Esta página contém os termos do glossário da avaliação de linguagem. Para conferir todos os termos do glossário, clique aqui.
A
atenção
Um mecanismo usado em uma rede neural que indica a importância de uma palavra ou parte de uma palavra específica. A atenção compacta a quantidade de informações que um modelo precisa para prever o próximo token/palavra. Um mecanismo de atenção típico pode consistir em uma soma ponderada sobre um conjunto de entradas, em que o peso de cada entrada é calculado por outra parte da rede neural.
Consulte também autoatenção e autoatenção multicabeça, que são os blocos de construção dos transformadores.
Consulte LLMs: What's a large language model? no Curso intensivo de machine learning para mais informações sobre a auto-atenção.
codificador automático
Um sistema que aprende a extrair as informações mais importantes da entrada. Os autoencoders são uma combinação de um codificador e decodificador. Os autoencoders dependem do seguinte processo em duas etapas:
- O codificador mapeia a entrada para um formato (normalmente) com perda de menor dimensão (intermediário).
- O decodificador cria uma versão com perdas da entrada original mapeando o formato de menor dimensão para o formato de entrada de maior dimensão original.
Os autoencoders são treinados de ponta a ponta, fazendo com que o decodificador tente reconstruir a entrada original do formato intermediário do codificador o mais próximo possível. Como o formato intermediário é menor (de menor dimensão) do que o original, o autoencoder é forçado a aprender quais informações na entrada são essenciais, e a saída não será perfeitamente idêntica à entrada.
Exemplo:
- Se os dados de entrada forem um gráfico, a cópia não exata será semelhante ao gráfico original, mas um pouco modificada. Talvez a cópia não exata remova o ruído do gráfico original ou preencha alguns pixels ausentes.
- Se os dados de entrada forem de texto, um autoencoder vai gerar um novo texto que imita (mas não é idêntico) ao texto original.
Consulte também autocodificadores variacionais.
avaliação automática
Usar software para avaliar a qualidade da saída de um modelo.
Quando a saída do modelo é relativamente simples, um script ou programa pode comparar a saída do modelo com uma resposta ideal. Esse tipo de avaliação automática às vezes é chamado de avaliação programática. Métricas como ROUGE ou BLEU geralmente são úteis para avaliação programática.
Quando a saída do modelo é complexa ou não tem uma única resposta correta, um programa de ML separado chamado de autoavaliador às vezes realiza a avaliação automática.
Compare com a avaliação humana.
avaliação do autor automático
Um mecanismo híbrido para avaliar a qualidade da saída de um modelo de IA generativa que combina avaliação humana com avaliação automática. Um autor é um modelo de ML treinado com dados criados por avaliação humana. O ideal é que um autor aprenda a imitar um avaliador humano.Há autores automáticos pré-criados disponíveis, mas os melhores são ajustados especificamente para a tarefa que você está avaliando.
modelo autorregressivo
Um modelo que infere uma previsão com base nas próprias previsões anteriores. Por exemplo, os modelos de linguagem auto-regressivos preveem o próximo token com base nos tokens previstos anteriormente. Todos os modelos de linguagem grandes baseados no Transformer são autoregressivos.
Por outro lado, os modelos de imagem baseados em GAN geralmente não são autorregressivos, porque geram uma imagem em uma única passagem para frente e não iterativamente em etapas. No entanto, alguns modelos de geração de imagens são autorregressivos porque geram uma imagem em etapas.
precisão média em k
Uma métrica para resumir a performance de um modelo em uma única solicitação que gera resultados classificados, como uma lista numerada de recomendações de livros. A precisão média em k é a média dos valores de precisão em k para cada resultado relevante. A fórmula para a precisão média em k é a seguinte:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
em que:
- \(n\) é o número de itens relevantes na lista.
Compare com a recordação em k.
B
saco de palavras
Uma representação das palavras em uma frase ou passagem, independentemente da ordem. Por exemplo, o bag of words representa as seguintes três frases de forma idêntica:
- o cachorro pula
- pula o cachorro
- cachorro pula o
Cada palavra é mapeada para um índice em um vetor esparsa, em que o vetor tem um índice para cada palavra no vocabulário. Por exemplo, a frase the dog jumps é mapeada para um vetor de recursos com valores não nulos nos três índices correspondentes às palavras the, dog e jumps. O valor diferente de zero pode ser um dos seguintes:
- Um 1 para indicar a presença de uma palavra.
- Uma contagem do número de vezes que uma palavra aparece no saco. Por exemplo, se a frase fosse o cachorro marrom é um cachorro com pelagem marrom, marrom e cachorro seriam representados como 2, enquanto as outras palavras seriam representadas como 1.
- Outro valor, como o logaritmo da contagem do número de vezes que uma palavra aparece no conjunto.
BERT (representações de codificador bidirecional de transformadores)
Uma arquitetura de modelo para a representação de texto. Um modelo BERT treinado pode atuar como parte de um modelo maior para classificação de texto ou outras tarefas de ML.
O BERT tem as seguintes características:
- Usa a arquitetura do Transformer e, portanto, depende da autoatenção.
- Usa a parte codificador do transformador. O trabalho do codificador é produzir boas representações de texto, em vez de realizar uma tarefa específica, como a classificação.
- É bidirecional.
- Usa mascaramento para treinamento não supervisionado.
As variantes do BERT incluem:
Consulte Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing para ter uma visão geral do BERT.
bidirecional
Termo usado para descrever um sistema que avalia o texto que antecede e segue uma seção de texto de destino. Por outro lado, um sistema unidirecional avalia apenas o texto que precede uma seção de texto de destino.
Por exemplo, considere um modelo de linguagem mascarado que precisa determinar as probabilidades da palavra ou das palavras que representam o sublinhado na seguinte pergunta:
Como você está?
Um modelo de linguagem unidirecional precisaria basear as probabilidades apenas no contexto fornecido pelas palavras "What", "is" e "the". Em contraste, um modelo de linguagem bidirecional também pode receber contexto de "com" e "você", o que pode ajudar o modelo a gerar previsões melhores.
modelo de linguagem bidirecional
Um modelo de linguagem que determina a probabilidade de um determinado token estar presente em um determinado local em um trecho de texto com base no texto anterior e seguinte.
bigram
Um n-grama em que N=2.
BLEU (assistente de avaliação bilíngue)
Uma métrica entre 0,0 e 1,0 para avaliar traduções automáticas, por exemplo, do espanhol para o japonês.
Para calcular uma pontuação, o BLEU normalmente compara a tradução de um modelo de ML (texto gerado) com a tradução de um especialista humano (texto de referência). O grau em que os n-gramas no texto gerado e no texto de referência correspondem determina a pontuação BLEU.
O artigo original sobre essa métrica é BLEU: a Method for Automatic Evaluation of Machine Translation.
Consulte também BLEURT.
BLEURT (assistente de avaliação bilíngue de transformadores)
Uma métrica para avaliar as traduções automáticas de um idioma para outro, principalmente do e para o inglês.
Para traduções de e para o inglês, o BLEURT se alinha mais às classificações humanas do que o BLEU. Ao contrário do BLEU, o BLEURT enfatiza as semelhanças semânticas (de significado) e pode acomodar paráfrases.
O BLEURT usa um modelo de linguagem grande pré-treinado (BERT, para ser exato) que é ajustado em textos de tradutores humanos.
O artigo original sobre essa métrica é BLEURT: Learning Robust Metrics for Text Generation.
C
modelo de linguagem causal
Sinônimo de modelo de linguagem unidirecional.
Consulte modelo de linguagem bidirecional para contrastar diferentes abordagens direcionais na modelagem de linguagem.
comandos de fluxo de consciência
Uma técnica de engenharia de comandos que incentiva um modelo de linguagem grande (LLM) a explicar o raciocínio, passo a passo. Por exemplo, considere o seguinte comando, prestando atenção especial à segunda frase:
Quantas forças g um motorista sentiria em um carro que vai de 0 a 100 km/h em 7 segundos? Na resposta, mostre todos os cálculos relevantes.
A resposta do LLM provavelmente:
- Mostre uma sequência de fórmulas de física, inserindo os valores 0, 60 e 7 nos lugares apropriados.
- Explique por que escolheu essas fórmulas e o significado das várias variáveis.
O comando de fluxo de pensamento força o LLM a realizar todos os cálculos, o que pode levar a uma resposta mais correta. Além disso, a solicitação de cadeia de pensamento permite que o usuário examine as etapas do LLM para determinar se a resposta faz sentido ou não.
chat
O conteúdo de uma conversa com um sistema de ML, geralmente um modelo de linguagem grande. A interação anterior em um chat (o que você digitou e como o modelo de linguagem grande respondeu) se torna o contexto para as partes subsequentes do chat.
Um chatbot é uma aplicação de um modelo de linguagem grande.
confabulação
Sinônimo de alucinação.
A confabulação é provavelmente um termo mais preciso do que a alucinação. No entanto, a alucinação se tornou popular primeiro.
Análise de distrito eleitoral
Divida uma frase em estruturas gramaticais menores ("constituintes"). Uma parte posterior do sistema de ML, como um modelo de compreensão de linguagem natural, pode analisar os elementos de maneira mais fácil do que a frase original. Por exemplo, considere a seguinte frase:
Meu amigo adotou dois gatos.
Um analisador de constituintes pode dividir esta frase nos seguintes elementos:
- Meu amigo é uma frase nominal.
- adotou dois gatos é uma frase verbal.
Esses elementos podem ser subdivididos em elementos menores. Por exemplo, a frase verbal
adotou dois gatos
pode ser subdividido em:
- Adopted é um verbo.
- dois gatos é outro sintagma nominal.
Incorporação de linguagem contextualizada
Um embedding que se aproxima de "entender" palavras e frases da mesma forma que falantes nativos. Os embeddings de linguagem contextualizados podem entender sintaxe, semântica e contexto complexos.
Por exemplo, considere as inclusões da palavra em inglês cow. Incorporações mais antigas, como o word2vec, podem representar palavras em inglês de modo que a distância no espaço de incorporação de cow (vaca) a bull (boi) seja semelhante à distância de ewe (ovelha) a ram (bode) ou de female (fêmea) a male (macho). As representações de linguagem contextualizadas podem ir além, reconhecendo que os falantes de inglês às vezes usam casualmente a palavra cow para se referir a vaca ou touro.
janela de contexto
O número de tokens que um modelo pode processar em um determinado comando. Quanto maior a janela de contexto, mais informações o modelo pode usar para fornecer respostas coerentes e consistentes ao comando.
crash blossom
Uma frase ou expressão com um significado ambíguo. As flores de acidente representam um problema significativo na compreensão de linguagem natural. Por exemplo, o título Burocratismo impede a construção de arranha-céus é um crash blossom porque um modelo de NLU pode interpretar o título literalmente ou figurativamente.
D
decodificador
Em geral, qualquer sistema de ML que converta de uma representação processada, densa ou interna para uma representação mais bruta, esparsa ou externa.
Os decodificadores geralmente são um componente de um modelo maior, em que são frequentemente associados a um codificador.
Em tarefas de sequência para sequência, um decodificador começa com o estado interno gerado pelo codificador para prever a próxima sequência.
Consulte Transformer para ver a definição de um decodificador na arquitetura do Transformer.
Consulte Modelos de linguagem grandes no Curso intensivo de machine learning para mais informações.
redução de ruído
Uma abordagem comum de aprendizado autosupervisionado em que:
A remoção de ruídos permite o aprendizado com exemplos não rotulados. O dataset original serve como destino ou rótulo, e os dados com ruído como entrada.
Alguns modelos de linguagem mascarados usam a redução de ruído da seguinte maneira:
- O ruído é adicionado artificialmente a uma frase não rotulada mascarando alguns dos tokens.
- O modelo tenta prever os tokens originais.
comando direto
Sinônimo de comando zero-shot.
E
editar distância
Uma medida de quão semelhantes duas strings de texto são uma à outra. No aprendizado de máquina, a distância de edição é útil pelos seguintes motivos:
- A distância de edição é fácil de calcular.
- A distância de edição pode comparar duas strings conhecidas por serem semelhantes.
- A distância de edição pode determinar o grau em que strings diferentes são semelhantes a uma determinada string.
Há várias definições de distância de edição, cada uma usando operações de string diferentes. Consulte Distância de Levenshtein para conferir um exemplo.
camada de embedding
Uma camada oculta especial que é treinada em um recurso categórico de alta dimensão para aprender gradualmente um vetor de incorporação de dimensão inferior. Uma camada de incorporação permite que uma rede neural seja treinada de maneira muito mais eficiente do que apenas com o recurso categórico de alta dimensão.
Por exemplo, o Earth atualmente oferece suporte a cerca de 73 mil espécies de árvores. Suponha que a espécie de árvore seja um atributo no modelo. Assim, a camada de entrada do modelo inclui um vetor único de 73.000 elementos.
Por exemplo, baobab seria representado da seguinte maneira:

Uma matriz de 73.000 elementos é muito longa. Se você não adicionar uma camada de incorporação ao modelo, o treinamento vai consumir muito tempo devido à multiplicação de 72.999 zeros. Talvez você escolha a camada de embedding para consistir em 12 dimensões. Consequentemente, a camada de incorporação vai aprender gradualmente um novo vetor de incorporação para cada espécie de árvore.
Em determinadas situações, a criação de hash é uma alternativa razoável para uma camada de incorporação.
Consulte Incorporações no Curso intensivo de machine learning para mais informações.
espaço de embedding
O espaço vetorial d-dimensional que apresenta recursos de um espaço vetorial de dimensão superior. O ideal é que o espaço de embedding contenha uma estrutura que gere resultados matemáticos significativos. Por exemplo, em um espaço de embedding ideal, a adição e a subtração de embeddings podem resolver tarefas de analogia de palavras.
O produto escalar de duas embeddings é uma medida de similaridade.
embedding de vetor
De modo geral, uma matriz de números de ponto flutuante extraída de qualquer camada oculta que descreve as entradas para essa camada oculta. Muitas vezes, um vetor de embedding é a matriz de números de ponto flutuante treinada em uma camada de embedding. Por exemplo, suponha que uma camada de embedding precise aprender um vetor de embedding para cada uma das 73.000 espécies de árvores da Terra. Talvez a matriz a seguir seja o vetor de embedding de uma árvore de baobá:

Um vetor de inserção não é um monte de números aleatórios. Uma camada de embedding determina esses valores durante o treinamento, de forma semelhante à maneira como uma rede neural aprende outros pesos durante o treinamento. Cada elemento da matriz é uma classificação com algumas características de uma espécie de árvore. Qual elemento representa a característica de qual espécie de árvore? Isso é muito difícil para os humanos determinarem.
A parte matematicamente notável de um vetor de embedding é que itens semelhantes têm conjuntos semelhantes de números de ponto flutuante. Por exemplo, espécies de árvores semelhantes têm um conjunto de números de ponto flutuante mais semelhante do que espécies de árvores diferentes. As sequoias e as sequoias-vermelhas são espécies de árvores relacionadas, portanto, elas terão um conjunto mais semelhante de números de ponto flutuante do que as sequoias-vermelhas e as palmeiras de coco. Os números no vetor de incorporação vão mudar sempre que você treinar o modelo novamente, mesmo que com uma entrada idêntica.
codificador
Em geral, qualquer sistema de ML que converta de uma representação bruta, esparsa ou externa em uma representação mais processada, densa ou interna.
Os codificadores geralmente são um componente de um modelo maior, em que são frequentemente associados a um decodificador. Alguns Transformers emparelham codificadores com decodificadores, mas outros Transformers usam apenas o codificador ou apenas o decodificador.
Alguns sistemas usam a saída do codificador como entrada para uma rede de classificação ou regressão.
Em tarefas de sequência para sequência, um codificador recebe uma sequência de entrada e retorna um estado interno (um vetor). Em seguida, o decodificador usa esse estado interno para prever a próxima sequência.
Consulte Transformer para ver a definição de um codificador na arquitetura do Transformer.
Consulte LLMs: What's a large language model no Curso intensivo de machine learning para mais informações.
evals
É usado principalmente como uma abreviação para avaliações de LLM. De forma mais ampla, avaliações é uma abreviação para qualquer forma de avaliação.
Avaliação
O processo de medir a qualidade de um modelo ou comparar modelos diferentes.
Para avaliar um modelo de aprendizado de máquina supervisionado, normalmente você o compara a um conjunto de validação e um conjunto de teste. A avaliação de um LLM normalmente envolve avaliações mais amplas de qualidade e segurança.
F
comando de poucos disparos
Um comando que contém mais de um (um "pouco") exemplo demonstrando como o modelo de linguagem grande precisa responder. Por exemplo, o comando longo a seguir contém dois exemplos que mostram a um modelo de linguagem grande como responder a uma consulta.
| Partes de uma instrução | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Um exemplo. |
| Reino Unido: GBP | Outro exemplo. |
| Índia: | A consulta real. |
Os comandos de poucos disparos geralmente produzem resultados mais desejáveis do que comandos sem disparos e comandos de um disparo. No entanto, o comando de poucos disparos exige uma solicitação mais longa.
Comandos de poucos disparos (few-shot) são uma forma de aprendizado de poucos disparos aplicada à aprendizagem baseada em comandos.
Consulte Engenharia de comandos no Curso intensivo de machine learning para mais informações.
Violino
Uma biblioteca de configuração com prioridade em Python que define os valores de funções e classes sem código ou infraestrutura invasivos. No caso do Pax e de outros códigos-base de ML, essas funções e classes representam modelos e treinamento hiperparâmetros.
O Fiddle pressupõe que as bases de código de machine learning geralmente são divididas em:
- Código da biblioteca, que define as camadas e os otimizadores.
- Código de "cola" do conjunto de dados, que chama as bibliotecas e conecta tudo.
O Fiddle captura a estrutura de chamada do código de união em uma forma não avaliada e mutável.
ajuste fino
Uma segunda passagem de treinamento específica para a tarefa realizada em um modelo pré-treinado para refinar os parâmetros de um caso de uso específico. Por exemplo, a sequência de treinamento completa para alguns modelos de linguagem grandes é a seguinte:
- Pré-treinamento:treine um modelo de linguagem grande em um vasto conjunto de dados geral, como todas as páginas da Wikipedia em inglês.
- Ajuste fino:treine o modelo pré-treinado para realizar uma tarefa específica, como responder a consultas médicas. O ajuste fino normalmente envolve centenas ou milhares de exemplos focados na tarefa específica.
Como outro exemplo, a sequência de treinamento completa para um modelo de imagem grande é esta:
- Pré-treinamento:treine um modelo de imagem grande em um vasto conjunto de imagens geral, como todas as imagens no Wikimedia Commons.
- Ajuste fino:treine o modelo pré-treinado para realizar uma tarefa específica, como gerar imagens de orcas.
O ajuste fino pode envolver qualquer combinação das seguintes estratégias:
- Modificar todos os parâmetros do modelo pré-treinado. Às vezes, isso é chamado de ajuste fino completo.
- Modificar apenas alguns dos parâmetros do modelo pré-treinado (normalmente, as camadas mais próximas da camada de saída), mantendo os outros parâmetros inalterados (normalmente, as camadas mais próximas da camada de entrada). Consulte ajustes de eficiência de parâmetros.
- Adicionar mais camadas, normalmente sobre as camadas existentes mais próximas da camada de saída.
O ajuste fino é uma forma de aprendizado por transferência. Assim, o ajuste fino pode usar uma função de perda ou um tipo de modelo diferente daqueles usados para treinar o modelo pré-treinado. Por exemplo, você pode ajustar um modelo de imagem grande pré-treinado para produzir um modelo de regressão que retorna o número de pássaros em uma imagem de entrada.
Compare e contraste o ajuste fino com os seguintes termos:
Consulte Ajuste fino no Curso intensivo de machine learning para mais informações.
Linho
Uma biblioteca de código aberto de alto desempenho para aprendizado profundo criada com base no JAX. O Flax fornece funções para treinar redes neurais, bem como métodos para avaliar a performance delas.
Flaxformer
Uma biblioteca de Transformer de código aberto, criada com base no Flax, projetada principalmente para processamento de linguagem natural e pesquisa multimodal.
G
Gemini
O ecossistema que inclui a IA mais avançada do Google. Os elementos desse ecossistema incluem:
- Vários modelos Gemini.
- A interface de conversação interativa de um modelo Gemini. Os usuários digitam comandos, e o Gemini responde a eles.
- Várias APIs Gemini.
- Vários produtos empresariais com base nos modelos Gemini, por exemplo, o Gemini para Google Cloud.
Modelos do Gemini
Modelos multimodais baseados em Transformer de última geração do Google. Os modelos do Gemini foram criados especificamente para serem integrados a agentes.
Os usuários podem interagir com os modelos do Gemini de várias maneiras, incluindo uma interface de diálogo interativa e SDKs.
texto gerado
Em geral, o texto que um modelo de ML gera. Ao avaliar modelos de linguagem grandes, algumas métricas comparam o texto gerado com o texto de referência. Por exemplo, suponha que você esteja tentando determinar a eficácia da tradução de um modelo de ML do francês para o holandês. Nesse caso:
- O texto gerado é a tradução em holandês que o modelo de ML gera.
- O texto de referência é a tradução para o holandês que um tradutor humano (ou software) cria.
Algumas estratégias de avaliação não envolvem texto de referência.
IA generativa
Um campo transformador emergente sem definição formal. A maioria dos especialistas concorda que os modelos de IA generativa podem criar ("gerar") conteúdo que seja:
- complexo
- coerente
- original
Por exemplo, um modelo de IA generativa pode criar textos ou imagens sofisticados.
Algumas tecnologias anteriores, incluindo LSTMs e RNNs, também podem gerar conteúdo original e coerente. Alguns especialistas consideram essas tecnologias anteriores como IA generativa, enquanto outros acreditam que a verdadeira IA generativa exige uma saída mais complexa do que essas tecnologias anteriores.
Compare com o ML preditivo.
resposta dourada
Uma resposta conhecida por ser boa. Por exemplo, considerando o seguinte prompt:
2 + 2
A resposta ideal é:
4
GPT (transformador generativo pré-treinado)
Uma família de modelos de linguagem grandes baseados em Transformer desenvolvidos pela OpenAI.
As variantes da GPT podem ser aplicadas a várias modalidades, incluindo:
- geração de imagens (por exemplo, ImageGPT)
- Geração de texto para imagem (por exemplo, DALL-E).
H
alucinação
A produção de uma saída aparentemente plausível, mas factualmente incorreta, por um modelo de IA generativa que pretende fazer uma declaração sobre o mundo real. Por exemplo, um modelo de IA generativa que afirma que Barack Obama morreu em 1865 está alucinando.
avaliação humana
Um processo em que pessoas avaliam a qualidade da saída de um modelo de ML. Por exemplo, pessoas bilíngues podem avaliar a qualidade de um modelo de tradução de ML. A avaliação humana é particularmente útil para avaliar modelos que não têm uma resposta certa.
Compare com a avaliação automática e a avaliação do autoavaliador.
I
aprendizado contextual
Sinônimo de comando de poucos disparos (few-shot).
L
LaMDA (Language Model for Dialogue Applications)
Um modelo de linguagem grande baseado em transformador desenvolvido pelo Google e treinado em um grande conjunto de dados de diálogo que pode gerar respostas de conversação realistas.
LaMDA: nossa tecnologia de conversação inovadora oferece uma visão geral.
modelo de linguagem
Um modelo que estima a probabilidade de um token ou sequência de tokens ocorrer em uma sequência mais longa de tokens.
modelo de linguagem grande
No mínimo, um modelo de linguagem com um número muito alto de parâmetros. De forma mais informal, qualquer modelo de linguagem baseado em Transformer, como o Gemini ou o GPT.
espaço latente
Sinônimo de espaço de embedding.
Distância de Levenshtein
Uma métrica de distância de edição que calcula as operações de exclusão, inserção e substituição mais curtas necessárias para mudar uma palavra por outra. Por exemplo, a distância de Levenshtein entre as palavras "heart" e "darts" é três, porque as três edições a seguir são as mudanças mínimas para transformar uma palavra na outra:
- coração → deart (substitua "h" por "d")
- deart → dart (delete "e")
- dardo → dardos (insira "s")
A sequência anterior não é o único caminho de três edições.
LLM
Abreviação de modelo de linguagem grande.
Avaliações de LLM (avaliações)
Um conjunto de métricas e comparativos de mercado para avaliar o desempenho de modelos de linguagem grandes (LLMs). De modo geral, as avaliações de LLMs:
- Ajude os pesquisadores a identificar áreas em que os LLMs precisam de melhorias.
- São úteis para comparar diferentes LLMs e identificar o melhor LLM para uma tarefa específica.
- Ajudar a garantir que os LLMs sejam seguros e éticos.
LoRA
Abreviação de adaptabilidade de baixa classificação.
Adaptabilidade de baixa classificação (LoRA)
Uma técnica eficiente em termos de parâmetros para ajuste fino que "congela" os pesos pré-treinados do modelo para que não possam mais ser modificados e, em seguida, insere um pequeno conjunto de pesos treináveis no modelo. Esse conjunto de pesos treináveis (também conhecido como "matrizes de atualização") é consideravelmente menor do que o modelo base e, portanto, é muito mais rápido de treinar.
O LoRA oferece os seguintes benefícios:
- Melhora a qualidade das previsões de um modelo para o domínio em que o ajuste fino é aplicado.
- Faz ajustes mais rápidos do que técnicas que exigem ajustes em todos os parâmetros de um modelo.
- Reduz o custo computacional da inferência ao permitir a veiculação simultânea de vários modelos especializados que compartilham o mesmo modelo de base.
M
modelo de linguagem mascarada
Um modelo de linguagem que prevê a probabilidade de tokens candidatos preencherem espaços em branco em uma sequência. Por exemplo, um modelo de linguagem mascarado pode calcular as probabilidades de palavras candidatas para substituir o sublinhado na seguinte frase:
O ____ no chapéu voltou.
A documentação geralmente usa a string "MASK" em vez de sublinhado. Exemplo:
A "MÁSCARA" no chapéu voltou.
A maioria dos modelos de linguagem mascarados modernos são bidirecionais.
Precisão média em k (mAP@k)
A média estatística de todas as pontuações de precisão média em k em um conjunto de dados de validação. Um uso da precisão média em k é para julgar a qualidade das recomendações geradas por um sistema de recomendação.
Embora a frase "média da média" pareça redundante, o nome da métrica é apropriado. Afinal, essa métrica encontra a média de vários valores de precisão média em k.
metaaprendizagem
Um subconjunto de machine learning que descobre ou melhora um algoritmo de aprendizado. Um sistema de metaaprendizagem também pode ter como objetivo treinar um modelo para aprender rapidamente uma nova tarefa com uma pequena quantidade de dados ou com a experiência adquirida em tarefas anteriores. Os algoritmos de metaaprendizado geralmente tentam alcançar o seguinte:
- Melhore ou aprenda recursos criados manualmente, como um inicializador ou um otimizador.
- Seja mais eficiente em dados e computação.
- Melhorar a generalização.
O metaaprendizado está relacionado ao aprendizado de poucas imagens.
mistura de especialistas
Um esquema para aumentar a eficiência da rede neural usando apenas um subconjunto de parâmetros (conhecido como expert) para processar um determinado token de entrada ou exemplo. Uma rede de restrição encaminha cada token de entrada ou exemplo para o especialista adequado.
Para mais detalhes, consulte um dos seguintes documentos:
- Redes neurais escandalosamente grandes: a camada de mistura de especialistas com portão pouco aberto
- Mixture-of-Experts com roteamento de escolha de especialista
MMIT
Abreviação de multimodal instruction-tuned.
modality
Uma categoria de dados de alto nível. Por exemplo, números, texto, imagens, vídeo e áudio são cinco modalidades diferentes.
modelo de paralelismo
Uma forma de dimensionar o treinamento ou a inferência que coloca diferentes partes de um modelo em diferentes dispositivos. O paralelismo de modelos permite modelos grandes demais para caber em um único dispositivo.
Para implementar o paralelismo de modelo, um sistema geralmente faz o seguinte:
- Fragmenta (divide) o modelo em partes menores.
- Distribui o treinamento dessas partes menores em vários processadores. Cada processador treina a própria parte do modelo.
- Combina os resultados para criar um único modelo.
O paralelismo de modelos atrasa o treinamento.
Consulte também paralelismo de dados.
MOE
Abreviação de mistura de especialistas.
autoatenção multicabeça
Uma extensão da auto-atenção que aplica o mecanismo de auto-atenção várias vezes para cada posição na sequência de entrada.
Transformers introduziu a autoatenção com várias cabeças.
Ajuste por instruções multimodais
Um modelo sintonizado por instruções que pode processar entradas além de texto, como imagens, vídeo e áudio.
modelo multimodal
Um modelo em que as entradas e/ou saídas incluem mais de uma modalidade. Por exemplo, considere um modelo que usa uma imagem e uma legenda de texto (duas modalidades) como features e exibe uma pontuação indicando o quanto a legenda de texto é apropriada para a imagem. As entradas desse modelo são multimodais, e a saída é unimodal.
N
processamento de linguagem natural
O campo de ensino de computadores para processar o que um usuário disse ou digitou usando regras linguísticas. Quase todo processamento de linguagem natural moderno depende do machine learning.processamento de linguagem natural
Um subconjunto de processamento de linguagem natural que determina as intenções de algo dito ou digitado. A compreensão de linguagem natural pode ir além do processamento de linguagem natural para considerar aspectos complexos da linguagem, como contexto, sarcasmo e sentimento.
N-gram
Uma sequência ordenada de N palavras. Por exemplo, truly madly é um bigrama. Como a ordem é relevante, madly truly é um bigrama diferente de truly madly.
| N | Nome(s) para esse tipo de n-grama | Exemplos |
|---|---|---|
| 2 | bigram ou bigrama | to go, go to, eat lunch, eat dinner |
| 3 | trigrama ou trigrama | comeu demais, três ratinhos cegos, a campainha toca |
| 4 | 4 gramas | walk in the park, dust in the wind, the boy ate lentils |
Muitos modelos de processamento de linguagem natural dependem de N-gramas para prever a próxima palavra que o usuário vai digitar ou dizer. Por exemplo, suponha que um usuário digitou three blind. Um modelo PLN baseado em trigramas provavelmente vai prever que o usuário vai digitar mice em seguida.
Compare os n-gramas com a bolsa de palavras, que são conjuntos não ordenados de palavras.
PLN
Abreviação de processamento de linguagem natural.
PLN
Abreviação de compreensão de linguagem natural.
nenhuma resposta certa (NORA)
Um comando com várias respostas adequadas. Por exemplo, o comando a seguir não tem uma resposta certa:
Conte uma piada sobre elefantes.
Avaliar comandos sem uma resposta certa pode ser um desafio.
NORA
Abreviação de não há uma resposta certa.
O
comando one-shot
Um comando que contém um exemplo demonstrando como o modelo de linguagem grande deve responder. Por exemplo, o comando a seguir contém um exemplo que mostra a um modelo de linguagem grande como responder a uma consulta.
| Partes de uma instrução | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Um exemplo. |
| Índia: | A consulta real. |
Compare e contraste a solicitação única com os seguintes termos:
P
ajuste da eficiência dos parâmetros
Um conjunto de técnicas para ajustar um modelo de linguagem grande pré-treinado (PLM) de maneira mais eficiente do que o ajuste completo. O ajuste com eficiência de parâmetros normalmente ajusta com eficiência muito menos parâmetros do que o ajuste fino completo, mas geralmente produz um modelo de linguagem grande que tem o mesmo desempenho (ou quase o mesmo) de um modelo de linguagem grande criado com o ajuste fino completo.
Compare o ajuste da eficiência dos parâmetros com:
O ajuste com eficiência de parâmetros também é conhecido como ajuste fino com eficiência de parâmetros.
pipeline
Uma forma de paralelismo de modelo em que o processamento de um modelo é dividido em etapas consecutivas e cada etapa é executada em um dispositivo diferente. Enquanto um estágio está processando um lote, o estágio anterior pode trabalhar no próximo lote.
Consulte também treinamento em etapas.
PLM
Abreviação de modelo de linguagem pré-treinado.
codificação posicional
Uma técnica para adicionar informações sobre a posição de um token em uma sequência à incorporação do token. Os modelos Transformer usam a codificação de posição para entender melhor a relação entre diferentes partes da sequência.
Uma implementação comum de codificação posicional usa uma função sinusoidal. Especificamente, a frequência e a amplitude da função sinusoidal são determinadas pela posição do token na sequência. Essa técnica permite que um modelo Transformer aprenda a atender a diferentes partes da sequência com base na posição delas.
modelo pós-treinamento
Termo vagamente definido que geralmente se refere a um modelo pré-treinado que passou por algum pós-processamento, como um ou mais dos seguintes:
precisão em k (precision@k)
Uma métrica para avaliar uma lista de itens classificada (ordenada). A precisão em k identifica a fração dos primeiros k itens na lista que são "relevantes". Ou seja:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
O valor de k precisa ser menor ou igual ao comprimento da lista retornada. O tamanho da lista retornada não faz parte do cálculo.
A relevância é muitas vezes subjetiva. Até mesmo avaliadores humanos experientes muitas vezes discordam sobre quais itens são relevantes.
Comparar com:
modelo pré-treinado
Normalmente, um modelo que já foi treinado. O termo também pode significar um vetor de embeddings treinado anteriormente.
O termo modelo de linguagem pré-treinado geralmente se refere a um modelo de linguagem grande já treinado.
pré-treinamento
O treinamento inicial de um modelo em um grande conjunto de dados. Alguns modelos pré-treinados são gigantes desajeitados e geralmente precisam ser refinados com mais treinamento. Por exemplo, especialistas em ML podem pré-treinar um modelo de linguagem grande em um grande conjunto de dados de texto, como todas as páginas em inglês da Wikipédia. Após o pré-treinamento, o modelo resultante pode ser refinado com qualquer uma das seguintes técnicas:
prompt
Qualquer texto inserido como entrada em um modelo de linguagem grande para condicionar o modelo a se comportar de uma determinada maneira. As solicitações podem ser tão curtas quanto uma frase ou arbitrariamente longas (por exemplo, o texto inteiro de um romance). As instruções se dividem em várias categorias, incluindo as mostradas na tabela a seguir:
| Categoria de comando | Exemplo | Observações |
|---|---|---|
| Pergunta | A que velocidade um pombo pode voar? | |
| Instrução | Escreva um poema engraçado sobre arbitragem. | Um comando que pede ao modelo de linguagem grande para fazer algo. |
| Exemplo | Traduzir o código Markdown para HTML. Por exemplo:
Markdown: * item da lista HTML: <ul> <li>item da lista</li> </ul> |
A primeira frase neste exemplo de comando é uma instrução. O restante da instrução é o exemplo. |
| Papel | Explique por que a descida do gradiente é usada no treinamento de machine learning para um PhD em Física. | A primeira parte da frase é uma instrução. A frase "a um PhD em física" é a parte do papel. |
| Entrada parcial para o modelo concluir | O primeiro-ministro do Reino Unido mora em | Um comando de entrada parcial pode terminar abruptamente (como neste exemplo) ou com um sublinhado. |
Um modelo de IA generativa pode responder a um comando com texto, código, imagens, embeddings, vídeos... quase tudo.
aprendizagem baseada em instruções
Um recurso de determinados modelos que permite que eles adaptem o comportamento em resposta a entradas de texto arbitrárias (comandos). Em um paradigma de aprendizado típico baseado em comandos, um modelo de linguagem grande responde a um comando gerando texto. Por exemplo, suponha que um usuário insira o seguinte comando:
Resuma a terceira lei do movimento de Newton.
Um modelo capaz de aprendizado com base em comandos não é treinado especificamente para responder ao comando anterior. Em vez disso, o modelo "sabe" muitos fatos sobre física, muitas regras gerais de linguagem e muito sobre o que constitui respostas geralmente úteis. Esse conhecimento é suficiente para fornecer uma resposta útil. Outros feedbacks humanos ("Essa resposta foi muito complicada" ou "O que é uma reação?") permitem que alguns sistemas de aprendizagem baseados em comandos melhorem gradualmente a utilidade das respostas.
design de comandos
Sinônimo de engenharia de comando.
engenharia de comando
A arte de criar comandos que extraem as respostas desejadas de um modelo de linguagem grande. Os humanos fazem a engenharia de comandos. Escrever comandos bem estruturados é uma parte essencial para garantir respostas úteis de um modelo de linguagem grande. A engenharia de prompts depende de muitos fatores, incluindo:
- O conjunto de dados usado para pré-treinar e, possivelmente, ajustar o modelo de linguagem grande.
- A temperatura e outros parâmetros de decodificação que o modelo usa para gerar respostas.
Consulte Introdução à criação de comandos para mais detalhes sobre como escrever comandos úteis.
Design de comandos é sinônimo de engenharia de comandos.
ajuste de comando
Um mecanismo de ajuste eficiente de parâmetros que aprende um "prefixo" que o sistema adiciona ao comando.
Uma variação do ajuste de comando, às vezes chamada de ajuste de prefixo, é adicionar o prefixo em cada camada. Em contraste, a maioria dos ajustes de comando só adiciona um prefixo à camada de entrada.
R
recall at k (recall@k)
Uma métrica para avaliar sistemas que geram uma lista classificada (ordenada) de itens. A recuperação em k identifica a fração de itens relevantes nos primeiros k itens dessa lista do número total de itens relevantes retornados.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Contraste com precisão em k.
texto de referência
A resposta de um especialista a um comando. Por exemplo, considerando o seguinte comando:
Traduzir a pergunta "What is your name?" (Qual é seu nome?) do inglês para o francês.
A resposta de um especialista pode ser:
Comment vous appelez-vous?
Várias métricas (como ROUGE) medem o grau em que o texto de referência corresponde ao texto gerado de um modelo de ML.
comando de função
Uma parte opcional de um comando que identifica um público-alvo para a resposta de um modelo de IA generativa. Sem um comando de função, um modelo de linguagem grande fornece uma resposta que pode ou não ser útil para a pessoa que faz as perguntas. Com um comando de função, um modelo de linguagem grande pode responder de uma maneira mais adequada e útil para um público-alvo específico. Por exemplo, a parte do comando de função dos comandos a seguir está em negrito:
- Resuma este artigo para um PhD em economia.
- Descrever como as marés funcionam para uma criança de 10 anos.
- Explique a crise financeira de 2008. Fale como se estivesse falando com uma criança ou um golden retriever.
Subestudo orientado para recordação para avaliação Gisting (ROUGE, na sigla em inglês)
Uma família de métricas que avaliam modelos de resumo automático e tradução automática. As métricas ROUGE determinam o grau em que um texto de referência se sobrepõe ao texto gerado de um modelo de ML. Cada membro da família ROUGE mede a sobreposição de maneira diferente. Pontuações ROUGE mais altas indicam mais semelhança entre o texto de referência e o texto gerado do que pontuações ROUGE mais baixas.
Cada membro da família ROUGE geralmente gera as seguintes métricas:
- Precisão
- Recall
- F1
Para detalhes e exemplos, consulte:
ROUGE-L
Um membro da família ROUGE focado no comprimento da maior subsequência comum no texto de referência e texto gerado. As fórmulas a seguir calculam o recall e a precisão do ROUGE-L:
Em seguida, use F1 para agrupar a precisão e o recall do ROUGE-L em uma única métrica:
O ROUGE-L ignora todos os caracteres de nova linha no texto de referência e no texto gerado. Assim, a maior subsequência comum pode cruzar várias frases. Quando o texto de referência e o texto gerado envolvem várias frases, uma variação de ROUGE-L chamada ROUGE-Lsum geralmente é uma métrica melhor. O ROUGE-Lsum determina a maior subsequência comum de cada frase em uma passagem e calcula a média dessas subsequências comuns mais longas.
ROUGE-N
Um conjunto de métricas na família ROUGE que compara os n-gramas compartilhados de um determinado tamanho no texto de referência e no texto gerado. Exemplo:
- O ROUGE-1 mede o número de tokens compartilhados no texto de referência e no texto gerado.
- O ROUGE-2 mede o número de bigramas (2-gramas) compartilhados no texto de referência e no texto gerado.
- O ROUGE-3 mede o número de trigramas (3-gramas) compartilhados no texto de referência e no texto gerado.
Você pode usar as fórmulas abaixo para calcular a precisão e a recuperação do ROUGE-N para qualquer membro da família ROUGE-N:
Em seguida, use F1 para agrupar a precisão ROUGE-N e a precisão ROUGE-N em uma única métrica:
ROUGE-S
Uma forma tolerante de ROUGE-N que permite a correspondência de skip-gram. Ou seja, o ROUGE-N só conta N-grams que correspondem exatamente, mas o ROUGE-S também conta N-grams separados por uma ou mais palavras. Por exemplo, considere o seguinte:
- texto de referência: nuvens brancas
- Texto gerado: nuvens brancas
Ao calcular o ROUGE-N, o 2-gram, White clouds não corresponde a White billowing clouds. No entanto, ao calcular o ROUGE-S, nuvens brancas correspondem a nuvens brancas infladas.
S
autoatenção (também chamada de camada de autoatenção)
Uma camada de rede neural que transforma uma sequência de embeddings (por exemplo, embeddings de token) em outra sequência de embeddings. Cada embedding na sequência de saída é construída pela integração de informações dos elementos da sequência de entrada por um mecanismo de atenção.
A parte self de autoatenção se refere à sequência que se atende a si mesma, e não a outro contexto. A autoatenção é um dos principais blocos de construção dos transformadores e usa a terminologia de pesquisa de dicionário, como "consulta", "chave" e "valor".
Uma camada de autoatenção começa com uma sequência de representações de entrada, uma para cada palavra. A representação de entrada de uma palavra pode ser uma incorporação simples. Para cada palavra em uma sequência de entrada, a rede avalia a relevância da palavra para cada elemento em toda a sequência de palavras. Os índices de relevância determinam o quanto a representação final da palavra incorpora as representações de outras palavras.
Por exemplo, considere a seguinte frase:
O animal não atravessou a rua porque estava muito cansado.
A ilustração a seguir (do artigo Transformer: A Novel Neural Network Architecture for Language Understanding) mostra o padrão de atenção de uma camada de autoatenção para o pronome it, com a intensidade de cada linha indicando o quanto cada palavra contribui para a representação:
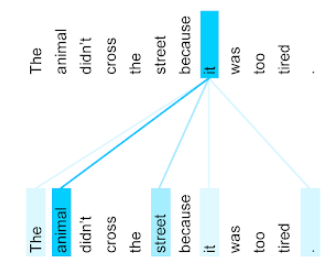
A camada de autoatenção destaca as palavras relevantes para "it". Nesse caso, a camada de atenção aprendeu a destacar palavras que ela pode se referir, atribuindo o maior peso a animal.
Para uma sequência de n tokens, a autoatenção transforma uma sequência de embeddings n vezes separadas, uma vez em cada posição da sequência.
Consulte também atenção e auto-atenção multicabeça.
análise de sentimento
Usar algoritmos de aprendizado de máquina ou estatísticos para determinar a atitude geral de um grupo (positiva ou negativa) em relação a um serviço, produto, organização ou tópico. Por exemplo, usando o processamento de linguagem natural, um algoritmo pode realizar a análise de sentimento no feedback textual de um curso universitário para determinar o grau de satisfação dos estudantes com o curso.
tarefa de sequência para sequência
Uma tarefa que converte uma sequência de entrada de tokens em uma sequência de saída de tokens. Por exemplo, dois tipos comuns de tarefas de sequência para sequência são:
- Tradutores:
- Exemplo de sequência de entrada: "Eu te amo".
- Exemplo de sequência de saída: "Je t'aime".
- Respostas a perguntas:
- Exemplo de sequência de entrada: "Preciso do meu carro em Nova York?"
- Exemplo de sequência de saída: "Não. Deixe o carro em casa."
skip-gram
Um n-grama que pode omitir (ou "pular") palavras do contexto original, o que significa que as N palavras podem não ter sido originalmente adjacentes. Mais precisamente, um "n-gram de k-skip" é um n-gram em que até k palavras podem ter sido ignoradas.
Por exemplo, "a raposa marrom ligeira" tem os seguintes bigramas possíveis:
- "a rápida"
- "marrom rápido"
- "raposa marrom"
Um "1-skip-2-gram" é um par de palavras com no máximo uma palavra entre elas. Portanto, "a raposa marrom ligeira" tem os seguintes bigramas com um salto:
- "a marrom"
- "raposa rápida"
Além disso, todos os bigramas também são bigramas de 1-salto-2, já que menos de uma palavra pode ser ignorada.
Os skip-grams são úteis para entender melhor o contexto em torno de uma palavra. No exemplo, "fox" foi associado diretamente a "quick" no conjunto de 1-skip-2-grams, mas não no conjunto de 2-grams.
Os skip-grams ajudam a treinar modelos de embedding de palavras.
ajuste de comando suave
Uma técnica para ajustar um modelo de linguagem grande para uma tarefa específica, sem recursos intensivos de ajuste fino. Em vez de treinar novamente todos os pesos no modelo, o ajuste suave do comando ajusta automaticamente um comando para alcançar o mesmo objetivo.
Dado um comando textual, o ajuste de comando suave normalmente anexa outras embeddings de token ao comando e usa a propagação de volta para otimizar a entrada.
Um comando "difícil" contém tokens reais, em vez de incorporações de token.
atributo esparso
Um elemento cujos valores são predominantemente nulos ou vazios. Por exemplo, um recurso que contém um único valor 1 e um milhão de valores 0 é esparso. Por outro lado, um recurso denso tem valores que não são predominantemente nulos ou vazios.
No aprendizado de máquina, um número surpreendente de atributos são atributos raros. Os atributos categóricos geralmente são escassos. Por exemplo, das 300 espécies de árvores possíveis em uma floresta, um único exemplo pode identificar apenas uma árvore de bordo. Ou, dos milhões de vídeos possíveis em uma biblioteca de vídeos, um único exemplo pode identificar apenas "Casablanca".
Em um modelo, você geralmente representa atributos esparsos com codificação one-hot. Se a codificação one-hot for grande, você poderá colocar uma camada de incorporação sobre a codificação one-hot para maior eficiência.
representação esparsa
Armazenar apenas as posições de elementos diferentes de zero em um elemento disperso.
Por exemplo, suponha que um elemento categórico chamado species identifique as 36
espécies de árvores em uma floresta específica. Suponha também que cada
exemplo identifica apenas uma única espécie.
Você pode usar um vetor one-hot para representar as espécies de árvores em cada exemplo.
Um vetor one-hot conteria um único 1 (para representar
a espécie de árvore específica nesse exemplo) e 35 0s (para representar as
35 espécies de árvores não nesse exemplo). Assim, a representação one-hot
de maple pode ser semelhante a esta:

Como alternativa, a representação esparsa simplesmente identificaria a posição da
espécie específica. Se maple estiver na posição 24, a representação esparsa
de maple será simplesmente:
24
A representação esparsa é muito mais compacta do que a representação única.
Clique no ícone para conferir um exemplo um pouco mais complexo.
Suponha que cada exemplo no seu modelo precise representar as palavras, mas não a ordem delas, em uma frase em inglês. O inglês consiste em cerca de 170.000 palavras, então o inglês é um recurso categórico com cerca de 170.000 elementos. A maioria das frases em inglês usa uma fração extremamente pequena dessas 170.000 palavras. Portanto, o conjunto de palavras em um exemplo único quase certamente será de dados dispersos.
Considere a seguinte frase:
My dog is a great dog
Você pode usar uma variante do vetor one-hot para representar as palavras nesta frase. Nessa variante, várias células no vetor podem conter um valor diferente de zero. Além disso, nessa variante, uma célula pode conter um número inteiro diferente de um. Embora as palavras "my", "is", "a" e "great" apareçam apenas uma vez na frase, a palavra "dog" aparece duas vezes. O uso dessa variante de vetores one-hot para representar as palavras nesta frase gera o seguinte vetor de 170.000 elementos:

Uma representação esparsa da mesma frase seria simplesmente:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
treinamento em etapas
Uma tática de treinamento de um modelo em uma sequência de estágios discretos. O objetivo pode ser acelerar o processo de treinamento ou alcançar uma melhor qualidade do modelo.
Confira abaixo uma ilustração da abordagem de empilhamento progressivo:
- A fase 1 contém 3 camadas ocultas, a fase 2 contém 6 camadas ocultas e a fase 3 contém 12 camadas ocultas.
- A etapa 2 começa o treinamento com os pesos aprendidos nas 3 camadas ocultas da etapa 1. A etapa 3 começa o treinamento com os pesos aprendidos nas 6 camadas ocultas da etapa 2.

Consulte também pipelining.
token de subpalavra
Em modelos de linguagem, um token é uma substring de uma palavra, que pode ser a palavra inteira.
Por exemplo, uma palavra como "itemizar" pode ser dividida em "item" (uma palavra raiz) e "izar" (um sufixo), cada um representado pelo próprio token. A divisão de palavras incomuns em partes, chamadas de subpalavras, permite que os modelos de linguagem operem nas partes constituintes mais comuns da palavra, como prefixos e sufixos.
Por outro lado, palavras comuns como "ir" podem não ser divididas e podem ser representadas por um único token.
T
T5
Um modelo de aprendizado de transferência de texto para texto lançado pela Google AI em 2020. O T5 é um modelo codificador-decodificador, baseado na arquitetura Transformer, treinado em um conjunto de dados extremamente grande. Ele é eficaz em várias tarefas de processamento de linguagem natural, como gerar texto, traduzir idiomas e responder a perguntas de forma conversacional.
O T5 recebe o nome dos cinco Ts em "Text-to-Text Transfer Transformer" (transformador de transferência de texto para texto).
T5X
Um framework de machine learning de código aberto projetado para criar e treinar modelos de processamento de linguagem natural (PLN) em grande escala. O T5 é implementado na base de código do T5X, que é criada com JAX e Flax.
temperatura
Um hiperparâmetro que controla o grau de aleatoriedade da saída de um modelo. Temperaturas mais altas resultam em saídas mais aleatórias, enquanto temperaturas mais baixas resultam em saídas menos aleatórias.
A escolha da melhor temperatura depende da aplicação específica e das propriedades preferidas da saída do modelo. Por exemplo, você provavelmente aumentaria a temperatura ao criar um aplicativo que gera saídas criativas. Por outro lado, você provavelmente diminuiria a temperatura ao criar um modelo que classifica imagens ou texto para melhorar a precisão e a consistência do modelo.
A temperatura é frequentemente usada com softmax.
intervalo de texto
O intervalo de índice de matriz associado a uma subseção específica de uma string de texto.
Por exemplo, a palavra good na string Python s="Be good now" ocupa
o intervalo de texto de 3 a 6.
token
Em um modelo de linguagem, a unidade atômica que o modelo usa para treinar e fazer previsões. Um token geralmente é um dos seguintes:
- uma palavra. Por exemplo, a frase "dogs like cats" consiste em três tokens de palavra: "dogs", "like" e "cats".
- um caractere. Por exemplo, a frase "bike fish" consiste em nove tokens de caractere. O espaço em branco conta como um dos tokens.
- subpalavras, em que uma única palavra pode ser um único token ou vários tokens. Uma subpalavra consiste em uma palavra raiz, um prefixo ou um sufixo. Por exemplo, um modelo de linguagem que usa subpalavras como tokens pode considerar a palavra "dogs" como dois tokens (a palavra raiz "dog" e o sufixo plural "s"). Esse mesmo modelo de linguagem pode considerar a palavra "taller" como duas subpalavras (a palavra raiz "tall" e o sufixo "er").
Em domínios fora dos modelos de linguagem, os tokens podem representar outros tipos de unidades atômicas. Por exemplo, em visão computacional, um token pode ser um subconjunto de uma imagem.
acurácia top-k
É a porcentagem de vezes que um "rótulo de destino" aparece nas primeiras k posições das listas geradas. As listas podem ser recomendações personalizadas ou uma lista de itens ordenados por softmax.
A precisão Top-k também é conhecida como precisão em k.
conteúdo tóxico
O grau em que o conteúdo é abusivo, ameaçador ou ofensivo. Muitos modelos de machine learning podem identificar e medir a toxicidade. A maioria desses modelos identifica a toxicidade em vários parâmetros, como o nível de linguagem abusiva e o nível de linguagem ameaçadora.
Transformer
Uma arquitetura de rede neural desenvolvida no Google que depende de mecanismos de auto-atenção para transformar uma sequência de embeddings de entrada em uma sequência de embeddings de saída sem depender de convoluções ou redes neurais recorrentes. Um transformador pode ser considerado uma pilha de camadas de autoatenção.
Um transformador pode incluir qualquer um dos seguintes:
- um codificador
- um decodificador
- um codificador e um decodificador
Um codificador transforma uma sequência de embeddings em uma nova sequência do mesmo tamanho. Um codificador inclui N camadas idênticas, cada uma contendo duas subcamadas. Essas duas subcamadas são aplicadas em cada posição da sequência de incorporação de entrada, transformando cada elemento da sequência em uma nova incorporação. A primeira subcamada do codificador agrega informações de toda a sequência de entrada. A segunda subcamada do codificador transforma as informações agregadas em uma incorporação de saída.
Um decodificador transforma uma sequência de incorporações de entrada em uma sequência de incorporações de saída, possivelmente com um comprimento diferente. Um decodificador também inclui N camadas idênticas com três subcamadas, sendo que duas são semelhantes às subcamadas do codificador. A terceira subcamada do decodificador recebe a saída do codificador e aplica o mecanismo de autoatenção para coletar informações dele.
A postagem do blog Transformer: uma nova arquitetura de rede neural para compreensão de linguagem é uma boa introdução aos transformadores.
trigrama
Um n-grama em que N=3.
U
unidirecional
Um sistema que avalia apenas o texto que antecede uma seção de texto de destino. Em contraste, um sistema bidirecional avalia o texto que antecede e segue uma seção de texto de destino. Consulte bidirecional para mais detalhes.
modelo de linguagem unidirecional
Um modelo de linguagem que baseia as probabilidades apenas nos tokens que aparecem antes, e não depois, dos tokens de destino. Compare com o modelo de linguagem bidirecional.
V
autocodificador variacional (VAE, na sigla em inglês)
Um tipo de autoencoder que aproveita a discrepância entre entradas e saídas para gerar versões modificadas das entradas. Os codificadores automáticos variacionais são úteis para IA generativa.
Os VAEs são baseados na inferência variacional, uma técnica para estimar os parâmetros de um modelo de probabilidade.
W
embedding de palavras
Representação de cada palavra em um conjunto de palavras em um vetor de inserção, ou seja, representação de cada palavra como um vetor de valores de ponto flutuante entre 0,0 e 1,0. Palavras com significados semelhantes têm representações mais semelhantes do que palavras com significados diferentes. Por exemplo, cenouras, salsão e pepinos teriam representações relativamente semelhantes, que seriam muito diferentes das representações de avião, óculos de sol e pasta de dente.
Z
comando zero-shot
Um comando que não fornece um exemplo de como você quer que o modelo de linguagem grande responda. Exemplo:
| Partes de uma instrução | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| Índia: | A consulta real. |
O modelo de linguagem grande pode responder com qualquer uma das seguintes opções:
- Rúpia
- INR
- ₹
- Rúpias indianas
- A rúpia
- A rupia indiana
Todas as respostas estão corretas, mas você pode preferir um formato específico.
Compare e contraste a ativação de zero-shot com os seguintes termos: