Esta página contém termos do glossário de IA generativa. Para conferir todos os termos do glossário, clique aqui.
A
adaptação
Sinônimo de ajuste ou ajuste fino.
agente
Software que pode raciocinar sobre as entradas do usuário para planejar e executar ações em nome dele.
No aprendizado por reforço, um agente é a entidade que usa uma política para maximizar o retorno esperado obtido com a transição entre estados do ambiente.
agêntico / agêntica
A forma adjetiva de agente. Agêntico se refere às qualidades que os agentes têm (como autonomia).
fluxo de trabalho com agentes
Um processo dinâmico em que um agente planeja e executa ações de forma autônoma para alcançar uma meta. O processo pode envolver raciocínio, invocação de ferramentas externas e autocorreção do plano.
IA slop
Saída de um sistema de IA generativa que prioriza a quantidade em vez da qualidade. Por exemplo, uma página da Web com IA slop é preenchida com conteúdo de baixa qualidade, gerado com IA e produzido de forma barata.
avaliação automática
Usar software para julgar a qualidade da saída de um modelo.
Quando a saída do modelo é relativamente simples, um script ou programa pode comparar a saída do modelo com uma resposta ideal. Esse tipo de avaliação automática às vezes é chamado de avaliação programática. Métricas como ROUGE ou BLEU costumam ser úteis para avaliação programática.
Quando a saída do modelo é complexa ou não tem uma resposta certa, um programa de ML separado chamado autorrater às vezes realiza a avaliação automática.
Contraste com a avaliação humana.
avaliação do avaliador automático
Um mecanismo híbrido para julgar a qualidade da saída de um modelo de IA generativa que combina avaliação humana com avaliação automática. Um autoavaliador é um modelo de ML treinado com dados criados por avaliação humana. O ideal é que um avaliador automático aprenda a imitar um avaliador humano.Há avaliadores automáticos pré-criados, mas os melhores são ajustados especificamente para a tarefa que você está avaliando.
modelo autorregressivo
Um modelo que infere uma previsão com base nas próprias previsões anteriores. Por exemplo, os modelos de linguagem autorregressivos preveem o próximo token com base nos tokens previstos anteriormente. Todos os modelos de linguagem grande baseados em Transformer são autorregressivos.
Em contraste, os modelos de imagem baseados em GAN geralmente não são autorregressivos, já que geram uma imagem em uma única passagem direta e não de forma iterativa em etapas. No entanto, alguns modelos de geração de imagens são autorregressivos porque geram uma imagem em etapas.
B
modelo de base
Um modelo pré-treinado que pode servir como ponto de partida para ajustes para lidar com tarefas ou aplicativos específicos.
Consulte também modelo pré-treinado e modelo de fundação.
C
Comandos com linha de raciocínio
Uma técnica de engenharia de comando que incentiva um modelo de linguagem grande (LLM) a explicar o raciocínio dele, etapa por etapa. Por exemplo, considere o seguinte comando, prestando atenção especial à segunda frase:
Quantas forças G um motorista sentiria em um carro que vai de 0 a 100 km/h em 7 segundos? Na resposta, mostre todos os cálculos relevantes.
A resposta do LLM provavelmente:
- Mostre uma sequência de fórmulas de física, inserindo os valores 0, 60 e 7 nos lugares apropriados.
- Explique por que ele escolheu essas fórmulas e o que significam as várias variáveis.
Os comandos com linha de raciocínio forçam o LLM a realizar todos os cálculos, o que pode levar a uma resposta mais correta. Além disso, o comando de cadeia de pensamento permite que o usuário examine as etapas do LLM para determinar se a resposta faz sentido.
chat
O conteúdo de um diálogo entre duas pessoas com um sistema de ML, geralmente um modelo de linguagem grande. A interação anterior em uma conversa (o que você digitou e como o modelo de linguagem grande respondeu) se torna o contexto para as partes subsequentes da conversa.
Um chatbot é um aplicativo de um modelo de linguagem grande.
embedding de linguagem contextualizada
Uma embedding que se aproxima da "compreensão" de palavras e frases da mesma forma que falantes humanos fluentes. Os encodings de linguagem contextualizada podem entender sintaxe, semântica e contexto complexos.
Por exemplo, considere embeddings da palavra em inglês cow. Embeddings mais antigos, como word2vec, podem representar palavras em inglês de modo que a distância no espaço de embedding de cow (vaca) para bull (touro) seja semelhante à distância de ewe (ovelha fêmea) para ram (carneiro) ou de female (feminino) para male (masculino). As incorporações de linguagem contextualizada podem ir além, reconhecendo que os falantes de inglês às vezes usam casualmente a palavra cow para se referir a vaca ou touro.
janela de contexto
O número de tokens que um modelo pode processar em um determinado comando. Quanto maior a janela de contexto, mais informações o modelo pode usar para fornecer respostas coerentes e consistentes ao comando.
programação conversacional
Um diálogo iterativo entre você e um modelo de IA generativa com o objetivo de criar software. Você emite um comando descrevendo um software. Em seguida, o modelo usa essa descrição para gerar código. Em seguida, você envia um novo comando para corrigir as falhas no comando anterior ou no código gerado, e o modelo gera um código atualizado. Vocês dois vão continuar trocando informações até que o software gerado seja bom o suficiente.
A programação de conversas é essencialmente o significado original de vibe coding.
Contraste com a programação especificacional.
D
comando direto
Sinônimo de comando zero-shot.
destilação
O processo de redução do tamanho de um modelo (conhecido como professor) em um modelo menor (conhecido como estudante) que emula as previsões do modelo original da forma mais fiel possível. A destilação é útil porque o modelo menor tem dois benefícios principais em relação ao modelo maior (o professor):
- Tempo de inferência mais rápido
- Uso reduzido de memória e energia
No entanto, as previsões dos estudantes geralmente não são tão boas quanto as dos professores.
A destilação treina o modelo estudante para minimizar uma função de perda com base na diferença entre as saídas das previsões dos modelos estudante e professor.
Compare e contraste a destilação com os seguintes termos:
Consulte LLMs: ajuste fino, destilação e engenharia de comando no Curso intensivo de machine learning para mais informações.
E
avaliações
Usado principalmente como abreviação de avaliações de LLM. De modo geral, avaliações é uma abreviação de qualquer forma de avaliação.
Avaliação
O processo de medir a qualidade de um modelo ou comparar diferentes modelos entre si.
Para avaliar um modelo de machine learning supervisionado, normalmente você o compara a um conjunto de validação e a um conjunto de teste. Avaliar um LLM normalmente envolve avaliações mais amplas de qualidade e segurança.
F
veracidade
No mundo do ML, uma propriedade que descreve um modelo cuja saída é baseada na realidade. A veracidade é um conceito, não uma métrica. Por exemplo, suponha que você envie o seguinte comando para um modelo de linguagem grande:
Qual é a fórmula química do sal de cozinha?
Um modelo que otimiza a veracidade responderia:
NaCl
É tentador presumir que todos os modelos devem ser baseados em fatos. No entanto, alguns comandos, como os seguintes, devem fazer com que um modelo de IA generativa otimize a criatividade em vez da factualidade.
Conte uma sátira sobre um astronauta e uma lagarta.
É improvável que o limerique resultante seja baseado na realidade.
Contraste com o fundamento.
decaimento rápido
Uma técnica de treinamento para melhorar a performance dos LLMs. O decaimento rápido envolve a diminuição rápida da taxa de aprendizado durante o treinamento. Essa estratégia ajuda a evitar que o modelo faça overfitting nos dados de treinamento e melhora a generalização.
comando de poucos disparos
Um comando que contém mais de um exemplo (alguns) demonstrando como o modelo de linguagem grande deve responder. Por exemplo, o comando longo a seguir contém dois exemplos que mostram a um modelo de linguagem grande como responder a uma consulta.
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Por exemplo, |
| Reino Unido: GBP | Outro exemplo. |
| Índia: | A consulta real. |
Em geral, os comandos de poucos disparos (few-shot) produzem resultados mais interessantes do que os comandos zero-shot e one-shot. No entanto, o comando de poucos disparos exige um comando mais longo.
O comando de poucos disparos é uma forma de aprendizado few-shot aplicada ao aprendizado baseado em comandos.
Consulte Engenharia de comando no Curso intensivo de machine learning para mais informações.
ajuste
Uma segunda passagem de treinamento específica para tarefas realizada em um modelo pré-treinado para refinar os parâmetros dele em um caso de uso específico. Por exemplo, a sequência de treinamento completa para alguns modelos de linguagem grandes é a seguinte:
- Pré-treinamento:treine um modelo de linguagem grande em um vasto conjunto de dados geral, como todas as páginas da Wikipédia em inglês.
- Ajuste de detalhes:treine o modelo pré-treinado para realizar uma tarefa específica, como responder a consultas médicas. O ajuste geralmente envolve centenas ou milhares de exemplos focados na tarefa específica.
Como outro exemplo, a sequência de treinamento completa para um modelo de imagem grande é a seguinte:
- Pré-treinamento:treine um modelo de imagem grande em um vasto conjunto de dados de imagens gerais, como todas as imagens do Wikimedia Commons.
- Ajuste:treine o modelo pré-treinado para realizar uma tarefa específica, como gerar imagens de orcas.
O ajuste fino pode envolver qualquer combinação das seguintes estratégias:
- Modificar todos os parâmetros do modelo pré-treinado. Às vezes, isso é chamado de ajuste fino completo.
- Modificar apenas alguns dos parâmetros atuais do modelo pré-treinado (normalmente, as camadas mais próximas da camada de saída), mantendo outros parâmetros inalterados (normalmente, as camadas mais próximas da camada de entrada). Consulte ajuste da eficiência de parâmetros.
- Adicionar mais camadas, geralmente acima das camadas atuais mais próximas da camada de saída.
O ajuste é uma forma de aprendizado por transferência. Assim, o ajuste fino pode usar uma função de perda ou um tipo de modelo diferente daqueles usados para treinar o modelo pré-treinado. Por exemplo, é possível ajustar um modelo de imagem grande pré-treinado para produzir um modelo de regressão que retorne o número de pássaros em uma imagem de entrada.
Compare e contraste o ajuste fino com os seguintes termos:
Consulte Ajuste refinado no Curso intensivo de machine learning para mais informações.
Modelo do flash
Uma família de modelos Gemini relativamente pequenos otimizados para velocidade e baixa latência. Os modelos Flash são projetados para uma ampla variedade de aplicativos em que respostas rápidas e alta capacidade de processamento são cruciais.
modelo de fundação
Um modelo pré-treinado muito grande treinado em um conjunto de treinamento enorme e diversificado. Um modelo de fundação pode fazer o seguinte:
- Responder bem a uma ampla variedade de solicitações.
- Servir como um modelo de base para outros ajustes refinados ou personalizações.
Em outras palavras, um modelo de fundação já é muito capaz em um sentido geral, mas pode ser ainda mais personalizado para se tornar ainda mais útil para uma tarefa específica.
fração de sucessos
Uma métrica para avaliar o texto gerado de um modelo de ML. A fração de sucessos é o número de saídas de texto geradas "bem-sucedidas" dividido pelo número total de saídas de texto geradas. Por exemplo, se um modelo de linguagem grande gerar 10 blocos de código, cinco dos quais foram bem-sucedidos, a fração de sucessos será de 50%.
Embora a fração de sucessos seja útil em estatísticas, no aprendizado de máquina, essa métrica é usada principalmente para medir tarefas verificáveis, como geração de código ou problemas de matemática.
G
Gemini
O ecossistema que inclui a IA mais avançada do Google. Os elementos desse ecossistema incluem:
- Vários modelos do Gemini.
- A interface de conversa interativa para um modelo do Gemini. Os usuários digitam comandos, e o Gemini responde a eles.
- Várias APIs Gemini.
- Vários produtos comerciais baseados em modelos do Gemini, por exemplo, o Gemini para Google Cloud.
Modelos do Gemini
Modelos multimodais de última geração do Google baseados em Transformer. Os modelos do Gemini foram criados especificamente para integração com agentes.
Os usuários podem interagir com os modelos do Gemini de várias maneiras, incluindo uma interface de diálogo interativa e SDKs.
Gemma
Uma família de modelos abertos leves criados com base na mesma pesquisa e tecnologia usadas para criar os modelos do Gemini. Vários modelos diferentes da Gemma estão disponíveis, cada um com recursos diferentes, como visão, código e instruções a seguir. Consulte Gemma para mais detalhes.
IA generativa ou IA generativa
Abreviação de IA generativa.
texto gerado
Em geral, o texto gerado por um modelo de ML. Ao avaliar modelos de linguagem grandes, algumas métricas comparam o texto gerado com o texto de referência. Por exemplo, suponha que você esteja tentando determinar a eficácia de um modelo de ML na tradução do francês para o holandês. Neste caso:
- O texto gerado é a tradução em holandês que o modelo de ML gera.
- O texto de referência é a tradução em holandês criada por um tradutor humano (ou software).
Algumas estratégias de avaliação não envolvem texto de referência.
IA generativa
Um campo transformador emergente sem uma definição formal. No entanto, a maioria dos especialistas concorda que os modelos de IA generativa podem criar ("gerar") conteúdo que seja:
- complexo
- coerente
- original
Exemplos de IA generativa:
- Modelos de linguagem grandes, que podem gerar textos originais sofisticados e responder a perguntas.
- Modelo de geração de imagens, que pode produzir imagens exclusivas.
- Modelos de geração de áudio e música, que podem compor músicas originais ou gerar fala realista.
- Modelos de geração de vídeo, que podem criar vídeos originais.
Algumas tecnologias anteriores, incluindo LSTMs e RNNs, também podem gerar conteúdo original e coerente. Alguns especialistas consideram essas tecnologias anteriores como IA generativa, enquanto outros acham que a IA generativa de verdade exige uma saída mais complexa do que essas tecnologias podem produzir.
Contraste com a ML preditiva.
resposta de ouro
Uma resposta conhecida por ser boa. Por exemplo, considerando o seguinte comando:
2 + 2
A resposta ideal é:
4
GPT (transformer generativo pré-treinado)
Uma família de modelos de linguagem grandes baseados em Transformer desenvolvida pela OpenAI.
As variantes do GPT podem ser aplicadas a várias modalidades, incluindo:
- geração de imagens (por exemplo, ImageGPT)
- conversão de texto em imagem (por exemplo, DALL-E).
H
alucinação
A produção de resultados que parecem plausíveis, mas são factualmente incorretos, por um modelo de IA generativa que pretende fazer uma declaração sobre o mundo real. Por exemplo, um modelo de IA generativa que afirma que Barack Obama morreu em 1865 está alucinando.
avaliação humana
Um processo em que pessoas avaliam a qualidade da saída de um modelo de ML. Por exemplo, pessoas bilíngues avaliam a qualidade de um modelo de tradução de ML. A avaliação humana é especialmente útil para julgar modelos que não têm uma resposta certa.
Contraste com a avaliação automática e a avaliação do autorrater.
human in the loop (HITL)
Uma expressão mal definida que pode significar uma das seguintes opções:
- Uma política de analisar a saída da IA generativa de forma crítica ou cética.
- Uma estratégia ou um sistema para garantir que as pessoas ajudem a moldar, avaliar e refinar o comportamento de um modelo. Manter um humano no processo permite que uma IA se beneficie da inteligência humana e de máquina. Por exemplo, um sistema em que uma IA gera código que engenheiros de software revisam é um sistema humano no loop.
I
aprendizado contextual
Sinônimo de comando de poucos disparos (few-shot).
inferência
No machine learning tradicional, o processo de fazer previsões aplicando um modelo treinado a exemplos sem rótulo. Consulte Aprendizado supervisionado no curso "Introdução ao ML" para saber mais.
Em modelos de linguagem grandes, a inferência é o processo de usar um modelo treinado para gerar uma resposta a um comando.
A inferência tem um significado um pouco diferente em estatística. Consulte o artigo da Wikipédia sobre inferência estatística para mais detalhes.
ajuste de instruções
Uma forma de ajuste refinado que melhora a capacidade de um modelo de IA generativa de seguir instruções. O ajuste de instruções envolve treinar um modelo em uma série de comandos de instrução, geralmente abrangendo uma ampla variedade de tarefas. O modelo ajustado com instruções tende a gerar respostas úteis para comandos zero-shot em várias tarefas.
Comparar e contrastar com:
L
modelo de linguagem grande
No mínimo, um modelo de linguagem com um número muito alto de parâmetros. De maneira mais informal, qualquer modelo de linguagem baseado em Transformer, como o Gemini ou o GPT.
Consulte Modelos de linguagem grandes (LLMs) no Curso intensivo de machine learning para mais informações.
latência
O tempo que um modelo leva para processar a entrada e gerar uma resposta. Uma resposta de alta latência leva mais tempo para ser gerada do que uma de baixa latência.
Os fatores que influenciam a latência dos modelos de linguagem grandes incluem:
- Comprimentos de tokens de entrada e saída
- Complexidade do modelo
- A infraestrutura em que o modelo é executado
A otimização para latência é essencial para criar aplicativos responsivos e fáceis de usar.
LLM
Abreviação de modelo de linguagem grande.
Avaliações de LLM
Um conjunto de métricas e comparativos de mercado para avaliar a performance de modelos de linguagem grandes (LLMs). Em um nível alto, as avaliações de LLM:
- Ajudar os pesquisadores a identificar áreas em que os LLMs precisam melhorar.
- São úteis para comparar diferentes LLMs e identificar o melhor para uma tarefa específica.
- Ajudar a garantir que os LLMs sejam seguros e éticos para uso.
Consulte Modelos de linguagem grandes (LLMs) no Curso intensivo de machine learning para mais informações.
LoRA
Abreviação de adaptabilidade de baixa classificação.
Adaptabilidade de classificação baixa (LoRA)
Uma técnica eficiente em parâmetros para ajuste fino que "congela" os pesos pré-treinados do modelo (para que não possam mais ser modificados) e insere um pequeno conjunto de pesos treináveis no modelo. Esse conjunto de pesos treináveis (também conhecido como "matrizes de atualização") é consideravelmente menor do que o modelo de base e, portanto, muito mais rápido de treinar.
A LoRA oferece os seguintes benefícios:
- Melhora a qualidade das previsões de um modelo para o domínio em que o ajuste refinado é aplicado.
- Faz ajustes mais rápidos do que técnicas que exigem o ajuste de detalhes de todos os parâmetros de um modelo.
- Reduz o custo computacional da inferência ao permitir a exibição simultânea de vários modelos especializados que compartilham o mesmo modelo de base.
M
tradução automática
Usar um software (normalmente, um modelo de machine learning) para converter texto de um idioma humano para outro, por exemplo, de inglês para japonês.
Precisão média em k (mAP@k)
A média estatística de todas as pontuações de precisão média em k em um conjunto de dados de validação. Um uso da precisão média em k é julgar a qualidade das recomendações geradas por um sistema de recomendação.
Embora a frase "média média" pareça redundante, o nome da métrica é adequado. Afinal, essa métrica encontra a média de vários valores de precisão média em k.
mistura de especialistas
Um esquema para aumentar a eficiência da rede neural usando apenas um subconjunto dos parâmetros dela (conhecido como especialista) para processar um determinado token ou exemplo de entrada. Uma rede de controle de acesso encaminha cada token ou exemplo de entrada para os especialistas adequados.
Para mais detalhes, consulte um dos seguintes artigos:
- Redes neurais extremamente grandes: a camada de mistura de especialistas com poucos portões
- Mixture-of-Experts com roteamento de escolha de especialistas
MMIT
Abreviação de multimodal instruction-tuned.
cascata de modelos
Um sistema que escolhe o modelo ideal para uma consulta de inferência específica.
Imagine um grupo de modelos, que variam de muito grandes (muitos parâmetros) a muito menores (muito menos parâmetros). Modelos muito grandes consomem mais recursos computacionais no momento da inferência do que modelos menores. No entanto, modelos muito grandes geralmente conseguem inferir solicitações mais complexas do que modelos menores. A cascata de modelos determina a complexidade da consulta de inferência e escolhe o modelo adequado para realizar a inferência. A principal motivação para o encadeamento de modelos é reduzir os custos de inferência selecionando modelos menores e só escolhendo um modelo maior para consultas mais complexas.
Imagine que um modelo pequeno seja executado em um smartphone e uma versão maior desse modelo seja executada em um servidor remoto. Uma boa cascata de modelos reduz o custo e a latência, permitindo que o modelo menor processe solicitações simples e chame o modelo remoto apenas para solicitações complexas.
Consulte também roteador de modelo.
roteador de modelo
O algoritmo que determina o modelo ideal para inferência no encadeamento de modelos. Um roteador de modelo é normalmente um modelo de machine learning que aprende gradualmente a escolher o melhor modelo para uma determinada entrada. No entanto, um roteador de modelo às vezes pode ser um algoritmo mais simples, sem machine learning.
MOE
Abreviação de mistura de especialistas.
MT
Abreviação de tradução automática.
N
Nano
Um modelo do Gemini relativamente pequeno projetado para uso no dispositivo. Consulte Gemini Nano para mais detalhes.
NORA (no one right answer, em inglês)
Um comando com várias respostas corretas. Por exemplo, o comando a seguir não tem uma resposta certa:
Conte uma piada engraçada sobre elefantes.
Avaliar as respostas a comandos sem uma resposta certa geralmente é muito mais subjetivo do que avaliar comandos com uma resposta certa. Por exemplo, avaliar uma piada de elefante requer uma maneira sistemática de determinar o quanto ela é engraçada.
NORA
Abreviação de não existe uma resposta certa.
NotebookLM
Uma ferramenta baseada no Gemini que permite aos usuários fazer upload de documentos e usar comandos para fazer perguntas, resumir ou organizar esses documentos. Por exemplo, um autor pode fazer upload de vários contos e pedir ao NotebookLM para encontrar os temas em comum ou identificar qual deles seria o melhor filme.
O
uma resposta certa (ORA)
Um comando com uma única resposta correta. Por exemplo, considere o seguinte comando:
Verdadeiro ou falso: Saturno é maior que Marte.
A única resposta correta é verdadeira.
Contraste com não existe uma resposta certa.
comando one-shot
Um comando que contém um exemplo demonstrando como o modelo de linguagem grande deve responder. Por exemplo, o comando a seguir contém um exemplo que mostra a um modelo de linguagem grande como ele deve responder a uma consulta.
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Por exemplo, |
| Índia: | A consulta real. |
Compare e contraste o comando one-shot com os seguintes termos:
ORA
Abreviação de uma resposta certa.
P
ajuste da eficiência de parâmetros
Um conjunto de técnicas para ajustar um modelo de linguagem pré-treinado (PLM) grande de maneira mais eficiente do que o ajuste completo. O ajuste com eficiência de parâmetros geralmente ajusta muito menos parâmetros do que o ajuste fino completo, mas geralmente produz um modelo de linguagem grande que tem um desempenho tão bom (ou quase tão bom) quanto um modelo de linguagem grande criado com ajuste fino completo.
Compare e contraste o ajuste da eficiência dos parâmetros com:
O ajuste com eficiência de parâmetros também é conhecido como ajuste fino com eficiência de parâmetros.
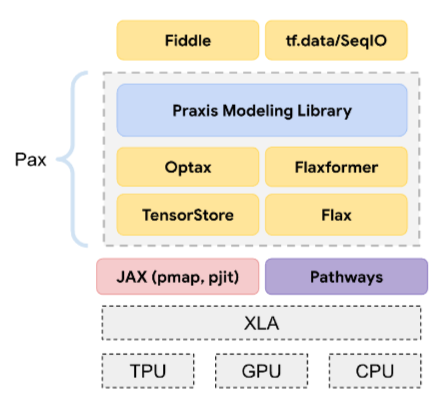
Pax
Um framework de programação projetado para treinar modelos de rede neural em grande escala tão grandes que abrangem várias TPUs, chips aceleradores, frações ou pods.
O Pax é baseado no Flax, que é baseado no JAX.
PLM
Abreviação de modelo de linguagem pré-treinado.
modelo com ajuste fino
Termo mal definido que normalmente se refere a um modelo pré-treinado que passou por algum pós-processamento, como um ou mais dos seguintes:
modelo pré-treinado
Embora esse termo possa se referir a qualquer modelo ou vetor de incorporação treinado, agora ele geralmente se refere a um modelo de linguagem grande pré-treinado ou outra forma de modelo de IA generativa pré-treinado.
Consulte também modelo de base e modelo de fundação.
autoguiado
O treinamento inicial de um modelo em um grande conjunto de dados. Alguns modelos pré-treinados são gigantes desajeitados e geralmente precisam ser refinados com mais treinamento. Por exemplo, especialistas em ML podem pré-treinar um modelo de linguagem grande em um vasto conjunto de dados de texto, como todas as páginas em inglês da Wikipédia. Após o pré-treinamento, o modelo resultante pode ser refinado ainda mais usando qualquer uma das seguintes técnicas:
- destilação
- ajuste de detalhes
- ajuste de instruções
- ajuste com eficiência de parâmetros
- prompt-tuning
Pro
Um modelo do Gemini com menos parâmetros que o Ultra, mas mais parâmetros que o Nano. Consulte Gemini Pro para mais detalhes.
comando
Qualquer texto inserido como entrada em um modelo de linguagem grande para condicionar o modelo a se comportar de uma determinada maneira. As solicitações podem ser tão curtas quanto uma frase ou arbitrariamente longas (por exemplo, o texto inteiro de um romance). Os comandos se enquadram em várias categorias, incluindo as mostradas na tabela a seguir:
| Categoria de comando | Exemplo | Observações |
|---|---|---|
| Pergunta | A que velocidade um pombo consegue voar? | |
| Instrução | Escreva um poema engraçado sobre arbitragem. | Um comando que pede ao modelo de linguagem grande para fazer algo. |
| Exemplo | Traduza o código Markdown para HTML. Por exemplo:
Markdown: * item da lista HTML: <ul> <li>item da lista</li> </ul> |
A primeira frase neste exemplo é uma instrução. O restante do comando é o exemplo. |
| Papel | Explique por que o gradiente descendente é usado no treinamento de machine learning para um PhD em física. | A primeira parte da frase é uma instrução, e a frase "para um PhD em Física" é a parte da função. |
| Entrada parcial para o modelo concluir | O primeiro-ministro do Reino Unido mora em | Um comando de entrada parcial pode terminar abruptamente (como neste exemplo) ou com um sublinhado. |
Um modelo de IA generativa pode responder a um comando com texto, código, imagens, embeddings, vídeos… quase tudo.
aprendizagem baseada em comandos
Uma capacidade de determinados modelos que permite adaptar o comportamento deles em resposta a entradas de texto arbitrárias (comandos). Em um paradigma típico de aprendizado baseado em comandos, um modelo de linguagem grande responde a um comando gerando texto. Por exemplo, suponha que um usuário insira o seguinte comando:
Resuma a terceira lei de Newton.
Um modelo capaz de aprendizado baseado em comandos não é treinado especificamente para responder ao comando anterior. Em vez disso, o modelo "conhece" muitos fatos sobre física, muitas regras gerais de linguagem e muito sobre o que constitui respostas geralmente úteis. Esse conhecimento é suficiente para fornecer uma resposta (esperamos) útil. Outros feedbacks humanos ("Essa resposta foi muito complicada" ou "O que é uma reação?") permitem que alguns sistemas de aprendizado baseados em comandos melhorem gradualmente a utilidade das respostas.
design de comandos
Sinônimo de engenharia de comando.
engenharia de comando
A arte de criar comandos que extraem as respostas desejadas de um modelo de linguagem grande. Os humanos fazem engenharia de comandos. Escrever comandos bem estruturados é essencial para garantir respostas úteis de um modelo de linguagem grande. A engenharia de comando depende de muitos fatores, incluindo:
- O conjunto de dados usado para pré-treinar e possivelmente ajustar o modelo de linguagem grande.
- A temperatura e outros parâmetros de decodificação que o modelo usa para gerar respostas.
Design de comandos é sinônimo de engenharia de comandos.
Consulte Introdução à criação de comandos para mais detalhes sobre como escrever comandos úteis.
conjunto de comandos
Um grupo de comandos para avaliar um modelo de linguagem grande. Por exemplo, a ilustração a seguir mostra um conjunto de comandos com três opções:
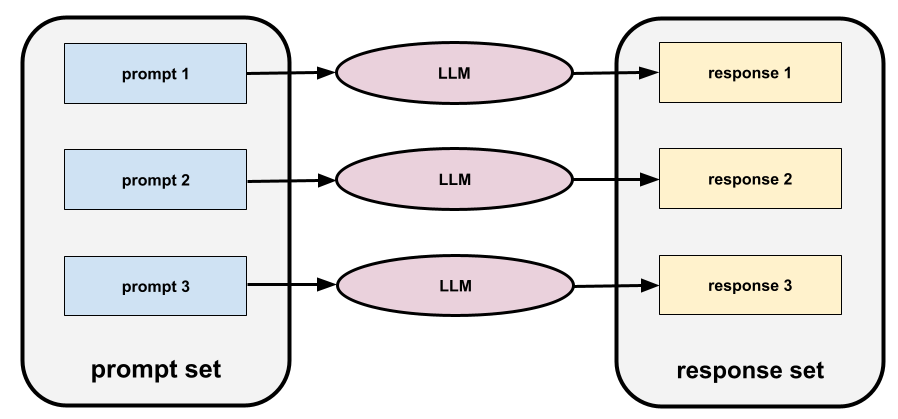
Um bom conjunto de comandos consiste em uma coleção suficientemente "ampla" de comandos para avaliar completamente a segurança e a utilidade de um modelo de linguagem grande.
Consulte também conjunto de respostas.
ajuste de comandos
Um mecanismo de ajuste eficiente de parâmetros que aprende um "prefixo" que o sistema adiciona ao comando.
Uma variação do ajuste de comandos, às vezes chamado de ajuste de prefixo, é adicionar o prefixo a todas as camadas. Em contraste, a maioria dos ajustes de comandos apenas adiciona um prefixo à camada de entrada.
R
texto de referência
A resposta de um especialista a um comando. Por exemplo, considerando o seguinte comando:
Traduza a pergunta "What is your name?" do inglês para o francês.
A resposta de um especialista pode ser:
Comment vous appelez-vous?
Várias métricas (como ROUGE) medem o grau em que o texto de referência corresponde ao texto gerado de um modelo de ML.
reflexão
Uma estratégia para melhorar a qualidade de um fluxo de trabalho de agente examinando (refletindo sobre) a saída de uma etapa antes de passar essa saída para a próxima etapa.
O examinador geralmente é o mesmo LLM que gerou a resposta (embora possa ser um LLM diferente). Como o mesmo LLM que gerou uma resposta pode ser um juiz imparcial dela? O "truque" é colocar o LLM em uma mentalidade crítica (reflexiva). Esse processo é semelhante a um escritor que usa uma mentalidade criativa para escrever um primeiro rascunho e depois muda para uma mentalidade crítica para editá-lo.
Por exemplo, imagine um fluxo de trabalho com agentes em que a primeira etapa é criar texto para xícaras de café. O comando para esta etapa pode ser:
Você é um criativo. Gere um texto original e divertido de menos de 50 caracteres adequado para uma xícara de café.
Agora imagine o seguinte comando reflexivo:
Você gosta de café. Você acharia a resposta anterior engraçada?
O fluxo de trabalho pode passar para a próxima etapa apenas o texto que recebe uma pontuação alta de reflexão.
Aprendizado por reforço com feedback humano (RLHF)
Usar o feedback de avaliadores humanos para melhorar a qualidade das respostas de um modelo. Por exemplo, um mecanismo de RLHF pode pedir aos usuários para avaliar a qualidade da resposta de um modelo com um emoji 👍 ou 👎. Assim, o sistema pode ajustar as respostas futuras com base nesse feedback.
resposta
O texto, as imagens, o áudio ou o vídeo que um modelo de IA generativa infere. Em outras palavras, um comando é a entrada de um modelo de IA generativa, e a resposta é a saída.
conjunto de respostas
O conjunto de respostas que um modelo de linguagem grande retorna para um conjunto de comandos de entrada.
criação de comandos de papel
Um comando, geralmente começando com o pronome você, que diz a um modelo de IA generativa para fingir ser uma determinada pessoa ou função ao gerar a resposta. Os comandos de função podem ajudar um modelo de IA generativa a entrar no "estado de espírito" certo para gerar uma resposta mais útil. Por exemplo, qualquer um dos seguintes comandos de função pode ser adequado, dependendo do tipo de resposta que você está procurando:
Você tem um PhD em ciência da computação.
Você é um engenheiro de software que gosta de dar explicações pacientes sobre Python para novos estudantes de programação.
Você é um herói de ação com um conjunto muito específico de habilidades de programação. Me garanta que você vai encontrar um item específico em uma lista do Python.
S
ajuste de comandos flexível
Uma técnica para ajustar um modelo de linguagem grande para uma tarefa específica, sem o ajuste fino, que exige muitos recursos. Em vez de treinar novamente todos os pesos no modelo, o ajuste de comandos leves ajusta automaticamente um comando para alcançar o mesmo objetivo.
Dado um comando de texto, o ajuste de comandos leves geralmente anexa mais incorporações de token ao comando e usa backpropagation para otimizar a entrada.
Um comando "hard" contém tokens reais em vez de incorporações de tokens.
codificação especificacional
O processo de escrever e manter um arquivo em uma linguagem humana (por exemplo, inglês) que descreve um software. Em seguida, peça a um modelo de IA generativa ou a outro engenheiro de software para criar o software que atenda a essa descrição.
O código gerado automaticamente geralmente requer iteração. Na programação especificacional, você itera no arquivo de descrição. Por outro lado, na programação por conversa, você itera na caixa de comando. Na prática, a geração automática de código às vezes envolve uma combinação de programação especificacional e conversacional.
T
temperatura
Um hiperparâmetro que controla o grau de aleatoriedade da saída de um modelo. Temperaturas mais altas resultam em saídas mais aleatórias, enquanto temperaturas mais baixas resultam em saídas menos aleatórias.
A escolha da temperatura ideal depende do aplicativo específico e/ou dos valores de string.
U
Ultra
O modelo do Gemini com o maior número de parâmetros. Consulte Gemini Ultra para mais detalhes.
V
Vertex
Plataforma do Google Cloud para IA e machine learning. A Vertex oferece ferramentas e infraestrutura para criar, implantar e gerenciar aplicativos de IA, incluindo acesso aos modelos do Gemini.vibe coding
Comandar um modelo de IA generativa para criar software. Ou seja, seus comandos descrevem a finalidade e os recursos do software, que um modelo de IA generativa traduz em código-fonte. O código gerado nem sempre corresponde às suas intenções, então a vibe coding geralmente exige iteração.
Andrej Karpathy criou o termo vibe coding nesta postagem no X. Na postagem no X, Karpathy descreve isso como "um novo tipo de programação...em que você se entrega totalmente às vibes..." Portanto, o termo originalmente implicava uma abordagem intencionalmente flexível para criar software em que talvez você nem examine o código gerado. No entanto, o termo evoluiu rapidamente em muitos círculos para significar qualquer forma de programação gerada por IA.
Para uma descrição mais detalhada da codificação de vibe, consulte O que é vibe coding?.
Além disso, compare e contraste o vibe coding com:
Z
comando zero-shot
Um comando que não fornece um exemplo de como você quer que o modelo de linguagem grande responda. Exemplo:
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| Índia: | A consulta real. |
O modelo de linguagem grande pode responder com qualquer uma das opções a seguir:
- Rúpia
- INR
- ₹
- Rúpias indianas
- A rupia
- A rupia indiana
Todas as respostas estão corretas, mas talvez você prefira um formato específico.
Compare e contraste o comando zero-shot com os seguintes termos: