בדף הזה מופיעים מונחים במילון המונחים של AI גנרטיבי. כאן אפשר לראות את כל המונחים במילון המונחים.
A
התאמה
מילה נרדפת לשיפור או לכוונון עדין.
סוכן
תוכנה שיכולה להסיק מסקנות לגבי קלט של משתמשים כדי לתכנן ולבצע פעולות בשם המשתמש.
בלמידת חיזוק, סוכן הוא הישות שמשתמשת במדיניות כדי למקסם את התשואה הצפויה שמתקבלת ממעבר בין מצבים של הסביבה.
אג'נטי
צורת התואר של agent. המונח 'אקטיבי' מתייחס לתכונות של סוכנים (כמו אוטונומיה).
תהליך עבודה אג'נטי
תהליך דינמי שבו סוכן מתכנן ומבצע פעולות באופן אוטונומי כדי להשיג מטרה. התהליך עשוי לכלול ניתוח, הפעלה של כלים חיצוניים ותיקון עצמי של התוכנית.
סלופ
פלט ממערכת AI גנרטיבי שמעדיפה כמות על פני איכות. לדוגמה, דף אינטרנט עם רפש של בינה מלאכותית מלא בתוכן באיכות נמוכה שנוצר על ידי AI בעלות נמוכה.
הערכה אוטומטית
שימוש בתוכנה כדי לשפוט את איכות הפלט של מודל.
כשהפלט של המודל פשוט יחסית, סקריפט או תוכנה יכולים להשוות את הפלט של המודל לתשובה מושלמת. הסוג הזה של הערכה אוטומטית נקרא לפעמים הערכה פרוגרמטית. מדדים כמו ROUGE או BLEU שימושיים לעיתים קרובות להערכה פרוגרמטית.
כשפלט המודל מורכב או אין תשובה נכונה אחת, לפעמים מתבצעת הערכה אוטומטית על ידי תוכנת ML נפרדת שנקראת בודק אוטומטי.
השוואה לבדיקה אנושית.
הערכה של כלי לדירוג אוטומטי
מנגנון היברידי להערכת האיכות של הפלט של מודל AI גנרטיבי, שמשלב הערכה אנושית עם הערכה אוטומטית. מודל דירוג אוטומטי הוא מודל ML שאומן על נתונים שנוצרו על ידי הערכה אנושית. באופן אידיאלי, מערכת דירוג אוטומטית לומדת לחקות בודק אנושי.יש מערכות מוכנות מראש למתן ציונים אוטומטיים, אבל המערכות הכי טובות הן אלה שעברו כוונון עדין במיוחד למשימה שאתם מעריכים.
מודל אוטו-רגרסיבי
מודל שמסיק חיזוי על סמך החיזויים הקודמים שלו. לדוגמה, מודלים אוטומטיים של שפה חוזים את הטוקן הבא על סמך הטוקנים שנחזו קודם. כל המודלים הגדולים של שפה שמבוססים על Transformer הם אוטורגרסיביים.
לעומת זאת, מודלים של תמונות שמבוססים על GAN בדרך כלל לא רגרסיביים אוטומטיים, כי הם יוצרים תמונה במעבר קדימה יחיד ולא באופן איטרטיבי בשלבים. עם זאת, מודלים מסוימים ליצירת תמונות הם אוטומטיים רגרסיביים כי הם יוצרים תמונה בשלבים.
B
מודל בסיס
מודל שאומן מראש שיכול לשמש כנקודת התחלה לכוונון עדין כדי לטפל במשימות או באפליקציות ספציפיות.
כדאי לעיין גם במודל שעבר אימון מראש ובמודל בסיסי.
C
הנחיות בטכניקת שרשרת חשיבה
טכניקה של הנדסת הנחיות שמעודדת מודל שפה גדול (LLM) להסביר את החשיבה הרציונלית שלו, שלב אחר שלב. לדוגמה, נבחן את ההנחיה הבאה, תוך שימת לב מיוחדת למשפט השני:
כמה כוחות G יחווה נהג ברכב שמאיץ מ-0 ל-60 מייל לשעה ב-7 שניות? בתשובה, צריך להציג את כל החישובים הרלוונטיים.
התשובה של ה-LLM תהיה כנראה:
- תציג רצף של נוסחאות בפיזיקה, ותציב את הערכים 0, 60 ו-7 במקומות המתאימים.
- תסביר למה היא בחרה בנוסחאות האלה ומה המשמעות של המשתנים השונים.
הנחיות בטכניקת שרשרת חשיבה מאלצות את מודל ה-LLM לבצע את כל החישובים, מה שעשוי להוביל לתשובה נכונה יותר. בנוסף, הנחיה מסוג chain-of-thought מאפשרת למשתמש לבדוק את השלבים של מודל ה-LLM כדי לקבוע אם התשובה הגיונית.
צ'אט, צ'ט, צאט, צט
התוכן של דיאלוג הלוך ושוב עם מערכת למידת מכונה, בדרך כלל מודל שפה גדול. האינטראקציה הקודמת בצ'אט (מה שכתבתם ואיך מודל השפה הגדול הגיב) הופכת להקשר לחלקים הבאים של הצ'אט.
צ'אטבוט הוא יישום של מודל שפה גדול.
הטמעת שפה בהתאם להקשר
הטמעה שמתקרבת ל'הבנה' של מילים וביטויים בדומה למה שדוברים שוטפים יכולים לעשות. הטמעות של שפה בהקשר יכולות להבין תחביר, סמנטיקה והקשר מורכבים.
לדוגמה, נבחן הטמעות של המילה cow באנגלית. הטמעות ישנות יותר, כמו word2vec, יכולות לייצג מילים באנגלית כך שהמרחק במרחב ההטמעה מcow (פרה) לbull (שור) דומה למרחק מewe (כבשה) לram (איל) או מfemale (נקבה) לmale (זכר). הטמעות שפה בהקשר יכולות ללכת צעד אחד קדימה ולזהות שדוברי אנגלית משתמשים לפעמים במילה cow כדי להתייחס גם לפרה וגם לשור.
חלון ההקשר
מספר הטוקנים שמודל יכול לעבד בהנחיה נתונה. ככל שחלון ההקשר גדול יותר, המודל יכול להשתמש ביותר מידע כדי לספק תשובות עקביות וקוהרנטיות להנחיה.
תכנות בממשק שיחה
שיחה איטרטיבית ביניכם לבין מודל AI גנרטיבי, במטרה ליצור תוכנה. אתם מזינים הנחיה שמתארת תוכנה מסוימת. לאחר מכן, המודל משתמש בתיאור הזה כדי ליצור קוד. אחר כך, מזינים הנחיה חדשה כדי לטפל בפגמים בהנחיה הקודמת או בקוד שנוצר, והמודל יוצר קוד מעודכן. אתם ממשיכים להחליף תשובות עד שהתוכנה שנוצרה מספיק טובה.
קידוד שיחות הוא למעשה המשמעות המקורית של תכנות בשיטת Vibe coding.
ההפך מקידוד לפי מפרט.
D
הנחיות ישירות
מילה נרדפת להנחיות בלי דוגמאות (zero-shot prompting).
זיקוק
תהליך של הקטנת הגודל של מודל אחד (שנקרא מורה) למודל קטן יותר (שנקרא תלמיד) שמדמה את התחזיות של המודל המקורי בצורה נאמנה ככל האפשר. זיקוק מועיל כי למודל הקטן יש שני יתרונות מרכזיים על פני המודל הגדול יותר (המודל המלמד):
- זמן הסקת מסקנות מהיר יותר
- צריכת זיכרון ואנרגיה מופחתת
עם זאת, בדרך כלל התחזיות של התלמידים לא טובות כמו התחזיות של המורים.
בזיקוק, המודל התלמיד עובר אימון כדי למזער פונקציית הפסד על סמך ההבדל בין התוצאות של התחזיות של מודל התלמיד ומודל המורה.
השוו והבדילו בין זיקוק לבין המונחים הבאים:
מידע נוסף מופיע במאמר מודלים גדולים של שפה (LLM): כוונון עדין, זיקוק והנדסת הנחיות בקורס המקוצר על למידת מכונה.
E
evals
משמש בעיקר כקיצור להערכות של מודלים גדולים של שפה. באופן כללי, evals הוא קיצור לכל סוג של הערכה.
הערכה
התהליך של מדידת האיכות של מודל או השוואה בין מודלים שונים.
כדי להעריך מודל של למידת מכונה מבוקרת, בדרך כלל משווים אותו לקבוצת נתונים לתיקוף ולקבוצת נתונים לבדיקה. הערכה של מודל שפה גדול כוללת בדרך כלל הערכות רחבות יותר של איכות ובטיחות.
F
עובדתיות
בעולם של למידת מכונה, מאפיין שמתאר מודל שהפלט שלו מבוסס על המציאות. המושג 'עובדתיות' הוא מושג ולא מדד. לדוגמה, נניח שאתם שולחים את הפרומפט הבא אל מודל שפה גדול:
מהו הכתיב הכימי של מלח שולחן?
מודל שמבצע אופטימיזציה של נכונות העובדות ישיב:
NaCl
קל להניח שכל המודלים צריכים להתבסס על עובדות. עם זאת, יש הנחיות מסוימות, כמו ההנחיות הבאות, שגורמות למודל AI גנרטיבי לבצע אופטימיזציה של יצירתיות ולא של דיוק עובדתי.
תספר לי חמשיר על אסטרונאוט וזחל.
לא סביר שהלימריק שיתקבל יתבסס על המציאות.
ההבדל בין המושג הזה לבין התבססות על עובדות.
fast decay
טכניקת אימון לשיפור הביצועים של מודלים גדולים של שפה (LLM). התפוגה המהירה כוללת הפחתה מהירה של קצב הלמידה במהלך האימון. השיטה הזו עוזרת למנוע התאמת יתר של המודל לנתוני האימון, ומשפרת את ההכללה.
הנחיות עם כמה דוגמאות (few-shot prompting)
פרומפט שמכיל יותר מדוגמה אחת (מספר דוגמאות) שמדגימות איך מודל השפה הגדול צריך להשיב. לדוגמה, ההנחיה הארוכה הבאה מכילה שתי דוגמאות שמראות למודל שפה גדול איך לענות על שאילתה.
| החלקים של הנחיה | הערות |
|---|---|
| מהו המטבע הרשמי של המדינה שצוינה? | השאלה שרוצים שה-LLM יענה עליה. |
| צרפת: EUR | דוגמה אחת. |
| בריטניה: GBP | דוגמה נוספת. |
| הודו: | השאילתה בפועל. |
בדרך כלל, הנחיות עם כמה דוגמאות מניבות תוצאות טובות יותר מאשר הנחיות בלי דוגמאות והנחיות עם דוגמה אחת. עם זאת, כדי לעצב הנחיות עם כמה דוגמאות צריך להשתמש בהנחיה ארוכה יותר.
הנחיה עם כמה דוגמאות היא סוג של למידה עם כמה דוגמאות שמוחלת על למידה מבוססת-הנחיות.
מידע נוסף מופיע במאמר הנדסת הנחיות בקורס המקוצר על למידת מכונה.
כוונון עדין
שלב שני של אימון ספציפי למשימה שמתבצע במודל שעבר אימון מראש כדי לשפר את הפרמטרים שלו לתרחיש שימוש ספציפי. לדוגמה, רצף האימון המלא של חלק ממודלים גדולים של שפה הוא כזה:
- אימון מראש: אימון מודל שפה גדול (LLM) על מערך נתונים כללי עצום, כמו כל הדפים בוויקיפדיה באנגלית.
- כוונון עדין: אימון המודל שעבר אימון מראש לביצוע משימה ספציפית, כמו מענה לשאלות רפואיות. בדרך כלל, כוונון עדין כולל מאות או אלפי דוגמאות שמתמקדות במשימה הספציפית.
דוגמה נוספת: רצף האימון המלא של מודל גדול של תמונות הוא כדלקמן:
- אימון מראש: אימון של מודל תמונות גדול על מערך נתונים גדול של תמונות כלליות, כמו כל התמונות ב-Wikimedia Commons.
- כוונון עדין: אימון של מודל שעבר אימון מראש לביצוע משימה ספציפית, כמו יצירת תמונות של לווייתנים קטלניים.
תהליך הכוונון העדין יכול לכלול כל שילוב של האסטרטגיות הבאות:
- שינוי של כל הפרמטרים הקיימים של המודל שעבר אימון מראש. התהליך הזה נקרא לפעמים כוונון עדין מלא.
- שינוי רק של חלק מהפרמטרים הקיימים של המודל שאומן מראש (בדרך כלל, השכבות הכי קרובות לשכבת הפלט), בלי לשנות את שאר הפרמטרים הקיימים (בדרך כלל, השכבות הכי קרובות לשכבת הקלט). כוונון יעיל בפרמטרים
- הוספת עוד שכבות, בדרך כלל מעל השכבות הקיימות הכי קרובות לשכבת הפלט.
כוונון עדין הוא סוג של למידת העברה. לכן, יכול להיות שבמהלך הכוונון העדין נעשה שימוש בפונקציית הפסד שונה או בסוג מודל שונה מאלה ששימשו לאימון המודל שאומן מראש. לדוגמה, אפשר לבצע כוונון עדין של מודל גדול של תמונות שעבר אימון מראש כדי ליצור מודל רגרסיה שמחזיר את מספר הציפורים בתמונת קלט.
השוואה וניגוד בין כוונון עדין לבין המונחים הבאים:
מידע נוסף זמין במאמר Fine-tuning (כוונון עדין) בקורס המקוצר על למידת מכונה.
דגם הפלאש
משפחה של מודלים קטנים יחסית של Gemini שעברו אופטימיזציה למהירות ולזמן טעינה נמוך. מודלים של Flash מיועדים למגוון רחב של אפליקציות שבהן חשובות תשובות מהירות וקצב העברה גבוה.
מודל בסיס
מודל שעבר אימון מראש גדול מאוד שאומן על קבוצת נתונים לאימון עצומה ומגוונת. מודל בסיס יכול לבצע את שתי הפעולות הבאות:
- להגיב בצורה טובה למגוון רחב של בקשות.
- לשמש כמודל בסיסי לכוונון עדין נוסף או להתאמה אישית אחרת.
במילים אחרות, מודל בסיסי כבר מסוגל לבצע משימות רבות באופן כללי, אבל אפשר להתאים אותו עוד יותר כדי שיהיה שימושי יותר למשימה ספציפית.
fraction of successes
מדד להערכת הטקסט שנוצר על ידי מודל ML. המדד 'חלק ההצלחות' הוא מספר הפלט של הטקסט שנוצר בהצלחה חלקי המספר הכולל של פלט הטקסט שנוצר. לדוגמה, אם מודל שפה גדול יצר 10 בלוקים של קוד, וחמישה מהם היו מוצלחים, אז שיעור ההצלחה יהיה 50%.
למרות שהמדד 'שיעור ההצלחות' שימושי ברוב התחומים בסטטיסטיקה, בלמידת מכונה הוא שימושי בעיקר למדידת משימות שניתן לאמת, כמו יצירת קוד או בעיות מתמטיות.
G
Gemini
הסביבה העסקית שכוללת את ה-AI הכי מתקדם של Google. המרכיבים של המערכת האקולוגית הזו כוללים:
- מודלים שונים של Gemini.
- ממשק שיחה אינטראקטיבי עם מודל Gemini. המשתמשים מקלידים הנחיות ו-Gemini משיב להנחיות האלה.
- ממשקי Gemini API שונים.
- מוצרים עסקיים שונים שמבוססים על מודלים של Gemini, לדוגמה, Gemini for Google Cloud.
המודלים של Gemini
מודלים מולטימודאליים מבוססי Transformer חדשניים של Google. מודלים של Gemini מיועדים במיוחד לשילוב עם סוכנים.
המשתמשים יכולים לקיים אינטראקציה עם מודלים של Gemini במגוון דרכים, כולל באמצעות ממשק דיאלוג אינטראקטיבי וערכות SDK.
Gemma
משפחה של מודלים קלים ופתוחים שמבוססים על אותם מחקרים וטכנולוגיות ששימשו ליצירת מודלים של Gemini. יש כמה מודלים שונים של Gemma, וכל אחד מהם מספק תכונות שונות, כמו ראייה, קוד וביצוע הוראות. פרטים נוספים מופיעים במאמר בנושא Gemma.
AI גנרטיבי או AI גנרטיבי
קיצור של בינה מלאכותית גנרטיבית.
טקסט שנוצר
באופן כללי, הטקסט שמופק על ידי מודל ML. כשמעריכים מודלים גדולים של שפה, חלק מהמדדים משווים בין הטקסט שנוצר לבין טקסט ייחוס. לדוגמה, נניח שאתם מנסים לקבוע עד כמה מודל למידת מכונה מתרגם ביעילות מצרפתית להולנדית. במקרה זה:
- הטקסט שנוצר הוא התרגום להולנדית שהמודל של למידת המכונה מוציא.
- טקסט העזר הוא התרגום להולנדית שמתרגם אנושי (או תוכנה) יוצר.
חשוב לדעת: חלק מאסטרטגיות ההערכה לא כוללות טקסט להשוואה.
בינה מלאכותית גנרטיבית
תחום מתפתח ומשנה את פני הדברים, ללא הגדרה רשמית. עם זאת, רוב המומחים מסכימים שמודלים של AI גנרטיבי יכולים ליצור ("לגנרר") תוכן שהוא כל אחד מהדברים הבאים:
- מורכב
- קוהרנטי
- מקורית
דוגמאות ל-AI גנרטיבי:
- מודלים גדולים של שפה, שיכולים ליצור טקסט מקורי מתוחכם ולענות על שאלות.
- מודל ליצירת תמונות, שיכול ליצור תמונות ייחודיות.
- מודלים ליצירת אודיו ומוזיקה, שיכולים ליצור מוזיקה מקורית או ליצור דיבור ריאליסטי.
- מודלים ליצירת סרטונים, שיכולים ליצור סרטונים מקוריים.
טכנולוגיות מוקדמות יותר, כולל LSTM ו-RNN, יכולות גם ליצור תוכן מקורי ועקבי. יש מומחים שרואים בטכנולוגיות המוקדמות האלה AI גנרטיבי, ויש מומחים שחושבים ש-AI גנרטיבי אמיתי צריך להיות מסוגל להפיק פלט מורכב יותר ממה שהטכנולוגיות המוקדמות האלה יכולות להפיק.
ההבדל בין למידת מכונה חיזויית לבין למידת מכונה תיאורית.
תשובה לדוגמה
תשובה שידוע שהיא טובה. לדוגמה, אם נותנים את ההנחיה הבאה:
2 + 2
התשובה המושלמת היא:
4
GPT (Generative Pre-trained Transformer)
משפחה של מודלים גדולים של שפה שמבוססים על Transformer ופותחו על ידי OpenAI.
גרסאות של GPT יכולות להתאים לכמה אופנים, כולל:
- יצירת תמונות (לדוגמה, ImageGPT)
- יצירת תמונות לפי טקסט (לדוגמה, DALL-E).
H
הזיה
הפקת פלט שנראה סביר אבל העובדות שבו שגויות על ידי מודל AI גנרטיבי שמצהיר שהוא מציג טענה לגבי העולם האמיתי. לדוגמה, מודל AI גנרטיבי שטוען שברק אובמה מת בשנת 1865 מייצר הזיות.
בדיקה אנושית
תהליך שבו אנשים שופטים את איכות הפלט של מודל ML. לדוגמה, אנשים דו-לשוניים שופטים את האיכות של מודל ML לתרגום. הערכה אנושית שימושית במיוחד לבדיקת מודלים שאין להם תשובה נכונה אחת.
ההבדל בין זה לבין הערכה אוטומטית והערכה על ידי מערכת אוטומטית למתן ציונים.
האדם שבתהליך (HITL)
ביטוי לא מוגדר היטב שיכול להיות שהוא מתייחס לאחת מהאפשרויות הבאות:
- מדיניות של צפייה בתוצרים של AI גנרטיבי באופן ביקורתי או סקפטי.
- אסטרטגיה או מערכת שמבטיחות שאנשים יעזרו לעצב, להעריך ולשפר את ההתנהגות של מודל. השארת אדם בתהליך מאפשרת ל-AI ליהנות מאינטליגנציה של מכונה וגם מאינטליגנציה אנושית. לדוגמה, מערכת שבה AI יוצר קוד שמהנדסי תוכנה בודקים אותו היא מערכת האדם שבתהליך.
I
למידה בהקשר
מילה נרדפת ל-few-shot prompting.
היקש
בלמידת מכונה מסורתית, התהליך של ביצוע חיזויים על ידי החלת מודל שעבר אימון על דוגמאות לא מסומנות. מידע נוסף זמין במאמר בנושא למידה מפוקחת בקורס 'מבוא ל-ML'.
במודלים גדולים של שפה, היקש הוא התהליך של שימוש במודל מאומן כדי ליצור תשובה לקלט הנחיה.
למונח 'היסק' יש משמעות שונה בסטטיסטיקה. פרטים נוספים זמינים במאמר בוויקיפדיה בנושא הסקה סטטיסטית.
התאמת מודל להנחיות
סוג של כוונון עדין שמשפר את היכולת של מודל AI גנרטיבי לפעול לפי הוראות. כוונון לפי הוראות כולל אימון של מודל על סדרה של הנחיות, שלרוב מכסות מגוון רחב של משימות. המודל שמתקבל אחרי כוונון לפי הוראות נוטה ליצור תשובות שימושיות להנחיות ללא דוגמאות במגוון משימות.
השוואה וניגוד עם:
L
מודל שפה גדול
לפחות, מודל שפה עם מספר גבוה מאוד של פרמטרים. באופן לא רשמי, כל מודל שפה שמבוסס על Transformer, כמו Gemini או GPT.
מידע נוסף זמין במאמר מודלים גדולים של שפה (LLM) בקורס המקוצר בנושא למידת מכונה.
זמן אחזור
משך הזמן שלוקח למודל לעבד קלט וליצור תשובה. תשובה עם זמן אחזור גבוה לוקחת יותר זמן ליצירה מאשר תשובה עם זמן אחזור נמוך.
הגורמים שמשפיעים על זמן הטעינה של מודלים גדולים של שפה כוללים:
- אורכי הטוקנים של הקלט והפלט
- מורכבות המודל
- התשתית שבה המודל פועל
אופטימיזציה של זמן האחזור היא חיונית ליצירת אפליקציות רספונסיביות וידידותיות למשתמש.
LLM
קיצור של מודל שפה גדול.
הערכות של מודלים גדולים של שפה (LLM)
קבוצה של מדדים ונקודות השוואה להערכת הביצועים של מודלים גדולים של שפה (LLM). ברמת העל, הערכות של מודלים גדולים של שפה (LLM):
- לעזור לחוקרים לזהות תחומים שבהם צריך לשפר את מודלי ה-LLM.
- הם שימושיים להשוואה בין מודלי LLM שונים ולזיהוי מודל ה-LLM הכי טוב למשימה מסוימת.
- עוזרים להבטיח שהשימוש במודלים גדולים של שפה (LLM) יהיה בטוח ואתי.
מידע נוסף זמין במאמר מודלים גדולים של שפה (LLM) בקורס המקוצר על למידת מכונה.
LoRA
קיצור של Low-Rank Adaptability (התאמה לדרגה נמוכה).
Low-Rank Adaptability (LoRA)
טכניקה יעילה מבחינת פרמטרים לכוונון עדין שבה המערכת 'מקפיאה' את המשקולות של המודל שעבר אימון מראש (כך שאי אפשר לשנות אותן יותר), ואז מוסיפה למודל קבוצה קטנה של משקולות שאפשר לאמן. קבוצת המשקלים שאפשר לאמן (שנקראת גם 'מטריצות עדכון') קטנה משמעותית ממודל הבסיס, ולכן האימון שלה מהיר הרבה יותר.
היתרונות של LoRA:
- משפר את איכות התחזיות של מודל עבור הדומיין שבו מוחל הכוונון העדין.
- הוא מאפשר לבצע התאמה עדינה מהר יותר מטכניקות שדורשות התאמה עדינה של כל הפרמטרים של המודל.
- התכונה הזו מצמצמת את עלות החישוב של הסקת מסקנות על ידי הפעלה של הצגה בו-זמנית של כמה מודלים מיוחדים שמשתפים את אותו מודל בסיסי.
M
תרגום אוטומטי
שימוש בתוכנה (בדרך כלל, מודל למידת מכונה) כדי להמיר טקסט משפה אנושית אחת לשפה אנושית אחרת, למשל מאנגלית ליפנית.
דיוק ממוצע ממוצע ב-k (mAP@k)
הממוצע הסטטיסטי של כל הציונים של דיוק ממוצע ב-k במערך נתוני אימות. אחד השימושים של מדד הדיוק הממוצע ב-k הוא להעריך את איכות ההמלצות שנוצרות על ידי מערכת המלצות.
למרות שהביטוי 'ממוצע ממוצע' נשמע מיותר, השם של המדד מתאים. בסופו של דבר, המדד הזה מחשב את הממוצע של כמה ערכים של דיוק ממוצע ב-k.
תערובת של מומחים
שיטה להגדלת היעילות של רשת נוירונים באמצעות שימוש רק בקבוצת משנה של הפרמטרים שלה (שנקראת מומחה) כדי לעבד טוקן או דוגמה נתונים. רשת שערים מעבירה כל טוקן קלט או דוגמה למומחה המתאים.
פרטים נוספים זמינים במאמרים הבאים:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mixture-of-Experts עם ניתוב Expert Choice
MMIT
קיצור של multimodal instruction-tuned.
מודלים מדורגים
מערכת שבוחרת את המודל האידיאלי לשאילתת הסקה ספציפית.
תארו לעצמכם קבוצה של מודלים, החל ממודלים גדולים מאוד (עם הרבה פרמטרים) ועד למודלים קטנים בהרבה (עם הרבה פחות פרמטרים). מודלים גדולים מאוד צורכים יותר משאבי מחשוב בזמן הסקת מסקנות מאשר מודלים קטנים יותר. עם זאת, מודלים גדולים מאוד יכולים בדרך כלל להסיק בקשות מורכבות יותר ממודלים קטנים יותר. המודל קובע את מורכבות שאילתת ההיקש, ואז בוחר את המודל המתאים לביצוע ההיקש. הסיבה העיקרית לשימוש במודלים מדורגים היא לצמצם את עלויות ההסקה. בדרך כלל המערכת בוחרת מודלים קטנים יותר, ורק לשאילתות מורכבות יותר היא בוחרת מודל גדול יותר.
נניח שמודל קטן פועל בטלפון וגרסה גדולה יותר של אותו מודל פועלת בשרת מרוחק. העברת בקשות בין מודלים בצורה טובה מפחיתה את העלות ואת זמן האחזור, כי המודל הקטן יותר יכול לטפל בבקשות פשוטות, והמודל המרוחק מופעל רק כדי לטפל בבקשות מורכבות.
מידע נוסף מופיע במאמר בנושא ניתוב מודלים.
נתב לדוגמה
האלגוריתם שקובע את המודל האידיאלי להסקת מסקנות במודל מדורג. נתב מודלים הוא בדרך כלל מודל למידת מכונה שלומד בהדרגה איך לבחור את המודל הכי טוב לקלט נתון. עם זאת, נתב מודלים יכול להיות לפעמים אלגוריתם פשוט יותר שאינו מבוסס על למידת מכונה.
MOE
קיצור של תערובת של מומחים.
MT
קיצור של תרגום אוטומטי.
לא
Nano
מודל Gemini קטן יחסית שמיועד לשימוש במכשיר. פרטים נוספים זמינים במאמר בנושא Gemini Nano.
כדאי לעיין גם במאמרים בנושא Pro ו-Ultra.
אין תשובה נכונה אחת (NORA)
הנחיה עם כמה תשובות נכונות. לדוגמה, להנחיה הבאה אין תשובה נכונה אחת:
תספר לי בדיחה מצחיקה על פילים.
הערכת התשובות להנחיות שאין להן תשובה נכונה אחת היא בדרך כלל סובייקטיבית הרבה יותר מהערכת הנחיות עם תשובה נכונה אחת. לדוגמה, כדי להעריך בדיחה על פיל צריך שיטה שיטתית לקביעת רמת ההומור של הבדיחה.
NORA
קיצור של אין תשובה נכונה אחת.
Notebook LM
כלי מבוסס-Gemini שמאפשר למשתמשים להעלות מסמכים ואז להשתמש בהנחיות כדי לשאול שאלות לגבי המסמכים, לסכם אותם או לארגן אותם. לדוגמה, סופר יכול להעלות כמה סיפורים קצרים ולבקש מ-NotebookLM למצוא את הנושאים המשותפים שלהם או לזהות איזה מהם יהיה הכי מתאים לעיבוד לסרט.
O
תשובה נכונה אחת (ORA)
הנחיה עם תשובה נכונה אחת. לדוגמה, נניח את ההנחיה הבאה:
נכון או לא נכון: שבתאי גדול יותר ממאדים.
התשובה הנכונה היחידה היא true.
ההפך מאין תשובה נכונה אחת.
הנחיות עם דוגמה אחת (one-shot prompting)
הנחיה שמכילה דוגמה אחת שמראה איך מודל שפה גדול צריך להגיב. לדוגמה, ההנחיה הבאה מכילה דוגמה אחת שמראה למודל שפה גדול איך עליו לענות על שאילתה.
| החלקים של הנחיה | הערות |
|---|---|
| מהו המטבע הרשמי של המדינה שצוינה? | השאלה שרוצים שה-LLM יענה עליה. |
| צרפת: EUR | דוגמה אחת. |
| הודו: | השאילתה בפועל. |
השוואה וניגוד בין הנחיות עם דוגמה אחת (one-shot prompting) לבין המונחים הבאים:
ORA
קיצור של תשובה נכונה אחת.
P
כוונון יעיל בפרמטרים
קבוצה של טכניקות לכוונון עדין של מודל שפה גדול שאומן מראש (PLM) בצורה יעילה יותר מאשר כוונון עדין מלא. בדרך כלל, כוונון יעיל בפרמטרים מכוונן הרבה פחות פרמטרים מאשר כוונון מלא, אבל בדרך כלל הוא יוצר מודל שפה גדול עם ביצועים טובים (או כמעט טובים) כמו מודל שפה גדול שנבנה מכוונון מלא.
השוואה בין כוונון יעיל בפרמטרים לבין:
כוונון יעיל בפרמטרים נקרא גם כוונון עדין ויעיל בפרמטרים.
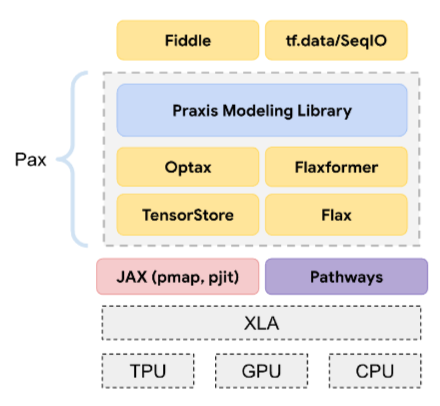
Pax
Framework לתכנות שנועד לאימון של מודלים של רשתות נוירונים בקנה מידה גדול, כלומר מודלים כל כך גדולים שהם מתפרסים על פני כמה יחידות TPU, פרוסות או אשכולות של שבבי האצה.
Pax מבוסס על Flax, שמבוסס על JAX.
PLM
קיצור של מודל שפה שעבר אימון מראש.
מודל שעבר אימון נוסף
מונח לא מוגדר היטב שמתייחס בדרך כלל למודל שעבר אימון מקדים ועבר עיבוד כלשהו, כמו אחד או יותר מהשלבים הבאים:
מודל שעבר אימון מראש
למרות שהמונח הזה יכול להתייחס לכל מודל מאומן או לווקטור הטמעה מאומן, כיום המונח 'מודל שעבר אימון מראש' מתייחס בדרך כלל למודל שפה גדול (LLM) מאומן או לצורה אחרת של מודל מאומן של AI גנרטיבי.
כדאי לעיין גם בערכים מודל בסיס ומודל בסיסי.
אימון מראש
אימון ראשוני של מודל על מערך נתונים גדול. חלק מהמודלים שעברו אימון מראש הם מודלים גדולים ומסורבלים, ובדרך כלל צריך לשפר אותם באמצעות אימון נוסף. לדוגמה, מומחים ללמידת מכונה יכולים לאמן מראש מודל שפה גדול על מערך נתונים עצום של טקסט, כמו כל הדפים באנגלית בוויקיפדיה. אחרי האימון המקדים, אפשר לשפר את המודל שנוצר באמצעות אחת מהטכניקות הבאות:
Pro
מודל Gemini עם פחות פרמטרים מ-Ultra אבל יותר פרמטרים מ-Nano. פרטים נוספים זמינים במאמר בנושא Gemini Pro.
הנחיה
כל טקסט שמוזן כקלט למודל שפה גדול כדי להתנות את המודל להתנהג בצורה מסוימת. ההנחיות יכולות להיות קצרות כמו ביטוי, או ארוכות ככל שרוצים (לדוגמה, הטקסט המלא של רומן). ההנחיות מחולקות לכמה קטגוריות, כולל אלה שמוצגות בטבלה הבאה:
| קטגוריית ההנחיה | דוגמה | הערות |
|---|---|---|
| שאלה | מהי מהירות התעופה של יונה? | |
| הוראות | תכתוב שיר מצחיק על ארביטראז'. | פרומפט שמבקש ממודל שפה גדול לעשות משהו. |
| דוגמה | תרגום קוד Markdown ל-HTML. לדוגמה:
Markdown: * list item HTML: <ul> <li>list item</li> </ul> |
המשפט הראשון בהנחיה לדוגמה הזו הוא הוראה. שאר ההנחיה היא הדוגמה. |
| תפקיד | תסביר למה משתמשים בשיטת גרדיאנט ירידה באימון של למידת מכונה, ברמה של דוקטורט בפיזיקה. | החלק הראשון של המשפט הוא הוראה, והביטוי to a PhD in Physics הוא החלק שמתייחס לתפקיד. |
| קלט חלקי שהמודל צריך להשלים | ראש ממשלת בריטניה מתגורר בכתובת | הנחיה חלקית לקלט יכולה להסתיים בפתאומיות (כמו בדוגמה הזו) או להסתיים בקו תחתון. |
מודל AI גנרטיבי יכול להגיב להנחיה באמצעות טקסט, קוד, תמונות, הטמעות, סרטונים… כמעט כל דבר.
למידה מבוססת-הנחיות
יכולת של מודלים מסוימים שמאפשרת להם להתאים את ההתנהגות שלהם בתגובה לקלט טקסט שרירותי (הנחיות). בפרדיגמה טיפוסית של למידה מבוססת-הנחיה, מודל שפה גדול מגיב להנחיה על ידי יצירת טקסט. לדוגמה, נניח שמשתמש מזין את ההנחיה הבאה:
סכמו את חוק התנועה השלישי של ניוטון.
מודל שיכול ללמוד על סמך הנחיות לא עובר אימון ספציפי כדי לענות על ההנחיה הקודמת. במקום זאת, המודל 'יודע' הרבה עובדות על פיזיקה, הרבה על כללי שפה כלליים והרבה על מה נחשב לתשובות שימושיות באופן כללי. הידע הזה מספיק כדי לספק תשובה (בתקווה) מועילה. משוב אנושי נוסף ("התשובה הזו הייתה מסובכת מדי" או "מה זה תגובה?") מאפשר למערכות מסוימות של למידה מבוססת-הנחיות לשפר בהדרגה את התועלת של התשובות שלהן.
עיצוב הנחיות
מילה נרדפת להנדסת הנחיות.
הנדסת הנחיות
האומנות של יצירת הנחיות שמניבות את התשובות הרצויות ממודל שפה גדול. בני אדם מבצעים הנדסת הנחיות. כתיבת הנחיות מובנות היטב היא חלק חיוני בהבטחת תשובות מועילות ממודל שפה גדול. הנדסת הנחיות תלויה בגורמים רבים, כולל:
- קבוצת הנתונים שמשמשת לאימון מוקדם ואולי לכוונון עדין של מודל שפה גדול (LLM).
- רמת האקראיות ופרמטרים אחרים של פענוח שהמודל משתמש בהם כדי ליצור תשובות.
עיצוב פרומפטים הוא מונח נרדף להנדסת פרומפטים.
פרטים נוספים על כתיבת הנחיות מועילות מופיעים במאמר מבוא לעיצוב הנחיות.
קבוצת הנחיות
קבוצה של הנחיות להערכה של מודל שפה גדול. לדוגמה, באיור הבא מוצג סט של הנחיות שכולל שלוש הנחיות:

קבוצות טובות של פרומפטים כוללות אוסף מספיק "רחב" של פרומפטים כדי להעריך באופן יסודי את הבטיחות והתועלת של מודל שפה גדול.
אפשר לעיין גם במאמר בנושא קבוצת תשובות.
כוונון הנחיות
מנגנון כוונון יעיל בפרמטרים שלומד 'קידומת' שהמערכת מוסיפה לפני ההנחיה בפועל.
אחת מהווריאציות של שיפור הנחיות – שנקראת לפעמים שיפור באמצעות קידומת – היא הוספת הקידומת לכל שכבה. לעומת זאת, ברוב המקרים, כוונון הנחיות מוסיף רק קידומת לשכבת הקלט.
R
טקסט לדוגמה
תשובה של מומחה להנחיה. לדוגמה, אם נותנים את ההנחיה הבאה:
תרגם את השאלה "What is your name?" מאנגלית לצרפתית.
תשובה של מומחה יכולה להיות:
Quel est votre nom?
מדדים שונים (כמו ROUGE) מודדים את מידת ההתאמה בין טקסט ההפניה לבין הטקסט שנוצר על ידי מודל ML.
הרהורים
אסטרטגיה לשיפור האיכות של תהליך עבודה מבוסס-סוכן על ידי בדיקה (רפלקציה) של פלט של שלב מסוים לפני העברת הפלט הזה לשלב הבא.
הבודק הוא לרוב אותו LLM שיצר את התשובה (אבל יכול להיות שזה יהיה LLM אחר). איך יכול להיות שאותו LLM שיצר תשובה ישפוט בצורה הוגנת את התשובה שהוא יצר? הטריק הוא להכניס את ה-LLM למצב חשיבה ביקורתי (רפלקטיבי). התהליך הזה דומה לתהליך שבו סופר משתמש בחשיבה יצירתית כדי לכתוב טיוטה ראשונה, ואז עובר לחשיבה ביקורתית כדי לערוך אותה.
לדוגמה, נניח שיש תהליך עבודה מבוסס-סוכן שהשלב הראשון שלו הוא ליצור טקסט לספלי קפה. ההנחיה לשלב הזה יכולה להיות:
אתם אנשים יצירתיים. תייצר טקסט הומוריסטי ומקורי באורך של פחות מ-50 תווים שמתאים לספל קפה.
עכשיו דמיינו את ההנחיה הרפלקטיבית הבאה:
אתה שותה קפה. האם התגובה הקודמת מצחיקה?
לאחר מכן, יכול להיות שרק טקסט שמקבל ציון גבוה של השתקפות יעבור לשלב הבא בתהליך העבודה.
למידה חיזוקית ממשוב אנושי (RLHF)
שימוש במשוב ממדרגים אנושיים כדי לשפר את האיכות של התשובות של המודל. לדוגמה, מנגנון RLHF יכול לבקש מהמשתמשים לדרג את איכות התשובה של המודל באמצעות אמוג'י של לייק (👍) או דיסלייק (👎). המערכת יכולה לשנות את התשובות העתידיות שלה על סמך המשוב הזה.
תשובה
הטקסט, התמונות, האודיו או הסרטון שמודל AI גנרטיבי מסיק. במילים אחרות, הנחיה היא הקלט למודל AI גנרטיבי, והתשובה היא הפלט.
קבוצת תשובות
אוסף התשובות שמודל שפה גדול מחזיר לקלט של הנחיות.
הנחיות לגילום תפקידים
הנחיה, בדרך כלל מתחילה בכינוי את/אתה/אתם, שמורה למודל AI גנרטיבי להתנהג כמו אדם מסוים או למלא תפקיד מסוים כשהוא יוצר את התשובה. הנחיות שקשורות לתפקיד יכולות לעזור למודל AI גנרטיבי להיכנס ל "מצב המחשבה" הנכון כדי ליצור תשובה שימושית יותר. לדוגמה, כל אחת מההנחיות הבאות להגדרת תפקיד יכולה להתאים בהתאם לסוג התשובה שאתם מחפשים:
יש לך דוקטורט במדעי המחשב.
אתה מהנדס תוכנה שאוהב לתת הסברים סבלניים על Python לתלמידים חדשים בתחום התכנות.
אתה גיבור פעולה עם כישורי תכנות מאוד ספציפיים. תמצא פריט מסוים ברשימת Python.
S
כוונון הנחיות רך
טכניקה לכוונון מודל שפה גדול למשימה מסוימת, בלי כוונון עדין שדורש הרבה משאבים. במקום לאמן מחדש את כל המשקלים במודל, שינוי עדין של הנחיה משנה באופן אוטומטי הנחיה כדי להשיג את אותה מטרה.
בהינתן הנחיה טקסטואלית, כוונון הנחיה רך בדרך כלל מוסיף להנחיה הטמעות של טוקנים נוספים ומבצע אופטימיזציה של הקלט באמצעות הפצת שגיאה לאחור.
הנחיה 'קשה' מכילה טוקנים בפועל במקום הטבעות של טוקנים.
קידוד לפי מפרט
התהליך של כתיבה ותחזוקה של קובץ בשפה טבעית (לדוגמה, אנגלית) שמתאר תוכנה. אחר כך אפשר להנחות מודל AI גנרטיבי או מהנדס תוכנה אחר ליצור את התוכנה שתואמת לתיאור הזה.
בדרך כלל צריך לבצע איטרציה על קוד שנוצר באופן אוטומטי. בקידוד ספציפי, חוזרים על הפעולה בקובץ התיאור. לעומת זאת, בתכנות שיחתי, חוזרים על הפעולה בתיבת ההנחיה. בפועל, יצירת קוד אוטומטית כוללת לפעמים שילוב של גם קידוד ספציפי וגם קידוד שיחתי.
T
טמפרטורה
היפרפרמטר ששולט במידת הרנדומיזציה של הפלט של מודל. טמפרטורות גבוהות יותר יובילו לתוצאות אקראיות יותר, ואילו טמפרטורות נמוכות יותר יובילו לתוצאות פחות אקראיות.
הטמפרטורה הטובה ביותר תלויה באפליקציה הספציפית ובערכי המחרוזת.
U
Ultra
מודל Gemini עם הכי הרבה פרמטרים. פרטים נוספים זמינים במאמר בנושא Gemini Ultra.
כדאי לעיין גם במאמרים בנושא Pro ו-Nano.
V
שיא
הפלטפורמה של Google Cloud ל-AI ולמידת מכונה. Vertex מספקת כלים ותשתית לפיתוח, לפריסה ולניהול של אפליקציות AI, כולל גישה למודלים של Gemini.תכנות בשיטת Vibe coding
הזנת הנחיה למודל AI גנרטיבי כדי ליצור תוכנה. כלומר, ההנחיות מתארות את המטרה והתכונות של התוכנה, ומודל AI גנרטיבי מתרגם אותן לקוד מקור. הקוד שנוצר לא תמיד תואם לכוונות שלכם, ולכן בדרך כלל נדרשת איטרציה בתכנות בשיטת Vibe coding.
אנדריי קרפטי טבע את המונח תכנות בשיטת Vibe coding בפוסט הזה ב-X. בפוסט ב-X, קרפתי מתאר את זה כ "סוג חדש של קידוד...שבו נכנעים לגמרי לאווירה..." לכן, המונח במקור התייחס לגישה מכוונת וגמישה ליצירת תוכנה, שבה יכול להיות שאפילו לא בודקים את הקוד שנוצר. עם זאת, המונח התפתח במהירות בתחומים רבים, ועכשיו הוא מתייחס לכל סוג של קוד שנוצר על ידי AI.
לתיאור מפורט יותר של תכנות בשיטת Vibe coding, אפשר לעיין במאמר מה זה תכנות בשיטת Vibe coding?
בנוסף, השוו והבדילו בין תכנות בשיטת Vibe coding לבין:
Z
הנחיות בלי דוגמאות (zero-shot prompting)
הנחיה שלא כוללת דוגמה לאופן שבו מודל שפה גדול צריך להגיב. לדוגמה:
| החלקים של הנחיה | הערות |
|---|---|
| מהו המטבע הרשמי של המדינה שצוינה? | השאלה שרוצים שה-LLM יענה עליה. |
| הודו: | השאילתה בפועל. |
מודל השפה הגדול עשוי להגיב באחת מהדרכים הבאות:
- רופיות
- INR
- ₹
- רופי הודי
- רופי
- רופי הודי
כל התשובות נכונות, אבל יכול להיות שתעדיפו פורמט מסוים.
השוואה וניגוד בין הנחיות בלי דוגמאות (zero-shot prompting) לבין המונחים הבאים: