หน้านี้มีคำศัพท์ในอภิธานศัพท์ของโมเดลรูปภาพ ดูคำศัพท์ทั้งหมดในอภิธานศัพท์ได้โดยการคลิกที่นี่
A
Augmented Reality
เทคโนโลยีที่วางซ้อนภาพที่สร้างโดยคอมพิวเตอร์บนมุมมองของผู้ใช้เกี่ยวกับโลกแห่งความเป็นจริง จึงให้มุมมองแบบผสม
ตัวเข้ารหัสอัตโนมัติ
ระบบที่เรียนรู้วิธีดึงข้อมูลที่สำคัญที่สุดจากอินพุต โปรแกรมเปลี่ยนไฟล์อัตโนมัติเป็นชุดค่าผสมของโปรแกรมเปลี่ยนไฟล์และโปรแกรมถอดรหัส โปรแกรมเข้ารหัสอัตโนมัติใช้กระบวนการ 2 ขั้นตอนต่อไปนี้
- ตัวเข้ารหัสจะแมปอินพุตเป็นรูปแบบ (โดยปกติ) ที่มีการสูญเสียและมิติข้อมูลต่ำลง (ระดับกลาง)
- ตัวถอดรหัสจะสร้างอินพุตต้นฉบับเวอร์ชันที่สูญเสียคุณภาพโดยการแมปรูปแบบมิติข้อมูลต่ำกับรูปแบบอินพุตมิติข้อมูลสูงเดิม
ระบบจะฝึก Autoencoder ตั้งแต่ต้นจนจบโดยให้ตัวถอดรหัสพยายามสร้างอินพุตเดิมขึ้นมาใหม่จากรูปแบบกลางของตัวเข้ารหัสให้ใกล้เคียงกับต้นฉบับมากที่สุด เนื่องจากรูปแบบกลางมีขนาดเล็กกว่า (มิติข้อมูลต่ำกว่า) รูปแบบเดิม ระบบจึงบังคับให้ตัวเข้ารหัสอัตโนมัติต้องเรียนรู้ว่าข้อมูลใดในอินพุตมีความสําคัญ และเอาต์พุตจะไม่เหมือนกับอินพุตอย่างสมบูรณ์
เช่น
- หากข้อมูลอินพุตเป็นกราฟิก สำเนาที่ไม่ใช่สำเนาที่ตรงกันทั้งหมดจะคล้ายกับกราฟิกต้นฉบับ แต่มีการแก้ไขเล็กน้อย อาจเป็นเพราะสำเนาที่ไม่ใช่สำเนาที่ตรงกันทั้งหมดได้นำสัญญาณรบกวนออกจากกราฟิกต้นฉบับหรือเติมพิกเซลที่ขาดหายไป
- หากข้อมูลอินพุตเป็นข้อความ ตัวเข้ารหัสอัตโนมัติจะสร้างข้อความใหม่ที่เลียนแบบ (แต่ไม่เหมือนกับ) ข้อความต้นฉบับ
ดูข้อมูลเพิ่มเติมได้ที่ตัวแปร Autoencoder
โมเดลอนุกรมเวลาแบบเลื่อนไปข้างหน้า
โมเดลที่อนุมานการคาดการณ์ตามการคาดการณ์ก่อนหน้าของตนเอง ตัวอย่างเช่น โมเดลภาษาแบบย้อนกลับอัตโนมัติจะคาดการณ์โทเค็นถัดไปโดยอิงตามโทเค็นที่คาดการณ์ไว้ก่อนหน้านี้ โมเดลภาษาขนาดใหญ่ทั้งหมดที่อิงตาม Transformer จะเป็นแบบย้อนกลับอัตโนมัติ
ในทางตรงกันข้าม โมเดลรูปภาพที่อิงตาม GAN มักจะไม่แสดงการถดถอยอัตโนมัติเนื่องจากสร้างรูปภาพในขั้นตอนเดียวแบบไปข้างหน้า ไม่ใช่แบบซ้ำๆ ในขั้นตอน อย่างไรก็ตาม โมเดลการสร้างรูปภาพบางรุ่นเป็นแบบถดถอยอัตโนมัติเนื่องจากสร้างรูปภาพเป็นขั้นตอน
B
กรอบล้อมรอบ
ในรูปภาพ พิกัด (x, y) ของสี่เหลี่ยมผืนผ้ารอบๆ พื้นที่ที่น่าสนใจ เช่น สุนัขในรูปภาพด้านล่าง

C
การฟัซชัน
ในคณิตศาสตร์ หมายถึงการผสมผสานของฟังก์ชัน 2 รายการ ในแมชชีนเลิร์นนิง การฟัซซิชันจะผสมฟิลเตอร์ฟัซซิชันเข้ากับเมทริกซ์อินพุตเพื่อฝึกน้ำหนัก
คําว่า "Conv" ในแมชชีนเลิร์นนิงมักเป็นวิธีเรียกสั้นๆ ของการดำเนินการ Conv หรือเลเยอร์ Conv
หากไม่มีการดำเนินการฟิวชัน อัลกอริทึมของแมชชีนเลิร์นนิงจะต้องเรียนรู้น้ำหนักแยกกันสำหรับทุกเซลล์ใน เทนเซอร์ขนาดใหญ่ ตัวอย่างเช่น การฝึกอัลกอริทึมแมชชีนเลิร์นนิงด้วยรูปภาพขนาด 2K x 2K จะบังคับให้ต้องหาน้ำหนักแยกกัน 4 ล้านรายการ การใช้การกรองแบบ Convolution ทำให้อัลกอริทึมของแมชชีนเลิร์นนิงต้องค้นหาเฉพาะน้ำหนักของทุกเซลล์ในฟิลเตอร์แบบ Convolution ซึ่งจะช่วยลดหน่วยความจําที่จําเป็นในการฝึกโมเดลได้อย่างมาก เมื่อใช้ตัวกรองแบบ Convolutional ระบบจะทําซ้ำตัวกรองนี้ในเซลล์ต่างๆ เพื่อให้แต่ละเซลล์คูณด้วยตัวกรอง
ดูข้อมูลเพิ่มเติมได้ที่การนําเสนอเครือข่ายประสาทแบบConvolutiveในหลักสูตรการจัดประเภทรูปภาพ
ฟิลเตอร์แบบ Convolutional
หนึ่งใน 2 องค์ประกอบในการดำเนินการแบบ Convolution (ตัวแปรอื่นๆ คือส่วนหนึ่งของเมทริกซ์อินพุต) ฟิลเตอร์แบบ Convolution คือเมทริกซ์ที่มีอันดับเหมือนกับเมทริกซ์อินพุต แต่มีรูปร่างที่เล็กกว่า เช่น เมื่อใช้เมทริกซ์อินพุต 28x28 ตัวกรองอาจเป็นเมทริกซ์ 2 มิติที่เล็กกว่า 28x28
ในการจัดการภาพ โดยทั่วไปแล้วเซลล์ทั้งหมดในตัวกรองแบบ Convolution จะมีการกําหนดให้เป็นรูปแบบ 1 และ 0 คงที่ ในแมชชีนเลิร์นนิง โดยทั่วไปแล้วตัวกรองแบบ Convolution จะได้รับการกำหนดค่าเริ่มต้นด้วยตัวเลขสุ่ม จากนั้นเครือข่ายจะฝึกค่าที่เหมาะสม
ดูข้อมูลเพิ่มเติมที่การกรองข้อมูลในหลักสูตรการจัดประเภทรูปภาพ
เลเยอร์ Conv
เลเยอร์ของโครงข่ายประสาทแบบลึก ซึ่งฟิลเตอร์แบบ Convolution ส่งผ่านเมทริกซ์อินพุต ตัวอย่างเช่น ลองพิจารณาตัวกรองแบบ Convolution ขนาด 3x3 ต่อไปนี้
![เมทริกซ์ 3x3 ที่มีค่าต่อไปนี้ [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=8&hl=th)
ภาพเคลื่อนไหวต่อไปนี้แสดงชั้น ConvNet ประกอบด้วยการดำเนินการ ConvNet 9 รายการที่เกี่ยวข้องกับเมทริกซ์อินพุต 5x5 โปรดทราบว่าการดำเนินการเชิงกรวยแต่ละรายการจะทำงานกับส่วน 3x3 ที่ต่างกันของเมทริกซ์อินพุต เมทริกซ์ 3x3 ที่ได้ (ทางด้านขวา) ประกอบด้วยผลลัพธ์ของการดำเนินการฟีเจอร์แมป 9 รายการดังนี้
![ภาพเคลื่อนไหวแสดงเมทริกซ์ 2 รายการ เมทริกซ์แรกคือเมทริกซ์ 5x5 ดังนี้ [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]]
เมทริกซ์ที่ 2 คือเมทริกซ์ 3x3 ดังนี้
[[181,303,618], [115,338,605], [169,351,560]]
แมทริกซ์ที่ 2 คำนวณโดยใช้ตัวกรองการแปลงคอนโวลูชัน [[0, 1, 0], [1, 0, 1], [0, 1, 0]] ในชุดย่อย 3x3 ที่แตกต่างกันของเมทริกซ์ 5x5](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=8&hl=th)
ดูข้อมูลเพิ่มเติมได้ในเลเยอร์แบบ Fully Connected ในหลักสูตรการแยกประเภทรูปภาพ
โครงข่ายประสาทแบบ Convolutive
เครือข่ายประสาทเทียมที่มีชั้นเป็นชั้น Conv อย่างน้อย 1 ชั้น โดยทั่วไปแล้ว เครือข่ายประสาทแบบ ConvNet จะประกอบด้วยชั้นต่อไปนี้
เครือข่ายประสาทแบบใช้ตัวคูณ (Convolutional Neural Network) ประสบความสําเร็จอย่างมากกับปัญหาบางประเภท เช่น การจดจํารูปภาพ
การดำเนินการแบบ Convolution
การดำเนินการทางคณิตศาสตร์แบบ 2 ขั้นตอนต่อไปนี้
- การคูณทีละองค์ประกอบของฟิลเตอร์คอนเววลูชันกับส่วนของเมทริกซ์อินพุต (ส่วนของเมทริกซ์อินพุตมีลําดับและขนาดเดียวกับตัวกรองแบบ Convolution)
- การรวมค่าทั้งหมดในเมทริกซ์ผลิตภัณฑ์ที่ได้
ตัวอย่างเช่น ลองพิจารณาเมทริกซ์อินพุต 5x5 ต่อไปนี้
![เมทริกซ์ 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=8&hl=th)
ลองจินตนาการถึงตัวกรองคอนเวโลชัน 2x2 ต่อไปนี้
![เมทริกซ์ 2x2: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=8&hl=th)
การดำเนินการแบบกรวย 1 รายการเกี่ยวข้องกับส่วน 2x2 เดียวของเมทริกซ์อินพุต ตัวอย่างเช่น สมมติว่าเราใช้ส่วน 2x2 ที่ด้านซ้ายบนของเมทริกซ์อินพุต ดังนั้น การดำเนินการฟิวชันกับส่วนนี้จึงมีลักษณะดังนี้
![การใช้ตัวกรองแบบ Convolutional [[1, 0], [0, 1]] กับส่วน 2x2 ที่ด้านซ้ายบนของเมทริกซ์อินพุต ซึ่งก็คือ [[128,97], [35,22]]
ตัวกรองคอนเวโลชันจะคงค่า 128 และ 22 ไว้ แต่ทำให้ค่า 97 และ 35 เป็น 0 ดังนั้น การดำเนินการฟิวชันจึงให้ค่า 150 (128+22)](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=8&hl=th)
ชั้น Conv ประกอบด้วยชุดการดำเนินการ Conv โดยแต่ละรายการจะดำเนินการกับส่วนต่างๆ ของเมทริกซ์อินพุต
D
การเสริมข้อมูล
การเพิ่มช่วงและจํานวนตัวอย่างการฝึกด้วยการเปลี่ยนรูปแบบตัวอย่างที่มีอยู่เพื่อสร้างตัวอย่างเพิ่มเติม ตัวอย่างเช่น สมมติว่ารูปภาพเป็นหนึ่งในฟีเจอร์ แต่ชุดข้อมูลของคุณไม่มีตัวอย่างรูปภาพเพียงพอที่จะช่วยให้โมเดลเรียนรู้การเชื่อมโยงที่เป็นประโยชน์ โดยหลักการแล้ว คุณควรเพิ่มรูปภาพที่ติดป้ายกำกับลงในชุดข้อมูลให้เพียงพอเพื่อให้โมเดลได้รับการฝึกอย่างเหมาะสม หากทำไม่ได้ การขยายข้อมูลจะหมุน ยืด และสะท้อนแต่ละรูปภาพเพื่อสร้างรูปภาพต้นฉบับหลายรูปแบบ ซึ่งอาจให้ข้อมูลที่ติดป้ายกำกับเพียงพอสำหรับการทําการฝึกที่ยอดเยี่ยม
โครงข่ายประสาทแบบ Convolutive ที่แยกตามมิติความลึกได้ (sepCNN)
สถาปัตยกรรมโครงข่ายประสาทแบบ Convolutiveที่อิงตาม Inception แต่ใช้ Convolutive แบบแยกตามระดับความลึกแทนโมดูล Inception หรือที่เรียกว่า Xception
การกรองเชิงลึกแบบแยกส่วน (หรือเรียกสั้นๆ ว่า "การกรองแบบแยกส่วน") จะแยกการกรอง 3 มิติมาตรฐานออกเป็น 2 การดำเนินการกรองแยกกัน ซึ่งมีประสิทธิภาพในการประมวลผลมากกว่า การดำเนินการแรกคือการกรองเชิงลึกที่มีความลึก 1 (n ✕ n ✕ 1) และการดำเนินการที่ 2 คือการกรองแบบจุดที่มีความกว้างและความยาว 1 (1 ✕ 1 ✕ n)
ดูข้อมูลเพิ่มเติมได้ที่ Xception: Deep Learning with Depthwise Separable Convolutions
การลดขนาด
คําที่มีความหมายหลายอย่างซึ่งอาจหมายถึงอย่างใดอย่างหนึ่งต่อไปนี้
- การลดปริมาณข้อมูลในฟีเจอร์เพื่อฝึกโมเดลให้มีประสิทธิภาพมากขึ้น เช่น การปรับขนาดรูปภาพความละเอียดสูงเป็นรูปแบบความละเอียดต่ำก่อนฝึกโมเดลการจดจำรูปภาพ
- การฝึกด้วยตัวอย่างคลาสที่มีจำนวนมากเกินไปในเปอร์เซ็นต์ที่ต่ำไม่สมส่วนเพื่อปรับปรุงการฝึกโมเดลในคลาสที่มีจำนวนน้อย เช่น ในชุดข้อมูลที่มีคลาสไม่สมดุล โมเดลมีแนวโน้มที่จะเรียนรู้เกี่ยวกับคลาสส่วนใหญ่มาก แต่เรียนรู้เกี่ยวกับคลาสน้อยไม่เพียงพอ การลดขนาดช่วยปรับสมดุลปริมาณการฝึกในคลาสส่วนใหญ่และคลาสส่วนน้อย
ดูข้อมูลเพิ่มเติมได้ที่ชุดข้อมูล: ชุดข้อมูลที่ไม่สมดุลในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
F
การปรับแต่ง
การฝึกครั้งที่ 2 สำหรับงานเฉพาะที่ดำเนินการกับโมเดลที่ฝึกล่วงหน้าเพื่อปรับแต่งพารามิเตอร์สำหรับกรณีการใช้งานที่เฉพาะเจาะจง ตัวอย่างเช่น ลำดับการฝึกแบบเต็มสำหรับโมเดลภาษาขนาดใหญ่บางรายการมีดังนี้
- การฝึกล่วงหน้า: ฝึกโมเดลภาษาขนาดใหญ่ด้วยชุดข้อมูลทั่วไปขนาดใหญ่ เช่น หน้า Wikipedia ภาษาอังกฤษทั้งหมด
- การปรับแต่ง: ฝึกโมเดลที่ฝึกไว้ล่วงหน้าให้ทํางานที่เฉพาะเจาะจง เช่น การตอบคําถามทางการแพทย์ โดยปกติการปรับแต่งแบบละเอียดจะเกี่ยวข้องกับตัวอย่างหลายร้อยหรือหลายพันรายการที่มุ่งเน้นไปที่งานหนึ่งๆ
อีกตัวอย่างหนึ่งคือลําดับการฝึกแบบเต็มสําหรับโมเดลรูปภาพขนาดใหญ่มีดังนี้
- การฝึกล่วงหน้า: ฝึกโมเดลรูปภาพขนาดใหญ่ในชุดข้อมูลรูปภาพทั่วไปขนาดใหญ่ เช่น รูปภาพทั้งหมดใน Wikimedia Commons
- การปรับแต่ง: ฝึกโมเดลที่ฝึกไว้ล่วงหน้าให้ทํางานเฉพาะ เช่น สร้างรูปภาพโลมาน้ำจืด
การปรับแต่งอาจใช้กลยุทธ์ต่อไปนี้ร่วมกัน
- การแก้ไขพารามิเตอร์ที่มีอยู่ทั้งหมดของโมเดลที่ผ่านการฝึกอบรมไว้ล่วงหน้า บางครั้งเรียกว่าการปรับแต่งอย่างละเอียด
- การแก้ไขพารามิเตอร์ที่มีอยู่บางส่วนของโมเดลที่ผ่านการฝึกอบรมล่วงหน้า (โดยปกติแล้วคือชั้นที่อยู่ใกล้กับชั้นเอาต์พุตมากที่สุด) โดยไม่เปลี่ยนแปลงพารามิเตอร์อื่นๆ ที่มีอยู่ (โดยปกติแล้วคือชั้นที่อยู่ใกล้กับชั้นอินพุตมากที่สุด) ดูการปรับแต่งที่มีประสิทธิภาพในแง่พารามิเตอร์
- การเพิ่มเลเยอร์ โดยปกติจะวางไว้บนเลเยอร์ที่มีอยู่ซึ่งอยู่ใกล้กับเลเยอร์เอาต์พุตมากที่สุด
การปรับแต่งเป็นรูปแบบหนึ่งของการเรียนรู้แบบโอน ดังนั้นการปรับแต่งอาจใช้ฟังก์ชันการสูญเสียหรือโมเดลประเภทอื่นที่แตกต่างจากที่ใช้ฝึกโมเดลที่ผ่านการฝึกอบรมล่วงหน้า เช่น คุณอาจปรับแต่งโมเดลรูปภาพขนาดใหญ่ที่ฝึกไว้ล่วงหน้าเพื่อสร้างโมเดลการหาค่าประมาณที่จะแสดงจํานวนนกในรูปภาพอินพุต
เปรียบเทียบการปรับแต่งกับคําต่อไปนี้
ดูข้อมูลเพิ่มเติมได้ที่การปรับแต่งในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
G
Gemini
ระบบนิเวศที่ประกอบด้วย AI ที่ล้ำหน้าที่สุดของ Google องค์ประกอบของระบบนิเวศนี้ได้แก่
- โมเดล Gemini ต่างๆ
- อินเทอร์เฟซการสนทนาแบบอินเทอร์แอกทีฟกับโมเดล Gemini ผู้ใช้พิมพ์พรอมต์และ Gemini จะตอบกลับพรอมต์เหล่านั้น
- Gemini API ต่างๆ
- ผลิตภัณฑ์ทางธุรกิจต่างๆ ที่อิงตามโมเดล Gemini เช่น Gemini สำหรับ Google Cloud
รูปแบบของ Gemini
โมเดลมัลติโมดที่อิงตาม Transformer ที่ทันสมัยของ Google โมเดล Gemini ได้รับการออกแบบมาโดยเฉพาะเพื่อผสานรวมกับตัวแทน
ผู้ใช้โต้ตอบกับโมเดล Gemini ได้หลายวิธี เช่น ผ่านอินเทอร์เฟซการสนทนาแบบอินเทอร์แอกทีฟและผ่าน SDK
Generative AI
ช่องการเปลี่ยนแปลงที่เกิดขึ้นใหม่ซึ่งไม่มีคำจำกัดความอย่างเป็นทางการ อย่างไรก็ตาม ผู้เชี่ยวชาญส่วนใหญ่ยอมรับว่าโมเดล Generative AI สามารถสร้าง ("สร้าง") เนื้อหาที่มีลักษณะต่อไปนี้ได้ทั้งหมด
- ซับซ้อน
- สอดคล้องกัน
- เดิม
เช่น โมเดล Generative AI สามารถสร้างเรียงความหรือรูปภาพที่ซับซ้อน
เทคโนโลยีรุ่นก่อนหน้าบางรายการ เช่น LSTM และ RNN สามารถสร้างเนื้อหาต้นฉบับที่สอดคล้องกันได้ด้วย ผู้เชี่ยวชาญบางรายมองว่าเทคโนโลยียุคแรกๆ เหล่านี้เป็น Generative AI ขณะที่ผู้เชี่ยวชาญอีกกลุ่มหนึ่งเชื่อว่า Generative AI ที่แท้จริงต้องใช้เอาต์พุตที่ซับซ้อนกว่าที่เทคโนโลยียุคแรกๆ เหล่านั้นจะผลิตได้
ตรงข้ามกับ ML เชิงคาดการณ์
I
การรู้จำรูปภาพ
กระบวนการจัดประเภทวัตถุ ลวดลาย หรือแนวคิดในรูปภาพ การจดจํารูปภาพเรียกอีกอย่างว่าการจัดประเภทรูปภาพ
ดูข้อมูลเพิ่มเติมได้ที่ML Practicum: Image Classification
ดูข้อมูลเพิ่มเติมได้ที่หลักสูตร ML Practicum: การแยกประเภทรูปภาพ
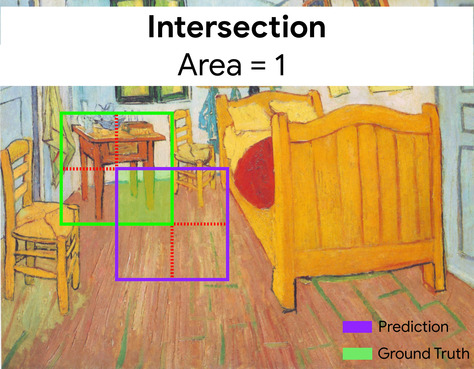
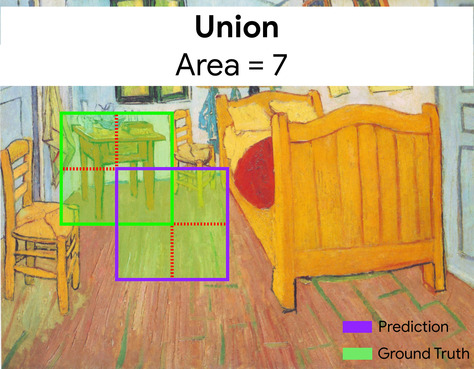
Intersection over Union (IoU)
ส่วนตัดกันของ 2 ชุดหารด้วยผลรวมของชุด ในภารกิจการตรวจจับภาพด้วยแมชชีนเลิร์นนิง ระบบจะใช้ IoU เพื่อวัดความแม่นยำของกรอบขอบเขตที่คาดการณ์ไว้ของโมเดลเทียบกับกรอบขอบเขตข้อมูลจากการสังเกตการณ์โดยตรง ในกรณีนี้ IoU สำหรับกล่อง 2 กล่องคืออัตราส่วนระหว่างพื้นที่ที่ทับซ้อนกันและพื้นที่ทั้งหมด และค่าของ IoU จะอยู่ระหว่าง 0 (กรอบขอบเขตที่คาดการณ์ไว้และกรอบขอบเขตข้อมูลจากการสังเกตการณ์โดยตรงไม่ทับซ้อนกัน) ถึง 1 (กรอบขอบเขตที่คาดการณ์ไว้และกรอบขอบเขตข้อมูลจากการสังเกตการณ์โดยตรงมีพิกัดตำแหน่งเดียวกันทุกประการ)
ตัวอย่างเช่น ในรูปภาพด้านล่าง
- กรอบขอบเขตที่คาดการณ์ (พิกัดที่กําหนดขอบเขตตำแหน่งที่โมเดลคาดการณ์ว่าโต๊ะข้างเตียงในภาพวาดอยู่) จะแสดงเป็นเส้นขอบสีม่วง
- กล่องขอบเขตของข้อมูลจริง (พิกัดที่กําหนดขอบเขตตําแหน่งของโต๊ะกลางในภาพวาด) จะวาดเส้นขอบสีเขียว

ในที่นี้ จุดตัดของกรอบขอบเขตสำหรับการคาดการณ์และข้อมูลจากการสังเกตการณ์โดยตรง (ด้านล่างซ้าย) คือ 1 และสหภาพของกรอบขอบเขตสำหรับการคาดการณ์และข้อมูลจากการสังเกตการณ์โดยตรง (ด้านล่างขวา) คือ 7 ดังนั้น IoU จึงเป็น \(\frac{1}{7}\)
K
keypoints
พิกัดขององค์ประกอบบางอย่างในรูปภาพ เช่น สำหรับโมเดลการจดจำรูปภาพที่แยกแยะพันธุ์ดอกไม้ จุดสังเกตอาจเป็นจุดศูนย์กลางของกลีบแต่ละกลีบ ลำต้น เกสร และอื่นๆ
L
จุดสังเกต
คำพ้องความหมายของประเด็นสำคัญ
M
MMIT
ตัวย่อของ Multimodal Instruction-Tuned
MNIST
ชุดข้อมูลสาธารณสมบัติที่ LeCun, Cortes และ Burges รวบรวมไว้ซึ่งมีรูปภาพ 60,000 ภาพ โดยแต่ละภาพแสดงวิธีที่มนุษย์เขียนตัวเลข 0-9 ด้วยตนเอง ระบบจะจัดเก็บรูปภาพแต่ละรูปเป็นอาร์เรย์จำนวนเต็มขนาด 28x28 โดยที่จำนวนเต็มแต่ละค่าจะเป็นค่าสีเทาระหว่าง 0 ถึง 255 (รวม)
MNIST เป็นชุดข้อมูล Canonical สําหรับแมชชีนเลิร์นนิง ซึ่งมักใช้ในการทดสอบแนวทางใหม่ๆ ของแมชชีนเลิร์นนิง โปรดดูรายละเอียดที่ ฐานข้อมูล MNIST ของตัวเลขที่เขียนด้วยมือ
MOE
ตัวย่อของ mixture of experts
P
การรวมกลุ่ม
การลดเมทริกซ์ (หรือเมทริกซ์) ที่สร้างขึ้นโดยชั้น Conv ก่อนหน้าให้เป็นเมทริกซ์ขนาดเล็กลง โดยปกติแล้วการรวมกลุ่มจะเกี่ยวข้องกับการนำค่าสูงสุดหรือค่าเฉลี่ยจากพื้นที่ที่รวม ตัวอย่างเช่น สมมติว่าเรามีเมทริกซ์ 3x3 ต่อไปนี้
![เมทริกซ์ 3x3 ของ [[5,3,1], [8,2,5], [9,4,3]]](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=8&hl=th)
การดำเนินการรวมกลุ่มจะแบ่งเมทริกซ์ออกเป็นส่วนๆ เช่นเดียวกับการดำเนินการ Conv จากนั้นจะเลื่อนการดำเนินการ Conv นั้นตามระยะ ตัวอย่างเช่น สมมติว่าการดำเนินการการรวมกลุ่มจะแบ่งเมทริกซ์การแปลงคอนโวลูชันออกเป็นส่วนๆ ขนาด 2x2 ที่มีระยะ 1x1 ดังที่แผนภาพต่อไปนี้แสดง การดำเนินการรวมมี 4 รายการ ลองจินตนาการว่าการดำเนินการรวมแต่ละรายการจะเลือกค่าสูงสุดของ 4 รายการในส่วนนั้นๆ
![เมทริกซ์อินพุตคือ 3x3 ที่มีค่า [[5,3,1], [8,2,5], [9,4,3]]
อนุมาตร 2x2 ที่ด้านซ้ายบนของเมทริกซ์อินพุตคือ [[5,3], [8,2]] ดังนั้นการดำเนินการรวมข้อมูลด้านซ้ายบนจึงให้ค่า 8 (ซึ่งเป็นค่าสูงสุดของ 5, 3, 8 และ 2) อนุมาตร 2x2 ที่ด้านขวาบนของเมทริกซ์อินพุตคือ [[3,1], [2,5]] ดังนั้นการดำเนินการรวมที่ด้านขวาบนจึงให้ค่า 5 อนุมาตรย่อย 2x2 ที่ด้านซ้ายล่างของเมทริกซ์อินพุตคือ [[8,2], [9,4]] ดังนั้นการดำเนินการรวมข้อมูลด้านซ้ายล่างจึงให้ค่า 9 อนุมาตร 2x2 ที่ด้านขวาล่างของเมทริกซ์อินพุตคือ [[2,5], [4,3]] ดังนั้นการดำเนินการรวมที่ด้านขวาล่างจะให้ค่า 5 โดยสรุปแล้ว การดำเนินการรวมกลุ่มจะให้ผลลัพธ์เป็นเมทริกซ์ 2x2 ดังนี้
[[8,5], [9,5]]](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=8&hl=th)
การรวมกลุ่มช่วยบังคับใช้การคงที่แบบแปลในเมทริกซ์อินพุต
การรวมสำหรับแอปพลิเคชันการมองเห็นเรียกอย่างเป็นทางการว่าการรวมเชิงพื้นที่ แอปพลิเคชันอนุกรมเวลามักเรียกการรวมข้อมูลว่าการรวมข้อมูลตามช่วงเวลา Pooling มักเรียกอย่างไม่เป็นทางการว่าการสุ่มตัวอย่างย่อยหรือการสุ่มตัวอย่างลง
โมเดลหลังการฝึก
คําที่กําหนดไว้อย่างหลวมๆ ซึ่งโดยทั่วไปหมายถึงโมเดลที่ผ่านการฝึกล่วงหน้าซึ่งผ่านกระบวนการประมวลผลขั้นสุดท้ายแล้ว เช่น การดำเนินการต่อไปนี้อย่างน้อย 1 อย่าง
โมเดลที่ฝึกล่วงหน้า
โดยปกติแล้วคือโมเดลที่ผ่านการฝึกแล้ว หรืออาจหมายถึงเวกเตอร์การฝังที่ผ่านการฝึกก่อนหน้านี้
คําว่าโมเดลภาษาที่ฝึกล่วงหน้ามักจะหมายถึงโมเดลภาษาขนาดใหญ่ที่ผ่านการฝึกแล้ว
การฝึกขั้นต้น
การฝึกโมเดลครั้งแรกในชุดข้อมูลขนาดใหญ่ โมเดลที่ผ่านการฝึกล่วงหน้าบางรุ่นเป็นโมเดลที่ทำงานได้ไม่ดีนัก และมักจะต้องได้รับการปรับแต่งผ่านการฝึกเพิ่มเติม ตัวอย่างเช่น ผู้เชี่ยวชาญด้าน ML อาจฝึกโมเดลภาษาขนาดใหญ่ล่วงหน้าด้วยชุดข้อมูลข้อความขนาดใหญ่ เช่น หน้าภาษาอังกฤษทั้งหมดใน Wikipedia หลังจากการฝึกล่วงหน้าแล้ว โมเดลที่ได้อาจได้รับการปรับแต่งเพิ่มเติมผ่านเทคนิคต่อไปนี้
R
ความไม่แปรปรวนตามการหมุน
ในปัญหาการจัดประเภทรูปภาพ ความสามารถของอัลกอริทึมในการจัดประเภทรูปภาพได้สําเร็จแม้ว่าการวางแนวของรูปภาพจะเปลี่ยนไป ตัวอย่างเช่น อัลกอริทึมจะยังคงระบุไม้เทนนิสได้ไม่ว่าจะชี้ขึ้น ข้างๆ หรือลง โปรดทราบว่าการคงที่ในการหมุนไม่ใช่สิ่งที่ต้องการเสมอไป เช่น ไม่ควรจัดประเภท 9 กลับหัวเป็น 9
ดูข้อมูลเพิ่มเติมได้ที่การคงที่แบบแปลภาษาและการคงที่ของขนาด
S
ความไม่เปลี่ยนแปลงตามขนาด
ในปัญหาการจัดประเภทรูปภาพ ความสามารถของอัลกอริทึมในการจัดประเภทรูปภาพให้สำเร็จแม้ว่าขนาดของรูปภาพจะเปลี่ยนแปลงไป ตัวอย่างเช่น อัลกอริทึมจะยังคงระบุแมวได้ไม่ว่าจะใช้พื้นที่ 2 ล้านพิกเซลหรือ 200,000 พิกเซล โปรดทราบว่าอัลกอริทึมการจัดประเภทรูปภาพที่ดีที่สุดก็ยังมีข้อจำกัดด้านขนาดที่คงที่ ตัวอย่างเช่น อัลกอริทึม (หรือมนุษย์) ไม่สามารถจัดประเภทรูปภาพแมวที่มีขนาดเพียง 20 พิกเซลได้อย่างถูกต้อง
ดูข้อมูลเพิ่มเติมได้ที่การคงที่แบบแปลและการคงที่แบบหมุน
การรวมข้อมูลเชิงพื้นที่
ดูการรวม
ระยะก้าว
ในการดำเนินการแบบ Convolution หรือ Pooling เดลต้าในแต่ละมิติข้อมูลของชุดข้อมูลถัดไป ตัวอย่างเช่น ภาพเคลื่อนไหวต่อไปนี้แสดงระยะ (1,1) ระหว่างการดำเนินการ Conv ดังนั้น ข้อมูลโค้ดถัดไปจึงเริ่มต้นที่ตำแหน่งด้านขวาของข้อมูลโค้ดก่อนหน้า 1 ตำแหน่ง เมื่อการดำเนินการถึงขอบขวาแล้ว ส่วนของภาพถัดไปจะเลื่อนไปทางซ้ายสุดแต่ลง 1 ตำแหน่ง
ตัวอย่างก่อนหน้านี้แสดงการก้าว 2 มิติ หากเมทริกซ์อินพุตเป็นแบบ 3 มิติ ระยะห่างจะเป็นแบบ 3 มิติด้วย
การสุ่มตัวอย่างย่อย
ดูการรวม
T
อุณหภูมิ
ไฮเปอร์พารามิเตอร์ที่ควบคุมระดับความสุ่มของเอาต์พุตของโมเดล อุณหภูมิที่สูงขึ้นจะทำให้เอาต์พุตเป็นแบบสุ่มมากขึ้น ส่วนอุณหภูมิที่ต่ำลงจะทำให้เอาต์พุตเป็นแบบสุ่มน้อยลง
การเลือกอุณหภูมิที่เหมาะสมที่สุดขึ้นอยู่กับแอปพลิเคชันเฉพาะและพร็อพเพอร์ตี้ที่ต้องการของเอาต์พุตของโมเดล เช่น คุณอาจเพิ่มอุณหภูมิเมื่อสร้างแอปพลิเคชันที่สร้างเอาต์พุตครีเอทีฟโฆษณา ในทางกลับกัน คุณอาจลดอุณหภูมิเมื่อสร้างโมเดลที่จัดประเภทรูปภาพหรือข้อความเพื่อปรับปรุงความแม่นยำและความสอดคล้องของโมเดล
อุณหภูมิมักใช้ร่วมกับ softmax
การเปลี่ยนรูปแบบ
ในปัญหาการจัดประเภทรูปภาพ ความสามารถของอัลกอริทึมในการจัดประเภทรูปภาพให้สำเร็จแม้ว่าตำแหน่งของวัตถุภายในรูปภาพจะเปลี่ยนไป ตัวอย่างเช่น อัลกอริทึมจะยังคงระบุสุนัขได้ ไม่ว่าจะอยู่ตรงกลางเฟรมหรือที่ด้านซ้ายสุดของเฟรม
ดูข้อมูลเพิ่มเติมได้ที่การคงขนาดและการคงการหมุน