تحتوي هذه الصفحة على مصطلحات مسرد نماذج الصور. للاطّلاع على جميع مصطلحات المسرد، انقر على هذا الرابط.
A
الواقع المعزّز
تقنية تُظهر صورة يتم إنشاؤها على جهاز كمبيوتر على ما يراه المستخدم من العالم الواقعي، ما يوفر عرضًا مركبًا.
برنامج ترميز تلقائي
نظام يتعلّم استخراج أهم المعلومات من المدخلات أدوات الترميز التلقائي هي عبارة عن مزيج من أداة ترميز و أداة فك ترميز. تعتمد برامج الترميز التلقائي على العملية المكونة من خطوتَين التاليتَين:
- يُعرِض برنامج الترميز الإدخال بتنسيق (متوسط) ذي أبعاد أقلّ (عادةً) مع فقدان للبيانات.
- ينشئ برنامج الترميز العكسي نسخة ذات فقدان للبيانات من الإدخال الأصلي من خلال ربط التنسيق ذي الأبعاد الأقل بتنسيق الإدخال الأصلي ذي الأبعاد الأعلى.
يتم تدريب برامج الترميز التلقائية من البداية إلى النهاية من خلال محاولة وحدة فك التشفير إعادة إنشاء الإدخال الأصلي من التنسيق الوسيط لوحدة الترميز بأكبر قدر ممكن من الدقة. وبما أنّ التنسيق الوسيط أصغر (أبعاده أقل) من التنسيق الأصلي، يتم إجبار الترميز التلقائي على معرفة المعلومات الأساسية في الإدخال، ولن يكون الإخراج متطابقًا تمامًا مع الإدخال.
على سبيل المثال:
- إذا كانت بيانات الإدخال عبارة عن رسم، ستكون النسخة غير الدقيقة مشابهة للرسم الأصلي، ولكن تم تعديلها إلى حد ما. من المحتمل أنّ النسخة غير الدقيقة تزيل التشويش من الرسم الأصلي أو تملأ بعض وحدات البكسل المفقودة.
- إذا كانت بيانات الإدخال نصًا، سينشئ الترميز الآلي نصًا جديدًا يشبه النص الأصلي (ولكن ليس مطابقًا له).
راجِع أيضًا الترميز الذاتي المتغيّر.
النموذج التدرّجي التلقائي
نموذج يستنتج توقّعًا استنادًا إلى توقّعاته السابقة على سبيل المثال، تتوقّع نماذج اللغة التسلسلية التلقائية العنصر التالي استنادًا إلى العناصر التي تم توقّعها سابقًا. جميع النماذج اللغوية الكبيرة المستندة إلى نموذج Transformer هي نماذج ذاتية الرجوع.
في المقابل، لا تكون نماذج الصور المستندة إلى GAN عادةً متراجِعة تلقائيًا، لأنّها تُنشئ صورة في خطوة واحدة إلى الأمام وليس بشكلٍ متكرّر في الخطوات. ومع ذلك، تكون بعض نماذج إنشاء الصور متراجِعة تلقائيًا لأنّها تُنشئ صورة على مراحل.
B
مربّع الحدود
في الصورة، الإحداثيتان (x وy) لمستطيل حول منطقة تشكل ملفًا شخصيًا، مثل الكلب في الصورة أدناه

C
الالتفاف
في الرياضيات، يشير هذا المصطلح إلى مزيج من دالتَين. في تعلُّم الآلة، يمزج أسلوب التفاف الملف الشخصي التفافي مع مصفوفة الإدخال من أجل تدريب المَعلمات.
غالبًا ما يشير مصطلح "التفاف" في تعلُّم الآلة إلى العملية التفافية أو الطبقة التفافية.
بدون عمليات التفاف، على خوارزمية التعلم الآلي تعلُّم معامل وزن منفصل لكل خلية في مصفوفة تانسور كبيرة. على سبيل المثال، سيضطرّ تدريب خوارزمية تعلُّم الآلة على صور بدقة 2K x 2K إلى العثور على 4 ملايين وزن منفصل. بفضل عمليات التفاف النطاق، ما على خوارزمية تعلُّم الآلة سوى العثور على أوزان لكل خلية في فلتر التفاف النطاق، ما يؤدي إلى تقليل المساحة المتوفّرة في الذاكرة اللازمة لتدريب النموذج بشكل كبير. عند تطبيق الفلتر التدرّبي، تتم ببساطة نسخه على الخلايا بحيث يتم ضرب كل خلية فيه.
اطّلِع على لمحة عن الشبكات العصبية الملتفة في دورة تدريبية عن تصنيف الصور للحصول على مزيد من المعلومات.
فلتر التفافي
أحد المشغّلين في عملية تحويلية. (العنصر الآخر هو شريحة من مصفوفة إدخال). الفلتر التجميعي هو مصفوفة لها ترتيب مماثل لترتيب مصفوفة الإدخال، ولكن بحجم أصغر. على سبيل المثال، في حال توفّر مصفوفة إدخال بحجم 28x28، يمكن أن يكون الفلتر أي مصفوفة ثنائية الأبعاد أصغر من 28x28.
في عمليات التلاعب بالصور، يتم عادةً ضبط جميع الخلايا في الفلتر التدرّبي على نمط ثابت من الأرقام 1 و0. في تعلُّم الآلة، تتم عادةً زراعة ملفّات التمويه التدرّجية بأرقام عشوائية، ثم تُدرِّب الشبكة القيم المثالية.
اطّلِع على التفاف في دورة تدريبية عن تصنيف الصور للحصول على مزيد من المعلومات.
طبقة التفافية
طبقة من الشبكة العصبية العميقة التي يمر فيها فلتر تفافي على هُرم إدخال. على سبيل المثال، فكِّر في الفلتر التدرّبي التالي الذي أبعاده 3×3:
![مصفوفة 3×3 بالقيم التالية: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=00&hl=ar)
تعرض الصورة المتحركة التالية طبقة تحويلية تتألف من 9 عمليات تحويلية تتضمّن مصفوفة الإدخال 5×5. لاحظ أنّ كل عملية تدرّجية تعمل على شريحة مختلفة من 3×3 من مصفوفة الإدخال. تتألّف المصفوفة الناتجة 3×3 (على اليمين) من نتائج 9 عمليات تحويلية:
![صورة متحرّكة تعرِض صفيفتَين المصفوفة الأولى هي المصفوفة
5×5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
المصفوفة الثانية هي المصفوفة 3×3:
[[181,303,618], [115,338,605], [169,351,560]].
يتم احتساب المصفوفة الثانية من خلال تطبيق ملف التمويه
[[0, 1, 0], [1, 0, 1], [0, 1, 0]] على
مجموعات فرعية مختلفة من 3×3 من المصفوفة 5×5.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=00&hl=ar)
اطّلِع على الطبقات المتصلّة بالكامل في دورة تدريبية عن تصنيف الصور للحصول على مزيد من المعلومات.
شبكة عصبية تلافيفية
شبكة عصبية تتضمّن طبقة واحدة على الأقل هي طبقة تلافيفية. تتألف الشبكة العصبية التجميعية النموذجية من بعض المجموعات من الطبقات التالية:
حققت الشبكات العصبية الالتفافية نجاحًا كبيرًا في أنواع معيّنة من المشاكل، مثل التعرّف على الصور.
عملية الالتفاف
العملية الحسابية المكونة من خطوتَين التالية:
- الضرب العنصري ل فلتر التفاف وشريحة من مصفوفة الإدخال (لقطعة مصفوفة الإدخال ترتيب و حجم الفلتر التجميعي نفسهما).
- مجموع كل القيم في مصفوفة المنتجات الناتجة
على سبيل المثال، فكِّر في مصفوفة الإدخال 5×5 التالية:
![المصفوفة 5×5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=00&hl=ar)
لنفترض الآن الفلتر التفاعلي 2×2 التالي:
![المصفوفة 2×2: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=00&hl=ar)
تتضمّن كل عملية تجميعية شريحة واحدة بحجم 2×2 من مصفوفة الإدخال. على سبيل المثال، لنفترض أنّنا نستخدم شريحة 2×2 في أعلى يمين مصفوفة الإدخال. وبالتالي، تبدو عملية التفاف الالتفاف على هذه الشريحة على النحو التالي:
![تطبيق الفلتر التجميعي [[1, 0], [0, 1]] على القسم العلوي الأيمن
2×2 من مصفوفة الإدخال، والذي يمثّل [[128,97], [35,22]].
يترك الفلتر التفافي الرقمَين 128 و22 سليمَين، ولكنه يُلغي الرقمَين 97 و35. نتيجةً لذلك، تؤدي عملية التفاف إلى توليد
القيمة 150 (128+22).](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=00&hl=ar)
تتألّف الطبقة التوليدية من سلسلة من العمليات التوليدية، يعمل كلّ منها على شريحة مختلفة من مصفوفة الإدخال.
D
زيادة البيانات
زيادة النطاق وعدد مثالي التدريب بشكل مصطنع من خلال تحويل مثالي الحالية لإنشاء أمثلة إضافية على سبيل المثال، لنفترض أنّ الصور هي أحد السمات، ولكنّ مجموعة البيانات لا تتضمن أمثلة كافية للصور ليتعلّم النموذج ارتباطات مفيدة. من الأفضل إضافة عدد كافٍ من الصور المصنّفة إلى مجموعة البيانات ل السماح لنموذجك بالتدريب بشكل صحيح. إذا لم يكن ذلك ممكنًا، يمكن أن تؤدي ميزة "تعزيز البيانات" إلى تدوير كل صورة وتمديدها وعكسها لإنشاء العديد من الصيغ للصورة الأصلية، ما قد يؤدي إلى توفير بيانات مصنّفة كافية لتمكين عملية تدريب ممتازة.
شبكة عصبية تفافية قابلة للفصل حسب العمق (sepCNN)
بنية شبكة عصبية تفافية تستند إلى Inception، ولكن يتم استبدال وحدات Inception بعمليات التفاف القابلة للفصل على مستوى العمق. يُعرف أيضًا باسم Xception.
تُقسِّم عملية الدمج القابل للفصل حسب العمق (التي يُشار إليها أيضًا باسم الدمج القابل للفصل) عملية الدمج العادية الثلاثية الأبعاد إلى عمليتَي دمج منفصلتَين أكثر فعالية من الناحية الحسابية: أولاً، عملية دمج قابلة للفصل حسب العمق، بعمق 1 (n ✕ n ✕ 1)، ثم عملية دمج قابلة للفصل حسب النقطة، بطول وعرض 1 (1 ✕ 1 ✕ n).
لمزيد من المعلومات، يُرجى الاطّلاع على مقالة Xception: Deep Learning with Depthwise Separable Convolutions.
تصغير نطاق العيّنات
مصطلح يحمل أكثر من معنى واحد، ويمكن أن يعني أيًا مما يلي:
- تقليل كمية المعلومات في ميزة بهدف تدريب نموذج بكفاءة أكبر على سبيل المثال، قبل تدريب نموذج التعرّف على الصور، يتم تقليل دقة الصور العالية الدقة إلى تنسيق بدرجة دقة أقل.
- التدريب على نسبة منخفضة بشكل غير متناسب من أمثلة الفئة الممثّلة بشكل زائد من أجل تحسين تدريب النموذج على الفئات الممثّلة بشكل غير كافٍ على سبيل المثال، في مجموعة بيانات غير متوازنة من حيث الفئات، تميل النماذج إلى التعلّم كثيرًا عن الفئة الأكثر شيوعًا وليس بما يكفي عن الفئة الأقل شيوعًا. تساعد ميزة "تقليل العينة" في توازن مقدار التدريب على فئات الأغلبية والأقلية.
اطّلِع على مجموعات البيانات: مجموعات البيانات غير المتوازنة في الدورة المكثّفة عن تعلُّم الآلة للحصول على مزيد من المعلومات.
F
التحسين
جولة تدريب ثانية خاصة بالمهمة يتم إجراؤها على نموذج تم تدريبه مسبقًا لتحسين مَعلماته في حالة استخدام معيّنة. على سبيل المثال، تتمثل تسلسل التدريب الكامل لبعض النماذج اللغوية الكبيرة على النحو التالي:
- التدريب المُسبَق: يتم تدريب نموذج لغوي كبير على مجموعة بيانات عامة واسعة النطاق، مثل جميع صفحات Wikipedia باللغة الإنجليزية.
- التحسين: يمكنك تدريب النموذج المدَّرب مسبقًا لتنفيذ مهمة معيّنة، مثل الردّ على طلبات البحث الطبية. تشمل عملية التحسين عادةً مئات أو آلاف الأمثلة التي تركّز على مهمة معيّنة.
في ما يلي مثال آخر على تسلسل التدريب الكامل لنموذج صور كبير:
- التدريب المُسبَق: يمكنك تدريب نموذج صور كبير على مجموعة بيانات عامة واسعة من الصور، مثل جميع الصور في Wikimedia commons.
- الضبط الدقيق: يمكنك تدريب النموذج المدَّرب مسبقًا لتنفيذ مهمة معيّنة، مثل إنشاء صور لحيوانات الأوركا.
يمكن أن تتضمّن عملية التحسين الدقيق أيّ مجموعة من الاستراتيجيات التالية:
- تعديل جميع مَعلمات النموذج المدَّرب مسبقًا يُعرف ذلك أحيانًا باسم التحسين الكامل.
- تعديل بعض المَعلمات الحالية للنموذج المدّرب مسبقًا فقط (عادةً الطبقات الأقرب إلى طبقة الإخراج)، مع إبقاء المَعلمات الحالية الأخرى بدون تغيير (عادةً الطبقات الأقرب إلى طبقة الإدخال) راجِع الضبط الفعال للمَعلمات.
- إضافة المزيد من الطبقات، عادةً فوق الطبقات الحالية الأقرب إلى طبقة الإخراج
التحسين الدقيق هو شكل من أشكال التعلُّم بالاستناد إلى نماذج سابقة. وبناءً على ذلك، قد تستخدِم عملية التحسين الدقيق دالة خسارة مختلفة أو نوعًا مختلفًا من النماذج مقارنةً بتلك المستخدَمة لتدريب النموذج المدّرب مسبقًا. على سبيل المثال، يمكنك تحسين نموذج صور كبير مدرَّب مسبقًا لإنشاء نموذج انحدار يُظهر عدد الطيور في صورة الإدخال.
قارِن بين التحسين الدقيق والمصطلحات التالية:
يمكنك الاطّلاع على التحسين في دورة "مكثّفة عن تعلُّم الآلة" للحصول على مزيد من المعلومات.
G
Gemini
منظومة متكاملة تتضمّن تكنولوجيات الذكاء الاصطناعي الأكثر تقدّمًا من Google تشمل عناصر هذا النظام البيئي ما يلي:
- نماذج Gemini المختلفة
- واجهة المحادثة التفاعلية لنموذج Gemini يكتب المستخدمون طلبات ويردّ Gemini عليها.
- واجهات برمجة تطبيقات Gemini المختلفة
- منتجات مختلفة للأنشطة التجارية تستند إلى نماذج Gemini، مثل Gemini في Google Cloud
طُرز Gemini
أحدث نماذج متعددة الوسائط المستندة إلى تكنولوجيا تحويل البيانات من Google تم تحديد نماذج Gemini خصيصًا للدمج مع موظّفي الدعم.
يمكن للمستخدمين التفاعل مع نماذج Gemini بطرق متنوعة، بما في ذلك من خلال واجهة حوار تفاعلية ومن خلال حِزم تطوير البرامج (SDK).
الذكاء الاصطناعي التوليدي
مجال تحويلي ناشئ بدون تعريف رسمي ومع ذلك، يتفق معظم الخبراء على أنّ نماذج الذكاء الاصطناعي التوليدي يمكنها إنشاء ("توليد") محتوى يتضمن كل ما يلي:
- معقّد
- متّسقة
- الصورة الأصلية
على سبيل المثال، يمكن أن ينشئ نموذج الذكاء الاصطناعي التوليدي مقالات أو صورًا معقدة.
يمكن لبعض التقنيات السابقة، بما في ذلك النماذج اللغوية طويلة المدى (LSTM) والنماذج العصبية التسلسلية (RNN)، أيضًا إنشاء محتوى أصلي ومتسق. يرى بعض الخبراء أنّ هذه التقنيات السابقة هي نوع من الذكاء الاصطناعي التوليدي، بينما يرى آخرون أنّ الذكاء الاصطناعي التوليدي الحقيقي يتطلّب مخرجات أكثر تعقيدًا من تلك التي يمكن أن تنتجها هذه التقنيات السابقة.
يختلف ذلك عن تعلُّم الآلة التوقّعي.
I
التعرّف على الصورة
عملية لفهرسة الأجسام أو الأنماط أو المفاهيم في الصورة يُعرَف التعرّف على الصور أيضًا باسم تصنيف الصور.
لمزيد من المعلومات، يُرجى الاطّلاع على ML Practicum: Image Classification.
اطّلِع على ML Practicum: Image Classification course لمزيد من المعلومات.
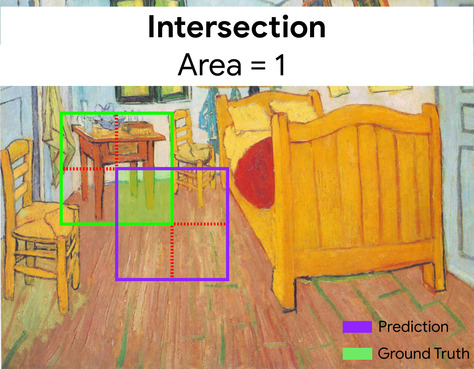
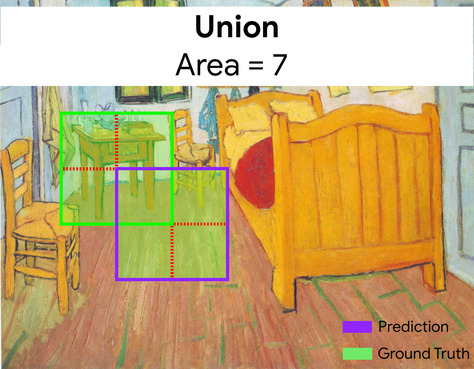
نسبة التداخل إلى الاتحاد (IoU)
تقاطع مجموعتَين مقسومًا على اتحادهما في مهام معالجة الصور باستخدام تعلُّم الآلة، يتم استخدام معامل IoU لقياس دقة المربّع المحيط المتوقّع للنموذج في ما يتعلّق بالمربّع المحيط للحقيقة الأساسية. في هذه الحالة، تكون نسبة IoU للصندوقين هي النسبة بين المنطقة المتداخلة وإجمالي المنطقة، وتتراوح قيمتها من 0 (لا يتداخل صندوق الحدود المتوقّع مع صندوق حدود الحقيقة المرصودة) إلى 1 (يتطابق صندوق الحدود المتوقّع مع صندوق حدود الحقيقة المرصودة تمامًا).
على سبيل المثال، في الصورة أدناه:
- تم تحديد حدود المربّع المحدَّد مسبقًا (الإحداثيات التي تحدّد مكان الجدول الليلي في اللوحة الذي يتوقعه النموذج) باللون الأرجواني.
- يظهر مربّع الحدود لبيانات الأساس (الإحداثيات التي تحدّد مكان ملفه الشخصي في اللوحة) باللون الأخضر.
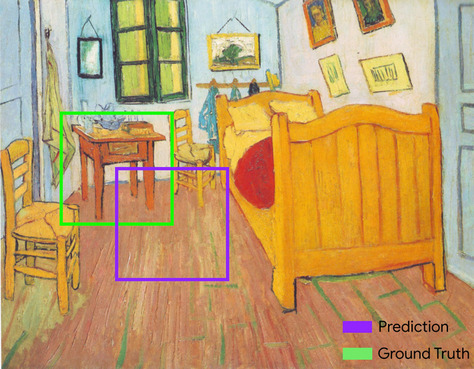
في هذه الحالة، تبلغ قيمة تقاطع مربّعات الحدود للتنبؤ والحقيقة المرجعية (أسفل يمين الصفحة) 1، وقيمة تجميع مربّعات الحدود للتنبؤ والحقيقة المرجعية (أسفل يسار الصفحة) 7، وبالتالي تكون قيمة IoU هي \(\frac{1}{7}\).
K
النقاط الرئيسية
إحداثيات ميزات معيّنة في صورة على سبيل المثال، في نموذج التعرّف على الصور الذي يميز أنواع الزهور، قد تكون النقاط الرئيسية هي مركز كلّ بتلة، والساق، وعضو التلقيح، وما إلى ذلك.
L
المعالم
مرادف لـ النقاط الرئيسية.
M
MMIT
اختصار لعبارة مُعدّة للتعليمات المتعدّدة الوسائط.
MNIST
مجموعة بيانات تابعة للملك العام جمعها كلّ من LeCun وCortes وBurges وتتضمّن 60,000 صورة، تعرض كلّ صورة كيف كتب شخص ما رقمًا معيّنًا من 0 إلى 9 يدويًا. يتم تخزين كل صورة كصفيف من الأعداد الصحيحة بحجم 28×28، حيث يكون كل عدد صحيح قيمة للون الرمادي تتراوح بين 0 و255، بما في ذلك هذين الرقمَين.
MNIST هي مجموعة بيانات أساسية لتعلُّم الآلة، وغالبًا ما تُستخدَم لاختبار أساليب جديدة تتعلّق بالتعلم الآلي. لمعرفة التفاصيل، يُرجى الاطّلاع على قاعدة بيانات MNIST للأرقام المكتوبة بخط اليد.
MOE
اختصار مجموعة من الخبراء.
P
تجميع
تقليل مصفوفة (أو مصفوفات) تم إنشاؤها من قبل طبقة تلافيفية سابقة إلى مصفوفة أصغر عادةً ما تتضمن عملية التجميع أخذ الحد الأقصى أو المتوسط للقيمة على مستوى المنطقة التي تم تجميعها. على سبيل المثال، لنفترض أنّ لدينا المصفوفة 3×3 التالية:
![المصفوفة 3×3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=00&hl=ar)
تمامًا مثل عملية الالتفاف، تقسم عملية التجميع تلك المصفّفة إلى شرائح ثم تُحرِّك عملية الالتفاف هذه باستخدام الخطوات. على سبيل المثال، لنفترض أنّ عملية التجميع تقسّم المصفوفة التجميعية إلى شرائح 2×2 بخطوة 1×1. كما يوضّح الرسم البياني التالي، تحدث أربع عمليات تجميع. لنفترض أنّ كل عملية تجميع تختار الحد الأقصى لقيمة الأربعة في هذا المقطع:
![مصفوفة الإدخال هي 3×3 بالقيم: [[5,3,1], [8,2,5], [9,4,3]].
المصفوفة الفرعية 2×2 في أعلى يمين مصفوفة الإدخال هي [[5,3]، [8,2]]، لذا
تؤدي عملية التجميع في أعلى يمين المصفوفة إلى القيمة 8 (وهي
الحد الأقصى من 5 و3 و8 و2). المصفوفة الفرعية 2×2 في أعلى يسار مصفوفة
الإدخال هي [[3,1]، [2,5]]، لذا تؤدي عملية التجميع في أعلى يسار المصفوفة
إلى القيمة 5. المصفوفة الفرعية 2×2 في أسفل يمين مصفوفة الإدخال هي
[[8,2], [9,4]], لذا تؤدي عملية التجميع في أسفل يمين المصفوفة إلى القيمة
9. المصفوفة الفرعية 2×2 في أسفل يسار مصفوفة الإدخال هي
[[2,5], [4,3]], لذا تؤدي عملية التجميع في أسفل يسار المصفوفة إلى القيمة
5. باختصار، تؤدي عملية التجميع إلى إنشاء المصفوفة 2×2 التالية:
[[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=00&hl=ar)
تساعد عملية التجميع في فرض عدم التغير الناتج عن الترجمة في مصفوفة الإدخال.
يُعرف تجميع البيانات لتطبيقات الرؤية رسميًا باسم التجميع المكاني. تشير تطبيقات السلاسل الزمنية عادةً إلى التجميع باسم التجميع الزمني. ويُطلق على الدمج أحيانًا اسم تحليل عيّنات فرعية أو تقليل الحجم.
نموذج مدرَّب بعد ذلك
مصطلح غير محدّد بدقة يشير عادةً إلى نموذج تم تدريبه مسبقًا وخضع لبعض المعالجة اللاحقة، مثل إجراء واحد أو أكثر مما يلي:
نموذج مدرَّب مسبقًا
عادةً ما يكون نموذجًا سبق تدريبه. يمكن أن يشير المصطلح أيضًا إلى متجه التضمين الذي تم تدريبه سابقًا.
يشير مصطلح النموذج اللغوي المُدرَّب مسبقًا عادةً إلى نموذج لغوي كبير سبق أن تم تدريبه.
التدريب المُسبَق
التدريب الأولي لنموذج على مجموعة بيانات كبيرة إنّ بعض النماذج المدربة مسبقًا هي نماذج عملاقة وبطيئة، ويجب عادةً تحسينها من خلال تدريب إضافي. على سبيل المثال، قد يُجري خبراء تعلُّم الآلة تدريبًا مسبقًا على نموذج لغة كبير باستخدام مجموعة بيانات نصية ضخمة، مثل جميع الصفحات باللغة الإنجليزية في "ويكيبيديا". بعد التدريب المُسبَق، يمكن تحسين النموذج الناتج بشكلٍ أكبر باستخدام أيّ من التقنيات التالية:
R
الثبات الدوراني
في مشكلة تصنيف الصور، هي قدرة الخوارزمية على تصنيف الصور بنجاح حتى في حال تغيُّر اتجاه الصورة. على سبيل المثال، يظل بإمكان الخوارزمية التعرّف على مضرب تنس سواء كان موجهًا للأعلى أو بجانبه أو للأسفل. يُرجى العلم أنّ عدم الاعتماد على الاتجاه ليس مرغوبًا فيه دائمًا، على سبيل المثال، يجب عدم تصنيف الرقم 9 مقلوبًا على أنّه 9.
اطّلِع أيضًا على الثبات الانتقالي و الثبات الحجمي.
S
الثبات الحجمي
في مشكلة تصنيف الصور، هي قدرة الخوارزمية على تصنيف الصور بنجاح حتى في حال تغيُّر حجمها. على سبيل المثال، يظل بإمكان الخوارزمية التعرّف على قطة سواء كانت تستهلك مليونَي بكسل أو 200 ألف بكسل. يُرجى العِلم أنّ أفضل خوارزميات تصنيف الصور لا تزال لها حدود عملية في ما يتعلق بعدم الاعتماد على الحجم. على سبيل المثال، من غير المرجّح أن تحدّد الخوارزمية (أو الإنسان) بشكل صحيح محتوى صورة قطة تستهلك 20 بكسل فقط.
اطّلِع أيضًا على الثبات الانتقالي و الثبات الدوراني.
اختزال مكاني
اطّلِع على الجمع.
خطوة
في عملية تحويل تلافعي أو تجميع، الاختلاف في كل سمة من سمات السلسلة التالية من شرائح الإدخال على سبيل المثال، يوضّح المخطّط المتحرّك التالي خطوة (1،1) أثناء عملية تحويلية. لذلك، تبدأ شريحة الإدخال التالية في موضع واحد على يسار شريحة الإدخال السابقة. عندما تصل العملية إلى الحافة اليمنى، يتم نقل الشريحة التالية بالكامل إلى اليسار ولكن بمقدار موضع واحد للأسفل.
يوضّح المثال السابق خطوة ثنائية الأبعاد. إذا كانت مصفوفة السلسلة المدخلة ثلاثية الأبعاد، ستكون الخطوة أيضًا ثلاثية الأبعاد.
جمع عيّنات جزئية
اطّلِع على الجمع.
T
درجة الحرارة
مَعلمة فائقة تتحكّم في درجة العشوائية لمخرجات النموذج تؤدي درجات الحرارة المرتفعة إلى زيادة العشوائية في النتائج، بينما تؤدي درجات الحرارة المنخفضة إلى تقليل العشوائية في النتائج.
يعتمد اختيار أفضل درجة حرارة على التطبيق المحدّد والخصائص المفضّلة لمخرجات النموذج. على سبيل المثال، قد تحتاج إلى رفع درجة الحرارة عند إنشاء تطبيق يُنشئ مواد إبداعية. في المقابل، من المحتمل أن تخفض درجة الحرارة عند إنشاء نموذج يصنف الصور أو النصوص لتحسين دقة النموذج واتساقه.
غالبًا ما يتم استخدام درجة الحرارة مع softmax.
الثبات الانتقالي
في مشكلة تصنيف الصور، هي قدرة الخوارزمية على تصنيف الصور بنجاح حتى عندما يتغيّر موضع الأجسام داخل الصورة. على سبيل المثال، لا يزال بإمكان الخوارزمية التعرّف على كلب، سواء كان في وسط الإطار أو على يمينه.
اطّلِع أيضًا على الثبات الحجمي و الثبات الدوراني.