Diese Seite enthält Glossarbegriffe für die Sprachbewertung. Für alle Glossarbegriffe klicken Sie hier.
A
aufmerksamkeit
Mechanismus in einem neuronalen Netzwerk, der angibt, die Bedeutung eines bestimmten Wortes oder Teils eines Wortes. Aufmerksamkeitskompresse die Menge an Informationen, die ein Modell benötigt, um das nächste Token/Wort vorherzusagen. Ein typischer Aufmerksamkeitsmechanismus gewichtete Summe über eine Reihe von Eingaben, wobei der Wert Das weight für jede Eingabe wird von einem anderen Teil des neuronalen Netzes.
Weitere Informationen finden Sie unter Selbstaufmerksamkeit und mehrköpfige Selbstaufmerksamkeit, Bausteine von Transformers.
Autoencoder
Ein System, das lernt, die wichtigsten Informationen aus der Eingabe. Autoencoder sind eine Kombination aus einem Encoder und Decoder verwenden. Autoencoder basieren auf dem folgenden zweistufigen Prozess:
- Der Encoder ordnet die Eingabe einer (in der Regel) verlustbehafteten, niedrigeren Dimension zu (Zwischenformat).
- Der Decoder erstellt eine verlustbehaftete Version der ursprünglichen Eingabe, indem er dem niedrigdimensionalen Format zum ursprünglichen, höherdimensionalen Format Eingabeformat.
Autoencoder werden durchgängig trainiert, indem der Decoder versucht, die ursprüngliche Eingabe aus dem Zwischenformat des Encoders rekonstruieren so genau wie möglich. Da das Zwischenformat kleiner ist, (geringere Dimension) als das Originalformat haben, wird der Autoencoder erzwungen. welche Informationen in der Eingabe wichtig sind, und die Ausgabe mit der Eingabe identisch sein.
Beispiel:
- Handelt es sich bei den Eingabedaten um grafische Darstellungen, entspricht die nicht exakte Kopie der folgenden: Originalgrafik, aber etwas modifiziert. Vielleicht die bei einem unpassenden Text das Rauschen aus der Originalgrafik entfernt oder einige fehlende Pixel.
- Handelt es sich bei den Eingabedaten um Text, generiert ein Autoencoder neuen Text, der ahmt den Originaltext nach, ist aber nicht damit identisch.
Weitere Informationen finden Sie unter Variative Autoencoder.
automatisch regressives Modell
Ein Modell, das eine Vorhersage anhand seiner eigenen vorherigen Vorhersagen zu treffen. Automatisch regressive Sprachmodelle sagen beispielsweise token basiert auf den zuvor vorhergesagten Tokens. Alle Transformer-basierten Large Language Models sind automatisch regressiv.
Im Gegensatz dazu sind GAN-basierte Bildmodelle normalerweise nicht automatisch regressiv. da sie ein Bild mit einem einzigen Vorwärtsdurchlauf und nicht iterativ in Schritte. Bestimmte Modelle zur Bildgenerierung sind jedoch automatisch regressiv, wird schrittweise ein Bild generiert.
B
Bag of Words
Darstellung der Wörter in einer Wortgruppe oder Passage unabhängig von der Reihenfolge. Beispiel: Bag of Words steht für die auf die gleiche Weise:
- Der Hund springt
- springt den Hund
- Hund springt
Jedes Wort wird einem Index in einem dünnen Vektor zugeordnet, wobei hat der Vektor einen Index für jedes Wort im Vokabular. Beispiel: Der Ausdruck der Hund springt wird einem Featurevektor mit einer Zahl ungleich null zugeordnet. Werte in den drei Indexen, die den Wörtern the, dog und Sprünge. Bei einem Wert ungleich null kann es sich um einen der folgenden Werte handeln:
- Eine 1, die angibt, dass ein Wort vorhanden ist.
- Gibt an, wie oft ein Wort in einer Tasche erscheint. Beispiel: Wenn die Wortgruppe der kastanienbraune Hund ist ein Hund mit kastanienbraunem Fell wäre, dann gilt sowohl maroon und dog werden als 2 dargestellt, während die anderen Wörter als 1 dargestellt werden.
- Ein anderer Wert, z. B. der Logarithmus der Anzahl Mal, wenn ein Wort in der Tasche erscheint.
BERT (Bidirektionaler Encoder) Darstellungen von Transformern)
Eine Modellarchitektur für die Textdarstellung. Ein geschulter BERT-Modells können Teil eines größeren Modells zur Textklassifizierung oder zum und andere ML-Aufgaben.
BERT hat die folgenden Eigenschaften:
- Verwendet die Transformer-Architektur und verlässt sich daher auf zur Selbstaufmerksamkeit.
- Verwendet den Encoder-Teil des Transformers. Die Aufgabe des Encoders gute Textdarstellungen zu erstellen, anstatt eine bestimmte wie die Klassifizierung.
- Sie ist bidirektional.
- Verwendet Maskierung für unüberwachtes Training:
Zu den BERT-Varianten gehören:
Siehe BERT für Open Sourcing: State-of-the-Art Pre-Training for Natural Language Wird verarbeitet um einen Überblick über BERT zu erhalten.
bidirektional
Ein Begriff, der ein System beschreibt, das den Text auswertet, der vorher und folgt einem Zieltextabschnitt. Im Gegensatz dazu Nur unidirektionales System wertet den Text aus, der einem Zieltextabschnitt vor ist.
Nehmen wir als Beispiel ein maskiertes Sprachmodell, das müssen die Wahrscheinlichkeiten für das Wort oder die Wörter bestimmen, die den Unterstrich in folgende Frage:
Was ist _____ bei dir?
Ein unidirektionales Sprachmodell müsste nur auf seine Wahrscheinlichkeiten basieren. zum Kontext der Wörter „Was“, „ist“ und „der“. Im Gegensatz dazu könnte ein bidirektionales Language Model auch Kontext durch und „you“, was dem Modell helfen kann, bessere Vorhersagen zu generieren.
Bidirektionales Sprachmodell
Ein Sprachmodell, das die Wahrscheinlichkeit bestimmt, dass ein an einer bestimmten Stelle in einem Textauszug vorhanden ist, vorangehenden und folgenden Text verwenden.
Bigram
Ein N-Gramm mit N=2.
BLEU (Bilingual Evaluation Understudy)
Ein Wert zwischen 0,0 und 1,0 (jeweils einschließlich), der die Qualität einer Übersetzung angibt. zwischen zwei menschlichen Sprachen (z. B. Englisch und Russisch) zu vergleichen. Ein Bleu ein Wert von 1,0 bedeutet, dass die Übersetzung perfekt ist. Ein BLEU-Wert von 0,0 zeigt an, eine schlechte Übersetzung.
C
kausales Language Model
Synonym für unidirektionales Sprachmodell.
Weitere Informationen finden Sie unter bidirektionales Sprachmodell verschiedene Richtungsansätze in der Sprachmodellierung gegenüberzustellen.
Chain-of-Thought Prompting
Eine Prompt-Engineering-Technik, die dazu beiträgt, ein Large Language Model (LLM) nutzen, um seine Logik, Schritt für Schritt. Betrachten Sie zum Beispiel den folgenden Prompt: insbesondere auf den zweiten Satz:
Wie viele g-Kräfte würde ein Fahrer in einem Auto von 0 auf 60 erleben Meilen pro Stunde in 7 Sekunden? Zeigen Sie in der Antwort alle relevanten Berechnungen an.
Die Antwort des LLM würde wahrscheinlich:
- Eine Reihe physikalischer Formeln zeigen, wobei die Werte 0, 60 und 7 eingesetzt werden an geeigneten Stellen.
- Erklären Sie, warum diese Formeln gewählt wurden und was die verschiedenen Variablen bedeuten.
Das LLM zwingt das LLM, alle Berechnungen durchzuführen, was zu einer richtigen Antwort führen könnte. Darüber hinaus ist eine Chain-of-Thinking-Methode Prompts ermöglichen es Nutzenden, die Schritte des LLM zu untersuchen, um festzustellen, ob die Antwort sinnvoll ist.
Chat
Die Inhalte eines wechselseitigen Dialogs mit einem ML-System, in der Regel Large Language Model: Vorherige Interaktion in einem Chat was Sie eingegeben haben und wie das Large Language Model geantwortet hat. Kontext für die nachfolgenden Teile des Chats.
Ein Chatbot ist eine Anwendung eines Large Language Model.
Konfabulation
Synonym für Halluzination.
Konfabulation ist technisch wahrscheinlich ein besserer Begriff als Halluzination. Halluzinationen wurden jedoch zuerst beliebt.
Wahlkreis-Parsing
Das Unterteilen eines Satzes in kleinere grammatische Strukturen („Bestandteile“). Einen späteren Teil des ML-Systems, z. B. Natural Language Understanding verwendet, die Bestandteile leichter parsen können als der ursprüngliche Satz. Beispiel: stellen Sie sich den folgenden Satz vor:
Mein Freund hat zwei Katzen adoptiert.
Ein Wahlkreisparser kann diesen Satz in folgende unterteilen: zwei Personen:
- Mein Freund ist eine Nominalphrase.
- adopted two cats ist eine Verbphrase.
Diese Personen lassen sich in kleinere Unterteilungen unterteilen. Zum Beispiel kann das Verb
hat zwei Katzen adoptiert
könnte weiter unterteilt werden in:
- adopted ist ein Verb.
- zwei Katzen ist eine weitere Nominalphrase.
kontextbezogene Spracheinbettung
Eine Einbettung, die dem „Verständnis“ nahekommt Wörter und Formulierungen auf eine Art und Weise, wie Muttersprachler es können. Kontextbezogene Sprache Einbettungen können komplexe Syntax, Semantik und Kontext verstehen.
Sehen wir uns als Beispiel Einbettungen des englischen Wortes cow an. Ältere Einbettungen wie word2vec für Englisch stehen. Wörter, sodass die Entfernung im eingebetteten Bereich von Kuh nach Bull ist ähnlich der Entfernung von ewe (weibliche Schafe) bis ram (männliche Schafe) oder weiblich zu männlich. Kontextbezogene Sprache Einbettungen können sogar noch einen Schritt weiter gehen, da sie erkennen, dass englischsprachige Nutzer das Wort Kuh für Kuh oder Stier.
Kontextfenster
Die Anzahl der Tokens, die ein Modell in einem bestimmten Prompt: Je größer das Kontextfenster, desto mehr Informationen das Modell verwenden kann, um kohärente und konsistente Antworten zu liefern zur Aufforderung hinzu.
Crash Blossom
Ein Satz oder Ausdruck mit mehrdeutiger Bedeutung. Absturzblüten stellen ein erhebliches Problem in natürlichen Sprachverständnis. Die Überschrift Rotes Klebeband hält Skyscraper ist beispielsweise eine weil ein NLU-Modell die Schlagzeile wörtlich interpretieren könnte im übertragenen Sinne.
D
Decoder
Im Allgemeinen ist jedes ML-System, das eine Konvertierung von einem verarbeiteten, interne Darstellung in eine roher, dünnbesetzte oder externe Darstellung.
Decodierer sind oft eine Komponente eines größeren Modells, mit einem Encoder gekoppelt.
Bei Sequenz-zu-Sequenz-Aufgaben: Ein Decoder beginnt mit dem internen Zustand, der vom Encoder generiert wird, um den nächsten Sequenz hinzufügen.
Unter Transformer finden Sie die Definition eines Decoders in der Transformer-Architektur.
Entrauschen
Ein gängiger Ansatz für selbstüberwachtes Lernen Dabei gilt:
Die Rauschunterdrückung ermöglicht das Lernen aus Beispielen ohne Labels. Das ursprüngliche Dataset dient als Ziel oder label und die Daten mit Rauschen als Eingabe.
Einige maskierte Sprachmodelle verwenden die Rauschunterdrückung. wie folgt:
- Rauschen wird einem Satz ohne Label künstlich hinzugefügt, indem einige der die Tokens.
- Das Modell versucht, die ursprünglichen Tokens vorherzusagen.
direkte Aufforderungen
Synonym für Zero-Shot-Prompting.
E
Strecke bearbeiten
Ein Maß dafür, wie ähnlich zwei Textzeichenfolgen einander sind. Beim maschinellen Lernen ist die Bearbeitung von Entfernungen nützlich, und eine effektive Möglichkeit zum Vergleichen von zwei Strings, die bekanntermaßen die einer bestimmten Zeichenfolge ähnlich sind.
Es gibt mehrere Definitionen für die Bearbeitung von Entfernungen, die jeweils eine andere Zeichenfolge verwenden Geschäftsabläufe. Beispiel: Der Parameter <ph type="x-smartling-placeholder"></ph> Levenshtein-Distanz berücksichtigt die wenigsten Lösch-, Einfüge- und Ersetzungsvorgänge.
Zum Beispiel der Levenshtein-Abstand zwischen den Wörtern „Herz“ und "darts". ist 3, weil die folgenden 3 Änderungen die wenigsten Änderungen darstellen, um ein Wort zu ändern. in das andere:
- Herz → herabsetzen (ersetzen Sie "h" durch "d")
- deart → dart (löschen "e")
- dart → darts (einfügen "s")
Einbettungsebene
Eine spezielle verborgene Ebene, die auf einem ein hochdimensionales kategoriales Feature einen Einbettungsvektor niedrigerer Dimension lernen. Eine kann ein neuronales Netzwerk weitaus mehr als nur das hochdimensionale kategoriale Merkmal trainieren.
So unterstützt Google Earth derzeit etwa 73.000 Baumarten. Angenommen,
Die Baumart ist ein Merkmal in Ihrem Modell.
Die Eingabeebene enthält einen One-Hot-Vektor 73.000
Elemente lang sein.
Beispielsweise würde baobab in etwa so dargestellt:

Ein Array mit 73.000 Elementen ist sehr lang. Wenn Sie keine Einbettungsebene hinzufügen ist das Training sehr zeitaufwändig, multipliziert mit 72.999 Nullen. Vielleicht wählen Sie die Einbettungsebene aus, von 12 Dimensionen. Daher lernt die Einbettungsebene allmählich einen neuen Einbettungsvektor für jede Baumart erstellen.
In bestimmten Situationen ist Hashing eine sinnvolle Alternative. mit einer Einbettungsebene.
Einbettungsbereich
Der d-dimensionale Vektorraum, der aus einem höherdimensionalen Vektorraum besteht Vektorraum zugeordnet ist. Im Idealfall enthält der Einbettungsbereich einen Struktur, die aussagekräftige mathematische Ergebnisse liefert, zum Beispiel in einem idealen Einbettungsbereich addieren oder subtrahieren. Wortanalytik-Aufgaben lösen können.
Punktprodukt zweier Einbettungen ist ein Maß für ihre Ähnlichkeit.
Einbettungsvektor
Im Grunde ist ein Array von Gleitkommazahlen aus beliebigen verborgenen Layer, der die Eingaben für diese verborgene Ebene beschreibt. Häufig ist ein Einbettungsvektor ein Array von Gleitkommazahlen, eine Einbettungsebene. Angenommen, eine Einbettungsebene muss Einbettungsvektor für jede der 73.000 Baumarten auf der Erde. Vielleicht die folgendes Array ist der Einbettungsvektor für einen Affenbrotbaum:

Ein Einbettungsvektor ist kein Haufen Zufallszahlen. Eine Einbettungsebene ermittelt diese Werte durch Training, ähnlich wie lernt das neuronale Netzwerk während des Trainings andere Gewichtungen. Jedes Element des Array ist eine Bewertung anhand eines Merkmals einer Baumart. Welche -Element darstellt, welche Baumart charakteristischen Merkmale? Das ist sehr schwierig damit Menschen feststellen können.
Das mathematisch bemerkenswerteste Teil eines Einbettungsvektors ist, Elemente haben ähnliche Mengen von Gleitkommazahlen. Ähnliche Baumarten eine ähnliche Menge von Gleitkommazahlen haben als unterschiedlichen Baumarten. Mammutbäume und Mammutbäume sind verwandte Baumarten. sodass sie einen ähnlichen Satz von Gleitkommazahlen haben als Mammutbäume und Kokospalmen. Die Zahlen im Einbettungsvektor sich jedes Mal ändern, wenn Sie das Modell neu trainieren, auch wenn Sie es neu trainieren mit identischer Eingabe.
Encoder
Im Allgemeinen ist jedes ML-System, das von einem rohen, dünnbesetzten oder externen in eine stärker verarbeitete, dichtere oder internere Darstellung umwandeln.
Encoder sind oft eine Komponente eines größeren Modells, mit einem Decoder kombiniert werden. Einige Transformatoren Kodierer mit Decodern koppeln, während andere Transformer nur den Encoder verwenden oder nur den Decoder.
Einige Systeme nutzen die Ausgabe des Encoders als Eingabe für eine Klassifizierung oder Regressionsnetzwerks.
Bei Sequenz-zu-Sequenz-Aufgaben: ein Encoder nimmt eine Eingabesequenz und gibt einen internen Status (einen Vektor) zurück. Das Feld decoder verwendet diesen internen Status, um die nächste Sequenz vorherzusagen.
Unter Transformer findest du die Definition eines Encoders in der Transformer-Architektur.
F
Wenige-Shot-Prompts
Eine Aufforderung, die mehrere Beispiele enthält dem Large Language Model sollte antworten. Die folgende lange Aufforderung enthält beispielsweise zwei Beispiele für die Beantwortung einer Abfrage in einem Large Language Model.
| Bestandteile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Frankreich: EUR | Ein Beispiel. |
| Vereinigtes Königreich: GBP | Ein weiteres Beispiel. |
| Indien: | Die eigentliche Abfrage. |
Prompts mit wenigen Aufnahmen führen in der Regel zu besseren Ergebnissen als Zero-Shot-Prompting und One-Shot-Prompts: Prompts mit wenigen Aktionen können jedoch erfordert einen längeren Prompt.
Prompts mit wenigen Aufnahmen sind eine Form des Lernens mit wenigen Schritten. auf Prompt-basiertes Lernen angewendet.
Geige
Eine Konfigurationsbibliothek vor Python, die den Parameter Werte von Funktionen und Klassen ohne invasiven Code oder eine invasive Infrastruktur. Im Fall von Pax – und anderen ML-Codebasen – werden diese Funktionen und Klassen stellen Modelle und Training dar. Hyperparameter.
Geige wird angenommen, dass Codebasen für maschinelles Lernen in der Regel in folgende Kategorien unterteilt sind:
- Bibliothekscode, der die Layer und Optimierungstools definiert.
- Dataset „Glue“ mit dem die Bibliotheken aufgerufen und alles zusammen verkabelt wird.
Fiddle erfasst die Aufrufstruktur des Glue-Codes in einem nicht bewerteten änderbare Form.
Feinabstimmung
Ein zweiter, aufgabenspezifischer Trainingspass, vortrainiertes Modell, um seine Parameter für eine bestimmten Anwendungsfall. Die vollständige Trainingssequenz für einige Large Language Models ist so aufgebaut:
- Vor dem Training:Trainieren Sie ein Large Language Model mit einem umfangreichen allgemeinen Dataset zum Beispiel alle englischsprachigen Wikipedia-Seiten.
- Feinabstimmung: Trainieren Sie das vortrainierte Modell, um eine bestimmte Aufgabe auszuführen. z. B. auf medizinische Anfragen. Die Feinabstimmung umfasst in der Regel Hunderte oder Tausende von Beispielen für die jeweilige Aufgabe.
Ein weiteres Beispiel: Die vollständige Trainingssequenz für ein großes Bildmodell ist folgt:
- Vor dem Training:Modell mit großem Bild anhand eines allgemeinen allgemeinen Bilds trainieren Datasets, wie z. B. alle Bilder in Wikimedia Commons.
- Feinabstimmung: Trainieren Sie das vortrainierte Modell, um eine bestimmte Aufgabe auszuführen. z. B. Bilder von Orcas generieren.
Die Optimierung kann eine beliebige Kombination der folgenden Strategien umfassen:
- Alle vorhandenen des vortrainierten Modells ändern parameters fest. Dies wird auch als vollständige Feinabstimmung bezeichnet.
- Nur einige der vorhandenen Parameter des vortrainierten Modells ändern (in der Regel die Schichten, die der Ausgabeschicht am nächsten sind) während andere vorhandene Parameter unverändert bleiben (normalerweise werden die Layers der der Eingabeebene am nächsten liegt. Weitere Informationen finden Sie unter parametereffiziente Abstimmung.
- Es werden weitere Ebenen hinzugefügt, in der Regel über den vorhandenen Ebenen, die dem Ausgabeebene.
Die Feinabstimmung ist eine Form des Lerntransfers. Daher kann für die Abstimmung eine andere Verlustfunktion oder ein anderes Modell verwendet werden -Typ als diejenigen, die zum Trainieren des vortrainierten Modells verwendet wurden. Zum Beispiel könnten Sie ein vortrainiertes großes Bildmodell feinabstimmen, um ein Regressionsmodell zu erstellen, gibt die Anzahl der Vögel in einem Eingabebild zurück.
Vergleichen Sie die Feinabstimmung mit den folgenden Begriffen:
Kristallgrau
Eine leistungsstarke Open-Source-Lösung Bibliothek für Deep Learning, das auf JAX basiert. Flachs bietet Funktionen für Schulungen in neuronalen Netzwerken sowie für als Methode zur Bewertung ihrer Leistung.
Flaxformer
Ein Open-Source-Transformer Bibliothek Basiert auf Flax und wurde in erster Linie für Natural Language Processing entwickelt und multimodaler Forschung.
G
generative KI
Ein aufstrebendes transformatives Feld ohne formale Definition. Dennoch sind sich die meisten Experten einig, dass Generative-AI-Modelle Inhalte erstellen („generieren“), die die folgenden Kriterien erfüllen:
- komplex
- kohärent
- ursprünglich
Ein generatives KI-Modell kann zum Beispiel komplexe Essays oder Bilder.
Einige frühere Technologien, darunter LSTMs und RNNs können auch eigene kohärenten Content. Einige Experten betrachten diese früheren Technologien generative KI, während andere der Meinung sind, dass generative KI komplexer ist als diese früheren Technologien erzeugen können.
Im Gegensatz zu prädiktivem ML.
GPT (Generativer vortrainierter Transformer)
Eine Familie von Transformer-basierten Large Language Models entwickelt von OpenAI
GPT-Varianten können für mehrere Modalitäten angewendet werden, darunter:
- Bildgenerierung (z. B. ImageGPT)
- Text-zu-Bild-Generierung (z. B. DALL-E) zurück.
H
KI-Halluzination
Die Produktion einer plausibel scheinen, aber faktisch falschen Ausgabe durch eine generatives KI-Modell, das eine Aussage über die reale Welt. Beispiel: Ein generatives KI-Modell, das behauptet, Barack Obama sei 1865 gestorben. halluziniert.
I
kontextbezogenes Lernen
Synonym für wenige-shot-Prompting.
L
LaMDA (Language Model for Dialogue Applications)
Einen Transformer-basierten Large Language Model von Google, trainiert mit ein großes Dialog-Dataset zur Generierung realistischer dialogorientierter Antworten.
LaMDA: Unsere bahnbrechende Unterhaltung Technologie bietet einen Überblick.
Language Model
Ein Modell, das die Wahrscheinlichkeit eines Tokens schätzt. oder Abfolge von Tokens, die in einer längeren Tokensequenz auftreten.
Large Language Model
Ein informeller Begriff ohne feste Definition, der normalerweise ein Sprachmodell mit einer hohen Anzahl an parameters Einige Large Language Models enthalten über 100 Milliarden Parameter.
latenter Bereich
Synonym für Einbettungsbereich.
LLM
Abkürzung für Large Language Model.
LoRA
Abkürzung für Anpassungsfähigkeit bei niedrigem Rang.
Anpassungsfähigkeit auf niedrigem Rang (LoRA)
Ein Algorithmus zur Durchführung Parameterbasierte Feinabstimmung, Es wird nur eine Teilmenge einer bestimmten Feinabstimmung Large Language model-Parameter. LoRA bietet die folgenden Vorteile:
- Feinabstimmungen schneller als Techniken, die eine Feinabstimmung aller Parameter.
- Reduziert die Rechenkosten von Inferenzen in der und ein abgestimmtes Modell.
Ein auf LoRA abgestimmtes Modell erhält oder verbessert die Qualität seiner Vorhersagen.
LoRA ermöglicht mehrere spezialisierte Versionen eines Modells.
M
maskiertes Sprachmodell
Ein Sprachmodell, das die Wahrscheinlichkeit von Kandidatentokens zum Ausfüllen von Lücken in einer Sequenz. Beispiel: Maskiertes Language Model kann Wahrscheinlichkeiten für Kandidatenwort(e) berechnen. um die Unterstreichung im folgenden Satz zu ersetzen:
Der ____ im Hut kam zurück.
In der Literatur wird üblicherweise die Zeichenfolge „MASK“ verwendet. statt unterstrichen sind. Beispiel:
Die „MASK“ kam zurück.
Die meisten modernen maskierten Sprachmodelle sind bidirektional.
Meta-Learning
Teilmenge des maschinellen Lernens, die einen Lernalgorithmus erkennt oder verbessert. Ein Meta-Lernsystem kann ein Modell auch so trainieren, dass es schnell etwas Neues lernt. einer Aufgabe anhand einer kleinen Datenmenge oder anhand von Erfahrungen aus vorherigen Aufgaben. Meta-Lernalgorithmen zielen in der Regel auf Folgendes ab:
- Von Hand entwickelte Funktionen (wie Initialisierer oder Optimierer).
- Daten- und recheneffizienter arbeiten
- Generalisierung verbessern
Meta-Lernen bezieht sich auf wenige Schritte.
Modalität
Eine allgemeine Datenkategorie. Zum Beispiel Zahlen, Text, Bilder, Videos und Audio fünf verschiedene Modalitäten.
Modellparallelität
Eine Methode zur Skalierung von Training oder Inferenz, bei der verschiedene Teile eines Modell auf verschiedenen Geräten verwenden. Modellparallelität ermöglicht Modelle, die zu groß für ein einziges Gerät sind.
Zur Implementierung der Modellparallelität führt ein System in der Regel folgende Schritte aus:
- Teilt das Modell in kleinere Teile auf.
- Verteilt das Training dieser kleineren Teile auf mehrere Prozessoren. Jeder Prozessor trainiert seinen eigenen Teil des Modells.
- Kombiniert die Ergebnisse, um ein einzelnes Modell zu erstellen.
Die Modellparallelität verlangsamt das Training.
Siehe auch Datenparallelität.
mehrköpfige Selbstaufmerksamkeit
Eine Erweiterung der Selbstaufmerksamkeit, bei der die für jede Position in der Eingabesequenz wiederholt.
Transformers führte die mehrköpfige Selbstaufmerksamkeit ein.
multimodales Modell
Ein Modell, dessen Eingaben und/oder Ausgaben mehr als eins enthalten Modalität. Nehmen wir z. B. ein Modell, das sowohl ein ein Bild und eine Bildunterschrift (zwei Modalitäten) als Funktionen und gibt eine Punktzahl aus, die angibt, wie angemessen die Textuntertitelung für das Bild ist. Die Eingaben dieses Modells sind multimodal und die Ausgabe unimodal.
N
Natural Language Understanding
Ermittlung der Absichten eines Nutzers anhand dessen, was er eingegeben oder gesagt hat. Eine Suchmaschine nutzt Natural Language Understanding, um Er kann anhand dessen, was er eingegeben oder gesagt hat, ermitteln, wonach er sucht.
N-Gramm
Eine geordnete Folge von N-Wörtern. Zum Beispiel ist wirklich madly ein Gewicht von 2 Gramm. Weil Reihenfolge ist relevant, wörtlich wirklich ist ein anderes 2-Gramm als wirklich verrückt.
| N | Name(n) für diese Art von N-Gramm | Beispiele |
|---|---|---|
| 2 | Bigram oder 2-Gramm | umgehen, gehen, zu Mittag essen, Abendessen essen |
| 3 | Trigramm oder 3-Gramm | zu viel gegessen, drei blinde Mäuse, die Glocke läuten |
| 4 | 4 Gramm | im Park spazieren gehen, Staub im Wind, der Junge aß Linsen |
Viel Natural Language Understanding Modelle nutzen N-Gramme, um das nächste Wort vorherzusagen, das die Nutzenden eingeben werden oder sagen. Beispiel: Ein Nutzer hat drei Blinde eingegeben. Ein auf Trigrammen basierendes NLU-Modell würde wahrscheinlich voraussagen, dass das Der Nutzer gibt als Nächstes Mäuse ein.
N-Gramme mit Bag of Words gegenüberstellen, die ungeordneten Satzes von Wörtern.
NLU
Abkürzung für natürliche Sprache zu verstehen.
O
One-Shot-Prompting
Eine Aufforderung, die ein Beispiel enthält, das zeigt, wie die Large Language Model sollte antworten. Beispiel: Der folgende Prompt enthält ein Beispiel für ein Large Language Model, sollte sie eine Frage beantworten.
| Bestandteile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Frankreich: EUR | Ein Beispiel. |
| Indien: | Die eigentliche Abfrage. |
Vergleichen Sie One-Shot-Prompts mit den folgenden Begriffen:
P
Parameter-effiziente Abstimmung
Verfahren zur Feinabstimmung vortrainiertes Language Model (PLM) effizienter als eine vollständige Abstimmung. Parametereffizient Durch die Feinabstimmung werden in der Regel weit weniger Parameter optimiert als bei vollem und führt in der Regel zu einer Large Language Model mit hoher Leistung sowie ein Large Language Model, das aus vollständigen die Feinabstimmung.
Parametereffiziente Abstimmung vergleichen und gegenüberstellen mit:
Parametereffiziente Abstimmung wird auch als parametereffiziente Feinabstimmung bezeichnet.
Rohrleitungen
Eine Form der Modellparallelität, bei der die Leistung eines Modells Die Verarbeitung ist in aufeinanderfolgende Phasen unterteilt und jede Phase wird ausgeführt. auf einem anderen Gerät. Während in einer Phase ein Batch verarbeitet wird, mit dem nächsten Batch arbeiten kann.
Weitere Informationen finden Sie unter Gestaffelte Schulung.
PLM
Abkürzung für vortrainiertes Sprachmodell.
Positionscodierung
Verfahren zum Hinzufügen von Informationen zur Position eines Tokens in einer Sequenz die Einbettung des Tokens. Transformer-Modelle verwenden positionale um die Beziehung zwischen verschiedenen Teilen des Sequenz hinzufügen.
Eine gängige Implementierung der Positionscodierung verwendet eine Sinusoidfunktion. Genauer gesagt, die Frequenz und Amplitude der sinusoidalen Funktion durch die Position des Tokens in der Sequenz bestimmt.) Diese Technik kann ein Transformer-Modell lernen, sich mit verschiedenen Teilen des Position basierend auf ihrer Position.
vortrainiertes Modell
Modelle oder Modellkomponenten (z. B. Einbettungsvektor) hochgeladen, die bereits trainiert wurden. Manchmal speisen Sie vortrainierte Einbettungsvektoren in ein neuronalen Netzwerks zu testen. In anderen Fällen trainiert Ihr Modell die Einbettungsvektoren selbst nutzen, anstatt sich auf die vortrainierten Einbettungen zu verlassen.
Der Begriff vortrainiertes Sprachmodell bezieht sich auf ein Large Language Model, das bereits vor dem Training.
Vorabtraining
Das erste Training eines Modells mit einem großen Dataset. Einige vortrainierte Modelle sind tollpatschige Giganten und müssen in der Regel durch zusätzliche Trainings optimiert werden. Beispielsweise können ML-Fachleute ein Large Language Model für ein umfangreiches Text-Dataset verwenden, zum Beispiel alle englischsprachigen Seiten in Wikipedia. Im Anschluss an die Vorschulung Das resultierende Modell kann mit einer der folgenden Methoden weiter verfeinert werden: Techniken:
- Destillation
- Feinabstimmung
- Abstimmung der Anweisungen
- parametereffiziente Abstimmung
- Abstimmung per Eingabe
prompt
Beliebiger Text, der als Eingabe für ein Large Language Model eingegeben wurde um das Modell so zu konditionieren, dass es sich auf eine bestimmte Weise verhält. Prompts können so kurz sein wie Wortgruppe oder beliebig lang sein (z. B. der gesamte Text eines Romans). Aufforderungen in mehrere Kategorien fallen, einschließlich der in der folgenden Tabelle aufgeführten:
| Prompt-Kategorie | Beispiel | Hinweise |
|---|---|---|
| Frage | Wie schnell kann eine Taube fliegen? | |
| Anleitung | Schreib ein lustiges Gedicht über Arbitrage. | Einen Prompt, der das Large Language Model zu einer Aktion auffordert. |
| Beispiel | Markieren Sie den Markdown-Code in HTML. Hier einige Beispiele:
Markdown: * Listeneintrag HTML: <ul> <li>Listeneintrag</li> </ul> |
Der erste Satz in diesem Beispiel-Prompt ist eine Anweisung. Der Rest des Prompts ist das Beispiel. |
| Rolle | Erläutern Sie, warum das Gradientenverfahren beim Training von Machine Learning verwendet wird, in Physik. | Der erste Teil des Satzes ist eine Anweisung. die Wortgruppe „Doktortitel in Physik“ ist der Rollenteil. |
| Teileingabe für das Modell | Der Premierminister des Vereinigten Königreichs lebt in | Eine Teileingabesaufforderung kann entweder abrupt enden (wie in diesem Beispiel). oder enden mit einem Unterstrich. |
Ein Generative-AI-Modell kann auf einen Prompt mit Text, Code, Bilder, Einbettungen, Videos... und fast alles.
Prompt-basiertes Lernen
Fähigkeit bestimmter Modelle, sich anzupassen. ihr Verhalten als Reaktion auf beliebige Texteingaben (Aufforderungen) reagieren. Bei einem typischen Prompt-basierten Lernparadigma Large Language Model reagiert auf eine Aufforderung durch Text generiert wird. Angenommen, ein Nutzer gibt den folgenden Prompt ein:
Fasse das dritte Newtonsche Gesetz der Bewegung zusammen.
Ein Modell, das auf Prompts basierendes Lernen ermöglicht, wurde nicht speziell dafür trainiert, zum vorherigen Prompt. Vielmehr „weiß“ das Modell, viele Fakten über Physik, viel über allgemeine Sprachregeln und darüber, was im Allgemeinen hilfreiche Antworten zu liefern. Dieses Wissen reicht aus, um einen (hoffentlich) nützlichen Antwort. Zusätzliches menschliches Feedback („Diese Antwort war zu kompliziert.“ oder „Was ist eine Reaktion?“. ermöglicht einigen Prompt-basierten Lernsystemen, um die Nützlichkeit ihrer Antworten zu verbessern.
Prompt-Entwurf
Synonym für prompt Engineering.
Prompt Engineering
Aufforderungen erstellen, die die gewünschten Antworten auslösen Large Language Model erstellen. Prompt wird von Menschen ausgeführt Engineering. Gut strukturierte Prompts sind wichtig, in einem Large Language Model nützliche Antworten zu liefern. Das Prompt-Engineering viele Faktoren, darunter:
- Das Dataset, das zum Vortrainieren und möglicherweise Large Language Model optimieren
- Die temperature und andere Decodierungsparameter, die der das Modell zum Generieren von Antworten verwendet.
Weitere Informationen finden Sie unter Einführung in den Prompt-Entwurf finden Sie weitere Informationen zum Schreiben hilfreicher Prompts.
Prompt-Design ist ein Synonym für Prompt Engineering.
Prompt-Feinabstimmung
Ein Parameterbasierter Abstimmungsmechanismus ein „Präfix“ oder die das System dem tatsächlichen Prompt.
Eine Variante der Feinabstimmung von Aufforderungen, die auch als Präfixabstimmung bezeichnet wird, besteht darin, Stellen Sie das Präfix jeder Ebene voran. Bei den meisten Prompt-Feinabstimmungen fügt der Eingabeebene ein Präfix hinzu.
R
Rollen-Prompting
Optionaler Teil einer Aufforderung zur Angabe einer Zielgruppe für die Antwort eines Generative-AI-Modells. Ohne Rolle bietet ein Large Language Model eine Antwort, die nützlich oder unbrauchbar ist für die Person, die die Fragen stellt. Mit einer Rollenaufforderung, einer großen Sprache Modell antworten kann, die für eine bestimmte Person passender und hilfreicher sind. für eine bestimmte Zielgruppe. Beispiel: Der Rollen-Prompt-Teil von Prompts sind fett formatiert:
- Fasse diesen Artikel für einen Doktortitel in Wirtschaft zusammen.
- Beschreiben Sie, wie die Gezeiten bei einem Zehnjährigen funktionieren.
- Erklären Sie die Finanzkrise von 2008. Sprechen Sie wie Sie mit einem kleinen Kind, oder Golden Retriever.
S
Selbstaufmerksamkeit (auch Selbstaufmerksamkeitsschicht genannt)
Eine neuronale Netzwerkschicht, die eine Folge von Einbettungen (z. B. Token-Einbettungen) in eine andere Einbettungssequenz umwandeln. Jede Einbettung in der Ausgabesequenz ist durch Integration von Informationen aus den Elementen der Eingabesequenz konstruiert. durch einen Aufmerksamkeitsmechanismus.
Der Teil Selbst der Selbstaufmerksamkeit bezieht sich auf die Reihenfolge, und nicht in einen anderen Kontext. Selbstaufmerksamkeit ist eine der wichtigsten für Transformers und verwendet die Wörterbuchsuche Begriffe wie „Abfrage“, „Schlüssel“ und „Wert“.
Eine Selbstaufmerksamkeitsschicht beginnt mit einer Reihe von Eingabedarstellungen. für jedes Wort ein. Die Eingabedarstellung für ein Wort kann ein einfaches und Einbettungen. Für jedes Wort in einer Eingabesequenz weist das Netzwerk bewertet die Relevanz des Wortes für jedes Element in der gesamten Wörter. Die Relevanzwerte bestimmen, wie stark die endgültige Darstellung des Wortes die Darstellungen anderer Wörter enthält.
Betrachten Sie zum Beispiel den folgenden Satz:
Das Tier ist nicht über die Straße gegangen, weil es so müde war.
Die folgende Abbildung (aus Transformer: Eine neuartige neuronale Netzwerkarchitektur für Sprachen Verständnis) zeigt das Aufmerksamkeitsmuster der Selbstaufmerksamkeitsschicht für das Pronomen it, wobei die Dunkelheit jeder Zeile, die angibt, wie viel jedes Wort zum Darstellung:
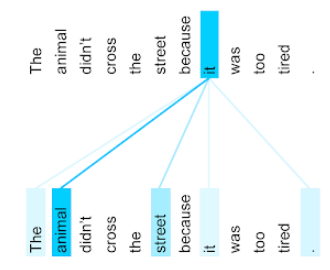
Die Ebene der Selbstaufmerksamkeit hebt Wörter hervor, die für „sie“ relevant sind. In dieser hat die Aufmerksamkeitsschicht gelernt, Wörter hervorzuheben, die möglicherweise Tier das höchste Gewicht zuweisen.
Für eine Sequenz von n Tokens transformiert Selbstaufmerksamkeit eine Sequenz von Einbettungen n Mal getrennt, einmal an jeder Position der Sequenz.
Weitere Informationen finden Sie unter Aufmerksamkeit und mehrköpfige Selbstaufmerksamkeit.
Sentimentanalyse
Den Erfolg einer Gruppe mithilfe statistischer Algorithmen oder Algorithmen des maschinellen Lernens zu bestimmen. eine positive oder negative Einstellung zu einer Dienstleistung, Organisation oder Thema. Wenn Sie beispielsweise Natural Language Understanding könnte ein Algorithmus eine Sentimentanalyse des Textfeedbacks durchführen, eines Universitätskurses, um den Abschluss zu bestimmen, den Kurs insgesamt gefallen oder nicht.
Sequenz-zu-Sequenz-Task
Eine Aufgabe, die eine Eingabesequenz von Tokens in eine Ausgabe umwandelt Sequenz von Tokens. Zwei beliebte Arten von Sequenz-zu-Sequenz-Tags, Aufgaben:
- Übersetzer:
<ph type="x-smartling-placeholder">
- </ph>
- Beispiel-Eingabesequenz: „Ich liebe dich.“
- Beispielausgabesequenz: „Je t'aime“
- Question Answering:
<ph type="x-smartling-placeholder">
- </ph>
- Beispiel für eine Eingabesequenz: „Brauche ich mein Auto in New York City?“
- Beispielausgabesequenz: „Nein. Bitte lass dein Auto zu Hause.“
skip-gram
Ein N-Gramm, das Wörter im Original weglassen (oder „überspringen“) kann Kontext, d. h., die N Wörter standen möglicherweise nicht aneinander. Mehr genau ein „k-skip-n-gram“ ist ein N-Gramm, für das bis zu k Wörter wurden übersprungen.
Beispiel: „der schnelle braune Fuchs“ hat folgende mögliche 2-Gramme:
- „The Quick“
- "Quick Braun"
- „Braun Fuchs“
„1-skip-2-gram“ ist ein Paar aus Wörtern, zwischen denen höchstens ein Wort besteht. Deshalb ist „der schnelle braune Fuchs“ enthält die folgenden 1-Überspringen-2-Gramme:
- "the braun"
- "Quick Fox"
Außerdem sind alle 2 Gramme auch 1-überspringen-2-Gramm, da weniger als ein Wort übersprungen werden.
Überspringungsgramme sind nützlich, um den Kontext eines Wortes besser zu verstehen. Im Beispiel ist „fox“ direkt mit „schnell“ in Verbindung gebracht werden, in der Gruppe von 1-überspringen-2-Gramm, aber nicht in der Menge von 2-Grammen.
Skip-Gramme helfen beim Training Worteinbettungsmodelle.
Feinabstimmung mit weichen Aufforderungen
Verfahren zur Abstimmung eines Large Language Models für eine bestimmte Aufgabe ohne ressourcenintensive Feinabstimmung: Anstatt alle weights im Modell, weiche Prompt-Feinabstimmung passt einen Prompt automatisch an, um dasselbe Ziel zu erreichen.
Bei Eingabe eines Prompts in Textform, Feinabstimmung weicher Prompts hängt in der Regel zusätzliche Tokeneinbettungen an den Prompt an und verwendet Rückpropagierung, um die Eingabe zu optimieren.
Eine „schwierige“ Prompt enthält echte Tokens anstelle von Tokeneinbettungen.
dünnbesetztes Feature
Ein feature, dessen Werte überwiegend null oder leer sind. Ein Feature mit einem einzelnen 1-Wert und einer Million 0-Werten dünnbesetzt sind. Ein dichtes Feature hingegen hat Werte, meistens nicht null oder leer sind.
Beim maschinellen Lernen handelt es sich bei einer überraschenden Anzahl von Features um dünnbesetzte Features. Kategoriale Merkmale sind in der Regel dünnbesetzte Merkmale. Von den 300 möglichen Baumarten in einem Wald könnte ein einziges lediglich einen Ahornbaum erkennen. Oder von den Millionen in einer Videobibliothek gibt, könnte ein Beispiel nur „Casablanca“.
In einem Modell stellen Sie dünnbesetzte Features normalerweise mit One-Hot-Codierung. Wenn die One-Hot-Codierung groß ist, können Sie eine Einbettungsebene über das Bild One-Hot-Codierung für mehr Effizienz.
Dünnbesetzte Darstellung
Nur die Position(en) von Elementen ungleich null in einem dünnbesetzten Feature speichern.
Angenommen, ein kategoriales Feature namens species identifiziert die 36
in einem bestimmten Wald zu finden. Nehmen wir weiter an, dass jedes
Beispiel für nur eine einzelne Spezies.
Sie können einen One-Hot-Vektor verwenden, um die Baumarten in jedem Beispiel darzustellen.
Ein One-Hot-Vektor würde einen einzelnen 1 enthalten (um
die jeweilige Baumart in diesem Beispiel) und 35 0s (zur Darstellung der
35 Baumarten nicht in diesem Beispiel). Die One-Hot-Darstellung
von maple könnte etwa so aussehen:

Alternativ würde bei der dünnbesetzten Darstellung einfach die Position des
bestimmte Spezies. Wenn sich maple auf Position 24 befindet, ist die dünnbesetzte Darstellung
von maple wäre einfach:
24
Beachten Sie, dass die dünnbesetzte Darstellung viel kompakter ist als die One-Hot-Darstellung. Darstellung.
Klicken Sie auf das Symbol, um ein etwas komplexeres Beispiel aufzurufen.
Angenommen, jedes Beispiel in Ihrem Modell muss die Wörter darstellen, aber nicht die Reihenfolge dieser Wörter in einem englischen Satz. Englisch besteht aus etwa 170.000 Wörtern, daher ist Englisch -Element mit etwa 170.000 Elementen. Die meisten englischen Sätze enthalten ein Zeichen nur ein sehr kleiner Bruchteil dieser 170.000 Wörter, sodass die Wörter in einem wird mit ziemlicher Sicherheit dünnbesetzte Daten sein.
Betrachten Sie den folgenden Satz:
My dog is a great dog
Sie könnten eine Variante des One-Hot-Vektors verwenden, um die Wörter in diesem Satz. Bei dieser Variante können mehrere Zellen im Vektor Elemente enthalten, einen Wert ungleich null. Außerdem kann eine Zelle bei dieser Variante eine Ganzzahl enthalten. als eine andere. Die Wörter "mein", "ist", "ein" und "prima" nur anzeigen einmal im Satz das Wort „Hund“ erscheint zweimal. Verwendung dieser Variante von One-Hot-Vektoren zur Darstellung der Wörter in diesem Satz ergeben Folgendes: Vektor mit 170.000 Elementen:

Eine dünnbesetzte Darstellung desselben Satzes würde einfach wie folgt aussehen:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
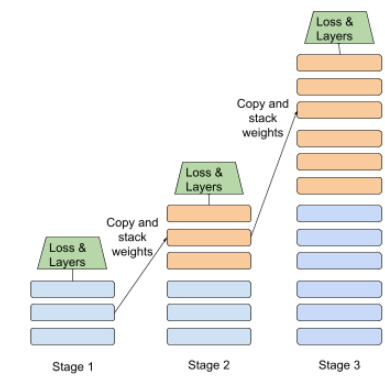
Gestaffeltes Training
Taktik zum Trainieren eines Modells in einer Abfolge diskreter Phasen. Das Ziel kann um das Training zu beschleunigen oder die Modellqualität zu verbessern.
Hier sehen Sie eine Abbildung des Progressive-Stacking-Ansatzes:
- Phase 1 enthält drei versteckte Ebenen, Phase 2 sechs ausgeblendete Ebenen und Phase 3 enthält 12 versteckte Layer.
- In Phase 2 beginnt das Training mit den erlernten Gewichten in den drei verborgenen Ebenen. Phase 1. In Phase 3 beginnt das Training mit den in der 6. mit verborgenen Ebenen in Phase 2.
Weitere Informationen finden Sie unter Pipelining.
Unterworttoken
In Sprachmodellen ist ein Token, das ein Teilzeichenfolge eines Worts, bei der es sich um das ganze Wort handeln kann.
Zum Beispiel kann ein Wort wie „itemize“ in die Teile „item“ (ein Stammwort) und "ize" (ein Suffix), von denen jedes durch ein eigenes Token. Das Aufteilen ungewöhnlicher Wörter in solche Stücke, sogenannte Subwörter, ermöglicht Language Models, die mit den häufiger verwendeten Bestandteilen des Wortes arbeiten, wie Präfixe und Suffixe.
Übliche Wörter wie „auf dem Weg“ ist möglicherweise nicht aufgeteilt durch ein einzelnes Token dargestellt wird.
T
T5
Ein Modell für Lerntransfer von Text zu Text eingeführt von Google AI im Jahr 2020 T5 ist ein Encoder-Decoder-Modell, das auf dem Transformer-Architektur, trainiert mit einem extrem großen Dataset. Sie kann bei einer Vielzahl an Aufgaben im Bereich Natural Language Processing, z. B. Text generieren, Sprachen übersetzen und Fragen in dialogorientiert.
T5 ist nach den fünf Ts in „Text-to-Text Transfer Transformer“ benannt.
Logo: T5X
Ein Open-Source-Framework für maschinelles Lernen, das entwickelt wurde, zum Erstellen und Trainieren von Natural Language Processing in großem Umfang (NLP-Modelle). T5 ist auf der T5X-Codebasis implementiert (die basierend auf JAX und Flax).
Temperatur
Ein Hyperparameter, der den Grad der Zufälligkeit steuert eines Modells aus. Höhere Temperaturen führen zu mehr zufälligen Ergebnissen, während niedrigere Temperaturen zu einer weniger zufälligen Ausgabe führen.
Die Auswahl der besten Temperatur hängt von der jeweiligen Anwendung und die bevorzugten Attribute der Modellausgabe. Zum Beispiel würden Sie erhöhen wahrscheinlich die Temperatur, wenn Sie eine Anwendung erstellen, die Creative-Ausgabe generiert. Umgekehrt würden Sie wahrscheinlich die Temperatur senken, wenn Sie ein Modell erstellen, das Bilder oder Text klassifiziert, um Genauigkeit und Konsistenz des Modells verbessern.
Die Temperatur wird oft mit Softmax verwendet.
Textspanne
Die Array-Indexspanne, die einem bestimmten Unterabschnitt einer Textzeichenfolge zugeordnet ist.
So belegt beispielsweise das Wort good im Python-String s="Be good now"
von 3 bis 6.
Token
In einem Sprachmodell die atomare Einheit, in der sich das Modell befindet zu trainieren und Vorhersagen zu treffen. Ein Token ist normalerweise eines der Folgendes:
- ein Wort, zum Beispiel die Wortgruppe „Hunde wie Katzen“ besteht aus drei Wörtern Tokens: "Hunde", "Gefällt mir" und "Katzen".
- ein Zeichen, z. B. der Satz "Fahrradfisch" besteht aus neun Zeichen-Tokens. Das Leerzeichen zählt als eines der Tokens.
- Unterwörter, bei denen ein einzelnes Wort ein einzelnes Token oder mehrere Tokens sein kann. Ein Unterwort besteht aus einem Stammwort, einem Präfix oder einem Suffix. Beispiel: Ein Sprachmodell, das Unterwörter als Token verwendet, könnte das Wort „Hunde“ sehen. als zwei Tokens (das Stammwort „dog“ und das Pluralsuffix „s“). Das Gleiche Language Model das einzelne Wort „höher“ erkennt, als zwei Unterwörter (die Stammwort „hoch“ und das Suffix „er“).
In Domains außerhalb von Language Models können Tokens andere Arten von atomare Einheiten. Beim maschinellen Sehen kann ein Token beispielsweise eine Teilmenge sein eines Bildes.
Transformer
Eine bei Google entwickelte neuronale Netzwerkarchitektur, die nutzt Selbstaufmerksamkeit, Sequenz von Eingabeeinbettungen in eine Ausgabesequenz Einbettungen ohne Faltungen oder recurrent Neural Networks. Ein Transformator kann als ein Stapel aus Selbstaufmerksamkeitsschichten betrachtet.
Ein Transformator kann Folgendes enthalten:
Ein Encoder wandelt eine Sequenz von Einbettungen in eine neue Sequenz der gleich lang sind. Ein Encoder besteht aus n identischen Schichten, die jeweils zwei Schichten untergeordneten Ebenen. Diese beiden Unterebenen werden an jeder Position der Eingabe Einbettungssequenz, wobei jedes Element der Sequenz in eine neue und Einbettungen. Die erste Encoder-Teilebene fasst Informationen aus der . Die zweite Encoder-Teilschicht transformiert in eine Ausgabeeinbettung.
Ein Decoder wandelt eine Folge von Eingabeeinbettungen in eine Folge von Ausgabeeinbettungen, möglicherweise mit einer anderen Länge. Ein Decoder umfasst außerdem N identische Schichten mit drei Unterebenen, von denen zwei dem werden die Unterebenen des Encoders verwendet. Die dritte Decoder-Unterschicht übernimmt die Ausgabe der Encoder und wendet den Selbstaufmerksamkeitsmechanismus auf Informationen zu sammeln.
Im Blogpost Transformer: A Novel Neural Network Architecture for Language Verständnis bietet eine gute Einführung in Transformers.
Trigramm
Ein N-Gramm mit N=3.
U
einseitig
Ein System, das nur den Text bewertet, der einem Zieltext vorher ist. Im Gegensatz dazu wertet ein bidirektionales System sowohl Text, der vorangestellt ist und auf einen Textabschnitt folgt. Weitere Informationen finden Sie unter Bidirektional.
Unidirektionales Sprachmodell
Ein Sprachmodell, das seine Wahrscheinlichkeiten nur auf dem Tokens, die vor und nicht nach den Zieltokens angezeigt werden. Sie stellt einen Kontrast mit dem bidirektionalen Sprachmodell her.
V
Variations-Autoencoder (VAE)
Eine Art von Autoencoder, der die Diskrepanz ausnutzt zwischen Ein- und Ausgaben, um modifizierte Versionen der Eingaben zu generieren. Variations-Autoencoder sind nützlich für generative KI.
VAEs basieren auf Variationsinferenz: einer Technik zur Schätzung Parameter eines Wahrscheinlichkeitsmodells.
W
Worteinbettung
Darstellung jedes Wortes in einer Wortgruppe in einem Einbettungsvektor d. h. jedes Wort als einen Vektor von Gleitkommawerten zwischen 0,0 und 1,0. Wörter mit Ähnlichem Bedeutungen haben eine ähnlichere Darstellung als Wörter mit unterschiedlichen Bedeutungen. So wären beispielsweise Karotten, Seller und Gurken relativ wahrscheinlich ähnliche Darstellungen, die sich stark von den Darstellungen unterscheiden, Flugzeug, Sonnenbrille und Zahnpasta.
Z
Zero-Shot-Prompting
Eine Aufforderung, die kein Beispiel dafür enthält, Large Language Model verwenden. Beispiel:
| Bestandteile eines Prompts | Hinweise |
|---|---|
| Was ist die offizielle Währung des angegebenen Landes? | Die Frage, die das LLM beantworten soll. |
| Indien: | Die eigentliche Abfrage. |
Das Large Language Model könnte so antworten:
- Rupie
- INR
- ₹
- Indische Rupie
- Die Rupie
- Indische Rupie
Alle Antworten sind richtig, auch wenn Sie möglicherweise ein bestimmtes Format bevorzugen.
Vergleichen Sie Zero-Shot-Prompts mit den folgenden Begriffen: