Ta strona zawiera terminy z glosariusza generatywnej AI. Aby wyświetlić wszystkie terminy z glosariusza, kliknij tutaj.
A
adaptacja
Synonim dostrajania lub precyzyjnego dostrajania.
agent
Oprogramowanie, które potrafi analizować multimodalne dane wejściowe użytkownika, aby planować i wykonywać działania w jego imieniu.
W uczeniu przez wzmacnianie agent to podmiot, który używa strategii, aby zmaksymalizować oczekiwany zysk uzyskany w wyniku przechodzenia między stanami środowiska.
agentowy,
Przymiotnikowa forma słowa agent. Pojęcie „agentic” odnosi się do cech, które posiadają agenci (np. autonomii).
przepływ pracy agenta
Dynamiczny proces, w którym agent autonomicznie planuje i wykonuje działania w celu osiągnięcia celu. Proces ten może obejmować wnioskowanie, wywoływanie zewnętrznych narzędzi i samodzielne korygowanie planu.
AI slop
Dane wyjściowe z systemu generatywnej AI, który stawia na ilość, a nie na jakość. Na przykład strona internetowa z treściami wygenerowanymi przez AI jest wypełniona tanimi, wygenerowanymi przez AI treściami niskiej jakości.
automatyczna ocena,
Używanie oprogramowania do oceny jakości danych wyjściowych modelu.
Gdy dane wyjściowe modelu są stosunkowo proste, skrypt lub program może porównać dane wyjściowe modelu z wzorcową odpowiedzią. Ten typ automatycznej oceny jest czasami nazywany oceną programową. Do oceny automatycznej często przydają się dane takie jak ROUGE czy BLEU.
Gdy dane wyjściowe modelu są złożone lub nie ma jednej prawidłowej odpowiedzi, automatyczną ocenę przeprowadza czasami oddzielny program ML zwany automatycznym oceniającym.
Porównaj z oceną przez człowieka.
ocena automatyczna,
Mechanizm hybrydowy do oceny jakości danych wyjściowych modelu generatywnej AI, który łączy ocenę przez człowieka z oceną automatyczną. Automatyczny oceniający to model ML wytrenowany na danych utworzonych na podstawie oceny przez człowieka. W idealnym przypadku narzędzie automatyczne uczy się naśladować weryfikatora.Dostępne są gotowe automatyczne oceny, ale najlepsze z nich są dostosowane do konkretnego zadania, które oceniasz.
model autoregresyjny,
Model, który wyciąga wnioski na podstawie własnych wcześniejszych prognoz. Na przykład autoregresyjne modele językowe przewidują następny token na podstawie wcześniej przewidzianych tokenów. Wszystkie duże modele językowe oparte na architekturze Transformer są autoregresyjne.
Z kolei modele obrazów oparte na GAN zwykle nie są autoregresywne, ponieważ generują obraz w jednym przejściu do przodu, a nie iteracyjnie w krokach. Niektóre modele generowania obrazów są jednak autoregresywne, ponieważ generują obraz w krokach.
B
model podstawowy,
Wytrenowany model, który może służyć jako punkt wyjścia do dostrajania pod kątem konkretnych zadań lub zastosowań.
Zobacz też wstępnie wytrenowany model i model podstawowy.
C
wykorzystanie w prompcie łańcucha myśli
Technika inżynierii promptów, która zachęca duży model językowy (LLM) do wyjaśniania swojego rozumowania krok po kroku. Rozważmy na przykład ten prompt, zwracając szczególną uwagę na drugie zdanie:
Jakie przeciążenie odczuje kierowca samochodu, który przyspiesza od 0 do 96 km/h w 7 sekund? W odpowiedzi podaj wszystkie istotne obliczenia.
Odpowiedź LLM prawdopodobnie:
- Wyświetl sekwencję wzorów fizycznych, wstawiając wartości 0, 60 i 7 w odpowiednich miejscach.
- Wyjaśnij, dlaczego wybrano te formuły i co oznaczają poszczególne zmienne.
Promptowanie z użyciem ciągu myśli zmusza LLM do wykonania wszystkich obliczeń, co może prowadzić do uzyskania bardziej poprawnej odpowiedzi. Dodatkowo prompting typu chain-of-thought umożliwia użytkownikowi sprawdzenie kroków modelu LLM, aby określić, czy odpowiedź jest sensowna.
czat
Treść rozmowy z systemem ML, zwykle z dużym modelem językowym. Poprzednia interakcja na czacie (to, co zostało wpisane, i jak zareagował duży model językowy) staje się kontekstem dla kolejnych części czatu.
Czatbot to aplikacja oparta na dużym modelu językowym.
kontekstowy wektor dystrybucyjny języka
Osadzenie, które jest bliskie „rozumieniu” słów i wyrażeń w sposób, w jaki robią to osoby biegle posługujące się danym językiem. Osadzenia języka w kontekście potrafią zrozumieć złożoną składnię, semantykę i kontekst.
Rozważmy na przykład wektory dystrybucyjne angielskiego słowa cow. Starsze wektory dystrybucyjne, takie jak word2vec, mogą reprezentować angielskie słowa w taki sposób, że odległość w przestrzeni wektorów dystrybucyjnych od cow do bull jest podobna do odległości od ewe (owca) do ram (baran) lub od female do male. Osadzenia językowe uwzględniające kontekst mogą pójść o krok dalej i rozpoznać, że osoby anglojęzyczne czasami używają słowa cow w znaczeniu „krowa” lub „byk”.
okno kontekstu
Liczba tokenów, które model może przetworzyć w ramach danego promptu. Im większe okno kontekstu, tym więcej informacji może wykorzystać model, aby udzielać spójnych i konsekwentnych odpowiedzi na prompt.
kodowanie konwersacyjne
Interaktywny dialog między Tobą a modelem generatywnej AI w celu tworzenia oprogramowania. Wydajesz prompt opisujący oprogramowanie. Następnie model używa tego opisu do wygenerowania kodu. Następnie wydajesz nowy prompt, aby wyeliminować wady poprzedniego promptu lub wygenerowanego kodu, a model generuje zaktualizowany kod. Będziecie się wymieniać informacjami, aż wygenerowane oprogramowanie będzie wystarczająco dobre.
Kodowanie konwersacji to w zasadzie pierwotne znaczenie kodowania nastroju.
Porównaj z kodowaniem specyfikacyjnym.
D
bezpośrednie promptowanie
Synonim promptów „zero-shot”.
destylacja
Proces zmniejszania rozmiaru jednego modelu (zwanego modelem nauczycielskim) do mniejszego modelu (zwanego modelem uczniowskim), który jak najwierniej naśladuje prognozy modelu oryginalnego. Destylacja jest przydatna, ponieważ mniejszy model ma 2 główne zalety w porównaniu z większym modelem (nauczycielem):
- Szybszy czas wnioskowania
- mniejsze zużycie pamięci i energii,
Prognozy uczniów zwykle nie są jednak tak dobre jak prognozy nauczyciela.
Destylacja trenuje model ucznia, aby zminimalizować funkcję straty na podstawie różnicy między wynikami prognoz modeli ucznia i nauczyciela.
Porównaj destylację z tymi pojęciami:
Więcej informacji znajdziesz w szybkim szkoleniu z uczenia maszynowego w sekcji LLM: dostrajanie, destylacja i inżynieria promptów.
E
oceny
Używany głównie jako skrót od ocen modeli LLM. Ogólnie rzecz biorąc, oceny to skrót od dowolnej formy oceny.
ocena
Proces pomiaru jakości modelu lub porównywania różnych modeli ze sobą.
Aby ocenić nadzorowany model uczenia maszynowego, zwykle porównujesz go ze zbiorem walidacyjnym i zbiorem testowym. Ocena LLM zwykle obejmuje szersze oceny jakości i bezpieczeństwa.
P
zgodność z prawdą,
W świecie ML jest to właściwość opisująca model, którego dane wyjściowe są oparte na rzeczywistości. Faktyczność to pojęcie, a nie dane. Załóżmy na przykład, że wysyłasz do dużego modelu językowego ten prompt:
Jaki jest wzór chemiczny soli kuchennej?
Model optymalizujący pod kątem faktów odpowiedziałby:
NaCl
Można założyć, że wszystkie modele powinny opierać się na faktach. Niektóre prompty, np. te poniżej, powinny jednak spowodować, że model generatywnej AI będzie optymalizować kreatywność, a nie rzetelność.
Ułóż limeryk o astronautce i gąsienicy.
Jest mało prawdopodobne, aby powstały wierszyk był oparty na rzeczywistości.
Kontrast z uzasadnieniem.
szybki spadek
Technika trenowania, która zwiększa wydajność dużych modeli językowych. Szybkie zmniejszanie polega na szybkim zmniejszaniu szybkości uczenia podczas trenowania. Ta strategia pomaga zapobiegać nadmiernemu dopasowaniu modelu do danych treningowych i zwiększa uogólnianie.
prompty „few-shot”
Prompt zawierający więcej niż 1 przykład (kilka przykładów) pokazujący, jak powinien odpowiadać duży model językowy. Na przykład ten długi prompt zawiera 2 przykłady pokazujące modelowi językowemu, jak odpowiadać na zapytanie.
| Elementy jednego prompta | Uwagi |
|---|---|
| Jaka jest oficjalna waluta w wybranym kraju? | Pytanie, na które ma odpowiedzieć LLM. |
| Francja: EUR | Przykład. |
| Wielka Brytania: GBP | Inny przykład. |
| Indie: | Faktyczne zapytanie. |
Prompty typu „few-shot” zwykle dają lepsze wyniki niż prompty typu „zero-shot” i „one-shot”. Prompty „few-shot” wymagają jednak dłuższego prompta.
Prompty „few-shot” to forma uczenia się „few-shot” stosowana w uczeniu się na podstawie promptów.
Więcej informacji znajdziesz w szybkim szkoleniu z uczenia maszynowego w sekcji Projektowanie promptów.
dostrajanie,
Drugi etap trenowania, który jest wykonywany na wytrenowanym modelu i jest dostosowany do konkretnego zadania. Ma on na celu dopracowanie parametrów modelu pod kątem konkretnego zastosowania. Na przykład pełna sekwencja trenowania niektórych dużych modeli językowych wygląda tak:
- Wstępne trenowanie: trenowanie dużego modelu językowego na obszernym ogólnym zbiorze danych, np. na wszystkich stronach Wikipedii w języku angielskim.
- Dostrajanie: trenowanie wstępnie wytrenowanego modelu w celu wykonywania konkretnego zadania, np. odpowiadania na pytania medyczne. Dostrajanie zwykle obejmuje setki lub tysiące przykładów związanych z konkretnym zadaniem.
Inny przykład: pełna sekwencja trenowania dużego modelu obrazów wygląda tak:
- Wstępne trenowanie: wytrenuj duży model obrazów na olbrzymim zbiorze ogólnych obrazów, np. na wszystkich obrazach w Wikimedia Commons.
- Dostrojenie: trenowanie wstępnie wytrenowanego modelu w celu wykonania określonego zadania, np. generowania obrazów orek.
Dostrajanie może obejmować dowolną kombinację tych strategii:
- Zmiana wszystkich dotychczasowych parametrów wstępnie wytrenowanego modelu. Czasami nazywa się to pełnym dostrajaniem.
- Zmiana tylko niektórych istniejących parametrów wstępnie wytrenowanego modelu (zwykle warstw najbliższych warstwie wyjściowej), przy jednoczesnym zachowaniu innych istniejących parametrów bez zmian (zwykle warstw najbliższych warstwie wejściowej). Zobacz dostrajanie konkretnych parametrów.
- Dodawanie kolejnych warstw, zwykle na istniejących warstwach najbliższych warstwie wyjściowej.
Dostrajanie to forma uczenia transferowego. Dlatego dostrajanie może wykorzystywać inną funkcję straty lub inny typ modelu niż te, które zostały użyte do wytrenowania wstępnie wytrenowanego modelu. Możesz na przykład dostroić wstępnie wytrenowany duży model obrazów, aby uzyskać model regresji, który zwraca liczbę ptaków na obrazie wejściowym.
Porównaj dostrajanie z tymi terminami:
Więcej informacji znajdziesz w sekcji Dostrajanie w szybkim szkoleniu z uczenia maszynowego.
Model lampy błyskowej
Rodzina stosunkowo małych modeli Gemini zoptymalizowanych pod kątem szybkości i niskich opóźnień. Modele Flash są przeznaczone do szerokiego zakresu zastosowań, w których kluczowe są szybkie odpowiedzi i wysoka przepustowość.
model podstawowy
Bardzo duży wytrenowany model, który został wytrenowany na ogromnym i zróżnicowanym zbiorze treningowym. Model podstawowy może wykonywać obie te czynności:
- dobrze reagować na szeroki zakres żądań,
- Służyć jako model podstawowy do dodatkowego dostrajania lub innego dostosowywania.
Innymi słowy, model podstawowy jest już bardzo przydatny w ogólnym sensie, ale można go dodatkowo dostosować, aby był jeszcze bardziej przydatny w konkretnym zadaniu.
odsetek sukcesów
Dane do oceny wygenerowanego tekstu przez model ML. Ułamek sukcesów to liczba „udanych” wygenerowanych wyników tekstowych podzielona przez łączną liczbę wygenerowanych wyników tekstowych. Jeśli na przykład duży model językowy wygenerował 10 bloków kodu, z których 5 działało prawidłowo, odsetek udanych prób wyniesie 50%.
Chociaż odsetek sukcesów jest ogólnie przydatny w statystyce, w uczeniu maszynowym ten wskaźnik jest przydatny głównie do pomiaru zadań weryfikowalnych, takich jak generowanie kodu lub rozwiązywanie problemów matematycznych.
G
Gemini
Ekosystem obejmujący najbardziej zaawansowaną AI od Google. Elementy tego ekosystemu to:
- Różne modele Gemini.
- Interaktywny interfejs konwersacyjny do modelu Gemini. Użytkownicy wpisują prompty, a Gemini na nie odpowiada.
- Różne interfejsy Gemini API.
- Różne usługi dla firm oparte na modelach Gemini, np. Gemini w Google Cloud.
Modele Gemini
najnowocześniejsze modele multimodalne oparte na Transformerze od Google. Modele Gemini zostały zaprojektowane specjalnie z myślą o integracji z agentami.
Użytkownicy mogą wchodzić w interakcje z modelami Gemini na różne sposoby, m.in. za pomocą interaktywnego interfejsu dialogowego i zestawów SDK.
Gemma
Rodzina lekkich modeli otwartych, które powstały na podstawie tych samych badań i technologii, które zostały wykorzystane do stworzenia modeli Gemini. Dostępnych jest kilka różnych modeli Gemma, z których każdy oferuje inne funkcje, takie jak widzenie, kodowanie i wykonywanie instrukcji. Więcej informacji znajdziesz w sekcji Gemma.
generatywna AI lub GenAI
Skrót od generatywnej AI.
wygenerowany tekst,
Ogólnie rzecz biorąc, tekst wygenerowany przez model ML. Podczas oceny dużych modeli językowych niektóre dane porównują wygenerowany tekst z tekstem referencyjnym. Załóżmy na przykład, że chcesz sprawdzić, jak skutecznie model ML tłumaczy z francuskiego na holenderski. W tym przypadku:
- Wygenerowany tekst to tłumaczenie na język niderlandzki, które wygenerował model ML.
- Tekst referencyjny to tłumaczenie na język niderlandzki utworzone przez tłumacza (lub oprogramowanie).
Pamiętaj, że niektóre strategie oceny nie obejmują tekstu referencyjnego.
generatywna AI,
To nowa, przełomowa dziedzina, która nie ma formalnej definicji. Większość ekspertów zgadza się jednak, że modele generatywnej AI mogą tworzyć („generować”) treści, które są:
- złożone,
- spójny,
- oryginał
Przykłady generatywnej AI:
- Duże modele językowe, które mogą generować zaawansowane oryginalne teksty i odpowiadać na pytania.
- Model generowania obrazów, który może tworzyć unikalne obrazy.
- modele generowania dźwięku i muzyki, które mogą komponować oryginalną muzykę lub generować realistyczną mowę;
- modele do generowania filmów, które mogą tworzyć oryginalne filmy;
Niektóre starsze technologie, w tym LSTM i RNN, również mogą generować oryginalne i spójne treści. Niektórzy eksperci uważają te wcześniejsze technologie za generatywną AI, podczas gdy inni uważają, że prawdziwa generatywna AI wymaga bardziej złożonych wyników niż te wcześniejsze technologie.
Porównaj z prognozującym uczeniem maszynowym.
złota odpowiedź
Odpowiedź, która jest uznawana za dobrą. Na przykład w przypadku tego prompta:
2 + 2
Idealna odpowiedź to:
4
GPT (Generative Pre-trained Transformer)
Rodzina dużych modeli językowych opartych na architekturze Transformer opracowanych przez OpenAI.
Warianty GPT mogą być stosowane w przypadku różnych modalności, w tym:
- generowanie obrazów (np. ImageGPT),
- generowanie obrazów z tekstu (np. DALL-E);
H
halucynacje
Generowanie przez model generatywnej AI, który ma na celu przedstawienie twierdzenia o rzeczywistym świecie, danych wyjściowych, które wydają się wiarygodne, ale są niezgodne z faktami. Na przykład model generatywnej AI, który twierdzi, że Barack Obama zmarł w 1865 roku, halucynuje.
ocena przez człowieka,
Proces, w którym osoby oceniają jakość danych wyjściowych modelu ML, np. dwujęzyczni użytkownicy oceniają jakość tłumaczenia maszynowego. Weryfikacja manualna jest szczególnie przydatna w przypadku modeli, które nie mają jednej prawidłowej odpowiedzi.
Porównaj z oceną automatyczną i oceną przez automatyczny program oceny.
proces z udziałem człowieka
Luźno zdefiniowany idiom, który może oznaczać jedno z tych stwierdzeń:
- Zasady krytycznego lub sceptycznego podejścia do danych wyjściowych generatywnej AI.
- Strategia lub system zapewniający, że użytkownicy pomagają kształtować, oceniać i ulepszać zachowanie modelu. Utrzymanie człowieka w procesie umożliwia AI korzystanie zarówno z inteligencji maszynowej, jak i ludzkiej. Na przykład system, w którym AI generuje kod, a inżynierowie oprogramowania go sprawdzają, jest systemem z udziałem człowieka.
I
uczenie w kontekście,
Synonim promptów „few-shot”.
wnioskowanie
W tradycyjnym uczeniu maszynowym proces prognozowania polegający na zastosowaniu wytrenowanego modelu do nieoznaczonych przykładów. Więcej informacji znajdziesz w module Uczenie z nadzorem w kursie Wprowadzenie do uczenia maszynowego.
W dużych modelach językowych wnioskowanie to proces polegający na używaniu wytrenowanego modelu do generowania odpowiedzi na prompta.
W statystyce wnioskowanie ma nieco inne znaczenie. Szczegółowe informacje znajdziesz w artykule w Wikipedii na temat wnioskowania statystycznego.
dostrajanie przy użyciu instrukcji,
Rodzaj dostrajania, który zwiększa zdolność modelu generatywnej AI do wykonywania instrukcji. Dostrajanie przy użyciu instrukcji polega na trenowaniu modelu na podstawie serii promptów z instrukcjami, które zwykle obejmują szeroki zakres zadań. Model dostrojony do instrukcji ma wtedy tendencję do generowania przydatnych odpowiedzi na pytania bez przykładów w przypadku różnych zadań.
Porównaj z:
L
duży model językowy
Co najmniej model językowy z bardzo dużą liczbą parametrów. Bardziej nieformalnie: dowolny model językowy oparty na architekturze Transformer, np. Gemini lub GPT.
Więcej informacji znajdziesz w sekcji Duże modele językowe (LLM) w szybkim szkoleniu z uczenia maszynowego.
opóźnienie
Czas potrzebny modelowi na przetworzenie danych wejściowych i wygenerowanie odpowiedzi. Wygenerowanie odpowiedzi o dużym opóźnieniu trwa dłużej niż odpowiedzi o małym opóźnieniu.
Na opóźnienie dużych modeli językowych wpływają m.in. te czynniki:
- Długości tokenów wejściowych i wyjściowych
- Złożoność modelu
- Infrastruktura, na której działa model
Optymalizacja pod kątem opóźnień jest kluczowa w przypadku tworzenia aplikacji, które szybko reagują na działania użytkownika i są dla niego przyjazne.
LLM
Skrót od dużego modelu językowego.
Oceny LLM
Zestaw danych i punktów odniesienia do oceny wydajności dużych modeli językowych (LLM). Ogólnie rzecz biorąc, oceny LLM:
- pomagać badaczom w określaniu obszarów, w których modele LLM wymagają ulepszeń;
- Przydają się do porównywania różnych LLM i określania, który z nich najlepiej nadaje się do konkretnego zadania.
- pomagać w zapewnieniu bezpieczeństwa i etycznego charakteru LLM;
Więcej informacji znajdziesz w szybkim szkoleniu z uczenia maszynowego w sekcji Duże modele językowe (LLM).
LoRA
Skrót od Low-Rank Adaptability (adaptacja niskiego rzędu).
Adaptacja niskiego rzędu (LoRA)
Wydajna pod względem liczby parametrów technika dostrajania, która „zamraża” wstępnie wytrenowane wagi modelu (tak, aby nie można było ich już modyfikować), a następnie wstawia do modelu niewielki zestaw wag, które można trenować. Ten zestaw wag, które można wytrenować (zwany też „macierzami aktualizacji”), jest znacznie mniejszy niż model podstawowy, a co za tym idzie, jego trenowanie jest znacznie szybsze.
LoRA zapewnia te korzyści:
- Poprawia jakość prognoz modelu w domenie, w której zastosowano dostrajanie.
- Dostosowuje się szybciej niż techniki, które wymagają dostosowania wszystkich parametrów modelu.
- Zmniejsza koszt obliczeniowy wnioskowania, umożliwiając jednoczesne udostępnianie wielu wyspecjalizowanych modeli, które korzystają z tego samego modelu bazowego.
M
tłumaczenie maszynowe,
Używanie oprogramowania (zwykle modelu uczenia maszynowego) do przekształcania tekstu z jednego języka na inny, np. z angielskiego na japoński.
średnia precyzja przy k (mAP@k),
Średnia statystyczna wszystkich wyników średniej precyzji przy k w zbiorze danych do weryfikacji. Średnia precyzja przy k jest używana do oceny jakości rekomendacji generowanych przez system rekomendacji.
Chociaż wyrażenie „średnia arytmetyczna” brzmi redundantnie, nazwa wskaźnika jest odpowiednia. W końcu ten wskaźnik oblicza średnią z wielu wartości średniej precyzji przy k.
model mieszanin ekspertów,
Schemat zwiększania wydajności sieci neuronowej przez używanie tylko podzbioru jej parametrów (nazywanego ekspertem) do przetwarzania danego wejściowego tokena lub przykładu. Sieć bramkująca kieruje każdy token wejściowy lub przykład do odpowiednich ekspertów.
Szczegółowe informacje znajdziesz w tych artykułach:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mixture-of-Experts with Expert Choice Routing
MMIT
Skrót od multimodal instruction-tuned.
kaskadowe modele
System, który wybiera idealny model dla konkretnego zapytania o wnioskowanie.
Wyobraź sobie grupę modeli, od bardzo dużych (z wieloma parametrami) po znacznie mniejsze (z dużo mniejszą liczbą parametrów). Bardzo duże modele zużywają więcej zasobów obliczeniowych w czasie wnioskowania niż mniejsze modele. Jednak bardzo duże modele mogą zwykle obsługiwać bardziej złożone żądania niż mniejsze modele. Kaskadowe modele określają złożoność zapytania o wnioskowanie, a następnie wybierają odpowiedni model do przeprowadzenia wnioskowania. Główną motywacją do stosowania kaskadowego modelu jest zmniejszenie kosztów wnioskowania przez wybieranie mniejszych modeli i używanie większych modeli tylko w przypadku bardziej złożonych zapytań.
Wyobraź sobie, że mały model działa na telefonie, a większa wersja tego modelu działa na serwerze zdalnym. Dobre kaskadowe modele obniżają koszty i opóźnienia, ponieważ mniejszy model może obsługiwać proste żądania, a model zdalny jest wywoływany tylko w przypadku złożonych żądań.
Zobacz też router modelu.
router modelu
Algorytm, który określa idealny model na potrzeby wnioskowania w kaskadowym łączeniu modeli. Router modeli jest zwykle modelem uczenia maszynowego, który stopniowo uczy się wybierać najlepszy model dla danego wejścia. Router modeli może jednak czasami być prostszym algorytmem niezwiązanym z uczeniem maszynowym.
MOE
Skrót od mixture of experts (mieszanka ekspertów).
MT
Skrót od tłumaczenia maszynowego.
N
Nano
Stosunkowo mały model Gemini przeznaczony do użytku na urządzeniu. Więcej informacji znajdziesz w sekcji Gemini Nano.
nie ma jednej prawidłowej odpowiedzi (NORA),
Prompt z wieloma prawidłowymi odpowiedziami. Na przykład ten prompt nie ma jednej prawidłowej odpowiedzi:
Opowiedz mi zabawny dowcip o słoniach.
Ocena odpowiedzi na prompty, które nie mają jednej prawidłowej odpowiedzi, jest zwykle znacznie bardziej subiektywna niż ocena promptów, które mają jedną prawidłową odpowiedź. Na przykład ocena dowcipu o słoniu wymaga systematycznego sposobu określenia, jak śmieszny jest dany żart.
NORA
Skrót od no one right answer.
Notebook LM
Narzędzie oparte na Gemini, które umożliwia użytkownikom przesyłanie dokumentów, a następnie zadawanie pytań, podsumowywanie i organizowanie tych dokumentów za pomocą promptów. Na przykład autor może przesłać kilka opowiadań i poprosić NotebookLM o znalezienie wspólnych motywów lub określenie, które z nich najlepiej nadaje się na film.
O
jedna poprawna odpowiedź (ORA),
Prompt z jedną prawidłową odpowiedzią. Rozważmy na przykład ten prompt:
Prawda czy fałsz: Saturn jest większy od Marsa.
Jedyna prawidłowa odpowiedź to prawda.
W przeciwieństwie do nie ma jednej prawidłowej odpowiedzi.
prompty „one-shot”
Prompt zawierający jeden przykład pokazujący, jak powinien odpowiadać duży model językowy. Na przykład poniższy prompt zawiera 1 przykład pokazujący dużemu modelowi językowemu, jak powinien odpowiadać na zapytanie.
| Elementy jednego prompta | Uwagi |
|---|---|
| Jaka jest oficjalna waluta w wybranym kraju? | Pytanie, na które ma odpowiedzieć LLM. |
| Francja: EUR | Przykład. |
| Indie: | Faktyczne zapytanie. |
Porównaj promptowanie z jednym przykładem z tymi terminami:
ORA
Skrót od jedna poprawna odpowiedź.
P
dostrajanie konkretnych parametrów,
Zbiór technik dostrajania dużego wstępnie wytrenowanego modelu językowego (PLM) bardziej efektywnie niż w przypadku pełnego dostrajania. Dostrajanie konkretnych parametrów zwykle dostraja znacznie mniej parametrów niż pełne dostrajanie, ale zwykle tworzy duży model językowy, który działa tak samo (lub prawie tak samo) jak duży model językowy utworzony na podstawie pełnego dostrajania.
Porównaj dostrajanie konkretnych parametrów z:
Dostrajanie konkretnych parametrów jest też nazywane dostrajaniem konkretnych parametrów.
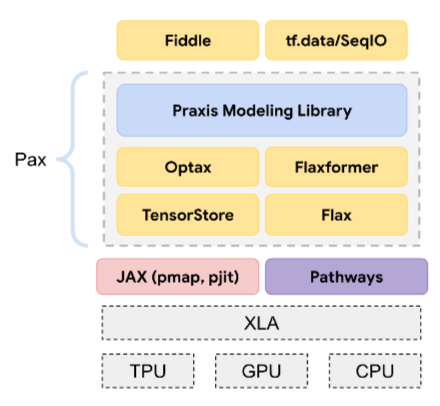
Pax
Platforma programistyczna przeznaczona do trenowania dużych modeli sieci neuronowych , które są tak duże, że obejmują wiele układów TPU, akceleratorów lub podów.
Pax jest oparty na Flax, który z kolei jest oparty na JAX.
PLM
Skrót od wytrenowanego modelu językowego.
dotrenowany model
Ogólne określenie, które zwykle odnosi się do wytrenowanego modelu, który przeszedł pewne przetwarzanie końcowe, np. co najmniej 1 z tych procesów:
wytrenowany model,
Chociaż to pojęcie może odnosić się do dowolnego wytrenowanego modelu lub wytrenowanego wektora osadzania, obecnie termin „wytrenowany model” zwykle odnosi się do wytrenowanego dużego modelu językowego lub innej formy wytrenowanego modelu generatywnej AI.
Zobacz też model podstawowy i model podstawowy.
wstępne trenowanie,
Początkowe trenowanie modelu na dużym zbiorze danych. Niektóre wstępnie wytrenowane modele są nieporadnymi gigantami i zwykle wymagają dopracowania w ramach dodatkowego trenowania. Na przykład eksperci w dziedzinie uczenia maszynowego mogą wstępnie wytrenować duży model językowy na podstawie obszernego zbioru danych tekstowych, np. wszystkich stron Wikipedii w języku angielskim. Po wstępnym trenowaniu model można jeszcze ulepszyć za pomocą jednej z tych technik:
- destylacja
- dostrajanie,
- dostrajanie przy użyciu instrukcji,
- dostrajanie konkretnych parametrów
- prompt-tuning
Pro
Model Gemini z mniejszą liczbą parametrów niż Ultra, ale większą niż Nano. Więcej informacji znajdziesz w sekcji Gemini Pro.
prompt
Tekst wprowadzany jako dane wejściowe do dużego modelu językowego w celu warunkowania modelu, aby zachowywał się w określony sposób. Prompty mogą być krótkie, np. w postaci frazy, lub dowolnie długie (np. cały tekst powieści). Prompty należą do różnych kategorii, w tym do tych, które przedstawia poniższa tabela:
| Kategoria prompta | Przykład | Uwagi |
|---|---|---|
| Pytanie | Jak szybko może lecieć gołąb? | |
| Instrukcja | Napisz zabawny wiersz o arbitrażu. | Prompt, w którym prosisz duży model językowy o wykonanie jakiegoś działania. |
| Przykład | Przetłumacz kod Markdown na HTML. Przykład:
Markdown: * list item HTML: <ul> <li>list item</li> </ul> |
Pierwsze zdanie w tym przykładowym prompcie to instrukcja. Pozostała część promptu to przykład. |
| Rola | Wyjaśnij, dlaczego w uczeniu maszynowym stosuje się metodę spadku gradientowego. | Pierwsza część zdania to instrukcja, a wyrażenie „to a PhD in Physics” to część dotycząca roli. |
| Częściowe dane wejściowe, które model ma uzupełnić. | Premier Wielkiej Brytanii mieszka w | Częściowy prompt wejściowy może się nagle kończyć (jak w tym przykładzie) lub kończyć się podkreśleniem. |
Model generatywnej AI może odpowiadać na prompty za pomocą tekstu, kodu, obrazów, wektorów dystrybucyjnych, filmów… prawie wszystkiego.
uczenie oparte na promptach,
Funkcja niektórych modeli, która umożliwia im dostosowywanie zachowania w odpowiedzi na dowolne dane wejściowe w postaci tekstu (prompty). W typowym paradygmacie uczenia opartego na promptach duży model językowy odpowiada na prompt, generując tekst. Załóżmy na przykład, że użytkownik wpisuje ten prompt:
Podsumuj trzecią zasadę dynamiki Newtona.
Model zdolny do uczenia się na podstawie promptów nie jest specjalnie trenowany pod kątem odpowiadania na poprzedni prompt. Model „zna” wiele faktów z zakresu fizyki, wiele ogólnych reguł językowych i wiele informacji o tym, co stanowi ogólnie przydatne odpowiedzi. Ta wiedza wystarczy, aby udzielić (miejmy nadzieję) przydatnej odpowiedzi. Dodatkowe opinie użytkowników („Ta odpowiedź była zbyt skomplikowana” lub „Czym jest reakcja?”) umożliwiają niektórym systemom uczenia się na podstawie promptów stopniowe zwiększanie przydatności odpowiedzi.
projektowanie promptów,
Synonim terminu tworzenie promptów.
tworzenie promptów,
Sztuka tworzenia promptów, które pozwalają uzyskać oczekiwane odpowiedzi od dużego modelu językowego. Ludzie przeprowadzają inżynierię promptów. Tworzenie dobrze skonstruowanych promptów jest niezbędne, aby uzyskać przydatne odpowiedzi z dużego modelu językowego. Inżynieria promptów zależy od wielu czynników, m.in.:
- Zbiór danych używany do wstępnego trenowania i ewentualnego dostrajania dużego modelu językowego.
- Temperatura i inne parametry dekodowania, których model używa do generowania odpowiedzi.
Projektowanie promptów to synonim tworzenia promptów.
Więcej informacji o tworzeniu przydatnych promptów znajdziesz w artykule Wprowadzenie do projektowania promptów.
zestaw promptów,
Grupa promptów do oceny dużego modelu językowego. Na przykład poniższa ilustracja przedstawia zestaw promptów składający się z 3 promptów:

Dobre zestawy promptów składają się z wystarczająco „szerokiej” kolekcji promptów, aby dokładnie ocenić bezpieczeństwo i przydatność dużego modelu językowego.
Zobacz też zestaw odpowiedzi.
dostrajanie promptów,
Mechanizm wydajnego dostrajania parametrów, który uczy się „prefiksu” dodawanego przez system przed rzeczywistym promptem.
Jedną z odmian dostrajania promptów, czasami nazywaną dostrajaniem prefiksów, jest dodawanie prefiksu na każdej warstwie. W przeciwieństwie do tego większość metod dostrajania promptów dodaje tylko prefiks do warstwy wejściowej.
R
tekst referencyjny,
Odpowiedź eksperta na prompt. Na przykład w przypadku tego prompta:
Przetłumacz pytanie „What is your name?” z języka angielskiego na francuski.
Odpowiedź eksperta może brzmieć:
Comment vous appelez-vous?
Różne wskaźniki (np. ROUGE) mierzą stopień, w jakim tekst referencyjny pasuje do wygenerowanego tekstu modelu ML.
refleksja
Strategia poprawy jakości przepływu pracy agenta polegająca na analizowaniu (refleksji) danych wyjściowych kroku przed przekazaniem ich do następnego kroku.
Sprawdzającym jest często ten sam LLM, który wygenerował odpowiedź (może to być jednak inny LLM). Jak ten sam LLM, który wygenerował odpowiedź, może być obiektywnym sędzią własnej odpowiedzi? „Sztuczka” polega na wprowadzeniu LLM w stan krytycznego (refleksyjnego) myślenia. Ten proces jest podobny do pracy pisarza, który najpierw tworzy pierwszą wersję roboczą, a potem ją edytuje.
Wyobraź sobie na przykład przepływ pracy oparty na agentach, którego pierwszym krokiem jest utworzenie tekstu na kubki do kawy. Prompt dla tego kroku może wyglądać tak:
Jesteś twórcą. Wygeneruj zabawny, oryginalny tekst o długości nieprzekraczającej 50 znaków, który będzie pasować na kubek do kawy.
Wyobraź sobie teraz ten prompt refleksyjny:
Pijesz kawę. Czy powyższa odpowiedź jest zabawna?
W takim przypadku przepływ pracy może przekazywać do następnego etapu tylko tekst, który uzyskał wysoki wynik odzwierciedlenia.
Uczenie się przez wzmacnianie na podstawie opinii użytkowników (RLHF)
Wykorzystywanie opinii osób oceniających do poprawy jakości odpowiedzi modelu. Na przykład mechanizm RLHF może poprosić użytkowników o ocenę jakości odpowiedzi modelu za pomocą emotikonu 👍 lub 👎. System może następnie dostosowywać przyszłe odpowiedzi na podstawie tych opinii.
odpowiedź
Tekst, obrazy, dźwięki lub filmy, które generatywny model AI wywnioskuje. Innymi słowy, prompt to dane wejściowe dla modelu generatywnej AI, a odpowiedź to dane wyjściowe.
zbiór odpowiedzi,
Zbiór odpowiedzi dużego modelu językowego jest zwracany do zestawu promptów wejściowych.
role prompting
Prompt, który zwykle zaczyna się od zaimka ty i mówi modelowi generatywnej AI, aby podczas generowania odpowiedzi udawał określoną osobę lub odgrywał określoną rolę. Prompt odgrywający rolę może pomóc modelowi generatywnej AI wejść w odpowiedni „stan umysłu”, aby wygenerować bardziej przydatną odpowiedź. Na przykład w zależności od rodzaju odpowiedzi, jakiej oczekujesz, możesz użyć dowolnego z tych promptów dotyczących roli:
Masz tytuł doktora informatyki.
Jesteś inżynierem oprogramowania, który lubi cierpliwie tłumaczyć podstawy Pythona nowym studentom programowania.
Jesteś bohaterem kina akcji o bardzo specyficznych umiejętnościach programistycznych. Zapewnij mnie, że znajdziesz konkretny element na liście Pythona.
S
dostrajanie promptów miękkich
Technika dostrajania dużego modelu językowego do konkretnego zadania bez wymagającego dużych zasobów dostrajania. Zamiast ponownie trenować wszystkie wagi w modelu, dostrajanie miękkiego promptu automatycznie dostosowuje prompt, aby osiągnąć ten sam cel.
W przypadku prompta tekstowego dostrajanie prompta zwykle dodaje do niego dodatkowe osadzenia tokenów i używa propagacji wstecznej do optymalizacji danych wejściowych.
„Twardy” prompt zawiera rzeczywiste tokeny zamiast osadzeń tokenów.
kodowanie specyfikacyjne,
Proces tworzenia i aktualizowania pliku w języku naturalnym (np. angielskim), który opisuje oprogramowanie. Następnie możesz poprosić model generatywnej AI lub innego inżyniera oprogramowania o utworzenie oprogramowania zgodnego z tym opisem.
Wygenerowany automatycznie kod zwykle wymaga iteracji. W kodowaniu specyfikacyjnym iterujesz na pliku opisu. Natomiast w kodowaniu konwersacyjnym iteracje wykonujesz w polu promptu. W praktyce automatyczne generowanie kodu czasami obejmuje zarówno kodowanie specyfikacyjne, jak i konwersacyjne.
T
temperatura
Hiperparametr, który kontroluje stopień losowości danych wyjściowych modelu. Wyższe temperatury dają bardziej losowe wyniki, a niższe – mniej losowe.
Wybór najlepszej temperatury zależy od konkretnego zastosowania i wartości ciągu znaków.
U
Ultra
Model Gemini z największą liczbą parametrów. Więcej informacji znajdziesz w sekcji Gemini Ultra.
V
Vertex
Platforma Google Cloud do sztucznej inteligencji i uczenia maszynowego. Vertex udostępnia narzędzia i infrastrukturę do tworzenia, wdrażania i zarządzania aplikacjami AI, w tym dostęp do modeli Gemini.vibe coding
Wydawanie modelowi generatywnej AI poleceń tworzenia oprogramowania. Oznacza to, że prompty opisują przeznaczenie i funkcje oprogramowania, które model generatywnej AI przekłada na kod źródłowy. Wygenerowany kod nie zawsze odpowiada Twoim intencjom, dlatego kodowanie wibracyjne zwykle wymaga iteracji.
Andrej Karpathy ukuł termin „vibe coding” w tym poście na X. W poście na platformie X Karpathy opisuje ten styl jako „nowy rodzaj kodowania, w którym w pełni poddajesz się atmosferze…”. Początkowo termin ten oznaczał celowo luźne podejście do tworzenia oprogramowania, w którym nie musisz nawet sprawdzać wygenerowanego kodu. Jednak w wielu kręgach termin ten szybko ewoluował i obecnie oznacza każdą formę kodu wygenerowanego przez AI.
Bardziej szczegółowy opis kodowania wibracji znajdziesz w artykule Co to jest vibe coding?
Porównaj też kodowanie wibracyjne z:
Z
prompty „zero-shot”
Prompt, który nie zawiera przykładu tego, jak ma odpowiadać duży model językowy. Na przykład:
| Elementy jednego prompta | Uwagi |
|---|---|
| Jaka jest oficjalna waluta w wybranym kraju? | Pytanie, na które ma odpowiedzieć LLM. |
| Indie: | Faktyczne zapytanie. |
Duży model językowy może odpowiedzieć w jeden z tych sposobów:
- Rupia
- INR
- ₹
- Rupia indyjska
- rupia,
- Rupia indyjska
Wszystkie odpowiedzi są prawidłowe, ale możesz preferować określony format.
Porównaj promptowanie bez przykładów z tymi terminami: