このページには、言語評価の用語集が掲載されています。すべての用語集で こちらをクリックしてください。
A
Attention、
ニューラル ネットワークで使用されるメカニズムのひとつで、 特定の単語や単語の一部の重要性を示します。Attention は モデルが次のトークン/単語を予測するために必要な情報量。 典型的なアテンション機構は、 一連の入力に対する加重合計です。ここで、 各入力の重みは、 ニューラル ネットワークです。
セルフ アテンションと マルチヘッド セルフ アテンション: Transformer の構成要素。
オートエンコーダ
最も重要な情報を抽出することを学習する 表示されます。オートエンコーダは、エンコーダと decoder。オートエンコーダは次の 2 段階のプロセスに依存します。
- エンコーダは、入力を(通常は)損失の多い低次元の (中級)形式にします。
- デコーダは、元の入力の非可逆バージョンを、 低次元の形式を元の高次元の形式に変換できます。 できます。
オートエンコーダは、デコーダにシーケンスを エンコーダの中間形式から元の入力を再構築する できる限り近い位置に集計します中間形式はサイズが小さいため (低次元)である場合、オートエンコーダは 入力のどの情報が必須であるかを学習し、出力は 入力と完全に同じになります。
例:
- 入力データがグラフィックの場合、正確なコピーは 若干変更されています。おそらく、 元の画像からノイズを取り除いたり、画像を塗りつぶしたりします。 ドット抜けがあります
- 入力データがテキストの場合、オートエンコーダは、入力内容に基づいて 元のテキストを模倣している(同じではありません)
変分オートエンコーダもご覧ください。
自己回帰モデル
独自の過去のモデルに基づいて予測を推測するモデル 説明します。たとえば、自己回帰言語モデルは、 トークン: 以前に予測されたトークンに基づきます。 すべて Transformer ベース 大規模言語モデルは自己回帰的です。
対照的に、GAN ベースの画像モデルは通常、自己回帰的ではない 反復処理ではなく、単一のフォワードパスで画像を生成するため できます。ただし、特定の画像生成モデルは自己回帰的です。 段階的に画像を生成します。
B
言葉のバッグ
フレーズやパッセージ内の単語の表現 表示されます。たとえば、bag of words という単語は、 次の 3 つのフレーズを同じように検索します。
- 犬がジャンプする
- 犬をジャンプさせる
- 犬がジャンプする
各単語はスパース ベクトルのインデックスにマッピングされます。 ベクトルには語彙内のすべての単語に対するインデックスがある。たとえば 「the dog jumps」というフレーズが、ゼロ以外の特徴ベクトルにマッピングされます。 単語 the、犬、および ジャンプ:ゼロ以外の値は次のいずれかです。
- 1 の場合は単語の存在を示します。
- バッグの中に単語が出現する回数。たとえば フレーズがマルーンの犬はマルーンの毛皮の犬であるの場合、両方 マルーンと犬は 2 と表され、他の単語は以下のように表現されます。 表します。
- その他の値(特定のイベントに対する数のカウントの対数など) 出現回数をカウントします。
BERT(双方向エンコーダ) Transformers による表現)
テキスト表現のモデル アーキテクチャ。トレーニング済みの BERT モデルは、テキスト分類用の大規模なモデルの一部として機能できます。 学習します
BERT には次の特徴があります。
- Transformer アーキテクチャを使用しているため、 セルフ アテンションを重視します。
- Transformer の encoder 部分を使用します。エンコーダのジョブ 特定のタスクを実行するのではなく、 学習します。
- 双方向である。
- マスキングを使用: 教師なしトレーニング。
BERT の亜種は次のとおりです。
で確認できます。オープン ソーシング BERT: 自然言語向けの最先端の事前トレーニングをご覧ください。 処理中 をご覧ください。
双方向
先行するテキストを評価するシステムを表す用語 テキストのターゲット セクションのフォロー。これに対して 単方向システムのみ テキストのターゲット セクションの前のテキストを評価します。
たとえば、マスクされた言語モデルについて考えてみましょう。 確率分布関数で下線を表す単語の確率を 質問です。
あなたの _____ は何ですか?
単方向言語モデルでは、その確率のみに基づいて “What”、“is”、“the”という言葉で与えられる文脈で表現します。一方 双方向の言語モデルは、テキスト メッセージを使って「with」から「あなた」が モデルがより良い予測を生成するのに役立つ場合があります。
双方向言語モデル
言語モデルは、特定の単語が出現する確率を 基づくテキストの抜粋で、特定のトークンが 前と後のテキスト。
バイグラム
N=2 である N グラム。
BLEU(Bilingual Evaluation Understudy)
翻訳の品質を示す 0.0 ~ 1.0 のスコア (英語とロシア語など)。BLEU スコア 1.0 は完全な翻訳を示します。BLEU スコアが 0.0 の場合は ひどい訳です。
C
因果言語モデル
単方向言語モデルと同義。
双方向言語モデルを参照して、 言語モデリングにおけるさまざまな方向性のアプローチを対比します。
Chain-of-Thought プロンプト
プロンプト エンジニアリングの手法: 大規模言語モデル(LLM)を使って、 一つひとつ解説しますたとえば、次のプロンプトについて考えてみましょう。 次の文に特に注意を払ってください。
0 から 60 までの自動車では、ドライバーが経験する G フォースはいくつありますか。 マイル/h 7 秒?関連するすべての計算を解答に表示します。
LLM のレスポンスは次のようになると考えられます。
- 0、60、7 の値を代入して、一連の物理公式を表示する 適切な場所に配置する必要があります。
- これらの数式を選択した理由と、さまざまな変数の意味を説明してください。
Chain-of-Thought プロンプトにより、LLM はすべての計算を実行せざるを得なくなります。 より正しい回答につながる可能性があります。さらに、Chain-of-Thought、 プロンプトにより、ユーザーは LLM の手順を調べて、 答えが合理的かどうかです
チャット
ML システムとやり取りされる内容。通常は 大規模言語モデル。 チャットの以前のやり取り (入力した内容と大規模言語モデルがどのように応答したか)が、 コンテキストに基づいて説明します。
chatbot は大規模言語モデルのアプリケーションです。
打ち合わせ
幻覚と同義。
技術的には、「幻覚」よりも「混同」のほうが正確な用語でしょう。 しかし、ハルシネーションが最初に普及しました。
選挙区の解析
文を小さな文法構造(「構成要素」)に分割する。 ML システムの後方の部分(API など)は、 自然言語理解モデル は元の文よりも構成要素を簡単に解析できます。たとえば 次の一文を考えてみましょう。
友だちが 2 匹の猫を育てました。
選挙区パーサーは、この文を次のように分割できます。 2 つの構成要素があります。
- My Friend は名詞句です。
- adopted Two cats は動詞句です。
これらの構成要素は、さらに小さな構成要素に細分化できます。 たとえば、動詞フレーズは、
2 匹の猫を飼う
次のようにさらに分類できます。
- adopted は動詞です。
- two cats は、名詞句の一つです。
コンテキスト化された言語のエンベディング
「理解」に近いエンベディング単語 ネイティブな人間の話者と同じような方法で表現できます。コンテキスト化された言語 エンベディングでは、複雑な構文、セマンティクス、コンテキストを理解できます。
たとえば、英語の単語「cow」のエンベディングについて考えてみましょう。古いエンベディング たとえば word2vec は英語を表す エンベディング空間内の距離が から 雄牛までの距離は、ewe(メスの羊)から (オスの羊)またはメスからオスに。コンテキスト化された言語 エンベディングでは、英語を話すユーザーがいることを認識することで、 「牛」または「雄牛」を意味する「cow」はカジュアルな意味で使います。
コンテキスト ウィンドウ
特定の期間内にモデルが処理できるトークンの数 prompt。コンテキスト ウィンドウが大きいほど、より多くの情報が示されます。 一貫性があり一貫した応答を提供するためにモデルが使用できる 追加します。
クラッシュ ブラッサム
意味が曖昧な文やフレーズ。 花咲く花は、自然界で重大な問題をもたらします。 言語理解に重点を置いています。 たとえば、「Red Tape Holds Up Skyscraper」という見出しは なぜなら NLU モデルは見出しを文字どおり解釈したり、 表します。
D
デコーダ
一般に、処理済み、高密度、高密度モデルからデータを変換する より未加工、スパース、または外部表現に内部表現を変換できます。
デコーダは、多くの場合、大規模なモデルのコンポーネントであり、 エンコーダとペア。
シーケンス ツー シーケンス タスクでは、デコーダは エンコーダによって生成された内部状態から始めて、 あります。
デコーダの定義については、Transformer を参照してください。 Transformer アーキテクチャの概要を説明しています。
ノイズ除去
自己教師あり学習への一般的なアプローチ 各要素の意味は次のとおりです。
ノイズを除去することで、ラベルなしのサンプルからの学習が可能になります。 元のデータセットがターゲットまたは ラベルと ノイズの多いデータを入力として受け取ります。
一部のマスクされた言語モデルでノイズ除去を使用 次のとおりです。
- ラベルのない文には、ノイズが人為的に追加されます。 作成されます。
- モデルは元のトークンを予測しようとします。
ダイレクト プロンプト
ゼロショット プロンプトと同義。
E
距離を編集
2 つの文字列が互いにどの程度類似しているかを示す測定値。 ML で距離の編集が役立つのは、 2 つの文字列を比較するための効果的な方法も確認しました。 指定した文字列に類似した文字列を検索したりできます。
編集距離にはいくつかの定義があり、それぞれが異なる文字列を使用しています。 必要があります。たとえば、 <ph type="x-smartling-placeholder"></ph> レーベンシュタイン距離 削除、挿入、置換オペレーションが最小限に抑えられます。
例: 「ハート」という単語間のレーベンシュタイン距離「ダーツ」 3 です。これは、次の 3 つの編集で 1 語になるために必要な変更が少ないためです。 次のように置き換えます。
- ハート → deart(「h」を「d」に置き換える)
- deart → dart(「e」を削除)
- dart → darts("s" を挿入)
エンベディング レイヤ
トレーニング用の特別な隠れ層 高次元カテゴリ特徴を作成して、 下位次元のエンベディング ベクトルを徐々に学習します。「 エンべディング レイヤを使用することで、ニューラル ネットワークは 高次元カテゴリ特徴量だけをトレーニングするよりも効率的です。
たとえば、地球は現在約 73,000 種の樹木をサポートしています。仮説
樹木の種類はモデルの特徴量であるため、モデルの
ワンホット ベクトルを含む 73,000
指定することもできます。
たとえば、baobab は次のように表されます。

73,000 要素からなる配列は非常に長いです。エンベディング レイヤを追加しない場合 トレーニングに膨大な時間がかかります。 72,999 個のゼロを乗算しますエンベディング レイヤを 1 つのレイヤに 12 次元です。その結果、エンベディング レイヤは徐々に学習し、 新しいエンベディング ベクトルを作成します。
状況によっては、ハッシュ化が妥当な代替手段である エンベディング レイヤに渡します。
エンベディング空間
高次元の特徴を持つ d 次元ベクトル空間は、 ベクトル空間にマッピングされます。エンべディング空間には、入力シーケンスが 意味のある数学的結果が得られる構造たとえば 理想的なエンベディング空間でのエンベディングの加算と減算 文章にたとえて単語を解き放つことができます。
ドット積 その類似性の尺度となります。
エンベディング ベクトル
大まかに言うと、any から取得した浮動小数点数の配列 隠れ層への入力を記述する隠れ層。 多くの場合、エンベディング ベクトルは Google Cloud でトレーニングされた浮動小数点数の配列 エンベディング レイヤです。たとえば、エンベディング レイヤが新しいパターンを学習し、 エンべディング ベクトルを作成します。おそらく、 次の配列は、バオバブの木のエンベディング ベクトルです。

エンベディング ベクトルは乱数の集まりではありません。エンベディング レイヤ トレーニングによってこれらの値を決定します。これは、 トレーニング中に他の重みも学習します。各要素の 配列は、樹木種の特性に沿った評価です。対象 どの樹木種がどうすればよいでしょうか。それはすごく難しい 判断できます
エンべディング ベクトルの数学的に注目すべき点は、エンべディング ベクトルが アイテムには同様の浮動小数点数のセットがあります。たとえば、 浮動小数点数のセットは、樹木の種類のほうが 異なる種類の樹木のことです。セコイアとセコイアは関連する樹種です。 浮動小数点数と浮動小数点数のセットが セコイアやヤシの木などで育ちますエンべディング ベクトルの数値は、 再トレーニングのたびに変化する値の変化に できます。
エンコーダ
一般に、未加工、スパース、または外部からデータを変換する より処理済み、高密度、または内部的な表現に変換できます。
エンコーダは、多くの場合、大規模なモデルのコンポーネントであり、 デコーダとペアリングします。一部の Transformer 対になりますが、他の Transformer では、エンコーダとデコーダを デコーダのみを指定できます。
一部のシステムでは、エンコーダの出力を分類システムへの入力として使用し、 ネットワークです
シーケンス ツー シーケンス タスクでは、エンコーダは 入力シーケンスを受け取り、内部状態(ベクトル)を返します。次に、 decoder はその内部状態を使用して次のシーケンスを予測します。
エンコーダの定義については、Transformer を Transformer アーキテクチャの概要を説明しています。
F
少数ショット プロンプト
複数(「少数」の)例を含むプロンプト 大規模言語モデルが 応答が必要です。たとえば、次の長いプロンプトには 2 つの 大規模言語モデルでクエリに応答する方法を示す例。
| 1 つのプロンプトを構成する要素 | メモ |
|---|---|
| 指定された国の公式通貨は何ですか? | LLM に回答させたい質問。 |
| フランス: EUR | 一例です。 |
| 英国: GBP | 別の例を見てみましょう。 |
| インド: | 実際のクエリ。 |
一般的に、少数ショット プロンプトのほうが望ましい結果が ゼロショット プロンプトと ワンショット プロンプト。ただし、少数ショット プロンプトは 長いプロンプトが必要です。
少数ショット プロンプトは少数ショット学習の一種 プロンプトベースの学習に適用しました。
フィドル
Python ファーストの構成ライブラリで、 関数やクラスの価値をモニタリングできます。 Pax や他の ML コードベースの場合、これらの関数と クラスはモデルとトレーニングを表す ハイパーパラメータ。
フィドル 通常、ML コードベースは次のように分割されることを想定しています。
- レイヤとオプティマイザを定義するライブラリ コード。
- データセット「glue」このコードでは、ライブラリを呼び出して、すべてをつなぎ合わせます。
Fiddle は、未評価のグルーコードの呼び出し構造をキャプチャし、 あります。
ファインチューニング
2 つ目のタスク固有のトレーニング パスは、 事前トレーニング済みモデルを使って、特定のタスクのためにパラメータを 判断できますたとえば、一部のトレーニング シーケンスは、 大規模言語モデルは次のとおりです。
- 事前トレーニング: 大規模な言語モデルを大規模な一般データセットでトレーニングします。 たとえば英語版のウィキペディアの すべてのページなどです
- ファインチューニング: 特定のタスクを実行するように事前トレーニング済みモデルをトレーニングします。 医療質問への対応などですファインチューニングでは通常 特定のタスクに焦点を当てた何百、何千ものサンプルが存在します。
別の例として、大規模な画像モデルの完全なトレーニング シーケンスは次のようになります。 次のようになります。
- 事前トレーニング: 巨大な一般的な画像で大規模な画像モデルをトレーニングする Wikimedia Commons 内のすべての画像などのデータセットを収集します。
- ファインチューニング: 特定のタスクを実行するように事前トレーニング済みモデルをトレーニングします。 シャチの画像を生成するなどです。
ファインチューニングでは、次の戦略を任意に組み合わせて行うことができます。
- 事前トレーニング済みモデルのすべての変更 パラメータ。これはフル ファインチューニングとも呼ばれます。
- 事前トレーニング済みモデルの既存のパラメータの一部のみを変更する (通常は出力レイヤに最も近いレイヤ)。 他の既存のパラメータ(通常は 入力レイヤに最も近いもの)。詳しくは、 パラメータ効率チューニング。
- レイヤを追加する(通常は、レイヤに最も近い既存のレイヤの上に) 出力レイヤです。
ファインチューニングは転移学習の一種です。 そのため、ファインチューニングでは異なる損失関数や別のモデルが使用される場合があります。 使用するものよりも望ましい方法です。たとえば、 トレーニング済みの大規模画像モデルをファインチューニングして、 入力画像に含まれる鳥の数を返します。
ファインチューニングを次の用語と比較してください。
亜麻
高パフォーマンスのオープンソース ライブラリ JAX 上に構築されたディープ ラーニング。Flax が提供する関数 トレーニング ニューラル ネットワーク用 パフォーマンスを評価する手段として利用できます
Flaxformer
オープンソースの Transformer library 主に自然言語処理用に設計された Flax 上に構築 多岐にわたります。
G
生成 AI
正式な定義のない、新たな革新的分野。 とはいえ、ほとんどの専門家は、生成 AI モデルは 以下のすべてを満たすコンテンツを作成(「生成」)します。
- 複雑
- 一貫性がある
- オリジナル
たとえば、生成 AI モデルでは高度な エッセイや画像などです
LSTMs などの以前のテクノロジー RNN など)を使用して、元の画像とテキスト、 明確で一貫性のあるコンテンツです。一部の専門家は、こうした初期のテクノロジーを 真の生成 AI にはより複雑なものが必要だと考える人もいます。 生成できるものはありません。
予測 ML も参照してください。
GPT(Generative Pre-trained Transformer)
Transformer ベースのファミリー Google Cloud が開発した大規模言語モデル OpenAI。
GPT のバリエーションは、次のような複数のモダリティに適用できます。
- 画像生成(ImageGPT など)
- テキストから画像を生成する(例: DALL-E)。
H
ハルシネーション
一見、もっともらしく見えても事実に反する出力を、 生成 AI モデルであり、 アサーションが必要です。 例: バラク オバマが 1865 年に亡くなったと主張する生成 AI モデル ハルシネーションを起こします。
I
コンテキスト内学習
少数ショット プロンプトと同義。
L
LaMDA(Language Model for Dialogue Applications)
Transformer ベースの トレーニング済みで Google が開発した大規模言語モデル 現実的な会話レスポンスを生成できる大規模な対話データセット。
LaMDA: 画期的な会話 Technology は概要です。
言語モデル
トークンの確率を推定するモデル トークン、つまり、より長いシーケンスのトークンで生成されるシーケンスです。
大規模言語モデル
厳密に定義されていない略式用語。通常は 言語モデルの パラメータ。 一部の大規模言語モデルには 1,000 億を超えるパラメータが含まれています。
潜在空間
エンベディング空間と同義。
LLM
大規模言語モデルの略語。
LoRA
低ランクの適応性(LoRA)
以下を実行するアルゴリズムは、 パラメータ効率調整により 特定のサブセットのみをファインチューニング 大規模言語モデルのパラメータ。 LoRA には次の利点があります。
- モデルのすべてのファインチューニングが必要な手法よりも高速にファインチューニング あります。
- モジュールで推論にかかる計算費用を削減 モデルです。
LoRA でチューニングされたモデルは、予測の品質を維持または改善します。
LoRA を使用すると、モデルの複数の専用バージョンが可能になります。
M
マスク言語モデル
次の確率を予測する言語モデル: 候補トークンを順番に並べて空白を埋めます。たとえば、 マスクされた言語モデルで候補単語の確率を計算できる を使用して、次の文の下線を置き換えます。
帽子の ____ が戻ってきた。
文献では通常、文字列「MASK」が使用されています。ハイライト表示されます。 例:
「マスク」戻ってきたわね。
最新のマスク言語モデルのほとんどは双方向です。
メタラーニング
学習アルゴリズムを検出または改善する ML のサブセット。 メタラーニング システムでは、新しい情報をすばやく学習するようにモデルをトレーニングすることも 少量のデータやこれまでのタスクで得た経験から トレーニングすることもできます 一般的に、メタ学習アルゴリズムは次のことを実現しようとします。
- 手動で設計された機能(イニシャライザや オプティマイザー)です。
- データ効率とコンピューティング効率を高める。
- 一般化を改善する。
メタラーニングは少数ショット学習に関連しています。
モダリティ
大まかなデータのカテゴリ。たとえば、数値、テキスト、画像、動画、 5 つの異なるモダリティです。
モデル並列処理
トレーニングまたは推論をスケーリングする方法 model をさまざまなデバイスにモデル化。モデル並列処理 1 台のデバイスには収まらない大きすぎるモデルにも対応できます。
モデル並列処理を実装するために、システムは通常、次のことを行います。
- モデルを小さな部分にシャーディング(分割)します。
- これらの小さな部分のトレーニングを複数のプロセッサに分散します。 各プロセッサは、モデルの独自の部分をトレーニングします。
- 結果を結合して 1 つのモデルを作成します。
モデル並列処理によってトレーニングが遅くなる。
データ並列処理もご覧ください。
マルチヘッド セルフ アテンション
セルフ アテンションを、 自己注意機構は入力シーケンスの位置ごとに複数回出現します。
Transformers は、マルチヘッド セルフ アテンションを導入しました。
マルチモーダル モデル
入力と出力のいずれかまたは両方に複数の値が含まれるモデル モダリティです。たとえば、入力文と出力値の両方を受け取る 特徴量としてのテキスト キャプション(2 つのモダリティ) は、画像に対するテキスト キャプションがどの程度適切かを示すスコアを出力します。 つまり、このモデルの入力はマルチモーダルであり、出力はユニモーダルです。
N
自然言語理解
ユーザーの入力内容や発言に基づいてユーザーの意図を判断します。 たとえば、検索エンジンは自然言語理解を使用して ユーザーの入力内容や発言内容から、ユーザーが検索している内容を判別する。
N グラム
N 単語の順序付きシーケンス。たとえば、truly madly は 2 グラムです。なぜなら、 order が関連性である場合、madly real は truly madly とは異なる 2 グラムです。
| N | この種の N グラムの名前 | 例 |
|---|---|---|
| 2 | バイグラムまたは 2 グラム | 行く、行く、ランチを食べる、ディナーを食べる |
| 3 | トライグラムまたは 3 グラム | 食べすぎ、目が覚めた 3 匹のネズミ、鐘の死、 |
| 4 | 4 グラム | 公園を歩く、風に吹いた塵、少年はレンズ豆を食べた |
多くの自然言語理解 モデルは N グラムを使用して、ユーザーが次に入力する単語を予測します。 できます。たとえば、ユーザーが「スリーブラインド」と入力したとします。 トライグラムに基づく NLU モデルでは、 次に「mice」と入力します。
N グラムとバッグ オブ ワードを対比します。 順序付けられていない単語の集合です。
NLU
O
ワンショット プロンプト
プロンプト - 1 つの例を含む 大規模言語モデルで応答する必要があります。たとえば 次のプロンプトには、大規模言語モデルの例を示しています。 クエリに応答するはずです
| 1 つのプロンプトを構成する要素 | メモ |
|---|---|
| 指定された国の公式通貨は何ですか? | LLM に回答させたい質問。 |
| フランス: EUR | 一例です。 |
| インド: | 実際のクエリ。 |
ワンショット プロンプトを以下の用語と比較します。
P
パラメータ効率チューニング
大規模なイベントをファインチューニングする一連の手法 事前トレーニング済み言語モデル(PLM) 完全なファインチューニングよりも効率的です。パラメータ効率 一般に、フル チューニングよりもはるかに少ないパラメータを微調整できる 微調整されていますが、通常は 優れたパフォーマンスを備えた大規模言語モデル 完全な言語から構築された大規模言語モデルや 微調整できます。
パラメータ効率チューニングと以下を比較対照します。
パラメータ効率チューニングは、パラメータ効率ファインチューニングとも呼ばれます。
パイプライン化
モデル並列処理の一形態であり、 処理は連続したステージに分割され、各ステージは ダウンロードします。ステージが 1 つのバッチを処理している間、前の 次のバッチで処理できます
段階的なトレーニングもご覧ください。
PLM
事前トレーニング済み言語モデルの略語。
位置エンコード
シーケンス内のトークンの位置に関する情報を トークンのエンベディング。Transformer モデルでは、位置 異なる部分間の関係をより深く理解するために、 あります。
位置エンコードの一般的な実装では、正弦関数を使用します。 (具体的には、正弦関数の周波数と振幅は、 シーケンス内のトークンの位置によって決まります)。この手法は、 これにより、Transformer モデルはモデルのさまざまな部分に注意を シーケンスを表現します。
事前トレーニング済みモデル
モデルまたはモデル コンポーネント( エンベディング ベクトル)が表示されます。 場合によっては、トレーニング済みのエンベディング ベクトルを ニューラル ネットワーク。逆に、トレーニングしたモデルに、 エンベディング ベクトル自体をトレーニング エンベディング ベクトル自体に変換する方法を学びます。
事前トレーニング済み言語モデルという用語は、 大規模言語モデル 事前トレーニング。
事前トレーニング
大規模なデータセットでのモデルの初期トレーニング。一部の事前トレーニング済みモデルは 不器用な巨人で、通常は追加のトレーニングで洗練させなければなりません。 たとえば、ML エキスパートはモデルを使用して 膨大なテキスト データセット上の大規模言語モデル たとえば ウィキペディアの英語のページが 多数あるとします事前トレーニングの後、 結果として得られるモデルは、次のいずれかによってさらに精緻化される可能性があります。 手法:
prompt
大規模言語モデルへの入力として入力されたテキスト 特定の動作をするようモデルに与えますプロンプトは、出力シーケンスの 任意の長さ(小説の本文全体など)。プロンプト 次の表に示す複数のカテゴリに分類できます。
| プロンプトのカテゴリ | 例 | メモ |
|---|---|---|
| 質問 | ハトはどれくらいの速さで飛べますか? | |
| 手順 | アービトラージについて面白い詩を書いて。 | 大規模言語モデルに何かを行うように求めるプロンプト。 |
| 例 | マークダウン コードを HTML に変換します。次に例を示します。
マークダウン: * リストアイテム HTML: <ul><li>リストアイテム</li></ul> |
このサンプル プロンプトの最初の文は指示です。 プロンプトの残りの部分が例です。 |
| ロール | ML のトレーニングで勾配降下法を使用する理由を説明し、 物理学の博士号を取得しています | 文章の最初の部分は指示です。フレーズ "物理学の博士号へ"ロールの部分です |
| モデルへの入力の一部のみを完了 | 英国首相は | 部分入力プロンプトは(この例のように)突然終了することも、 末尾にアンダースコアを付けます。 |
生成 AI モデルは、テキストでプロンプトに応答できます。 コード、画像、エンベディング、動画など、あらゆるものに対応します。
プロンプト型学習
適応を可能にする特定のモデルの機能 任意のテキスト入力(プロンプト)に応答する動作。 典型的なプロンプトベースの学習パラダイムでは、 大規模言語モデル: プロンプトに 生成します。たとえば、ユーザーが次のプロンプトを入力したとします。
ニュートンの運動の第 3 法則を要約してください。
プロンプトベースの学習が可能なモデルが、回答するように特別にトレーニングされていない 使用します。むしろ、モデルは、物理学に関する多くのことを 一般的な言語ルールや、一般的な言語ルールの 答えが得られます。その知識は、(うまくいけば)役に立つ あります。人間による追加のフィードバック(「回答が複雑すぎた」、 「リアクションとは何ですか?」など、プロンプトベースの学習システムは、 回答の有用性を高めることができます。
プロンプト設計
プロンプト エンジニアリングと同義。
プロンプト エンジニアリング
望ましいレスポンスを引き出すプロンプトを作成する技術 大規模言語モデルから作成されました。人間がプロンプトを実行する 学びました適切に構造化されたプロンプトを記述することは、 有用なレスポンスを返すことができます。プロンプト エンジニアリングは、 次のようなさまざまな要因があります。
- 事前トレーニングに使用されるデータセットで、必要に応じて 大規模言語モデルをファインチューニングします。
- temperature とその他のデコード パラメータで、 回答を生成するために使われます。
詳しくは、 プロンプト設計の概要 を参照してください。
プロンプト設計は、プロンプト エンジニアリングと同義です。
プロンプト調整
パラメータ効率調整メカニズム 単語の「接頭辞」を先頭に「」が付加され、 実際のプロンプト。
プロンプト調整のバリエーションの 1 つ(プレフィックス チューニングとも呼ばれます)があります。 すべてのレイヤで接頭辞を付けます。対照的に、ほとんどのプロンプト調整は、 入力レイヤに接頭辞を追加します。
R
ロール プロンプト
対象グループを識別するプロンプトのオプション部分 生成 AI モデルのレスポンスに対して使用します。ロールなし 大規模言語モデルは、有用な回答とは言えない回答を提供する 答えるのに役立ちます。ロール プロンプトを使用すると、 より適切で有用な回答を 返すことができます 特定のターゲットオーディエンスに リーチできますたとえば、次のロール プロンプト部分は、 プロンプトは太字で表示されています。
- 経済学の博士号を取得するためのこの記事を要約してください。
- 10 歳の子どもの潮流がどのように変化するか説明する。
- 2008 年の金融危機について説明します。幼い子どもに語りかける。 ゴールデンレトリバーです
S
セルフ アテンション(セルフ アテンション レイヤ)
一連のニューラル ネットワークを エンベディング(token エンベディングなど) 別のエンベディング シーケンスに変換できます。出力シーケンスの各エンベディングは、 入力シーケンスの要素からの情報を統合して構築 アテンション機構によって実現されます。
セルフ アテンションの自己部分は、 他のコンテキストに与えません。セルフアテンションは、 Transformers の構成要素であり、辞書検索を使用 「query」、「key」、「value」などの用語を使用します。
自己注意レイヤは、入力表現のシーケンスから始まります。 表示されます。単語の入力表現は単純なもので、 説明します。入力シーケンスの各単語に対して、 シーケンス全体のすべての要素に対する単語の関連性をスコア付けします。 あります。関連性スコアによって、その単語の最終的な表現がどの程度 他の単語の表現が組み込まれています。
たとえば、次の文について考えてみましょう。
動物は疲れすぎていたため、通りを渡らなかった。
次の図( Transformer: 言語のための新しいニューラル ネットワーク アーキテクチャ 理解) 代名詞 it に対する自己注意レイヤのアテンション パターンを示します。 各単語がパフォーマンスに及ぼす影響の度合いを 表現:
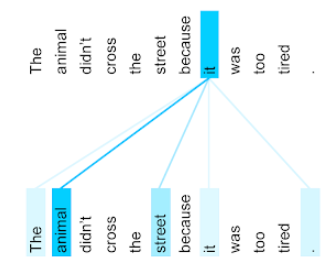
セルフ アテンション レイヤは、「it」に関連する単語をハイライト表示します。この 場合、アテンション レイヤは、 animal に最大の重みを割り当てます。
n 個のトークンのシーケンスに対して、セルフ アテンションはシーケンスを変換します。 n 回(シーケンス内の各位置で 1 回ずつ)のエンベディングを作成します。
感情分析
統計的アルゴリズムまたは機械学習アルゴリズムを使用して、 サービス、プロダクト、サービスに対する全体的な態度(肯定的か否定的か) できます。たとえば、 自然言語理解、 アルゴリズムでテキスト フィードバックの感情分析を実行できる 大学の講義から得た知識に基づいて、 評価します。
シーケンス ツー シーケンス タスク
トークンの入力シーケンスを出力に変換するタスク トークンのシーケンスです。たとえば、シーケンスからシーケンスへの変換には、 次のとおりです。
- 翻訳者:
<ph type="x-smartling-placeholder">
- </ph>
- 入力シーケンスの例: 「I love you」
- 出力シーケンスの例: 「Je t'aime」
- 質問応答:
<ph type="x-smartling-placeholder">
- </ph>
- 入力シーケンスの例: 「ニューヨーク市で車は必要ですか?」
- 出力シーケンス例: 「いいえ。車は自宅に置いてください。」
skip-gram
元の単語から単語を省略(または「スキップ」)できる N グラム つまり、N 個の単語は元々隣接していない可能性があります。さらに表示 正確には「k-skip-n-gram」です。最大 k 個の単語が持つ可能性がある N グラムです。 スキップされました
例: 「急ぎの茶色のキツネ」次の 2 グラムが考えられます。
- 「すばやく」
- 「早い茶色」
- "茶色のフォックス"
「1 スキップ 2 グラム」単語と単語の間の最大 1 つの単語からなる単語のペアです。 したがって、「the short brown fox」は次の 1 スキップ 2 グラムがあります:
- 「the brown」
- 「quick fox」
また、2 グラムはすべて 1 スキップ 2 グラムでもあります。 スキップされる可能性があります。
スキップグラムは、単語の周囲のコンテキストをより深く理解するのに役立ちます。 この例では「fox」です。「quick」に直接関連していた次のセットで 1 スキップ 2 グラムだが、2 グラムの集合には含まれない。
スキップグラムを使用したトレーニング 単語エンベディング モデル。
ソフト プロンプト チューニング
大規模言語モデルのチューニング手法 リソースを大量に消費することなく、特定のタスクに ファインチューニング。すべての特徴量を再トレーニングする代わりに モデル内の重み、ソフト プロンプト チューニング 同じ目標を達成するためにプロンプトを自動的に調整する。
与えられたテキスト プロンプトで、ソフト プロンプト調整 通常はプロンプトに追加のトークン エンベディングを付加し、 入力を最適化します。
「ハード」トークン エンベディングではなく実際のトークンが含まれます。
スパースな特徴
値がほぼ 0 または空の特徴。 たとえば、1 つの値と 100 万個の値を含む特徴は、 です。一方、密な特徴には、 大部分はゼロや空ではありません
ML では、驚くほど多くの特徴量がスパースな特徴量になっています。 カテゴリ特徴量は通常、スパース特徴量です。 たとえば、ある森林で見られる樹木 300 種のうち、 単なるカエデの木を識別できるかもしれません。何百万もの 動画ライブラリに含まれる可能性のある動画の数によって、1 つの例で “カサブランカ”と言います
モデルでは通常、スパースな特徴を ワンホット エンコーディング。ワンホット エンコーディングが大きい場合、 エンベディング レイヤをそのレイヤの上に配置できます。 ワンホット エンコーディングを使用します。
スパース表現
スパースな特徴にゼロ以外の要素の位置のみを保存する。
たとえば、species という名前のカテゴリ特徴が 36
予測しています。さらに、各データセットが
example は 1 種のみを識別します。
それぞれの例で、樹木の種類を表すワンホット ベクトルを使用できます。
ワンホット ベクトルには、単一の 1 が含まれます(
と 35 個の 0(
35 種類の樹木。この例では該当なし)。ワンホット表現は、
maple は次のようになります。

あるいは、スパース表現では単純に画像の位置を特定するだけで
判断できますmaple が 24 番目である場合、スパース表現は
maple は、単に次のようになります。
24
スパース表現は、ワンホット表現よりもはるかにコンパクトであることに 必要があります。
少し複雑な例を見るには、アイコンをクリックします。
モデル内の各例が単語を表す必要があるが、実際には 単語の順序を英語の文で表します。 英語は約 170,000 語で構成されているため、英語はカテゴリカル 約 170,000 個の要素がありますほとんどの英語の文には、 170,000 語のごく一部であり、 ほぼ間違いなくスパースデータです
次の文を考えてみましょう。
My dog is a great dog
ワンホット ベクトルのバリアントを使用して、この単語に含まれる単語を あります。このバリアントでは、ベクトルの複数のセルに 指定することもできます。さらに、このバリアントでは、セルに整数値を含めることができます。 あります。「my」、「is」、「a」、「great」という言葉は表示のみ 単語「犬」は、表示されます。このバリアントを使用すると、 この文内の単語を表すワンホット ベクトルを作成すると、 170,000 要素ベクトル:

同じ文のスパース表現は、単純に次のようになります。
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
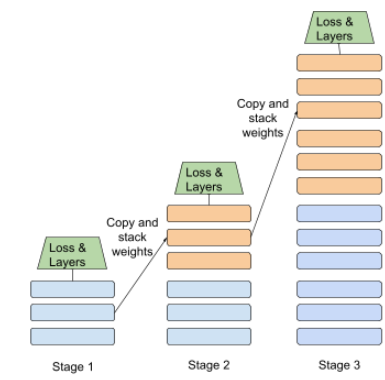
段階的なトレーニング
一連の個別のステージでモデルをトレーニングする戦術。目標は トレーニング プロセスをスピードアップするか、モデルの品質を向上させるかのいずれかです。
プログレッシブ スタッキング アプローチの図を以下に示します。
- ステージ 1 には 3 つの隠れ層、ステージ 2 には 6 つの隠れ層、 ステージ 3 には 12 個の隠れ層が含まれています。
- ステージ 2 では、3 つの隠れ層で学習した重みを使用してトレーニングを開始する 説明しますステージ 3 では、ステップ 6 で学習した重みを使用してトレーニングを開始します。 レイヤに分割されます。
パイプライン処理もご覧ください。
サブワード トークン
言語モデルでは、トークンとして 単語の部分文字列(単語全体が含まれる場合もあります)
たとえば「itemize」などの単語は「アイテム」という断片に分割されることもあります。 (根語)と「ize」を(サフィックス)。各 ID は、それぞれ固有の名前で表され、 あります。一般的でない単語をサブワードと呼ばれる部分に分割することで、 単語のより一般的な構成部分で動作させることができます。 使用できます
逆に「行く」などの一般的な言葉は分割されていない可能性があり、 単一のトークンで表されます。
T
T5
テキストからテキストへの転移学習 モデル 導入元 2020 年の Google AI。 T5 は、エンコーダ - デコーダ モデルで、 非常に大規模な環境でトレーニングされた Transformer アーキテクチャ 見てみましょう。さまざまな自然言語処理タスクに効果的です。 自然言語によるテキストの生成、言語の翻訳、質問への回答など、 会話形式で学習します。
T5 の名前は、「Text-to-Text Transfer Transformer」にある 5 つの T に由来します。
T5X
設計されたオープンソースの機械学習フレームワーク。 大規模な自然言語処理を構築してトレーニング モデルです。T5 は T5X コードベース( JAX と Flax を基盤としている)。
温度
ランダム性の度合いを制御するハイパーパラメータ 必要があります。温度を高くすると出力がランダムになり、 温度を低くするとランダムな出力が少なくなります。
最適な温度の選択は、個々の用途や 優先されるプロパティを定義します。たとえば、次のようにします。 温度を上げることをおすすめします。 クリエイティブな出力を生成します。逆に、温度を下げて 画像やテキストを分類するモデルを構築する際に モデルの精度と一貫性を確保します
温度は多くの場合、ソフトマックスとともに使用されます。
テキストスパン
テキスト文字列の特定のサブセクションに関連付けられた配列インデックス スパン。
たとえば、Python 文字列 s="Be good now" の単語 good が占有されます。
テキストスパンを 3 ~ 6 に設定します。
token
言語モデルにおいて、モデルを構成する原子単位。 基づいて予測を行いますトークンは通常、 次のとおりです。
- 単語(例: 「犬が猫のような」というフレーズ)3 つの単語からなる 「dogs」、「like」、「cats」というトークンがあります。
- 文字(「bike fish」など)9 つの Pod で 使用できます。(空白もトークンの 1 つとしてカウントされます)。
- サブワードを使用します。このサブワードでは、1 つの単語が 1 つのトークンまたは複数のトークンになります。 サブワードは、語根、接頭辞、または接尾辞で構成されます。たとえば トークンとしてサブワードを使用する言語モデルでは、「dogs」という単語を 2 つのトークン(根語の「dog」と複数形の接尾辞「s」)で表現します。同じ 「taller」という 1 つの単語が2 つのサブワード(「 語根「tall」「er」など)を指定します。
言語モデル以外のドメインでは、トークンは他の種類の です。たとえばコンピュータビジョンでは、トークンは 作成します。
Transformer
Google が開発したニューラル ネットワーク アーキテクチャは、 セルフ アテンションのメカニズムによって、 入力エンべディングのシーケンスを、出力シーケンスの 畳み込みや、ML アルゴリズムに依存しない 再帰型ニューラル ネットワーク。Transformer は 自己注意レイヤの積み重ねと見なされます。
Transformer には次のいずれかを含めることができます。
エンコーダは、エンベディングのシーケンスを新しいシーケンスの 同じ長さにします。エンコーダは N 個の同じレイヤからなり、各レイヤには 2 つのレイヤが サブレイヤです。これら 2 つのサブレイヤは、入力レイヤの各位置に適用されます。 エンベディング シーケンスを作成し、シーケンスの各要素を新しい 説明します。1 つ目のエンコーダ サブレイヤは、エンコーダから出力された 生成します。第 2 のエンコーダ サブレイヤは、集約されたデータを 出力エンべディングに変換されます。
デコーダは、入力エンベディングのシーケンスを 異なる長さのエンべディングがあります。デコーダには、エンコーダと 3 つのサブレイヤを持つ、N 個の同一レイヤ。そのうちの 2 つは あります。3 つ目のデコーダ サブレイヤは、デコーダの出力を セルフ アテンション機構を 情報を集めます。
ブログ投稿 Transformer: A New Neural Network Architecture for Language 理解 Transformers の概要を示しています。
トライグラム
N=3 である N グラム。
U
単方向
テキストの対象セクションの前のテキストのみを評価するシステム。 これに対して双方向システムでは、 テキストの対象セクションの前および後のテキスト。 詳しくは、双方向をご覧ください。
単方向言語モデル
次の確率のみに基づく言語モデル ターゲット トークンの後ではなく、前に出現するトークン。 双方向言語モデルも参照してください。
V
変分オートエンコーダ(VAE)
差異を利用するオートエンコーダの一種 入力と出力の間の変換を行って、入力の変更されたバージョンを生成します。 変分オートエンコーダは、生成 AI に役立ちます。
VAE は、変分推論に基づいています。 確率モデルのパラメータになります。
W
単語のエンベディング
ある単語セット内の単語セット内の各単語を表現 エンベディング ベクトル。つまり、各単語を 0.0 ~ 1.0 の浮動小数点値のベクトル。類似する単語 意味の表現は、異なる意味を持つ単語よりも類似しています。 たとえば、「にんじん」、「セロリ」、「きゅうり」は、 実際の表現とはかなり異なるものであるため、 「飛行機」、「サングラス」、「歯磨き粉」。
Z
ゼロショット プロンプト
希望の例を提供しないプロンプト 大規模言語モデルを使用して対応します。例:
| 1 つのプロンプトを構成する要素 | メモ |
|---|---|
| 指定された国の公式通貨は何ですか? | LLM に回答させたい質問。 |
| インド: | 実際のクエリ。 |
大規模言語モデルは、次のいずれかを返すことがあります。
- ルピー
- INR
- ₹
- ルピー(インド)
- ルピー
- インドルピー
すべての選択肢が正解ですが、特定の形式を希望するかもしれません。
ゼロショット プロンプトを以下の用語と比較します。