בדף הזה מפורטים מונחים ממילון המונחים של מודלים של תמונות. כאן מפורטות כל ההגדרות במילון.
A
מציאות רבודה
טכנולוגיה שמאפשרת להציג תמונה שנוצרה על ידי מחשב על התצוגה של המשתמש בעולם האמיתי, וכך ליצור תצוגה מורכבת.
אוטו-קונדרטור
מערכת שמלמדת לחלץ את המידע החשוב ביותר מהקלט. אוטו-קונדים הם שילוב של מקודד ומפענח. אוטו-קונדים מסתמכים על התהליך הדו-שלבי הבא:
- המקודד ממפה את הקלט לפורמט (בדרך כלל) עם אובדן נתונים (לא איכותי) בעל ממדים נמוכים יותר (פורמט ביניים).
- המפענח יוצר גרסה עם אובדן נתונים של הקלט המקורי על ידי מיפוי של הפורמט בעל המאפיינים הנמוכים יותר לפורמט הקלט המקורי בעל המאפיינים הגבוהים יותר.
מקודדים אוטומטיים עוברים אימון מקצה לקצה, כך שהפעמקוד מנסה לשחזר את הקלט המקורי מהפורמט הביניים של המקודד בצורה הקרובה ביותר האפשרית. מכיוון שהפורמט הביניים קטן יותר (בממדים נמוכים יותר) מהפורמט המקורי, האוטו-קונברטור נאלץ ללמוד איזה מידע בקלט חיוני, והפלט לא יהיה זהה לחלוטין לקלט.
לדוגמה:
- אם נתוני הקלט הם גרפיקה, העותק הלא מדויק יהיה דומה לגרפיקה המקורית, אבל ישתנה במידה מסוימת. יכול להיות שהעותק הלא מדויק מסיר רעש מהגרפיקה המקורית או ממלא פיקסלים חסרים.
- אם נתוני הקלט הם טקסט, אוטו-קונדר יוצר טקסט חדש שמחקה את הטקסט המקורי (אבל לא זהה לו).
אפשר לעיין גם במאמר בנושא מקודדים אוטומטיים וריאציוניים (VAE).
מודל אוטו-רגרסיבי
מודל שמסיק חיזוי על סמך החיזויים הקודמים שלו. לדוגמה, מודלים של שפה חזרהית חוזים את האסימון הבא על סמך האסימונים שחזו קודם. כל מודלים גדולים של שפה שמבוססים על Transformer הם אוטו-רגרסיביים.
לעומת זאת, מודלים של תמונות שמבוססים על GAN הם בדרך כלל לא רגרסיביים אוטומטיים, כי הם יוצרים תמונה בפעולה קדימה אחת ולא באופן איטרטיבי בשלבים. עם זאת, מודלים מסוימים ליצירת תמונות הם מודלים רגרסיביים אוטומטיים כי הם יוצרים תמונה בשלבים.
B
תיבה תוחמת (bounding box)
בתמונה, הקואורדינטות (x, y) של מלבן סביב אזור עניין, כמו הכלב בתמונה שבהמשך.

C
convolve
במתמטיקה, באופן לא רשמי, שילוב של שתי פונקציות. בלמידת מכונה, עיבוד נתונים מבוסס-עיבוי (convolution) מעורבב עם מסנן העיבוי ומטריצת הקלט כדי לאמן משקלים.
המונח 'קבולציה' בלמידת מכונה הוא בדרך כלל דרך קצרה להתייחס לפעולה קונבולוציה או לשכבה קונבולוציה.
בלי עיבוד קוונטי, אלגוריתם למידת מכונה יצטרך ללמוד משקל נפרד לכל תא בטנסור גדול. לדוגמה, אימון של אלגוריתם למידת מכונה על תמונות בגודל 2K x 2K יאלץ למצוא 4 מיליון משקלים נפרדים. בזכות עיבוד קוונטי, אלגוריתם של למידת מכונה צריך למצוא משקלים רק לכל תא במסנן קוונטי, וכך לצמצם באופן משמעותי את נפח הזיכרון הנדרש לאימון המודל. כשמחילים את המסנן הקוונטי, הוא מוכפל בכל התאים כך שכל אחד מהם מוכפל במסנן.
מידע נוסף זמין בקטע מבוא לרשתות נוירונליות קונבולוציוניות בקורס 'סיווג תמונות'.
מסנן קוונטילי
אחד משני הגורמים בפעולת עיבוד נתונים (convolution). (השחקן השני הוא פרוסת מטריצה של קלט). מסנן קוונטי הוא מטריצה שיש לה את אותו דרג כמו למטריצה של הקלט, אבל בצורה קטנה יותר. לדוגמה, אם נתונה מטריצת קלט בגודל 28x28, המסנן יכול להיות כל מטריצת 2D בגודל קטן מ-28x28.
בתמונות שעברו מניפולציה, בדרך כלל כל התאים במסנן קוונטי מוגדר לדפוס קבוע של אפסים ואחדים. בלמידת מכונה, בדרך כלל מסננים קונבולוציוניים מתחילים עם מספרים אקראיים, ואז הרשת מתאמנת על הערכים האידיאליים.
מידע נוסף זמין בקטע Convolution בקורס 'סיווג תמונות'.
שכבת convolve
שכבה של רשת עצבית עמוקה שבה מסנן קוונטי עובר לאורך מטריצת קלט. לדוגמה, מסנן קוונטילציה בגודל 3x3:
![מטריצת 3x3 עם הערכים הבאים: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=00&hl=he)
באנימציה הבאה מוצגת שכבת convolutinon שמכילה 9 פעולות convolutinon שכוללות את מטריית הקלט 5x5. שימו לב שכל פעולה קוונטית פועלת על פרוסה שונה בגודל 3x3 של מטריצת הקלט. המטריצה 3x3 שמתקבלת (בצד שמאל) מורכבת מהתוצאות של 9 פעולות הקיפול:
![אנימציה שבה מוצגות שתי מטריצות. המטריצה הראשונה היא מטריצה 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
המטריצה השנייה היא המטריצה 3x3:
[[181,303,618], [115,338,605], [169,351,560]].
המטריצה השנייה מחושבת על ידי החלת המסנן הקוונטי [[0, 1, 0], [1, 0, 1], [0, 1, 0]] על קבוצות משנה שונות בגודל 3x3 של המטריצה בגודל 5x5.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=00&hl=he)
מידע נוסף זמין בקטע שכבות מקושרות בקורס 'סיווג תמונות'.
רשת נוירונים מלאכותית (CNN)
רשת נוירונים שבה שכבה אחת לפחות היא שכבה קוונטית. רשת נוירונלית רגילה מסוג convolutional מורכבת משילוב כלשהו של השכבות הבאות:
רשתות נוירונים מלאכותיות (CNN) הצליחו מאוד בפתרון בעיות מסוימות, כמו זיהוי תמונות.
פעולת convolve
הפעולה המתמטית הבאה בשני שלבים:
- מכפלה של כל רכיב במסנן קוונטי ופרוסה של מטריצה של קלט. (לפרוסת מטריצת הקלט יש את אותו דירוג וגודל כמו המסנן הקוונטי).
- סיכום כל הערכים במטריצה של המוצר שנוצר.
לדוגמה, נניח את מטריצת הקלט הבאה בגודל 5x5:
![המטריצה 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=00&hl=he)
עכשיו נדמיין מסנן קוונטי 2x2:
![המטריצה 2x2: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=00&hl=he)
כל פעולת convolve כוללת פרוסה אחת בגודל 2x2 של מטריצת הקלט. לדוגמה, נניח שאנחנו משתמשים בפרוסת 2x2 בפינה הימנית העליונה של מטריצת הקלט. לכן, פעולת ההתמרה ההרמונית על הפרוסה הזו נראית כך:
![החלת המסנן הקוונטי [[1, 0], [0, 1]] על הקטע 2x2 בפינה הימנית העליונה של מטריצת הקלט, שהוא [[128,97], [35,22]].
המסנן הקוונטי משנה את הערכים של 128 ו-22, אבל משאיר את הערכים של 97 ו-35 ללא שינוי. לכן, פעולת ההתמרה מניבת את הערך 150 (128+22).](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=00&hl=he)
שכבת convolve מורכבת מסדרה של פעולות convolve, שכל אחת פועלת על פרוסה אחרת של מטריצת הקלט.
D
הרחבת נתונים
הגדלה מלאכותית של המגוון והמספר של דוגמאות לאימון, על ידי שינוי של דוגמאות קיימות כדי ליצור דוגמאות נוספות. לדוגמה, נניח שתמונות הן אחת מהמאפיינים שלכם, אבל מערך הנתונים לא מכיל מספיק דוגמאות של תמונות כדי שהמודל יוכל ללמוד אסוציאציות מועילות. באופן אידיאלי, כדאי להוסיף למערך הנתונים מספיק תמונות מתויגות כדי לאפשר לאמן את המודל בצורה תקינה. אם זה לא אפשרי, אפשר להשתמש בהגדלת נתונים כדי לסובב, למתוח ולהציג תמונת מראה של כל תמונה כדי ליצור הרבה וריאציות של התמונה המקורית. כך אפשר לקבל מספיק נתונים מתויגים כדי לאפשר אימון מצוין.
רשת עצבית קונבולוציה (CNN) עם הפרדה לפי עומק (sepCNN)
ארכיטקטורה של רשת עצבית קונבולוציונית שמבוססת על Inception, אבל שבה המודולים של Inception מוחלפים בקונטרוולים ניתנים להפרדה לפי עומק. ידוע גם כ-Xception.
עיבוד נתונים באמצעות convolve נפרד לפי עומק (נקרא גם convolve נפרד) מחלק convolve 3D רגיל לשתי פעולות convolve נפרדות שיעילות יותר מבחינה חישובית: ראשית, convolve לפי עומק, עם עומק של 1 (n ✕ n ✕ 1), ולאחר מכן convolve לפי נקודה, עם אורך ורוחב של 1 (1 ✕ 1 ✕ n).
מידע נוסף זמין במאמר Xception: Deep Learning with Depthwise Separable Convlutions.
downsampling
מונח בעל עומס יתר שיכול להיות אחד מהמונחים הבאים:
- הפחתת כמות המידע בתכונה כדי לאמן מודל בצורה יעילה יותר. לדוגמה, לפני אימון מודל לזיהוי תמונות, אפשר להקטין את הדגימה של תמונות ברזולוציה גבוהה לפורמט ברזולוציה נמוכה יותר.
- אימון על אחוז נמוך באופן לא פרופורציונלי של דוגמאות לכיתות שמיוצגות יתר על המידה, כדי לשפר את אימון המודל על כיתות שמיוצגות פחות. לדוגמה, במערך נתונים עם חוסר איזון בין הקטגוריות, המודלים נוטים ללמוד הרבה על הקטגוריה הגדולה יותר ולא מספיק על הקטגוריה הקטנה יותר. דגימה לאחור עוזרת לאזן את כמות האימון של הכיתות הגדולות והקטנות.
למידע נוסף, ראו מערכי נתונים: מערכי נתונים לא מאוזנים בקורס המקוצר בנושא למידת מכונה.
F
כוונון עדין
סבב אימון שני ספציפי למשימה, שמתבצע במודל שעבר אימון מראש כדי לשפר את הפרמטרים שלו לצורך תרחיש לדוגמה ספציפי. לדוגמה, רצף האימון המלא של חלק ממודלים גדולים של שפה הוא:
- אימון מראש: אימון מודל גדול של שפה על מערך נתונים כללי עצום, כמו כל הדפים של ויקיפדיה באנגלית.
- התאמה אישית: אימון המודל שעבר אימון מראש לביצוע משימה ספציפית, כמו מענה לשאילתות רפואיות. תהליך השיפור כולל בדרך כלל מאות או אלפי דוגמאות שמתמקדות במשימה הספציפית.
דוגמה נוספת: רצף האימון המלא של מודל תמונה גדול הוא:
- אימון מראש: אימון מודל תמונות גדול על קבוצת נתונים כללית גדולה של תמונות, כמו כל התמונות ב-Wikimedia Commons.
- התאמה אישית: אימון המודל שעבר אימון מראש לביצוע משימה ספציפית, כמו יצירת תמונות של אורקות.
השיפור יכול לכלול כל שילוב של השיטות הבאות:
- שינוי כל הפרמטרים הקיימים של המודל שעבר אימון מראש. התהליך הזה נקרא לפעמים כוונון מדויק מלא.
- שינוי של חלק מהפרמטרים הקיימים של המודל המאומן מראש (בדרך כלל השכבות הקרובות ביותר לשכבת הפלט), תוך שמירה על הפרמטרים הקיימים האחרים ללא שינוי (בדרך כלל השכבות הקרובות ביותר לשכבת הקלט). כוונון יעיל בפרמטרים
- הוספת שכבות נוספות, בדרך כלל מעל השכבות הקיימות הקרובות ביותר לשכבת הפלט.
כוונון מדויק הוא סוג של למידה באמצעות העברה. לכן, יכול להיות שבתהליך השיפור המדויק נעשה שימוש בפונקציית אובדן או בסוג מודל שונים מאלה ששימשו לאימון המודל המאומן מראש. לדוגמה, אפשר לשפר מודל תמונה גדול שעבר אימון מראש כדי ליצור מודל רגרסיה שמחזיר את מספר הציפורים בתמונה קלט.
השוואה וניגוד בין כוונון מדויק לבין המונחים הבאים:
מידע נוסף זמין בקטע התאמה אישית במאמר קורס מקוצר על למידת מכונה.
G
Gemini
הסביבה העסקית שמכילה את ה-AI המתקדם ביותר של Google. רכיבים במערכת האקולוגית הזו כוללים:
- מודלים שונים של Gemini.
- ממשק השיחה האינטראקטיבי למודל Gemini. המשתמשים מקלידים הנחיות ו-Gemini משיב להנחיות האלה.
- ממשקי Gemini API שונים.
- מוצרים עסקיים שונים שמבוססים על מודלים של Gemini, למשל Gemini for Google Cloud.
מודלים של Gemini
מודלים מולטימודאליים מבוססי Transformer מתקדמים של Google. המודלים של Gemini תוכננו במיוחד לשילוב עם סוכנים.
המשתמשים יכולים לקיים אינטראקציה עם המודלים של Gemini במגוון דרכים, כולל באמצעות ממשק אינטראקטיבי של תיבת דו-שיח ו-SDK.
בינה מלאכותית גנרטיבית
תחום מתפתח של טרנספורמציה ללא הגדרה רשמית. עם זאת, רוב המומחים מסכימים שמודלים של AI גנרטיבי יכולים ליצור ('לגנרטור') תוכן שעומד בכל הקריטריונים הבאים:
- מורכבים
- עקבי
- מקורית
לדוגמה, מודל של AI גנרטיבי יכול ליצור תמונות או מאמרים מתוחכמים.
גם טכנולוגיות קודמות מסוימות, כולל LSTM ו-RNN, יכולות ליצור תוכן מקורי ועקבי. יש מומחים שמתייחסים לטכנולוגיות הקודמות האלה כאל AI גנרטיבי, ויש מומחים אחרים שחושבים ש-AI גנרטיבי אמיתי דורש תוצרים מורכבים יותר ממה שאפשר ליצור באמצעות הטכנולוגיות הקודמות האלה.
בניגוד ללמידת מכונה חזוי.
I
זיהוי תמונות, זיהוי תמונה
תהליך שמסווג אובייקטים, דפוסים או מושגים בתמונה. זיהוי תמונות נקרא גם סיווג תמונות.
מידע נוסף זמין במאמר ML Practicum: Image Classification.
מידע נוסף זמין בקורס ML Practicum: Image Classification.
חיתוך על איחוד (IoU)
החיתוך של שתי קבוצות חלקי האיחוד שלהן. במשימות של זיהוי תמונות בלמידת מכונה, נעשה שימוש ב-IoU כדי למדוד את הדיוק של תיבת הסימון הצפויה של המודל ביחס לתיבת הסימון של האמת המוחלטת. במקרה כזה, ערך ה-IoU של שתי התיבות הוא היחס בין האזור החופף לאזור הכולל, והוא נע בין 0 (אין חפיפה בין תיבת ה-bounding הצפויה לתיבת ה-bounding של עובדות הקרקע) ל-1 (לתיבת ה-bounding הצפויה ולתיבת ה-bounding של עובדות הקרקע יש אותן קואורדינטות בדיוק).
לדוגמה, בתמונה הבאה:
- תיבת הגבול הצפויה (הקואורדינטות שמגדירות את המיקום שבו המודל צופה שהשולחן ליד המיטה נמצא בציור) מסומנת בקו סגול.
- תיבת הגבול של האמת (הקואורדינטות שמגדירות את המיקום בפועל של שולחן הלילה בציור) מסומנת בקו ירוק.
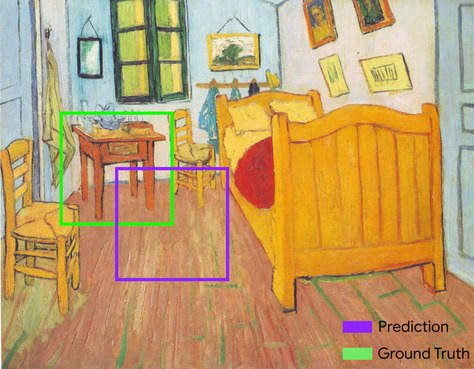
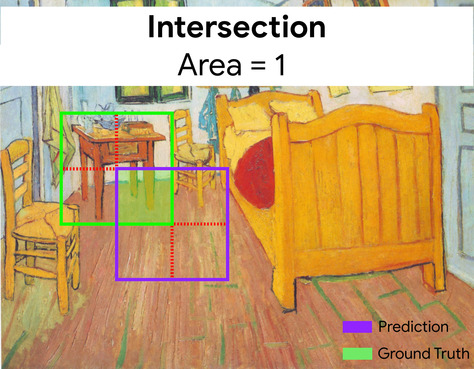
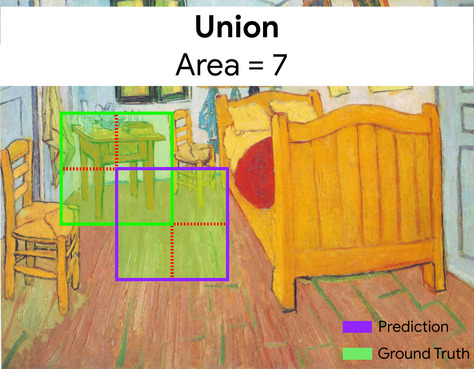
כאן, החיתוך של תיבות הסף לחיזוי ולעובדות (בפינה הימנית התחתונה) הוא 1, והאיחוד של תיבות הסף לחיזוי ולעובדות (בפינה הימנית התחתונה) הוא 7, כך ש-IoU הוא \(\frac{1}{7}\).
K
נקודות עיקריות
הקואורדינטות של תכונות מסוימות בתמונה. לדוגמה, במודל זיהוי תמונות שמבדיל בין מינים של פרחים, נקודות מפתח יכולות להיות מרכז כל כותרת, הגבעול, האבקן וכו'.
L
ציוני דרך
מילה נרדפת לנקודות מפתח.
M
MMIT
קיצור של multimodal instruction-tuned.
MNIST
מערך נתונים בתחום הציבורי שנאסף על ידי LeCun, Cortes ו-Burges, ומכיל 60,000 תמונות. בכל תמונה מוצגת דרך שבה אדם כתב באופן ידני ספרה מסוימת מ-0 עד 9. כל תמונה מאוחסנת כמערך של מספרים שלמים בגודל 28x28, כאשר כל מספר שלם הוא ערך בגווני אפור בין 0 ל-255, כולל.
MNIST הוא מערך נתונים קנוני ללמידת מכונה, שמשמש לרוב לבדיקת גישות חדשות ללמידת מכונה. פרטים נוספים זמינים במאמר בסיס הנתונים MNIST של ספרות בכתב יד.
MOE
קיצור של תערובת של מומחים.
P
איחוד
צמצום של מטריצה (או מטריצות) שנוצרו על ידי שכבת convolutin מוקדמת יותר למטריצה קטנה יותר. בדרך כלל, הצבירה כוללת את הערך המקסימלי או הממוצע של האזור המצטבר. לדוגמה, נניח שיש לנו את המטריצה הבאה בגודל 3x3:
![המטריצה 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=00&hl=he)
פעולת צבירה, כמו פעולת convolve, מחלקת את המטריצה הזו לפרוסות ואז מחליקה את פעולת ה-convolve לפי strides. לדוגמה, נניח שפעולת ה-pooling מחלקת את מטריצת ה-convolution לפרוסות בגודל 2x2 עם צעד של 1x1. כפי שמוצג בתרשים הבא, מתבצעות ארבע פעולות של איסוף בקטגוריות. נניח שכל פעולת איסוף בוחרת את הערך המקסימלי מתוך ארבעת הערכים באותו פרוסת זמן:
![מטריצת הקלט היא 3x3 עם הערכים: [[5,3,1], [8,2,5], [9,4,3]].
מטריצת המשנה 2x2 בפינה הימנית העליונה של מטריצת הקלט היא [[5,3], [8,2]], כך שפעולת ה-pooling בפינה הימנית העליונה מניבה את הערך 8 (הערך המקסימלי של 5, 3, 8 ו-2). מטריצת המשנה 2x2 בפינה השמאלית העליונה של מטריצת הקלט היא [[3,1], [2,5]], כך שפעולת ה-pooling בפינה השמאלית העליונה מניבה את הערך 5. מטריצת המשנה 2x2 בפינה הימנית התחתונה של מטריצת הקלט היא
[[8,2], [9,4]], כך שפעולת ה-pooling בפינה הימנית התחתונה מניבה את הערך
9. מטריצת המשנה 2x2 בפינה השמאלית התחתונה של מטריצת הקלט היא
[[2,5], [4,3]], כך שפעולת ה-pooling בפינה השמאלית התחתונה מניבה את הערך
5. לסיכום, פעולת ה-pooling מניבה את המטריצה 2x2 [[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=00&hl=he)
המצטבר עוזר לאכוף עמידות בטרנספורמציה במטריית הקלט.
הצבירה של מודלים לאפליקציות ראייה ידועה באופן רשמי יותר בתור צבירה מרחבית. באפליקציות של סדרות זמן, בדרך כלל קוראים לצבירה צבירה זמנית. באופן לא רשמי, יצירת מאגרים נקראת לעיתים קרובות דגימה משנית או דגימה לגודל קטן יותר.
מידע נוסף זמין במאמר מבוא לרשתות עצביות מתקפלות בקורס ML Practicum: Image Classification.
מודל לאחר אימון
מונח לא מוגדר במדויק שמתייחס בדרך כלל למודל שהודרן מראש שעבר עיבוד פוסט-טראיטמנט, כמו אחת או יותר מהפעולות הבאות:
מודל שעבר אימון מקדים
בדרך כלל, מודל שכבר אומן. המונח יכול גם להתייחס לוקטור הטמעה שעבר אימון קודם.
המונח מודל שפה שהודרן מראש מתייחס בדרך כלל למודל שפה גדול שכבר אומן.
אימון מקדים
האימון הראשוני של מודל על מערך נתונים גדול. חלק מהמודלים שהוכשרו מראש הם 'ענקים גמלוניים', ובדרך כלל צריך לשפר אותם באמצעות אימון נוסף. לדוגמה, מומחי למידת מכונה עשויים לאמן מראש מודל שפה גדול על מערך נתונים עצום של טקסט, כמו כל הדפים באנגלית בוויקיפדיה. אחרי האימון המקדים, אפשר לשפר את המודל שנוצר באמצעות אחת מהשיטות הבאות:
R
סבילות לסיבוב
בבעיה של סיווג תמונות, היכולת של אלגוריתם לסווג תמונות גם כשהכיוון שלהן משתנה. לדוגמה, האלגוריתם עדיין יכול לזהות מחבט טניס גם אם הוא מופנה למעלה, לצדדים או למטה. חשוב לזכור שלא תמיד רצוי שהתמונה תהיה עקבית ביחס לסיבוב. לדוגמה, לא צריך לסווג מספר 9 הפוך כמספר 9.
אפשר גם לעיין במאמרים עמידות בטרנסלציה ועמידות בגודל.
S
שינוי גודל
בבעיה של סיווג תמונות, היכולת של אלגוריתם לסווג תמונות בהצלחה גם כשגודל התמונה משתנה. לדוגמה, האלגוריתם עדיין יכול לזהות חתול גם אם הוא צורך 2 מיליון פיקסלים וגם אם הוא צורך 200 אלף פיקסלים. חשוב לזכור שלאלגוריתמים הטובים ביותר לסיווג תמונות עדיין יש מגבלות מעשיות על חוסר תלות בגודל. לדוגמה, סביר להניח שאלגוריתם (או אדם) לא יסווג בצורה נכונה תמונה של חתול שמכילה רק 20 פיקסלים.
אפשר לעיין גם במאמרים בנושא אי-תלות בטרנסלציה ואי-תלות בכיוון.
מידע נוסף זמין בקורס הקיבוץ.
צבירת נתונים מרחבית
פסיעה
בפעולה עיבוד נתונים עמוקה (CNN) או ב-pooling, הדלתה בכל מאפיין של הסדרה הבאה של פרוסות הקלט. לדוגמה, באנימציה הבאה מוצגת פסיעה (1,1) במהלך פעולת convolve. לכן, פרוסת הקלט הבאה מתחילה במיקום אחד מימין לפרוסת הקלט הקודמת. כשהפעולה מגיעה לקצה הימני, הפרוסה הבאה נמצאת בצד ימין אבל עמודה אחת למטה.
הדוגמה הקודמת מדגימה צעד דו-מימדי. אם מטריצת הקלט תהיה תלת-ממדית, גם הצעדה תהיה תלת-ממדית.
דגימת משנה
T
טמפרטורה
פרמטר היפר שקובע את מידת הרנדומיזציה של הפלט של מודל. ככל שהטמפרטורה גבוהה יותר, התוצאה תהיה יותר אקראית, ואילו ככל שהטמפרטורה נמוכה יותר, התוצאה תהיה פחות אקראית.
בחירת הטמפרטורה הטובה ביותר תלויה באפליקציה הספציפית ובמאפיינים המועדפים של הפלט של המודל. לדוגמה, כדאי להגדיל את הטמפרטורה כשיוצרים אפליקציה שמפיקה נכסי קריאייטיב. לעומת זאת, כשיוצרים מודל לסיווג תמונות או טקסט, כדאי להוריד את הטמפרטורה כדי לשפר את הדיוק והעקביות של המודל.
טמפרטורה משמשת לרוב עם softmax.
טרנספורמציה חסרת תלות
בבעיה של סיווג תמונות, היכולת של אלגוריתם לסווג תמונות בהצלחה גם כשהמיקום של האובייקטים בתמונה משתנה. לדוגמה, האלגוריתם עדיין יכול לזהות כלב, גם אם הוא במרכז המסגרת וגם אם הוא בקצה השמאלי של המסגרת.
אפשר לעיין גם במאמרים בנושא עמידות בגודל ועמידות בסיבוב.