Cette page contient les termes du glossaire de l'évaluation linguistique. Pour connaître tous les termes du glossaire, cliquez ici.
A
"Attention",
Mécanisme utilisé dans un réseau de neurones qui indique l'importance d'un mot ou d'une partie de mot spécifique. L'attention compresse la quantité d'informations dont un modèle a besoin pour prédire le prochain jeton/mot. Un mécanisme d'attention typique peut consister en une somme pondérée sur un ensemble d'entrées, où le poids de chaque entrée est calculé par une autre partie du réseau de neurones.
Consultez également la auto-attention et l'auto-attention multitête, qui sont les éléments de base des Transformers.
Pour en savoir plus sur l'attention automatique, consultez LLM: qu'est-ce qu'un grand modèle de langage ? dans le cours d'initiation au machine learning.
auto-encodeur
Système qui apprend à extraire les informations les plus importantes de l'entrée. Les autoencodeurs sont une combinaison d'un encodeur et d'un décodeur. Les autoencodeurs reposent sur le processus en deux étapes suivant:
- L'encodeur mappe l'entrée sur un format (intermédiaire) à faible dimension (généralement avec perte).
- Le décodeur crée une version avec perte de l'entrée d'origine en mappant le format à faible dimension sur le format d'entrée d'origine à dimension élevée.
Les autoencodeurs sont entraînés de bout en bout en demandant au décodeur de tenter de reconstruire l'entrée d'origine à partir du format intermédiaire de l'encodeur le plus fidèlement possible. Étant donné que le format intermédiaire est plus petit (à dimension inférieure) que le format d'origine, l'autoencodeur est contraint d'apprendre quelles informations de l'entrée sont essentielles, et la sortie ne sera pas parfaitement identique à l'entrée.
Exemple :
- Si les données d'entrée sont un graphique, la copie non exacte sera semblable au graphique d'origine, mais quelque peu modifiée. Il est possible que la copie non exacte supprime le bruit de l'image originale ou remplisse certains pixels manquants.
- Si les données d'entrée sont du texte, un autoencodeur génère un nouveau texte qui imite (mais n'est pas identique) le texte d'origine.
Voir également les auto-encodeurs variationnels.
évaluation automatique
Utiliser un logiciel pour évaluer la qualité de la sortie d'un modèle.
Lorsque la sortie du modèle est relativement simple, un script ou un programme peut comparer la sortie du modèle à une réponse d'or. Ce type d'évaluation automatique est parfois appelé évaluation programmatique. Les métriques telles que ROUGE ou BLEU sont souvent utiles pour l'évaluation programmatique.
Lorsque la sortie du modèle est complexe ou qu'il n'existe pas de bonne réponse unique, un programme de ML distinct appelé auto-évaluateur effectue parfois l'évaluation automatique.
À comparer à l'évaluation humaine.
évaluation de l'outil d'évaluation automatique
Mécanisme hybride permettant d'évaluer la qualité de la sortie d'un modèle d'IA générative, qui combine une évaluation humaine et une évaluation automatique. Un outil d'évaluation automatique est un modèle de ML entraîné sur des données créées par une évaluation humaine. Dans l'idéal, un outil d'évaluation automatique apprend à imiter un évaluateur humain.Des outils d'automatisation prédéfinis sont disponibles, mais les meilleurs sont affinés spécifiquement pour la tâche que vous évaluez.
modèle autorégressif
Modèle qui infère une prédiction en fonction de ses propres prédictions précédentes. Par exemple, les modèles de langage autorégressifs prédisent le prochain jeton en fonction des jetons précédemment prédits. Tous les grands modèles de langage basés sur Transformer sont autorégressifs.
En revanche, les modèles d'image basés sur des GAN ne sont généralement pas autorégressifs, car ils génèrent une image en une seule passe avant et non de manière itérée par étapes. Toutefois, certains modèles de génération d'images sont autorégressifs, car ils génèrent une image par étapes.
précision moyenne à k
Métrique permettant de résumer les performances d'un modèle pour une seule invite qui génère des résultats classés, comme une liste numérotée de recommandations de livres. La précision moyenne à k correspond à la moyenne des valeurs de précision à k pour chaque résultat pertinent. La formule de la précision moyenne à k est donc la suivante:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
où :
- \(n\) correspond au nombre d'éléments pertinents dans la liste.
À comparer au rappel à k.
B
sac de mots
Représentation des mots d'une expression ou d'un extrait, quel que soit leur ordre. Par exemple, un sac de mots représente les trois phrases suivantes à l'identique:
- the dog jumps
- jumps the dog
- dog jumps the
Chaque mot est mappé à un indice dans un vecteur sparse, où le vecteur a un indice pour chaque mot du vocabulaire. Par exemple, la phrase the dog jumps est mappée dans un vecteur de caractéristiques dont les trois indices correspondant aux mots the, dog et jumps auront des valeurs non nulles. La valeur non nulle peut être l'une des suivantes:
- 1 pour indiquer la présence d'un mot.
- Nombre d'apparitions d'un mot dans le sac. Par exemple, si l'expression est the maroon dog is a dog with maroon fur, les mots maroon et dog seront représentés par la valeur 2, tandis que les autres mots seront représentés par la valeur 1.
- Une autre valeur, telle que le logarithme du nombre d'apparition d'un mot dans le sac.
BERT (Bidirectional Encoder Representations from Transformers)
Architecture de modèle pour la représentation du texte. Un modèle BERT entraîné peut faire partie d'un modèle plus vaste pour la classification de texte ou d'autres tâches de ML.
BERT présente les caractéristiques suivantes:
- Utilise l'architecture Transformer et s'appuie donc sur l'auto-attention.
- Utilise la partie encodeur du Transformer. La tâche de l'encodeur est de produire de bonnes représentations de texte, plutôt que d'effectuer une tâche spécifique comme la classification.
- est bidirectionnel ;
- Utilise le masquage pour l'entraînement non supervisé.
Voici quelques variantes de BERT:
Pour en savoir plus sur BERT, consultez Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing (BERT en Open source : pré-entraînement de pointe pour le traitement du langage naturel).
bidirectionnel
Terme utilisé pour décrire un système qui évalue le texte qui précède et suit une section cible de texte. En revanche, un système unidirectionnel n'évalue que le texte qui précède une section cible de texte.
Prenons l'exemple d'un modèle de langage masqué qui doit déterminer les probabilités pour le ou les mots représentant le soulignement dans la question suivante:
Qu'est-ce qui ne va pas chez vous ?
Un modèle de langage unidirectionnel ne devrait baser ses probabilités que sur le contexte fourni par les mots "quoi", "est" et "le". À l'inverse, un modèle de langage bidirectionnel peut également obtenir du contexte à partir de "avec" et de "vous", ce qui peut l'aider à générer de meilleures prédictions.
modèle de langage bidirectionnel
Modèle de langage qui détermine la probabilité qu'un jeton donné soit présent à un emplacement donné dans un extrait de texte en fonction du texte précédent et suivant.
bigramme
Un N-gramme dans lequel N=2.
BLEU (Bilingual Evaluation Understudy)
Métrique comprise entre 0,0 et 1,0 pour évaluer les traductions automatiques, par exemple de l'espagnol vers le japonais.
Pour calculer un score, BLEU compare généralement la traduction d'un modèle de ML (texte généré) à celle d'un expert humain (texte de référence). Le degré de correspondance des n-grammes dans le texte généré et le texte de référence détermine le score BLEU.
L'article d'origine sur cette métrique est BLEU: a Method for Automatic Evaluation of Machine Translation (BLEU : une méthode d'évaluation automatique de la traduction automatique).
Voir également BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
Métrique permettant d'évaluer les traductions automatiques d'une langue à une autre, en particulier de l'anglais vers l'anglais et de l'anglais vers d'autres langues.
Pour les traductions vers et depuis l'anglais, BLEURT s'aligne plus étroitement sur les évaluations humaines que BLEU. Contrairement à BLEU, BLEURT met l'accent sur les similitudes sémantiques (de sens) et peut prendre en charge le paraphrasage.
BLEURT repose sur un grand modèle de langage pré-entraîné (BERT, pour être exact) qui est ensuite affiné sur le texte de traducteurs humains.
L'article d'origine sur cette métrique est BLEURT: Learning Robust Metrics for Text Generation.
C
modèle de langage causal
Synonyme de modèle de langage unidirectionnel.
Consultez modèle de langage bidirectionnel pour comparer les différentes approches directionnelles dans le modèle de langage.
requêtes en chaîne de pensée
Technique d'ingénierie des requêtes qui encourage un grand modèle de langage (LLM) à expliquer son raisonnement, étape par étape. Prenons l'exemple de l'invite suivante, en accordant une attention particulière à la deuxième phrase:
Combien de g un conducteur ressentira-t-il dans une voiture qui passe de 0 à 96 km/h en 7 secondes ? Dans la réponse, indiquez tous les calculs pertinents.
La réponse du LLM est susceptible de:
- Affichez une séquence de formules de physique, en insérant les valeurs 0, 60 et 7 aux endroits appropriés.
- Expliquez pourquoi il a choisi ces formules et la signification des différentes variables.
Les requêtes en chaîne de pensée obligent le LLM à effectuer tous les calculs, ce qui peut conduire à une réponse plus correcte. De plus, les invites de la chaîne de pensée permettent à l'utilisateur d'examiner les étapes de la LLM pour déterminer si la réponse est logique ou non.
chat
Contenu d'un dialogue avec un système de ML, généralement un grand modèle de langage. L'interaction précédente dans une discussion (ce que vous avez saisi et la réponse du grand modèle de langage) devient le contexte des parties suivantes de la discussion.
Un chatbot est une application d'un grand modèle de langage.
confabulation
Synonyme de hallucination.
La confabulation est probablement un terme plus techniquement précis que l'hallucination. Cependant, l'hallucination est devenue populaire en premier.
Analyse des circonscriptions
Divisez une phrase en structures grammaticales plus petites ("constituants"). Une partie ultérieure du système de ML, comme un modèle de compréhension du langage naturel, peut analyser les constituants plus facilement que la phrase d'origine. Prenons l'exemple de la phrase suivante:
Mon ami a adopté deux chats.
Un analyseur de constituants peut diviser cette phrase en deux constituants:
- Mon ami est une expression nominale.
- a adopté deux chats est un groupe verbal.
Ces constituants peuvent être subdivisés en constituants plus petits. Par exemple, la locution verbale
a adopté deux chats ;
peut être subdivisé en:
- adopté est un verbe.
- deux chats est un autre syntagme nominal.
embeddings de langage contextualisés
Ensemble d'éléments qui se rapproche de la "compréhension" des mots et des expressions comme le font les locuteurs humains. Les représentations vectorielles continues du langage contextualisées peuvent comprendre la syntaxe, la sémantique et le contexte complexes.
Prenons l'exemple des représentations vectorielles continues du mot anglais cow (vache). Les anciens représentations vectorielles continues, telles que word2vec, peuvent représenter des mots anglais de sorte que la distance dans l'espace d'embedding entre cow (vache) et bull (taureau) soit semblable à celle entre ewe (brebis) et ram (bélier) ou entre female (femelle) et male (mâle). Les représentations vectorielles continues de langage contextualisées peuvent aller plus loin en reconnaissant que les anglophones utilisent parfois le mot cow pour désigner une vache ou un taureau.
fenêtre de contexte
Nombre de jetons qu'un modèle peut traiter dans une invite donnée. Plus la fenêtre de contexte est grande, plus le modèle peut utiliser d'informations pour fournir des réponses cohérentes et cohérentes à la requête.
phrase équivoque
Phrase ou expression au sens ambigu. Les phrases équivoques posent un problème majeur pour la compréhension du langage naturel. Par exemple, l'expression au pied de la lettre est une phrase équivoque, car un modèle NLU peut l'interpréter littéralement ou figurativement.
D
décodeur
En général, tout système de ML qui convertit une représentation traitée, dense ou interne en une représentation plus brute, sporadique ou externe.
Les décodeurs sont souvent un composant d'un modèle plus vaste, où ils sont souvent associés à un encodeur.
Dans les tâches de séquence à séquence, un décodeur commence par l'état interne généré par l'encodeur pour prédire la séquence suivante.
Consultez Transformer pour connaître la définition d'un décodeur dans l'architecture Transformer.
Pour en savoir plus, consultez la section Grands modèles de langage dans le cours d'initiation au machine learning.
suppression du bruit
Une approche courante de l'apprentissage autosupervisé:
- Du bruit est ajouté artificiellement à l'ensemble de données.
- Le modèle s'efforce de supprimer le bruit.
Le dénoyage permet d'apprendre à partir d'exemples non étiquetés. L'ensemble de données d'origine sert de cible ou de libellé, et les données bruyantes servent d'entrée.
Certains modèles de langage masqués utilisent le dénoising comme suit:
- Du bruit est ajouté artificiellement à une phrase non annotée en masquant certains des jetons.
- Le modèle tente de prédire les jetons d'origine.
requête directe
Synonyme de requête zero-shot.
E
Modifier la distance
Mesure du degré de similarité entre deux chaînes de texte. Dans le machine learning, la distance d'édition est utile pour les raisons suivantes:
- La distance d'édition est facile à calculer.
- La distance de modification peut comparer deux chaînes connues pour être similaires.
- La distance de modification peut déterminer dans quelle mesure différentes chaînes sont similaires à une chaîne donnée.
Il existe plusieurs définitions de la distance d'édition, chacune utilisant des opérations de chaîne différentes. Pour en savoir plus, consultez Distance de Levenshtein.
couche d'embedding
Couche cachée spéciale qui s'entraîne sur une caractéristique catégorique à haute dimension pour apprendre progressivement un vecteur d'embedding de dimension inférieure. Une couche d'intégration permet à un réseau de neurones de s'entraîner beaucoup plus efficacement que de s'entraîner uniquement sur la caractéristique catégorielle haute dimensionnelle.
Par exemple, la Terre compte actuellement environ 73 000 espèces d'arbres. Supposons que les espèces d'arbres soient une fonctionnalité dans votre modèle. La couche d'entrée de votre modèle inclut donc un vecteur one-hot de 73 000 éléments.
Par exemple, baobab pourrait être représenté comme suit:

Un tableau de 73 000 éléments est très long. Si vous n'ajoutez pas de couche d'encapsulation au modèle, l'entraînement sera très long,car vous devrez multiplier 72 999 zéros. Vous pouvez choisir que la couche d'embedding se compose de 12 dimensions. Par conséquent, la couche d'embedding apprendra progressivement un nouveau vecteur d'embedding pour chaque espèce d'arbre.
Dans certains cas, le hachage constitue une alternative raisonnable à une couche d'encapsulation.
Pour en savoir plus, consultez la section Embeddings dans le cours d'initiation au machine learning.
espace d'embedding
Les espaces vectoriels à d dimensions auxquelles les caractéristiques d'un espace vectoriel de plus grande dimension sont mappés. L'espace d'encapsulation est entraîné pour capturer la structure qui est pertinente pour l'application prévue.
Le produit scalaire de deux espaces de représentation vectorielle est une mesure de leur similarité.
vecteur d'embedding
De manière générale, il s'agit d'un tableau de nombres à virgule flottante extrait de n'importe quelle couche cachée qui décrit les entrées de cette couche cachée. Souvent, un vecteur d'embedding est le tableau de nombres à virgule flottante entraîné dans une couche d'embedding. Par exemple, supposons qu'une couche d'encapsulation doit apprendre un vecteur d'encapsulation pour chacune des 73 000 espèces d'arbres sur Terre. Le tableau suivant est peut-être le vecteur d'embedding d'un arbre baobab:

Un vecteur d'embedding n'est pas un ensemble de nombres aléatoires. Une couche d'embedding détermine ces valeurs via l'entraînement, de la même manière qu'un réseau de neurones apprend d'autres poids pendant l'entraînement. Chaque élément du tableau correspond à une note attribuée à une caractéristique d'une espèce d'arbre. Quel élément représente la caractéristique de quelle espèce d'arbre ? C'est très difficile à déterminer pour les humains.
La partie mathématiquement remarquable d'un vecteur d'embedding est que les éléments similaires ont des ensembles de nombres à virgule flottante similaires. Par exemple, les espèces d'arbres similaires ont un ensemble de nombres à virgule flottante plus similaire que les espèces d'arbres dissemblables. Les séquoias et les séquoias géants sont des espèces d'arbres apparentées. Ils auront donc un ensemble de nombres à virgule flottante plus similaire que les séquoias géants et les cocotiers. Les nombres du vecteur d'embedding changent à chaque fois que vous réentraînez le modèle, même si vous le réentraînez avec une entrée identique.
encodeur
En général, tout système de ML qui convertit une représentation brute, clairsemée ou externe en une représentation plus traitée, plus dense ou plus interne.
Les encodeurs sont souvent un composant d'un modèle plus vaste, où ils sont souvent associés à un décodeur. Certains transformateurs associent des encodeurs à des décodeurs, tandis que d'autres n'utilisent que l'encodeur ou que le décodeur.
Certains systèmes utilisent la sortie de l'encodeur comme entrée d'un réseau de classification ou de régression.
Dans les tâches de séquence à séquence, un encodeur prend une séquence d'entrée et renvoie un état interne (un vecteur). Ensuite, le décodeur utilise cet état interne pour prédire la séquence suivante.
Consultez Transformer pour connaître la définition d'un encodeur dans l'architecture Transformer.
Pour en savoir plus, consultez LLM: qu'est-ce qu'un grand modèle de langage dans le cours d'initiation au machine learning.
evals
Abréviation principalement utilisée pour les évaluations de LLM. Plus largement, evals est une abréviation de toute forme d'évaluation.
hors connexion
Processus consistant à mesurer la qualité d'un modèle ou à comparer différents modèles entre eux.
Pour évaluer un modèle de machine learning supervisé, vous le comparez généralement à un ensemble de validation et à un ensemble de test. Évaluer un LLM implique généralement des évaluations plus larges de la qualité et de la sécurité.
F
requêtes few-shot
Invite contenant plusieurs (quelques-uns) exemples montrant comment le grand modèle de langage doit répondre. Par exemple, l'invite longue suivante contient deux exemples montrant à un grand modèle de langage comment répondre à une requête.
| Composants d'une requête | Remarques |
|---|---|
| Quelle est la devise officielle du pays spécifié ? | Question à laquelle le LLM doit répondre. |
| France: EUR | Voici un exemple. |
| Royaume-Uni: GBP | Autre exemple. |
| Inde: | Requête réelle. |
Les requêtes few-shot génèrent généralement des résultats plus intéressants que les requêtes zero-shot et les requêtes one-shot. Toutefois, les requêtes few-shot nécessitent une requête plus longue.
Les requêtes few-shot sont une forme d'apprentissage few-shot appliquée à l'apprentissage basé sur les requêtes.
Pour en savoir plus, consultez la section Ingénierie des requêtes du cours d'initiation au machine learning.
Violon
Bibliothèque de configuration Python first qui définit les valeurs des fonctions et des classes sans code ni infrastructure intrusifs. Dans le cas de Pax (et d'autres codebases de ML), ces fonctions et classes représentent des modèles et des hyperparamètres d'entraînement.
Fiddle part du principe que les codebases de machine learning sont généralement divisés en:
- Code de bibliothèque, qui définit les couches et les optimiseurs.
- Code de liaison de l'ensemble de données, qui appelle les bibliothèques et relie tous les éléments.
Fiddle capture la structure d'appel du code de liaison sous une forme non évaluée et modifiable.
affiner
Une deuxième étape d'entraînement spécifique à la tâche effectuée sur un modèle pré-entraîné pour affiner ses paramètres pour un cas d'utilisation spécifique. Par exemple, la séquence d'entraînement complète de certains grands modèles de langage est la suivante:
- Pré-entraînement:entraînez un grand modèle de langage sur un vaste ensemble de données général, comme toutes les pages de Wikipedia en anglais.
- Ajustement:entraînez le modèle pré-entraîné pour qu'il effectue une tâche spécifique, comme répondre à des requêtes médicales. Le réglage fin implique généralement des centaines ou des milliers d'exemples axés sur la tâche spécifique.
Autre exemple : la séquence d'entraînement complète d'un grand modèle d'image se présente comme suit :
- Pré-entraînement:entraînez un grand modèle d'image sur un vaste ensemble de données d'images générales, comme toutes les images de Wikimedia Commons.
- Affinement:entraînez le modèle pré-entraîné pour qu'il effectue une tâche spécifique, comme générer des images d'orques.
Le réglage fin peut impliquer n'importe quelle combinaison des stratégies suivantes:
- Modifier tous les paramètres existants du modèle pré-entraîné. On parle parfois de réglage fin complet.
- Modifier seulement certains des paramètres existants du modèle pré-entraîné (généralement, les couches les plus proches de la couche de sortie), tout en laissant les autres paramètres existants inchangés (généralement, les couches les plus proches de la couche d'entrée). Consultez la section Réglage des paramètres avec optimisation.
- Ajouter des calques, généralement au-dessus des calques existants les plus proches du calque de sortie.
L'optimisation est une forme d'apprentissage par transfert. Par conséquent, l'ajustement fin peut utiliser une fonction de perte ou un type de modèle différents de ceux utilisés pour entraîner le modèle pré-entraîné. Par exemple, vous pouvez affiner un grand modèle d'image pré-entraîné pour produire un modèle de régression qui renvoie le nombre d'oiseaux dans une image d'entrée.
Comparez l'ajustement fin aux termes suivants:
Pour en savoir plus, consultez la section Ajustement du cours d'initiation au machine learning.
Lin
Bibliothèque Open Source hautes performances pour le deep learning, basée sur JAX. Flax fournit des fonctions pour entraîner des réseaux de neurones, ainsi que des méthodes pour évaluer leurs performances.
Flaxformer
Bibliothèque Transformer Open Source, basée sur Flax, conçue principalement pour le traitement du langage naturel et la recherche multimodale.
G
Gemini
Écosystème composé de l'IA la plus avancée de Google. Voici quelques éléments de cet écosystème:
- Différents modèles Gemini.
- Interface conversationnelle interactive pour un modèle Gemini. Les utilisateurs saisissent des requêtes, et Gemini y répond.
- Diverses API Gemini
- Divers produits professionnels basés sur des modèles Gemini, par exemple Gemini pour Google Cloud.
Modèles Gemini
Les modèles multimodaux de pointe de Google basés sur des transformateurs Les modèles Gemini sont spécifiquement conçus pour s'intégrer aux agents.
Les utilisateurs peuvent interagir avec les modèles Gemini de différentes manières, y compris via une interface de boîte de dialogue interactive et via des SDK.
texte généré
En général, le texte généré par un modèle de ML. Lors de l'évaluation de grands modèles de langage, certaines métriques comparent le texte généré à un texte de référence. Par exemple, supposons que vous essayiez de déterminer l'efficacité d'un modèle de ML pour traduire du français vers le néerlandais. Dans ce cas :
- Le texte généré correspond à la traduction néerlandaise générée par le modèle de ML.
- Le texte de référence est la traduction néerlandaise créée par un traducteur humain (ou un logiciel).
Notez que certaines stratégies d'évaluation n'impliquent pas de texte de référence.
IA générative
Champ émergent et transformateur sans définition formelle. Cela dit, la plupart des experts s'accordent à dire que les modèles d'IA générative peuvent créer (ou "générer") du contenu qui présente les caractéristiques suivantes:
- complexe
- cohérent
- originale
Par exemple, un modèle d'IA générative peut créer des essais ou des images sophistiqués.
Certaines technologies antérieures, y compris les LSTM et les RNN, peuvent également générer des contenus originaux et cohérents. Certains experts considèrent ces technologies antérieures comme de l'IA générative, tandis que d'autres estiment que la véritable IA générative nécessite des résultats plus complexes que ces technologies antérieures ne peuvent produire.
À comparer au ML prédictif.
réponse dorée
Réponse connue comme étant correcte. Par exemple, avec la invite suivante:
2 + 2
La réponse idéale est la suivante:
4
GPT (Generative Pre-trained Transformer)
Famille de grands modèles de langage basés sur Transformer développés par OpenAI.
Les variantes GPT peuvent s'appliquer à plusieurs modalités, y compris les suivantes:
- la génération d'images (par exemple, ImageGPT) ;
- Génération d'images à partir de texte (par exemple, DALL-E)
H
hallucination
Production de résultats qui semblent plausibles, mais qui sont en fait incorrects, par un modèle d'IA générative qui prétend faire une affirmation sur le monde réel. Par exemple, un modèle d'IA générative qui affirme que Barack Obama est mort en 1865 est en hallucination.
évaluation humaine
Processus par lequel des personnes évaluent la qualité de la sortie d'un modèle de ML (par exemple, en demandant à des personnes bilingues d'évaluer la qualité d'un modèle de traduction de ML). L'évaluation humaine est particulièrement utile pour évaluer des modèles pour lesquels il n'existe pas de réponse unique.
À comparer à l'évaluation automatique et à l'évaluation par l'outil d'évaluation automatique.
I
apprentissage en contexte
Synonyme de requête few-shot.
L
LaMDA (Language Model for Dialogue Applications)
Grand modèle de langage basé sur un transformateur développé par Google et entraîné sur un grand ensemble de données de dialogue capable de générer des réponses conversationnelles réalistes.
LaMDA: notre technologie conversationnelle révolutionnaire vous en donne un aperçu.
modèle de langage
Modèle qui estime la probabilité qu'un jeton ou une séquence de jetons se produise dans une séquence de jetons plus longue.
Pour en savoir plus, consultez la section Qu'est-ce qu'un modèle de langage ? dans le cours d'initiation au machine learning.
grand modèle de langage
Au minimum, un modèle de langage comportant un très grand nombre de paramètres. Plus officieusement, tout modèle de langage basé sur un Transformer, comme Gemini ou GPT.
Pour en savoir plus, consultez la section Grands modèles de langage (LLM) dans le cours d'initiation au machine learning.
espace latent
Synonyme de espace d'embedding.
Distance Levenshtein
Métrique de distance de modification qui calcule le nombre minimal d'opérations de suppression, d'insertion et de substitution nécessaires pour remplacer un mot par un autre. Par exemple, la distance de Levenshtein entre les mots "cœur" et "fléchettes" est de trois, car les trois modifications suivantes sont les moins nombreuses à transformer un mot en l'autre:
- cœur → deart (remplacez "h" par "d")
- deart → dart (supprimez "e")
- dart → darts (insérer "s")
Notez que la séquence précédente n'est pas le seul chemin de trois modifications.
LLM
Abréviation de grand modèle de langage.
Évaluations des LLM (évaluations)
Ensemble de métriques et de benchmarks permettant d'évaluer les performances des grands modèles de langage (LLM). De manière générale, les évaluations des LLM:
- Aidez les chercheurs à identifier les domaines dans lesquels les LLM doivent être améliorés.
- Ils sont utiles pour comparer différents LLM et identifier le meilleur LLM pour une tâche spécifique.
- Assurez-vous que les LLM sont sûrs et éthiques.
Pour en savoir plus, consultez la section Grands modèles de langage (LLM) dans le cours d'initiation au machine learning.
LoRA
Abréviation de adaptabilité de faible rang.
Adaptabilité à faible rang (LoRA)
Technique efficace en termes de paramètres pour l'ajustement fin qui "gèle" les poids pré-entraînés du modèle (de sorte qu'ils ne puissent plus être modifiés), puis insère un petit ensemble de poids enregistrables dans le modèle. Cet ensemble de poids enregistrables (également appelés "matrices de mise à jour") est considérablement plus petit que le modèle de base et est donc beaucoup plus rapide à entraîner.
LoRA offre les avantages suivants:
- Améliore la qualité des prédictions d'un modèle pour le domaine où le réglage fin est appliqué.
- Il effectue un ajustement plus rapide que les techniques qui nécessitent d'ajuster tous les paramètres d'un modèle.
- Réduit le coût de calcul de l'inférence en permettant la diffusion simultanée de plusieurs modèles spécialisés partageant le même modèle de base.
M
modèle de langage masqué
Modèle de langage qui prédit la probabilité que des jetons candidats remplissent des espaces vides dans une séquence. Par exemple, un modèle de langage masqué peut calculer les probabilités des mots candidats pour remplacer le texte souligné dans la phrase suivante:
Le ____ dans le chapeau est revenu.
La littérature utilise généralement la chaîne "MASK" au lieu d'un trait de soulignement. Exemple :
Le mot "MASK" sur le chapeau est revenu.
La plupart des modèles de langage masqués modernes sont bidirectionnels.
Précision moyenne à k (mAP@k)
Moyenne statistique de tous les scores de précision moyenne à k dans un ensemble de données de validation. L'une des utilisations de la précision moyenne à k est d'évaluer la qualité des recommandations générées par un système de recommandation.
Bien que l'expression "moyenne moyenne" semble redondante, le nom de la métrique est approprié. Après tout, cette métrique calcule la moyenne de plusieurs valeurs de précision moyenne à k.
méta-apprentissage
Sous-ensemble du machine learning qui découvre ou améliore un algorithme d'apprentissage. Un système de méta-apprentissage peut également viser à entraîner un modèle pour qu'il apprenne rapidement une nouvelle tâche à partir d'une petite quantité de données ou de l'expérience acquise lors de tâches précédentes. Les algorithmes de méta-apprentissage tentent généralement d'atteindre les objectifs suivants:
- Améliorer ou apprendre des fonctionnalités conçues manuellement (telles qu'un initialiseur ou un optimiseur)
- Améliorez l'efficacité des données et du calcul.
- Améliorer la généralisation
Le méta-apprentissage est lié à l'apprentissage few-shot.
mélange d'experts
Méthode permettant d'augmenter l'efficacité d'un réseau de neurones en n'utilisant qu'un sous-ensemble de ses paramètres (appelé expert) pour traiter un jeton ou un exemple d'entrée donné. Un réseau de filtrage achemine chaque jeton d'entrée ou exemple vers le ou les experts appropriés.
Pour en savoir plus, consultez l'un des articles suivants:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mélange d'experts avec routage par choix d'experts
MMIT
Abréviation de multimodal instruction-tuned (multimodal tuned instruction).
modality
Catégorie de données de haut niveau. Par exemple, les nombres, le texte, les images, les vidéos et l'audio sont cinq modalités différentes.
parallélisme de modèle
Méthode permettant de faire évoluer l'entraînement ou l'inférence en répartissant les différentes parties d'un modèle sur différents appareils. Le parallélisme des modèles permet d'utiliser des modèles trop volumineux pour tenir sur un seul appareil.
Pour implémenter le parallélisme de modèle, un système procède généralement comme suit:
- Il divise le modèle en parties plus petites.
- Répartit l'entraînement de ces petites parties sur plusieurs processeurs. Chaque processeur entraîne sa propre partie du modèle.
- Combine les résultats pour créer un seul modèle.
Le parallélisme des modèles ralentit l'entraînement.
Voir également le parallélisme de données.
ME
Abréviation de mélange d'experts.
auto-attention multi-tête
Extension de l'auto-attention qui applique le mécanisme d'auto-attention plusieurs fois pour chaque position de la séquence d'entrée.
Les modèles Transformer ont introduit l'auto-attention multitête.
multimodal instruction-tuned
Modèle adapté aux instructions pouvant traiter des entrées autres que du texte, telles que des images, des vidéos et des contenus audio.
modèle multimodal
Modèle dont les entrées, les sorties ou les deux incluent plusieurs modalités. Prenons l'exemple d'un modèle qui utilise à la fois une image et un sous-titre textuel (deux modalités) comme caractéristiques, et qui génère un score indiquant dans quelle mesure le sous-titre textuel est approprié pour l'image. Les entrées de ce modèle sont donc multimodales et la sortie est unimodale.
N
traitement du langage naturel
Domaine qui consiste à apprendre aux ordinateurs à traiter ce qu'un utilisateur a dit ou saisi à l'aide de règles linguistiques. Presque tout le traitement du langage naturel moderne repose sur le machine learning.compréhension du langage naturel
Sous-ensemble du traitement du langage naturel qui détermine les intentions d'une déclaration ou d'une saisie. La compréhension du langage naturel peut aller au-delà du traitement du langage naturel pour prendre en compte des aspects complexes du langage, comme le contexte, le sarcasme et les sentiments.
N-gramme
Séquence ordonnée de N mots. Par exemple, vraiment follement est un 2-grammes. L'ordre a une importance : follement vraiment est un 2-grammes différent de vraiment follement.
| N | Nom(s) pour ce genre de N-gramme | Exemples |
|---|---|---|
| 2 | bigramme ou 2-gramme | to go, go to, eat lunch, eat dinner |
| 3 | trigramme ou 3-gramme | ate too much, happily ever after, the bell tolls |
| 4 | 4-gramme | walk in the park, dust in the wind, the boy ate lentils |
De nombreux modèles de compréhension du langage naturel reposent sur les N-grammes pour prédire le prochain mot que l'utilisateur saisira ou énoncera. Par exemple, supposons qu'un utilisateur ait saisi happily ever. Un modèle NLU basé sur des trigrammes prédira probablement que l'utilisateur saisira ensuite le mot après.
Faire la distinction entre les N-grammes et les sacs de mots, qui sont des listes de mots non ordonnées.
Pour en savoir plus, consultez la section Grands modèles de langage dans le cours d'initiation au machine learning.
NLP
Abréviation de traitement du langage naturel.
NLU (Natural Language Understanding, compréhension du langage naturel) - 1st occurrence only, then use "NLU".
Abréviation de compréhension du langage naturel.
pas de réponse unique (NORA)
Invite avec plusieurs réponses appropriées. Par exemple, la requête suivante n'a pas de réponse unique:
Raconte-moi une blague sur les éléphants.
L'évaluation des invites sans bonne réponse peut s'avérer difficile.
NORA
Abréviation de pas de bonne réponse unique.
O
requêtes one-shot
Une invite contenant un exemple illustrant comment le grand modèle de langage doit répondre. Par exemple, l'invite suivante contient un exemple montrant à un grand modèle de langage comment répondre à une requête.
| Composants d'une requête | Remarques |
|---|---|
| Quelle est la devise officielle du pays spécifié ? | Question à laquelle le LLM doit répondre. |
| France: EUR | Voici un exemple. |
| Inde: | Requête réelle. |
Comparez la invite ponctuelle aux termes suivants:
P
réglage des paramètres avec optimisation
Ensemble de techniques permettant d'affiner un grand modèle de langage pré-entraîné (PLM) plus efficacement que l'affinage complet. L'optimisation des paramètres affine généralement beaucoup moins de paramètres que l'affinage complet, mais produit généralement un grand modèle de langage qui fonctionne aussi bien (ou presque) qu'un grand modèle de langage créé à partir d'un affinage complet.
Comparez et contrastez le réglage des paramètres avec optimisation avec:
Le réglage des paramètres avec optimisation est également appelé optimisation du réglage des paramètres.
pipeline
Forme de parallélisme de modèle dans laquelle le traitement d'un modèle est divisé en étapes consécutives, et chaque étape est exécutée sur un appareil différent. Pendant qu'une étape traite un lot, l'étape précédente peut travailler sur le lot suivant.
Voir également entraînement par étapes.
PLM
Abréviation de modèle de langage pré-entraîné.
encodage en position
Technique permettant d'ajouter des informations sur la position d'un jeton dans une séquence à l'encapsulation du jeton. Les modèles Transformer utilisent l'encodage de position pour mieux comprendre la relation entre les différentes parties de la séquence.
Une implémentation courante de l'encodage de position utilise une fonction sinusoïdale. (Plus précisément, la fréquence et l'amplitude de la fonction sinusoïdale sont déterminées par la position du jeton dans la séquence.) Cette technique permet à un modèle Transformer d'apprendre à s'intéresser à différentes parties de la séquence en fonction de leur position.
modèle post-entraîné
Terme vaguement défini qui désigne généralement un modèle pré-entraîné ayant subi un post-traitement, tel qu'un ou plusieurs des éléments suivants:
Précision à k (precision@k)
Métrique permettant d'évaluer une liste d'éléments classés (triés). La précision à k identifie la fraction des premiers k éléments de cette liste qui sont "pertinents". Par exemple :
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
La valeur de k doit être inférieure ou égale à la longueur de la liste renvoyée. Notez que la longueur de la liste renvoyée n'est pas prise en compte dans le calcul.
La pertinence est souvent subjective. Même les évaluateurs humains experts sont souvent en désaccord sur les éléments pertinents.
Comparer avec :
modèle pré-entraîné
Il s'agit généralement d'un modèle qui a déjà été entraîné. Le terme peut également désigner un vecteur d'embedding précédemment entraîné.
Le terme modèle de langage pré-entraîné désigne généralement un grand modèle de langage déjà entraîné.
pré-entraînement
Entraînement initial d'un modèle sur un grand ensemble de données. Certains modèles pré-entraînés sont des géants maladroits et doivent généralement être affinés par un entraînement supplémentaire. Par exemple, les experts en ML peuvent pré-entraîner un grand modèle de langage sur un vaste ensemble de données textuelles, comme toutes les pages en anglais de Wikipédia. Après le pré-entraînement, le modèle obtenu peut être affiné à l'aide de l'une des techniques suivantes:
- distillation
- affinage
- réglage des instructions
- Réglage des paramètres avec optimisation
- prompt-tuning
requête
Tout texte saisi en entrée d'un grand modèle de langage pour conditionner le modèle à se comporter d'une certaine manière. Les requêtes peuvent être aussi courtes qu'une phrase ou aussi longues que vous le souhaitez (par exemple, le texte complet d'un roman). Les requêtes se répartissent en plusieurs catégories, y compris celles indiquées dans le tableau suivant:
| Catégorie de requête | Exemple | Remarques |
|---|---|---|
| Question | À quelle vitesse un pigeon peut-il voler ? | |
| Instruction | Écris un poème amusant sur l'arbitrage. | Requête demandant au grand modèle de langage de faire quelque chose. |
| Exemple | Traduire le code Markdown en HTML. Par exemple :
Markdown: * élément de liste HTML: <ul> <li>élément de liste</li> </ul> |
La première phrase de cet exemple d'invite est une instruction. Le reste de la requête est l'exemple. |
| Rôle | Expliquez pourquoi la descente de gradient est utilisée dans l'entraînement de machine learning à un doctorat en physique. | La première partie de la phrase est une instruction. La phrase "un doctorat en physique" correspond à la partie du rôle. |
| Entrée partielle que le modèle doit compléter | Le Premier ministre du Royaume-Uni réside à | Une invite d'entrée partielle peut se terminer brusquement (comme dans cet exemple) ou se terminer par un trait de soulignement. |
Un modèle d'IA générative peut répondre à une requête avec du texte, du code, des images, des représentations vectorielles continues, des vidéos… presque n'importe quoi.
apprentissage basé sur des requêtes
Capacité de certains modèles qui leur permet d'adapter leur comportement en réponse à une entrée de texte arbitraire (invites). Dans un paradigme d'apprentissage basé sur des requêtes, un grand modèle de langage répond à une requête en générant du texte. Par exemple, supposons qu'un utilisateur saisisse la requête suivante:
Résumez la troisième loi du mouvement de Newton.
Un modèle capable d'apprendre à partir d'invites n'est pas spécifiquement entraîné pour répondre à l'invite précédente. Le modèle "sait" plutôt beaucoup de choses sur la physique, les règles générales du langage et ce qui constitue des réponses généralement utiles. Ces connaissances sont suffisantes pour fournir une réponse (espérons-le) utile. Des commentaires humains supplémentaires ("Cette réponse était trop compliquée" ou "Qu'est-ce qu'une réaction ?") permettent à certains systèmes d'apprentissage basés sur des invites d'améliorer progressivement l'utilité de leurs réponses.
conception de requête
Synonyme de ingénierie des requêtes.
prompt engineering
Art de créer des requêtes qui génèrent les réponses souhaitées à partir d'un grand modèle de langage. Les humains effectuent une ingénierie rapide. Pour obtenir des réponses utiles à partir d'un grand modèle de langage, il est essentiel de rédiger des requêtes bien structurées. L'ingénierie des requêtes dépend de nombreux facteurs, parmi lesquels:
- Ensemble de données utilisé pour pré-entraîner et éventuellement affiner le grand modèle de langage.
- La température et les autres paramètres de décodage que le modèle utilise pour générer des réponses.
La conception d'invites est synonyme d'ingénierie des requêtes.
Pour en savoir plus sur la rédaction de requêtes utiles, consultez la section Présentation de la conception de requête.
réglage des requêtes
Mécanisme de réglage des paramètres avec optimisation qui apprend un "préfixe" que le système ajoute au message d'invite.
Une variante du réglage des requêtes (parfois appelée réglage du préfixe) consiste à ajouter le préfixe à chaque couche. En revanche, la plupart des réglages d'invite n'ajoutent qu'un préfixe à la couche d'entrée.
R
rappel à k (recall@k)
Métrique permettant d'évaluer les systèmes qui génèrent une liste d'éléments classés (triés). Le rappel à k identifie la fraction des éléments pertinents dans les k premiers éléments de cette liste par rapport au nombre total d'éléments pertinents renvoyés.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
À comparer à la précision à k.
texte de référence
Réponse d'un expert à une invite. Par exemple, avec l'invite suivante:
Traduire la question "Quel est votre nom ?" de l'anglais vers le français.
Voici ce qu'un expert pourrait répondre:
Comment vous appelez-vous ?
Diverses métriques (telles que ROUGE) mesurent le degré de correspondance entre le texte de référence et le texte généré d'un modèle de ML.
invite de rôle
Partie facultative d'une requête qui identifie une audience cible pour la réponse d'un modèle d'IA générative. Sans requête de rôle, un grand modèle de langage fournit une réponse qui peut ou non être utile à la personne qui pose les questions. Avec une requête de rôle, un grand modèle de langage peut répondre de manière plus appropriée et plus utile pour une audience cible spécifique. Par exemple, la partie de l'invite de rôle des requêtes suivantes est en gras:
- Résume ce document pour un doctorat en économie.
- Expliquez le fonctionnement des marées à un enfant de 10 ans.
- Expliquez la crise financière de 2008. Parlez comme vous le feriez avec un jeune enfant ou un golden retriever.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Famille de métriques qui évaluent les modèles de résumé automatique et de traduction automatique. Les métriques ROUGE déterminent le degré de chevauchement d'un texte de référence avec le texte généré d'un modèle de ML. Chaque membre de la famille ROUGE mesure le chevauchement d'une manière différente. Plus le score ROUGE est élevé, plus le texte généré est semblable au texte de référence.
Chaque membre de la famille ROUGE génère généralement les métriques suivantes:
- Précision
- Rappel
- F1
Pour en savoir plus et obtenir des exemples, consultez les pages suivantes:
ROUGE-L
Un membre de la famille ROUGE s'est concentré sur la longueur de la sous-séquence commune la plus longue dans le texte de référence et le texte généré. Les formules suivantes calculent le rappel et la précision pour ROUGE-L:
Vous pouvez ensuite utiliser F1 pour regrouper le rappel ROUGE-L et la précision ROUGE-L dans une seule métrique:
ROUGE-L ignore les sauts de ligne dans le texte de référence et le texte généré. Par conséquent, la sous-séquence commune la plus longue peut s'étendre sur plusieurs phrases. Lorsque le texte de référence et le texte généré comportent plusieurs phrases, une variante de ROUGE-L appelée ROUGE-Lsum est généralement une meilleure métrique. ROUGE-Lsum détermine la sous-séquence commune la plus longue pour chaque phrase d'un passage, puis calcule la moyenne de ces sous-séquences communes les plus longues.
ROUGE-N
Ensemble de métriques de la famille ROUGE qui compare les N-grammes partagés d'une certaine taille dans le texte de référence et le texte généré. Exemple :
- ROUGE-1 mesure le nombre de jetons partagés dans le texte de référence et le texte généré.
- ROUGE-2 mesure le nombre de bigrammes (2-grammes) partagés dans le texte de référence et le texte généré.
- ROUGE-3 mesure le nombre de trigrammes (3-grammes) partagés dans le texte de référence et le texte généré.
Vous pouvez utiliser les formules suivantes pour calculer la précision et la récence ROUGE-N pour n'importe quel membre de la famille ROUGE-N:
Vous pouvez ensuite utiliser F1 pour regrouper le rappel ROUGE-N et la précision ROUGE-N dans une seule métrique:
ROUGE-S
Forme tolérante de ROUGE-N qui permet la mise en correspondance de skip-gram. Autrement dit, ROUGE-N ne compte que les n-grammes qui correspondent exactement, mais ROUGE-S compte également les n-grammes séparés par un ou plusieurs mots. Nous vous conseillons, par exemple, de suivre les recommandations suivantes :
- texte de référence: Nuages blancs
- generated text: Des nuages blancs en forme de ballons
Lors du calcul de ROUGE-N, le 2-gramme nuages blancs ne correspond pas à nuages blancs en forme de volutes. Toutefois, lors du calcul de ROUGE-S, Nuages blancs correspond à Nuages blancs en forme de volutes.
S
auto-attention (également appelée couche d'auto-attention)
Couche de réseau de neurones qui transforme une séquence d'embeddings (par exemple, des embeddings de jeton) en une autre séquence d'embeddings. Chaque imbrication de la séquence de sortie est construite en intégrant les informations des éléments de la séquence d'entrée via un mécanisme d'attention.
La partie auto-attention de l'auto-attention fait référence à la séquence qui s'occupe d'elle-même plutôt que d'un autre contexte. L'auto-attention est l'un des principaux composants des transformateurs et utilise la terminologie de recherche dans un dictionnaire, comme "requête", "clé" et "valeur".
Une couche d'auto-attention commence par une séquence de représentations d'entrée, une pour chaque mot. La représentation d'entrée d'un mot peut être un simple vecteur d'encapsulation. Pour chaque mot d'une séquence d'entrée, le réseau évalue la pertinence du mot par rapport à chaque élément de la séquence complète de mots. Les scores de pertinence déterminent dans quelle mesure la représentation finale du mot intègre les représentations d'autres mots.
Prenons l'exemple de la phrase suivante:
L'animal n'a pas traversé la rue, car il était trop fatigué.
L'illustration suivante (issue de Transformer: A Novel Neural Network Architecture for Language Understanding) montre le modèle d'attention d'une couche d'auto-attention pour le pronom it, l'intensité de chaque ligne indiquant dans quelle mesure chaque mot contribue à la représentation:

La couche d'auto-attention met en avant les mots pertinents pour "it". Dans ce cas, la couche d'attention a appris à mettre en évidence les mots auxquels elle peut faire référence, en attribuant la pondération la plus élevée à animal.
Pour une séquence de jetons n, l'attention automatique transforme une séquence d'embeddings n fois, une fois à chaque position de la séquence.
Consultez également attention et attention auto-attentive multitête.
analyse des sentiments
Utilisation d'algorithmes statistiques ou de machine learning pour déterminer l'attitude globale d'un groupe (positive ou négative) à l'égard d'un service, d'un produit, d'une organisation ou d'un sujet. Par exemple, en utilisant la compréhension du langage naturel, un algorithme pourrait effectuer une analyse des sentiments sur les commentaires textuels d'un cours universitaire afin de déterminer le degré d'appréciation des étudiants pour ce cours.
Pour en savoir plus, consultez le guide Classification du texte.
tâche de séquence à séquence
Une tâche qui convertit une séquence d'entrée de jetons en séquence de jetons de sortie. Par exemple, voici deux types de tâches de séquence à séquence populaires:
- Traducteurs :
- Exemple de séquence d'entrée: "Je t'aime."
- Exemple de séquence de sortie: "Je t'aime."
- Systèmes de questions-réponses :
- Exemple de séquence d'entrée: "Ai-je besoin de ma voiture à New York ?"
- Exemple de séquence de sortie: "Non. Laissez votre voiture à la maison."
skip-gram
N-gramme pouvant omettre (ou "sauter") des mots du contexte d'origine, ce qui signifie que les N mots n'étaient peut-être pas initialement adjacents. Plus précisément, un "k-skip-n-gram" est un n-gramme pour lequel jusqu'à k mots peuvent avoir été ignorés.
Par exemple, "the quick brown fox" présente les bigrammes suivants:
- "the quick"
- "quick brown"
- "renard brun"
Un "1-skip-2-gram" est une paire de mots séparés par un maximum d'un mot. Par conséquent, "the quick brown fox" comporte les bigrammes à saut 1 suivants:
- "the brown"
- "quick fox"
De plus, tous les bigrammes sont également des bigrammes à saut unique, car un seul mot peut être ignoré.
Les skip-grams sont utiles pour mieux comprendre le contexte entourant un mot. Dans l'exemple, "renard" était directement associé à "rapide" dans l'ensemble des bigrammes à saut 1, mais pas dans l'ensemble des bigrammes.
Les skip-grams permettent d'entraîner des modèles d'embedding de mots.
réglage des requêtes douces
Technique permettant d'ajuster un grand modèle de langage pour une tâche spécifique, sans ajustement précis gourmand en ressources. Au lieu de réentraîner tous les poids du modèle, l'ajustement doux de la requête ajuste automatiquement une requête pour atteindre le même objectif.
Lorsqu'une requête textuelle est fournie, le réglage de la requête douce ajoute généralement des embeddings de jetons supplémentaires à la requête et utilise la rétropropagation pour optimiser l'entrée.
Une requête "dure" contient des jetons réels au lieu d'embeddings de jetons.
caractéristique creuse
Élément géographique dont les valeurs sont pour la plupart nulles ou vides. Par exemple, une fonctionnalité contenant une seule valeur 1 et un million de valeurs 0 est sporadique. À l'inverse, une entité dense a des valeurs qui ne sont pas principalement nulles ou vides.
En machine learning, un nombre surprenant de caractéristiques sont des caractéristiques peu denses. Les caractéristiques catégorielles sont généralement des caractéristiques peu denses. Par exemple, parmi les 300 espèces d'arbres possibles dans une forêt, un seul exemple peut n'identifier qu'un érable. Par exemple, parmi les millions de vidéos possibles dans une bibliothèque vidéo, un seul exemple peut identifier "Casablanca".
Dans un modèle, vous représentez généralement des caractéristiques creuses à l'aide de l'encodage one-hot. Si l'encodage one-hot est volumineux, vous pouvez placer une couche d'encapsulation au-dessus de l'encodage one-hot pour plus d'efficacité.
représentation creuse
Stocker uniquement la ou les positions des éléments non nuls dans une fonctionnalité sporadique.
Par exemple, supposons qu'une caractéristique catégorielle nommée species identifie les 36 espèces d'arbres d'une forêt donnée. Supposons également que chaque exemple n'identifie qu'une seule espèce.
Vous pouvez utiliser un vecteur à valeurs uniques pour représenter les espèces d'arbres dans chaque exemple.
Un vecteur one-hot contiendrait un seul 1 (pour représenter l'espèce d'arbre particulière dans cet exemple) et 35 0 (pour représenter les 35 espèces d'arbres non dans cet exemple). Ainsi, la représentation one-hot de maple peut ressembler à ceci:

En revanche, la représentation sporadique identifie simplement la position de l'espèce en question. Si maple se trouve à la position 24, la représentation creuse de maple est simplement la suivante:
24
Notez que la représentation sparse est beaucoup plus compacte que la représentation one-hot.
Cliquez sur l'icône pour voir un exemple un peu plus complexe.
Supposons que chaque exemple de votre modèle doit représenter les mots (mais pas l'ordre de ces mots) dans une phrase en anglais. L'anglais comprend environ 170 000 mots. Il s'agit donc d'une caractéristique catégorielle avec environ 170 000 éléments. La plupart des phrases en anglais utilisent une fraction extrêmement faible de ces 170 000 mots. Par conséquent, l'ensemble de mots d'un seul exemple sera presque certainement des données peu denses.
Considérons la phrase suivante:
My dog is a great dog
Vous pouvez utiliser une variante du vecteur one-hot pour représenter les mots de cette phrase. Dans cette variante, plusieurs cellules du vecteur peuvent contenir une valeur non nulle. De plus, dans cette variante, une cellule peut contenir un entier autre que un. Bien que les mots "mon", "est", "un" et "super" n'apparaissent qu'une seule fois dans la phrase, le mot "chien" apparaît deux fois. L'utilisation de cette variante de vecteurs one-hot pour représenter les mots de cette phrase donne le vecteur à 170 000 éléments suivant:

Une représentation creuse de la même phrase serait simplement la suivante:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Pour en savoir plus, consultez la section Utiliser des données catégorielles dans le cours d'initiation au machine learning.
entraînement par étapes
Stratégie consistant à entraîner un modèle dans une séquence d'étapes distinctes. L'objectif peut être d'accélérer le processus d'entraînement ou d'obtenir une meilleure qualité de modèle.
Vous trouverez ci-dessous une illustration de l'approche d'empilement progressif:
- L'étape 1 contient trois couches cachées, l'étape 2 six couches cachées et l'étape 3 12 couches cachées.
- L'étape 2 commence l'entraînement avec les poids appris dans les trois couches cachées de l'étape 1. L'étape 3 commence l'entraînement avec les poids appris dans les six couches cachées de l'étape 2.
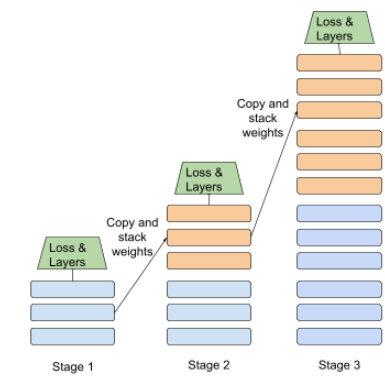
Voir également pipeline.
jeton de sous-mot
Dans les modèles de langage, jeton qui est une sous-chaîne d'un mot, qui peut être l'ensemble du mot.
Par exemple, un mot comme "énumérer" peut être divisé en "élément" (un mot racine) et "iser" (un suffixe), chacun étant représenté par son propre jeton. En divisant les mots inhabituels en éléments tels que des sous-mots, les modèles de langage peuvent fonctionner sur les parties constituantes les plus courantes du mot, telles que les préfixes et les suffixes.
À l'inverse, les mots courants comme "aller" peuvent ne pas être divisés et être représentés par un seul jeton.
T
T5
Modèle d'apprentissage par transfert de texte à texte, lancé par Google AI en 2020. T5 est un modèle encodeur-décodeur, basé sur l'architecture Transformer, entraîné sur un ensemble de données extrêmement volumineux. Il est efficace pour diverses tâches de traitement du langage naturel, telles que la génération de texte, la traduction de langues et la réponse à des questions de manière conversationnelle.
Le nom T5 vient des cinq T de "Text-to-Text Transfer Transformer" (transformateur de transfert texte-vers-texte).
T5X
Framework de machine learning Open Source conçu pour créer et entraîner des modèles de traitement du langage naturel (TLN) à grande échelle. T5 est implémenté sur le codebase T5X (basé sur JAX et Flax).
température
Hyperparamètre qui contrôle le degré de hasard de la sortie d'un modèle. Des températures plus élevées entraînent une sortie plus aléatoire, tandis que des températures plus basses entraînent une sortie moins aléatoire.
Le choix de la meilleure température dépend de l'application spécifique et des propriétés préférées de la sortie du modèle. Par exemple, vous augmenterez probablement la température lorsque vous créerez une application qui génère des résultats créatifs. À l'inverse, vous devriez probablement baisser la température lorsque vous créez un modèle qui classe des images ou du texte afin d'améliorer sa précision et sa cohérence.
La température est souvent utilisée avec la fonction softmax.
étendue de texte
Intervalle d'indice de tableau associé à une sous-section spécifique d'une chaîne de texte.
Par exemple, le mot good dans la chaîne Python s="Be good now" occupe la plage de texte de 3 à 6.
jeton
Dans un modèle de langage, unité atomique sur laquelle le modèle effectue l'entraînement et les prédictions. Un jeton est généralement l'un des éléments suivants:
- un mot : par exemple, l'expression "chiens aiment les chats" se compose de trois jetons de mot : "chiens", "aiment" et "chats".
- un caractère (par exemple, l'expression "poisson vélo" se compose de neuf jetons de caractères). (Notez que l'espace vide compte comme l'un des jetons.)
- sous-mots, dans lesquels un seul mot peut être un seul jeton ou plusieurs jetons. Un sous-mot se compose d'un mot racine, d'un préfixe ou d'un suffixe. Par exemple, un modèle de langage qui utilise des sous-mots comme jetons peut considérer le mot "chiens" comme deux jetons (le mot racine "chien" et le suffixe au pluriel "s"). Ce même modèle de langage peut considérer le mot unique "plus grand" comme deux sous-mots (le mot racine "grand" et le suffixe "er").
Dans les domaines autres que les modèles de langage, les jetons peuvent représenter d'autres types d'unités atomiques. Par exemple, dans les applications de vision par ordinateur, un jeton peut être un sous-ensemble d'une image.
Pour en savoir plus, consultez la section Grands modèles de langage dans le cours d'initiation au machine learning.
Précision top-K
Pourcentage de fois où un "libellé cible" apparaît dans les premières k positions des listes générées. Il peut s'agir de recommandations personnalisées ou d'une liste d'éléments triés par softmax.
La précision top-k est également appelée précision à k.
toxique
Le degré d'abus, de menace ou d'incitation à la haine du contenu De nombreux modèles de machine learning peuvent identifier et mesurer la toxicité. La plupart de ces modèles identifient la toxicité en fonction de plusieurs paramètres, tels que le niveau de langage abusif et le niveau de langage menaçant.
Transformer
Architecture de réseau de neurones développée chez Google, qui s'appuie sur des mécanismes d'attention sélective pour transformer une séquence d'embeddings d'entrée en séquence d'embeddings de sortie sans s'appuyer sur des convolutions ni sur des réseaux de neurones récurrents. Un Transformer peut être considéré comme une pile de couches d'auto-attention.
Un transformateur peut inclure l'un des éléments suivants:
Un encodeur transforme une séquence d'embeddings en une nouvelle séquence de la même longueur. Un encodeur comprend N couches identiques, chacune contenant deux sous-couches. Ces deux sous-couches sont appliquées à chaque position de la séquence d'encapsulation d'entrée, transformant chaque élément de la séquence en un nouvel encapsulage. La première sous-couche de l'encodeur agrège les informations de la séquence d'entrée. La deuxième sous-couche de l'encodeur transforme les informations agrégées en un embedding de sortie.
Un décodeur transforme une séquence d'embeddings d'entrée en une séquence d'embeddings de sortie, éventuellement de longueur différente. Un décodeur comprend également N couches identiques avec trois sous-couches, dont deux sont similaires aux sous-couches de l'encodeur. La troisième sous-couche du décodeur prend la sortie de l'encodeur et applique le mécanisme d'auto-attention pour en extraire des informations.
L'article de blog Transformer: une nouvelle architecture de réseau de neurones pour la compréhension du langage fournit une bonne introduction aux Transformers.
Pour en savoir plus, consultez LLM: qu'est-ce qu'un grand modèle de langage ? dans le cours d'initiation au machine learning.
trigramme
Un N-gramme dans lequel N=3.
U
unidirectionnel
Système qui n'évalue que le texte qui précède une section cible de texte. À l'inverse, un système bidirectionnel évalue à la fois le texte qui précède et suit une section cible de texte. Pour en savoir plus, consultez la section bidirectionnel.
modèle de langage unidirectionnel
Modèle de langage qui ne base ses probabilités que sur les jetons qui apparaissent avant, et non après, le ou les jetons cibles. À comparer au modèle de langage bidirectionnel.
V
un auto-encodeur variationnel (VAE) ;
Type d'autoencodeur qui exploite la divergence entre les entrées et les sorties pour générer des versions modifiées des entrées. Les auto-encodeurs variationnels sont utiles pour l'IA générative.
Les VAEs sont basés sur l'inférence variationnelle, une technique permettant d'estimer les paramètres d'un modèle de probabilité.
W
embedding lexical
Représentation de chaque mot d'un ensemble de mots dans un vecteur d'encapsulation, c'est-à-dire représentation de chaque mot sous la forme d'un vecteur de valeurs à virgule flottante comprises entre 0,0 et 1,0. Les mots ayant des significations similaires ont des représentations plus similaires que les mots ayant des significations différentes. Par exemple, les carottes, le céleri et les concombres ont des représentations relativement similaires, qui sont très différentes de celles d'un avion, de lunettes de soleil et de dentifrice.
Z
requêtes zero-shot
Une requête qui ne fournit pas d'exemple de la façon dont vous souhaitez que le grand modèle de langage réponde. Exemple :
| Composants d'une requête | Remarques |
|---|---|
| Quelle est la devise officielle du pays spécifié ? | Question à laquelle le LLM doit répondre. |
| Inde: | Requête réelle. |
Le grand modèle de langage peut répondre par l'une des réponses suivantes:
- Roupie
- INR
- ₹
- Roupie indienne
- La roupie
- Roupie indienne
Toutes les réponses sont correctes, mais vous pouvez préférer un format particulier.
Comparez les invites sans entraînement aux termes suivants: