Esta página contiene los términos del glosario de los modelos de imágenes. Para ver todos los términos del glosario, haz clic aquí.
A
realidad aumentada
Es una tecnología que superpone una imagen generada por computadora en la vista del mundo real de un usuario, lo que proporciona una vista compuesta.
codificador automático
Un sistema que aprende a extraer la información más importante de la entrada. Los autoencoders son una combinación de un codificador y un decodificador. Los autoencoders se basan en el siguiente proceso de dos pasos:
- El codificador asigna la entrada a un formato (por lo general) con pérdida de menor dimensión (intermedia).
- El decodificador crea una versión con pérdida de la entrada original asignando el formato de menor dimensión al formato de entrada original de mayor dimensión.
Los autoencoders se entrenan de extremo a extremo haciendo que el decodificador intente reconstruir la entrada original del formato intermedio del codificador lo más cerca posible. Debido a que el formato intermedio es más pequeño (de menor dimensión) que el formato original, el autocodificador se ve obligado a aprender qué información de la entrada es esencial, y el resultado no será perfectamente idéntico a la entrada.
Por ejemplo:
- Si los datos de entrada son gráficos, la copia no exacta sería similar al gráfico original, pero algo modificado. Quizás la copia no exacta quite el ruido del gráfico original o complete algunos píxeles faltantes.
- Si los datos de entrada son texto, un autocodificador generaría texto nuevo que imita (pero no es idéntico) al texto original.
Consulta también codificadores automáticos variacionales.
modelo autorregresivo
Un modelo que infiere una predicción en función de sus propias predicciones anteriores. Por ejemplo, los modelos de lenguaje autoregresivo predicen el siguiente token según los tokens pronosticados anteriormente. Todos los modelos de lenguaje extenso basados en Transformer son de regresión automática.
Por el contrario, los modelos de imágenes basados en GAN suelen no ser autorregresivos, ya que generan una imagen en un solo pase hacia adelante y no de forma iterativa en pasos. Sin embargo, algunos modelos de generación de imágenes son autorregresivos porque generan una imagen en pasos.
B
cuadro de límite
En una imagen, las coordenadas (x, y) de un rectángulo alrededor de un área de interés, como el perro en la siguiente imagen.

C
convolución
En matemática, la convolución es (informalmente) una manera de mezclar dos funciones que mide cuanta superposición hay entre las dos funciones. En el aprendizaje automático, una convolución mezcla el filtro convolucional y la matriz de entrada para entrenar los pesos.
El término “convolución” en el aprendizaje automático suele ser una forma abreviada de referirse a la operación de convolución o a la capa de convolución.
Sin convoluciones, un algoritmo de aprendizaje automático tendría que aprender un peso separado para cada celda en un tensor grande. Por ejemplo, un algoritmo de aprendizaje automático que se entrena en imágenes de 2K × 2K se vería obligado a encontrar 4 millones de pesos separados. Gracias a las convoluciones, un algoritmo de aprendizaje automático solo tiene que encontrar pesos para cada celda en el filtro convolucional, lo que reduce drásticamente la memoria necesaria para entrenar el modelo. Cuando se aplica el filtro convolucional, se replica en todas las celdas de modo que cada una se multiplique por el filtro.
Consulta Introducción a las redes neuronales convolucionales en el curso de Clasificación de imágenes para obtener más información.
filtro convolucional
Uno de los dos actores en una operación convolucional (el otro es una porción de una matriz de entrada). Un filtro convolucional es una matriz que tiene el mismo rango que la de entrada, pero una forma más pequeña. Por ejemplo, en una matriz de entrada 28 x 28, el filtro podría ser cualquier matriz 2D más pequeña que 28 x 28.
En la manipulación fotográfica, por lo general, todas las celdas de un filtro de convolución se configuran en un patrón constante de unos y ceros. En el aprendizaje automático, los filtros convolucionales suelen inicializarse con números aleatorios y, luego, la red entrena los valores ideales.
Consulta Convolución en el curso de Clasificación de imágenes para obtener más información.
capa convolucional
Una capa de una red neuronal profunda en la que un filtro convolucional pasa a lo largo de una matriz de entrada. Por ejemplo, considera el siguiente filtro convolucional de 3 x 3:
![Una matriz de 3 × 3 con los siguientes valores: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=00&hl=es)
En la siguiente animación, se muestra una capa convolucional que consta de 9 operaciones convolucionales que involucran la matriz de entrada de 5 × 5. Observa que cada operación convolucional funciona en una porción 3 × 3 diferente de la matriz de entrada. La matriz resultante de 3 × 3 (a la derecha) consta de los resultados de las 9 operaciones convolucionales:
![Una animación que muestra dos matrices. La primera matriz es la matriz 5 × 5: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
La segunda matriz es la matriz 3 × 3:
[[181,303,618], [115,338,605], [169,351,560]].
Para calcular la segunda matriz, se aplica el filtro convolucional [[0, 1, 0], [1, 0, 1], [0, 1, 0]] en diferentes subconjuntos de 3 × 3 de la matriz de 5 × 5.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=00&hl=es)
Consulta Capas completamente conectadas en el curso de Clasificación de imágenes para obtener más información.
red neuronal convolucional
Una red neuronal en la que al menos una capa es una capa convolucional. Una red neuronal convolucional típica consta de alguna combinación de las siguientes capas:
Las redes neuronales convolucionales tuvieron un gran éxito en ciertos tipos de problemas, como el reconocimiento de imágenes.
operación convolucional
La siguiente operación matemática de dos pasos:
- Multiplicación por elementos del filtro convolucional y una porción de una matriz de entrada (la porción de la matriz de entrada tiene el mismo rango y tamaño que el filtro convolucional)
- Es la suma de todos los valores en la matriz de producto resultante.
Por ejemplo, considera la siguiente matriz de entrada de 5 × 5:
![La matriz de 5 × 5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=00&hl=es)
Ahora, imagina el siguiente filtro convolucional de 2 × 2:
![La matriz 2 × 2: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=00&hl=es)
Cada operación de convolución implica una sola porción de 2 × 2 de la matriz de entrada. Por ejemplo, supongamos que usamos la porción de 2 × 2 en la parte superior izquierda de la matriz de entrada. Por lo tanto, la operación de convolución en esta porción se ve de la siguiente manera:
![Aplicación del filtro de convolución [[1, 0], [0, 1]] a la sección 2 × 2 de la parte superior izquierda de la matriz de entrada, que es [[128,97], [35,22]].
El filtro convolucional deja los 128 y 22 intactos, pero anula los 97 y 35. En consecuencia, la operación de convolución genera el valor 150 (128 + 22).](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=00&hl=es)
Una capa convolucional consiste en una serie de operaciones convolucionales que actúan en porciones diferentes de la matriz de entrada.
D
magnificación de datos
Se incrementa de forma artificial el rango y la cantidad de ejemplos de entrenamiento a través de transformaciones sobre los ejemplos existentes para crear ejemplos nuevos. Por ejemplo, supongamos que las imágenes son una de tus características, pero tu conjunto de datos no contiene suficientes ejemplos de imágenes para que el modelo aprenda asociaciones útiles. Lo ideal sería agregar suficientes imágenes etiquetadas al conjunto de datos para permitir que el modelo se entrene adecuadamente. De no ser posible, la magnificación de datos puede rotar, estirar y reflejar cada imagen para producir variantes de la imagen original, lo que producirá, posiblemente, suficientes datos etiquetados para permitir un excelente entrenamiento.
red neuronal convolucional separable en profundidad (sepCNN)
Una arquitectura de red neuronal convolucional basada en Inception, pero en la que los módulos de Inception se reemplazan por contracciones separables en profundidad. También se conoce como Xception.
Una convolución separable en profundidad (también abreviada como convolución separable) divide una convolución 3D estándar en dos operaciones de convolución separadas que son más eficientes en términos de procesamiento: primero, una convolución en profundidad, con una profundidad de 1 (n × n × 1) y, luego, una convolución puntual, con una longitud y un ancho de 1 (1 × 1 × n).
Para obtener más información, consulta Xception: Aprendizaje profundo con convoluciones separables en profundidad.
reducción de muestreo
Término sobrecargado que puede significar una de las siguientes opciones:
- Reducir la cantidad de información en un atributo para entrenar un modelo de forma más eficiente. Por ejemplo, antes de entrenar un modelo de reconocimiento de imágenes, se reduce el muestreo llevando las imágenes de alta resolución a un formato de resolución más baja.
- Entrenar con un porcentaje desproporcionalmente bajo de ejemplos de clase sobrerrepresentada para mejorar el entrenamiento del modelo en clases subrepresentadas. Por ejemplo, en un conjunto de datos con desequilibrio de clases, los modelos tienden a aprender mucho sobre la clase mayoritaria y no lo suficiente sobre la clase minoritaria. La reducción de muestreo ayuda a equilibrar la cantidad de entrenamiento en las clases mayoritarias y minoritarias.
Consulta Conjuntos de datos: Conjuntos de datos desequilibrados en el Curso intensivo de aprendizaje automático para obtener más información.
F
ajuste
Un segundo pase de entrenamiento específico para la tarea que se realiza en un modelo previamente entrenado para definir mejor sus parámetros para un caso de uso específico. Por ejemplo, la secuencia de entrenamiento completa de algunos modelos grandes de lenguaje es la siguiente:
- Entrenamiento previo: Entrena un modelo de lenguaje grande en un vasto conjunto de datos general, como todas las páginas de Wikipedia en inglés.
- Ajuste fino: Entrena el modelo previamente entrenado para que realice una tarea específica, como responder consultas médicas. El perfeccionamiento suele implicar cientos o miles de ejemplos enfocados en la tarea específica.
A modo de ejemplo, la secuencia de entrenamiento completa para un modelo de imagen grande es la siguiente:
- Entrenamiento previo: Entrena un modelo de imagen grande en un vasto conjunto de datos de imágenes generales, como todas las imágenes de Wikimedia Commons.
- Ajuste fino: Entrena el modelo previamente entrenado para que realice una tarea específica, como generar imágenes de orcas.
El perfeccionamiento puede implicar cualquier combinación de las siguientes estrategias:
- Modificar todos los parámetros existentes del modelo previamente entrenado A veces, esto se denomina ajuste fino completo.
- Modificar solo algunos de los parámetros existentes del modelo previamente entrenado (por lo general, las capas más cercanas a la capa de salida) y mantener sin cambios otros parámetros existentes (por lo general, las capas más cercanas a la capa de entrada) Consulta ajuste eficiente de parámetros.
- Agregar más capas, por lo general, sobre las capas existentes más cercanas a la capa de salida
El ajuste fino es una forma de aprendizaje por transferencia. Por lo tanto, el ajuste fino puede usar una función de pérdida o un tipo de modelo diferente de los que se usan para entrenar el modelo con entrenamiento previo. Por ejemplo, podrías ajustar un modelo de imagen grande previamente entrenado para producir un modelo de regresión que muestre la cantidad de aves en una imagen de entrada.
Compara y contrasta el perfeccionamiento con los siguientes términos:
Consulta Ajuste fino en el Curso intensivo de aprendizaje automático para obtener más información.
G
Gemini
El ecosistema que comprende la IA más avanzada de Google. Entre los elementos de este ecosistema, se incluyen los siguientes:
- Varios modelos de Gemini
- La interfaz de conversación interactiva de un modelo de Gemini. Los usuarios escriben instrucciones y Gemini responde a ellas.
- Varias APIs de Gemini
- Varios productos empresariales basados en modelos de Gemini, por ejemplo, Gemini para Google Cloud.
Modelos de Gemini
Los modelos multimodales de última generación de Google basados en Transformers Los modelos de Gemini están diseñados específicamente para integrarse con agentes.
Los usuarios pueden interactuar con los modelos de Gemini de diferentes maneras, por ejemplo, a través de una interfaz de diálogo interactiva y de SDKs.
IA generativa
Es un campo transformador emergente sin definición formal. Dicho esto, la mayoría de los expertos coinciden en que los modelos de IA generativa pueden crear ("generar") contenido que cumpla con las siguientes características:
- emergencia compleja,
- coherente
- original
Por ejemplo, un modelo de IA generativa puede crear ensayos o imágenes sofisticados.
Algunas tecnologías anteriores, como las LSTM y las RNN, también pueden generar contenido original y coherente. Algunos expertos consideran que estas tecnologías anteriores son IA generativa, mientras que otros creen que la verdadera IA generativa requiere resultados más complejos que los que pueden producir esas tecnologías anteriores.
Compara esto con el AA predictivo.
I
reconocimiento de imágenes
Proceso que clasifica objetos, patrones o conceptos en una imagen. El reconocimiento de imágenes también se conoce como clasificación de imágenes.
Para obtener más información, consulta Práctica de AA: Clasificación de imágenes.
Consulta el curso Práctica de AA: Clasificación de imágenes para obtener más información.
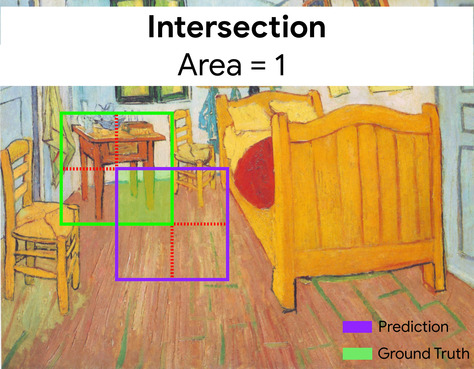
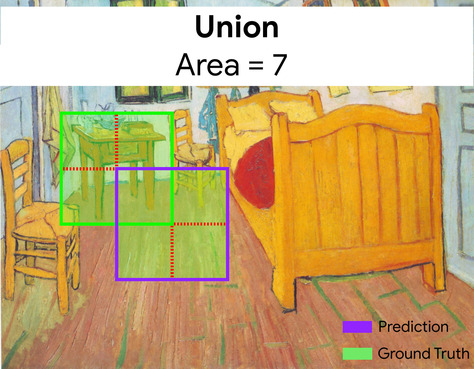
intersección sobre la unión (IoU)
La intersección de dos conjuntos dividida por su unión. En las tareas de detección de imágenes con aprendizaje automático, el IoU se usa para medir la precisión del cuadro de límite previsto del modelo en relación con el cuadro de límite de verdad fundamental. En este caso, el IoU de los dos cuadros es la proporción entre el área superpuesta y el área total, y su valor varía de 0 (sin superposición del cuadro de límite previsto y el cuadro de límite de la verdad fundamental) a 1 (el cuadro de límite previsto y el cuadro de límite de la verdad fundamental tienen las mismas coordenadas exactas).
Por ejemplo, en la siguiente imagen:
- El cuadro de límite previsto (las coordenadas que delimitan dónde el modelo predijo que se encuentra la mesa de noche en el cuadro) se describe en púrpura.
- El cuadro de límite de la verdad fundamental (las coordenadas que delimitan dónde se encuentra la mesa de noche en el cuadro) está delineado en verde.
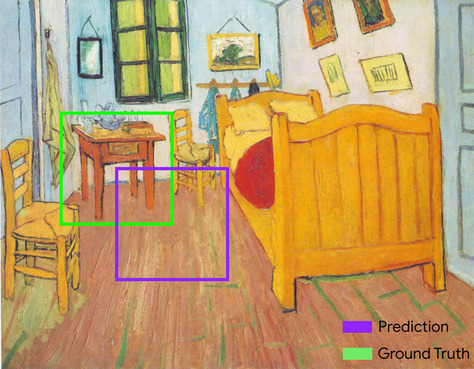
Aquí, la intersección de los cuadros de límite para la predicción y la verdad fundamental (abajo a la izquierda) es 1, y la unión de los cuadros de límite para la predicción y la verdad fundamental (abajo a la derecha) es 7, por lo que el IoU es \(\frac{1}{7}\).
K
puntos clave
Son las coordenadas de componentes específicos en una imagen. Por ejemplo, para un modelo de reconocimiento de imágenes que distingue las especies de flores, los puntos clave podrían ser el centro de cada pétalo, el tallo, el estambre, etcétera.
L
puntos de referencia
Sinónimo de puntos de interés.
M
MMIT
Abreviatura de ajuste de instrucciones multimodales.
MNIST
Un conjunto de datos de dominio público compilado por LeCun, Cortes y Burges que contiene 60,000 imágenes, cada imagen muestra cómo un ser humano escribió de forma manual un dígito particular del 0 al 9. Cada imagen se almacena como una matriz de enteros de 28 × 28, donde cada número entero es un valor de una escala de grises entre 0 y 255, ambos incluidos.
MNIST es un conjunto de datos canónico para el aprendizaje automático que a menudo se utiliza para probar nuevos enfoques de AA. Para obtener más información, consulta The MNIST Database of Handwritten Digits.
MOE
Abreviatura de combinación de expertos.
P
agrupación
Reducir una matriz (o matrices) creada por una capa convolucional anterior a una matriz más pequeña. Por lo general, la agrupación implica tomar el valor máximo o promedio en el área agrupada. Por ejemplo, supongamos que tenemos la siguiente matriz de 3 × 3:
![La matriz 3 × 3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=00&hl=es)
Una operación de reducción, al igual que una convolucional, divide esa matriz en porciones y luego desliza esa operación convolucional en pasos. Por ejemplo, supongamos que la operación de reducción divide la matriz convolucional en porciones de 2 × 2 con un paso de 1 × 1. Como se ilustra en el siguiente diagrama, se realizan cuatro operaciones de agrupación. Imagina que cada operación de agrupación elige el valor máximo de los cuatro en esa porción:
![La matriz de entrada es 3 × 3 con los valores: [[5,3,1], [8,2,5], [9,4,3]].
La submatriz 2 × 2 superior izquierda de la matriz de entrada es [[5,3], [8,2]], por lo que la operación de agrupación superior izquierda genera el valor 8 (que es el máximo de 5, 3, 8 y 2). La submatriz 2 × 2 superior derecha de la matriz de entrada es [[3,1], [2,5]], por lo que la operación de reducción superior derecha genera el valor 5. La submatriz 2 × 2 inferior izquierda de la matriz de entrada es [[8,2], [9,4]], por lo que la operación de agregación inferior izquierda genera el valor 9. La submatriz 2 × 2 inferior derecha de la matriz de entrada es [[2,5], [4,3]], por lo que la operación de reducción inferior derecha genera el valor 5. En resumen, la operación de agrupación genera la matriz 2 × 2 [[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=00&hl=es)
La reducción permite aplicar la invariancia traslacional en la matriz de entrada.
El agrupamiento para aplicaciones de visión se conoce más formalmente como agrupamiento espacial. Por lo general, las aplicaciones de series temporales se refieren a la agrupación como agrupación temporal. De manera menos formal, la agrupación se suele denominar submuestreo o muestreo reducido.
modelo después del entrenamiento
Es un término definido de forma imprecisa que, por lo general, hace referencia a un modelo previamente entrenado que pasó por algún procesamiento posterior, como una o más de las siguientes opciones:
modelo previamente entrenado
Por lo general, un modelo que ya se entrenó. El término también podría referirse a un vector de incorporación previamente entrenado.
El término modelo de lenguaje previamente entrenado suele referirse a un modelo de lenguaje grande ya entrenado.
entrenamiento previo
El entrenamiento inicial de un modelo en un conjunto de datos grande. Algunos modelos previamente entrenados son gigantes torpes y, por lo general, deben definirse mejor mediante un entrenamiento adicional. Por ejemplo, los expertos en AA podrían entrenar previamente un modelo de lenguaje grande en un vasto conjunto de datos de texto, como todas las páginas en inglés de Wikipedia. Después del entrenamiento previo, el modelo resultante se puede definir mejor con cualquiera de las siguientes técnicas:
R
invariancia rotacional
En un problema de clasificación de imágenes, la capacidad de un algoritmo para clasificar imágenes correctamente incluso cuando cambia la orientación de la imagen. Por ejemplo, el algoritmo aún puede identificar una raqueta de tenis, ya sea que esté apuntando hacia arriba, hacia un lado o hacia abajo. Ten en cuenta que la invariancia rotacional no siempre es deseable; por ejemplo, un 9 al revés no debe clasificarse como un 9.
Consulta también invariancia de traslación y invariancia de tamaño.
S
invariancia de tamaño
En un problema de clasificación de imágenes, la capacidad de un algoritmo para clasificar correctamente las imágenes, incluso cuando cambia el tamaño de la imagen. Por ejemplo, el algoritmo aún puede identificar a un gato si consume 2 millones de píxeles o 200,000 píxeles. Ten en cuenta que incluso los mejores algoritmos de clasificación de imágenes aún tienen límites prácticos en la invariancia de tamaño. Por ejemplo, es poco probable que un algoritmo (o persona) clasifique correctamente una imagen de gato que consuma solo 20 píxeles.
Consulta también invariancia de traslación y invariancia rotacional.
reducción espacial
Consulta agrupación.
stride
En una operación convolucional o de reducción, el delta en cada dimensión de la siguiente serie de porciones de entrada. Por ejemplo, la siguiente animación muestra un paso (1,1) durante una operación de convolución. Por lo tanto, la siguiente porción de entrada comienza una posición a la derecha de la porción de entrada anterior. Cuando la operación llega al borde derecho, la siguiente porción está completamente a la izquierda, pero una posición hacia abajo.
En el ejemplo anterior, se muestra un paso de dos dimensiones. Si la matriz de entrada es tridimensional, el paso también lo será.
submuestreo
Consulta agrupación.
T
temperatura
Un hiperparámetro que controla el grado de aleatoriedad del resultado de un modelo. Las temperaturas más altas generan resultados más aleatorios, mientras que las temperaturas más bajas generan resultados menos aleatorios.
La elección de la mejor temperatura depende de la aplicación específica y de las propiedades preferidas del resultado del modelo. Por ejemplo, es probable que aumentes la temperatura cuando crees una aplicación que genere resultados creativos. Por el contrario, es probable que disminuyas la temperatura cuando crees un modelo que clasifique imágenes o texto para mejorar su precisión y coherencia.
La temperatura se suele usar con softmax.
invariancia traslacional
En un problema de clasificación de imágenes, la capacidad de un algoritmo para clasificar imágenes de manera correcta incluso cuando cambia la posición de los objetos dentro de la imagen. Por ejemplo, el algoritmo aún puede identificar un perro, ya sea en el centro del marco o en el extremo izquierdo de este.
Consulta también invariancia de tamaño y invariancia rotacional.