На этой странице содержатся термины глоссария моделей изображений. Чтобы просмотреть все термины глоссария, нажмите здесь .
А
дополненная реальность
Технология, которая накладывает изображение, созданное компьютером, на представление пользователя о реальном мире, создавая таким образом составное представление.
автоэнкодер
Система, которая учится извлекать наиболее важную информацию из входных данных. Автоэнкодеры представляют собой комбинацию кодера и декодера . Автоэнкодеры полагаются на следующий двухэтапный процесс:
- Кодер преобразует входные данные в (обычно) низкоразмерный (промежуточный) формат с потерями.
- Декодер создает версию исходного ввода с потерями, сопоставляя формат меньшей размерности с исходным входным форматом более высокой размерности.
Автокодировщики обучаются сквозно, заставляя декодер пытаться как можно точнее восстановить исходный входной сигнал из промежуточного формата кодера. Поскольку промежуточный формат меньше (меньшая размерность), чем исходный формат, автокодировщику приходится узнавать, какая информация на входе важна, и выходные данные не будут полностью идентичны входным.
Например:
- Если входные данные представляют собой графику, неточная копия будет похожа на исходную графику, но несколько изменена. Возможно, неточная копия удаляет шум из исходной графики или заполняет некоторые недостающие пиксели.
- Если входные данные представляют собой текст, автокодировщик сгенерирует новый текст, который имитирует (но не идентичен) исходному тексту.
См. также вариационные автоэнкодеры .
авторегрессионная модель
Модель , которая делает прогноз на основе собственных предыдущих прогнозов. Например, авторегрессионные языковые модели прогнозируют следующий токен на основе ранее предсказанных токенов. Все модели большого языка на основе Transformer являются авторегрессионными.
Напротив, модели изображений на основе GAN обычно не являются авторегрессионными, поскольку они генерируют изображение за один проход вперед, а не поэтапно итеративно. Однако некоторые модели генерации изображений являются авторегрессионными, поскольку они генерируют изображение поэтапно.
Б
ограничивающая рамка
На изображении координаты ( x , y ) прямоугольника вокруг интересующей области, например собаки на изображении ниже.

С
свертка
В математике, условно говоря, смесь двух функций. В машинном обучении свертка смешивает сверточный фильтр и входную матрицу для обучения весов .
Термин «свертка» в машинном обучении часто является сокращением для обозначения сверточной операции или сверточного слоя .
Без сверток алгоритму машинного обучения пришлось бы изучать отдельный вес для каждой ячейки в большом тензоре . Например, алгоритм машинного обучения, обучающийся на изображениях размером 2K x 2K, будет вынужден найти 4M отдельных весов. Благодаря сверткам алгоритму машинного обучения достаточно найти веса для каждой ячейки в сверточном фильтре , что значительно сокращает объем памяти, необходимой для обучения модели. Когда применяется сверточный фильтр, он просто реплицируется по ячейкам, так что каждая из них умножается на фильтр.
Дополнительную информацию см. в разделе «Введение в сверточные нейронные сети» в курсе «Классификация изображений».
сверточный фильтр
Один из двух участников сверточной операции . (Другой актер — это часть входной матрицы.) Сверточный фильтр — это матрица того же ранга , что и входная матрица, но меньшей формы. Например, для входной матрицы размером 28x28 фильтром может быть любая двумерная матрица размером меньше 28x28.
При фотографических манипуляциях для всех ячеек сверточного фильтра обычно устанавливается постоянный набор единиц и нулей. В машинном обучении сверточные фильтры обычно заполняют случайными числами, а затем сеть обучает идеальные значения.
Дополнительную информацию см. в разделе «Свертка» в курсе «Классификация изображений».
сверточный слой
Слой глубокой нейронной сети , в котором сверточный фильтр проходит по входной матрице. Например, рассмотрим следующий сверточный фильтр 3x3:
![Матрица 3x3 со следующими значениями: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=8&hl=ru)
Следующая анимация показывает сверточный слой, состоящий из 9 сверточных операций с входной матрицей 5x5. Обратите внимание, что каждая сверточная операция работает с отдельным фрагментом входной матрицы размером 3x3. Полученная матрица 3x3 (справа) состоит из результатов 9 сверточных операций:
![Анимация, показывающая две матрицы. Первая матрица — 5х5. матрица: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]]. Вторая матрица — это матрица 3х3: [[181 303 618], [115 338 605], [169 351 560]]. Вторая матрица вычисляется путем применения сверточного метода фильтровать [[0, 1, 0], [1, 0, 1], [0, 1, 0]] по различные подмножества 3x3 матрицы 5x5.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=8&hl=ru)
Дополнительную информацию см. в разделе «Полностью связанные слои» курса «Классификация изображений».
сверточная нейронная сеть
Нейронная сеть , в которой хотя бы один слой является сверточным . Типичная сверточная нейронная сеть состоит из некоторой комбинации следующих слоев:
Сверточные нейронные сети добились больших успехов в решении определенных задач, таких как распознавание изображений.
сверточная операция
Следующая двухэтапная математическая операция:
- Поэлементное умножение сверточного фильтра и среза входной матрицы. (Срез входной матрицы имеет тот же ранг и размер, что и сверточный фильтр.)
- Суммирование всех значений в результирующей матрице продуктов.
Например, рассмотрим следующую входную матрицу 5x5:
![Матрица 5х5: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=8&hl=ru)
Теперь представьте себе следующий сверточный фильтр 2x2:
![Матрица 2x2: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=8&hl=ru)
Каждая сверточная операция включает в себя один срез входной матрицы размером 2x2. Например, предположим, что мы используем срез 2x2 в верхнем левом углу входной матрицы. Итак, операция свертки на этом срезе выглядит следующим образом:
![Применение сверточного фильтра [[1, 0], [0, 1]] в верхнем левом углу Раздел входной матрицы размером 2x2, то есть [[128,97], [35,22]]. Сверточный фильтр оставляет 128 и 22 нетронутыми, но обнуляет из 97 и 35. Следовательно, операция свертки дает значение 150 (128+22).](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=8&hl=ru)
Сверточный слой состоит из серии сверточных операций, каждая из которых действует на отдельный фрагмент входной матрицы.
Д
увеличение данных
Искусственное увеличение диапазона и количества обучающих примеров путем преобразования существующих примеров для создания дополнительных примеров. Например, предположим, что изображения являются одним из ваших объектов , но ваш набор данных не содержит достаточно примеров изображений, чтобы модель могла изучить полезные ассоциации. В идеале вы должны добавить в свой набор данных достаточно помеченных изображений, чтобы ваша модель могла правильно обучаться. Если это невозможно, увеличение данных может вращать, растягивать и отражать каждое изображение, чтобы создать множество вариантов исходного изображения, возможно, давая достаточно помеченных данных, чтобы обеспечить отличное обучение.
сверточная нейронная сеть с глубоким разделением (sepCNN)
Архитектура сверточной нейронной сети, основанная на Inception , но в которой модули Inception заменены глубинно разделимыми свертками. Также известен как Xception.
Разделимая по глубине свертка (также сокращенно называемая разделимой сверткой) разделяет стандартную трехмерную свертку на две отдельные операции свертки, которые более эффективны в вычислительном отношении: во-первых, глубинная свертка с глубиной 1 (n ✕ n ✕ 1), а затем, во-вторых, точечная свертка длиной и шириной 1 (1 ✕ 1 ✕ n).
Чтобы узнать больше, см. Xception: Deep Learning with Depthwise Separable Convolutions .
понижение частоты дискретизации
Перегруженный термин, который может означать одно из следующего:
- Уменьшение количества информации в признаке для более эффективного обучения модели. Например, перед тренировкой модели распознавания изображений необходимо выполнить преобразование изображений с высоким разрешением в формат с более низким разрешением.
- Обучение на непропорционально низком проценте примеров перепредставленных классов с целью улучшения обучения модели на недостаточно представленных классах. Например, в наборе данных с несбалансированным классом модели, как правило, много узнают о классе большинства и недостаточно о классе меньшинства . Понижение выборки помогает сбалансировать объем обучения в классах большинства и меньшинства.
Дополнительную информацию см. в разделе «Наборы данных: несбалансированные наборы данных» в ускоренном курсе машинного обучения.
Ф
тонкая настройка
Второй проход обучения для конкретной задачи, выполняемый на предварительно обученной модели для уточнения ее параметров для конкретного варианта использования. Например, полная последовательность обучения для некоторых больших языковых моделей выглядит следующим образом:
- Предварительное обучение: обучите большую языковую модель на обширном общем наборе данных, например на всех англоязычных страницах Википедии.
- Точная настройка: обучение предварительно обученной модели выполнению конкретной задачи, например ответа на медицинские запросы. Точная настройка обычно включает сотни или тысячи примеров, ориентированных на конкретную задачу.
В качестве другого примера полная последовательность обучения для модели большого изображения выглядит следующим образом:
- Предварительное обучение: обучите большую модель изображения на обширном общем наборе данных изображений, например на всех изображениях в Wikimedia Commons.
- Точная настройка: обучение предварительно обученной модели выполнению конкретной задачи, например генерации изображений косаток.
Точная настройка может включать любую комбинацию следующих стратегий:
- Изменение всех существующих параметров предварительно обученной модели. Иногда это называют полной тонкой настройкой .
- Изменение только некоторых существующих параметров предварительно обученной модели (обычно слоев, ближайших к выходному слою ), сохраняя при этом другие существующие параметры неизменными (обычно слои, ближайшие к входному слою ). См. настройку с эффективным использованием параметров .
- Добавление дополнительных слоев, обычно поверх существующих слоев, ближайших к выходному слою.
Точная настройка — это форма трансферного обучения . Таким образом, при точной настройке может использоваться другая функция потерь или другой тип модели, чем те, которые используются для обучения предварительно обученной модели. Например, вы можете точно настроить предварительно обученную модель большого изображения для создания регрессионной модели, которая возвращает количество птиц во входном изображении.
Сравните и сопоставьте тонкую настройку со следующими терминами:
Дополнительные сведения см. в разделе «Точная настройка ускоренного курса машинного обучения».
Г
Близнецы
Экосистема, включающая самый передовой искусственный интеллект Google. К элементам этой экосистемы относятся:
- Различные модели Gemini .
- Интерактивный диалоговый интерфейс модели Gemini . Пользователи вводят запросы, и Gemini отвечает на эти запросы.
- Различные API Gemini.
- Различные бизнес-продукты на основе моделей Gemini; например, Gemini для Google Cloud .
Модели Близнецов
Новейшие мультимодальные модели Google на основе Transformer . Модели Gemini специально разработаны для интеграции с агентами .
Пользователи могут взаимодействовать с моделями Gemini различными способами, в том числе через интерактивный диалоговый интерфейс и через SDK.
генеративный ИИ
Возникающее преобразующее поле без формального определения. Тем не менее, большинство экспертов сходятся во мнении, что генеративные модели ИИ могут создавать («генерировать») контент, который имеет все следующие характеристики:
- сложный
- последовательный
- оригинальный
Например, генеративная модель ИИ может создавать сложные эссе или изображения.
Некоторые более ранние технологии, включая LSTM и RNN , также могут генерировать оригинальный и связный контент. Некоторые эксперты рассматривают эти более ранние технологии как генеративный ИИ, в то время как другие считают, что настоящий генеративный ИИ требует более сложных результатов, чем те, которые могут произвести более ранние технологии.
Сравните с прогнозным ML .
я
распознавание изображений
Процесс, который классифицирует объект(ы), шаблон(ы) или концепцию(и) на изображении. Распознавание изображений также известно как классификация изображений .
Дополнительные сведения см. в разделе Практикум по машинному обучению: классификация изображений .
Дополнительную информацию см. в курсе ML Practicum: классификация изображений .
пересечение через объединение (IoU)
Пересечение двух множеств, разделенных их объединением. В задачах машинного обучения по обнаружению изображений IoU используется для измерения точности прогнозируемой ограничивающей рамки модели по отношению к истинной ограничивающей рамке. В этом случае IoU для двух блоков представляет собой соотношение между перекрывающейся площадью и общей площадью, а его значение варьируется от 0 (нет перекрытия прогнозируемой ограничивающей рамки и основной истинной ограничивающей рамки) до 1 (прогнозируемая ограничивающая рамка и основная ограничивающая рамка). -правда ограничивающая рамка имеет точно такие же координаты).
Например, на изображении ниже:
- Предсказанная ограничивающая рамка (координаты, определяющие место расположения ночного столика на картине, по прогнозам модели) обведена фиолетовым контуром.
- Ограничивающая рамка основной истины (координаты, определяющие место фактического расположения ночного столика на картине) обведена зеленым контуром.
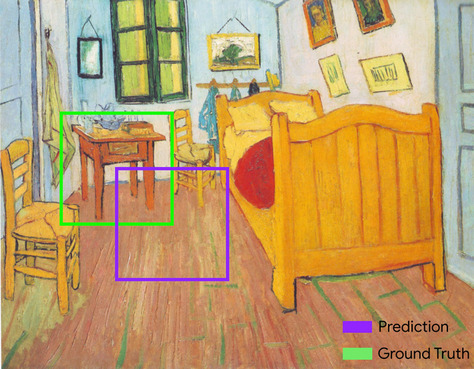
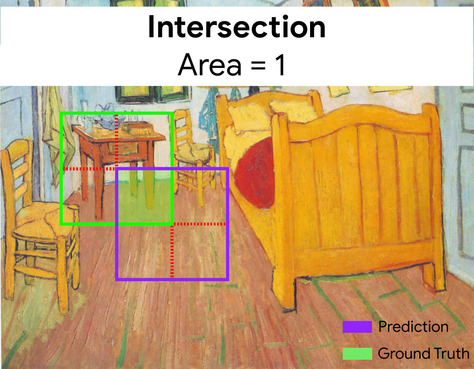
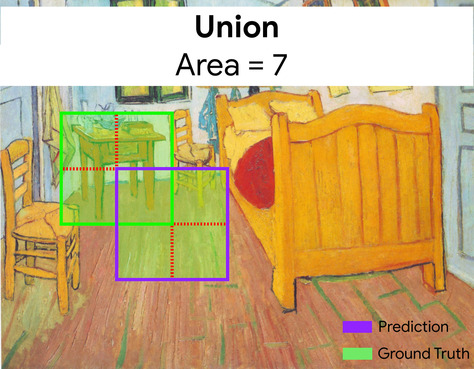
Здесь пересечение ограничивающих рамок для предсказания и основной истины (внизу слева) равно 1, а объединение ограничивающих рамок для предсказания и основной истины (внизу справа) равно 7, поэтому IoU равен \(\frac{1}{7}\).
К
ключевые точки
Координаты отдельных объектов на изображении. Например, для модели распознавания изображений , которая различает виды цветов, ключевыми точками могут быть центр каждого лепестка, стебель, тычинка и т. д.
л
достопримечательности
Синоним ключевых точек .
М
ММИТ
Аббревиатура для мультимодальных инструкций, настроенных .
МНИСТ
Общедоступный набор данных, составленный ЛеКуном, Кортесом и Берджесом, содержащий 60 000 изображений, каждое из которых показывает, как человек вручную написал определенную цифру от 0 до 9. Каждое изображение хранится в виде массива целых чисел размером 28x28, где каждое целое число представляет собой значение шкалы серого от 0 до 255 включительно.
MNIST — это канонический набор данных для машинного обучения, который часто используется для тестирования новых подходов к машинному обучению. Подробности см. в базе данных рукописных цифр MNIST .
МЧС
Сокращение от смеси экспертов .
П
объединение
Сокращение матрицы (или матриц), созданных более ранним сверточным слоем, до матрицы меньшего размера. Объединение обычно предполагает получение максимального или среднего значения по объединенной области. Например, предположим, что у нас есть следующая матрица 3x3:
![Матрица 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=8&hl=ru)
Операция объединения, как и сверточная операция, делит эту матрицу на фрагменты, а затем сдвигает эту сверточную операцию по шагам . Например, предположим, что операция объединения делит сверточную матрицу на фрагменты 2x2 с шагом 1x1. Как показано на следующей диаграмме, выполняются четыре операции объединения. Представьте, что каждая операция объединения выбирает максимальное значение из четырех в этом срезе:
![Входная матрица имеет размер 3x3 со значениями: [[5,3,1], [8,2,5], [9,4,3]]. Верхняя левая подматрица входной матрицы размером 2x2 равна [[5,3], [8,2]], поэтому операция объединения в верхнем левом углу дает значение 8 (которое является максимум 5, 3, 8 и 2). Верхняя правая подматрица 2x2 входных данных. матрица равна [[3,1], [2,5]], поэтому операция объединения в правом верхнем углу дает значение 5. Нижняя левая подматрица 2x2 входной матрицы равна [[8,2], [9,4]], поэтому операция объединения в левом нижнем углу дает значение 9. Нижняя правая подматрица входной матрицы размером 2x2: [[2,5], [4,3]], поэтому операция объединения в правом нижнем углу дает значение 5. Таким образом, операция объединения дает матрицу 2x2. [[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=8&hl=ru)
Объединение в пул помогает обеспечить трансляционную инвариантность во входной матрице.
Объединение в пулы для приложений машинного зрения более формально известно как пространственное объединение . Приложения временных рядов обычно называют группирование временным пулом . Менее формально объединение часто называют субдискретизацией или понижением выборки .
постобученная модель
Свободно определенный термин, который обычно относится к предварительно обученной модели , прошедшей некоторую постобработку, например одно или несколько из следующих действий:
предварительно обученная модель
Обычно это уже обученная модель. Этот термин также может означать ранее обученный вектор внедрения .
Термин «предварительно обученная языковая модель» обычно относится к уже обученной большой языковой модели .
предварительная подготовка
Начальное обучение модели на большом наборе данных. Некоторые предварительно обученные модели являются неуклюжими гигантами и обычно требуют доработки посредством дополнительного обучения. Например, эксперты по машинному обучению могут предварительно обучить большую языковую модель на обширном наборе текстовых данных, например на всех английских страницах в Википедии. После предварительного обучения полученная модель может быть дополнительно уточнена с помощью любого из следующих методов:
- дистилляция
- тонкая настройка
- инструкция по настройке
- настройка с эффективным использованием параметров
- оперативная настройка
Р
вращательная инвариантность
В задаче классификации изображений — способность алгоритма успешно классифицировать изображения даже при изменении их ориентации. Например, алгоритм все равно может идентифицировать теннисную ракетку независимо от того, направлена ли она вверх, в сторону или вниз. Обратите внимание, что вращательная инвариантность не всегда желательна; например, перевернутую 9 не следует классифицировать как 9.
См. также трансляционную инвариантность и инвариантность размера .
С
неизменность размера
В задаче классификации изображений - способность алгоритма успешно классифицировать изображения, даже если их размер изменяется. Например, алгоритм все равно может идентифицировать кошку независимо от того, использует ли она 2 миллиона пикселей или 200 тысяч пикселей. Обратите внимание, что даже лучшие алгоритмы классификации изображений по-прежнему имеют практические ограничения на неизменность размера. Например, алгоритм (или человек) вряд ли сможет правильно классифицировать изображение кошки, занимающее всего 20 пикселей.
См. также трансляционную инвариантность и вращательную инвариантность .
пространственное объединение
См . объединение .
шагать
В сверточной операции или объединении — дельта в каждом измерении следующей серии входных срезов. Например, следующая анимация демонстрирует шаг (1,1) во время сверточной операции. Таким образом, следующий входной фрагмент начинается на одну позицию справа от предыдущего входного фрагмента. Когда операция достигает правого края, следующий срез оказывается полностью левее, но на одну позицию ниже.
Предыдущий пример демонстрирует двумерный шаг. Если входная матрица трехмерна, шаг также будет трехмерным.
субдискретизация
См . объединение .
Т
температура
Гиперпараметр , который контролирует степень случайности выходных данных модели. Более высокие температуры приводят к более случайному выходному сигналу, тогда как более низкие температуры приводят к менее случайному выходному сигналу.
Выбор оптимальной температуры зависит от конкретного применения и предпочтительных свойств выходной модели. Например, вы, вероятно, повысите температуру при создании приложения, генерирующего творческий результат. И наоборот, вы, вероятно, понизите температуру при построении модели, которая классифицирует изображения или текст, чтобы повысить точность и согласованность модели.
Температура часто используется с softmax .
трансляционная инвариантность
В задаче классификации изображений — способность алгоритма успешно классифицировать изображения, даже если положение объектов внутри изображения меняется. Например, алгоритм все равно может идентифицировать собаку, находится ли она в центре кадра или в левом конце кадра.
См. также размерную инвариантность и вращательную инвариантность .