessità dei dati di addestramento. Molti problemi possono causare un adattamento insufficiente, tra cui:
- Addestramento sul set errato di funzionalità.
- Addestramento per un numero troppo basso di epoche o a un tasso di apprendimento troppo basso.
- Addestramento con un tasso di regolarizzazione troppo elevato.
- Fornire un numero troppo basso di strati nascosti in una rete neurale profonda.
Per saperne di più, consulta la sezione Overfitting di Machine Learning Crash Course.
esempio senza etichetta
Un esempio che contiene funzionalità, ma nessuna etichetta. Ad esempio, la tabella seguente mostra tre esempi senza etichetta di un modello di valutazione di una casa, ognuno con tre caratteristiche ma senza valore della casa:
| Numero di camere | Numero di bagni | Età della casa |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
Nel machine learning supervisionato, i modelli vengono addestrati su esempi etichettati e fanno previsioni su esempi non etichettati.
Nell'apprendimento semi-supervisionato e non supervisionato, vengono utilizzati esempi non etichettati durante l'addestramento.
Confronta l'esempio senza etichetta con l'esempio con etichetta��.
machine learning non supervisionato
Addestramento di un modello per trovare pattern in un set di dati, in genere un set di dati senza etichette.
L'utilizzo più comune del machine learning non supervisionato è quello di raggruppare i dati in gruppi di esempi simili. Ad esempio, un algoritmo di machine learning non supervisionato può raggruppare i brani in base a varie proprietà della musica. I cluster risultanti possono diventare un input per altri algoritmi di machine learning (ad esempio, per un servizio di consigli musicali). Il clustering può essere utile quando le etichette utili sono scarse o assenti. Ad esempio, in domini come l'anti-abuso e le frodi, i cluster possono aiutare le persone a comprendere meglio i dati.
Contrasto con il machine learning supervisionato.
Per saperne di più, consulta Che cos'è il machine learning? nel corso Introduction to ML.
V
convalida
La valutazione iniziale della qualità di un modello. La convalida verifica la qualità delle previsioni di un modello rispetto al set di validazione.
Poiché il set di validazione è diverso dal set di addestramento, la validazione aiuta a evitare l'overfitting.
Puoi considerare la valutazione del modello rispetto al set di validazione come il primo round di test e la valutazione del modello rispetto al test set come il secondo round di test.
perdita di convalida
Una metrica che rappresenta la perdita di un modello sul set di validazione durante una particolare iterazione dell'addestramento.
Vedi anche la curva di generalizzazione.
set di validazione
Il sottoinsieme del set di dati che esegue la valutazione iniziale rispetto a un modello addestrato. In genere, valuti il modello addestrato in base al set di validazione più volte prima di valutarlo in base al test set.
Tradizionalmente, gli esempi nel set di dati vengono suddivisi nei seguenti tre sottoinsiemi distinti:
- un set di addestramento
- un set di validazione
- un test set
Idealmente, ogni esempio nel set di dati dovrebbe appartenere a uno solo dei sottoinsiemi precedenti. Ad esempio, un singolo esempio non deve appartenere sia al set di addestramento sia al set di validazione.
Per saperne di più, consulta Set di dati: divisione del set di dati originale in Machine Learning Crash Course.
M
peso
Un valore che un modello moltiplica per un altro valore. L'addestramento è il processo di determinazione dei pesi ideali di un modello; l'inferenza è il processo di utilizzo di questi pesi appresi per fare previsioni.
Per saperne di più, consulta Regressione lineare in Machine Learning Crash Course.
somma ponderata
La somma di tutti i valori di input pertinenti moltiplicati per i pesi corrispondenti. Ad esempio, supponiamo che gli input pertinenti siano i seguenti:
| valore di input | peso dell'input |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
La somma ponderata è quindi:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Una somma ponderata è l'argomento di input di una funzione di attivazione.
Z
Normalizzazione del punteggio z
Una tecnica di scalabilità che sostituisce un valore di caratteristica non elaborato con un valore in virgola mobile che rappresenta il numero di deviazioni standard dalla media di quella caratteristica. Ad esempio, considera una funzionalità con una media di 800 e una deviazione standard di 100. La tabella seguente mostra come la normalizzazione Z-score mapperebbe il valore non elaborato al suo Z-score:
| Valore non elaborato | Z-score |
|---|---|
| 800 | 0 |
| 950 | +1,5 |
| 575 | -2,25 |
Il modello di machine learning viene quindi addestrato sugli Z-score di questa funzionalità anziché sui valori non elaborati.
Per saperne di più, consulta Dati numerici: normalizzazione in Machine Learning Crash Course.