This page contains Language Evaluation glossary terms. For all glossary terms, click here.
A
attention
A mechanism used in a neural network that indicates the importance of a particular word or part of a word. Attention compresses the amount of information a model needs to predict the next token/word. A typical attention mechanism might consist of a weighted sum over a set of inputs, where the weight for each input is computed by another part of the neural network.
Refer also to self-attention and multi-head self-attention, which are the building blocks of Transformers.
See LLMs: What's a large language model? in Machine Learning Crash Course for more information about self-attention.
autoencoder
A system that learns to extract the most important information from the input. Autoencoders are a combination of an encoder and decoder. Autoencoders rely on the following two-step process:
- The encoder maps the input to a (typically) lossy lower-dimensional (intermediate) format.
- The decoder builds a lossy version of the original input by mapping the lower-dimensional format to the original higher-dimensional input format.
Autoencoders are trained end-to-end by having the decoder attempt to reconstruct the original input from the encoder's intermediate format as closely as possible. Because the intermediate format is smaller (lower-dimensional) than the original format, the autoencoder is forced to learn what information in the input is essential, and the output won't be perfectly identical to the input.
For example:
- If the input data is a graphic, the non-exact copy would be similar to the original graphic, but somewhat modified. Perhaps the non-exact copy removes noise from the original graphic or fills in some missing pixels.
- If the input data is text, an autoencoder would generate new text that mimics (but is not identical to) the original text.
See also variational autoencoders.
automatic evaluation
Using software to judge the quality of a model's output.
When model output is relatively straightforward, a script or program can compare the model's output to a golden response. This type of automatic evaluation is sometimes called programmatic evaluation. Metrics such as ROUGE or BLEU are often useful for programmatic evaluation.
When model output is complex or has no one right answer, a separate ML program called an autorater sometimes performs the automatic evaluation.
Contrast with human evaluation.
autorater evaluation
A hybrid mechanism for judging the quality of a generative AI model's output that combines human evaluation with automatic evaluation. An autorater is an ML model trained on data created by human evaluation. Ideally, an autorater learns to mimic a human evaluator.Prebuilt autoraters are available, but the best autoraters are fine-tuned specifically to the task you are evaluating.
auto-regressive model
A model that infers a prediction based on its own previous predictions. For example, auto-regressive language models predict the next token based on the previously predicted tokens. All Transformer-based large language models are auto-regressive.
In contrast, GAN-based image models are usually not auto-regressive since they generate an image in a single forward-pass and not iteratively in steps. However, certain image generation models are auto-regressive because they generate an image in steps.
average precision at k
A metric for summarizing a model's performance on a single prompt that generates ranked results, such as a numbered list of book recommendations. Average precision at k is, well, the average of the precision at k values for each relevant result. The formula for average precision at k is therefore:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
where:
- \(n\) is the number of relevant items in the list.
Contrast with recall at k.
B
bag of words
A representation of the words in a phrase or passage, irrespective of order. For example, bag of words represents the following three phrases identically:
- the dog jumps
- jumps the dog
- dog jumps the
Each word is mapped to an index in a sparse vector, where the vector has an index for every word in the vocabulary. For example, the phrase the dog jumps is mapped into a feature vector with non-zero values at the three indexes corresponding to the words the, dog, and jumps. The non-zero value can be any of the following:
- A 1 to indicate the presence of a word.
- A count of the number of times a word appears in the bag. For example, if the phrase were the maroon dog is a dog with maroon fur, then both maroon and dog would be represented as 2, while the other words would be represented as 1.
- Some other value, such as the logarithm of the count of the number of times a word appears in the bag.
BERT (Bidirectional Encoder Representations from Transformers)
A model architecture for text representation. A trained BERT model can act as part of a larger model for text classification or other ML tasks.
BERT has the following characteristics:
- Uses the Transformer architecture, and therefore relies on self-attention.
- Uses the encoder part of the Transformer. The encoder's job is to produce good text representations, rather than to perform a specific task like classification.
- Is bidirectional.
- Uses masking for unsupervised training.
BERT's variants include:
See Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing for an overview of BERT.
bidirectional
A term used to describe a system that evaluates the text that both precedes and follows a target section of text. In contrast, a unidirectional system only evaluates the text that precedes a target section of text.
For example, consider a masked language model that must determine probabilities for the word or words representing the underline in the following question:
What is the _____ with you?
A unidirectional language model would have to base its probabilities only on the context provided by the words "What", "is", and "the". In contrast, a bidirectional language model could also gain context from "with" and "you", which might help the model generate better predictions.
bidirectional language model
A language model that determines the probability that a given token is present at a given location in an excerpt of text based on the preceding and following text.
bigram
An N-gram in which N=2.
BLEU (Bilingual Evaluation Understudy)
A metric between 0.0 and 1.0 for evaluating machine translations, for example, from Spanish to Japanese.
To calculate a score, BLEU typically compares an ML model's translation (generated text) to a human expert's translation (reference text). The degree to which N-grams in the generated text and reference text match determines the BLEU score.
The original paper on this metric is BLEU: a Method for Automatic Evaluation of Machine Translation.
See also BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
A metric for evaluating machine translations from one language to another, particularly to and from English.
For translations to and from English, BLEURT aligns more closely to human ratings than BLEU. Unlike BLEU, BLEURT emphasizes semantic (meaning) similarities and can accommodate paraphrasing.
BLEURT relies on a pre-trained large language model (BERT to be exact) that is then fine-tuned on text from human translators.
The original paper on this metric is BLEURT: Learning Robust Metrics for Text Generation.
C
causal language model
Synonym for unidirectional language model.
See bidirectional language model to contrast different directional approaches in language modeling.
chain-of-thought prompting
A prompt engineering technique that encourages a large language model (LLM) to explain its reasoning, step by step. For example, consider the following prompt, paying particular attention to the second sentence:
How many g forces would a driver experience in a car that goes from 0 to 60 miles per hour in 7 seconds? In the answer, show all relevant calculations.
The LLM's response would likely:
- Show a sequence of physics formulas, plugging in the values 0, 60, and 7 in appropriate places.
- Explain why it chose those formulas and what the various variables mean.
Chain-of-thought prompting forces the LLM to perform all the calculations, which might lead to a more correct answer. In addition, chain-of-thought prompting enables the user to examine the LLM's steps to determine whether or not the answer makes sense.
chat
The contents of a back-and-forth dialogue with an ML system, typically a large language model. The previous interaction in a chat (what you typed and how the large language model responded) becomes the context for subsequent parts of the chat.
A chatbot is an application of a large language model.
confabulation
Synonym for hallucination.
Confabulation is probably a more technically accurate term than hallucination. However, hallucination became popular first.
constituency parsing
Dividing a sentence into smaller grammatical structures ("constituents"). A later part of the ML system, such as a natural language understanding model, can parse the constituents more easily than the original sentence. For example, consider the following sentence:
My friend adopted two cats.
A constituency parser can divide this sentence into the following two constituents:
- My friend is a noun phrase.
- adopted two cats is a verb phrase.
These constituents can be further subdivided into smaller constituents. For example, the verb phrase
adopted two cats
could be further subdivided into:
- adopted is a verb.
- two cats is another noun phrase.
contextualized language embedding
An embedding that comes close to "understanding" words and phrases in ways that fluent human speakers can. Contextualized language embeddings can understand complex syntax, semantics, and context.
For example, consider embeddings of the English word cow. Older embeddings such as word2vec can represent English words such that the distance in the embedding space from cow to bull is similar to the distance from ewe (female sheep) to ram (male sheep) or from female to male. Contextualized language embeddings can go a step further by recognizing that English speakers sometimes casually use the word cow to mean either cow or bull.
context window
The number of tokens a model can process in a given prompt. The larger the context window, the more information the model can use to provide coherent and consistent responses to the prompt.
crash blossom
A sentence or phrase with an ambiguous meaning. Crash blossoms present a significant problem in natural language understanding. For example, the headline Red Tape Holds Up Skyscraper is a crash blossom because an NLU model could interpret the headline literally or figuratively.
D
decoder
In general, any ML system that converts from a processed, dense, or internal representation to a more raw, sparse, or external representation.
Decoders are often a component of a larger model, where they are frequently paired with an encoder.
In sequence-to-sequence tasks, a decoder starts with the internal state generated by the encoder to predict the next sequence.
Refer to Transformer for the definition of a decoder within the Transformer architecture.
See Large language models in Machine Learning Crash Course for more information.
denoising
A common approach to self-supervised learning in which:
Denoising enables learning from unlabeled examples. The original dataset serves as the target or label and the noisy data as the input.
Some masked language models use denoising as follows:
- Noise is artificially added to an unlabeled sentence by masking some of the tokens.
- The model tries to predict the original tokens.
direct prompting
Synonym for zero-shot prompting.
E
edit distance
A measurement of how similar two text strings are to each other. In machine learning, edit distance is useful for the following reasons:
- Edit distance is easy to compute.
- Edit distance can compare two strings known to be similar to each other.
- Edit distance can determine the degree to which different strings are similar to a given string.
There are several definitions of edit distance, each using different string operations. See Levenshtein distance for an example.
embedding layer
A special hidden layer that trains on a high-dimensional categorical feature to gradually learn a lower dimension embedding vector. An embedding layer enables a neural network to train far more efficiently than training just on the high-dimensional categorical feature.
For example, Earth currently supports about 73,000 tree species. Suppose
tree species is a feature in your model, so your model's
input layer includes a one-hot vector 73,000
elements long.
For example, perhaps baobab would be represented something like this:

A 73,000-element array is very long. If you don't add an embedding layer to the model, training is going to be very time consuming due to multiplying 72,999 zeros. Perhaps you pick the embedding layer to consist of 12 dimensions. Consequently, the embedding layer will gradually learn a new embedding vector for each tree species.
In certain situations, hashing is a reasonable alternative to an embedding layer.
See Embeddings in Machine Learning Crash Course for more information.
embedding space
The d-dimensional vector space that features from a higher-dimensional vector space are mapped to. Embedding space is trained to capture structure that is meaningful for the intended application.
The dot product of two embeddings is a measure of their similarity.
embedding vector
Broadly speaking, an array of floating-point numbers taken from any hidden layer that describe the inputs to that hidden layer. Often, an embedding vector is the array of floating-point numbers trained in an embedding layer. For example, suppose an embedding layer must learn an embedding vector for each of the 73,000 tree species on Earth. Perhaps the following array is the embedding vector for a baobab tree:

An embedding vector is not a bunch of random numbers. An embedding layer determines these values through training, similar to the way a neural network learns other weights during training. Each element of the array is a rating along some characteristic of a tree species. Which element represents which tree species' characteristic? That's very hard for humans to determine.
The mathematically remarkable part of an embedding vector is that similar items have similar sets of floating-point numbers. For example, similar tree species have a more similar set of floating-point numbers than dissimilar tree species. Redwoods and sequoias are related tree species, so they'll have a more similar set of floating-pointing numbers than redwoods and coconut palms. The numbers in the embedding vector will change each time you retrain the model, even if you retrain the model with identical input.
encoder
In general, any ML system that converts from a raw, sparse, or external representation into a more processed, denser, or more internal representation.
Encoders are often a component of a larger model, where they are frequently paired with a decoder. Some Transformers pair encoders with decoders, though other Transformers use only the encoder or only the decoder.
Some systems use the encoder's output as the input to a classification or regression network.
In sequence-to-sequence tasks, an encoder takes an input sequence and returns an internal state (a vector). Then, the decoder uses that internal state to predict the next sequence.
Refer to Transformer for the definition of an encoder in the Transformer architecture.
See LLMs: What's a large language model in Machine Learning Crash Course for more information.
evals
Primarily used as an abbreviation for LLM evaluations. More broadly, evals is an abbreviation for any form of evaluation.
evaluation
The process of measuring a model's quality or comparing different models against each other.
To evaluate a supervised machine learning model, you typically judge it against a validation set and a test set. Evaluating a LLM typically involves broader quality and safety assessments.
F
few-shot prompting
A prompt that contains more than one (a "few") example demonstrating how the large language model should respond. For example, the following lengthy prompt contains two examples showing a large language model how to answer a query.
| Parts of one prompt | Notes |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| France: EUR | One example. |
| United Kingdom: GBP | Another example. |
| India: | The actual query. |
Few-shot prompting generally produces more desirable results than zero-shot prompting and one-shot prompting. However, few-shot prompting requires a lengthier prompt.
Few-shot prompting is a form of few-shot learning applied to prompt-based learning.
See Prompt engineering in Machine Learning Crash Course for more information.
Fiddle
A Python-first configuration library that sets the values of functions and classes without invasive code or infrastructure. In the case of Pax—and other ML codebases—these functions and classes represent models and training hyperparameters.
Fiddle assumes that machine learning codebases are typically divided into:
- Library code, which defines the layers and optimizers.
- Dataset "glue" code, which calls the libraries and wires everything together.
Fiddle captures the call structure of the glue code in an unevaluated and mutable form.
fine-tuning
A second, task-specific training pass performed on a pre-trained model to refine its parameters for a specific use case. For example, the full training sequence for some large language models is as follows:
- Pre-training: Train a large language model on a vast general dataset, such as all the English language Wikipedia pages.
- Fine-tuning: Train the pre-trained model to perform a specific task, such as responding to medical queries. Fine-tuning typically involves hundreds or thousands of examples focused on the specific task.
As another example, the full training sequence for a large image model is as follows:
- Pre-training: Train a large image model on a vast general image dataset, such as all the images in Wikimedia commons.
- Fine-tuning: Train the pre-trained model to perform a specific task, such as generating images of orcas.
Fine-tuning can entail any combination of the following strategies:
- Modifying all of the pre-trained model's existing parameters. This is sometimes called full fine-tuning.
- Modifying only some of the pre-trained model's existing parameters (typically, the layers closest to the output layer), while keeping other existing parameters unchanged (typically, the layers closest to the input layer). See parameter-efficient tuning.
- Adding more layers, typically on top of the existing layers closest to the output layer.
Fine-tuning is a form of transfer learning. As such, fine-tuning might use a different loss function or a different model type than those used to train the pre-trained model. For example, you could fine-tune a pre-trained large image model to produce a regression model that returns the number of birds in an input image.
Compare and contrast fine-tuning with the following terms:
See Fine-tuning in Machine Learning Crash Course for more information.
Flax
A high-performance open-source library for deep learning built on top of JAX. Flax provides functions for training neural networks, as well as methods for evaluating their performance.
Flaxformer
An open-source Transformer library, built on Flax, designed primarily for natural language processing and multimodal research.
G
Gemini
The ecosystem comprising Google's most advanced AI. Elements of this ecosystem include:
- Various Gemini models.
- The interactive conversational interface to a Gemini model. Users type prompts and Gemini responds to those prompts.
- Various Gemini APIs.
- Various business products based on Gemini models; for example, Gemini for Google Cloud.
Gemini models
Google's state-of-the-art Transformer-based multimodal models. Gemini models are specifically designed to integrate with agents.
Users can interact with Gemini models in a variety of ways, including through an interactive dialog interface and through SDKs.
generated text
In general, the text that an ML model outputs. When evaluating large language models, some metrics compare generated text against reference text. For example, suppose you are trying to determine how effectively an ML model translates from French to Dutch. In this case:
- The generated text is the Dutch translation that the ML model outputs.
- The reference text is the Dutch translation that a human translator (or software) creates.
Note that some evaluation strategies don't involve reference text.
generative AI
An emerging transformative field with no formal definition. That said, most experts agree that generative AI models can create ("generate") content that is all of the following:
- complex
- coherent
- original
For example, a generative AI model can create sophisticated essays or images.
Some earlier technologies, including LSTMs and RNNs, can also generate original and coherent content. Some experts view these earlier technologies as generative AI, while others feel that true generative AI requires more complex output than those earlier technologies can produce.
Contrast with predictive ML.
golden response
An answer known to be good. For example, given the following prompt:
2 + 2
The golden response is hopefully:
4
GPT (Generative Pre-trained Transformer)
A family of Transformer-based large language models developed by OpenAI.
GPT variants can apply to multiple modalities, including:
- image generation (for example, ImageGPT)
- text-to-image generation (for example, DALL-E).
H
hallucination
The production of plausible-seeming but factually incorrect output by a generative AI model that purports to be making an assertion about the real world. For example, a generative AI model that claims that Barack Obama died in 1865 is hallucinating.
human evaluation
A process in which people judge the quality of an ML model's output; for example, having bilingual people judge the quality of an ML translation model. Human evaluation is particularly useful for judging models that have no one right answer.
Contrast with automatic evaluation and autorater evaluation.
I
in-context learning
Synonym for few-shot prompting.
L
LaMDA (Language Model for Dialogue Applications)
A Transformer-based large language model developed by Google trained on a large dialogue dataset that can generate realistic conversational responses.
LaMDA: our breakthrough conversation technology provides an overview.
language model
A model that estimates the probability of a token or sequence of tokens occurring in a longer sequence of tokens.
See What is a language model? in Machine Learning Crash Course for more information.
large language model
At a minimum, a language model having a very high number of parameters. More informally, any Transformer-based language model, such as Gemini or GPT.
See Large language models (LLMs) in Machine Learning Crash Course for more information.
latent space
Synonym for embedding space.
Levenshtein Distance
An edit distance metric that calculates the fewest delete, insert, and substitute operations required to change one word to another. For example, the Levenshtein distance between the words "heart" and "darts" is three because the following three edits are the fewest changes to turn one word into the other:
- heart → deart (substitute "h" with "d")
- deart → dart (delete "e")
- dart → darts (insert "s")
Note that the preceding sequence isn't the only path of three edits.
LLM
Abbreviation for large language model.
LLM evaluations (evals)
A set of metrics and benchmarks for assessing the performance of large language models (LLMs). At a high level, LLM evaluations:
- Help researchers identify areas where LLMs need improvement.
- Are useful in comparing different LLMs and identifying the best LLM for a particular task.
- Help ensure that LLMs are safe and ethical to use.
See Large language models (LLMs) in Machine Learning Crash Course for more information.
LoRA
Abbreviation for Low-Rank Adaptability.
Low-Rank Adaptability (LoRA)
A parameter-efficient technique for fine tuning that "freezes" the model's pre-trained weights (such that they can no longer be modified) and then inserts a small set of trainable weights into the model. This set of trainable weights (also known as "update matrixes") is considerably smaller than the base model and is therefore much faster to train.
LoRA provides the following benefits:
- Improves the quality of a model's predictions for the domain where the fine tuning is applied.
- Fine-tunes faster than techniques that require fine-tuning all of a model's parameters.
- Reduces the computational cost of inference by enabling concurrent serving of multiple specialized models sharing the same base model.
M
masked language model
A language model that predicts the probability of candidate tokens to fill in blanks in a sequence. For example, a masked language model can calculate probabilities for candidate word(s) to replace the underline in the following sentence:
The ____ in the hat came back.
The literature typically uses the string "MASK" instead of an underline. For example:
The "MASK" in the hat came back.
Most modern masked language models are bidirectional.
mean average precision at k (mAP@k)
The statistical mean of all average precision at k scores across a validation dataset. One use of mean average precision at k is to judge the quality of recommendations generated by a recommendation system.
Although the phrase "mean average" sounds redundant, the name of the metric is appropriate. After all, this metric finds the mean of multiple average precision at k values.
meta-learning
A subset of machine learning that discovers or improves a learning algorithm. A meta-learning system can also aim to train a model to quickly learn a new task from a small amount of data or from experience gained in previous tasks. Meta-learning algorithms generally try to achieve the following:
- Improve or learn hand-engineered features (such as an initializer or an optimizer).
- Be more data-efficient and compute-efficient.
- Improve generalization.
Meta-learning is related to few-shot learning.
mixture of experts
A scheme to increase neural network efficiency by using only a subset of its parameters (known as an expert) to process a given input token or example. A gating network routes each input token or example to the proper expert(s).
For details, see either of the following papers:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mixture-of-Experts with Expert Choice Routing
MMIT
Abbreviation for multimodal instruction-tuned.
modality
A high-level data category. For example, numbers, text, images, video, and audio are five different modalities.
model parallelism
A way of scaling training or inference that puts different parts of one model on different devices. Model parallelism enables models that are too big to fit on a single device.
To implement model parallelism, a system typically does the following:
- Shards (divides) the model into smaller parts.
- Distributes the training of those smaller parts across multiple processors. Each processor trains its own part of the model.
- Combines the results to create a single model.
Model parallelism slows training.
See also data parallelism.
MOE
Abbreviation for mixture of experts.
multi-head self-attention
An extension of self-attention that applies the self-attention mechanism multiple times for each position in the input sequence.
Transformers introduced multi-head self-attention.
multimodal instruction-tuned
An instruction-tuned model that can process input beyond text, such as images, video, and audio.
multimodal model
A model whose inputs, outputs, or both include more than one modality. For example, consider a model that takes both an image and a text caption (two modalities) as features, and outputs a score indicating how appropriate the text caption is for the image. So, this model's inputs are multimodal and the output is unimodal.
N
natural language processing
The field of teaching computers to process what a user said or typed using linguistic rules. Almost all modern natural language processing relies on machine learning.natural language understanding
A subset of natural language processing that determines the intentions of something said or typed. Natural language understanding can go beyond natural language processing to consider complex aspects of language like context, sarcasm, and sentiment.
N-gram
An ordered sequence of N words. For example, truly madly is a 2-gram. Because order is relevant, madly truly is a different 2-gram than truly madly.
| N | Name(s) for this kind of N-gram | Examples |
|---|---|---|
| 2 | bigram or 2-gram | to go, go to, eat lunch, eat dinner |
| 3 | trigram or 3-gram | ate too much, happily ever after, the bell tolls |
| 4 | 4-gram | walk in the park, dust in the wind, the boy ate lentils |
Many natural language understanding models rely on N-grams to predict the next word that the user will type or say. For example, suppose a user typed happily ever. An NLU model based on trigrams would likely predict that the user will next type the word after.
Contrast N-grams with bag of words, which are unordered sets of words.
See Large language models in Machine Learning Crash Course for more information.
NLP
Abbreviation for natural language processing.
NLU
Abbreviation for natural language understanding.
no one right answer (NORA)
A prompt having multiple appropriate responses. For example, the following prompt has no one right answer:
Tell me a joke about elephants.
Evaluating no-one-right-answer prompts can be challenging.
NORA
Abbreviation for no one right answer.
O
one-shot prompting
A prompt that contains one example demonstrating how the large language model should respond. For example, the following prompt contains one example showing a large language model how it should answer a query.
| Parts of one prompt | Notes |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| France: EUR | One example. |
| India: | The actual query. |
Compare and contrast one-shot prompting with the following terms:
P
parameter-efficient tuning
A set of techniques to fine-tune a large pre-trained language model (PLM) more efficiently than full fine-tuning. Parameter-efficient tuning typically fine-tunes far fewer parameters than full fine-tuning, yet generally produces a large language model that performs as well (or almost as well) as a large language model built from full fine-tuning.
Compare and contrast parameter-efficient tuning with:
Parameter-efficient tuning is also known as parameter-efficient fine-tuning.
pipelining
A form of model parallelism in which a model's processing is divided into consecutive stages and each stage is executed on a different device. While a stage is processing one batch, the preceding stage can work on the next batch.
See also staged training.
PLM
Abbreviation for pre-trained language model.
positional encoding
A technique to add information about the position of a token in a sequence to the token's embedding. Transformer models use positional encoding to better understand the relationship between different parts of the sequence.
A common implementation of positional encoding uses a sinusoidal function. (Specifically, the frequency and amplitude of the sinusoidal function are determined by the position of the token in the sequence.) This technique enables a Transformer model to learn to attend to different parts of the sequence based on their position.
post-trained model
Loosely-defined term that typically refers to a pre-trained model that has gone through some post-processing, such as one or more of the following:
precision at k (precision@k)
A metric for evaluating a ranked (ordered) list of items. Precision at k identifies the fraction of the first k items in that list that are "relevant." That is:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
The value of k must be less than or equal to the length of the returned list. Note that the length of the returned list is not part of the calculation.
Relevance is often subjective; even expert human evaluators often disagree on which items are relevant.
Compare with:
pre-trained model
Typically, a model that has already been trained. The term could also mean a previously trained embedding vector.
The term pre-trained language model usually refers to an already trained large language model.
pre-training
The initial training of a model on a large dataset. Some pre-trained models are clumsy giants and must typically be refined through additional training. For example, ML experts might pre-train a large language model on a vast text dataset, such as all the English pages in Wikipedia. Following pre-training, the resulting model might be further refined through any of the following techniques:
prompt
Any text entered as input to a large language model to condition the model to behave in a certain way. Prompts can be as short as a phrase or arbitrarily long (for example, the entire text of a novel). Prompts fall into multiple categories, including those shown in the following table:
| Prompt category | Example | Notes |
|---|---|---|
| Question | How fast can a pigeon fly? | |
| Instruction | Write a funny poem about arbitrage. | A prompt that asks the large language model to do something. |
| Example | Translate Markdown code to HTML. For example:
Markdown: * list item HTML: <ul> <li>list item</li> </ul> |
The first sentence in this example prompt is an instruction. The remainder of the prompt is the example. |
| Role | Explain why gradient descent is used in machine learning training to a PhD in Physics. | The first part of the sentence is an instruction; the phrase "to a PhD in Physics" is the role portion. |
| Partial input for the model to complete | The Prime Minister of the United Kingdom lives at | A partial input prompt can either end abruptly (as this example does) or end with an underscore. |
A generative AI model can respond to a prompt with text, code, images, embeddings, videos…almost anything.
prompt-based learning
A capability of certain models that enables them to adapt their behavior in response to arbitrary text input (prompts). In a typical prompt-based learning paradigm, a large language model responds to a prompt by generating text. For example, suppose a user enters the following prompt:
Summarize Newton's Third Law of Motion.
A model capable of prompt-based learning isn't specifically trained to answer the previous prompt. Rather, the model "knows" a lot of facts about physics, a lot about general language rules, and a lot about what constitutes generally useful answers. That knowledge is sufficient to provide a (hopefully) useful answer. Additional human feedback ("That answer was too complicated." or "What's a reaction?") enables some prompt-based learning systems to gradually improve the usefulness of their answers.
prompt design
Synonym for prompt engineering.
prompt engineering
The art of creating prompts that elicit the desired responses from a large language model. Humans perform prompt engineering. Writing well-structured prompts is an essential part of ensuring useful responses from a large language model. Prompt engineering depends on many factors, including:
- The dataset used to pre-train and possibly fine-tune the large language model.
- The temperature and other decoding parameters that the model uses to generate responses.
Prompt design is a synonym for prompt engineering.
See Introduction to prompt design for more details on writing helpful prompts.
prompt tuning
A parameter efficient tuning mechanism that learns a "prefix" that the system prepends to the actual prompt.
One variation of prompt tuning—sometimes called prefix tuning—is to prepend the prefix at every layer. In contrast, most prompt tuning only adds a prefix to the input layer.
R
recall at k (recall@k)
A metric for evaluating systems that output a ranked (ordered) list of items. Recall at k identifies the fraction of relevant items in the first k items in that list out of the total number of relevant items returned.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Contrast with precision at k.
reference text
An expert's response to a prompt. For example, given the following prompt:
Translate the question "What is your name?" from English to French.
An expert's response might be:
Comment vous appelez-vous?
Various metrics (such as ROUGE) measure the degree to which the reference text matches an ML model's generated text.
role prompting
An optional part of a prompt that identifies a target audience for a generative AI model's response. Without a role prompt, a large language model provides an answer that may or may not be useful for the person asking the questions. With a role prompt, a large language model can answer in a way that's more appropriate and more helpful for a specific target audience. For example, the role prompt portion of the following prompts are in boldface:
- Summarize this document for a PhD in economics.
- Describe how tides work for a ten-year old.
- Explain the 2008 financial crisis. Speak as you might to a young child, or a golden retriever.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
A family of metrics that evaluate automatic summarization and machine translation models. ROUGE metrics determine the degree to which a reference text overlaps an ML model's generated text. Each member of the ROUGE family measures overlap in a different way. Higher ROUGE scores indicate more similarity between the reference text and generated text than lower ROUGE scores.
Each ROUGE family member typically generates the following metrics:
- Precision
- Recall
- F1
For details and examples, see:
ROUGE-L
A member of the ROUGE family focused on the length of the longest common subsequence in the reference text and generated text. The following formulas calculate recall and precision for ROUGE-L:
You can then use F1 to roll up ROUGE-L recall and ROUGE-L precision into a single metric:
ROUGE-L ignores any newlines in the reference text and generated text, so the longest common subsequence could cross multiple sentences. When the reference text and generated text involve multiple sentences, a variation of ROUGE-L called ROUGE-Lsum is generally a better metric. ROUGE-Lsum determines the longest common subsequence for each sentence in a passage and then calculates the mean of those longest common subsequences.
ROUGE-N
A set of metrics within the ROUGE family that compares the shared N-grams of a certain size in the reference text and generated text. For example:
- ROUGE-1 measures the number of shared tokens in the reference text and generated text.
- ROUGE-2 measures the number of shared bigrams (2-grams) in the reference text and generated text.
- ROUGE-3 measures the number of shared trigrams (3-grams) in the reference text and generated text.
You can use the following formulas to calculate ROUGE-N recall and ROUGE-N precision for any member of the ROUGE-N family:
You can then use F1 to roll up ROUGE-N recall and ROUGE-N precision into a single metric:
ROUGE-S
A forgiving form of ROUGE-N that enables skip-gram matching. That is, ROUGE-N only counts N-grams that match exactly, but ROUGE-S also counts N-grams separated by one or more words. For example, consider the following:
- reference text: White clouds
- generated text: White billowing clouds
When calculating ROUGE-N, the 2-gram, White clouds doesn't match White billowing clouds. However, when calculating ROUGE-S, White clouds does match White billowing clouds.
S
self-attention (also called self-attention layer)
A neural network layer that transforms a sequence of embeddings (for example, token embeddings) into another sequence of embeddings. Each embedding in the output sequence is constructed by integrating information from the elements of the input sequence through an attention mechanism.
The self part of self-attention refers to the sequence attending to itself rather than to some other context. Self-attention is one of the main building blocks for Transformers and uses dictionary lookup terminology, such as "query", "key", and "value".
A self-attention layer starts with a sequence of input representations, one for each word. The input representation for a word can be a simple embedding. For each word in an input sequence, the network scores the relevance of the word to every element in the whole sequence of words. The relevance scores determine how much the word's final representation incorporates the representations of other words.
For example, consider the following sentence:
The animal didn't cross the street because it was too tired.
The following illustration (from Transformer: A Novel Neural Network Architecture for Language Understanding) shows a self-attention layer's attention pattern for the pronoun it, with the darkness of each line indicating how much each word contributes to the representation:
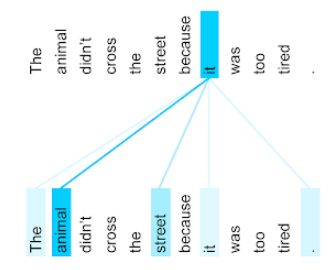
The self-attention layer highlights words that are relevant to "it". In this case, the attention layer has learned to highlight words that it might refer to, assigning the highest weight to animal.
For a sequence of n tokens, self-attention transforms a sequence of embeddings n separate times, once at each position in the sequence.
Refer also to attention and multi-head self-attention.
sentiment analysis
Using statistical or machine learning algorithms to determine a group's overall attitude—positive or negative—toward a service, product, organization, or topic. For example, using natural language understanding, an algorithm could perform sentiment analysis on the textual feedback from a university course to determine the degree to which students generally liked or disliked the course.
See the Text classification guide for more information.
sequence-to-sequence task
A task that converts an input sequence of tokens to an output sequence of tokens. For example, two popular kinds of sequence-to-sequence tasks are:
- Translators:
- Sample input sequence: "I love you."
- Sample output sequence: "Je t'aime."
- Question answering:
- Sample input sequence: "Do I need my car in New York City?"
- Sample output sequence: "No. Keep your car at home."
skip-gram
An n-gram which may omit (or "skip") words from the original context, meaning the N words might not have been originally adjacent. More precisely, a "k-skip-n-gram" is an n-gram for which up to k words may have been skipped.
For example, "the quick brown fox" has the following possible 2-grams:
- "the quick"
- "quick brown"
- "brown fox"
A "1-skip-2-gram" is a pair of words that have at most 1 word between them. Therefore, "the quick brown fox" has the following 1-skip 2-grams:
- "the brown"
- "quick fox"
In addition, all the 2-grams are also 1-skip-2-grams, since fewer than one word may be skipped.
Skip-grams are useful for understanding more of a word's surrounding context. In the example, "fox" was directly associated with "quick" in the set of 1-skip-2-grams, but not in the set of 2-grams.
Skip-grams help train word embedding models.
soft prompt tuning
A technique for tuning a large language model for a particular task, without resource intensive fine-tuning. Instead of retraining all the weights in the model, soft prompt tuning automatically adjusts a prompt to achieve the same goal.
Given a textual prompt, soft prompt tuning typically appends additional token embeddings to the prompt and uses backpropagation to optimize the input.
A "hard" prompt contains actual tokens instead of token embeddings.
sparse feature
A feature whose values are predominately zero or empty. For example, a feature containing a single 1 value and a million 0 values is sparse. In contrast, a dense feature has values that are predominantly not zero or empty.
In machine learning, a surprising number of features are sparse features. Categorical features are usually sparse features. For example, of the 300 possible tree species in a forest, a single example might identify just a maple tree. Or, of the millions of possible videos in a video library, a single example might identify just "Casablanca."
In a model, you typically represent sparse features with one-hot encoding. If the one-hot encoding is big, you might put an embedding layer on top of the one-hot encoding for greater efficiency.
sparse representation
Storing only the position(s) of nonzero elements in a sparse feature.
For example, suppose a categorical feature named species identifies the 36
tree species in a particular forest. Further assume that each
example identifies only a single species.
You could use a one-hot vector to represent the tree species in each example.
A one-hot vector would contain a single 1 (to represent
the particular tree species in that example) and 35 0s (to represent the
35 tree species not in that example). So, the one-hot representation
of maple might look something like the following:

Alternatively, sparse representation would simply identify the position of the
particular species. If maple is at position 24, then the sparse representation
of maple would simply be:
24
Notice that the sparse representation is much more compact than the one-hot representation.
Click the icon for a slightly more complex example.
Suppose each example in your model must represent the words—but not the order of those words—in an English sentence. English consists of about 170,000 words, so English is a categorical feature with about 170,000 elements. Most English sentences use an extremely tiny fraction of those 170,000 words, so the set of words in a single example is almost certainly going to be sparse data.
Consider the following sentence:
My dog is a great dog
You could use a variant of one-hot vector to represent the words in this sentence. In this variant, multiple cells in the vector can contain a nonzero value. Furthermore, in this variant, a cell can contain an integer other than one. Although the words "my", "is", "a", and "great" appear only once in the sentence, the word "dog" appears twice. Using this variant of one-hot vectors to represent the words in this sentence yields the following 170,000-element vector:

A sparse representation of the same sentence would simply be:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
See Working with categorical data in Machine Learning Crash Course for more information.
staged training
A tactic of training a model in a sequence of discrete stages. The goal can be either to speed up the training process, or to achieve better model quality.
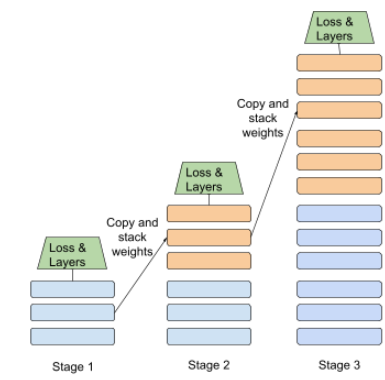
An illustration of the progressive stacking approach is shown below:
- Stage 1 contains 3 hidden layers, stage 2 contains 6 hidden layers, and stage 3 contains 12 hidden layers.
- Stage 2 begins training with the weights learned in the 3 hidden layers of Stage 1. Stage 3 begins training with the weights learned in the 6 hidden layers of Stage 2.
See also pipelining.
subword token
In language models, a token that is a substring of a word, which may be the entire word.
For example, a word like "itemize" might be broken up into the pieces "item" (a root word) and "ize" (a suffix), each of which is represented by its own token. Splitting uncommon words into such pieces, called subwords, allows language models to operate on the word's more common constituent parts, such as prefixes and suffixes.
Conversely, common words like "going" might not be broken up and might be represented by a single token.
T
T5
A text-to-text transfer learning model introduced by Google AI in 2020. T5 is an encoder-decoder model, based on the Transformer architecture, trained on an extremely large dataset. It is effective at a variety of natural language processing tasks, such as generating text, translating languages, and answering questions in a conversational manner.
T5 gets its name from the five T's in "Text-to-Text Transfer Transformer."
T5X
An open-source, machine learning framework designed to build and train large-scale natural language processing (NLP) models. T5 is implemented on the T5X codebase (which is built on JAX and Flax).
temperature
A hyperparameter that controls the degree of randomness of a model's output. Higher temperatures result in more random output, while lower temperatures result in less random output.
Choosing the best temperature depends on the specific application and the preferred properties of the model's output. For example, you would probably raise the temperature when creating an application that generates creative output. Conversely, you would probably lower the temperature when building a model that classifies images or text in order to improve the model's accuracy and consistency.
Temperature is often used with softmax.
text span
The array index span associated with a specific subsection of a text string.
For example, the word good in the Python string s="Be good now" occupies
the text span from 3 to 6.
token
In a language model, the atomic unit that the model is training on and making predictions on. A token is typically one of the following:
- a word—for example, the phrase "dogs like cats" consists of three word tokens: "dogs", "like", and "cats".
- a character—for example, the phrase "bike fish" consists of nine character tokens. (Note that the blank space counts as one of the tokens.)
- subwords—in which a single word can be a single token or multiple tokens. A subword consists of a root word, a prefix, or a suffix. For example, a language model that uses subwords as tokens might view the word "dogs" as two tokens (the root word "dog" and the plural suffix "s"). That same language model might view the single word "taller" as two subwords (the root word "tall" and the suffix "er").
In domains outside of language models, tokens can represent other kinds of atomic units. For example, in computer vision, a token might be a subset of an image.
See Large language models in Machine Learning Crash Course for more information.
top-k accuracy
The percentage of times that a "target label" appears within the first k positions of generated lists. The lists could be personalized recommendations or a list of items ordered by softmax.
Top-k accuracy is also known as accuracy at k.
toxicity
The degree to which content is abusive, threatening, or offensive. Many machine learning models can identify and measure toxicity. Most of these models identify toxicity along multiple parameters, such as the level of abusive language and the level of threatening language.
Transformer
A neural network architecture developed at Google that relies on self-attention mechanisms to transform a sequence of input embeddings into a sequence of output embeddings without relying on convolutions or recurrent neural networks. A Transformer can be viewed as a stack of self-attention layers.
A Transformer can include any of the following:
An encoder transforms a sequence of embeddings into a new sequence of the same length. An encoder includes N identical layers, each of which contains two sub-layers. These two sub-layers are applied at each position of the input embedding sequence, transforming each element of the sequence into a new embedding. The first encoder sub-layer aggregates information from across the input sequence. The second encoder sub-layer transforms the aggregated information into an output embedding.
A decoder transforms a sequence of input embeddings into a sequence of output embeddings, possibly with a different length. A decoder also includes N identical layers with three sub-layers, two of which are similar to the encoder sub-layers. The third decoder sub-layer takes the output of the encoder and applies the self-attention mechanism to gather information from it.
The blog post Transformer: A Novel Neural Network Architecture for Language Understanding provides a good introduction to Transformers.
See LLMs: What's a large language model? in Machine Learning Crash Course for more information.
trigram
An N-gram in which N=3.
U
unidirectional
A system that only evaluates the text that precedes a target section of text. In contrast, a bidirectional system evaluates both the text that precedes and follows a target section of text. See bidirectional for more details.
unidirectional language model
A language model that bases its probabilities only on the tokens appearing before, not after, the target token(s). Contrast with bidirectional language model.
V
variational autoencoder (VAE)
A type of autoencoder that leverages the discrepancy between inputs and outputs to generate modified versions of the inputs. Variational autoencoders are useful for generative AI.
VAEs are based on variational inference: a technique for estimating the parameters of a probability model.
W
word embedding
Representing each word in a word set within an embedding vector; that is, representing each word as a vector of floating-point values between 0.0 and 1.0. Words with similar meanings have more-similar representations than words with different meanings. For example, carrots, celery, and cucumbers would all have relatively similar representations, which would be very different from the representations of airplane, sunglasses, and toothpaste.
Z
zero-shot prompting
A prompt that does not provide an example of how you want the large language model to respond. For example:
| Parts of one prompt | Notes |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| India: | The actual query. |
The large language model might respond with any of the following:
- Rupee
- INR
- ₹
- Indian rupee
- The rupee
- The Indian rupee
All of the answers are correct, though you might prefer a particular format.
Compare and contrast zero-shot prompting with the following terms: