Nesta página, você encontra os termos do glossário da avaliação de idiomas. Para todos os termos do glossário, clique aqui.
A
atenção
Um mecanismo usado em uma rede neural que indica a importância de uma palavra específica ou parte de uma palavra. Compacta a atenção a quantidade de informações que um modelo precisa para prever o próximo token/palavra. Um mecanismo de atenção típico pode consistir soma ponderada sobre um conjunto de entradas, em que o weight para cada entrada é calculado por outra parte do rede neural profunda.
Consulte também a autoatenção e autoatenção de várias cabeças, que são elementos básicos dos Transformers.
codificador automático
Um sistema que aprende a extrair as informações mais importantes das entrada. Codificadores automáticos são uma combinação de um codificador e decodificador. Os codificadores automáticos usam o seguinte processo de duas etapas:
- O codificador mapeia a entrada para uma dimensão inferior com perdas (normalmente) (intermediário).
- O decodificador cria uma versão com perda da entrada original mapeando do formato de dimensão inferior para a dimensão superior original o formato de entrada.
Codificadores automáticos são treinados de ponta a ponta fazendo com que o decodificador reconstruem a entrada original usando o formato intermediário do codificador o mais próximo possível. Como o formato intermediário é menor (dimensional) que o formato original, o codificador automático é forçado para saber quais informações na entrada são essenciais e a saída não será perfeitamente idêntica à entrada.
Exemplo:
- Se os dados de entrada forem um gráfico, a cópia não exata será semelhante a o gráfico original, mas ligeiramente modificado. Talvez o a cópia não exata remove o ruído do gráfico original ou o preenche alguns pixels ausentes.
- Se os dados de entrada forem texto, um codificador automático geraria um novo texto que imita (mas não é idêntico) ao texto original.
Consulte também codificadores automáticos variáveis.
modelo autoregressivo
Um modelo que infere uma previsão com base na própria previsões. Por exemplo, modelos de linguagem autorregressivos preveem o próximo token com base nos tokens previstos anteriormente. Todos os modelos baseados em Transformer Os modelos de linguagem grandes são autoregressivos.
Por outro lado, os modelos de imagem baseados em GAN geralmente não são autoregressivos já que geram uma imagem em uma única passagem para a frente e não de forma iterativa em etapas. No entanto, alguns modelos de geração de imagem são autoregressivos porque uma imagem é gerada em etapas.
B
pacote de palavras
Uma representação das palavras em uma frase ou passagem independente da ordem. Por exemplo, saco de palavras representa três frases idênticas a seguir:
- O cachorro pula
- pula o cachorro
- cachorro pula
Cada palavra é mapeada para um índice em um vetor esparso, em que o vetor tem um índice para cada palavra no vocabulário. Por exemplo: a frase o cachorro pula é mapeada em um vetor de atributo com valor diferente de zero nos três índices correspondentes às palavras the, dog e saltos. O valor diferente de zero pode ser qualquer um destes:
- O número 1 indica a presença de uma palavra.
- Contagem do número de vezes que uma palavra aparece na bolsa. Por exemplo: se a frase fosse the cão marrom é um cachorro com pelo marrom, então ambas maroon e dog seriam representados como 2, enquanto as outras palavras representado como 1.
- Algum outro valor, como o logaritmo da contagem do número de vezes que uma palavra aparece na bolsa.
BERT (codificador bidirecional) representações de transformadores)
Um modelo de arquitetura para representação de textos. Um modelo O modelo BERT pode atuar como parte de um modelo maior de classificação de texto ou outras tarefas de ML.
O BERT tem as seguintes características:
- Usa a arquitetura Transformer e, portanto, depende sobre autoatenção.
- Usa a parte codificador do transformador. A função do codificador é produzir boas representações textuais, em vez de realizar uma para uma tarefa específica, como classificação.
- É bidirecional.
- Usa mascaramento para treinamento não supervisionado.
As variantes do BERT incluem:
.Consulte Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processamento para uma visão geral do BERT.
bidirecional
Um termo usado para descrever um sistema que avalia o texto precedido e segue uma seção de destino do texto. Por outro lado, Somente sistema unidirecional avalia o texto que antecede uma seção de destino do texto.
Por exemplo, considere um modelo de linguagem mascarada que deve determinar as probabilidades das palavras que representam o sublinhado a seguinte pergunta:
Como está _____ com você?
Um modelo de linguagem unidirecional teria que basear apenas as probabilidades com base no contexto fornecido pelas palavras "o que", "é" e "o". Por outro lado, um modelo de linguagem bidirecional também pode obter contexto de "com" e "você", o que pode ajudar o modelo a gerar previsões melhores.
modelo de linguagem bidirecional
Um modelo de linguagem que determina a probabilidade de uma token fornecido está presente em um determinado local em um trecho de texto com base em o texto anterior e seguinte.
bigrama
Um N-grama em que N=2.
BLEU (Subestudo de avaliação bilíngue)
Uma pontuação entre 0,0 e 1,0, indicando a qualidade de uma tradução. entre dois idiomas humanos (por exemplo, inglês e russo). BLEU o score de 1,0 indica uma tradução perfeita; uma pontuação BLEU de 0,0 indica péssima.
C
modelo de linguagem causal
Sinônimo de modelo de linguagem unidirecional.
Consulte o modelo de linguagem bidirecional para contrastar as diferentes abordagens direcionais na modelagem de linguagem.
comandos de cadeia de pensamento
Uma técnica de engenharia de comando que incentiva um modelo de linguagem grande (LLM) para explicar sua raciocínio, passo a passo. Por exemplo, considere o comando a seguir, atenção especial à segunda frase:
Quantas forças g um motorista experimentaria em um carro que varia de 0 a 60 milhas por hora em 7 segundos? Na resposta, mostre todos os cálculos relevantes.
A resposta do LLM provavelmente:
- Mostrar uma sequência de fórmulas da física, conectando os valores 0, 60 e 7 nos locais apropriados.
- Explique por que ele escolheu essas fórmulas e o que as diversas variáveis significam.
Os comandos de cadeia de pensamento forçam o LLM a realizar todos os cálculos, o que pode levar a uma resposta mais correta. Além disso, a cadeia de pensamento a criação de prompts permite que o usuário examine as etapas do LLM para determinar se ou não, a resposta faz sentido.
chat
O conteúdo de um diálogo com um sistema de ML, normalmente um modelo de linguagem grande. a interação anterior em um chat (o que você digitou e como o modelo de linguagem grande respondeu) se torna o contexto para as partes seguintes do chat.
Um chatbot é um aplicativo de um modelo de linguagem grande.
confabulação
Sinônimo de alucinação artificial.
"Confabulação" é provavelmente um termo tecnicamente mais preciso do que alucinação. No entanto, a alucinação ficou conhecida primeiro.
análise de distrito eleitoral
Dividir uma sentença em estruturas gramaticais menores ("constituintes"). Uma parte posterior do sistema de ML, como modelo de compreensão de linguagem natural, pode analisar os constituintes mais facilmente do que a frase original. Por exemplo: considere a seguinte frase:
Meu amigo adotou dois gatos.
Um analisador de distrito eleitoral pode dividir esta frase nas seguintes dois componentes:
- Myfriend é um sintagma nominal.
- adopted two cats (em inglês) é um sintagma verbal.
Esses constituintes podem ser subdivididos em partes menores. Por exemplo, a frase verbal
adotou dois gatos
poderia ser subdividida em:
- adopted é um verbo.
- two cats é outro sintagma nominal.
incorporação de linguagem contextualizada
Uma incorporação que chega perto de "compreensão". palavras e frases de uma maneira que os falantes humanos nativos podem fazer. Linguagem contextualizada os embeddings entendem sintaxe, semântica e contexto complexos.
Por exemplo, considere embeddings da palavra em inglês cow. Embeddings mais antigos como word2vec pode representar palavras para que a distância no espaço de embedding de vaca para touro é semelhante à distância de ewe (ovelha fêmea) até macho (ovelha macho) ou de fêmea para macho. Linguagem contextualizada os embeddings podem ir além, reconhecendo que falantes de inglês às vezes casualmente use a palavra vaca para significar vaca ou touro.
janela de contexto
O número de tokens que um modelo pode processar em um determinado comando. Quanto maior a janela de contexto, mais informações o modelo pode usar para fornecer respostas coerentes e consistentes ao comando.
flor esmagadora
Uma sentença com um significado ambíguo. As flores típicas representam um problema significativo na natureza natural compreensão da linguagem. Por exemplo, o título A fita vermelha segura o arranha-céu é uma porque um modelo PLN poderia interpretar o título literalmente ou figurativamente.
D
decodificador
Em geral, qualquer sistema de ML que converte de uma camada processada, densa ou interna para uma representação mais bruta, esparsa ou externa.
Decodificadores são componentes de um modelo maior, em que são usados pareado com um codificador.
Em tarefas sequência para sequência, um decodificador começa com o estado interno gerado pelo codificador para prever a próxima sequência.
Consulte Transformer para a definição de um decodificador em a arquitetura de transformador.
remover ruído
Uma abordagem comum de aprendizado autossupervisionado em que:
A remoção de ruído permite aprender com exemplos não rotulados. O conjunto de dados original serve como o destino ou label e os dados com ruído como entrada.
Alguns modelos de linguagem mascarada usam a remoção de ruído. da seguinte forma:
- O ruído é adicionado artificialmente a uma frase não rotulada mascarando algumas os tokens.
- O modelo tenta prever os tokens originais.
comandos diretos
Sinônimo de comando zero-shot.
E
editar distância
Uma medida da semelhança entre duas strings de texto. No machine learning, editar distância é útil porque é simples e uma forma eficaz de comparar duas strings conhecidas como semelhantes ou para encontrar strings semelhantes a uma determinada string.
Há várias definições para edição da distância, cada uma usando strings diferentes. as operações. Por exemplo, o Distância de Levenshtein considera o menor número de operações de exclusão, inserção e substituição.
Por exemplo, a distância de Levenshtein entre as palavras "coração" e "dardos" é 3 porque as três edições a seguir são o menor número de alterações para transformar uma palavra no outro:
- coração → deart (substitua "h" por "d")
- deart → dart (excluir "e")
- dart → darts (insert "s")
camada de embedding
Uma camada escondida especial que é treinada em uma atributo categórico de alta dimensão para aprender gradualmente um vetor de embedding de dimensão menor. Um a camada de embedding permite que uma rede neural treine muito mais mais eficiente do que treinar apenas com o atributo categórico de alta dimensão.
Por exemplo, a Terra atualmente suporta cerca de 73.000 espécies de árvores. Suponha
espécie de árvore é um atributo no seu modelo, portanto,
a camada de entrada inclui um vetor one-hot 73.000
de comprimento de elementos.
Por exemplo, talvez baobab fosse representado algo assim:

Uma matriz de 73.000 elementos é muito longa. Se você não adicionar uma camada de embedding ao modelo, o treinamento vai levar muito tempo, porque multiplicando 72.999 zeros. Talvez você escolha a camada de embedding para consistir de 12 dimensões. Consequentemente, a camada de embedding aprenderá gradualmente um novo vetor de embedding para cada espécie de árvore.
Em determinadas situações, gerar hash é uma alternativa razoável para uma camada de embedding.
espaço de embedding
O espaço vetorial d-dimensional que pertence a uma dimensão superior espaço de vetor são mapeados. Idealmente, o espaço de embedding contém um que produz resultados matemáticos significativos, por exemplo, Em um espaço de embedding ideal, a adição e subtração de embeddings pode resolver tarefas de analogia de palavras.
O produto de pontos de dois embeddings é uma medida da semelhança deles.
vetor de embedding
De modo geral, uma matriz de números de ponto flutuante retirados de qualquer camada escondida que descrevem as entradas dela. Muitas vezes, um vetor de embedding é a matriz de números de ponto flutuante treinados em uma camada de embedding. Por exemplo, suponha que uma camada de embedding precise aprender uma vetor de embedding para cada uma das 73 mil espécies de árvores na Terra. Talvez o matriz a seguir é o vetor de embedding de um baobá:

Um vetor de embedding não é um monte de números aleatórios. Uma camada de embedding determina esses valores pelo treinamento, semelhante à maneira a rede neural aprende outros pesos durante o treinamento. Cada elemento do matriz é uma classificação juntamente com alguma característica de uma espécie de árvore. Que representa quais espécies de árvores característica? Isso é muito difícil para que humanos possam determinar.
A parte matematicamente notável de um vetor de embedding é que itens têm conjuntos semelhantes de números de ponto flutuante. Por exemplo, semelhantes espécies de árvores têm um conjunto mais semelhante de números de ponto flutuante do que diferentes espécies de árvores. Sequoias e sequoias são espécies de árvores relacionadas, então eles terão um conjunto mais semelhante de números de ponto flutuante do que sequoias e coqueiros. Os números no vetor de embedding mudam a cada novo treinamento do modelo, mesmo que isso com entradas idênticas.
codificador
Em geral, qualquer sistema de ML que converte dados brutos, esparsos ou em uma representação mais processada, densa ou mais interna.
Codificadores são componentes de um modelo maior, em que são usados pareado com um decodificador. Alguns transformadores codificadores e decodificadores, embora outros transformadores usem apenas o ou só o decodificador.
Alguns sistemas usam a saída do codificador como entrada para uma classificação ou rede de regressão.
Nas tarefas sequência para sequência, um codificador toma uma sequência de entrada e retorna um estado interno (um vetor). Depois, decoder usa esse estado interno para prever a próxima sequência.
Consulte Transformer para a definição de um codificador em a arquitetura de transformador.
F
comandos few-shot
Um comando que contém mais de um exemplo (um "poucos") demonstrando como o modelo de linguagem grande deve responder. Por exemplo, o comando a seguir contém duas que mostram um modelo de linguagem grande como responder a uma consulta.
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Um exemplo. |
| Reino Unido: GBP | Outro exemplo. |
| Índia: | A consulta real. |
Os comandos few-shot geralmente produzem resultados mais desejáveis do que comandos zero-shot e Comandos one-shot: No entanto, os comandos few-shot exige um comando mais longo.
Os comandos few-shot são uma forma de aprendizado few-shot aplicados ao aprendizado baseado em comandos.
Violino
Uma biblioteca de configuração que prioriza o Python e define valores de funções e classes sem código ou infraestrutura invasivos. No caso de Pax (e outras bases de código de ML), essas funções e As classes representam modelos e treinamento hiperparâmetros.
Violão presume que as bases de código de machine learning são normalmente divididas em:
- Código da biblioteca, que define as camadas e os otimizadores.
- "cola" do conjunto de dados que chama as bibliotecas e conecta tudo.
O Fiddle captura a estrutura de chamada do código agrupador em um intervalo não avaliado em uma forma mutável.
ajuste
Um segundo passe de treinamento específico para uma tarefa modelo pré-treinado para refinar seus parâmetros para uma para um caso de uso específico. Por exemplo, a sequência de treinamento completa de alguns modelos de linguagem grandes são os seguintes:
- Pré-treinamento:treine um modelo de linguagem grande em um conjunto de dados geral amplo. como todas as páginas da Wikipédia em inglês.
- Ajuste:treine o modelo pré-treinado para executar uma tarefa específica. como ao responder consultas médicas. O ajuste fino normalmente envolve centenas ou milhares de exemplos focados na tarefa específica.
Como outro exemplo, a sequência de treinamento completa de um modelo de imagem grande é igual a da seguinte forma:
- Pré-treinamento:treine um modelo de imagem grande em uma imagem geral ampla conjunto de dados, como todas as imagens na Wikimedia commons.
- Ajuste:treine o modelo pré-treinado para executar uma tarefa específica. como a geração de imagens de orcas.
O ajuste fino pode envolver qualquer combinação das seguintes estratégias:
- Modificar todas as configurações atuais do modelo pré-treinado parameters. Às vezes, isso é chamado de ajuste total.
- Modificar apenas alguns dos parâmetros do modelo pré-treinado (normalmente, as camadas mais próximas da camada de saída), mantendo os outros parâmetros inalterados (normalmente, as camadas mais perto da camada de entrada). Consulte ajuste com eficiência de parâmetros.
- Adicionar mais camadas, normalmente sobre as camadas existentes mais próximas ao camada final.
O ajuste é uma forma de aprendizado por transferência. Assim, o ajuste pode usar uma função de perda diferente ou um modelo diferente. do que os usados para treinar o modelo pré-treinado. Por exemplo, é possível ajustar um modelo de imagem grande pré-treinado para produzir um modelo de regressão que retorna o número de pássaros em uma imagem de entrada.
Compare os ajustes com os seguintes termos:
Linho
Um software de código aberto de alto desempenho biblioteca para aprendizado profundo baseado no JAX. O flax fornece funções no treinamento de redes neurais, como métodos para avaliar seu desempenho.
Flaxformer
Um Transformer de código aberto biblioteca, criado com base no Flax e desenvolvido principalmente para processamento de linguagem natural multimodal.
G
IA generativa
Um campo transformador emergente sem definição formal. Dito isso, a maioria dos especialistas concorda que os modelos de IA generativa podem criam ("gerar") conteúdo que seja tudo isto:
- complexo
- coerentes
- original
Por exemplo, um modelo de IA generativa pode criar modelos como artigos ou imagens.
Algumas tecnologias anteriores, incluindo LSTMs e RNNs, também podem gerar valores conteúdo coerente. Alguns especialistas veem essas tecnologias anteriores como a IA generativa, enquanto outros acham que a verdadeira IA generativa exige do que as tecnologias anteriores podem produzir.
Compare com o ML preditivo.
GPT (Transformer Generative Pre-trained)
Uma família de objetos baseados em Transformer modelos de linguagem grandes desenvolvidos pela OpenAI.
As variantes da GPT podem ser aplicadas a várias modalidades, incluindo:
- geração de imagens (por exemplo, ImageGPT)
- texto para imagem (por exemplo, DALL-E).
H
alucinação artificial
A produção de uma saída aparentemente plausível, mas factualmente incorreta por uma modelo de IA generativa que finge estar criando afirmativa sobre o mundo real. Por exemplo, um modelo de IA generativa que afirma que Barack Obama morreu em 1865 é alucinante.
I
aprendizado em contexto
Sinônimo de comandosfew-shot.
L
LaMDA (Language Model for Dialogue Applications)
Uma instância baseada em Transformer modelo de linguagem grande desenvolvido pelo Google treinado com um grande conjunto de dados de diálogos capazes de gerar respostas conversacionais realistas.
LaMDA: nossa conversa inovadora tecnologia fornece uma visão geral.
modelo de linguagem
Um modelo que estima a probabilidade de um token ou sequência de tokens que ocorrem em uma sequência mais longa.
modelo de linguagem grande
Um termo informal sem definição estrita que geralmente significa uma modelo de linguagem com um alto número de parâmetros. Alguns modelos de linguagem grandes têm mais de 100 bilhões de parâmetros.
espaço latente
Sinônimo de embedding Space.
LLM
Abreviação de modelo de linguagem grande (em inglês).
LoRA
Abreviação de Adaptabilidade de classificação baixa.
Adaptabilidade de baixa classificação (LoRA)
Um algoritmo para realizar ajuste eficiente de parâmetros que ajusta somente um subconjunto de um modelos de linguagem grandes. A LoRA oferece os seguintes benefícios:
- Ajusta mais rapidamente do que as técnicas que exigem o ajuste de todas as configurações parâmetros.
- Reduz o custo computacional de inferência no um modelo bem ajustado.
Um modelo ajustado com o LoRA mantém ou melhora a qualidade de suas previsões.
A LoRA permite várias versões especializadas de um modelo.
M
modelo de linguagem mascarada
Um modelo de linguagem que prevê a probabilidade de tokens candidatos para preencher espaços em branco em uma sequência. Por exemplo, um o modelo de linguagem mascarada pode calcular probabilidades de palavras candidatas para substituir o sublinhado na seguinte frase:
O(a) ____ de chapéu veio de volta.
Geralmente, a literatura usa a string "MASK" ("MASK", em inglês). em vez de sublinhado. Exemplo:
A "MÁSCARA" de gorjeta voltou.
A maioria dos modelos modernos de linguagem mascarada é bidirecional.
metaaprendizado
Um subconjunto de machine learning que descobre ou melhora um algoritmo de aprendizado. Um sistema de metaaprendizagem também pode tentar treinar um modelo para aprender rapidamente uma nova tarefa com uma pequena quantidade de dados ou com base na experiência adquirida em tarefas anteriores. Os algoritmos de metaaprendizado geralmente tentam fazer o seguinte:
- Melhore ou aprenda recursos desenvolvidos manualmente (como um inicializador ou um otimizador).
- Maior eficiência em termos de dados e computação.
- Melhorar a generalização.
O metaaprendizado está relacionado ao aprendizado few-shot.
modality
Uma categoria de dados de alto nível. Por exemplo, números, texto, imagens, vídeo e de áudio são cinco modalidades diferentes.
paralelismo de modelos
uma maneira de escalonar o treinamento ou a inferência que coloca diferentes partes de um model em dispositivos diferentes. Paralelismo de modelos permite modelos que são grandes demais para caber em um único dispositivo.
Para implementar o paralelismo de modelos, um sistema normalmente faz o seguinte:
- Ela fragmenta (divide) o modelo em partes menores.
- distribui o treinamento dessas partes menores em vários processadores. Cada processador treina a própria parte do modelo.
- Combina os resultados para criar um único modelo.
O paralelismo de modelos atrasa o treinamento.
Consulte também paralelismo de dados.
autoatenção com várias cabeças
Uma extensão da autoatenção que aplica mecanismo de autoatenção várias vezes para cada posição na sequência de entrada.
Os Transformers introduziram a autoatenção de várias cabeças.
modelo multimodal
um modelo com entradas e/ou saídas que incluem mais de um modalidade. Por exemplo, considere um modelo que usa uma imagem e uma legenda de texto (duas modalidades) como recursos, e gera uma pontuação que indica a adequação da legenda de texto à imagem. Portanto, as entradas desse modelo são multimodais, e a saída é unimodal.
N
processamento de linguagem natural
Determinar as intenções de um usuário com base no que ele digitou ou disse. Por exemplo, um mecanismo de pesquisa usa processamento de linguagem natural para determinam o que o usuário está pesquisando com base no que ele digitou ou disse.
N-grama
Uma sequência ordenada de N palavras. Por exemplo, truly madly é um bloco de 2 gramas. Devido ao a ordem for relevante, madly true é um 2-grama diferente de truly madly.
| N | Nomes para esse tipo de N-grama | Exemplos |
|---|---|---|
| 2 | bigrama ou 2 gramas | ir, ir, almoçar, jantar |
| 3 | trigrama ou 3 gramas | comeu demais, três ratos cegos, o pedágio |
| 4 | 4 gramas | caminhar no parque, poeira ao vento, o menino comeu lentilhas |
Muitos processamento de linguagem natural os modelos dependem de N-gramas para prever a próxima palavra que o usuário vai digitar ou dizer. Por exemplo, suponha que um usuário digitou três cegos. Um modelo PLN baseado em trigramas provavelmente prevê que o o usuário vai digitar mice.
Compare os N-gramas com saco de palavras, que são conjuntos desordenados de palavras.
PLN
Abreviação de linguagem natural compreensão.
O
comandos one-shot
Um comando que contém um exemplo que demonstra como o O modelo de linguagem grande deve responder. Por exemplo: o comando a seguir contém um exemplo que mostra um modelo de linguagem grande ele deve responder a uma consulta.
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Um exemplo. |
| Índia: | A consulta real. |
Compare os comandos one-shot com os seguintes termos:
P
ajuste de eficiência de parâmetros
Um conjunto de técnicas para ajustar um modelo Modelo de linguagem pré-treinado (PLM, na sigla em inglês) mais eficiente do que o ajuste completo. Eficiente em parâmetros O ajuste normalmente ajusta muito menos parâmetros do que refinamento, mas geralmente produz um modelo de linguagem grande que executa tão bem (ou quase tão bem) quanto um modelo de linguagem grande criado ajustes.
Compare e contraste o ajuste com eficiência de parâmetros com:
Esse recurso também é conhecido como ajustes finos com eficiência de parâmetros.
pipeline
Uma forma de paralelismo de modelos em que o valor o processamento é dividido em estágios consecutivos, e cada estágio é executado em um dispositivo diferente. Enquanto uma etapa estiver processando um lote, a fase anterior pode funcionar no próximo lote.
Consulte também o treinamento por etapas.
PLM
Abreviação de modelo de linguagem pré-treinado (em inglês).
codificação posicional
Uma técnica para adicionar informações sobre a posição de um token em uma sequência para o embedding do token. Os modelos de transformador usam codificação para entender melhor a relação entre diferentes partes da sequência.
Uma implementação comum da codificação posicional usa uma função senoidal. (Especificamente, a frequência e a amplitude da função senoidal são determinada pela posição do token na sequência.) Essa técnica permite que um modelo de transformador aprenda a atender a diferentes partes da com base em sua posição.
modelo pré-treinado
Modelos ou componentes de modelo (como um vetor de embedding) que já foram treinados. Às vezes, você alimenta vetores de embedding pré-treinados em uma rede neural. Outras vezes, o modelo treina em vez de depender de embeddings pré-treinados.
O termo modelo de linguagem pré-treinado se refere modelo de linguagem grande que passou pré-treinamento:
pré-treinamento
O treinamento inicial de um modelo em um grande conjunto de dados. Alguns modelos pré-treinados são desastrados e precisam ser refinados com treinamento adicional. Por exemplo, especialistas em ML podem pré-treinar modelo de linguagem grande em um conjunto de dados de texto amplo, como todas as páginas em inglês da Wikipédia. Após o pré-treinamento, modelo resultante pode ser ainda mais refinado por meio de qualquer técnicas:
prompt
Qualquer texto inserido como entrada para um modelo de linguagem grande para condicionar o modelo a se comportar de uma determinada maneira. Os comandos podem ser curtos de frase ou arbitrariamente longo (por exemplo, o texto inteiro de um romance). Comandos se enquadram em várias categorias, incluindo as mostradas na tabela a seguir:
| Categoria da solicitação | Exemplo | Observações |
|---|---|---|
| Pergunta | Qual é a velocidade de um pombo voar? | |
| Instrução | Escreva um poema engraçado sobre arbitragem. | Um comando que pede ao modelo de linguagem grande para fazer algo. |
| Exemplo | Converta o código Markdown em HTML. Por exemplo:
Markdown: * item de lista HTML: <ul> <li>item da lista</li> </ul> |
A primeira frase do comando de exemplo é uma instrução. O restante do comando é o exemplo. |
| Papel | Explicar por que o gradiente descendente é usado no treinamento de machine learning para com doutorado em física. | A primeira parte da frase é uma instrução. a frase "a um doutorado em física" é a parte da função. |
| Entrada parcial para o modelo concluir | O primeiro-ministro do Reino Unido mora | Um comando de entrada parcial pode terminar abruptamente (como neste exemplo) ou terminar com um sublinhado. |
Um modelo de IA generativa pode responder a um comando com texto, códigos, imagens, embeddings, vídeos... quase tudo.
aprendizado baseado em comandos
A capacidade de determinados modelos que permite que eles se adaptem o comportamento deles em resposta a entradas de texto arbitrárias (comandos). Em um paradigma de aprendizado baseado em comandos, um modelo de linguagem grande responde a um comando para gerar texto. Por exemplo, suponha que um usuário digite o seguinte comando:
Resumir a terceira lei de Newton.
Um modelo de aprendizado baseado em comandos não é treinado especificamente para responder ao comando anterior. Em vez disso, o modelo "sabe" muitos fatos sobre a física, muito sobre as regras gerais da linguagem e muito sobre o que constitui respostas úteis. Esse conhecimento é suficiente para fornecer uma responder. Feedback humano adicional ("Essa resposta foi muito complicada." ou "O que é uma reação?") permite que alguns sistemas de aprendizagem baseados em comandos façam gradualmente a melhorar a utilidade das respostas.
design de comandos
Sinônimo de engenharia de comando.
engenharia de comando
A arte de criar comandos que evocam as respostas desejadas de um modelo de linguagem grande. Os humanos realizam o comando com engenharia de atributos. Escrever comandos bem-estruturados é essencial para garantir respostas úteis de um modelo de linguagem grande. A engenharia de prompts depende muitos fatores, incluindo:
- O conjunto de dados usado para pré-treinamento e possivelmente ajustar o modelo de linguagem grande.
- A temperatura e outros parâmetros de decodificação que o usa para gerar respostas.
Consulte Introdução à criação de comandos para mais detalhes sobre como escrever comandos úteis.
Design de comandos é sinônimo de engenharia de comando.
ajuste de comandos
Um mecanismo de ajuste eficiente de parâmetros que aprende um "prefixo" que o sistema inclua no início comando real.
Uma variação do ajuste de prompts, às vezes chamado de ajuste de prefixo, é inclua o prefixo em todas as camadas. Em contraste, a maioria dos ajustes de prompts adiciona um prefixo à camada de entrada.
R
solicitação de papéis
Parte opcional de um comando que identifica um público-alvo. para a resposta de um modelo de IA generativa. Sem um papel comando, um modelo de linguagem grande fornece uma resposta que pode ou não ser útil para a pessoa que fez as perguntas. Com uma instrução de função, uma linguagem grande modelo pode responder de uma forma que seja mais apropriada e útil para um público-alvo específico. Por exemplo, a parte da solicitação de papéis do comandos estão em negrito:
- Resuma este artigo para um doutorado em economia.
- Descreva como as marés funcionam para uma criança de dez anos de idade.
- Explique a crise financeira de 2008. Fale como você falaria com uma criança, ou golden retriever.
S
autoatenção (também chamada de camada de autoatenção)
Uma camada de rede neural que transforma uma sequência de embeddings (por exemplo, embeddings token) em outra sequência de embeddings. Cada embedding na sequência de saída é construído pela integração de informações dos elementos da sequência de entrada usando um mecanismo de atenção.
A parte self da autoatenção refere-se à sequência que atende em si, em vez de algum outro contexto. A autoatenção é um dos principais elementos básicos para Transformers e usa a pesquisa de dicionário terminologia, como "consulta", "chave" e "valor".
Uma camada de autoatenção começa com uma sequência de representações de entrada, de cada palavra. A representação de entrada de uma palavra pode ser e incorporações. Para cada palavra em uma sequência de entrada, a rede pontua a relevância da palavra para cada elemento em toda a sequência de palavras As pontuações de relevância determinam o quanto a representação final da palavra incorpora as representações de outras palavras.
Por exemplo, considere a seguinte frase:
O animal não atravessou a rua porque estava muito cansado.
A ilustração a seguir (de Transformer: uma nova arquitetura de rede neural para linguagem Noções básicas) mostra o padrão de atenção de uma camada de autoatenção para o pronome it, com a escuridão de cada linha, indicando quanto cada palavra contribui para a representação:
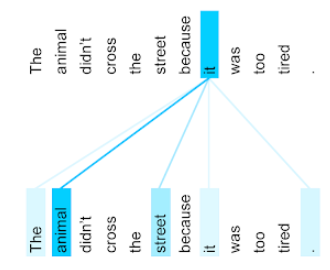
A camada de autoatenção destaca as palavras relevantes para "ele". Neste caso, a camada de atenção aprendeu a destacar palavras que pode a que se refere, atribuindo o peso mais alto a animal.
Para uma sequência de n tokens, a autoatenção transforma uma sequência de embeddings n momentos separados, uma vez em cada posição na sequência.
Consulte também atenção e autoatenção de vários cabeçalhos.
análise de sentimento
Usar algoritmos estatísticos ou de machine learning para determinar a uma atitude geral (positiva ou negativa) em relação a um serviço, produto organização ou tópico. Por exemplo, usar compreensão de linguagem natural, um algoritmo pode realizar a análise de sentimento no feedback textual de um curso universitário para determinar o grau de em geral gostaram ou não gostaram do curso.
tarefa sequência a sequência
Tarefa que converte uma sequência de entrada de tokens em uma saída. de tokens. Por exemplo, dois tipos conhecidos de sequência para sequência tarefas são:
- Tradutores:
- Exemplo de sequência de entrada: "Eu te amo".
- Exemplo de sequência de saída: "Je t'aime".
- Respostas a perguntas:
- Exemplo de sequência de entrada: "Preciso do meu carro em Nova York?"
- Exemplo de sequência de saída: "No. Fiquem com o carro em casa."
skip-gram
Um n-grama que pode omitir (ou "pular") palavras do original contexto, ou seja, as palavras N podem não ter sido originalmente adjacentes. Mais um "k-skip-n-gram" é um n-grama para o qual até k palavras podem ter foi ignorado.
Por exemplo, "a rápida raposa marrom" tem os seguintes 2-gramas possíveis:
- "a rápida"
- "marrom rápido"
- "raposa marrom"
Um exemplo de "1-skip-2-gram" é um par de palavras com no máximo uma palavra entre elas. Portanto, "a rápida raposa marrom" tem os seguintes 1-skip 2-gramas:
- "marrom"
- "raposa rápida"
Além disso, todos os 2-gramas também são 1-skip-2-grams, já que menos mais de uma palavra pode ser ignorada.
Skip-grams são úteis para entender melhor o contexto de uma palavra. No exemplo, "fox" foi diretamente associada ao termo "rápido" no conjunto de 1-skip-2-gramas, mas não no conjunto de 2-gramas.
Skip-grams ajudam no treinamento modelos de incorporação de palavras.
ajuste de comandos flexíveis
Uma técnica para ajustar um modelo de linguagem grande para uma tarefa específica, sem consumir muitos recursos ajustes. Em vez de treinar de novo pesos no modelo, ajuste de comandos flexíveis ajusta automaticamente um comando para atingir o mesmo objetivo.
Com um comando textual, o ajuste de comandos flexíveis geralmente anexa embeddings adicionais de token ao comando e usa e retropropagação para otimizar a entrada.
Uma pergunta “difícil” contém tokens reais em vez de embeddings de token.
atributo esparso
Um atributo com valores predominantemente zero ou vazio. Por exemplo, um atributo que contém um único valor 1 e um milhão de valores é esparsas. Por outro lado, um atributo denso tem valores que predominantemente não são zero nem valores vazios.
Em machine learning, um número surpreendente de atributos são atributos esparsos. Os atributos categóricos geralmente são esparsos. Por exemplo, das 300 espécies de árvores possíveis em uma floresta, pode identificar apenas uma árvore de bordo. Ou dos milhões de possíveis vídeos em uma biblioteca de vídeos, um único exemplo pode identificar apenas "Casablanca".
Em um modelo, você normalmente representa atributos esparsos codificação one-hot: Se a codificação one-hot for grande, é possível colocar uma camada de incorporação sobre com codificação one-hot para aumentar a eficiência.
representação esparsa
Armazenamento de apenas as posições de elementos diferentes de zero em um atributo esparso.
Por exemplo, suponha que um atributo categórico chamado species identifique os 36
espécies de árvores em uma determinada floresta. Suponha ainda que cada
example identifica somente uma espécie.
É possível usar um vetor one-hot para representar as espécies de árvores em cada exemplo.
Um vetor one-hot conteria um único 1 (para representar
a espécie de árvore específica desse exemplo) e 35 0s (para representar o
35 espécies de árvores não nesse exemplo). A representação one-hot
de maple pode ser semelhante ao seguinte:

Já a representação esparsa identifica a posição do
espécie específica. Se maple estiver na posição 24, a representação esparsa
de maple seria:
24
Observe que a representação esparsa é muito mais compacta do que representação visual.
Clique no ícone para ver um exemplo um pouco mais complexo.
Suponha que cada exemplo em seu modelo represente as palavras, mas não a ordem dessas palavras, em uma frase. O inglês tem cerca de 170.000 palavras, então ele é uma com cerca de 170 mil elementos. A maioria das frases em inglês usa uma fração extremamente minúscula dessas 170.000 palavras, o conjunto de palavras em uma exemplo único são dados esparsos.
Considere a seguinte frase:
My dog is a great dog
É possível usar uma variante do vetor one-hot para representar as palavras frase. Nesta variante, várias células no vetor podem conter um valor diferente de zero. Além disso, nesta variante, uma célula pode conter um número inteiro diferente de um. Embora as palavras "meu", "é", "um" e "ótimo" aparecem apenas uma vez na frase, a palavra "cachorro" aparece duas vezes. Usar esta variante de vetores one-hot para representar as palavras dessa frase resulta no seguinte vetor de 170.000 elementos:

Uma representação esparsa da mesma frase seria simplesmente:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
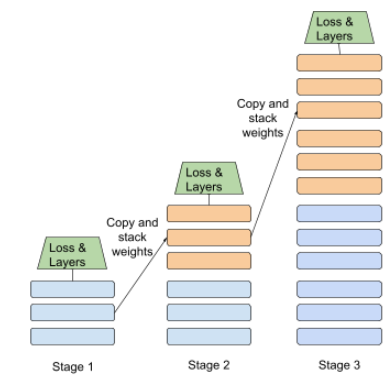
treinamento em etapas
É uma tática de treinar um modelo em uma sequência de estágios distintos. A meta pode ser seja para acelerar o processo de treinamento ou para melhorar a qualidade do modelo.
Veja abaixo uma ilustração da abordagem de empilhamento progressivo:
- A fase 1 contém 3 camadas escondidas, a fase 2 contém 6 camadas escondidas e e a terceira contém 12 camadas escondidas.
- A fase 2 começa o treinamento com os pesos aprendidos nas 3 camadas escondidas do Estágio 1. A etapa 3 começa o treinamento com os pesos aprendidos as camadas escondidas do Estágio 2.
Consulte também pipeline.
token de subpalavra
Nos modelos de linguagem, um token que é um substring de uma palavra, que pode ser a palavra inteira.
Por exemplo, uma palavra como "itemize" pode ser dividido em partes "item" (uma palavra raiz) e "ize" (um sufixo), cada um dos quais é representado por seu próprio com base no token correto anterior. Dividir palavras incomuns nessas partes, chamadas de subpalavras, permite de linguagem grandes para operar nas partes constituintes mais comuns da palavra, como prefixos e sufixos.
Por outro lado, palavras comuns como "vai" pode não estar dividido e pode ser representado por um único token.
T
T5
Um modelo de aprendizado por transferência de texto para texto introduzido por IA do Google em 2020. T5 é um modelo de codificador-decodificador baseado arquitetura de Transformer, treinada em uma no conjunto de dados. Ele é eficaz em várias tarefas de processamento de linguagem natural, como gerar texto, traduzir idiomas e responder a perguntas em um jeito conversacional.
O T5 tem esse nome por causa dos cinco Ts em "Transformador de transferência de texto para texto".
Conexão T5X
Um framework de machine learning de código aberto criado para criar e treinar processamento de linguagem natural em grande escala de PLN. T5 (link em inglês) é implementado na base de código T5X (que é baseado no JAX e no Flax).
temperatura
Um hiperparâmetro que controla o grau de aleatoriedade da saída de um modelo. Temperaturas mais altas resultam em saídas mais aleatórias, enquanto temperaturas mais baixas resultam em saídas menos aleatórias.
A escolha da melhor temperatura depende do aplicativo específico e as propriedades preferidas da saída do modelo. Por exemplo, provavelmente aumenta a temperatura ao criar um aplicativo gera resultados criativos. Por outro lado, você provavelmente diminuiria a temperatura ao criar um modelo que classifica imagens ou texto para melhorar a acurácia e a consistência do modelo.
A temperatura é frequentemente usada com a softmax.
período do texto
A extensão do índice da matriz associada a uma subseção específica de uma string de texto.
Por exemplo, a palavra good na string Python s="Be good now" ocupa
do texto vão de 3 a 6.
token
Em um modelo de linguagem, a unidade atômica em que o modelo é para o treinamento e as previsões. Um token é normalmente um dos seguinte:
- uma palavra, por exemplo, a frase "cachorros como gatos" consiste em três palavras tokens: "dogs", "like" e "cats".
- um caractere, por exemplo, a frase "bicicleta peixe" consiste em nove tokens de caractere. O espaço em branco conta como um dos tokens.
- subpalavras, nas quais uma única palavra pode ser um único token ou vários tokens. Uma subpalavra consiste em uma palavra raiz, um prefixo ou um sufixo. Por exemplo: um modelo de linguagem que usa subpalavras como tokens pode ver a palavra “cães” como dois tokens (a palavra raiz "cachorro" e o sufixo plural "s"). O mesmo de linguagem grande pode ver a única palavra "mais alto" como duas subpalavras (a palavra raiz "alto" e o sufixo "er").
Em domínios fora dos modelos de linguagem, os tokens podem representar outros tipos de unidades atômicas. Por exemplo, em visão computacional, um token pode ser um subconjunto de uma imagem.
Transformer
Uma arquitetura de rede neural desenvolvida no Google que depende de mecanismos de autoatenção para transformar sequência de embeddings de entrada em uma sequência de saída embeddings sem depender de convoluções ou redes neurais recorrentes. Um transformador pode ser vista como uma pilha de camadas de autoatenção.
Um transformador pode incluir qualquer um dos seguintes itens:
- um codificador
- um decodificador
- um codificador e um decodificador,
Um codificador transforma uma sequência de embeddings em uma nova sequência do mesmo tamanho. Um codificador inclui N camadas idênticas, cada uma contendo duas subcamadas. Essas duas subcamadas são aplicadas em cada posição da entrada de embedding, transformando cada elemento da sequência em um novo e incorporações. A primeira subcamada do codificador agrega informações sequência de entrada. A segunda subcamada do codificador transforma os dados informações em um embedding de saída.
Um decodificador transforma uma sequência de embeddings de entrada em uma sequência de os embeddings de saída, possivelmente com um comprimento diferente. Um decodificador também inclui N camadas idênticas com três subcamadas, duas das quais são semelhantes à codificadores. A terceira subcamada do decodificador recebe a saída da e aplica o mecanismo de autoatenção ao e coletar informações deles.
A postagem do blog Transformer: uma nova arquitetura de rede neural para linguagem Noções básicas fornece uma boa introdução aos transformadores.
trigrama
Um N-grama em que N=3.
U
unidirecional
Um sistema que avalia apenas o texto que antecede uma seção de destino do texto. Por outro lado, um sistema bidirecional avalia um texto que antes e segue uma seção de destino do texto. Consulte bidirecional para mais detalhes.
modelo de linguagem unidirecional
Um modelo de linguagem que baseia as probabilidades apenas no tokens que aparecem antes, não depois, dos tokens de destino. Já está em contraste com o modelo de linguagem bidirecional.
V
codificador automático variacional (VAE, na sigla em inglês)
Um tipo de codificador automático que aproveita a discrepância entre entradas e saídas para gerar versões modificadas das entradas. Codificadores automáticos variacionais são úteis para a IA generativa.
Os VAEs são baseados na inferência variacional: uma técnica para estimar o parâmetros de um modelo de probabilidade.
W
incorporação de palavras
Representação de cada palavra de um conjunto de palavras em uma vetor de incorporação ou seja, representar cada palavra um vetor de valores de ponto flutuante entre 0,0 e 1,0. Palavras com semelhantes significados têm representações mais semelhantes do que palavras com significados diferentes. Por exemplo, cenouras, aipo e pepinos têm relativamente com representações semelhantes, o que é muito diferente das representações de avião, óculos de sol e pasta de dente.
Z
comandos zero-shot
Um comando que não forneça um exemplo de como você quer o modelo de linguagem grande para responder. Exemplo:
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| Índia: | A consulta real. |
O modelo de linguagem grande pode responder com qualquer um dos seguintes itens:
- Rúpia
- INR
- ₹
- Rúpias indianas
- A rúpia
- A rúpia indiana
Todas as respostas estão corretas, mas você pode preferir um formato específico.
Compare os comandos zero-shot com os seguintes termos: