Bu sayfada Dil Değerlendirmesi sözlüğü terimleri bulunur. Tüm sözlük terimleri için burayı tıklayın.
A
dikkat
Nöral ağda kullanılan mekanizma, bunların belirli bir kelimenin veya sözcüğün önemini öğrenebilirsiniz. Dikkat sıkıştırır bir modelin bir sonraki jetonu/kelimeyi tahmin etmesi için gereken bilgi miktarıdır. Sıradan bir dikkat mekanizması, Bir girdi kümesi üzerinden ağırlıklı toplam her giriş için ağırlık, nöral ağdır.
Ayrıca kendi kendine dikkat çok başlı kendi kendine dikkat Transformatörlerin yapı taşları.
otomatik kodlayıcı
Web sitesinden en önemli bilgileri çıkarmayı öğrenen bir sistem giriş. Otomatik kodlayıcılar, bir kodlayıcı ve kod çözücü ile gönderin. Otomatik kodlayıcılar aşağıdaki iki adımlı süreci temel alır:
- Kodlayıcı, girişi (tipik olarak) kayıplı bir alt boyutla eşler (orta) biçimdedir.
- Kod çözücü, haritalama yaparak orijinal girişin kayıplı bir sürümünü oluşturur düşük boyutlu biçimden orijinal yüksek boyutlu biçime giriş biçimini kullanın.
Otomatik kodlayıcılar, kod çözücünün kodu çözmeyi deneyerek uçtan uca eğitilir. kodlayıcının ara biçiminden orijinal girişi yeniden oluşturur olabildiğince yakından bakmalısınız. Ara biçim daha küçük olduğu için (daha düşük boyutlu) olduğunda, otomatik kodlayıcı girişteki hangi bilginin gerekli olduğunu, çıktının ise girdiyle tamamen aynı olmalıdır.
Örneğin:
- Girdi verileri bir grafikse tam olmayan kopya biraz değiştirilmiş. Belki bire bir aynı olmayan kopya, orijinal grafikteki paraziti ortadan kaldırır veya eksik pikseller var.
- Giriş verileri metin ise, bir otomatik kodlayıcı yeni metin orijinal metni taklit eder (ancak onunla aynı değildir).
Ayrıca değişken otomatik kodlayıcılar konusuna bakın.
otomatik regresif model
Kendi önceki özelliklerine dayalı olarak bir tahminde bulunan bir model tahminler. Örneğin, otomatik regresif dil modelleri bir sonraki jetonunu kullanın. Tamamı Transformer tabanlı büyük dil modelleri otomatik regresyonludur.
Buna karşın GAN tabanlı görüntü modelleri genellikle otomatik regresif değildir. çünkü bu işlemi yinelemeli olarak değil, tek bir ileriye adımları. Ancak bazı görüntü üretme modelleri otomatik regresyona göre otomatik regresyona sahiptir. adımlar halinde bir görsel oluşturur.
B
.kelime yığını
Bir kelime öbeği veya pasajdaki kelimelerin temsili elde edebiliyorlar. Örneğin, bir kelime torbası şu üç ifadeyi aynı şekilde ekleyin:
- zıplayan köpek
- köpeği atlayan
- zıplayan köpek
Her kelime, seyrek vektör içindeki bir dizine eşlenir. Burada vektörün sözlükteki her kelime için bir dizini vardır. Örneğin, köpek atlayış ifadesi, sıfır olmayan bir özellik vektörüne eşlenir the, dog ve kelimelerine karşılık gelen üç dizinde değerler atlar. Sıfır olmayan değer aşağıdakilerden herhangi biri olabilir:
- Bir kelimenin varlığını belirtmek için 1.
- Bir kelimenin çantada kaç kez göründüğünün sayısıdır. Örneğin, bordo köpek, bordo kürklü bir köpektir kelime öbeğini kullanıyorsanız her ikisi de bordo ve köpek 2 olarak temsil edilir, diğer kelimeler ise 2 olarak temsil edilir 1 olarak temsil edilir.
- Başka bir değer, örneğin sayı sayısının logaritması kez geçiyor.
BERT (İki Yönlü Kodlayıcı) Transformers temsilleri)
Metin temsili için model mimari. Eğitimli BERT modeli, daha büyük bir modelin parçası olarak kullanılabilir. üzerine konuşacağız.
BERT aşağıdaki özelliklere sahiptir:
- Transformer mimarisini kullanır ve bu nedenle kendi kendine dikkat
- Dönüştürücünün kodlayıcı bölümünü kullanır. Kodlayıcının işi belirli bir araç seti yerine iyi metin temsilleri üretmek üzerine konuşacağız.
- İki yönlü olmalıdır.
- Aşağıdakiler için maskeleme kullanır: gözetimli olmayan eğitimlere tabidir.
BERT'in varyantları şunları içerir:
ziyaret edin.Open Sourcing BERT: Son Teknoloji Eğitim Öncesi Eğitim (Doğal Dil İçin Son Teknoloji Eğitim) başlıklı makaleyi inceleyin İşleniyor BERT'e genel bakış.
iki yönlü
Metni ilk önce önce ve metnin bir hedef bölümünü takip eder. Öte yandan Yalnızca tek yönlü sistem metnin hedef bölümünden öncesi metni değerlendirir.
Örneğin, izin verilmeyen bir maskeli dil modeli alt çizgiyi temsil eden kelime veya kelimelerin olasılıklarını şu soru var:
Sizde _____ nedir?
Tek yönlü bir dil modelinin yalnızca olasılıklarını bağlam hakkında daha çok bilgi edindiniz. Öte yandan iki yönlü bir dil modeli, aynı zamanda "birlikte" ifadesinden bağlam da alabilir. ve "siz", Bu da modelin daha iyi tahminler oluşturmasına yardımcı olabilir.
iki yönlü dil modeli
Bir kullanıcının belirli bir isteği yerine getirme olasılığını belirleyen bir dil modeli belirtilen konuma dayalı bir metin alıntısında belirtilen konum önceki ve sonraki metin.
Bigram
N=2 olan bir N-gram.
BLEU (İki Dilli Değerlendirme Alt Çalışması)
Çevirinin kalitesini gösteren 0, 0 ile 1, 0 (dahil) arasında bir puan iki insan dili arasında (örneğin, İngilizce ve Rusça arasında). BLEU 1,0 puan mükemmel bir çeviri olduğunu gösterir; 0,0 olan bir BLEU puanı kötü bir çeviri olabilir.
C
nedensel dil modeli
Tek yönlü dil modeli ile eş anlamlıdır.
Şu işlemler için çift yönlü dil modelini inceleyin: Dil modellemedeki farklı yönlü yaklaşımları ayırt etme ve karşılaştırma.
düşünce zincirine dayalı istem
Bir istem mühendisliği tekniği olarak, büyük dil modeli (LLM) kullanarak ve akıl yürütmeyi öğreneceksiniz. Örneğin, şu istemi dikkate alın: aşağıdaki cümleye çok dikkat etmeniz gerekir:
0'dan 60'a giden bir arabada sürücü kaç g kuvveti yaşar? 7 saniyede mil/saat mi? Yanıtta tüm alakalı hesaplamaları gösterin.
LLM'nin yanıtı muhtemelen:
- 0, 60 ve 7 değerlerini dikkate alarak bir fizik formülleri dizisini göster koymanız gerekir.
- Şirketin bu formülleri neden seçtiğini ve çeşitli değişkenlerin ne anlama geldiğini açıklayın.
Düşünce zinciri istenmesi, LLM'yi tüm hesaplamaları yapmaya zorlar, Bu da daha doğru bir yanıt almanızı sağlayabilir. Bunun yanı sıra, proje istemi, kullanıcının LLM'nin adımlarını incelemesine olanak tanır. Böylece, cevabın anlamlı olup olmadığını sorun.
sohbet
Bir ML sistemiyle yapılan diyalogların içeriği, genelde büyük dil modelini kullanın. Bir sohbetteki önceki etkileşim (yazdığınız kelimeler ve büyük dil modelinin yanıt verme şekli) daha ayrıntılı bağlam bilgisi sunar.
Chatbot, büyük dil modelinin bir uygulamasıdır.
sohbet
halüsinasyon ile eş anlamlıdır.
"Kafa" terimi, teknik olarak halüsinasyondan daha doğru bir terimdir. Ancak önce halüsinasyon popüler oldu.
seçim bölgesi ayrıştırma
Bir cümleyi daha küçük dil bilgisi yapılarına ("bileşenler") bölme. Makine öğrenimi sisteminin daha sonra doğal dil anlama modelini kullanır ve bileşenleri, orijinal cümleye göre daha kolay ayrıştırabilir. Örneğin, şu cümleyi düşünün:
Arkadaşım iki kedi sahiplendi.
Bir seçim bölgesi ayrıştırıcısı bu cümleyi aşağıdaki bölümlere bölebilir şu iki bileşenden oluşur:
- Arkadaşım bir isim kelime öbeğidir.
- iki kedi sahiplenme fiil ifadesidir.
Bu bileşenler, daha küçük alt bölümlere ayrılabilir. Örneğin, fiil ifadesi
iki kedi sahiplendi
şu alt bölümlere ayrılabilir:
- kabullenilmiş bir fiildir.
- iki kedi başka bir isim kelime öbeğidir.
bağlama dayalı dil yerleştirme
"Anlama"ya yakın bir yerleştirme kelimeler şekilde ifade etmesine yardımcı olur. Bağlama dayalı dil yerleştirilmiş öğeler karmaşık söz dizimini, anlamları ve bağlamı anlayabilir.
Örneğin, İngilizce inek kelimesini yerleştirebilirsiniz. Daha eski yerleştirilmiş öğeler word2vec gibi bir ifade İngilizceyi temsil edebilir yerleştirme alanındaki mesafe gibi kelimeler ewe (dişi koyun) ile boğa arasındaki mesafe, ewe (dişi koyun) ile koç (erkek koyun) veya dişi'den erkek'e. Bağlama dayalı dil Böylece, İngilizce konuşan kullanıcıların bazen daha fazla bilgi sahibi resmi olarak inek veya boğa anlamına gelen inek kelimesini kullanmayın.
bağlam penceresi
Bir modelin belirli bir sürede işleyebileceği jeton sayısı istem. Bağlam penceresi ne kadar büyükse o kadar fazla bilgi tutarlı ve tutarlı yanıtlar vermek için kullanabileceği komut istemine ekleyin.
kaza çiçek
Belirsiz bir anlamı olan cümle veya ifade. Çarpışma çiçekleri, doğal temada önemli bir sorun dil anlama konusuna bakın. Örneğin, Kırmızı Bant Dikey Kenarda başlığı, Çünkü NLU modeli, başlığı olduğu gibi yorumlayabilir veya bir anlam ifade eder.
D
kod çözücü
Genel olarak, işlenmiş, yoğun veya veya dış temsile dönüştürme sürecidir.
Kod çözücüler, genelde daha büyük bir modelin bileşenidir ve genelde bir kodlayıcı ile eşlenmiştir.
Diziden sıralı görevlerde, kod çözücü bir sonraki aşamayı tahmin etmek için kodlayıcı tarafından oluşturulan dahili durumla başlar tıklayın.
İçinde kod çözücünün tanımı için Transformer bölümüne bakın. Transformer mimarisiyle ilgili epeyce yaklaşacaksınız.
parazit giderme
Kendi kendine gözetimli öğrenmeye yaygın bir yaklaşım burada:
Parazit giderme, etiketsiz örneklerden öğrenmeyi sağlar. Orijinal veri kümesi hedef label ve gürültülü verileri giriş olarak kullanır.
Bazı maskeli dil modelleri parazit giderme kullanır şu şekilde:
- Bazılarını maskeleyerek etiketsiz cümlelere yapay olarak gürültü eklenir. jetonlar.
- Model, orijinal jetonları tahmin etmeye çalışır.
doğrudan istem
Sıfır çekim istemi ile eş anlamlıdır.
E
mesafeyi düzenle
İki metin dizesinin birbirine ne kadar benzer olduğunun ölçümü. Makine öğreniminde mesafe düzenleme özelliği yararlıdır çünkü bilinen iki dizeyi karşılaştırmanın etkili bir yoludur. dizeleri bulmak için kullanabilirsiniz.
Düzenleme mesafesinin birkaç tanımı vardır. Her biri farklı bir dize kullanır anlamına gelir. Örneğin, Levenshtein mesafesi en az sayıda silme, ekleme ve değiştirme işlemini dikkate alır.
Örneğin, "kalp" kelimeleri arasındaki Levenshtein mesafesi ve "dart" 3'tür, çünkü aşağıdaki 3 düzenleme bir kelimeyi dönüştürmek için yapılacak en az değişikliktir diğerine:
- kalp → deart ("h" yerine "d")
- deart → dart ("e"yi silin)
- dart → dart ("s" girin)
yerleştirme katmanı
Gizli katman yüksek boyutlu kategorik özelliği daha alt boyutlu bir yerleştirme vektörünü yavaş yavaş öğrenir. yerleştirme katmanı, bir sinir ağının çok daha fazla kategorik özellikle ilgili eğitimden daha verimli bir şekilde
Örneğin, Earth şu anda yaklaşık 73.000 ağaç türünü desteklemektedir. Diyelim ki
ağaç türü, modelinizin bir özelliktir. Dolayısıyla modelinizin
giriş katmanında 73.000 adet tek sıcak vektör bulunuyor
öğe uzunluğunda olmalıdır.
Örneğin, baobab şuna benzer bir şekilde temsil edilir:

73.000 öğelik bir dizi çok uzundur. Yerleştirme katmanı eklemezseniz sahip olduğu için eğitim çok zaman alacak. 72.999 tane sıfır ile çarpılır. Belki gömme katmanını seçmiş olursunuz. emin olun. Bunun sonucunda, yerleştirme katmanı, her ağaç türü için yeni bir yerleştirme vektörü olacak.
Belirli durumlarda, karma oluşturma makul bir alternatiftir. ekleme katmanıdır.
yerleştirme alanı
Daha yüksek boyuttan gelen d boyutlu vektör uzayı yardımcı olduğu anlamına gelir. İdeal olarak, yerleştirme alanı anlamlı matematiksel sonuçlar veren yapıyı; örneğin, yerleştirme, yerleştirme ve çıkarma kelime analojisi görevlerini çözebilir.
Nokta ürünü öğeler, benzerliklerinin bir ölçüsüdür.
yerleştirme vektörü
Genel olarak, herhangi bir noktadan alınan kayan nokta sayıları dizisi gizli katman ekleyebilirsiniz. Yerleştirme vektörü genellikle bir yerleştirme katmanı içerir. Örneğin, bir yerleştirme katmanının her biri için bir yerleştirme vektörü oluşturdu. Belki aşağıdaki dizi, bir baobab ağacının yerleştirme vektörüdür:

Yerleştirme vektörü, rastgele sayılardan oluşan bir küme değildir. Yerleştirme katmanı Bu değerleri, tıpkı bir reklamveren gibi eğitim aracılığıyla belirler. nöral ağ, eğitim sırasında başka ağırlıkları da öğrenir. Her bir öğe dizisi, bir ağaç türünün bazı özelliklerine göre yapılan bir derecelendirmedir. Hangi öğesi, hangi ağaç türünü özellikleri nelerdir? Bu çok zor bu insanlar tarafından belirleniyor.
Yerleştirme vektörünün matematiksel açıdan dikkat çekici tarafı, öğeler benzer kayan nokta sayı kümelerine sahiptir. Örneğin, ağaç türlerinin kayan nokta sayılarına farklı ağaç türleri olabilir. Kızılağaç ve sekoyalar ilgili ağaç türleridir. daha benzer kayan noktalı sayılara sahip olurlar. kızılağaçlar ve hindistan cevizi palmiyeleri. Yerleştirme vektörindeki sayılar, modeli yeniden eğitseniz bile modeli her yeniden eğittiğinizde görürsünüz.
kodlayıcı
Genel olarak ham, seyrek veya harici veri dönüşümü yapan tüm makine öğrenimi sistemleri daha işlenmiş, yoğun veya daha içsel bir temsile dönüştürebilir.
Kodlayıcılar çoğu zaman büyük bir modelin bileşenidir. bir kod çözücü ile eşlenmiştir. Bazı Transformatörler kodlayıcıları kod çözücülerle eşlemeye devam ederken, diğer Transformatörler yalnızca kodlayıcıyı kullanır. veya yalnızca kod çözücüyü kullanabilirsiniz.
Bazı sistemler, kodlayıcının çıkışını bir sınıflandırmaya giriş olarak kullanır veya regresyon ağıdır.
Diziden sıralı görevlerde, kodlayıcı bir giriş dizisi alır ve dahili bir durum (bir vektör) döndürür. Ardından, kod çözücü, bir sonraki diziyi tahmin etmek için bu dahili durumu kullanır.
Kodlayıcının tanımı için Transformer'a bakın. Transformer mimarisiyle ilgili epeyce yaklaşacaksınız.
C
birkaç atışlık istem
Birden fazla ("birkaç") örnek içeren istem Bu da büyük dil modelinin cevap vermelidir. Örneğin, aşağıdaki uzun istemde iki veya daha fazla büyük dil modelini gösteren örnekler.
| Tek bir istemin bölümleri | Notlar |
|---|---|
| Belirtilen ülkenin resmi para birimi nedir? | LLM'nin yanıtlamasını istediğiniz soru. |
| Fransa: EUR | Bir örnek. |
| Birleşik Krallık: GBP | Başka bir örnek. |
| Hindistan: | Asıl sorgu. |
Birkaç denemede bulunulması genellikle sıfır çekim istemi ve tek seferlik istem. Bununla birlikte, birkaç atışlık istem daha uzun bir istem gerektirir.
Birkaç denemede yer alan istemler, birkaç hızlı öğrenme yöntemidir. isteme dayalı öğrenime uygulanır.
Keman
Python öncelikli bir yapılandırma kitaplığı işlevlerin ve sınıfların değerlerini daha belirgin hale getirir. Pax ve diğer makine öğrenimi kod tabanları söz konusu olduğunda, bu işlevler sınıflar modelleri ve eğitimi temsil eder hiperparametreler.
Kemal makine öğrenimi kod tabanlarının tipik olarak şu şekilde bölündüğünü varsayar:
- Katmanları ve optimize edicileri tanımlayan kitaplık kodu.
- Veri kümesi "yapıştırıcı" kodu içeren bu kod, kitaplıkları çağırarak her şeyi birbirine bağlar.
Fiddle, birleştirici kodun çağrı yapısını değerlendirilmemiş ve bir biçimdir.
ince ayar
İkinci bir, göreve özgü eğitim sınavından önceden eğitilmiş bir modelden yararlanarak kullanım alanına özgüdür. Örneğin, bazı eğitim kurumları için tam eğitim büyük dil modellerini aşağıdaki gibi görebilirsiniz:
- Ön eğitim: Büyük bir dil modelini kapsamlı bir genel veri kümesiyle eğitin. İngilizcedeki tüm Vikipedi sayfaları gibi.
- İnce ayar: Önceden eğitilmiş modeli belirli bir görevi gerçekleştirecek şekilde eğitin. örneğin tıbbi sorgulara yanıt verebilir. Hassas ayarlamalar genellikle belirli bir göreve odaklanan yüzlerce ya da binlerce örnek olabilir.
Başka bir örnek olarak, büyük bir görüntü modeli için tam eğitim sırası şöyle olur:
- Eğitim öncesi: Büyük bir resim modelini kapsamlı bir genel resim üzerinde eğitin Wikimedia Commons'taki tüm görüntüler gibi.
- İnce ayar: Önceden eğitilmiş modeli belirli bir görevi gerçekleştirecek şekilde eğitin. Örneğin orkaların resimlerini üretmek.
İnce ayar, aşağıdaki stratejilerin herhangi bir kombinasyonunu gerektirebilir:
- Önceden eğitilmiş mevcut modelin tümünü değiştirme parametrelerini kullanın. Bu işlem bazen tam ince ayar olarak da adlandırılır.
- Önceden eğitilmiş modelin mevcut parametrelerinden yalnızca bazılarını değiştirme (genellikle çıkış katmanına en yakın katmanlar), mevcut parametreleri değiştirmeden (genellikle giriş katmanına en yakın olan) girin. Görüntüleyin parametre açısından verimli ayarlama.
- Daha fazla katman (genellikle şuna en yakın mevcut katmanların üzerine) çıkış katmanıdır.
İnce ayar, bir öğrenmeyi aktarma biçimidir. Bu nedenle, ince ayar için farklı bir kayıp fonksiyonu veya farklı bir model kullanılabilir modeli eğitmek için kullanılan modellerden farklıdır. Örneğin herkesin regresyon modeli oluşturmak için önceden eğitilmiş büyük bir görüntü modeline bir giriş görüntüsündeki kuş sayısını döndürür.
İnce ayarları aşağıdaki terimlerle karşılaştırın:
Keten
Yüksek performanslı bir açık kaynak kitaplığı: JAX üzerine inşa edilen derin öğrenme. Flax, çeşitli işlevleri ve eğitim nöral ağları için de geçerlidir yöntemleri olarak kullanabilir.
Flaxformer
Açık kaynak bir Transformer kitaplık, temel olarak doğal dil işleme için tasarlanmış Flax'ta geliştirilmiştir geliştirmeyi öğreneceksiniz.
Y
üretken yapay zeka
Resmi tanımı olmayan, yeni gelişen ve dönüştürücü bir alan. Bununla birlikte çoğu uzman, üretken yapay zeka modellerinin aşağıdakilerin tümüne sahip bir içerik oluşturma ("oluşturma"):
- karmaşık
- tutarlı
- orijinal
Örneğin, üretken yapay zeka modeli ile makale veya resim kullanabilirsiniz.
LSTMs gibi bazı eski teknolojiler ve RNN'ler gibi özgün ve tutarlı içeriğe sahip olmasını sağlar. Bazı uzmanlar bu eski teknolojilerin üretken yapay zeka, gerçek üretken yapay zekanın daha karmaşık ve eski teknolojilerden çok daha fazla verim sağlayabilir.
Tahmine dayalı makine öğrenimi ile kontrast oluşturun.
GPT (Önceden Eğitilmiş Üretici Dönüştürücü)
Transformer tabanlı bir aile grubu tarafından geliştirilen büyük dil modellerini OpenAI.
GPT varyantları, aşağıdakiler de dahil olmak üzere birden fazla moda uygulanabilir:
- resim üretme (örneğin, ImageGPT)
- metinden görsele dönüştürme (örneğin, DALL-E) içerebilir.
H
halüsinasyon
Bir kullanıcı tarafından, makul görünen ancak olgusal açıdan yanlış çıktıların üretilmesi üretken yapay zeka modeli ortaya çıkarmasını sağlamaya yardımcı olur. Örneğin, Barack Obama'nın 1865'te öldüğünü iddia eden bir üretken yapay zeka modeli halüsinasyona giriyor.
I
bağlam içi öğrenme
Birkaç çekim istemi ile eş anlamlıdır.
L
LaMDA (Diyalog Uygulamaları İçin Dil Modeli)
Transformer tabanlı bir Google tarafından geliştirilen büyük dil modeli gerçekçi diyalog yanıtları oluşturabilen geniş bir diyalog veri kümesidir.
LaMDA: Çığır açan görüşmemiz teknolojisi genel bir bakış sağlar.
dil modeli
Bir jetonun olasılığını tahmin eden bir model veya daha uzun bir kod dizisinde gerçekleşen token dizisidir.
büyük dil modeli
Katı bir tanımı olmayan, genellikle resmî olmayan görüntüleme sayısı yüksek olan dil modelini parametrelerini kullanın. Bazı büyük dil modelleri 100 milyardan fazla parametre içerir.
gizli alan
Yerleştirme alanı ile eş anlamlı.
LLM
Büyük dil modeli'nin kısaltmasıdır.
LoRA
Düşük Dereceli Uyarlanabilirlik'in kısaltmasıdır.
Düşük Seviyede Uyarlanabilirlik (LoRA)
Bir projeyi yürütmek için parametre açısından verimli ayarlama ince müzikler, büyük dil modelinin parametrelerini kullanabilirsiniz. LoRA aşağıdaki avantajları sağlar:
- Modelin tüm özellikleri üzerinde ince ayar yapılmasını gerektiren tekniklere kıyasla daha hızlı ince ayarlar parametreleridir.
- Çıkarımın işlem maliyetini modelimiz olabilir.
LoRA ile ayarlanmış bir model, tahminlerinin kalitesini korur veya iyileştirir.
LoRA, bir modelin birden fazla özel versiyonunu kullanabilmenizi sağlar.
M
maskeli dil modeli
Yaşanma olasılığını tahmin eden bir dil modeli bir dizideki boşlukları doldurmak için aday jetonlar. Örneğin, maskelenmiş dil modeli, aday kelimelerin olasılıklarını hesaplayabilir kullanabilirsiniz:
Şapkadaki ____ geri geldi.
Literatürde genellikle "MASK" dizesi kullanılmaktadır tercih edebilirsiniz. Örneğin:
"MASK" geri döndük.
Modern maskeli dil modellerinin çoğu iki yönlüdür.
meta-öğrenim
Bir öğrenme algoritmasını keşfeden veya iyileştiren makine öğrenimi alt kümesi. Bir meta öğrenme sistemi, yeni bir bilgiyi hızla öğrenecek bir model eğitmeyi de ya da önceki görevlerde edinilen deneyime dayalı olarak yapılan bir görevdir. Meta öğrenme algoritmaları genellikle aşağıdakileri sağlamaya çalışır:
- El tarafından geliştirilen özellikleri (ör. başlatıcı veya unutmayın.
- Veri ve işlem açısından daha verimlidir.
- Genelleştirmeyi geliştirin.
Meta öğrenme, birkaç atışlık öğrenmeyle ilgilidir.
modalite
Üst düzey bir veri kategorisi. Örneğin sayılar, metin, resimler, video ve ses ise beş farklı modalitedir.
model paralelliği
Belli bir terimin farklı parçalarını koyarak çıkarımları ya da eğitimi ölçeklendirme yöntemi model farklı cihazlarda. Model paralelliği tek bir cihaza sığmayacak kadar büyük modelleri etkinleştirir.
Bir sistem, model paralelliğini uygulamak için genellikle aşağıdakileri yapar:
- Modeli daha küçük parçalara ayırır (bölür).
- Bu küçük parçaların eğitimini birden fazla işlemciye dağıtır. Her işlemci, modelin kendi bölümünü eğitir.
- Tek bir model oluşturmak için sonuçları birleştirir.
Model paralelliği, eğitimi yavaşlatır.
Ayrıca veri paralelliği konusunu inceleyin.
birden fazla kafa ile kendi kendine dikkat
Kendi kendine dikkat özelliğinin uzantısı şu şekildedir: kendi kendine dikkat mekanizmasını, giriş dizisindeki her konum için birden çok kez kullanabilirsiniz.
Transformers, birden çok kafalı öz dikkat becerisini tanıttı.
çok modlu model
Birden fazla giriş ve/veya çıkış içeren model modalite. Örneğin, hem büyük hem de küçük özellik olarak bir resim ve bir metin başlığı (iki mod) ve metin başlığının resim için ne kadar uygun olduğunu gösteren bir puan verir. Dolayısıyla bu modelin girişleri çok modlu, çıktıları ise tek modludur.
N
doğal dil anlama
Kullanıcının yazdıklarına veya söylediklerine göre niyetini belirleme. Örneğin bir arama motoru, şunları yapmak için doğal dil anlama özelliğini kullanır: kullanıcının yazdıklarına veya söylediklerine bağlı olarak kullanıcının ne aradığını belirler.
N-gram
N kelimelik sıralı bir dizi. Örneğin, gerçekten çılgın ifadesi 2 gramlık bir kelimedir. Çünkü bir çünkü gerçekten çok çılgınca 2 gramlıktan farklıdır.
| N | Bu N-gram türü için adlar | Örnekler |
|---|---|---|
| 2 | bigram veya 2 gram | gidip gitme, öğle yemeği içme, akşam yemeği yeme |
| 3 | trigram veya 3 gram | çok fazla yeme, üç görme engelli fare ve zil zıplama |
| 4 | 4 gram | parkta yürüyün, rüzgârda toz kıstırın, çocuk mercimek yediyse |
Birçok doğal dil anlama modeller, kullanıcının yazacağı bir sonraki kelimeyi tahmin etmek için N-gramlardan yararlanır veya deyin. Örneğin, bir kullanıcının üç kör yazdığını varsayalım. Trigramlara dayalı bir NLU modeli, büyük olasılıkla kullanıcı mikro yazar.
N-gramları kelime kesitleri ile kontrast: sırasız kelime gruplarıdır.
NLU
Doğal dil kısaltması öğrenebilirsiniz.
O
tek seferlik istem
Bir örnek içeren istem büyük dil modelinin yanıt vermesi gerekir. Örneğin, aşağıdaki istem, büyük bir dil modelinin nasıl uygulandığını gösteren bir sorguyu yanıtlayacaktır.
| Tek bir istemin bölümleri | Notlar |
|---|---|
| Belirtilen ülkenin resmi para birimi nedir? | LLM'nin yanıtlamasını istediğiniz soru. |
| Fransa: EUR | Bir örnek. |
| Hindistan: | Asıl sorgu. |
Tek seferlik isteme özelliğini aşağıdaki terimlerle karşılaştırın:
P
parametre verimli ayarlama
Büyük ve küçük bir reklamda ince ayar yapmak önceden eğitilmiş dil modeli (PLM) tam ince ayar'lardan daha verimlidir. Parametre açısından verimli ayarı genellikle tam ayara kıyasla çok daha az parametreye ince ayar yapar ancak genellikle modelin yüksek performans gösteren büyük dil modeli aynı zamanda (ya da neredeyse aynı) tam sürümden ve ince ayar.
Parametre verimli ayarı aşağıdakilerle kıyaslayın ve karşılaştırın:
Parametre verimli ayarlama, parametre açısından verimli ince ayar olarak da bilinir.
ardışık düzen
Bir modelin paralellik (model paralelliği) işleme ardışık aşamalara bölünür ve her aşama yürütülür açın. Bir aşama bir grubu işlerken önceki grup nasıl çalışabileceğine bakalım.
Ayrıca aşamalı eğitimlere de göz atın.
PLM
Önceden eğitilmiş dil modeli'nin kısaltmasıdır.
konumsal kodlama
Bir jetonun bir dizideki konumu hakkında bilgi ekleyerek jetonun yerleştirilmesi. Dönüştürücü modelleri, konum verilerini kullanır. bileşenleri arasındaki ilişkiyi daha iyi anlamak için kodlama tıklayın.
Konumsal kodlamanın yaygın bir uygulaması, sinüsoidal fonksiyonları kullanır. (Sinüzoidal fonksiyonun frekansı ve genliği jetonun sıradaki konumuna göre belirlenir.) Bu teknik bir Transformer modelinin farklı kısımlara katılmayı öğrenmesini sağlar. bir sıralamaya sahip olabilir.
önceden eğitilmiş model
Modeller veya model bileşenleri (örneğin, yerleştirme vektörü) ekleyin. Bazen, önceden eğitilmiş yerleştirme vektörlerini sinirsel ağ. Bazı durumlarda ise modeliniz yerleştirme vektörleri yerleştirme yöntemidir.
Önceden eğitilmiş dil modeli terimi, yeni ve büyük dil modeli ön eğitim.
ön eğitim
Bir modelin büyük bir veri kümesi üzerinde ilk eğitimi. Önceden eğitilmiş bazı modeller sakar devlerdir ve genellikle ek eğitimle rafine olmaları gerekir. Örneğin, makine öğrenimi uzmanları bir geniş metin veri kümesinde büyük dil modeli İngilizce sayfalar için de geçerli. Ön eğitimin ardından elde edilen model, aşağıdaki yöntemlerden herhangi biri kullanılarak daha da hassaslaştırılabilir. teknikler:
istem
Büyük dil modeline giriş olarak girilen metinler davranış şekli koşulmasını sağlar. İstemler en az bir kelime öbeği veya rastgele uzun (örneğin, bir romandaki tüm metin). İstem sayısı aşağıdaki tabloda gösterilenler dahil olmak üzere birden çok kategoriye ayrılabilir:
| İstem kategorisi | Örnek | Notlar |
|---|---|---|
| Soru | Güvercin ne kadar hızlı uçabilir? | |
| Talimat | Arbitraj hakkında komik bir şiir yazın. | Büyük dil modelinden bir işlem yapmasını isteyen bir istem. |
| Örnek | Markdown kodunu HTML'ye çevirin. Örnek:
. Markdown: * liste öğesi . HTML: <ul> <li>liste öğesi</li> </ul> |
Bu örnek istemdeki ilk cümle bir talimattır. İstemin geri kalanı örnek olarak verilmiştir. |
| Rol | Derecelendirme inişinin makine öğrenimi eğitiminde neden kullanıldığını açıklama Fizik doktorası yaptım. | Cümlenin ilk bölümü bir talimattır. ifade "Fizik doktorası" rol kısmıdır. |
| Modelin tamamlanması için kısmi giriş | Birleşik Krallık Başbakanı'nın yaşadığı yer | Kısmi giriş istemi aniden sonlanabilir (bu örnekte olduğu gibi) veya alt çizgiyle biter. |
Üretken yapay zeka modelleri, istemlere metin, resim veya Kod, resimler, yerleştirmeler, videolar, neredeyse her şey.
isteme dayalı öğrenim
Belirli modellerin uyum sağlamalarını sağlayan özellik rastgele metin girişlerine (istemler) göre davranışları. Tipik bir istem tabanlı öğrenme paradigmasında büyük dil modeli, isteklere metin oluşturuyoruz. Örneğin, bir kullanıcının aşağıdaki istemi girdiğini varsayalım:
Newton'un üçüncü hareket yasasını özetleme.
İsteme dayalı öğrenme yeteneğine sahip bir model, sorunu yanıtlamak için özel olarak eğitilmemiş karar verebilir. Aksine, model fizik hakkında birçok bilgi genel dil kuralları ve genel olarak neyin geçerli faydalı cevaplar. Bu bilgi (umarız) yararlı bir olasılık sağlamak için ver. İnsan kaynaklı ek geri bildirim ("Bu yanıt çok karmaşıktı" veya "Tepki nedir?"") istem temelli bazı öğrenim sistemlerinin, daha faydalı olmasını sağlayabilir.
istem tasarımı
İstem mühendisliği ile eş anlamlıdır.
istem mühendisliği
İstenen yanıtları veren istemler oluşturma sanatı büyük dil modeli kullanarak. İstem yapan insanlar mühendisliği. İyi yapılandırılmış istemler yazmak, büyük dil modelinden faydalı yanıtlar almaktır. İstem mühendisliği birçok faktörü vardır. Örneğin:
- Önceden eğitmek için kullanılan veri kümesi ve muhtemelen büyük dil modelinde ince ayar yapın.
- Ayarlanan temperature ve diğer kod çözme parametreleri modelimiz var.
Görüntüleyin İstem tasarımına giriş daha fazla bilgi edinebilirsiniz.
İstem tasarımı, istem mühendisliği ile eş anlamlıdır.
istem ayarı
Parametre açısından verimli ayarlama mekanizması "önek" öğrenen eklemesi gereken gerçek istem.
İstem ayarlamanın bir varyasyonu da (bazen önek ayarı olarak da adlandırılır) her katmanın başına öneki ekleyin. Öte yandan, çoğu istem ayarı yalnızca giriş katmanına bir önek ekler.
K
rol isteme
Hedef kitleyi tanımlayan isteğe bağlı bir istem bölümü üretken yapay zeka modelinin yanıtı için Rol olmayan büyük dil modeli, faydalı olabilecek ya da olmayabilecek bir yanıt sağlıyorsa önemli bir adımdır. Rol istemi, büyük bir dil ile daha uygun ve yararlı bir şekilde yanıt verebilir belirli bir hedef kitlede Örneğin, istemleri kalın harflerle gösterilmiştir:
- Ekonomi alanında doktora yapmak için bu makaleyi özetleyin.
- On yaşında bir çocuk için akıntıların nasıl gerçekleştiğini açıklama.
- 2008 ekonomik krizini açıkla. Küçük bir çocukla konuşur gibi konuşun, tercih eder.
S
kendi kendine dikkat (kendi kendine dikkat katmanı olarak da adlandırılır)
Bir diziyi dönüştüren bir nöral ağ katmanı yerleştirmeler (örneğin, jeton yerleştirmeleri) ekleme sırasına koyabilirsiniz. Çıkış sırasına yapılan her bir yerleştirme işlemi giriş dizisi öğelerinden elde edilen bilgilerin entegre edilmesiyle oluşturulur dikkat mekanizması aracılığıyla desteklediğinizi gösterin.
Kendi kendine dikkat çekmenin kendi kısmı, bire bir görüşmelere bir bağlam sunar. Kendine dikkat etmek, Dönüştürücüler için yapı taşları ve sözlük araması kullanır "query", "key" ve "value" gibi terimleri kullanabilirsiniz.
Kişisel dikkat katmanı bir dizi giriş gösterimiyle başlar. tıklayın. Bir kelimenin giriş gösterimi basit olabilir bir öğedir. Bir giriş dizisindeki her kelime için ağ kelimenin tüm dizideki her öğeyle alaka düzeyini kelimeler. Alaka düzeyi puanları, kelimenin nihai temsilinin ne kadar olduğunu belirler başka kelimelerin temsillerini içerir.
Örneğin, şu cümleyi ele alalım:
Hayvan çok yorgun olduğu için karşıdan karşıya geçmedi.
Aşağıdaki çizim ( Transformer: Dil için Yeni Bir Nöral Ağ Mimarisi Anlama) it zamiri için öz dikkat katmanının dikkat modelini gösterir, her satırın koyu renk tonunu gösterir ve her kelimenin temsil eder:
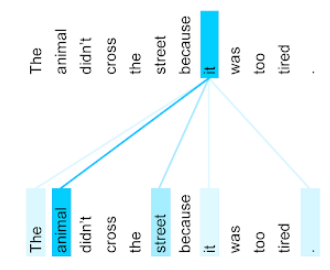
Kendine dikkat katmanı, "kendine dikkat" katmanı ile alakalı kelimeleri vurgular. Burada dikkat katmanının, bir sonraki sayfada kendisine en yüksek ağırlığı hayvana atamak anlamına gelir.
Kendi kendine dikkat, n jeton dizisi için bir diziyi dönüştürür n ayrı kez, dizideki her konumda bir kez.
Ayrıca dikkate ve çok başlı dikkat.
yaklaşım analizi
Bir grubun performansını belirlemek için istatistiksel veya makine öğrenimi karşı olumlu ya da olumsuz genel olarak ya da konuya odaklanıyor. Örneğin, doğal dil anlama, bir algoritmanın metin tabanlı geri bildirim üzerinde yaklaşım analizi gerçekleştirebileceğini öğrencilerin eğitim düzeylerini belirlemek için üniversite dersinden beğenme veya beğenmeme ihtimalini ifade eder.
sıralı görev
Jetonlardan oluşan bir giriş dizisini çıkışa dönüştüren görev jeton dizisi. Örneğin, popüler olan iki yaygın diziden bire görevleri şunlardır:
- Çevirmenler:
- Örnek giriş sırası: "Seni seviyorum."
- Örnek çıkış sırası: "Je t'aime."
- Soru yanıtlama:
- Örnek giriş sırası: "Arabamın New York'ta olması gerekiyor mu?"
- Örnek çıkış sırası: "Hayır. Lütfen arabanızı evde tutun."
skip-gram
Orijinal kelimedeki kelimeleri atlayan (veya "atlanabilen") bir n-gram bağlam, yani N kelime başlangıçta bitişik olmayabilir. Daha fazla daha doğrusu "k-skip-n-gram" en fazla k kelimenin sahip olabileceği bir n-gramdır atlandı.
Örneğin, "süper tilki" aşağıdaki olası 2 gramlık bir değere sahiptir:
- "hızlı"
- "hızlı kahverengi"
- "kahverengi tilki"
"1-at-2-gram" arasında en fazla bir kelime bulunan bir kelime çiftidir. Öyleyse "sıcak kahverengi tilki" aşağıdaki 1 atlama 2 gram'a sahiptir:
- "kahverengi"
- "hızlı tilki"
Ayrıca, tüm 2 gram ağırlığı ayrıca 1-2 gramdır çünkü daha az birden fazla kelime atlanabilir.
Atlama gramları, kelimenin çevresindeki bağlamı daha iyi anlamaya yardımcı olur. Örneğimizdeki "fox" "quick" ile doğrudan ilişkilendirildi 1-2 gramlık olarak atlanabilir, ancak 2 gramlık grupta değil.
Atlama gramları antrenmana yardımcı olur kelime yerleştirme modelleridir.
yumuşak istem ayarı
Büyük dil modelini ayarlamak için kullanılan bir teknik ya da yoğun kaynak ihtiyacı olmadan ince ayarlar. Tüm bu bilgileri yeniden eğitmek yerine Modeldeki ağırlıklar, yumuşak istem ayarı Bir istem aynı hedefe ulaşmak için otomatik olarak ayarlanır.
Metin biçiminde istem, yumuşak istem ayarı genellikle isteme ek jeton yerleştirmeleri ekler ve geri yayılımı vardır.
“Zor” istemi, jeton yerleştirmeler yerine gerçek jetonlar içeriyor.
seyrek özellik
Değerleri ağırlıklı olarak sıfır veya boş olan bir özellik. Örneğin, tek bir 1 değeri ve milyon 0 değeri içeren bir özellik, çok azdır. Buna karşılık yoğun bir özellik, çoğunlukla sıfır veya boş değildir.
Makine öğreniminde şaşırtıcı sayıda özellik çok azdır. Kategorik özellikler genellikle az sayıdadır. Örneğin, bir ormandaki olası 300 ağaç türünden tek bir örnek sadece bir akçaağaç tanımlanabilir. Ya da olası videolar arasında yer alır. Tek bir örnekle, yalnızca "Kazablanka".
Bir modelde genelde seyrek özellikleri, tek kullanımlık kodlama. Tek seferlik kodlama çok büyükse, sayfanın üst kısmına bir yerleştirme katmanı yerleştirebilirsiniz: tek kullanımlık kodlama ile verimliliği artırır.
seyrek temsil
Sıfır olmayan öğelerin yalnızca konumlarını seyrek bir özellikte depolama.
Örneğin, species adlı bir kategorik özelliğin
türleri hakkında bilgi edindiniz. Dahası, her bir
example yalnızca tek bir türü tanımlar.
Her örnekte ağaç türlerini göstermek için tek seferlik bir vektör kullanabilirsiniz.
Tek sıcak bir vektör, tek bir 1 (
ağaç türünü temsil etmesi için) ve 35 0 (
(bu örnekte 35 ağaç türü değildir). Bu yüzden bire bir temsil
maple aşağıdaki gibi görünebilir:

Buna karşılık, seyrek gösterim, görevin
türü olabilir. maple 24. konumdaysa seyrek temsil
maple şöyle bir ifade eder:
24
Seyrek temsilin, tek sıcak görüntüye göre çok daha kompakt olduğuna dikkat edin temsil eder.
Biraz daha karmaşık bir örnek için simgeyi tıklayın.
Modelinizdeki her bir örneğin, kelimeleri temsil etmesi gerektiğini İngilizce bir cümlede, bu kelimelerin sırası. İngilizce yaklaşık 170.000 kelimeden oluşur, dolayısıyla İngilizce kategorik bir dildir yaklaşık 170.000 öğeli bir özellik. Çoğu İngilizce cümlede çok küçük bir bölümü olduğundan bir kelime kümesi tek bir örneğin az veri olacağı kesindir.
Şu cümleyi ele alalım:
My dog is a great dog
Buradaki kelimeleri göstermek için tek sıcak vektörün bir değişkenini kullanabilir cümledir. Bu varyantta, vektörde birden çok hücre bulunabilir değeri sıfır olmayan bir değerdir. Ayrıca bu varyantta, hücreler bir tam sayı içerebilir. görebilirsiniz. "Benim", "is", "bir" ve "harika" kelimeleri olsa da yalnızca görünür cümlede bir kere "köpek" kelimesi iki kez görünür. Şu varyantı kullanılıyor: bu cümledeki kelimeleri temsil eden tek sıcak vektör şu sonucu verir: 170.000 öğeli vektör:

Aynı cümlenin seyrek bir temsili şöyle olacaktır:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
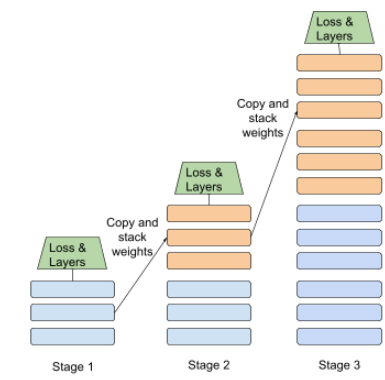
aşamalı eğitim
Bir modeli bir dizi ayrı aşama halinde eğitme taktiği. Hedef, ya eğitim sürecini hızlandırmak ya da daha iyi model kalitesi elde etmek olabilir.
Progresif yığınlama yaklaşımının bir resmi aşağıda gösterilmektedir:
- 1. aşama 3 gizli katman, 2. aşama 6 gizli katman ve 3. aşama 12 gizli katman içeriyor.
- 2. aşama, 3 gizli katmanda öğrenilen ağırlıklarla eğitime başlar aşamadır. 3. Aşama 6. adımda alınan ağırlıklarla eğitime başlar gizli katmanları var mı?
Ardışık düzen konusunu da inceleyin.
alt kelime jetonu
Dil modellerinde kullanılan jeton alt dizesi oluşturabilirsiniz. Bu, kelimenin tamamı olabilir.
Örneğin, "itemize" gibi bir kelime, "öğe" parçalarına ayrılabilir. (kök kelime) ve "ize" gibi (sonek) (her biri kendi kendisiyle temsil edilir) jeton. Yaygın olmayan kelimeleri alt kelime adı verilen bu tür parçalara ayırmak, yaygın olarak kullanılan parçalar üzerinde çalışmak için farklı olabilir.
Bunun aksine, "gitmek" gibi yaygın kelimeler bölünmemiş olabilir tek bir jetonla temsil edilir.
S
T5
Metinden metne öğrenmeyi aktarma modeli sunan 2020'de Google Yapay Zeka. T5, temel alınmıştır. Son derece büyük bir ölçekte eğitilmiş Transformer mimarisi veri kümesiyle eşleştirilir. Pek çok doğal dil işleme görevinde etkilidir. metin oluşturma, yabancı dilleri çevirme ve soruları cevaplama gibi çeşitli kaynaklar konuşmaya başlayabilirsiniz.
T5, adını "Metin-Metin Aktarım Dönüştürücüsü"ndeki beş T'den alır.
T5X
Google'ın geliştirdiği açık kaynaklı makine öğrenimi çerçevesi büyük ölçekli doğal dil işleme geliştirip eğitmek (NLP) modellerinin yanı sıra T5, T5X kod tabanında (yani JAX ve Flax tabanlı olarak oluşturulur).
sıcaklık
Rastgelelik derecesini kontrol eden bir hiperparametre bir model çıktısı. Daha yüksek sıcaklıklar daha rastgele çıkış sağlar. daha düşük sıcaklıklar ise daha az rastgele çıkışla sonuçlanır.
En iyi sıcaklığı seçmek ilgili uygulamaya ve model çıkışının tercih edilen özelliklerini belirler. Örneğin, yüksek sıcaklıklar elde etmek istediğiniz reklam öğesi çıktısı üretir. Buna karşılık, sıcaklığı muhtemelen düşürecek kullanarak görselleri veya metinleri sınıflandıran bir model oluştururken ve tutarlı olmasını sağlar.
Sıcaklık genellikle softmax ile kullanılır.
metin aralığı
Bir metin dizesinin belirli bir alt bölümüyle ilişkilendirilmiş dizi dizini aralığı.
Örneğin, Python dizesindeki s="Be good now" dizesinde good kelimesi
metin, 3'ten 6'ya kadar değişir.
token
Dil modelinde, modelin kullandığı atom birimi ve tahminlerde bulunmayı da kapsıyor. Jeton genellikle takip etmek için:
- bir kelime (örneğin, "kedi gibi köpekler" ifadesi) üç kelimeden oluşur jetonlar: "köpekler", "beğeni" ve "kediler".
- bir karakter (örneğin, "bisiklet balık" ifadesi) dokuzdan oluşur kullanılabilir. (Boş alanın, jetonlardan biri olarak sayıldığını unutmayın.)
- alt kelimeler (bu kelimelerde tek bir kelime, tek bir simge veya birden çok simge olabilir). Alt kelime bir kök kelime, bir ön ek veya bir son ekten oluşur. Örneğin, alt kelimeleri jeton olarak kullanan bir dil modeli, "köpekler" kelimesini görüntüleyebilir ("köpek" kök kelimesi ve çoğul soneki "s") şeklinde iki simge şeklinde biçimlendirilmiştir. Aynı dil modeli, "uzun" tek kelimesini görebilir ( kök kelime "uzun" ve "er" sonekini kullanın.
Dil modelleri dışındaki alanlarda jetonlar, farklı türlerdeki atom birimlerini kullanabilirsiniz. Örneğin bilgisayar vizyonunda bir jeton, bir resim.
Transformatör
Google'da geliştirilen nöral ağ mimarisi, kendi kendine dikkat mekanizmalarını kullanarak bir çıktı dizisine yerleştirilen girişler dizisi evrimlere bağlı olmadan veya yinelenen nöral ağlar. Transformatör, dikkat katmanlarından oluşan bir yığın olarak görünür.
Bir Dönüştürücü, aşağıdakilerden herhangi birini içerebilir:
- bir kodlayıcı
- kod çözücü
- hem kodlayıcı hem de kod çözücü
Kodlayıcı, bir yerleştirme dizisini yeni bir yerleştirme dizisine dönüştürür. aynı uzunlukta. Kodlayıcıda her biri iki tane olmak üzere özdeş N katman bulunur olduğunu unutmayın. Bu iki alt katman, girişin her bir konumuna uygulanır. dizinin her bir öğesini yeni bir öğe olacak şekilde değiştirerek bir öğedir. İlk kodlayıcı alt katmanı, giriş sırası. İkinci kodlayıcı alt katmanı, toplanan verileri bir çıkış yerleştirmeye dönüştürüyor.
Kod çözücü, giriş yerleştirme dizisini bir diziye dönüştürür. çıkışlar eklemeniz gerekir. Kod çözücü ayrıca İkisi birbirine benzer olan üç alt katmana sahip özdeş N katman kodlayıcı alt katmanlarını oluşturur. Üçüncü kod çözücü alt katmanı, ve kendi kendine dikkat mekanizmasını bilgi toplamaya çalışıyor.
Transformer: A Novel Nural Network Architecture for Language (Dönüştürücü: Dil için Yeni Bir Nöral Ağ Mimarisi) Anlama Transformers hakkında iyi bir giriş sağlar.
trigram
N=3 olan bir N-gram.
U
tek yönlü
Yalnızca metnin hedef bölümünden önce gelen metni değerlendiren bir sistem. Buna karşılık çift yönlü bir sistem hem Metnin bir hedef bölümünden öncesi ve sonraki metin. Daha fazla ayrıntı için çift yönlü konusuna bakın.
tek yönlü dil modeli
Olasılıklarını yalnızca şuna dayandıran bir dil modeli: jetonların hedef jetonlardan önce, sonra görünmesidir. İki yönlü dil modeli ile kontrast oluşturun.
V
varyasyon otomatik kodlayıcı (VAE)
Tutarsızlıktan yararlanan bir otomatik kodlayıcı türü oluşturmak için giriş ve çıkışlar arasında geçiş yapın. Varyasyonsal otomatik kodlayıcılar, üretken yapay zeka için kullanışlıdır.
VAE'ler varyasyon çıkarımına dayanır: dönüşüm oranını tahmin etmek için parametreleridir.
W
kelime yerleştirme
Bir kelime grubu içindeki her kelimeyi temsil eden yerleştirme vektörü; her kelimeyi 0,0 ile 1,0 arasında kayan nokta değerlerinin vektörü. Benzer görselleri olan kelimeler anlamları, farklı anlamlara gelen kelimelere göre daha fazla benzer temsile sahiptir. Örneğin, havuç, kereviz ve salatalık nispeten daha yüksek olacaktır. Bunlar, tüm mevcut modellerden çok farklı uçak, güneş gözlüğü ve diş macunu.
Z
sıfır atış isteme
Nasıl istediğinize dair örnek sunmayan bir istem büyük dil modeline göre yanıt verin. Örneğin:
| Tek bir istemin bölümleri | Notlar |
|---|---|
| Belirtilen ülkenin resmi para birimi nedir? | LLM'nin yanıtlamasını istediğiniz soru. |
| Hindistan: | Asıl sorgu. |
Büyük dil modeli, aşağıdakilerden herhangi biriyle yanıt verebilir:
- Rupi
- INR
- ₹
- Hint rupisi
- Rupi
- Hint rupisi
Tüm yanıtlar doğru olsa da tercih ettiğiniz bir format olabilir.
Sıfır çekim istemini aşağıdaki terimlerle karşılaştırın: