Questa pagina contiene i termini del glossario dell'AI generativa. Per tutti i termini del glossario, fai clic qui.
A
adattamento
Sinonimo di ottimizzazione o ottimizzazione avanzata.
agente
Software in grado di ragionare sugli input dell'utente per pianificare ed eseguire azioni per suo conto.
Nel reinforcement learning, un agente è l'entità che utilizza una policy per massimizzare il rendimento previsto ottenuto dal passaggio tra gli stati dell'ambiente.
agentico
La forma aggettivale di agente. Il termine "agente" si riferisce alle qualità che possiedono gli agenti (come l'autonomia).
workflow agentico
Un processo dinamico in cui un agente pianifica ed esegue autonomamente azioni per raggiungere un obiettivo. Il processo può comportare ragionamenti, l'invocazione di strumenti esterni e l'autocorrezione del piano.
AI slop
Output di un sistema di AI generativa che privilegia la quantità rispetto alla qualità. Ad esempio, una pagina web con AI slop è piena di contenuti di bassa qualità, generati dall'AI e prodotti a basso costo.
valutazione automatica
Utilizzo di software per valutare la qualità dell'output di un modello.
Quando l'output del modello è relativamente semplice, uno script o un programma può confrontare l'output del modello con una risposta di riferimento. Questo tipo di valutazione automatica è talvolta chiamato valutazione programmatica. Metriche come ROUGE o BLEU sono spesso utili per la valutazione programmatica.
Quando l'output del modello è complesso o non ha una risposta giusta, a volte la valutazione automatica viene eseguita da un programma ML separato chiamato valutatore automatico.
Contrasto con la valutazione umana.
valutazione automatica
Un meccanismo ibrido per giudicare la qualità dell'output di un modello di AI generativa che combina la valutazione umana con la valutazione automatica. Un sistema di valutazione automatica è un modello ML addestrato su dati creati tramite valutazione umana. Idealmente, un sistema di valutazione automatica impara a imitare un valutatore umano.Sono disponibili valutatori automatici predefiniti, ma i migliori sono ottimizzati in modo specifico per l'attività che stai valutando.
modello autoregressivo
Un modello che deduce una previsione in base alle proprie previsioni precedenti. Ad esempio, i modelli linguistici autoregressivi prevedono il successivo token in base ai token previsti in precedenza. Tutti i modelli linguistici di grandi dimensioni basati su Transformer sono autoregressivi.
Al contrario, i modelli di immagini basati su GAN di solito non sono autoregressivi in quanto generano un'immagine in un singolo passaggio in avanti e non in modo iterativo in più passaggi. Tuttavia, alcuni modelli di generazione di immagini sono autoregressivi perché generano un'immagine in più passaggi.
B
modello di base
Un modello preaddestrato che può fungere da punto di partenza per l'ottimizzazione per svolgere attività o applicazioni specifiche.
Vedi anche modello preaddestrato e foundation model.
C
prompting chain-of-thought
Una tecnica di prompt engineering che incoraggia un modello linguistico di grandi dimensioni (LLM) a spiegare il suo ragionamento, passo dopo passo. Ad esempio, considera il seguente prompt, prestando particolare attenzione alla seconda frase:
Quante forze G sperimenterebbe un conducente in un'auto che passa da 0 a 96 km/h in 7 secondi? Nella risposta, mostra tutti i calcoli pertinenti.
La risposta del LLM probabilmente:
- Mostra una sequenza di formule di fisica, inserendo i valori 0, 60 e 7 nei punti appropriati.
- Spiega perché ha scelto queste formule e cosa significano le varie variabili.
La prompting chain-of-thought costringe l'LLM a eseguire tutti i calcoli, il che potrebbe portare a una risposta più corretta. Inoltre, il prompting chain-of-thought consente all'utente di esaminare i passaggi dell'LLM per determinare se la risposta è sensata o meno.
chat
I contenuti di un dialogo bot e utente con un sistema di ML, in genere un modello linguistico di grandi dimensioni. L'interazione precedente in una chat (ciò che hai digitato e la risposta del modello linguistico di grandi dimensioni) diventa il contesto per le parti successive della chat.
Un chatbot è un'applicazione di un modello linguistico di grandi dimensioni (LLM).
embedding contestuale del linguaggio
Un embedding che si avvicina alla "comprensione" di parole e frasi in modo simile a quello di una persona che parla fluentemente. Gli incorporamenti del linguaggio contestualizzato possono comprendere sintassi, semantica e contesto complessi.
Ad esempio, considera gli incorporamenti della parola inglese cow. Gli embedding precedenti, come word2vec, possono rappresentare le parole in inglese in modo che la distanza nello spazio di embedding da cow a bull sia simile alla distanza da ewe (pecora femmina) a ram (pecora maschio) o da female a male. Gli incorporamenti del linguaggio contestualizzato possono fare un ulteriore passo avanti riconoscendo che gli anglofoni a volte usano casualmente la parola cow per indicare sia la mucca che il toro.
finestra contestuale
Il numero di token che un modello può elaborare in un determinato prompt. Più è ampia la finestra contestuale, maggiore è la quantità di informazioni che il modello può utilizzare per fornire risposte coerenti e consistenti al prompt.
programmazione conversazionale
Un dialogo iterativo tra te e un modello di AI generativa allo scopo di creare software. Emetti un prompt che descrive un software. Poi, il modello utilizza questa descrizione per generare il codice. Poi, emetti un nuovo prompt per risolvere i difetti del prompt precedente o del codice generato e il modello genera il codice aggiornato. Continuate a fare avanti e indietro finché il software generato non è abbastanza buono.
La codifica della conversazione è essenzialmente il significato originale di vibe coding.
Contrasta con la codifica delle specifiche.
D
prompt diretto
Sinonimo di prompting zero-shot.
distillazione
Il processo di riduzione delle dimensioni di un modello (noto come insegnante) in un modello più piccolo (noto come studente) che emula le previsioni del modello originale nel modo più fedele possibile. La distillazione è utile perché il modello più piccolo presenta due vantaggi chiave rispetto al modello più grande (l'insegnante):
- Tempi di inferenza più rapidi
- Riduzione dell'utilizzo di memoria ed energia
Tuttavia, le previsioni dello studente in genere non sono buone come quelle dell'insegnante.
La distillazione addestra il modello studente a ridurre al minimo una funzione di perdita in base alla differenza tra gli output delle previsioni dei modelli studente e insegnante.
Confronta e contrapponi la distillazione con i seguenti termini:
Per saperne di più, consulta LLM: fine-tuning, distillazione e prompt engineering in Machine Learning Crash Course.
E
evals
Utilizzato principalmente come abbreviazione di valutazioni LLM. Più in generale, valutazioni è l'abbreviazione di qualsiasi forma di valutazione.
valutazione
Il processo di misurazione della qualità di un modello o di confronto tra modelli diversi.
Per valutare un modello di machine learning supervisionato, in genere lo si confronta con un set di validazione e un test set. La valutazione di un LLM in genere comporta valutazioni più ampie di qualità e sicurezza.
V
oggettività
Nel mondo del machine learning, una proprietà che descrive un modello il cui output si basa sulla realtà. L'accuratezza è un concetto, non una metrica. Ad esempio, supponi di inviare il seguente prompt a un modello linguistico di grandi dimensioni:
Qual è la formula chimica del sale da tavola?
Un modello che ottimizza l'accuratezza risponderebbe:
NaCl
È allettante presumere che tutti i modelli debbano basarsi sulla veridicità. Tuttavia, alcuni prompt, come i seguenti, devono indurre un modello di AI generativa a ottimizzare la creatività anziché l'accuratezza.
Scrivi una filastrocca su un astronauta e un bruco.
È improbabile che il limerick risultante si basi sulla realtà.
Contrasto con l'ancoraggio.
decadimento rapido
Una tecnica di addestramento per migliorare le prestazioni degli LLM. Il decadimento rapido comporta una diminuzione rapida del tasso di apprendimento durante l'addestramento. Questa strategia aiuta a evitare che il modello esegua un overfitting dei dati di addestramento e migliora la generalizzazione.
prompting few-shot
Un prompt che contiene più di un esempio che dimostra come il modello linguistico di grandi dimensioni deve rispondere. Ad esempio, il seguente prompt lungo contiene due esempi che mostrano a un modello linguistico di grandi dimensioni come rispondere a una query.
| Parti di un prompt | Note |
|---|---|
| Qual è la valuta ufficiale del paese specificato? | La domanda a cui vuoi che l'LLM risponda. |
| Francia: EUR | Un esempio. |
| Regno Unito: GBP | Un altro esempio. |
| India: | La query effettiva. |
Il prompt few-shot in genere produce risultati più desiderabili rispetto al prompt zero-shot e al prompt one-shot. Tuttavia, il prompt few-shot richiede un prompt più lungo.
Il prompting few-shot è una forma di apprendimento few-shot applicata all'apprendimento basato su prompt.
Per saperne di più, consulta la sezione Prompt engineering in Machine Learning Crash Course.
ottimizzazione
Un secondo passaggio di addestramento specifico per l'attività eseguito su un modello preaddestrato per perfezionarne i parametri per un caso d'uso specifico. Ad esempio, la sequenza di addestramento completa per alcuni modelli linguistici di grandi dimensioni è la seguente:
- Preaddestramento: addestra un modello linguistico di grandi dimensioni su un vasto set di dati generici, come tutte le pagine di Wikipedia in lingua inglese.
- Ottimizzazione:addestra il modello preaddestrato a svolgere un'attività specifica, come rispondere a domande mediche. Il fine-tuning in genere prevede centinaia o migliaia di esempi incentrati sull'attività specifica.
Un altro esempio è la sequenza di addestramento completa per un modello di immagini di grandi dimensioni:
- Pre-addestramento:addestra un modello di immagini di grandi dimensioni su un vasto set di dati di immagini generiche, ad esempio tutte le immagini di Wikimedia Commons.
- Ottimizzazione:addestra il modello preaddestrato a svolgere un'attività specifica, come la generazione di immagini di orche.
Il perfezionamento può comportare una qualsiasi combinazione delle seguenti strategie:
- Modifica di tutti i parametri esistenti del modello preaddestrato. Questa operazione viene a volte chiamata ottimizzazione completa.
- Modifica solo alcuni dei parametri esistenti del modello preaddestrato (in genere, i livelli più vicini al livello di output), mantenendo invariati gli altri parametri esistenti (in genere, i livelli più vicini al livello di input). Consulta la sezione Ottimizzazione efficiente dei parametri.
- Aggiungendo altri livelli, in genere sopra i livelli esistenti più vicini al livello di output.
L'ottimizzazione è una forma di transfer learning. Pertanto, il perfezionamento potrebbe utilizzare una funzione di perdita o un tipo di modello diverso da quelli utilizzati per addestrare il modello preaddestrato. Ad esempio, potresti ottimizzare un modello di immagini di grandi dimensioni preaddestrato per produrre un modello di regressione che restituisca il numero di uccelli in un'immagine di input.
Confronta e contrapponi il fine-tuning con i seguenti termini:
Per saperne di più, consulta la sezione Ottimizzazione di Machine Learning Crash Course.
Modello flash
Una famiglia di modelli Gemini relativamente piccoli, ottimizzati per la velocità e la bassa latenza. I modelli Flash sono progettati per un'ampia gamma di applicazioni in cui risposte rapide e throughput elevato sono fondamentali.
foundation model
Un modello preaddestrato molto grande addestrato su un set di addestramento enorme e diversificato. Un foundation model può eseguire entrambe le seguenti operazioni:
- Rispondere bene a un'ampia gamma di richieste.
- Funge da modello di base per l'ottimizzazione o altre personalizzazioni.
In altre parole, un foundation model è già molto efficace in senso generale, ma può essere ulteriormente personalizzato per diventare ancora più utile per un'attività specifica.
frazione di successi
Una metrica per valutare il testo generato di un modello ML. La frazione di successi è il numero di output di testo generati "riusciti" diviso per il numero totale di output di testo generati. Ad esempio, se un modello linguistico di grandi dimensioni ha generato 10 blocchi di codice, cinque dei quali sono stati eseguiti correttamente, la frazione di esecuzioni riuscite sarebbe del 50%.
Sebbene la frazione di successi sia ampiamente utile in tutta la statistica, all'interno del machine learning, questa metrica è utile principalmente per misurare attività verificabili come la generazione di codice o i problemi di matematica.
G
Gemini
L'ecosistema che comprende l'AI più avanzata di Google. Gli elementi di questo ecosistema includono:
- Vari modelli Gemini.
- L'interfaccia conversazionale interattiva di un modello Gemini. Gli utenti digitano i prompt e Gemini risponde.
- Varie API Gemini.
- Vari prodotti aziendali basati sui modelli Gemini; ad esempio, Gemini for Google Cloud.
Modelli Gemini
Modelli multimodali all'avanguardia di Google basati su Transformer. I modelli Gemini sono progettati specificamente per integrarsi con gli agenti.
Gli utenti possono interagire con i modelli Gemini in vari modi, ad esempio tramite un'interfaccia di dialogo interattiva e tramite SDK.
Gemma
Una famiglia di modelli aperti leggeri creati sulla base della stessa ricerca e tecnologia utilizzata per creare i modelli Gemini. Sono disponibili diversi modelli Gemma, ognuno dei quali offre funzionalità diverse, come visione, codice e rispetto delle istruzioni. Per maggiori dettagli, vedi Gemma.
AI generativa o AI generativa
Abbreviazione di AI generativa.
testo generato
In generale, il testo generato da un modello ML. Quando si valutano modelli linguistici di grandi dimensioni, alcune metriche confrontano il testo generato con il testo di riferimento. Ad esempio, supponiamo che tu stia cercando di determinare l'efficacia con cui un modello ML traduce dal francese all'olandese. In questo caso:
- Il testo generato è la traduzione in olandese restituita dal modello di ML.
- Il testo di riferimento è la traduzione in olandese creata da un traduttore umano (o da un software).
Tieni presente che alcune strategie di valutazione non prevedono testo di riferimento.
AI generativa
Un campo trasformativo emergente senza una definizione formale. Detto questo, la maggior parte degli esperti concorda sul fatto che i modelli di AI generativa possono creare ("generare") contenuti che siano tutte le seguenti cose:
- complesso
- coerente
- originale
Esempi di AI generativa:
- Modelli linguistici di grandi dimensioni (LLM), che possono generare testi originali sofisticati e rispondere alle domande.
- Modello di generazione delle immagini, che può produrre immagini uniche.
- Modelli di generazione di audio e musica, che possono comporre musica originale o generare un parlato realistico.
- Modelli di generazione video, che possono generare video originali.
Anche alcune tecnologie precedenti, tra cui LSTM e RNN, possono generare contenuti originali e coerenti. Alcuni esperti considerano queste tecnologie precedenti come AI generativa, mentre altri ritengono che la vera AI generativa richieda un output più complesso di quello che possono produrre queste tecnologie precedenti.
Contrasta con il machine learning predittivo.
risposta di riferimento
Una risposta nota per essere buona. Ad esempio, dato il seguente prompt:
2 + 2
La risposta ideale è:
4
GPT (Generative Pre-trained Transformer)
Una famiglia di modelli linguistici di grandi dimensioni basati su Transformer sviluppati da OpenAI.
Le varianti GPT possono essere applicate a più modalità, tra cui:
- generazione di immagini (ad esempio, ImageGPT)
- generazione di immagini da testo (ad esempio, DALL-E).
H
allucinazione
La produzione di output apparentemente plausibili ma di fatto errati da parte di un modello di AI generativa che dichiara di fare un'affermazione sul mondo reale. Ad esempio, un modello di AI generativa che afferma che Barack Obama è morto nel 1865 sta allucinando.
valutazione umana
Un processo in cui persone giudicano la qualità dell'output di un modello ML; ad esempio, persone bilingue giudicano la qualità di un modello di traduzione ML. La valutazione umana è particolarmente utile per giudicare i modelli che non hanno una sola risposta corretta.
Contrasta con la valutazione automatica e la valutazione del sistema di valutazione automatico.
human-in-the-loop (HITL)
Un idioma definito in modo generico che potrebbe significare una delle seguenti opzioni:
- Una policy di visualizzazione critica o scettica dell'output dell'AI generativa.
- Una strategia o un sistema per garantire che le persone contribuiscano a modellare, valutare e perfezionare il comportamento di un modello. Mantenere un essere umano nel ciclo consente a un'AI di trarre vantaggio sia dall'intelligenza artificiale sia da quella umana. Ad esempio, un sistema in cui un'AI genera codice che viene poi esaminato dagli ingegneri informatici è un sistema human-in-the-loop.
I
apprendimento in-context
Sinonimo di prompt few-shot.
inferenza
Nel machine learning tradizionale, il processo di fare previsioni applicando un modello addestrato a esempi non etichettati. Per saperne di più, consulta la sezione Apprendimento supervisionato del corso Introduzione al machine learning.
Nei modelli linguistici di grandi dimensioni, l'inferenza è il processo di utilizzo di un modello addestrato per generare una risposta a un prompt di input.
L'inferenza ha un significato leggermente diverso in statistica. Per maggiori dettagli, consulta l' articolo di Wikipedia sull'inferenza statistica.
ottimizzazione delle istruzioni
Una forma di ottimizzazione che migliora la capacità di un modello di AI generativa di seguire le istruzioni. L'ottimizzazione delle istruzioni prevede l'addestramento di un modello su una serie di prompt di istruzioni, in genere relativi a un'ampia gamma di attività. Il modello ottimizzato per le istruzioni risultante tende quindi a generare risposte utili a prompt zero-shot in una serie di attività.
Confrontare e contrapporre con:
L
modello linguistico di grandi dimensioni
Come minimo, un modello linguistico con un numero molto elevato di parametri. In termini più informali, qualsiasi modello linguistico basato su Transformer, come Gemini o GPT.
Per saperne di più, consulta la sezione Modelli linguistici di grandi dimensioni (LLM) del corso intensivo su Machine Learning.
latenza
Il tempo necessario a un modello per elaborare l'input e generare una risposta. Una risposta a latenza elevata richiede più tempo per essere generata rispetto a una risposta a latenza bassa.
I fattori che influenzano la latenza dei modelli linguistici di grandi dimensioni includono:
- Lunghezze dei token di input e output
- Complessità del modello
- L'infrastruttura su cui viene eseguito il modello
L'ottimizzazione per la latenza è fondamentale per creare applicazioni reattive e facili da usare.
LLM
Abbreviazione di modello linguistico di grandi dimensioni.
Valutazioni LLM
Un insieme di metriche e benchmark per valutare le prestazioni dei modelli linguistici di grandi dimensioni (LLM). A livello generale, valutazioni LLM:
- Aiutare i ricercatori a identificare le aree in cui i modelli LLM devono essere migliorati.
- Sono utili per confrontare diversi LLM e identificare quello migliore per una determinata attività.
- Contribuire a garantire che gli LLM siano sicuri ed etici da utilizzare.
Per saperne di più, consulta Modelli linguistici di grandi dimensioni (LLM) in Machine Learning Crash Course.
LoRA
Abbreviazione di Low-Rank Adaptability.
Adattamento a basso ranking (LoRA)
Una tecnica efficiente in termini di parametri per l'ottimizzazione che"congela" i pesi preaddestrati del modello (in modo che non possano più essere modificati) e poi inserisce un piccolo insieme di pesi addestrabili nel modello. Questo insieme di pesi addestrabili (noto anche come "matrici di aggiornamento") è notevolmente più piccolo del modello di base ed è quindi molto più veloce da addestrare.
LoRA offre i seguenti vantaggi:
- Migliora la qualità delle previsioni di un modello per il dominio in cui viene applicato il fine tuning.
- L'ottimizzazione è più rapida rispetto alle tecniche che richiedono l'ottimizzazione di tutti i parametri di un modello.
- Riduce il costo computazionale dell'inferenza consentendo l'erogazione simultanea di più modelli specializzati che condividono lo stesso modello di base.
M
traduzione automatica
Utilizzo di un software (in genere, un modello di machine learning) per convertire il testo da una lingua umana a un'altra, ad esempio dall'inglese al giapponese.
precisione media a k (mAP@k)
La media statistica di tutti i punteggi di precisione media a k in un set di dati di convalida. Un utilizzo della precisione media media a k è quello di valutare la qualità dei suggerimenti generati da un sistema di suggerimenti.
Sebbene la frase "media aritmetica" sembri ridondante, il nome della metrica è appropriato. Dopo tutto, questa metrica trova la media di più valori di precisione media a k.
mix di esperti
Un sistema per aumentare l'efficienza della rete neurale utilizzando solo un sottoinsieme dei suoi parametri (noto come esperto) per elaborare un determinato token o esempio di input. Una rete di gating indirizza ogni token o esempio di input all'esperto o agli esperti giusti.
Per maggiori dettagli, consulta uno dei seguenti documenti:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mixture-of-Experts con Expert Choice Routing
MMIT
Abbreviazione di multimodal instruction-tuned.
cascata di modelli
Un sistema che sceglie il modello ideale per una query di inferenza specifica.
Immagina un gruppo di modelli, che vanno da molto grandi (molti parametri) a molto più piccoli (molti meno parametri). I modelli molto grandi consumano più risorse di calcolo in fase di inferenza rispetto ai modelli più piccoli. Tuttavia, i modelli molto grandi possono in genere dedurre richieste più complesse rispetto ai modelli più piccoli. La concatenazione dei modelli determina la complessità della query di inferenza e poi sceglie il modello appropriato per eseguire l'inferenza. La motivazione principale per la concatenazione dei modelli è ridurre i costi di inferenza selezionando in genere modelli più piccoli e selezionando un modello più grande solo per query più complesse.
Immagina che un modello piccolo venga eseguito su uno smartphone e una versione più grande dello stesso modello venga eseguita su un server remoto. Una buona cascata di modelli riduce i costi e la latenza consentendo al modello più piccolo di gestire le richieste semplici e chiamando il modello remoto solo per gestire le richieste complesse.
Vedi anche router modello.
model router
L'algoritmo che determina il modello ideale per l'inferenza nella cascata di modelli. Un router di modelli è in genere un modello di machine learning che impara gradualmente a scegliere il modello migliore per un determinato input. Tuttavia, un router di modelli a volte potrebbe essere un algoritmo più semplice, non di machine learning.
MOE
Abbreviazione di mixture of experts.
MT
Abbreviazione di traduzione automatica.
No
Nano
Un modello Gemini relativamente piccolo progettato per l'utilizzo sul dispositivo. Per maggiori dettagli, vedi Gemini Nano.
nessuna risposta corretta (NORA)
Un prompt con più risposte corrette. Ad esempio, il seguente prompt non ha una risposta giusta:
Raccontami una barzelletta divertente sugli elefanti.
Valutare le risposte ai prompt senza una risposta giusta è in genere molto più soggettivo che valutare i prompt con una risposta giusta. Ad esempio, la valutazione di una barzelletta sugli elefanti richiede un modo sistematico per determinare quanto sia divertente.
NORA
Abbreviazione di nessuna risposta giusta.
NotebookLM
Uno strumento basato su Gemini che consente agli utenti di caricare documenti e poi utilizzare prompt per porre domande, riassumere o organizzare i documenti. Ad esempio, un autore potrebbe caricare diversi racconti e chiedere a NotebookLM di trovare i temi comuni o di identificare quale potrebbe essere il miglior film.
O
una risposta corretta (ORA)
Un prompt con una singola risposta corretta. Ad esempio, considera il seguente prompt:
Vero o falso: Saturno è più grande di Marte.
L'unica risposta corretta è Vero.
Contrasto con non esiste una risposta giusta.
prompting one-shot
Un prompt che contiene un esempio che mostra come deve rispondere il modello linguistico di grandi dimensioni. Ad esempio, il seguente prompt contiene un esempio che mostra a un modello linguistico di grandi dimensioni come deve rispondere a una query.
| Parti di un prompt | Note |
|---|---|
| Qual è la valuta ufficiale del paese specificato? | La domanda a cui vuoi che l'LLM risponda. |
| Francia: EUR | Un esempio. |
| India: | La query effettiva. |
Confronta e contrapponi il prompt one-shot con i seguenti termini:
ORA
Abbreviazione di una risposta corretta.
P
ottimizzazione efficiente dei parametri
Un insieme di tecniche per ottimizzare un modello linguistico di grandi dimensioni preaddestrato (PLM) in modo più efficiente rispetto all'ottimizzazione completa. L'ottimizzazione efficiente dei parametri in genere ottimizza un numero molto inferiore di parametri rispetto all'ottimizzazione completa, ma in genere produce un modello linguistico di grandi dimensioni che ha un rendimento pari (o quasi pari) a quello di un modello linguistico di grandi dimensioni creato con l'ottimizzazione completa.
Confronta e contrapponi l'ottimizzazione efficiente dei parametri con:
L'ottimizzazione efficiente dei parametri è nota anche come ottimizzazione efficiente.
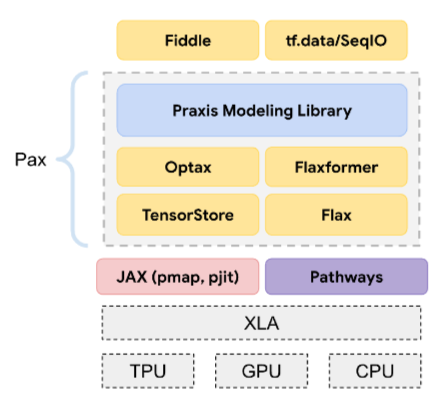
Pax
Un framework di programmazione progettato per l'addestramento di modelli di rete neurale su larga scala così grandi da estendersi su più TPU, chip di accelerazione, slice o pod.
Pax è basato su Flax, che a sua volta è basato su JAX.
PLM
Abbreviazione di modello linguistico preaddestrato.
modello postaddestrato
Termine definito in modo generico che in genere si riferisce a un modello preaddestrato che è stato sottoposto a un'elaborazione successiva, ad esempio una o più delle seguenti:
modello preaddestrato
Sebbene questo termine possa riferirsi a qualsiasi modello addestrato o vettore di incorporamento addestrato, ora il modello preaddestrato in genere si riferisce a un modello linguistico di grandi dimensioni addestrato o a un'altra forma di modello di AI generativa addestrato.
Vedi anche modello di base e foundation model.
pre-training
L'addestramento iniziale di un modello su un grande set di dati. Alcuni modelli pre-addestrati sono giganti goffi e in genere devono essere perfezionati tramite un addestramento aggiuntivo. Ad esempio, gli esperti di ML potrebbero pre-addestrare un modello linguistico di grandi dimensioni su un vasto set di dati di testo, come tutte le pagine in inglese di Wikipedia. Dopo il pre-addestramento, il modello risultante può essere ulteriormente perfezionato mediante una delle seguenti tecniche:
- distillation
- ottimizzazione
- Ottimizzazione delle istruzioni
- Ottimizzazione efficiente dei parametri
- prompt-tuning
Pro
Un modello Gemini con meno parametri di Ultra, ma più parametri di Nano. Per maggiori dettagli, consulta la pagina Gemini Pro.
prompt
Qualsiasi testo inserito come input in un modello linguistico di grandi dimensioni per condizionare il modello a comportarsi in un determinato modo. I prompt possono essere brevi come una frase o arbitrariamente lunghi (ad esempio, l'intero testo di un romanzo). I prompt rientrano in più categorie, tra cui quelle mostrate nella tabella seguente:
| Categoria di prompt | Esempio | Note |
|---|---|---|
| Domanda | A che velocità può volare un piccione? | |
| Istruzione | Scrivi una poesia divertente sull'arbitraggio. | Un prompt che chiede al modello linguistico di grandi dimensioni di fare qualcosa. |
| Esempio | Traduci il codice Markdown in HTML. Ad esempio:
Markdown: * list item HTML: <ul> <li>list item</li> </ul> |
La prima frase di questo prompt di esempio è un'istruzione. Il resto del prompt è l'esempio. |
| Ruolo | Spiega perché la discesa del gradiente viene utilizzata nell'addestramento del machine learning a un dottorato in fisica. | La prima parte della frase è un'istruzione; la frase "to a PhD in Physics" è la parte relativa al ruolo. |
| Input parziale da completare per il modello | Il primo ministro del Regno Unito vive a | Un prompt di input parziale può terminare bruscamente (come in questo esempio) o con un trattino basso. |
Un modello di AI generativa può rispondere a un prompt con testo, codice, immagini, embedding, video… praticamente qualsiasi cosa.
apprendimento basato su prompt
Una funzionalità di alcuni modelli che consente loro di adattare il proprio comportamento in risposta a input di testo arbitrari (prompt). In un tipico paradigma di apprendimento basato sui prompt, un modello linguistico di grandi dimensioni (LLM) risponde a un prompt generando testo. Ad esempio, supponiamo che un utente inserisca il seguente prompt:
Riassumi il terzo principio della dinamica di Newton.
Un modello in grado di apprendere in base ai prompt non è addestrato in modo specifico per rispondere al prompt precedente. Il modello "conosce" molti fatti sulla fisica, molte regole linguistiche generali e molti elementi che costituiscono risposte generalmente utili. Queste informazioni sono sufficienti per fornire una risposta (si spera) utile. Il feedback umano aggiuntivo ("La risposta era troppo complicata" o "Che cos'è una reazione?") consente ad alcuni sistemi di apprendimento basati su prompt di migliorare gradualmente l'utilità delle loro risposte.
progettazione dei prompt
Sinonimo di prompt engineering.
ingegneria del prompt
L'arte di creare prompt che generano le risposte desiderate da un modello linguistico di grandi dimensioni. Gli esseri umani eseguono l'ingegneria dei prompt. Scrivere prompt ben strutturati è una parte essenziale per garantire risposte utili da un modello linguistico di grandi dimensioni. L'ingegneria dei prompt dipende da molti fattori, tra cui:
- Il set di dati utilizzato per il preaddestramento e, possibilmente, per l'ottimizzazione del modello linguistico di grandi dimensioni.
- La temperatura e altri parametri di decodifica che il modello utilizza per generare le risposte.
Progettazione dei prompt è un sinonimo di prompt engineering.
Per saperne di più su come scrivere prompt utili, consulta Introduzione alla progettazione dei prompt.
set di prompt
Un gruppo di prompt per valutare un modello linguistico di grandi dimensioni. Ad esempio, la seguente illustrazione mostra un insieme di prompt composto da tre prompt:

I buoni set di prompt sono costituiti da una raccolta di prompt sufficientemente "ampia" per valutare a fondo la sicurezza e l'utilità di un modello linguistico di grandi dimensioni.
Vedi anche insieme di risposte.
ottimizzazione dei prompt
Un meccanismo di ottimizzazione efficiente dei parametri che apprende un "prefisso" che il sistema antepone al prompt effettivo.
Una variante della messa a punto del prompt, a volte chiamata messa a punto del prefisso, consiste nell'anteporre il prefisso a ogni livello. Al contrario, la maggior parte delle tecniche di ottimizzazione dei prompt aggiunge solo un prefisso al livello di input.
R
testo di riferimento
La risposta di un esperto a un prompt. Ad esempio, dato il seguente prompt:
Traduci la domanda "Come ti chiami?" dall'inglese al francese.
La risposta di un esperto potrebbe essere:
Comment vous appelez-vous?
Varie metriche (come ROUGE) misurano il grado di corrispondenza tra il testo di riferimento e il testo generato di un modello ML.
introspezione
Una strategia per migliorare la qualità di un flusso di lavoro autonomo esaminando (riflettendo su) l'output di un passaggio prima di passarlo al passaggio successivo.
L'esaminatore è spesso lo stesso LLM che ha generato la risposta (anche se potrebbe essere un LLM diverso). Come può lo stesso LLM che ha generato una risposta essere un giudice imparziale della propria risposta? Il "trucco" è mettere l'LLM in una mentalità critica (riflessiva). Questo processo è analogo a quello di uno scrittore che utilizza una mentalità creativa per scrivere una prima bozza e poi passa a una mentalità critica per modificarla.
Ad esempio, immagina un flusso di lavoro con agenti il cui primo passaggio è creare testo per le tazze da caffè. Il prompt per questo passaggio potrebbe essere:
Sei un creativo. Genera un testo umoristico e originale di meno di 50 caratteri adatto a una tazza di caffè.
Ora immagina il seguente prompt riflessivo:
Sei un bevitore di caffè. Trovi divertente la risposta precedente?
Il flusso di lavoro potrebbe quindi passare alla fase successiva solo il testo che riceve un punteggio di riflessione elevato.
Apprendimento per rinforzo con feedback umano (RLHF)
Utilizzo del feedback dei valutatori umani per migliorare la qualità delle risposte di un modello. Ad esempio, un meccanismo RLHF può chiedere agli utenti di valutare la qualità della risposta di un modello con un'emoji 👍 o 👎. Il sistema può quindi modificare le risposte future in base a questo feedback.
risposta
Il testo, le immagini, l'audio o il video che un modello di AI generativa inferisce. In altre parole, un prompt è l'input di un modello di AI generativa e la risposta è l'output.
set di risposte
L'insieme di risposte che un modello linguistico di grandi dimensioni restituisce a un input set di prompt.
prompting dei ruoli
Un prompt, che in genere inizia con il pronome tu, che dice a un modello di IA generativa di fingere di essere una determinata persona o un determinato ruolo quando genera la risposta. I prompt di ruolo possono aiutare un modello di AI generativa a entrare nel giusto "stato mentale" per generare una risposta più utile. Ad esempio, a seconda del tipo di risposta che cerchi, potrebbe essere appropriato uno dei seguenti prompt per i ruoli:
Hai un dottorato in informatica.
Sei un ingegnere software che ama fornire spiegazioni pazienti su Python ai nuovi studenti di programmazione.
Sei un eroe d'azione con un insieme molto particolare di competenze di programmazione. Assicurami che troverai un determinato elemento in un elenco Python.
S
ottimizzazione dei prompt soft
Una tecnica per ottimizzare un modello linguistico di grandi dimensioni per un'attività specifica, senza un'ottimizzazione che richieda molte risorse. Anziché riaddestrare tutti i pesi nel modello, la messa a punto del prompt soft regola automaticamente un prompt per raggiungere lo stesso obiettivo.
Dato un prompt testuale, la messa a punto del soft prompt in genere aggiunge incorporamenti di token aggiuntivi al prompt e utilizza la retropropagazione per ottimizzare l'input.
Un prompt "hard" contiene token effettivi anziché incorporamenti di token.
specificational coding
Il processo di scrittura e manutenzione di un file in una lingua umana (ad esempio, l'inglese) che descrive il software. Puoi quindi chiedere a un modello di AI generativa o a un altro ingegnere software di creare il software che soddisfi questa descrizione.
Il codice generato automaticamente in genere richiede iterazioni. Nella codifica specificazionale, si itera sul file di descrizione. Al contrario, nella programmazione conversazionale, esegui iterazioni all'interno della casella del prompt. In pratica, la generazione automatica di codice a volte comporta una combinazione di codifica basata su specifiche e codifica conversazionale.
T
temperatura
Un iperparametro che controlla il grado di casualità dell'output di un modello. Temperature più alte generano un output più casuale, mentre temperature più basse generano un output meno casuale.
La scelta della temperatura migliore dipende dall'applicazione specifica e/o dai valori delle stringhe.
U
Ultra
Il modello Gemini con il maggior numero di parametri. Per maggiori dettagli, vedi Gemini Ultra.
V
Vertex
La piattaforma di Google Cloud per l'AI e il machine learning. Vertex fornisce strumenti e infrastrutture per creare, implementare e gestire applicazioni di AI, incluso l'accesso ai modelli Gemini.vibe coding
Richiedere a un modello di AI generativa di creare software. ovvero i prompt descrivono lo scopo e le funzionalità del software, che un modello di AI generativa traduce in codice sorgente. Il codice generato non sempre corrisponde alle tue intenzioni, quindi il vibe coding di solito richiede iterazioni.
Andrej Karpathy ha coniato il termine vibe coding in questo post su X. Nel post su X, Karpathy lo descrive come "un nuovo tipo di programmazione...in cui ti lasci completamente trasportare dalle vibrazioni..." Quindi, il termine originariamente implicava un approccio intenzionalmente approssimativo alla creazione di software in cui potresti non esaminare nemmeno il codice generato. Tuttavia, il termine si è evoluto rapidamente in molti ambienti fino a significare qualsiasi forma di programmazione generata dall'AI.
Per una descrizione più dettagliata della codifica delle vibrazioni, vedi Che cos'è il vibe coding?
Inoltre, confronta e metti in contrasto il vibe coding con:
Z
prompting zero-shot
Un prompt che non fornisce un esempio di come vuoi che risponda il modello linguistico di grandi dimensioni. Ad esempio:
| Parti di un prompt | Note |
|---|---|
| Qual è la valuta ufficiale del paese specificato? | La domanda a cui vuoi che l'LLM risponda. |
| India: | La query effettiva. |
Il modello linguistico di grandi dimensioni potrebbe rispondere con uno dei seguenti messaggi:
- Rupia
- INR
- ₹
- Rupia indiana
- La rupia
- Rupia indiana
Tutte le risposte sono corrette, anche se potresti preferire un formato particolare.
Confronta e contrapponi il prompt zero-shot con i seguenti termini: