本頁面包含圖像模型的詞彙表。如要查看所有詞彙表術語,請按這裡。
A
擴增實境
這項技術會在使用者看到的實體畫面上疊加電腦產生的圖像,進而提供合成畫面。
自動編碼器
系統會學習從輸入內容中擷取最重要的資訊。自動編碼器是編碼器和解碼器的組合。自動編碼器會採用下列兩步驟程序:
- 編碼器會將輸入內容對應至 (通常) 有損的低維 (中間) 格式。
- 解碼器會將較低維度的格式對應至原始較高維度的輸入格式,藉此建立原始輸入內容的損失版本。
自動編碼器會透過解碼器嘗試盡可能從編碼器的中間格式,重建原始輸入內容,進行端對端訓練。由於中間格式比原始格式小 (維度較低),因此自動編碼器會強制學習輸入內容中哪些資訊是必要的,輸出內容不會與輸入內容完全相同。
例如:
- 如果輸入資料是圖形,非精確複製的圖形會與原始圖形相似,但會略為修改。或許非精確複製內容會移除原始圖片的雜訊,或是填入一些缺少的像素。
- 如果輸入資料是文字,自動編碼器會產生模仿原始文字的新文字 (但不會完全相同)。
另請參閱變分自動編碼器。
自動迴歸模型
模型:根據先前的預測結果推斷預測結果。舉例來說,自動迴歸語言模型會根據先前預測的符記預測下一個符記。所有以 Transformer 為基礎的大型語言模型都是自動迴歸模型。
相較之下,以 GAN 為基礎的圖像模型通常不是自動迴歸模型,因為它們會在單一前向傳遞中產生圖像,而不是在步驟中逐漸產生圖像。不過,某些圖像產生模型是自動迴歸的,因為它們會分步驟產生圖像。
B
定界框
在圖片中,指定感興趣區域 (例如下圖中的狗) 的矩形 (x、y) 座標。

C
卷積
在數學中,指的是兩個函式的混合。在機器學習中,卷積會將卷積篩選器和輸入矩陣混合,以便訓練權重。
如果沒有卷積運算,機器學習演算法就必須為大型張量中的每個單元格學習個別權重。舉例來說,如果機器學習演算法訓練 2K x 2K 圖片,就會被迫尋找 4M 個個別權重。有了卷積運算,機器學習演算法只需為卷積濾鏡中的每個單元格找出權重,大幅減少訓練模型所需的記憶體。套用卷積篩選器時,只需在各個單元格中複製該篩選器,讓每個單元格都乘以該篩選器。
如需更多資訊,請參閱圖像分類課程中的「卷積神經網路簡介」。
卷積濾波器
卷積運算中的兩個角色之一。(另一個演算子是輸入矩陣的切片)。卷積濾鏡是矩陣,其秩與輸入矩陣相同,但形狀較小。舉例來說,如果有 28x28 的輸入矩陣,篩選器可以是任何小於 28x28 的 2D 矩陣。
在影像處理中,卷積濾鏡中的所有單元格通常會設為一和零的常數模式。在機器學習中,卷積濾鏡通常會使用隨機數值進行播種,然後網路會訓練理想值。
卷積層
深度神經網路的層,其中卷積篩選器會沿著輸入矩陣傳遞。舉例來說,請考慮下列 3x3 卷積式濾鏡:
![3x3 矩陣,其中包含以下值:[[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=00&hl=zh-tw)
以下動畫顯示卷積層,其中包含 5x5 輸入矩陣的 9 個卷積運算。請注意,每個卷積運算作業都會處理輸入矩陣的不同 3x3 切片。產生的 3x3 矩陣 (在右側) 包含 9 個卷積運算的結果:
![動畫:顯示兩個矩陣。第一個矩陣是 5x5 矩陣:[[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]]。第二個矩陣是 3x3 矩陣:
[[181,303,618], [115,338,605], [169,351,560]].
計算第二個矩陣時,會在 5x5 矩陣的不同 3x3 子集上套用卷積濾鏡 [[0, 1, 0], [1, 0, 1], [0, 1, 0]]。](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=00&hl=zh-tw)
詳情請參閱圖像分類課程中的「完全連結層」。
卷積類神經網路
神經網路,其中至少有一層是卷積層。典型的卷積神經網路包含下列層的組合:
卷積類神經網路在圖像辨識等特定問題上,已取得相當亮眼的成果。
卷積運算
以下是兩步驟數學運算:
- 將卷積濾鏡和輸入矩陣的切片以元素為單位相乘。(輸入矩陣的切片與卷積濾鏡具有相同的秩和大小)。
- 產生產品矩陣中的所有值總和。
舉例來說,請考慮下列 5x5 輸入矩陣:
![5x5 矩陣:[[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=00&hl=zh-tw)
請想像以下 2x2 卷積濾鏡:
![2x2 矩陣:[[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=00&hl=zh-tw)
每個卷積運算都涉及輸入矩陣的單一 2x2 切片。舉例來說,假設我們使用輸入矩陣左上方的 2x2 切片。因此,這個切片的卷積運算如下所示:
![將卷積濾鏡 [[1, 0], [0, 1]] 套用至輸入矩陣的左上方 2x2 區塊,即 [[128,97], [35,22]]。卷積濾波器會保留 128 和 22,但會將 97 和 35 設為零。因此,卷積運算會產生值 150 (128+22)。](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=00&hl=zh-tw)
卷積層由一系列卷積運算組成,每個運算都會作用於輸入矩陣的不同切片。
D
資料擴增
透過轉換現有的範例來建立其他範例,藉此人為地提升訓練範例的範圍和數量。舉例來說,假設圖片是您的特徵之一,但資料集未包含足夠的圖片範例,模型就無法學習到實用的關聯。理想情況下,您應在資料集中加入足夠的已標示圖片,讓模型能夠正確訓練。如果無法做到這點,資料增強功能可以旋轉、拉伸和反射每張圖片,產生原始圖片的許多變化版本,進而產生足夠的標記資料,以利進行優質訓練。
深度可分離卷積類神經網路 (sepCNN)
卷積類神經網路架構,以Inception 為基礎,但 Inception 模組會替換為深度可分離卷積。又稱為 Xception。
深度可分離卷積 (亦簡稱為可分離卷積) 會將標準 3D 卷積分解為兩個可提高運算效率的獨立卷積運算:首先是深度為 1 (n ✕ n ✕ 1) 的深度卷積,接著是長度和寬度皆為 1 (1 ✕ 1 ✕ n) 的點卷積。
如需瞭解詳情,請參閱「Xception:使用深度可分離卷積運算進行深度學習」。
downsampling
這個詞彙可指下列任一項:
- 減少特徵中的資訊量,以便更有效率地訓練模型。舉例來說,在訓練圖像辨識模型前,先將高解析度圖片降採樣為低解析度格式。
- 針對過度代表的類別樣本 (比例偏低) 進行訓練,以改善模型在代表性不足的類別上訓練的效果。舉例來說,在類別不平衡的資料集中,模型傾向於大量學習多數類別,而無法充分學習少數類別。下採樣有助於平衡多數和少數類別的訓練量。
F
微調
對預先訓練模型進行第二階段的特定任務訓練,以便修正相關參數,將模型用於特定用途。舉例來說,某些大型語言模型的完整訓練序列如下:
- 預先訓練:使用大量一般資料集 (例如所有英文版 Wikipedia 網頁) 訓練大型語言模型。
- 微調:訓練預先訓練模型,以便執行特定任務,例如回應醫療查詢。精修通常會使用數百或數千個專注於特定任務的樣本。
舉另一個例子來說,大型圖片模型的完整訓練序列如下:
- 預先訓練:使用大量一般圖片資料集 (例如 Wikimedia Commons 中的所有圖片) 訓練大型圖片模型。
- 微調:訓練預先訓練模型,以便執行特定任務,例如產生虎鯨圖片。
微調可採用下列任意組合策略:
- 修改預先訓練模型的所有參數。這也稱為「完整微調」。
- 只修改預先訓練模型的部分現有參數 (通常是離輸出層最近的層),其他現有參數則保持不變 (通常是離輸入層最近的層)。請參閱高效參數調整。
- 新增更多圖層,通常是在最靠近輸出圖層的現有圖層上方。
微調是一種遷移學習。因此,微調可能會使用與訓練預先訓練模型時不同的損失函數或模型類型。舉例來說,您可以微調預先訓練的大型圖像模型,產生回傳輸入圖像中鳥類數量的迴歸模型。
請比較並對照精細調整與下列術語:
G
Gemini
這個生態系統包含 Google 最先進的 AI 技術。這個生態系統的元素包括:
- 各種 Gemini 模型。
- Gemini 模型的互動式對話介面。使用者輸入提示,Gemini 回應這些提示。
- 各種 Gemini API。
- 各種以 Gemini 模型為基礎的業務產品,例如 Gemini 版 Google Cloud。
Gemini 模型
Google 最先進的Transformer 型多模態模型。Gemini 模型專門用於整合代理程式。
使用者可以透過多種方式與 Gemini 模型互動,包括透過互動式對話介面和 SDK。
生成式 AI
這是一門新興的變革領域,尚未有正式定義。不過,大多數專家都認為,生成式 AI 模型可以建立 (「生成」) 下列所有內容:
- 複雜
- 一致
- 原始圖片
舉例來說,生成式 AI 模型可以產生精緻的文章或圖像。
有些早期的技術 (包括 LSTM 和 RNN) 也能產生原創且連貫的內容。有些專家認為這些早期技術就是生成式 AI,但其他專家則認為,真正的生成式 AI 需要比這些早期技術更複雜的輸出內容。
請參閱預測機器學習。
I
圖片辨識
這個程序可將圖片中的物件、模式或概念分類。圖像辨識也稱為「圖像分類」。
詳情請參閱ML 實習:圖像分類。
詳情請參閱ML 實習:圖像分類課程。
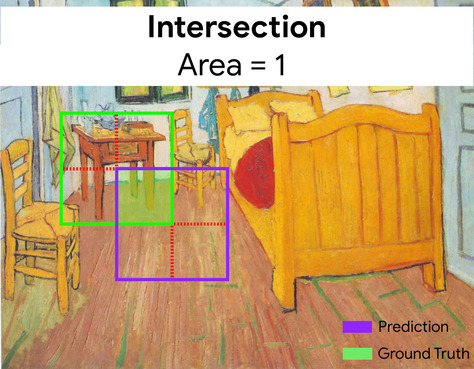
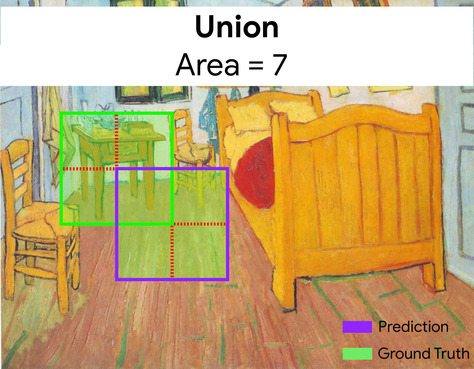
交併比 (IoU)
兩個集合的交集除以兩個集合的並集。在機器學習圖像偵測工作中,交併比用於評估模型預測的定界框與真值定界框的準確度。在這種情況下,兩個方塊的交併比是重疊區域與總面積的比率,其值範圍從 0 (預測定界框和實際資料定界框沒有重疊) 到 1 (預測定界框和實際資料定界框有相同的座標)。
例如,在下圖中:
- 預測的邊界框 (模型預測畫作中夜間桌子的座標) 以紫色標示。
- 實際資料邊界框 (即繪畫中夜間桌子的實際位置座標) 以綠色標示。
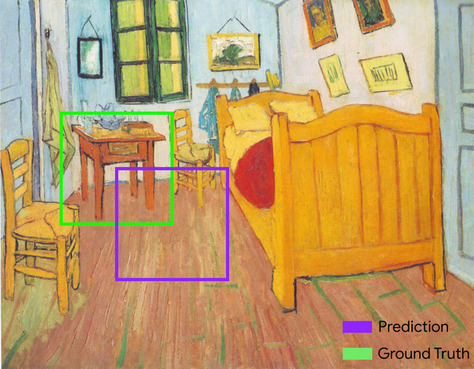
在此範例中,預測和實際資料定界框的交集 (左下方) 為 1,而預測和實際資料定界框的並集 (右下方) 為 7,因此交併比為 \(\frac{1}{7}\)。
K
重點
圖片中特定地圖項目的座標。舉例來說,如果圖像辨識模型用於區分花朵種類,關鍵點可能會是每片花瓣的中心、莖、雄蕊等等。
L
地標
keypoints 的同義詞。
M
MMIT
多模態指令調整的縮寫。
MNIST
由 LeCun、Cortes 和 Burges 編製的公共領域資料集,包含 60,000 張圖片,每張圖片都顯示人類手寫 0 到 9 之間特定數字的樣貌。每張圖片都會儲存為 28x28 的整數陣列,其中每個整數都是介於 0 和 255 之間的灰階值 (含首尾)。
MNIST 是機器學習的標準資料集,通常用於測試新的機器學習做法。詳情請參閱 MNIST 手寫數字資料庫。
MOE
混合專家的縮寫。
P
彙整
將先前卷積層建立的矩陣 (或矩陣) 縮減為較小的矩陣。彙整通常會涉及在彙整區域中取得最大值或平均值。舉例來說,假設我們有以下 3x3 矩陣:
![3x3 矩陣 [[5,3,1], [8,2,5], [9,4,3]]。](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=00&hl=zh-tw)
集區運算與卷積運算一樣,會將矩陣分割成多個切片,然後以步幅滑動該卷積運算。舉例來說,假設匯集作業會將卷積矩陣以 1x1 步幅分割成 2x2 的切片。如下圖所示,會執行四個匯集作業。假設每個匯集作業都會從該切片中挑選四個最大值:
![輸入矩陣為 3x3,值如下:[[5,3,1], [8,2,5], [9,4,3]]。
輸入矩陣的左上方 2x2 子矩陣為 [[5,3], [8,2]],因此左上方匯集運算會產生值 8 (這是 5、3、8 和 2 的最大值)。輸入矩陣的右上方 2x2 子矩陣為 [[3,1], [2,5]],因此右上方匯集運算會產生 5 這個值。輸入矩陣的左下方 2x2 子矩陣為 [[8,2], [9,4]],因此左下方匯集運算會產生 9 的值。輸入矩陣的右下方 2x2 子矩陣為 [[2, 5], [4, 3]],因此右下方匯集運算會產生值 5。總而言之,集區運算會產生 2x2 矩陣 [[8,5], [9,5]]。](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=00&hl=zh-tw)
彙整有助於在輸入矩陣中強制執行平移不變性。
視覺應用程式的彙整作業正式名稱為空間彙整。時序應用程式通常會將彙整作業稱為「時間彙整」。在非正式場合中,彙整通常稱為「子樣本」或「降採樣」。
請參閱機器學習實驗室:圖像分類課程中的「介紹卷積類神經網路」。
訓練後模型
這項術語定義較為寬鬆,通常是指經過某些後置處理程序的預先訓練模型,例如下列一或多項:
預先訓練模型
通常是指已訓練的模型。這個詞彙也可能代表先前訓練的嵌入向量。
「預先訓練的語言模型」一詞通常是指已訓練過的大型語言模型。
預先訓練
在大型資料集上初步訓練模型。部分預先訓練模型是笨重的巨人,通常必須透過額外訓練才能精進。舉例來說,機器學習專家可能會在大量文字資料集 (例如 Wikipedia 中的所有英文頁面) 上預先訓練大型語言模型。預先訓練完成後,您可以使用下列任一技術進一步精進產生的模型:
R
旋轉不變性
在圖片分類問題中,演算法即使在圖片方向變更的情況下,也能成功分類圖片。舉例來說,無論網球拍是朝上、側向或向下,演算法仍可辨識。請注意,旋轉不變性不一定是理想的做法;舉例來說,倒過的 9 不應歸類為 9。
S
縮放不變性
在圖像分類問題中,即使圖片大小有所變動,演算法仍能成功分類圖片。舉例來說,無論演算法使用 200 萬像素還是 20 萬像素,仍可辨識貓咪。請注意,即使是最佳的圖像分類演算法,在尺寸不變的情況下仍有實際限制。舉例來說,演算法 (或人類) 不太可能正確分類只使用 20 個像素的貓咪圖片。
詳情請參閱分群課程。
空間資料彙整
請參閱共用。
跨距
在卷積運算或池化中,下一個系列輸入切片的每個維度的差異。例如,下列動畫示範卷積運算期間的 (1,1) 步距。因此,下一個輸入切片會從上一個輸入切片右側的一個位置開始。當運算達到右邊緣時,下一個切片會向左移動一個位置。
上述範例說明瞭二維步幅。如果輸入矩陣是三維,步距也會是三維。
向下取樣
請參閱共用。
T
溫度
超參數,用於控制模型輸出內容的隨機程度。溫度越高,輸出內容的隨機性就越高;溫度越低,輸出內容的隨機性就越低。
選擇最佳溫度時,請考量特定應用程式和模型輸出的偏好屬性。舉例來說,如果您要建立產生創意輸出的應用程式,可能會提高溫度。反之,建構圖片或文字分類模型時,您可能會降低溫度,以提高模型的準確度和一致性。
溫度通常會與 softmax 搭配使用。
平移不變性
在圖像分類問題中,即使圖像中物件的相對位置有所變動,演算法仍能成功分類圖像。舉例來說,無論狗在影格中央還是左側,演算法仍可辨識狗。