Auf dieser Seite finden Sie Begriffe aus dem Glossar zur Sprachbewertung. Hier finden Sie alle Begriffe aus dem Glossar.
A
aufmerksamkeit
Ein Mechanismus in einem neuronalen Netzwerk, der die Bedeutung eines bestimmten Wortes oder Teils eines Wortes angibt. Die Aufmerksamkeit komprimiert die Menge an Informationen, die ein Modell benötigt, um das nächste Token/Wort vorherzusagen. Ein typischer Aufmerksamkeitsmechanismus kann aus einer gewichteten Summe einer Reihe von Eingaben bestehen, wobei das Gewicht für jede Eingabe von einem anderen Teil des neuronalen Netzes berechnet wird.
Weitere Informationen finden Sie unter Selbstaufmerksamkeit und Mehrere Selbstaufmerksamkeits-Köpfe. Dies sind die Bausteine von Transformern.
Weitere Informationen zur Selbstaufmerksamkeit finden Sie im Machine Learning Crash Course unter LLMs: What's a large language model?.
Autoencoder
Ein System, das lernt, die wichtigsten Informationen aus der Eingabe zu extrahieren. Autoencoder sind eine Kombination aus einem Encoder und einem Decoder. Autoencoder basieren auf dem folgenden zweistufigen Prozess:
- Der Encoder ordnet die Eingabe einem (in der Regel) verlustbehafteten, niedrigerdimensionalen (Zwischen-)Format zu.
- Der Decoder erstellt eine verlustbehaftete Version der ursprünglichen Eingabe, indem er das niedrigerdimensionale Format dem ursprünglichen höherdimensionalen Eingabeformat zuordnet.
Autoencoder werden end-to-end trainiert, indem der Decoder versucht, die ursprüngliche Eingabe aus dem Zwischenformat des Encoders so genau wie möglich zu rekonstruieren. Da das Zwischenformat kleiner (niedriger dimensional) als das Originalformat ist, muss der Autoencoder lernen, welche Informationen in der Eingabe wichtig sind. Die Ausgabe ist also nicht genau mit der Eingabe identisch.
Beispiel:
- Wenn die Eingabedaten eine Grafik sind, ähnelt die nicht exakte Kopie der ursprünglichen Grafik, ist aber etwas modifiziert. Vielleicht entfernt die nicht exakte Kopie das Rauschen aus der Originalgrafik oder füllt einige fehlende Pixel aus.
- Wenn die Eingabedaten Text sind, generiert ein Autoencoder neuen Text, der dem Originaltext ähnelt, aber nicht identisch mit ihm ist.
Weitere Informationen finden Sie unter Variations-Autoencoder.
Automatische Bewertung
Software zur Beurteilung der Qualität der Ausgabe eines Modells.
Wenn die Modellausgabe relativ einfach ist, kann ein Script oder Programm die Ausgabe des Modells mit einer Golden Response vergleichen. Diese Art der automatischen Bewertung wird manchmal auch als programmatische Bewertung bezeichnet. Messwerte wie ROUGE oder BLEU sind oft nützlich für die programmatische Bewertung.
Wenn die Modellausgabe komplex ist oder keine eindeutige richtige Antwort hat, wird die automatische Bewertung manchmal von einem separaten ML-Programm namens Autorater durchgeführt.
Im Gegensatz zur menschlichen Bewertung.
Autorater-Bewertung
Ein Hybridmechanismus zur Beurteilung der Qualität der Ausgabe eines generativen KI-Modells, der eine menschliche Bewertung mit einer automatischen Bewertung kombiniert. Ein Autorator ist ein ML-Modell, das mit Daten trainiert wird, die durch menschliche Bewertung erstellt wurden. Im Idealfall lernt ein Autorator, einen menschlichen Prüfer nachzuahmen.Es sind vordefinierte automatische Rater verfügbar, die besten sind jedoch speziell auf die Aufgabe abgestimmt, die Sie bewerten.
autoregressives Modell
Ein Modell, das eine Vorhersage auf der Grundlage seiner eigenen bisherigen Vorhersagen ableitet. Autoregressive Language Models sagen beispielsweise das nächste Token anhand der zuvor vorhergesagten Tokens voraus. Alle Transformer-basierten Large Language Models sind autoregressiv.
GAN-basierte Bildmodelle sind dagegen in der Regel nicht autoregressiv, da sie ein Bild in einem einzigen Vorwärtsdurchlauf und nicht iterativ in Schritten generieren. Bestimmte Modelle zur Bildgenerierung sind jedoch autoregressiv, da sie ein Bild in Schritten generieren.
Durchschnittliche Precision bei k
Ein Messwert, mit dem die Leistung eines Modells für einen einzelnen Prompt zusammengefasst wird, der sortierte Ergebnisse generiert, z. B. eine nummerierte Liste mit Buchempfehlungen. Die durchschnittliche Precision bei k ist der Durchschnitt der Precision bei k-Werte für jedes relevante Ergebnis. Die Formel für die durchschnittliche Precision bei k lautet daher:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
Dabei gilt:
- \(n\) ist die Anzahl der relevanten Elemente in der Liste.
Im Gegensatz zu recall at k.
B
Bag of Words
Eine Darstellung der Wörter in einer Wortgruppe oder einem Textabschnitt, unabhängig von der Reihenfolge. Beispielsweise werden die folgenden drei Wortgruppen im Bag-of-Words-Modell identisch dargestellt:
- der Hund springt
- springt auf den Hund
- Hund springt über
Jedem Wort wird ein Index in einem sperrigen Vektor zugeordnet, wobei der Vektor einen Index für jedes Wort im Vokabular hat. Beispielsweise wird der Ausdruck der Hund springt einem Feature-Vektor mit nicht nullwertigen Werten an den drei Indizes zugeordnet, die den Wörtern der, Hund und springt entsprechen. Der Wert ungleich 0 kann einer der folgenden sein:
- Eine „1“, um das Vorhandensein eines Wortes anzugeben.
- Die Anzahl der Male, die ein Wort im Sack vorkommt. Wenn der Ausdruck beispielsweise der kastanienbraune Hund ist ein Hund mit kastanienbraunem Fell lautet, werden sowohl kastanienbraun als auch Hund mit 2 dargestellt, während die anderen Wörter mit 1 dargestellt werden.
- Ein anderer Wert, z. B. der Logarithmus der Anzahl der Vorkommen eines Wortes im Sack.
BERT (Bidirectional Encoder Representations from Transformers)
Eine Modellarchitektur für die Darstellung von Text. Ein trainiertes BERT-Modell kann als Teil eines größeren Modells für die Textklassifizierung oder andere ML-Aufgaben dienen.
BERT hat folgende Eigenschaften:
- Sie verwendet die Transformer-Architektur und basiert daher auf Self-Attention.
- Verwendet den Encoder des Transformer. Die Aufgabe des Encoders besteht darin, gute Textdarstellungen zu erstellen, anstatt eine bestimmte Aufgabe wie die Klassifizierung auszuführen.
- Sie ist bidirektional.
- Verwendet Maskierung für das unbeaufsichtigte Training.
Zu den Varianten von BERT gehören:
Eine Übersicht über BERT finden Sie unter BERT als Open-Source-Modell: Hochmodernes Training im Voraus für die natürliche Sprachverarbeitung.
bidirektional
Ein Begriff, der ein System beschreibt, das den Text sowohl vor als auch nach einem Zieltextabschnitt auswertet. Ein einseitig ausgerichtetes System hingegen wertet nur den Text aus, der vor einem Zieltextabschnitt steht.
Betrachten wir beispielsweise ein maskiertes Language Model, das die Wahrscheinlichkeiten für das Wort oder die Wörter bestimmen muss, die in der folgenden Frage durch Unterstreichung gekennzeichnet sind:
Was ist _____ mit Ihnen los?
Ein einseitiges Sprachmodell müsste seine Wahrscheinlichkeiten nur auf dem Kontext der Wörter „Was“, „ist“ und „das“ basieren. Ein zweisprachiges Sprachmodell kann dagegen auch Kontext aus „mit“ und „du“ gewinnen, was dem Modell helfen kann, bessere Vorhersagen zu treffen.
Bidirektionales Sprachmodell
Ein Sprachmodell, das anhand des vorangehenden und nachfolgenden Texts die Wahrscheinlichkeit bestimmt, dass sich ein bestimmtes Token an einer bestimmten Stelle in einem Textausschnitt befindet.
Bigram
Ein N-Gramm mit N=2.
BLEU (Bilingual Evaluation Understudy)
Ein Messwert zwischen 0,0 und 1,0 zur Bewertung von maschinellen Übersetzungen, z.B.von Spanisch nach Japanisch.
Zur Berechnung einer Bewertung vergleicht BLEU in der Regel die Übersetzung eines ML-Modells (generierter Text) mit der Übersetzung eines menschlichen Experten (Referenztext). Der BLEU-Wert wird anhand des Übereinstimmungsgrades der N-Gramme im generierten Text und im Referenztext bestimmt.
Der ursprüngliche Artikel zu diesem Messwert ist BLEU: a Method for Automatic Evaluation of Machine Translation.
Siehe auch BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
Ein Messwert zur Bewertung von maschinellen Übersetzungen von einer Sprache in eine andere, insbesondere von und ins Englische.
Bei Übersetzungen von und ins Englische stimmt BLEURT stärker mit den Bewertungen von Menschen überein als BLEU. Im Gegensatz zu BLEU legt BLEURT den Schwerpunkt auf semantische (bedeutungsbezogene) Ähnlichkeiten und kann Paraphrasierungen berücksichtigen.
BLEURT basiert auf einem vortrainierten Large Language Model (genauer gesagt BERT), das dann anhand von Texten von menschlichen Übersetzern optimiert wird.
Das Originalpapier zu diesem Messwert ist BLEURT: Learning Robust Metrics for Text Generation.
C
kausales Sprachmodell
Synonym für unidirektionales Sprachmodell.
Unter bidirektionales Sprachmodell finden Sie einen Vergleich verschiedener Richtungsansätze bei der Sprachmodellierung.
Chain-of-Thought Prompting
Eine Prompt-Engineering-Technik, die ein Large Language Model (LLM) dazu anregt, seine Argumentation Schritt für Schritt zu erklären. Betrachten Sie beispielsweise den folgenden Prompt und achten Sie dabei besonders auf den zweiten Satz:
Wie viele g-Kräfte wirken auf einen Fahrer in einem Auto, das in 7 Sekunden von 0 auf 100 km/h beschleunigt? Geben Sie in der Antwort alle relevanten Berechnungen an.
Die Antwort des LLM würde wahrscheinlich:
- Zeigen Sie eine Reihe von Physikformeln an und setzen Sie an den entsprechenden Stellen die Werte 0, 60 und 7 ein.
- Erläutern Sie, warum diese Formeln ausgewählt wurden und was die verschiedenen Variablen bedeuten.
Prompts mit einer Gedankenkette zwingen das LLM, alle Berechnungen durchzuführen, was zu einer korrekteren Antwort führen kann. Außerdem können Nutzer mithilfe von Prompts zur Denkkette die Schritte des LLM prüfen, um festzustellen, ob die Antwort sinnvoll ist.
Chat
Der Inhalt eines Dialogs mit einem ML-System, in der Regel einem Large Language Model. Die vorherige Interaktion in einem Chat (was Sie eingegeben haben und wie das Large Language Model geantwortet hat) wird zum Kontext für nachfolgende Teile des Chats.
Ein Chatbot ist eine Anwendung eines Large Language Models.
Konfabulation
Synonym für Halluzination.
Konfabulation ist wahrscheinlich ein technisch genauerer Begriff als Halluzination. Hallucination wurde jedoch zuerst populär.
Parsen von Wahlkreisen
Ein Satz wird in kleinere grammatische Strukturen („Konstituenten“) unterteilt. Ein späterer Teil des ML-Systems, z. B. ein Modell für das Verstehen natürlicher Sprache, kann die Bestandteile leichter analysieren als den ursprünglichen Satz. Betrachten Sie beispielsweise den folgenden Satz:
Meine Freundin hat zwei Katzen adoptiert.
Ein Konstituentenparser kann diesen Satz in die folgenden zwei Konstituenten unterteilen:
- Mein Freund ist ein Nomen.
- zwei Katzen adoptiert ist eine Verbphrase.
Diese Bestandteile können weiter in kleinere Bestandteile unterteilt werden. Zum Beispiel die Verbphrase
zwei Katzen adoptiert
kann weiter unterteilt werden in:
- adopted ist ein Verb.
- zwei Katzen ist eine weitere Nominalphrase.
Kontextbezogene Sprach-Embeddings
Eine Embedding-Technologie, die Wörter und Wortgruppen so „versteht“, wie es Muttersprachler tun. Kontextbezogene Sprach-Embeddings können komplexe Syntax, Semantik und Kontext verstehen.
Betrachten wir beispielsweise die Einbettungen des englischen Wortes cow. Ältere Einbettungen wie word2vec können englische Wörter so darstellen, dass die Entfernung im Embedding-Raum von Kuh zu Stier der Entfernung von Schaf zu Bock oder von weiblich zu männlich entspricht. Kontextbezogene Sprach-Embeddings können noch einen Schritt weiter gehen, indem sie erkennen, dass englischsprachige Personen das Wort cow manchmal ungezwungen für „Kuh“ oder „Stier“ verwenden.
Kontextfenster
Die Anzahl der Tokens, die ein Modell in einem bestimmten Prompt verarbeiten kann. Je größer das Kontextfenster ist, desto mehr Informationen kann das Modell verwenden, um kohärente und konsistente Antworten auf den Prompt zu geben.
Crash Blossom
Ein Satz oder eine Wortgruppe mit mehrdeutiger Bedeutung. Crash Blossoms stellen ein erhebliches Problem beim Verstehen von natürlicher Sprache dar. Die Überschrift Red Tape Holds Up Skyscraper (Bürokratie verzögert Wolkenkratzer) ist beispielsweise ein Crash Blossom, da ein NLU-Modell die Überschrift wörtlich oder bildlich interpretieren könnte.
D
Decoder
Im Allgemeinen jedes ML-System, das von einer verarbeiteten, dichten oder internen Darstellung in eine eher rohe, spärliche oder externe Darstellung konvertiert.
Decoder sind oft Teil eines größeren Modells, in dem sie häufig mit einem Encoder kombiniert werden.
Bei Sequenz-zu-Sequenz-Aufgaben beginnt ein Decoder mit dem vom Encoder generierten internen Status, um die nächste Sequenz vorherzusagen.
Die Definition eines Decoders in der Transformer-Architektur finden Sie unter Transformer.
Weitere Informationen finden Sie im Machine Learning Crash Course unter Large Language Models.
Entfernen von Rauschen
Ein gängiger Ansatz für selbstüberwachtes Lernen:
Durch das Entfernen von Rauschen können Sie aus unbeschrifteten Beispielen lernen. Das ursprüngliche Dataset dient als Ziel oder Label und die verrauschten Daten als Eingabe.
Bei einigen verschleierten Sprachmodellen wird die Geräuschunterdrückung so verwendet:
- Einem unbeschrifteten Satz wird durch Maskieren einiger Tokens künstlich Rauschen hinzugefügt.
- Das Modell versucht, die ursprünglichen Tokens vorherzusagen.
Direkte Aufforderung
Synonym für Zero-Shot-Prompts.
E
Edit distance
Ein Maß dafür, wie ähnlich sich zwei Textstrings sind. Im Bereich maschinelles Lernen ist die Edit-Distanz aus folgenden Gründen nützlich:
- Die Edit-Distanz lässt sich leicht berechnen.
- Mit der Edit-Distanz können zwei Strings verglichen werden, die bekanntlich ähnlich sind.
- Mit der Edit-Distanz lässt sich bestimmen, inwiefern verschiedene Strings einem bestimmten String ähneln.
Es gibt mehrere Definitionen der Edit-Distanz, die jeweils unterschiedliche Stringoperationen verwenden. Ein Beispiel finden Sie unter Levenshtein-Distanz.
Einbettungsschicht
Eine spezielle versteckte Schicht, die mit einem hochdimensionalen kategorischen Merkmal trainiert wird, um nach und nach einen Einbettungsvektor mit niedrigerer Dimension zu lernen. Mit einer Einbettungsebene kann ein neuronales Netzwerk viel effizienter trainiert werden als nur mit dem hochdimensionalen kategorischen Merkmal.
In Google Earth werden derzeit beispielsweise etwa 73.000 Baumarten unterstützt. Angenommen, die Baumart ist ein Attribut in Ihrem Modell. Die Eingabeschicht Ihres Modells enthält dann einen One-Hot-Vektor mit 73.000 Elementen.
baobab könnte beispielsweise so dargestellt werden:

Ein Array mit 73.000 Elementen ist sehr lang. Wenn Sie dem Modell keine Einbettungsschicht hinzufügen, ist das Training aufgrund der Multiplikation von 72.999 Nullen sehr zeitaufwendig. Angenommen, Sie legen fest, dass die Einbettungsebene aus 12 Dimensionen bestehen soll. Daher lernt die Embedding-Ebene nach und nach einen neuen Embedding-Vektor für jede Baumart.
In bestimmten Situationen ist Hashing eine angemessene Alternative zu einer Einbettungsebene.
Weitere Informationen finden Sie im Machine Learning Crash Course unter Embeddings.
Einbettungsbereich
Der d-dimensionale Vektorraum, auf den Elemente aus einem höherdimensionalen Vektorraum abgebildet werden. Im Idealfall enthält der Einbettungsraum eine Struktur, die aussagekräftige mathematische Ergebnisse liefert. In einem idealen Einbettungsraum können beispielsweise Wortanalogieaufgaben durch Addition und Subtraktion von Einbettungen gelöst werden.
Das Skalarprodukt zweier Einbettungen ist ein Maß für ihre Ähnlichkeit.
Einbettungsvektor
Im Allgemeinen ein Array von Gleitkommazahlen aus jeder verborgenen Schicht, die die Eingaben in diese verborgene Schicht beschreiben. Ein Einbettungsvektor ist oft das Array von Gleitkommazahlen, das in einer Einbettungsschicht trainiert wurde. Angenommen, eine Einbettungsschicht muss einen Einbettungsvektor für jede der 73.000 Baumarten auf der Erde lernen. Vielleicht ist das folgende Array der Einbettungsvektor für einen Affenbrotbaum:

Ein Einbettungsvektor besteht nicht aus einer Reihe von Zufallszahlen. Eine Einbettungsschicht bestimmt diese Werte durch Training, ähnlich wie ein neuronales Netzwerk andere Gewichte während des Trainings lernt. Jedes Element des Arrays ist eine Bewertung einer Eigenschaft einer Baumart. Welches Element steht für welche Eigenschaft der Baumart? Das ist für Menschen sehr schwer zu bestimmen.
Das mathematisch Bemerkenswerte an einem Einbettungsvektor ist, dass ähnliche Elemente ähnliche Gleitkommazahlen haben. Beispielsweise haben ähnliche Baumarten ähnlichere Gleitkommazahlen als unterschiedliche Baumarten. Redwoods und Mammutbäume sind verwandte Baumarten, daher haben sie ähnliche Gleitkommazahlen wie Redwoods und Kokospalmen. Die Zahlen im Einbettungsvektor ändern sich jedes Mal, wenn Sie das Modell neu trainieren, auch wenn Sie es mit derselben Eingabe neu trainieren.
Encoder
Im Allgemeinen jedes ML-System, das von einer Roh-, spärlichen oder externen Darstellung in eine stärker verarbeitete, dichtere oder internere Darstellung konvertiert.
Encoder sind oft Teil eines größeren Modells, in dem sie häufig mit einem Decoder kombiniert werden. Einige Transformer koppeln Encoder mit Decodern, andere verwenden nur den Encoder oder nur den Decoder.
Bei einigen Systemen wird die Ausgabe des Encoders als Eingabe für ein Klassifizierungs- oder Regressionsnetzwerk verwendet.
Bei Sequenz-zu-Sequenz-Aufgaben nimmt ein Encoder eine Eingabesequenz entgegen und gibt einen internen Status (einen Vektor) zurück. Der Decoder verwendet dann diesen internen Status, um die nächste Sequenz vorherzusagen.
Die Definition eines Encoders in der Transformer-Architektur finden Sie unter Transformer.
Weitere Informationen finden Sie im Machine Learning Crash Course unter LLMs: What's a large language model.
evals
Wird hauptsächlich als Abkürzung für LLM-Bewertungen verwendet. Im weiteren Sinne ist evals eine Abkürzung für jede Form der Bewertung.
Evaluierung
Prozess, bei dem die Qualität eines Modells gemessen oder verschiedene Modelle miteinander verglichen werden.
Um ein Modell für beaufsichtigtes maschinelles Lernen zu bewerten, wird es in der Regel anhand eines Validierungs-Sets und eines Test-Sets beurteilt. Die Bewertung eines LLM umfassen in der Regel umfassendere Qualität- und Sicherheitsbewertungen.
F
Few-Shot-Prompting
Ein Prompt, der mehr als ein (ein „paar“) Beispiel enthält, das zeigt, wie das Large Language Model reagieren soll. Der folgende ausführliche Prompt enthält beispielsweise zwei Beispiele, die einem Large Language Model zeigen, wie eine Suchanfrage beantwortet werden kann.
| Teile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Frankreich: EUR | Ein Beispiel: |
| Vereinigtes Königreich: GBP | Ein weiteres Beispiel: |
| Indien: | Die tatsächliche Suchanfrage. |
Few-Shot-Prompts liefern in der Regel bessere Ergebnisse als Zero-Shot-Prompts und One-Shot-Prompts. Für Few-Shot-Prompting ist jedoch ein längerer Prompt erforderlich.
Few-Shot-Prompting ist eine Form des Few-Shot-Lernens, die auf das promptbasierte Lernen angewendet wird.
Weitere Informationen finden Sie im Machine Learning Crash Course unter Prompt-Design.
Geige
Eine Python-first-Konfigurationsbibliothek, mit der die Werte von Funktionen und Klassen ohne invasiven Code oder Infrastruktur festgelegt werden. Bei Pax und anderen ML-Codebases stehen diese Funktionen und Klassen für Modelle und Trainings Hyperparameter.
Fiddle geht davon aus, dass Codebases für maschinelles Lernen in der Regel in folgende Bereiche unterteilt sind:
- Bibliothekscode, der die Ebenen und Optimierer definiert.
- „Verbindender“ Code für den Datensatz, der die Bibliotheken aufruft und alles miteinander verbindet.
Fiddle erfasst die Aufrufstruktur des Glue-Codes in einer nicht ausgewerteten und veränderbaren Form.
Feinabstimmung
Ein zweiter, aufgabenspezifischer Trainingsdurchlauf, der auf einem vortrainierten Modell durchgeführt wird, um seine Parameter für einen bestimmten Anwendungsfall zu optimieren. Die vollständige Trainingssequenz für einige Large Language Models sieht beispielsweise so aus:
- Vortraining: Ein Large Language Model wird mit einem umfangreichen generellen Dataset trainiert, z. B. mit allen englischsprachigen Wikipedia-Seiten.
- Optimierung: Das vortrainierte Modell wird für die Ausführung einer bestimmten Aufgabe trainiert, z. B. für die Beantwortung von medizinischen Suchanfragen. Die Feinabstimmung umfasst in der Regel Hunderte oder Tausende von Beispielen, die sich auf die jeweilige Aufgabe konzentrieren.
Hier ist ein weiteres Beispiel für die vollständige Trainingssequenz für ein Modell mit großen Bildern:
- Vortraining: Trainieren Sie ein großes Bildmodell mit einem umfangreichen allgemeinen Bild-Dataset, z. B. mit allen Bildern in Wikimedia Commons.
- Optimierung: Das vortrainierte Modell wird für eine bestimmte Aufgabe trainiert, z. B. für die Generierung von Bildern von Orcas.
Die Optimierung kann eine beliebige Kombination der folgenden Strategien umfassen:
- Alle vorhandenen Parameter des vortrainierten Modells ändern. Dieser Vorgang wird auch als volle Feinabstimmung bezeichnet.
- Sie ändern nur einige der vorhandenen Parameter des vorab trainierten Modells (in der Regel die Schichten, die der Ausgabeschicht am nächsten sind), während andere vorhandene Parameter unverändert bleiben (in der Regel die Schichten, die der Eingabeschicht am nächsten sind). Weitere Informationen finden Sie unter Parametereffiziente Abstimmung.
- Durch Hinzufügen weiterer Ebenen, in der Regel über den vorhandenen Ebenen, die der Ausgabeebene am nächsten sind.
Die Feinabstimmung ist eine Form des Übertragungslernens. Daher kann für die Feinabstimmung eine andere Verlustfunktion oder ein anderer Modelltyp verwendet werden als für das Training des vorab trainierten Modells. Sie können beispielsweise ein vortrainiertes Modell für große Bilder optimieren, um ein Regressionsmodell zu erstellen, das die Anzahl der Vögel in einem Eingabebild zurückgibt.
Vergleichen Sie die Feinabstimmung mit den folgenden Begriffen:
Weitere Informationen finden Sie im Machine Learning Crash Course unter Feintuning.
Flachs
Eine leistungsstarke Open-Source- Bibliothek für Deep Learning, die auf JAX basiert. Flax bietet Funktionen zum Training von Neural Networks sowie Methoden zur Bewertung ihrer Leistung.
Flaxformer
Eine Open-Source-Transformer-Bibliothek, die auf Flax basiert und hauptsächlich für die Verarbeitung natürlicher Sprache und die multimodale Forschung entwickelt wurde.
G
Gemini
Das Ökosystem mit der innovativsten KI von Google. Zu den Elementen dieses Ökosystems gehören:
- Verschiedene Gemini-Modelle
- Die interaktive Konversationsoberfläche für ein Gemini-Modell. Nutzer geben Prompts ein und Gemini antwortet darauf.
- Verschiedene Gemini APIs
- Verschiedene Geschäftsprodukte, die auf Gemini-Modellen basieren, z. B. Gemini for Google Cloud.
Gemini-Modelle
Die neuesten Transformer-basierten multimodalen Modelle von Google Gemini-Modelle sind speziell für die Einbindung in Kundenservicemitarbeiter konzipiert.
Nutzer können auf verschiedene Weise mit Gemini-Modellen interagieren, z. B. über eine interaktive Dialogoberfläche und über SDKs.
generierter Text
Im Allgemeinen der Text, der von einem ML-Modell ausgegeben wird. Bei der Bewertung von Large Language Models wird bei einigen Messwerten der generierte Text mit einem Referenztext verglichen. Angenommen, Sie möchten herausfinden, wie effektiv ein ML-Modell vom Französischen ins Niederländische übersetzt. In diesem Fall gilt:
- Der generierte Text ist die niederländische Übersetzung, die vom ML-Modell ausgegeben wird.
- Der Referenztext ist die niederländische Übersetzung, die von einem menschlichen Übersetzer (oder einer Software) erstellt wird.
Hinweis: Bei einigen Bewertungsstrategien wird kein Referenztext verwendet.
generative KI
Ein neues, transformatives Feld ohne formale Definition. Die meisten Experten sind sich jedoch einig, dass generative KI-Modelle Inhalte erstellen („generieren“) können, die
- Komplex
- kohärent
- ursprünglich
So kann ein generatives KI-Modell beispielsweise anspruchsvolle Essays oder Bilder erstellen.
Einige ältere Technologien, darunter LSTMs und RNNs, können ebenfalls originelle und kohärente Inhalte generieren. Einige Experten betrachten diese früheren Technologien als generative KI, während andere der Meinung sind, dass echte generative KI eine komplexere Ausgabe erfordert, als diese früheren Technologien produzieren können.
Im Gegensatz zu vorhersageorientiertem ML.
Goldene Antwort
Eine Antwort, die als gut bekannt ist. Angenommen, Sie haben den folgenden Prompt:
2 + 2
Die ideale Antwort lautet:
4
GPT (Generative Pre-trained Transformer)
Eine Familie von Transformer-basierten Large Language Models, die von OpenAI entwickelt wurden.
GPT-Varianten können auf mehrere Modalitäten angewendet werden, darunter:
- Bildgenerierung (z. B. ImageGPT)
- Text-zu-Bild-Generierung (z. B. DALL-E)
H
Halluzination
Die Erstellung von plausibel erscheinenden, aber faktisch falschen Ergebnissen durch ein generatives KI-Modell, das angeblich eine Aussage über die reale Welt trifft. Ein generatives KI-Modell, das behauptet, dass Barack Obama 1865 gestorben ist, halluziniert.
manuelle Überprüfung
Ein Prozess, bei dem Menschen die Qualität der Ausgabe eines ML-Modells beurteilen, z. B. zweisprachige Personen, die die Qualität eines ML-Übersetzungsmodells beurteilen. Die manuelle Bewertung ist besonders nützlich, um Modelle zu beurteilen, für die es keine eindeutige richtige Antwort gibt.
Im Gegensatz zur automatischen Bewertung und zur Bewertung durch den Autorater.
I
Kontextbezogenes Lernen
Synonym für Few-Shot-Prompting.
L
LaMDA (Language Model for Dialogue Applications)
Ein von Google entwickeltes Transformer-basiertes Large Language Model, das mit einem großen Dialog-Dataset trainiert wurde und realistische Konversationsantworten generieren kann.
LaMDA: our breakthrough conversation technology (LaMDA: unsere bahnbrechende Konversationstechnologie) bietet einen Überblick.
Sprachmodell
Ein Modell, mit dem die Wahrscheinlichkeit geschätzt wird, dass ein Token oder eine Tokenfolge in einer längeren Tokenfolge auftritt.
Large Language Model
Mindestens ein Sprachmodell mit einer sehr hohen Anzahl von Parametern. Im informellen Sprachgebrauch: jedes Transformer-basierte Sprachmodell, z. B. Gemini oder GPT.
Latenzraum
Synonym für Einbettungsbereich.
Levenshtein-Distanz
Ein Messwert für die Änderungsdistanz, der die geringste Anzahl von Lösch-, Einfüge- und Ersetzungsvorgängen berechnet, die erforderlich sind, um ein Wort in ein anderes zu ändern. Die Levenshtein-Distanz zwischen den Wörtern „Herz“ und „Darts“ beträgt beispielsweise drei, da mit den folgenden drei Änderungen das eine Wort in das andere umgewandelt werden kann:
- Herz → Deart (Ersetzen Sie „h“ durch „d“)
- deart → dart (entfernen des „e“)
- dart → darts (insert "s")
Die vorherige Abfolge ist nicht der einzige Pfad mit drei Änderungen.
LLM
Abkürzung für Large Language Model.
LLM-Bewertungen (evals)
Eine Reihe von Messwerten und Benchmarks zur Bewertung der Leistung von Large Language Models (LLMs). LLM-Bewertungen bieten folgende Vorteile:
- Sie helfen Forschern, Bereiche zu identifizieren, in denen LLMs verbessert werden müssen.
- Sie sind nützlich, um verschiedene LLMs zu vergleichen und das beste LLM für eine bestimmte Aufgabe zu ermitteln.
- Sie tragen dazu bei, dass LLMs sicher und ethisch eingesetzt werden.
LoRA
Abkürzung für Low-Rank Adaptability (Niedrigrangige Anpassungsfähigkeit).
Low-Rank Adaptation (LoRA)
Eine parametereffiziente Methode zur Feinabstimmung, bei der die vortrainierten Gewichte des Modells „eingefroren“ (d. h. nicht mehr geändert) und dann eine kleine Gruppe trainierbarer Gewichte in das Modell eingefügt werden. Dieser Satz trainierbarer Gewichte (auch als „Aktualisierungsmatrizen“ bezeichnet) ist deutlich kleiner als das Basismodell und daher viel schneller zu trainieren.
LoRA bietet folgende Vorteile:
- Verbessert die Qualität der Vorhersagen eines Modells für die Domain, in der die Feinabstimmung angewendet wird.
- Die Feinabstimmung erfolgt schneller als bei Verfahren, bei denen alle Parameter eines Modells angepasst werden müssen.
- Reduziert die Rechenkosten für die Inferenz, indem die gleichzeitige Bereitstellung mehrerer spezialisierter Modelle mit demselben Basismodell ermöglicht wird.
M
Maskiertes Sprachmodell
Ein Language Model, das die Wahrscheinlichkeit vorhersagt, mit der Token Lücken in einer Sequenz füllen. Ein Masked Language Model kann beispielsweise Wahrscheinlichkeiten für Kandidatenwörter berechnen, um die Unterstreichungen im folgenden Satz zu ersetzen:
Der ____ im Hut ist zurückgekehrt.
In der Literatur wird in der Regel der String „MASK“ anstelle eines Unterstrichs verwendet. Beispiel:
Die „MASKE“ im Hut ist zurückgekehrt.
Die meisten modernen Masked Language Models sind bidirektional.
Mittlere durchschnittliche Precision bei k (mAP@k)
Der statistische Mittelwert aller durchschnittlichen Precision bei k-Werte in einem Validierungsdatensatz. Die mittlere durchschnittliche Präzision bei k kann beispielsweise verwendet werden, um die Qualität der Empfehlungen zu beurteilen, die von einem Empfehlungssystem generiert werden.
Auch wenn der Ausdruck „durchschnittlicher Mittelwert“ redundant klingt, ist der Name des Messwerts angemessen. Schließlich wird mit diesem Messwert der Mittelwert mehrerer durchschnittlicher Precision bei k berechnet.
Meta-Lernen
Eine Teilmenge des maschinellen Lernens, bei der ein Lernalgorithmus entdeckt oder verbessert wird. Ein Meta-Lernsystem kann auch darauf abzielen, ein Modell zu trainieren, um schnell eine neue Aufgabe aus einer kleinen Menge an Daten oder aus der Erfahrung zu lernen, die bei früheren Aufgaben gesammelt wurde. Meta-Lernalgorithmen versuchen in der Regel, Folgendes zu erreichen:
- Manuell erstellte Funktionen wie Initializer oder Optimierer verbessern oder kennenlernen
- Sie sind daten- und recheneffizienter.
- Generalisierung verbessern.
Meta-Lernen ist mit dem Lernen mit wenigen Beispielen verwandt.
Experten aus verschiedenen Bereichen
Ein Verfahren zur Steigerung der Effizienz eines Neural-Netzwerks, bei dem nur ein Teil seiner Parameter (Experte) zur Verarbeitung eines bestimmten Eingabe-Tokens oder Beispiels verwendet wird. Ein Gating-Netzwerk leitet jedes Eingabetoken oder Beispiel an die zuständigen Experten weiter.
Weitere Informationen finden Sie in den folgenden Artikeln:
- Unverschämt große neuronale Netze: Die Schicht mit der spärlichen Gatterung von Expertenmischung
- Mixture-of-Experts mit Expert Choice-Routing
MMIT
Abkürzung für multimodal instruction-tuned (multimodale Anweisungen abgestimmt).
Modalität
Eine Datenkategorie der obersten Ebene. Zahlen, Text, Bilder, Video und Audio sind beispielsweise fünf verschiedene Modalitäten.
Modellparallelität
Eine Möglichkeit zur Skalierung von Training oder Inferenz, bei der verschiedene Teile eines Modells auf verschiedenen Geräten ausgeführt werden. Mit dem Modellparallelismus können Modelle verwendet werden, die zu groß für ein einzelnes Gerät sind.
Um die Modellparallelität zu implementieren, führt ein System in der Regel Folgendes aus:
- Das Modell wird in kleinere Teile aufgeteilt.
- Das Training dieser kleineren Teile wird auf mehrere Prozessoren verteilt. Jeder Prozessor trainiert seinen eigenen Teil des Modells.
- Die Ergebnisse werden kombiniert, um ein einzelnes Modell zu erstellen.
Die Modellparallelität verlangsamt das Training.
Weitere Informationen finden Sie unter Datenparallelität.
MOE
Abkürzung für Mix aus Experten.
Mehrfach-Self-Attention
Eine Erweiterung der Selbstaufmerksamkeit, bei der der Selbstaufmerksamkeitsmechanismus mehrmals auf jede Position in der Eingabesequenz angewendet wird.
Transformer haben die mehrschichtige Selbstaufmerksamkeit eingeführt.
Multimodale Anleitung
Ein anhand von Anweisungen optimiertes Modell, das neben Text auch Eingaben wie Bilder, Videos und Audio verarbeiten kann.
multimodales Modell
Ein Modell, dessen Eingaben und/oder Ausgaben mehr als eine Modalität umfassen. Angenommen, ein Modell nimmt sowohl ein Bild als auch eine Bildunterschrift (zwei Modalitäten) als Features an und gibt eine Bewertung aus, die angibt, wie passend die Bildunterschrift zum Bild ist. Die Eingaben dieses Modells sind also multimodal und die Ausgabe ist unimodal.
N
Natural Language Processing
Das Feld, in dem Computer dazu gebracht werden, das, was ein Nutzer gesagt oder eingegeben hat, anhand linguistischer Regeln zu verarbeiten. Fast alle modernen Verfahren zur Verarbeitung natürlicher Sprache beruhen auf maschinellem Lernen.Natural Language Understanding
Ein Teilbereich der Natural Language Processing, der die Intentionen von gesprochenen oder eingegebenen Texten bestimmt. Das Verstehen natürlicher Sprache kann über Natural Language Processing hinausgehen und komplexe Aspekte der Sprache wie Kontext, Sarkasmus und Sentiment berücksichtigen.
N-Gramm
Eine geordnete Sequenz von N Wörtern. Truly madly ist beispielsweise ein 2-Gramm. Da die Reihenfolge relevant ist, ist madly truly ein anderes 2-Gramm als truly madly.
| N | Name(n) für diese Art von N-Gramm | Beispiele |
|---|---|---|
| 2 | Bigram oder 2-Gramm | to go, go to, eat lunch, eat dinner |
| 3 | Trigramm oder 3-Gramm | ate too much, three blind mice, the bell tolls |
| 4 | 4-Gramm | walk in the park, dust in the wind, the boy ate lentils |
Viele Natural Language Understanding-Modelle nutzen N-Gramme, um das nächste Wort vorherzusagen, das der Nutzer eingeben oder sagen wird. Angenommen, ein Nutzer hat drei blind eingegeben. Ein NLU-Modell, das auf Trigrammen basiert, würde wahrscheinlich vorhersagen, dass der Nutzer als Nächstes Mäuse eingibt.
N-Gramme sind im Gegensatz zu Wortgruppen, die ungeordnete Wortgruppen sind.
NLP
Abkürzung für Natural Language Processing.
NLU
Abkürzung für Natural Language Understanding.
Keine richtige Antwort (NORA)
Ein Prompt mit mehreren geeigneten Antworten. Für den folgenden Prompt gibt es beispielsweise keine richtige Antwort:
Erzählen Sie mir einen Witz über Elefanten.
Die Bewertung von Aufgaben, bei denen es keine richtige Antwort gibt, kann schwierig sein.
NORA
Abkürzung für keine richtige Antwort.
O
One-Shot-Prompts
Ein Prompt mit einem Beispiel, das zeigt, wie das Large Language Model reagieren soll. Der folgende Prompt enthält beispielsweise ein Beispiel, in dem einem Large Language Model gezeigt wird, wie es eine Suchanfrage beantworten soll.
| Teile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Frankreich: EUR | Ein Beispiel: |
| Indien: | Die tatsächliche Suchanfrage. |
Vergleichen Sie One-Shot-Prompts mit den folgenden Begriffen:
P
Parametereffiziente Abstimmung
Eine Reihe von Techniken, mit denen ein großes vortrainiertes Sprachmodell (PLM) fein abgestimmt werden kann, was effizienter ist als eine vollständige Feinabstimmung. Bei der parametereffizienten Optimierung werden in der Regel deutlich weniger Parameter optimiert als bei der vollständigen Optimierung. Trotzdem wird in der Regel ein Large Language Model erstellt, das genauso gut (oder fast genauso gut) funktioniert wie ein Large Language Model, das durch vollständige Optimierung erstellt wurde.
Vergleichen Sie die parametereffiziente Abstimmung mit:
Die parametereffiziente Abstimmung wird auch als parametereffiziente Feinabstimmung bezeichnet.
Pipeline
Eine Form der Modellparallelität, bei der die Verarbeitung eines Modells in aufeinanderfolgende Phasen unterteilt wird und jede Phase auf einem anderen Gerät ausgeführt wird. Während in einer Phase ein Batch verarbeitet wird, kann die vorherige Phase mit dem nächsten Batch arbeiten.
Weitere Informationen finden Sie unter gestuftes Training.
PLM
Abkürzung für vortrainiertes Language Model.
Positionscodierung
Ein Verfahren, mit dem Informationen zur Position eines Tokens in einer Sequenz in die Einbettung des Tokens eingefügt werden. Transformer-Modelle verwenden die Positionscodierung, um die Beziehung zwischen verschiedenen Teilen der Sequenz besser zu verstehen.
Eine gängige Implementierung der Positionscodierung verwendet eine Sinusfunktion. Insbesondere werden die Frequenz und Amplitude der Sinusfunktion durch die Position des Tokens in der Sequenz bestimmt. Mit dieser Technik kann ein Transformer-Modell lernen, je nach Position auf unterschiedliche Teile der Sequenz zu achten.
Nach dem Training
Weitgehend unscharfer Begriff, der in der Regel auf ein vortrainiertes Modell verweist, das einer Nachbearbeitung unterzogen wurde, z. B. einer oder mehreren der folgenden:
Precision bei k (precision@k)
Ein Messwert zur Auswertung einer sortierten (geordneten) Liste von Elementen. Die Genauigkeit bei k gibt den Anteil der ersten k Elemente in dieser Liste an, die „relevant“ sind. Das bedeutet:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Der Wert von k muss kleiner oder gleich der Länge der zurückgegebenen Liste sein. Die Länge der zurückgegebenen Liste ist nicht Teil der Berechnung.
Die Relevanz ist oft subjektiv. Selbst erfahrene Bewerter sind sich oft nicht einig, welche Elemente relevant sind.
Vergleichen mit:
vortrainiertes Modell
Normalerweise ein Modell, das bereits trainiert wurde. Der Begriff kann auch einen zuvor trainierten Embedding-Vektor bezeichnen.
Der Begriff vortrainiertes Sprachmodell bezieht sich in der Regel auf ein bereits trainiertes Large Language Model.
Vortraining
Das erste Training eines Modells mit einem großen Dataset. Einige vortrainierte Modelle sind sperrige Riesen und müssen in der Regel durch zusätzliches Training optimiert werden. So können ML-Experten beispielsweise ein Large Language Model mit einem riesigen Text-Dataset vortrainieren, z. B. mit allen englischsprachigen Seiten in Wikipedia. Nach dem Vortraining kann das resultierende Modell mithilfe einer der folgenden Methoden weiter optimiert werden:
prompt
Jeder Text, der als Eingabe in ein Large Language Model eingegeben wird, um das Modell auf eine bestimmte Weise zu steuern. Prompts können so kurz wie eine Wortgruppe oder beliebig lang sein (z. B. der gesamte Text eines Romans). Prompts lassen sich in mehrere Kategorien unterteilen, darunter die in der folgenden Tabelle aufgeführten:
| Prompt-Kategorie | Beispiel | Hinweise |
|---|---|---|
| Frage | Wie schnell kann eine Taube fliegen? | |
| Anleitung | Schreib ein lustiges Gedicht über Arbitrage. | Ein Prompt, in dem das Large Language Model aufgefordert wird, etwas zu tun. |
| Beispiel | Markdown-Code in HTML umwandeln. Beispiel:
Markdown: * Listenelement HTML: <ul> <li>Listenelement</li> </ul> |
Der erste Satz in diesem Beispiel ist eine Anweisung. Der Rest des Prompts ist das Beispiel. |
| Rolle | Erläutern Sie einem Doktoranden in Physik, warum der Gradientenabstieg beim Training von Machine-Learning-Modellen verwendet wird. | Der erste Teil des Satzes ist eine Anweisung; der Ausdruck „mit einem Doktortitel in Physik“ ist der Teil zur Rolle. |
| Teilweise Eingabe, die das Modell vervollständigen soll | Der Premierminister des Vereinigten Königreichs wohnt unter folgender Adresse: | Ein Prompt für die teilweise Eingabe kann entweder abrupt enden (wie in diesem Beispiel) oder mit einem Unterstrich. |
Ein Modell für generative KI kann auf einen Prompt mit Text, Code, Bildern, Embeddings, Videos und so weiter reagieren.
Promptbasiertes Lernen
Eine Funktion bestimmter Modelle, die es ihnen ermöglicht, ihr Verhalten auf beliebige Texteingaben (Prompts) anzupassen. Bei einem typischen promptbasierten Lernparadigma antwortet ein Large Language Model auf einen Prompt, indem es Text generiert. Angenommen, ein Nutzer gibt den folgenden Prompt ein:
Fassen Sie das dritte Newtonsche Gesetz zusammen.
Ein Modell, das promptbasiertes Lernen unterstützt, ist nicht speziell darauf trainiert, den vorherigen Prompt zu beantworten. Vielmehr „weiß“ das Modell viele Fakten über die Physik, viele allgemeine Sprachregeln und viel darüber, was allgemein nützliche Antworten ausmacht. Dieses Wissen reicht aus, um eine (hoffentlich) nützliche Antwort zu geben. Durch zusätzliches Feedback von Menschen („Diese Antwort war zu kompliziert.“ oder „Was ist eine Reaktion?“) können einige promptbasierte Lernsysteme die Nützlichkeit ihrer Antworten nach und nach verbessern.
Prompt-Design
Synonym für Prompt Engineering.
Prompt Engineering
Die Kunst, Prompts zu erstellen, die die gewünschten Antworten aus einem Large Language Model hervorrufen. Menschen führen Prompt Engineering aus. Gut strukturierte Prompts sind wichtig, um nützliche Antworten von einem Large Language Model zu erhalten. Die Prompt-Entwicklung hängt von vielen Faktoren ab, darunter:
- Das Dataset, das zum Vortrainieren und gegebenenfalls zur Feinabstimmung des Large Language Models verwendet wird.
- Die Temperatur und andere Dekodierungsparameter, die das Modell zum Generieren von Antworten verwendet.
Weitere Informationen zum Verfassen hilfreicher Prompts finden Sie unter Einführung in das Prompt-Design.
Prompt-Design ist ein Synonym für Prompt Engineering.
Prompt-Tuning
Ein parametereffizienter Tuning-Mechanismus, der ein „Präfix“ lernt, das dem tatsächlichen Prompt vorangestellt wird.
Eine Variante der Prompt-Optimierung, die manchmal als Präfix-Optimierung bezeichnet wird, besteht darin, das Präfix vor jeder Ebene einzufügen. Bei der meisten Prompt-Optimierung wird der Eingabeebene dagegen nur ein Präfix hinzugefügt.
R
Recall bei k (recall@k)
Ein Messwert zur Bewertung von Systemen, die eine sortierte (geordnete) Liste von Elementen ausgeben. Der Recall bei k gibt den Anteil der relevanten Elemente in den ersten k Elementen dieser Liste an, bezogen auf die Gesamtzahl der zurückgegebenen relevanten Elemente.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Im Gegensatz zur Precision bei k.
Referenztext
Die Antwort eines Experten auf einen Prompt. Angenommen, Sie erhalten den folgenden Prompt:
Übersetzen Sie die Frage „Wie heißen Sie?“ vom Englischen ins Französische.
Eine Antwort eines Experten könnte so lauten:
Comment vous appelez-vous?
Mit verschiedenen Messwerten wie ROUGE wird der Grad gemessen, in dem der Referenztext mit dem generierten Text eines ML-Modells übereinstimmt.
Rollenaufforderungen
Optionaler Teil eines Prompts, mit dem eine Zielgruppe für die Antwort eines generativen KI-Modells angegeben wird. Ohne einen Rollen-Prompt liefert ein Large Language Model eine Antwort, die für die Person, die die Fragen stellt, nützlich sein kann oder auch nicht. Mit einem Rollen-Prompt kann ein Large Language Model auf eine Weise antworten, die für eine bestimmte Zielgruppe angemessener und hilfreicher ist. In den folgenden Prompts ist beispielsweise der Teil mit dem Rollenvorschlag fett formatiert:
- Fassen Sie diesen Artikel für einen Doktoranden in Wirtschaftswissenschaften zusammen.
- Beschreiben Sie die Funktionsweise der Gezeiten für ein zehnjähriges Kind.
- Erläutern Sie die Finanzkrise von 2008. Sprechen Sie so, wie Sie es mit einem kleinen Kind oder einem Golden Retriever tun würden.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Eine Reihe von Messwerten zur Bewertung von Modellen für automatische Zusammenfassungen und maschinelle Übersetzung. Mit ROUGE-Messwerten wird der Grad bestimmt, in dem ein Referenztext mit dem generierten Text eines ML-Modells übereinstimmt. Jedes Mitglied der ROUGE-Familie misst Überschneidungen auf unterschiedliche Weise. Je höher der ROUGE-Wert, desto ähnlicher sind der Referenztext und der generierte Text.
Für jedes Mitglied der ROUGE-Familie werden in der Regel die folgenden Messwerte generiert:
- Precision
- Recall
- F1
Weitere Informationen und Beispiele finden Sie unter:
ROUGE-L
Ein Mitglied der ROUGE-Familie, das sich auf die Länge der längsten gemeinsamen Untersequenz im Referenztext und im generierten Text konzentriert. Mit den folgenden Formeln werden Recall und Precision für ROUGE-L berechnet:
Mit F1 können Sie die ROUGE-L-Trefferquote und die ROUGE-L-Genauigkeit in einem einzigen Messwert zusammenfassen:
Bei ROUGE-L werden alle Zeilenumbrüche im Referenztext und im generierten Text ignoriert. Die längste gemeinsame Untersequenz kann also mehrere Sätze umfassen. Wenn der Referenztext und der generierte Text mehrere Sätze enthalten, ist eine Variante von ROUGE-L namens ROUGE-Lsum in der Regel ein besserer Messwert. Bei ROUGE-Lsum wird die längste gemeinsame Untersequenz für jeden Satz in einem Abschnitt ermittelt und dann der Mittelwert dieser längsten gemeinsamen Untersequenzen berechnet.
ROUGE-N
Eine Reihe von Messwerten innerhalb der ROUGE-Familie, mit denen die gemeinsamen N-Gramme einer bestimmten Größe im Referenztext und im generierten Text verglichen werden. Beispiel:
- ROUGE-1 misst die Anzahl der gemeinsamen Tokens im Referenztext und im generierten Text.
- ROUGE-2 misst die Anzahl der gemeinsamen Bigramme (2-Gramme) im Referenztext und im generierten Text.
- ROUGE-3 misst die Anzahl der gemeinsamen Trigramme (3-Gramme) im Referenztext und im generierten Text.
Mit den folgenden Formeln können Sie die ROUGE-N-Wiedererkennungsrate und die ROUGE-N-Genauigkeit für jedes Mitglied der ROUGE-N-Familie berechnen:
Mit F1 können Sie die ROUGE-N-Trefferquote und die ROUGE-N-Genauigkeit zu einem einzigen Messwert zusammenfassen:
ROUGE-S
Eine fehlertolerante Form von ROUGE-N, die Skip-Gram-Abgleiche ermöglicht. Das heißt, bei ROUGE-N werden nur N-Gramme gezählt, die genau übereinstimmen. Bei ROUGE-S werden auch N-Gramme gezählt, die durch ein oder mehrere Wörter getrennt sind. Sie könnten beispielsweise Folgendes versuchen:
- Referenztext: Weiße Wolken
- generierter Text: Weiße aufsteigende Wolken
Bei der Berechnung von ROUGE-N stimmt das 2-Gramm Weiße Wolken nicht mit Weiße aufsteigende Wolken überein. Bei der Berechnung von ROUGE-S stimmt Weiße Wolken jedoch mit Weiße aufsteigende Wolken überein.
S
Selbstaufmerksamkeit (auch Selbstaufmerksamkeitslayer genannt)
Eine neuronale Netzwerkschicht, die eine Sequenz von Einbettungen (z. B. Token-Embeddings) in eine andere Sequenz von Einbettungen umwandelt. Jede Einbettung in der Ausgabesequenz wird durch die Integration von Informationen aus den Elementen der Eingabesequenz über einen Aufmerksamkeitsmechanismus erstellt.
Der Begriff Selbst in Selbstaufmerksamkeit bezieht sich auf die Sequenz, die sich auf sich selbst und nicht auf einen anderen Kontext konzentriert. Die Selbstausrichtung ist einer der Hauptbausteine von Transformern und verwendet Wörterbuchsuchbegriffe wie „Abfrage“, „Schlüssel“ und „Wert“.
Eine Schicht mit Selbstaufmerksamkeit beginnt mit einer Sequenz von Eingabedarstellungen, eine für jedes Wort. Die Eingabedarstellung für ein Wort kann ein einfaches Einbettungsmodell sein. Für jedes Wort in einer Eingabesequenz bewertet das Netzwerk die Relevanz des Wortes für jedes Element in der gesamten Wortsequenz. Die Relevanzbewertungen geben an, inwieweit die endgültige Darstellung des Wortes die Darstellungen anderer Wörter enthält.
Betrachten Sie beispielsweise den folgenden Satz:
Das Tier hat die Straße nicht überquert, weil es zu müde war.
Die folgende Abbildung (aus Transformer: A Novel Neural Network Architecture for Language Understanding) zeigt das Aufmerksamkeitsmuster einer Schicht mit selbstausgerichteter Aufmerksamkeit für das Pronomen es. Die Dunkelheit der einzelnen Linien gibt an, wie viel jedes Wort zur Repräsentation beiträgt:
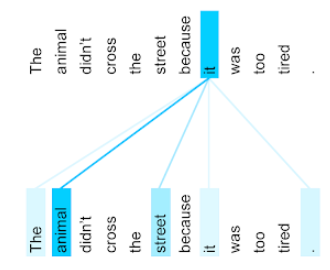
In der Selbstaufmerksamkeitsschicht werden Wörter hervorgehoben, die für „es“ relevant sind. In diesem Fall hat die Aufmerksamkeitsschicht gelernt, Wörter hervorzuheben, auf die es sich beziehen könnte. Dabei wird Tier das höchste Gewicht zugewiesen.
Bei einer Sequenz von n Tokens wird eine Sequenz von Einbettungen n Mal transformiert, einmal an jeder Position in der Sequenz.
Weitere Informationen finden Sie unter Aufmerksamkeit und Multi-Head-Selbstaufmerksamkeit.
Sentimentanalyse
Die Gesamteinstellung einer Gruppe (positiv oder negativ) gegenüber einem Dienst, Produkt, einer Organisation oder einem Thema anhand statistischer oder Algorithmen für maschinelles Lernen bestimmen. Mithilfe von Natural Language Understanding könnte ein Algorithmus beispielsweise eine Sentimentanalyse des Textfeedbacks eines Hochschulkurses durchführen, um zu ermitteln, inwiefern der Kurs den Schülern im Allgemeinen gefallen hat oder nicht.
Sequenz-zu-Sequenz-Aufgabe
Eine Aufgabe, die eine Eingabesequenz von Tokens in eine Ausgabesequenz von Tokens umwandelt. Zwei gängige Arten von Sequenz-zu-Sequenz-Aufgaben sind beispielsweise:
- Übersetzer:
- Beispiel für eine Eingabesequenz: „Ich liebe dich.“
- Beispiel für eine Ausgabesequenz: „Je t'aime.“
- Fragebeantwortung:
- Beispiel für eine Eingabesequenz: „Brauche ich mein Auto in New York City?“
- Beispiel für eine Ausgabesequenz: „Nein. Bitte lassen Sie Ihr Auto stehen.“
Skip-Gram
Ein N-Gramm, das Wörter aus dem ursprünglichen Kontext auslassen (oder „überspringen“) kann, d. h., die N Wörter waren ursprünglich möglicherweise nicht nebeneinander. Genauer gesagt ist ein „k-Überspring-N-Gramm“ ein N-Gramm, bei dem bis zu k Wörter übersprungen wurden.
Für „der schnelle braune Fuchs“ gibt es beispielsweise die folgenden möglichen Zweigramme:
- „der schnelle“
- „quick brown“
- „brauner Fuchs“
Ein „1-Skip-2-Gramm“ besteht aus zwei Wörtern, zwischen denen höchstens ein Wort liegt. Daher hat „der schnelle braune Fuchs“ die folgenden 2-Gramme mit einem Sprung:
- „die braune“
- „schneller Fuchs“
Außerdem sind alle Zwei-Gramme auch Ein-Übersprung-Zwei-Gramme, da weniger als ein Wort übersprungen werden kann.
Skip-Grams sind hilfreich, um den Kontext eines Wortes besser zu verstehen. Im Beispiel wurde „Fox“ im Satz der 1-Übersprung-2-Gramme direkt mit „quick“ verknüpft, aber nicht im Satz der 2-Gramme.
Skip-Grams helfen beim Trainieren von Wort-Embeddings.
Feinabstimmung von Prompts
Eine Methode zum Optimieren eines Large Language Models für eine bestimmte Aufgabe, ohne ressourcenintensive Feinabstimmung. Anstatt alle Gewichte im Modell neu zu trainieren, passt die Soft-Prompt-Optimierung automatisch einen Prompt an, um dasselbe Ziel zu erreichen.
Bei der weichen Prompt-Optimierung werden einem Textprompt in der Regel zusätzliche Token-Ebenen hinzugefügt und die Eingabe wird mithilfe der Backpropagation optimiert.
Ein „harter“ Prompt enthält tatsächliche Tokens anstelle von Token-Embeddings.
dünnbesetztes Feature
Eine Funktion, deren Werte überwiegend null oder leer sind. Ein Beispiel für ein solches Feature ist ein Feature mit einem einzelnen Wert „1“ und einer Million Nullwerte. Ein dichtes Merkmal hat dagegen Werte, die überwiegend nicht null oder leer sind.
Beim maschinellen Lernen sind eine überraschend große Anzahl von Merkmalen spärlich. Kategoriale Merkmale sind in der Regel spärliche Merkmale. Von den 300 möglichen Baumarten in einem Wald wird beispielsweise in einem einzigen Beispiel nur ein Ahorn identifiziert. Oder von den Millionen möglichen Videos in einer Videomediathek wird nur „Casablanca“ als Beispiel erkannt.
In einem Modell werden spärliche Merkmale in der Regel mit One-Hot-Codierung dargestellt. Wenn die One-Hot-Codierung groß ist, können Sie für mehr Effizienz eine Embedding-Ebene über die One-Hot-Codierung legen.
Sparse Darstellung
Es werden nur die Positionen der nicht nullwertigen Elemente in einem spärlichen Attribut gespeichert.
Angenommen, ein kategorisches Feature namens species gibt die 36 Baumarten in einem bestimmten Wald an. Angenommen, jedes Beispiel identifiziert nur eine einzige Art.
Sie könnten einen One-Hot-Vektor verwenden, um die Baumarten in jedem Beispiel darzustellen.
Ein One-Hot-Vektor würde eine einzelne 1 (für die jeweilige Baumart in diesem Beispiel) und 35 0s (für die 35 Baumarten, die in diesem Beispiel nicht vorkommen) enthalten. Die One-Hot-Darstellung von maple könnte also so aussehen:

Alternativ würde die spärliche Darstellung einfach die Position der jeweiligen Art angeben. Wenn maple an Position 24 steht, lautet die sparse Darstellung von maple einfach:
24
Die sparse Darstellung ist viel kompakter als die One-Hot-Darstellung.
Klicken Sie auf das Symbol, um ein etwas komplexeres Beispiel zu sehen.
Angenommen, jedes Beispiel in Ihrem Modell muss die Wörter in einem englischen Satz repräsentieren, aber nicht die Reihenfolge dieser Wörter. Englisch umfasst etwa 170.000 Wörter. Daher ist Englisch eine kategorische Funktion mit etwa 170.000 Elementen. Die meisten englischen Sätze verwenden einen extrem kleinen Teil dieser 170.000 Wörter. Daher sind die Wörter in einem einzelnen Beispiel mit ziemlicher Sicherheit spärlich.
Betrachten Sie den folgenden Satz:
My dog is a great dog
Sie könnten eine Variante des One-Hot-Vektors verwenden, um die Wörter in diesem Satz darzustellen. Bei dieser Variante können mehrere Zellen im Vektor einen Wert ungleich 0 enthalten. Außerdem kann in dieser Variante eine Zelle einen anderen Ganzzahlwert als 1 enthalten. Die Wörter „mein“, „ist“, „ein“ und „toll“ kommen nur einmal im Satz vor, das Wort „Hund“ dagegen zweimal. Wenn wir diese Variante von One-Hot-Vektoren verwenden, um die Wörter in diesem Satz darzustellen, ergibt sich der folgende Vektor mit 170.000 Elementen:

Eine sparse Darstellung desselben Satzes würde einfach so aussehen:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
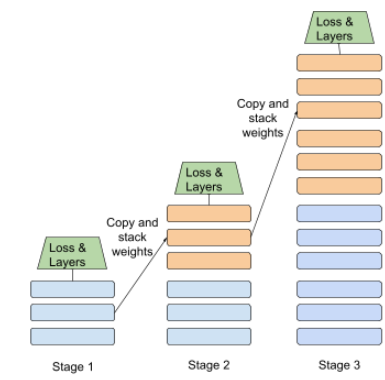
Stufenweises Training
Eine Taktik, bei der ein Modell in einer Abfolge von einzelnen Phasen trainiert wird. Das Ziel kann entweder darin bestehen, den Trainingsvorgang zu beschleunigen oder eine bessere Modellqualität zu erreichen.
Unten sehen Sie eine Abbildung des progressiven Stapelns:
- Stufe 1 enthält 3 verborgene Schichten, Stufe 2 6 verborgene Schichten und Stufe 3 12 verborgene Schichten.
- In Phase 2 beginnt das Training mit den Gewichten, die in den drei verborgenen Schichten von Phase 1 gelernt wurden. In Phase 3 beginnt das Training mit den Gewichten, die in den sechs verborgenen Schichten von Phase 2 gelernt wurden.
Weitere Informationen finden Sie unter Pipeline-Verarbeitung.
Unterwort-Token
In Sprachmodellen ist ein Token ein Teilstring eines Wortes, der auch das gesamte Wort sein kann.
Ein Wort wie „auflisten“ kann beispielsweise in die Teile „Artikel“ (ein Stammwort) und „isieren“ (ein Suffix) zerlegt werden, die jeweils durch ein eigenes Token dargestellt werden. Wenn seltene Wörter in solche Teile zerlegt werden, die als Subwords bezeichnet werden, können Sprachmodelle mit den gängigeren Bestandteilen des Wortes arbeiten, z. B. Präfixen und Suffixen.
Umgekehrt werden häufig verwendete Wörter wie „gehen“ möglicherweise nicht aufgeteilt und durch ein einzelnes Token dargestellt.
T
T5
Ein Transfer-Learning-Modell für die Text-zu-Text-Transformation, das 2020 von Google AI eingeführt wurde. T5 ist ein Encoder-Decoder-Modell, das auf der Transformer-Architektur basiert und auf einem extrem großen Dataset trainiert wurde. Es eignet sich für eine Vielzahl von Aufgaben der natürlichen Sprachverarbeitung, z. B. für die Textgenerierung, die Übersetzung von Sprachen und die Beantwortung von Fragen in natürlicher Sprache.
T5 leitet sich von den fünf Ts in „Text-to-Text Transfer Transformer“ ab.
T5X
Ein Open-Source-Machine-Learning-Framework, mit dem sich groß angelegte Modelle für die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) erstellen und trainieren lassen. T5 ist in der T5X-Codebasis implementiert, die auf JAX und Flax basiert.
Temperatur
Ein Hyperparameter, der den Grad der Zufälligkeit der Ausgabe eines Modells steuert. Höhere Temperaturen führen zu einer stärker zufälligen Ausgabe, während niedrigere Temperaturen zu einer weniger zufälligen Ausgabe führen.
Die Auswahl der optimalen Temperatur hängt von der jeweiligen Anwendung und den gewünschten Eigenschaften der Ausgabe des Modells ab. Sie würden die Temperatur beispielsweise wahrscheinlich erhöhen, wenn Sie eine Anwendung erstellen, die kreative Inhalte generiert. Umgekehrt würden Sie die Temperatur wahrscheinlich senken, wenn Sie ein Modell erstellen, das Bilder oder Text klassifiziert, um die Genauigkeit und Konsistenz des Modells zu verbessern.
Die Temperatur wird häufig mit softmax verwendet.
Textspanne
Der Arrayindexbereich, der mit einem bestimmten Teil eines Textstrings verknüpft ist.
Das Wort good im Python-String s="Be good now" nimmt beispielsweise die Textspanne von 3 bis 6 ein.
Token
In einem Language Model ist es die atomare Einheit, anhand derer das Modell trainiert und Vorhersagen trifft. Ein Token ist in der Regel eines der folgenden:
- ein Wort. Der Ausdruck „Hunde mögen Katzen“ besteht beispielsweise aus drei Wort-Tokens: „Hunde“, „mögen“ und „Katzen“.
- ein Zeichen. Der Begriff „Fahrrad Fisch“ besteht beispielsweise aus neun Zeichentokens. Hinweis: Das Leerzeichen zählt als eines der Tokens.
- Subwords: Ein einzelnes Wort kann ein einzelnes Token oder mehrere Tokens sein. Ein Teilwort besteht aus einem Stammwort, einem Präfix oder einem Suffix. Ein Sprachmodell, das Subwörter als Tokens verwendet, könnte das Wort „Hunde“ beispielsweise als zwei Tokens betrachten: das Stammwort „Hund“ und das Pluralsuffix „-e“. Dieses Sprachmodell könnte das einzelne Wort „größer“ als zwei Teilwörter betrachten (das Stammwort „groß“ und das Suffix „er“).
In anderen Bereichen als Sprachmodellen können Tokens auch andere Arten von atomaren Einheiten darstellen. Beim maschinellen Sehen kann ein Token beispielsweise ein Teil eines Bildes sein.
Top-K-Genauigkeit
Der Prozentsatz, mit dem ein „Ziellabel“ in den ersten k Positionen der generierten Listen erscheint. Die Listen können personalisierte Empfehlungen oder eine Liste von Elementen sein, die nach softmax sortiert sind.
Die Top-K-Genauigkeit wird auch als Genauigkeit bei k bezeichnet.
Toxizität
Der Grad, in dem Inhalte missbräuchlich, bedrohlich oder anstößig sind. Viele Modelle für maschinelles Lernen können Toxizität erkennen und messen. Die meisten dieser Modelle erkennen toxisches Verhalten anhand mehrerer Parameter, z. B. anhand des Ausmaßes an missbräuchlicher und bedrohlicher Sprache.
Transformer
Eine von Google entwickelte Architektur für künstliche neuronale Netze, die auf Selbstaufmerksamkeitsmechanismen basiert, um eine Sequenz von Eingabe-Embeddings in eine Sequenz von Ausgabe-Embeddings umzuwandeln, ohne Konvolutionen oder rekurrente neuronale Netze zu verwenden. Ein Transformer kann als Stapel von Self-Attention-Schichten betrachtet werden.
Ein Transformator kann Folgendes enthalten:
Ein Encoder wandelt eine Sequenz von Einbettungen in eine neue Sequenz derselben Länge um. Ein Encoder besteht aus N identischen Schichten, von denen jede zwei Unterschichten enthält. Diese beiden Unterschichten werden an jeder Position der Eingabe-Embedding-Sequenz angewendet und wandeln jedes Element der Sequenz in ein neues Embedding um. Die erste Encoder-Unterschicht aggregiert Informationen aus der gesamten Eingabesequenz. Die zweite Encoder-Unterschicht wandelt die aggregierten Informationen in ein Ausgabe-Embedding um.
Ein Decoder wandelt eine Sequenz von Eingabe-Embeddings in eine Sequenz von Ausgabe-Embeddings um, möglicherweise mit einer anderen Länge. Ein Decoder enthält außerdem N identische Schichten mit drei Unterschichten, von denen zwei den Unterschichten des Encoders ähneln. Die dritte Decoder-Unterschicht nimmt die Ausgabe des Encoders und wendet den Mechanismus der Selbstaufmerksamkeit an, um Informationen daraus zu gewinnen.
Der Blogpost Transformer: A Novel Neural Network Architecture for Language Understanding bietet eine gute Einführung in Transformer.
Trigramm
Ein N-Gramm mit N=3.
U
unidirektional
Ein System, das nur den Text prüft, der vor einem Zieltextabschnitt steht. Ein bidirektionales System hingegen wertet sowohl den Text aus, der vor als auch den, der nach dem Zieltextabschnitt kommt. Weitere Informationen finden Sie unter bidirektional.
unidirektionales Sprachmodell
Ein Sprachmodell, das seine Wahrscheinlichkeiten nur auf den Tokens gründet, die vor, nicht nach dem Zieltoken bzw. den Zieltokens erscheinen. Im Gegensatz zu einem bidirektionalen Sprachmodell.
V
Variations-Autoencoder (VAE)
Eine Art Autoencoder, der die Abweichung zwischen Eingaben und Ausgaben nutzt, um modifizierte Versionen der Eingaben zu generieren. Variationale Autoencoder sind nützlich für generative KI.
VAEs basieren auf der Variationsinference, einem Verfahren zur Schätzung der Parameter eines Wahrscheinlichkeitsmodells.
W
Worteinbettung
Darstellung jedes Wortes in einem Wortsatz in einem Embedding-Vektor, d.h.Darstellung jedes Wortes als Vektor von Gleitkommawerten zwischen 0,0 und 1,0. Wörter mit ähnlicher Bedeutung haben ähnlichere Darstellungen als Wörter mit unterschiedlicher Bedeutung. Beispielsweise würden Karotten, Sellerie und Gurken alle relativ ähnliche Darstellungen haben, die sich stark von den Darstellungen von Flugzeugen, Sonnenbrillen und Zahnpasta unterscheiden würden.
Z
Zero-Shot-Prompts
Ein Prompt, der kein Beispiel dafür enthält, wie das Large Language Model antworten soll. Beispiel:
| Teile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Indien: | Die tatsächliche Suchanfrage. |
Das Large Language Model könnte mit einer der folgenden Antworten antworten:
- Rupie
- INR
- ₹
- Indische Rupie
- Die Rupie
- Die indische Rupie
Alle Antworten sind richtig, aber Sie bevorzugen möglicherweise ein bestimmtes Format.
Vergleichen Sie Zero-Shot-Prompts mit den folgenden Begriffen: