इस पेज पर, जनरेटिव एआई की शब्दावली के बारे में जानकारी दी गई है. सभी शब्दावली के लिए, यहां क्लिक करें.
A
अडैप्टेशन
ट्यूनिंग या फ़ाइन ट्यूनिंग के लिए इस्तेमाल किया जाने वाला समानार्थी शब्द.
एजेंट
ऐसा सॉफ़्टवेयर जो उपयोगकर्ता के इनपुट को क्रम से लगा सकता है, ताकि उपयोगकर्ता की ओर से कार्रवाइयां प्लान और लागू की जा सकें.
रीइन्फ़ोर्समेंट लर्निंग में, एजेंट वह इकाई होती है जो नीति का इस्तेमाल करके, एनवायरमेंट की स्टेट के बीच ट्रांज़िशन से मिलने वाले अनुमानित रिटर्न को ज़्यादा से ज़्यादा करती है.
एजेंटिक
यह agent का विशेषण फ़ॉर्म है. एजेंटिक का मतलब उन क्वालिटी से है जो एजेंट के पास होती हैं. जैसे, स्वायत्तता.
एजेंटिक वर्कफ़्लो
यह एक डाइनैमिक प्रोसेस है. इसमें एजेंट, किसी लक्ष्य को हासिल करने के लिए अपने-आप प्लान बनाता है और कार्रवाइयाँ करता है. इस प्रोसेस में, वजह बताना, बाहरी टूल इस्तेमाल करना, और अपने प्लान को खुद ठीक करना शामिल हो सकता है.
एआई स्लोप
जनरेटिव एआई सिस्टम से मिला ऐसा जवाब जिसमें क्वालिटी के बजाय मात्रा पर ज़ोर दिया गया हो. उदाहरण के लिए, एआई स्लोप वाले वेब पेज पर, कम कीमत में तैयार किया गया, एआई से जनरेट किया गया, और खराब क्वालिटी वाला कॉन्टेंट मौजूद होता है.
अपने-आप होने वाला आकलन
सॉफ़्टवेयर का इस्तेमाल करके, मॉडल के आउटपुट की क्वालिटी का आकलन करना.
जब मॉडल का आउटपुट काफ़ी आसान हो, तब कोई स्क्रिप्ट या प्रोग्राम, मॉडल के आउटपुट की तुलना गोल्डन रिस्पॉन्स से कर सकता है. इस तरह के अपने-आप होने वाले आकलन को कभी-कभी प्रोग्रामैटिक आकलन कहा जाता है. प्रोग्राम के हिसाब से आकलन करने के लिए, ROUGE या BLEU जैसी मेट्रिक अक्सर काम की होती हैं.
जब मॉडल का आउटपुट जटिल होता है या उसमें कोई एक सही जवाब नहीं होता, तो कभी-कभी ऑटोरेटर नाम का एक अलग एमएल प्रोग्राम, अपने-आप मूल्यांकन करता है.
इसकी तुलना मैन्युअल तरीके से किए जाने वाले आकलन से करें.
ऑटोरेटर की परफ़ॉर्मेंस का आकलन
यह जनरेटिव एआई मॉडल के आउटपुट की क्वालिटी का आकलन करने का एक हाइब्रिड तरीका है. इसमें मैन्युअल तरीके से आकलन करने के साथ-साथ ऑटोमैटिक तरीके से आकलन भी किया जाता है. ऑटोरेटर, एमएल मॉडल होता है. इसे मैन्युअल तरीके से किए गए आकलन के आधार पर तैयार किए गए डेटा से ट्रेन किया जाता है. आदर्श रूप से, ऑटोमेटेड रेटिंग देने वाला सिस्टम, मैन्युअल तरीके से रेटिंग देने वाले व्यक्ति की तरह काम करता है.पहले से तैयार किए गए ऑटोरेटर्स उपलब्ध हैं. हालांकि, सबसे अच्छे ऑटोरेटर्स को खास तौर पर उस टास्क के लिए फ़ाइन-ट्यून किया जाता है जिसका आकलन किया जा रहा है.
ऑटो-रिग्रेसिव मॉडल
ऐसा मॉडल जो अपने पिछले अनुमानों के आधार पर अनुमान लगाता है. उदाहरण के लिए, ऑटो-रिग्रेसिव भाषा मॉडल, पहले से अनुमानित किए गए टोकन के आधार पर अगले टोकन का अनुमान लगाते हैं. ट्रांसफ़ॉर्मर पर आधारित सभी लार्ज लैंग्वेज मॉडल, ऑटो-रिग्रेसिव होते हैं.
इसके उलट, GAN पर आधारित इमेज मॉडल आम तौर पर ऑटो-रिग्रेसिव नहीं होते. ऐसा इसलिए, क्योंकि वे एक ही फ़ॉरवर्ड-पास में इमेज जनरेट करते हैं. वे चरणों में बार-बार इमेज जनरेट नहीं करते. हालांकि, इमेज जनरेट करने वाले कुछ मॉडल ऑटो-रिग्रेसिव होते हैं, क्योंकि वे इमेज को चरणों में जनरेट करते हैं.
B
बेस मॉडल
यह पहले से ट्रेन किया गया मॉडल है. इसका इस्तेमाल, फ़ाइन-ट्यूनिंग के लिए शुरुआती पॉइंट के तौर पर किया जा सकता है. इससे खास टास्क या ऐप्लिकेशन को पूरा किया जा सकता है.
पहले से ट्रेन किया गया मॉडल और फ़ाउंडेशन मॉडल भी देखें.
C
चेन-ऑफ़-थॉट प्रॉम्प्ट
यह प्रॉम्प्ट इंजीनियरिंग की एक ऐसी तकनीक है जो लार्ज लैंग्वेज मॉडल (एलएलएम) को, जवाब देने के पीछे की वजह को क्रम से बताने के लिए बढ़ावा देती है. उदाहरण के लिए, इस प्रॉम्प्ट को देखें. इसमें दूसरे वाक्य पर खास ध्यान दें:
अगर कोई कार 7 सेकंड में 0 से 60 मील प्रति घंटे की रफ़्तार पकड़ लेती है, तो ड्राइवर को कितने G फ़ोर्स का अनुभव होगा? जवाब में, सभी ज़रूरी कैलकुलेशन दिखाएं.
एलएलएम का जवाब ऐसा हो सकता है:
- फ़िज़िक्स के फ़ॉर्मूलों का क्रम दिखाओ. इसमें सही जगहों पर 0, 60, और 7 वैल्यू डालो.
- यह भी बताएं कि उन फ़ॉर्मूलों को क्यों चुना गया और अलग-अलग वैरिएबल का क्या मतलब है.
चेन-ऑफ़-थॉट प्रॉम्प्टिंग से, एलएलएम को सभी कैलकुलेशन करनी पड़ती हैं. इससे ज़्यादा सही जवाब मिल सकता है. इसके अलावा, चेन-ऑफ़-थॉट प्रॉम्प्टिंग की मदद से उपयोगकर्ता, एलएलएम के जवाब देने के तरीके की जांच कर सकता है. इससे यह पता चलता है कि जवाब सही है या नहीं.
चैट
किसी एमएल सिस्टम के साथ बातचीत का कॉन्टेंट. आम तौर पर, यह लार्ज लैंग्वेज मॉडल होता है. चैट में पिछली बातचीत (आपने क्या टाइप किया और लार्ज लैंग्वेज मॉडल ने कैसे जवाब दिया) को चैट के बाद के हिस्सों के लिए कॉन्टेक्स्ट माना जाता है.
चैटबॉट, लार्ज लैंग्वेज मॉडल का एक ऐप्लिकेशन है.
संदर्भ के हिसाब से भाषा को एंबेड करना
एम्बेडिंग, शब्दों और वाक्यांशों को "समझने" के लिए इस्तेमाल की जाती है. यह इंसानों की तरह ही काम करती है. कॉन्टेक्स्ट के हिसाब से तैयार किए गए भाषा मॉडल, मुश्किल सिंटैक्स, सिमैंटिक, और कॉन्टेक्स्ट को समझ सकते हैं.
उदाहरण के लिए, अंग्रेज़ी शब्द cow के एम्बेडिंग पर विचार करें. word2vec जैसे पुराने एम्बेडिंग, अंग्रेज़ी शब्दों को इस तरह से दिखा सकते हैं कि एम्बेडिंग स्पेस में गाय से बैल की दूरी, भेड़ी (मादा भेड़) से भेड़ा (नर भेड़) या महिला से पुरुष की दूरी के बराबर हो. कॉन्टेक्स्ट के हिसाब से भाषा के एम्बेडिंग, एक कदम आगे बढ़कर यह पहचान सकते हैं कि अंग्रेज़ी बोलने वाले लोग कभी-कभी cow शब्द का इस्तेमाल, गाय या बैल के लिए करते हैं.
कॉन्टेक्स्ट विंडो
किसी मॉडल के लिए, दिए गए प्रॉम्प्ट में प्रोसेस किए जा सकने वाले टोकन की संख्या. कॉन्टेक्स्ट विंडो जितनी बड़ी होगी, मॉडल उतनी ही ज़्यादा जानकारी का इस्तेमाल करके, प्रॉम्प्ट के लिए सटीक और एक जैसे जवाब दे पाएगा.
बातचीत करके कोडिंग करना
सॉफ़्टवेयर बनाने के मकसद से, जनरेटिव एआई मॉडल और आपके बीच होने वाली बातचीत. आपने किसी सॉफ़्टवेयर के बारे में जानकारी देने वाला कोई प्रॉम्प्ट दिया हो. इसके बाद, मॉडल उस ब्यौरे का इस्तेमाल करके कोड जनरेट करता है. इसके बाद, पिछले प्रॉम्प्ट या जनरेट किए गए कोड में मौजूद कमियों को ठीक करने के लिए, एक नया प्रॉम्प्ट दिया जाता है. इसके बाद, मॉडल अपडेट किया गया कोड जनरेट करता है. जब तक जनरेट किया गया सॉफ़्टवेयर आपकी उम्मीद के मुताबिक न हो जाए, तब तक दोनों के बीच बातचीत जारी रहती है.
बातचीत कोडिंग का मतलब, वाइब कोडिंग का मूल मतलब है.
स्पेसिफ़िकेशनल कोडिंग से अलग.
D
सीधे तौर पर प्रॉम्प्ट देना
ज़ीरो-शॉट प्रॉम्प्ट के लिए समानार्थी शब्द.
डिस्टिलेशन
यह एक मॉडल (जिसे टीचर कहा जाता है) के साइज़ को कम करके, एक छोटा मॉडल (जिसे छात्र कहा जाता है) बनाने की प्रोसेस है. यह छोटा मॉडल, ओरिजनल मॉडल के अनुमानों को ज़्यादा से ज़्यादा सटीक तरीके से दोहराता है. डिस्टिलेशन का इस्तेमाल करना फ़ायदेमंद होता है, क्योंकि छोटे मॉडल के दो मुख्य फ़ायदे होते हैं. ये फ़ायदे, बड़े मॉडल (टीचर) के मुकाबले ज़्यादा होते हैं:
- जवाब देने में कम समय लगता है
- मेमोरी और बैटरी की खपत कम होती है
हालांकि, छात्र या छात्रा के अनुमान आम तौर पर शिक्षक के अनुमानों जितने सटीक नहीं होते.
डिस्टिलेशन, छात्र मॉडल को इस तरह से ट्रेन करता है कि वह लॉस फ़ंक्शन को कम कर सके. यह छात्र और शिक्षक मॉडल की अनुमानित वैल्यू के बीच के अंतर पर आधारित होता है.
आसवन की तुलना इन शब्दों से करें:
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में एलएलएम: फ़ाइन-ट्यूनिंग, डिस्टिलेशन, और प्रॉम्प्ट इंजीनियरिंग देखें.
E
आकलन
इसका इस्तेमाल मुख्य रूप से, एलएलएम के आकलन के लिए किया जाता है. मोटे तौर पर, इवैल, इवैलुएशन का संक्षिप्त रूप है.
आकलन
किसी मॉडल की क्वालिटी को मेज़र करने या अलग-अलग मॉडल की तुलना करने की प्रोसेस.
सुपरवाइज़्ड मशीन लर्निंग मॉडल का आकलन करने के लिए, आम तौर पर इसकी तुलना मान्य डेटा सेट और टेस्ट डेटा सेट से की जाती है. किसी एलएलएम का आकलन करने में आम तौर पर, क्वालिटी और सुरक्षा से जुड़े बड़े पैमाने पर आकलन शामिल होते हैं.
F
तथ्यों का सही होना
मशीन लर्निंग की दुनिया में, यह एक ऐसी प्रॉपर्टी है जो किसी ऐसे मॉडल के बारे में बताती है जिसका आउटपुट, असलियत पर आधारित होता है. तथ्यों के सही होने का सिद्धांत, मेट्रिक के बजाय एक कॉन्सेप्ट है. उदाहरण के लिए, मान लें कि आपने लार्ज लैंग्वेज मॉडल को यह प्रॉम्प्ट भेजा है:
खाने के नमक का केमिकल फ़ॉर्मूला क्या है?
तथ्यों को सही रखने के लिए ऑप्टिमाइज़ किया गया मॉडल, इस तरह जवाब देगा:
NaCl
यह मान लेना आसान है कि सभी मॉडल तथ्यों पर आधारित होने चाहिए. हालांकि, कुछ प्रॉम्प्ट ऐसे होने चाहिए जिनसे जनरेटिव एआई मॉडल, तथ्यों के बजाय क्रिएटिविटी को बेहतर बना सके. जैसे, यहां दिए गए प्रॉम्प्ट.
मुझे एक अंतरिक्ष यात्री और एक कैटरपिलर के बारे में लिमरिक सुनाओ.
इस बात की संभावना कम है कि जवाब में मिली कविता, असल जानकारी पर आधारित हो.
भरोसेमंद स्रोतों से जानकारी लेने के सिद्धांत के साथ कंट्रास्ट.
तेज़ी से कम होना
एलएलएम की परफ़ॉर्मेंस को बेहतर बनाने के लिए, ट्रेनिंग की एक तकनीक. फ़ास्ट डिके में, ट्रेनिंग के दौरान लर्निंग रेट को तेज़ी से कम किया जाता है. इस रणनीति से मॉडल को ट्रेनिंग डेटा के हिसाब से ओवरफ़िट होने से रोकने में मदद मिलती है. साथ ही, सामान्यीकरण को बेहतर बनाया जा सकता है.
उदाहरण के साथ डाले गए प्रॉम्प्ट
एक ऐसा प्रॉम्प्ट जिसमें एक से ज़्यादा ("कुछ") उदाहरण शामिल हों. इनसे यह पता चलता है कि लार्ज लैंग्वेज मॉडल को कैसे जवाब देना चाहिए. उदाहरण के लिए, यहां दिए गए लंबे प्रॉम्प्ट में दो उदाहरण दिए गए हैं. इनमें बताया गया है कि लार्ज लैंग्वेज मॉडल को किसी क्वेरी का जवाब कैसे देना चाहिए.
| एक प्रॉम्ट के हिस्से | नोट |
|---|---|
| चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब आपको एलएलएम से चाहिए. |
| फ़्रांस: EUR | एक उदाहरण. |
| यूनाइटेड किंगडम: पाउंड स्टर्लिंग | एक और उदाहरण. |
| भारत: | असल क्वेरी. |
फ़्यू-शॉट प्रॉम्प्ट (उदाहरण के साथ डाले गए प्रॉम्प्ट) से आम तौर पर, ज़ीरो-शॉट प्रॉम्प्ट और वन-शॉट प्रॉम्प्ट की तुलना में ज़्यादा बेहतर नतीजे मिलते हैं. हालांकि, फ़्यू-शॉट प्रॉम्प्ट (उदाहरण के साथ डाले गए प्रॉम्प्ट) के लिए, लंबा प्रॉम्प्ट डालना ज़रूरी होता है.
उदाहरण के साथ डाले गए प्रॉम्प्ट, उदाहरण के साथ सीखने का एक तरीका है. इसका इस्तेमाल प्रॉम्प्ट के आधार पर सीखने के लिए किया जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में प्रॉम्प्ट इंजीनियरिंग देखें.
फ़ाइन-ट्यूनिंग
यह किसी टास्क के हिसाब से की जाने वाली दूसरी ट्रेनिंग है. इसे पहले से ट्रेन किए गए मॉडल पर किया जाता है, ताकि किसी खास इस्तेमाल के उदाहरण के लिए इसके पैरामीटर को बेहतर बनाया जा सके. उदाहरण के लिए, कुछ लार्ज लैंग्वेज मॉडल के लिए ट्रेनिंग का पूरा क्रम इस तरह है:
- प्री-ट्रेनिंग: किसी लार्ज लैंग्वेज मॉडल को सामान्य डेटासेट के बड़े हिस्से पर ट्रेन करें. जैसे, अंग्रेज़ी भाषा के सभी Wikipedia पेज.
- फ़ाइन-ट्यूनिंग: पहले से ट्रेन किए गए मॉडल को किसी खास टास्क को पूरा करने के लिए ट्रेन करें. जैसे, चिकित्सा से जुड़ी क्वेरी के जवाब देना. फ़ाइन-ट्यूनिंग में आम तौर पर, किसी खास टास्क पर फ़ोकस करने वाले सैकड़ों या हज़ारों उदाहरण शामिल होते हैं.
एक अन्य उदाहरण के तौर पर, किसी बड़े इमेज मॉडल के लिए ट्रेनिंग का पूरा क्रम इस तरह है:
- प्री-ट्रेनिंग: किसी बड़े इमेज मॉडल को सामान्य इमेज के बड़े डेटासेट पर ट्रेन करें. जैसे, Wikimedia Commons में मौजूद सभी इमेज.
- फ़ाइन-ट्यूनिंग: पहले से ट्रेन किए गए मॉडल को किसी खास टास्क को पूरा करने के लिए ट्रेन करें. जैसे, किलर व्हेल की इमेज जनरेट करना.
फ़ाइन-ट्यूनिंग में, यहां दी गई रणनीतियों का कोई भी कॉम्बिनेशन शामिल हो सकता है:
- पहले से ट्रेन किए गए मॉडल के सभी मौजूदा पैरामीटर में बदलाव करना. इसे कभी-कभी फ़ुल फ़ाइन-ट्यूनिंग भी कहा जाता है.
- प्री-ट्रेन किए गए मॉडल के मौजूदा पैरामीटर में से सिर्फ़ कुछ में बदलाव करना. आम तौर पर, आउटपुट लेयर के सबसे नज़दीक वाली लेयर में बदलाव किया जाता है. वहीं, अन्य मौजूदा पैरामीटर में कोई बदलाव नहीं किया जाता. आम तौर पर, इनपुट लेयर के सबसे नज़दीक वाली लेयर में बदलाव नहीं किया जाता. पैरामीटर-इफ़िशिएंट ट्यूनिंग देखें.
- ज़्यादा लेयर जोड़ना. आम तौर पर, ये लेयर मौजूदा लेयर के ऊपर जोड़ी जाती हैं. ये लेयर, आउटपुट लेयर के सबसे करीब होती हैं.
फ़ाइन-ट्यूनिंग, ट्रांसफ़र लर्निंग का एक तरीका है. इसलिए, फ़ाइन-ट्यूनिंग में, प्री-ट्रेन किए गए मॉडल को ट्रेन करने के लिए इस्तेमाल किए गए लॉस फ़ंक्शन या मॉडल टाइप से अलग लॉस फ़ंक्शन या मॉडल टाइप का इस्तेमाल किया जा सकता है. उदाहरण के लिए, पहले से ट्रेन किए गए बड़े इमेज मॉडल को फ़ाइन-ट्यून करके, रिग्रेशन मॉडल बनाया जा सकता है. यह मॉडल, इनपुट इमेज में मौजूद पक्षियों की संख्या दिखाता है.
फ़ाइन-ट्यूनिंग की तुलना इन शब्दों से करें और इनके बीच अंतर बताएं:
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में फ़ाइन-ट्यूनिंग देखें.
फ़्लैश मॉडल
Gemini मॉडल का एक ग्रुप, जो अपेक्षाकृत छोटे होते हैं. इन्हें तेज़ गति और कम लेटेंसी के लिए ऑप्टिमाइज़ किया गया है. Flash मॉडल को कई तरह के ऐप्लिकेशन के लिए डिज़ाइन किया गया है. इनमें तेज़ी से जवाब देना और ज़्यादा थ्रूपुट ज़रूरी होता है.
फ़ाउंडेशन मॉडल
यह एक बहुत बड़ा पहले से ट्रेन किया गया मॉडल है. इसे अलग-अलग तरह के ट्रेनिंग सेट पर ट्रेन किया गया है. फ़ाउंडेशन मॉडल, यहां दिए गए दोनों काम कर सकता है:
- अलग-अलग तरह के अनुरोधों का सही जवाब दे सकता है.
- यह अन्य फ़ाइन-ट्यूनिंग या पसंद के मुताबिक बनाने के लिए, बेस मॉडल के तौर पर काम करता है.
दूसरे शब्दों में कहें, तो फ़ाउंडेशन मॉडल सामान्य तौर पर पहले से ही बहुत बेहतर होता है. हालांकि, इसे किसी खास काम के लिए और भी ज़्यादा बेहतर बनाया जा सकता है.
सफलताओं का फ़्रैक्शन
यह एमएल मॉडल के जनरेट किए गए टेक्स्ट का आकलन करने के लिए इस्तेमाल की जाने वाली मेट्रिक है. सफलता की दर, जनरेट किए गए "सफल" टेक्स्ट आउटपुट की संख्या को जनरेट किए गए टेक्स्ट आउटपुट की कुल संख्या से भाग देने पर मिलती है. उदाहरण के लिए, अगर किसी लार्ज लैंग्वेज मॉडल ने कोड के 10 ब्लॉक जनरेट किए हैं और उनमें से पांच ब्लॉक सही हैं, तो सही ब्लॉक का फ़्रैक्शन 50% होगा.
हालांकि, आंकड़ों में फ़्रैक्शन ऑफ़ सक्सेस काफ़ी काम आता है, लेकिन एमएल में यह मेट्रिक मुख्य रूप से ऐसे कामों का आकलन करने के लिए काम आती है जिनकी पुष्टि की जा सकती है. जैसे, कोड जनरेट करना या गणित की समस्याएं हल करना.
G
Gemini
यह Google के सबसे ऐडवांस एआई से बना है. इस इकोसिस्टम में ये शामिल हैं:
- अलग-अलग Gemini मॉडल.
- Gemini मॉडल के साथ इंटरैक्टिव बातचीत करने के लिए इंटरफ़ेस. उपयोगकर्ता प्रॉम्प्ट टाइप करते हैं और Gemini उन प्रॉम्प्ट के जवाब देता है.
- Gemini के अलग-अलग एपीआई.
- Gemini मॉडल पर आधारित कारोबार से जुड़े अलग-अलग प्रॉडक्ट. उदाहरण के लिए, Gemini for Google Cloud.
Gemini के मॉडल
Google के नए और बेहतरीन ट्रांसफ़ॉर्मर पर आधारित मल्टीमॉडल. Gemini मॉडल को खास तौर पर एजेंट के साथ इंटिग्रेट करने के लिए डिज़ाइन किया गया है.
उपयोगकर्ता, Gemini मॉडल के साथ कई तरह से इंटरैक्ट कर सकते हैं. जैसे, इंटरैक्टिव डायलॉग इंटरफ़ेस और एसडीके के ज़रिए.
जेमा
यह एक लाइटवेट ओपन मॉडल है. इसे Gemini मॉडल में इस्तेमाल की गई रिसर्च और टेक्नोलॉजी का इस्तेमाल करके बनाया गया है. Gemma के कई अलग-अलग मॉडल उपलब्ध हैं. हर मॉडल में अलग-अलग सुविधाएं मिलती हैं. जैसे, विज़न, कोड, और निर्देशों का पालन करना. ज़्यादा जानकारी के लिए, Gemma देखें.
GenAI या genAI
जनरेटिव एआई का संक्षिप्त नाम.
जनरेट किया गया टेक्स्ट
आम तौर पर, एमएल मॉडल से मिलने वाला टेक्स्ट. लार्ज लैंग्वेज मॉडल का आकलन करते समय, कुछ मेट्रिक जनरेट किए गए टेक्स्ट की तुलना रेफ़रंस टेक्स्ट से करती हैं. उदाहरण के लिए, मान लें कि आपको यह पता लगाना है कि कोई एमएल मॉडल, फ़्रेंच से डच में कितनी अच्छी तरह से अनुवाद करता है. इस मामले में:
- जनरेट किया गया टेक्स्ट, डच भाषा में किया गया अनुवाद है. यह अनुवाद, एमएल मॉडल से मिला है.
- रेफ़रंस टेक्स्ट, डच भाषा में किया गया वह अनुवाद होता है जिसे कोई व्यक्ति या सॉफ़्टवेयर करता है.
ध्यान दें कि कुछ आकलन रणनीतियों में रेफ़रंस टेक्स्ट शामिल नहीं होता है.
जनरेटिव एआई
यह एक ऐसा क्षेत्र है जिसमें बदलाव हो रहा है और इसकी कोई औपचारिक परिभाषा नहीं है. हालांकि, ज़्यादातर विशेषज्ञ इस बात से सहमत हैं कि जनरेटिव एआई मॉडल, ऐसा कॉन्टेंट बना सकते हैं ("जनरेट" कर सकते हैं) जो इन सभी शर्तों को पूरा करता हो:
- जटिल
- समझ में आने वाला
- मूल
जनरेटिव एआई के उदाहरणों में ये शामिल हैं:
- लार्ज लैंग्वेज मॉडल, जो ओरिजनल टेक्स्ट जनरेट कर सकते हैं और सवालों के जवाब दे सकते हैं.
- इमेज जनरेट करने वाला मॉडल, जो यूनीक इमेज जनरेट कर सकता है.
- ऑडियो और संगीत जनरेट करने वाले मॉडल. ये ओरिजनल संगीत कंपोज़ कर सकते हैं या असल जैसी लगने वाली आवाज़ जनरेट कर सकते हैं.
- वीडियो जनरेट करने वाले मॉडल, जो ओरिजनल वीडियो जनरेट कर सकते हैं.
एलएसटीएम और आरएनएन जैसी कुछ पुरानी टेक्नोलॉजी भी ओरिजनल और सुसंगत कॉन्टेंट जनरेट कर सकती हैं. कुछ विशेषज्ञ, इन पुरानी टेक्नोलॉजी को जनरेटिव एआई मानते हैं. वहीं, कुछ का मानना है कि जनरेटिव एआई को इन पुरानी टेक्नोलॉजी के मुकाबले ज़्यादा जटिल आउटपुट की ज़रूरत होती है.
अनुमान लगाने वाले एमएल से तुलना करें.
गोल्डन रिस्पॉन्स
ऐसा जवाब जो अच्छा माना जाता है. उदाहरण के लिए, यहां दिए गए प्रॉम्प्ट के लिए:
2 + 2
उम्मीद है कि सबसे अच्छा जवाब यह होगा:
4
GPT (जनरेटिव प्री-ट्रेन्ड ट्रांसफ़ॉर्मर)
यह OpenAI ने बनाया है. यह ट्रांसफ़ॉर्मर पर आधारित लार्ज लैंग्वेज मॉडल का एक ग्रुप है.
GPT के वैरिएंट, कई मोडेलिटी पर लागू हो सकते हैं. जैसे:
- इमेज जनरेट करने की प्रोसेस (उदाहरण के लिए, ImageGPT)
- टेक्स्ट से इमेज जनरेट करने की सुविधा (उदाहरण के लिए, DALL-E).
H
गलत जानकारी
जनरेटिव एआई मॉडल से ऐसा आउटपुट जनरेट होना जो देखने में सही लगे, लेकिन असल में गलत हो. साथ ही, यह दावा करना कि यह आउटपुट असल दुनिया के बारे में जानकारी दे रहा है. उदाहरण के लिए, अगर कोई जनरेटिव एआई मॉडल यह दावा करता है कि बराक ओबामा की मौत 1865 में हुई थी, तो यह भ्रम पैदा कर रहा है.
लोगों के सुझाव, शिकायत या राय
यह एक ऐसी प्रोसेस है जिसमें लोग, मशीन लर्निंग मॉडल के आउटपुट की क्वालिटी का आकलन करते हैं. उदाहरण के लिए, दो भाषाओं का ज्ञान रखने वाले लोगों से, मशीन लर्निंग ट्रांसलेशन मॉडल की क्वालिटी का आकलन कराना. मैन्युअल तरीके से आकलन करना, उन मॉडल का आकलन करने के लिए खास तौर पर फ़ायदेमंद होता है जिनके एक से ज़्यादा सही जवाब होते हैं.
इसकी तुलना अपने-आप होने वाले आकलन और ऑटोरेटर के आकलन से करें.
मैन्युअल प्रक्रिया वाला चरण (एचआईटीएल)
यह एक मुहावरा है, जिसका मतलब इनमें से कोई भी हो सकता है:
- जनरेटिव एआई के आउटपुट को गंभीरता से या संदेह की नज़र से देखने की नीति.
- यह एक रणनीति या सिस्टम है. इससे यह पक्का किया जाता है कि लोग, मॉडल के व्यवहार को बेहतर बनाने, उसका आकलन करने, और उसे बेहतर बनाने में मदद करें. मानवीय समीक्षा की मदद से, एआई को मशीन इंटेलिजेंस और मानवीय इंटेलिजेंस, दोनों से फ़ायदा मिलता है. उदाहरण के लिए, एक ऐसा सिस्टम जिसमें एआई कोड जनरेट करता है और सॉफ़्टवेयर इंजीनियर उसकी समीक्षा करते हैं, वह ह्यूमन-इन-द-लूप सिस्टम है.
I
कॉन्टेक्स्ट के हिसाब से सीखने की सुविधा
उदाहरण के साथ डाले गए प्रॉम्प्ट के लिए समानार्थी शब्द.
अनुमान
ट्रेडिशनल मशीन लर्निंग में, बिना लेबल वाले उदाहरणों पर ट्रेन किए गए मॉडल को लागू करके अनुमान लगाने की प्रोसेस. ज़्यादा जानने के लिए, एमएल के बारे में जानकारी देने वाले कोर्स में सुपरवाइज़्ड लर्निंग देखें.
लार्ज लैंग्वेज मॉडल में, अनुमान लगाने की प्रोसेस का इस्तेमाल किया जाता है. इस प्रोसेस में, ट्रेनिंग पा चुके मॉडल का इस्तेमाल करके, प्रॉम्प्ट के जवाब के तौर पर जवाब जनरेट किया जाता है.
आंकड़ों में अनुमान का मतलब कुछ अलग होता है. ज़्यादा जानकारी के लिए, सांख्यिकीय अनुमान के बारे में Wikipedia लेख देखें.
निर्देशों के मुताबिक मॉडल को फ़ाइन-ट्यून करना
यह फ़ाइन-ट्यूनिंग का एक तरीका है. इससे जनरेटिव एआई मॉडल को निर्देशों का पालन करने में मदद मिलती है. निर्देशों के हिसाब से मॉडल को ट्रेन करने के लिए, उसे निर्देशों वाले कई प्रॉम्प्ट दिए जाते हैं. आम तौर पर, इनमें अलग-अलग तरह के टास्क शामिल होते हैं. इसके बाद, निर्देशों के मुताबिक काम करने वाला मॉडल, अलग-अलग टास्क के लिए ज़ीरो-शॉट प्रॉम्प्ट के जवाब जनरेट करता है.
इनके साथ तुलना करें:
L
लार्ज लैंग्वेज मॉडल
कम से कम, एक लैंग्वेज मॉडल, जिसमें बहुत ज़्यादा संख्या में पैरामीटर हों. आसान शब्दों में कहें, तो Transformer पर आधारित कोई भी भाषा मॉडल, जैसे कि Gemini या GPT.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लार्ज लैंग्वेज मॉडल (एलएलएम) देखें.
प्रतीक्षा अवधि
किसी मॉडल को इनपुट प्रोसेस करने और जवाब जनरेट करने में लगने वाला समय. ज़्यादा समय में मिलने वाले जवाब को जनरेट होने में, कम समय में मिलने वाले जवाब की तुलना में ज़्यादा समय लगता है.
लार्ज लैंग्वेज मॉडल की लेटेन्सी पर इन बातों का असर पड़ता है:
- इनपुट और आउटपुट टोकन की लंबाई
- मॉडल की जटिलता
- वह इन्फ़्रास्ट्रक्चर जिस पर मॉडल काम करता है
कम समय में जवाब देने वाले और लोगों के लिए इस्तेमाल में आसान ऐप्लिकेशन बनाने के लिए, लेटेन्सी को ऑप्टिमाइज़ करना ज़रूरी है.
LLM
लार्ज लैंग्वेज मॉडल का संक्षिप्त नाम.
एलएलएम के आकलन (इवैल)
यह लार्ज लैंग्वेज मॉडल (एलएलएम) की परफ़ॉर्मेंस का आकलन करने के लिए, मेट्रिक और बेंचमार्क का एक सेट है. एलएलएम के आकलन के लिए, ये काम किए जाते हैं:
- शोधकर्ताओं को उन क्षेत्रों की पहचान करने में मदद करना जहां एलएलएम को बेहतर बनाने की ज़रूरत है.
- इनसे अलग-अलग एलएलएम की तुलना करने और किसी टास्क के लिए सबसे सही एलएलएम की पहचान करने में मदद मिलती है.
- यह पक्का करने में मदद करना कि एलएलएम का इस्तेमाल सुरक्षित और ज़िम्मेदारी से किया जा रहा है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में लार्ज लैंग्वेज मॉडल (एलएलएम) देखें.
LoRA
लो-रैंक अडैप्टेबिलिटी का संक्षिप्त नाम.
लो-रैंक अडैप्टेबिलिटी (LoRA)
यह पैरामीटर-इफ़िशिएंट तकनीक है. इसका इस्तेमाल फ़ाइन ट्यूनिंग के लिए किया जाता है. यह मॉडल के पहले से ट्रेन किए गए वेट को "फ़्रीज़" कर देती है, ताकि उन्हें बदला न जा सके. इसके बाद, यह मॉडल में ट्रेनिंग दिए जा सकने वाले वेट का एक छोटा सेट डालती है. ट्रेन किए जा सकने वाले वज़न का यह सेट (इसे "अपडेट मैट्रिक्स" भी कहा जाता है) बेस मॉडल से काफ़ी छोटा होता है. इसलिए, इसे ट्रेन करने में कम समय लगता है.
LoRA से ये फ़ायदे मिलते हैं:
- इससे उस डोमेन के लिए मॉडल के अनुमानों की क्वालिटी बेहतर होती है जहां फ़ाइन ट्यूनिंग लागू की जाती है.
- यह उन तकनीकों की तुलना में ज़्यादा तेज़ी से फ़ाइन-ट्यून होता है जिनके लिए मॉडल के सभी पैरामीटर को फ़ाइन-ट्यून करने की ज़रूरत होती है.
- यह अनुमान की कंप्यूटेशनल लागत को कम करता है. ऐसा इसलिए होता है, क्योंकि यह एक ही बेस मॉडल को शेयर करने वाले कई खास मॉडल को एक साथ सेवा देने की सुविधा चालू करता है.
M
मशीन से अनुवाद
किसी सॉफ़्टवेयर (आम तौर पर, मशीन लर्निंग मॉडल) का इस्तेमाल करके, टेक्स्ट को एक भाषा से दूसरी भाषा में बदलना. उदाहरण के लिए, अंग्रेज़ी से जापानी में बदलना.
k पर औसत सटीक नतीजे (mAP@k)
यह पुष्टि करने वाले डेटासेट में, सभी k पर औसत सटीक स्कोर का सांख्यिकीय माध्य होता है. के पर औसत सटीक दर का इस्तेमाल, सुझाव देने वाले सिस्टम से जनरेट किए गए सुझावों की क्वालिटी का आकलन करने के लिए किया जाता है.
भले ही, "औसत" शब्द का इस्तेमाल दो बार किया गया है, लेकिन मेट्रिक का नाम सही है. आखिरकार, यह मेट्रिक कई k पर औसत सटीक दर वैल्यू का औसत निकालती है.
एक्सपर्ट का मिक्सचर
यह एक ऐसी स्कीम है जिससे न्यूरल नेटवर्क की परफ़ॉर्मेंस को बेहतर बनाया जाता है. इसके लिए, किसी दिए गए इनपुट टोकन या उदाहरण को प्रोसेस करने के लिए, इसके सिर्फ़ कुछ पैरामीटर (जिन्हें एक्सपर्ट कहा जाता है) का इस्तेमाल किया जाता है. गेटेड नेटवर्क, हर इनपुट टोकन या उदाहरण को सही विशेषज्ञ के पास भेजता है.
ज़्यादा जानकारी के लिए, इनमें से कोई एक पेपर देखें:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- एक्सपर्ट चॉइस राउटिंग के साथ मिक्सचर-ऑफ़-एक्सपर्ट
एमएमआईटी
मल्टीमॉडल इंस्ट्रक्शन-ट्यूनिंग का छोटा नाम.
मॉडल कैस्केडिंग
यह एक ऐसा सिस्टम है जो किसी खास अनुमान लगाने वाली क्वेरी के लिए, सबसे सही मॉडल चुनता है.
मान लें कि आपके पास अलग-अलग साइज़ के मॉडल का एक ग्रुप है. इसमें बहुत बड़े मॉडल (जिनमें बहुत सारे पैरामीटर होते हैं) से लेकर बहुत छोटे मॉडल (जिनमें बहुत कम पैरामीटर होते हैं) शामिल हैं. बहुत बड़े मॉडल, छोटे मॉडल की तुलना में अनुमान लगाने के समय ज़्यादा कंप्यूटेशनल संसाधनों का इस्तेमाल करते हैं. हालांकि, बड़े मॉडल, छोटे मॉडल की तुलना में ज़्यादा मुश्किल अनुरोधों को समझ सकते हैं. मॉडल कैस्केडिंग से, अनुमान लगाने के लिए की गई क्वेरी की जटिलता का पता चलता है. इसके बाद, अनुमान लगाने के लिए सही मॉडल चुना जाता है. मॉडल कैस्केडिंग का मुख्य मकसद, अनुमान लगाने की लागत को कम करना है. इसके लिए, आम तौर पर छोटे मॉडल चुने जाते हैं. साथ ही, ज़्यादा मुश्किल क्वेरी के लिए ही बड़े मॉडल चुने जाते हैं.
मान लें कि एक छोटा मॉडल किसी फ़ोन पर काम करता है और उस मॉडल का बड़ा वर्शन किसी रिमोट सर्वर पर काम करता है. मॉडल कैस्केडिंग की मदद से, लागत और लेटेंसी को कम किया जा सकता है. ऐसा इसलिए, क्योंकि छोटे मॉडल को आसान अनुरोधों को हैंडल करने की अनुमति दी जाती है. साथ ही, मुश्किल अनुरोधों को हैंडल करने के लिए सिर्फ़ रिमोट मॉडल को कॉल किया जाता है.
मॉडल राउटर भी देखें.
मॉडल राऊटर
यह एल्गोरिदम, मॉडल कैस्केडिंग में अनुमान के लिए सबसे सही मॉडल तय करता है. मॉडल राउटर, आम तौर पर एक मशीन लर्निंग मॉडल होता है. यह धीरे-धीरे यह सीखता है कि किसी इनपुट के लिए सबसे अच्छा मॉडल कैसे चुना जाए. हालांकि, मॉडल राउटर कभी-कभी एक आसान, नॉन-मशीन लर्निंग एल्गोरिदम हो सकता है.
MOE
यह मिक्सचर ऑफ़ एक्सपर्ट का संक्षिप्त नाम है.
MT
मशीन से अनुवाद के लिए इस्तेमाल किया जाने वाला संक्षिप्त नाम.
नहीं
Nano
यह Gemini मॉडल, डिवाइस पर इस्तेमाल करने के लिए बनाया गया है. यह मॉडल, अन्य Gemini मॉडल की तुलना में छोटा है. ज़्यादा जानकारी के लिए, Gemini Nano लेख पढ़ें.
Pro और Ultra के बारे में भी जानें.
कोई भी जवाब सही नहीं है (नोरा)
एक ऐसा प्रॉम्प्ट जिसके कई सही जवाब हों. उदाहरण के लिए, इस प्रॉम्प्ट का कोई एक सही जवाब नहीं है:
मुझे हाथियों के बारे में कोई मज़ेदार चुटकुला सुनाओ.
एक से ज़्यादा सही जवाब वाले सवालों के जवाबों की जांच करना, एक सही जवाब वाले सवालों के जवाबों की जांच करने की तुलना में ज़्यादा मुश्किल होता है. उदाहरण के लिए, हाथी के बारे में किसी चुटकुले का आकलन करने के लिए, यह तय करने का एक व्यवस्थित तरीका होना चाहिए कि चुटकुला कितना मज़ेदार है.
नोरा
कोई एक सही जवाब नहीं है के लिए इस्तेमाल किया जाने वाला छोटा नाम.
Notebook LM
Gemini पर आधारित यह टूल, लोगों को दस्तावेज़ अपलोड करने की सुविधा देता है. इसके बाद, वे प्रॉम्प्ट का इस्तेमाल करके, उन दस्तावेज़ों के बारे में सवाल पूछ सकते हैं, उनकी खास जानकारी पा सकते हैं या उन्हें व्यवस्थित कर सकते हैं. उदाहरण के लिए, कोई लेखक कई छोटी कहानियां अपलोड कर सकता है और NotebookLM से यह पता लगाने के लिए कह सकता है कि उनमें कौनसी थीम एक जैसी हैं या उनमें से कौनसी कहानी पर सबसे अच्छी फ़िल्म बन सकती है.
O
एक सही जवाब (ओआरए)
ऐसा प्रॉम्प्ट जिसका एक ही सही जवाब हो. उदाहरण के लिए, यहां दिया गया प्रॉम्प्ट देखें:
सही या गलत: शनि, मंगल से बड़ा है.
सिर्फ़ सही जवाब सही है.
कोई एक सही जवाब नहीं होता से अलग.
वन-शॉट प्रॉम्प्ट
एक ऐसा प्रॉम्प्ट जिसमें एक उदाहरण दिया गया हो. इससे यह पता चलता है कि लार्ज लैंग्वेज मॉडल को किस तरह जवाब देना चाहिए. उदाहरण के लिए, यहां दिए गए प्रॉम्प्ट में एक उदाहरण शामिल है. इसमें लार्ज लैंग्वेज मॉडल को यह बताया गया है कि उसे किसी क्वेरी का जवाब कैसे देना चाहिए.
| एक प्रॉम्ट के हिस्से | नोट |
|---|---|
| चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब आपको एलएलएम से चाहिए. |
| फ़्रांस: EUR | एक उदाहरण. |
| भारत: | असल क्वेरी. |
एक बार में जवाब पाने के लिए प्रॉम्प्ट लिखना की तुलना इन शब्दों से करें और इनमें अंतर बताएं:
ओआरए
यह एक सही जवाब का संक्षिप्त रूप है.
P
पैरामीटर-इफ़िशिएंट ट्यूनिंग
यह एक ऐसी तकनीक है जिसकी मदद से, फ़ुल फ़ाइन-ट्यूनिंग की तुलना में, लार्ज प्री-ट्रेन लैंग्वेज मॉडल (पीएलएम) को ज़्यादा असरदार तरीके से फ़ाइन-ट्यून किया जा सकता है. पैरामीटर-इफ़िशिएंट ट्यूनिंग में, फ़ुल फ़ाइन-ट्यूनिंग की तुलना में काफ़ी कम पैरामीटर को फ़ाइन-ट्यून किया जाता है. हालांकि, आम तौर पर इससे ऐसा लार्ज लैंग्वेज मॉडल तैयार होता है जो फ़ुल फ़ाइन-ट्यूनिंग से बनाए गए लार्ज लैंग्वेज मॉडल की तरह ही (या लगभग उतना ही) काम करता है.
पैरामीटर-इफ़िशिएंट फ़ाइन-ट्यूनिंग की तुलना इनके साथ करें:
पैरामीटर-इफ़िशिएंट ट्यूनिंग को पैरामीटर-इफ़िशिएंट फ़ाइन-ट्यूनिंग भी कहा जाता है.
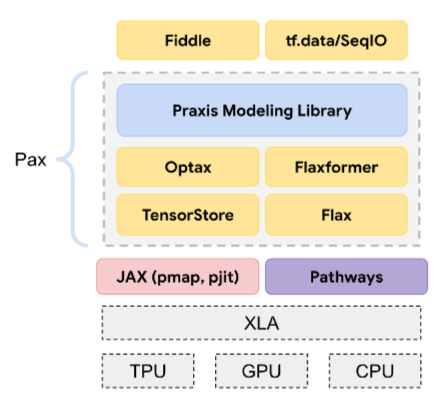
Pax
यह एक प्रोग्रामिंग फ़्रेमवर्क है. इसे बड़े पैमाने पर न्यूरल नेटवर्क मॉडल को ट्रेन करने के लिए डिज़ाइन किया गया है. ये मॉडल इतने बड़े होते हैं कि ये कई टीपीयू ऐक्सलरेटर चिप स्लाइस या पॉड में फैले होते हैं.
Pax को Flax पर बनाया गया है. वहीं, Flax को JAX पर बनाया गया है.
PLM
पहले से ट्रेन किए गए लैंग्वेज मॉडल का संक्षिप्त नाम.
पोस्ट-ट्रेनिंग मॉडल
यह एक ऐसा शब्द है जिसे आम तौर पर पहले से ट्रेन किए गए मॉडल के लिए इस्तेमाल किया जाता है. इस मॉडल को पोस्ट-प्रोसेसिंग के बाद इस्तेमाल किया जाता है. जैसे, इनमें से एक या एक से ज़्यादा काम किए जाते हैं:
पहले से ट्रेन किया गया मॉडल
हालांकि, इस शब्द का इस्तेमाल किसी भी ट्रेन किए गए मॉडल या ट्रेन किए गए एम्बेडिंग वेक्टर के लिए किया जा सकता है, लेकिन अब आम तौर पर प्री-ट्रेन किए गए मॉडल का मतलब, ट्रेन किया गया लार्ज लैंग्वेज मॉडल या ट्रेन किए गए जनरेटिव एआई मॉडल का कोई अन्य फ़ॉर्म होता है.
बेस मॉडल और फ़ाउंडेशन मॉडल के बारे में भी जानें.
प्री-ट्रेनिंग
किसी मॉडल को बड़े डेटासेट पर ट्रेन करना. पहले से ट्रेन किए गए कुछ मॉडल, बहुत ज़्यादा डेटा पर काम करते हैं. इसलिए, आम तौर पर उन्हें बेहतर बनाने के लिए, अतिरिक्त ट्रेनिंग देनी पड़ती है. उदाहरण के लिए, एमएल विशेषज्ञ, टेक्स्ट के बड़े डेटासेट पर लार्ज लैंग्वेज मॉडल को पहले से ही ट्रेन कर सकते हैं. जैसे, Wikipedia के सभी अंग्रेज़ी पेज. प्री-ट्रेनिंग के बाद, मॉडल को बेहतर बनाने के लिए इनमें से किसी भी तकनीक का इस्तेमाल किया जा सकता है:
- डिस्टिलेशन
- फ़ाइन-ट्यूनिंग
- निर्देशों के मुताबिक जवाब देने की सुविधा
- पैरामीटर-इफ़िशिएंट ट्यूनिंग
- प्रॉम्प्ट-ट्यूनिंग
Pro
यह Gemini मॉडल है. इसमें Ultra से कम पैरामीटर हैं, लेकिन Nano से ज़्यादा पैरामीटर हैं. ज़्यादा जानकारी के लिए, Gemini Pro देखें.
prompt
किसी लार्ज लैंग्वेज मॉडल में इनपुट के तौर पर डाला गया कोई भी टेक्स्ट, ताकि मॉडल को किसी खास तरीके से काम करने के लिए तैयार किया जा सके. प्रॉम्प्ट, एक छोटे से वाक्यांश से लेकर बहुत लंबे टेक्स्ट तक हो सकते हैं. उदाहरण के लिए, किसी उपन्यास का पूरा टेक्स्ट. प्रॉम्प्ट को कई कैटगरी में बांटा गया है. इनमें से कुछ कैटगरी यहां दी गई टेबल में दिखाई गई हैं:
| प्रॉम्प्ट कैटगरी | उदाहरण | नोट |
|---|---|---|
| सवाल | कबूतर कितनी तेज़ गति से उड़ सकता है? | |
| निर्देश | आर्बिट्राज के बारे में एक मज़ेदार कविता लिखो. | ऐसा प्रॉम्प्ट जिसमें लार्ज लैंग्वेज मॉडल को कोई काम करने के लिए कहा गया हो. |
| उदाहरण | मार्कडाउन कोड को एचटीएमएल में बदलें. उदाहरण के लिए:
मार्कडाउन: * सूची का आइटम एचटीएमएल: <ul> <li>सूची का आइटम</li> </ul> |
इस उदाहरण प्रॉम्प्ट में पहला वाक्य, निर्देश है. प्रॉम्प्ट का बाकी हिस्सा उदाहरण है. |
| भूमिका | फ़िज़िक्स में पीएचडी करने वाले व्यक्ति को बताओ कि मशीन लर्निंग की ट्रेनिंग में ग्रेडिएंट डिसेंट का इस्तेमाल क्यों किया जाता है. | वाक्य का पहला हिस्सा निर्देश है. "भौतिक विज्ञान में पीएचडी करने वाले व्यक्ति को" वाक्यांश, भूमिका वाला हिस्सा है. |
| मॉडल को पूरा करने के लिए कुछ हद तक इनपुट दिया गया है | यूनाइटेड किंगडम के प्रधानमंत्री का आधिकारिक निवास | इनपुट प्रॉम्प्ट का कुछ हिस्सा अचानक खत्म हो सकता है. जैसे, इस उदाहरण में हुआ है. इसके अलावा, यह अंडरस्कोर से भी खत्म हो सकता है. |
जनरेटिव एआई मॉडल, किसी प्रॉम्प्ट का जवाब टेक्स्ट, कोड, इमेज, एम्बेडिंग, वीडियो…किसी भी फ़ॉर्मैट में दे सकता है.
प्रॉम्प्ट के आधार पर लर्निंग
यह कुछ मॉडल की एक ऐसी सुविधा है जिसकी मदद से वे किसी भी टेक्स्ट इनपुट (प्रॉम्प्ट) के हिसाब से अपने व्यवहार में बदलाव कर सकते हैं. प्रॉम्प्ट के आधार पर सीखने के सामान्य पैराडाइम में, लार्ज लैंग्वेज मॉडल, प्रॉम्प्ट का जवाब टेक्स्ट जनरेट करके देता है. उदाहरण के लिए, मान लें कि कोई उपयोगकर्ता यह प्रॉम्प्ट डालता है:
न्यूटन के गति के तीसरे नियम के बारे में खास जानकारी दो.
प्रॉम्प्ट के आधार पर सीखने की क्षमता रखने वाले मॉडल को, खास तौर पर पिछले प्रॉम्प्ट का जवाब देने के लिए ट्रेन नहीं किया जाता है. इसके बजाय, मॉडल को फ़िज़िक्स के बारे में कई तथ्यों की जानकारी होती है. साथ ही, उसे भाषा के सामान्य नियमों के बारे में भी काफ़ी जानकारी होती है. इसके अलावा, उसे यह भी पता होता है कि आम तौर पर किन जवाबों को मददगार माना जाता है. यह जानकारी, (उम्मीद है कि) काम का जवाब देने के लिए काफ़ी है. लोगों से मिले सुझाव, शिकायत या राय ("जवाब बहुत मुश्किल था." या "रिएक्शन क्या होता है?") की मदद से, प्रॉम्प्ट पर आधारित कुछ लर्निंग सिस्टम, अपने जवाबों को धीरे-धीरे बेहतर बना पाते हैं.
प्रॉम्प्ट डिज़ाइन
प्रॉम्प्ट इंजीनियरिंग के लिए समानार्थी शब्द.
प्रॉम्प्ट इंजीनियरिंग
प्रॉम्प्ट बनाने की कला, ताकि लार्ज लैंग्वेज मॉडल से मनमुताबिक जवाब मिल सकें. प्रॉम्प्ट इंजीनियरिंग का काम इंसान करते हैं. लार्ज लैंग्वेज मॉडल से काम के जवाब पाने के लिए, अच्छी तरह से स्ट्रक्चर किए गए प्रॉम्प्ट लिखना ज़रूरी है. प्रॉम्प्ट इंजीनियरिंग कई बातों पर निर्भर करती है. जैसे:
- इस डेटासेट का इस्तेमाल, लार्ज लैंग्वेज मॉडल को प्री-ट्रेन करने के लिए किया जाता है. साथ ही, इसका इस्तेमाल फ़ाइन-ट्यून करने के लिए भी किया जा सकता है.
- temperature और अन्य डिकोडिंग पैरामीटर, जिनका इस्तेमाल मॉडल जवाब जनरेट करने के लिए करता है.
प्रॉम्प्ट डिज़ाइन, प्रॉम्प्ट इंजीनियरिंग का दूसरा नाम है.
मददगार प्रॉम्प्ट लिखने के बारे में ज़्यादा जानने के लिए, प्रॉम्प्ट डिज़ाइन के बारे में बुनियादी जानकारी देखें.
प्रॉम्प्ट सेट
लार्ज लैंग्वेज मॉडल का आकलन करने के लिए, प्रॉम्प्ट का ग्रुप. उदाहरण के लिए, इस इमेज में तीन प्रॉम्प्ट वाला एक प्रॉम्प्ट सेट दिखाया गया है:

अच्छे प्रॉम्प्ट सेट में, प्रॉम्प्ट का "बड़ा" कलेक्शन होता है. इससे लार्ज लैंग्वेज मॉडल की सुरक्षा और मददगार होने का पूरी तरह से आकलन किया जा सकता है.
जवाबों का सेट के बारे में भी जानें.
प्रॉम्प्ट ट्यूनिंग
यह पैरामीटर एफ़िशिएंट ट्यूनिंग का एक तरीका है. इसमें एक "प्रीफ़िक्स" सीखा जाता है, जिसे सिस्टम, असली प्रॉम्प्ट से पहले जोड़ता है.
प्रॉम्प्ट ट्यूनिंग के एक वैरिएशन को कभी-कभी प्रीफ़िक्स ट्यूनिंग कहा जाता है. इसमें प्रीफ़िक्स को हर लेयर में जोड़ा जाता है. इसके उलट, ज़्यादातर प्रॉम्प्ट ट्यूनिंग में सिर्फ़ इनपुट लेयर में प्रीफ़िक्स जोड़ा जाता है.
R
रेफ़रंस टेक्स्ट
किसी विशेषज्ञ का प्रॉम्प्ट के जवाब में दिया गया सुझाव. उदाहरण के लिए, यह प्रॉम्प्ट दिया गया है:
"आपका नाम क्या है?" सवाल का अंग्रेज़ी से फ़्रेंच में अनुवाद करो.
किसी विशेषज्ञ का जवाब ऐसा हो सकता है:
आपका नाम क्या है?
अलग-अलग मेट्रिक (जैसे, ROUGE) से यह पता चलता है कि रेफ़रंस टेक्स्ट, एमएल मॉडल के जनरेट किए गए टेक्स्ट से कितना मेल खाता है.
गंभीर
यह एजेंटिक वर्कफ़्लो की क्वालिटी को बेहतर बनाने की एक रणनीति है. इसमें किसी चरण के आउटपुट की जांच की जाती है. इसके बाद, उस आउटपुट को अगले चरण में भेजा जाता है.
जवाब की जांच करने वाला LLM अक्सर वही होता है जिसने जवाब जनरेट किया है. हालांकि, यह कोई दूसरा एलएलएम भी हो सकता है. जवाब जनरेट करने वाला एलएलएम, अपने जवाब का सही आकलन कैसे कर सकता है? "ट्रिक" यह है कि एलएलएम को आलोचनात्मक (सोचने-समझने वाला) माइंडसेट में रखा जाए. यह प्रोसेस, किसी लेखक की प्रोसेस से मिलती-जुलती है. लेखक, पहला ड्राफ़्ट लिखते समय क्रिएटिव माइंडसेट का इस्तेमाल करता है. इसके बाद, उसे एडिट करते समय क्रिटिकल माइंडसेट का इस्तेमाल करता है.
उदाहरण के लिए, मान लें कि एक एजेंटिक वर्कफ़्लो है. इसका पहला चरण, कॉफ़ी मग के लिए टेक्स्ट बनाना है. इस चरण के लिए प्रॉम्प्ट यह हो सकता है:
मान लें कि आप एक क्रिएटिव हैं. कॉफ़ी मग के लिए, 50 से कम वर्णों वाला मज़ेदार और ओरिजनल टेक्स्ट जनरेट करो.
अब इस तरह के सवाल के बारे में सोचें:
मान लो कि तुम कॉफ़ी पीने वाले व्यक्ति हो. क्या आपको ऊपर दिया गया जवाब मज़ेदार लगा?
इसके बाद, वर्कफ़्लो सिर्फ़ ऐसे टेक्स्ट को अगले चरण में भेज सकता है जिसे रिफ़्लेक्शन स्कोर ज़्यादा मिला हो.
लोगों के सुझाव पर आधारित रीइन्फ़ोर्समेंट लर्निंग (आरएलएचएफ़)
मॉडल के जवाबों की क्वालिटी को बेहतर बनाने के लिए, लोगों से मिले सुझाव/राय या शिकायत का इस्तेमाल करना. उदाहरण के लिए, RLHF की प्रोसेस में उपयोगकर्ताओं से यह पूछा जा सकता है कि वे किसी मॉडल के जवाब की क्वालिटी को 👍 या 👎 इमोजी से रेट करें. इसके बाद, सिस्टम उस सुझाव/राय या शिकायत के आधार पर, आने वाले समय में अपने जवाबों में बदलाव कर सकता है.
जवाब
वह टेक्स्ट, इमेज, ऑडियो या वीडियो जिसे जनरेटिव एआई मॉडल अनुमानित करता है. दूसरे शब्दों में, प्रॉम्प्ट, जनरेटिव एआई मॉडल के लिए इनपुट होता है और जवाब, आउटपुट होता है.
जवाबों का सेट
जवाबों का वह कलेक्शन जो लार्ज लैंग्वेज मॉडल, प्रॉम्प्ट सेट के इनपुट के तौर पर देता है.
भूमिका के हिसाब से प्रॉम्प्ट देना
यह एक प्रॉम्प्ट होता है. आम तौर पर, इसकी शुरुआत तुम सर्वनाम से होती है. इसमें जनरेटिव एआई मॉडल को यह निर्देश दिया जाता है कि वह जवाब जनरेट करते समय, किसी व्यक्ति या भूमिका के तौर पर काम करे. रोल प्रॉम्प्टिंग से, जनरेटिव एआई मॉडल को सही "माइंडसेट" में लाने में मदद मिल सकती है, ताकि वह ज़्यादा काम का जवाब जनरेट कर सके. उदाहरण के लिए, आपको जिस तरह का जवाब चाहिए उसके हिसाब से, इनमें से कोई भी भूमिका वाला प्रॉम्प्ट सही हो सकता है:
आपने कंप्यूटर साइंस में पीएचडी की हो.
तुम एक सॉफ़्टवेयर इंजीनियर हो. तुम्हें प्रोग्रामिंग सीखने वाले नए छात्र-छात्राओं को Python के बारे में विस्तार से जानकारी देना पसंद है.
तुम एक ऐक्शन हीरो हो और तुम्हारे पास प्रोग्रामिंग की खास तरह की स्किल हैं. मुझे भरोसा दिलाओ कि तुम Python की किसी लिस्ट में कोई आइटम ढूंढ सकते हो.
S
सॉफ़्ट प्रॉम्प्ट ट्यूनिंग
यह किसी टास्क के लिए, फ़ाइन-ट्यूनिंग के लिए ज़्यादा संसाधनों की ज़रूरत के बिना, किसी लार्ज लैंग्वेज मॉडल को ट्यून करने की एक तकनीक है. मॉडल में मौजूद सभी वज़न को फिर से ट्रेन करने के बजाय, सॉफ्ट प्रॉम्प्ट ट्यूनिंग एक ही लक्ष्य को हासिल करने के लिए, प्रॉम्प्ट को अपने-आप अडजस्ट कर देती है.
टेक्स्ट वाले प्रॉम्प्ट के लिए, सॉफ़्ट प्रॉम्प्ट ट्यूनिंग आम तौर पर प्रॉम्प्ट में अतिरिक्त टोकन एम्बेडिंग जोड़ती है और इनपुट को ऑप्टिमाइज़ करने के लिए बैकप्रॉपैगेशन का इस्तेमाल करती है.
"हार्ड" प्रॉम्प्ट में टोकन एम्बेडिंग के बजाय असल टोकन होते हैं.
स्पेसिफ़िकेशनल कोडिंग
सॉफ़्टवेयर के बारे में जानकारी देने वाली फ़ाइल को किसी आम भाषा (जैसे, अंग्रेज़ी) में लिखने और उसे अपडेट रखने की प्रोसेस. इसके बाद, जनरेटिव एआई मॉडल या किसी अन्य सॉफ़्टवेयर इंजीनियर को, उस जानकारी के हिसाब से सॉफ़्टवेयर बनाने के लिए कहा जा सकता है.
अपने-आप जनरेट होने वाले कोड में आम तौर पर बदलाव करने की ज़रूरत होती है. स्पेसिफ़िकेशनल कोडिंग में, ब्यौरे वाली फ़ाइल को दोहराया जाता है. इसके उलट, बातचीत वाली कोडिंग में, आपको प्रॉम्प्ट बॉक्स में ही बदलाव करने का विकल्प मिलता है. असल में, कोड अपने-आप जनरेट होने की प्रोसेस में कभी-कभी, स्पेसिफ़िकेशनल कोडिंग और बातचीत वाली कोडिंग, दोनों का इस्तेमाल किया जाता है.
T
तापमान
यह एक हाइपरपैरामीटर है. यह मॉडल के आउटपुट में रैंडमनेस की डिग्री को कंट्रोल करता है. तापमान जितना ज़्यादा होगा, आउटपुट उतना ही ज़्यादा रैंडम होगा. वहीं, तापमान जितना कम होगा, आउटपुट उतना ही कम रैंडम होगा.
सबसे सही तापमान चुनना, ऐप्लिकेशन और/या स्ट्रिंग वैल्यू पर निर्भर करता है.
U
Ultra
सबसे ज़्यादा पैरामीटर वाला Gemini मॉडल. ज़्यादा जानकारी के लिए, Gemini Ultra लेख पढ़ें.
Pro और Nano के बारे में भी जानें.
V
शीर्ष बिंदु
Google Cloud का एआई और मशीन लर्निंग प्लैटफ़ॉर्म. Vertex, एआई ऐप्लिकेशन बनाने, डिप्लॉय करने, और मैनेज करने के लिए टूल और इन्फ़्रास्ट्रक्चर उपलब्ध कराता है. इसमें Gemini मॉडल का ऐक्सेस भी शामिल है.वाइब कोडिंग
सॉफ़्टवेयर बनाने के लिए, जनरेटिव एआई मॉडल को प्रॉम्प्ट करना. इसका मतलब है कि आपके प्रॉम्प्ट में सॉफ़्टवेयर के मकसद और सुविधाओं के बारे में बताया गया है. जनरेटिव एआई मॉडल, इसे सोर्स कोड में बदलता है. जनरेट किया गया कोड हमेशा आपकी उम्मीदों के मुताबिक नहीं होता. इसलिए, वाइब कोडिंग के लिए आम तौर पर दोहराव की ज़रूरत होती है.
आंद्रे करपाथी ने इस X पोस्ट में वाइब कोडिंग शब्द का इस्तेमाल किया था. X पर की गई पोस्ट में, कार्पेथी ने इसे "एक नई तरह की कोडिंग...जहां आप पूरी तरह से वाइब्स के हिसाब से काम करते हैं..." बताया है. इसलिए, इस शब्द का मूल मतलब यह है कि सॉफ़्टवेयर बनाने के लिए जान-बूझकर एक ढीला-ढाला तरीका अपनाया गया है. इसमें जनरेट किए गए कोड की जांच भी नहीं की जाती है. हालांकि, कई लोगों के लिए इस शब्द का मतलब अब तेज़ी से बदल गया है. अब इसका मतलब, एआई से जनरेट की गई कोडिंग के किसी भी रूप से है.
वाइब कोडिंग के बारे में ज़्यादा जानकारी के लिए, वाइब कोडिंग क्या है?.
इसके अलावा, वाइब कोडिंग की तुलना इन कोडिंग से करें और इनमें अंतर बताएं:
Z
बिना उदाहरण वाला प्रॉम्प्ट
ऐसा प्रॉम्प्ट जिसमें यह नहीं बताया गया है कि आपको लार्ज लैंग्वेज मॉडल से किस तरह का जवाब चाहिए. उदाहरण के लिए:
| एक प्रॉम्ट के हिस्से | नोट |
|---|---|
| चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब आपको एलएलएम से चाहिए. |
| भारत: | असल क्वेरी. |
लार्ज लैंग्वेज मॉडल इनमें से कोई भी जवाब दे सकता है:
- रुपया
- INR
- ₹
- भारतीय रुपया
- रुपया
- भारतीय रुपया
सभी जवाब सही हैं, हालांकि आपको कोई खास फ़ॉर्मैट पसंद आ सकता है.
ज़ीरो-शॉट प्रॉम्प्टिंग की तुलना इन शब्दों से करें और इनमें अंतर बताएं: