Esta página contém termos de glossário dos modelos de imagem. Para ver todos os termos do glossário, clique aqui.
A
realidade aumentada
Uma tecnologia que sobrepõe uma imagem gerada por computador à visão de um usuário do mundo real, fornecendo assim uma visão composta.
codificador automático
Um sistema que aprende a extrair as informações mais importantes da entrada. Codificadores automáticos são uma combinação de um codificador e um decodificador. Os codificadores automáticos dependem do seguinte processo de duas etapas:
- O codificador mapeia a entrada para um formato (normalmente) de dimensão inferior com perda (intermediário).
- O decodificador cria uma versão com perdas da entrada original mapeando o formato de baixa dimensão para o formato de entrada de dimensão superior original.
Os codificadores automáticos são treinados de ponta a ponta fazendo com que o decodificador tente reconstruir a entrada original a partir do formato intermediário do codificador da maneira mais próxima possível. Como o formato intermediário é menor (dimensional menor) que o original, o codificador automático é forçado a aprender quais informações na entrada são essenciais, e a saída não será perfeitamente idêntica à entrada.
Exemplo:
- Se os dados de entrada forem um gráfico, a cópia não exata será semelhante ao gráfico original, mas um pouco modificada. Talvez a cópia não exata remova o ruído do gráfico original ou preencha alguns pixels ausentes.
- Se os dados de entrada forem texto, um codificador automático vai gerar um novo texto que imite o texto original, mas não é idêntico.
Consulte também codificadores automáticos variáveis.
modelo autoregressivo
Um model que infere uma previsão com base nas próprias previsões anteriores. Por exemplo, os modelos de linguagem com regressão automática preveem o próximo token com base nos tokens previstos anteriormente. Todos os modelos de linguagem grandes baseados em Transformer são autorregressivos.
Por outro lado, os modelos de imagem baseados em GAN geralmente não são autoregressivos, porque geram uma imagem em uma única passagem direta e não de maneira iterativa em etapas. No entanto, alguns modelos de geração de imagens são autorregressivos porque geram uma imagem em etapas.
B
caixa delimitadora
Em uma imagem, as coordenadas (x, y) de um retângulo em torno de uma área de interesse, como o cachorro na imagem abaixo.

C
convolução
Na matemática, falando casualmente, uma combinação de duas funções. No machine learning, uma convolução mistura o filtro convolucional e a matriz de entrada para treinar os pesos.
O termo "convolução" no machine learning é, muitas vezes, uma forma abreviada de se referir a operação convolucional ou camada convolucional.
Sem as convoluções, um algoritmo de machine learning precisaria aprender um peso separado para cada célula em um tensor grande. Por exemplo, um treinamento de algoritmo de machine learning em imagens 2.000 x 2.000 seria forçado a encontrar 4 milhões de pesos separados. Graças às convoluções, o algoritmo de machine learning precisa encontrar somente os pesos de cada célula no filtro convolucional, o que reduz drasticamente a memória necessária para treinar o modelo. Quando o filtro convolucional é aplicado, ele é simplesmente replicado nas células de modo que cada uma seja multiplicada pelo filtro.
filtro convolucional
Um dos dois atores em uma operação convolucional. O outro ator é uma fração de uma matriz de entrada. Um filtro convolucional é uma matriz que tem a mesma classificação da matriz de entrada, mas uma forma menor. Por exemplo, considerando uma matriz de entrada de 28x28, o filtro pode ser qualquer matriz 2D menor que 28x28.
Na manipulação fotográfica, todas as células em um filtro convolucional geralmente são definidas com um padrão constante de 1 e 0. Em machine learning, os filtros convolucionais geralmente são propagados com números aleatórios e, em seguida, a rede treina os valores ideais.
camada convolucional
Uma camada de uma rede neural profunda na qual um filtro convolucional passa ao longo de uma matriz de entrada. Por exemplo, considere o filtro convolucional de 3x3 a seguir:
![Uma matriz 3x3 com os seguintes valores: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=0000&hl=pt)
A animação a seguir mostra uma camada convolucional composta por nove operações convolucionais que envolvem a matriz de entrada de 5x5. Observe que cada operação convolucional funciona em uma fração 3x3 diferente da matriz de entrada. A matriz 3x3 resultante (à direita) consiste nos resultados das 9 operações convolucionais:
![Uma animação mostrando duas matrizes. A primeira é a matriz 5x5: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,7].
A segunda matriz é a 3x3: [[181.303.618], [115.338.605], [169.351.560]].
A segunda matriz é calculada aplicando o filtro convolucional [[0, 1, 0], [1, 0, 1], [0, 1, 0]] em diferentes subconjuntos 3x3 da matriz 5x5.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=0000&hl=pt)
rede neural convolucional
Uma rede neural em que pelo menos uma camada é uma camada convolucional. Uma rede neural convolucional típica consiste em uma combinação das seguintes camadas:
As redes neurais convolucionais tiveram grande sucesso em certos tipos de problemas, como o reconhecimento de imagem.
operação convolucional
Esta operação matemática de duas etapas:
- Multiplicação por elementos do filtro convolucional e uma fração de uma matriz de entrada. A fração da matriz de entrada tem a mesma classificação e tamanho que o filtro convolucional.
- Soma de todos os valores na matriz de produto resultante.
Por exemplo, considere a seguinte matriz de entrada 5x5:
![A matriz 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,10,10](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=0000&hl=pt)
Agora imagine o seguinte filtro convolucional 2x2:
![A matriz 2x2: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=0000&hl=pt)
Cada operação convolucional envolve uma única fração 2x2 da matriz de entrada. Por exemplo, suponha que usemos a fração 2x2 no canto superior esquerdo da matriz de entrada. Assim, a operação de convolução nessa fração é semelhante à seguinte:
![O filtro convolucional [[1, 0], [0, 1]] é aplicado à seção 2x2 do canto superior esquerdo da matriz de entrada, que é [[128,97], [35,22]].
O filtro convolucional deixa os 128 e 22 intactos, mas zera os 97 e 35. Consequentemente, a operação de convolução gera o valor 150 (128+22).](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=0000&hl=pt)
Uma camada convolucional consiste em uma série de operações convolucionais, cada uma agindo em uma fração diferente da matriz de entrada.
D
ampliação de dados
Aumento artificial do intervalo e do número de exemplos de treinamento, transformando os exemplos atuais para criar mais exemplos. Por exemplo, suponha que as imagens sejam um dos seus recursos, mas o conjunto de dados não contém exemplos de imagens suficientes para que o modelo aprenda associações úteis. O ideal é adicionar imagens rotuladas suficientes ao conjunto de dados para permitir que o modelo seja treinado corretamente. Se isso não for possível, a ampliação de dados poderá girar, esticar e refletir cada imagem para produzir muitas variantes da imagem original, possivelmente produzindo dados rotulados suficientes para permitir um treinamento excelente.
rede neural convolucional separável em profundidade (sepCNN)
Uma arquitetura de rede neural convolucional baseada no Inception, mas em que os módulos do Inception são substituídos por convoluções separáveis em profundidade. Também conhecida como xception.
Uma convolução separável em profundidade (também abreviada como convolução separável) fatora uma convolução 3D padrão em duas operações de convolução separadas que são mais eficientes em termos computacionais: primeiro, uma convolução de profundidade, com profundidade de 1 (n ✕ n ✕ 1), e a segunda, uma convolução pontual, com comprimento e largura 1 (1 ✕ 1).
Para saber mais, consulte Xception: aprendizado profundo com convoluções Depthwise Separable.
redução de amostragem
Termo sobrecarregado que pode significar uma das seguintes opções:
- Reduzir a quantidade de informações em um recurso para treinar um modelo com mais eficiência. Por exemplo, antes de treinar um modelo de reconhecimento de imagens, reduza a amostragem de imagens de alta resolução para um formato de resolução mais baixa.
- Treinamento em uma porcentagem desproporcionalmente baixa de exemplos de classe super-representados para melhorar o treinamento de modelos em classes sub-representadas. Por exemplo, em um conjunto de dados desequilibrado de classes, os modelos tendem a aprender muito sobre a classe majoritária e não o suficiente sobre a classe minoritária. O downsample ajuda a equilibrar a quantidade de treinamento nas classes majoritárias e minoritárias.
F
ajuste
Um segundo cartão de treinamento específico da tarefa realizado em um modelo pré-treinado para refinar os parâmetros dele para um caso de uso específico. Por exemplo, a sequência de treinamento completa para alguns modelos de linguagem grandes é a seguinte:
- Pré-treinamento:treine um modelo de linguagem grande em um conjunto de dados geral vasto, como todas as páginas da Wikipédia em inglês.
- Ajuste: treine o modelo pré-treinado para executar uma tarefa específica, como responder a consultas médicas. O ajuste geralmente envolve centenas ou milhares de exemplos focados na tarefa específica.
Como outro exemplo, a sequência completa de treinamento para um modelo de imagem grande é a seguinte:
- Pré-treinamento: treine um modelo de imagem grande em um conjunto de dados de imagens geral vasto, como todas as imagens em Wikimedia commons.
- Ajuste:treine o modelo pré-treinado para executar uma tarefa específica, como gerar imagens de orcas.
O ajuste pode envolver qualquer combinação das seguintes estratégias:
- Modificar todos os parâmetros do modelo pré-treinado. Isso às vezes é chamado de ajuste completo.
- Modificar apenas alguns dos parâmetros atuais do modelo pré-treinado (geralmente, as camadas mais próximas da camada de saída), enquanto mantém os outros parâmetros atuais inalterados (geralmente, as camadas mais próximas da camada de entrada). Consulte ajuste de eficiência de parâmetros.
- Adição de mais camadas, geralmente sobre as camadas existentes mais próximas da camada de saída.
O ajuste é uma forma de aprendizado por transferência. Assim, o ajuste fino pode usar uma função de perda diferente ou um tipo de modelo diferente daqueles usados para treinar o modelo pré-treinado. Por exemplo, é possível ajustar um modelo de imagem grande pré-treinado para produzir um modelo de regressão que retorne o número de pássaros em uma imagem de entrada.
Compare e contraste o ajuste fino com os seguintes termos:
G
IA generativa
Um campo transformador emergente sem definição formal. Dito isso, a maioria dos especialistas concorda que os modelos de IA generativa podem criar ("gerar") conteúdo que é tudo o seguinte:
- complexo
- coerentes
- original
Por exemplo, um modelo de IA generativa pode criar ensaios ou imagens sofisticadas.
Algumas tecnologias anteriores, incluindo LSTMs e RNNs, também podem gerar conteúdo original e coerente. Alguns especialistas veem essas tecnologias anteriores como IA generativa, enquanto outros acreditam que a verdadeira IA generativa requer resultados mais complexos do que essas tecnologias anteriores podem produzir.
Contraste com o ML preditivo.
I
Reconhecimento de imagem
Um processo que classifica objetos, padrões ou conceitos em uma imagem. O reconhecimento de imagem também é conhecido como classificação de imagem.
Para mais informações, consulte Prática de ML: classificação de imagens.
Interseção sobre união (IoU, na sigla em inglês)
A interseção de dois conjuntos dividido pela união. Em tarefas de detecção de imagens de machine learning, a IoU é usada para medir a precisão da caixa delimitadora prevista do modelo em relação à caixa delimitadora de informações empíricas. Nesse caso, a IoU das duas caixas é a proporção entre a área sobreposta e a área total, e o valor varia de 0 (sem sobreposição de caixa delimitadora prevista e de informações empíricas) a 1 (a caixa delimitadora prevista e a caixa delimitadora das informações empíricas têm exatamente as mesmas coordenadas).
Por exemplo, na imagem abaixo:
- A caixa delimitadora prevista (as coordenadas que delimitam o local em que o modelo prevê a localização da mesa à noite na pintura) é destacada em roxo.
- A caixa delimitadora de informações empíricas (as coordenadas que delimitam onde a tabela noturna na pintura está realmente localizada) é destacada em verde.
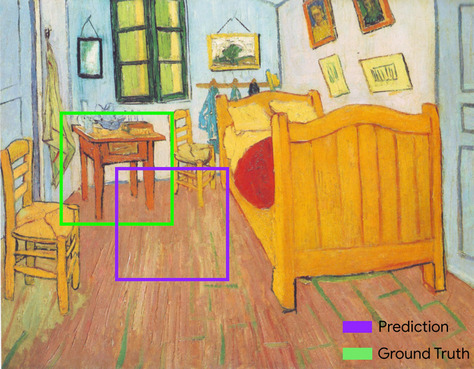
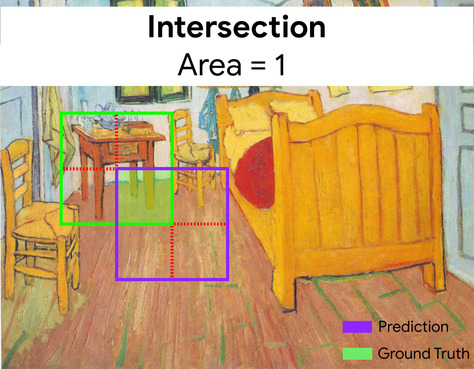
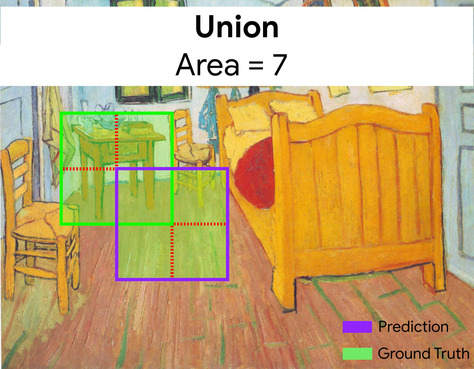
Aqui, a interseção das caixas delimitadoras para previsão e informações empíricas (abaixo à esquerda) é 1, e a união das caixas delimitadoras para previsão e informações empíricas (abaixo à direita) é 7, então a IoU é \(\frac{1}{7}\).
K
pontos-chave
As coordenadas de elementos específicos em uma imagem. Por exemplo, para um modelo de reconhecimento de imagem que diferencia espécies de flores, os pontos-chave podem ser o centro de cada pétala, o caule, o estômen e assim por diante.
L
pontos de referência
Sinônimo de keypoints.
M
MNIST
Conjunto de dados de domínio público compilado por LeCun, Cortes e Burges com 60.000 imagens. Cada imagem mostra como um ser humano escreveu manualmente um dígito específico de 0 a 9. Cada imagem é armazenada como uma matriz de números inteiros de 28x28, em que cada número inteiro é um valor em escala de cinza entre 0 e 255, inclusive.
O MNIST é um conjunto de dados canônico para machine learning, muitas vezes usado para testar novas abordagens de aprendizado de máquina. Para mais detalhes, consulte O banco de dados MNIST de dígitos manuscritos.
P
pool
Reduzir uma matriz (ou matrizes) criada por uma camada convolucional anterior para uma matriz menor. O pooling geralmente envolve o valor máximo ou médio da área. Por exemplo, suponha que temos a seguinte matriz 3x3:
![A matriz 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=0000&hl=pt)
Assim como uma operação convolucional, uma operação de pooling divide a matriz em frações e desliza a operação convolucional por passos (em inglês). Por exemplo, suponha que a operação de pool divida a matriz convolucional em frações 2x2 com um salto de 1x1. Conforme ilustrado no diagrama a seguir, ocorrem quatro operações de pooling. Imagine que cada operação de pooling escolha o valor máximo dos quatro nessa fração:
![A matriz de entrada é 3x3 com os valores: [[5,3,1], [8,2,5], [9,4,3]].
A submatriz 2x2 superior esquerda da matriz de entrada é [[5,3], [8,2]], de modo que a operação de pooling superior esquerdo gera o valor 8 (que é o máximo de 5, 3, 8 e 2). A submatriz 2x2 no canto superior direito da matriz de entrada é [[3,1], [2,5]], de modo que a operação de pooling superior direito gera o valor 5. A submatriz 2x2 no canto inferior esquerdo da matriz de entrada é [[8,2], [9,4]], de modo que a operação de pooling no canto inferior esquerdo gera o valor 9. A submatriz 2x2 inferior direita da matriz de entrada é
[[2,5], [4,3]], de modo que a operação de pooling inferior direita gera o valor
5. Em resumo, a operação de pooling produz a matriz 2x2 [[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=0000&hl=pt)
O pool ajuda a aplicar a invariância translacional (link em inglês) na matriz de entrada.
O pooling para aplicativos de visão é conhecido mais formalmente como pooling espacial. Os aplicativos de série temporal geralmente se referem ao pooling como pooling temporal. Menos formalmente, o pooling é frequentemente chamado de subamostragem ou redução.
modelo pré-treinado
Modelos ou componentes do modelo (como um vetor de embedding) que já foram treinados. Às vezes, você alimenta os vetores de embedding pré-treinados em uma rede neural. Outras vezes, o modelo treinará os próprios vetores de embedding em vez de depender de embeddings pré-treinados.
O termo modelo de linguagem pré-treinado refere-se a um modelo de linguagem grande que passou por pré-treinamento.
pré-treinamento
O treinamento inicial de um modelo em um grande conjunto de dados. Alguns modelos pré-treinados são gigantes desajeitados e normalmente precisam ser refinados com treinamento adicional. Por exemplo, os especialistas em ML podem pré-treinar um modelo de linguagem grande em um vasto conjunto de dados de texto, como todas as páginas em inglês na Wikipédia. Após o pré-treinamento, o modelo resultante pode ser refinado ainda mais por meio de qualquer uma das técnicas a seguir:
R
invariância rotacional
Em um problema de classificação de imagens, a capacidade do algoritmo de classificar imagens com êxito, mesmo quando a orientação delas é alterada. Por exemplo, o algoritmo ainda pode identificar se uma raquete de tênis está apontando para cima, de lado ou para baixo. Observe que a invariância rotacional nem sempre é desejável. Por exemplo, um 9 de cabeça para baixo não deve ser classificado como 9.
Consulte também invariância translacional e invariância de tamanho.
S
variância de tamanho
Em um problema de classificação de imagens, a capacidade do algoritmo de classificar imagens com sucesso, mesmo quando o tamanho delas muda. Por exemplo, o algoritmo ainda pode identificar um gato se ele consome 2 milhões de pixels ou 200 mil pixels. Até mesmo os melhores algoritmos de classificação de imagens ainda têm limites práticos de invariância de tamanho. Por exemplo, é improvável que um algoritmo (ou humano) classifique corretamente uma imagem de gato que consuma apenas 20 pixels.
Consulte também invariância translacional e invariância rotacional.
pooling espacial
Consulte pooling.
stride
Em uma operação convolucional ou pooling, o delta em cada dimensão da próxima série de frações de entrada. Por exemplo, a animação a seguir demonstra um salto (1,1) durante uma operação convolucional. Portanto, a próxima fração de entrada começa uma posição à direita da fração de entrada anterior. Quando a operação atinge a borda direita, a próxima fração está totalmente à esquerda, mas uma posição abaixo.
O exemplo anterior demonstra um salto bidimensional. Se a matriz de entrada for tridimensional, o salto também será tridimensional.
subamostragem
Consulte pooling.
T
temperatura
Um hiperparâmetro que controla o grau de aleatoriedade da saída de um modelo. Temperaturas mais altas resultam em uma saída mais aleatória, enquanto temperaturas mais baixas resultam em uma saída menos aleatória.
Escolher a melhor temperatura depende do aplicativo específico e das propriedades preferenciais da saída do modelo. Por exemplo, você provavelmente aumentaria a temperatura ao criar um aplicativo que gera resultados criativos. Por outro lado, você provavelmente diminuiria a temperatura ao criar um modelo que classifica imagens ou textos para melhorar a precisão e consistência.
A temperatura costuma ser usada com softmax.
invariância translacional
Em um problema de classificação de imagens, a capacidade do algoritmo de classificar imagens com sucesso mesmo quando a posição dos objetos dentro delas muda. Por exemplo, o algoritmo ainda pode identificar um cachorro, esteja no centro ou na extremidade esquerda do frame.
Consulte também a invariância de tamanho e a invariância por rotação.