इस पेज पर, भाषा की जांच से जुड़ी शब्दावली के शब्द मौजूद हैं. ग्लॉसरी में मौजूद सभी शब्दों के लिए, यहां क्लिक करें.
A
ध्यान देना
न्यूरल नेटवर्क में इस्तेमाल किया जाने वाला एक तरीका, जो किसी शब्द या शब्द के हिस्से की अहमियत बताता है. अटेंशन, अगले टोकन/शब्द का अनुमान लगाने के लिए, मॉडल को ज़रूरी जानकारी को कम करता है. आम तौर पर, ध्यान देने की सुविधा में इनपुट के सेट पर वज़न वाला योग शामिल हो सकता है. इसमें हर इनपुट के लिए वज़न का हिसाब, न्यूरल नेटवर्क के किसी दूसरे हिस्से से लगाया जाता है.
सेल्फ़-अटेंशन और मल्टी-हेड सेल्फ़-अटेंशन के बारे में भी जानें. ये ट्रांसफ़ॉर्मर के बुनियादी ब्लॉक हैं.
सेल्फ़-अटेंशन के बारे में ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में एलएलएम: लार्ज लैंग्वेज मॉडल क्या है? देखें.
ऑटोएन्कोडर
यह ऐसा सिस्टम है जो इनपुट से सबसे ज़रूरी जानकारी निकालना सीखता है. ऑटोएन्कोडर, एन्कोडर और डिकोडर का कॉम्बिनेशन होते हैं. ऑटोएन्कोडर, दो चरणों वाली इस प्रोसेस पर निर्भर करते हैं:
- एन्कोडर, इनपुट को आम तौर पर कम डाइमेंशन वाले (इंटरमीडिएट) और लॉस वाले फ़ॉर्मैट में मैप करता है.
- डिकोडर, कम डाइमेंशन वाले फ़ॉर्मैट को ओरिजनल ज़्यादा डाइमेंशन वाले इनपुट फ़ॉर्मैट में मैप करके, ओरिजनल इनपुट का लॉस वाला वर्शन बनाता है.
ऑटोएन्कोडर को एंड-टू-एंड ट्रेनिंग दी जाती है. इसके लिए, डिकोडर, एन्कोडर के इंटरमीडिएट फ़ॉर्मैट से ओरिजनल इनपुट को फिर से बनाने की कोशिश करता है. इंटरमीडिएट फ़ॉर्मैट, ओरिजनल फ़ॉर्मैट से छोटा (कम डाइमेंशन वाला) होता है. इसलिए, ऑटोएन्कोडर को यह सीखना पड़ता है कि इनपुट में कौनसी जानकारी ज़रूरी है. साथ ही, आउटपुट, इनपुट से पूरी तरह मेल नहीं खाएगा.
उदाहरण के लिए:
- अगर इनपुट डेटा कोई ग्राफ़िक है, तो नॉन-एग्ज़ैक्ट कॉपी, ओरिजनल ग्राफ़िक से मिलती-जुलती होगी, लेकिन उसमें कुछ बदलाव किया गया होगा. ऐसा हो सकता है कि एआई की मदद से बनाई गई कॉपी, ओरिजनल ग्राफ़िक से ग़ैर-ज़रूरी चीज़ों को हटा दे या कुछ पिक्सल जोड़ दे.
- अगर इनपुट डेटा टेक्स्ट है, तो ऑटोएन्कोडर नया टेक्स्ट जनरेट करेगा. यह टेक्स्ट, ओरिजनल टेक्स्ट से मिलता-जुलता होगा, लेकिन एक जैसा नहीं होगा.
वैरिएशनल ऑटोएन्कोडर भी देखें.
अपने-आप होने वाला आकलन
मॉडल के आउटपुट की क्वालिटी का आकलन करने के लिए, सॉफ़्टवेयर का इस्तेमाल करना.
जब मॉडल का आउटपुट आसान होता है, तो कोई स्क्रिप्ट या प्रोग्राम, मॉडल के आउटपुट की तुलना गोल्डन रिस्पॉन्स से कर सकता है. इस तरह के अपने-आप होने वाले आकलन को कभी-कभी प्रोग्रामैटिक आकलन भी कहा जाता है. प्रोग्राम के आधार पर आकलन करने के लिए, ROUGE या BLEU जैसी मेट्रिक का इस्तेमाल अक्सर किया जाता है.
जब मॉडल का आउटपुट जटिल होता है या उसमें कोई एक सही जवाब नहीं होता, तो ऑटोरेटर नाम का एक अलग एमएल प्रोग्राम, अपने-आप आकलन करता है.
मैन्युअल तरीके से किए गए आकलन के साथ तुलना करें.
ऑटोरेटर का आकलन
जनरेटिव एआई मॉडल के आउटपुट की क्वालिटी का आकलन करने के लिए, एक हाइब्रिड मशीन. इसमें मैन्युअल तरीके से की गई समीक्षा और ऑटोमेटेड तरीके से की गई समीक्षा, दोनों का इस्तेमाल किया जाता है. ऑटोरेटर एक ऐसा एमएल मॉडल है जिसे मैन्युअल तरीके से किए गए आकलन से मिले डेटा पर ट्रेन किया जाता है. आम तौर पर, अपने-आप रेटिंग देने वाला सिस्टम, कॉन्टेंट की समीक्षा करने वाले व्यक्ति की नकल करता है.पहले से बने ऑटोरेटर उपलब्ध हैं, लेकिन सबसे अच्छे ऑटोरेटर, खास तौर पर उस टास्क के लिए बेहतर बनाए जाते हैं जिसका आकलन किया जा रहा है.
ऑटो-रिग्रेसिव मॉडल
ऐसा मॉडल जो अपने पिछले अनुमानों के आधार पर अनुमान लगाता है. उदाहरण के लिए, अपने-आप कम होने वाले भाषा मॉडल, पहले से अनुमानित टोकन के आधार पर अगले टोकन का अनुमान लगाते हैं. ट्रांसफ़ॉर्मर पर आधारित सभी लार्ज लैंग्वेज मॉडल, अपने-आप रिग्रेसिव होते हैं.
इसके उलट, GAN पर आधारित इमेज मॉडल आम तौर पर अपने-आप रिग्रेसिव नहीं होते, क्योंकि ये एक फ़ॉरवर्ड-पास में इमेज जनरेट करते हैं, न कि चरणों में बार-बार. हालांकि, इमेज जनरेट करने के कुछ मॉडल अपने-आप रिग्रेसिव होते हैं, क्योंकि ये चरणों में इमेज जनरेट करते हैं.
k पर औसत प्रीसिज़न
किसी एक प्रॉम्प्ट पर मॉडल की परफ़ॉर्मेंस की खास जानकारी देने वाली मेट्रिक. यह रैंक वाले नतीजे जनरेट करती है, जैसे कि किताब के सुझावों की नंबर वाली सूची. k पर औसत सटीक नतीजा, हर काम के नतीजे के लिए, k पर सटीक नतीजा वैल्यू का औसत होता है. इसलिए, k पर औसत सटीक नतीजों का फ़ॉर्मूला यह है:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
कहां:
- \(n\) , सूची में मौजूद काम के आइटम की संख्या है.
k पर रीकॉल करें के साथ तुलना करें.
B
शब्दों का बैग
किसी वाक्यांश या पैसेज में मौजूद शब्दों का क्रम से कोई लेना-देना नहीं होता. उदाहरण के लिए, शब्दों का बैग, यहां दिए गए तीन वाक्यांशों को एक जैसा दिखाता है:
- कुत्ता कूदता है
- कुत्ता कूदता है
- कुत्ता
हर शब्द को स्पैस वेक्टर में इंडेक्स से मैप किया जाता है. इसमें वेक्टर में, शब्दावली के हर शब्द का इंडेक्स होता है. उदाहरण के लिए, कुत्ता कूदता है वाक्यांश को एक फ़ीचर वेक्टर में मैप किया जाता है. इसमें कुत्ता, कूदता है, और शब्दों के तीन इंडेक्स में, शून्य से ज़्यादा वैल्यू होती हैं. शून्य से ज़्यादा की वैल्यू इनमें से कोई भी हो सकती है:
- किसी शब्द की मौजूदगी दिखाने के लिए 1.
- बैग में किसी शब्द के दिखने की संख्या. उदाहरण के लिए, अगर वाक्यांश मारून रंग का कुत्ता, मारून रंग के बालों वाला कुत्ता है है, तो मारून और कुत्ता, दोनों को 2 के तौर पर दिखाया जाएगा. वहीं, दूसरे शब्दों को 1 के तौर पर दिखाया जाएगा.
- कोई दूसरी वैल्यू, जैसे कि बैग में किसी शब्द के दिखने की संख्या के लॉगरिदम.
BERT (बाईडायरेक्शनल एन्कोडर रिप्रज़ेंटेशन्स फ़्रॉम ट्रांसफ़ॉर्मर्स)
टेक्स्ट के प्रज़ेंटेशन के लिए मॉडल आर्किटेक्चर. ट्रेन किया गया BERT मॉडल, टेक्स्ट की कैटगरी तय करने या एमएल के अन्य टास्क के लिए, बड़े मॉडल का हिस्सा बन सकता है.
BERT की ये विशेषताएं हैं:
- यह Transformer आर्किटेक्चर का इस्तेमाल करता है. इसलिए, यह सेल्फ़-अटेन्शन पर निर्भर करता है.
- यह ट्रांसफ़ॉर्मर के एन्कोडर हिस्से का इस्तेमाल करता है. एन्कोडर का काम, टेक्स्ट को बेहतर तरीके से दिखाना होता है, न कि कैटगरी तय करना.
- दोतरफ़ा है.
- बिना निगरानी वाली ट्रेनिंग के लिए, मास्किंग का इस्तेमाल करता है.
BERT के वैरिएंट में ये शामिल हैं:
BERT के बारे में खास जानकारी पाने के लिए, ओपन सोर्स BERT: नेचुरल लैंग्वेज प्रोसेसिंग के लिए सबसे बेहतर प्री-ट्रेनिंग देखें.
दोनों तरफ़ ले जाया जा सकने वाला
इस शब्द का इस्तेमाल, ऐसे सिस्टम के बारे में बताने के लिए किया जाता है जो टेक्स्ट के टारगेट सेक्शन से पहले और बाद के टेक्स्ट का आकलन करता है. इसके उलट, एकतरफ़ा सिस्टम सिर्फ़ उस टेक्स्ट का आकलन करता है जो टेक्स्ट के टारगेट सेक्शन से पहले आता है.
उदाहरण के लिए, मास्क किए गए भाषा मॉडल पर विचार करें. इसे नीचे दिए गए सवाल में, अंडरलाइन किए गए शब्द या शब्दों की संभावनाओं का पता लगाना होगा:
आपके पास _____ क्या है?
एकतरफ़ा भाषा मॉडल को अपनी संभावनाओं को सिर्फ़ "क्या", "है", और "वह" शब्दों से मिले कॉन्टेक्स्ट के आधार पर तय करना होगा. इसके उलट, दोतरफ़ा भाषा मॉडल "साथ" और "आप" से भी संदर्भ हासिल कर सकता है, जिससे मॉडल को बेहतर अनुमान जनरेट करने में मदद मिल सकती है.
द्विभाषी लैंग्वेज मॉडल
यह एक भाषा मॉडल है, जो यह संभावना तय करता है कि कोई दिया गया टोकन, टेक्स्ट के किसी हिस्से में मौजूद है या नहीं. यह संभावना, पहले और बाद में मौजूद टेक्स्ट के आधार पर तय की जाती है.
bigram
N-ग्राम, जिसमें N=2 है.
BLEU (Bilingual Evaluation Understudy)
मशीन से अनुवाद का आकलन करने के लिए, 0.0 से 1.0 के बीच की मेट्रिक. उदाहरण के लिए, स्पैनिश से जैपनीज़ में अनुवाद.
स्कोर का हिसाब लगाने के लिए, आम तौर पर BLEU, किसी एमएल मॉडल के अनुवाद (जनरेट किया गया टेक्स्ट) की तुलना, किसी विशेषज्ञ के अनुवाद (रेफ़रंस टेक्स्ट) से करता है. जनरेट किए गए टेक्स्ट और रेफ़रंस टेक्स्ट में एन-ग्राम के मैच होने की डिग्री से, BLEU स्कोर तय होता है.
इस मेट्रिक के बारे में मूल पेपर, BLEU: मशीन से अनुवाद करने की सुविधा का अपने-आप आकलन करने का तरीका है.
BLEURT भी देखें.
BLEURT (Bilingual Evaluation Understudy from Transformers)
एक भाषा से दूसरी भाषा में किए गए मशीन से अनुवाद का आकलन करने वाली मेट्रिक. खास तौर पर, अंग्रेज़ी से और अंग्रेज़ी में किए गए अनुवाद का आकलन करने वाली मेट्रिक.
अंग्रेज़ी से अनुवाद करने और उसमें अनुवाद करने के लिए, BLEURT, BLEU की तुलना में, इंसानों की रेटिंग के ज़्यादा करीब होता है. BLEU के उलट, BLEURT में सेमैनटिक (मतलब) मिलती-जुलती चीज़ों पर ज़ोर दिया जाता है. साथ ही, इसमें पैराफ़्रेज़िंग की सुविधा भी शामिल होती है.
BLEURT, पहले से ट्रेन किए गए लार्ज लैंग्वेज मॉडल (सटीक तौर पर, BERT) पर आधारित है. इसके बाद, अनुवादकों के टेक्स्ट के आधार पर, इसे बेहतर बनाया जाता है.
इस मेट्रिक के बारे में मूल पेपर, BLEURT: Learning Robust Metrics for Text Generation है.
C
कैज़ल लैंग्वेज मॉडल
यूनीडायरेक्शनल लैंग्वेज मॉडल का समानार्थी शब्द.
भाषा मॉडलिंग में अलग-अलग दिशाओं के तरीकों की तुलना करने के लिए, दोतरफ़ा भाषा मॉडल देखें.
सिलसिलेवार तरीके से दिया जाने वाला प्रॉम्प्ट
प्रॉम्प्ट इंजीनियरिंग तकनीक, जिसकी मदद से लार्ज लैंग्वेज मॉडल (एलएलएम) को, अपनी वजह को सिलसिलेवार तरीके से बताने के लिए बढ़ावा दिया जाता है. उदाहरण के लिए, इस प्रॉम्प्ट पर ध्यान दें और दूसरे वाक्य पर खास ध्यान दें:
7 सेकंड में 0 से 60 मील प्रति घंटे की रफ़्तार तक पहुंचने वाली कार में, ड्राइवर को कितने जी फ़ोर्स का अनुभव होगा? जवाब में, काम की सभी गणनाएं दिखाएं.
एलएलएम का जवाब इस तरह का हो सकता है:
- फ़िज़िक्स के फ़ॉर्मूला का क्रम दिखाएं. इसके लिए, सही जगहों पर 0, 60, और 7 वैल्यू डालें.
- बताएं कि उसने उन फ़ॉर्मूला को क्यों चुना और अलग-अलग वैरिएबल का क्या मतलब है.
सिलसिलेवार तरीके से सवाल पूछने पर, एलएलएम को सभी गणनाएं करनी पड़ती हैं. इससे, ज़्यादा सटीक जवाब मिल सकता है. इसके अलावा, सिलसिलेवार तरीके से सवाल पूछने की सुविधा की मदद से, उपयोगकर्ता एलएलएम के चरणों की जांच कर सकता है. इससे यह पता चलता है कि जवाब सही है या नहीं.
चैट
आम तौर पर, लार्ज लैंग्वेज मॉडल जैसे एमएल सिस्टम के साथ हुई बातचीत का कॉन्टेंट. चैट में पिछली बातचीत (आपने क्या टाइप किया और लार्ज लैंग्वेज मॉडल ने कैसे जवाब दिया) से, चैट के अगले हिस्सों के लिए कॉन्टेक्स्ट बन जाता है.
चैटबॉट, लार्ज लैंग्वेज मॉडल का एक ऐप्लिकेशन है.
ग़लत जानकारी देना
मतिभ्रम का समानार्थी शब्द.
भ्रम की तुलना में, ग़लत जानकारी देना तकनीकी तौर पर ज़्यादा सटीक शब्द है. हालांकि, पहले हैलुसिनेशन लोकप्रिय हुआ.
चुनावी क्षेत्र को पार्स करना
किसी वाक्य को छोटे-छोटे व्याकरणिक स्ट्रक्चर ("कॉन्स्टिट्यूएंट") में बांटना. एमएल सिस्टम का बाद का हिस्सा, जैसे कि नैचुरल लैंग्वेज अंडरस्टैंडिंग मॉडल, मूल वाक्य की तुलना में कॉम्पोनेंट को ज़्यादा आसानी से पार्स कर सकता है. उदाहरण के लिए, यह वाक्य देखें:
मेरे दोस्त ने दो बिल्लियों को गोद लिया.
ज़िल्से-एवं-विधानसभा क्षेत्र के हिसाब से डेटा को अलग-अलग करने वाला टूल, इस वाक्य को इन दो हिस्सों में बांट सकता है:
- मेरा दोस्त एक संज्ञा वाक्यांश है.
- दो बिल्लियों को गोद लिया एक क्रिया वाक्यांश है.
इन कॉम्पोनेंट को और छोटे कॉम्पोनेंट में बांटा जा सकता है. उदाहरण के लिए, क्रिया वाक्यांश
दो बिल्लियों को गोद लिया
को इनमें बांटा जा सकता है:
- adopted एक क्रिया है.
- दो बिल्लियां एक और संज्ञा वाक्यांश है.
संदर्भ के हिसाब से भाषा को एम्बेड करना
ऐसा एम्बेड जो शब्दों और वाक्यांशों को उसी तरह "समझता" है जिस तरह किसी भाषा के मूल निवासी उसे समझते हैं. कॉन्टेक्स्ट के हिसाब से भाषा के एम्बेडमेंट, सिंटैक्स, सेमेटिक्स, और कॉन्टेक्स्ट को समझ सकते हैं.
उदाहरण के लिए, अंग्रेज़ी के शब्द cow के एम्बेड देखें. word2vec जैसे पुराने एम्बेडिंग, अंग्रेज़ी के शब्दों को इस तरह दिखा सकते हैं कि एम्बेडिंग स्पेस में गाय से बैल की दूरी, भेड़ (मादा भेड़) से बकरा (नर भेड़) या महिला से पुरुष की दूरी जैसी हो. कॉन्टेक्स्ट के हिसाब से भाषा के एम्बेडमेंट, एक कदम आगे जाकर यह पहचान सकते हैं कि अंग्रेज़ी बोलने वाले लोग कभी-कभी गाय या बैल के लिए, गाय शब्द का इस्तेमाल करते हैं.
कॉन्टेक्स्ट विंडो
किसी दिए गए प्रॉम्प्ट में, मॉडल कितने टोकन प्रोसेस कर सकता है. कॉन्टेक्स्ट विंडो जितनी बड़ी होगी, मॉडल उतनी ही ज़्यादा जानकारी का इस्तेमाल करके प्रॉम्प्ट के लिए बेहतर और एक जैसे जवाब दे पाएगा.
क्रैश ब्लॉसम
ऐसा वाक्य या वाक्यांश जिसका मतलब साफ़ तौर पर न पता चल रहा हो. क्रैश ब्लॉसम, सामान्य भाषा को समझने में एक बड़ी समस्या है. उदाहरण के लिए, हेडलाइन रेड टेप से स्काईस्क्रेपर का निर्माण रुका एक क्रैश ब्लॉसम है, क्योंकि एनएलयू मॉडल हेडलाइन का मतलब, सही या फिर अलंकार के तौर पर समझ सकता है.
D
डिकोडर
आम तौर पर, कोई भी एमएल सिस्टम जो प्रोसेस किए गए, घने या अंदरूनी डेटा को ज़्यादा रॉ, स्पैर्स या बाहरी डेटा में बदलता है.
डिकोडर, अक्सर बड़े मॉडल का एक कॉम्पोनेंट होता है. आम तौर पर, इन्हें एन्कोडर के साथ जोड़ा जाता है.
सीक्वेंस-टू-सीक्वेंस टास्क में, डिकोडर अगले सीक्वेंस का अनुमान लगाने के लिए, एन्कोडर से जनरेट की गई इंटरनल स्टेटस से शुरू होता है.
Transformer आर्किटेक्चर में डिकोडर की परिभाषा के लिए, Transformer देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में बड़े लैंग्वेज मॉडल देखें.
ग़ैर-ज़रूरी आवाज़ें हटाना
सेल्फ़-सुपरवाइज़्ड लर्निंग के लिए एक सामान्य तरीका, जिसमें:
- डेटासेट में कृत्रिम तरीके से ग़ैर-ज़रूरी आवाज़ें जोड़ी जाती हैं.
- मॉडल, ग़ैर-ज़रूरी आवाज़ों को हटाने की कोशिश करता है.
ग़ैर-ज़रूरी चीज़ों को हटाने की सुविधा से, लेबल न किए गए उदाहरणों से सीखने में मदद मिलती है. ओरिजनल डेटासेट, टारगेट या लेबल के तौर पर काम करता है. साथ ही, ग़ैर-ज़रूरी डेटा, इनपुट के तौर पर काम करता है.
कुछ मास्क किए गए लैंग्वेज मॉडल, ग़ैर-ज़रूरी आवाज़ों को हटाने के लिए इस तरह का इस्तेमाल करते हैं:
- कुछ टोक़न को मास्क करके, लेबल नहीं किए गए वाक्य में ग़ैर-ज़रूरी जानकारी को कृत्रिम तरीके से जोड़ा जाता है.
- मॉडल, ओरिजनल टोकन का अनुमान लगाने की कोशिश करता है.
सीधे तौर पर निर्देश देना
ज़ीरो-शॉट प्रॉम्प्ट का समानार्थी शब्द.
E
दूरी में बदलाव करना
इससे पता चलता है कि दो टेक्स्ट स्ट्रिंग एक-दूसरे से कितनी मिलती-जुलती हैं. मशीन लर्निंग में, बदलाव की दूरी इन वजहों से काम की होती है:
- बदलाव की दूरी का हिसाब लगाना आसान है.
- बदलाव की दूरी की सुविधा, दो ऐसी स्ट्रिंग की तुलना कर सकती है जो एक-दूसरे से मिलती-जुलती हों.
- बदलाव की दूरी से यह पता चलता है कि अलग-अलग स्ट्रिंग, किसी दी गई स्ट्रिंग से कितनी मिलती-जुलती हैं.
बदलाव की दूरी की कई परिभाषाएं हैं. हर परिभाषा में अलग-अलग स्ट्रिंग ऑपरेशन का इस्तेमाल किया जाता है. उदाहरण के लिए, लेवेंश्टाइन दूरी देखें.
एम्बेड करने वाली लेयर
एक खास हाइडन लेयर, जो कम डाइमेंशन वाले एम्बेडिंग वेक्टर को धीरे-धीरे सीखने के लिए, ज़्यादा डाइमेंशन वाली कैटगरी वाली सुविधा पर ट्रेन करती है. एम्बेडिंग लेयर की मदद से, न्यूरल नेटवर्क को सिर्फ़ कैटगरी वाली हाई-डाइमेंशनल सुविधा पर ट्रेनिंग देने के मुकाबले, ज़्यादा बेहतर तरीके से ट्रेन किया जा सकता है.
उदाहरण के लिए, Earth पर फ़िलहाल पेड़ों की करीब 73,000 प्रजातियों की जानकारी उपलब्ध है. मान लें कि आपके मॉडल में पेड़ की प्रजाति एक सुविधा है. इसलिए, आपके मॉडल की इनपुट लेयर में 73,000 एलिमेंट वाला वन-हॉट वेक्टर शामिल है.
उदाहरण के लिए, baobab को कुछ इस तरह दिखाया जाएगा:

73,000 एलिमेंट वाला कलेक्शन बहुत बड़ा है. अगर मॉडल में एम्बेडिंग लेयर नहीं जोड़ी जाती है, तो 72,999 शून्य को गुणा करने की वजह से, ट्रेनिंग में काफ़ी समय लगेगा. मान लें कि आपने एम्बेड करने वाली लेयर को 12 डाइमेंशन के साथ चुना है. इस वजह से, एम्बेडिंग लेयर धीरे-धीरे हर पेड़ की प्रजाति के लिए, एक नया एम्बेडिंग वेक्टर सीख लेगी.
कुछ मामलों में, एम्बेडिंग लेयर के बजाय हैश का इस्तेमाल करना बेहतर होता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में एम्बेड देखें.
स्पेस को एम्बेड करना
d-डाइमेंशन वाला वेक्टर स्पेस, जिसे ज़्यादा डाइमेंशन वाले वेक्टर स्पेस से मैप किया जाता है. आम तौर पर, एम्बेडिंग स्पेस में ऐसा स्ट्रक्चर होता है जिससे गणित के हिसाब से काम के नतीजे मिलते हैं. उदाहरण के लिए, किसी सही एम्बेडिंग स्पेस में, एम्बेडिंग को जोड़ने और घटाने से, शब्द से मिलते-जुलते शब्दों के टास्क हल किए जा सकते हैं.
दो एम्बेडमेंट के डॉट प्रॉडक्ट से उनकी समानता का पता चलता है.
एम्बेडिंग वेक्टर
आम तौर पर, यह किसी भी हाइडन लेयर से लिया गया, फ़्लोटिंग-पॉइंट नंबर का एक कलेक्शन होता है. यह उस हाइडन लेयर के इनपुट के बारे में बताता है. आम तौर पर, एम्बेडिंग वेक्टर, एम्बेडिंग लेयर में ट्रेन किए गए फ़्लोटिंग-पॉइंट नंबर का कलेक्शन होता है. उदाहरण के लिए, मान लें कि किसी एम्बेडिंग लेयर को पृथ्वी पर मौजूद 73,000 पेड़ों की हर प्रजाति के लिए एम्बेडिंग वेक्टर सीखना है. शायद यह ऐरे, बेओबैब ट्री के लिए एम्बेड किया गया वेक्टर है:

एम्बेडिंग वेक्टर, बेतरतीब नंबरों का ग्रुप नहीं होता. एम्बेडिंग लेयर, ट्रेनिंग की मदद से इन वैल्यू का पता लगाती है. यह उसी तरह होता है जिस तरह एक न्यूरल नेटवर्क, ट्रेनिंग के दौरान अन्य वेट सीखता है. ऐरे का हर एलिमेंट, किसी पेड़ की प्रजाति की किसी विशेषता के हिसाब से रेटिंग होती है. कौनसा एलिमेंट, पेड़ की किस प्रजाति की विशेषता को दिखाता है? यह तय करना बहुत मुश्किल है कि
एम्बेडिंग वेक्टर का गणितीय तौर पर सबसे अहम हिस्सा यह है कि मिलते-जुलते आइटम में फ़्लोटिंग-पॉइंट नंबर के मिलते-जुलते सेट होते हैं. उदाहरण के लिए, एक जैसी पेड़ की प्रजातियों के लिए, अलग-अलग पेड़ की प्रजातियों के मुकाबले फ़्लोटिंग-पॉइंट वाली संख्याओं का सेट ज़्यादा मिलता-जुलता होता है. रेडवुड और सिकोया, पेड़ की एक ही प्रजाति के हैं. इसलिए, इनके लिए फ़्लोटिंग-पॉइंट वाली संख्याओं का सेट, रेडवुड और नारियल के पेड़ों के मुकाबले ज़्यादा मिलता-जुलता होगा. हर बार मॉडल को फिर से ट्रेन करने पर, एम्बेडिंग वेक्टर में मौजूद संख्याएं बदल जाएंगी. भले ही, आपने मॉडल को एक जैसे इनपुट के साथ फिर से ट्रेन किया हो.
एन्कोडर
आम तौर पर, कोई भी एमएल सिस्टम जो रॉ, स्पैर्स या बाहरी डेटा को ज़्यादा प्रोसेस किए गए, ज़्यादा डेटा वाले या ज़्यादा इंटरनल डेटा में बदलता है.
आम तौर पर, एन्कोडर किसी बड़े मॉडल का कॉम्पोनेंट होता है. इसमें अक्सर डिकोडर के साथ जोड़ा जाता है. कुछ ट्रांसफ़ॉर्मर, एन्कोडर को डिकोडर के साथ जोड़ते हैं. हालांकि, कुछ ट्रांसफ़ॉर्मर सिर्फ़ एन्कोडर या सिर्फ़ डिकोडर का इस्तेमाल करते हैं.
कुछ सिस्टम, एन्कोडर के आउटपुट को क्लासिफ़िकेशन या रिग्रेशन नेटवर्क के इनपुट के तौर पर इस्तेमाल करते हैं.
सीक्वेंस-टू-सीक्वेंस टास्क में, एन्कोडर एक इनपुट सीक्वेंस लेता है और एक इंटरनल स्टेटस (वेक्टर) दिखाता है. इसके बाद, अगले क्रम का अनुमान लगाने के लिए, डिकोडर उस इंटरनल स्टेटस का इस्तेमाल करता है.
Transformer आर्किटेक्चर में एन्कोडर की परिभाषा के लिए, Transformer देखें.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में एलएलएम: लार्ज लैंग्वेज मॉडल क्या है देखें.
evals
इसका इस्तेमाल मुख्य रूप से एलएलएम के आकलन के लिए किया जाता है. ज़्यादा जानकारी के लिए, evals किसी भी तरह के इवैल्यूएशन का छोटा नाम है.
आकलन
किसी मॉडल की क्वालिटी को मेज़र करने या अलग-अलग मॉडल की तुलना करने की प्रोसेस.
सुपरवाइज़्ड मशीन लर्निंग मॉडल का आकलन करने के लिए, आम तौर पर पुष्टि करने वाले सेट और टेस्ट सेट के आधार पर इसका आकलन किया जाता है. एलएलएम का आकलन करने के लिए, आम तौर पर क्वालिटी और सुरक्षा से जुड़े बड़े आकलन किए जाते हैं.
F
उदाहरण के साथ डाले गए प्रॉम्प्ट
ऐसा प्रॉम्प्ट जिसमें एक से ज़्यादा (कुछ) उदाहरण शामिल हों. इनसे पता चलता हो कि लार्ज लैंग्वेज मॉडल को कैसे जवाब देना चाहिए. उदाहरण के लिए, यहां दिए गए लंबे प्रॉम्प्ट में दो उदाहरण दिए गए हैं. इनसे पता चलता है कि लार्ज लैंग्वेज मॉडल को क्वेरी का जवाब देने का तरीका कैसे बताया जाता है.
| एक प्रॉम्प्ट के हिस्से | नोट |
|---|---|
| चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब आपको एलएलएम से चाहिए. |
| फ़्रांस: यूरो | एक उदाहरण. |
| यूनाइटेड किंगडम: पाउंड स्टर्लिंग | एक और उदाहरण. |
| भारत: | असल क्वेरी. |
आम तौर पर, फ़्यू-शॉट प्रॉम्प्टिंग से, ज़ीरो-शॉट प्रॉम्प्टिंग और वन-शॉट प्रॉम्प्टिंग की तुलना में बेहतर नतीजे मिलते हैं. हालांकि, उदाहरण के साथ डाले गए प्रॉम्प्ट के लिए, लंबे प्रॉम्प्ट की ज़रूरत होती है.
उदाहरण के साथ डाले गए प्रॉम्प्ट, फ़ew-शॉट लर्निंग का एक फ़ॉर्म है. इसे प्रॉम्प्ट-आधारित लर्निंग पर लागू किया जाता है.
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में प्रॉम्प्ट को बेहतर बनाने की प्रोसेस देखें.
वायलिन
Python-first कॉन्फ़िगरेशन लाइब्रेरी, जो बिना किसी कोड या इन्फ़्रास्ट्रक्चर के फ़ंक्शन और क्लास की वैल्यू सेट करती है. Pax और अन्य एमएल कोडबेस के मामले में, ये फ़ंक्शन और क्लास मॉडल और ट्रेनिंग के हाइपरपैरामीटर दिखाते हैं.
Fiddle के हिसाब से, मशीन लर्निंग कोडबेस को आम तौर पर इनमें बांटा जाता है:
- लाइब्रेरी कोड, जो लेयर और ऑप्टिमाइज़र तय करता है.
- डेटासेट "ग्लू" कोड, जो लाइब्रेरी को कॉल करता है और सभी चीज़ों को एक साथ जोड़ता है.
Fiddle, ग्लू कोड के कॉल स्ट्रक्चर को बिना आकलन किए और बदले जा सकने वाले फ़ॉर्मैट में कैप्चर करता है.
फ़ाइन-ट्यूनिंग
पहले से ट्रेन किए गए मॉडल पर, टास्क के हिसाब से दूसरा ट्रेनिंग पास किया जाता है. इससे, किसी खास इस्तेमाल के उदाहरण के लिए, मॉडल के पैरामीटर को बेहतर बनाया जा सकता है. उदाहरण के लिए, कुछ बड़े लैंग्वेज मॉडल के लिए, ट्रेनिंग का पूरा क्रम इस तरह है:
- पहले से ट्रेनिंग: किसी बड़े लैंग्वेज मॉडल को बड़े सामान्य डेटासेट पर ट्रेन करें. जैसे, अंग्रेज़ी भाषा के सभी Wikipedia पेज.
- बेहतर बनाना: पहले से ट्रेन किए गए मॉडल को खास टास्क पूरा करने के लिए ट्रेन करना. जैसे, मेडिकल क्वेरी का जवाब देना. आम तौर पर, बेहतर बनाने की प्रोसेस में किसी खास टास्क पर फ़ोकस करने वाले सैकड़ों या हज़ारों उदाहरण शामिल होते हैं.
एक और उदाहरण के तौर पर, बड़ी इमेज वाले मॉडल के लिए ट्रेनिंग का पूरा क्रम इस तरह है:
- पहले से ट्रेनिंग: बड़े इमेज मॉडल को सामान्य इमेज डेटासेट पर ट्रेन करें. जैसे, Wikimedia Commons में मौजूद सभी इमेज.
- बेहतर बनाना: पहले से ट्रेन किए गए मॉडल को खास टास्क पूरा करने के लिए ट्रेन करें. जैसे, ऑर्का की इमेज जनरेट करना.
रणनीतियों को बेहतर बनाने के लिए, इनमें से किसी भी कॉम्बिनेशन का इस्तेमाल किया जा सकता है:
- पहले से ट्रेन किए गए मॉडल के मौजूदा पैरामीटर में सभी बदलाव करना. इसे कभी-कभी पूरी तरह से फ़ाइन-ट्यून करना भी कहा जाता है.
- पहले से ट्रेन किए गए मॉडल के मौजूदा पैरामीटर में से सिर्फ़ कुछ पैरामीटर में बदलाव करना (आम तौर पर, आउटपुट लेयर के सबसे करीब वाली लेयर), जबकि अन्य मौजूदा पैरामीटर में कोई बदलाव न करना (आम तौर पर, इनपुट लेयर के सबसे करीब वाली लेयर). पैरामीटर-बेहतर ट्यूनिंग देखें.
- ज़्यादा लेयर जोड़ना. आम तौर पर, ये लेयर आउटपुट लेयर के सबसे करीब मौजूद मौजूदा लेयर के ऊपर जोड़ी जाती हैं.
फ़ाइन-ट्यूनिंग, ट्रांसफ़र लर्निंग का एक तरीका है. इसलिए, फ़ाइन-ट्यूनिंग में, पहले से ट्रेन किए गए मॉडल को ट्रेन करने के लिए इस्तेमाल किए गए लॉस फ़ंक्शन या मॉडल टाइप के बजाय, किसी दूसरे लॉस फ़ंक्शन या मॉडल टाइप का इस्तेमाल किया जा सकता है. उदाहरण के लिए, पहले से ट्रेन किए गए बड़े इमेज मॉडल को बेहतर बनाकर, ऐसा रिग्रेशन मॉडल बनाया जा सकता है जो किसी इनपुट इमेज में पक्षियों की संख्या बताता है.
यहां दिए गए शब्दों के साथ, फ़ाइन-ट्यूनिंग की तुलना करें:
ज़्यादा जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स में बेहतर बनाना देखें.
फ़्लैक्स
JAX पर आधारित, बेहतर परफ़ॉर्मेंस वाली डीप लर्निंग के लिए बनाई गई ओपन सोर्स लाइब्रेरी. Flax, न्यूरल नेटवर्क को ट्रेनिंग देने के लिए फ़ंक्शन उपलब्ध कराता है. साथ ही, उनकी परफ़ॉर्मेंस का आकलन करने के तरीके भी उपलब्ध कराता है.
Flaxformer
Transformer पर आधारित, ओपन सोर्स Transformer लाइब्रेरी. इसे मुख्य रूप से, नैचुरल लैंग्वेज प्रोसेसिंग और मल्टीमोडल रिसर्च के लिए डिज़ाइन किया गया है.
G
Gemini
यह नेटवर्क, Google के सबसे बेहतर एआई से बना है. इस नेटवर्क में ये चीज़ें शामिल हैं:
- Gemini के अलग-अलग मॉडल.
- Gemini मॉडल के लिए, इंटरैक्टिव बातचीत वाला इंटरफ़ेस. उपयोगकर्ता प्रॉम्प्ट टाइप करते हैं और Gemini उन प्रॉम्प्ट का जवाब देता है.
- Gemini के अलग-अलग एपीआई.
- Gemini मॉडल पर आधारित कारोबार के लिए अलग-अलग प्रॉडक्ट. उदाहरण के लिए, Google Cloud के लिए Gemini.
Gemini मॉडल
Google के सबसे आधुनिक ट्रांसफ़ॉर्मर-आधारित मल्टीमोडल मॉडल. Gemini मॉडल को खास तौर पर, एजेंट के साथ इंटिग्रेट करने के लिए डिज़ाइन किया गया है.
उपयोगकर्ता, Gemini मॉडल के साथ कई तरीकों से इंटरैक्ट कर सकते हैं. जैसे, इंटरैक्टिव डायलॉग इंटरफ़ेस और SDKs की मदद से.
जनरेट किया गया टेक्स्ट
आम तौर पर, वह टेक्स्ट जो एमएल मॉडल से मिलता है. लार्ज लैंग्वेज मॉडल का आकलन करते समय, कुछ मेट्रिक जनरेट किए गए टेक्स्ट की तुलना रेफ़रंस टेक्स्ट से करती हैं. उदाहरण के लिए, मान लें कि आपको यह पता करना है कि एमएल मॉडल, फ़्रेंच से डच में कितनी असरदार तरीके से अनुवाद करता है. इस मामले में:
- जनरेट किया गया टेक्स्ट, डच भाषा में अनुवाद है, जो एमएल मॉडल से मिलता है.
- रेफ़रंस टेक्स्ट, डच भाषा में अनुवाद होता है. इसे कोई अनुवादक या सॉफ़्टवेयर बनाता है.
ध्यान दें कि आकलन की कुछ रणनीतियों में रेफ़रंस टेक्स्ट शामिल नहीं होता.
जनरेटिव एआई
यह एक ऐसा फ़ील्ड है जो बदलावों को बढ़ावा देता है. हालांकि, इसकी कोई आधिकारिक परिभाषा नहीं है. हालांकि, ज़्यादातर विशेषज्ञ इस बात से सहमत हैं कि जनरेटिव एआई मॉडल, ऐसा कॉन्टेंट बना सकते हैं ("जनरेट" कर सकते हैं) जो इन सभी चीज़ों के मुताबिक हो:
- जटिल
- एक-दूसरे से जुड़े हुए
- मूल
उदाहरण के लिए, जनरेटिव एआई मॉडल बेहतरीन तरह के लेख या इमेज बना सकता है.
LSTMs और RNNs जैसी कुछ पुरानी टेक्नोलॉजी से भी ओरिजनल और एक जैसा कॉन्टेंट जनरेट किया जा सकता है. कुछ विशेषज्ञ इन पुरानी टेक्नोलॉजी को जनरेटिव एआई मानते हैं, जबकि कुछ का मानना है कि असल जनरेटिव एआई के लिए, ज़्यादा जटिल आउटपुट की ज़रूरत होती है, जो इन पुरानी टेक्नोलॉजी से नहीं मिल सकता.
अनुमानित एमएल के साथ तुलना करें.
गोल्डन रिस्पॉन्स
ऐसा जवाब जो सही हो. उदाहरण के लिए, नीचे दिया गया प्रॉम्प्ट:
2 + 2
उम्मीद है कि आपका जवाब इस तरह का होगा:
4
जीपीटी (जनरेटिव प्री-ट्रेन्ड ट्रांसफ़ॉर्मर)
OpenAI ने Transformer पर आधारित लार्ज लैंग्वेज मॉडल का एक फ़ैमिली बनाया है.
GPT वैरिएंट, कई मोड पर लागू हो सकते हैं. इनमें ये शामिल हैं:
- इमेज जनरेशन (उदाहरण के लिए, ImageGPT)
- टेक्स्ट से इमेज जनरेट करने की सुविधा (उदाहरण के लिए, DALL-E).
H
मतिभ्रम
जनरेटिव एआई मॉडल से ऐसा आउटपुट जनरेट होना जो सही लगने के बावजूद, असल में गलत हो. यह मॉडल, असल दुनिया के बारे में दावा करता है. उदाहरण के लिए, जनरेटिव एआई मॉडल का यह दावा करना कि बराक ओबामा की मृत्यु 1865 में हो गई थी, गलत है.
मानवीय आकलन
यह एक ऐसी प्रोसेस है जिसमें लोग, एमएल मॉडल के आउटपुट की क्वालिटी का आकलन करते हैं. उदाहरण के लिए, दो भाषाओं के जानकार लोग, अनुवाद करने वाले एमएल मॉडल की क्वालिटी का आकलन करते हैं. मानवीय आकलन, खास तौर पर उन मॉडल का आकलन करने के लिए फ़ायदेमंद होता है जिनके लिए कोई एक सही जवाब नहीं होता.
अपने-आप होने वाले आकलन और अपने-आप रेटिंग देने वाले टूल के आकलन के साथ तुलना करें.
I
कॉन्टेक्स्ट के हिसाब से सीखना
उदाहरण के साथ डाले गए प्रॉम्प्ट का समानार्थी शब्द.
L
LaMDA (बातचीत आधारित ऐप्लिकेशन के लिए भाषा का मॉडल)
Transformer पर आधारित लार्ज लैंग्वेज मॉडल. इसे Google ने तैयार किया है. यह बड़े डायलॉग डेटासेट पर ट्रेन किया गया है. इससे बातचीत के हिसाब से सटीक जवाब जनरेट किए जा सकते हैं.
LaMDA: बातचीत की हमारी बेहतरीन टेक्नोलॉजी में इसकी खास जानकारी दी गई है.
लैंग्वेज मॉडल
यह एक मॉडल है, जो टोकन के लंबे क्रम में किसी टोकन या टोकन के क्रम के होने की संभावना का अनुमान लगाता है.
लार्ज लैंग्वेज मॉडल
कम से कम, ऐसा लैंग्वेज मॉडल जिसमें पैरामीटर की संख्या बहुत ज़्यादा हो. आम तौर पर, ट्रांसफ़ॉर्मर पर आधारित कोई भी भाषा मॉडल, जैसे कि Gemini या GPT.
लैटेंट स्पेस
स्पेस एम्बेड करना का समानार्थी शब्द.
लेवेंश्टाइन डिस्टेंस
बदलाव की दूरी मेट्रिक, जो एक शब्द को दूसरे में बदलने के लिए, मिटाने, डालने, और बदलने के कम से कम ऑपरेशन का हिसाब लगाती है. उदाहरण के लिए, "heart" और "darts" शब्दों के बीच का लेवनश्टाइन डिस्टेंस तीन है, क्योंकि एक शब्द को दूसरे में बदलने के लिए, यहां दिए गए तीन बदलाव सबसे कम हैं:
- heart → deart ("h" को "d" से बदलें)
- deart → dart ("e" मिटाएं)
- डार्ट → डार्ट ("s" डालें)
ध्यान दें कि तीन बदलावों का यह क्रम ही एकमात्र तरीका नहीं है.
LLM
लार्ज लैंग्वेज मॉडल का छोटा नाम.
एलएलएम के आकलन (evals)
लार्ज लैंग्वेज मॉडल (एलएलएम) की परफ़ॉर्मेंस का आकलन करने के लिए, मेट्रिक और मानदंडों का सेट. हाई लेवल पर, एलएलएम के आकलन:
- शोधकर्ताओं को उन क्षेत्रों की पहचान करने में मदद करना जहां एलएलएम में सुधार की ज़रूरत है.
- ये अलग-अलग एलएलएम की तुलना करने और किसी खास टास्क के लिए सबसे अच्छे एलएलएम की पहचान करने में मदद करते हैं.
- यह पक्का करने में मदद मिलती है कि एलएलएम का इस्तेमाल सुरक्षित और सही तरीके से किया जा रहा है.
LoRA
कम रैंक के लिए अडैप्ट करने की सुविधा का छोटा नाम.
कम रैंक वाला अडैप्टैबिलिटी (LoRA)
बेहतर बनाने के लिए, पैरामीटर के हिसाब से बेहतर तकनीक. यह मॉडल के पहले से ट्रेन किए गए वज़न को "फ़्रीज़" कर देती है, ताकि उनमें बदलाव न किया जा सके. इसके बाद, मॉडल में ट्रेन किए जा सकने वाले वज़न का एक छोटा सेट डालती है. ट्रेन किए जा सकने वाले वेट का यह सेट, बेस मॉडल से काफ़ी छोटा होता है. इसलिए, इसे ट्रेन करने में काफ़ी कम समय लगता है. इसे "अपडेट मैट्रिक" भी कहा जाता है.
LoRA से ये फ़ायदे मिलते हैं:
- इससे उस डोमेन के लिए मॉडल के अनुमान की क्वालिटी बेहतर होती है जहां फ़ाइन-ट्यूनिंग लागू की जाती है.
- यह उन तकनीकों की तुलना में तेज़ी से फ़ाइन-ट्यून करता है जिनमें मॉडल के सभी पैरामीटर को फ़ाइन-ट्यून करना पड़ता है.
- एक ही बेस मॉडल को शेयर करने वाले कई खास मॉडल को एक साथ दिखाने की सुविधा चालू करके, अनुमान लगाने के लिए कंप्यूटेशनल लागत को कम करता है.
M
मास्क किया गया लैंग्वेज मॉडल
यह एक भाषा मॉडल है, जो किसी क्रम में खाली जगहों को भरने के लिए, उम्मीदवार टोकनों की संभावना का अनुमान लगाता है. उदाहरण के लिए, मास्क किया गया भाषा मॉडल, नीचे दिए गए वाक्य में अंडरलाइन किए गए शब्दों की जगह, संभावित शब्दों की संभावनाओं का हिसाब लगा सकता है:
टोपी में मौजूद ____ वापस आ गया.
आम तौर पर, दस्तावेज़ में अंडरलाइन के बजाय स्ट्रिंग "MASK" का इस्तेमाल किया जाता है. उदाहरण के लिए:
टोपी में "MASK" वापस आ गया.
ज़्यादातर आधुनिक मास्क किए गए भाषा मॉडल, दोतरफ़ा होते हैं.
k पर औसत सटीक अनुमान (mAP@k)
पुष्टि करने वाले डेटासेट में, सभी k पर औसत सटीक नतीजे के स्कोर का आंकड़ों के हिसाब से औसत. k पर औसत सटीकता का एक इस्तेमाल, सुझाव देने वाले सिस्टम से जनरेट किए गए सुझावों की क्वालिटी का आकलन करना है.
"औसत" वाक्यांश का इस्तेमाल करना ज़रूरी नहीं है, लेकिन मेट्रिक का नाम सही है. आखिरकार, यह मेट्रिक कई k पर औसत सटीक वैल्यू का औसत ढूंढती है.
मेटा-लर्निंग
मशीन लर्निंग का एक सबसेट, जो लर्निंग एल्गोरिदम को खोजता है या उसे बेहतर बनाता है. मेटा-लर्निंग सिस्टम का मकसद, किसी मॉडल को ट्रेनिंग देना भी हो सकता है, ताकि वह कम डेटा या पिछले टास्क से मिले अनुभव से, नया टास्क तेज़ी से सीख सके. मेटा-लर्निंग एल्गोरिदम आम तौर पर ये काम करने की कोशिश करते हैं:
- मैन्युअल तरीके से बनाई गई सुविधाओं (जैसे, शुरू करने वाला टूल या ऑप्टिमाइज़र) को बेहतर बनाएं या उनके बारे में जानें.
- डेटा और कंप्यूट के लिए ज़्यादा कुशल हों.
- सामान्यीकरण को बेहतर बनाना.
मेटा-लर्निंग, फ़्यू-शॉट लर्निंग से जुड़ा है.
विशेषज्ञों का मिश्रण
न्यूरल नेटवर्क की परफ़ॉर्मेंस को बेहतर बनाने के लिए बनाई गई एक योजना. इसमें, किसी दिए गए इनपुट टोकन या उदाहरण को प्रोसेस करने के लिए, इसके पैरामीटर (जिन्हें एक्सपर्ट कहा जाता है) के सिर्फ़ सबसेट का इस्तेमाल किया जाता है. गेटिंग नेटवर्क, हर इनपुट टोकन या उदाहरण को सही विशेषज्ञों को भेजता है.
ज़्यादा जानकारी के लिए, इनमें से कोई एक पेपर देखें:
- बहुत बड़े न्यूरल नेटवर्क: कम गेट वाली विशेषज्ञों की लेयर
- विशेषज्ञों की पसंद के हिसाब से रूटिंग के साथ, विशेषज्ञों का मिश्रण
MMIT
मल्टीमोडल निर्देश-ट्यून के लिए छोटा नाम.
मोडैलिटी
डेटा की हाई-लेवल कैटगरी. उदाहरण के लिए, संख्याएं, टेक्स्ट, इमेज, वीडियो, और ऑडियो, पांच अलग-अलग मोड हैं.
मॉडल पैरलललिज़्म
ट्रेनिंग या अनुमान लगाने की प्रोसेस को स्केल करने का एक तरीका, जिसमें एक मॉडल के अलग-अलग हिस्सों को अलग-अलग डिवाइसों पर डाला जाता है. मॉडल के पैरलल प्रोसेस की सुविधा, ऐसे मॉडल को इस्तेमाल करने की अनुमति देती है जो एक ही डिवाइस में फ़िट नहीं होते.
मॉडल पैरलललिज़्म लागू करने के लिए, सिस्टम आम तौर पर ये काम करता है:
- मॉडल को छोटे-छोटे हिस्सों में बांटता है.
- इन छोटे हिस्सों की ट्रेनिंग को कई प्रोसेसर पर बांटता है. हर प्रोसेसर, मॉडल के अपने हिस्से को ट्रेन करता है.
- एक मॉडल बनाने के लिए, नतीजों को जोड़ता है.
मॉडल के पैरलल प्रोसेस होने की वजह से, ट्रेनिंग धीमी हो जाती है.
डेटा पैरलेलिज्म भी देखें.
MOE
विशेषज्ञों के मिश्रण का छोटा नाम.
मल्टी-हेड सेल्फ़-अटेंशन
सेल्फ़-अटेंशन का एक एक्सटेंशन, जो इनपुट क्रम में हर पोज़िशन के लिए, सेल्फ़-अटेंशन मैकेनिज्म को कई बार लागू करता है.
Transformers ने मल्टी-हेड सेल्फ़-अटेंशन की सुविधा शुरू की.
मल्टीमोडल निर्देशों के हिसाब से ट्यून किया गया
निर्देश के हिसाब से बनाया गया मॉडल, जो टेक्स्ट के अलावा इमेज, वीडियो, और ऑडियो जैसे इनपुट को भी प्रोसेस कर सकता है.
मल्टीमोडल मॉडल
ऐसा मॉडल जिसके इनपुट और/या आउटपुट में एक से ज़्यादा मोड शामिल होते हैं. उदाहरण के लिए, एक ऐसे मॉडल पर विचार करें जो इमेज और टेक्स्ट कैप्शन, दोनों को सुविधाओं के तौर पर लेता है. साथ ही, यह एक स्कोर दिखाता है, जिससे पता चलता है कि टेक्स्ट कैप्शन, इमेज के लिए कितना सही है. इसलिए, इस मॉडल के इनपुट मल्टीमोडल होते हैं और आउटपुट यूनिमोडल होता है.
नहीं
नैचुरल लैंग्वेज प्रोसेसिंग
कंप्यूटर को यह सिखाने का तरीका कि वह भाषा के नियमों का इस्तेमाल करके, उपयोगकर्ता के बोले या टाइप किए गए शब्दों को प्रोसेस करे. नैचुरल लैंग्वेज प्रोसेसिंग की तकरीबन सभी आधुनिक सुविधाएं, मशीन लर्निंग पर निर्भर करती हैं.नैचुरल लैंग्वेज अंडरस्टैंडिंग
नैचुरल लैंग्वेज प्रोसेसिंग का सबसेट, जो बोले गए या टाइप किए गए किसी वाक्य के इरादे का पता लगाता है. नैचुरल लैंग्वेज प्रोसेसिंग के अलावा, नैचुरल लैंग्वेज अंडरस्टैंडिंग की मदद से, भाषा के जटिल पहलुओं को समझा जा सकता है. जैसे, संदर्भ, व्यंग्य, और भावना.
एन-ग्राम
N शब्दों का क्रम. उदाहरण के लिए, truly madly एक दो-ग्राम है. क्रम का ज़रूरी होना, madly truly को truly madly से अलग बनाता है.
| नहीं | इस तरह के एन-ग्राम का नाम | उदाहरण |
|---|---|---|
| 2 | बिग्राम या दो वर्णों वाला ग्रुप | जाना, जाना, लंच करना, डिनर करना |
| 3 | ट्रिग्रम या तीन वर्णों का ग्रुप | ate too much, three blind mice, the bell tolls |
| 4 | 4-gram | पार्क में टहलना, हवा में धूल उड़ना, लड़के ने दाल खाना |
सामान्य भाषा को समझने वाले कई मॉडल, उपयोगकर्ता के टाइप किए गए या बोले गए अगले शब्द का अनुमान लगाने के लिए, एन-ग्राम पर भरोसा करते हैं. उदाहरण के लिए, मान लें कि किसी उपयोगकर्ता ने three blind टाइप किया. ट्राइग्राम पर आधारित एनएलयू मॉडल, इस बात का अनुमान लगा सकता है कि उपयोगकर्ता अगले शब्द के तौर पर चूहे टाइप करेगा.
एन-ग्राम की तुलना बैग ऑफ़ वर्ड से करें. ये शब्दों के क्रम से लगाए गए सेट होते हैं.
एनएलपी
नैचुरल लैंग्वेज प्रोसेसिंग का छोटा नाम.
एनएलयू
नैचुरल लैंग्वेज अंडरस्टैंडिंग का छोटा नाम.
कोई एक सही जवाब नहीं है (NORA)
ऐसा प्रॉम्प्ट जिसमें एक से ज़्यादा सही जवाब हों. उदाहरण के लिए, इस प्रॉम्प्ट का कोई एक सही जवाब नहीं है:
मुझे हाथियों के बारे में कोई चुटकुला सुनाओ.
जिन सवालों का कोई सही जवाब नहीं होता उनके लिए, एलिमेंट का आकलन करना मुश्किल हो सकता है.
NORA
कोई सही जवाब नहीं है का छोटा रूप.
O
वन-शॉट प्रॉम्प्ट
प्रॉम्प्ट, जिसमें एक उदाहरण शामिल है. इससे पता चलता है कि लार्ज लैंग्वेज मॉडल को किस तरह जवाब देना चाहिए. उदाहरण के लिए, यहां दिए गए प्रॉम्प्ट में एक उदाहरण दिया गया है. इसमें लार्ज लैंग्वेज मॉडल को यह दिखाया गया है कि उसे किसी क्वेरी का जवाब कैसे देना चाहिए.
| एक प्रॉम्प्ट के हिस्से | नोट |
|---|---|
| चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब आपको एलएलएम से चाहिए. |
| फ़्रांस: यूरो | एक उदाहरण. |
| भारत: | असल क्वेरी. |
एक बार में प्रॉम्प्ट करने की सुविधा की तुलना इन शब्दों से करें:
P
पैरामीटर-इफ़िशिएंट ट्यूनिंग
पहले से ट्रेन किए गए भाषा मॉडल (पीएलएम) को पूरी तरह से फ़ाइन-ट्यून करने के मुकाबले, ज़्यादा असरदार तरीके से फ़ाइन-ट्यून करने के लिए तकनीकों का सेट. पैरामीटर के हिसाब से बेहतर ट्यूनिंग, आम तौर पर पूरे फ़ाइन-ट्यूनिंग की तुलना में बहुत कम पैरामीटर को फ़ाइन-ट्यून करती है. इसके बावजूद, आम तौर पर यह एक ऐसा बड़ा लैंग्वेज मॉडल बनाती है जो पूरे फ़ाइन-ट्यूनिंग से बनाए गए बड़े लैंग्वेज मॉडल की तरह ही परफ़ॉर्म करता है या लगभग वैसा ही परफ़ॉर्म करता है.
पैरामीटर-इफ़िशिएंट ट्यूनिंग की तुलना इनसे करें:
पैरामीटर-इफ़िशिएंट ट्यूनिंग को पैरामीटर-इफ़िशिएंट फ़ाइन-ट्यूनिंग भी कहा जाता है.
पाइपलाइन
मॉडल के पैरलल प्रोसेसिंग का एक फ़ॉर्म, जिसमें मॉडल की प्रोसेसिंग को लगातार चरण में बांटा जाता है और हर चरण को अलग-अलग डिवाइस पर चलाया जाता है. जब कोई चरण एक बैच को प्रोसेस कर रहा होता है, तब पिछला चरण अगले बैच पर काम कर सकता है.
स्टेज की गई ट्रेनिंग भी देखें.
PLM
पहले से ट्रेन किए गए लैंग्वेज मॉडल का छोटा नाम.
पोज़िशनल कोड
टोकन को एम्बेड करने के लिए, किसी क्रम में टोकन की स्थिति की जानकारी जोड़ने की तकनीक. ट्रांसफ़ॉर्मर मॉडल, पोज़िशनल एन्कोडिंग का इस्तेमाल करके, क्रम के अलग-अलग हिस्सों के बीच के संबंध को बेहतर तरीके से समझते हैं.
पोज़िशनल कोडिंग को लागू करने के लिए, आम तौर पर साइनस फ़ंक्शन का इस्तेमाल किया जाता है. (खास तौर पर, साइनसोइडल फ़ंक्शन की फ़्रीक्वेंसी और ऐम्प्ल्यट्यूड, क्रम में टोकन की पोज़िशन से तय होता है.) इस तकनीक की मदद से, ट्रांसफ़ॉर्मर मॉडल, क्रम के अलग-अलग हिस्सों पर ध्यान देना सीखता है.
ट्रेनिंग के बाद का मॉडल
यह एक ऐसा शब्द है जिसे अलग-अलग तरीके से परिभाषित किया जा सकता है. आम तौर पर, इसका मतलब पहले से ट्रेन किए गए मॉडल से होता है, जिसे पोस्ट-प्रोसेसिंग के कुछ चरणों से गुज़रना पड़ा है. जैसे, इनमें से एक या एक से ज़्यादा चरण:
k पर सटीक (precision@k)
आइटम की रैंक वाली सूची का आकलन करने वाली मेट्रिक. k पर सटीक नतीजे, सूची में पहले k आइटम में से "काम के" आइटम के हिस्से की पहचान करते हैं. यानी:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
k की वैल्यू, लिस्ट में मौजूद आइटम की संख्या से कम या उसके बराबर होनी चाहिए. ध्यान दें कि लौटाई गई सूची की लंबाई, हिसाब लगाने का हिस्सा नहीं है.
काम का होना या न होना, अक्सर व्यक्तिगत राय पर निर्भर करता है. विश्लेषक भी अक्सर इस बात पर सहमत नहीं होते कि कौनसे आइटम काम के हैं.
इसके साथ तुलना करें:
पहले से ट्रेन किया गया मॉडल
आम तौर पर, ऐसा मॉडल जिसे पहले ही ट्रेन किया जा चुका है. इस शब्द का मतलब, पहले से ट्रेन किए गए एम्बेडिंग वेक्टर से भी हो सकता है.
पहले से ट्रेन किए गए लैंग्वेज मॉडल का मतलब आम तौर पर, पहले से ट्रेन किए गए बड़े लैंग्वेज मॉडल से होता है.
प्री-ट्रेनिंग
बड़े डेटासेट पर मॉडल की शुरुआती ट्रेनिंग. पहले से ट्रेन किए गए कुछ मॉडल, बड़े और जटिल होते हैं. आम तौर पर, उन्हें अतिरिक्त ट्रेनिंग देकर बेहतर बनाया जाता है. उदाहरण के लिए, एमएल विशेषज्ञ किसी बड़े टेक्स्ट डेटासेट पर, बड़े लैंग्वेज मॉडल को पहले से ट्रेन कर सकते हैं. जैसे, विकिपीडिया के सभी अंग्रेज़ी पेज. प्री-ट्रेनिंग के बाद, इनमें से किसी भी तकनीक का इस्तेमाल करके, मॉडल को और बेहतर बनाया जा सकता है:
प्रॉम्प्ट
लार्ज लैंग्वेज मॉडल के लिए इनपुट के तौर पर डाला गया कोई भी टेक्स्ट, ताकि मॉडल किसी खास तरीके से काम कर सके. प्रॉम्प्ट, किसी वाक्यांश जितना छोटा या ज़रूरत के हिसाब से लंबा हो सकता है. उदाहरण के लिए, किसी उपन्यास का पूरा टेक्स्ट. प्रॉम्प्ट कई कैटगरी में आते हैं. इनमें से कुछ कैटगरी नीचे दी गई टेबल में दिखाई गई हैं:
| प्रॉम्प्ट की कैटगरी | उदाहरण | नोट |
|---|---|---|
| सवाल | कबूतर कितनी तेज़ी से उड़ सकता है? | |
| निर्देश | अरेबिट्रेज के बारे में कोई मज़ेदार कविता लिखें. | ऐसा प्रॉम्प्ट जिसमें लार्ज लैंग्वेज मॉडल से कुछ करने के लिए कहा जाता है. |
| उदाहरण | Markdown कोड को एचटीएमएल में बदलें. उदाहरण के लिए:
Markdown: * सूची का आइटम एचटीएमएल: <ul> <li>सूची का आइटम</li> </ul> |
इस उदाहरण वाले प्रॉम्प्ट का पहला वाक्य एक निर्देश है. प्रॉम्प्ट का बाकी हिस्सा उदाहरण है. |
| भूमिका | बताएं कि भौतिकी में पीएचडी करने के लिए, मशीन लर्निंग ट्रेनिंग में ग्रेडिएंट डिसेंट का इस्तेमाल क्यों किया जाता है. | वाक्य का पहला हिस्सा निर्देश है; "भौतिकी में पीएचडी" वाला वाक्यांश, भूमिका का हिस्सा है. |
| मॉडल को पूरा करने के लिए, कुछ इनपुट | यूनाइटेड किंगडम के प्रधानमंत्री का घर | कुछ हिस्से वाला इनपुट प्रॉम्प्ट, अचानक खत्म हो सकता है (जैसा कि इस उदाहरण में है) या अंडरस्कोर के साथ खत्म हो सकता है. |
जनरेटिव एआई मॉडल, टेक्स्ट, कोड, इमेज, एम्बेड, वीडियो वगैरह के साथ प्रॉम्प्ट का जवाब दे सकता है.
प्रॉम्प्ट-आधारित लर्निंग
यह कुछ मॉडल की एक सुविधा है. इसकी मदद से, वे अपने व्यवहार में बदलाव कर सकते हैं, ताकि वे किसी भी टेक्स्ट इनपुट (प्रॉम्प्ट) के जवाब में सही जवाब दे सकें. प्रॉम्प्ट पर आधारित लर्निंग पैराडाइम में, लार्ज लैंग्वेज मॉडल, टेक्स्ट जनरेट करके प्रॉम्प्ट का जवाब देता है. उदाहरण के लिए, मान लें कि कोई उपयोगकर्ता यह प्रॉम्प्ट डालता है:
न्यूटन के गति के तीसरे नियम के बारे में खास जानकारी दें.
प्रॉम्प्ट के आधार पर लर्निंग करने वाले मॉडल को, पिछले प्रॉम्प्ट के जवाब देने के लिए खास तौर पर ट्रेनिंग नहीं दी जाती. इसके बजाय, मॉडल को भौतिकी के बारे में काफ़ी तथ्य "मालूम" हैं. साथ ही, उसे भाषा के सामान्य नियमों और आम तौर पर काम के जवाबों के बारे में काफ़ी जानकारी है. इस जानकारी से, उम्मीद है कि आपको काम का जवाब मिल जाएगा. लोगों के सुझाव, शिकायत या राय ("वह जवाब बहुत मुश्किल था" या "प्रतिक्रिया क्या है?") से, प्रॉम्प्ट पर आधारित लर्निंग सिस्टम को अपने जवाबों को धीरे-धीरे बेहतर बनाने में मदद मिलती है.
प्रॉम्प्ट डिज़ाइन
प्रॉम्प्ट इंजीनियरिंग का समानार्थी शब्द.
प्रॉम्प्ट इंजीनियरिंग
प्रॉम्प्ट बनाने की कला, जो लार्ज लैंग्वेज मॉडल से मनमुताबिक जवाब पाने में मदद करते हैं. प्रॉम्प्ट को इंसान बनाते हैं. लार्ज लैंग्वेज मॉडल से काम के जवाब पाने के लिए, सही तरीके से बनाए गए प्रॉम्प्ट लिखना ज़रूरी है. प्रॉम्प्ट इंजीनियरिंग कई बातों पर निर्भर करती है. जैसे:
- लार्ज लैंग्वेज मॉडल को पहले से ट्रेन करने और शायद बेहतर बनाने के लिए इस्तेमाल किया जाने वाला डेटासेट.
- temperature और डिकोड करने से जुड़े अन्य पैरामीटर, जिनका इस्तेमाल मॉडल जवाब जनरेट करने के लिए करता है.
मददगार प्रॉम्प्ट लिखने के बारे में ज़्यादा जानने के लिए, प्रॉम्प्ट डिज़ाइन के बारे में जानकारी देखें.
प्रॉम्प्ट डिज़ाइन, प्रॉम्प्ट इंजीनियरिंग का दूसरा नाम है.
प्रॉम्प्ट ट्यूनिंग
पैरामीटर को बेहतर तरीके से ट्यून करने का एक तरीका, जो "प्रीफ़िक्स" को सीखता है. सिस्टम, प्रॉम्प्ट के पहले इस प्रीफ़िक्स को जोड़ता है.
प्रॉम्प्ट ट्यूनिंग का एक वैरिएशन, प्रीफ़िक्स ट्यूनिंग है. इसमें हर लेयर में प्रीफ़िक्स जोड़ा जाता है. इसके उलट, ज़्यादातर प्रॉम्प्ट ट्यूनिंग सिर्फ़ इनपुट लेयर में प्रीफ़िक्स जोड़ती है.
R
k पर रीकॉल (recall@k)
आइटम की रैंक वाली सूची दिखाने वाले सिस्टम का आकलन करने वाली मेट्रिक. k पर रीकॉल, सूची में मौजूद काम के आइटम की कुल संख्या में से, पहले k आइटम में मौजूद काम के आइटम के हिस्से की पहचान करता है.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
k पर सटीक के साथ कंट्रास्ट करें.
रेफ़रंस टेक्स्ट
प्रॉम्प्ट के लिए विशेषज्ञ का जवाब. उदाहरण के लिए, यह प्रॉम्प्ट दिया गया है:
"आपका नाम क्या है?" सवाल को अंग्रेज़ी से फ़्रेंच में अनुवाद करें.
विशेषज्ञ का जवाब इस तरह का हो सकता है:
Comment vous appelez-vous?
ROUGE जैसी अलग-अलग मेट्रिक से यह पता चलता है कि रेफ़रंस टेक्स्ट, एमएल मॉडल के जनरेट किए गए टेक्स्ट से कितना मैच करता है.
भूमिका के लिए निर्देश
प्रॉम्प्ट का एक वैकल्पिक हिस्सा, जो जनरेटिव एआई मॉडल के जवाब के लिए टारगेट ऑडियंस की पहचान करता है. भूमिका के प्रॉम्प्ट बिना, लार्ज लैंग्वेज मॉडल ऐसा जवाब देता है जो सवाल पूछने वाले व्यक्ति के लिए मददगार हो सकता है या नहीं. भूमिका के हिसाब से प्रॉम्प्ट की मदद से, लार्ज लैंग्वेज मॉडल किसी खास टारगेट ऑडियंस के लिए ज़्यादा सही और मददगार जवाब दे सकता है. उदाहरण के लिए, यहां दिए गए प्रॉम्प्ट में भूमिका से जुड़ा प्रॉम्प्ट, बोल्ड फ़ॉन्ट में है:
- इकोनॉमिक्स में पीएचडी के लिए, इस लेख का खास हिस्सा बताएं.
- दस साल के बच्चे के लिए बताएं कि ज्वार कैसे काम करते हैं.
- साल 2008 के वित्तीय संकट के बारे में बताएं. जैसे किसी छोटे बच्चे या गोल्डन रिट्रीवर से बात की जाती है वैसे ही बोलें.
आरओयूजीई (गिसटिंग इवैलुएशन के लिए रीकॉल-ओरिएंटेड अंडरस्टडी)
मेट्रिक का एक फ़ैमिली, जो अपने-आप खास जानकारी देने और मशीन से अनुवाद करने वाले मॉडल का आकलन करता है. ROUGE मेट्रिक से यह पता चलता है कि रेफ़रंस टेक्स्ट, एमएल मॉडल के जनरेट किए गए टेक्स्ट से कितना ओवरलैप होता है. ROUGE परिवार के हर सदस्य के मेज़रमेंट अलग-अलग तरीके से ओवरलैप होते हैं. ROUGE के ज़्यादा स्कोर से पता चलता है कि रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट के बीच, कम स्कोर के मुकाबले ज़्यादा समानता है.
आम तौर पर, ROUGE परिवार का हर सदस्य ये मेट्रिक जनरेट करता है:
- स्पष्टता
- रीकॉल
- F1
ज़्यादा जानकारी और उदाहरणों के लिए, यहां जाएं:
ROUGE-L
ROUGE फ़ैमिली का एक सदस्य, जो रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में, सबसे लंबे कॉमन सबसिक्वेंस की लंबाई पर फ़ोकस करता है. नीचे दिए गए फ़ॉर्मूले, ROUGE-L के लिए रीकॉल और सटीकता का हिसाब लगाते हैं:
इसके बाद, F1 का इस्तेमाल करके, ROUGE-L रिकॉल और ROUGE-L प्रिसिज़न को एक ही मेट्रिक में रोल अप किया जा सकता है:
ROUGE-L, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में मौजूद किसी भी नई लाइन को अनदेखा करता है. इसलिए, सबसे लंबा कॉमन सबसीक्वेंस एक से ज़्यादा वाक्यों में हो सकता है. जब रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में कई वाक्य होते हैं, तो आम तौर पर ROUGE-Lsum नाम का ROUGE-L का वैरिएशन एक बेहतर मेट्रिक होती है. ROUGE-Lsum, किसी पैसेज में मौजूद हर वाक्य के लिए सबसे लंबा सामान्य सबसिक्वेंस तय करता है. इसके बाद, उन सबसे लंबे सामान्य सबसिक्वेंस का औसत निकालता है.
ROUGE-N
ROUGE फ़ैमिली में मौजूद मेट्रिक का एक सेट, जो रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में, किसी खास साइज़ के शेयर किए गए N-gram की तुलना करता है. उदाहरण के लिए:
- ROUGE-1, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में शेयर किए गए टोकन की संख्या को मेज़र करता है.
- ROUGE-2, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में, शेयर किए गए बिग्राम (2-ग्राम) की संख्या को मेज़र करता है.
- ROUGE-3, रेफ़रंस टेक्स्ट और जनरेट किए गए टेक्स्ट में, शेयर किए गए ट्राइग्राम (3-ग्राम) की संख्या का आकलन करता है.
ROUGE-N फ़ैमिली के किसी भी सदस्य के लिए, ROUGE-N रीकॉल और ROUGE-N प्रिसिज़न का हिसाब लगाने के लिए, नीचे दिए गए फ़ॉर्मूले का इस्तेमाल किया जा सकता है:
इसके बाद, F1 का इस्तेमाल करके, ROUGE-N रिकॉल और ROUGE-N प्रिसीज़न को एक ही मेट्रिक में रोल अप किया जा सकता है:
ROUGE-S
ROUGE-N का एक ऐसा वर्शन जिसमें स्किप-ग्राम मैचिंग की सुविधा होती है. इसका मतलब है कि ROUGE-N सिर्फ़ उन N-ग्राम की गिनती करता है जो एग्ज़ैक्ट मैच करते हैं. हालांकि, ROUGE-S उन N-ग्राम की भी गिनती करता है जो एक या उससे ज़्यादा शब्दों से अलग होते हैं. उदाहरण के लिए, आप नीचे दिया गया तरीका अपना सकते हैं:
- रेफ़रंस टेक्स्ट: सफ़ेद बादल
- जनरेट किया गया टेक्स्ट: सफ़ेद रंग के बादल
ROUGE-N का हिसाब लगाते समय, दो ग्राम वाला सफ़ेद बादल, सफ़ेद बादल से मेल नहीं खाता. हालांकि, ROUGE-S का हिसाब लगाते समय, सफ़ेद बादल और सफ़ेद बादल एक-दूसरे से मेल खाते हैं.
S
सेल्फ़-अटेंशन (इसे सेल्फ़-अटेंशन लेयर भी कहा जाता है)
एक न्यूरल नेटवर्क लेयर, जो एम्बेडिंग के क्रम (उदाहरण के लिए, टोकन एम्बेडिंग) को एम्बेडिंग के दूसरे क्रम में बदल देती है. आउटपुट क्रम में मौजूद हर एम्बेडिंग को, ध्यान वाले तरीके से इनपुट क्रम के एलिमेंट की जानकारी को इंटिग्रेट करके बनाया जाता है.
सेल्फ़-अटेन्शन के सेल्फ़ हिस्से का मतलब, किसी दूसरे कॉन्टेक्स्ट के बजाय, खुद पर ध्यान देने वाले क्रम से है. सेल्फ़-अटेन्शन, Transformers के मुख्य बिल्डिंग ब्लॉक में से एक है. यह "क्वेरी", "की", और "वैल्यू" जैसी डिक्शनरी लुकअप टर्म का इस्तेमाल करता है.
सेल्फ़-अटेंशन लेयर, इनपुट रिप्रज़ेंटेशन के क्रम से शुरू होती है. हर शब्द के लिए एक रिप्रज़ेंटेशन होता है. किसी शब्द के लिए इनपुट का प्रतिनिधित्व, एक आसान एम्बेडिंग हो सकता है. किसी इनपुट क्रम में मौजूद हर शब्द के लिए, नेटवर्क, शब्दों के पूरे क्रम में मौजूद हर एलिमेंट के लिए, शब्द के काम के होने का स्कोर तय करता है. काम के होने के आधार पर मिलने वाले स्कोर से यह तय होता है कि शब्द के आखिरी वर्शन में, दूसरे शब्दों के वर्शन कितने शामिल हैं.
उदाहरण के लिए, नीचे दिया गया वाक्य देखें:
जानवर बहुत थक गया था, इसलिए वह सड़क पार नहीं कर पाया.
यहां दी गई इमेज (Transformer: A Novel Neural Network Architecture for Language Understanding से ली गई है) में, सर्वनाम it के लिए, सेल्फ़-अटेन्शन लेयर का अटेन्शन पैटर्न दिखाया गया है. हर लाइन के गहरे रंग से पता चलता है कि हर शब्द, प्रॉडक्ट के बारे में बताने में कितना योगदान देता है:
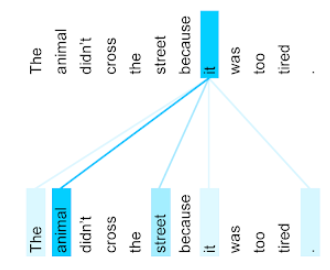
सेल्फ़-अटेन्शन लेयर, "it" से जुड़े शब्दों को हाइलाइट करती है. इस मामले में, ऐटेंशन लेयर ने उन शब्दों को हाइलाइट करना सीख लिया है जिनका यह इस्तेमाल कर सकती है. साथ ही, जानवर को सबसे ज़्यादा अहमियत दी गई है.
n टोकन के सीक्वेंस के लिए, सेल्फ़-अटेंशन एल्गोरिदम, एम्बेड के सीक्वेंस को n अलग-अलग बार बदलता है. यह बदलाव, सीक्वेंस में हर पोज़िशन पर एक बार होता है.
ध्यान और मल्टी-हेड सेल्फ़-अटेंशन के बारे में भी पढ़ें.
भावनाओं का विश्लेषण
किसी सेवा, प्रॉडक्ट, संगठन या विषय के लिए, किसी ग्रुप के ज़्यादातर लोगों के सकारात्मक या नेगेटिव नज़रिए का पता लगाने के लिए, आंकड़ों या मशीन लर्निंग एल्गोरिदम का इस्तेमाल करना. उदाहरण के लिए, नैचुरल लैंग्वेज यूंडरस्टैंडिंग का इस्तेमाल करके, एल्गोरिदम किसी यूनिवर्सिटी कोर्स के टेक्स्ट वाले सुझावों या राय पर सेंटिमेंट का विश्लेषण कर सकता है. इससे यह पता चलता है कि आम तौर पर, छात्र-छात्राओं को कोर्स कितना पसंद आया या नापसंद आया.
सीक्वेंस-टू-सीक्वेंस टास्क
यह एक ऐसा टास्क है जो टोकन के इनपुट क्रम को टोकन के आउटपुट क्रम में बदलता है. उदाहरण के लिए, सीक्वेंस-टू-सीक्वेंस के दो लोकप्रिय टास्क ये हैं:
- अनुवादक:
- इनपुट क्रम का सैंपल: "मुझे आपसे प्यार है."
- आउटपुट के क्रम का सैंपल: "Je t'aime."
- सवालों के जवाब देना:
- इनपुट क्रम का सैंपल: "क्या मुझे न्यूयॉर्क सिटी में अपनी कार की ज़रूरत है?"
- आउटपुट के क्रम का सैंपल: "नहीं. कृपया अपनी कार घर पर ही रखें."
स्किप-ग्राम
ऐसा एन-ग्राम जो ओरिजनल कॉन्टेक्स्ट से शब्दों को हटा सकता है या "स्किप" कर सकता है. इसका मतलब है कि हो सकता है कि एन शब्द मूल रूप से एक-दूसरे के बगल में न हों. ज़्यादा सटीक तरीके से, "k-स्किप-n-ग्राम" एक ऐसा n-ग्राम होता है जिसमें ज़्यादा से ज़्यादा k शब्द छोड़े गए हों.
उदाहरण के लिए, "the quick brown fox" में ये दो-ग्राम हो सकते हैं:
- "the quick"
- "quick brown"
- "brown fox"
"1-स्किप-2-ग्राम", शब्दों का ऐसा जोड़ा होता है जिनके बीच में ज़्यादा से ज़्यादा एक शब्द होता है. इसलिए, "the quick brown fox" में एक-स्किप वाले ये दो-ग्राम हैं:
- "the brown"
- "quick fox"
इसके अलावा, सभी दो-ग्राम, एक-स्किप-दो-ग्राम भी होते हैं, क्योंकि एक से ज़्यादा शब्द छोड़े जा सकते हैं.
स्किप-ग्राम, किसी शब्द के आस-पास के कॉन्टेक्स्ट को बेहतर तरीके से समझने में मदद करते हैं. उदाहरण में, "फ़ॉक्स" सीधे तौर पर "क्विक" से जुड़ा था, लेकिन 2-ग्राम के सेट में नहीं.
स्किप-ग्राम, वर्ड एम्बेडिंग मॉडल को ट्रेन करने में मदद करते हैं.
सॉफ़्ट प्रॉम्प्ट ट्यूनिंग
किसी खास टास्क के लिए, लार्ज लैंग्वेज मॉडल को ट्यून करने की एक तकनीक. इसमें ज़्यादा संसाधनों की ज़रूरत वाले फ़ाइन-ट्यूनिंग की ज़रूरत नहीं होती. मॉडल में सभी वेट को फिर से ट्रेन करने के बजाय, सॉफ़्ट प्रॉम्प्ट ट्यूनिंग एक ही लक्ष्य को हासिल करने के लिए, प्रॉम्प्ट में अपने-आप बदलाव करती है.
टेक्स्ट प्रॉम्प्ट के लिए, आम तौर पर सॉफ़्ट प्रॉम्प्ट ट्यूनिंग, प्रॉम्प्ट में अतिरिक्त टोकन एम्बेड जोड़ती है. साथ ही, इनपुट को ऑप्टिमाइज़ करने के लिए बैकप्रोपगेशन का इस्तेमाल करती है.
"हार्ड" प्रॉम्प्ट में, टोकन एम्बेड के बजाय असली टोकन होते हैं.
स्पैर्स फ़ीचर
ऐसी सुविधा जिसकी वैल्यू ज़्यादातर शून्य या खाली होती हैं. उदाहरण के लिए, एक वैल्यू 1 और एक लाख वैल्यू 0 वाली सुविधा, कम डेटा वाली सुविधा है. इसके उलट, डेंस फ़ीचर की वैल्यू, आम तौर पर शून्य या खाली नहीं होती हैं.
मशीन लर्निंग में, बहुत सारी सुविधाएं स्पैर्स सुविधाएं होती हैं. कैटगरी वाली सुविधाएं आम तौर पर कम होती हैं. उदाहरण के लिए, किसी जंगल में मौजूद 300 पेड़ों की प्रजातियों में से, किसी एक उदाहरण से सिर्फ़ मेपल ट्री की पहचान की जा सकती है. इसके अलावा, किसी वीडियो लाइब्रेरी में मौजूद लाखों वीडियो में से, एक उदाहरण से सिर्फ़ "Casablanca" की पहचान की जा सकती है.
आम तौर पर, किसी मॉडल में कम सुविधाओं को वन-हॉट एन्कोडिंग की मदद से दिखाया जाता है. अगर वन-हॉट एन्कोडिंग बड़ी है, तो बेहतर परफ़ॉर्मेंस के लिए, वन-हॉट एन्कोडिंग के ऊपर एम्बेडिंग लेयर डाली जा सकती है.
स्पैर्स प्रज़ेंटेशन
स्पैर्स फ़ीचर में, सिर्फ़ उन एलिमेंट की पोज़िशन सेव करना जिनकी वैल्यू शून्य से ज़्यादा है.
उदाहरण के लिए, मान लें कि species नाम की कैटगरी वाली सुविधा, किसी खास जंगल में मौजूद 36 तरह के पेड़ों की पहचान करती है. इसके अलावा, मान लें कि हर उदाहरण में सिर्फ़ एक प्रजाति की जानकारी दी गई है.
हर उदाहरण में पेड़ की प्रजाति दिखाने के लिए, वन-हॉट वेक्टर का इस्तेमाल किया जा सकता है.
एक-हॉट वेक्टर में एक 1 (उस उदाहरण में पेड़ की किसी खास प्रजाति को दिखाने के लिए) और 35 0 (उस उदाहरण में पेड़ की नहीं 35 प्रजातियों को दिखाने के लिए) शामिल होंगे. इसलिए, maple का वन-हॉट वर्शन कुछ ऐसा दिख सकता है:

इसके अलावा, स्पैर्स रिप्रज़ेंटेशन से सिर्फ़ किसी खास प्रजाति की जगह की पहचान की जा सकती है. अगर maple 24वें स्थान पर है, तो maple का स्पैर्स रिप्रज़ेंटेशन इस तरह होगा:
24
ध्यान दें कि स्पैर्स रिप्रज़ेंटेशन, वन-हॉट रिप्रज़ेंटेशन की तुलना में काफ़ी छोटा होता है.
ज़्यादा जटिल उदाहरण के लिए, आइकॉन पर क्लिक करें.
मान लें कि आपके मॉडल में मौजूद हर उदाहरण में, अंग्रेज़ी वाक्य में शब्दों को दिखाया जाना चाहिए, लेकिन उन शब्दों के क्रम को नहीं. अंग्रेज़ी भाषा में करीब 1,70,000 शब्द होते हैं. इसलिए, अंग्रेज़ी एक कैटगरी वाली भाषा है, जिसमें करीब 1,70,000 एलिमेंट होते हैं. अंग्रेज़ी के ज़्यादातर वाक्यों में, उन 1,70,000 शब्दों में से बहुत कम शब्दों का इस्तेमाल किया जाता है. इसलिए, किसी एक उदाहरण में मौजूद शब्दों का सेट, ज़्यादातर मामलों में बहुत कम डेटा होगा.
इस वाक्य पर ध्यान दें:
My dog is a great dog
इस वाक्य में मौजूद शब्दों को दिखाने के लिए, वन-हॉट वैक्टर के किसी वैरिएंट का इस्तेमाल किया जा सकता है. इस वैरिएंट में, वेक्टर की कई सेल में शून्य से ज़्यादा वैल्यू हो सकती है. इसके अलावा, इस वैरिएंट में किसी सेल में एक के अलावा कोई और इंटेजर भी हो सकता है. इस वाक्य में "मेरा", "है", "एक", और "शानदार" शब्द सिर्फ़ एक बार दिखते हैं, जबकि "कुत्ता" शब्द दो बार दिखता है. इस वाक्य में मौजूद शब्दों को दिखाने के लिए, वन-हॉट वेक्टर के इस वैरिएंट का इस्तेमाल करने पर, 1,70,000 एलिमेंट वाला यह वेक्टर मिलता है:

उसी वाक्य को कम शब्दों में लिखने पर, यह दिखेगा:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
चरणों में ट्रेनिंग
अलग-अलग चरणों के क्रम में मॉडल को ट्रेनिंग देने की रणनीति. इसका मकसद, ट्रेनिंग प्रोसेस को तेज़ करना या मॉडल की क्वालिटी को बेहतर बनाना हो सकता है.
प्रोग्रेसिव स्टैकिंग के तरीके का इलस्ट्रेशन यहां दिया गया है:
- पहले चरण में तीन छिपी हुई लेयर, दूसरे चरण में छह छिपी हुई लेयर, और तीसरे चरण में 12 छिपी हुई लेयर होती हैं.
- दूसरा चरण, पहले चरण की तीन छिपी हुई लेयर में सीखे गए वेट के साथ ट्रेनिंग शुरू करता है. तीसरे चरण में, दूसरे चरण की छह छिपी हुई लेयर में सीखे गए वेट का इस्तेमाल करके ट्रेनिंग शुरू की जाती है.
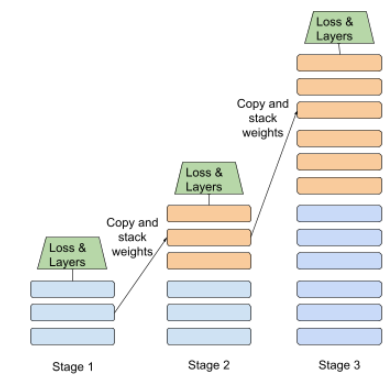
पाइपलाइनिंग भी देखें.
सबवर्ड टोकन
भाषा मॉडल में, टोकन, किसी शब्द का सबसे छोटा हिस्सा होता है. यह पूरा शब्द भी हो सकता है.
उदाहरण के लिए, "itemize" जैसे शब्द को "item" (रूट शब्द) और "ize" (सर्फ़िक्स) में बांटा जा सकता है. इनमें से हर शब्द को अपने टोकन से दिखाया जाता है. आम तौर पर इस्तेमाल न होने वाले शब्दों को ऐसे हिस्सों में बांटने पर, उन्हें सबवर्ड कहा जाता है. इससे भाषा मॉडल, शब्द के सामान्य हिस्सों पर काम कर पाते हैं. जैसे, प्रीफ़िक्स और सफ़िक्स.
इसके उलट, हो सकता है कि "going" जैसे सामान्य शब्दों को अलग-अलग टुकड़ों में न बांटा जाए और उन्हें एक टोक़न से दिखाया जाए.
T
T5
टेक्स्ट-टू-टेक्स्ट ट्रांसफ़र लर्निंग मॉडल, जिसे Google के एआई ने 2020 में लॉन्च किया था. T5, एन्कोडर-डिकोडर मॉडल है. यह ट्रांसफ़ॉर्मर आर्किटेक्चर पर आधारित है और इसे बहुत बड़े डेटासेट पर ट्रेन किया गया है. यह नैचुरल लैंग्वेज प्रोसेसिंग से जुड़े कई कामों में असरदार है. जैसे, टेक्स्ट जनरेट करना, भाषाओं का अनुवाद करना, और बातचीत वाले तरीके से सवालों के जवाब देना.
T5 का नाम, "टेक्स्ट-टू-टेक्स्ट ट्रांसफ़र ट्रांसफ़ॉर्मर" में मौजूद पांच T से मिलता है.
T5X
यह एक ओपन-सोर्स, मशीन लर्निंग फ़्रेमवर्क है. इसे बड़े पैमाने पर नैचुरल लैंग्वेज प्रोसेसिंग (एनएलपी) मॉडल बनाने और ट्रेन करने के लिए डिज़ाइन किया गया है. T5 को T5X कोडबेस पर लागू किया गया है. यह कोडबेस, JAX और Flax पर आधारित है.
तापमान
हाइपरपैरामीटर, जो मॉडल के आउटपुट के लिए, यादृच्छिकता की डिग्री को कंट्रोल करता है. ज़्यादा तापमान पर, रैंडम आउटपुट ज़्यादा मिलता है, जबकि कम तापमान पर रैंडम आउटपुट कम मिलता है.
सबसे सही तापमान चुनना, खास ऐप्लिकेशन और मॉडल के आउटपुट की पसंदीदा प्रॉपर्टी पर निर्भर करता है. उदाहरण के लिए, क्रिएटिव आउटपुट जनरेट करने वाला ऐप्लिकेशन बनाते समय, शायद आप टेंपरेचर बढ़ाना चाहें. इसके उलट, इमेज या टेक्स्ट को अलग-अलग कैटगरी में बांटने वाले मॉडल को बनाते समय, शायद आप तापमान को कम कर दें. इससे मॉडल की सटीकता और एक जैसी परफ़ॉर्मेंस को बेहतर बनाया जा सकता है.
तापमान का इस्तेमाल अक्सर softmax के साथ किया जाता है.
टेक्स्ट स्पैन
टेक्स्ट स्ट्रिंग के किसी खास सबसेक्शन से जुड़ा ऐरे इंडेक्स स्पैन.
उदाहरण के लिए, Python स्ट्रिंग s="Be good now" में good शब्द, टेक्स्ट स्पैन में 3 से 6 तक का होता है.
टोकन
भाषा मॉडल में, वह एटमिक यूनिट जिस पर मॉडल को ट्रेनिंग दी जा रही है और जिस पर अनुमान लगाया जा रहा है. आम तौर पर, टोकन इनमें से कोई एक होता है:
- कोई शब्द—उदाहरण के लिए, "कुत्ते बिल्लियों को पसंद करते हैं" वाक्यांश में तीन वर्ड टोक़न हैं: "कुत्ते", "पसंद करते हैं", और "बिल्लियां".
- वर्ण—उदाहरण के लिए, "बाइक फ़िश" फ़्रेज़ में नौ वर्ण वाले टोकन हैं. (ध्यान दें कि खाली जगह को एक टोकन माना जाता है.)
- सबवर्ड—इसमें एक शब्द एक टोकन या कई टोकन हो सकता है. सबवर्ड में रूट शब्द, प्रीफ़िक्स या सफ़िक्स होता है. उदाहरण के लिए, ऐसा भाषा मॉडल जो सबवर्ड को टोकन के तौर पर इस्तेमाल करता है, वह "कुत्ते" शब्द को दो टोकन (मूल शब्द "कुत्ता" और बहुवचन प्रत्यय "ए") के तौर पर देख सकता है. वही भाषा मॉडल, "लंबा" शब्द को दो सबवर्ड (मूल शब्द "लंबा" और सफ़िक्स "er") के तौर पर देख सकता है.
भाषा मॉडल के बाहर के डोमेन में, टोकन अन्य तरह की एटमिक यूनिट को दिखा सकते हैं. उदाहरण के लिए, कंप्यूटर विज़न में, टोकन किसी इमेज का सबसेट हो सकता है.
टॉप-k सटीक
जनरेट की गई सूचियों की पहली k पोज़िशन में, "टारगेट लेबल" दिखने की संख्या का प्रतिशत. ये सूचियां, आपके हिसाब से सुझाव हो सकती हैं या softmax के हिसाब से क्रम में लगाए गए आइटम की सूची हो सकती हैं.
टॉप-k सटीक जानकारी को k पर सटीक जानकारी भी कहा जाता है.
बुरा बर्ताव
कॉन्टेंट में बुरे बर्ताव, धमकी या आपत्तिजनक कॉन्टेंट किस हद तक है. मशीन लर्निंग के कई मॉडल, आपत्तिजनक कॉन्टेंट की पहचान कर सकते हैं और उसका आकलन कर सकते हैं. इनमें से ज़्यादातर मॉडल, कई पैरामीटर के आधार पर नुकसान पहुंचाने वाले कॉन्टेंट की पहचान करते हैं. जैसे, अपशब्दों के इस्तेमाल का लेवल और धमकी देने वाली भाषा का लेवल.
ट्रांसफ़र्मर
Google ने न्यूरल नेटवर्क का एक आर्किटेक्चर विकसित किया है. यह सेल्फ़-अटेंशन मशीन पर आधारित है. इसकी मदद से, इनपुट एम्बेडिंग के क्रम को आउटपुट एम्बेडिंग के क्रम में बदला जा सकता है. इसके लिए, कंवोल्यूशन या रीकurrent न्यूरल नेटवर्क का इस्तेमाल नहीं किया जाता. ट्रांसफ़ॉर्मर को, सेल्फ़-अटेंशन लेयर के स्टैक के तौर पर देखा जा सकता है.
किसी ट्रांसफ़ॉर्मर में इनमें से कोई भी शामिल हो सकता है:
एन्कोडर, एम्बेड किए गए वैल्यू के क्रम को उसी लंबाई के नए क्रम में बदल देता है. एन्कोडर में N एक जैसी लेयर होती हैं. इनमें से हर लेयर में दो सब-लेयर होती हैं. ये दो सब-लेयर, इनपुट एम्बेडिंग क्रम की हर पोज़िशन पर लागू होते हैं. इससे, क्रम के हर एलिमेंट को एक नए एम्बेडिंग में बदल दिया जाता है. पहली एन्कोडर सब-लेयर, पूरे इनपुट क्रम से जानकारी इकट्ठा करती है. दूसरी एन्कोडर सब-लेयर, एग्रीगेट की गई जानकारी को आउटपुट एम्बेडिंग में बदल देती है.
डिकोडर, इनपुट एम्बेडिंग के क्रम को आउटपुट एम्बेडिंग के क्रम में बदल देता है. ऐसा हो सकता है कि आउटपुट एम्बेडिंग की लंबाई अलग हो. डिकोडर में भी तीन सब-लेयर वाली N एक जैसी लेयर शामिल होती हैं. इनमें से दो लेयर, एन्कोडर की सब-लेयर से मिलती-जुलती होती हैं. तीसरी डिकोडर सब-लेयर, एन्कोडर का आउटपुट लेती है और उससे जानकारी इकट्ठा करने के लिए, सेल्फ़-अटेंशन मशीन लर्निंग मॉडल लागू करती है.
Transformer: A Novel Neural Network Architecture for Language Understanding ब्लॉग पोस्ट में, ट्रांसफ़ॉर्मर के बारे में अच्छी जानकारी दी गई है.
ट्रिग्रम
एन-ग्राम, जिसमें N=3 है.
U
एकतरफ़ा
यह एक ऐसा सिस्टम है जो सिर्फ़ टेक्स्ट के टारगेट सेक्शन से पहले मौजूद टेक्स्ट का आकलन करता है. इसके उलट, द्वि-दिशा वाला सिस्टम, टेक्स्ट के टारगेट सेक्शन से पहले और बाद के टेक्स्ट, दोनों का आकलन करता है. ज़्यादा जानकारी के लिए, दोतरफ़ा देखें.
यूनीडायरेक्शनल लैंग्वेज मॉडल
भाषा मॉडल, जो टारगेट किए गए टोकन के बाद नहीं, बल्कि पहले दिखने वाले टोकन के आधार पर संभावनाओं का अनुमान लगाता है. दोतरफ़ा लैंग्वेज मॉडल के साथ तुलना करें.
V
वैरिएशनल ऑटोएन्कोडर (VAE)
ऑटोएन्कोडर का एक टाइप, जो इनपुट और आउटपुट के बीच के अंतर का फ़ायदा उठाकर, इनपुट के बदले हुए वर्शन जनरेट करता है. वैरिएशनल ऑटोएन्कोडर, जनरेटिव एआई के लिए काम के होते हैं.
वैरिएशनल इंफ़रेंस पर आधारित VAEs: यह किसी संभाव्यता मॉडल के पैरामीटर का अनुमान लगाने की तकनीक है.
W
शब्दों को एम्बेड करना
प्रतिनिधित्व करने के लिए, किसी वर्ड सेट में मौजूद हर शब्द को एम्बेडिंग वेक्टर में डाला जाता है. इसका मतलब है कि हर शब्द को 0.0 से 1.0 के बीच की फ़्लोटिंग-पॉइंट वैल्यू के वेक्टर के तौर पर दिखाया जाता है. मिलते-जुलते मतलब वाले शब्दों के बीच, अलग-अलग मतलब वाले शब्दों के मुकाबले ज़्यादा समानता होती है. उदाहरण के लिए, गाजर, सेलेरी, और ककड़ी, सभी के लिए एक जैसे विज़ुअल इस्तेमाल किए जा सकते हैं. हालांकि, ये विज़ुअल हवाई जहाज़, सनग्लास, और टूथपेस्ट के विज़ुअल से काफ़ी अलग होंगे.
Z
बिना उदाहरण वाला प्रॉम्प्ट
ऐसा प्रॉम्प्ट जिसमें यह उदाहरण नहीं दिया गया हो कि आपको लार्ज लैंग्वेज मॉडल से किस तरह का जवाब चाहिए. उदाहरण के लिए:
| एक प्रॉम्प्ट के हिस्से | नोट |
|---|---|
| चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब आपको एलएलएम से चाहिए. |
| भारत: | असल क्वेरी. |
लार्ज लैंग्वेज मॉडल इनमें से किसी भी तरह का जवाब दे सकता है:
- रुपया
- INR
- ₹
- भारतीय रुपया
- रुपया
- भारतीय रुपया
सभी जवाब सही हैं. हालांकि, हो सकता है कि आप किसी खास फ़ॉर्मैट को प्राथमिकता दें.
ज़ीरो-शॉट प्रॉम्प्टिंग की तुलना इन शब्दों से करें: