Ta strona zawiera terminy z glosariusza oceny języka. Dla wszystkich terminów używanych w glosariuszu kliknij tutaj.
A
uwaga
Mechanizm stosowany w sieci neuronowej, który wskazuje, znaczenie konkretnego słowa lub jego części. Uwaga kompresuje ilość informacji, których model potrzebuje, aby przewidzieć następny token/słowo. Typowy mechanizm uwagi może składać się suma ważona na zbiorze danych wejściowych, gdzie waga poszczególnych danych wejściowych jest obliczana przez inną część dzięki sieci neuronowej.
Przeczytaj też artykuły o samodzielnej koncentracji i wielofunkcyjnego skupienia, czyli elementów składowych Transformerów.
autokoder
System, który uczy się wyodrębniać najważniejsze informacje z dane wejściowe. Automatyczne kodery to połączenie kodera dekodera. Autokodery opierają się na tym dwuetapowym procesie:
- Koder mapuje dane wejściowe na (zwykle) stratny, mniej-wymiarowy (pośredni).
- Dekoder kompiluje stratną wersję pierwotnych danych wejściowych przez mapowanie format niższy niż oryginalny, format wprowadzania.
Autokodery są w pełni trenowane, ponieważ dekoder próbuje zrekonstruować oryginalne dane wejściowe z formatu pośredniego kodera jak najczęściej. Format pośredni jest mniejszy (mniejszy wymiar) niż w formacie oryginalnym, autokoder jest wymuszany aby dowiedzieć się, jakie informacje wejściowe są niezbędne, a dane wyjściowe nie będą będą całkowicie identyczne z danymi wejściowymi.
Na przykład:
- Jeśli dane wejściowe mają postać graficzną, niedokładna kopia będzie podobna do oryginalną, ale nieco zmodyfikowaną grafikę. Być może kopia niedokładna usuwa szum z oryginalnej grafiki lub wypełnia brakujące piksele.
- Jeśli danymi wejściowymi jest tekst, autokoder wygeneruje nowy tekst, imituje (ale nie jest identyczny) oryginalny tekst.
Zobacz też automatyczne kodery zmiennoprzecinkowe.
model autoregresywny
Model, który szacuje prognozę na podstawie swojego wcześniejszego i generowanie prognoz. Na przykład automatycznie regresywne modele językowe przewidują kolejne token na podstawie wcześniej przewidywanych tokenów. Wszystkie modele oparte na Transformer duże modele językowe są automatycznie regresywne.
W przeciwieństwie do tego modele obrazów oparte na GAN zwykle nie są autoregresywne. ponieważ generują obraz w pojedynczym przejściu do przodu, a nie iteracyjnie kroków. Jednak niektóre modele generowania obrazów są automatycznie regresywne, ponieważ krok po kroku generują obraz.
B
torba słów
reprezentację słów w wyrażeniu lub pasażu; niezależnie od kolejności. Na przykład torba słów reprezentuje te 3 wyrażenia w identyczny sposób:
- pies podskakuje
- skaczący pies
- pies skaczący
Każde słowo jest mapowane na indeks w rozproszonym wektorze, gdzie wektor ma indeks każdego słowa w słowniku. Przykład: wyrażenie pies skacze jest mapowane na wektor cech o wartości innej niż zero. wartości w trzech indeksach odpowiadających słowom , pies oraz skoki. Wartość inna niż 0 może być dowolną z tych wartości:
- 1 oznacza obecność słowa.
- Liczba wystąpień słowa w torbie. Przykład: jeśli wyrażenie brzmi: kasztanowy pies to pies z kasztanowym futrem, wtedy oba Hasła kasztanowy i pies są przedstawiane jako 2, a pozostałe słowa – są reprezentowane jako 1.
- Inna wartość, np. logarytm liczby razy jakieś słowo pojawi się w torbie.
BERT (koder dwukierunkowy prezentacje z przekształceń)
Architektura modelu do reprezentacji tekstu. Przeszkolony model BERT może być częścią większego modelu klasyfikacji tekstu lub i innych zadaniach ML.
BERT ma następujące cechy:
- Wykorzystuje architekturę Transformer, dlatego wymaga samouważności.
- Wykorzystuje element encoder Transformatora. Zadanie kodera jest generowanie dobrych reprezentacji tekstowych, a nie konkretnego takich jak klasyfikacja.
- Jest dwukierunkowe.
- Stosuje maskowanie do: trenowanie nienadzorowane.
Warianty modelu BERT obejmują:
.Zobacz Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Przetwarzam aby dowiedzieć się więcej o modelu BERT.
dwukierunkowa
Termin używany do opisania systemu oceniającego tekst, który następuje i śledzi docelową sekcję tekstu. Natomiast tylko system jednokierunkowy ocenia tekst, który wyprzedza docelowy fragment tekstu.
Rozważmy na przykład model językowy z maskowaniem, który musi określać prawdopodobieństwo dla słów lub słów reprezentujących podkreślenie w następujące pytanie:
Jaka jest _____ z Tobą?
Jednokierunkowy model językowy musiałby opierać się tylko na prawdopodobieństwach w kontekście zawartym w wyrażeniach „Co”, „jest” i „co”. W przeciwieństwie do tego: dwukierunkowy model językowy może też uzyskać kontekst dzięki słowu „z” i „Ty”, co może pomóc modelowi w generowaniu lepszych prognoz.
dwukierunkowy model językowy
Model językowy, który określa prawdopodobieństwo, że dany token jest obecny w danej lokalizacji we fragmencie tekstu na podstawie poprzedni i następny tekst.
bigram
N-gram, w którym N=2.
BLEU (Bilingual Evaluation Understudy)
Wynik od 0,0 do 1,0 włącznie, który wskazuje jakość tłumaczenia między 2 językami ludzkimi (np. angielskim i rosyjskim). A BLEU Wynik 1,0 oznacza tłumaczenie perfekcyjne; Wynik BLEU równy 0,0 wskazuje kiepskie tłumaczenie.
C
przyczynowy model językowy
Synonim jednokierunkowego modelu językowego.
Zobacz dwukierunkowy model językowy, aby: kontrastują różne podejścia kierunkowe w modelowaniu językowym.
wykorzystanie w prompcie łańcucha myśli
To technika promptów, która umożliwia dużym modelem językowym (LLM) do wyjaśnienia krok po kroku. Przyjrzyjmy się temu przykładowi: zwrócić szczególną uwagę na drugie zdanie:
Ile ciężarów g-my wystąpi w samochodzie, którego wartość mieści się w zakresie od 0 do 60 mil na godzinę w 7 sekundach? W odpowiedzi pokaż wszystkie odpowiednie obliczenia.
Odpowiedź LLM prawdopodobnie:
- Pokaż sekwencję wzorów fizycznych, dołączając wartości 0, 60 i 7 w odpowiednich miejscach.
- Wyjaśnij, dlaczego wybrał te formuły i co oznaczają poszczególne zmienne.
Podpowiedzi typu „łańcuch myśli” wymuszają na LLM wykonywanie wszystkich obliczeń, co może doprowadzić do lepszej odpowiedzi. Dodatkowo, łańcuch myśli pozwala użytkownikowi zbadać kroki LLM w celu określenia, czy ta odpowiedź jest nie sensowna.
czat
Zawartość toczącego się dialogu z systemem ML, zwykle dużym modelu językowym. poprzednią interakcję na czacie; (wpisany tekst i odpowiedzi dużego modelu językowego) stają się w kontekście kolejnych części czatu.
Czatbot to aplikacja dużego modelu językowego.
konfabulacja
Synonim słowa halucynacje.
Konfabulacja jest prawdopodobnie lepszym terminem pod względem technicznym niż halucynacje. Jednak najpierw zyskały na popularności.
analiza składniowa
Dzielenie zdania na mniejsze struktury gramatyczne („składniki”). Kolejna część systemu ML, np. modelu rozumienia języka naturalnego, może przeanalizować składniki składowe łatwiej niż oryginalne zdanie. Przykład: pomyśl o tym zdaniu:
Moja znajoma adoptowała dwa koty.
Parser okręgu wyborczego może podzielić to zdanie na następujące dwa składniki:
- Mój przyjaciel to rzeczownik.
- adoptowane dwa koty to czasownik.
Składniki te można następnie podzielić na mniejsze składniki. Na przykład wyrażenie z czasownikiem
adoptowała dwa koty
można podzielić na te kategorie:
- adopted to czasownik.
- dwa koty to kolejne wyrażenie rzeczownikowe.
osadzanie kontekstowe
Umieszczanie, które jest bliskie „zrozumienia” słowa i wyrażenia w sposób, który umożliwi rodzimym użytkownikom języka. Język oparty na kontekście wektory dystrybucyjne mogą zrozumieć złożoną składnię, semantykę i kontekst.
Weź pod uwagę na przykład reprezentacje właściwościowe z angielskiego słowa cow. Starsze wektory dystrybucyjne np. word2vec, może oznaczać polski takie jak odległość w obszarze umieszczanym. od krowy do byka jest podobna do odległości od ewe (sama owca) do Ram (samiec owcy) lub kobieta na mężczyznę. Język oparty na kontekście reprezentacje właściwościowe mogą pójść o krok dalej, wiedząc, że użytkownicy anglojęzyczni czasami swobodnie używaj słowa krowa zamiast krowy lub byka.
okno kontekstu
Liczba tokenów, które model może przetworzyć w danym okresie. komunikat. Im większe okno kontekstu, tym więcej informacji model może wykorzystać, aby uzyskać spójne i spójne odpowiedzi do promptu.
rozkwit
Zdanie lub wyrażenie o niejednoznacznym znaczeniu. Kwitnące kwitnące drzewa są poważnym problemem w środowisku naturalnym rozumienia języków. Na przykład nagłówek Czerwona taśma trzymająca wieżowiec to ponieważ model NLU mógł dosłownie zinterpretować nagłówek lub przekonująco.
D
dekoder
Ogólnie rzecz biorąc, każdy system ML, który konwertuje z przetworzonych, gęstych lub na bardziej surową, rozproszoną lub zewnętrzną reprezentację.
Dekodery są często składnikami większego modelu, który często sparowany z koderem.
W zadaniach sekwencyjnych dekoder rozpoczyna się od wewnętrznego stanu wygenerowanego przez koder w celu przewidywania następnego kolejne wartości.
Definicję dekodera w obrębie znajdziesz w artykule Transformer. o architekturze Transformer.
odszumianie
Powszechne podejście do samonadzorowanego uczenia się gdzie:
Wyciszanie szumów umożliwia uczenie się na podstawie przykładów bez etykiet. Pierwotny zbiór danych służy jako docelowy lub label i zaszumione dane.
Niektóre zamaskowane modele językowe używają funkcji wyciszania szumów w następujący sposób:
- Szum jest sztucznie dodawany do zdania bez etykiety przez maskowanie części tokeny.
- Model próbuje przewidzieć oryginalne tokeny.
prompty bezpośrednie
Synonim promptów typu „zero-shot”.
E
edytuj odległość
Pomiar podobieństwa dwóch ciągów tekstowych. W uczeniu maszynowym edytowanie odległości jest przydatne, ponieważ Compute i efektywny sposób porównywania dwóch ciągów, o których wiadomo, podobnych lub znajdować ciągi podobne do danego ciągu.
Istnieje kilka definicji odległości służącej do edycji, a każda z nich zawiera inny ciąg znaków operacji. Na przykład parametr Odległość w Levenshtein uwzględnia najmniejszą liczbę operacji usuwania, wstawiania i zastępowania.
Na przykład odległość Levenshteina między słowami „serce” i „rzutki” wynosi 3, ponieważ następujące 3 zmiany to najmniejsze zmiany, które zmieniają słowo na inne:
- serce → deart (zastąp literę „h” przez „d”)
- deart → dart (usuń „e”)
- dart → rzutki (wstaw „s”)
warstwa wektorowa
Specjalną warstwą ukrytą, która trenuje na wielowymiarowa funkcja kategoryczna, stopniowo uczyć się wektora wektora dystrybucyjnego dla niższych wymiarów. An warstwa wektora dystrybucyjnego umożliwia sieci neuronowej lepsze trenowanie wydajniej niż trenowanie na wysokich wymiarach cechach kategorialnych.
Na przykład na Ziemi obecnie obsługiwanych jest około 73 000 gatunków drzew. Załóżmy, że
gatunek drzewa jest cechą na Twoim modelu, więc model
warstwa wejściowa zawiera jeden gorący wektor 73 000,
.
Wartość baobab zostałaby przedstawiona w ten sposób:

Tablica z 73 000 elementów jest bardzo długa. Jeśli nie dodasz warstwy osadzania trenowanie będzie bardzo czasochłonne, mnożenia przez 72 999 zer. Być może wybierzesz warstwę osadzania, z 12 wymiarów. W efekcie warstwa osadzania będzie stopniowo uczyć się nowego wektora dystrybucyjnego dla każdego gatunku drzewa.
W niektórych sytuacjach szyfrowanie jest rozsądnym rozwiązaniem. do warstwy osadzonej.
przestrzeń wektorowa
Przestrzeń wektorowa w wymiarze D obejmująca do przestrzeni wektorowej. W idealnym przypadku przestrzeń umieszczania zawiera konstrukcja przynosząca istotne wyniki matematyczne; np. w idealnej przestrzeni wektora dystrybucyjnego przy dodawaniu i odejmowaniu wektorów dystrybucyjnych i rozwiązuj zadania związane z analogią słowną.
iloczyn punktowy. jest miarą ich podobieństwa.
wektor dystrybucyjny
Ogólnie rzecz biorąc, tablica liczb zmiennoprzecinkowych pobieranych z dowolnej ukryta warstwa, która opisuje dane wejściowe do tej ukrytej warstwy. Często wektorem dystrybucyjnym jest tablica liczb zmiennoprzecinkowych wytrenowanych w i warstwy wektora dystrybucyjnego. Na przykład załóżmy, że warstwa osadzona musi nauczyć się wektora dystrybucyjnego dla każdego z 73 000 gatunków drzew na Ziemi. Być może Następująca tablica to wektor reprezentacji drzewa baobabu:

Wektor dystrybucyjny nie jest grupą liczb losowych. Warstwa wektorowa Określa te wartości przez trenowanie, podobnie jak sieć neuronowa uczy się innych ciężarów podczas trenowania. Każdy element argumentu tablica to ocena powiązana z jakąś cechą gatunku drzewa. Który reprezentuje wybrane gatunki drzew jest cechą charakterystyczną? To bardzo trudne co człowiek może określić.
Niezwykła matematyczna część wektora dystrybucyjnego jest podobna elementy mają podobne zestawy liczb zmiennoprzecinkowych. Na przykład podobne mają bardziej podobny zestaw liczb zmiennoprzecinkowych niż odmiennych gatunków drzew. Sekwoja i sekwoje to pokrewne gatunki drzew, więc otrzymają one bardziej podobny zestaw liczb zmiennoprzecinkowych niż sekwoje i palm kokosowych. Liczby w wektorze dystrybucyjnym są zmieniane przy każdym trenowaniu modelu, nawet jeśli ten z identycznym wpisywaniem.
koder
Ogólnie rzecz biorąc, każdy system ML, który konwertuje z nieprzetworzonych, rozproszonych lub zewnętrznych do bardziej przetworzonej, gęstszej lub bardziej wewnętrznej.
Kodery są często składnikami większego modelu, który często sparowany z dekoderem. Niektóre Transformery parować kodery z dekoderami, chociaż inne Transformatory korzystają tylko z nich lub tylko dekodera.
Niektóre systemy wykorzystują dane wyjściowe kodera jako danych wejściowych do klasyfikacji lub w sieci regresji.
W zadaniach sekwencyjnych koder pobiera sekwencję wejściową i zwraca stan wewnętrzny (wektor). Następnie funkcja Na podstawie tego stanu wewnętrznego dekoder przewiduje następną sekwencję.
Definicję kodera znajdziesz w artykule Transformer (w języku angielskim). o architekturze Transformer.
F
prompty „few-shot”
Prompt zawierający więcej niż 1 przykład („kilka”) pokazując, jak duży model językowy powinien zareagować. Na przykład ten długi prompt zawiera dwa Przykłady odpowiedzi na zapytanie przez duży model językowy (LLM).
| Elementy jednego promptu | Uwagi |
|---|---|
| Jaka jest oficjalna waluta w danym kraju? | Pytanie, na które ma odpowiedzieć LLM. |
| Francja: EUR | Przykład: |
| Wielka Brytania: GBP | Kolejny przykład. |
| Indie: | Faktyczne zapytanie. |
Krótkie prompty pozwalają zwykle uzyskać lepsze wyniki niż promptów typu „zero-shot”, jedno-razowe prompty. Jednak prompty typu „few-shot” wymaga dłuższego promptu.
prompty typu „few-shot” to forma nauki „few-shot”. stosowane w nauce opartej na promptach.
Skrzypce
Biblioteka konfiguracji skoncentrowana na Pythonie, która ustawia wartości funkcji i klas bez inwazyjnego kodu i infrastruktury. W przypadku Pax i innych baz kodu systemów uczących się te funkcje oraz klasy reprezentują modele i szkolenia. hiperparametrów.
Skrzypce zakłada, że bazy kodu systemów uczących się są zwykle podzielone na:
- Kod biblioteczny, który definiuje warstwy i optymalizatory.
- Zbiór danych „glue” który wywołuje biblioteki i przewody.
Fiddle przechwytuje strukturę wywołania kodu glue w elemencie nieocenionym lub zmiennej postaci.
dostrajanie
Druga karnet szkoleniowy dotyczący konkretnego zadania wykonany na już wytrenowanego modelu, aby doprecyzować jego parametry do konkretnego przypadku użycia. Na przykład pełna sekwencja trenowania dla niektórych dużych modeli językowych wygląda tak:
- Przed trenowaniem: wytrenuj duży model językowy na dużym ogólnym zbiorze danych. np. wszystkich stron Wikipedii w języku angielskim.
- Dostrajanie: wytrenuj już wytrenowany model do wykonania określonego zadania. np. odpowiadania na pytania medyczne. Dostrajanie zwykle obejmuje lub tysiące przykładów koncentrujących się na konkretnym zadaniu.
Innym przykładem jest pełna sekwencja trenowania dużego modelu obrazu. następujące:
- Przed trenowaniem: wytrenuj duży model obrazu na dużym obrazie ogólnym takich jak wszystkie obrazy w witrynie Wikimedia Commons.
- Dostrajanie: wytrenuj już wytrenowany model do wykonania określonego zadania. np. przez generowanie obrazów orek.
Dostrajanie może obejmować dowolną kombinację tych strategii:
- Zmodyfikowanie wszystkich wytrenowanych modeli parametry. Czasami nazywa się to pełnym dostrajaniem.
- Zmodyfikowanie tylko niektórych istniejących parametrów wytrenowanego modelu (zwykle warstwy najbliższe warstwie wyjściowej), a inne istniejące parametry nie zmieniają się (zwykle warstwy najbliżej warstwy wejściowej). Zobacz dostrajania i optymalizowania pod kątem wydajności.
- Dodawanie większej liczby warstw, zazwyczaj na istniejących warstwach znajdujących się najbliżej warstwę wyjściową.
Dostrajanie to forma nauki transferowej. W związku z tym do dostrajania może być używana inna funkcja straty lub inny model. niż używany do trenowania wytrenowanego modelu. Możesz na przykład: dostrajać wytrenowany duży model obrazów w celu wygenerowania modelu regresji, zwraca liczbę ptaków na obrazie wejściowym.
Porównaj dostrajanie z zastosowaniem tych haseł:
Len
Wydajny oprogramowanie typu open source biblioteka dla deep learning oparte na technologii JAX. Len zapewnia funkcje do szkoleń sieci neuronowych, a także do oceny ich skuteczności.
Flaxformer
Transformer – oprogramowanie open source biblioteka, stworzono w oparciu o Flax i został zaprojektowany głównie z myślą o przetwarzaniu języka naturalnego i badania multimodalne.
G
generatywna AI
Rozwijające się pole transformacyjne bez formalnej definicji. Jednak większość ekspertów zgadza się, że modele generatywnej AI mogą tworzyć („generować”) treści, która jest:
- Złożone
- spójne
- oryginał
Na przykład model generatywnej AI może tworzyć zaawansowane wypracowania lub grafiki.
niektóre wcześniejsze technologie, w tym LSTMs. i RNN, mogą też generować spójną treścią. Niektórzy eksperci traktują te wcześniejsze technologie jako generatywnej AI, podczas gdy inni uważają, że prawdziwa generatywna AI wymaga niż te wcześniejsze technologie.
Przeciwieństwem są systemy uczące się predykcyjne.
GPT (wytrenowany generatywny transformer)
Rodzina produktów opartych na Transformer dużych modeli językowych opracowanych przez OpenAI.
Warianty GPT można stosować w wielu modalnościach, takich jak:
- generowanie obrazów (np. ImageGPT)
- generowanie tekstu na obraz (na przykład DALL-E).
H
halucynacje
Tworzenie wiarygodnie pozornych, ale niepoprawnych merytorycznie treści generatywnej AI, który rzekomo tworzy o tym, co prawdziwa prawda. Na przykład generatywny model AI twierdzi, że Barack Obama zmarł w 1865 roku. jest hallucynacyjny.
I
uczenie się w kontekście
Synonim promptów typu „few-shot”.
L
LaMDA (Language Model for Dialogue Applications)
Oparta na Transformer duży model językowy opracowany przez Google i wytrenowany na duży zbiór danych dialogowych, który może generować realistyczne odpowiedzi konwersacyjne.
LaMDA: przełomowa rozmowa znajdziesz ogólny opis.
model językowy
Model, który szacuje prawdopodobieństwo wystąpienia tokenu lub sekwencji tokenów występujących w dłuższej sekwencji tokenów.
duży model językowy
Termin nieformalny bez dokładnej definicji, który zwykle oznacza model językowy o dużej liczbie parameters. Niektóre duże modele językowe zawierają ponad 100 miliardów parametrów.
przestrzeń utajona
Synonim terminu umieszczanie miejsca.
LLM
Skrót od large model Language (duży model językowy).
LoRA
Skrót od terminu Low-Rank Adaptability.
Dostosowanie niskiego rankingu (LoRA)
Algorytm wykonywania efektywne dostrajanie parametrów, dostrajania tylko w przypadku parametrów dużego modelu językowego. LoRA zapewnia te korzyści:
- Dostrajanie odbywa się szybciej niż w przypadku technik wymagających dostrajania wszystkich .
- Zmniejsza koszty obliczeniowe wnioskowania w dostrojony model.
Model dostrojony przy użyciu LoRA utrzymuje lub poprawia jakość prognoz.
LoRA umożliwia korzystanie z wielu wyspecjalizowanych wersji modelu.
M
zamaskowany model językowy
Model językowy, który prognozuje prawdopodobieństwo tokeny kandydujące, aby uzupełnić luki w sekwencji. Na przykład plik zamaskowany model językowy może obliczać prawdopodobieństwo dla słów kandydatów możesz zastąpić podkreślenie w następującym zdaniu:
____ w kapeluszu wróciła.
W literaturze zwykle używany jest ciąg „MASK” zamiast podkreślenia. Na przykład:
„MASK” wrócił do kapelusza.
Większość współczesnych modeli językowych maskowanych działa dwukierunkowo.
metanauka
Podzbiór systemów uczących się, które wykrywają lub ulepszają algorytm uczenia się. System metanaukowy może również dążyć do wytrenowania modelu w celu szybkiego uczenia się na podstawie niewielkiej ilości danych lub z doświadczenia zdobytego w poprzednich zadaniach. Algorytmy metalearningu zwykle dążą do:
- Poznawaj lub ulepszaj ręcznie opracowane funkcje (takie jak inicjator lub optymalizatora).
- zwiększyć wydajność przetwarzania danych i przetwarzania danych.
- Popraw uogólnienie.
Meta-uczenie się jest związane z nauką krótkoterminową.
modalność
Ogólna kategoria danych. Mogą to być na przykład liczby, tekst, obrazy, filmy oraz można wybrać jeden z 5 różnych modalności.
równoległość modelu
Sposób skalowania trenowania lub wnioskowania, który polega na umieszczaniu różnych części model na różnych urządzeniach. Równoległość modelu Umożliwiają modele, które są za duże, aby zmieścić się na jednym urządzeniu.
Aby wdrożyć równoległość modelu, system zwykle wykonuje te czynności:
- Fragmenty (dzielenie) modelu na mniejsze części.
- Rozdziela trenowanie tych mniejszych części na wiele procesorów. Każdy procesor trenuje własną część modelu.
- Łączy wyniki w celu utworzenia jednego modelu.
Równoległość modelu spowalnia trenowanie.
Zobacz też artykuł na temat równoległości danych.
wielogłowa autouwaga
Przedłużenie samouwagi, które polega na funkcję samouważności, wielokrotnie dla każdej pozycji w sekwencji wejściowej.
Platforma Transformers wprowadziła wielogłowową funkcję samodzielnej uwagi.
model multimodalny
Model, którego dane wejściowe lub wyjściowe zawierają więcej niż jeden modalność. Rozważmy na przykład model, który uwzględnia zarówno obraz i podpis tekstowy (2 modalności) jako funkcje, zwraca wynik wskazujący stopień dopasowania podpisu tekstowego do obrazu. Dane wejściowe tego modelu są multimodalne, a dane wyjściowe są jednomodalne.
N
rozumienie języka naturalnego
Określanie zamiarów użytkownika na podstawie tego, co wpisał lub powiedział. Na przykład wyszukiwarka używa rozpoznawania języka naturalnego do określać, czego szuka użytkownik, na podstawie tego, co wpisał lub powiedział.
N-gram
Uporządkowana sekwencja N słów. Na przykład naprawdę do szaleństwa to 2 gramy. Ponieważ kolejność ma znaczenie, szalenie naprawdę to inne 2 gramy niż naprawdę szalenie.
| N | Nazwy tego rodzaju N-gram | Przykłady |
|---|---|---|
| 2 | bigram lub 2-gram | iść do, iść, zjeść obiad, zjeść kolację |
| 3 | trygram lub 3-gram | zjadli za dużo, trzy niewidome myszy, i dzwonki na telefon |
| 4 | 4 gram | spacer po parku, kurz na wietrze, chłopiec zjadł soczewicę |
rozumienia wielu języków naturalnych; modele korzystają z Ngramów do przewidywania następnego słowa, które użytkownik wpisze lub powiedzmy. Załóżmy na przykład, że użytkownik wpisał three blind (3 niewidome). Model NLU oparty na trygramach prawdopodobnie przewidywałby, że użytkownik wpisze wtedy myszy.
Porównaj n-gramy z torem słów, które są nieuporządkowanych zestawów słów.
NLU
Skrót od języka naturalnego
O
prompty jednorazowe
Prompt zawierający jeden przykład przedstawiający sposób, w jaki duży model językowy powinien odpowiedzieć. Przykład: poniższy prompt zawiera przykład pokazujący duży model językowy, jak powinien udzielić odpowiedzi na pytanie.
| Elementy jednego promptu | Uwagi |
|---|---|
| Jaka jest oficjalna waluta w danym kraju? | Pytanie, na które ma odpowiedzieć LLM. |
| Francja: EUR | Przykład: |
| Indie: | Faktyczne zapytanie. |
Wskaż podobieństwa i różnice między promptami jedno-strzałowymi z następującymi terminami:
P
dostrajanie zapewniające wydajność parametrów
Zestaw technik dostrajania dużej wytrenowany model językowy (PLM) wydajniej niż pełne dostrajanie. Wydajne pod względem parametrów dostrajanie zwykle dostosowuje znacznie mniej parametrów niż pełne ale zwykle generuje duży model językowy, który wydajnie jak również duży model językowy utworzony z pełnych i optymalizacji.
Porównaj dostrajanie ekonomiczne w zakresie:
Dostrajanie pod kątem wydajności jest też nazywane dostrajaniem energooszczędnym.
potokowanie
Forma równoległości modelu, w której model Przetwarzanie dzieli się na kolejne etapy, a każdy z nich jest realizowany na innym urządzeniu. Gdy etap przetwarza 1 wsad, poprzedzający może pracować z następną wsadem.
Zobacz też trenowanie etapowe.
PLM
Skrót od terminu wstępnie wytrenowanego modelu językowego.
kodowanie pozycjonujące
Technika dodawania informacji o pozycji tokena w sekwencji do przez umieszczenie tokena. Modele transformatorów korzystają z pozycjonowania w kodowaniu, aby lepiej zrozumieć zależności między różnymi częściami kolejne wartości.
Typowa implementacja kodowania pozycyjnego wykorzystuje funkcję sinusoidalną. (Częstotliwość i amplituda funkcji sinusoidalnej są określone na podstawie pozycji tokena w sekwencji). Ta technika który pozwala modelowi Transformer nauczyć się uczestniczyć w różnych częściach na podstawie ich pozycji.
wytrenowany model
Modele lub komponenty modelu (takie jak embedding vector), które zostały już wytrenowane. Czasami przekazujesz wytrenowane wektory dystrybucyjne do sieci neuronowej. Innym razem model wytrenuje model same wektory dystrybucyjne, zamiast korzystać z już wytrenowanych wektorów dystrybucyjnych.
Termin wytrenowany model językowy odnosi się do duży model językowy, który sprawdza się przed szkoleniem.
trening wstępny
Wstępne trenowanie modelu na dużym zbiorze danych. Niektóre wytrenowane modele są niezdarnymi olbrzymami i trzeba je zwykle ulepszyć przez dodatkowe szkolenie. Eksperci ds. systemów uczących się mogą na przykład wstępnie przeszkolić duży model językowy na ogromnym zbiorze danych tekstowych, takich jak wszystkie strony w języku angielskim w Wikipedii. Po szkoleniu wynikowy model może być dodatkowo doprecyzowany przez dowolny z poniższych techniki:
prompt
Każdy tekst wpisany jako dane wejściowe w dużym modelu językowym. aby uwarunkować działanie modelu w określony sposób. Prompty mogą być krótkie wyrażenie lub dowolną długość (np. cały tekst powieści). Prośby należą do wielu kategorii, m.in. w tej tabeli:
| Kategoria promptu | Przykład | Uwagi |
|---|---|---|
| Pytanie | Jak szybko może latać gołąb? | |
| Instrukcja | Napisz zabawny wiersz o arbitrażu. | Prompt z prośbą o zrobienie czegoś przez duży model językowy. |
| Przykład | Przetłumacz kod Markdown na HTML. Na przykład:
Markdown: * element listy HTML: <ul> <li>element listy</li> </ul> |
Pierwsze zdanie w tym przykładowym promptie to instrukcja. Pozostała część promptu to przykład. |
| Rola | Wyjaśnij, dlaczego gradient gradientowy jest używany w trenowaniu systemów uczących się do doktora fizyki. | Pierwsza część zdania jest instrukcją. wyrażenie „doktor fizyki” jest związana z rolą. |
| Częściowe dane wejściowe do ukończenia przez model | Premier Wielkiej Brytanii mieszka w | Częściowy prompt dla danych wejściowych może nagle się zakończyć (jak w tym przykładzie) lub kończyć podkreśleniem. |
Model generatywnej AI może odpowiedzieć na prompt za pomocą tekstu, kod, obrazy, umieszczanie na stronie, filmy... prawie wszystko.
uczenie się oparte na promptach
Zdolność określonych modeli, która umożliwia im adaptację ich zachowanie w odpowiedzi na dowolnie wybrany tekst (prompty). W typowym modelu uczenia się opartym na promptach duży model językowy odpowiada na prompt przez podczas generowania tekstu. Załóżmy na przykład, że użytkownik wpisuje taki prompt:
Podsumuj trzecią zasadę dynamiki Newtona.
Model zdolny do uczenia się na podstawie promptów nie został specjalnie wytrenowany tak, aby udzielać odpowiedzi poprzedniego promptu. Model „wie” i dużo ciekawostek na temat fizyki o zasadach i konsekwencjach przydatne odpowiedzi. Wiedza ta wystarcza, aby (mamy nadzieję) . Dodatkowa opinia człowieka („Ta odpowiedź była zbyt skomplikowana” lub „Co to jest reakcja?”) umożliwia niektórym systemom uczenia się opartym na promptach stopniowe zwiększają przydatność ich odpowiedzi.
projektowanie promptów
Synonim wyrażenia inżynieria promptów.
techniki tworzenia promptów
Sztuka tworzenia próśb, które skłaniają do uzyskania pożądanych odpowiedzi z dużego modelu językowego. Ludzie wykonują prompt i inżynierią. Pisanie dobrze ustrukturyzowanych promptów to kluczowy element przydatne odpowiedzi z dużego modelu językowego. Inżynieria promptów zależy od wiele czynników, w tym:
- Zbiór danych używany do wstępnego trenowania i prawdopodobnie dostrój duży model językowy (LLM).
- temperature i inne parametry dekodowania, wykorzystuje model do generowania odpowiedzi.
Zobacz Wprowadzenie do projektowania promptów , aby dowiedzieć się więcej o tworzeniu pomocnych promptów.
Projektowanie promptów to synonim inżynierii promptów.
dostrajanie promptów
Mechanizm efektywnego dostrajania parametrów które uczy się „prefiksu” który system dodaje na początku rzeczywisty prompt.
Jedną z wariantów dostrajania promptów (czasami nazywanych dostrajaniem prefiksów) jest na początku każdej warstwy. W przeciwieństwie do tego większość dostrajania promptów dotyczy tylko dodaje prefiks do warstwy wejściowej.
R
prośba o rolę
Opcjonalna część prośby, która określa docelowych odbiorców. dla odpowiedzi modelu generatywnej AI. Bez roli duży model językowy podaje odpowiedź, która może, ale nie musi być przydatna za osobę zadającą pytania. Po wyświetleniu prośby o rolę, duży język może odpowiadać w sposób, który jest bardziej odpowiedni i pomocny dla konkretnej grupy odbiorców. Na przykład: część z promptem roli prompty są pogrubione:
- Streść ten artykuł doktora ekonomii.
- Opisz, jak działają pływy u 10-letniego dziecka.
- Wyjaśnij kryzys finansowy w 2008 roku. Mów jak do małego dziecka, lub golden retrievera.
S
samoutrzymanie (zwana też warstwą samoobsługi)
Warstwa sieci neuronowej, która przekształca sekwencję wektory dystrybucyjne (np. wektory dystrybucyjne token) w inną sekwencję wektorów dystrybucyjnych. Każde umieszczenie w sekwencji wyjściowej jest tworzone przez integrowanie informacji z elementów sekwencji wejściowej korzystając z mechanizmu uważności.
Część ja samouwagi odnosi się do sekwencji uwzględniającej a nie do innego kontekstu. Jedną z najważniejszych elementy składowe dla Transformers oraz korzystające z wyszukiwania w słowniku. terminologię taką jak „zapytanie”, „klucz” i „wartość”.
Warstwa samouważności zaczyna się od sekwencji reprezentacji danych wejściowych, do każdego słowa. Wprowadzana reprezentacja słowa może być prosta wektora dystrybucyjnego. Dla każdego słowa w sekwencji wejściowej funkcja sieci określa trafność słowa do każdego elementu w całej sekwencji słowa kluczowe. Wyniki trafności określają stopień reprezentacji konkretnego słowa uwzględnia reprezentacje innych słów.
Weźmy na przykład to zdanie:
Zwierzę nie przeszło przez ulicę, ponieważ było zbyt zmęczone.
Poniższa ilustracja (od Transformer: nowatorska architektura sieci neuronowych dla języka Interpretacja danych) pokazuje wzorzec koncentracji uwagi na zaimku it, z każda linia jest zaciemniona, wskazując, w jakim stopniu poszczególne słowa mają swój wkład reprezentacja:
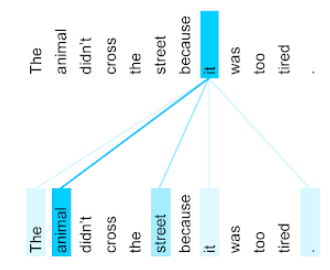
Warstwa samouważności wyróżnia słowa, które są związane z tym hasłem. W tym przypadkiem, warstwa uważności nauczyła się wyróżniać słowa, które może przypisując najwyższą wagę zwierzętom.
W przypadku sekwencji n tokenów samouważność przekształca sekwencję wektorów dystrybucyjnych n razy, po jednym razie w każdej pozycji w sekwencji.
Więcej informacji znajdziesz w artykułach Uwaga oraz swojej wielostronnej uwagi.
analiza nastawienia
Zastosowanie statystycznych lub algorytmów uczenia maszynowego do określania ogólnym nastawieniem – pozytywnym czy negatywnym – do usługi, produktu organizacji lub tematu. Na przykład użycie rozumienie języka naturalnego, algorytm może przeprowadzić analizę nastawienia na podstawie informacji tekstowych od kierunku studiów uniwersyteckich w celu określenia stopnia, ogólnie ocenili ten kurs lub nie.
zadanie sekwencyjne z sekwencją
Zadanie, które konwertuje sekwencję wejściową tokenów na dane wyjściowe z sekwencją tokenów. Na przykład 2 popularne rodzaje danych „od sekwencji do sekwencji” są następujące zadania:
- Tłumacze:
- Przykładowa sekwencja wejściowa: „Kocham Cię”.
- Przykładowa sekwencja wyjściowa: „Je t'aime”.
- Odpowiadanie na pytania:
- Przykładowa sekwencja danych wejściowych: „Czy potrzebuję samochodu w Krakowie?”.
- Przykładowa sekwencja wyjściowa: „Nie. Zostań w domu”.
skip-gram
n-gram, który może pominąć (lub „pominąć”) słowa w oryginale. kontekstu, co oznacza, że N słów mógł nie sąsiadują ze sobą. Więcej a dokładnie „k-skip-n-gram” to n-gram, dla którego może zostały pominięte.
Na przykład „szybki brązowy lis” ma takie 2 gramy:
- „szybkość”
- „szybki brązowy”
- „brązowy lis”
„1 pominięcie 2 gramów” to para słów, które mają między sobą maksymalnie 1 słowo. Dlatego: „szybki brązowy lis” ma następujące 2 gramy z pominięciem:
- „brązowy”
- „szybki lis”
Poza tym wszystkie 2 gramy to 1 pomijanie/2 g, ponieważ mniej jedno słowo może zostać pominięte.
Fragmenty ze słowami pomiń ułatwiają zrozumienie kontekstu danego słowa. W tym przykładzie: „lis” było bezpośrednio powiązane ze słowem „szybkie” w zbiorze 1 pomijać 2 gramy, ale nie w zestawie 2 gramów.
Pomijanie gramów – pomoc w trenowaniu modele umieszczania słów.
łagodne dostrajanie promptów
Technika dostrajania dużego modelu językowego do konkretnego zadania i nie wymaga dużych nakładów pracy dostrajaniu. Zamiast ponownie szkolić wszystkich wagi w modelu, dostrajanie promptów automatycznie dostosowuje komunikat, aby osiągnąć ten sam cel.
Po otrzymaniu promptu tekstowego dostrajanie dosłownego promptu zwykle dołącza do promptu dodatkowe wektory dystrybucyjne tokenów i używa przez propagację wsteczną, aby zoptymalizować dane wejściowe.
„Twarde” zawiera rzeczywiste tokeny, a nie wektory dystrybucyjne.
cecha rozproszona
Cecha, której wartości mają głównie zero lub są puste. Na przykład cecha zawierająca pojedynczą wartość 1 i milion 0 to rozproszony. Natomiast obiekt gęsty ma wartości, które nie są zerowe ani puste.
W systemach uczących się zaskakująca liczba funkcji to rzadkie funkcje. Cechy kategorialne są zwykle rozproszone. Na przykład z 300 możliwych gatunków drzew w lesie jeden przykład może rozpoznać po prostu klon. Lub spośród milionów filmów dostępnych w bibliotece, jeden przykład może wskazać tylko „Casablanca”.
W modelu zazwyczaj są przedstawiane rozproszone cechy, kodowanie jedno- gorące. Jeśli jedno gorące kodowanie jest duże, możesz umieścić na niej warstwę umieszczania 1 kodowanie jednorazowe, co pozwala zwiększyć wydajność.
reprezentacja rozproszona
Przechowywanie w obiekcie rozproszonym tylko pozycji elementów innych niż zero.
Załóżmy na przykład, że cecha kategorialna o nazwie species identyfikuje 36
gatunków drzew w konkretnym lesie. Zakładamy więc, że każdy
przykład wskazuje tylko jeden gatunek.
Do reprezentowania gatunków drzew w każdym przykładzie możesz użyć wektora 1 gorąca.
Wektor o jednej wartości gorącej mógłby zawierać pojedynczy element 1 (oznaczający
konkretnego gatunku drzewa z tego przykładu) i 35 kształtów 0 (reprezentujących
35 gatunków drzew w tym przykładzie). Wyjątkowa reprezentacja
z maple może wyglądać mniej więcej tak:

Ewentualnie rozproszona reprezentacja określałaby po prostu pozycję
konkretnego gatunku. Jeśli maple znajduje się na pozycji 24, to reprezentacja rozproszona
w maple będzie po prostu:
24
Zwróć uwagę, że reprezentacja rozproszona jest znacznie bardziej zwięzła niż danych „jedno gorące”. reprezentacja.
Aby zobaczyć nieco bardziej złożony przykład, kliknij ikonę.
Załóżmy, że każdy przykład w modelu musi reprezentować słowa, ale nie kolejność tych słów – w zdaniu anglojęzycznym. angielski składa się z około 170 000 słów,więc angielski jest kategoryzacją, z około 170 000 elementów. W większości zdań po angielsku bardzo mały ułamek z tych 170 000 słów, więc zestaw słów jeden przykład to z pewnością ubogie dane.
Zastanów się nad następującym zdaniem:
My dog is a great dog
Możesz użyć wariantu jednego gorącego wektora do reprezentowania słów w tym zdania. W tym wariancie wiele komórek w wektorze może zawierać wartość różna od zera. Ponadto w tym wariancie komórka może zawierać liczbę całkowitą inny niż jeden. Chociaż słowa „mój”, „to”, „a” i „świetny” pojawiają się tylko raz w zdaniu słowo „pies”, pojawia się dwukrotnie. Używanie tego wariantu: jedno gorące wektory reprezentujące słowa w tym zdaniu daje następujący wynik Wektor o 170 000 elementów:

Rzadkie przedstawienie tego samego zdania wyglądałoby po prostu tak:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
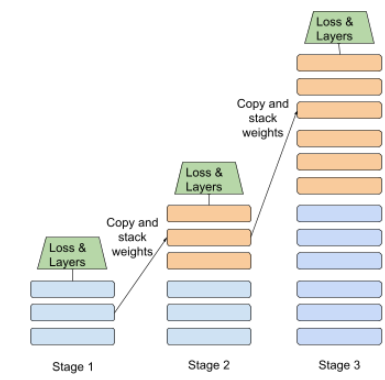
trening etapowy
Taktyka trenowania modelu w sekwencji odrębnych etapów. Celem może być albo przyspieszyć proces trenowania, albo uzyskać lepszą jakość modelu.
Oto ilustracja metody progresywnego nakładania:
- Etap 1 obejmuje 3 ukryte warstwy, etap 2 – 6 oraz 6 warstw Etap 3 obejmuje 12 ukrytych warstw.
- Etap 2 zaczyna trenowanie z ciężarami nauczonymi w 3 ukrytych warstwach Etapu 1. Etap 3 zaczyna trenowanie z wagami nauczonymi w 6 i ukryte warstwy etapu 2.
Zobacz też tworzenie potoków.
token podsłowia
W modelach językowych token, który jest podłańcucha wyrazu, który może stanowić całe słowo.
Na przykład słowo takie jak „wymieniaj” można podzielić na „elementy”, (słowo kluczowe) i „ize” (sufiks), z których każdy jest reprezentowany przez własną token. Podzielenie nietypowych słów na takie, nazywane podsłowami, pozwala modeli językowych do operowania na bardziej powszechnych częściach składowych słowa takich jak prefiksy i sufiksy.
a na odwrót – popularne słowa, takie jak „idę”; mogą nie być podzielone i mogą być reprezentowane przez pojedynczy token.
T
T5
Model transferu wiedzy z tekstu na tekst wprowadzone przez AI od Google w 2020 roku. T5 to model kodera-dekodera oparty na Architektura Transformer wytrenowana na bardzo dużym w gromadzeniu danych. Świetnie sprawdza się w różnych zadaniach związanych z przetwarzaniem języka naturalnego, takich jak generowanie tekstu, tłumaczenie języków i odpowiadanie na pytania w sposób konwersacyjny.
Nazwa T5 pochodzi od liter T w funkcji „Transformer przesyłania tekstu na tekst”.
T5X
Opracowana w formie platformy typu open source platforma systemów uczących się do tworzenia i trenowania przetwarzania języka naturalnego na dużą skalę (NLP). T5 jest zaimplementowany w bazie kodu T5X (która jest (stworzona w formatach JAX i Flax).
temperatura
hiperparametr, który kontroluje stopień losowości. danych wyjściowych modelu. Im wyższa temperatura, tym bardziej losowe wyniki a niższe temperatury – mniej losowe wartości.
Wybór najlepszej temperatury zależy od konkretnego zastosowania preferowane właściwości danych wyjściowych modelu. Na przykład: mogą zwiększyć temperaturę podczas tworzenia aplikacji, aby wygenerować kreacje wyjściowe. I na odwrót – prawdopodobnie obniżysz temperaturę podczas tworzenia modelu, który klasyfikuje obrazy lub tekst, aby poprawić dokładności i spójności modelu.
W przypadku funkcji softmax często używa się temperatury.
rozpiętość tekstu
Zakres indeksu tablicy powiązany z określoną podsekcją ciągu tekstowego.
Na przykład słowo good w ciągu znaków w języku Python s="Be good now" zajmuje
zakres tekstu od 3 do 6.
token
W modelu językowym jest to jednostka atomowa, i wykonywać prognozy. Tokenem jest zwykle :
- słowo – na przykład wyrażenie „psy jak koty”. składa się z trzech słów tokeny: „psy”, „podobne” i „koty”.
- znak – np. wyrażenie „ryba rowerowa”; składa się z dziewięciu tokeny znaków. (Pamiętaj, że puste miejsce jest liczone jako jeden z tokenów).
- podsłów, w których jedno słowo może być pojedynczym tokenem lub większą liczbą tokenów. Podsłowo składa się ze słowa głównego, prefiksu lub sufiksu. Przykład: model językowy, który używa słów podrzędnych jako tokenów, może wyświetlać słowo „psy” jako dwa tokeny (słowo główne „pies” i sufiks liczby mnogiej „s”). Ta sama model językowy może wyświetlać pojedyncze słowo „wysoki” jako dwa podsłowa ( słowo główne „wysoki” i sufiks „er”).
W domenach spoza modeli językowych tokeny mogą reprezentować inne rodzaje jednostek atomowych. Na przykład w rozpoznawaniu obrazów token może być podzbiorem obrazu.
Transformator
Architektura sieci neuronowej opracowana w Google, opiera się na mechanizmach skupienia się, sekwencja wektorów dystrybucyjnych wejściowych w sekwencję danych wyjściowych wektory dystrybucyjne bez splotów lub powracające sieci neuronowe. Transformer może być to zbiór warstw do skupienia się na sobie.
Transformer może zawierać te elementy:
Koder przekształca sekwencję wektorów dystrybucyjnych do nowej sekwencji tej samej długości. Koder zawiera N identycznych warstw, z których każda zawiera dwie i warstwy podrzędne. Te dwie warstwy podrzędne są stosowane na każdej pozycji danych wejściowych sekwencji wektora dystrybucyjnego, przekształcając każdy element sekwencji w nowy wektora dystrybucyjnego. Pierwsza warstwa podrzędna kodera gromadzi informacje z całego regionu sekwencji wejściowej. Druga warstwa podrzędna kodera przekształca zagregowany do wektora dystrybucyjnego dla danych wyjściowych.
Dekoder przekształca sekwencję wektorów dystrybucyjnych wejściowych w sekwencję wektorów dystrybucyjnych, które mogą mieć inną długość. Dekoder zawiera też N identycznych warstw z trzema warstwami podrzędnymi, z których dwie są podobne do i warstw podrzędnych kodera. Trzecia podwarstwa dekodera pobiera dane wyjściowe funkcji kodera i stosuje mechanizm samodzielnego zwracania uwagi, zbierać od nich informacje.
Post na blogu Transformer: A Novel Neural Network Architecture for Language (Transformer: Novel Neural Network Architecture for Language) Zrozumienie stanowi dobre wprowadzenie do Transformers.
trygram
N-gram, w którym N=3.
U
jednokierunkowa
System oceniający tylko tekst, który postępuje przed docelowym fragmentem tekstu. W przeciwieństwie do tego układ dwukierunkowy ocenia zarówno tekstu, który postępuje i następuje po docelowej sekcji tekstu. Więcej informacji znajdziesz w sekcji Dwukierunkowe.
jednokierunkowy model językowy
Model językowy, który opiera swoje prawdopodobieństwo wyłącznie na podstawie tokeny występujące przed, a nie po tokenach docelowych. Różnica z dwukierunkowym modelem językowym.
V
wariacyjny autokoder (VAE)
Typ autokodera, który wykorzystuje rozbieżność. między danymi wejściowymi a wyjściowymi w celu wygenerowania zmodyfikowanych wersji danych wejściowych. W przypadku generatywnej AI przydają się warunkowe autokodery.
VAE bazuje na wnioskowaniu wariacyjnym, czyli metodzie szacowania wartości w modelu prawdopodobieństwa.
W
umieszczanie słów
Reprezentowanie każdego słowa w zestawie słów w elemencie wektor umieszczania; czyli reprezentujące każde słowo jako wektora wartości zmiennoprzecinkowych od 0,0 do 1,0. Słowa z podobnymi znaczenie przedstawia bardziej podobnie niż słowa o innym znaczeniu. Na przykład marchew, seler i ogórki mają względnie które znacznie różnią się od reprezentacji samolot, okulary przeciwsłoneczne i pasta do zębów.
Z
prompt typu zero-shot
Prompt, który nie zawiera przykładu, w jaki sposób chcesz uzyskać duży model językowy do odpowiadania. Na przykład:
| Elementy jednego promptu | Uwagi |
|---|---|
| Jaka jest oficjalna waluta w danym kraju? | Pytanie, na które ma odpowiedzieć LLM. |
| Indie: | Faktyczne zapytanie. |
Duży model językowy może reagować na jeden z tych warunków:
- Rupia
- INR
- ₹
- Rupia indyjska
- rupia
- rupia indyjska
Wszystkie odpowiedzi są prawidłowe, ale preferowany jest konkretny format.
Porównaj zachowania typu zero-shot z tymi terminami: