Cette page contient les termes du glossaire des modèles d'images. Pour connaître tous les termes du glossaire, cliquez ici.
A
réalité augmentée
Technologie qui superpose une image générée par ordinateur à la vue du monde réel de l'utilisateur, offrant ainsi une vue composite.
auto-encodeur
Système qui apprend à extraire les informations les plus importantes de l'entrée. Les autoencodeurs sont une combinaison d'un encodeur et d'un décodeur. Les autoencodeurs reposent sur le processus en deux étapes suivant:
- L'encodeur mappe l'entrée sur un format (intermédiaire) à faible dimension (généralement avec perte).
- Le décodeur crée une version avec perte de l'entrée d'origine en mappant le format à dimension inférieure sur le format d'entrée d'origine à dimension supérieure.
Les autoencodeurs sont entraînés de bout en bout en demandant au décodeur de tenter de reconstruire l'entrée d'origine à partir du format intermédiaire de l'encodeur le plus fidèlement possible. Étant donné que le format intermédiaire est plus petit (de dimension inférieure) que le format d'origine, l'autoencodeur est contraint d'apprendre quelles informations de l'entrée sont essentielles, et la sortie ne sera pas parfaitement identique à l'entrée.
Exemple :
- Si les données d'entrée sont un graphique, la copie non exacte sera semblable au graphique d'origine, mais quelque peu modifiée. Il est possible que la copie non exacte supprime le bruit de l'image originale ou remplisse certains pixels manquants.
- Si les données d'entrée sont du texte, un autoencodeur génère un nouveau texte qui imite (mais n'est pas identique) le texte d'origine.
Voir également les auto-encodeurs variationnels.
modèle autorégressif
Modèle qui infère une prédiction en fonction de ses propres prédictions précédentes. Par exemple, les modèles de langage autorégressifs prédisent le prochain jeton en fonction des jetons précédemment prédits. Tous les grands modèles de langage basés sur Transformer sont autorégressifs.
En revanche, les modèles d'image basés sur des GAN ne sont généralement pas autorégressifs, car ils génèrent une image en une seule passe avant et non de manière itérée par étapes. Toutefois, certains modèles de génération d'images sont autorégressifs, car ils génèrent une image par étapes.
B
cadre de délimitation
Dans une image, les coordonnées (x, y) d'un rectangle autour d'une zone d'intérêt, comme le chien dans l'image ci-dessous.

C
convolution
En mathématiques, de manière informelle, mélange de deux fonctions. Dans le machine learning, une convolution mélange le filtre convolutif et la matrice d'entrée afin d'entraîner les pondérations.
Le terme "convolution" en machine learning est souvent un raccourci pour désigner une opération de convolution ou une couche de convolution.
Sans convolution, un algorithme de machine learning devrait apprendre une pondération différente pour chaque cellule d'un grand tensor. Par exemple, un algorithme de machine learning dont l'entraînement s'effectue sur des images de 2K x 2K serait forcé de trouver 4 millions de pondérations. Grâce aux convolutions, un algorithme de machine learning ne doit trouver des pondérations que pour chaque cellule du filtre convolutif, ce qui réduit considérablement la mémoire nécessaire à l'entraînement du modèle. Lorsque le filtre convolutif est appliqué, il est simplement répliqué dans les cellules de sorte que chacune d'elles soit multipliée par le filtre.
Pour en savoir plus, consultez la section Présentation des réseaux de neurones convolutifs du cours sur la classification d'images.
filtre convolutif
L'un des deux acteurs d'une opération convolutive. (L'autre acteur est une tranche d'une matrice d'entrée.) Un filtre convolutif est une matrice de même rang que la matrice d'entrée, mais de forme plus petite. Par exemple, étant donné une matrice d'entrée 28 x 28, le filtre peut être n'importe quelle matrice 2D de taille inférieure à 28 x 28.
Dans la manipulation photographique, toutes les cellules d'un filtre convolutif sont généralement définies sur un motif constant d'uns et de zéros. En machine learning, les filtres convolutifs sont généralement amorcés avec des nombres aléatoires, puis le réseau s'entraîne avec les valeurs idéales.
Pour en savoir plus, consultez la section Convolution du cours sur la classification des images.
couche convolutive
Couche d'un réseau de neurones profond dans laquelle un filtre convolutif transfère une matrice d'entrée. Soit, par exemple, le filtre convolutif 3 x 3 suivant:
![Une matrice 3x3 avec les valeurs suivantes: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=00&hl=fr)
L'animation suivante montre une couche convolutive composée de neuf opérations convolutives impliquant la matrice d'entrée 5 x 5. Notez que chaque opération convolutive fonctionne sur une tranche 3x3 différente de la matrice d'entrée. La matrice 3 x 3 résultante (à droite) est constituée des résultats des 9 opérations convolutives:
![Animation montrant deux matrices. La première matrice est la matrice 5x5: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
La deuxième matrice est la matrice 3x3 :
[[181,303,618], [115,338,605], [169,351,560]].
La deuxième matrice est calculée en appliquant le filtre convolutif [[0, 1, 0], [1, 0, 1], [0, 1, 0]] sur différents sous-ensembles 3 x 3 de la matrice 5 x 5.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=00&hl=fr)
Pour en savoir plus, consultez la section Couches entièrement connectées du cours sur la classification des images.
réseau de neurones convolutif
Réseau de neurones dans lequel au moins une couche est une couche convolutive. Un réseau de neurones convolutif typique consiste en une combinaison des couches suivantes:
Les réseaux de neurones convolutifs ont eu beaucoup de succès pour certains types de problèmes, notamment la reconnaissance d'images.
opération convolutive
L'opération mathématique en deux étapes suivante:
- Multiplication élément par élément du filtre convolutif et d'une tranche d'une matrice d'entrée. La tranche de la matrice d'entrée est de même rang et de même taille que le filtre convolutif.
- Somme de toutes les valeurs de la matrice de produits résultante.
Prenons l'exemple de la matrice d'entrée 5 x 5 suivante:
![Matrice 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=00&hl=fr)
Soit, à présent, le filtre convolutif 2 x 2 suivant:
![Matrice 2x2: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=00&hl=fr)
Chaque opération de convolution implique une seule tranche 2x2 de la matrice d'entrée. Par exemple, supposons que nous utilisions la tranche 2 x 2 en haut à gauche de la matrice d'entrée. L'opération convolutive sur cette tranche est alors:
![Application du filtre convolutif [[1, 0], [0, 1]] à la section 2 x 2 en haut à gauche de la matrice d'entrée, qui est [[128,97], [35,22]].
Le filtre convolutif laisse les valeurs 128 et 22 intactes, mais met à zéro les valeurs 97 et 35. Par conséquent, l'opération de convolution renvoie la valeur 150 (128 + 22).](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=00&hl=fr)
Une couche convolutive consiste en une série d'opérations convolutives, chacune agissant sur une tranche différente de la matrice d'entrée.
D
augmentation des données
Augmenter artificiellement l'éventail et le nombre d'exemples d'entraînement en transformant les exemples existants afin d'en créer de nouveaux. Supposons que votre ensemble de données contienne des exemples d'images, mais pas suffisamment pour que le modèle apprenne des associations utiles. Dans l'idéal, vous allez ajouter suffisamment d'images étiquetées à votre ensemble de données pour que votre modèle puisse s'entraîner correctement. Si ce n'est pas possible, l'augmentation des données peut faire pivoter, étirer et faire un reflet de chaque image afin de créer de nombreuses variantes de l'image originale, ce qui produira éventuellement suffisamment de données avec libellé pour un entraînement d'excellente qualité.
Réseau de neurones convolutifs séparables en profondeur (sepCNN)
Architecture de réseau de neurones convolutifs basée sur Inception, mais où les modules Inception sont remplacés par des convolutions séparables en profondeur. Également appelé Xception.
Une convolution séparable en profondeur (également abrégée en "convolution séparable") factorise une convolution 3D standard en deux opérations de convolution distinctes plus efficaces en termes de calcul: d'abord, une convolution en profondeur, avec une profondeur de 1 (n ✕ n ✕ 1), puis une convolution ponctuelle, avec une longueur et une largeur de 1 (1 ✕ 1 ✕ n).
Pour en savoir plus, consultez Xception : Deep Learning with Depthwise Separable Convolutions (Xception : Deep Learning with Depthwise Separable Convolutions).
sous-échantillonnage
Terme complexe qui désigne l'un des deux concepts suivants, selon les cas:
- Réduction de la quantité d'informations dans une fonctionnalité afin d'entraîner un modèle plus efficacement. Par exemple, avant d'entraîner un modèle de reconnaissance d'images, procéder au sous-échantillonnage d'images haute résolution dans un format de résolution inférieure.
- Entraînement du modèle sur un pourcentage excessivement faible d'exemples de classe surreprésentés afin d'améliorer l'entraînement sur les classes sous-représentées. Par exemple, dans un ensemble de données déséquilibré par classe, les modèles ont tendance à apprendre beaucoup sur la classe majoritaire et pas assez sur la classe minoritaire. Le sous-échantillonnage permet d'équilibrer la durée d'entraînement sur les classes majoritaires et minoritaires.
Pour en savoir plus, consultez la section Ensembles de données: ensembles de données déséquilibrés dans le cours d'initiation au machine learning.
F
affiner
Deuxième étape d'entraînement spécifique à la tâche effectuée sur un modèle pré-entraîné pour affiner ses paramètres pour un cas d'utilisation spécifique. Par exemple, la séquence d'entraînement complète de certains grands modèles de langage est la suivante:
- Pré-entraînement:entraînez un grand modèle de langage sur un vaste ensemble de données général, comme toutes les pages de Wikipedia en anglais.
- Ajustement:entraînez le modèle pré-entraîné pour qu'il effectue une tâche spécifique, comme répondre à des requêtes médicales. Le réglage fin implique généralement des centaines ou des milliers d'exemples axés sur la tâche spécifique.
Autre exemple : la séquence d'entraînement complète d'un grand modèle d'image se présente comme suit :
- Pré-entraînement:entraînez un grand modèle d'image sur un vaste ensemble de données d'images générales, comme toutes les images de Wikimedia Commons.
- Affinement:entraînez le modèle pré-entraîné pour qu'il effectue une tâche spécifique, comme générer des images d'orques.
Le réglage fin peut impliquer n'importe quelle combinaison des stratégies suivantes:
- Modifier tous les paramètres existants du modèle pré-entraîné. On parle parfois de réglage fin complet.
- Modifier seulement certains des paramètres existants du modèle pré-entraîné (généralement, les couches les plus proches de la couche de sortie), tout en laissant les autres paramètres existants inchangés (généralement, les couches les plus proches de la couche d'entrée). Consultez la section Réglage des paramètres avec optimisation.
- Ajouter des calques, généralement au-dessus des calques existants les plus proches du calque de sortie.
L'optimisation est une forme d'apprentissage par transfert. Par conséquent, l'ajustement fin peut utiliser une fonction de perte ou un type de modèle différents de ceux utilisés pour entraîner le modèle pré-entraîné. Par exemple, vous pouvez affiner un grand modèle d'image pré-entraîné pour produire un modèle de régression qui renvoie le nombre d'oiseaux dans une image d'entrée.
Comparez l'ajustement fin aux termes suivants:
Pour en savoir plus, consultez la section Ajustement du cours d'initiation au machine learning.
G
Gemini
Écosystème composé de l'IA la plus avancée de Google. Voici quelques éléments de cet écosystème:
- Différents modèles Gemini
- Interface conversationnelle interactive pour un modèle Gemini. Les utilisateurs saisissent des requêtes, et Gemini y répond.
- Diverses API Gemini
- Divers produits professionnels basés sur des modèles Gemini, par exemple Gemini pour Google Cloud.
Modèles Gemini
Les modèles multimodaux de pointe de Google basés sur Transformer Les modèles Gemini sont spécialement conçus pour s'intégrer aux agents.
Les utilisateurs peuvent interagir avec les modèles Gemini de différentes manières, y compris via une interface de boîte de dialogue interactive et via des SDK.
IA générative
Champ émergent et transformateur sans définition formelle. Cela dit, la plupart des experts s'accordent à dire que les modèles d'IA générative peuvent créer ("générer") du contenu qui présente les caractéristiques suivantes:
- complexe
- cohérent
- originale
Par exemple, un modèle d'IA générative peut créer des essais ou des images sophistiqués.
Certaines technologies antérieures, y compris les LSTM et les RNN, peuvent également générer des contenus originaux et cohérents. Certains experts considèrent ces technologies antérieures comme de l'IA générative, tandis que d'autres estiment que la véritable IA générative nécessite des résultats plus complexes que ces technologies antérieures ne peuvent produire.
À comparer au ML prédictif.
I
reconnaissance d'image
Processus de classification des objets, des formes ou des concepts dans une image. La reconnaissance d'image est également appelée classification d'images.
Pour en savoir plus, consultez Travaux pratiques sur le machine learning: Classification d'images.
Pour en savoir plus, consultez le cours Travaux pratiques sur le machine learning: Classification d'images.
Intersection over Union (IoU)
Intersection de deux ensembles divisée par leur union. Dans les tâches de détection d'images de machine learning, l'IoU permet de mesurer la justesse du cadre de délimitation prédit du modèle par rapport au cadre de délimitation de la vérité terrain. Dans ce cas, l'IoU des deux cadres correspond au ratio entre la zone de chevauchement et la zone totale. Sa valeur varie de 0 (pas de chevauchement entre le cadre de délimitation prédit et le cadre de délimitation de la vérité terrain) à 1 (le cadre de délimitation prédit et le cadre de délimitation de la vérité terrain ont exactement les mêmes coordonnées).
Par exemple, dans l'image ci-dessous:
- Le cadre de délimitation prévu (les coordonnées délimitant l'emplacement de la table de chevet dans le tableau, selon le modèle) est entouré en violet.
- Le cadre de délimitation de vérité terrain (les coordonnées délimitant l'emplacement réel de la table de chevet dans le tableau) est encadré en vert.
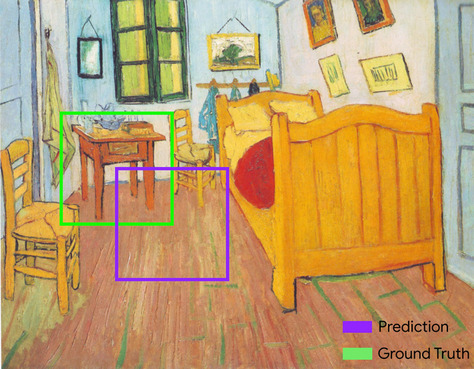
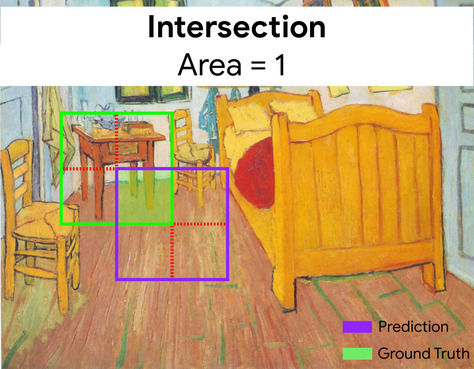
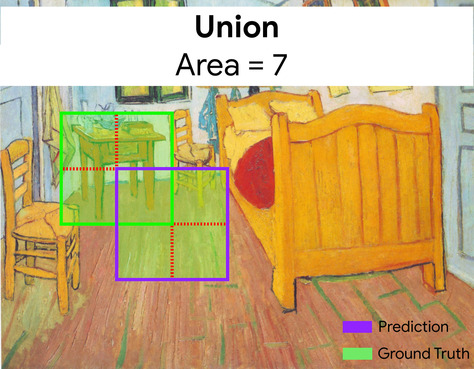
Ici, l'intersection des cadres de délimitation pour la prédiction et la vérité terrain (en bas à gauche) est de 1, et l'union des cadres de délimitation pour la prédiction et la vérité terrain (en bas à droite) est de 7. L'IoU est donc \(\frac{1}{7}\).
K
points clés
Coordonnées de caractéristiques particulières d'une image. Par exemple, pour un modèle de reconnaissance d'image qui distingue les espèces de fleurs, les points clés peuvent être le centre de chaque pétale, la tige, les étamines, etc.
L
landmarks
Synonyme de points clés.
M
MMIT
Abréviation de multimodal instruction-tuned (multimodal tuned instruction).
MNIST
Ensemble de données du domaine public compilé par LeCun, Cortes et Burges qui contient 60 000 images montrant chacune un chiffre manuscrit compris entre 0 et 9. Chaque image est stockée sous forme de tableau d'entiers 28x28, chaque entier représentant une valeur d'échelle de gris comprise entre 0 et 255 inclus.
MNIST est un ensemble de données canonique pour le machine learning, souvent utilisé pour tester de nouvelles approches de machine learning. Pour en savoir plus, consultez la Base de données MNIST de chiffres écrits à la main.
ME
Abréviation de mélange d'experts.
P
pooling
Réduction d'une matrice (ou de matrices) créée par une couche convolutive antérieure à une matrice plus petite. Le pooling consiste généralement à prendre la valeur maximale ou moyenne sur la zone groupée. Soit, par exemple, la matrice 3 x 3 suivante:
![La matrice 3 x 3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=00&hl=fr)
Une opération de pooling, tout comme une opération convolutive, divise cette matrice en tranches, puis déplace cette opération convolutive selon un certain pas. Par exemple, supposons que l'opération de pooling divise la matrice convolutive en tranches 2 x 2 avec un pas de 1 x 1. Comme illustré dans le diagramme suivant, quatre opérations de pooling ont lieu. Imaginons que chaque opération de pooling sélectionne la valeur maximale des quatre valeurs de cette tranche:
![La matrice d'entrée est de 3 x 3 avec les valeurs: [[5,3,1], [8,2,5], [9,4,3]].
La sous-matrice 2x2 en haut à gauche de la matrice d'entrée est [[5,3], [8,2]]. L'opération de pooling en haut à gauche génère donc la valeur 8 (qui est la valeur maximale de 5, 3, 8 et 2). La sous-matrice 2x2 en haut à droite de la matrice d'entrée est [[3,1], [2,5]]. L'opération de pooling en haut à droite donne donc la valeur 5. La sous-matrice 2x2 en bas à gauche de la matrice d'entrée est [[8,2], [9,4]]. L'opération de pooling en bas à gauche génère donc la valeur 9. La sous-matrice 2x2 en bas à droite de la matrice d'entrée est [[2,5], [4,3]]. L'opération de pooling en bas à droite donne donc la valeur 5. En résumé, l'opération de pooling génère la matrice 2x2 [[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=00&hl=fr)
Le pooling permet d'appliquer l'invariance par translation dans la matrice d'entrée.
Le pooling pour les applications de vision est plus communément appelé pooling spatial. Les applications de séries temporelles appellent généralement le regroupement regroupement temporel. De manière moins formelle, le pooling est souvent appelé sous-échantillonnage ou rééchantillonnage.
modèle post-entraîné
Terme vaguement défini qui désigne généralement un modèle pré-entraîné ayant subi un post-traitement, tel qu'un ou plusieurs des éléments suivants:
modèle pré-entraîné
Il s'agit généralement d'un modèle qui a déjà été entraîné. Le terme peut également désigner un vecteur d'embedding précédemment entraîné.
Le terme modèle de langage pré-entraîné désigne généralement un grand modèle de langage déjà entraîné.
pré-entraînement
Entraînement initial d'un modèle sur un grand ensemble de données. Certains modèles pré-entraînés sont des géants maladroits et doivent généralement être affinés par un entraînement supplémentaire. Par exemple, les experts en ML peuvent pré-entraîner un grand modèle de langage sur un vaste ensemble de données textuelles, comme toutes les pages en anglais de Wikipédia. Après le pré-entraînement, le modèle obtenu peut être affiné à l'aide de l'une des techniques suivantes:
- distillation
- ajustement
- réglage des instructions
- Réglage des paramètres avec optimisation
- prompt-tuning
R
invariance rotationnelle
Dans un problème de classification d'images, capacité d'un algorithme à classer correctement les images, même lorsque leur orientation change. Par exemple, l'algorithme peut toujours identifier une raquette de tennis, qu'elle soit orientée vers le haut, sur le côté ou vers le bas. Notez que l'invariance rotationnelle n'est pas toujours souhaitable. Par exemple, un 9 à l'envers ne devrait pas être classé comme étant un 9.
Consultez également les sections invariance par translation et invariance par redimensionnement.
S
invariance par redimensionnement
Dans un problème de classification d'images, capacité d'un algorithme à classer correctement les images, même lorsque leur taille change. Par exemple, l'algorithme peut identifier un chat, qu'il consomme 2 millions de pixels ou 200 000 pixels. Notez que même les meilleurs algorithmes de classification d'images présentent encore des limites pratiques au niveau de l'invariance par redimensionnement. Par exemple, il est peu probable qu'un algorithme (ou une personne) puisse classer correctement une image de chat de seulement 20 pixels.
Consultez également les pages invariance de translation et invariance de rotation.
pooling spatial
Voir pooling.
stride
Dans une opération convolutive ou un pooling, le delta dans chaque dimension de la série suivante de tranches d'entrée. Par exemple, l'animation suivante montre une longueur de foulée (1,1) lors d'une opération de convolution. Par conséquent, le prochain segment d'entrée commence à une position à droite du segment d'entrée précédent. Lorsque l'opération atteint le bord droit, le segment suivant est tout à gauche, mais une position plus bas.
L'exemple précédent illustre une longueur de pas bidimensionnelle. Si la matrice d'entrée est tridimensionnelle, le pas est également tridimensionnel.
sous-échantillonnage
Voir pooling.
T
température
Hyperparamètre qui contrôle le degré de hasard de la sortie d'un modèle. Des températures plus élevées entraînent des sorties plus aléatoires, tandis que des températures plus basses entraînent des sorties moins aléatoires.
Le choix de la meilleure température dépend de l'application spécifique et des propriétés préférées de la sortie du modèle. Par exemple, vous augmenterez probablement la température lorsque vous créerez une application qui génère des résultats créatifs. À l'inverse, vous devriez probablement baisser la température lorsque vous créez un modèle qui classe des images ou du texte afin d'améliorer sa précision et sa cohérence.
La température est souvent utilisée avec la fonction softmax.
invariance par translation
Dans un problème de classification d'images, capacité d'un algorithme à classer correctement les images, même lorsque la position des objets dans l'image change. Par exemple, l'algorithme peut identifier un chien comme tel, qu'il se trouve au centre ou à gauche de l'image.
Consultez également les sections Invariance de taille et Invariance de rotation.