इस पेज में भाषा मूल्यांकन शब्दावली शब्द शामिल हैं. शब्दावली शब्दों के लिए, यहां क्लिक करें.
A
ध्यान देना
न्यूरल नेटवर्क में इस्तेमाल किया जाने वाला एक तरीका, जो किसी खास शब्द या शब्द के किसी हिस्से की अहमियत. ध्यान कंप्रेस करना जानकारी की वह मात्रा जिसकी ज़रूरत किसी मॉडल को अगले टोकन/शब्द का अनुमान लगाने के लिए होती है. ध्यान देने के एक सामान्य तरीके में ये चीज़ें शामिल हो सकती हैं वेटेड योग, इनपुट के सेट के ऊपर होता है, जहां हर इनपुट के लिए वेट की गणना न्यूरल नेटवर्क.
खुद का ध्यान रखना और मल्टी-हेड सेल्फ़-अटेंशन ट्रांसफ़ॉर्मर के बिल्डिंग ब्लॉक.
ऑटोएन्कोडर
यह एक ऐसा सिस्टम है जो इनपुट. ऑटोएन्कोडर, एन्कोडर और डीकोडर. ऑटोएन्कोडर, नीचे दी गई दो चरणों वाली प्रोसेस पर भरोसा करते हैं:
- एन्कोडर, इनपुट को (आम तौर पर) कम-डाइमेंशन वाले कम-डाइमेंशन वाले मोड में मैप करता है (इंटरमीडिएट) फ़ॉर्मैट में.
- डिकोडर, मैप करके मूल इनपुट का नुकसान पहुंचाने वाला वर्शन बनाता है लोअर-डाइमेंशन वाला फ़ॉर्मैट और ओरिजनल हाई-डाइमेंशन वाला फ़ॉर्मैट इनपुट प्रारूप.
ऑटोएन्कोडर को शुरू से आखिर तक ट्रेनिंग दी जाती है. ऐसा करने के लिए वे डिकोडर की मदद लेते हैं एन्कोडर के इंटरमीडिएट फ़ॉर्मैट से ओरिजनल इनपुट को फिर से बनाएं जितना संभव हो सके. क्योंकि इंटरमीडिएट फ़ॉर्मैट छोटा होता है (लोअर-डाइमेंशन) मूल फ़ॉर्मैट की तुलना में, ऑटोएन्कोडर ज़बरदस्ती लागू होता है यह जानने के लिए कि इनपुट में कौन-सी जानकारी आवश्यक है और आउटपुट पूरी तरह से इनपुट के समान हो.
उदाहरण के लिए:
- अगर इनपुट डेटा ग्राफ़िक है, तो पूरी तरह से सटीक नहीं होने वाली कॉपी इसके समान होगी में असली ग्राफ़िक लगा था, लेकिन उसमें कुछ बदलाव किए गए थे. शायद नॉन-एग्ज़ैक्ट कॉपी जो मूल ग्राफ़िक से शोर को हटा देती है या अपने-आप जानकारी भर जाती है कुछ पिक्सल मौजूद नहीं हैं.
- अगर इनपुट डेटा टेक्स्ट है, तो ऑटोएन्कोडर ऐसा नया टेक्स्ट जनरेट करेगा जो मूल टेक्स्ट जैसा ही है, लेकिन इसके जैसा नहीं है.
अलग-अलग ऑटोएन्कोडर भी देखें.
ऑटो-रिग्रेसिव मॉडल
ऐसा मॉडल जो अपने पिछले अनुमान के आधार पर अनुमान लगाता है सुझाव. उदाहरण के लिए, ऑटो-रिग्रेसिव लैंग्वेज मॉडल अगले पहले से अनुमानित टोकन के आधार पर टोकन. Transformer-आधारित सभी बड़े लैंग्वेज मॉडल अपने-आप रिग्रेटिव होते हैं.
इसके उलट, GAN पर आधारित इमेज मॉडल आम तौर पर ऑटो-रिग्रेसिव नहीं होते क्योंकि वे सिंगल फ़ॉरवर्ड-पास में इमेज जनरेट करते हैं, न कि बार-बार चरण पूरे करें. हालांकि, इमेज जनरेट करने वाले कुछ मॉडल ऑटो-रिग्रेसिव होते हैं, क्योंकि वे चरणों में इमेज जनरेट करते हैं.
B
अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया हैशब्दों का झोंका
किसी वाक्यांश या पैसेज में शब्दों को निरूपण, वह चाहे किसी भी क्रम में हो. उदाहरण के लिए, शब्दों का बैग आगे दिए गए तीन वाक्यांशों को समान रूप से:
- कुत्ता उछलता है
- जंप द डॉग
- कुत्ता उछलता है
हर शब्द को स्पार्स वेक्टर के इंडेक्स से मैप किया जाता है, जहां वेक्टर में शब्दावली के हर शब्द का इंडेक्स होता है. उदाहरण के लिए, वाक्यांश द डॉग जंप, एक ऐसे फ़ीचर वेक्टर में मैप किया गया है जिसमें शून्य शून्य नहीं है the, dogfood, और शब्दों से संबंधित तीन इंडेक्स पर वैल्यू जंप. शून्य के अलावा, इनमें से कोई भी वैल्यू हो सकती है:
- किसी शब्द की मौजूदगी को दिखाने के लिए 1.
- बैग में कोई शब्द कितनी बार दिखता है. उदाहरण के लिए, अगर इस वाक्यांश को लिखा जा सकता है मरून फ़र वाला मरून फ़र वाला कुत्ता, तो दोनों मरून और कुत्ते को 2 से दिखाया जाएगा, जबकि दूसरे शब्दों को को 1 के तौर पर दिखाया जाएगा.
- कुछ अन्य वैल्यू, जैसे कि इस संख्या की गणना का लॉगारिद्म बैग में कोई शब्द कब दिखता है.
BERT (बायडायरेक्शनल एन्कोडर) ट्रांसफ़ॉर्मर की ओर से प्रतिनिधित्व)
टेक्स्ट प्रज़ेंटेशन के लिए मॉडल आर्किटेक्चर. एक प्रशिक्षित BERT मॉडल, टेक्स्ट की कैटगरी तय करने के लिए बड़े मॉडल के हिस्से के तौर पर काम कर सकता है या मशीन लर्निंग के लिए दिए गए अन्य टास्क भी शामिल हैं.
BERT की विशेषताएं ये हैं:
- Transformer आर्किटेक्चर का इस्तेमाल करता है. इसलिए, यह खुद का ध्यान रखने की सुविधा पर ध्यान दें.
- यह ट्रांसफ़ॉर्मर के एन्कोडर वाले हिस्से का इस्तेमाल करता है. एन्कोडर का काम एक विशिष्ट प्रदर्शन करने के बजाय, अच्छा लेख निरूपण करना है कर सकते हैं.
- दोनों तरफ़ दो रास्ते हों.
- इनके लिए, मास्किंग का इस्तेमाल किया जाता है बिना निगरानी वाली ट्रेनिंग.
BERT के वैरिएंट में ये शामिल हैं:
ओपन सोर्सिंग BERT: नैचुरल लैंग्वेज के लिए प्री-ट्रेनिंग की स्थिति देखें प्रोसेस जारी है देखें.
दोतरफ़ा
ऐसे सिस्टम के लिए इस्तेमाल किया जाने वाला शब्द जो उस टेक्स्ट का आकलन करता है जो पहले, दोनों फ़ॉर्मैट में था और टेक्स्ट के टारगेट सेक्शन का फ़ॉलो करता है. इसके उलट, सिर्फ़ एकतरफ़ा सिस्टम उस टेक्स्ट का आकलन करता है जो टेक्स्ट के टारगेट सेक्शन से पीछे होता है.
उदाहरण के लिए, मास्क की गई भाषा के किसी मॉडल पर विचार करें को अंडरलाइन करने वाले शब्द या शब्दों के लिए प्रायिकता तय करनी चाहिए नीचे दिया गया सवाल:
_____ आपके साथ क्या है?
एकतरफ़ा भाषा वाले मॉडल को सिर्फ़ अपनी प्रायिकताओं को आधार बनाना होगा "What", "is", और "the" शब्दों के ज़रिए दिए गए संदर्भ के हिसाब से तय होता है. इसके उलट, एक द्विदिशात्मक भाषा मॉडल भी "के साथ" से संदर्भ पा सकता है और "आप", इससे मॉडल को बेहतर अनुमान लगाने में मदद मिल सकती है.
दो-तरफ़ा लैंग्वेज मॉडल
भाषा का ऐसा मॉडल जो यह संभावना बताता है कि दिया गया टोकन दिए गए स्थान पर पहले से मौजूद और फ़ॉलो किया जा रहा टेक्स्ट.
बिगम
कोई N-ग्राम, जिसमें N=2 हो.
BLEU (बाइलिंगुअल इवैलुएशन अंडरस्टडी)
0.0 और 1.0 के बीच का स्कोर, जो अनुवाद की क्वालिटी दिखाता है दो मैन्युअल भाषाओं के बीच स्विच करता है. उदाहरण के लिए, अंग्रेज़ी और रशियन. ए BLEU 1.0 का स्कोर बताता है कि अनुवाद सही है; 0.0 का BLEU स्कोर बताता है कि बहुत खराब अनुवाद किया है.
C
कॉज़ल लैंग्वेज मॉडल
एकतरफ़ा लैंग्वेज मॉडल का समानार्थी शब्द.
इसके लिए, दो-तरफ़ा भाषा का मॉडल देखें लैंग्वेज मॉडलिंग में, अलग-अलग दिव्यांगों के लिए अलग-अलग तरीके अपनाए.
चेन-ऑफ़-थॉट प्रॉम्प्ट
एक प्रॉम्प्ट इंजीनियरिंग तकनीक, जो एक बड़े लैंग्वेज मॉडल (एलएलएम) में, जो तर्क के साथ, सिलसिलेवार तरीक़े से. उदाहरण के लिए, नीचे दिए गए प्रॉम्प्ट के हिसाब से पेमेंट करें दूसरे वाक्य पर विशेष ध्यान दें:
0 से 60 के बीच की दूरी पर जाने वाली किसी कार में, ड्राइवर को कितने g बल लगा सकते हैं 7 सेकंड में मील प्रति घंटा? जवाब में, काम के सभी कैलकुलेशन दिखाएं.
एलएलएम से ये जवाब मिल सकते हैं:
- वैल्यू 0, 60, और 7 जोड़ते हुए, फ़िज़िक्स के फ़ॉर्मूले का क्रम दिखाएं ज़रूरत के हिसाब से डाला जा सकता है.
- बताएं कि इसने वे फ़ॉर्मूले क्यों चुने और अलग-अलग वैरिएबल का क्या मतलब है.
चेन-ऑफ़-विचार, एलएलएम को सभी कैलकुलेशन करने के लिए मजबूर करता है, इससे आपको ज़्यादा सही जवाब मिल सकता है. इसके अलावा, एक के बाद एक कई प्रॉम्प्ट की मदद से, लोग एलएलएम के चरणों की जांच करके यह पता लगा सकते हैं कि क्या भी जवाब सही नहीं है.
चैट
मशीन लर्निंग सिस्टम (एमएल सिस्टम) के साथ होने वाली लगातार होने वाली बातचीत का कॉन्टेंट. आम तौर पर, बड़ा लैंग्वेज मॉडल. चैट में की गई पिछली बातचीत (आपने क्या टाइप किया और बड़े लैंग्वेज मॉडल ने कैसे जवाब दिया) संदर्भ भी शामिल करें.
चैटबॉट, बड़े लैंग्वेज मॉडल का ऐप्लिकेशन है.
बातचीत
गलत जानकारी का पर्यायवाची.
हो सकता है कि कन्फ़ैब्युलेशन, गलत जानकारी के मुकाबले ज़्यादा सटीक शब्द हो. हालांकि, गलत जानकारी पहले लोकप्रिय हुई.
चुनाव क्षेत्र की पार्सिंग
किसी वाक्य को व्याकरण के हिसाब से छोटे-छोटे स्ट्रक्चर में बांटना. एमएल सिस्टम का बाद का हिस्सा, जैसे कि सामान्य भाषा की समझ मॉडल, मूल वाक्य की तुलना में अवयवों को ज़्यादा आसानी से पार्स कर सकता है. उदाहरण के लिए, इस वाक्य पर विचार करें:
मेरे दोस्त ने दो बिल्लियों को गोद लिया है.
निर्वाचन क्षेत्र पार्सर इस वाक्य को इसमें ये दो लोग शामिल हैं:
- मेरा दोस्त एक संज्ञा वाक्यांश है.
- optedtwo cats में क्रिया के रूप में लिखा जाता है.
इन उम्मीदवारों को छोटे-छोटे हिस्सों में बांटा जा सकता है. उदाहरण के लिए, क्रिया के वाक्यांश
दो बिल्लियों को गोद लिया
इन्हें इन ग्रुप में बांटा जा सकता है:
- adopt एक क्रिया है.
- two cats, एक और संज्ञा वाक्यांश है.
कॉन्टेक्स्ट के हिसाब से भाषा जोड़ना
एम्बेड करने की सुविधा, जिसमें "समझौते" के बारे में ज़्यादा बताया गया हो शब्द और वाक्यांशों का इस्तेमाल किया जाता है. प्रासंगिक भाषा एम्बेड करने की सुविधा मुश्किल सिंटैक्स, सिमेंटिक्स, और कॉन्टेक्स्ट को समझ सकती है.
उदाहरण के लिए, अंग्रेज़ी शब्द cow को एम्बेड करने के बारे में सोचें. पुराने वीडियो एम्बेड करना जैसे कि word2vec, अंग्रेज़ी को ऐसे शब्द जैसे कि एम्बेड करने की जगह की दूरी गाय से बैल तक की दूरी युवा (महिला भेड़) से दूरी के बराबर है राम (पुरुष) या महिला से पुरुष. प्रासंगिक भाषा एम्बेड करने की सुविधा से, वीडियो को और बेहतर बनाने के लिए, कभी-कभी अंग्रेज़ी बोलने वाले लोगों की पहचान की जा सकती है आम तौर पर गाय शब्द का इस्तेमाल गाय या बैल का मतलब समझने के लिए किया जाता है.
कॉन्टेक्स्ट विंडो
किसी मॉडल में कितने टोकन प्रोसेस किए जा सकते हैं प्रॉम्प्ट. संदर्भ विंडो जितनी बड़ी होती है, उतनी ही ज़्यादा जानकारी होती है इस मॉडल का इस्तेमाल, आसान और सटीक जवाब देने के लिए किया जा सकता है. प्रॉम्प्ट तक.
क्रैश ब्लॉसम
ऐसा वाक्य या वाक्यांश जिसका मतलब साफ़ तौर पर न हो. क्रैश ब्लॉसम प्राकृतिक भाषा की समझ. उदाहरण के लिए, हेडलाइन Red Tape होल्ड्स अप स्काईस्क्रेपर क्रैश ब्लॉसम क्योंकि एक NLU मॉडल हेडलाइन को सही-सही समझ सकता है या रूप से.
D
डिकोडर
आम तौर पर, कोई भी ऐसा एमएल सिस्टम जो प्रोसेस किए गए, सघन या ज़्यादा रॉ, विरल या बाहरी कॉन्टेंट को संगठन के अंदर दिखाना.
डिकोडर अक्सर किसी बड़े मॉडल का हिस्सा होते हैं, जहां वे अक्सर एन्कोडर के साथ जोड़ा गया हो.
सिलसिलेवार टास्क में, डिकोडर इसकी शुरुआत एन्कोडर की मदद से जनरेट की गई अंदरूनी स्थिति से शुरू होती है, ताकि अगले चरण का अनुमान लगाया जा सके क्रम.
अंदर मौजूद डिकोडर की परिभाषा जानने के लिए, Transformer देखें देखें.
ग़ैर-ज़रूरी आवाज़ें हटाना
सेल्फ़-सुपरवाइज़्ड लर्निंग इस्तेमाल करने का एक सामान्य तरीका जिसमें:
ग़ैर-ज़रूरी आवाज़ें कम करने की सुविधा, बिना लेबल वाले उदाहरणों से सीखने में मदद करती है. ओरिजनल डेटासेट को टारगेट के तौर पर इस्तेमाल किया जाता है या label और शोर वाला डेटा है.
मास्क की गई भाषा के कुछ मॉडल में, ग़ैर-ज़रूरी आवाज़ें कम करने की सुविधा का इस्तेमाल किया जाता है इस तरह से:
- बिना लेबल वाले वाक्य में कुछ जानकारी को मास्क करके, बिना आवाज़ वाले वाक्य को बनावटी तरीके से जोड़ा जाता है टोकन.
- मॉडल, ओरिजनल टोकन का अनुमान लगाने की कोशिश करता है.
सीधे तौर पर प्रॉम्प्ट
ज़ीरो-शॉट प्रॉम्प्ट का पर्यायवाची.
E
दूरी में बदलाव करें
एक जैसी दो टेक्स्ट स्ट्रिंग एक-दूसरे से कितनी मिलती-जुलती हैं. मशीन लर्निंग में, दूरी में बदलाव करना फ़ायदेमंद होता है, क्योंकि और दो स्ट्रिंग की तुलना करने का एक असरदार तरीका है. मिलती-जुलती स्ट्रिंग खोजने के लिए.
दूरी में बदलाव करने की कई परिभाषाएं दी गई हैं. हर परिभाषा के लिए अलग स्ट्रिंग का इस्तेमाल किया जाता है कार्रवाइयां. उदाहरण के लिए, लेवेंशेन की दूरी कम से कम हटाना, डालना, और स्थानापन्न ऑपरेशन पर विचार करता है.
उदाहरण के लिए, "दिल" शब्दों के बीच लेवेनशेटिन की दूरी और "डार्ट" 3 है क्योंकि निम्न 3 संपादन एक शब्द में सबसे कम परिवर्तन हैं दूसरे में:
- दिल → डीआर्ट ("h" को "d" से बदलें)
- डीआर्ट → डार्ट (मिटाएं "e")
- डार्ट → डार्ट ("s" डालें)
एम्बेडिंग लेयर
एक विशेष छिपी हुई लेयर जो बड़े पैमाने पर उपलब्ध कैटगरिकल सुविधा का इस्तेमाल करके, लोअर डाइमेंशन एम्बेडिंग वेक्टर को धीरे-धीरे सीखें. अगर आप एम्बेडिंग लेयर की मदद से, न्यूरल नेटवर्क को बेहतर तरीके से ट्रेनिंग देने में मदद मिलती है न कि सिर्फ़ हाई-डाइमेंशन वाली कैटगरी वाली सुविधा पर ट्रेनिंग देने से ज़्यादा.
उदाहरण के लिए, फ़िलहाल Earth, पेड़ों की करीब 73,000 प्रजातियों का समर्थन करती है. मान लें
आपके मॉडल में मौजूद पेड़ों की संख्या एक सुविधा है. इसलिए, आपके मॉडल
इनपुट लेयर में वन-हॉट वेक्टर 73,000 शामिल है
एलिमेंट की अवधि बढ़ाएं.
उदाहरण के लिए, शायद baobab कुछ ऐसा दिखाया जाएगा:

73,000 एलिमेंट का अरे बहुत लंबा होता है. अगर आप एम्बेडिंग लेयर नहीं जोड़ते हैं, तो मॉडल की तुलना में, ट्रेनिंग में काफ़ी समय लगेगा. ऐसा इसलिए है, क्योंकि 72,999 शून्यों को गुणा करना. हो सकता है कि आप शामिल करने के लिए एम्बेडिंग लेयर को चुनें 12 डाइमेंशन चुने जा सकते हैं. ऐसा करने से, एम्बेडिंग लेयर धीरे-धीरे पेड़ की हर प्रजाति के लिए एक नया एम्बेड वेक्टर.
कुछ मामलों में, हैशिंग एक सही विकल्प है को एम्बेड करने वाली लेयर पर ले जाया जा सकता है.
एम्बेड करने की जगह
डी-डाइमेंशन वाला वेक्टर स्पेस, जो हाई-डायमेंशनल से मिलता-जुलता है वेक्टर स्पेस को मैप किया जाता है. आम तौर पर, एम्बेड करने की जगह में ऐसी संरचना जो गणित के अर्थ वाले नतीजे देती हो; उदाहरण के लिए, इसमें वीडियो को एम्बेड करने की सबसे अच्छी जगह मिलती है. शब्दों की तुलना करने वाले टास्क हल कर सकते हैं.
बिंदु वाला प्रॉडक्ट की दो इमेज, एक-दूसरे से जुड़ी होती हैं.
एम्बेडिंग वेक्टर
आम तौर पर, किसी भी फ़्लोटिंग-पॉइंट नंबर की कलेक्शन छिपी हुई लेयर, जो उस छिपी हुई लेयर के इनपुट के बारे में बताती है. अक्सर, एक एम्बेडिंग वेक्टर, फ़्लोटिंग-पॉइंट संख्याओं का कलेक्शन होता है एक एम्बेडिंग लेयर. उदाहरण के लिए, मान लें कि एम्बेडिंग लेयर को पृथ्वी पर पेड़ की 73,000 प्रजातियों में से हर एक के लिए एम्बेडिंग वेक्टर. शायद नीचे दी गई अरे बेओबैब ट्री के लिए एम्बेडिंग वेक्टर है:

एम्बेडिंग वेक्टर, रैंडम नंबरों का ग्रुप नहीं होता. एम्बेडिंग लेयर ट्रेनिंग के ज़रिए इन वैल्यू को तय करता है. यह वैसे ही होता है जैसे न्यूरल नेटवर्क को ट्रेनिंग के दौरान अन्य चीज़ों के बारे में पता चलता है. इसका हर एक एलिमेंट अरे, पेड़ की प्रजातियों की कुछ खासियतों के साथ मिलने वाली रेटिंग है. कौनसा एलिमेंट दिखाता है कि किस पेड़ की प्रजाति' विशेषता? यह बहुत मुश्किल है तय करें.
एम्बेडिंग वेक्टर का गणितीय तौर पर सबसे अहम हिस्सा यह है कि आइटम में फ़्लोटिंग-पॉइंट संख्याओं के समान सेट होते हैं. उदाहरण के लिए, मिलते-जुलते पेड़ों की प्रजातियों की संख्या, फ़्लोटिंग-पॉइंट संख्याओं के सेट से ज़्यादा मिलती-जुलती होती है पेड़ों की अलग-अलग किस्में हैं. रेडवुड और सिक्वॉया, एक-दूसरे से संबंधित पेड़ों की प्रजातियां हैं. इसलिए, उनके पास फ़्लोटिंग-पॉइंटिंग नंबरों का सेट रेडवुड और नारियल के पेड़. एम्बेडिंग वेक्टर में संख्याएं मॉडल को फिर से ट्रेनिंग देते समय, हर बार मॉडल को बदला जाए, भले ही आप मॉडल को फिर से ट्रेनिंग दें एक जैसे इनपुट के साथ.
एन्कोडर
आम तौर पर, कोई भी एमएल सिस्टम जो रॉ, स्पार्स या एक्सटर्नल से कन्वर्ट होता है और ज़्यादा प्रोसेस, सघन या ज़्यादा अंदरूनी रूप से दिखाना.
एन्कोडर अक्सर किसी बड़े मॉडल का हिस्सा होता है, जहां अक्सर डीकोडर के साथ जुड़ा हो. कुछ ट्रांसफ़ॉर्मर एन्कोडर को डिकोडर के साथ जोड़ें, हालांकि दूसरे ट्रांसफ़ॉर्मर सिर्फ़ एन्कोडर का इस्तेमाल करते हैं या सिर्फ़ डिकोडर.
कुछ सिस्टम, कैटगरी तय करने के लिए इनपुट के तौर पर एन्कोडर के आउटपुट का इस्तेमाल करते हैं या रिग्रेशन नेटवर्क.
सिलसिलेवार टास्क में, एक एन्कोडर इनपुट क्रम लेता है और एक अंदरूनी स्थिति (वेक्टर) देता है. इसके बाद, डीकोडर उस अंदरूनी स्थिति का इस्तेमाल करके, अगले क्रम का अनुमान लगाता है.
किसी एन्कोडर की परिभाषा जानने के लिए, Transformer देखें देखें.
F
कुछ शॉट के साथ प्रॉम्प्ट देना
ऐसा प्रॉम्प्ट जिसमें एक से ज़्यादा ("कुछ") उदाहरण शामिल हों यह दिखाता है कि बड़ा लैंग्वेज मॉडल को जवाब देना चाहिए. उदाहरण के लिए, नीचे दिए गए लंबे प्रॉम्प्ट में दो क्वेरी शामिल हैं ये उदाहरण, क्वेरी का जवाब देने के लिए बड़ा लैंग्वेज मॉडल दिखाते हैं.
| एक प्रॉम्प्ट के हिस्से | नोट |
|---|---|
| किसी चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब एलएलएम से देना है. |
| फ़्रांस: EUR | एक उदाहरण. |
| यूनाइटेड किंगडम: GBP | एक और उदाहरण. |
| भारत: | असल क्वेरी. |
आम तौर पर, कुछ शॉट के साथ प्रॉम्प्ट दिखाने पर ज़्यादा काम के नतीजे मिलते हैं. ज़ीरो-शॉट प्रॉम्प्ट और वन-शॉट प्रॉम्प्ट. हालांकि, कुछ ही शॉट में के लिए एक लंबा प्रॉम्प्ट चाहिए.
फ़्यू-शॉट प्रॉम्प्ट को कुछ शॉट से सीखें में इस्तेमाल किया जा सकता है प्रॉम्प्ट पर आधारित लर्निंग पर लागू किया जाता है.
वायलिन
Python-फ़र्स्ट कॉन्फ़िगरेशन वाली कॉन्फ़िगरेशन लाइब्रेरी, जो इनवेसिव कोड या इन्फ़्रास्ट्रक्चर के बिना फ़ंक्शन और क्लास की वैल्यू. Pax और अन्य एमएल कोडबेस के मामले में, ये फ़ंक्शन और क्लास में मॉडल और ट्रेनिंग को दिखाया जाता है हाइपर पैरामीटर.
फ़िडल यह मानता है कि आम तौर पर मशीन लर्निंग कोड बेस में बंटे होते हैं:
- लाइब्रेरी कोड, जो लेयर और ऑप्टिमाइज़र के बारे में बताता है.
- "glue" डेटासेट कोड, जो लाइब्रेरी को कॉल करता है और सब कुछ एक साथ कनेक्ट करता है.
Fiddle, बिना आकलन किए गए ग्लू कोड के कॉल स्ट्रक्चर को कैप्चर करता है और बदला जा सकता है.
फ़ाइन ट्यूनिंग
एक दूसरा, टास्क के हिसाब से ट्रेनिंग पास, जिसे प्री-ट्रेन किए गए मॉडल का इस्तेमाल इस्तेमाल के उदाहरण के हिसाब से. उदाहरण के लिए, कुछ लोगों के लिए ट्रेनिंग का पूरा क्रम बड़े लैंग्वेज मॉडल के बारे में यहां बताया गया है:
- प्री-ट्रेनिंग: एक बड़े सामान्य डेटासेट की मदद से, बड़े लैंग्वेज मॉडल को ट्रेनिंग दें, जैसे कि अंग्रेज़ी भाषा के सभी Wikipedia पेज.
- फ़ाइन-ट्यूनिंग: पहले से ट्रेन किए गए मॉडल को कोई खास टास्क करने के लिए ट्रेनिंग दें, जैसे, स्वास्थ्य से जुड़ी क्वेरी का जवाब देना. आम तौर पर, फ़ाइन ट्यूनिंग के दौरान किसी खास टास्क पर फ़ोकस करने वाले सैकड़ों या हज़ारों उदाहरण.
दूसरे उदाहरण के तौर पर, किसी बड़े इमेज मॉडल के लिए पूरी ट्रेनिंग का क्रम इस तरह है अनुसरण करता है:
- प्री-ट्रेनिंग: बड़ी सामान्य इमेज के आधार पर, बड़े इमेज मॉडल को ट्रेनिंग दें डेटासेट का इस्तेमाल करें, जैसे कि Wikimedia Commons की सभी इमेज.
- फ़ाइन-ट्यूनिंग: पहले से ट्रेन किए गए मॉडल को कोई खास टास्क करने के लिए ट्रेनिंग दें, जैसे कि ओर्का की इमेज जनरेट करना.
ऐसेट को बेहतर बनाने के लिए, यहां दी गई रणनीतियों का कोई भी कॉम्बिनेशन इस्तेमाल किया जा सकता है:
- पहले से ट्रेन किए गए सभी मौजूदा मॉडल में बदलाव करना पैरामीटर. इसे कभी-कभी फ़ुल फ़ाइन ट्यूनिंग भी कहा जाता है.
- पहले से ट्रेन किए गए मॉडल के सिर्फ़ कुछ पैरामीटर में बदलाव करना (आम तौर पर, आउटपुट लेयर के सबसे करीब की लेयर), जबकि अन्य मौजूदा पैरामीटर में कोई परिवर्तन न करें (आमतौर पर, परतें यह इनपुट लेयर के सबसे नज़दीक होता है. यहां जाएं: पैरामीटर की बेहतर ट्यूनिंग.
- आमतौर पर लेयर के सबसे नज़दीक वाली मौजूदा लेयर में ज़्यादा लेयर जोड़ना आउटपुट लेयर.
फ़ाइन ट्यूनिंग, ट्रांसफ़र लर्निंग का एक तरीका है. इसलिए, फ़ाइन ट्यूनिंग अलग लॉस फ़ंक्शन या अलग मॉडल का इस्तेमाल कर सकता है का इस्तेमाल करने पर मिलती है. उदाहरण के लिए, आपके पास ये विकल्प हैं ऐसा रिग्रेशन मॉडल बनाने के लिए, पहले से ट्रेनिंग पा चुके बड़े इमेज मॉडल को बेहतर बनाएं इनपुट इमेज में पक्षियों की संख्या दिखाता है.
फ़ाइन-ट्यूनिंग की तुलना, नीचे दिए गए शब्दों से करें:
फ़्लैक्स
बेहतर परफ़ॉर्मेंस वाला ओपन सोर्स लाइब्रेरी के लिए डीप लर्निंग को JAX पर बनाया गया है. फ़्लैक्स फ़ंक्शन देता है ट्रेनिंग के न्यूरल नेटवर्क के लिए भी उनकी परफ़ॉर्मेंस का आकलन करने के तरीकों के बारे में बताया गया है.
Flaxformer
ओपन सोर्स Transformer लाइब्रेरी, फ़्लेक्स पर बनाया गया, जिसे खास तौर पर नैचुरल लैंग्वेज प्रोसेसिंग के लिए डिज़ाइन किया गया है और मल्टीमोडल रिसर्च शामिल करें.
G
जनरेटिव एआई
बदलाव लाने वाला उभरता हुआ फ़ील्ड, जिसकी कोई औपचारिक परिभाषा नहीं है. हालांकि, ज़्यादातर विशेषज्ञ इस बात से सहमत हैं कि जनरेटिव एआई मॉडल बनाने ("जनरेट करने") वाला ऐसा कॉन्टेंट बनाएं जिसमें ये सभी चीज़ें शामिल हों:
- जटिल
- आसानी से समझ में आने वाला
- मूल
उदाहरण के लिए, जनरेटिव एआई मॉडल, एआई की मदद से निबंध या इमेज.
पहले की कुछ टेक्नोलॉजी, जिनमें LSTMs शामिल है और RNN भी ओरिजनल मैसेज जनरेट कर सकते हैं और आसानी से इस्तेमाल किया जा सकता है. कुछ विशेषज्ञ इन पुरानी टेक्नोलॉजी को जनरेटिव एआई, जबकि कुछ अन्य लोगों को लगता है कि सही जनरेटिव एआई के लिए ज़्यादा मुश्किल जितनी पुरानी टेक्नोलॉजी की मदद से आउटपुट मिल सकता है.
अनुमानित ML में अंतर करें.
GPT (जनरेटिव प्री-ट्रेन्ड ट्रांसफ़ॉर्मर)
Transformer-आधारित परिवार बड़े लैंग्वेज मॉडल, जिन्हें इन्होंने बनाया है OpenAI.
GPT के वैरिएंट कई मॉडलिंग पर लागू किए जा सकते हैं. इनमें ये शामिल हैं:
- इमेज जनरेट करना (उदाहरण के लिए, ImageGPT)
- टेक्स्ट को इमेज में बदलने की सुविधा (उदाहरण के लिए, DALL-E).
H
गलत जानकारी
अनुमान के हिसाब से दिखने वाले, लेकिन तथ्यों के हिसाब से गलत आउटपुट का इस्तेमाल जनरेटिव एआई मॉडल का इस्तेमाल असल दुनिया पर किए गए दावे. उदाहरण के लिए, ऐसा जनरेटिव एआई मॉडल जिसमें दावा किया गया हो कि बराक ओबामा की 1865 में मौत हुई थी गलत जानकारी देता है.
I
इन-कॉन्टेक्स्ट लर्निंग
कुछ शॉट प्रॉम्प्ट के लिए समानार्थी शब्द.
L
LaMDA (बातचीत ऐप्लिकेशन के लिए भाषा का मॉडल)
Transformer-आधारित बड़ा लैंग्वेज मॉडल. इसे Google ने डेवलप किया है. इसे Google ने ट्रेनिंग दी है यह एक बड़ा डायलॉग डेटासेट है, जो बातचीत के असली लगने वाले जवाब दे सकता है.
LaMDA: हमारी अहम बातचीत टेक्नोलॉजी से खास जानकारी मिलती है.
लैंग्वेज मॉडल
ऐसा मॉडल जो टोकन की संभावना का अनुमान लगाता है या टोकन की एक लंबी सूची में होने वाले टोकन का क्रम.
लार्ज लैंग्वेज मॉडल
एक अनौपचारिक शब्द जिसमें कोई सख्त परिभाषा नहीं होती है, जिसका मतलब आम तौर पर भाषा के मॉडल को चुनें पैरामीटर. बड़े लैंग्वेज मॉडल में 100 अरब से ज़्यादा पैरामीटर होते हैं.
लैटेंट स्पेस
स्पेस एम्बेड करने का समानार्थी शब्द.
LLM
बड़े लैंग्वेज मॉडल के लिए छोटा नाम.
LoRA
कम रैंक के हिसाब से ढल जाने की क्षमता का छोटा नाम.
कम रैंक के हिसाब से ढलने की क्षमता (LoRA)
बेहतर परफ़ॉर्म करने वाला एल्गोरिदम पैरामीटर की बेहतर ट्यूनिंग, जो फ़ाइन-ट्यून बड़े लैंग्वेज मॉडल के पैरामीटर. LoRA से ये फ़ायदे मिलते हैं:
- ऐसी तकनीकों से ज़्यादा तेज़ी से फ़ाइन-ट्यून करता है, जिनके लिए किसी मॉडल की सभी को फ़ाइन-ट्यून करने की ज़रूरत होती है पैरामीटर का इस्तेमाल करें.
- अनुमान की कंप्यूटेशनल लागत को कम करता है: मॉडल को बेहतर बनाना.
LoRA के साथ तैयार किया गया मॉडल अपने अनुमानों की क्वालिटी को बनाए रखता है या उसे बेहतर बनाता है.
LoRA किसी मॉडल के कई खास वर्शन को चालू करता है.
M
मास्क्ड लैंग्वेज मॉडल
भाषा का ऐसा मॉडल जो यह अनुमान लगाता है कि खाली जगह को भरने के लिए, उम्मीदवार के टोकन का इस्तेमाल करें. उदाहरण के लिए, मास्क वाला लैंग्वेज मॉडल, उम्मीदवार के शब्दों की प्रायिकता का हिसाब लगा सकता है नीचे दिए गए वाक्य में अंडरलाइन को बदलने के लिए:
टोपी में ____ वापस आ गया.
साहित्य में आम तौर पर "MASK" स्ट्रिंग का इस्तेमाल किया जाता है ध्यान रखें. उदाहरण के लिए:
"MASK" टोपी में वापस आ गया.
ज़्यादातर आधुनिक मास्क वाले लैंग्वेज मॉडल दो-तरफ़ा हैं.
मेटा-लर्निंग
मशीन लर्निंग का एक सबसेट जो लर्निंग एल्गोरिदम को खोजता है या उसे बेहतर बनाता है. मेटा-लर्निंग सिस्टम का लक्ष्य किसी मॉडल को ट्रेनिंग देना, ताकि वह किसी नए मॉडल को तुरंत सीख सके छोटे डेटा से या पिछले टास्क में मिले अनुभव के आधार पर मिला टास्क. मेटा-लर्निंग एल्गोरिदम आम तौर पर इन कामों को करने की कोशिश करते हैं:
- हाथ से बनी सुविधाओं (जैसे, इनीशियलाइज़र या ऑप्टिमाइज़र होते हैं.
- डेटा की कम खपत और गणना करने की क्षमता होनी चाहिए.
- सामान्य जानकारी को बेहतर बनाएं.
मेटा-लर्निंग, कुछ शॉट के साथ सीखना से जुड़ा है.
मोडलिटी
डेटा की बेहतर कैटगरी. उदाहरण के लिए, संख्याएं, टेक्स्ट, इमेज, वीडियो, और ऑडियो पांच अलग-अलग तरीके हैं.
मॉडल पैरलिज़्म
यह ट्रेनिंग या अनुमान को स्केल करने का एक तरीका है, जिसमें अलग-अलग हिस्सों में ट्रेनिंग दी जाती है अलग-अलग डिवाइस पर मॉडल का इस्तेमाल करें. मॉडल समानांतरवाद ऐसे मॉडल को चालू करता है जो एक डिवाइस पर फ़िट होने के लिए बहुत बड़े होते हैं.
मॉडल समानता को लागू करने के लिए, सिस्टम आम तौर पर ये काम करता है:
- शार्ड, मॉडल को छोटे-छोटे हिस्सों में बांटते हैं.
- उन छोटे पार्ट को बनाने की ट्रेनिंग, एक से ज़्यादा प्रोसेसर के बीच बांटती है. हर प्रोसेसर, मॉडल का अपना हिस्सा खुद ही तैयार करता है.
- नतीजों को जोड़कर एक मॉडल बनाता है.
मॉडल पैरलिज़्म ट्रेनिंग को धीमा कर देता है.
डेटा समानता भी देखें.
मल्टी-हेड सेल्फ़-अटेंशन
खुद का ध्यान रखने की सुविधा का एक एक्सटेंशन, जो इनपुट सीक्वेंस में हर पोज़िशन के लिए, कई बार सेल्फ़-अटेंशन मैकेनिज़्म.
ट्रांसफ़ॉर्मर ने मल्टी-हेड सेल्फ़-अटेंशन पेश किया.
मल्टीमोडल मॉडल
ऐसा मॉडल जिसके इनपुट और/या आउटपुट में एक से ज़्यादा फ़ील्ड शामिल हैं मोडैलिटी का इस्तेमाल करें. उदाहरण के लिए, ऐसे मॉडल पर विचार करें जो दोनों एक इमेज और एक टेक्स्ट का कैप्शन (दो तरीके) सुविधाएँ के तौर पर, और एक स्कोर देता है, जो बताता है कि इमेज के लिए टेक्स्ट का कैप्शन कितना सही है. इसलिए, इस मॉडल के इनपुट मल्टीमोडल होते हैं और आउटपुट यूनिमोडल होता है.
नहीं
नैचुरल लैंग्वेज अंडरस्टैंडिंग
उपयोगकर्ता ने क्या टाइप किया है या क्या कहा है, इस आधार पर उपयोगकर्ता का इरादा तय करना. उदाहरण के लिए, सर्च इंजन आम भाषा की समझ का इस्तेमाल इन कामों के लिए करता है उपयोगकर्ता ने क्या टाइप किया है या क्या कहा है, इसके आधार पर यह तय किया जा सकता है कि उपयोगकर्ता क्या खोज रहा है.
एन-ग्राम
N शब्दों का ऑर्डर किया गया क्रम. उदाहरण के लिए, पूरी तरह से पागलपन में 2-ग्राम होता है. क्योंकि में ऑर्डर करना चाहिए, लेकिन पूरी तरह से पूरी तरह से पागल की तुलना में एक अलग 2-ग्राम होता है.
| नहीं | इस तरह के एन-ग्राम के लिए नाम | उदाहरण |
|---|---|---|
| 2 | बड़ाम या 2-ग्राम | जाना, जाना, दोपहर का खाना, खाना |
| 3 | ट्राइग्राम या 3-ग्राम | बहुत ज़्यादा खाया, तीन अंधे चूहे, बेल टोल |
| 4 | 4 ग्राम | पार्क में टहलना, हवा में धूल भरी आंधी, बच्चे ने दाल खा ली |
सामान्य भाषा की समझ मॉडल, N-ग्राम की मदद से यह अनुमान लगाते हैं कि उपयोगकर्ता कौनसा शब्द टाइप करेगा या कहें. उदाहरण के लिए, मान लें कि किसी उपयोगकर्ता ने तीन ब्लाइंड टाइप किया. त्रिकोणमिति पर आधारित एक एनएलयू मॉडल यह अनुमान लगाएगा कि उपयोगकर्ता, अगली बार माइस टाइप करेगा.
शब्दों के बैग के साथ N-ग्राम के बीच अंतर करें, जो कि शब्दों का बिना क्रम वाला सेट.
एनएलयू
प्राकृतिक भाषा के लिए संक्षिप्त नाम समझना.
O
वन-शॉट प्रॉम्प्ट
एक ऐसा प्रॉम्प्ट जिसमें एक उदाहरण शामिल हो. इसमें बताया गया हो कि कैसे बड़े लैंग्वेज मॉडल का जवाब देना चाहिए. उदाहरण के लिए, नीचे दिए गए प्रॉम्प्ट में एक उदाहरण शामिल है. इसमें लार्ज लैंग्वेज मॉडल को दिखाया गया है कि इससे किसी क्वेरी का जवाब मिलना चाहिए.
| एक प्रॉम्प्ट के हिस्से | नोट |
|---|---|
| किसी चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब एलएलएम से देना है. |
| फ़्रांस: EUR | एक उदाहरण. |
| भारत: | असल क्वेरी. |
वन-शॉट प्रॉम्प्ट की तुलना नीचे दिए गए शब्दों से करें:
P
पैरामीटर-कुशल ट्यूनिंग
बड़े पैमाने पर बेहतर तकनीकों का सेट प्री-ट्रेन्ड लैंग्वेज मॉडल (पीएलएम) ज़्यादा बेहतर तरीके से काम करती है. फ़ाइन-ट्यूनिंग का इस्तेमाल करती है. पैरामीटर-कुशल आम तौर पर, ट्यूनिंग पूरे डेटा के मुकाबले काफ़ी कम पैरामीटर होते हैं लेकिन आम तौर पर, बड़ा लैंग्वेज मॉडल, जो या करीब-करीब पूरे डेटा से बना एक बड़ा लैंग्वेज मॉडल भी फ़ाइन-ट्यून.
पैरामीटर-कुशल ट्यूनिंग की इनके साथ तुलना करें:
पैरामीटर-कुशल ट्यूनिंग को पैरामीटर-कुशल फ़ाइन-ट्यूनिंग भी कहा जाता है.
पाइपलाइनिंग
मॉडल पैरलिज़्म का एक फ़ॉर्म, जिसमें मॉडल प्रोसेसिंग को लगातार अलग-अलग चरणों में बांटा जाता है और हर चरण पूरा किया जाता है किसी अन्य डिवाइस पर इंस्टॉल करें. जब कोई चरण एक बैच को प्रोसेस कर रहा होता है, तो उसके पहले वाले बैच को प्रोसेस किया जाता है स्टेज अगले बैच पर काम कर सकता है.
स्टेज की गई ट्रेनिंग भी देखें.
PLM
पहले से ट्रेन की गई भाषा के मॉडल का छोटा नाम.
पोज़िशनल एन्कोडिंग
किसी क्रम में टोकन की रैंक के बारे में जानकारी जोड़ने की तकनीक टोकन को एम्बेड करना. ट्रांसफ़ॉर्मर मॉडल पोज़िशनल का इस्तेमाल करते हैं के विभिन्न भागों के बीच के संबंध को बेहतर ढंग से समझने के लिए एन्कोडिंग क्रम.
पोज़िशनल एन्कोडिंग को आम तौर पर लागू करने के लिए, साइनसोइडल फ़ंक्शन का इस्तेमाल किया जाता है. (खास तौर पर, साइनसोइडल फ़ंक्शन की फ़्रीक्वेंसी और डाइमेंशन क्रम में टोकन की पोज़िशन से तय होता है.) इस तकनीक की मदद से, ट्रांसफ़ॉर्मर मॉडल को स्कूल के अलग-अलग हिस्सों में मौजूद क्रम में दिखाया जाएगा.
पहले से ट्रेन किया गया मॉडल
मॉडल या मॉडल कॉम्पोनेंट (जैसे, एम्बेडिंग वेक्टर) भेजना होगा, जिसे पहले ही ट्रेनिंग दी जा चुकी है. कभी-कभी, आप पहले से ट्रेन किए गए एम्बेडिंग वेक्टर को न्यूरल नेटवर्क का इस्तेमाल करें. अन्य मामलों में, आपका मॉडल वेक्टर खुद ही एम्बेड हो जाता है, न कि वह पहले से ट्रेन की गई एम्बेडिंग पर निर्भर रहता है.
प्री-ट्रेन्ड लैंग्वेज मॉडल शब्द का मतलब बड़ा लैंग्वेज मॉडल, जो अब इस्तेमाल किया जा चुका है प्री-ट्रेनिंग.
प्री-ट्रेनिंग
एक बड़े डेटासेट पर मॉडल की शुरुआती ट्रेनिंग. कुछ ऐसे मॉडल जिन्हें पहले से ट्रेनिंग दी गई है अनाड़ी दिग्गज होते हैं और उन्हें आम तौर पर अतिरिक्त ट्रेनिंग की ज़रूरत होती है. उदाहरण के लिए, मशीन लर्निंग के विशेषज्ञ बड़े टेक्स्ट डेटासेट पर, बड़ा लैंग्वेज मॉडल, जैसे कि विकिपीडिया के सभी अंग्रेज़ी पेज. प्री-ट्रेनिंग के बाद, आगे दिए गए विकल्पों में से किसी का इस्तेमाल करके, मॉडल को बेहतर बनाया जा सकता है तकनीकें:
मैसेज
बड़े लैंग्वेज मॉडल के इनपुट के तौर पर डाला गया कोई भी टेक्स्ट का इस्तेमाल करें. प्रॉम्प्ट इतने छोटे हो सकते हैं वाक्यांश या फिर मनचाहे तरीके से लंबा पासवर्ड डालें. उदाहरण के लिए, किसी उपन्यास का पूरा टेक्स्ट. प्रॉम्प्ट कई कैटगरी में आते हैं. इनमें, इस टेबल में दी गई कैटगरी भी शामिल हैं:
| प्रॉम्प्ट की कैटगरी | उदाहरण | नोट |
|---|---|---|
| सवाल | कबूतर कितनी तेज़ी से उड़ सकता है? | |
| निर्देश | आर्बिट्रेज के बारे में एक मज़ेदार कविता लिखें. | ऐसा प्रॉम्प्ट जिसमें बड़े लैंग्वेज मॉडल को कुछ करने के लिए कहा जाता है. |
| उदाहरण | मार्कडाउन कोड का अनुवाद एचटीएमएल में करें. जैसे:
अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है मार्कडाउन: * सूची आइटम अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है एचटीएमएल: <ul> <li>आइटम की सूची बनाएं</li> </ul> |
इस उदाहरण में पहला वाक्य एक निर्देश है. प्रॉम्प्ट का बाकी हिस्सा, उदाहरण के तौर पर दिया गया है. |
| भूमिका | यह बताना कि मशीन लर्निंग ट्रेनिंग में, ग्रेडिएंट डिसेंट का इस्तेमाल क्यों होता है आपने फ़िज़िक्स में पीएचडी की डिग्री ली है. | वाक्य का पहला हिस्सा एक निर्देश है; वाक्यांश "फ़िज़िक्स में पीएचडी की डिग्री हासिल की" भूमिका वाला हिस्सा है. |
| मॉडल को पूरा करने के लिए इनपुट का कुछ हिस्सा | यूनाइटेड किंगडम के प्रधानमंत्री यहां रहते हैं | पार्शियल इनपुट प्रॉम्प्ट या तो अचानक खत्म हो सकता है (जैसा कि इस उदाहरण में दिखाया गया है) या अंडरस्कोर पर खत्म होता है. |
जनरेटिव एआई मॉडल, किसी सवाल का जवाब, टेक्स्ट के ज़रिए दे सकता है. कोड, इमेज, एम्बेड करना, वीडियो...बहुत कुछ.
प्रॉम्प्ट के आधार पर सीखने की सुविधा
कुछ खास मॉडल की क्षमता, जो उन्हें किसी खास प्रॉडक्ट के हिसाब से ढलने में मदद करते हैं आर्बिट्रेरी टेक्स्ट इनपुट (प्रॉम्प्ट) के जवाब में उनका व्यवहार. प्रॉम्प्ट पर आधारित सीखने के एक आम मॉडल में, बड़े लैंग्वेज मॉडल के जवाब में, टेक्स्ट जनरेट कर रहा है. उदाहरण के लिए, मान लें कि कोई उपयोगकर्ता यह प्रॉम्प्ट डालता है:
न्यूटन के गति के तीसरे नियम का सारांश लिखें.
प्रॉम्प्ट के आधार पर सीखने में मदद करने वाले मॉडल को, जवाब देने के लिए ख़ास तौर पर ट्रेनिंग नहीं दी गई है पिछला प्रॉम्प्ट. इसके बजाय, मॉडल "जानता है" भौतिक विज्ञान के बारे में भाषा के सामान्य नियमों की जानकारी दी गई हो और उन चीज़ों के बारे में ज़्यादा जानकारी दी गई हो जिनमें सामान्य तौर पर उपयोगी जवाब. यह जानकारी (उम्मीद है कि) उपयोगी जानकारी देने के लिए काफ़ी है जवाब. लोगों से मिला अन्य सुझाव, जैसे कि "यह जवाब काफ़ी मुश्किल था." या "प्रतिक्रिया क्या होती है?"), प्रॉम्प्ट पर आधारित कुछ लर्निंग सिस्टम और उनके जवाबों को ज़्यादा काम का बनाया जा सके.
प्रॉम्प्ट डिज़ाइन
प्रॉम्प्ट इंजीनियरिंग का समानार्थी शब्द.
प्रॉम्प्ट इंजीनियरिंग
मनचाहा जवाब पाने वाले प्रॉम्प्ट बनाने की कला बड़े लैंग्वेज मॉडल से लिया गया है. प्रॉम्प्ट की कार्रवाई करते हुए इंसान इंजीनियरिंग. अच्छी तरह से स्ट्रक्चर किए गए प्रॉम्प्ट लिखना, यह पक्का करने का एक अहम हिस्सा है लार्ज लैंग्वेज मॉडल से काम के जवाब पाएँ. प्रॉम्प्ट इंजीनियरिंग इन चीज़ों पर निर्भर करती है कई बातों पर निर्भर करता है, जिनमें ये शामिल हैं:
- वह डेटासेट जिसका इस्तेमाल प्री-ट्रेन करने के लिए किया गया था और हो सकता है कि बड़े लैंग्वेज मॉडल को बेहतर बनाएं.
- तापमान और डिकोड करने के दूसरे पैरामीटर मॉडल, जवाब जनरेट करने के लिए इस्तेमाल करता है.
यहां जाएं: प्रॉम्प्ट के डिज़ाइन के बारे में जानकारी देखें.
प्रॉम्प्ट डिज़ाइन, प्रॉम्प्ट इंजीनियरिंग का एक समानार्थी शब्द है.
प्रॉम्प्ट ट्यूनिंग
पैरामीटर की बेहतर ट्यूनिंग का तरीका जो "प्रीफ़िक्स" का इस्तेमाल करता है लागू होने के बाद, सिस्टम असल प्रॉम्प्ट.
प्रॉम्प्ट ट्यूनिंग के एक वैरिएशन को प्रीफ़िक्स ट्यूनिंग भी कहा जाता है. हर लेयर में प्रीफ़िक्स जोड़ें. इसके उलट, ज़्यादातर प्रॉम्प्ट ट्यूनिंग इनपुट लेयर में प्रीफ़िक्स जोड़ता है.
R
भूमिका के लिए प्रॉम्प्ट
प्रॉम्प्ट का एक वैकल्पिक हिस्सा, जो टारगेट ऑडियंस की पहचान करता है जनरेटिव एआई मॉडल से मिले रिस्पॉन्स के लिए, डाइग्नोस्टिक टूल का इस्तेमाल किया जा सकता है. किसी भूमिका के बिना प्रॉम्प्ट, बड़ा लैंग्वेज मॉडल ऐसा जवाब देता है जो काम का हो भी सकता है और नहीं भी सवाल पूछने वाले व्यक्ति के लिए. रोल प्रॉम्प्ट के साथ, एक बड़ी भाषा मॉडल इस तरह से जवाब दे सकता है कि जो किसी खास टारगेट ऑडियंस को टारगेट करना. उदाहरण के लिए, नीचे दिए गए भूमिका प्रॉम्प्ट वाला हिस्सा प्रॉम्प्ट बोल्डफ़ेस में होते हैं:
- अर्थशास्त्र में पीएचडी के लिए इस लेख का सारांश बनाओ.
- बताओ कि 10 साल के बच्चे के लिए ज्वार कैसे काम करता है.
- 2008 की वित्तीय संकट के बारे में बताओ. जैसे, छोटे बच्चे से बात करें, या गोल्डन रिट्रीवर नस्ल का कुत्ता.
S
खुद का ध्यान रखना (इसे सेल्फ़-अटेंशन लेयर भी कहा जाता है)
एक न्यूरल नेटवर्क लेयर, जो एम्बेड करना (उदाहरण के लिए, टोकन एम्बेड करना) एम्बेड करने के एक और क्रम में जोड़ा जा सकता है. आउटपुट क्रम में हर एम्बेडिंग है यह इनपुट क्रम के एलिमेंट से मिली जानकारी को शामिल करके बनाया गया है ध्यान देने के तरीके से किया जाता है.
सेल्फ़-ध्यान रखने का खुद हिस्सा दिखाने का मतलब है, करने की ज़रूरत नहीं है. खुद का ध्यान रखना ट्रांसफ़ॉर्मर के लिए बिल्डिंग ब्लॉक और डिक्शनरी लुकअप का इस्तेमाल करता है शब्दावली, जैसे कि "query", "key", और "value".
खुद पर ध्यान देने वाली लेयर, इनपुट के सिलसिलेवार निर्देशों से शुरू होती है. डालें. किसी शब्द को इनपुट के तौर पर दिखाने के लिए, एम्बेड करना. किसी इनपुट क्रम में मौजूद हर शब्द के लिए, नेटवर्क कीवर्ड के हर एलिमेंट के लिए, शब्द के हिसाब से स्कोर तय करता है. शब्द. प्रासंगिकता से जुड़े स्कोर से यह तय होता है कि शब्द को कितनी बार लिखा गया है अन्य शब्दों के प्रतिनिधित्व शामिल करता है.
उदाहरण के लिए, इस वाक्य पर गौर करें:
जानवर बहुत थका हुआ था, इसलिए वह सड़क पार नहीं किया.
नीचे दिया गया उदाहरण (इससे) ट्रांसफ़ॉर्मर: भाषा के लिए एक नॉवल न्यूरल नेटवर्क आर्किटेक्चर समझना) it सर्वनाम के लिए, खुद पर ध्यान देने वाली लेयर का पैटर्न दिखाता है. हर पंक्ति का अंधेरा यह दिखाता है कि हर शब्द का कितना योगदान है प्रतिनिधित्व:
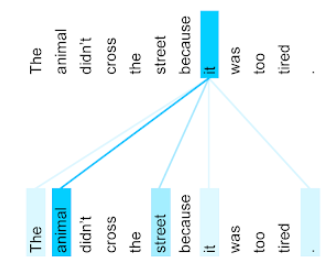
खुद पर ध्यान देने वाली लेयर, "इससे" काम के शब्दों को हाइलाइट करती है. इसमें केस, अटेंशन लेयर ने उन शब्दों को हाइलाइट करना सीख लिया है जिन्हें यह जानवर को सबसे ज़्यादा भार असाइन करना.
n टोकन के सीक्वेंस के लिए, खुद को ध्यान में रखने से एक क्रम बदल जाता है क्रम में हर जगह पर एक बार, n अलग-अलग बार एम्बेड करने की सुविधा.
ध्यान भी दें और मल्टी-हेड सेल्फ़-अटेंशन.
भावनाओं का विश्लेषण
किसी समूह की किसी सेवा, प्रॉडक्ट, संगठन या विषय. उदाहरण के लिए, सामान्य भाषा की समझ, एल्गोरिदम, टेक्स्ट वाले सुझाव पर भावनाओं का विश्लेषण कर सकता है यूनिवर्सिटी के कोर्स की मदद से, यह तय किया है कि किस छात्र/छात्रा ने किस डिग्री पर सामान्य रूप से कोर्स को पसंद या नापसंद किया.
टास्क को क्रम से लगाने के लिए इस्तेमाल किया जाने वाला टास्क
ऐसा टास्क जो टोकन के इनपुट क्रम को आउटपुट में बदलता है टोकन का क्रम तय नहीं कर सकता. उदाहरण के लिए, अनुक्रम-से-क्रम के दो लोकप्रिय प्रकार टास्क हैं:
- अनुवादक:
- इनपुट का क्रम: "मुझे तुमसे प्यार है".
- आउटपुट सीक्वेंस का सैंपल: "Je t'aime."
- सवाल का जवाब दें:
- इनपुट का क्रम: "क्या मुझे न्यूयॉर्क में अपनी कार चाहिए?"
- सैंपल आउटपुट सीक्वेंस: "नहीं. कृपया अपनी कार घर पर रखें."
skip-gram
एक n-gram, जो मूल शब्दों को छोड़ सकता है (या "स्किप" कर सकता है) संदर्भ का इस्तेमाल किया जाता है, तो हो सकता है कि N शब्द मूल रूप से उनके आस-पास न हों. ज़्यादा देखें ठीक है, "k-skip-n-gram" को एक n-ग्राम होता है, जिसके लिए k शब्द तक हो सकते हैं छोड़ा गया.
उदाहरण के लिए, "The Quick Brown fox" ये 2-ग्राम की हो सकती हैं:
- "तेज़"
- "क्विक ब्राउन"
- "भूरी लोमड़ी"
"1-स्किप-2-ग्राम" शब्दों का एक जोड़ा होता है, जिसमें ज़्यादा से ज़्यादा 1 शब्द हो सकता है. इसलिए, "द क्विक ब्राउन लोमड़ी" इसमें ये 1 स्किप 2 ग्राम हों:
- "द ब्राउन"
- "झटपट लोमड़ी"
इसके अलावा, सभी 2-ग्राम 1-स्किप-2-ग्राम भी होते हैं, क्योंकि कम एक शब्द से ज़्यादा स्किप किया जा सकता है.
स्किप-ग्राम की मदद से, किसी शब्द से जुड़े कॉन्टेक्स्ट को बेहतर तरीके से समझा जा सकता है. उदाहरण में, "लोमड़ी" "क्विक" से सीधे तौर पर जुड़ा था डेटा सेट में 1-स्किप-2-ग्राम, लेकिन 2-ग्राम के सेट में नहीं.
स्किप-ग्राम की मदद से ट्रेनिंग करें वर्ड एम्बेड करने के मॉडल.
सॉफ़्ट प्रॉम्प्ट ट्यूनिंग
बड़े लैंग्वेज मॉडल को ट्यून करने की तकनीक किसी विशेष कार्य के लिए, वह भी बिना संसाधन के फ़ाइन-ट्यूनिंग. उन सभी चीज़ों को फिर से ट्रेनिंग देने के बजाय मॉडल में वेट, सॉफ़्ट प्रॉम्प्ट ट्यूनिंग उसी लक्ष्य को पाने के लिए, प्रॉम्प्ट में अपने-आप बदलाव करता है.
टेक्स्ट प्रॉम्प्ट और सॉफ़्ट प्रॉम्प्ट ट्यूनिंग आम तौर पर, प्रॉम्प्ट में अतिरिक्त टोकन एम्बेड करता है और बैकप्रोपैगेशन का इस्तेमाल करें.
एक "हार्ड" प्रॉम्प्ट में टोकन एम्बेड करने के बजाय असल टोकन शामिल होते हैं.
विरल सुविधा
ऐसी सुविधा जिसकी वैल्यू शून्य या खाली है. उदाहरण के लिए, अगर किसी सुविधा में एक वैल्यू और 0 मिलियन 0 वैल्यू हों कम इसके उलट, सघनता वाली सुविधा में ऐसे मान होते हैं जो मुख्य रूप से शून्य या खाली नहीं हैं.
मशीन लर्निंग में, बहुत सारी सुविधाएं कम काम की होती हैं. कैटगरी के हिसाब से मिलने वाली सुविधाएं, आम तौर पर कम जानकारी वाली होती हैं. उदाहरण के लिए, जंगल में मौजूद पेड़ों की 300 संभावित प्रजातियों में से, सिर्फ़ मैपल ट्री की पहचान कर सकती है. या लाखों में से वीडियो लाइब्रेरी में संभावित वीडियो की संख्या में से एक है. बस "कैसाब्लांका."
मॉडल में, आम तौर पर कम सुविधाएं वन-हॉट एन्कोडिंग का इस्तेमाल करें. अगर वन-हॉट एन्कोडिंग बड़ी है, आपके पास सबसे ऊपर एम्बेडिंग लेयर का इस्तेमाल करने का विकल्प होता है बेहतर परफ़ॉर्मेंस के लिए, वन-हॉट एन्कोडिंग.
स्पैर्स रिप्रज़ेंटेशन
स्पार्स सुविधा में, शून्य के अलावा अन्य एलिमेंट की सिर्फ़ पोज़िशन को स्टोर करना.
उदाहरण के लिए, मान लें कि species नाम की एक कैटगरी वाली सुविधा, Google Analytics 36
किसी जंगल में किस तरह के पेड़ हैं. इसके अलावा, मान लीजिए कि हर
example सिर्फ़ एक प्रजाति की पहचान करता है.
हर उदाहरण में पेड़ की प्रजाति को दिखाने के लिए, वन-हॉट वेक्टर का इस्तेमाल किया जा सकता है.
वन-हॉट वेक्टर में एक 1 होगा (
उस उदाहरण में पेड़ों की खास प्रजातियां) और 35 0 (
उस उदाहरण में पेड़ों की 35 प्रजातियां नहीं हैं). इसलिए,
का maple कुछ ऐसा दिख सकता है:

इसके अलावा, विरल निरूपण से सिर्फ़
खास प्रजाति का इस्तेमाल किया जाता है. अगर maple, पोज़िशन 24 पर है, तो स्पैर्स रिप्रज़ेंटेशन
का maple बस होगा:
24
ध्यान दें कि विरल निरूपण वन-हॉट की तुलना में अधिक संक्षिप्त है प्रतिनिधित्व.
थोड़ा और जटिल उदाहरण देखने के लिए आइकॉन पर क्लिक करें.
मान लीजिए कि आपके मॉडल के प्रत्येक उदाहरण में शब्दों का प्रतिनिधित्व करना होगा—लेकिन उन शब्दों का क्रम—अंग्रेजी वाक्य में. अंग्रेज़ी में करीब 1,70,000 शब्द हैं. इसलिए, अंग्रेज़ी को एक खास कैटगरी है जिसमें करीब 1,70,000 एलिमेंट शामिल हैं. ज़्यादातर अंग्रेज़ी वाक्यों में इन 170,000 शब्दों का बहुत छोटा सा अंश है, इसलिए शब्दों का सेट में से एक उदाहरण काफ़ी हद तक कम जानकारी वाला डेटा होगा.
इस वाक्य पर गौर करें:
My dog is a great dog
इस वाक्य. इस वैरिएंट में, वेक्टर की एक से ज़्यादा सेल में ये शामिल हो सकते हैं शून्य के अलावा अन्य वैल्यू. इसके अलावा, इस वैरिएंट की सेल में एक पूर्णांक हो सकता है एक को छोड़कर. हालांकि, "मेरा", "है", "a", और "शानदार" शब्द इस्तेमाल किए गए हैं केवल दिखाई देते हैं एक वाक्य में "कुत्ता" शब्द दो बार दिखाई देता है. इसके इस वैरिएंट का इस्तेमाल करके इस वाक्य में शब्दों को दर्शाने के लिए वन-हॉट वेक्टर से ये नतीजे मिलते हैं 1,70,000 एलिमेंट वाला वेक्टर:

एक ही वाक्य को कम शब्दों में इस तरह पेश किया जाएगा:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
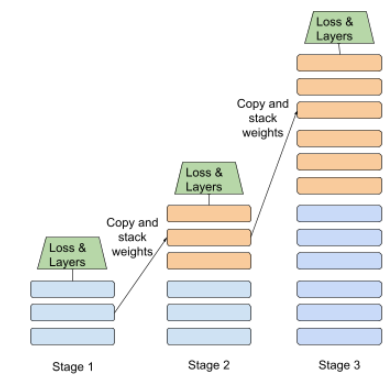
कुछ लोगों के लिए ट्रेनिंग
अलग-अलग स्टेज के हिसाब से किसी मॉडल को ट्रेनिंग देने की रणनीति. लक्ष्य कोई भी हो सकता है या तो ट्रेनिंग प्रोसेस को तेज़ करने या मॉडल की क्वालिटी को बेहतर बनाने के लिए.
प्रोग्रेसिव स्टैकिंग अप्रोच का इलस्ट्रेशन नीचे दिखाया गया है:
- पहले चरण में तीन छिपी हुई लेयर होती हैं और दूसरे चरण में छह छिपी हुई लेयर होती हैं. स्टेज 3 में 12 छिपी हुई लेयर हैं.
- स्टेज 2, छिपी हुई तीन लेयर में सीखे गए वज़न के साथ ट्रेनिंग शुरू करता है पहला चरण. स्टेज 3, 6 क्लास में सीखे गए वज़न के साथ ट्रेनिंग शुरू करती है स्टेज 2 की छिपी हुई लेयर.
पाइपलाइनिंग भी देखें.
सबवर्ड टोकन
भाषा के मॉडल में, एक टोकन जो किसी शब्द की सबस्ट्रिंग, जो पूरा शब्द हो सकता है.
उदाहरण के लिए, "itemize" जैसा कोई शब्द अलग-अलग हिस्सों में बांटे गए "आइटम" (मूल शब्द) और "ize" (एक प्रत्यय), जिनमें से हर एक को खुद ही दिखाया गया है टोकन. असामान्य शब्दों को सब-वर्ड (सबवर्ड) में बांटने की सुविधा इस्तेमाल करने से शब्द के सामान्य तौर पर इस्तेमाल होने वाले भाषा मॉडल, जैसे कि प्रीफ़िक्स और सफ़िक्स.
इसके उलट, "going" जैसे सामान्य शब्द हो सकता है कि वह बंटा न हो और जिसे एक टोकन से दिखाया जाता है.
T
T5
टेक्स्ट-टू-टेक्स्ट ट्रांसफ़र लर्निंग मॉडल इसने पेश किया साल 2020 में Google का एआई. T5 एक एन्कोडर-डीकोडर मॉडल है, जो Transformer आर्किटेक्चर, जिसे बहुत बड़ी डेटासेट. यह कई तरह के नैचुरल लैंग्वेज प्रोसेसिंग टास्क में असरदार है, जैसे, टेक्स्ट जनरेट करना, भाषाओं का अनुवाद करना, और बातचीत करने का तरीका बताया गया है.
"टेक्स्ट-टू-टेक्स्ट ट्रांसफ़र ट्रांसफ़ॉर्मर" में पांच T5 गेम का नाम T5 है.
टी5एक्स
यह एक ओपन सोर्स मशीन लर्निंग फ़्रेमवर्क है बड़े पैमाने पर नैचुरल लैंग्वेज प्रोसेसिंग को बनाने और ट्रेन करने के लिए (एनएलपी) मॉडल. T5 को T5X कोड बेस पर लागू किया जाता है (जो इसे JAX और Flax पर बनाया गया है).
तापमान
ऐसा हाइपर पैरामीटर जो रैंडमनेस को कंट्रोल करता है होता है. ज़्यादा तापमान से नतीजे अलग-अलग दिखते हैं, जबकि कम तापमान से कम रैंडम आउटपुट मिलता है.
सबसे अच्छा तापमान चुनना, अलग-अलग तरह के ऐप्लिकेशन और मॉडल के आउटपुट की पसंदीदा प्रॉपर्टी. उदाहरण के लिए, आपको ऐसा ऐप्लिकेशन बनाते समय तापमान बढ़ा सकता है जो क्रिएटिव आउटपुट जनरेट करता है. इसके उलट, शायद आप तापमान को कम करेंगे जब एक ऐसा मॉडल बनाया जाता है जो इमेज या टेक्स्ट की कैटगरी तय करता है, मॉडल कितना सटीक और एक जैसा है.
तापमान का इस्तेमाल अक्सर softmax के साथ किया जाता है.
टेक्स्ट स्पैन
यह अरे इंडेक्स स्पैन, जो किसी टेक्स्ट स्ट्रिंग के किसी खास सब-सेक्शन से जुड़ा होता है.
उदाहरण के लिए, Python स्ट्रिंग s="Be good now" में good शब्द इस्तेमाल किया जा रहा है
टेक्स्ट में 3 से 6 तक का समय शामिल करें.
टोकन
भाषा के मॉडल में, इस मॉडल की ऐटॉमिक यूनिट तैयार करने और उनके लिए अनुमान लगाने में मदद करता है. टोकन आम तौर पर, फ़ॉलो किया जा रहा है:
- कोई शब्द—उदाहरण के लिए, वाक्यांश "कुत्तों को बिल्लियों जैसा" इसमें तीन शब्द हैं टोकन: "कुत्ते", "पसंद", और "बिल्लियां".
- कोई वर्ण—उदाहरण के लिए, वाक्यांश "बाइक मछली" नौ शामिल हैं वर्ण टोकन. (ध्यान दें कि खाली जगह को एक टोकन के तौर पर गिना जाता है.)
- सबवर्ड—जिसमें एक शब्द एक टोकन या एक से ज़्यादा टोकन हो सकता है. सबवर्ड में रूट शब्द, प्रीफ़िक्स या सफ़िक्स होता है. उदाहरण के लिए, अगर भाषा मॉडल में सबवर्ड का इस्तेमाल टोकन के तौर पर किया जाता है, तो हो सकता है कि आपको "कुत्ते" शब्द दिखे दो टोकन के रूप में (रूट शब्द "डॉग" और बहुवचन सफ़िक्स "s"). वही हो सकता है कि भाषा मॉडल में एक शब्द "लंबा" दिखे दो सबवर्ड के तौर पर ( मूल शब्द "tall" और प्रत्यय "er").
भाषा मॉडल के बाहर के डोमेन के टोकन, ऐटॉमिक यूनिट. उदाहरण के लिए, कंप्यूटर विज़न में टोकन, एक सबसेट हो सकता है इमेज होती है.
ट्रांसफ़र्मर
Google में डेवलप किया गया एक न्यूरल नेटवर्क आर्किटेक्चर में बदलाव करने के लिए, खुद का ध्यान रखने के तरीकों का इस्तेमाल किया जाता है आउटपुट के किसी क्रम में इनपुट एम्बेड करने का क्रम बातचीत के भरोसे रहकर एम्बेड करना या बार-बार होने वाले न्यूरल नेटवर्क. ट्रांसफ़ॉर्मर कोई ऐसा हो सकता है खुद पर ध्यान देने वाली कई लेयर के तौर पर देखा जा सकता है.
ट्रांसफ़ॉर्मर में इनमें से कुछ भी शामिल किया जा सकता है:
एन्कोडर एम्बेड करने के क्रम को, इतना ही नहीं. एन्कोडर में N एक जैसी लेयर होती हैं. हर लेयर में दो लेयर होती हैं सब-लेयर. ये दो सब-लेयर, इनपुट की हर जगह पर लागू होते हैं सीक्वेंस को एम्बेड करना, सीक्वेंस के हर एलिमेंट को एक नए एम्बेड करना. पहला एन्कोडर सब-लेयर, दुनिया भर में इनपुट का क्रम. दूसरी एन्कोडर सब-लेयर, एग्रीगेट किए गए डेटा को बदल देती है आउटपुट एम्बेड करने में जानकारी शामिल करता है.
डीकोडर, इनपुट एम्बेड करने के क्रम को क्रम में बदल देता है आउटपुट एम्बेडिंग, अलग-अलग लंबाई वाली हो सकती है. डिकोडर में यह भी शामिल होता है: तीन सब-लेयर वाली N समान लेयर, जिनमें से दो लेयर सब-लेयर में से किसी एक को चुनना होगा. तीसरा डिकोडर सब-लेयर और इन कामों के लिए खुद का ध्यान रखने की सुविधा इस्तेमाल करता है उससे जानकारी इकट्ठा करना.
ब्लॉग पोस्ट ट्रांसफ़ॉर्मर: अ नॉवल न्यूरल नेटवर्क आर्किटेक्चर फ़ॉर लैंग्वेज समझना Transformers के बारे में सही जानकारी देता है.
ट्राइग्राम
ऐसा N-ग्राम जिसमें N=3 हो.
U
एकतरफ़ा
एक सिस्टम जो सिर्फ़ टेक्स्ट के टारगेट सेक्शन से पहले उस टेक्स्ट का आकलन करता है. इसके उलट, बाय-डायरेक्शनल सिस्टम, ऐसा टेक्स्ट जो टेक्स्ट के टारगेट सेक्शन से पहले और बाद में आता है. ज़्यादा जानकारी के लिए, दो रास्ते पर जाएं.
एकतरफ़ा लैंग्वेज मॉडल
ऐसा भाषा का मॉडल जो इसकी संभावनाओं को सिर्फ़ टोकन, टारगेट टोकन के बाद के बजाय बाद में दिखते हैं. दो-तरफ़ा भाषा के मॉडल से कंट्रास्ट अलग होना चाहिए.
V
वैरिएशनल ऑटोएन्कोडर (VAE)
यह एक तरह का ऑटोएन्कोडर है, जो अंतर का इस्तेमाल करता है इनपुट और आउटपुट के बीच में बदलाव कर सकते हैं. वैरिएशनल ऑटोएन्कोडर, जनरेटिव एआई के लिए मददगार हैं.
वीएई, वैरिएशनल अनुमान पर आधारित होते हैं: प्रॉबबिलिटी मॉडल के पैरामीटर दिए गए हैं.
W
शब्द एम्बेड करना
किसी शब्द के सेट के हर शब्द को प्रज़ेंट करने एम्बेडिंग वेक्टर; इसका मतलब है कि हर शब्द को 0.0 और 1.0 के बीच के फ़्लोटिंग-पॉइंट वैल्यू का वेक्टर. मिलते-जुलते शब्द अलग-अलग मतलब वाले शब्दों की तुलना में, मतलब एक जैसे होते हैं. उदाहरण के लिए गाजर, अजवाइन, और खीरे इसमें एक ही तरह का निरूपण होता है, जो हवाई जहाज़, धूप का चश्मा, और टूथपेस्ट की ज़रूरत होती है.
Z
ज़ीरो-शॉट प्रॉम्प्ट
एक प्रॉम्प्ट, जिसमें आपकी पसंद का उदाहरण शामिल नहीं किया गया है जवाब देने के लिए, बड़ा लैंग्वेज मॉडल. उदाहरण के लिए:
| एक प्रॉम्प्ट के हिस्से | नोट |
|---|---|
| किसी चुने गए देश की आधिकारिक मुद्रा क्या है? | वह सवाल जिसका जवाब एलएलएम से देना है. |
| भारत: | असल क्वेरी. |
बड़ा लैंग्वेज मॉडल इनमें से किसी का भी जवाब दे सकता है:
- रुपया
- INR
- ₹
- भारतीय रुपया
- रुपया
- भारतीय रुपया
सभी जवाब सही हैं, लेकिन हो सकता है कि आपको कोई खास फ़ॉर्मैट इस्तेमाल करना पड़े.
ज़ीरो-शॉट प्रॉम्प्ट की तुलना नीचे दिए गए शब्दों से करें: