Diese Seite enthält Glossarbegriffe zu Bildmodellen. Hier finden Sie alle Begriffe aus dem Glossar.
A
Augmented Reality
Eine Technologie, bei der ein computergeneriertes Bild auf die reale Umgebung des Nutzers projiziert wird, um eine zusammengesetzte Ansicht zu erhalten.
Autoencoder
Ein System, das lernt, die wichtigsten Informationen aus der Eingabe zu extrahieren. Autoencoder sind eine Kombination aus einem Encoder und einem Decoder. Autoencoder basieren auf dem folgenden zweistufigen Prozess:
- Der Encoder ordnet die Eingabe einem (in der Regel) verlustbehafteten, niedrigerdimensionalen (Zwischen-)Format zu.
- Der Decoder erstellt eine verlustbehaftete Version der ursprünglichen Eingabe, indem er das niedrigerdimensionale Format dem ursprünglichen höherdimensionalen Eingabeformat zuordnet.
Autoencoder werden end-to-end trainiert, indem der Decoder versucht, die ursprüngliche Eingabe aus dem Zwischenformat des Encoders so genau wie möglich zu rekonstruieren. Da das Zwischenformat kleiner (niedriger dimensional) als das Originalformat ist, muss der Autoencoder lernen, welche Informationen in der Eingabe wichtig sind. Die Ausgabe ist also nicht genau mit der Eingabe identisch.
Beispiel:
- Wenn die Eingabedaten eine Grafik sind, ähnelt die nicht exakte Kopie der ursprünglichen Grafik, ist aber etwas modifiziert. Vielleicht entfernt die nicht exakte Kopie das Rauschen aus der Originalgrafik oder füllt einige fehlende Pixel aus.
- Wenn die Eingabedaten Text sind, generiert ein Autoencoder neuen Text, der dem Originaltext ähnelt, aber nicht identisch mit ihm ist.
Weitere Informationen finden Sie unter Variations-Autoencoder.
autoregressives Modell
Ein Modell, das eine Vorhersage auf der Grundlage seiner eigenen bisherigen Vorhersagen ableitet. Autoregressive Language Models sagen beispielsweise das nächste Token anhand der zuvor vorhergesagten Tokens voraus. Alle Transformer-basierten Large Language Models sind autoregressiv.
GAN-basierte Bildmodelle sind dagegen in der Regel nicht autoregressiv, da sie ein Bild in einem einzigen Vorwärtsdurchlauf und nicht iterativ in Schritten generieren. Bestimmte Modelle zur Bildgenerierung sind jedoch autoregressiv, da sie ein Bild in Schritten generieren.
B
Begrenzungsrahmen
Die (x, y)-Koordinaten eines Rechtecks um einen Bereich von Interesse in einem Bild, z. B. den Hund im Bild unten.

C
Faltung
In der Mathematik ist eine Kombination aus zwei Funktionen gemeint. Bei der maschinellen Lerne werden bei einer Convolution der Convolutional-Filter und die Eingabematrix gemischt, um Gewichte zu trainieren.
Der Begriff „Convolution“ (Konvolution) im Bereich maschinelles Lernen bezieht sich oft entweder auf einen Convolutionsvorgang oder eine Convolutionsschicht.
Ohne Convolutionen müsste ein Algorithmus für maschinelles Lernen ein separates Gewicht für jede Zelle in einem großen Tensor lernen. Ein Algorithmus für maschinelles Lernen, der mit 2K × 2K-Bildern trainiert wird, müsste beispielsweise 4 Millionen separate Gewichte finden. Dank der Convolutionen muss ein Algorithmus für maschinelles Lernen nur Gewichte für jede Zelle im Convolutionsfilter finden, wodurch der für das Training des Modells erforderliche Arbeitsspeicher drastisch reduziert wird. Wenn der Convolutional-Filter angewendet wird, wird er einfach in den Zellen repliziert, sodass jede Zelle mit dem Filter multipliziert wird.
Weitere Informationen finden Sie im Kurs zur Bildklassifizierung unter Convolutional Neural Networks (CNNs).
Convolutionsfilter
Einer der beiden Akteure bei einer Convolutionsoperation. (Der andere Akteur ist ein Ausschnitt einer Eingabematrix.) Ein Convolutionsfilter ist eine Matrix mit demselben Rang wie die Eingabematrix, aber einer kleineren Form. Bei einer Eingabematrix von 28 × 28 kann der Filter beispielsweise eine beliebige 2D-Matrix sein, die kleiner als 28 × 28 ist.
Bei der fotografischen Manipulation werden alle Zellen in einem Convolutional-Filter in der Regel auf ein konstantes Muster von Einsen und Nullen gesetzt. Beim maschinellen Lernen werden Convolutional-Filter in der Regel mit Zufallszahlen initialisiert und dann traint das Netzwerk die idealen Werte.
Weitere Informationen finden Sie im Kurs zur Bildklassifizierung unter Convolution.
Convolutional Layer
Eine Schicht eines Deep-Learning-Netzwerks, in der ein Konvolutionsfilter eine Eingabematrix weitergibt. Betrachten Sie beispielsweise den folgenden 3 × 3-Konvolutionsfilter:
![Eine 3 × 3-Matrix mit den folgenden Werten: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=8&hl=de)
Die folgende Animation zeigt eine Convolutional Layer mit 9 Convolutional-Vorgängen, die die 5 × 5 Eingabematrix betreffen. Beachten Sie, dass jeder konvolutionelle Vorgang auf einem anderen 3 × 3 Pixel großen Ausschnitt der Eingabematrix ausgeführt wird. Die resultierende 3 × 3-Matrix (rechts) besteht aus den Ergebnissen der 9 Konvolutionsoperationen:
![Eine Animation mit zwei Matrizen. Die erste Matrix ist die 5 × 5-Matrix: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
Die zweite Matrix ist die 3 × 3-Matrix:
[[181,303,618], [115,338,605], [169,351,560]].
Die zweite Matrix wird berechnet, indem der Konvolutionsfilter [[0, 1, 0], [1, 0, 1], [0, 1, 0]] auf verschiedene 3 × 3-Untermengen der 5 × 5-Matrix angewendet wird.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=8&hl=de)
Weitere Informationen finden Sie im Kurs zur Bildklassifizierung unter Vollständig verbundene Schichten.
Convolutional Neural Network (CNN)
Ein neuronales Netzwerk, bei dem mindestens eine Schicht eine Convolutional Layer ist. Ein typisches Convolutional Neural Network besteht aus einer Kombination der folgenden Schichten:
Convolutional Neural Networks haben bei bestimmten Arten von Problemen, z. B. bei der Bilderkennung, große Erfolge erzielt.
Convolutionsoperation
Die folgende zweistufige mathematische Operation:
- Elementweise Multiplikation des Konvolutionsfilters mit einem Ausschnitt einer Eingabematrix. Der Ausschnitt der Eingabematrix hat denselben Rang und dieselbe Größe wie der Convolutional-Filter.
- Summe aller Werte in der resultierenden Produktmatrix.
Betrachten Sie beispielsweise die folgende 5 × 5-Matrix:
![5 × 5-Matrix: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=8&hl=de)
Stellen Sie sich nun den folgenden 2 × 2-Konvolutionsfilter vor:
![Die 2 × 2-Matrix: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=8&hl=de)
Jeder konvolutionelle Vorgang umfasst einen einzelnen 2 × 2 Pixel großen Ausschnitt der Eingabematrix. Angenommen, wir verwenden den 2 × 2 Pixel großen Ausschnitt oben links in der Eingabematrix. Die Convolutionsoperation auf diesem Ausschnitt sieht also so aus:
![Anwendung des Convolutional-Filters [[1, 0], [0, 1]] auf den 2 × 2 Pixel großen Bereich oben links in der Eingabematrix [[128,97], [35,22]].
Der Konvolutionsfilter lässt die Werte 128 und 22 unverändert, setzt aber 97 und 35 auf Null. Die Faltung ergibt daher den Wert 150 (128 + 22).](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=8&hl=de)
Eine Convolutionsschicht besteht aus einer Reihe von Convolutions-Operationen, die jeweils auf einen anderen Ausschnitt der Eingabematrix angewendet werden.
D
Datenerweiterung
Erweitern Sie die Bandbreite und Anzahl der Trainingsbeispiele, indem Sie vorhandene Beispiele umwandeln, um zusätzliche Beispiele zu erstellen. Angenommen, Bilder sind eines Ihrer Features, Ihr Dataset enthält aber nicht genügend Bildbeispiele, damit das Modell nützliche Verknüpfungen lernen kann. Idealerweise fügen Sie Ihrem Dataset genügend beschriftete Bilder hinzu, damit Ihr Modell richtig trainiert werden kann. Ist das nicht möglich, können Sie mithilfe der Datenaugmentation jedes Bild drehen, strecken und spiegeln, um viele Varianten des Originalbilds zu erstellen. So lassen sich möglicherweise genügend beschriftete Daten für ein hervorragendes Training gewinnen.
ein räumlich trennbares Convolutional Neural Network (sepCNN)
Eine Architektur für Convolutional Neural Networks, die auf Inception basiert, bei der die Inception-Module jedoch durch tiefenbasiert trennbare Convolutionen ersetzt werden. Wird auch als Xception bezeichnet.
Bei einer tiefenabhängig trennbaren 3D-Konvolution (auch als trennbare 3D-Konvolution abgekürzt) wird eine standardmäßige 3D-Konvolution in zwei separate Konvolutionsoperationen zerlegt, die verarbeitungseffizienter sind: eine tiefenabhängige Konvolution mit einer Tiefe von 1 (n × n × 1) und eine punktweise Konvolution mit einer Länge und Breite von 1 (1 × 1 × n).
Weitere Informationen finden Sie unter Xception: Deep Learning with Depthwise Separable Convolutons.
Downsampling
Dieser Begriff kann Folgendes bedeuten:
- Verringerung der Informationsmenge in einem Feature, um ein Modell effizienter zu trainieren. Beispielsweise können Sie vor dem Training eines Bilderkennungsmodells hochauflösende Bilder auf ein Format mit niedrigerer Auflösung herunterskalieren.
- Training mit einem unverhältnismäßig niedrigen Prozentsatz an Beispielen für überrepräsentierte Klassen, um das Modelltraining für unterrepräsentierte Klassen zu verbessern. In einem Dataset mit unausgeglichenen Klassen lernen Modelle beispielsweise viel über die Mehrheitsklasse, aber nicht genug über die Minderheitsklasse. Durch die Downsampling-Methode wird die Trainingsmenge für die Mehrheits- und Minderheitenklassen ausgeglichen.
Weitere Informationen finden Sie im Machine Learning Crash Course unter Datasets: Ungleichgewichtige Datasets.
F
Feinabstimmung
Ein zweiter, aufgabenspezifischer Trainingsdurchlauf, der auf einem vortrainierten Modell durchgeführt wird, um seine Parameter für einen bestimmten Anwendungsfall zu optimieren. Die vollständige Trainingssequenz für einige Large Language Models sieht beispielsweise so aus:
- Vortraining: Ein Large Language Model wird mit einem umfangreichen generellen Dataset trainiert, z. B. mit allen englischsprachigen Wikipedia-Seiten.
- Optimierung: Das vortrainierte Modell wird für die Ausführung einer bestimmten Aufgabe trainiert, z. B. für die Beantwortung von medizinischen Suchanfragen. Die Feinabstimmung umfasst in der Regel Hunderte oder Tausende von Beispielen, die sich auf die jeweilige Aufgabe konzentrieren.
Hier ist ein weiteres Beispiel für die vollständige Trainingssequenz für ein Modell mit großen Bildern:
- Vortraining: Trainieren Sie ein großes Bildmodell mit einem umfangreichen allgemeinen Bild-Dataset, z. B. mit allen Bildern in Wikimedia Commons.
- Optimierung: Das vortrainierte Modell wird für eine bestimmte Aufgabe trainiert, z. B. für die Generierung von Bildern von Orcas.
Die Optimierung kann eine beliebige Kombination der folgenden Strategien umfassen:
- Alle vorhandenen Parameter des vortrainierten Modells ändern. Dieser Vorgang wird auch als volle Feinabstimmung bezeichnet.
- Sie ändern nur einige der vorhandenen Parameter des vorab trainierten Modells (in der Regel die Schichten, die der Ausgabeschicht am nächsten sind), während andere vorhandene Parameter unverändert bleiben (in der Regel die Schichten, die der Eingabeschicht am nächsten sind). Weitere Informationen finden Sie unter Parametereffiziente Abstimmung.
- Durch Hinzufügen weiterer Ebenen, in der Regel über den vorhandenen Ebenen, die der Ausgabeebene am nächsten sind.
Die Feinabstimmung ist eine Form des Übertragungslernens. Daher kann für die Feinabstimmung eine andere Verlustfunktion oder ein anderer Modelltyp verwendet werden als für das Training des vorab trainierten Modells. Sie können beispielsweise ein vortrainiertes Modell für große Bilder optimieren, um ein Regressionsmodell zu erstellen, das die Anzahl der Vögel in einem Eingabebild zurückgibt.
Vergleichen Sie die Feinabstimmung mit den folgenden Begriffen:
Weitere Informationen finden Sie im Machine Learning Crash Course unter Feintuning.
G
Gemini
Das Ökosystem mit der innovativsten KI von Google. Zu den Elementen dieses Ökosystems gehören:
- Verschiedene Gemini-Modelle
- Die interaktive Konversationsoberfläche für ein Gemini-Modell. Nutzer geben Prompts ein und Gemini antwortet darauf.
- Verschiedene Gemini APIs
- Verschiedene Geschäftsprodukte, die auf Gemini-Modellen basieren, z. B. Gemini for Google Cloud.
Gemini-Modelle
Die neuesten Transformer-basierten multimodalen Modelle von Google Gemini-Modelle sind speziell für die Einbindung in Kundenservicemitarbeiter konzipiert.
Nutzer können auf verschiedene Weise mit Gemini-Modellen interagieren, z. B. über eine interaktive Dialogoberfläche und über SDKs.
generative KI
Ein neues, transformatives Feld ohne formale Definition. Die meisten Experten sind sich jedoch einig, dass generative KI-Modelle Inhalte erstellen („generieren“) können, die
- Komplex
- kohärent
- ursprünglich
So kann ein generatives KI-Modell beispielsweise anspruchsvolle Essays oder Bilder erstellen.
Einige ältere Technologien, darunter LSTMs und RNNs, können ebenfalls originelle und kohärente Inhalte generieren. Einige Experten betrachten diese früheren Technologien als generative KI, während andere der Meinung sind, dass echte generative KI eine komplexere Ausgabe erfordert, als diese früheren Technologien produzieren können.
Im Gegensatz zu vorhersageorientiertem ML.
I
Bilderkennung
Ein Prozess, bei dem Objekte, Muster oder Konzepte in einem Bild klassifiziert werden. Die Bilderkennung wird auch als Bildklassifizierung bezeichnet.
Weitere Informationen finden Sie unter ML Practicum: Bildklassifizierung.
Weitere Informationen finden Sie im Kurs ML Practicum: Bildklassifizierung.
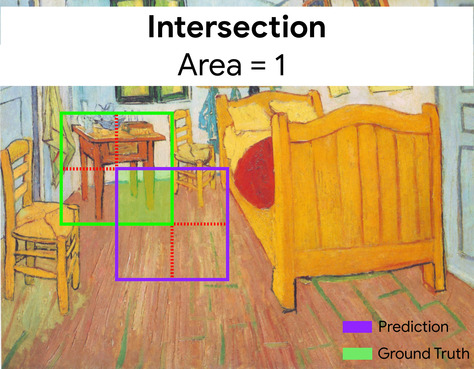
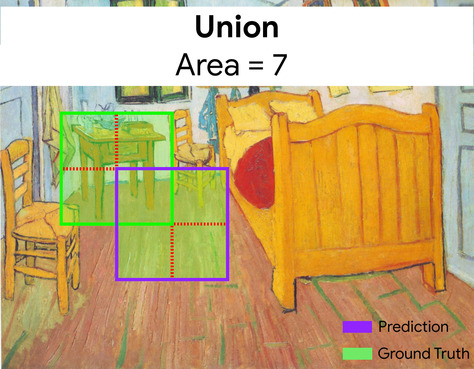
Intersection over Union (IoU)
Die Schnittmenge von zwei Mengen geteilt durch ihre Vereinigung. Bei Aufgaben zur Bilderkennung mit maschinellem Lernen wird der IoU verwendet, um die Genauigkeit des vorhergesagten Begrenzungsrahmens des Modells im Vergleich zum Ground-Truth-Begrenzungsrahmen zu messen. In diesem Fall ist der IoU für die beiden Rahmen das Verhältnis zwischen dem Überschneidungs- und dem Gesamtbereich. Der Wert reicht von 0 (keine Überschneidung zwischen dem vorhergesagten Begrenzungsrahmen und dem Ground-Truth-Begrenzungsrahmen) bis 1 (vorhergesagter Begrenzungsrahmen und Ground-Truth-Begrenzungsrahmen haben genau dieselben Koordinaten).
Im folgenden Bild ist das beispielsweise der Fall:
- Der vorhergesagte Begrenzungsrahmen (die Koordinaten, die die Position des Nachttischs im Gemälde nach der Vorhersage des Modells umreißen) ist lila umrandet.
- Der Ground-Truth-Begrenzungsrahmen (die Koordinaten, die die tatsächliche Position des Nachttischs im Gemälde festlegen) ist grün umrandet.
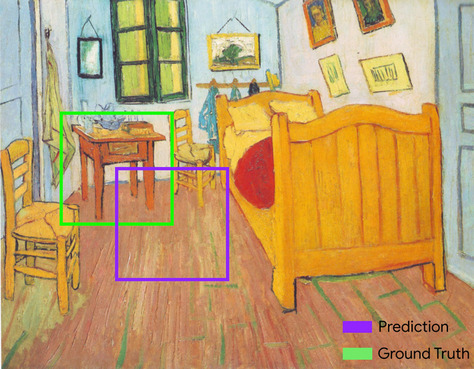
Hier ist die Überschneidung der Begrenzungsrahmen für die Vorhersage und die Ground Truth (unten links) 1 und die Vereinigung der Begrenzungsrahmen für die Vorhersage und die Ground Truth (unten rechts) 7. Der IoU-Wert ist also \(\frac{1}{7}\).
K
keypoints
Die Koordinaten bestimmter Elemente in einem Bild. Bei einem Modell für die Bilderkennung, das Blumenarten unterscheidet, können beispielsweise die Mitte jedes Blütenblatts, der Stängel oder die Staubblätter als wichtige Punkte dienen.
L
landmarks
Synonym für Keywords.
M
MMIT
Abkürzung für multimodal instruction-tuned (multimodale Anweisungen abgestimmt).
MNIST
Ein von LeCun, Cortes und Burges zusammengestellter öffentlicher Dataset mit 60.000 Bildern, auf denen jeweils zu sehen ist, wie eine Person eine bestimmte Ziffer von 0 bis 9 handschriftlich geschrieben hat. Jedes Bild wird als 28 x 28 Array von Ganzzahlen gespeichert, wobei jede Ganzzahl ein Graustufenwert zwischen 0 und 255 ist.
MNIST ist ein kanonischer Dataset für maschinelles Lernen, das häufig zum Testen neuer Ansätze für maschinelles Lernen verwendet wird. Weitere Informationen finden Sie unter MNIST Database of Handwritten Digits.
MOE
Abkürzung für Mix aus Experten.
P
Pooling
Reduzierung einer oder mehrerer Matrizen, die von einer früheren Convolutionsschicht erstellt wurden, auf eine kleinere Matrix. Beim Pooling wird in der Regel entweder der Maximal- oder der Durchschnittswert für den gesamten zusammengeführten Bereich ermittelt. Angenommen, wir haben die folgende 3 × 3-Matrix:
![Die 3 × 3-Matrix [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=8&hl=de)
Eine Pooling-Operation teilt diese Matrix wie eine konvolutionelle Operation in Scheiben auf und verschiebt diese konvolutionelle Operation dann um Schritte. Angenommen, der Pooling-Vorgang teilt die Convolutionsmatrix in 2 × 2 Scheiben mit einem Schritt von 1 × 1 auf. Wie das folgende Diagramm zeigt, werden vier Pooling-Vorgänge ausgeführt. Angenommen, bei jedem Pooling-Vorgang wird der maximale Wert der vier Werte in diesem Ausschnitt ausgewählt:
![Die Eingabematrix ist 3 × 3 mit den Werten [[5,3,1], [8,2,5], [9,4,3]].
Die linke obere 2 × 2-Untermatrix der Eingabematrix ist [[5,3], [8,2]]. Bei der Pooling-Operation links oben ergibt sich daher der Wert 8, das Maximum von 5, 3, 8 und 2. Die rechte obere 2 × 2-Untermatrix der Eingabematrix ist [[3,1], [2,5]]. Bei der Pooling-Operation rechts oben ergibt sich daher der Wert 5. Die untere linke 2 × 2-Untermatrix der Eingabematrix ist [[8,2], [9,4]]. Der Pooling-Vorgang unten links ergibt daher den Wert 9. Die untere rechte 2 × 2-Untermatrix der Eingabematrix ist [[2,5], [4,3]]. Der rechte untere Pooling-Vorgang ergibt daher den Wert 5. Zusammenfassend ergibt der Pooling-Vorgang die 2 × 2-Matrix [[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=8&hl=de)
Mit dem Pooling wird die Translationsinvarianz in der Eingabematrix erzwungen.
Das Pooling für Bildverarbeitungsanwendungen wird auch als räumliches Pooling bezeichnet. In Zeitreihenanwendungen wird Pooling in der Regel als zeitliches Pooling bezeichnet. In informeller Weise wird Pooling oft als Subsampling oder Downsampling bezeichnet.
Nach dem Training
Weitgehend unscharfer Begriff, der in der Regel auf ein vortrainiertes Modell verweist, das einer Nachbearbeitung unterzogen wurde, z. B. einer oder mehreren der folgenden:
vortrainiertes Modell
Normalerweise ein Modell, das bereits trainiert wurde. Der Begriff kann auch einen zuvor trainierten Embedding-Vektor bezeichnen.
Der Begriff vortrainiertes Sprachmodell bezieht sich in der Regel auf ein bereits trainiertes Large Language Model.
Vortraining
Das erste Training eines Modells mit einem großen Dataset. Einige vortrainierte Modelle sind sperrige Riesen und müssen in der Regel durch zusätzliches Training optimiert werden. So können ML-Experten beispielsweise ein Large Language Model mit einem riesigen Text-Dataset vortrainieren, z. B. mit allen englischsprachigen Seiten in Wikipedia. Nach dem Vortraining kann das resultierende Modell mithilfe einer der folgenden Methoden weiter optimiert werden:
R
Rotationsinvarianz
Bei einem Problem der Bildklassifizierung die Fähigkeit eines Algorithmus, Bilder auch dann erfolgreich zu klassifizieren, wenn sich die Ausrichtung des Bildes ändert. So kann der Algorithmus beispielsweise einen Tennisschläger erkennen, unabhängig davon, ob er nach oben, zur Seite oder nach unten zeigt. Die Drehungsinvarianz ist jedoch nicht immer wünschenswert. Eine umgedrehte 9 sollte beispielsweise nicht als 9 klassifiziert werden.
Weitere Informationen finden Sie unter Translationsinvarianz und Größeinvarianz.
S
Größeninvarianz
Bei einem Problem der Bildklassifizierung die Fähigkeit eines Algorithmus, Bilder auch dann erfolgreich zu klassifizieren, wenn sich die Größe des Bildes ändert. Beispielsweise kann der Algorithmus eine Katze erkennen, unabhängig davon, ob sie 2 Millionen oder 200.000 Pixel einnimmt. Selbst die besten Algorithmen zur Bildklassifizierung haben praktische Grenzen bei der Größeninvarianz. Es ist beispielsweise unwahrscheinlich, dass ein Algorithmus (oder ein Mensch) ein Katzenbild mit nur 20 Pixeln richtig klassifizieren kann.
Siehe auch Translationsinvarianz und Rotationsinvarianz.
räumliches Pooling
Weitere Informationen finden Sie unter Pooling.
Stride
Bei einem Convolutional- oder Pooling-Vorgang das Delta in jeder Dimension der nächsten Reihe von Eingabescheiben. In der folgenden Animation wird beispielsweise ein Schritt von (1,1) während einer Convolutionsoperation veranschaulicht. Daher beginnt der nächste Eingabeabschnitt eine Position rechts vom vorherigen Eingabeabschnitt. Wenn der Vorgang den rechten Rand erreicht, wird der nächste Ausschnitt ganz nach links, aber eine Position nach unten verschoben.
Das vorherige Beispiel zeigt einen zweidimensionalen Schritt. Wenn die Eingabematrix dreidimensional ist, ist auch der Schritt dreidimensional.
Subsampling
Weitere Informationen finden Sie unter Pooling.
T
Temperatur
Ein Hyperparameter, der den Grad der Zufälligkeit der Ausgabe eines Modells steuert. Höhere Temperaturen führen zu einer stärker zufälligen Ausgabe, während niedrigere Temperaturen zu einer weniger zufälligen Ausgabe führen.
Die Auswahl der optimalen Temperatur hängt von der jeweiligen Anwendung und den gewünschten Eigenschaften der Ausgabe des Modells ab. Sie würden die Temperatur beispielsweise wahrscheinlich erhöhen, wenn Sie eine Anwendung erstellen, die kreative Inhalte generiert. Umgekehrt würden Sie die Temperatur wahrscheinlich senken, wenn Sie ein Modell erstellen, das Bilder oder Text klassifiziert, um die Genauigkeit und Konsistenz des Modells zu verbessern.
Die Temperatur wird häufig mit softmax verwendet.
Translationsinvarianz
Bei einem Bildklassifizierungsproblem die Fähigkeit eines Algorithmus, Bilder auch dann erfolgreich zu klassifizieren, wenn sich die Position der Objekte im Bild ändert. Der Algorithmus kann beispielsweise einen Hund erkennen, unabhängig davon, ob er sich in der Mitte oder am linken Ende des Frames befindet.
Weitere Informationen finden Sie unter Größeninvarianz und Drehsymmetrie.