このページでは、生成 AI の用語集の用語について説明します。用語集のすべての用語については、こちらをクリックしてください。
A
適応
チューニングまたはファインチューニングと同義。
エージェント
マルチモーダル ユーザー入力について推論し、ユーザーに代わってアクションを計画して実行できるソフトウェア。
強化学習では、エージェントは ポリシーを使用して、環境の状態間の移行から得られる期待収益を最大化するエンティティです。
エージェントの/代理人の
エージェントの形容詞形。エージェント性とは、エージェントが持つ特性(自律性など)を指します。
エージェント ワークフロー
エージェントが目標を達成するためにアクションを自律的に計画して実行する動的プロセス。このプロセスでは、推論、外部ツールの呼び出し、計画の自己修正が行われることがあります。
AI スロップ
品質よりも量を重視する生成 AI システムからの出力。たとえば、AI スロップのあるウェブページは、安価に作成された AI 生成の低品質なコンテンツで埋め尽くされています。
自動評価
ソフトウェアを使用してモデルの出力の品質を判断する。
モデルの出力が比較的単純な場合は、スクリプトまたはプログラムでモデルの出力をゴールデン レスポンスと比較できます。このタイプの自動評価は、プログラマティック評価と呼ばれることもあります。ROUGE や BLEU などの指標は、プログラムによる評価に役立つことがよくあります。
モデルの出力が複雑な場合や、正解が 1 つではない場合は、自動採点者と呼ばれる別の ML プログラムが自動評価を行うことがあります。
人間による評価と比較してください。
自動評価
人間による評価と自動評価を組み合わせた、生成 AI モデルの出力の品質を判定するハイブリッド メカニズム。自動評価ツールは、人間による評価で作成されたデータでトレーニングされた ML モデルです。理想的には、自動評価ツールは人間の評価者を模倣することを学習します。事前構築済みの自動評価ツールを使用できますが、最適な自動評価ツールは、評価するタスクに合わせて特別にファインチューニングされています。
自己回帰モデル
独自の過去の予測に基づいて予測を推論するモデル。たとえば、自己回帰言語モデルは、以前に予測されたトークンに基づいて次のトークンを予測します。Transformer ベースの大規模言語モデルはすべて自動回帰です。
一方、GAN ベースの画像モデルは、通常、自己回帰ではありません。これは、画像をステップごとに反復的に生成するのではなく、単一のフォワード パスで生成するためです。ただし、一部の画像生成モデルは、画像を段階的に生成するため、自己回帰的です。
B
ベースモデル
特定のタスクやアプリケーションに対応するためのファイン チューニングの出発点として使用できる事前トレーニング済みモデル。
事前トレーニング済みモデルと基盤モデルもご覧ください。
C
Chain-of-Thought プロンプト
大規模言語モデル(LLM)に推論を段階的に説明するように促すプロンプト エンジニアリング手法。たとえば、次のプロンプトについて考えてみましょう。特に 2 番目の文に注目してください。
時速 0 マイルから時速 60 マイルまで 7 秒で加速する車に乗っているドライバーが受ける G フォースはどのくらいですか?回答には、関連する計算をすべて示してください。
LLM のレスポンスは、次のようになります。
- 物理の公式のシーケンスを表示し、適切な場所に 0、60、7 の値を代入します。
- 選択した数式とその理由、さまざまな変数の意味を説明します。
Chain-of-thought プロンプトを使用すると、LLM はすべての計算を実行する必要があるため、より正確な回答が得られる可能性があります。また、連鎖思考プロンプトを使用すると、ユーザーは LLM の手順を調べて、回答が妥当かどうかを判断できます。
チャット
ML システム(通常は大規模言語モデル)とのやり取りの内容。チャットでの以前のやり取り(入力した内容と大規模言語モデルの回答)が、チャットの後続部分のコンテキストになります。
chatbot は大規模言語モデルのアプリケーションです。
コンテキスト化された言語エンベディング
流暢な人間の話者が単語やフレーズを理解する方法に近い方法で単語やフレーズを「理解」するエンベディング。コンテキスト化された言語エンベディングは、複雑な構文、セマンティクス、コンテキストを理解できます。
たとえば、英語の単語「cow」のエンベディングについて考えてみましょう。word2vec などの古いエンベディングでは、cow から bull までのエンベディング空間内の距離が、ewe(雌羊)から ram(雄羊)までの距離や、female から male までの距離と類似するように、英単語を表現できます。コンテキスト化された言語エンベディングは、英語話者が「cow」という単語を牛または雄牛の意味でカジュアルに使用することがあることを認識することで、さらに一歩進むことができます。
コンテキスト ウィンドウ
モデルが特定のプロンプトで処理できるトークンの数。コンテキスト ウィンドウが大きいほど、モデルはより多くの情報を使用して、プロンプトに明解で一貫性のある回答を提供できます。
会話型コーディング
ソフトウェアを作成する目的で、ユーザーと生成 AI モデルの間で行われる反復的なダイアログ。ソフトウェアについて説明するプロンプトを発行します。モデルは、その説明を使用してコードを生成します。次に、前のプロンプトまたは生成されたコードの欠陥に対処する新しいプロンプトを発行すると、モデルは更新されたコードを生成します。生成されたソフトウェアが十分に優れていると判断されるまで、このやり取りが繰り返されます。
会話コーディングは、基本的にバイブ コーディングの本来の意味です。
仕様コーディングも参照してください。
D
直接プロンプト
ゼロショット プロンプトと同義。
での精製
1 つのモデル(教師と呼ばれる)のサイズを、元のモデルの予測を可能な限り忠実にエミュレートする小さなモデル(生徒と呼ばれる)に縮小するプロセス。蒸留が有用なのは、小規模なモデルには大規模なモデル(教師)よりも 2 つの大きなメリットがあるためです。
- 推論時間の短縮
- メモリとエネルギー使用量の削減
ただし、生徒の予測は通常、教師の予測ほど正確ではありません。
蒸留では、生徒モデルと教師モデルの予測の出力の差に基づいて、損失関数を最小限に抑えるように生徒モデルをトレーニングします。
蒸留と次の用語を比較対照します。
詳細については、ML 集中講座の LLM: ファインチューニング、蒸留、プロンプト エンジニアリングをご覧ください。
E
evals
主に LLM 評価の略語として使用されます。広義には、evals は、評価のあらゆる形式の略語です。
評価
モデルの品質を測定したり、異なるモデルを比較したりするプロセス。
教師あり機械学習モデルを評価するには、通常、検証セットとテストセットに対してモデルを評価します。LLM の評価には通常、品質と安全性のより広範な評価が含まれます。
F
事実性
ML の世界では、出力が現実に基づいているモデルを表すプロパティ。事実性は指標ではなくコンセプトです。たとえば、次のようなプロンプトを大規模言語モデルに送信するとします。
食塩の化学式は何ですか?
事実性を最適化するモデルは次のように応答します。
NaCl
すべてのモデルは事実に基づいていなければならないと考えるのは当然です。ただし、次のようなプロンプトでは、生成 AI モデルは事実性ではなく創造性を最適化する必要があります。
宇宙飛行士とイモムシについての五行詩を教えて。
結果として得られるリメリックは、現実に基づいたものにはならないでしょう。
グラウンディングと比較してください。
急速な減衰
LLM のパフォーマンスを向上させるためのトレーニング手法。高速減衰では、トレーニング中に学習率を急速に減衰させます。この戦略は、モデルがトレーニング データに過剰適合するのを防ぎ、一般化を改善するのに役立ちます。
少数ショット プロンプト
大規模言語モデルにどのように回答すればよいかを示す例を複数(少数)含むプロンプト。たとえば、次の長いプロンプトには、大規模言語モデルにクエリへの回答方法を示す 2 つの例が含まれています。
| 1 つのプロンプトの各部分 | メモ |
|---|---|
| 指定された国の公式通貨は何ですか? | LLM に回答させたい質問。 |
| フランス: EUR | 例 1: |
| 英国: GBP | 別の例。 |
| インド: | 実際のクエリ。 |
一般的に、少数ショット プロンプトは、ゼロショット プロンプトやワンショット プロンプトよりも望ましい結果が得られます。ただし、少数ショット プロンプトでは長いプロンプトが必要になります。
少数ショット プロンプトは、プロンプト ベースの学習に適用される少数ショット学習の一種です。
詳細については、ML 集中講座のプロンプト エンジニアリングをご覧ください。
ファインチューニング
パラメータを特定のユースケースに合わせて最適化するために、事前トレーニングされたモデルに対してさらに行うタスク固有のトレーニングです。たとえば、一部の大規模言語モデルの完全なトレーニング シーケンスは次のとおりです。
- 事前トレーニング: 英語の Wikipedia ページ全体など、膨大な一般的なデータセットで大規模言語モデルをトレーニングします。
- ファインチューニング: 事前トレーニング済みモデルをトレーニングして、医療に関する質問への回答などの特定のタスクを実行します。通常、ファインチューニングでは、特定のタスクに焦点を当てた数百または数千の例を使用します。
別の例として、大規模な画像モデルの完全なトレーニング シーケンスは次のようになります。
- 事前トレーニング: Wikimedia Commons のすべての画像など、大規模な一般的な画像データセットで大規模な画像モデルをトレーニングします。
- ファインチューニング: シャチの画像を生成するなど、特定のタスクを実行するように事前トレーニング済みモデルをトレーニングします。
ファインチューニングでは、次の戦略を任意に組み合わせることができます。
- 事前トレーニング済みモデルの既存のパラメータのすべてを変更する。これは「フル ファインチューニング」と呼ばれることもあります。
- 事前トレーニング済みモデルの既存のパラメータの一部(通常は出力レイヤに最も近いレイヤ)のみを変更し、他の既存のパラメータ(通常は入力レイヤに最も近いレイヤ)は変更しない。パラメータ効率チューニングをご覧ください。
- 通常、出力レイヤに最も近い既存のレイヤの上にレイヤを追加します。
ファインチューニングは、転移学習の一種です。そのため、ファインチューニングでは、事前トレーニング済みモデルのトレーニングに使用されたものとは異なる損失関数やモデルタイプが使用されることがあります。たとえば、事前トレーニング済みの大規模な画像モデルをファインチューニングして、入力画像内の鳥の数を返す回帰モデルを作成できます。
ファインチューニングと次の用語を比較対照します。
詳細については、ML 集中講座のファインチューニングをご覧ください。
フラッシュ モデル
速度と低レイテンシ向けに最適化された、比較的小さな Gemini モデルのファミリー。Flash モデルは、迅速なレスポンスと高スループットが重要な幅広いアプリケーション向けに設計されています。
基盤モデル
膨大で多様なトレーニング セットでトレーニングされた、非常に大規模な事前トレーニング済みモデル。基盤モデルは、次の両方を行うことができます。
- 幅広いリクエストに適切に対応する。
- 追加のファインチューニングやその他のカスタマイズのベースモデルとして機能します。
つまり、基盤モデルは一般的な意味ですでに非常に有能ですが、特定のタスクでさらに有用になるようにカスタマイズできます。
成功の割合
ML モデルの生成されたテキストを評価するための指標。成功の割合は、生成されたテキスト出力の総数で「成功」した生成テキスト出力の数を割った値です。たとえば、大規模言語モデルが 10 個のコードブロックを生成し、そのうち 5 個が成功した場合、成功の割合は 50% になります。
成功率の指標は統計全体で幅広く使用できますが、ML では主にコード生成や数学の問題などの検証可能なタスクの測定に使用されます。
G
Gemini
Google の最先端 AI で構成されたエコシステム。このエコシステムの要素は次のとおりです。
- さまざまな Gemini モデル。
- Gemini モデルへのインタラクティブな会話型インターフェース。ユーザーがプロンプトを入力すると、Gemini がそのプロンプトに応答します。
- 各種 Gemini API。
- Gemini モデルに基づくさまざまなビジネス プロダクト(Gemini for Google Cloud など)。
Gemini モデル
Google の最先端の Transformer ベースのマルチモーダル モデル。Gemini モデルは、エージェントと統合するように特別に設計されています。
ユーザーは、対話型ダイアログ インターフェースや SDK など、さまざまな方法で Gemini モデルを操作できます。
Gemma
Gemini モデルの作成に使用されたものと同じ研究とテクノロジーに基づいて構築された、軽量なオープンモデルのファミリーです。Gemma モデルは複数あり、それぞれにビジョン、コード、指示の実行などの異なる機能が用意されています。詳しくは、Gemma をご覧ください。
GenAI または genAI
生成 AI の略語。
生成されたテキスト
一般に、ML モデルが出力するテキスト。大規模言語モデルを評価する際、一部の指標では、生成されたテキストと参照テキストを比較します。たとえば、ML モデルがフランス語からオランダ語にどれだけ効果的に翻訳できるかを判断しようとしているとします。この例の場合は、次のようになります。
- 生成されたテキストは、ML モデルが出力するオランダ語の翻訳です。
- 参照テキストは、人間の翻訳者(またはソフトウェア)が作成したオランダ語の翻訳です。
評価戦略によっては、参照テキストを使用しないものもあります。
生成 AI
正式な定義のない、変革的な新しい分野です。ただし、ほとんどの専門家は、生成 AI モデルが次のすべての条件を満たすコンテンツを作成(「生成」)できることに同意しています。
- 複雑
- 一貫性のある
- オリジナル
生成 AI の例:
- 大規模言語モデル。高度なオリジナルのテキストを生成し、質問に答えることができます。
- 独自の画像を生成できる画像生成モデル。
- オーディオと音楽の生成モデル。オリジナルの音楽を作曲したり、リアルな音声を生成したりできます。
- オリジナル動画を生成できる動画生成モデル。
LSTM や RNN などの以前のテクノロジーでも、オリジナルで一貫性のあるコンテンツを生成できます。これらの初期のテクノロジーを生成 AI と見なす専門家もいれば、真の生成 AI には、これらの初期のテクノロジーが生成できるよりも複雑な出力が必要だと考える専門家もいます。
予測 ML との対比。
ゴールデン レスポンス
レスポンスが良好であることがわかっている。たとえば、次のようなプロンプトがあるとします。
2 + 2
理想的なレスポンスは次のとおりです。
4
GPT(Generative Pre-trained Transformer)
OpenAI が開発した Transformer ベースの大規模言語モデルのファミリー。
GPT バリアントは、次のような複数のモダリティに適用できます。
- 画像生成(ImageGPT など)
- テキスト画像変換(DALL-E など)。
H
ハルシネーション
現実世界について主張しているように見えるが、実際には事実と異なる出力を生成 AI モデルが生成すること。たとえば、バラク オバマが 1865 年に死亡したと主張する生成 AI モデルは、ハルシネーションを起こしています。
人間による評価
人が ML モデルの出力の品質を判断するプロセス。たとえば、バイリンガルの人が ML 翻訳モデルの品質を判断するなど。人間による評価は、正解が 1 つではないモデルを判断する際に特に役立ちます。
自動評価と自動評価ツールによる評価と比較してください。
人間参加型(HITL)
次のいずれかを意味する可能性のある、曖昧な定義のイディオム。
- 生成 AI の出力を批判的または懐疑的に見るポリシー。
- モデルの動作を人間が形成、評価、改善するための戦略またはシステム。人間参加型にすることで、AI は機械の知能と人間の知能の両方を活用できます。たとえば、AI がコードを生成し、ソフトウェア エンジニアがそれをレビューするシステムは、人間がループに関与するシステムです。
I
コンテキスト内学習
少数ショット プロンプトと同義。
推論
従来の ML では、トレーニング済みのモデルをラベルなしの例に適用して予測を行うプロセス。詳細については、ML の概要コースの教師あり学習をご覧ください。
大規模言語モデルでは、推論は、トレーニング済みのモデルを使用して、入力プロンプトに対するレスポンスを生成するプロセスです。
統計では、推論はやや異なる意味を持ちます。詳しくは、 統計的推論に関する Wikipedia の記事をご覧ください。
指示チューニング
生成 AI モデルが指示に従う能力を向上させるファインチューニングの一種。指示チューニングでは、通常はさまざまなタスクを対象とする一連の指示プロンプトでモデルをトレーニングします。その結果、指示チューニングされたモデルは、さまざまなタスクにわたってゼロショット プロンプトに対して有用なレスポンスを生成する傾向があります。
比較対照:
L
大規模言語モデル
少なくとも、非常に多くのパラメータを持つ言語モデル。より非公式には、Gemini や GPT などの Transformer ベースの言語モデル。
詳細については、ML 集中講座の大規模言語モデル(LLM)をご覧ください。
遅延
モデルが入力を処理してレスポンスを生成するまでにかかる時間。レイテンシの高いレスポンスは、レイテンシの低いレスポンスよりも生成に時間がかかります。
大規模言語モデルのレイテンシに影響する要因は次のとおりです。
- 入力トークンと出力トークンの長さ
- モデルの複雑さ
- モデルが実行されるインフラストラクチャ
レイテンシの最適化は、レスポンシブでユーザー フレンドリーなアプリケーションを作成するうえで非常に重要です。
LLM
大規模言語モデルの略語。
LLM 評価
大規模言語モデル(LLM)のパフォーマンスを評価するための指標とベンチマークのセット。LLM 評価の概要は次のとおりです。
- LLM の改善が必要な領域を研究者が特定するのに役立ちます。
- さまざまな LLM を比較し、特定のタスクに最適な LLM を特定するのに役立ちます。
- LLM の安全で倫理的な使用を確保します。
詳細については、ML 集中講座の大規模言語モデル(LLM)をご覧ください。
LoRA
Low-Rank Adaptability(LoRA)
モデルの事前トレーニングされた重みを「凍結」し(変更できなくなる)、トレーニング可能な重みの小さなセットをモデルに挿入する、ファインチューニングのためのパラメータ効率手法。このトレーニング可能な重みのセット(更新行列とも呼ばれます)は、ベースモデルよりもはるかに小さいため、トレーニングがはるかに高速になります。
LoRA には次のような利点があります。
- ファインチューニングが適用されるドメインのモデルの予測の品質を向上させます。
- モデルのすべてのパラメータのファインチューニングを必要とする手法よりも高速にファインチューニングを行います。
- 同じベースモデルを共有する複数の特殊モデルの同時サービングを可能にすることで、推論の計算コストを削減します。
M
機械翻訳
ソフトウェア(通常は ML モデル)を使用して、ある言語から別の言語にテキストを変換すること(例: 英語から日本語)。
k での平均適合率の平均(mAP@k)
検証データセット全体で計算されたすべての k における平均適合率スコアの統計的平均。k における平均適合率の用途の一つは、レコメンデーション システムによって生成された推奨事項の品質を判断することです。
「平均平均」というフレーズは冗長に聞こえますが、指標の名前としては適切です。この指標は、複数の k における平均適合率の値の平均を求めるためです。
mixture of experts
ニューラル ネットワークのパラメータのサブセット(エキスパートと呼ばれる)のみを使用して、特定の入力トークンまたは例を処理することで、ニューラル ネットワークの効率を高めるスキーム。ゲーティング ネットワークは、各入力トークンまたは例を適切なエキスパートに転送します。
詳細については、次のいずれかの論文をご覧ください。
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- エキスパート選択ルーティングによる Mixture-of-Experts
MMIT
モデルのカスケード
特定の推論クエリに最適なモデルを選択するシステム。
非常に大きなモデル(多数のパラメータ)から、はるかに小さなモデル(パラメータが少ない)まで、さまざまなモデルのグループを想像してください。非常に大きなモデルは、小さなモデルよりも推論時に多くのコンピューティング リソースを消費します。ただし、非常に大規模なモデルは、通常、小規模なモデルよりも複雑なリクエストを推論できます。モデル カスケードは、推論クエリの複雑さを判断し、推論を実行する適切なモデルを選択します。モデル カスケードの主な動機は、一般的に小さいモデルを選択し、より複雑なクエリに対してのみ大きいモデルを選択することで、推論費用を削減することです。
たとえば、スマートフォンで小規模なモデルが実行され、そのモデルのより大規模なバージョンがリモート サーバーで実行されるとします。適切なモデル カスケードにより、小規模なモデルで単純なリクエストを処理し、複雑なリクエストの処理にのみリモートモデルを呼び出すことができるため、費用とレイテンシを削減できます。
モデルルーターもご覧ください。
モデルルーター
モデル カスケードで推論に最適なモデルを決定するアルゴリズム。モデルルーター自体は通常、特定の入力に最適なモデルを選択する方法を徐々に学習する ML モデルです。ただし、モデルルーターは、よりシンプルな非 ML アルゴリズムである場合もあります。
MOE
MT
機械翻訳の略。
N
Nano
デバイス内での使用を想定して設計された、比較的小さな Gemini モデル。詳しくは、Gemini Nano をご覧ください。
正解は 1 つではない(NORA)
複数の正解のレスポンスがあるプロンプト。たとえば、次のプロンプトには正解がありません。
象に関する面白いジョークを教えて。
評価は、通常、正解が 1 つあるプロンプトを評価するよりも、正解がないプロンプトに対する回答を評価する方が主観的です。たとえば、象のジョークを評価するには、ジョークの面白さを判断する体系的な方法が必要です。
NORA
no one right answer の略語。
Notebook LM
ユーザーがドキュメントをアップロードし、プロンプトを使用して、ドキュメントに関する質問をしたり、ドキュメントを要約したり、整理したりできる Gemini ベースのツール。たとえば、著者が複数の短編小説をアップロードして、共通のテーマを見つけるよう NotebookLM に依頼したり、どの短編小説が映画に最適かを特定するよう依頼したりできます。
O
1 つの正解(ORA)
単一の正しいレスポンスを持つプロンプト。たとえば、次のプロンプトについて考えてみましょう。
土星は火星よりも大きい。これは正しいでしょうか、誤りでしょうか。
正しい回答は true のみです。
正解は 1 つではないを参照してください。
ワンショット プロンプト
大規模言語モデルにどのように回答すればよいかを示す例を 1 つ含むプロンプト。たとえば、次のプロンプトには、大規模言語モデルがクエリにどのように回答すべきかを示す例が 1 つ含まれています。
| 1 つのプロンプトの各部分 | メモ |
|---|---|
| 指定された国の公式通貨は何ですか? | LLM に回答させたい質問。 |
| フランス: EUR | 例 1: |
| インド: | 実際のクエリ。 |
ワンショット プロンプトと次の用語を比較対照します。
ORA
正解は 1 つの略語。
P
パラメータ効率チューニング
完全なファインチューニングよりも効率的に大規模な事前トレーニング済み言語モデル(PLM)をファインチューニングする一連の手法。パラメータ効率チューニングでは、通常、フル ファインチューニングよりもはるかに少ないパラメータをファインチューニングしますが、一般に、フル ファインチューニングで構築された大規模言語モデルと同等(またはほぼ同等)のパフォーマンスを発揮する大規模言語モデルが生成されます。
パラメータ効率チューニングと次のものを比較対照します。
パラメータ効率チューニングは、パラメータ効率ファインチューニングとも呼ばれます。
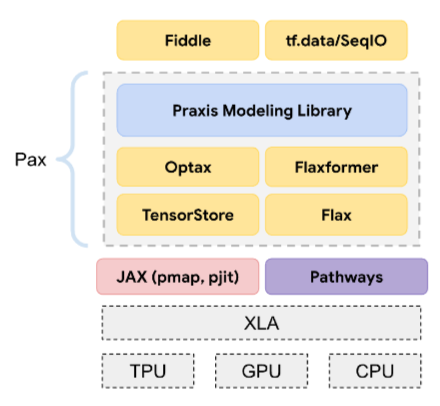
Pax
複数の TPU アクセラレータ チップ スライスまたは Pod にまたがるほど大規模な ニューラル ネットワーク モデルのトレーニング用に設計されたプログラミング フレームワーク。
Pax は JAX 上に構築された Flax 上に構築されています。
PLM
事前トレーニング済み言語モデルの略語。
事後トレーニング済みモデル
一般的に、次の 1 つ以上の後処理が行われた事前トレーニング済みモデルを指す、緩やかに定義された用語。
事前トレーニング済みモデル
この用語は、トレーニング済みのモデルまたはトレーニング済みのエンベディング ベクトルを指すこともありますが、現在では通常、トレーニング済みの大規模言語モデルまたはトレーニング済みの生成 AI モデルを指します。
事前トレーニング
大規模なデータセットでのモデルの最初のトレーニング。一部の事前トレーニング済みモデルは扱いにくく、通常は追加のトレーニングで調整する必要があります。たとえば、ML エキスパートは、Wikipedia のすべての英語ページなど、膨大なテキスト データセットで大規模言語モデルを事前トレーニングする場合があります。事前トレーニングの後、次のいずれかの手法でモデルをさらに改良できます。
Pro
Ultra よりも少ないが、Nano よりも多いパラメータを持つGemini モデル。詳細については、Gemini Pro をご覧ください。
プロンプト
大規模言語モデルに入力として入力されるテキスト。モデルが特定の動作をするように条件付けます。プロンプトは、フレーズのように短いものから、小説の全文のように任意に長いものまで使用できます。プロンプトは、次の表に示すカテゴリなど、複数のカテゴリに分類されます。
| プロンプト カテゴリ | 例 | メモ |
|---|---|---|
| 質問 | ハトはどれくらいの速さで飛ぶことができますか? | |
| 手順 | アービトラージについての面白い詩を書いて。 | 大規模言語モデルに何かを実行するように求めるプロンプト。 |
| 例 | Markdown コードを HTML に変換します。例:
Markdown: * list item HTML: <ul> <li>list item</li> </ul> |
この例のプロンプトの最初の文は指示です。プロンプトの残りの部分は例です。 |
| ロール | 物理学の博士号を持つ人に、ML トレーニングで勾配降下法が使用される理由を説明してください。 | 文の前半は指示、後半の「物理学の博士号を持つ」というフレーズは役割の部分です。 |
| モデルが完了する部分入力 | 英国首相の官邸は | 部分入力プロンプトは、この例のように突然終了するか、アンダースコアで終了します。 |
生成 AI モデルは、テキスト、コード、画像、エンベディング、動画など、ほぼすべてのプロンプトに応答できます。
プロンプトベースの学習
特定のモデルの機能で、任意のテキスト入力(プロンプト)に応じて動作を適応させることができます。一般的なプロンプトベースの学習パラダイムでは、大規模言語モデルがテキストを生成してプロンプトに応答します。たとえば、ユーザーが次のプロンプトを入力したとします。
ニュートンの運動の第 3 法則を要約してください。
プロンプトベースの学習が可能なモデルは、以前のプロンプトに回答するように特別にトレーニングされていません。むしろ、モデルは物理学に関する多くの事実、一般的な言語規則に関する多くのこと、一般的に有用な回答を構成する多くのことを「知って」います。この知識があれば、有用な回答を提供できるはずです。人間からの追加のフィードバック(「回答が複雑すぎる」、「リアクションとは何ですか?」など)により、一部のプロンプト ベースの学習システムは回答の有用性を徐々に向上させることができます。
プロンプト設計
プロンプト エンジニアリングと同義。
プロンプト エンジニアリング
大規模言語モデルから望ましいレスポンスを引き出すプロンプトを作成する技術。人間がプロンプト エンジニアリングを行います。適切に構造化されたプロンプトを作成することは、大規模言語モデルから有用なレスポンスを得るために不可欠な要素です。プロンプト エンジニアリングは、次のような多くの要因に左右されます。
- 大規模言語モデルの事前トレーニングと、場合によってはファイン チューニングに使用されるデータセット。
- モデルがレスポンスの生成に使用する温度などのデコード パラメータ。
プロンプト設計は、プロンプト エンジニアリングの同義語です。
役立つプロンプトの作成について詳しくは、プロンプト設計の概要をご覧ください。
プロンプト セット
大規模言語モデルを評価するためのプロンプトのグループ。たとえば、次の図は 3 つのプロンプトで構成されるプロンプト セットを示しています。
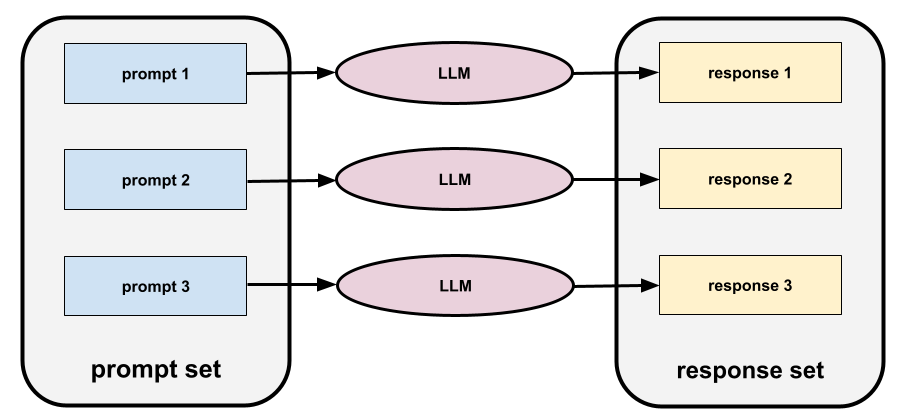
優れたプロンプト セットは、大規模言語モデルの安全性と有用性を徹底的に評価するのに十分な「幅広い」プロンプトのコレクションで構成されています。
レスポンス セットもご覧ください。
プロンプト チューニング
システムが実際のプロンプトに付加する「接頭辞」を学習するパラメータ効率チューニング メカニズム。
プロンプト チューニングの一種(プレフィックス チューニングと呼ばれることもあります)では、すべてのレイヤでプレフィックスを先頭に追加します。一方、ほとんどのプロンプト チューニングでは、入力レイヤに接頭辞を追加するだけです。
R
参照テキスト
プロンプトに対するエキスパートの回答。たとえば、次のプロンプトを指定します。
「What is your name?」という質問を英語からフランス語に翻訳してください。
専門家の回答は次のようになります。
Comment vous appelez-vous?
さまざまな指標(ROUGE など)は、参照テキストが ML モデルの生成テキストと一致する度合いを測定します。
reflection
ステップの出力を次のステップに渡す前に、その出力を検証(反映)することで、エージェント ワークフローの品質を向上させる戦略。
多くの場合、審査員は回答を生成したのと同じ LLM です(別の LLM の場合もあります)。回答を生成した LLM が、その回答を公平に判断できるのでしょうか?「コツ」は、LLM を批判的(反射的)な考え方にすることです。このプロセスは、クリエイティブな考え方で下書きを作成し、批判的な考え方で編集するライターに似ています。
たとえば、コーヒー マグカップのテキストを作成するエージェント ワークフローを考えてみましょう。このステップのプロンプトは次のようになります。
あなたはクリエイターです。コーヒー マグカップに適した、50 文字未満のユーモラスでオリジナルのテキストを生成します。
次の内省的なプロンプトを考えてみましょう。
あなたはコーヒーを飲む人です。上記の回答はユーモラスだと思いますか?
ワークフローでは、高いリフレクション スコアを受け取ったテキストのみを次のステージに渡すことができます。
人間からのフィードバックを用いた強化学習(RLHF)
人間の評価者からのフィードバックを使用して、モデルの回答の品質を向上させます。たとえば、RLHF メカニズムでは、モデルのレスポンスの品質を 👍 または 👎 の絵文字で評価するようユーザーに求めることができます。システムは、そのフィードバックに基づいて今後のレスポンスを調整できます。
レスポンス
生成 AI モデルが推論するテキスト、画像、音声、動画。つまり、プロンプトは生成 AI モデルへの入力であり、レスポンスは出力です。
レスポンス セット
大規模言語モデルが入力プロンプト セットに返すレスポンスのコレクション。
ロール プロンプト
通常は代名詞の「you」で始まり、生成 AI モデルに、レスポンスを生成する際に特定の人物や役割を演じるよう指示するプロンプト。ロール プロンプトを使用すると、生成 AI モデルが適切な「マインドセット」になり、より有用なレスポンスを生成できます。たとえば、求める回答の種類に応じて、次のロール プロンプトのいずれかが適切である可能性があります。
コンピュータ サイエンスの博士号を取得している。
あなたは、プログラミングを始めたばかりの生徒に Python について丁寧に説明するのが好きなソフトウェア エンジニアです。
あなたは、非常に特殊なプログラミング スキルを持つアクション ヒーローです。Python リストで特定のアイテムを見つけることを保証してください。
S
ソフト プロンプト チューニング
リソースを大量に消費するファインチューニングを行わずに、特定のタスク用に大規模言語モデルをチューニングする手法。ソフト プロンプト チューニングでは、モデル内のすべての重みを再トレーニングする代わりに、同じ目標を達成するためにプロンプトが自動的に調整されます。
通常、ソフト プロンプト チューニングでは、テキスト プロンプトが指定されると、追加のトークン エンベディングがプロンプトに追加され、逆伝播を使用して入力が最適化されます。
「ハード」プロンプトには、トークン エンベディングではなく実際のトークンが含まれます。
specificational coding
ソフトウェアを説明するファイルを人間言語(英語など)で作成して維持するプロセス。次に、生成 AI モデルまたは別のソフトウェア エンジニアに、その説明を満たすソフトウェアを作成するように指示します。
自動生成されたコードには通常、反復処理が必要です。仕様コーディングでは、説明ファイルを繰り返し処理します。一方、会話型コーディングでは、プロンプト ボックス内で反復処理を行います。実際には、自動コード生成には仕様コーディングと会話型コーディングの両方が組み合わされることがあります。
T
温度
モデルの出力のランダム性の度合いを制御するハイパーパラメータ。温度が高いほど、ランダムな出力が多くなり、温度が低いほど、ランダムな出力が少なくなります。
最適な温度は、特定のアプリケーションや文字列の値によって異なります。
U
Ultra
最も多くのパラメータを持つ Gemini モデル。詳しくは、Gemini Ultra をご覧ください。
V
Vertex
AI と ML 向けの Google Cloud のプラットフォーム。Vertex は、Gemini モデルへのアクセスなど、AI アプリケーションの構築、デプロイ、管理のためのツールとインフラストラクチャを提供します。バイブ コーディング
生成 AI モデルにプロンプトしてソフトウェアを作成する。つまり、プロンプトでソフトウェアの目的と機能を記述すると、生成 AI モデルがそれをソースコードに変換します。生成されたコードが意図と一致するとは限らないため、バイブ コーディングには通常、反復処理が必要です。
Andrej Karpathy は、この X の投稿でバイブ コーディングという用語を作りました。Karpathy 氏は X の投稿で、これを「バイブに完全に身を委ねる新しい種類のコーディング」と説明しています。そのため、この用語は元々、生成されたコードを検査しない可能性もある、意図的に緩いアプローチでソフトウェアを作成することを意味していました。しかし、多くの分野でこの用語は急速に進化し、現在では AI によって生成されたコーディングのあらゆる形式を意味するようになりました。
バイブス コーディングの詳細については、 バイブ コーディングとは何ですか?
また、バイブ コーディングを次のものと比較対照します。
Z
ゼロショット プロンプト
大規模言語モデルにどのように回答してほしいかの例が示されていないプロンプト。次に例を示します。
| 1 つのプロンプトの各部分 | メモ |
|---|---|
| 指定された国の公式通貨は何ですか? | LLM に回答させたい質問。 |
| インド: | 実際のクエリ。 |
大規模言語モデルは、次のいずれかのレスポンスを返す可能性があります。
- ルピー
- INR
- ₹
- ルピー(インド)
- ルピー
- インドルピー
どの形式も正解ですが、特定の形式が好まれる場合があります。
ゼロショット プロンプトと次の用語を比較対照します。