Esta página contiene los términos del glosario de Evaluación de lenguaje. Para ver todos los términos del glosario, haz clic aquí.
A
Attention,
Es un mecanismo que se usa en una red neuronal que indica la importancia de una palabra o parte de una palabra en particular. La atención comprime la cantidad de información que un modelo necesita para predecir el siguiente token o palabra. Un mecanismo de atención típico puede consistir en una suma ponderada sobre un conjunto de entradas, en la que otra parte de la red neuronal calcula el peso de cada entrada.
Consulta también la atención automática y la atención automática multidireccional, que son los componentes básicos de los transformadores.
Consulta LLM: ¿Qué es un modelo de lenguaje grande? en el Curso intensivo de aprendizaje automático para obtener más información sobre la autoatención.
codificador automático
Un sistema que aprende a extraer la información más importante de la entrada. Los autoencoders son una combinación de un codificador y un decodificador. Los autoencoders se basan en el siguiente proceso de dos pasos:
- El codificador asigna la entrada a un formato (por lo general) con pérdida de menor dimensión (intermedia).
- El decodificador crea una versión con pérdida de la entrada original asignando el formato de menor dimensión al formato de entrada original de mayor dimensión.
Los autoencoders se entrenan de extremo a extremo haciendo que el decodificador intente reconstruir la entrada original del formato intermedio del codificador lo más cerca posible. Debido a que el formato intermedio es más pequeño (de menor dimensión) que el formato original, el autocodificador se ve obligado a aprender qué información de la entrada es esencial, y el resultado no será perfectamente idéntico a la entrada.
Por ejemplo:
- Si los datos de entrada son gráficos, la copia no exacta sería similar al gráfico original, pero algo modificado. Quizás la copia no exacta quite el ruido del gráfico original o complete algunos píxeles faltantes.
- Si los datos de entrada son texto, un autocodificador generaría texto nuevo que imita (pero no es idéntico) al texto original.
Consulta también codificadores automáticos variacionales.
evaluación automática
Usar software para juzgar la calidad del resultado de un modelo
Cuando el resultado del modelo es relativamente sencillo, una secuencia de comandos o un programa puede comparar el resultado del modelo con una respuesta ideal. A veces, este tipo de evaluación automática se denomina evaluación programática. Las métricas como ROUGE o BLEU suelen ser útiles para la evaluación programática.
Cuando el resultado del modelo es complejo o no tiene una respuesta correcta, a veces un programa de AA independiente llamado calificador automático realiza la evaluación automática.
Compara esto con la evaluación humana.
evaluación del evaluador automático
Un mecanismo híbrido para juzgar la calidad del resultado de un modelo de IA generativa que combina la evaluación humana con la evaluación automática. Un evaluador automático es un modelo de AA entrenado con datos creados por la evaluación humana. Idealmente, un autor aprende a imitar a un evaluador humano.Hay autores calificadores precompilados disponibles, pero los mejores están ajustados específicamente a la tarea que evalúas.
modelo autorregresivo
Un modelo que infiere una predicción en función de sus propias predicciones anteriores. Por ejemplo, los modelos de lenguaje autoregresivo predicen el siguiente token según los tokens pronosticados anteriormente. Todos los modelos de lenguaje extenso basados en Transformer son de regresión automática.
Por el contrario, los modelos de imágenes basados en GAN suelen no ser autorregresivos, ya que generan una imagen en un solo pase hacia adelante y no de forma iterativa en pasos. Sin embargo, algunos modelos de generación de imágenes son autorregresivos porque generan una imagen en pasos.
precisión promedio en k
Es una métrica para resumir el rendimiento de un modelo en una sola instrucción que genera resultados clasificados, como una lista numerada de recomendaciones de libros. La precisión promedio en k es el promedio de los valores de precisión en k para cada resultado relevante. Por lo tanto, la fórmula de la precisión promedio en k es la siguiente:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
Donde:
- \(n\) es la cantidad de elementos relevantes de la lista.
Compara esto con la recuperación en k.
B
bolsa de palabras
Representación de las palabras de una frase o pasaje, sin importar el orden. Por ejemplo, una bolsa de palabras representa las tres frases siguientes de forma idéntica:
- el perro salta
- salta el perro
- perro salta el
Cada palabra se asigna a un índice en un vector disperso, en el que el vector tiene un índice para cada palabra del vocabulario. Por ejemplo, la frase el perro salta se asigna a un vector de características con valores distintos de cero en los tres índices correspondientes a las palabras el, perro y salta. El valor distinto de cero puede ser cualquiera de los siguientes:
- Un 1 para indicar la presencia de una palabra
- Es el recuento de la cantidad de veces que una palabra aparece en la bolsa. (por ejemplo, si la frase fuera el perro marrón es un perro con pelaje marrón, entonces tanto marrón como perro se representarían con un 2, mientras que las demás palabras con un 1)
- Algún otro valor, como el logaritmo de la cantidad de veces que una palabra aparece en la bolsa
BERT (Representaciones de codificador bidireccional de transformadores)
Una arquitectura de modelo para la representación de texto. Un modelo BERT entrenado puede actuar como parte de un modelo más grande para la clasificación de texto o para otras tareas de AA.
BERT tiene las siguientes características:
- Usa la arquitectura de Transformer y, por lo tanto, se basa en la autoatención.
- Usa la parte del codificador del transformador. La tarea del codificador es producir buenas representaciones de texto, en lugar de realizar una tarea específica, como la clasificación.
- Es bidireccional.
- Usa enmascaramiento para el entrenamiento no supervisado.
Entre las variantes de BERT, se incluyen las siguientes:
Consulta Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing para obtener una descripción general de BERT.
bidireccional
Es un término que se usa para describir un sistema que evalúa el texto que precede y sigue a una sección de texto objetivo. Por el contrario, un sistema unidireccional solo evalúa el texto que precede a una sección de texto objetivo.
Por ejemplo, considera un modelo de lenguaje con enmascaramiento que debe determinar las probabilidades de la palabra o las palabras que representan la línea debajo de la siguiente pregunta:
¿Qué tal _____?
Un modelo de lenguaje unidireccional tendría que basar sus probabilidades solo en el contexto que proporcionan las palabras "¿Qué", "es" y "el". En cambio, un modelo de lenguaje bidireccional también podría obtener contexto de "con" y "tú", lo que podría ayudar al modelo a generar mejores predicciones.
modelo de lenguaje bidireccional
Un modelo de lenguaje que determina la probabilidad de que un token determinado esté presente en una ubicación determinada en un extracto de texto según el texto anterior y posterior.
bigrama
Un n-grama en el que n=2.
BLEU (Bilingual Evaluation Understudy)
Es una métrica entre 0.0 y 1.0 para evaluar las traducciones automáticas, por ejemplo, del español al japonés.
Para calcular una puntuación, BLEU suele comparar la traducción de un modelo de AA (texto generado) con la traducción de un experto humano (texto de referencia). El grado en que coinciden los n-gramas en el texto generado y el texto de referencia determina la puntuación BLEU.
El artículo original sobre esta métrica es BLEU: a Method for Automatic Evaluation of Machine Translation.
Consulta también BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
Es una métrica para evaluar las traducciones automáticas de un idioma a otro, en particular, de y hacia el inglés.
En el caso de las traducciones de y hacia inglés, BLEURT se alinea más con las calificaciones humanas que BLEU. A diferencia de BLEU, BLEURT enfatiza las similitudes semánticas (de significado) y puede adaptarse al parafraseo.
BLEURT se basa en un modelo de lenguaje grande previamente entrenado (BERT, para ser exactos) que luego se ajusta en el texto de traductores humanos.
El artículo original sobre esta métrica es BLEURT: Learning Robust Metrics for Text Generation.
C
modelo de lenguaje causal
Sinónimo de modelo de lenguaje unidireccional.
Consulta modelo de lenguaje bidireccional para comparar diferentes enfoques de direccionalidad en el modelado de lenguaje.
cadena de pensamientos
Una técnica de ingeniería de instrucciones que fomenta que un modelo de lenguaje grande (LLM) explique su razonamiento paso a paso. Por ejemplo, considera la siguiente consigna y presta especial atención a la segunda oración:
¿Cuántas fuerzas g experimentaría un conductor en un automóvil que pasa de 0 a 96 kilómetros por hora en 7 segundos? En la respuesta, muestra todos los cálculos relevantes.
Es probable que la respuesta del LLM haga lo siguiente:
- Muestra una secuencia de fórmulas de física y, luego, ingresa los valores 0, 60 y 7 en los lugares adecuados.
- Explica por qué eligió esas fórmulas y qué significan las diferentes variables.
Las instrucciones de cadena de pensamientos obligan al LLM a realizar todos los cálculos, lo que podría generar una respuesta más correcta. Además, las indicaciones de cadena de pensamiento le permiten al usuario examinar los pasos del LLM para determinar si la respuesta tiene sentido o no.
chatear
El contenido de un diálogo de ida y vuelta con un sistema de AA, por lo general, un modelo de lenguaje extenso. La interacción anterior en un chat (lo que escribiste y cómo respondió el modelo de lenguaje extenso) se convierte en el contexto para las partes posteriores del chat.
Un chatbot es una aplicación de un modelo de lenguaje extenso.
confabulación
Sinónimo de alucinación.
La confabulación es probablemente un término más técnicamente preciso que la alucinación. Sin embargo, la alucinación se hizo popular primero.
Análisis de distritos electorales
Consiste en dividir una oración en estructuras gramaticales más pequeñas ("constituyentes"). Una parte posterior del sistema de AA, como un modelo de comprensión del lenguaje natural, puede analizar los constituyentes con mayor facilidad que la oración original. Por ejemplo, considera la siguiente oración:
Mi amigo adoptó dos gatos.
Un analizador de constituyentes puede dividir esta oración en los siguientes dos constituyentes:
- Mi amigo es una frase nominal.
- adoptó dos gatos es una frase verbal.
Estos constituyentes se pueden subdividir en constituyentes más pequeños. Por ejemplo, la frase verbal
adoptó dos gatos
se puede subdividir en lo siguiente:
- adoptado es un verbo.
- dos gatos es otra frase nominal.
incorporación de lenguaje contextualizado
Un enriquecimiento que se acerca a “comprender” palabras y frases de la misma manera que lo hacen los hablantes humanos nativos. Las incorporaciones de lenguaje contextualizadas pueden comprender la sintaxis, la semántica y el contexto complejos.
Por ejemplo, considera las incorporaciones de la palabra en inglés cow. Las incorporaciones más antiguas, como word2vec, pueden representar palabras en inglés de modo que la distancia en el espacio de incorporación de cow a bull sea similar a la distancia de ewe (oveja hembra) a ram (oveja macho) o de female a male. Las incorporaciones de lenguaje contextualizadas pueden ir un paso más allá y reconocer que, a veces, quienes hablan inglés usan la palabra cow para referirse a una vaca o un toro.
ventana de contexto
Es la cantidad de tokens que un modelo puede procesar en una sugerencia determinada. Cuanto más grande sea la ventana de contexto, más información puede usar el modelo para proporcionar respuestas coherentes y coherentes a la instrucción.
crash blossom
Oración o frase con un significado ambiguo. Los crash blossoms presentan un problema importante para la comprensión del lenguaje natural. Por ejemplo, el titular La cinta roja que sostiene un rascacielos es un crash blossom porque un modelo CLN podría interpretar el titular en sentido literal o figurado.
D
decodificador
En general, cualquier sistema de AA que convierte de una representación procesada, densa o interna a una representación más sin procesar, dispersa o externa.
Los decodificadores suelen ser un componente de un modelo más grande, en el que a menudo se vinculan con un codificador.
En las tareas de secuencia a secuencia, un decodificador comienza con el estado interno que genera el codificador para predecir la siguiente secuencia.
Consulta Transformer para obtener la definición de un decodificador dentro de la arquitectura de Transformer.
Consulta Modelos de lenguaje extenso en el Curso intensivo de aprendizaje automático para obtener más información.
reducción de ruido
Un enfoque común del aprendizaje autosupervisado en el que se cumple lo siguiente:
La reducción de ruido permite aprender de ejemplos sin etiqueta. El conjunto de datos original sirve como objetivo o etiqueta, y los datos con ruido como entrada.
Algunos modelos de lenguaje enmascarado usan la reducción de ruido de la siguiente manera:
- Se agrega ruido artificialmente a una oración sin etiqueta enmascarando algunos de los tokens.
- El modelo intenta predecir los tokens originales.
instrucciones directas
Sinónimo de instrucción sin ejemplos.
E
editar distancia
Es una medición de la similitud entre dos cadenas de texto. En el aprendizaje automático, la distancia de edición es útil por los siguientes motivos:
- La distancia de edición es fácil de calcular.
- La distancia de edición puede comparar dos cadenas que se sabe que son similares entre sí.
- La distancia de edición puede determinar el grado en que diferentes cadenas son similares a una cadena determinada.
Existen varias definiciones de distancia de edición, cada una de las cuales usa diferentes operaciones de cadenas. Consulta Distancia de Levenshtein para ver un ejemplo.
capa de incorporación
Una capa oculta especial que se entrena en un atributo categórico de alta dimensión para aprender gradualmente un vector de incorporación de dimensión inferior. Una capa de incorporación permite que una red neuronal se entrene de manera mucho más eficiente que solo en el atributo categórico de alta dimensión.
Por ejemplo, la Tierra actualmente alberga alrededor de 73,000 especies de árboles. Supongamos que la especie de árbol es un atributo en tu modelo, por lo que la capa de entrada de tu modelo incluye un vector de un solo 1 de 73,000 elementos de longitud.
Por ejemplo, quizás baobab se representaría de la siguiente manera:

Un array de 73,000 elementos es muy largo. Si no agregas una capa de incorporación al modelo, el entrenamiento llevará mucho tiempo debido a que se multiplicarán 72,999 ceros. Quizás elijas que la capa de incorporación tenga 12 dimensiones. En consecuencia, la capa de incorporación aprenderá gradualmente un nuevo vector de incorporación para cada especie de árbol.
En algunas situaciones, el hash es una alternativa razonable a una capa de incorporación.
Consulta Inserciones en el Curso intensivo de aprendizaje automático para obtener más información.
espacio de embedding
Espacio de vector de d dimensiones al que se mapean atributos de un espacio de vector de más dimensiones. Idealmente, el espacio de incorporaciones posee una estructura que produce resultados matemáticos significativos; por ejemplo, en un espacio de incorporaciones ideal, la adición y sustracción de incorporaciones puede resolver tareas de similitud de palabras.
El producto escalar de dos incorporaciones es la medida de su similitud.
vector de incorporación
En términos generales, es un array de números de punto flotante tomados de cualquier capa oculta que describe las entradas de esa capa oculta. A menudo, un vector de incorporación es el array de números de punto flotante entrenado en una capa de incorporación. Por ejemplo, supongamos que una capa de incorporación debe aprender un vector de incorporación para cada una de las 73,000 especies de árboles de la Tierra. Quizás el siguiente array sea el vector de incorporación de un árbol de baobab:

Un vector de incorporación no es un conjunto de números aleatorios. Una capa de incorporación determina estos valores a través del entrenamiento, de manera similar a la forma en que una red neuronal aprende otros pesos durante el entrenamiento. Cada elemento del array es una calificación según alguna característica de una especie de árbol. ¿Qué elemento representa la característica de qué especie de árbol? Eso es muy difícil para que los humanos lo determinen.
La parte matemáticamente notable de un vector de incorporación es que los elementos similares tienen conjuntos similares de números de punto flotante. Por ejemplo, las especies de árboles similares tienen un conjunto más similar de números de punto flotante que las especies de árboles disímiles. Los robles rojos y las secuoyas son especies de árboles relacionadas, por lo que tendrán un conjunto más similar de números de punto flotante que los robles rojos y las palmeras de coco. Los números en el vector de incorporación cambiarán cada vez que vuelvas a entrenar el modelo, incluso si lo vuelves a entrenar con una entrada idéntica.
codificador
En general, cualquier sistema de AA que convierte una representación sin procesar, dispersa o externa en una representación más procesada, más densa o más interna.
Los codificadores suelen ser un componente de un modelo más grande, en el que a menudo se combinan con un decodificador. Algunos transformadores vinculan codificadores con decodificadores, aunque otros solo usan el codificador o solo el decodificador.
Algunos sistemas usan la salida del codificador como entrada de una red de clasificación o de regresión.
En las tareas de secuencia a secuencia, un codificador toma una secuencia de entrada y muestra un estado interno (un vector). Luego, el decodificador usa ese estado interno para predecir la siguiente secuencia.
Consulta Transformer para obtener la definición de un codificador en la arquitectura de Transformer.
Consulta LLM: ¿Qué es un modelo de lenguaje grande? en el Curso intensivo de aprendizaje automático para obtener más información.
evals
Se usa principalmente como abreviatura de evaluaciones de LLM. En términos más generales, evals es una abreviatura de cualquier forma de evaluación.
sin conexión
Es el proceso de medir la calidad de un modelo o comparar diferentes modelos entre sí.
Para evaluar un modelo de aprendizaje automático supervisado, por lo general, se lo compara con un conjunto de validación y un conjunto de prueba. Evaluar un LLM suele implicar evaluaciones de calidad y seguridad más amplias.
F
instrucción con varios ejemplos
Un prompt que contiene más de un ejemplo (algunos) que demuestra cómo debe responder el modelo de lenguaje extenso. Por ejemplo, la siguiente instrucción extensa contiene dos ejemplos que muestran a un modelo de lenguaje extenso cómo responder una consulta.
| Partes de una instrucción | Notas |
|---|---|
| ¿Cuál es la moneda oficial del país especificado? | La pregunta que quieres que responda el LLM. |
| Francia: EUR | Un ejemplo. |
| Reino Unido: GBP | Otro ejemplo. |
| India: | Es la consulta real. |
Por lo general, las instrucciones con varios ejemplos producen resultados más deseables que las instrucciones sin ejemplos y las instrucciones con un solo ejemplo. Sin embargo, las instrucciones con varios ejemplos requieren una instrucción más larga.
La instrucción con ejemplos limitados es una forma de aprendizaje en pocos intentos que se aplica al aprendizaje basado en instrucciones.
Consulta Ingeniería de instrucciones en el Curso intensivo de aprendizaje automático para obtener más información.
Violín tradicional
Una biblioteca de configuración que prioriza Python y establece los valores de las funciones y las clases sin código ni infraestructura invasivos. En el caso de Pax y otras bases de código de AA, estas funciones y clases representan modelos y hiperparámetros de entrenamiento.
Fiddle asume que las bases de código de aprendizaje automático suelen dividirse en lo siguiente:
- Código de la biblioteca, que define las capas y los optimizadores
- Código de "unión" del conjunto de datos, que llama a las bibliotecas y conecta todo.
Fiddle captura la estructura de llamadas del código de unión en una forma no evaluada y mutable.
ajuste
Un segundo pase de entrenamiento específico para la tarea que se realiza en un modelo previamente entrenado para definir mejor sus parámetros para un caso de uso específico. Por ejemplo, la secuencia de entrenamiento completa de algunos modelos grandes de lenguaje es la siguiente:
- Entrenamiento previo: Entrena un modelo de lenguaje grande en un vasto conjunto de datos general, como todas las páginas de Wikipedia en inglés.
- Ajuste fino: Entrena el modelo previamente entrenado para que realice una tarea específica, como responder consultas médicas. El perfeccionamiento suele implicar cientos o miles de ejemplos enfocados en la tarea específica.
A modo de ejemplo, la secuencia de entrenamiento completa para un modelo de imagen grande es la siguiente:
- Entrenamiento previo: Entrena un modelo de imagen grande en un vasto conjunto de datos de imágenes generales, como todas las imágenes de Wikimedia Commons.
- Ajuste fino: Entrena el modelo previamente entrenado para que realice una tarea específica, como generar imágenes de orcas.
El perfeccionamiento puede implicar cualquier combinación de las siguientes estrategias:
- Modificar todos los parámetros existentes del modelo previamente entrenado A veces, esto se denomina ajuste fino completo.
- Modificar solo algunos de los parámetros existentes del modelo previamente entrenado (por lo general, las capas más cercanas a la capa de salida) y mantener sin cambios otros parámetros existentes (por lo general, las capas más cercanas a la capa de entrada) Consulta ajuste eficiente de parámetros.
- Agregar más capas, por lo general, sobre las capas existentes más cercanas a la capa de salida
El ajuste fino es una forma de aprendizaje por transferencia. Por lo tanto, el ajuste fino puede usar una función de pérdida o un tipo de modelo diferente de los que se usan para entrenar el modelo con entrenamiento previo. Por ejemplo, podrías ajustar un modelo de imagen grande previamente entrenado para producir un modelo de regresión que muestre la cantidad de aves en una imagen de entrada.
Compara y contrasta el perfeccionamiento con los siguientes términos:
Consulta Ajuste fino en el Curso intensivo de aprendizaje automático para obtener más información.
Lino
Una biblioteca de código abierto de alto rendimiento para el aprendizaje profundo compilada en JAX. Flax proporciona funciones para entrenar redes neuronales, así como métodos para evaluar su rendimiento.
Flaxformer
Una biblioteca de Transformer de código abierto compilada en Flax, diseñada principalmente para el procesamiento de lenguaje natural y la investigación multimodal.
G
Gemini
El ecosistema que comprende la IA más avanzada de Google. Entre los elementos de este ecosistema, se incluyen los siguientes:
- Varios modelos de Gemini
- La interfaz de conversación interactiva de un modelo de Gemini. Los usuarios escriben instrucciones y Gemini responde a ellas.
- Varias APIs de Gemini
- Varios productos empresariales basados en modelos de Gemini, por ejemplo, Gemini para Google Cloud.
Modelos de Gemini
Los modelos multimodales de última generación de Google basados en Transformers Los modelos de Gemini están diseñados específicamente para integrarse con agentes.
Los usuarios pueden interactuar con los modelos de Gemini de diferentes maneras, por ejemplo, a través de una interfaz de diálogo interactiva y de SDKs.
texto generado
En general, el texto que genera un modelo de AA. Cuando se evalúan modelos de lenguaje extensos, algunas métricas comparan el texto generado con el texto de referencia. Por ejemplo, supongamos que estás tratando de determinar la eficacia con la que un modelo de AA traduce del francés al holandés. En este caso, ocurre lo siguiente:
- El texto generado es la traducción al holandés que genera el modelo de AA.
- El texto de referencia es la traducción al holandés que crea un traductor humano (o un software).
Ten en cuenta que algunas estrategias de evaluación no incluyen texto de referencia.
IA generativa
Es un campo transformador emergente sin definición formal. Dicho esto, la mayoría de los expertos coinciden en que los modelos de IA generativa pueden crear ("generar") contenido que cumpla con las siguientes características:
- emergencia compleja,
- coherente
- original
Por ejemplo, un modelo de IA generativa puede crear ensayos o imágenes sofisticados.
Algunas tecnologías anteriores, como las LSTM y las RNN, también pueden generar contenido original y coherente. Algunos expertos consideran que estas tecnologías anteriores son IA generativa, mientras que otros creen que la verdadera IA generativa requiere resultados más complejos que los que pueden producir esas tecnologías anteriores.
Compara esto con el AA predictivo.
respuesta dorada
Una respuesta que se sabe que es buena. Por ejemplo, dada la siguiente sugerencia:
2 + 2
La respuesta ideal es la siguiente:
4
GPT (transformador generativo previamente entrenado)
Es una familia de modelos de lenguaje grande basados en Transformer que desarrolló OpenAI.
Las variantes de GPT se pueden aplicar a varias modalidades, como las siguientes:
- generación de imágenes (por ejemplo, ImageGPT)
- generación de texto a imagen (por ejemplo, DALL-E).
H
alucinación
La producción de resultados que parecen plausibles, pero que son incorrectos, por parte de un modelo de IA generativa que pretende hacer una afirmación sobre el mundo real. Por ejemplo, un modelo de IA generativa que afirme que Barack Obama murió en 1865 está hallucinando.
evaluación humana
Es un proceso en el que personas juzgan la calidad del resultado de un modelo de AA. Por ejemplo, hacer que personas bilingües juzguen la calidad de un modelo de traducción de AA. La evaluación humana es particularmente útil para juzgar modelos que no tienen una respuesta correcta.
Compara esto con la evaluación automática y la evaluación del autocalificador.
I
aprendizaje en contexto
Es un sinónimo de instrucciones con ejemplos limitados.
L
LaMDA (Modelo de lenguaje para aplicaciones de diálogo)
Un modelo de lenguaje extenso basado en Transformer desarrollado por Google y entrenado en un conjunto de datos de diálogo grande que puede generar respuestas de conversación realistas.
LaMDA: nuestra innovadora tecnología conversacional proporciona una descripción general.
modelo de lenguaje
Un modelo que estima la probabilidad de que un token o una secuencia de tokens ocurra en una secuencia más larga de tokens.
modelo de lenguaje extenso
Como mínimo, un modelo de lenguaje que tenga una cantidad muy alta de parámetros. De manera más informal, cualquier modelo de lenguaje basado en Transformer, como Gemini o GPT.
espacio latente
Sinónimo de espacio de incorporación.
Distancia de Levenshtein
Es una métrica de distancia de edición que calcula la menor cantidad de operaciones de eliminación, inserción y sustitución necesarias para cambiar una palabra por otra. Por ejemplo, la distancia de Levenshtein entre las palabras “corazón” y “dardos” es tres porque las siguientes tres ediciones son los cambios más mínimos para convertir una palabra en la otra:
- corazón → deart (sustituye la “h” por la “d”)
- deart → dart (quita la "e")
- dardo → dardos (agregar “s”)
Ten en cuenta que la secuencia anterior no es la única ruta de tres ediciones.
LLM
Abreviatura de modelo de lenguaje extenso.
Evaluaciones de LLM (evals)
Un conjunto de métricas y comparativas para evaluar el rendimiento de los modelos de lenguaje extenso (LLM). A grandes rasgos, las evaluaciones de LLM hacen lo siguiente:
- Ayuda a los investigadores a identificar áreas en las que los LLM necesitan mejorar.
- Son útiles para comparar diferentes LLM y, así, identificar el mejor para una tarea en particular.
- Ayudar a garantizar que los LLM sean seguros y éticos de usar
Laura
Abreviatura de adaptabilidad de bajo rango.
Adaptabilidad de bajo rango (LoRA)
Una técnica eficiente en parámetros para el ajuste fino que “congela” los pesos previamente entrenados del modelo (de modo que ya no se puedan modificar) y, luego, inserta un pequeño conjunto de pesos entrenables en el modelo. Este conjunto de pesos entrenables (también conocidos como "matrices de actualización") es considerablemente más pequeño que el modelo base y, por lo tanto, es mucho más rápido de entrenar.
LoRA ofrece los siguientes beneficios:
- Mejora la calidad de las predicciones de un modelo para el dominio en el que se aplica el ajuste fino.
- Realiza ajustes más rápido que las técnicas que requieren ajustar todos los parámetros de un modelo.
- Reduce el costo de procesamiento de la inferencia, ya que habilita la entrega simultánea de varios modelos especializados que comparten el mismo modelo de base.
M
modelo de lenguaje enmascarado
Un modelo de lenguaje que predice la probabilidad de que los tokens candidatos completen espacios en blanco en una secuencia. Por ejemplo, un modelo de lenguaje con enmascaramiento puede calcular las probabilidades de las palabras candidatas para reemplazar el subrayado en la siguiente oración:
Volvió el ____ en el sombrero.
Por lo general, la literatura usa la cadena "MASK" en lugar de una línea debajo. Por ejemplo:
Volvió a aparecer la "MASCARA" en el sombrero.
La mayoría de los modelos de lenguaje con enmascaramiento modernos son bidireccionales.
precisión promedio en k (mAP@k)
Es la media estadística de todas las puntuaciones de precisión promedio en k en un conjunto de datos de validación. Un uso de la precisión promedio ponderada en k es juzgar la calidad de las recomendaciones que genera un sistema de recomendación.
Aunque la frase “promedio medio” suena redundante, el nombre de la métrica es apropiado. Después de todo, esta métrica encuentra el promedio de varios valores de precisión promedio en k.
metaaprendizaje
Es un subconjunto del aprendizaje automático que descubre o mejora un algoritmo de aprendizaje. Un sistema de metaaprendizaje también puede tener como objetivo entrenar un modelo para que aprenda rápidamente una tarea nueva a partir de una pequeña cantidad de datos o de la experiencia obtenida en tareas anteriores. Por lo general, los algoritmos de metaaprendizaje intentan lograr lo siguiente:
- Mejorar o aprender funciones diseñadas a mano (como un inicializador o un optimizador)
- Son más eficientes en el uso de datos y procesamiento.
- Mejora la generalización.
El metaaprendizaje está relacionado con el aprendizaje en pocos intentos.
mezcla de expertos
Un esquema para aumentar la eficiencia de la red neuronal con el uso de solo un subconjunto de sus parámetros (conocido como experto) para procesar un token o ejemplo de entrada determinado. Una red de control enruta cada token o ejemplo de entrada a los expertos adecuados.
Para obtener más información, consulta cualquiera de los siguientes documentos:
- Redes neuronales desmesuradamente grandes: la capa de mezcla de expertos con puertas escasas
- Mezcla de expertos con enrutamiento de Expert Choice
MMIT
Abreviatura de ajuste de instrucciones multimodales.
modality
Es una categoría de datos de alto nivel. Por ejemplo, los números, el texto, las imágenes, los videos y el audio son cinco modalidades diferentes.
paralelismo de modelos
Es una forma de escalar el entrenamiento o la inferencia que coloca diferentes partes de un modelo en diferentes dispositivos. El paralelismo de modelos permite que los modelos que son demasiado grandes para caber en un solo dispositivo.
Para implementar el paralelismo de modelos, un sistema suele hacer lo siguiente:
- Fragmenta (divide) el modelo en partes más pequeñas.
- Distribuye el entrenamiento de esas partes más pequeñas en varios procesadores. Cada procesador entrena su propia parte del modelo.
- Combina los resultados para crear un solo modelo.
El paralelismo de modelos ralentiza el entrenamiento.
Consulta también paralelismo de datos.
MOE
Abreviatura de combinación de expertos.
autoatención de múltiples cabezas
Es una extensión de la atención automática que aplica el mecanismo de atención automática varias veces para cada posición en la secuencia de entrada.
Transformers introdujo la autoatención multidireccional.
instrucción multimodal ajustada
Un modelo ajustado por instrucciones que puede procesar entradas más allá del texto, como imágenes, videos y audio.
modelo multimodal
Un modelo cuyas entradas o salidas incluyen más de una modalidad. Por ejemplo, considera un modelo que tome una imagen y una leyenda de texto (dos modalidades) como atributos y genere una puntuación que indique qué tan adecuada es la leyenda de texto para la imagen. Por lo tanto, las entradas de este modelo son multimodales y la salida es unimodal.
N
procesamiento de lenguaje natural
Es el campo de la enseñanza a las computadoras para que procesen lo que un usuario dijo o escribió con reglas lingüísticas. Casi todo el procesamiento de lenguaje natural moderno se basa en el aprendizaje automático.comprensión del lenguaje natural
Es un subconjunto del procesamiento de lenguaje natural que determina las intenciones de algo que se dijo o escribió. La comprensión del lenguaje natural puede ir más allá del procesamiento de lenguaje natural para considerar aspectos complejos del lenguaje, como el contexto, el sarcasmo y las opiniones.
N-grama
Es una secuencia ordenada de n palabras. Por ejemplo, realmente loco es un 2-grama. Ya que el orden es relevante, loco realmente es un 2-grama diferente a realmente loco.
| N | Nombres para este tipo de n-grama | Ejemplos |
|---|---|---|
| 2 | bigrama o 2-grama | ir por, por ir, asar carne, asar verduras |
| 3 | trigrama o 3-grama | ate too much, three blind mice, the bell tolls |
| 4 | 4-grama | walk in the park, dust in the wind, the boy ate lentils |
Muchos modelos de comprensión del lenguaje natural se basan en n-gramas para predecir la siguiente palabra que el usuario escribirá o dirá. Por ejemplo, que un usuario escribió tres tristes. Un modelo de CLN basado en trigramas probablemente predeciría que el usuario escribirá a continuación tigres.
Compara los n-gramas con la bolsa de palabras, que son conjuntos desordenados de palabras.
PLN
Abreviatura de procesamiento de lenguaje natural.
CLN
Abreviatura de comprensión del lenguaje natural.
No hay una sola respuesta correcta (NORA)
Una sugerencia que tiene varias respuestas adecuadas. Por ejemplo, la siguiente instrucción no tiene una respuesta correcta:
Cuéntame un chiste sobre elefantes.
Evaluar las consignas que no tienen una respuesta correcta puede ser un desafío.
NORA
Es la sigla en inglés de no hay una sola respuesta correcta.
O
instrucción con un solo ejemplo
Una sugerencia que contiene un ejemplo que demuestra cómo debería responder el modelo de lenguaje extenso. Por ejemplo, la siguiente instrucción contiene un ejemplo que muestra a un modelo de lenguaje extenso cómo debe responder una consulta.
| Partes de una instrucción | Notas |
|---|---|
| ¿Cuál es la moneda oficial del país especificado? | La pregunta que quieres que responda el LLM. |
| Francia: EUR | Un ejemplo. |
| India: | Es la consulta real. |
Compara y contrasta las instrucciones únicas con los siguientes términos:
P
ajuste eficiente de parámetros
Es un conjunto de técnicas para ajustar un modelo de lenguaje grande previamente entrenado (PLM) de manera más eficiente que el ajuste fino completo. El ajuste eficiente de parámetros suele ajustar muchos menos parámetros que el ajuste completo, pero, por lo general, produce un modelo de lenguaje grande que funciona tan bien (o casi tan bien) como un modelo de lenguaje grande creado a partir del ajuste completo.
Compara y contrasta el ajuste eficiente de parámetros con lo siguiente:
El ajuste eficiente de parámetros también se conoce como ajuste fino eficiente de parámetros.
canalización
Es una forma de paralelismo de modelos en la que el procesamiento de un modelo se divide en etapas consecutivas y cada una se ejecuta en un dispositivo diferente. Mientras una etapa procesa un lote, la etapa anterior puede trabajar en el siguiente lote.
Consulta también entrenamiento por etapas.
PLM
Abreviatura de modelo de lenguaje previamente entrenado.
Codificación posicional
Es una técnica para agregar información sobre la posición de un token en una secuencia a la incorporación del token. Los modelos de Transformer usan codificación posicional para comprender mejor la relación entre las diferentes partes de la secuencia.
Una implementación común de la codificación posicional usa una función sinusoidal. (Específicamente, la frecuencia y la amplitud de la función sinusoidal se determinan según la posición del token en la secuencia). Esta técnica permite que un modelo de Transformer aprenda a atender a diferentes partes de la secuencia según su posición.
modelo después del entrenamiento
Es un término definido de forma imprecisa que, por lo general, hace referencia a un modelo previamente entrenado que pasó por algún procesamiento posterior, como una o más de las siguientes opciones:
precisión en k (precision@k)
Es una métrica para evaluar una lista de elementos clasificados (ordenados). La precisión en k identifica la fracción de los primeros k elementos de esa lista que son "relevantes". Es decir:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
El valor de k debe ser menor o igual que la longitud de la lista que se muestra. Ten en cuenta que la longitud de la lista que se muestra no forma parte del cálculo.
La relevancia suele ser subjetiva. Incluso los evaluadores humanos expertos suelen estar en desacuerdo sobre qué elementos son relevantes.
Comparar con:
modelo previamente entrenado
Por lo general, un modelo que ya se entrenó. El término también podría referirse a un vector de incorporación previamente entrenado.
El término modelo de lenguaje previamente entrenado suele referirse a un modelo de lenguaje grande ya entrenado.
entrenamiento previo
El entrenamiento inicial de un modelo en un conjunto de datos grande. Algunos modelos previamente entrenados son gigantes torpes y, por lo general, deben definirse mejor mediante un entrenamiento adicional. Por ejemplo, los expertos en AA podrían entrenar previamente un modelo de lenguaje grande en un vasto conjunto de datos de texto, como todas las páginas en inglés de Wikipedia. Después del entrenamiento previo, el modelo resultante se puede definir mejor con cualquiera de las siguientes técnicas:
instrucción
Cualquier texto que se ingresa como entrada a un modelo de lenguaje extenso para condicionar el modelo para que se comporte de cierta manera. Las indicaciones pueden ser tan breves como una frase o arbitrariamente largas (por ejemplo, el texto completo de una novela). Las instrucciones se dividen en varias categorías, incluidas las que se muestran en la siguiente tabla:
| Categoría de instrucciones | Ejemplo | Notas |
|---|---|---|
| Pregunta | ¿Qué tan rápido puede volar una paloma? | |
| Instrucción | Escribe un poema divertido sobre el arbitraje. | Una instrucción que le pide al modelo de lenguaje grande que haga algo. |
| Ejemplo | Traduce el código Markdown a HTML. Por ejemplo:
Markdown: * elemento de lista HTML: <ul> <li>elemento de lista</li> </ul> |
La primera oración de esta instrucción de ejemplo es una instrucción. El resto de la instrucción es el ejemplo. |
| Rol | Explica por qué se usa el descenso de gradientes en el entrenamiento de aprendizaje automático a un doctorado en física. | La primera parte de la oración es una instrucción; la frase “a un doctorado en física” es la parte del puesto. |
| Entrada parcial para que el modelo la complete | El primer ministro del Reino Unido vive en | Una instrucción de entrada parcial puede terminar abruptamente (como en este ejemplo) o con un guion bajo. |
Un modelo de IA generativa puede responder a una instrucción con texto, código, imágenes, incorporaciones, videos… casi cualquier cosa.
aprendizaje basado en indicaciones
Es una función de ciertos modelos que les permite adaptar su comportamiento en respuesta a entradas de texto arbitrarias (indicaciones). En un paradigma de aprendizaje típico basado en instrucciones, un modelo de lenguaje grande responde a una instrucción generando texto. Por ejemplo, supongamos que un usuario ingresa la siguiente instrucción:
Resume la tercera ley del movimiento de Newton.
Un modelo capaz de aprender a partir de instrucciones no está entrenado específicamente para responder la instrucción anterior. En cambio, el modelo “sabe” muchos datos sobre la física, mucho sobre las reglas generales del lenguaje y mucho sobre lo que constituye respuestas generalmente útiles. Ese conocimiento es suficiente para proporcionar una respuesta (con suerte) útil. Los comentarios humanos adicionales ("Esa respuesta fue demasiado complicada" o "¿Qué es una reacción?") permiten que algunos sistemas de aprendizaje basados en indicaciones mejoren gradualmente la utilidad de sus respuestas.
diseño de instrucciones
Sinónimo de ingeniería de instrucciones.
ingeniería de instrucciones
El arte de crear instrucciones que generen las respuestas deseadas de un modelo de lenguaje grande. Los humanos realizan ingeniería de instrucciones. Escribir instrucciones bien estructuradas es una parte esencial de garantizar respuestas útiles de un modelo de lenguaje grande. La ingeniería oportuna depende de muchos factores, incluidos los siguientes:
- Es el conjunto de datos que se usa para entrenar previamente y, posiblemente, ajustar el modelo de lenguaje grande.
- La temperatura y otros parámetros de decodificación que el modelo usa para generar respuestas.
Consulta la sección Introducción al diseño de instrucciones para obtener más detalles sobre cómo escribir instrucciones útiles.
Diseño de instrucciones es un sinónimo de ingeniería de instrucciones.
ajuste de instrucciones
Un mecanismo de ajuste eficiente de parámetros que aprende un “prefijo” que el sistema agrega al prompt real.
Una variación del ajuste de instrucciones, que a veces se denomina ajuste de prefijos, es anteponer el prefijo en cada capa. En cambio, la mayoría de los ajustes de instrucciones solo agregan un prefijo a la capa de entrada.
R
recuperación en k (recall@k)
Es una métrica para evaluar sistemas que generan una lista de elementos clasificados (ordenados). La recuperación en k identifica la fracción de elementos relevantes en los primeros k elementos de esa lista de la cantidad total de elementos relevantes que se muestran.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Compara esto con la precisión en k.
texto de referencia
La respuesta de un experto a una sugerencia. Por ejemplo, dada la siguiente instrucción:
Traduce la pregunta “¿Cómo te llamas?” del inglés al francés.
La respuesta de un experto podría ser la siguiente:
Comment vous appelez-vous?
Varias métricas (como ROUGE) miden el grado en que el texto de referencia coincide con el texto generado de un modelo de AA.
indicaciones de roles
Es una parte opcional de una instrucción que identifica un público objetivo para la respuesta de un modelo de IA generativa. Sin una instrucción de rol, un modelo de lenguaje grande proporciona una respuesta que puede ser útil o no para la persona que hace las preguntas. Con una instrucción de rol, un modelo de lenguaje grande puede responder de una manera más apropiada y útil para un público objetivo específico. Por ejemplo, la parte de la instrucción de rol de las siguientes instrucciones está en negrita:
- Resume este artículo para un doctorado en economía.
- Describe cómo funcionan las mareas para un niño de diez años.
- Explica la crisis financiera de 2008. Habla como lo harías con un niño pequeño o un golden retriever.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Es una familia de métricas que evalúan los modelos de resumen automático y de traducción automática. Las métricas de ROUGE determinan el grado en que un texto de referencia se superpone con el texto generado de un modelo de IA. Cada miembro de la familia de ROUGE mide la superposición de una manera diferente. Las puntuaciones más altas de ROUGE indican una mayor similitud entre el texto de referencia y el texto generado que las puntuaciones más bajas de ROUGE.
Por lo general, cada miembro de la familia ROUGE genera las siguientes métricas:
- Precisión
- Recuperación
- F1
Para obtener detalles y ejemplos, consulta lo siguiente:
ROUGE-L
Un miembro de la familia ROUGE se enfoca en la longitud de la subsecuencia común más larga en el texto de referencia y el texto generado. Las siguientes fórmulas calculan la recuperación y la precisión de ROUGE-L:
Luego, puedes usar F1 para combinar la recuperación de ROUGE-L y la precisión de ROUGE-L en una sola métrica:
ROUGE-L ignora los saltos de línea en el texto de referencia y el texto generado, por lo que la subsecuencia común más larga podría cruzar varias oraciones. Cuando el texto de referencia y el texto generado incluyen varias oraciones, una variación de ROUGE-L llamada ROUGE-Lsum suele ser una mejor métrica. ROUGE-Lsum determina la subsecuencia común más larga para cada oración en un pasaje y, luego, calcula la media de esas subsecuencias comunes más largas.
ROUGE-N
Es un conjunto de métricas dentro de la familia ROUGE que compara los n-gramas compartidos de un tamaño determinado en el texto de referencia y el texto generado. Por ejemplo:
- ROUGE-1 mide la cantidad de tokens compartidos en el texto de referencia y el texto generado.
- ROUGE-2 mide la cantidad de bigramas (2-gramas) compartidos en el texto de referencia y el texto generado.
- ROUGE-3 mide la cantidad de trigramas (3-gramas) compartidos en el texto de referencia y el texto generado.
Puedes usar las siguientes fórmulas para calcular la recuperación y la precisión de ROUGE-N para cualquier miembro de la familia ROUGE-N:
Luego, puedes usar F1 para combinar la recuperación de ROUGE-N y la precisión de ROUGE-N en una sola métrica:
ROUGE-S
Es una forma tolerante de ROUGE-N que permite la coincidencia de skip-gram. Es decir, ROUGE-N solo cuenta los n-gramas que coinciden exactamente, pero ROUGE-S también cuenta los n-gramas separados por una o más palabras. Por ejemplo, considera lo siguiente:
- texto de referencia: Nubes blancas
- texto generado: Nubes blancas ondulantes
Cuando se calcula ROUGE-N, el 2-gramo nubes blancas no coincide con nubes blancas ondulantes. Sin embargo, cuando se calcula ROUGE-S, Nubes blancas sí coincide con Nubes blancas ondulantes.
S
autoatención (también llamada capa de autoatención)
Es una capa de red neuronal que transforma una secuencia de embeddings (por ejemplo, tokens) en otra secuencia de embeddings. Cada incorporación en la secuencia de salida se construye mediante la integración de información de los elementos de la secuencia de entrada a través de un mecanismo de atención.
La parte self de self-attention se refiere a la secuencia que se atiende a sí misma en lugar de a algún otro contexto. La autoatención es uno de los principales bloques de construcción de los transformadores y usa la terminología de búsqueda de diccionarios, como "consulta", "clave" y "valor".
Una capa de autoatención comienza con una secuencia de representaciones de entrada, una para cada palabra. La representación de entrada de una palabra puede ser una incorporación simple. Para cada palabra de una secuencia de entrada, la red asigna una puntuación a la relevancia de la palabra para cada elemento de toda la secuencia de palabras. Las puntuaciones de relevancia determinan en qué medida la representación final de la palabra incorpora las representaciones de otras palabras.
Por ejemplo, considera la siguiente oración:
El animal no cruzó la calle porque estaba muy cansado.
En la siguiente ilustración (de Transformer: A Novel Neural Network Architecture for Language Understanding), se muestra el patrón de atención de una capa de autoatención para el pronombre it, en el que la oscuridad de cada línea indica cuánto contribuye cada palabra a la representación:
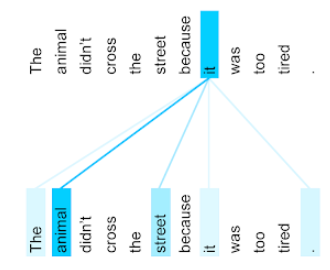
La capa de autoatención destaca las palabras que son relevantes para "it". En este caso, la capa de atención aprendió a destacar las palabras a las que se podría referir, asignando el mayor peso a animal.
Para una secuencia de n tokens, la autoatención transforma una secuencia de incorporaciones n veces, una vez en cada posición de la secuencia.
Consulta también atención y atención automática multidireccional.
análisis de opiniones
Usar algoritmos estadísticos o de aprendizaje automático para determinar la actitud general de un grupo (positiva o negativa) hacia un servicio, producto, organización o tema. Por ejemplo, con la comprensión del lenguaje natural, un algoritmo podría realizar un análisis de opiniones en los comentarios textuales de un curso universitario para determinar en qué grado les gustó o disgustó el curso a los estudiantes en general.
tarea de secuencia a secuencia
Es una tarea que convierte una secuencia de entrada de tokens en una secuencia de salida de tokens. Por ejemplo, estos son dos tipos populares de tareas de secuencia a secuencia:
- Traductores:
- Secuencia de entrada de muestra: "Te amo".
- Ejemplo de secuencia de salida: "Je t'aime".
- Búsqueda de respuestas:
- Ejemplo de secuencia de entrada: "¿Necesito mi auto en la ciudad de Nueva York?"
- Ejemplo de secuencia de salida: "No. Mantén el auto en casa".
skip-gram
Un n-grama que puede omitir (o “omitir”) palabras del contexto original, lo que significa que las N palabras podrían no haber estado adyacentes originalmente. Más precisamente, un "n-gram con omisión de k" es un n-gram para el que se pueden haber omitido hasta k palabras.
Por ejemplo, “the quick brown fox” tiene los siguientes 2-gramas posibles:
- "the quick"
- "quick brown"
- "zorro marrón"
Un "1-skip-2-gram" es un par de palabras que tienen como máximo 1 palabra entre ellas. Por lo tanto, “the quick brown fox” tiene los siguientes 2-gramas con 1 omisión:
- "the brown"
- "quick fox"
Además, todos los bigramas también son bigramas de 1 omisión, ya que se puede omitir menos de una palabra.
Los saltos de palabras son útiles para comprender mejor el contexto que rodea a una palabra. En el ejemplo, “fox” se asoció directamente con “quick” en el conjunto de 1-skip-2-grams, pero no en el conjunto de 2-grams.
Los saltos de palabras ayudan a entrenar modelos de incorporación de palabras.
Ajuste de indicaciones suaves
Es una técnica para ajustar un modelo de lenguaje extenso para una tarea en particular, sin un ajuste fino intensivo en recursos. En lugar de volver a entrenar todos los pesos del modelo, el ajuste de instrucciones suaves ajusta automáticamente una instrucción para lograr el mismo objetivo.
Dada una instrucción textual, el ajuste de instrucciones suaves suele adjuntar incorporaciones de tokens adicionales a la instrucción y usa la retropropagación para optimizar la entrada.
Una instrucción "difícil" contiene tokens reales en lugar de incorporaciones de tokens.
atributo disperso
Un atributo cuyos valores son predominantemente cero o están vacíos. Por ejemplo, un atributo que contiene un solo valor de 1 y un millón de valores de 0 es escaso. En cambio, un atributo denso tiene valores que, en su mayoría, no son cero ni están vacíos.
En el aprendizaje automático, una cantidad sorprendente de atributos son atributos dispersos. Los atributos categóricos suelen ser atributos dispersos. Por ejemplo, de las 300 especies de árboles posibles en un bosque, un solo ejemplo podría identificar solo un árbol de arce. O bien, de los millones de videos posibles en una biblioteca de video, un solo ejemplo podría identificar solo "Casablanca".
En un modelo, por lo general, representas atributos dispersos con codificación one-hot. Si la codificación one-hot es grande, puedes colocar una capa de incorporación sobre la codificación one-hot para obtener una mayor eficiencia.
representación dispersa
Almacena solo las posiciones de los elementos distintos de cero en un atributo disperso.
Por ejemplo, supongamos que un atributo categórico llamado species identifica las 36 especies de árboles en un bosque en particular. Supongamos además que cada ejemplo identifica solo una especie.
Podrías usar un vector de un valor para representar las especies de árboles en cada ejemplo.
Un vector one-hot contendría un solo 1 (para representar la especie de árbol en particular en ese ejemplo) y 35 0 (para representar las 35 especies de árboles que no están en ese ejemplo). Por lo tanto, la representación one-hot de maple podría verse de la siguiente manera:

Como alternativa, la representación dispersa simplemente identificaría la posición de la especie en particular. Si maple está en la posición 24, la representación dispersa de maple sería la siguiente:
24
Ten en cuenta que la representación dispersa es mucho más compacta que la representación de uno caliente.
Haz clic en el ícono para ver un ejemplo un poco más complejo.
Supongamos que cada ejemplo de tu modelo debe representar las palabras, pero no el orden de esas palabras, en una oración en inglés. El inglés consta de alrededor de 170,000 palabras, por lo que es una característica categórica con alrededor de 170,000 elementos. La mayoría de las oraciones en inglés usan una fracción extremadamente pequeña de esas 170,000 palabras, por lo que es casi seguro que el conjunto de palabras de un solo ejemplo sea de datos dispersos.
Considera la siguiente oración:
My dog is a great dog
Puedes usar una variante del vector one-hot para representar las palabras de esta oración. En esta variante, varias celdas del vector pueden contener un valor distinto de cero. Además, en esta variante, una celda puede contener un número entero distinto de uno. Aunque las palabras “mi”, “es”, “un” y “genial” aparecen solo una vez en la oración, la palabra “perro” aparece dos veces. El uso de esta variante de vectores one-hot para representar las palabras de esta oración genera el siguiente vector de 170,000 elementos:

Una representación dispersa de la misma oración sería simplemente:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
entrenamiento por etapas
Una táctica para entrenar un modelo en una secuencia de etapas discretas. El objetivo puede ser acelerar el proceso de entrenamiento o lograr una mejor calidad del modelo.
A continuación, se muestra una ilustración del enfoque de apilamiento progresivo:
- La etapa 1 contiene 3 capas ocultas, la etapa 2 contiene 6 capas ocultas y la etapa 3 contiene 12 capas ocultas.
- La etapa 2 comienza el entrenamiento con los pesos aprendidos en las 3 capas ocultas de la etapa 1. La etapa 3 comienza el entrenamiento con los pesos aprendidos en las 6 capas ocultas de la etapa 2.

Consulta también encadenar.
token de subpalabra
En los modelos de lenguaje, un token es una subcadena de una palabra, que puede ser la palabra completa.
Por ejemplo, una palabra como "detallar" podría dividirse en las partes "detallar" (una palabra raíz) y "izar" (un sufijo), cada una de las cuales está representada por su propio token. Dividir las palabras poco comunes en esas partes, llamadas subpalabras, permite que los modelos de lenguaje operen en las partes constituyentes más comunes de la palabra, como los prefijos y sufijos.
Por el contrario, es posible que las palabras comunes, como "ir", no se dividan y se representen con un solo token.
T
T5
Un modelo de transferencia de aprendizaje de texto a texto que presentó Google AI en 2020. T5 es un modelo de codificador-decodificador, basado en la arquitectura de Transformer, entrenado en un conjunto de datos extremadamente grande. Es eficaz en una variedad de tareas de procesamiento de lenguaje natural, como generar texto, traducir idiomas y responder preguntas de forma conversacional.
T5 recibe su nombre de las cinco T de "Text-to-Text Transfer Transformer".
T5X
Un framework de aprendizaje automático de código abierto diseñado para compilar y entrenar modelos de procesamiento de lenguaje natural (PLN) a gran escala. T5 se implementa en la base de código de T5X (que se compila en JAX y Flax).
temperatura
Un hiperparámetro que controla el grado de aleatoriedad del resultado de un modelo. Las temperaturas más altas generan resultados más aleatorios, mientras que las temperaturas más bajas generan resultados menos aleatorios.
La elección de la mejor temperatura depende de la aplicación específica y de las propiedades preferidas del resultado del modelo. Por ejemplo, es probable que aumentes la temperatura cuando crees una aplicación que genere resultados creativos. Por el contrario, es probable que disminuyas la temperatura cuando crees un modelo que clasifique imágenes o texto para mejorar su precisión y coherencia.
La temperatura se suele usar con softmax.
intervalo de texto
Es el intervalo de índice de array asociado con una subsección específica de una cadena de texto.
Por ejemplo, la palabra good en la cadena de Python s="Be good now" ocupa el intervalo de texto del 3 al 6.
token
En un modelo de lenguaje, es la unidad atómica con la que el modelo entrena y realiza predicciones. Por lo general, un token es uno de los siguientes:
- una palabra; por ejemplo, la frase "dogs like cats" consta de tres tokens de palabra: "dogs", "like" y "cats".
- un carácter; por ejemplo, la frase "bike fish" consta de nueve tokens de carácter. (Ten en cuenta que el espacio en blanco cuenta como uno de los tokens).
- subpalabras, en las que una sola palabra puede ser un solo token o varios tokens. Una subpalabra consta de una palabra raíz, un prefijo o un sufijo. Por ejemplo, un modelo de lenguaje que usa subpalabras como tokens podría ver la palabra "dogs" como dos tokens (la palabra raíz "dog" y el sufijo plural "s"). Ese mismo modelo de lenguaje podría ver la palabra única “más alto” como dos subpalabras (la palabra raíz “alto” y el sufijo “er”).
En dominios fuera de los modelos de lenguaje, los tokens pueden representar otros tipos de unidades atómicas. Por ejemplo, en la visión artificial, un token puede ser un subconjunto de una imagen.
precisión Top-K
Es el porcentaje de veces que aparece una "etiqueta de segmentación" en las primeras k posiciones de las listas generadas. Las listas pueden ser recomendaciones personalizadas o una lista de elementos ordenados por softmax.
La precisión Top-K también se conoce como precisión en k.
tóxico
El grado en que el contenido es abusivo, amenazante o ofensivo Muchos modelos de aprendizaje automático pueden identificar y medir la toxicidad. La mayoría de estos modelos identifican la toxicidad en función de varios parámetros, como el nivel de lenguaje abusivo y el nivel de lenguaje amenazante.
Transformador
Es una arquitectura de red neuronal desarrollada en Google que se basa en mecanismos de autoatención para transformar una secuencia de incorporaciones de entrada en una secuencia de incorporaciones de salida sin depender de convoluciones ni redes neuronales recurrentes. Un transformador se puede ver como una pila de capas de autoatención.
Un transformador puede incluir cualquiera de los siguientes elementos:
- un codificador
- un decodificador
- un codificador y un decodificador
Un codificador transforma una secuencia de incorporaciones en una secuencia nueva de la misma longitud. Un codificador incluye N capas idénticas, cada una de las cuales contiene dos subcapas. Estas dos subcapas se aplican en cada posición de la secuencia de incorporación de entrada y transforman cada elemento de la secuencia en una incorporación nueva. La primera subcapa del codificador agrega información de toda la secuencia de entrada. La segunda subcapa del codificador transforma la información agregada en una incorporación de salida.
Un decodificador transforma una secuencia de incorporaciones de entrada en una secuencia de incorporaciones de salida, posiblemente con una longitud diferente. Un decodificador también incluye N capas idénticas con tres subcapas, dos de las cuales son similares a las subcapas del codificador. La tercera subcapa del decodificador toma el resultado del codificador y aplica el mecanismo de autoatención para recopilar información de él.
La entrada de blog Transformer: A Novel Neural Network Architecture for Language Understanding proporciona una buena introducción a los transformadores.
trigrama
Un n-grama en el que n=3.
U
unidireccional
Un sistema que solo evalúa el texto que precede a una sección de texto objetivo. En cambio, un sistema bidireccional evalúa el texto que precede y sigue a una sección de texto objetivo. Consulta bidireccional para obtener más detalles.
modelo de lenguaje unidireccional
Un modelo de lenguaje que basa sus probabilidades solo en los tokens que aparecen antes, no después, de los tokens de destino. Compara esto con el modelo de lenguaje bidireccional.
V
codificador automático variacional (VAE)
Un tipo de autocodificador que aprovecha la discrepancia entre las entradas y las salidas para generar versiones modificadas de las entradas. Los autocodificadores variacionales son útiles para la IA generativa.
Los VAE se basan en la inferencia variacional, una técnica para estimar los parámetros de un modelo de probabilidad.
W
incorporación de palabras
Representa cada palabra en un conjunto de palabras dentro de un vector de incorporación; es decir, representa cada palabra como un vector de valores de punto flotante entre 0.0 y 1.0. Las palabras con significados similares tienen representaciones más similares que las palabras con significados diferentes. Por ejemplo, las zanahorias, el apio y los pepinos tendrían representaciones relativamente similares, que serían muy diferentes de las representaciones de avión, lentes de sol y pasta dental.
Z
instrucción sin ejemplos
Una instrucción que no proporciona un ejemplo de cómo quieres que responda el modelo de lenguaje extenso. Por ejemplo:
| Partes de una instrucción | Notas |
|---|---|
| ¿Cuál es la moneda oficial del país especificado? | La pregunta que quieres que responda el LLM. |
| India: | Es la consulta real. |
El modelo de lenguaje grande podría responder con cualquiera de las siguientes opciones:
- Rupia
- INR
- ₹
- Rupia hindú
- La rupia
- La rupia india
Todas las respuestas son correctas, aunque es posible que prefieras un formato en particular.
Compara y contrasta las sugerencias de cero tomas con los siguientes términos: