このページには、言語評価の用語集の用語が記載されています。用語集のすべての用語については、こちらをクリックしてください。
A
Attention、
特定の単語または単語の一部が重要であることを示すために、ニューラル ネットワークで使用されるメカニズム。アテンションは、モデルが次のトークンまたは単語を予測するために必要な情報量を圧縮します。一般的なアテンション メカニズムは、入力セットの重み付き和で構成されます。各入力の重みは、ニューラル ネットワークの別の部分で計算されます。
Transformer の構成要素である自己注意とマルチヘッド自己注意も参照してください。
セルフ アテンションの詳細については、機械学習集中講座の LLM: 大規模言語モデルとはをご覧ください。
オートエンコーダ
入力から最も重要な情報を抽出することを学習するシステム。オートエンコーダは、エンコーダとデコーダの組み合わせです。オートエンコーダは、次の 2 段階のプロセスに依存しています。
- エンコーダは、入力を(通常は)非可逆の低次元(中間)形式にマッピングします。
- デコーダは、低次元形式を元の高次元入力形式にマッピングすることで、元の入力の非可逆バージョンを構築します。
オートエンコーダは、デコーダがエンコーダの中間形式から元の入力をできるだけ正確に再構成しようとすることで、エンドツーエンドでトレーニングされます。中間形式は元の形式よりも小さい(低次元)ため、オートエンコーダは入力内のどの情報が重要かを学習する必要があります。出力は入力と完全には一致しません。
次に例を示します。
- 入力データがグラフィックの場合、正確でないコピーは元のグラフィックに似ていますが、多少変更されています。正確でないコピーでは、元のグラフィックからノイズが除去されたり、欠落しているピクセルが埋め込まれたりする可能性があります。
- 入力データがテキストの場合、オートエンコーダは元のテキストを模倣した(ただし同一ではない)新しいテキストを生成します。
変分オートエンコーダもご覧ください。
自動評価
ソフトウェアを使用してモデルの出力の品質を判断する。
モデルの出力が比較的単純な場合は、スクリプトまたはプログラムでモデルの出力をゴールド レスポンスと比較できます。このタイプの自動評価は、プログラムによる評価とも呼ばれます。ROUGE や BLEU などの指標は、プログラムによる評価に役立ちます。
モデルの出力が複雑であるか、正解が 1 つではない場合は、自動採点ツールと呼ばれる別の ML プログラムが自動評価を実行することがあります。
人間による評価とは対照的です。
自動評価
生成 AI モデルの出力の品質を判断するためのハイブリッド メカニズム。人間による評価と自動評価を組み合わせています。自動評価ツールは、人間による評価によって作成されたデータでトレーニングされた ML モデルです。理想的には、自動評価ツールは人間の評価者を模倣するように学習します。事前構築された自動評価ツールを使用できますが、最適な自動評価ツールは、評価するタスクに固有にファインチューニングされています。
自己回帰モデル
独自の過去の予測に基づいて予測を推定するモデル。たとえば、自己回帰言語モデルは、以前に予測されたトークンに基づいて次のトークンを予測します。Transformer ベースの大規模言語モデルはすべて自動回帰型です。
一方、GAN ベースの画像モデルは、ステップで反復処理せずに 1 回の順方向パスで画像を生成するため、通常は自己回帰的ではありません。ただし、特定の画像生成モデルは、画像を段階的に生成するため、自己回帰的です。
k での平均適合率
書籍のおすすめの番号付きリストなど、ランク付けされた結果を生成する単一のプロンプトでのモデルのパフォーマンスを要約するための指標。k での平均適合率は、各関連結果の k での適合率値の平均です。したがって、k での平均適合率の式は次のようになります。
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
ここで
- \(n\) は、リスト内の関連アイテムの数です。
k での再呼び出しとは対照的です。
B
バッグ オブ ワード
語句や文章内の単語の表現(順序は問いません)。たとえば、バッグ オブ ワードは次の 3 つのフレーズを同じ方法で表します。
- 犬がジャンプする
- 犬に飛びかかる
- 犬が
各単語は、スパース ベクトルのインデックスにマッピングされます。このベクトルには、語彙内のすべての単語のインデックスが含まれています。たとえば、「犬が飛び跳ねる」というフレーズは、単語「犬」、「飛び跳ねる」に対応する 3 つのインデックスでゼロ以外の値を持つ特徴ベクトルにマッピングされます。ゼロ以外の値は次のいずれかになります。
- 単語が存在することを示す 1。
- バッグに単語が出現する回数。たとえば、フレーズが「the maroon dog is a dog with maroon fur」の場合、maroon と dog の両方が 2 として表され、他の単語は 1 として表されます。
- 単語がバッグに出現する回数のログなど、その他の値。
BERT(Bidirectional Encoder Representations from Transformers)
テキストの表現用のモデル アーキテクチャ。トレーニング済みの BERT モデルは、テキスト分類やその他の ML タスク用の大規模モデルの一部として機能できます。
BERT には次の特徴があります。
- Transformer アーキテクチャを使用するため、自己注意に依存します。
- Transformer のエンコーダ部分を使用します。エンコーダの役割は、分類などの特定のタスクを実行することではなく、優れたテキスト表現を生成することです。
- 双方向です。
- 教師なしトレーニングにマスキングを使用します。
BERT のバリエーションには次のようなものがあります。
BERT の概要については、オープンソース化された BERT: 自然言語処理の最先端の事前トレーニングをご覧ください。
双方向
ターゲット テキストの区間の前後にあるテキストを評価するシステムを説明する用語。一方、単方向システムは、ターゲット セクションのテキストの前にあるテキストのみを評価します。
たとえば、次の質問で下線付きの単語の確率を決定する必要があるマスクされた言語モデルについて考えてみましょう。
お客様の _____ は
一方通行の言語モデルでは、「What」、「is」、「the」という単語から得られるコンテキストのみに基づいて確率を算出する必要があります。一方、双方向言語モデルは「with」と「you」からコンテキストを取得できるため、モデルがより良い予測を生成できる可能性があります。
双方向言語モデル
言語モデル。テキストの抜粋内の特定の位置に特定のトークンが存在する可能性を、その前後のテキストに基づいて判断します。
ビグラム
N=2 のN グラム。
BLEU(Bilingual Evaluation Understudy)
スペイン語から日本語への機械翻訳を評価するための 0.0 ~ 1.0 の指標。
スコアを計算するために、BLEU は通常、ML モデルの翻訳(生成テキスト)を人間の専門家の翻訳(参照テキスト)と比較します。BLEU スコアは、生成されたテキストと参照テキストのn グラムの一致度によって決まります。
この指標に関する元の論文は、BLEU: a Method for Automatic Evaluation of Machine Translation です。
BLEURT もご覧ください。
BLEURT(Bilingual Evaluation Understudy from Transformers)
ある言語から別の言語への機械翻訳(特に英語との間の翻訳)を評価するための指標。
英語との間の翻訳では、BLEURT は BLEU よりも人間の評価に近づいています。BLEU とは異なり、BLEURT は意味(意味)の類似性を重視し、パラフレーズに対応できます。
BLEURT は、事前トレーニング済みの大規模言語モデル(正確には BERT)に依存し、人間の翻訳者のテキストでファイン チューニングされます。
この指標に関する元の論文は BLEURT: Learning Robust Metrics for Text Generation です。
C
因果言語モデル
単方向言語モデルと同義。
言語モデルにおけるさまざまな方向性のアプローチを比較するには、双方向言語モデルをご覧ください。
Chain-of-Thought プロンプト
大規模言語モデル(LLM)が推論を段階的に説明するように促すプロンプト エンジニアリング手法。たとえば、次のプロンプトについて考えてみましょう。特に 2 番目の文に注意してください。
時速 0 マイルから時速 60 マイルに 7 秒で加速する自動車に乗っている場合、ドライバーはどのくらいの G 力を体験するでしょうか。回答に、関連するすべての計算を示します。
LLM のレスポンスは次のようになります。
- 0、60、7 の値を適切な場所に挿入して、一連の物理学式を表示します。
- これらの数式が選択された理由と、さまざまな変数の意味を説明します。
思考プロセス プロンプトを使用すると、LLM はすべての計算を実行するため、より正確な回答が得られる可能性があります。また、思考の流れプロンプトを使用すると、ユーザーは LLM のステップを調べて、回答が妥当かどうかを判断できます。
チャット
ML システム(通常は大規模言語モデル)とのやり取りの内容。チャットでの以前のやり取り(入力内容と大規模言語モデルの応答方法)が、チャットの後続部分のコンテキストになります。
chatbot は、大規模言語モデルのアプリケーションです。
虚構
hallucination の類義語。
技術的には、幻覚よりも虚言の方が正確な用語であると考えられます。しかし、幻覚が最初に広まりました。
選挙区の解析
文を小さな文法構造(「構成要素」)に分割する。自然言語理解モデルなど、ML システムの後半部分では、元の文よりも構成要素を簡単に解析できます。たとえば、次の文について考えてみましょう。
友人が 2 匹の猫を飼い始めた。
コンスティチュエンシー パーサーは、この文を次の 2 つの構成要素に分割できます。
- My friend は名詞句です。
- 2 匹の猫を飼い始めたは動詞句です。
これらの構成要素は、さらに小さな構成要素に分割できます。たとえば、動詞句
2 匹の猫を飼い始めた
はさらに次のように分類できます。
- adopted は動詞です。
- 2 匹の猫も名詞句です。
コンテキストに応じた言語エンベディング
ネイティブの人間の話者のように単語やフレーズを「理解」することに近いエンベディング。コンテキスト化された言語エンベディングは、複雑な構文、セマンティクス、コンテキストを理解できます。
たとえば、英語の単語「cow」のエンベディングについて考えてみましょう。word2vec などの古いエンベディングでは、エンベディング空間における cow から bull までの距離が、ewe(メスの羊)から ram(オスの羊)までの距離や、female から male までの距離と類似するように、英語の単語を表現できます。コンテキストに応じた言語エンベディングでは、英語話者が牛または雄牛のいずれかを指すために「cow」という単語を日常的に使用していることを認識することで、さらに一歩進んだことができます。
コンテキスト ウィンドウ
特定のプロンプトでモデルが処理できるトークンの数。コンテキスト ウィンドウが大きいほど、モデルはより多くの情報を使用して、プロンプトに一貫性のある回答を提供できます。
クラッシュ ブラッサム
意味があいまいな文またはフレーズ。クラッシュ ブロッサムは、自然言語理解において重大な問題となります。たとえば、ヘッドライン「Red Tape Holds Up Skyscraper」は、NLU モデルがヘッドラインを文字通りまたは比喩的に解釈する可能性があるため、クラッシュ ブロッサムです。
D
デコーダ
一般に、処理済み、高密度、内部表現から、より未加工、スパース、外部表現に変換する ML システム。
デコーダは多くの場合、より大きなモデルのコンポーネントであり、エンコーダとペアになっています。
シーケンス ツー シーケンス タスクでは、デコーダはエンコーダによって生成された内部状態から開始して、次のシーケンスを予測します。
Transformer アーキテクチャ内のデコーダの定義については、Transformer をご覧ください。
詳細については、ML 集中講座の大規模言語モデルをご覧ください。
ノイズ除去
自己教師あり学習の一般的なアプローチ。次のように機能します。
ノイズ除去により、ラベルのないサンプルから学習できます。元のデータセットがターゲットまたはラベルとして機能し、ノイズのあるデータが入力として機能します。
一部のマスクされた言語モデルは、次のようにノイズ除去を使用します。
- 一部のトークンをマスクすることで、ラベルのない文にノイズが人為的に追加されます。
- モデルは元のトークンを予測しようとします。
直接プロンプト
ゼロショット プロンプトと同義。
E
編集距離
2 つのテキスト文字列の類似度を測定する値。機械学習では、編集距離が次の理由で役立ちます。
- 編集距離は簡単に計算できます。
- 編集距離は、類似しているとわかっている 2 つの文字列を比較できます。
- 編集距離は、異なる文字列が特定の文字列にどれほど類似しているかを判断できます。
編集距離にはいくつかの定義があり、それぞれが異なる文字列演算を使用します。例については、Levenshtein 距離をご覧ください。
エンベディング レイヤ
高次元のカテゴリ特徴でトレーニングし、低次元のエンベディング ベクトルを徐々に学習する特別な隠れ層。エンベディング層を使用すると、高次元のカテゴリ特徴のみをトレーニングする場合よりも、ニューラル ネットワークをはるかに効率的にトレーニングできます。
たとえば、現在 Google Earth では約 73,000 種類の樹木をサポートしています。木の種類がモデルの特徴であるとします。モデルの入力レイヤには、73,000 要素の長さのワンホット ベクトルが含まれています。たとえば、baobab は次のように表されます。

73,000 要素の配列は非常に長いです。モデルにエンベディング レイヤを追加しないと、72,999 個のゼロを乗算するため、トレーニングに非常に時間がかかります。エンベディング レイヤを 12 つのディメンションで構成するとします。エンベディング レイヤは、木の種類ごとに新しいエンベディング ベクトルを徐々に学習します。
状況によっては、エンベディング レイヤの代わりにハッシュ化が適切な場合があります。
詳細については、機械学習集中講座のエンベディングをご覧ください。
エンベディング空間
高次元ベクトル空間の特徴がマッピングされる d 次元ベクトル空間。理想的には、埋め込み空間には意味のある数学的結果をもたらす構造が含まれています。たとえば、理想的な埋め込み空間では、埋め込みの加算と減算によって単語類似性タスクを解決できます。
2 つのエンベディングのドット積は、それらの類似度を測定したものです。
エンベディング ベクトル
広義には、その隠れ層への入力を表す隠れ層から取得された浮動小数点数の配列です。エンベディング ベクトルは、エンベディング レイヤでトレーニングされた浮動小数点数の配列であることがよくあります。たとえば、エンベディング レイヤが地球上の 73,000 種類の樹木のエンベディング ベクトルを学習する必要がある場合を考えてみましょう。次の配列は、バオバブ ツリーのエンベディング ベクトルです。

エンベディング ベクトルはランダムな数値の集まりではありません。エンベディング層は、トレーニング中にニューラル ネットワークが他の重みを学習するのと同様に、トレーニングを通じてこれらの値を決定します。配列の各要素は、樹種の特定の特性に関する評価です。どの要素がどの樹種の特徴を表していますか。これは人間が判断するのは非常に困難です。
エンベディング ベクトルの数学的に注目すべき点は、類似したアイテムが類似した浮動小数点数のセットを持ちます。たとえば、類似した樹木種の浮動小数点数は、類似していない樹木種の浮動小数点数よりも類似しています。レッドウッドとセコイアは関連する樹木種であるため、レッドウッドとココナッツ パームよりも浮動小数点数のセットが類似しています。エンベディング ベクトルの数値は、同じ入力でモデルを再トレーニングしても、モデルを再トレーニングするたびに変化します。
エンコーダ
一般に、未加工、スパース、または外部表現から、より処理された、より密度の高い、またはより内部的な表現に変換する ML システム。
エンコーダは多くの場合、より大きなモデルのコンポーネントであり、デコーダとペアになっています。一部の Transformer はエンコーダとデコーダをペアで使用しますが、他の Transformer はエンコーダまたはデコーダのみを使用します。
一部のシステムでは、エンコーダの出力を分類ネットワークまたは回帰ネットワークへの入力として使用します。
シーケンス間タスクでは、エンコーダは入力シーケンスを受け取り、内部状態(ベクトル)を返します。次に、デコーダがその内部状態を使用して次のシーケンスを予測します。
Transformer アーキテクチャでのエンコーダの定義については、Transformer をご覧ください。
詳細については、機械学習集中講座の LLM: 大規模言語モデルとはをご覧ください。
evals
主に LLM 評価の略語として使用されます。より広い意味で、evals はあらゆる形式の評価の略語です。
評価
モデルの品質を測定したり、異なるモデルを比較したりするプロセス。
教師あり機械学習モデルを評価するには、通常、検証セットとテストセットと比較して判断します。LLM の評価には通常、幅広い品質と安全性の評価が含まれます。
F
少数ショット プロンプト
大規模言語モデルがどのように応答すべきかを示す複数の(「少数」の)例を含むプロンプト。たとえば、次の長いプロンプトには、大規模言語モデルにクエリに回答する方法を示す 2 つの例が含まれています。
| 1 つのプロンプトの一部 | メモ |
|---|---|
| 指定した国の公式通貨は何ですか? | LLM に回答を求める質問。 |
| フランス: EUR | 1 つの例を挙げましょう。 |
| 英国: GBP | 別の例をご紹介します。 |
| インド: | 実際のクエリ。 |
一般的に、少数ショット プロンプトを使用すると、ゼロショット プロンプトやワンショット プロンプトよりも望ましい結果が得られます。ただし、少数ショット プロンプトでは長いプロンプトが必要になります。
少数ショット プロンプトは、プロンプトベースの学習に適用される少数ショット学習の一種です。
詳細については、機械学習集中講座のプロンプト エンジニアリングをご覧ください。
フィドル
侵入的なコードやインフラストラクチャを使用せずに、関数とクラスの値を設定する Python ファーストの構成ライブラリ。Pax やその他の ML コードベースの場合、これらの関数とクラスはモデルとトレーニングのハイパーパラメータを表します。
Fiddle は、機械学習のコードベースが通常次の 3 つに分割されていることを前提としています。
- レイヤとオプティマイザーを定義するライブラリ コード。
- ライブラリを呼び出してすべてを接続するデータセットの「グルー」コード。
Fiddle は、評価されていない変更可能な形式でグルーコードの呼び出し構造をキャプチャします。
ファインチューニング
2 つ目のタスク固有のトレーニング パスは、事前トレーニング済みモデルで実行され、特定のユースケースに合わせてパラメータを調整します。たとえば、一部の大規模言語モデルの完全なトレーニング シーケンスは次のとおりです。
- 事前トレーニング: すべての英語の Wikipedia ページなど、膨大な一般的なデータセットで大規模言語モデルをトレーニングします。
- ファインチューニング: 医療に関するクエリへの回答など、特定のタスクを実行するように事前トレーニング済みモデルをトレーニングします。通常、ファインチューニングでは、特定のタスクに焦点を当てた数百または数千のサンプルが使用されます。
別の例として、大規模な画像モデルの完全なトレーニング シーケンスは次のとおりです。
- 事前トレーニング: 膨大な一般的な画像データセット(ウィキメディア コモンズ内のすべての画像など)で大規模な画像モデルをトレーニングします。
- ファインチューニング: オルカの画像の生成など、特定のタスクを実行するように事前トレーニング済みモデルをトレーニングします。
ファインチューニングでは、次の戦略を組み合わせて使用できます。
- 事前トレーニング済みモデルの既存のパラメータをすべて変更する。これは「完全なファインチューニング」と呼ばれることもあります。
- 事前トレーニング済みモデルの既存のパラメータの一部のみを変更し(通常は出力レイヤに最も近いレイヤ)、他の既存のパラメータは変更しない(通常は入力レイヤに最も近いレイヤ)。パラメータ効率チューニングをご覧ください。
- レイヤを追加します。通常は、出力レイヤに最も近い既存のレイヤの上に追加します。
ファインチューニングは転移学習の一種です。そのため、ファインチューニングでは、トレーニング済みモデルのトレーニングに使用したものとは異なる損失関数やモデルタイプを使用する場合があります。たとえば、事前トレーニング済みの大規模画像モデルをファインチューニングして、入力画像の鳥の数を返す回帰モデルを生成できます。
ファインチューニングと次の用語を比較します。
詳細については、機械学習集中講座のファインチューニングをご覧ください。
亜麻
JAX 上に構築された、高性能のオープンソースのディープ ラーニング用 ライブラリ。Flax には、ニューラル ネットワークのトレーニング関数と、パフォーマンスを評価するメソッドが用意されています。
Flaxformer
Transformer 上に構築されたオープンソースの Transformer ライブラリ。主に自然言語処理とマルチモーダル研究向けに設計されています。
G
Gemini
Google の最先端の AI を構成するエコシステム。このエコシステムの要素には次のようなものがあります。
- さまざまな Gemini モデル。
- Gemini モデルへのインタラクティブな会話型インターフェース。ユーザーがプロンプトを入力すると、Gemini がそのプロンプトに応答します。
- 各種 Gemini API。
- Gemini モデルに基づくさまざまなビジネス プロダクト(Gemini for Google Cloud など)。
Gemini モデル
Google の最先端の Transformer ベースのマルチモーダル モデル。Gemini モデルは、エージェントと統合するように特別に設計されています。
ユーザーは、インタラクティブなダイアログ インターフェースや SDK など、さまざまな方法で Gemini モデルを操作できます。
生成されたテキスト
通常、ML モデルが出力するテキストです。大規模言語モデルを評価する場合、一部の指標では、生成されたテキストを参照テキストと比較します。たとえば、ML モデルがフランス語からオランダ語に翻訳する際の有効性を判断するとします。次のような場合があります。
- 生成されたテキストは、ML モデルが出力するオランダ語の翻訳です。
- 参照テキストは、人間の翻訳者(またはソフトウェア)が作成したオランダ語の翻訳です。
評価戦略によっては、参照テキストが使用されない場合があります。
生成 AI
正式な定義のない新しい変革分野。ただし、ほとんどの専門家は、生成 AI モデルが次のすべてのコンテンツを作成(「生成」)できると考えています。
- 複雑
- 一貫性
- オリジナル
たとえば、生成 AI モデルは高度なエッセイや画像を作成できます。
LSTM や RNN などの以前のテクノロジーでも、独自の整合性のあるコンテンツを生成できます。一部の専門家は、これらの初期のテクノロジーを生成 AI と見なしていますが、真の生成 AI には、それらの初期のテクノロジーが生成できるよりも複雑な出力が必要だと考える専門家もいます。
予測 ML とは対照的です。
ゴールデン レスポンス
正しいと知られている回答。たとえば、次のようなプロンプトがあるとします。
2 + 2
理想的な回答は次のとおりです。
4
GPT(Generative Pre-trained Transformer)
OpenAI が開発した Transformer ベースの大規模言語モデルのファミリー。
GPT バリアントを適用できるモダリティは次のとおりです。
- 画像生成(ImageGPT など)
- テキストから画像への生成(DALL-E など)。
H
ハルシネーション
現実世界について主張していると思われる生成 AI モデルによって、もっともらしいが事実と異なる出力が生成されること。たとえば、バラク オバマが 1865 年に亡くなったと主張する生成 AI モデルは幻覚を起こしています。
人間による評価
人間が ML モデルの出力の品質を判断するプロセス。たとえば、バイリンガルの人間に ML 翻訳モデルの品質を判断してもらうなどです。人間による評価は、正解が一つではないモデルの評価に特に役立ちます。
自動評価や自動評価ツールによる評価とは対照的です。
I
コンテキスト内学習
少数ショット プロンプトと同義。
L
LaMDA(対話アプリケーション用言語モデル)
Google が開発した Transformer ベースの大規模言語モデル。大規模な会話データセットでトレーニングされており、リアルな会話レスポンスを生成できます。
LaMDA: Google の画期的な会話テクノロジーで概要を確認できます。
言語モデル
長いトークン シーケンス内で発生するトークンまたはトークン シーケンスの確率を推定するモデル。
大規模言語モデル
少なくとも、パラメータが非常に多い言語モデルが必要です。よりカジュアルな言い方をすれば、Transformer ベースの言語モデル(Gemini や GPT など)。
潜在空間
エンベディング空間と同義。
Levenshtein 距離
ある単語を別の単語に変更するために必要な削除、挿入、置換オペレーションの最小数を計算する編集距離指標。たとえば、「heart」と「darts」の Levenshtein 距離は 3 です。これは、次の 3 つの編集が、1 つの単語を別の単語に変換するために必要な変更の最小数だからです。
- heart → deart(「h」を「d」に置き換える)
- deart → dart(「e」を削除)
- dart → darts(「s」を挿入)
上記の順序が 3 つの編集の唯一のパスはないことに注意してください。
LLM
大規模言語モデルの略語。
LLM の評価(evals)
大規模言語モデル(LLM)のパフォーマンスを評価するための一連の指標とベンチマーク。LLM 評価の概要は次のとおりです。
- 研究者が LLM の改善が必要な領域を特定できるようにします。
- さまざまな LLM を比較し、特定のタスクに最適な LLM を特定する場合に役立ちます。
- LLM を安全かつ倫理的に使用できるようにします。
LoRA
低ランク適応性の略。
低ランク適応(LoRA)
ファイン チューニングのためのパラメータ効率的な手法。モデルの事前トレーニング済み重みを「凍結」(変更できなくする)し、トレーニング可能な重みの小さなセットをモデルに挿入します。このトレーニング可能な重みセット(更新行列とも呼ばれます)はベースモデルよりもかなり小さいため、トレーニングが大幅に高速化されます。
LoRA には次の利点があります。
- ファインチューニングが適用されるドメインのモデルの予測の品質が向上します。
- モデルのすべてのパラメータをファインチューニングする手法よりも高速にファインチューニングできます。
- 同じベースモデルを共有する複数の特殊化モデルの同時提供を可能にすることで、推論の計算コストを削減します。
M
マスク言語モデル
シーケンス内の空白を埋める候補トークンの確率を予測する言語モデル。たとえば、マスクされた言語モデルは、次の文の下線に置き換える候補語の確率を計算できます。
帽子の ____ が戻ってきました。
通常、文献では下線ではなく「MASK」という文字列が使用されます。次に例を示します。
帽子の「MASK」が復元されました。
最新のマスク付き言語モデルのほとんどは双方向です。
K での平均適合率(mAP@k)
検証データセット全体のすべての 平均適合率(k で)スコアの統計的平均。k での平均適合率の 1 つの用途は、おすすめシステムによって生成されたおすすめの品質を判断することです。
「平均平均」というフレーズは冗長に聞こえますが、指標の名前としては適切です。この指標は、複数の k での平均適合率の平均値を求めます。
メタ学習
学習アルゴリズムを発見または改善する機械学習のサブセット。メタ学習システムでは、少量のデータや、以前のタスクで得た経験から新しいタスクをすばやく学習するようにモデルをトレーニングすることもできます。通常、メタ学習アルゴリズムは次の目標を達成しようとします。
- 手動で作成された特徴(初期化子やオプティマイザーなど)を改善または学習する。
- データとコンピューティングの効率を高める。
- 一般化を改善する。
メタ学習は少数ショット学習に関連しています。
専門家集団
パラメータのサブセット(エキスパート)のみを使用して特定の入力トークンまたは例を処理することで、ニューラル ネットワークの効率を高めるスキーム。ゲーティング ネットワークは、各入力トークンまたは例を適切なエキスパートに転送します。
詳しくは、次のいずれかの論文をご覧ください。
MMIT
モダリティ
上位のデータカテゴリ。たとえば、数値、テキスト、画像、動画、音声は 5 つの異なるモダリティです。
モデルの並列処理
1 つのモデルの異なる部分を異なるデバイスに配置するトレーニングまたは推論をスケーリングする方法。モデル並列処理を使用すると、1 つのデバイスに収まらない大きすぎるモデルを使用できます。
モデルの並列処理を実装するには、通常、システムは次のことを行います。
- モデルを小さな部分に分割します。
- これらの小さな部分のトレーニングを複数のプロセッサに分散します。各プロセッサは、モデルの独自の部分をトレーニングします。
- 結果を組み合わせて 1 つのモデルを作成します。
モデルの並列処理はトレーニングを遅らせます。
データ並列処理もご覧ください。
MOE
マルチヘッドセルフアテンション
自己注意の拡張機能で、入力シーケンスの各位置に自己注意メカニズムを複数回適用します。
Transformers では、マルチヘッド自己注意が導入されました。
マルチモーダル インストラクション チューニング
画像、動画、音声など、テキスト以外の入力を処理できる命令チューニングモデル。
マルチモーダル モデル
入力または出力に複数のモダリティが含まれるモデル。たとえば、画像とテキスト キャプション(2 つのモダリティ)の両方を特徴として受け取り、テキスト キャプションが画像にどの程度適しているかを示すスコアを出力するモデルについて考えてみましょう。したがって、このモデルの入力はマルチモーダルであり、出力は単一モードです。
N
自然言語処理
ユーザーが話したり入力したりした内容を、言語ルールを使用して処理するようにコンピュータに指示する分野。最新の自然言語処理のほとんどは機械学習に依存しています。自然言語理解
自然言語処理のサブセットで、発話または入力された内容の意図を判断します。自然言語の理解は、自然言語処理を超えて、コンテキスト、皮肉、感情などの複雑な言語の側面を考慮できます。
N グラム
順序付きの N 個の単語。たとえば、「truly madly」は 2 グラムです。順序が重要であるため、madly truly は truly madly とは異なる 2 グラムです。
| N | この種類の N グラムの名前 | 例 |
|---|---|---|
| 2 | バイグラムまたは 2 グラム | to go, go to, eat lunch, eat dinner |
| 3 | トリグラムまたは 3 グラム | ate too much, three blind mice, the bell tolls |
| 4 | 4 グラム | walk in the park, dust in the wind, the boy ate lentils |
多くの自然言語理解モデルは、N グラムを使用して、ユーザーが入力または発音する次の単語を予測します。たとえば、ユーザーが「three blind」と入力したとします。3 文字語に基づく NLU モデルは、ユーザーが次に「mice」と入力することを予測します。
N グラムは、単語の順序付けされていないセットであるバッグ オブ ワードとは対照的です。
NLP
自然言語処理の略語。
NLU
自然言語理解の略語。
正解なし(NORA)
複数の適切な回答があるプロンプト。たとえば、次のプロンプトには正解がありません。
ゾウに関するジョークを教えて。
正解のないプロンプトの評価は難しい場合があります。
NORA
正解は 1 つではないの略語。
O
ワンショット プロンプト
大規模言語モデルがどのように応答すべきかを示す1 つの例を含むプロンプト。たとえば、次のプロンプトには、クエリにどのように回答するかを大規模言語モデルに示す例が 1 つ含まれています。
| 1 つのプロンプトの一部 | メモ |
|---|---|
| 指定した国の公式通貨は何ですか? | LLM に回答を求める質問。 |
| フランス: EUR | 1 つの例を挙げましょう。 |
| インド: | 実際のクエリ。 |
ワンショット プロンプトと次の用語を比較します。
P
パラメータ効率チューニング
大規模な事前トレーニング済み言語モデル(PLM)を完全なファインチューニングよりも効率的にファインチューニングするための一連の手法。パラメータ効率チューニングでは、通常、完全なファインチューニングよりもはるかに少ないパラメータをファインチューニングしますが、通常、完全なファインチューニングから構築された大規模言語モデルと同等(またはほぼ同等)のパフォーマンスを示す大規模言語モデルが生成されます。
パラメータ効率チューニングと次の方法を比較します。
パラメータ効率チューニングは、パラメータ エフィシエント ファインチューニングとも呼ばれます。
パイプライン
モデル並列処理の一種で、モデルの処理が連続するステージに分割され、各ステージが異なるデバイスで実行されます。1 つのステージが 1 つのバッチを処理している間、前のステージは次のバッチで処理できます。
ステージングされたトレーニングもご覧ください。
PLM
事前トレーニング済み言語モデルの略称。
位置エンコード
シーケンス内のトークンの位置に関する情報をトークンのエンベディングに追加する手法。Transformer モデルは、位置エンコードを使用して、シーケンスのさまざまな部分間の関連性をより深く理解します。
位置エンコードの一般的な実装では、正弦関数を使用します。(具体的には、正弦関数の周波数と振幅は、シーケンス内のトークンの位置によって決まります)。この手法により、Transformer モデルは位置に基づいてシーケンスのさまざまな部分に注意を向けることを学習できます。
トレーニング後のモデル
厳密に定義されていない用語で、通常は、次のような 1 つ以上の後処理を行った事前トレーニング済みモデルを指します。
k での適合率(precision@k)
アイテムのランキング(順序付け)リストを評価するための指標。k での精度は、そのリストの最初の k 個の項目のうち「関連性が高い」項目の割合を示します。具体的には、次のことが求められます。
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
k の値は、返されるリストの長さ以下にする必要があります。返されるリストの長さは計算の対象外です。
関連性は主観的な要素が強いため、専門の人間の評価担当者であっても、関連性が高い項目について意見が一致しないことがよくあります。
比較対象日:
事前トレーニング済みモデル
通常は、すでにトレーニングされているモデルです。この用語は、以前にトレーニングされたエンベディング ベクトルを意味する場合もあります。
事前トレーニング済み言語モデルという用語は、通常、すでにトレーニングされている大規模言語モデルを指します。
事前トレーニング
大規模なデータセットでのモデルの初期トレーニング。一部の事前トレーニング済みモデルは巨大で扱いづらく、通常は追加のトレーニングで精度を高める必要があります。たとえば、ML の専門家は、Wikipedia のすべての英語ページなど、膨大なテキスト データセットで大規模言語モデルを事前トレーニングする場合があります。事前トレーニングの後、得られたモデルは、次のいずれかの手法でさらに精緻化できます。
プロンプト
大規模言語モデルへの入力として入力されるテキスト。これにより、モデルが特定の動作をするように条件付けられます。プロンプトは、フレーズのように短くすることも、小説のテキスト全体のように任意の長さにすることもできます。プロンプトは、次の表に示すような複数のカテゴリに分類されます。
| プロンプト カテゴリ | 例 | メモ |
|---|---|---|
| 質問 | ハトはどのくらいの速さで飛ぶことができますか? | |
| 手順 | アービトラージに関する面白い詩を書いてください。 | 大規模言語モデルに何かを実行するよう求めるプロンプト。 |
| 例 | Markdown コードを HTML に変換します。例:
マークダウン: * リストアイテム HTML: <ul> <li>リストアイテム</li> </ul> |
このサンプル プロンプトの最初の文は指示です。 プロンプトの残りの部分が例です。 |
| ロール | 機械学習のトレーニングで勾配降下法が使用される理由を、物理学の博士号取得者に説明します。 | 文の最初の部分は指示であり、「物理学博士号」というフレーズは役割の部分です。 |
| モデルが完了する部分入力 | 英国の首相は | 部分入力プロンプトは、この例のように突然終了することも、アンダースコアで終了することもできます。 |
生成 AI モデルは、テキスト、コード、画像、エンベディング、動画など、ほぼすべてのプロンプトに応答できます。
プロンプトベースの学習
特定のモデルの機能。任意のテキスト入力(プロンプト)に応じて動作を適応させることができます。一般的なプロンプトベースの学習パラダイムでは、大規模言語モデルがプロンプトに応答してテキストを生成します。たとえば、ユーザーが次のプロンプトを入力したとします。
ニュートンの運動の第 3 法則を要約します。
プロンプトベースの学習が可能なモデルは、前のメッセージに回答するように特別にトレーニングされていません。むしろ、モデルは物理学に関する多くの事実、一般的な言語ルール、一般的に有用な回答を構成する要素を「知っています」。この知識があれば、(うまくいけば)有用な回答を提供できます。人間からの追加のフィードバック(「その回答は複雑すぎる」や「反応はどうだった?」など)により、一部のプロンプトベースの学習システムでは、回答の有用性を徐々に改善できます。
プロンプト設計
プロンプト エンジニアリングと同義。
プロンプト エンジニアリング
大規模言語モデルから望ましい回答を引き出すプロンプトを作成する技術。プロンプトのエンジニアリングは人間が行います。適切に構造化されたプロンプトを作成することは、大規模言語モデルから有用なレスポンスを得るために不可欠な要素です。プロンプト エンジニアリングは、次のような多くの要因によって異なります。
- 大規模言語モデルの事前トレーニングと、必要に応じてファイン チューニングに使用されるデータセット。
- モデルがレスポンスの生成に使用する温度などのデコード パラメータ。
役立つプロンプトの作成について詳しくは、プロンプト設計の概要をご覧ください。
プロンプト設計はプロンプト エンジニアリングと同義です。
プロンプト調整
システムが実際のプロンプトの前に追加する「接頭辞」を学習するパラメータ効率チューニング メカニズム。
プロンプト チューニングの一種(接頭辞チューニングとも呼ばれる)は、すべてのレイヤに接頭辞を追加することです。一方、ほとんどのプロンプト チューニングでは、入力レイヤに接頭辞のみが追加されます。
R
k での再現率(recall@k)
アイテムのランク付けされた(順序付けられた)リストを出力するシステムを評価するための指標。k での再現率は、リスト内の最初の k 個のアイテムに含まれる関連アイテムの割合を、返された関連アイテムの合計数で割った値です。
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
k での精度とは対照的です。
参照テキスト
プロンプトに対するエキスパートの回答。たとえば、次のプロンプトがあるとします。
「名前を教えて」という質問を英語からフランス語に翻訳してください。
エキスパートの回答は次のようになります。
Comment vous appelez-vous?
さまざまな指標(ROUGE など)は、参照テキストが ML モデルの生成テキストと一致する度合いを測定します。
ロール プロンプト
生成 AI モデルのレスポンスのターゲット オーディエンスを識別するプロンプトのオプション パート。ロール プロンプトがない場合、大規模言語モデルは、質問したユーザーにとって有用な回答とそうでない回答の両方を返します。ロール プロンプトを使用すると、大規模言語モデルは、特定のターゲット ユーザーにとってより適切で有用な方法で回答できます。たとえば、次のプロンプトのロール プロンプト部分は太字になっています。
- 経済学博士号取得者向けに、この記事を要約してください。
- 潮汐の仕組みを10 歳の子どもに説明してください。
- 2008 年の金融危機について説明します。幼児やゴールデン レトリバーに話しかけるように話す。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
自動要約モデルと機械翻訳モデルを評価する指標ファミリー。ROUGE 指標は、参照テキストが ML モデルの生成テキストと重複する程度を決定します。ROUGE ファミリーの各メンバーは、重複を異なる方法で測定します。ROUGE スコアが高いほど、ROUGE スコアが低い場合よりも、参照テキストと生成テキストの類似性が高くなります。
通常、各 ROUGE ファミリー メンバーは次の指標を生成します。
- 適合率
- 再現率
- F1
詳細と例については、以下をご覧ください。
ROUGE-L
ROUGE ファミリーの一員で、リファレンス テキストと生成テキストの最長共通部分列の長さに焦点を当てています。次の式は、ROUGE-L の再現率と精度を計算します。
F1 を使用すると、ROUGE-L の再現率と ROUGE-L の精度を 1 つの指標にまとめることができます。
ROUGE-L は、リファレンス テキストと生成テキストの改行を無視するため、最長共通部分列が複数の文にまたがる可能性があります。リファレンス テキストと生成テキストに複数の文が含まれている場合は、通常、ROUGE-L のバリエーションである ROUGE-Lsum の方が優れた指標です。ROUGE-Lsum は、段落内の各文の最長共通部分列を決定し、それらの最長共通部分列の平均を計算します。
ROUGE-N
ROUGE ファミリー内の一連の指標。参照テキストと生成テキストの特定サイズの共有 N グラムを比較します。次に例を示します。
- ROUGE-1 は、参照テキストと生成テキストで共有されるトークンの数を測定します。
- ROUGE-2 は、参照テキストと生成テキストで共有される2 グラムの数を測定します。
- ROUGE-3 は、参照テキストと生成テキストで共有される3 グラムの数を測定します。
ROUGE-N ファミリーの任意のメンバーの ROUGE-N の再現率と ROUGE-N の精度を計算するには、次の式を使用します。
F1 を使用して、ROUGE-N の再現率と ROUGE-N の精度を 1 つの指標にまとめることができます。
ROUGE-S
ROUGE-N の寛容な形式で、スキップグラムのマッチングを可能にします。つまり、ROUGE-N は完全に一致するN グラムのみをカウントしますが、ROUGE-S は 1 つ以上の単語で区切られた N グラムもカウントします。たとえば、次の点を考えます。
ROUGE-N を計算する際、2 グラムの「白い雲」は「白い雲が渦巻く」と一致しません。ただし、ROUGE-S の計算では、白い雲は白い雲が渦巻いていると一致します。
S
セルフアテンション(セルフアテンションレイヤ)
エンベディングのシーケンス(トークン エンベディングなど)を別のエンベディングのシーケンスに変換するニューラル ネットワーク レイヤ。出力シーケンス内の各エンベディングは、アテンション メカニズムを通じて入力シーケンスの要素から情報を統合することで構築されます。
セルフアテンションの「セルフ」とは、他のコンテキストではなく、自身に注目するシーケンスを指します。自己注意は Transformer の主要な構成要素の一つであり、「クエリ」、「キー」、「値」などの辞書ルックアップ用語を使用します。
セルフアテンション レイヤは、単語ごとに 1 つずつ、入力表現のシーケンスから始まります。単語の入力表現は、単純なエンベディングにできます。入力シーケンス内の各単語について、ネットワークは単語のシーケンス全体のすべての要素に対する単語の関連性をスコアリングします。関連性スコアは、単語の最終表現に他の単語の表現がどの程度組み込まれているかを決定します。
たとえば、次の文について考えてみましょう。
動物は疲れていたため、道路を渡らなかった。
次の図(Transformer: A Novel Neural Network Architecture for Language Understanding より)は、代名詞 it に対するセルフ アテンション レイヤのアテンション パターンを示しています。各線の濃さは、各単語が表現に貢献する度合いを示しています。
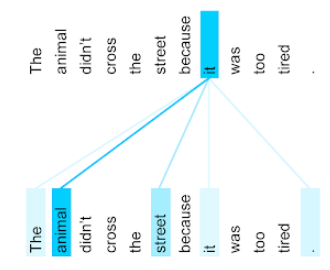
セルフアテンション レイヤは、「それ」に関連する単語をハイライト表示します。この場合、アテンション レイヤは、it が参照する可能性のある単語をハイライト表示し、animal に最も高い重みを割り当てることを学習しています。
n 個のトークンのシーケンスの場合、セルフ アテンションはエンベディングのシーケンスを n 回変換します(シーケンス内の各位置で 1 回)。
アテンションとマルチヘッドセルフアテンションも参照してください。
感情分析
統計アルゴリズムまたは機械学習アルゴリズムを使用して、サービス、プロダクト、組織、トピックに対するグループの全体的な態度(ポジティブまたはネガティブ)を判断します。たとえば、自然言語理解を使用して、大学のコースからのテキスト フィードバックに対して感情分析を実行し、学生がコースを好むか嫌うかを判断できます。
シーケンスからシーケンスへのタスク
トークンの入力シーケンスをトークンの出力シーケンスに変換するタスク。たとえば、一般的な 2 種類のシーケンスからシーケンスへのタスクは次のとおりです。
- 翻訳者:
- 入力シーケンスの例: 「愛してる」
- 出力シーケンスの例: 「Je t'aime.」
- 質問応答:
- サンプル入力シーケンス: 「ニューヨーク市で車は必要ですか?」
- 出力例: 「いいえ。車は家に置いておいてください。」
skip-gram
元のコンテキストから単語を省略(「スキップ」)する可能性があるn グラム。つまり、N 個の単語が元々隣接していない可能性があります。より正確には、「k スキップ n グラム」は、最大 k 個の単語がスキップされている n グラムです。
たとえば、「the quick brown fox」には次の 2 グラムが考えられます。
- 「the quick」
- "quick brown"
- "brown fox"
「1 スキップ 2 グラム」は、間に最大 1 つの単語が入る単語のペアです。したがって、「the quick brown fox」には、次の 1 スキップ 2 グラムがあります。
- "the brown"
- "quick fox"
また、2 つの単語がスキップされる可能性があるため、すべての 2 グラムは 1 スキップ 2 グラムでもあります。
スキップグラムは、単語の周囲のコンテキストをより深く理解するのに役立ちます。この例では、「fox」は 1 スキップ 2 グラムのセットで「quick」に直接関連付けられていますが、2 グラムのセットで直接関連付けられていません。
スキップグラムは、単語エンベディングモデルのトレーニングに役立ちます。
ソフト プロンプトのチューニング
リソースを大量に消費するファインチューニングを行わずに、特定のタスク用に大規模言語モデルをチューニングする手法。ソフト プロンプト チューニングでは、モデル内のすべての重みを再トレーニングするのではなく、同じ目標を達成するためにプロンプトを自動的に調整します。
テキスト プロンプトがある場合、通常、ソフト プロンプト チューニングでは、プロンプトに追加のトークン エンベディングを追加し、バックプロパゲーションを使用して入力を最適化します。
「ハード」なプロンプトには、トークン エンベディングではなく実際のトークンが含まれます。
スパースな特徴
値の大部分がゼロまたは空の特徴量。たとえば、1 つの値が 1 で、100 万個の値が 0 である特徴はスパースです。一方、密な特徴量の値は、ゼロまたは空ではないものがほとんどです。
機械学習では、驚くほど多くの特徴量がスパースな特徴量です。カテゴリ特徴は通常、スパースな特徴です。たとえば、森林に生息する 300 種類の樹木のうち、1 つのサンプルでカエデのみを特定できる場合があります。または、動画ライブラリに含まれる数百万もの動画のうち、1 つの例で「カサブランカ」と識別されることもあります。
モデルでは、通常、スパース特徴をワンホット エンコーディングで表します。ワンホット エンコーディングが大きい場合は、ワンホット エンコーディングの上にエンベディング レイヤを配置して効率を高めることができます。
スパース表現
ゼロ以外の要素の位置のみをスパース特徴に保存する。
たとえば、species という名前のカテゴリ特徴が、特定の森林内の 36 種類の樹木を識別するとします。さらに、各例が 1 つの種のみを識別すると仮定します。
1 ホット ベクトルを使用して、各例の樹木の種類を表すことができます。ワンホット ベクトルには、1 つの 1(その例の特定の樹木種を表す)と 35 個の 0(その例にない 35 個の樹木種を表す)が含まれます。したがって、maple の 1 ホット表現は次のようになります。

または、スパース表現では、特定の種の位置のみを特定します。maple が 24 番目の位置にある場合、maple のスパース表現は次のようになります。
24
スパース表現は、1 ホット表現よりもはるかにコンパクトです。
アイコンをクリックすると、もう少し複雑な例が表示されます。
モデル内の各例で、英語の文の単語(単語の順序は含まない)を表す必要があるとします。英語は約 17 万語で構成されているため、英語は約 17 万個の要素を持つカテゴリ型特徴量です。ほとんどの英語の文では、この 17 万語のごく一部しか使用されないため、1 つの例の単語セットは、ほぼ確実にスパース データになります。
次の文について考えてみましょう。
My dog is a great dog
この文の単語を表すには、ワンホット ベクトルのバリエーションを使用できます。このバリアントでは、ベクトルの複数のセルにゼロ以外の値を含めることができます。さらに、このバリエーションでは、セルに 1 以外の整数を含めることができます。「my」、「is」、「a」、「great」という単語は文中に 1 回しか表示されませんが、「dog」という単語は 2 回表示されています。このワンホット ベクトルのバリエーションを使用してこの文の単語を表すと、次の 170,000 要素のベクトルが得られます。

同じ文のスパース表現は次のようになります。
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
段階的なトレーニング
一連の個別のステージでモデルをトレーニングする手法。目標は、トレーニング プロセスの高速化またはモデル品質の向上です。
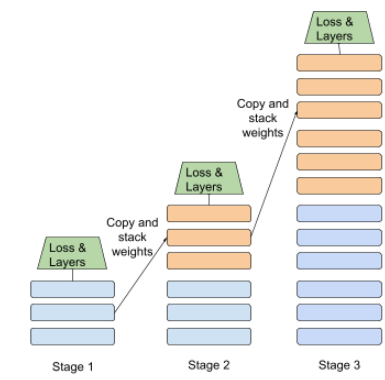
以下に、段階的なスタッキング アプローチの図を示します。
- ステージ 1 には 3 つの隠れ層、ステージ 2 には 6 つの隠れ層、ステージ 3 には 12 個の隠れ層があります。
- ステージ 2 は、ステージ 1 の 3 つの隠れ層で学習された重みを使用してトレーニングを開始します。ステージ 3 は、ステージ 2 の 6 つの隠れ層で学習された重みを使用してトレーニングを開始します。
パイプライン処理もご覧ください。
サブワード トークン
言語モデルでは、単語の部分文字列(単語全体の場合もあります)であるトークン。
たとえば、「itemize」という単語は、「item」(語根)と「ize」(接尾辞)に分割され、それぞれが独自のトークンで表されます。このようなサブワードと呼ばれる部分に単語を分割することで、言語モデルは接頭辞や接尾辞など、単語のより一般的な構成要素を操作できます。
逆に、「going」などの一般的な単語は分割されず、単一のトークンで表される場合があります。
T
T5
2020 年に Google AI によって導入されたテキストツーテキストの転移学習 モデル。T5 は、Transformer アーキテクチャに基づくエンコーダデコーダモデルで、非常に大規模なデータセットでトレーニングされています。テキストの生成、言語の翻訳、会話形式での質問への回答など、さまざまな自然言語処理タスクに効果的です。
T5 という名前は、「Text-to-Text Transfer Transformer」の 5 つの T に由来しています。
T5X
大規模な自然言語処理(NLP)モデルの構築とトレーニングを目的としたオープンソースのML フレームワーク。T5 は、T5X コードベース(JAX と Flax で構築)で実装されています。
温度
モデルの出力のランダム性の度合いを制御するハイパーパラメータ。温度が高いほど、出力のランダム性が高まり、温度が低いほど、出力のランダム性が低くなります。
最適な温度の選択は、特定のアプリケーションとモデルの出力の優先プロパティによって異なります。たとえば、クリエイティブな出力を生成するアプリを作成する場合は、温度を上げます。逆に、画像やテキストを分類するモデルを作成する場合は、モデルの精度と一貫性を高めるために温度を下げる必要があります。
Temperature は、softmax と併用されることがよくあります。
テキスト範囲
テキスト文字列の特定のサブセクションに関連付けられた配列インデックス範囲。たとえば、Python 文字列 s="Be good now" の単語 good は、テキスト範囲 3 ~ 6 を占有します。
token
言語モデルでは、モデルがトレーニングと予測を行う場合の原子単位です。トークンは通常、次のいずれかです。
- 単語 - たとえば、「犬は猫が好き」というフレーズは、「犬」、「は」、「猫」の 3 つの単語トークンで構成されています。
- 文字 - たとえば、「自転車 魚」というフレーズは 9 個の文字トークンで構成されています。(空白はトークンの 1 つとしてカウントされます)。
- サブワード - 単一の単語が単一のトークンまたは複数のトークンになる場合があります。サブワードは、ルートワード、接頭辞、接尾辞で構成されます。たとえば、サブワードをトークンとして使用する言語モデルでは、「dogs」という単語を 2 つのトークン(ルート単語「dog」と複数形接尾辞「s」)と見なします。同じ言語モデルでは、単一の単語「taller」を 2 つのサブワード(ルート単語「tall」と接尾辞「er」)と見なす場合があります。
言語モデル以外のドメインでは、トークンは他の種類の原子単位を表すことができます。たとえば、コンピュータ ビジョンでは、トークンは画像のサブセットとなる場合があります。
top-k の精度
生成されたリストの最初の k 個の位置に「ターゲット ラベル」が出現する割合。リストは、パーソナライズされたおすすめや、softmaxで並べ替えられたアイテムのリストにできます。
Top-k 精度は、k での精度とも呼ばれます。
有害
コンテンツが攻撃的、脅迫的、または不適切である程度。多くの ML モデルは、有害性を特定して測定できます。これらのモデルのほとんどは、冒とく的な表現のレベルや脅迫的な表現のレベルなど、複数のパラメータに基づいて有害性を特定します。
Transformer
Google で開発されたニューラル ネットワーク アーキテクチャ。セルフ アテンション メカニズムに依存して、畳み込みや再帰型ニューラル ネットワークに依存することなく、入力エンベディングのシーケンスを出力エンベディングのシーケンスに変換します。Transformer は、自己注意レイヤのスタックと見なすことができます。
Transformer には次のいずれかを含めることができます。
エンコーダは、エンベディングのシーケンスを同じ長さの新しいシーケンスに変換します。エンコーダには N 個の同一レイヤが含まれ、それぞれに 2 つのサブレイヤが含まれています。これらの 2 つのサブレイヤは、入力エンベディング シーケンスの各位置に適用され、シーケンスの各要素を新しいエンベディングに変換します。最初のエンコーダ サブレイヤは、入力シーケンス全体の情報を集めます。2 番目のエンコーダ サブレイヤは、集約された情報を出力エンベディングに変換します。
デコーダは、入力エンベディングのシーケンスを出力エンベディングのシーケンスに変換します。長さが異なる場合があります。デコーダには、3 つのサブレイヤを持つ N 個の同一レイヤも含まれます。このうち 2 つはエンコーダのサブレイヤに似ています。3 つ目のデコーダ サブレイヤは、エンコーダの出力を受け取り、セルフアテンション メカニズムを適用してエンコーダから情報を収集します。
ブログ投稿「Transformer: A Novel Neural Network Architecture for Language Understanding」では、Transformer の概要を説明しています。
3 グラム
N=3 の N グラム。
U
単一方向
対象のテキスト セクションの前にあるテキストのみを評価するシステム。一方、双方向システムは、対象のテキスト セクションの前と後のテキストの両方を評価します。詳しくは、双方向をご覧ください。
単一方向の言語モデル
ターゲット トークンの後ではなく前に出現するトークンのみに基づいて確率を計算する言語モデル。双方向言語モデルとは対照的です。
V
変分オートエンコーダ(VAE)
入力と出力の差異を利用して入力の変更バージョンを生成するオートエンコーダの一種。変分オートエンコーダは、生成 AI に役立ちます。
VAE は、確率モデルのパラメータを推定する手法である変分推論に基づいています。
W
ワード エンベディング
エンベディング ベクトル内の単語セット内の各単語を表す。つまり、各単語を 0.0 ~ 1.0 の浮動小数点値のベクトルとして表します。意味が類似する単語は、意味が異なる単語よりも類似した表現になります。たとえば、ニンジン、セロリ、きゅうりはすべて比較的類似した表現になりますが、飛行機、サングラス、歯磨き粉の表現とは大きく異なります。
Z
ゼロショット プロンプト
大規模言語モデルにどのように回答してほしいかを示しているプロンプトではありません。次に例を示します。
| 1 つのプロンプトの一部 | メモ |
|---|---|
| 指定した国の公式通貨は何ですか? | LLM に回答を求める質問。 |
| インド: | 実際のクエリ。 |
大規模言語モデルは、次のいずれかのレスポンスを返す場合があります。
- ルピー
- INR
- ₹
- ルピー(インド)
- ルピー
- インドルピー
上記の選択肢はすべて正しいが、特定の形式が好ましい場合もある。
ゼロショット プロンプトと次の用語を比較します。