Page Summary
-
Generative AI encompasses models that produce original content like text and images, using techniques like pre-training and fine-tuning to achieve this.
-
Prompt engineering is crucial for guiding LLMs, involving crafting effective prompts to elicit desired outputs, with methods like zero-shot, one-shot, and few-shot prompting.
-
Fine-tuning techniques, including distillation, instruction tuning, and parameter-efficient methods like LoRA, adapt pre-trained models for specific tasks while optimizing performance and resource usage.
-
LLMs utilize context windows to process information, employ contextualized language embeddings for nuanced understanding, and can be integrated into systems like RAG and model cascading for enhanced capabilities.
-
Prompt-based learning allows LLMs to adapt to tasks without extensive retraining, leveraging their knowledge base to respond to various instructions and inputs.
This page contains Generative AI glossary terms. For all glossary terms, click here.
A
adaptation
Synonym for tuning or fine-tuning.
agent
Software that can reason about user inputs in order to plan and execute actions on behalf of the user.
In reinforcement learning, an agent is the entity that uses a policy to maximize the expected return gained from transitioning between states of the environment.
agentic
The adjective form of agent. Agentic refers to the qualities that agents possess (such as autonomy).
agentic workflow
A dynamic process in which an agent autonomously plans and executes actions to achieve a goal. The process may involve reasoning, invoking external tools, and self-correcting its plan.
AI slop
Output from a generative AI system that favors quantity over quality. For example, a web page with AI slop is filled with cheaply produced, AI-generated, low-quality content.
automatic evaluation
Using software to judge the quality of a model's output.
When model output is relatively straightforward, a script or program can compare the model's output to a golden response. This type of automatic evaluation is sometimes called programmatic evaluation. Metrics such as ROUGE or BLEU are often useful for programmatic evaluation.
When model output is complex or has no one right answer, a separate ML program called an autorater sometimes performs the automatic evaluation.
Contrast with human evaluation.
autorater evaluation
A hybrid mechanism for judging the quality of a generative AI model's output that combines human evaluation with automatic evaluation. An autorater is an ML model trained on data created by human evaluation. Ideally, an autorater learns to mimic a human evaluator.Prebuilt autoraters are available, but the best autoraters are fine-tuned specifically to the task you are evaluating.
auto-regressive model
A model that infers a prediction based on its own previous predictions. For example, auto-regressive language models predict the next token based on the previously predicted tokens. All Transformer-based large language models are auto-regressive.
In contrast, GAN-based image models are usually not auto-regressive since they generate an image in a single forward-pass and not iteratively in steps. However, certain image generation models are auto-regressive because they generate an image in steps.
B
base model
A pre-trained model that can serve as the starting point for fine-tuning to address specific tasks or applications.
See also pre-trained model and foundation model.
C
chain-of-thought prompting
A prompt engineering technique that encourages a large language model (LLM) to explain its reasoning, step by step. For example, consider the following prompt, paying particular attention to the second sentence:
How many g forces would a driver experience in a car that goes from 0 to 60 miles per hour in 7 seconds? In the answer, show all relevant calculations.
The LLM's response would likely:
- Show a sequence of physics formulas, plugging in the values 0, 60, and 7 in appropriate places.
- Explain why it chose those formulas and what the various variables mean.
Chain-of-thought prompting forces the LLM to perform all the calculations, which might lead to a more correct answer. In addition, chain-of-thought prompting enables the user to examine the LLM's steps to determine whether or not the answer makes sense.
chat
The contents of a back-and-forth dialogue with an ML system, typically a large language model. The previous interaction in a chat (what you typed and how the large language model responded) becomes the context for subsequent parts of the chat.
A chatbot is an application of a large language model.
contextualized language embedding
An embedding that comes close to "understanding" words and phrases in ways that fluent human speakers can. Contextualized language embeddings can understand complex syntax, semantics, and context.
For example, consider embeddings of the English word cow. Older embeddings such as word2vec can represent English words such that the distance in the embedding space from cow to bull is similar to the distance from ewe (female sheep) to ram (male sheep) or from female to male. Contextualized language embeddings can go a step further by recognizing that English speakers sometimes casually use the word cow to mean either cow or bull.
context window
The number of tokens a model can process in a given prompt. The larger the context window, the more information the model can use to provide coherent and consistent responses to the prompt.
conversational coding
An iterative dialog between you and a generative AI model for the purpose of creating software. You issue a prompt describing some software. Then, the model uses that description to generate code. Then, you issue a new prompt to address the flaws in the previous prompt or in the generated code, and the model generates updated code. You two keep going back and forth until the generated software is good enough.
Conversation coding is essentially the original meaning of vibe coding.
Contrast with specificational coding.
D
direct prompting
Synonym for zero-shot prompting.
distillation
The process of reducing the size of one model (known as the teacher) into a smaller model (known as the student) that emulates the original model's predictions as faithfully as possible. Distillation is useful because the smaller model has two key benefits over the larger model (the teacher):
- Faster inference time
- Reduced memory and energy usage
However, the student's predictions are typically not as good as the teacher's predictions.
Distillation trains the student model to minimize a loss function based on the difference between the outputs of the predictions of the student and teacher models.
Compare and contrast distillation with the following terms:
See LLMs: Fine-tuning, distillation, and prompt engineering in Machine Learning Crash Course for more information.
E
evals
Primarily used as an abbreviation for LLM evaluations. More broadly, evals is an abbreviation for any form of evaluation.
evaluation
The process of measuring a model's quality or comparing different models against each other.
To evaluate a supervised machine learning model, you typically judge it against a validation set and a test set. Evaluating a LLM typically involves broader quality and safety assessments.
F
factuality
Within the ML world, a property describing a model whose output is based on reality. Factuality is a concept rather than a metric. For example, suppose you send the following prompt to a large language model:
What is the chemical formula for table salt?
A model optimizing factuality would respond:
NaCl
It is tempting to assume that all models should be based on factuality. However, some prompts, such as the following, should cause a generative AI model to optimize creativity rather than factuality.
Tell me a limerick about an astronaut and a caterpillar.
It is unlikely that the resulting limerick would be based on reality.
Contrast with groundedness.
fast decay
A training technique to improve the performance of LLMs. Fast decay involves rapidly decreasing the learning rate during training. This strategy helps prevent the model from overfitting to the training data, and improves generalization.
few-shot prompting
A prompt that contains more than one (a "few") example demonstrating how the large language model should respond. For example, the following lengthy prompt contains two examples showing a large language model how to answer a query.
| Parts of one prompt | Notes |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| France: EUR | One example. |
| United Kingdom: GBP | Another example. |
| India: | The actual query. |
Few-shot prompting generally produces more desirable results than zero-shot prompting and one-shot prompting. However, few-shot prompting requires a lengthier prompt.
Few-shot prompting is a form of few-shot learning applied to prompt-based learning.
See Prompt engineering in Machine Learning Crash Course for more information.
fine-tuning
A second, task-specific training pass performed on a pre-trained model to refine its parameters for a specific use case. For example, the full training sequence for some large language models is as follows:
- Pre-training: Train a large language model on a vast general dataset, such as all the English language Wikipedia pages.
- Fine-tuning: Train the pre-trained model to perform a specific task, such as responding to medical queries. Fine-tuning typically involves hundreds or thousands of examples focused on the specific task.
As another example, the full training sequence for a large image model is as follows:
- Pre-training: Train a large image model on a vast general image dataset, such as all the images in Wikimedia commons.
- Fine-tuning: Train the pre-trained model to perform a specific task, such as generating images of orcas.
Fine-tuning can entail any combination of the following strategies:
- Modifying all of the pre-trained model's existing parameters. This is sometimes called full fine-tuning.
- Modifying only some of the pre-trained model's existing parameters (typically, the layers closest to the output layer), while keeping other existing parameters unchanged (typically, the layers closest to the input layer). See parameter-efficient tuning.
- Adding more layers, typically on top of the existing layers closest to the output layer.
Fine-tuning is a form of transfer learning. As such, fine-tuning might use a different loss function or a different model type than those used to train the pre-trained model. For example, you could fine-tune a pre-trained large image model to produce a regression model that returns the number of birds in an input image.
Compare and contrast fine-tuning with the following terms:
See Fine-tuning in Machine Learning Crash Course for more information.
Flash model
A family of relatively small Gemini models optimized for speed and low latency. Flash models are designed for a wide range of applications where quick responses and high throughput are crucial.
foundation model
A very large pre-trained model trained on an enormous and diverse training set. A foundation model can do both of the following:
- Respond well to a wide range of requests.
- Serve as a base model for additional fine-tuning or other customization.
In other words, a foundation model is already very capable in a general sense but can be further customized to become even more useful for a specific task.
fraction of successes
A metric for evaluating an ML model's generated text. The fraction of successes is the number of "successful" generated text outputs divided by the total number of generated text outputs. For example, if a large language model generated 10 blocks of code, five of which were successful, then the fraction of successes would be 50%.
Although fraction of successes is broadly useful throughout statistics, within ML, this metric is primarily useful for measuring verifiable tasks like code generation or math problems.
G
Gemini
The ecosystem comprising Google's most advanced AI. Elements of this ecosystem include:
- Various Gemini models.
- The interactive conversational interface to a Gemini model. Users type prompts and Gemini responds to those prompts.
- Various Gemini APIs.
- Various business products based on Gemini models; for example, Gemini for Google Cloud.
Gemini models
Google's state-of-the-art Transformer-based multimodal models. Gemini models are specifically designed to integrate with agents.
Users can interact with Gemini models in a variety of ways, including through an interactive dialog interface and through SDKs.
Gemma
A family of lightweight open models built from the same research and technology used to create the Gemini models. Several different Gemma models are available, each providing different features, such as vision, code, and instruction following. See Gemma for details.
GenAI or genAI
Abbreviation for generative AI.
generated text
In general, the text that an ML model outputs. When evaluating large language models, some metrics compare generated text against reference text. For example, suppose you are trying to determine how effectively an ML model translates from French to Dutch. In this case:
- The generated text is the Dutch translation that the ML model outputs.
- The reference text is the Dutch translation that a human translator (or software) creates.
Note that some evaluation strategies don't involve reference text.
generative AI
An emerging transformative field with no formal definition. That said, most experts agree that generative AI models can create ("generate") content that is all of the following:
- complex
- coherent
- original
Examples of generative AI include:
- Large language models, which can generate sophisticated original text and answer questions.
- Image generation model, which can produce unique images.
- Audio and music generation models, which can compose original music or generate realistic speech.
- Video generation models, which can generate original videos.
Some earlier technologies, including LSTMs and RNNs, can also generate original and coherent content. Some experts view these earlier technologies as generative AI, while others feel that true generative AI requires more complex output than those earlier technologies can produce.
Contrast with predictive ML.
golden response
A response known to be good. For example, given the following prompt:
2 + 2
The golden response is hopefully:
4
GPT (Generative Pre-trained Transformer)
A family of Transformer-based large language models developed by OpenAI.
GPT variants can apply to multiple modalities, including:
- image generation (for example, ImageGPT)
- text-to-image generation (for example, DALL-E).
H
hallucination
The production of plausible-seeming but factually incorrect output by a generative AI model that purports to be making an assertion about the real world. For example, a generative AI model that claims that Barack Obama died in 1865 is hallucinating.
human evaluation
A process in which people judge the quality of an ML model's output; for example, having bilingual people judge the quality of an ML translation model. Human evaluation is particularly useful for judging models that have no one right answer.
Contrast with automatic evaluation and autorater evaluation.
human in the loop (HITL)
A loosely-defined idiom that could mean either of the following:
- A policy of viewing generative AI output critically or skeptically.
- A strategy or system for ensuring that people help shape, evaluate, and refine a model's behavior. Keeping a human in the loop enables an AI to benefit from both machine intelligence and human intelligence. For example, a system in which an AI generates code which software engineers then review is a human-in-the-loop system.
I
in-context learning
Synonym for few-shot prompting.
inference
In traditional machine learning, the process of making predictions by applying a trained model to unlabeled examples. See Supervised Learning in the Intro to ML course to learn more.
In large language models, inference is the process of using a trained model to generate a response to an input prompt.
Inference has a somewhat different meaning in statistics. See the Wikipedia article on statistical inference for details.
instruction tuning
A form of fine-tuning that improves a generative AI model's ability to follow instructions. Instruction tuning involves training a model on a series of instruction prompts, typically covering a wide variety of tasks. The resulting instruction-tuned model then tends to generate useful responses to zero-shot prompts across a variety of tasks.
Compare and contrast with:
L
large language model
At a minimum, a language model having a very high number of parameters. More informally, any Transformer-based language model, such as Gemini or GPT.
See Large language models (LLMs) in Machine Learning Crash Course for more information.
latency
The time it takes for a model to process input and generate a response. A high latency response takes takes longer to generate than a low latency response.
Factors that influence latency of large language models include:
- Input and output token lengths
- Model complexity
- The infrastructure the model runs on
Optimizing for latency is crucial for creating responsive and user-friendly applications.
LLM
Abbreviation for large language model.
LLM evaluations (evals)
A set of metrics and benchmarks for assessing the performance of large language models (LLMs). At a high level, LLM evaluations:
- Help researchers identify areas where LLMs need improvement.
- Are useful in comparing different LLMs and identifying the best LLM for a particular task.
- Help ensure that LLMs are safe and ethical to use.
See Large language models (LLMs) in Machine Learning Crash Course for more information.
LoRA
Abbreviation for Low-Rank Adaptability.
Low-Rank Adaptability (LoRA)
A parameter-efficient technique for fine tuning that "freezes" the model's pre-trained weights (such that they can no longer be modified) and then inserts a small set of trainable weights into the model. This set of trainable weights (also known as "update matrixes") is considerably smaller than the base model and is therefore much faster to train.
LoRA provides the following benefits:
- Improves the quality of a model's predictions for the domain where the fine tuning is applied.
- Fine-tunes faster than techniques that require fine-tuning all of a model's parameters.
- Reduces the computational cost of inference by enabling concurrent serving of multiple specialized models sharing the same base model.
M
machine translation
Using software (typically, a machine learning model) to convert text from one human language to another human language, for example, from English to Japanese.
mean average precision at k (mAP@k)
The statistical mean of all average precision at k scores across a validation dataset. One use of mean average precision at k is to judge the quality of recommendations generated by a recommendation system.
Although the phrase "mean average" sounds redundant, the name of the metric is appropriate. After all, this metric finds the mean of multiple average precision at k values.
mixture of experts
A scheme to increase neural network efficiency by using only a subset of its parameters (known as an expert) to process a given input token or example. A gating network routes each input token or example to the proper expert(s).
For details, see either of the following papers:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mixture-of-Experts with Expert Choice Routing
MMIT
Abbreviation for multimodal instruction-tuned.
model cascading
A system that picks the ideal model for a specific inference query.
Imagine a group of models, ranging from very large (lots of parameters) to much smaller (far fewer parameters). Very large models consume more computational resources at inference time than smaller models. However, very large models can typically infer more complex requests than smaller models. Model cascading determines the complexity of the inference query and then picks the appropriate model to perform the inference. The main motivation for model cascading is to reduce inference costs by generally selecting smaller models, and only selecting a larger model for more complex queries.
Imagine that a small model runs on a phone and a larger version of that model runs on a remote server. Good model cascading reduces cost and latency by enabling the smaller model to handle simple requests and only calling the remote model to handle complex requests.
See also model router.
model router
The algorithm that determines the ideal model for inference in model cascading. A model router is itself typically a machine learning model that gradually learns how to pick the best model for a given input. However, a model router could sometimes be a simpler, non-machine learning algorithm.
MOE
Abbreviation for mixture of experts.
MT
Abbreviation for machine translation.
N
Nano
A relatively small Gemini model designed for on-device use. See Gemini Nano for details.
no one right answer (NORA)
A prompt having multiple correct responses. For example, the following prompt has no one right answer:
Tell me a funny joke about elephants.
Evaluating the responses to no one right answer prompts is usually far more subjective than evaluating prompts with one right answer. For example, evaluating an elephant joke requires a systematic way to determine how funny the joke is.
NORA
Abbreviation for no one right answer.
Notebook LM
A Gemini-based tool that enables users to upload documents and then use prompts to ask questions about, summarize, or organize those documents. For example, an author could upload several short stories and ask Notebook LM to find their common themes or to identify which one would make the best movie.
O
one right answer (ORA)
A prompt having a single correct response. For example, consider the following prompt:
True or false: Saturn is bigger than Mars.
The only correct response is true.
Contrast with no one right answer.
one-shot prompting
A prompt that contains one example demonstrating how the large language model should respond. For example, the following prompt contains one example showing a large language model how it should answer a query.
| Parts of one prompt | Notes |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| France: EUR | One example. |
| India: | The actual query. |
Compare and contrast one-shot prompting with the following terms:
ORA
Abbreviation for one right answer.
P
parameter-efficient tuning
A set of techniques to fine-tune a large pre-trained language model (PLM) more efficiently than full fine-tuning. Parameter-efficient tuning typically fine-tunes far fewer parameters than full fine-tuning, yet generally produces a large language model that performs as well (or almost as well) as a large language model built from full fine-tuning.
Compare and contrast parameter-efficient tuning with:
Parameter-efficient tuning is also known as parameter-efficient fine-tuning.
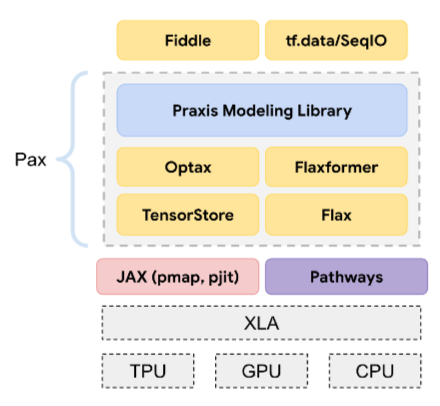
Pax
A programming framework designed for training large-scale neural network models so large that they span multiple TPU accelerator chip slices or pods.
Pax is built on Flax, which is built on JAX.
PLM
Abbreviation for pre-trained language model.
post-trained model
Loosely-defined term that typically refers to a pre-trained model that has gone through some post-processing, such as one or more of the following:
pre-trained model
Although this term could refer to any trained model or trained embedding vector, pre-trained model now typically refers to a trained large language model or other form of trained generative AI model.
See also base model and foundation model.
pre-training
The initial training of a model on a large dataset. Some pre-trained models are clumsy giants and must typically be refined through additional training. For example, ML experts might pre-train a large language model on a vast text dataset, such as all the English pages in Wikipedia. Following pre-training, the resulting model might be further refined through any of the following techniques:
Pro
A Gemini model with fewer parameters than Ultra but more parameters than Nano. See Gemini Pro for details.
prompt
Any text entered as input to a large language model to condition the model to behave in a certain way. Prompts can be as short as a phrase or arbitrarily long (for example, the entire text of a novel). Prompts fall into multiple categories, including those shown in the following table:
| Prompt category | Example | Notes |
|---|---|---|
| Question | How fast can a pigeon fly? | |
| Instruction | Write a funny poem about arbitrage. | A prompt that asks the large language model to do something. |
| Example | Translate Markdown code to HTML. For example:
Markdown: * list item HTML: <ul> <li>list item</li> </ul> |
The first sentence in this example prompt is an instruction. The remainder of the prompt is the example. |
| Role | Explain why gradient descent is used in machine learning training to a PhD in Physics. | The first part of the sentence is an instruction; the phrase "to a PhD in Physics" is the role portion. |
| Partial input for the model to complete | The Prime Minister of the United Kingdom lives at | A partial input prompt can either end abruptly (as this example does) or end with an underscore. |
A generative AI model can respond to a prompt with text, code, images, embeddings, videos…almost anything.
prompt-based learning
A capability of certain models that enables them to adapt their behavior in response to arbitrary text input (prompts). In a typical prompt-based learning paradigm, a large language model responds to a prompt by generating text. For example, suppose a user enters the following prompt:
Summarize Newton's Third Law of Motion.
A model capable of prompt-based learning isn't specifically trained to answer the previous prompt. Rather, the model "knows" a lot of facts about physics, a lot about general language rules, and a lot about what constitutes generally useful answers. That knowledge is sufficient to provide a (hopefully) useful answer. Additional human feedback ("That answer was too complicated." or "What's a reaction?") enables some prompt-based learning systems to gradually improve the usefulness of their answers.
prompt design
Synonym for prompt engineering.
prompt engineering
The art of creating prompts that elicit the desired responses from a large language model. Humans perform prompt engineering. Writing well-structured prompts is an essential part of ensuring useful responses from a large language model. Prompt engineering depends on many factors, including:
- The dataset used to pre-train and possibly fine-tune the large language model.
- The temperature and other decoding parameters that the model uses to generate responses.
Prompt design is a synonym for prompt engineering.
See Introduction to prompt design for more details on writing helpful prompts.
prompt set
A group of prompts for evaluating a large language model. For example, the following illustration shows a prompt set consisting of three prompts:
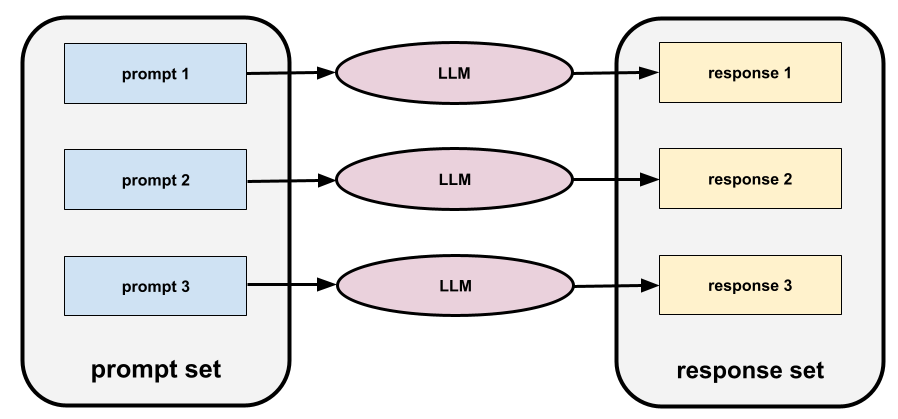
Good prompt sets consist of a sufficiently "wide" collection of prompts to thoroughly evaluate the safety and helpfulness of a large language model.
See also response set.
prompt tuning
A parameter efficient tuning mechanism that learns a "prefix" that the system prepends to the actual prompt.
One variation of prompt tuning—sometimes called prefix tuning—is to prepend the prefix at every layer. In contrast, most prompt tuning only adds a prefix to the input layer.
R
reference text
An expert's response to a prompt. For example, given the following prompt:
Translate the question "What is your name?" from English to French.
An expert's response might be:
Comment vous appelez-vous?
Various metrics (such as ROUGE) measure the degree to which the reference text matches an ML model's generated text.
reflection
A strategy for improving the quality of an agentic workflow by examining (reflecting on) a step's output before passing that output to the next step.
The examiner is often the same LLM that generated the response (though it could be a different LLM). How could the same LLM that generated a response be a fair judge of its own response? The "trick" is to put the LLM in a critical (reflective) mindset. This process is analogous to a writer who uses a creative mindset to write a first draft and then switches to a critical mindset to edit it.
For example, imagine an agentic workflow whose first step is to create text for coffee mugs. The prompt for this step might be:
You are a creative. Generate humorous, original text of less than 50 characters suitable for a coffee mug.
Now imagine the following reflective prompt:
You are a coffee drinker. Would you find the preceding response humorous?
The workflow might then only pass text that receives a high reflection score to the next stage.
Reinforcement Learning from Human Feedback (RLHF)
Using feedback from human raters to improve the quality of a model's responses. For example, an RLHF mechanism can ask users to rate the quality of a model's response with a 👍 or 👎 emoji. The system can then adjust its future responses based on that feedback.
response
The text, images, audio, or video that a generative AI model infers. In other words, a prompt is the input to a generative AI model and the response is the output.
response set
The collection of responses a large language model returns to an input prompt set.
role prompting
A prompt, typically beginning with the pronoun you, that tells a generative AI model to pretend to be a certain person or a certain role when generating the response. Role prompting can help a generative AI model get into the right "mindset" in order to generate a more useful response. For example, any of the following role prompts might be appropriate depending on the kind of response you are seeking:
You have a PhD in computer science.
You are a software engineer who enjoys giving patient explanations about Python to new programming students.
You are an action hero with a very particular set of programming skills. Assure me that you will find a particular item in a Python list.
S
soft prompt tuning
A technique for tuning a large language model for a particular task, without resource intensive fine-tuning. Instead of retraining all the weights in the model, soft prompt tuning automatically adjusts a prompt to achieve the same goal.
Given a textual prompt, soft prompt tuning typically appends additional token embeddings to the prompt and uses backpropagation to optimize the input.
A "hard" prompt contains actual tokens instead of token embeddings.
specificational coding
The process of writing and maintaining a file in a human language (for example, English) that describes software. You can then tell a generative AI model or another software engineer to create the software that fulfills that description.
Automatically-generated code generally requires iteration. In specificational coding, you iterate on the description file. By contrast, in conversational coding, you iterate within the prompt box. In practice, automatic code generation sometimes involves a combination of both specificational coding and conversational coding.
T
temperature
A hyperparameter that controls the degree of randomness of a model's output. Higher temperatures result in more random output, while lower temperatures result in less random output.
Choosing the best temperature depends on the specific application and or string values.
U
Ultra
The Gemini model with the most parameters. See Gemini Ultra for details.
V
Vertex
Google Cloud's platform for AI and machine learning. Vertex provides tools and infrastructure for building, deploying, and managing AI applications, including access to Gemini models.vibe coding
Prompting a generative AI model to create software. That is, your prompts describe the software's purpose and features, which a generative AI model translates into source code. The generated code doesn't always match your intentions, so vibe coding usually requires iteration.
Andrej Karpathy coined the term vibe coding in this X post. In the X post, Karpathy describes it as "a new kind of coding...where you fully give in to the vibes..." So, the term originally implied an intentionally loose approach to creating software in which you might not even examine the generated code. However, the term has rapidly evolved in many circles to now mean any form of AI-generated coding.
For a more detailed description of vibe coding, see What is vibe coding?.
In addition, compare and contrast vibe coding with:
Z
zero-shot prompting
A prompt that does not provide an example of how you want the large language model to respond. For example:
| Parts of one prompt | Notes |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| India: | The actual query. |
The large language model might respond with any of the following:
- Rupee
- INR
- ₹
- Indian rupee
- The rupee
- The Indian rupee
All of the answers are correct, though you might prefer a particular format.
Compare and contrast zero-shot prompting with the following terms: