Auf dieser Seite finden Sie Glossarbegriffe zu generativer KI. Hier finden Sie alle Glossarbegriffe.
A
Anpassung
Synonym für Optimierung oder Feinabstimmung.
Agent
Software, die Nutzeranfragen analysieren kann, um Aktionen im Namen des Nutzers zu planen und auszuführen.
Beim Reinforcement Learning ist ein Agent die Einheit, die eine Richtlinie verwendet, um den erwarteten Return zu maximieren, der durch den Übergang zwischen Zuständen der Umgebung erzielt wird.
agentisch
Die Adjektivform von Agent. „Agentic“ bezieht sich auf die Eigenschaften, die Agenten haben (z. B. Autonomie).
Agentischer Workflow
Ein dynamischer Prozess, bei dem ein Agent autonom Aktionen plant und ausführt, um ein Ziel zu erreichen. Der Prozess kann das Ziehen von Schlussfolgerungen, das Aufrufen externer Tools und das selbstständige Korrigieren des Plans umfassen.
AI Slop
Ausgabe eines Systems für generative KI, bei dem die Quantität über der Qualität steht. Eine Webseite mit „AI Slop“ ist beispielsweise mit billig produzierten, KI-generierten Inhalten von geringer Qualität gefüllt.
automatische Bewertung
Software verwenden, um die Qualität der Ausgabe eines Modells zu beurteilen.
Wenn die Modellausgabe relativ einfach ist, kann ein Skript oder Programm die Modellausgabe mit einer Referenzantwort vergleichen. Diese Art der automatischen Auswertung wird manchmal als programmatische Auswertung bezeichnet. Messwerte wie ROUGE oder BLEU sind oft für die programmatische Bewertung nützlich.
Wenn die Modellausgabe komplex ist oder keine richtige Antwort hat, wird die automatische Bewertung manchmal von einem separaten ML-Programm, dem Autorater, durchgeführt.
Autorater-Bewertung
Ein hybrider Mechanismus zur Beurteilung der Qualität der Ausgabe eines generativen KI-Modells, der menschliche Bewertung mit automatischer Bewertung kombiniert. Ein Autorater ist ein ML-Modell, das mit Daten trainiert wird, die durch menschliche Bewertung erstellt wurden. Im Idealfall lernt ein Autorater, einen menschlichen Prüfer zu imitieren.Es sind zwar vorgefertigte Autorater verfügbar, aber die besten Autorater sind speziell auf die Aufgabe abgestimmt, die Sie bewerten.
Autoregressives Modell
Ein Modell, das eine Vorhersage auf Grundlage seiner eigenen vorherigen Vorhersagen ableitet. Autoregressive Sprachmodelle sagen beispielsweise das nächste Token auf Grundlage der zuvor vorhergesagten Tokens voraus. Alle Transformer-basierten Large Language Models sind autoregressiv.
Im Gegensatz dazu sind GAN-basierte Bildmodelle in der Regel nicht autoregressiv, da sie ein Bild in einem einzigen Vorwärtsdurchlauf und nicht iterativ in Schritten generieren. Bestimmte Modelle zur Bildgenerierung sind jedoch autoregressiv, da sie ein Bild in Schritten generieren.
B
Basismodell
Ein vortrainiertes Modell, das als Ausgangspunkt für die Feinabstimmung für bestimmte Aufgaben oder Anwendungen dienen kann.
Siehe auch Vortrainiertes Modell und Foundation Model.
C
Chain-of-Thought Prompting
Eine Prompt-Engineering-Technik, die ein Large Language Model (LLM) dazu anregt, seine Argumentation Schritt für Schritt zu erläutern. Betrachten Sie beispielsweise den folgenden Prompt und achten Sie besonders auf den zweiten Satz:
Wie viele G-Kräfte würde ein Fahrer in einem Auto erfahren, das in 7 Sekunden von 0 auf 60 Meilen pro Stunde beschleunigt? Zeige in der Antwort alle relevanten Berechnungen.
Die Antwort des LLM würde wahrscheinlich:
- Zeige eine Reihe von physikalischen Formeln und setze die Werte 0, 60 und 7 an den entsprechenden Stellen ein.
- Erklären Sie, warum diese Formeln ausgewählt wurden und was die verschiedenen Variablen bedeuten.
Durch Chain-of-Thought-Prompts wird das LLM gezwungen, alle Berechnungen durchzuführen, was zu einer korrekteren Antwort führen kann. Außerdem kann der Nutzer durch Chain-of-Thought-Prompting die Schritte des LLM nachvollziehen und so prüfen, ob die Antwort sinnvoll ist.
Chat
Die Inhalte eines Dialogs mit einem ML-System, in der Regel einem Large Language Model. Die vorherige Interaktion in einem Chat (was Sie eingegeben haben und wie das Large Language Model reagiert hat) wird zum Kontext für nachfolgende Teile des Chats.
Ein Chatbot ist eine Anwendung eines Large Language Model.
kontextbezogene Spracheinbettung
Eine Einbettung, die sich dem „Verständnis“ von Wörtern und Wortgruppen durch fließend sprechende Menschen annähert. Kontextbezogene Spracheinbettungen können komplexe Syntax, Semantik und Kontext verstehen.
Betrachten Sie beispielsweise die Einbettungen des englischen Wortes cow (Kuh). Ältere Einbettungen wie word2vec können englische Wörter so darstellen, dass der Abstand im Einbettungsraum von cow (Kuh) zu bull (Bulle) ähnlich dem Abstand von ewe (weibliches Schaf) zu ram (männliches Schaf) oder von female (weiblich) zu male (männlich) ist. Kontextbezogene Spracheinbettungen können noch einen Schritt weiter gehen, indem sie erkennen, dass englischsprachige Nutzer das Wort cow (Kuh) manchmal umgangssprachlich für Kuh oder Stier verwenden.
Kontextfenster
Die Anzahl der Tokens, die ein Modell in einem bestimmten Prompt verarbeiten kann. Je größer das Kontextfenster ist, desto mehr Informationen kann das Modell verwenden, um kohärente und konsistente Antworten auf den Prompt zu geben.
Konversationelles Programmieren
Ein iterativer Dialog zwischen Ihnen und einem generativen KI‑Modell zum Erstellen von Software. Sie geben einen Prompt ein, in dem Sie eine Software beschreiben. Anschließend verwendet das Modell diese Beschreibung, um Code zu generieren. Anschließend geben Sie einen neuen Prompt ein, um die Fehler im vorherigen Prompt oder im generierten Code zu beheben. Das Modell generiert dann aktualisierten Code. Sie und die KI tauschen sich so lange aus, bis die generierte Software gut genug ist.
Die Konversationscodierung entspricht im Wesentlichen der ursprünglichen Bedeutung von Vibe Coding.
Im Gegensatz zur spezifikationsbezogenen Codierung.
D
Direktes Prompting
Synonym für Zero-Shot-Prompting.
Destillation
Bei diesem Verfahren wird die Größe eines Modells (dem Lehrermodell) in ein kleineres Modell (dem Schülermodell) reduziert, das die Vorhersagen des ursprünglichen Modells so genau wie möglich emuliert. Die Destillation ist nützlich, weil das kleinere Modell zwei wesentliche Vorteile gegenüber dem größeren Modell (dem Lehrer) hat:
- Schnellere Inferenzzeiten
- Geringerer Arbeitsspeicher- und Energieverbrauch
Die Vorhersagen des Schülers sind jedoch in der Regel nicht so gut wie die des Lehrers.
Bei der Destillation wird das Schülermodell so trainiert, dass eine Verlustfunktion basierend auf der Differenz zwischen den Ausgaben der Vorhersagen des Schüler- und des Lehrermodells minimiert wird.
Vergleichen Sie die Destillation mit den folgenden Begriffen und stellen Sie sie ihnen gegenüber:
Weitere Informationen finden Sie im Machine Learning Crash Course unter LLMs: Fine-tuning, distillation, and prompt engineering.
E
evals
Wird hauptsächlich als Abkürzung für LLM-Bewertungen verwendet. Im Allgemeinen ist Evals eine Abkürzung für jede Form von Bewertung.
Agentenbewertung
Prozess, bei dem die Qualität eines Modells gemessen oder verschiedene Modelle miteinander verglichen werden.
Um ein Modell für beaufsichtigtes maschinelles Lernen zu bewerten, vergleichen Sie es in der Regel mit einem Validierungsset und einem Testset. Bewertung eines LLM: Hier werden in der Regel umfassendere Qualitäts- und Sicherheitsbewertungen durchgeführt.
F
Faktizität
In der Welt des maschinellen Lernens eine Eigenschaft, die ein Modell beschreibt, dessen Ausgabe auf der Realität basiert. Faktualität ist ein Konzept und kein Messwert. Angenommen, Sie senden den folgenden Prompt an ein Large Language Model:
Wie lautet die chemische Formel für Kochsalz?
Ein Modell, das auf Faktualität optimiert ist, würde so antworten:
NaCl
Es liegt nahe, anzunehmen, dass alle Modelle auf Fakten basieren sollten. Bei einigen Prompts, z. B. dem folgenden, sollte ein generatives KI-Modell jedoch eher auf Kreativität als auf Faktualität optimieren.
Erzähl mir einen Limerick über einen Astronauten und eine Raupe.
Es ist unwahrscheinlich, dass der resultierende Limerick auf der Realität basiert.
Kontrast zur Fundierung.
schnelles Abklingen
Eine Trainingstechnik zur Verbesserung der Leistung von LLMs. Beim schnellen Abklingen wird die Lernrate während des Trainings schnell verringert. Diese Strategie trägt dazu bei, dass das Modell nicht überangepasst wird, und verbessert die Generalisierung.
Few-Shot-Prompting
Eine Prompt, die mehr als ein (einige) Beispiel enthält, das zeigt, wie das große Sprachmodell reagieren soll. Der folgende lange Prompt enthält beispielsweise zwei Beispiele, die einem Large Language Model zeigen, wie eine Anfrage beantwortet werden soll.
| Teile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Frankreich: EUR | Hier ein Beispiel. |
| Vereinigtes Königreich: GBP | Ein weiteres Beispiel. |
| Indien: | Die eigentliche Anfrage. |
Few-Shot-Prompts führen in der Regel zu besseren Ergebnissen als Zero-Shot-Prompts und One-Shot-Prompts. Für Few-Shot-Prompting ist jedoch ein längerer Prompt erforderlich.
Few-Shot-Prompting ist eine Form des Few-Shot-Lernens, das auf promptbasiertes Lernen angewendet wird.
Weitere Informationen finden Sie im Machine Learning Crash Course unter Prompt-Engineering.
Feinabstimmung
Ein zweiter, aufgabenspezifischer Trainingsdurchlauf, der für ein vortrainiertes Modell durchgeführt wird, um seine Parameter für einen bestimmten Anwendungsfall zu optimieren. Die vollständige Trainingssequenz für einige Large Language Models sieht beispielsweise so aus:
- Vortraining:Ein Large Language Model wird mit einem riesigen allgemeinen Dataset trainiert, z. B. mit allen englischsprachigen Wikipedia-Seiten.
- Abstimmung:Das vortrainierte Modell wird trainiert, um eine bestimmte Aufgabe auszuführen, z. B. auf medizinische Anfragen zu reagieren. Für die Feinabstimmung sind in der Regel Hunderte oder Tausende von Beispielen erforderlich, die sich auf die jeweilige Aufgabe konzentrieren.
Ein weiteres Beispiel: Die vollständige Trainingssequenz für ein großes Bildmodell sieht so aus:
- Vortraining:Trainieren Sie ein großes Bildmodell mit einem riesigen allgemeinen Bild-Dataset, z. B. mit allen Bildern in Wikimedia Commons.
- Feinabstimmung:Das vortrainierte Modell wird trainiert, um eine bestimmte Aufgabe auszuführen, z. B. Bilder von Orcas zu generieren.
Das Feinabstimmen kann eine beliebige Kombination der folgenden Strategien umfassen:
- Alle vorhandenen Parameter des vortrainierten Modells werden geändert. Das wird auch als vollständiges Fine-Tuning bezeichnet.
- Es werden nur einige der vorhandenen Parameter des vortrainierten Modells geändert (in der Regel die Ebenen, die der Ausgabeebene am nächsten sind), während andere vorhandene Parameter unverändert bleiben (in der Regel die Ebenen, die der Eingabeebene am nächsten sind). Weitere Informationen finden Sie unter Parametereffiziente Abstimmung.
- Es werden weitere Ebenen hinzugefügt, in der Regel über den vorhandenen Ebenen, die der Ausgabeschicht am nächsten sind.
Die Feinabstimmung ist eine Form des Transfer Learning. Daher kann beim Fine-Tuning eine andere Verlustfunktion oder ein anderer Modelltyp als beim Training des vortrainierten Modells verwendet werden. Sie können beispielsweise ein vortrainiertes großes Bildmodell optimieren, um ein Regressionsmodell zu erstellen, das die Anzahl der Vögel in einem Eingabebild zurückgibt.
Vergleichen Sie das Fine-Tuning mit den folgenden Begriffen und stellen Sie es ihnen gegenüber:
Weitere Informationen finden Sie im Machine Learning Crash Course unter Fine-tuning.
Flash-Modell
Eine Familie relativ kleiner Gemini-Modelle, die für Geschwindigkeit und niedrige Latenz optimiert sind. Flash-Modelle sind für eine Vielzahl von Anwendungen konzipiert, bei denen schnelle Antworten und ein hoher Durchsatz entscheidend sind.
Foundation Model
Ein sehr großes vortrainiertes Modell, das mit einem enormen und vielfältigen Trainingsset trainiert wurde. Ein Foundation Model kann beides:
- Auf eine Vielzahl von Anfragen gut reagieren.
- Als Basismodell für zusätzliches Feinabstimmung oder andere Anpassungen dienen.
Ein Foundation Model ist also bereits sehr leistungsfähig, kann aber weiter angepasst werden, um für eine bestimmte Aufgabe noch nützlicher zu sein.
Anteil der Erfolge
Eine Messwert zum Bewerten des generierten Texts eines ML-Modells. Der Anteil der Erfolge ist die Anzahl der „erfolgreichen“ generierten Textausgaben geteilt durch die Gesamtzahl der generierten Textausgaben. Wenn beispielsweise ein Large Language Model 10 Codeblöcke generiert hat, von denen fünf erfolgreich waren, beträgt der Anteil der Erfolge 50%.
Der Anteil der erfolgreichen Versuche ist in der Statistik allgemein nützlich. Im Bereich des maschinellen Lernens ist dieser Messwert jedoch hauptsächlich für die Messung überprüfbarer Aufgaben wie der Code-Generierung oder mathematischer Probleme nützlich.
G
Gemini
Das Ökosystem, das die leistungsstärkste KI von Google umfasst. Zu diesem Ökosystem gehören:
- Verschiedene Gemini-Modelle
- Die interaktive Konversationsoberfläche für ein Gemini-Modell. Nutzer geben Prompts ein und Gemini antwortet darauf.
- Verschiedene Gemini APIs.
- Verschiedene Geschäftsprodukte, die auf Gemini-Modellen basieren, z. B. Gemini für Google Cloud.
Gemini-Modelle
Die hochmodernen multimodalen Modelle von Google, die auf Transformer basieren. Gemini-Modelle sind speziell für die Integration mit KI-Agenten konzipiert.
Nutzer können auf verschiedene Weise mit Gemini-Modellen interagieren, z. B. über eine interaktive Dialogoberfläche und über SDKs.
Gemma
Eine Familie leichtgewichtiger offener Modelle, die auf derselben Forschung und Technologie basieren, die auch für die Erstellung der Gemini-Modelle verwendet werden. Es sind mehrere verschiedene Gemma-Modelle verfügbar, die jeweils unterschiedliche Funktionen bieten, z. B. Vision, Code und Befolgung von Anweisungen. Weitere Informationen finden Sie unter Gemma.
GenAI oder genAI
Abkürzung für generative KI.
generierter Text
Im Allgemeinen der Text, den ein ML-Modell ausgibt. Bei der Bewertung von Large Language Models werden mit einigen Messwerten generierte Texte mit Referenztexten verglichen. Angenommen, Sie möchten herausfinden, wie effektiv ein ML-Modell vom Französischen ins Niederländische übersetzt. In diesem Fall gilt:
- Der generierte Text ist die niederländische Übersetzung, die vom ML-Modell ausgegeben wird.
- Der Referenztext ist die niederländische Übersetzung, die von einem menschlichen Übersetzer oder einer Software erstellt wird.
Bei einigen Bewertungsstrategien wird kein Referenztext verwendet.
Generative KI
Ein aufstrebendes Transformationsfeld ohne formale Definition. Die meisten Experten sind sich jedoch einig, dass generative KI-Modelle Inhalte erstellen („generieren“) können, die alle der folgenden Eigenschaften aufweisen:
- komplex
- kohärent
- ursprünglich
Beispiele für generative KI:
- Large Language Models, die anspruchsvollen Originaltext generieren und Fragen beantworten können.
- Modell zur Bildgenerierung, mit dem einzigartige Bilder erstellt werden können.
- Modelle zur Audio- und Musikgenerierung, die Originalmusik komponieren oder realistische Sprache generieren können.
- Modelle zur Videogenerierung, die Originalvideos generieren können.
Einige ältere Technologien, darunter LSTMs und RNNs, können ebenfalls Originalinhalte und kohärente Inhalte generieren. Einige Experten betrachten diese früheren Technologien als generative KI, während andere der Meinung sind, dass echte generative KI komplexere Ergebnisse erfordert, als diese früheren Technologien liefern können.
Kontrast zu vorhersagendem maschinellen Lernen
Goldene Antwort
Eine Antwort, die als gut bekannt ist. Beispiel für einen Prompt:
2 + 2
Die goldene Antwort lautet hoffentlich:
4
GPT (Generative Pre-trained Transformer)
Eine Familie von Transformer-basierten Large Language Models, die von OpenAI entwickelt wurden.
GPT-Varianten können für mehrere Modalitäten gelten, darunter:
- Bildgenerierung (z. B. ImageGPT)
- Text-zu-Bild-Generierung (z. B. DALL-E).
H
KI-Halluzination
Die Erstellung von plausibel erscheinenden, aber faktisch falschen Ausgaben durch ein generatives KI-Modell, das eine Behauptung über die reale Welt aufstellt. Ein generatives KI-Modell, das behauptet, Barack Obama sei 1865 gestorben, halluziniert.
manuelle Bewertung
Ein Prozess, bei dem Menschen die Qualität der Ausgabe eines ML-Modells bewerten, z. B. indem zweisprachige Personen die Qualität eines ML-Übersetzungsmodells bewerten. Die manuelle Bewertung ist besonders nützlich, um Modelle zu beurteilen, bei denen es keine richtige Antwort gibt.
Automatische Bewertung und Bewertung durch Autorater
Human in the Loop (HITL)
Ein locker definierter Ausdruck, der Folgendes bedeuten kann:
- Eine Richtlinie, die besagt, dass die Ausgabe von generativer KI kritisch oder skeptisch betrachtet werden muss.
- Eine Strategie oder ein System, mit dem sichergestellt wird, dass Menschen das Verhalten eines Modells mitgestalten, bewerten und optimieren. Wenn ein Mensch in den Prozess eingebunden ist, kann eine KI sowohl von maschineller als auch von menschlicher Intelligenz profitieren. Ein Beispiel für ein System mit menschlicher Beteiligung ist ein System, in dem eine KI Code generiert, der dann von Softwareentwicklern überprüft wird.
I
Lernen im Kontext
Synonym für Few-Shot-Prompting.
Inferenz
Beim herkömmlichen maschinellen Lernen ist das der Prozess, bei dem Vorhersagen getroffen werden, indem ein trainiertes Modell auf Beispiele ohne Label angewendet wird. Weitere Informationen finden Sie im Kurs „Einführung in ML“ unter Supervised Learning.
Bei Large Language Models ist die Inferenz der Prozess, bei dem ein trainiertes Modell verwendet wird, um eine Antwort auf einen Prompt zu generieren.
In der Statistik hat der Begriff „Inferenz“ eine etwas andere Bedeutung. Weitere Informationen finden Sie im Wikipedia-Artikel zur statistischen Inferenz.
Optimierung von Anweisungen
Eine Form der Feinabstimmung, die die Fähigkeit eines generativen KI-Modells verbessert, Anweisungen zu befolgen. Beim Instruction Tuning wird ein Modell mit einer Reihe von Anweisungsprompts trainiert, die in der Regel eine Vielzahl von Aufgaben abdecken. Das resultierende, auf Anweisungen abgestimmte Modell generiert dann in der Regel nützliche Antworten auf Zero-Shot-Prompts für eine Vielzahl von Aufgaben.
Vergleichen und gegenüberstellen mit:
L
Large Language Model
Mindestens ein Sprachmodell mit einer sehr hohen Anzahl von Parametern. Informeller ausgedrückt: jedes Transformer-basierte Sprachmodell, z. B. Gemini oder GPT.
Weitere Informationen finden Sie im Machine Learning Crash Course unter Large Language Models (LLMs).
Latenz
Die Zeit, die ein Modell benötigt, um Eingaben zu verarbeiten und eine Antwort zu generieren. Die Generierung einer Antwort mit hoher Latenz dauert länger als die einer Antwort mit niedriger Latenz.
Faktoren, die die Latenz von Large Language Models beeinflussen:
- Längen von Eingabe- und Ausgabetokens
- Modellkomplexität
- Die Infrastruktur, auf der das Modell ausgeführt wird
Die Optimierung für Latenz ist entscheidend für die Entwicklung reaktionsschneller und nutzerfreundlicher Anwendungen.
LLM
Abkürzung für Large Language Model.
LLM-Bewertungen
Eine Reihe von Messwerten und Benchmarks zur Bewertung der Leistung von Large Language Models (LLMs). Auf hoher Ebene:
- Forschern helfen, Bereiche zu identifizieren, in denen LLMs verbessert werden müssen.
- Sie sind nützlich, um verschiedene LLMs zu vergleichen und das beste LLM für eine bestimmte Aufgabe zu ermitteln.
- Dazu beitragen, dass LLMs sicher und ethisch vertretbar sind.
Weitere Informationen finden Sie im Machine Learning Crash Course unter Large Language Models (LLMs).
LoRA
Abkürzung für Low-Rank Adaptability (Anpassungsfähigkeit mit niedrigem Rang).
Low-Rank Adaptability (LoRA)
Eine parametereffiziente Technik für die Feinabstimmung, bei der die vortrainierten Gewichte des Modells „eingefroren“ werden (sodass sie nicht mehr geändert werden können) und dann eine kleine Gruppe von trainierbaren Gewichten in das Modell eingefügt wird. Dieser Satz trainierbarer Gewichte (auch als „Aktualisierungsmatrizen“ bezeichnet) ist wesentlich kleiner als das Basismodell und lässt sich daher viel schneller trainieren.
LoRA bietet folgende Vorteile:
- Verbessert die Qualität der Vorhersagen eines Modells für die Domain, in der das Fine-Tuning angewendet wird.
- Die Feinabstimmung erfolgt schneller als bei Techniken, bei denen alle Parameter eines Modells feinabgestimmt werden müssen.
- Reduziert die Berechnungskosten für die Inferenz, da mehrere spezialisierte Modelle, die dasselbe Basismodell verwenden, gleichzeitig bereitgestellt werden können.
M
maschinelle Übersetzung
Software (in der Regel ein Modell für maschinelles Lernen) wird verwendet, um Text von einer menschlichen Sprache in eine andere zu übersetzen, z. B. von Englisch ins Japanische.
Mittlere durchschnittliche Precision bei k (mAP@k)
Der statistische Mittelwert aller durchschnittlichen Precision bei k-Werte in einem Validierungs-Dataset. Mit der mittleren durchschnittlichen Präzision bei k lässt sich die Qualität von Empfehlungen beurteilen, die von einem Empfehlungssystem generiert werden.
Obwohl die Formulierung „Mittelwert“ redundant klingt, ist der Name des Messwerts angemessen. Dieser Messwert ist schließlich der Mittelwert mehrerer durchschnittliche Precision bei k-Werte.
Mixture of Experts
Ein Verfahren zur Steigerung der Effizienz von neuronalen Netzwerken, bei dem nur eine Teilmenge der Parameter (als Expert bezeichnet) verwendet wird, um einen bestimmten Eingabe-Token oder ein Beispiel zu verarbeiten. Ein Gating-Netzwerk leitet jedes Eingabe-Token oder ‑Beispiel an den/die richtigen Experten weiter.
Weitere Informationen finden Sie in einem der folgenden Dokumente:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mixture-of-Experts mit Expert Choice-Routing
MMIT
Abkürzung für multimodal instruction-tuned (auf multimodale Anweisungen abgestimmt).
Kaskadierung von Modellen
Ein System, das das ideale Modell für eine bestimmte Inferenzanfrage auswählt.
Stellen Sie sich eine Gruppe von Modellen vor, die von sehr groß (viele Parameter) bis viel kleiner (viel weniger Parameter) reichen. Sehr große Modelle verbrauchen zur Inferenz mehr Rechenressourcen als kleinere Modelle. Sehr große Modelle können jedoch in der Regel komplexere Anfragen ableiten als kleinere Modelle. Bei der Modellkaskadierung wird die Komplexität der Inferenzanfrage bestimmt und dann das geeignete Modell für die Inferenz ausgewählt. Die Hauptmotivation für die Kaskadierung von Modellen besteht darin, die Inferenzkosten zu senken, indem in der Regel kleinere Modelle und nur für komplexere Anfragen ein größeres Modell ausgewählt wird.
Stellen Sie sich vor, dass ein kleines Modell auf einem Smartphone und eine größere Version dieses Modells auf einem Remote-Server ausgeführt wird. Durch eine gute Modellkaskadierung werden Kosten und Latenz reduziert, da das kleinere Modell einfache Anfragen verarbeiten kann und das Remote-Modell nur für komplexe Anfragen aufgerufen wird.
Siehe auch Modellrouter.
Modellrouter
Der Algorithmus, der das ideale Modell für die Inferenz in Modellkaskadierung bestimmt. Ein Modell-Router ist selbst in der Regel ein Modell für maschinelles Lernen, das nach und nach lernt, wie das beste Modell für eine bestimmte Eingabe ausgewählt wird. Ein Modellrouter kann jedoch manchmal ein einfacher, nicht auf maschinellem Lernen basierender Algorithmus sein.
MOE
Abkürzung für Mixture of Experts (Mischung von Experten).
MT
Abkürzung für maschinelle Übersetzung.
N
Nano
Ein relativ kleines Gemini-Modell, das für die On-Device-Nutzung entwickelt wurde. Weitere Informationen finden Sie unter Gemini Nano.
Keine richtige Antwort (NORA)
Ein Prompt mit mehreren richtigen Antworten. Für den folgenden Prompt gibt es beispielsweise keine allgemeingültige Antwort:
Erzähl mir einen lustigen Witz über Elefanten.
Die Bewertung von Antworten auf Prompts ohne richtige Antwort ist in der Regel viel subjektiver als die Bewertung von Prompts mit einer richtigen Antwort. Um beispielsweise einen Elefantenwitz zu bewerten, ist eine systematische Methode erforderlich, um zu bestimmen, wie lustig der Witz ist.
NORA
Abkürzung für no one right answer (es gibt keine richtige Antwort).
NotebookLM
Ein auf Gemini basierendes Tool, mit dem Nutzer Dokumente hochladen und dann Prompts verwenden können, um Fragen zu diesen Dokumenten zu stellen, sie zusammenzufassen oder zu organisieren. Ein Autor könnte beispielsweise mehrere Kurzgeschichten hochladen und NotebookLM bitten, die gemeinsamen Themen zu finden oder zu ermitteln, welche sich am besten für einen Film eignen würde.
O
eine richtige Antwort (ORA)
Ein Prompt mit einer einzigen richtigen Antwort. Betrachten Sie beispielsweise den folgenden Prompt:
Richtig oder falsch: Der Saturn ist größer als der Mars.
Die einzig richtige Antwort ist Wahr.
Im Gegensatz dazu gibt es keine richtige Antwort.
One-Shot-Prompting
Ein Prompt, der ein Beispiel dafür enthält, wie das Large Language Model reagieren soll. Der folgende Prompt enthält beispielsweise ein Beispiel, das einem großen Sprachmodell zeigt, wie es auf eine Anfrage antworten soll.
| Teile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Frankreich: EUR | Hier ein Beispiel. |
| Indien: | Die eigentliche Anfrage. |
Vergleichen Sie One-Shot-Prompts mit den folgenden Begriffen und stellen Sie die Unterschiede heraus:
ORA
Abkürzung für eine richtige Antwort.
P
parametereffiziente Abstimmung
Eine Reihe von Techniken zum Abstimmen eines großen vortrainierten Sprachmodells (Pre-trained Language Model, PLM), das effizienter ist als das vollständige Abstimmen. Bei der parametereffizienten Abstimmung werden in der Regel viel weniger Parameter als bei der vollständigen Feinabstimmung optimiert. Dennoch wird in der Regel ein Large Language Model erstellt, das genauso gut (oder fast genauso gut) funktioniert wie ein Large Language Model, das durch vollständige Feinabstimmung erstellt wurde.
Parametereffiziente Abstimmung im Vergleich zu:
Die parametereffiziente Abstimmung wird auch als parametereffiziente Feinabstimmung bezeichnet.
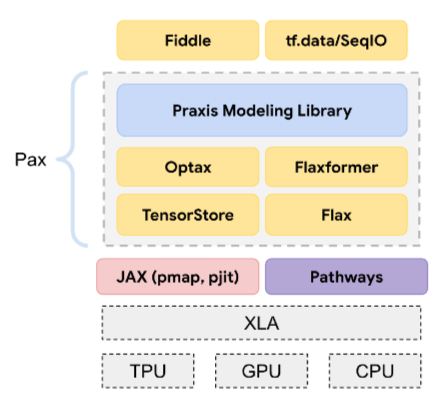
Pax
Ein Programmierframework, das für das Training von umfangreichen Modellen neuronaler Netzwerke entwickelt wurde, die so groß sind, dass sie sich über mehrere TPU-Beschleunigerchips Slices oder Pods erstrecken.
Pax basiert auf Flax, das auf JAX basiert.
PLM
Abkürzung für vortrainiertes Sprachmodell.
Nachtrainiertes Modell
Ein weit gefasster Begriff, der sich in der Regel auf ein vortrainiertes Modell bezieht, das eine Nachbearbeitung durchlaufen hat, z. B. einen oder mehrere der folgenden Schritte:
vortrainiertes Modell
Obwohl sich dieser Begriff auf jedes trainierte Modell oder jeden trainierten Einbettungsvektor beziehen kann, bezieht sich „vortrainiertes Modell“ heutzutage in der Regel auf ein trainiertes Large Language Model oder eine andere Form von trainiertem generativem KI-Modell.
Siehe auch Basismodell und Foundation Model.
Vortraining
Das anfängliche Training eines Modells mit einem großen Dataset. Einige vortrainierte Modelle sind unhandliche Giganten und müssen in der Regel durch zusätzliches Training verfeinert werden. ML-Experten könnten beispielsweise ein Large Language Model mit einem riesigen Text-Dataset vortrainieren, z. B. mit allen englischsprachigen Seiten in Wikipedia. Nach dem Vortraining kann das resultierende Modell mit einer der folgenden Techniken weiter optimiert werden:
- Destillation
- Feinabstimmung
- Optimierung von Anweisungen
- Parametereffiziente Abstimmung
- Prompt-Tuning
Pro
Ein Gemini-Modell mit weniger Parametern als Ultra, aber mehr Parametern als Nano. Weitere Informationen finden Sie unter Gemini Pro.
prompt
Jeder Text, der als Eingabe für ein Large Language Model eingegeben wird, um das Modell so zu trainieren, dass es sich auf eine bestimmte Weise verhält. Prompts können so kurz wie eine Wortgruppe oder beliebig lang sein (z. B. der gesamte Text eines Romans). Prompts lassen sich in verschiedene Kategorien einteilen, darunter die in der folgenden Tabelle:
| Prompt-Kategorie | Beispiel | Hinweise |
|---|---|---|
| Frage | Wie schnell kann eine Taube fliegen? | |
| Anleitung | Schreibe ein lustiges Gedicht über Arbitrage. | Ein Prompt, in dem das Large Language Model aufgefordert wird, etwas zu tun. |
| Beispiel | Markdown-Code in HTML übersetzen. Beispiel:
Markdown: * list item HTML: <ul> <li>list item</li> </ul> |
Der erste Satz in diesem Beispiel-Prompt ist eine Anweisung. Der Rest des Prompts ist das Beispiel. |
| Rolle | Erkläre einem PhD in Physik, warum Gradient Descent beim Training von Machine Learning verwendet wird. | Der erste Teil des Satzes ist eine Anweisung, der Ausdruck „to a PhD in Physics“ ist der Rollenanteil. |
| Teileingabe, die das Modell vervollständigen soll | Der Premierminister des Vereinigten Königreichs wohnt unter folgender Adresse: | Ein Prompt mit Teileingabe kann entweder abrupt enden (wie in diesem Beispiel) oder mit einem Unterstrich. |
Ein generatives KI‑Modell kann auf einen Prompt mit Text, Code, Bildern, Einbettungen, Videos und fast allem anderen reagieren.
Promptbasiertes Lernen
Eine Funktion bestimmter Modelle, mit der sie ihr Verhalten als Reaktion auf beliebige Texteingaben (Prompts) anpassen können. In einem typischen Prompt-basierten Lernparadigma reagiert ein Large Language Model auf einen Prompt, indem es Text generiert. Angenommen, ein Nutzer gibt den folgenden Prompt ein:
Fasse das dritte Newtonsches Gesetz zusammen.
Ein Modell, das promptbasiertes Lernen ermöglicht, wird nicht speziell darauf trainiert, den vorherigen Prompt zu beantworten. Vielmehr „weiß“ das Modell viel über Physik, über allgemeine Sprachregeln und darüber, was im Allgemeinen nützliche Antworten ausmacht. Dieses Wissen reicht aus, um eine (hoffentlich) nützliche Antwort zu geben. Zusätzliches menschliches Feedback („Diese Antwort war zu kompliziert.“ oder „Was ist eine Reaktion?“) ermöglicht es einigen promptbasierten Lernsystemen, die Nützlichkeit ihrer Antworten nach und nach zu verbessern.
Prompt-Design
Synonym für Prompt Engineering.
Prompt Engineering
Die Kunst, Prompts zu erstellen, die die gewünschten Antworten von einem Large Language Model auslösen. Menschen führen Prompt-Engineering durch. Gut strukturierte Prompts sind wichtig, um nützliche Antworten von einem Large Language Model zu erhalten. Das Erstellen von Prompts hängt von vielen Faktoren ab, darunter:
- Das Dataset, das zum Vortrainieren und möglicherweise zum Feinabstimmen des Large Language Model verwendet wird.
- Die Temperatur und andere Dekodierungsparameter, die das Modell zum Generieren von Antworten verwendet.
Prompt-Design ist ein Synonym für Prompt Engineering.
Weitere Informationen zum Schreiben hilfreicher Prompts finden Sie unter Einführung in das Prompt-Design.
Prompt-Set
Eine Gruppe von Prompts zum Bewerten eines Large Language Model. Die folgende Abbildung zeigt beispielsweise ein Prompt-Set mit drei Prompts:
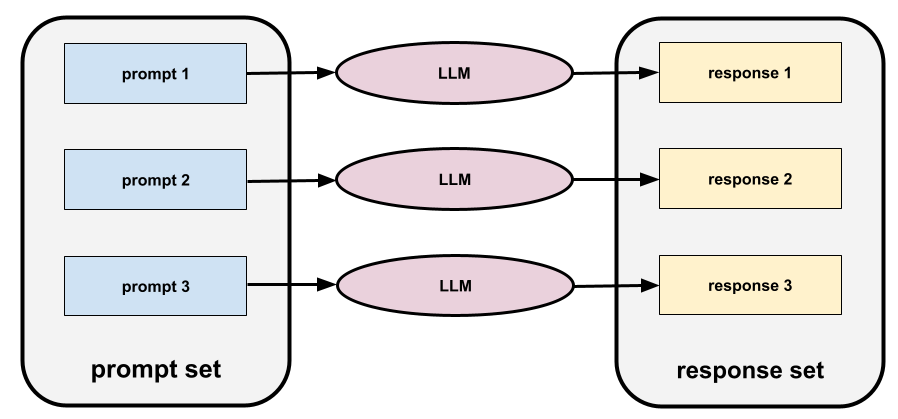
Gute Prompt-Sets bestehen aus einer ausreichend „breiten“ Sammlung von Prompts, um die Sicherheit und Nützlichkeit eines Large Language Model gründlich zu bewerten.
Siehe auch Antwortgruppe.
Prompt-Optimierung
Ein mechanismus zur parametereffizienten Abstimmung, der ein „Präfix“ lernt, das das System dem eigentlichen Prompt voranstellt.
Bei einer Variante des Prompt-Tunings, die manchmal als Prefix-Tuning bezeichnet wird, wird das Präfix jeder Ebene vorangestellt. Beim Prompt-Tuning wird der Eingabeschicht in der Regel nur ein Präfix hinzugefügt.
R
Referenztext
Die Antwort eines Experten auf einen Prompt. Beispiel:
Übersetze die Frage „What is your name?“ vom Englischen ins Französische.
Die Antwort eines Experten könnte so aussehen:
Comment vous appelez-vous?
Verschiedene Messwerte (z. B. ROUGE) messen, inwieweit der Referenztext mit dem generierten Text eines ML-Modells übereinstimmt.
Selbstreflexion
Eine Strategie zur Verbesserung der Qualität eines Agenten-Workflows, indem die Ausgabe eines Schritts geprüft (reflektiert) wird, bevor sie an den nächsten Schritt übergeben wird.
Der Prüfer ist oft dasselbe LLM, das die Antwort generiert hat (es könnte aber auch ein anderes LLM sein). Wie kann dasselbe LLM, das eine Antwort generiert hat, diese Antwort fair bewerten? Der „Trick“ besteht darin, das LLM in eine kritische (reflektierende) Denkweise zu versetzen. Dieser Prozess ähnelt dem eines Autors, der zuerst einen Entwurf mit einem kreativen Ansatz schreibt und dann zu einem kritischen Ansatz wechselt, um ihn zu bearbeiten.
Stellen Sie sich beispielsweise einen Agent-Workflow vor, dessen erster Schritt darin besteht, Text für Kaffeetassen zu erstellen. Der Prompt für diesen Schritt könnte lauten:
Du bist ein Kreativer. Generiere einen humorvollen, originellen Text mit weniger als 50 Zeichen, der für eine Kaffeetasse geeignet ist.
Stellen Sie sich nun den folgenden reflektierenden Prompt vor:
Sie trinken Kaffee. Finden Sie die vorherige Antwort humorvoll?
Im Workflow wird dann möglicherweise nur Text mit einem hohen Reflexionswert an die nächste Phase weitergeleitet.
Bestärkendes Lernen durch menschliches Feedback (RLHF)
Feedback von menschlichen Prüfern nutzen, um die Qualität der Antworten eines Modells zu verbessern. Bei einem RLHF-Mechanismus können Nutzer beispielsweise aufgefordert werden, die Qualität der Antwort eines Modells mit einem 👍- oder 👎-Emoji zu bewerten. Das System kann seine zukünftigen Antworten dann auf Grundlage dieses Feedbacks anpassen.
Antwort
Der Text, die Bilder, die Audioinhalte oder die Videos, die von einem generativen KI-Modell abgeleitet werden. Ein Prompt ist also die Eingabe für ein generatives KI-Modell und die Antwort ist die Ausgabe.
Antwortsatz
Die Sammlung von Antworten, die ein Large Language Model für einen Promptsatz zurückgibt.
Rollen-Prompts
Ein Prompt, der in der Regel mit dem Pronomen du beginnt und einem generativen KI-Modell sagt, dass es beim Generieren der Antwort so tun soll, als wäre es eine bestimmte Person oder in einer bestimmten Rolle. Mit Rollen-Prompts kann ein generatives KI-Modell in die richtige „Denkweise“ versetzt werden, um eine nützlichere Antwort zu generieren. Je nach Art der gewünschten Antwort können Sie beispielsweise einen der folgenden Rollen-Prompts verwenden:
Sie haben einen Doktortitel in Informatik.
Sie sind Softwareentwickler und erklären neuen Programmierstudenten gerne geduldig Python.
Du bist ein Actionheld mit ganz besonderen Programmierkenntnissen. Versichere mir, dass du ein bestimmtes Element in einer Python-Liste finden wirst.
S
Soft-Prompt-Optimierung
Eine Methode zum Abstimmen eines Large Language Model für eine bestimmte Aufgabe ohne ressourcenintensive Feinabstimmung. Anstatt alle Gewichte im Modell neu zu trainieren, wird beim Soft-Prompt-Tuning automatisch ein Prompt angepasst, um dasselbe Ziel zu erreichen.
Beim Soft-Prompt-Tuning werden in der Regel zusätzliche Token-Einbettungen an den Prompt angehängt und Backpropagation verwendet, um die Eingabe zu optimieren.
Ein „harter“ Prompt enthält tatsächliche Tokens anstelle von Token-Einbettungen.
Spezifikationscodierung
Der Prozess des Schreibens und Verwaltens einer Datei in einer menschlichen Sprache (z. B. Englisch), die Software beschreibt. Sie können dann ein generatives KI-Modell oder einen anderen Softwareentwickler bitten, die Software zu erstellen, die dieser Beschreibung entspricht.
Automatisch generierter Code erfordert in der Regel Iteration. Beim Spezifikations-Coding wird die Beschreibungsdatei iterativ bearbeitet. Beim Konversationscodieren iterieren Sie dagegen im Promptfeld. In der Praxis umfasst die automatische Codegenerierung manchmal eine Kombination aus beiden: Spezifikationscodierung und Konversationscodierung.
T
Temperatur
Ein Hyperparameter, der den Grad der Zufälligkeit der Ausgabe eines Modells steuert. Höhere Temperaturen führen zu zufälligeren Ausgaben, niedrigere Temperaturen zu weniger zufälligen Ausgaben.
Die beste Temperatur hängt von der jeweiligen Anwendung und/oder den Stringwerten ab.
U
Ultra
Das Gemini-Modell mit den meisten Parametern. Weitere Informationen finden Sie unter Gemini Ultra.
V
Vertex
Die Plattform von Google Cloud für KI und maschinelles Lernen. Vertex bietet Tools und Infrastruktur zum Erstellen, Bereitstellen und Verwalten von KI-Anwendungen, einschließlich des Zugriffs auf Gemini-Modelle.Vibe Coding
Einen Prompt für ein generatives KI-Modell erstellen, um Software zu generieren. Ihre Prompts beschreiben also den Zweck und die Funktionen der Software, die ein generatives KI-Modell in Quellcode übersetzt. Der generierte Code entspricht nicht immer Ihren Absichten. Daher ist beim Vibe-Coding in der Regel eine Iteration erforderlich.
Andrej Karpathy hat den Begriff „Vibe Coding“ in diesem X-Beitrag geprägt. In seinem X-Beitrag beschreibt Karpathy es als „eine neue Art des Programmierens … bei der man sich voll und ganz auf die Vibes einlässt …“ Der Begriff implizierte ursprünglich einen bewusst lockeren Ansatz zur Softwareerstellung, bei dem der generierte Code möglicherweise nicht einmal geprüft wird. Der Begriff hat sich jedoch in vielen Kreisen schnell weiterentwickelt und bedeutet jetzt jede Form von KI-generiertem Code.
Eine ausführlichere Beschreibung der Vibe-Codierung finden Sie unter Was ist Vibe Coding?
Vergleiche und stelle Vibe Coding außerdem gegenüber:
Z
Zero-Shot-Prompts
Ein Prompt, der kein Beispiel dafür enthält, wie das Large Language Model antworten soll. Beispiel:
| Teile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Indien: | Die eigentliche Anfrage. |
Das Large Language Model kann mit einer der folgenden Antworten reagieren:
- Rupie
- INR
- ₹
- Indische Rupie
- Die Rupie
- Indische Rupie
Alle Antworten sind richtig, aber vielleicht bevorzugen Sie ein bestimmtes Format.
Vergleichen Sie Zero-Shot-Prompting mit den folgenden Begriffen: