تحتوي هذه الصفحة على مصطلحات مسرد تقييم اللغة. للاطّلاع على جميع مصطلحات المسرد، انقر على هذا الرابط.
A
تنبيه
آلية تُستخدَم في الشبكة العصبية تشير إلى أهمية كلمة معيّنة أو جزء من كلمة. تعمل ميزة "التركيز" على ضغط مقدار المعلومات التي يحتاجها النموذج لتوقّع الرمز/الكلمة التاليَين. قد يتألّف آلية الانتباه النموذجية من مجموع مرجح لمجموعة من المدخلات، حيث يتم احتساب المرجح لكل مدخل من خلال جزء آخر من الشبكة العصبية.
يمكنك أيضًا الرجوع إلى التركيز الذاتي و التركيز الذاتي المتعدّد الرؤوس، وهما تشكلان الوحدات الأساسية لشبكات Transformer.
اطّلِع على النماذج اللغوية الكبيرة: ما هو المقصود بالعبارة "نموذج لغوي كبير"؟ في الدورة التدريبية المكثّفة لتعلُّم الآلة لمعرفة المزيد من المعلومات عن الانتباه الذاتي.
برنامج الترميز التلقائي
نظام يتعلّم استخراج أهم المعلومات من المدخلات أدوات الترميز التلقائي هي عبارة عن مزيج من أداة ترميز و أداة فك ترميز. تعتمد برامج الترميز التلقائي على العملية المكونة من خطوتَين التاليتَين:
- يُحدِّد برنامج الترميز الإدخال إلى تنسيق (متوسط) (عادةً) ببعد أقلّ (يتضمّن فقدانًا).
- ينشئ برنامج الترميز العكسي نسخة ذات فقدان للبيانات من الإدخال الأصلي من خلال ربط التنسيق ذي الأبعاد الأقل بتنسيق الإدخال الأصلي ذي الأبعاد الأعلى.
يتم تدريب برامج الترميز التلقائية من البداية إلى النهاية من خلال محاولة وحدة فك التشفير إعادة إنشاء الإدخال الأصلي من التنسيق الوسيط لوحدة الترميز بأكبر قدر ممكن من الدقة. وبما أنّ التنسيق الوسيط أصغر (أبعاده أقل) من التنسيق الأصلي، يتم إجبار الترميز التلقائي على معرفة المعلومات الأساسية في الإدخال، ولن يكون الإخراج متطابقًا تمامًا مع الإدخال.
على سبيل المثال:
- إذا كانت بيانات الإدخال عبارة عن رسم، ستكون النسخة غير الدقيقة مشابهة للرسم الأصلي، ولكن تم تعديلها إلى حد ما. من المحتمل أنّ النسخة غير الدقيقة تزيل التشويش من الرسم الأصلي أو تملأ بعض البكسلات المفقودة.
- إذا كانت بيانات الإدخال نصًا، سينشئ الترميز التلقائي نصًا جديدًا يشبه النص الأصلي (ولكن ليس مطابقًا له).
راجِع أيضًا الترميز الذاتي المتغيّر.
التقييم التلقائي
استخدام برامج لتقييم جودة نتائج النموذج
عندما تكون نتائج النموذج واضحة نسبيًا، يمكن لنص برمجي أو برنامج مقارنة نتائج النموذج باستجابة مثالية. يُطلَق على هذا النوع من التقييم التلقائي أحيانًا اسم التقييم الآلي. غالبًا ما تكون المقاييس، مثل ROUGE أو BLEU، مفيدة للتقييم الآلي.
عندما تكون نتيجة النموذج معقّدة أو لا تتضمّن إجابة صحيحة واحدة، يُجري برنامج تعلُّم آلي منفصل يُعرف باسم المقيّم التلقائي أحيانًا التقييم التلقائي.
يختلف ذلك عن التقييم البشري.
تقييم التقييم التلقائي
آلية مختلطة لتقييم جودة ناتج نموذج الذكاء الاصطناعي التوليدي، والتي تجمع بين التقييم البشري والتقييم الآلي أداة التقييم الآلي هي نموذج تعلُّم آلة تم تدريبه على بيانات تم إنشاؤها من خلال التقييم البشري. من الناحية المثالية، يتعلم نظام التقييم الآلي محاكاة أسلوب المقيّم البشري.تتوفّر أدوات كتابة محتوى آلية مُعدّة مسبقًا، ولكن يتم تعديل أفضل أدوات الكتابة الآلية خصيصًا للمهمة التي تقيّمها.
النموذج التدرّجي التلقائي
نموذج يستنتج توقّعًا استنادًا إلى توقّعاته السابقة على سبيل المثال، تتوقّع نماذج اللغة التسلسلية التلقائية العنصر التالي استنادًا إلى العناصر التي تم توقّعها سابقًا. جميع النماذج اللغوية الكبيرة المستندة إلى نموذج Transformer هي نماذج ذاتية الرجوع.
في المقابل، لا تكون نماذج الصور المستندة إلى GAN عادةً متراجِعة تلقائيًا، لأنّها تُنشئ صورة في خطوة واحدة للأمام وليس بشكلٍ متكرّر في الخطوات. ومع ذلك، تكون بعض نماذج إنشاء الصور ذاتية الرجوع لأنّها تُنشئ صورة على مراحل.
متوسّط الدقة عند k
مقياس لتلخيص أداء نموذج على طلب واحد يؤدي إلى توليد نتائج مصنّفة، مثل قائمة مرقّمة باقتراحات الكتب متوسّط الدقة عند k هو متوسّط قيم الدقة عند k لكل نتيجة ذات صلة. وبالتالي، تكون صيغة متوسط الدقة عند k هي:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
حيث:
- \(n\) هو عدد العناصر ذات الصلة في القائمة.
يُرجى الاطّلاع على الاسترجاع عند k.
B
مجموعة الكلمات
تمثيل للكلمات في عبارة أو فقرة، بغض النظر عن الترتيب على سبيل المثال، تمثّل مجموعة الكلمات العبارات الثلاث التالية بشكلٍ متطابق:
- الكلب يقفز
- كلب يقفز
- كلب يقفز
يتم ربط كل كلمة بفهرس في متّجه متناثر، حيث يحتوي المتّجه على فهرس لكل كلمة في القاموس. على سبيل المثال، تتم ترجمة العبارة يقف الكلب إلى متجه ميزات يحتوي على قيم غير صفرية في الفواصل الثلاثة التي تقابل الكلمات يقف والكلب ويقف. يمكن أن تكون القيمة غير الصفرية أيًّا ممّا يلي:
- 1 للإشارة إلى وجود كلمة
- عدد مرّات ظهور كلمة معيّنة في الحقيبة على سبيل المثال، إذا كانت العبارة هي الكلب البني هو كلب ذو فراء بني، سيتم تمثيل كل من بني وكلب بالعدد 2، بينما سيتم تمثيل الكلمات الأخرى بالعدد 1.
- أي قيمة أخرى، مثل اللوغاريتم لعدد المرات التي تظهر فيها كلمة في الحقيبة
BERT (تمثيلات الترميز الثنائية الاتجاه من المحولات)
بنية نموذج لتمثيل النصوص يمكن أن يعمل نموذج BERT مدرَّب كجزء من نموذج أكبر لتصنيف النصوص أو مهام تعلُّم الآلة الأخرى.
تتسم BERT بالسمات التالية:
- يستخدم بنية Transformer، وبالتالي يعتمد على التركيز الذاتي.
- يستخدم جزء المشفِّر من أداة Transformer. وظيفة الترميز هي توليد تمثيلات نصية جيدة، بدلاً من تنفيذ مهمة معيّنة مثل التصنيف.
- أن تكون ثنائية الاتجاه
- يستخدم التمويه ل التدريب غير الخاضع للإشراف.
تشمل الصيغ المختلفة لنموذج BERT ما يلي:
اطّلِع على الإصدار المفتوح المصدر من BERT: أحدث تقنيات التدريب المُسبَق لمعالجة اللغة الطبيعية للحصول على نظرة عامة على BERT.
ثنائي الاتجاه
مصطلح يُستخدَم لوصف نظام يُقيّم النص الذي يسبق ويتّبع قسمًا مستهدفًا من النص. في المقابل، يقيّم نظام الاتجاه الواحد فقط النص الذي يسبق قسمًا مستهدفًا من النص.
على سبيل المثال، لنفترض أنّ لدينا نموذجًا لغويًا مُموَّهًا عليه تحديد احتمالات الكلمة أو الكلمات التي تمّ وضع خط تحتها في السؤال التالي:
ما هو _____ معك؟
يجب أن يستند نموذج اللغة أحادي الاتجاه إلى الاحتمالات فقط على السياق الذي تقدّمه الكلمات "What" و"is" و "the". في المقابل، يمكن أن يحصل نموذج اللغة الثنائي الاتجاه أيضًا على سياق من "مع" و "أنت"، ما قد يساعد النموذج في إنشاء توقّعات أفضل.
نموذج لغوي ثنائي الاتجاه
نموذج لغوي يحدّد احتمالية ظهور علامة معيّنة في موضع معيّن في مقتطف من النص استنادًا إلى النص السابق والتالي
الثنائيات
نَمط تحليلي حيث يكون N=2
BLEU (Bilingual Evaluation Understudy)
مقياس يتراوح بين 0.0 و1.0 لتقييم الترجمات الآلية، على سبيل المثال، من الإسبانية إلى اليابانية
لاحتساب النتيجة، يقارن مقياس BLEU عادةً ترجمة نموذج تعلُّم الآلة (النص الذي تم إنشاؤه) بترجمة خبير بشري (النص المرجعي). تُحدِّد درجة تطابق النصوص التي تتألّف من عدد معيّن من الكلمات في النص الذي تم إنشاؤه والنص المرجعي نتيجة BLEU.
المقالة الأصلية حول هذا المقياس هي BLEU: a Method for Automatic Evaluation of Machine Translation.
يمكنك أيضًا الاطّلاع على BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
مقياس لتقييم الترجمات الآلية من لغة إلى أخرى، خاصةً من الإنجليزية وإليها
بالنسبة إلى الترجمات من الإنجليزية وإليها، يتوافق مقياس BLEURT بشكلٍ أقرب مع تقييمات المستخدمين مقارنةً بمقياس BLEU. على عكس BLEU، يُركّز مقياس BLEURT على التشابهات الدلالية (المعنى) ويمكنه استيعاب إعادة الصياغة.
يعتمد BLEURT على نموذج لغوي كبير تم تدريبه مسبقًا (BERT على وجه التحديد) ويتم بعد ذلك تحسينه استنادًا إلى نصوص من مترجمين بشريين.
المقالة الأصلية حول هذا المقياس هي BLEURT: Learning Robust Metrics for Text Generation.
C
النموذج اللغوي السببي
مرادف لـ نموذج لغوي أحادي الاتجاه.
اطّلِع على نموذج اللغة الثنائي الاتجاه لمقارنة النهجَين الاتجاهيَين المختلفَين في وضع نماذج اللغة.
توجيه سلسلة الأفكار
تقنية هندسة الطلبات التي تشجع النموذج اللغوي الكبير (LLM) على شرح الاستدلال الذي يستند إليه، خطوة بخطوة. على سبيل المثال، فكِّر في الطلب التالي، مع التركيز بشكل خاص على الجملة الثانية:
كم عدد قوى g التي سيواجهها السائق في سيارة تنطلق من 0 إلى 60 ميل في الساعة في 7 ثوانٍ؟ في الإجابة، يجب عرض جميع العمليات الحسابية ذات الصلة.
من المرجّح أن يكون ردّ النموذج اللغوي الكبير على النحو التالي:
- أظهِر تسلسلًا من صِيَغ الفيزياء، مع إدخال القيم 0 و60 و7 في الأماكن المناسبة.
- اشرح سبب اختيار هذه الصِيَغ وما تعنيه المتغيّرات المختلفة.
تجبر طلبات سلسلة التفكير نموذج اللغة المحوسبة الكبير على إجراء جميع العمليات الحسابية، ما قد يؤدي إلى تقديم إجابة أكثر صحة. بالإضافة إلى ذلك، تتيح طلبات تسلسل التفكير للمستخدم فحص خطوات الذكاء الاصطناعي اللغوي (LLM) لتحديد ما إذا كانت الإجابة منطقية أم لا.
محادثة
محتوى حوار متبادل مع نظام تعلُّم الآلة، عادةً هو نموذج لغوي كبير يصبح التفاعل السابق في محادثة (ما كتبته وطريقة استجابة النموذج اللغوي الكبير) هو السياق للأجزاء اللاحقة من المحادثة.
روبوت الدردشة هو تطبيق لنموذج لغوي كبير.
التزييف
مرادف لـ الهلوسة.
من المحتمل أنّ التزييف هو مصطلح أكثر دقة من الناحية الفنية من الهلوسة. ومع ذلك، أصبح الهلوسة شائعًا أولاً.
تحليل الدوائر الانتخابية
تقسيم الجملة إلى بنى نحوية أصغر ("عناصر") يمكن أن يعالج جزء لاحق من نظام تعلُّم الآلة، مثل نموذج فهم اللغة الطبيعية، العناصر بسهولة أكبر من الجملة الأصلية. على سبيل المثال، نأخذ الجملة التالية:
تبنّى صديقي قطتين.
يمكن لمحلل الوحدات التحليلية تقسيم هذه الجملة إلى المكوّنين التاليين:
- صديقي عبارة اسمية.
- تبنّى قطتَين عبارة فعل.
ويمكن تقسيم هذه المكوّنات إلى مكوّنات أصغر. على سبيل المثال، عبارة الفعل
تبني قطتين
يمكن تقسيمها إلى ما يلي:
- تمّت الموافقة هو فعل.
- هِرَّانِ هي عبارة اسمية أخرى.
تضمين اللغة في سياقها
إدراج يقترب من "فهم" الكلمات والعبارات بطرق يمكن للمستخدمين البشر الطلاقة استخدامها يمكن أن تفهم عمليات تضمين اللغة في السياق البنية النحوية والدلالية والسياق المعقدة.
على سبيل المثال، نأخذ في الاعتبار عمليات التضمين للكلمة الإنجليزية cow. يمكن أن تمثّل عمليات التضمين القديمة مثل word2vec الكلمات الإنجليزية بحيث تكون المسافة في مساحة التضمين من بقرة إلى ثور مشابهة للمسافة من نعجة (أنثى الأغنام) إلى كبش (ذكر الأغنام) أو من أنثى إلى ذكر. يمكن أن تأخذ عمليات تضمين اللغة في السياق خطوة إضافية من خلال التعرّف على أنّ المتحدثين باللغة الإنجليزية يستخدمون أحيانًا كلمة cow بشكل عفوي للإشارة إلى البقرة أو الثور.
قدرة الاستيعاب
عدد الرموز التي يمكن للنموذج معالجتها في طلب معيّن كلما زادت قدرة الاستيعاب، زادت المعلومات التي يمكن للنموذج استخدامها لتقديم ردود متسقة ومترابطة على الطلب.
رمز عطل
جملة أو عبارة ذات معنى غامض تُمثّل عبارات "الانهيار" مشكلة كبيرة في فهم اللغة الطبيعية. على سبيل المثال، العنوان الروتين البيروقراطي يؤخّر تشييد ناطحة سحاب هو عبارة غير مناسبة لأنّ نموذج الذكاء الاصطناعي اللغوي يمكن أن يفسّر العنوان بشكلٍ دقيق أو مجازي.
D
أداة فك الترميز
بشكل عام، أي نظام تعلُّم آلي يحوّل من تمثيل داخلي تمت معالجته أو كثيف أو مكثّف إلى تمثيل أكثر كثافة أو تمثيل خارجي
غالبًا ما تكون برامج الترميز جزءًا من نموذج أكبر، حيث يتم غالبًا إقرانها ببرنامج ترميز.
في مهام تسلسل إلى تسلسل، يبدأ المُشفِّر بالحالة الداخلية التي ينشئها المُشفِّر لتوقُّع التسلسل التالي.
راجِع Transformer للاطّلاع على تعريف وحدة فك الترميز ضمن بنية Transformer.
اطّلِع على النماذج اللغوية الكبيرة في دورة التعلّم الآلي المكثّفة للحصول على مزيد من المعلومات.
إزالة الضوضاء
منهج شائع للتعلُّم الذاتي المُوجَّه:
تتيح إزالة الضوضاء التعلّم من الأمثلة غير المصنّفة. تُستخدَم مجموعة البيانات الأصلية كمستهدَف أو تصنيف و البيانات المشوشة كمدخل.
تستخدِم بعض النماذج اللغوية المقنَّعة ميزة تقليل الضوضاء على النحو التالي:
- تتم إضافة تشويش بشكل مصطنع إلى جملة غير مصنّفة من خلال حجب بعض الرموز.
- يحاول النموذج توقّع الرموز الأصلية.
طلب مباشر
مرادف لـ الطلب بلا مثال.
E
مسافة التعديل
مقياس لدرجة تشابه سلسلتَي نص معًا في تعلُّم الآلة، يكون "مسافة التعديل" مفيدًا للأسباب التالية:
- من السهل احتساب مسافة التعديل.
- يمكن أن تقارن دالة Edit distance بين سلسلةَين معروف أنّهما متشابهتان.
- يمكن أن يحدِّد "مسافة التعديل" درجة تشابه سلاسل مختلفة مع سلسلة معيّنة.
هناك عدة تعريفات لمسافة التعديل، وكلّ منها يستخدم عمليات مختلفة على السلسلة. اطّلِع على مسافة Levenshtein للحصول على مثال.
طبقة التضمين
طبقة مخفية خاصة يتم تدريبها على سمة فئوية عالية الأبعاد بهدف تعلم مصفوفة إدراج ذات أبعاد أقل تدريجيًا تسمح طبقة التضمين للشبكة العصبية بالتدريب بفعالية أكبر بكثير مقارنةً بالتدريب على الميزة الفئوية العالية الأبعاد فقط.
على سبيل المثال، تتضمّن خدمة Earth حاليًا حوالي 73,000 نوع من الأشجار. لنفترض أنّ
أنواع الأشجار هي سمة في النموذج، لذا تتضمّن
طبقة الإدخال في النموذج متجهًا أحادي القيمة يبلغ طوله 73,000
عنصر.
على سبيل المثال، قد يتم تمثيل baobab على النحو التالي:

إنّ مصفوفة تتضمّن 73,000 عنصر طويلة جدًا. في حال عدم إضافة طبقة تضمين إلى النموذج، ستستغرق عملية التدريب وقتًا طويلاً جدًا بسبب مضاعفة 72,999 صفرًا. ربما اخترت أن تتألّف طبقة التضمين من 12 سمة. نتيجةً لذلك، ستتعرّف طبقة التضمين تدريجيًا على متجه تضمين جديد لكل نوع من أنواع الأشجار.
في بعض الحالات، يشكّل التجزئة بديلاً معقولاً لطبقة التضمين.
اطّلِع على عمليات التضمين في الدورة المكثّفة عن تعلُّم الآلة للحصول على مزيد من المعلومات.
مساحة التضمين
فضاء المتجهات ذي الأبعاد d الذي يتمّ ربط ميزات من فضاء متجهات ذو أبعاد أعلى به يتم تدريب مساحة التضمين لالتقاط البنية التي تكون ذات مغزى للتطبيق المقصود.
إنّ ناتج الضرب النقطي لإدراجَين هو مقياس لتشابههما.
متّجه التضمين
بشكل عام، هي مصفوفة من الأعداد الكسورية التي يتم أخذها من أي طبقة مخفية تصف المدخلات إلى تلك الطبقة المخفية. غالبًا ما يكون متجه التضمين هو صفيف الأرقام الكسور العشرية التي تم تدريبها في طبقة التضمين. على سبيل المثال، لنفترض أنّه يجب أن تتعرّف طبقة التضمين على ملف شخصي للتضمين لكل نوع من الأنواع الـ 73,000 من الأشجار على الأرض. ربما تكون الصفيفة التالية هي متجه التضمين لشجرة الباوباب:

إنّ متجه التضمين ليس مجموعة من الأرقام العشوائية. تحدِّد طبقة التضمين هذه القيم من خلال التدريب، على غرار الطريقة التي تتعلّم بها الشبكة العصبية الأوزان الأخرى أثناء التدريب. كل عنصر من عنصرَي السلسلة هو تقييم لبعض خصائص نوع شجرة معيّن. أيّ عنصر يمثّل سمة نوع الأشجار؟ من الصعب جدًا تحديد ذلك للمستخدمين.
إنّ الجزء المميّز رياضيًا من متجه التضمين هو أنّ العناصر المشابهة تحتوي على مجموعات متشابهة من الأعداد الكسورية. على سبيل المثال، تحتوي أنواع الأشجار المتشابهة على مجموعة أكثر تشابهًا من الأعداد الكسورية مقارنةً بأنواع الأشجار غير المتشابهة. تُعدّ أشجار السرو الأحمر وأشجار السكويا من أنواع الأشجار ذات الصلة، لذلك سيكون لها مجموعة أكثر تشابهًا من الأرقام ذات النقطة العائمة مقارنةً بمجموعة أشجار السرو الأحمر وأشجار النخيل. ستتغيّر الأرقام في مصفوفة التضمين في كل مرة تُعيد فيها تدريب النموذج، حتى إذا أعدت تدريبه باستخدام إدخال مطابق.
برنامج تشفير
بشكل عام، أي نظام تعلُّم آلي يحوّل من تمثيل كثيف أو خارجي أو تمثيل أولي إلى تمثيل أكثر كثافة أو تمثيل داخلي
غالبًا ما تكون برامج الترميز جزءًا من نموذج أكبر، حيث يتم غالبًا إقرانها ببرنامج فك ترميز. تُقرِن بعض أدوات التحويل برامج الترميز ببرامج فك التشفير، على الرغم من أنّ أدوات التحويل الأخرى تستخدِم برنامج الترميز أو برنامج فك التشفير فقط.
تستخدم بعض الأنظمة مخرج الترميز كمدخل لشبكة تصنيف أو انحدار.
في مهام تسلسل إلى تسلسل، يأخذ الترميز تسلسل إدخال ويعرض حالة داخلية (متجه). بعد ذلك، يستخدم المشفِّر هذه الحالة الداخلية للتنبؤ بالتسلسل التالي.
راجِع Transformer للاطّلاع على تعريف برنامج الترميز في بنية Transformer.
يمكنك الاطّلاع على النماذج اللغوية الكبيرة: ما هو المقصود بالعبارة "نماذج لغوية كبيرة"؟ في الدورة التدريبية المكثّفة عن تعلُّم الآلة للحصول على مزيد من المعلومات.
التقييمات
يُستخدَم بشكل أساسي كاختصار لتقييمات نموذج اللغة الضخمة. وعلى نطاق أوسع، التقييمات هي اختصار لأي شكل من أشكال التقييم.
التقييم
يشير ذلك المصطلح إلى عملية قياس جودة نموذج أو مقارنة نماذج مختلفة مع بعضها.
لتقييم نموذج تعلُّم آلي مُوجَّه ، يتم عادةً تقييمه مقارنةً بمجموعة التحقّق ومجموعة الاختبار. تقييم نموذج تعلم الآلة يتضمن عادةً تقييمات أوسع نطاقًا للجودة والسلامة.
F
الطلب بأمثلة قليلة
طلب يحتوي على أكثر من مثال واحد (أي "بضعة" أمثلة) يوضّح كيفية الردّ من خلال النموذج اللغوي الكبير على سبيل المثال، يحتوي الطلب الطويل التالي على مثالين يوضّحان لنموذج لغوي كبير كيفية الإجابة عن طلب بحث.
| أجزاء طلب واحد | ملاحظات |
|---|---|
| ما هي العملة الرسمية للبلد المحدّد؟ | السؤال الذي تريد أن يجيب عنه "نموذج اللغة المحوسبة" |
| فرنسا: يورو | مثال واحد |
| المملكة المتحدة: الجنيه الإسترليني | مثال آخر |
| الهند: | طلب البحث الفعلي |
يحقّق الطلب بأمثلة قليلة نتائج مرغوب فيها بشكل عام أكثر من الطلب بلا مثال و الطلب بمثال واحد. ومع ذلك، يتطلّب الطلب بأمثلة قليلة طلبًا أطول.
الطلب بأمثلة قليلة هو شكل من أشكال التعلّم ببضع فُرَص المطبَّق على التعلّم المستنِد إلى طلبات.
اطّلِع على هندسة الطلبات في دورة التعلّم المكثّفة عن تعلُّم الآلة للحصول على مزيد من المعلومات.
كمنجة
مكتبة إعدادات مخصّصة لاستخدام لغة Python أولاً، وهي تضبط قيم الدوال والفئات بدون استخدام رمز برمجي أو بنية تحتية غزيرة. في ما يتعلّق بـ Pax وقواعد بيانات تعلُّم الآلة الأخرى، تمثّل هذه الدوال والklassen النماذج والمَعلمات الفائقة للتدريب.
يفترض Fiddle أنّ قواعد بيانات تعلُّم الآلة تنقسم عادةً إلى:
- رمز المكتبة الذي يحدّد الطبقات والمحسّنات
- رمز "الربط" لمجموعة البيانات، الذي يستدعي المكتبات ويربط كل شيء معًا
يسجِّل Fiddle بنية استدعاء رمز التجميع في شكل غير مُقيَّم ومتغيّر.
التحسين
جولة تدريب ثانية خاصة بالمهمة يتم إجراؤها على نموذج تم تدريبه مسبقًا لتحسين مَعلماته في حالة استخدام معيّنة. على سبيل المثال، تتمثل تسلسل التدريب الكامل لبعض النماذج اللغوية الكبيرة على النحو التالي:
- التدريب المُسبَق: يمكنك تدريب نموذج لغوي كبير على مجموعة بيانات عامة واسعة النطاق، مثل جميع صفحات Wikipedia باللغة الإنجليزية.
- التحسين: يمكنك تدريب النموذج المدَّرب مسبقًا لتنفيذ مهمة معيّنة، مثل الردّ على طلبات البحث الطبية. تشمل عملية التحسين عادةً مئات أو آلاف الأمثلة التي تركّز على مهمة معيّنة.
في ما يلي مثال آخر على تسلسل التدريب الكامل لنموذج صور كبير:
- التدريب المُسبَق: يمكنك تدريب نموذج صور كبير على مجموعة بيانات عامة واسعة، مثل جميع الصور في Wikimedia commons.
- التحسين الدقيق: يمكنك تدريب النموذج المدَّرب مسبقًا لتنفيذ مهمة محدّدة، مثل إنشاء صور لحيوانات الأوركا.
يمكن أن تتضمّن عملية التحسين الدقيق أيّ مجموعة من الاستراتيجيات التالية:
- تعديل جميع مَعلمات النموذج المدَّرب مسبقًا يُعرف ذلك أحيانًا باسم التحسين الكامل.
- تعديل بعض المَعلمات الحالية للنموذج المدّرب مسبقًا فقط (عادةً الطبقات الأقرب إلى طبقة الإخراج)، مع إبقاء المَعلمات الحالية الأخرى بدون تغيير (عادةً الطبقات الأقرب إلى طبقة الإدخال) راجِع مقالة الضبط الفعال للمَعلمات.
- إضافة المزيد من الطبقات، عادةً فوق الطبقات الحالية الأقرب إلى طبقة الإخراج
التحسين الدقيق هو شكل من أشكال التعلم بالاستناد إلى نماذج سابقة. وبناءً على ذلك، قد تستخدِم عملية التحسين الدقيق وظيفة خسارة مختلفة أو نوعًا مختلفًا من النماذج مقارنةً بتلك المستخدَمة لتدريب النموذج المدّرب مسبقًا. على سبيل المثال، يمكنك تحسين نموذج صور كبير مدرَّب مسبقًا لإنشاء نموذج انحدار يُظهر عدد الطيور في صورة الإدخال.
قارِن بين التحسين الدقيق والمصطلحات التالية:
يمكنك الاطّلاع على التحسين في دورة التعلّم المكثّفة عن تعلُّم الآلة للحصول على مزيد من المعلومات.
الكتان
مكتبة مفتوحة المصدر عالية الأداء لمعالجة التعلم العميق مبنية على JAX يوفّر Flax دوالًا لتدريب الشبكات العصبية، بالإضافة إلى methods لتقييم أدائها.
Flaxformer
مكتبة Transformer مفتوحة المصدر، تم إنشاؤها استنادًا إلى Flax، وهي مصمّمة أساسًا لمعالجة اللغة الطبيعية والبحث المتعدّد الوسائط.
G
Gemini
المنظومة المتكاملة التي تتضمّن تكنولوجيات الذكاء الاصطناعي الأكثر تقدّمًا من Google تشمل عناصر هذا النظام البيئي ما يلي:
- نماذج Gemini المختلفة
- واجهة المحادثة التفاعلية لنموذج Gemini يكتب المستخدمون طلبات ويردّ Gemini عليها.
- واجهات برمجة تطبيقات Gemini المختلفة
- منتجات مختلفة للأنشطة التجارية تستند إلى نماذج Gemini، مثل Gemini في Google Cloud
نماذج Gemini
أحدث نماذج متعددة الوسائط المستندة إلى تكنولوجيا تحويل البيانات من Google تم تحديد نماذج Gemini خصيصًا للدمج مع موظّفي الدعم.
يمكن للمستخدمين التفاعل مع نماذج Gemini بطرق متنوعة، بما في ذلك من خلال واجهة حوار تفاعلية ومن خلال حِزم تطوير البرامج (SDK).
النص الذي يتم إنشاؤه
بشكل عام، النص الذي يُخرجه نموذج الذكاء الاصطناعي عند تقييم نماذج لغوية كبيرة، تقارن بعض المقاييس النص الذي تم إنشاؤه مقارنةً بأحد النصوص المرجعية. على سبيل المثال، لنفترض أنّك تحاول معرفة مدى فعالية نموذج تعلُّم الآلة في الترجمة من الفرنسية إلى الهولندية. في هذه الحالة:
- النص الذي تم إنشاؤه هو الترجمة الهولندية التي يعرضها نموذج الذكاء الاصطناعي.
- النص المرجعي هو الترجمة الهولندية التي ينشئها مترجم بشري (أو برنامج).
يُرجى العِلم أنّ بعض استراتيجيات التقييم لا تتضمّن نصًا مرجعيًا.
الذكاء الاصطناعي التوليدي
مجال تحويلي ناشئ بدون تعريف رسمي ومع ذلك، يتفق معظم الخبراء على أنّ نماذج الذكاء الاصطناعي التوليدي يمكنها إنشاء ("توليد") محتوى يتضمن كل ما يلي:
- معقّد
- متّسقة
- الصورة الأصلية
على سبيل المثال، يمكن أن ينشئ نموذج الذكاء الاصطناعي التوليدي مقالات أو صورًا معقدة.
يمكن لبعض التقنيات السابقة، بما في ذلك النماذج اللغوية طويلة المدى (LSTM) والنماذج العصبية التسلسلية (RNN)، أيضًا إنشاء محتوى أصلي ومتسق. يرى بعض الخبراء أنّ هذه التقنيات السابقة هي نوع من الذكاء الاصطناعي التوليدي، بينما يرى آخرون أنّ الذكاء الاصطناعي التوليدي الحقيقي يتطلّب مخرجات أكثر تعقيدًا من تلك التي يمكن أن تنتجها هذه التقنيات السابقة.
يختلف ذلك عن تعلُّم الآلة التوقّعي.
ردّ جيد
إجابة معروفة بأنّها جيدة على سبيل المثال، في ما يتعلّق بال الطلب التالي:
2 + 2
نأمل أن يكون الردّ على النحو التالي:
4
GPT (النموذج التوليدي المُدرَّب مسبقًا)
مجموعة من النماذج اللغوية الكبيرة المستندة إلى نموذج التحويل والتي طوّرتها شركة OpenAI
يمكن تطبيق صيغ GPT على طرُق متعددة، بما في ذلك:
- إنشاء الصور (مثل ImageGPT)
- إنشاء الصور من النصوص (مثل DALL-E)
H
الهلوسة
إنتاج ناتج يبدو معقولاً ولكنّه غير دقيق من الناحية الواقعية من خلال نموذج الذكاء الاصطناعي التوليدي الذي يُزعَم أنّه يقدّم ادعاءً عن العالم الواقعي على سبيل المثال، نموذج الذكاء الاصطناعي التوليدي الذي يدّعي أنّ باراك أوباما توفي في عام 1865 يتوهّم.
التقييم البشري
عملية يحكم فيها الأشخاص على جودة ناتج نموذج تعلُّم الآلة، على سبيل المثال، الاستعانة بأشخاص ثنائيي اللغة لتقييم جودة ناتج نموذج ترجمة تعلُّم الآلة يكون التقييم البشري مفيدًا بشكل خاص لتقييم النماذج التي تتضمن إجابات صحيحة متعددة.
يختلف هذا التقييم عن التقييم التلقائي وتقييم المراجع الآلي.
I
التعلّم في السياق
مرادف لـ الطلب بأمثلة قليلة.
L
نموذج لغوي مخصَّص لتطبيقات المحادثة (LaMDA)
نموذج لغوي كبير يستند إلى Transformer، تم تطويره من قِبل Google وتم تدريبه على مجموعة بيانات محادثات كبيرة يمكنها إنشاء ردود واقعية على المحادثات.
LaMDA: تكنولوجيا المحادثة المبتكرة تقدّم نظرة عامة.
النموذج اللغوي
نموذج يقدّر احتمالية ظهور رمز أو تسلسل من الرموز في تسلسل أطول من الرموز
يمكنك الاطّلاع على ما هو نموذج اللغة؟ في الدورة التدريبية المكثّفة عن تعلُّم الآلة للحصول على مزيد من المعلومات.
نموذج لغوي كبير
على الأقل، نموذج لغوي يتضمّن عددًا كبيرًا جدًا من المَعلمات بعبارة أخرى، أي نموذج لغوي يستند إلى Transformer، مثل Gemini أو GPT.
اطّلِع على النماذج اللغوية الكبيرة (LLM) في الدورة التدريبية المكثّفة عن تعلُّم الآلة للحصول على مزيد من المعلومات.
المساحة الكامنة
مرادف لمساحة التضمين.
مسافة Levenshtein
مقياس مسافة التعديل الذي يحسب أقل عدد من عمليات الحذف والإدراج والاستبدال المطلوبة لتغيير كلمة إلى أخرى على سبيل المثال، تبلغ المسافة بين كلمتَي heart وdarts ثلاثة لأنّ التعديلات الثلاثة التالية هي أقل التغييرات اللازمة لتحويل الكلمة الأولى إلى الكلمة الثانية:
- قلب → قلب (استبدِل "h" بـ "d")
- deart → dart (حذف "e")
- سهم → سهام (أدخِل "س")
يُرجى العلم أنّ التسلسل السابق ليس المسار الوحيد للتعديلات الثلاث.
LLM
اختصار النموذج اللغوي الكبير.
تقييمات النماذج اللغوية الكبيرة (evals)
مجموعة من المقاييس والمقاييس المعيارية لتقييم أداء النماذج اللغوية الكبيرة بشكل عام، تؤدي تقييمات LLM إلى ما يلي:
- مساعدة الباحثين في تحديد الجوانب التي تحتاج إلى تحسين في النماذج اللغوية الكبيرة
- مفيدة في مقارنة نماذج اللغة الكبيرة المختلفة وتحديد أفضل نموذج لغة كبيرة مهمة معيّنة.
- المساعدة في ضمان أمان النماذج اللغوية الكبيرة وأخلاقية استخدامها
اطّلِع على النماذج اللغوية الكبيرة (LLM) في دورة التعلُّم الآلي المكثّفة للحصول على مزيد من المعلومات.
LoRA
اختصار Low-Rank Adaptability.
Low-Rank Adaptability (LoRA)
تقنية فعّالة من حيث المَعلمات للتحسين الدقيق التي "تجميد" مَعلمات النموذج المدربة مسبقًا (كي لا يمكن تعديلها بعد ذلك) ثم تُدخِل مجموعة صغيرة من المَعلمات القابلة للتدريب في النموذج هذه المجموعة من الأوزان القابلة للتدريب (المعروفة أيضًا باسم "مصفوفات التعديل") أصغر بكثير من النموذج الأساسي، وبالتالي تتم عملية تدريبها بشكل أسرع بكثير.
توفّر شبكة LoRA المزايا التالية:
- تحسين جودة توقّعات النموذج للنطاق الذي يتم فيه تطبيق التحسين الدقيق
- تحسين الأداء بشكل أسرع من الأساليب التي تتطلّب تحسين جميع ملفّات إعدادات النموذج
- تقليل التكلفة الحسابية لعملية الاستنتاج من خلال تفعيل عرض نماذج متعدّدة ومتخصّصة بشكل متزامن تشترك في النموذج الأساسي نفسه
M
نموذج لغوي مُموَّه
نموذج لغوي يتنبّأ باحتمالية استخدام علامات مقترَحة لملء الفراغات في تسلسل معيّن على سبيل المثال، يمكن لنموذج اللغة المقنَّعة حساب احتمالات الكلمات المرشحة لاستبدال الخطوط السفلية في الجملة التالية:
عاد ____ في القبّعة.
تستخدم المراجع عادةً السلسلة "MASK" بدلاً من العلامة السفلية. على سبيل المثال:
عادت كلمة "قناع" في القبّعة.
معظم نماذج اللغة المقنَّعة الحديثة هي ثنائية الاتجاه.
متوسّط متوسط الدقّة عند k (mAP@k)
المتوسط الإحصائي لجميع نتائج متوسّط الدقة عند k على مستوى مجموعة بيانات التحقّق. من بين استخدامات متوسّط متوسط الدقة عند k هو تقييم جودة الاقتراحات التي ينشئها نظام التوصية.
على الرغم من أنّ عبارة "متوسط المتوسط" تبدو زائدة، إلا أنّ اسم المقياس مناسب. بعد كل شيء، يجد هذا المقياس متوسّط قيم متوسط الدقة عند k المتعددة.
التعلّم الوصفي
مجموعة فرعية من تعلُّم الآلة ترصد خوارزمية تعلُّم أو تحسّنها. يمكن أن يهدف نظام التعلّم الفائق أيضًا إلى تدريب نموذج لتعلّم مهمة جديدة بسرعة من خلال كمية صغيرة من البيانات أو من خلال الخبرة المكتسَبة في المهام السابقة. تحاول خوارزميات التعلم الفائق بشكل عام تحقيق ما يلي:
- تحسين الميزات المصمّمة يدويًا أو التعرّف عليها (مثل أداة الإعداد أو أداة التحسين)
- تحسين كفاءة استخدام البيانات والمعالجة
- تحسين التعميم
يرتبط التعلّم الوصفي بالتعلّم ببضع فُرَص.
مزيج من الخبراء
مخطّط لزيادة كفاءة الشبكة العصبية من خلال استخدام مجموعة فرعية فقط من مَعلماتها (المعروفة باسم الخبير) لمعالجة رمز إدخال معيّن أو مثال تُوجّه شبكة التوجيه كل رمز مميّز أو مثال إدخال إلى الخبراء المناسبين.
للاطّلاع على التفاصيل، يُرجى الاطّلاع على أيّ من المقالتَين التاليتَين:
- الشبكات العصبية الكبيرة بشكل غير معقول: طبقة "مزيج الخبراء" ذات البوابات القليلة
- مزيج من الخبراء مع "توجيه من خبير"
MMIT
اختصار لعبارة مُعدّة للتعليمات المتعددة الوسائط.
الوسيط
فئة بيانات عالية المستوى. على سبيل المثال، الأرقام والنصوص والصور والفيديوهات والمواد المسموعة هي خمسة أنماط مختلفة.
المعالجة الموازِية للنماذج
طريقة لتوسيع نطاق التدريب أو الاستنتاج من خلال وضع أجزاء مختلفة من أحد النماذج على أجهزة مختلفة يتيح نموذج "المعالجة المتزامنة" استخدام النماذج الكبيرة جدًا التي لا يمكن وضعها على جهاز واحد.
لتنفيذ التوازي في النماذج، ينفّذ النظام عادةً ما يلي:
- تجزئة (تقسيم) النموذج إلى أجزاء أصغر
- توزيع عملية تدريب هذه الأجزاء الأصغر على معالجات متعددة يُدرِّب كل معالج جزءًا من النموذج.
- دمج النتائج لإنشاء نموذج واحد
يؤدي توازُن النموذج إلى إبطاء عملية التدريب.
اطّلِع أيضًا على المعالجة المتزامنة للبيانات.
MOE
اختصار مجموعة من الخبراء.
الانتباه الذاتي المتعدّد الرؤوس
إضافة إلى التركيز الذاتي التي تطبّق آلية التركيز الذاتي عدّة مرات لكل موضع في تسلسل الإدخال.
أدخلت أدوات التحويل ميزة "الانتباه الذاتي المتعدّد الرؤوس".
مُعدّة للتعليمات المتعدّدة الوسائط
نموذج مُعدّ للتعليمات يمكنه معالجة الإدخال بخلاف النصوص، مثل الصور والفيديوهات والصوت
نموذج متعدد الوسائط
نموذج تتضمّن إدخالاته أو مخرجاته أو كليهما أكثر من وضع واحد على سبيل المثال، لنفترض أنّ هناك نموذجًا يستخدِم كلاً من الصورة والترجمة النصية (طريقتَان) كميزات، ويصنِّف النتيجة على أنّها تشير إلى مدى ملاءمة الترجمة النصية للصورة. وبالتالي، تكون مدخلات هذا النموذج متعددة الوسائط والمخرجات أحادية الوسائط.
لا
معالجة اللغات الطبيعية
مجال تعليم أجهزة الكمبيوتر معالجة ما قاله المستخدم أو كتبه باستخدام القواعد اللغوية. تعتمد جميع تقنيات معالجة اللغات الطبيعية الحديثة تقريبًا على تكنولوجيات تعلُّم الآلة.فهم اللغات الطبيعية
مجموعة فرعية من معالجة اللغات الطبيعية تحدّد النوايا المتعلّقة بعبارة يتم قولها أو كتابتها يمكن أن تتجاوز ميزة فهم اللغة معالجة اللغات الطبيعية لتشمل جوانب language معقدة، مثل السياق والسخرية والمشاعر.
السلسلة المكوّنة من n عنصر
تسلسل مرتب من N كلمة على سبيل المثال، truly madly عبارة عن 2 غرام. ولأنّ الترتيب مهم، فإنّ madly truly يختلف عن truly madly.
| لا | أسماء هذا النوع من النصوص القصيرة | أمثلة |
|---|---|---|
| 2 | ثنائية الكلمات أو ثنائية الوحدات | to go, go to, eat lunch, eat dinner |
| 3 | ثلاثي الوحدات أو ثلاثي المقاطع | أكل الكثير، وعاشوا في سعادة دائمة، دقّ الجرس |
| 4 | 4 غرام | walk in the park, dust in the wind, the boy ate lentils |
تعتمد العديد من نماذج فهم اللغة الطبيعية على مجموعات الكلمات لتوقع الكلمة التالية التي سيكتبها أو ينطقها المستخدم. على سبيل المثال، لنفترض أنّ أحد المستخدمين كتب happily ever. من المرجّح أن يتوقّع نموذج NLU المستنِد إلى المجموعات الثلاثية من الكلمات أن يكتب المستخدِم الكلمة بعد.
قارِن بين النصوص القصيرة ذات الوحدات المتعددة ومجموعة الكلمات، وهي مجموعات غير مرتبة من الكلمات.
اطّلِع على النماذج اللغوية الكبيرة في دورة التعلّم الآلي المكثّفة للحصول على مزيد من المعلومات.
معالجة اللغات الطبيعية
اختصار لعبارة معالجة اللغات الطبيعية.
فهم اللغات الطبيعية
اختصار لعبارة فهم اللغة الطبيعية.
لا إجابة صحيحة واحدة (NORA)
طلب يتضمّن عدة ردود مناسبة على سبيل المثال، لا تتضمّن الرسالة التالية إجابة صحيحة واحدة:
أريد سماع نكتة عن الفيلة.
قد يكون من الصعب تقييم طلبات لا تتضمّن إجابة صحيحة واحدة.
NORA
اختصار لا توجد إجابة صحيحة واحدة.
O
الطلب بمثال واحد
طلب يتضمّن مثالاً واحدًا يوضّح كيفية ردّ النموذج اللغوي الكبير على سبيل المثال، يحتوي الطلب التالي على مثال واحد يوضّح للنموذج اللغوي الكبير كيفية الردّ على طلب بحث.
| أجزاء طلب واحد | ملاحظات |
|---|---|
| ما هي العملة الرسمية للبلد المحدّد؟ | السؤال الذي تريد أن يجيب عنه "نموذج اللغة المحوسبة" |
| فرنسا: يورو | مثال واحد |
| الهند: | طلب البحث الفعلي |
قارِن بين طلبات الإجراء الواحد والمصطلحات التالية:
P
ضبط مُفعّل للمَعلمات
مجموعة من الأساليب لتحسين نموذج لغوي تم تدريبه مسبقًا (PLM) بفعالية أكبر من التحسين الكامل عادةً ما تؤدي عملية التحسين المُفعّلة للمَعلمات إلى تحسين عدد أقل بكثير من المَعلمات مقارنةً بعملية التحسين الكامل، ومع ذلك، تؤدي هذه العملية بشكل عام إلى إنشاء نموذج لغوي كبير يحقّق أداءً مماثلاً (أو شبه مماثل) لأداء نموذج لغوي كبير تم إنشاؤه من خلال عملية التحسين الكامل.
قارِن بين الضبط الفعال للمَعلمات وبين:
يُعرف الضبط الفعال للمَعلمات أيضًا باسم التحسين الفعال للمَعلمات.
معالجة البيانات في مجموعات
شكل من أشكال التوازي في النماذج يتم فيه تقسيم معالجة النموذج إلى مراحل متتالية ويتم تنفيذ كل مرحلة على جهاز مختلف. بينما تعالج مرحلة ما دفعة واحدة، يمكن للمرحلة السابقة العمل على الدفعة التالية.
اطّلِع أيضًا على التدريب على مراحل.
PLM
اختصار نموذج لغوي مدرَّب مسبقًا.
الترميز الموضعي
أسلوب لإضافة معلومات عن موضع الرمز المميّز في تسلسل إلى إدراج الرمز المميّز تستخدِم نماذج Transformer الترميز المتعلّق بالموضع لفهم العلاقة بين الأجزاء المختلفة من التسلسل بشكلٍ أفضل.
يستخدم أحد طرق تنفيذ الترميز الموضعي دالة جيبية. (على وجه التحديد، يتم تحديد معدّل تكرار الدالة الجيبية وamplitudها حسب موضع الرمز المميّز في التسلسل). تتيح هذه التقنية لنموذج Transformer تعلُّم التركيز على أجزاء مختلفة من التسلسل استنادًا إلى مواضعها.
نموذج مدرَّب بعد ذلك
مصطلح تعريفه فضفاض ويشير عادةً إلى نموذج تم تدريبه مسبقًا وخضع لبعض المعالجة اللاحقة، مثل إجراء واحد أو أكثر مما يلي:
الدقة عند k (precision@k)
مقياس لتقييم قائمة مرتّبة (مُرتّبة) من العناصر تحدد الدقة عند k النسبة المئوية لأول k عنصر في هذه القائمة التي تكون "ملائمة". والمقصود:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
يجب أن تكون قيمة k أقل من أو مساوية لطول القائمة المعروضة. يُرجى العلم أنّ طول القائمة المعروضة ليس جزءًا من العملية الحسابية.
غالبًا ما يكون مدى الصلة بالموضوع أمرًا شخصيًا، وحتى الخبراء لا يتفقون في أغلب الأحيان على العناصر التي تُعدّ ملائمة.
المقارنة بـ:
نموذج مدرَّب مسبقًا
عادةً ما يكون نموذجًا سبق تدريبه. يمكن أن يشير المصطلح أيضًا إلى متجه التضمين الذي تم تدريبه سابقًا.
يشير مصطلح النموذج اللغوي المُدرَّب مسبقًا عادةً إلى نموذج لغوي كبير سبق أن تم تدريبه.
التدريب المُسبَق
التدريب الأوّلي لنموذج على مجموعة بيانات كبيرة إنّ بعض النماذج المدربة مسبقًا هي نماذج عملاقة وبطيئة، ويجب عادةً تحسينها من خلال تدريب إضافي. على سبيل المثال، قد يُجري خبراء تعلُّم الآلة تدريبًا مسبقًا على نموذج لغة كبير باستخدام مجموعة بيانات نصية ضخمة، مثل جميع الصفحات باللغة الإنجليزية في "ويكيبيديا". بعد التدريب المُسبَق، يمكن تحسين النموذج الناتج بشكلٍ أكبر باستخدام أيّ من التقنيات التالية:
طلب
أي نص يتم إدخاله كإدخال إلى نموذج لغوي كبير لإعداد النموذج للعمل بطريقة معيّنة. يمكن أن تكون الطلبات قصيرة مثل عبارة أو طويلة بشكل عشوائي (على سبيل المثال، نص رواية بأكمله). تندرج الطلبات ضمن فئات متعدّدة، بما في ذلك تلك الواردة في الجدول التالي:
| فئة الطلب | مثال | ملاحظات |
|---|---|---|
| السؤال | ما هي سرعة طيران الحمام؟ | |
| مدرسة تعليم | كتابة قصيدة مضحكة عن المراجحة | طلب يطلب من النموذج اللغوي الكبير تنفيذ إجراء معيّن |
| مثال | ترجمة رمز Markdown إلى HTML على سبيل المثال:
Markdown: * عنصر قائمة HTML: <ul> <li>عنصر قائمة</li> </ul> |
الجملة الأولى في هذا المثال هي عبارة عن إرشاد. الباقي من الطلب هو المثال. |
| الدور | شرح سبب استخدام خوارزمية انحدار التدرج في تدريب تعلُّم الآلة للحصول على درجة الدكتوراه في الفيزياء | الجزء الأول من الجملة هو عبارة عن توجيه، وتشكل العبارة "إلى درجة الدكتوراه في الفيزياء" جزء الوظيفة. |
| إدخال جزئي لإكمال النموذج | يقيم رئيس وزراء المملكة المتحدة في | يمكن أن ينتهي طلب الإدخال الجزئي بشكل مفاجئ (كما هو الحال في هذا المثال) أو ينتهي بشرطة سفلية. |
يمكن لنموذج الذكاء الاصطناعي التوليدي الاستجابة لطلب باستخدام نص أو رمز برمجي أو صور أو إدراج أو فيديوهات أو أي شيء آخر تقريبًا.
التعلّم المستنِد إلى الطلبات
ميزة تتوفّر في بعض النماذج تتيح لها تعديل سلوكها استجابةً لإدخال نص عشوائي (الطلبات). في النموذج النموذجي للتعلم المستنِد إلى طلب، يردّ نموذج لغوي كبير على طلب من خلال إنشاء نص. على سبيل المثال، لنفترض أنّ أحد المستخدمين يُدخل الطلب التالي:
تلخيص قانون نيوتن الثالث للحركة
لا يتم تدريب النموذج القادر على التعلّم المستنِد إلى الطلبات على الإجابة عن الطلب السابق على وجه التحديد. بدلاً من ذلك، "يعرف" النموذج الكثير من الحقائق حول الفيزياء، وقواعد اللغة العامة، والكثير من المعلومات حول ما يشكّل بشكل عام إجابات مفيدة. هذه المعرفة كافية لتقديم إجابة مفيدة (على أمل ذلك). من خلال الملاحظات الإضافية التي يقدّمها المستخدمون ("كانت هذه الإجابة معقّدة جدًا" أو "ما هو ردّ الفعل؟")، يمكن لبعض أنظمة التعلّم المستندة إلى طلبات البحث تحسين فائدة إجاباتها تدريجيًا.
تصميم الطلب
مرادف لـ هندسة الطلبات.
هندسة الطلبات
فن إنشاء طلبات تؤدي إلى الحصول على الردود المطلوبة من نموذج لغوي كبير يُجري الأشخاص هندسة للطلبات. إنّ كتابة طلبات مساعدة منظَّمة جيدًا هو جزء أساسي من ضمانتلقّي ردود مفيدة من نموذج لغوي كبير. تعتمد هندسة الطلبات على عوامل متعدّدة، منها:
- مجموعة البيانات المستخدَمة للتدريب المُسبَق والتحسين المحتمل للنموذج اللغوي الكبير
- temperature ومَعلمات فك التشفير الأخرى التي يستخدمها النموذج لإنشاء الردود
تصميم الطلبات هو مصطلح مرادف لهندسة الطلبات.
يمكنك الاطّلاع على مقدّمة عن تصميم الطلبات لمزيد من التفاصيل حول كتابة طلبات مفيدة.
ضبط الطلبات
آلية ضبط فعّال للمَعلمات تتعرّف على "بادئة" يضيفها النظام إلى الطلب الفعلي
أحد أشكال ضبط الطلبات، والذي يُسمى أحيانًا ضبط البادئة، هو إضافتها في كل طبقة. في المقابل، لا يؤدي معظم عمليات ضبط الطلبات إلا إلى إضافة بادئة إلى طبقة الإدخال.
R
تذكُّر عند k (recall@k)
مقياس لتقييم الأنظمة التي تعرِض قائمة مرتّبة (مُرتّبة) بالعناصر. يحدِّد "التذكُّر عند k" نسبة العناصر ذات الصلة في أوّل k عنصر في تلك القائمة من إجمالي عدد العناصر ذات الصلة التي يتم عرضها.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
يُرجى المقارنة مع الدقة عند k.
نص مرجعي
ردّ الخبير على طلب على سبيل المثال، في ما يلي الطلب التالي:
ترجمة السؤال "ما اسمك؟" من الإنجليزية إلى الفرنسية
قد يكون ردّ الخبير على النحو التالي:
Comment vous appelez-vous?
تقيس مقاييس مختلفة (مثل ROUGE) درجة تطابق النص المرجعي مع النص الذي أنشأه نموذج تعلُّم الآلة.
طلب الدور
جزء اختياري من الطلب الذي يحدّد شريحة جمهور مستهدَفة لاستجابة نموذج الذكاء الاصطناعي التوليدي. بدون طلب تحديد الدور، يقدّم نموذج لغوي كبير إجابة قد تكون مفيدة أو غير مفيدة للشخص الذي يطرح الأسئلة. من خلال طلب دور، يمكن أن يقدّم نموذج لغوي كبير إجابة بطريقة أكثر ملاءمةً وفائدةً لجمهور مستهدف معيّن. على سبيل المثال، يظهر جزء طلب الدور من الطلبات التالية بخط عريض:
- تلخيص هذا المستند لرسالة دكتوراه في الاقتصاد
- وصف آلية عمل المد والجزر لطفل في العاشرة من عمره
- شرح الأزمة المالية لعام 2008 تحدّث كما تتحدّث مع طفل صغير، أو كلب من سلالة لابرادور.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
مجموعة من المقاييس التي تقيِّم نماذج التلخيص التلقائي والترجمة الآلية. تحدِّد مقاييس ROUGE درجة تداخل النص المرجعي مع النص الذي تم إنشاؤه من نموذج الذكاء الاصطناعي. تتداخل مقاييس عائلة ROUGE بطريقة مختلفة. تشير نتائج ROUGE الأعلى إلى تشابه أكبر بين النص المرجعي والنص الذي تم إنشاؤه مقارنةً بنتائج ROUGE الأقل.
ينشئ كل فرد من عائلة ROUGE عادةً المقاييس التالية:
- الدقة
- التذكُّر
- F1
لمعرفة التفاصيل والأمثلة، يُرجى الاطّلاع على:
ROUGE-L
أحد أفراد عائلة ROUGE يركز على طول أطول تسلسل فرعي شائع في النص المرجعي والنص الذي تم إنشاؤه. تحسب الصيغ التالية دقة ومستوى التذكر لـ ROUGE-L:
يمكنك بعد ذلك استخدام F1 لتجميع دقة ROUGE-L ومستوى استرجاع ROUGE-L في مقياس واحد:
يتجاهل مقياس ROUGE-L أيّ أسطر جديدة في النص المرجعي والنص الذي تم إنشاؤه، لذلك يمكن أن يشمل أطول تسلسل فرعي مشترك عدّة جمل. عندما يتضمّن النص المرجعي والنص الذي تم إنشاؤه عدة جمل، يكون ROUGE-Lsum، وهو أحد أشكال مقياس ROUGE-L، مقياسًا أفضل بشكل عام. يحدِّد مقياس ROUGE-Lsum أطول تسلسل فرعي مشترك لكل جملة في فقرة، ثم يحتسِب متوسّط هذه التسلسلات الفرعية المشتركة الأطول.
ROUGE-N
مجموعة من المقاييس ضمن عائلة ROUGE التي تقارن بين النصوص المشتركة التي تتألف من عدد معيّن من الكلمات في النص المرجعي والنص الذي تم إنشاؤه. على سبيل المثال:
- يقيس مقياس ROUGE-1 عدد الرموز المشترَكة في النص المرجعي والنص الذي تم إنشاؤه.
- يقيس مقياس ROUGE-2 عدد الثنائيات (الكلمات المكونة من كلمتَين) المشترَكة في النص المرجعي والنص الذي تم إنشاؤه.
- يقيس مقياس ROUGE-3 عدد الثلاثيات (3-grams) المشترَكة في النص المرجعي والنص الذي تم إنشاؤه.
يمكنك استخدام الصيغ التالية لاحتساب تذكر ROUGE-N و دقة ROUGE-N لأيّ عضو من عائلة ROUGE-N:
يمكنك بعد ذلك استخدام F1 لتجميع دقة ROUGE-N ومستوى استرجاع ROUGE-N في مقياس واحد:
ROUGE-S
يُعدّ هذا المقياس من ROUGE-N أكثر تساهلاً، إذ يتيح مطابقة النموذج الثنائي. وهذا يعني أنّ ROUGE-N لا يحسب سوى النصوص القصيرة التي تتألّف من N كلمة التي تتطابق تمامًا، ولكنّ ROUGE-S يحسب أيضًا النصوص القصيرة التي تتألّف من N كلمة مفصولة بكلمة واحدة أو أكثر. على سبيل المثال، يمكنك القيام بما يلي:
- النص المرجعي: سحب بيضاء
- النص الذي تم إنشاؤه: سحب بيضاء كثيفة
عند احتساب مقياس ROUGE-N، لا يتطابق الثنائي السحب البيضاء مع السحب البيضاء المتصاعدة. ومع ذلك، عند احتساب ROUGE-S، يتطابق السحب البيضاء مع السحب المتصاعدة البيضاء.
S
الانتباه الذاتي (يُعرف أيضًا باسم طبقة الانتباه الذاتي)
طبقة شبكة عصبية تحوّل تسلسلاً من الملفات المضمّنة (مثل ملفات الرمز المميّز المضمّنة) إلى تسلسل آخر من الملفات المضمّنة يتم تأسيس كلّ عملية تضمين في تسلسل الإخراج من خلال دمج المعلومات من عناصر تسلسل الإدخال من خلال آلية التركيز.
يشير جزء الذات من الانتباه الذاتي إلى التسلسل الذي يهتم بنفسه بدلاً من أي سياق آخر. إنّ الانتباه الذاتي هو أحد أساسيات الوحدات الأساسية لمعمارية Transformer، ويستخدم مصطلحات البحث في القاموس، مثل "طلب بحث" و"مفتاح" و "قيمة".
تبدأ طبقة الانتباه الذاتي بتسلسل من تمثيلات الإدخال، واحد لكل كلمة. يمكن أن يكون تمثيل الإدخال لكلمة ما هو إدراج بسيط. لكل كلمة في تسلسل الإدخال، تُحسِّن الشبكة صلة الكلمة بكل عنصر في التسلسل الكامل للكلمات. تحدِّد نتائج مدى الصلة مقدار دمج التمثيل النهائي للكلمة في تمثيلات الكلمات الأخرى.
على سبيل المثال، فكِّر في الجملة التالية:
لم يعبر الحيوان الشارع لأنّه كان متعبًا جدًا.
يعرض الرسم التوضيحي التالي (من مقالة Transformer: A Novel Neural Network Architecture for Language Understanding) نمط الانتباه لطبقة الانتباه الذاتي للضمير it، مع اختلاف كثافة كل سطر للإشارة إلى مقدار مساهمة كل كلمة في التمثيل:
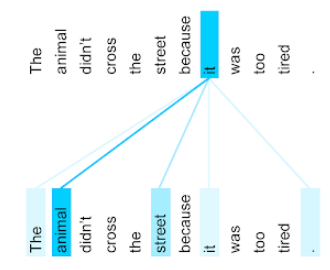
تُبرز طبقة الانتباه الذاتي الكلمات ذات الصلة بـ "it". في هذا الحالة، تعلّمت طبقة الانتباه تمييز الكلمات التي قد تتمثّل فيها، مع منح الأهمية الأكبر للكلمة حيوان.
بالنسبة إلى تسلسل من n رمز، تحوّل الانتباه الذاتي تسلسلاً من عمليات التضمين n مرّات منفصلة، مرّة واحدة في كل موضع في التسلسل.
راجِع أيضًا الاهتمام و الاهتمام الذاتي المتعدّد الرؤوس.
تحليل الآراء
استخدام الخوارزميات الإحصائية أو خوارزميات تعلُّم الآلة لتحديد الموقف العام للمجموعة، سواء كان إيجابيًا أو سلبيًا، تجاه خدمة أو منتج أو منظمة أو موضوع على سبيل المثال، باستخدام فهم اللغة الطبيعية، يمكن أن تُجري الخوارزمية تحليلًا للمشاعر استنادًا إلى الملاحظات النصية من دورة دراسية جامعية لتحديد مدى شعور الطلاب بالإعجاب أو عدم الإعجاب بالدورة بشكل عام.
اطّلِع على دليل تصنيف النصوص للحصول على مزيد من المعلومات.
مهمة من تسلسل إلى تسلسل
مهمة تعمل على تحويل تسلسل إدخال من الرموز المميّزة إلى تسلسل ناتج من الرموز المميّزة. على سبيل المثال، هناك نوعان شائعان من المهام المتعلّقة بتحويل تسلسل إلى تسلسل:
- المترجمون:
- مثال على تسلسل الإدخال: "أحبك".
- مثال على تسلسل النتائج: "Je t'aime".
- الإجابة عن الأسئلة:
- مثال على تسلسل الإدخال: "هل أحتاج إلى سيارتي في مدينة القاهرة؟"
- مثال على تسلسل الإخراج: "لا، يُرجى إبقاء سيارتك في المنزل".
skip-gram
نمط n-gram الذي قد يحذف (أو "يتخطّى") كلمات من السياق الأصلي، ما يعني أنّ الكلمات N قد لا تكون متجاورة في الأصل. بعبارة أدق، "ن-غرام بفاصل k" هو ن-غرام قد تم تخطّي ما يصل إلى k كلمة فيه.
على سبيل المثال، تحتوي العبارة "the quick brown fox" على الثنائيات التالية المحتمَلة:
- "السريع"
- "quick brown"
- "ثعلب بني"
"الثنائية ذات الفاصل" هي عبارة عن زوج من الكلمات تفصل بينهما كلمة واحدة كحد أقصى. لذلك، يحتوي المحتوى "the quick brown fox" على المقاطع التالية التي تتكوّن من كلمتَين مع تخطّي كلمة واحدة:
- "the brown"
- "ثعلب سريع"
بالإضافة إلى ذلك، تكون كل الثنائيات أيضًا ثنائيات تخطي كلمة واحدة، لأنّه قد يتم تخطي أقل من كلمة واحدة.
تكون ميزة "المقاطع التي يتم تخطّيها" مفيدة لفهم السياق المحيط بالكلمة بشكل أفضل. في المثال، كان "الثعلب" مرتبطًا مباشرةً بـ "سريع" في مجموعة المقاطع-الثنائية-بفاصل-واحد، ولكن ليس في مجموعة المقاطع-الثنائية.
تساعد ميزة "المقاطع التي تليها" في تدريب نماذج إدراج الكلمات.
ضبط الطلبات اللطيفة
أسلوب لضبط نموذج لغوي كبير لمهمة معيّنة، بدون استخدام موارد مكثفة في عملية التحسين الدقيق بدلاً من إعادة تدريب كل المَعلمات في النموذج، تعمل ميزة "ضبط الطلبات اللطيفة" على تعديل الطلب تلقائيًا لتحقيق الهدف نفسه.
استنادًا إلى طلب نصي، يؤدي تعديل الطلبات الناعمة عادةً إلى إلحاق عمليات إدراج رموز إضافية بالطلب واستخدام الانتشار العكسي لتحسين الإدخال.
يحتوي الطلب "الصعِب" على رموز مميّزة فعلية بدلاً من عمليات إدراج الرموز المميّزة.
خاصية متناثرة
سمة تكون قيمها في الغالب صفرًا أو فارغة على سبيل المثال، تكون الميزة التي تحتوي على قيمة 1 واحدة ومليون قيمة 0 متباعدة. في المقابل، تحتوي الميزة الكثيفة على قيم تكون في الغالب غير صفرية أو فارغة.
في مجال تعلُّم الآلة، هناك عدد كبير من الميزات المتفرقة. وتكون الميزات الفئوية عادةً ميزات متناثرة. على سبيل المثال، من بين 300 نوع من الأشجار المحتملة في الغابة، قد يحدِّد مثال واحد شجرة قيقب فقط. أو من بين ملايين الفيديوهات المحتمَلة في مكتبة فيديو، قد يحدِّد مثال واحد فقط "الدار البيضاء".
في النموذج، يتم عادةً تمثيل الميزات المتفرقة باستخدام التشفير الثنائي. إذا كان التشفير الواحد النشط كبيرًا، يمكنك وضع طبقة إدراج فوق التشفير الواحد النشط لتحقيق كفاءة أكبر.
تمثيل متناثر
تخزين المواضع للعناصر غير الصفرية فقط في سمة متفرّقة
على سبيل المثال، لنفترض أنّ سمة تصنيفية باسم species تحدّد 36
نوعًا من الأشجار في غابة معيّنة. لنفترض أيضًا أنّ كل
مثال يحدّد نوعًا واحدًا فقط.
يمكنك استخدام متجه أحادي القيمة لتمثيل أنواع الأشجار في كل مثال.
سيحتوي المتجه أحادي القيمة على 1 واحد (لتمثيل
أنواع الأشجار المحدّدة في هذا المثال) و35 0 (لتمثيل
أنواع الأشجار الـ 35 غير المُدرَجة في هذا المثال). وبالتالي، قد يبدو التمثيل الثنائي المميّز
لـ maple على النحو التالي:

بدلاً من ذلك، سيحدِّد التمثيل المتفرق ببساطة موضع
الأنواع المحدّدة. إذا كان maple في الموضع 24، سيكون التمثيل المتناثر
maple على النحو التالي:
24
يُرجى ملاحظة أنّ التمثيل المتفرق أكثر كثافة من التمثيل بقيم واحدة.
انقر على الرمز للحصول على مثال أكثر تعقيدًا قليلاً.
لنفترض أنّ كل مثال في النموذج يجب أن يمثّل الكلمات في جملة باللغة الإنجليزية، ولكن ليس ترتيب هذه الكلمات. تتألف اللغة الإنجليزية من 170,000 كلمة تقريبًا، لذا فإنّ اللغة الإنجليزية هي سمة فئوية تتضمّن 170,000 عنصر تقريبًا. تستخدم معظم الجمل الإنجليزية جزءًا صغيرًا جدًا من هذه الكلمات الـ 170,000، لذا من المؤكد تقريبًا أن تكون مجموعة الكلمات في مثال واحد من البيانات المتفرقة.
فكِّر في الجملة التالية:
My dog is a great dog
يمكنك استخدام نوع من المتجهات أحادية الحالة لتمثيل الكلمات في هذه الجملة. في هذا الصيغة، يمكن أن تحتوي خلايا متعددة في المتجه على قيمة غير صفرية. بالإضافة إلى ذلك، في هذا الصيغة، يمكن أن تحتوي الخلية على عدد صحيح بخلاف واحد. على الرغم من أنّ الكلمات "كلبي" و"هو" و"رائع" و "جدًا" تظهر فقط مرّة واحدة في الجملة، تظهر كلمة "كلب" مرّتين. باستخدام هذا الصيغة من المتجهات أحادية الحالة لتمثيل الكلمات في هذه الجملة، ينتج المتجه التالي المكوّن من 170,000 عنصر:

سيكون التمثيل المتناثر للجملة نفسها على النحو التالي:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
اطّلِع على العمل مع البيانات الفئوية في الدورة التدريبية المكثّفة حول تعلُّم الآلة للحصول على مزيد من المعلومات.
التدريب على مراحل
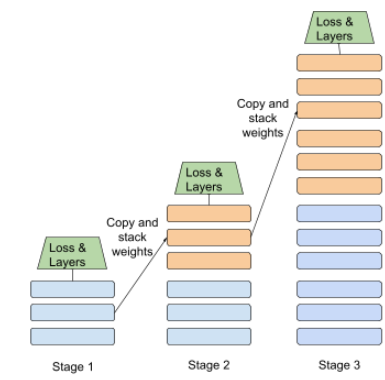
منهج لتدريب نموذج في تسلسل من المراحل المنفصلة ويمكن أن يكون الهدف هو تسريع عملية التدريب أو تحقيق جودة أفضل للنموذج.
في ما يلي صورة توضيحية لنهج التجميع التدريجي:
- يحتوي "المرحلة 1" على 3 طبقات مخفية، و"المرحلة 2" على 6 طبقات مخفية، و"المرحلة 3" على 12 طبقة مخفية.
- يبدأ "المرحلة 2" التدريب باستخدام الأوزان التي تم تعلّمها في الطبقات المخفية الثلاث من "المرحلة 1". تبدأ المرحلة 3 التدريب باستخدام الأوزان التي تم تعلّمها في ال6 طبقات المخفية للمرحلة 2.
اطّلِع أيضًا على المعالجة المخطّط لها.
رمز مميز للكلمة الفرعية
في النماذج اللغوية، العنصر هو سلسلة فرعية من كلمة، وقد تكون الكلمة بأكملها.
على سبيل المثال، قد يتم تقسيم كلمة مثل "itemize" إلى القطع "item" (كلمة أصلية) و "ize" (لاحقة)، ويتم تمثيل كل منهما بعلامة خاصة به. إنّ تقسيم الكلمات غير الشائعة إلى أجزاء كهذه، والتي تُعرف باسم الكلمات الفرعية، يسمح لنماذج اللغة بالعمل على الأجزاء الأكثر شيوعًا للكلمة، مثل البادئات واللاحقات.
في المقابل، قد لا يتم تقسيم الكلمات الشائعة مثل "going" وقد يتم تمثيلها برمز موحّد.
T
T5
نموذج تعلُّم الاستيعاب الذي طرحته تكنولوجيات الذكاء الاصطناعي من Google في عام 2020، وهو مخصّص للترجمة من نص إلى نص. T5 هو نموذج ترميز-فك ترميز، استنادًا إلى بنية Transformer، تم تدريبه على مجموعة ข้อมูล كبيرة جدًا. وهي فعّالة في مجموعة متنوعة من مهام معالجة اللغات الطبيعية، مثل إنشاء النصوص وترجمة اللغات والإجابة عن الأسئلة بطريقة حوارية.
يُستمَد اسم T5 من الأحرف الخمسة في "Text-to-Text Transfer Transformer".
T5X
إطار عمل مفتوح المصدر لتعلُّم الآلة مصمّم لإنشاء نماذج معالجة لغات طبيعية (NLP) على نطاق واسع وتدريبها يتم تنفيذ T5 على قاعدة بيانات T5X (التي يتم إنشاؤها استنادًا إلى JAX وFlax).
درجة الحرارة
مَعلمة فائقة تتحكّم في درجة العشوائية لمخرجات النموذج تؤدي درجات الحرارة المرتفعة إلى زيادة العشوائية في النتائج، بينما تؤدي درجات الحرارة المنخفضة إلى تقليل العشوائية في النتائج.
يعتمد اختيار أفضل درجة حرارة على التطبيق المحدّد والخصائص المفضّلة لمخرجات النموذج. على سبيل المثال، قد تحتاج إلى رفع درجة الحرارة عند إنشاء تطبيق يؤدي إلى إنشاء تصميمات إعلانية. في المقابل، من المحتمل أن تخفض درجة الحرارة عند إنشاء نموذج يصنف الصور أو النصوص لتحسين دقة النموذج واتساقه.
غالبًا ما يتم استخدام درجة الحرارة مع softmax.
نطاق النص
نطاق فهرس الصفيف المرتبط بقسم فرعي معيّن من سلسلة نصية.
على سبيل المثال، تشغل الكلمة good في سلسلة Python s="Be good now"
نطاق النص من 3 إلى 6.
رمز مميّز
في النموذج اللغوي، هي الوحدة الأساسية التي يتم تدريب النموذج عليها وإجراء التوقّعات استنادًا إليها. عادةً ما يكون الرمز المميّز أحد يليه:
- كلمة: على سبيل المثال، تتألف العبارة "الكلاب تحب القطط" من ثلاثة علامات كلمات: "الكلاب" و"تحب" و "القطط".
- حرف، على سبيل المثال، تتألف العبارة "دراجة سمكة" من تسعة رموز أحرف. (يُرجى العِلم أنّ المسافة الفارغة تُحتسَب كأحد الرموز).
- الكلمات الفرعية: حيث يمكن أن تكون الكلمة الواحدة رمزًا واحدًا أو رموزًا متعددة. تتألّف الكلمة الفرعية من كلمة أصلية أو بادئة أو لاحقة. على سبيل المثال، قد يعرض نموذج اللغة الذي يستخدم الكلمات الفرعية كعناصر مميزة الكلمة "كلاب" كعنصرَين مميزَين (الكلمة الأساسية "كلب" واللاحقة "س" للجمع). قد ينظر نموذج اللغة نفسه إلى الكلمة الواحدة "أطول" على أنّها كلمتان فرعيتان (كلمات الجذر "طويل" واللاحقة "er").
في النطاقات خارج النماذج اللغوية، يمكن أن تمثّل الرموز أنواعًا أخرى من الوحدات الأساسية. على سبيل المثال، في مجال الرؤية الحاسوبية، قد يكون الرمز المميّز مجموعة فرعية من الصورة.
اطّلِع على النماذج اللغوية الكبيرة في دورة التعلّم الآلي المكثّفة للحصول على مزيد من المعلومات.
دقة أفضل k
النسبة المئوية لعدد المرات التي يظهر فيها "تصنيف مستهدَف" ضمن أوّل k موضع من القوائم التي تم إنشاؤها. يمكن أن تكون القوائم اقتراحات مخصّصة أو قائمة بالعناصر مرتبة حسب softmax.
تُعرف دقة أفضل k عناصر أيضًا باسم الدقة عند k.
لغة غير لائقة
درجة مساءة المحتوى أو تهديده أو إساءته يمكن للعديد من نماذج تعلُّم الآلة تحديد المحتوى السام وقياسه. ترصد معظم هذه النماذج المحتوى المسيء استنادًا إلى مَعلمات متعدّدة، مثل مستوى اللغة المسيئة ومستوى اللغة التهديدية.
المحوّل
بنية شبكة عصبية تم تطويرها في Google والتي تعتمد على آليات التركيز الذاتي لتحويل تسلسل من عمليات إدراج الإدخال إلى تسلسل من عمليات إدراج المخرج بدون الاعتماد على عمليات التفاف أو الشبكات العصبية المتكررة. يمكن النظر إلى "المحوِّل" على أنّه حزمة من طبقات الانتباه الذاتي.
يمكن أن يتضمّن المحوِّل أيًا مما يلي:
- برنامج ترميز
- برنامج فك ترميز
- كل من برنامج الترميز وبرنامج فك الترميز
يحوّل برنامج الترميز تسلسلًا من عمليات التضمين إلى تسلسل جديد بالطول نفسه. يتضمّن برنامج الترميز N طبقات متطابقة، تحتوي كلّ طبقة منها على مرحلتين فرعيتين. يتم تطبيق هاتين الطبقتين الفرعيتين في كل موضع من تسلسل إدراج الإدخال، ما يحوّل كل عنصر من التسلسل إلى إدراج جديد. تجمع الطبقة الفرعية الأولى من برنامج الترميز المعلومات من ملف ملف السلسلة. تحوّل الطبقة الفرعية الثانية من برنامج الترميز المعلومات المُجمَّعة إلى عنصر إدراج في الإخراج.
يحوّل المشفِّر تسلسلًا من عمليات إدراج الإدخال إلى تسلسل من عمليات إدراج الإخراج، وقد يكون طوله مختلفًا. يتضمّن أداة فك التشفير أيضًا N طبقات متطابقة تحتوي على ثلاث طبقات فرعية، تشبه طبقتاً منها الطبقات الفرعية لأداة التشفير. تأخذ الطبقة الفرعية الثالثة لفك التشفير ناتج التشفير وتطبّق آلية التركيز الذاتي لجمع المعلومات منه.
تقدّم مشاركة المدونة Transformer: A Novel Neural Network Architecture for Language Understanding مقدمة جيدة عن نموذج التحويل.
يمكنك الاطّلاع على النماذج اللغوية الكبيرة: ما هي النماذج اللغوية الكبيرة؟ في الدورة التدريبية المكثّفة عن تعلُّم الآلة للحصول على مزيد من المعلومات.
ثلاثي الأحرف
نمط تحليلي من وحدات أساسية حيث يكون N=3
U
أحادي الاتجاه
نظام يقيّم فقط النص الذي يسبق قسمًا مستهدفًا من النص في المقابل، يُقيّم النظام الثنائي الاتجاه كلاً من النص الذي يسبق قسمًا مستهدفًا من النص ويليه. اطّلِع على الاتصال الثنائي الاتجاه لمزيد من التفاصيل.
نموذج لغوي أحادي الاتجاه
نموذج لغوي يستند إلى الاحتمالات فقط على الرموز التي تظهر قبل الرموز المستهدفة وليس بعدها يختلف هذا النموذج عن النموذج اللغوي ثنائي الاتجاه.
V
الترميز التلقائي المتغيّر (VAE)
نوع من المشفِّرات التلقائية التي تستفيد من الاختلاف بين المدخلات والمخرجات لإنشاء نُسخ معدَّلة من المدخلات. تكون أدوات الترميز الذاتي التفاضلية مفيدة للذكاء الاصطناعي التوليدي.
تستند نماذج VAE إلى الاستنتاج التنوّعي: وهو أسلوب لتقدير مَعلمات نموذج الاحتمالية.
واط
تضمين الكلمات
تمثيل كل كلمة في مجموعة كلمات ضمن مصفوفة إدراج، أي تمثيل كل كلمة كأحد مصفوفات القيم الكسورية العشرية التي تتراوح بين 0.0 و1.0 إنّ الكلمات التي تحمل معاني مشابهة لها تمثيلات أكثر تشابهًا من الكلمات التي تحمل معاني مختلفة. على سبيل المثال، سيكون لكل من الجزر والهليون والخيار تمثيلات مشابهة نسبيًا، والتي ستكون مختلفة جدًا عن تمثيلات الطائرة والنظارات الشمسية ومعجون الأسنان.
Z
الطلب بلا مثال
طلب لا يقدّم مثالاً على الردّ الذي تريده من النموذج اللغوي الكبير على سبيل المثال:
| أجزاء طلب واحد | ملاحظات |
|---|---|
| ما هي العملة الرسمية للبلد المحدّد؟ | السؤال الذي تريد أن يجيب عنه "نموذج اللغة المحوسبة" |
| الهند: | طلب البحث الفعلي |
قد يردّ النموذج اللغوي الكبير بأيّ مما يلي:
- روبية
- INR
- ر.ه.
- الروبية الهندية
- الروبية
- الروبية الهندية
جميع الإجابات صحيحة، ولكن قد تفضّل تنسيقًا معيّنًا.
قارِن بين طلبات البحث بدون أي معلومات سابقة والمصطلحات التالية: