Questa pagina contiene i termini del glossario delle metriche. Per tutti i termini del glossario, fai clic qui.
A
accuracy
Il numero di previsioni di classificazione corrette diviso per il numero totale di previsioni. Ossia:
Ad esempio, un modello che ha effettuato 40 previsioni corrette e 10 errate avrebbe un'accuratezza pari a:
La classificazione binaria fornisce nomi specifici per le diverse categorie di previsioni corrette e previsioni errate. Pertanto, la formula dell'accuratezza per la classificazione binaria è la seguente:
dove:
- TP è il numero di veri positivi (previsioni corrette).
- TN è il numero di veri negativi (previsioni corrette).
- FP è il numero di falsi positivi (previsioni errate).
- FN è il numero di falsi negativi (previsioni errate).
Confronta e metti a confronto l'accuratezza con la precisione e il richiamo.
Per saperne di più, consulta Classificazione: accuratezza, richiamo, precisione e metriche correlate in Machine Learning Crash Course.
area sotto la curva PR
Vedi AUC PR (area sotto la curva PR).
area sotto la curva ROC
Consulta la sezione AUC (Area sotto la curva ROC).
AUC (area sotto la curva ROC)
Un numero compreso tra 0,0 e 1,0 che rappresenta la capacità di un modello di classificazione binaria di separare le classi positive dalle classi negative. Più l'AUC è vicino a 1,0, migliore è la capacità del modello di separare le classi tra loro.
Ad esempio, la seguente illustrazione mostra un modello di classificazione che separa perfettamente le classi positive (ovali verdi) da quelle negative (rettangoli viola). Questo modello perfetto in modo non realistico ha un'AUC pari a 1,0:

Al contrario, l'illustrazione seguente mostra i risultati per un modello di classificazione che ha generato risultati casuali. Questo modello ha un AUC di 0,5:

Sì, il modello precedente ha un'AUC di 0,5, non di 0.
La maggior parte dei modelli si trova a metà strada tra i due estremi. Ad esempio, il seguente modello separa in qualche modo i positivi dai negativi e pertanto ha un'AUC compresa tra 0,5 e 1,0:

L'AUC ignora qualsiasi valore impostato per la soglia di classificazione. L'AUC, invece, prende in considerazione tutte le possibili soglie di classificazione.
Fai clic sull'icona per scoprire la relazione tra le curve AUC e ROC.
L'AUC rappresenta l'area sotto una curva ROC. Ad esempio, la curva ROC per un modello che separa perfettamente i positivi dai negativi è la seguente:
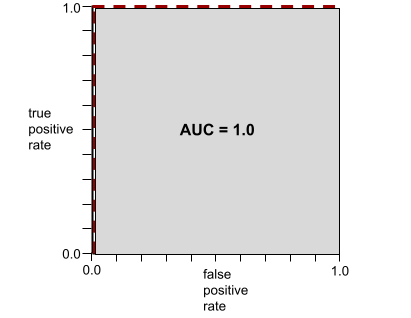
L'AUC è l'area della regione grigia nell'illustrazione precedente. In questo caso insolito, l'area è semplicemente la lunghezza della regione grigia (1.0) moltiplicata per la larghezza della regione grigia (1.0). Pertanto, il prodotto di 1,0 e 1,0 produce un AUC pari esattamente a 1,0, che è il punteggio AUC più alto possibile.
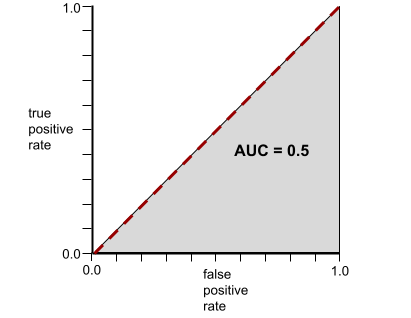
Al contrario, la curva ROC per un modello di classificazione che non può separare le classi è la seguente. L'area di questa regione grigia è 0,5.
Una curva ROC più tipica ha un aspetto simile al seguente:
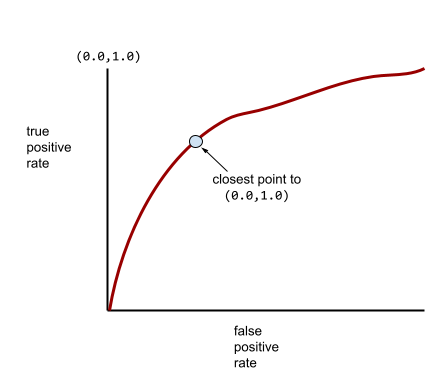
Calcolare manualmente l'area sotto questa curva sarebbe un'operazione laboriosa, motivo per cui in genere un programma calcola la maggior parte dei valori AUC.
Per saperne di più, consulta Classificazione: ROC e AUC in Machine Learning Crash Course.
precisione media a k
Una metrica per riassumere il rendimento di un modello su un singolo prompt che genera risultati classificati, ad esempio un elenco numerato di consigli di libri. La precisione media a k è la media dei valori di precisione a k per ogni risultato pertinente. La formula per la precisione media a k è quindi:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
dove:
- \(n\) è il numero di elementi pertinenti nell'elenco.
Contrasto con il richiamo a k.
B
base di riferimento
Un modello utilizzato come punto di riferimento per confrontare il rendimento di un altro modello (in genere, uno più complesso). Ad esempio, un modello di regressione logistica può fungere da buona base di riferimento per un modello profondo.
Per un problema specifico, la baseline aiuta gli sviluppatori di modelli a quantificare il rendimento minimo previsto che un nuovo modello deve raggiungere per essere utile.
Boolean Questions (BoolQ)
Un set di dati per valutare la competenza di un LLM nel rispondere a domande con risposta sì o no. Ognuna delle sfide nel set di dati è composta da tre componenti:
- Una query
- Un passaggio che implica la risposta alla query.
- La risposta corretta, che è sì o no.
Ad esempio:
- Query: ci sono centrali nucleari in Michigan?
- Passaggio: ...tre centrali nucleari forniscono al Michigan circa il 30% della sua elettricità.
- Risposta corretta: sì
I ricercatori hanno raccolto le domande da query di ricerca Google anonimizzate e aggregate e poi hanno utilizzato le pagine di Wikipedia per basare le informazioni.
Per saperne di più, consulta BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions.
BoolQ è un componente dell'ensemble SuperGLUE.
BoolQ
Abbreviazione di Boolean Questions.
C
CB
Abbreviazione di CommitmentBank.
Punteggio F di n-grammi di caratteri (ChrF)
Una metrica per valutare i modelli di traduzione automatica. L'F-score degli n-grammi di caratteri determina il grado di sovrapposizione degli n-grammi nel testo di riferimento con gli n-grammi nel testo generato di un modello ML.
Il punteggio F di N-grammi di caratteri è simile alle metriche delle famiglie ROUGE e BLEU, tranne per il fatto che:
- Il punteggio F degli n-grammi di caratteri opera sugli n-grammi di caratteri.
- ROUGE e BLEU operano su n-grammi di parole o token.
Scelta di alternative plausibili (COPA)
Un set di dati per valutare la capacità di un LLM di identificare la migliore tra due risposte alternative a una premessa. Ciascuna delle sfide nel set di dati è composta da tre componenti:
- Una premessa, che in genere è un'affermazione seguita da una domanda
- Due possibili risposte alla domanda posta nella premessa, una delle quali è corretta e l'altra errata
- La risposta corretta
Ad esempio:
- Premessa:l'uomo si è rotto un dito del piede. Qual è stata la CAUSA?
- Risposte possibili:
- Ha un buco nel calzino.
- Si è fatto cadere un martello sul piede.
- Risposta corretta: 2
COPA è un componente dell'ensemble SuperGLUE.
CommitmentBank (CB)
Un set di dati per valutare la competenza di un LLM nel determinare se l'autore di un passaggio crede in una clausola di destinazione all'interno di quel passaggio. Ogni voce del set di dati contiene:
- Un passaggio
- Una clausola di destinazione all'interno del passaggio
- Un valore booleano che indica se l'autore del passaggio ritiene che la clausola di destinazione
Ad esempio:
- Passaggio:che divertimento sentire ridere Artemide. È una bambina molto seria. Non sapevo che avesse un senso dell'umorismo.
- Clausola di targeting: aveva un senso dell'umorismo
- Booleano: True, il che significa che l'autore ritiene che la clausola di destinazione
CommitmentBank è un componente dell'insieme SuperGLUE.
COPA
Abbreviazione di Scelta di alternative plausibili.
costo
Sinonimo di perdita.
equità controfattuale
Una metrica di equità che controlla se un modello di classificazione produce lo stesso risultato per un individuo e per un altro individuo identico al primo, tranne per uno o più attributi sensibili. La valutazione di un modello di classificazione per l'equità controfattuale è un metodo per individuare potenziali fonti di bias in un modello.
Per ulteriori informazioni, consulta una delle seguenti risorse:
- Equità: equità controfattuale in Machine Learning Crash Course.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness (Quando i mondi si scontrano: integrare diverse ipotesi controfattuali nell'equità)
entropia incrociata
Una generalizzazione della perdita logaritmica per problemi di classificazione multiclasse. L'entropia incrociata quantifica la differenza tra due distribuzioni di probabilità. Vedi anche perplessità.
funzione di distribuzione cumulativa (CDF)
Una funzione che definisce la frequenza dei campioni minore o uguale a un valore target. Ad esempio, considera una distribuzione normale di valori continui. Una CDF indica che circa il 50% dei campioni deve essere inferiore o uguale alla media e che circa l'84% dei campioni deve essere inferiore o uguale a una deviazione standard sopra la media.
D
parità demografica
Una metrica di equità che viene soddisfatta se i risultati della classificazione di un modello non dipendono da un determinato attributo sensibile.
Ad esempio, se sia i lillipuziani che i brobdingnagiani fanno domanda all'Università di Glubbdubdrib, la parità demografica viene raggiunta se la percentuale di lillipuziani ammessi è la stessa di quella dei brobdingnagiani ammessi, indipendentemente dal fatto che un gruppo sia in media più qualificato dell'altro.
Contrasta con probabilità equalizzate e uguaglianza delle opportunità, che consentono ai risultati della classificazione aggregata di dipendere da attributi sensibili, ma non consentono ai risultati della classificazione per determinate etichette verità di riferimento specificate di dipendere da attributi sensibili. Consulta "Attacking discrimination with smarter machine learning" per una visualizzazione che esplora i compromessi quando si esegue l'ottimizzazione per la parità demografica.
Per saperne di più, consulta Equità: parità demografica in Machine Learning Crash Course.
E
Distanza di movimento terra (EMD)
Una misura della similarità relativa di due distribuzioni. Più bassa è la distanza del movimento di terra, più simili sono le distribuzioni.
edit distance
Una misurazione del grado di somiglianza tra due stringhe di testo. Nel machine learning, la distanza di modifica è utile per i seguenti motivi:
- La distanza di modifica è facile da calcolare.
- La distanza di modifica può confrontare due stringhe note per essere simili tra loro.
- La distanza di modifica può determinare il grado di somiglianza di stringhe diverse rispetto a una determinata stringa.
Esistono diverse definizioni di distanza di modifica, ognuna delle quali utilizza operazioni sulle stringhe diverse. Per un esempio, consulta Distanza di Levenshtein.
funzione di distribuzione cumulativa empirica (eCDF o EDF)
Una funzione di distribuzione cumulativa basata su misurazioni empiriche di un set di dati reale. Il valore della funzione in qualsiasi punto dell'asse x è la frazione di osservazioni nel set di dati che sono minori o uguali al valore specificato.
entropia
Nella teoria dell'informazione, una descrizione di quanto sia imprevedibile una distribuzione di probabilità. In alternativa, l'entropia è anche definita come la quantità di informazioni contenute in ogni esempio. Una distribuzione ha l'entropia più alta possibile quando tutti i valori di una variabile casuale sono ugualmente probabili.
L'entropia di un insieme con due possibili valori "0" e "1" (ad esempio, le etichette in un problema di classificazione binaria) ha la seguente formula:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
dove:
- H è l'entropia.
- p è la frazione di esempi "1".
- q è la frazione di esempi "0". Tieni presente che q = (1 - p)
- log è generalmente log2. In questo caso, l'unità di entropia è un bit.
Ad esempio, supponiamo quanto segue:
- 100 esempi contengono il valore "1"
- 300 esempi contengono il valore "0"
Pertanto, il valore di entropia è:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) - (0,75)log2(0,75) = 0,81 bit per esempio
Un insieme perfettamente bilanciato (ad esempio, 200 "0" e 200 "1") avrebbe un'entropia di 1 bit per esempio. Man mano che un set diventa più sbilanciato, la sua entropia tende a 0.0.
Negli alberi decisionali, l'entropia aiuta a formulare il guadagno di informazioni per aiutare lo splitter a selezionare le condizioni durante la crescita di un albero decisionale di classificazione.
Confronta l'entropia con:
- Impurità di Gini
- Funzione di perdita entropia incrociata
L'entropia viene spesso chiamata entropia di Shannon.
Per saperne di più, consulta la sezione Splitter esatto per la classificazione binaria con funzionalità numeriche del corso Decision Forests.
uguaglianza di opportunità
Una metrica di equità per valutare se un modello prevede il risultato desiderabile altrettanto bene per tutti i valori di un attributo sensibile. In altre parole, se il risultato desiderabile per un modello è la classe positiva, l'obiettivo sarebbe che il tasso di veri positivi sia uguale per tutti i gruppi.
L'uguaglianza delle opportunità è correlata alle probabilità equalizzate, che richiedono che entrambi i tassi di veri positivi e i tassi di falsi positivi siano uguali per tutti i gruppi.
Supponiamo che l'Università di Glubbdubdrib ammetta sia i lillipuziani che i brobdingnagiani a un rigoroso programma di matematica. Le scuole secondarie di Lilliput offrono un solido programma di corsi di matematica e la stragrande maggioranza degli studenti è qualificata per il programma universitario. Le scuole secondarie di Brobdingnag non offrono corsi di matematica e, di conseguenza, molti meno studenti sono qualificati. L'uguaglianza delle opportunità è soddisfatta per l'etichetta preferita di "ammesso" rispetto alla nazionalità (lillipuziana o brobdingnagiana) se gli studenti qualificati hanno la stessa probabilità di essere ammessi indipendentemente dal fatto che siano lillipuziani o brobdingnagiani.
Ad esempio, supponiamo che 100 lillipuziani e 100 brobdingnaghi facciano domanda all'Università di Glubbdubdrib e che le decisioni di ammissione vengano prese come segue:
Tabella 1. Candidati lillipuziani (il 90% è qualificato)
| Qualificato | Non qualificato | |
|---|---|---|
| Ammesso | 45 | 3 |
| Rifiutato | 45 | 7 |
| Totale | 90 | 10 |
|
Percentuale di studenti qualificati ammessi: 45/90 = 50% Percentuale di studenti non qualificati respinti: 7/10 = 70% Percentuale totale di studenti Lillipuziani ammessi: (45+3)/100 = 48% |
||
Tabella 2. Candidati brobdingnaghi (il 10% è qualificato):
| Qualificato | Non qualificato | |
|---|---|---|
| Ammesso | 5 | 9 |
| Rifiutato | 5 | 81 |
| Totale | 10 | 90 |
|
Percentuale di studenti qualificati ammessi: 5/10 = 50% Percentuale di studenti non qualificati respinti: 81/90 = 90% Percentuale totale di studenti di Brobdingnag ammessi: (5+9)/100 = 14% |
||
Gli esempi precedenti soddisfano la parità di opportunità per l'accettazione di studenti qualificati perché i lillipuziani e i brobdingnagiani qualificati hanno entrambi il 50% di possibilità di essere ammessi.
Sebbene l'uguaglianza delle opportunità sia soddisfatta, le seguenti due metriche di equità non sono soddisfatte:
- Parità demografica: lillipuziani e brobdingnagiani vengono ammessi all'università a tassi diversi; il 48% degli studenti lillipuziani viene ammesso, ma solo il 14% degli studenti brobdingnagiani.
- Probabilità equalizzate: mentre gli studenti lillipuziani e brobdingnagiani qualificati hanno la stessa probabilità di essere ammessi, il vincolo aggiuntivo che gli studenti lillipuziani e brobdingnagiani non qualificati abbiano la stessa probabilità di essere respinti non è soddisfatto. I Lillipuziani non qualificati hanno un tasso di rifiuto del 70%, mentre i Brobdingnagiani non qualificati hanno un tasso di rifiuto del 90%.
Per saperne di più, consulta Equità: pari opportunità in Machine Learning Crash Course.
probabilità equalizzate
Una metrica di equità per valutare se un modello prevede i risultati in modo equo per tutti i valori di un attributo sensibile rispetto sia alla classe positiva sia alla classe negativa, non solo a una classe o all'altra esclusivamente. In altre parole, sia la percentuale di veri positivi sia la percentuale di falsi negativi devono essere uguali per tutti i gruppi.
Le probabilità equalizzate sono correlate all'uguaglianza di opportunità, che si concentra solo sui tassi di errore per una singola classe (positiva o negativa).
Ad esempio, supponiamo che l'Università di Glubbdubdrib ammetta sia i lillipuziani che i brobdingnagiani a un rigoroso programma di matematica. Le scuole secondarie lillipuziane offrono un solido programma di corsi di matematica e la stragrande maggioranza degli studenti è qualificata per il programma universitario. Le scuole secondarie di Brobdingnag non offrono corsi di matematica e, di conseguenza, molti meno studenti sono qualificati. Le pari opportunità sono soddisfatte a condizione che, indipendentemente dal fatto che un candidato sia un lillipuziano o un brobdingnagiano, se è qualificato, ha la stessa probabilità di essere ammesso al programma e, se non è qualificato, ha la stessa probabilità di essere rifiutato.
Supponiamo che 100 Lillipuziani e 100 Brobdingnagiani facciano domanda all'Università di Glubbdubdrib e che le decisioni di ammissione vengano prese come segue:
Tabella 3. Candidati lillipuziani (il 90% è qualificato)
| Qualificato | Non qualificato | |
|---|---|---|
| Ammesso | 45 | 2 |
| Rifiutato | 45 | 8 |
| Totale | 90 | 10 |
|
Percentuale di studenti qualificati ammessi: 45/90 = 50% Percentuale di studenti non qualificati respinti: 8/10 = 80% Percentuale totale di studenti lillipuziani ammessi: (45+2)/100 = 47% |
||
Tabella 4. Candidati brobdingnaghi (il 10% è qualificato):
| Qualificato | Non qualificato | |
|---|---|---|
| Ammesso | 5 | 18 |
| Rifiutato | 5 | 72 |
| Totale | 10 | 90 |
|
Percentuale di studenti qualificati ammessi: 5/10 = 50% Percentuale di studenti non qualificati respinti: 72/90 = 80% Percentuale totale di studenti di Brobdingnag ammessi: (5+18)/100 = 23% |
||
La parità di probabilità è soddisfatta perché gli studenti lillipuziani e brobdingnaghi qualificati hanno entrambi il 50% di possibilità di essere ammessi, mentre quelli non qualificati hanno l'80% di possibilità di essere respinti.
Le probabilità equalizzate sono definite formalmente in "Equality of Opportunity in Supervised Learning" come segue: "il predittore Ŷ soddisfa le probabilità equalizzate rispetto all'attributo protetto A e al risultato Y se Ŷ e A sono indipendenti, condizionati a Y".
evals
Utilizzato principalmente come abbreviazione di valutazioni LLM. Più in generale, valutazioni è l'abbreviazione di qualsiasi forma di valutazione.
valutazione
Il processo di misurazione della qualità di un modello o di confronto tra modelli diversi.
Per valutare un modello di machine learning supervisionato, in genere lo si confronta con un set di validazione e un test set. La valutazione di un LLM in genere comporta valutazioni più ampie di qualità e sicurezza.
corrispondenza esatta
Una metrica tutto o niente in cui l'output del modello corrisponde esattamente al dato di fatto o al testo di riferimento. Ad esempio, se la risposta basata su dati di fatto è arancia, l'unico output del modello che soddisfa la corrispondenza esatta è arancia.
La corrispondenza esatta può anche valutare i modelli il cui output è una sequenza (un elenco classificato di elementi). In generale, la corrispondenza esatta richiede che l'elenco classificato generato corrisponda esattamente ai dati empirici reali, ovvero che ogni elemento in entrambi gli elenchi sia nello stesso ordine. Detto questo, se i dati empirici reali consistono in più sequenze corrette, la corrispondenza esatta richiede solo che l'output del modello corrisponda a una delle sequenze corrette.
Extreme Summarization (xsum)
Un set di dati per valutare la capacità di un LLM di riassumere un singolo documento. Ogni voce del set di dati è composta da:
- Un documento creato dalla British Broadcasting Corporation (BBC).
- Un riepilogo del documento in una frase.
Per maggiori dettagli, consulta Non darmi i dettagli, solo il riepilogo. Topic-Aware Convolutional Neural Networks for Extreme Summarization.
V
F1
Una metrica di classificazione binaria "roll-up" che si basa sia sulla precisione sia sul richiamo. Ecco la formula:
metrica di equità
Una definizione matematica di "equità" misurabile. Alcune metriche di equità di uso comune includono:
Molte metriche di equità si escludono a vicenda. Vedi Incompatibilità delle metriche di equità.
falso negativo (FN)
Un esempio in cui il modello prevede erroneamente la classe negativa. Ad esempio, il modello prevede che un determinato messaggio email non sia spam (la classe negativa), ma che in realtà sia spam.
percentuale di falsi negativi
La proporzione di esempi positivi effettivi per i quali il modello ha previsto erroneamente la classe negativa. La seguente formula calcola il tasso di falsi negativi:
Per saperne di più, consulta Soglie e matrice di confusione in Machine Learning Crash Course.
falso positivo (FP)
Un esempio in cui il modello prevede erroneamente la classe positiva. Ad esempio, il modello prevede che un determinato messaggio email sia spam (la classe positiva), ma che in realtà non lo sia.
Per saperne di più, consulta Soglie e matrice di confusione in Machine Learning Crash Course.
percentuale di falsi positivi (FPR)
La proporzione di esempi negativi effettivi per i quali il modello ha previsto erroneamente la classe positiva. La seguente formula calcola il tasso di falsi positivi:
La percentuale di falsi positivi è l'asse x di una curva ROC.
Per saperne di più, consulta Classificazione: ROC e AUC in Machine Learning Crash Course.
importanza delle caratteristiche
Sinonimo di importanza delle variabili.
foundation model
Un modello preaddestrato molto grande addestrato su un set di addestramento enorme e diversificato. Un foundation model può eseguire entrambe le seguenti operazioni:
- Rispondere bene a un'ampia gamma di richieste.
- Funge da modello di base per l'ottimizzazione o altre personalizzazioni.
In altre parole, un foundation model è già molto efficace in senso generale, ma può essere ulteriormente personalizzato per diventare ancora più utile per un'attività specifica.
frazione di successi
Una metrica per valutare il testo generato di un modello ML. La frazione di successi è il numero di output di testo generati "riusciti" diviso per il numero totale di output di testo generati. Ad esempio, se un modello linguistico di grandi dimensioni ha generato 10 blocchi di codice, cinque dei quali sono stati eseguiti correttamente, la frazione di esecuzioni riuscite sarebbe del 50%.
Sebbene la frazione di successi sia ampiamente utile in tutta la statistica, all'interno del machine learning, questa metrica è utile principalmente per misurare attività verificabili come la generazione di codice o i problemi di matematica.
G
Impurità di Gini
Una metrica simile all'entropia. Gli splitter utilizzano valori derivati dall'impurità di Gini o dall'entropia per comporre condizioni per gli alberi decisionali. L'information gain deriva dall'entropia. Non esiste un termine equivalente accettato universalmente per la metrica derivata dall'impurità di Gini; tuttavia, questa metrica senza nome è importante quanto l'information gain.
L'impurità di Gini è chiamata anche indice di Gini o semplicemente Gini.
H
perdita hinge
Una famiglia di funzioni di perdita per la classificazione progettate per trovare il confine decisionale il più lontano possibile da ogni esempio di addestramento, massimizzando così il margine tra gli esempi e il confine. KSVM utilizza la perdita hinge (o una funzione correlata, come la perdita hinge al quadrato). Per la classificazione binaria, la funzione di perdita hinge è definita come segue:
dove y è l'etichetta reale, -1 o +1, e y' è l'output non elaborato del modello di classificazione:
Di conseguenza, un grafico della perdita hinge rispetto a (y * y') ha il seguente aspetto:

I
incompatibilità delle metriche di equità
L'idea che alcuni concetti di equità siano reciprocamente incompatibili e non possano essere soddisfatti contemporaneamente. Di conseguenza, non esiste un'unica metrica universale per quantificare l'equità che possa essere applicata a tutti i problemi di ML.
Sebbene possa sembrare scoraggiante, l'incompatibilità delle metriche di equità non implica che gli sforzi per l'equità siano inutili. Suggerisce invece che l'equità deve essere definita in modo contestuale per un determinato problema di ML, con l'obiettivo di prevenire danni specifici per i suoi casi d'uso.
Per una discussione più dettagliata sull'incompatibilità delle metriche di equità, consulta "On the (im)possibility of fairness".
equità individuale
Una metrica di equità che controlla se individui simili vengono classificati in modo simile. Ad esempio, l'Accademia di Brobdingnag potrebbe voler soddisfare l'equità individuale assicurandosi che due studenti con voti identici e punteggi di test standardizzati abbiano la stessa probabilità di essere ammessi.
Tieni presente che l'equità individuale dipende interamente da come definisci la"similarità" (in questo caso, voti e punteggi dei test) e puoi correre il rischio di introdurre nuovi problemi di equità se la tua metrica di similarità non tiene conto di informazioni importanti (come il rigore del curriculum di uno studente).
Per una discussione più dettagliata sull'equità individuale, consulta la sezione "Equità attraverso la consapevolezza".
guadagno di informazioni
Nelle foreste decisionali, la differenza tra l'entropia di un nodo e la somma ponderata (in base al numero di esempi) dell'entropia dei relativi nodi secondari. L'entropia di un nodo è l'entropia degli esempi in quel nodo.
Ad esempio, considera i seguenti valori di entropia:
- entropia del nodo principale = 0,6
- entropia di un nodo secondario con 16 esempi pertinenti = 0,2
- entropia di un altro nodo secondario con 24 esempi pertinenti = 0,1
Pertanto, il 40% degli esempi si trova in un nodo secondario e il 60% nell'altro nodo secondario. Pertanto:
- somma dell'entropia ponderata dei nodi secondari = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Pertanto, l'information gain è:
- guadagno di informazioni = entropia del nodo principale - somma ponderata dell'entropia dei nodi secondari
- information gain = 0,6 - 0,14 = 0,46
La maggior parte degli splitter cerca di creare condizioni che massimizzino l'acquisizione di informazioni.
accordo tra valutatori
Una misurazione della frequenza con cui i valutatori umani sono d'accordo quando svolgono un'attività. Se i valutatori non sono d'accordo, potrebbe essere necessario migliorare le istruzioni dell'attività. A volte viene chiamato anche accordo tra annotatori o affidabilità inter-rater. Vedi anche Kappa di Cohen, una delle misure di concordanza inter-rater più utilizzate.
Per saperne di più, consulta Dati categorici: problemi comuni in Machine Learning Crash Course.
L
Perdita L1
Una funzione di perdita che calcola il valore assoluto della differenza tra i valori effettivi dell'etichetta e i valori previsti da un modello. Ad esempio, ecco il calcolo della perdita L1 per un batch di cinque esempi:
| Valore effettivo dell'esempio | Valore previsto del modello | Valore assoluto del delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 loss | ||
La perdita L1 è meno sensibile ai valori anomali rispetto alla perdita L2.
L'errore assoluto medio è la perdita L1 media per esempio.
Per saperne di più, consulta Regressione lineare: perdita in Machine Learning Crash Course.
Perdita L2
Una funzione di perdita che calcola il quadrato della differenza tra i valori effettivi dell'etichetta e i valori previsti da un modello. Ad esempio, ecco il calcolo della perdita L2 per un batch di cinque esempi:
| Valore effettivo dell'esempio | Valore previsto del modello | Quadrato del delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 loss | ||
A causa dell'elevazione al quadrato, la perdita L2 amplifica l'influenza degli outlier. ovvero la perdita L2 reagisce più fortemente alle previsioni errate rispetto alla perdita L1. Ad esempio, la perdita L1 per il batch precedente sarebbe 8 anziché 16. Nota che un singolo account anomalo rappresenta 9 dei 16.
I modelli di regressione in genere utilizzano la perdita L2 come funzione di perdita.
L'errore quadratico medio è la perdita L2 media per esempio. Perdita quadratica è un altro nome per la perdita L2.
Per saperne di più, consulta Regressione logistica: perdita e regolarizzazione in Machine Learning Crash Course.
Valutazioni LLM
Un insieme di metriche e benchmark per valutare le prestazioni dei modelli linguistici di grandi dimensioni (LLM). A livello generale, valutazioni LLM:
- Aiutare i ricercatori a identificare le aree in cui i modelli LLM devono essere migliorati.
- Sono utili per confrontare diversi LLM e identificare quello migliore per una determinata attività.
- Contribuire a garantire che gli LLM siano sicuri ed etici da utilizzare.
Per saperne di più, consulta Modelli linguistici di grandi dimensioni (LLM) in Machine Learning Crash Course.
perdita
Durante l'addestramento di un modello supervisionato, una misura della distanza tra la previsione di un modello e la sua etichetta.
Una funzione di perdita calcola la perdita.
Per saperne di più, consulta Regressione lineare: perdita in Machine Learning Crash Course.
funzione di perdita
Durante l'addestramento o il test, una funzione matematica che calcola la perdita su un batch di esempi. Una funzione di perdita restituisce una perdita inferiore per i modelli che fanno buone previsioni rispetto a quelli che fanno previsioni errate.
L'obiettivo dell'addestramento è in genere quello di ridurre al minimo la perdita restituita da una funzione di perdita.
Esistono molti tipi diversi di funzioni di perdita. Scegli la funzione di perdita appropriata per il tipo di modello che stai creando. Ad esempio:
- La perdita L2 (o errore quadratico medio) è la funzione di perdita per la regressione lineare.
- La perdita logaritmica è la funzione di perdita per la regressione logistica.
M
MBPP
Abbreviazione di Mostly Basic Python Problems.
Errore assoluto medio (MAE)
La perdita media per esempio quando viene utilizzata la perdita L1. Calcola l'errore assoluto medio come segue:
- Calcola la perdita L1 per un batch.
- Dividi la perdita L1 per il numero di esempi nel batch.
Ad esempio, considera il calcolo della perdita L1 sul seguente batch di cinque esempi:
| Valore effettivo dell'esempio | Valore previsto del modello | Perdita (differenza tra valore effettivo e previsto) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 loss | ||
Quindi, la perdita L1 è 8 e il numero di esempi è 5. Pertanto, l'errore assoluto medio è:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Confronta l'errore assoluto medio con l'errore quadratico medio e l'errore quadratico medio della radice.
precisione media a k (mAP@k)
La media statistica di tutti i punteggi di precisione media a k in un set di dati di convalida. Un utilizzo della precisione media media a k è quello di valutare la qualità dei suggerimenti generati da un sistema di suggerimenti.
Sebbene la frase "media aritmetica" sembri ridondante, il nome della metrica è appropriato. Dopo tutto, questa metrica trova la media di più valori di precisione media a k.
Errore quadratico medio (MSE)
La perdita media per esempio quando viene utilizzata la perdita L2. Calcola l'errore quadratico medio come segue:
- Calcola la perdita L2 per un batch.
- Dividi la perdita L2 per il numero di esempi nel batch.
Ad esempio, considera la perdita nel seguente batch di cinque esempi:
| Valore effettivo | Previsione del modello | Perdita | Errore quadratico |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 loss | |||
Pertanto, l'errore quadratico medio è:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
L'errore quadratico medio è un ottimizzatore di addestramento popolare, in particolare per la regressione lineare.
Confronta l'errore quadratico medio con l'errore assoluto medio e l'errore quadratico medio della radice.
TensorFlow Playground utilizza l'errore quadratico medio per calcolare i valori di perdita.
metrica
Una statistica che ti interessa.
Un obiettivo è una metrica che un sistema di machine learning tenta di ottimizzare.
API Metrics (tf.metrics)
Un'API TensorFlow per valutare i modelli. Ad esempio, tf.metrics.accuracy
determina la frequenza con cui le previsioni di un modello corrispondono alle etichette.
Perdita minimax
Una funzione di perdita per le reti generative avversariali, basata sull'entropia incrociata tra la distribuzione dei dati generati e dei dati reali.
La perdita minimax viene utilizzata nel primo articolo per descrivere le reti generative avversariali.
Per saperne di più, consulta Funzioni di perdita nel corso Generative Adversarial Networks.
capacità del modello
La complessità dei problemi che un modello può apprendere. Più complessi sono i problemi che un modello può apprendere, maggiore è la sua capacità. La capacità di un modello aumenta in genere con il numero di parametri del modello. Per una definizione formale della capacità del modello di classificazione, vedi Dimensione VC.
Mostly Basic Python Problems (MBPP)
Un set di dati per valutare la competenza di un LLM nella generazione di codice Python. Mostly Basic Python Problems fornisce circa 1000 problemi di programmazione di origine collettiva. Ogni problema nel set di dati contiene:
- Una descrizione dell'attività
- Codice della soluzione
- Tre scenari di test automatici
No
classe negativa
Nella classificazione binaria, una classe è definita positiva e l'altra è definita negativa. La classe positiva è l'elemento o l'evento che il modello sta testando, mentre la classe negativa è l'altra possibilità. Ad esempio:
- La classe negativa in un test medico potrebbe essere "non tumore".
- La classe negativa in un modello di classificazione delle email potrebbe essere "non spam".
Contrasto con la classe positiva.
O
scopo
Una metrica che l'algoritmo sta cercando di ottimizzare.
funzione obiettivo
La formula matematica o la metrica che un modello mira a ottimizzare. Ad esempio, la funzione obiettivo per la regressione lineare è in genere la perdita quadratica media. Pertanto, quando si addestra un modello di regressione lineare, l'addestramento mira a minimizzare la perdita quadratica media.
In alcuni casi, l'obiettivo è massimizzare la funzione obiettivo. Ad esempio, se la funzione obiettivo è l'accuratezza, l'obiettivo è massimizzare l'accuratezza.
Vedi anche perdita.
P
pass at k (pass@k)
Una metrica per determinare la qualità del codice (ad esempio Python) che genera un modello linguistico di grandi dimensioni. Più nello specifico, il valore di superamento a k indica la probabilità che almeno uno dei k blocchi di codice generati superi tutti i test delle unità.
I modelli linguistici di grandi dimensioni spesso faticano a generare codice valido per problemi di programmazione complessi. Gli ingegneri del software si adattano a questo problema chiedendo al modello linguistico di grandi dimensioni di generare più (k) soluzioni per lo stesso problema. Successivamente, gli ingegneri software testano ciascuna delle soluzioni rispetto ai test delle unità. Il calcolo di pass at k� dipende dal risultato dei test unitari:
- Se una o più di queste soluzioni superano il test unitario, il modello LLM supera la sfida di generazione del codice.
- Se nessuna delle soluzioni supera il test delle unità, il modello LLM non supera la sfida di generazione di codice.
La formula per il superamento a k è la seguente:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
In generale, valori più elevati di k producono punteggi pass@k più elevati; tuttavia, valori più elevati di k richiedono più risorse per i test delle unità e dei modelli linguistici di grandi dimensioni.
prestazioni
Termine sovraccarico con i seguenti significati:
- Il significato standard nell'ingegneria del software. ovvero: quanto velocemente (o in modo efficiente) viene eseguito questo software?
- Il significato nel machine learning. In questo caso, il rendimento risponde alla seguente domanda: quanto è corretto questo modello? ovvero quanto sono accurate le previsioni del modello?
importanza delle variabili di permutazione
Un tipo di importanza delle variabili che valuta l'aumento dell'errore di previsione di un modello dopo la permutazione dei valori della caratteristica. L'importanza delle variabili di permutazione è una metrica indipendente dal modello.
perplessità
Una misura dell'efficacia di un modello nello svolgimento della sua attività. Ad esempio, supponiamo che la tua attività sia leggere le prime lettere di una parola che un utente sta digitando sulla tastiera di uno smartphone e offrire un elenco di possibili parole di completamento. La perplessità, P, per questa attività è approssimativamente il numero di ipotesi che devi offrire affinché il tuo elenco contenga la parola effettiva che l'utente sta cercando di digitare.
La perplessità è correlata all'entropia incrociata nel seguente modo:
classe positiva
Il corso per cui stai eseguendo il test.
Ad esempio, la classe positiva in un modello per il cancro potrebbe essere "tumore". La classe positiva in un modello di classificazione delle email potrebbe essere "spam".
Contrasto con la classe negativa.
AUC PR (area sotto la curva PR)
Area sotto la curva di precisione-richiamo interpolata, ottenuta tracciando i punti (richiamo, precisione) per diversi valori della soglia di classificazione.
precisione
Una metrica per i modelli di classificazione che risponde alla seguente domanda:
Quando il modello ha previsto la classe positiva, qual è stata la percentuale di previsioni corrette?
Ecco la formula:
dove:
- vero positivo significa che il modello ha previsto correttamente la classe positiva.
- Un falso positivo significa che il modello ha previsto erroneamente la classe positiva.
Ad esempio, supponiamo che un modello abbia effettuato 200 previsioni positive. Di queste 200 previsioni positive:
- 150 erano veri positivi.
- 50 erano falsi positivi.
In questo caso:
Contrasta con accuratezza e richiamo.
Per saperne di più, consulta Classificazione: accuratezza, richiamo, precisione e metriche correlate in Machine Learning Crash Course.
precisione a k (precision@k)
Una metrica per valutare un elenco classificato (ordinato) di elementi. La precisione a k identifica la frazione dei primi k elementi dell'elenco che sono "pertinenti". Ossia:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Il valore di k deve essere minore o uguale alla lunghezza dell'elenco restituito. Tieni presente che la lunghezza dell'elenco restituito non fa parte del calcolo.
La pertinenza è spesso soggettiva; anche gli evaluatori umani esperti spesso non sono d'accordo su quali elementi siano pertinenti.
Confronta con:
curva di precisione-richiamo
Una curva di precisione rispetto al richiamo in corrispondenza di diverse soglie di classificazione.
bias di previsione
Un valore che indica la distanza tra la media delle previsioni e la media delle etichette nel set di dati.
Da non confondere con il termine di bias nei modelli di machine learning o con il bias in etica ed equità.
parità predittiva
Una metrica di equità che controlla se, per un dato modello di classificazione, i tassi di precisione sono equivalenti per i sottogruppi in esame.
Ad esempio, un modello che prevede l'ammissione all'università soddisferebbe la parità predittiva per nazionalità se il suo tasso di precisione è lo stesso per i lillipuziani e i brobdingnagiani.
La parità predittiva è talvolta chiamata anche parità predittiva delle tariffe.
Consulta la sezione "Spiegazione delle definizioni di equità" (sezione 3.2.1) per una discussione più dettagliata della parità predittiva.
parità tariffaria predittiva
Un altro nome per la parità predittiva.
funzione di densità di probabilità
Una funzione che identifica la frequenza dei campioni di dati che hanno esattamente un
valore specifico. Quando i valori di un set di dati sono numeri in virgola mobile continui, raramente si verificano corrispondenze esatte. Tuttavia, l'integrazione di una funzione di densità di probabilità dal valore x al valore y produce la frequenza prevista dei campioni di dati compresi tra x e y.
Ad esempio, considera una distribuzione normale con una media di 200 e una deviazione standard di 30. Per determinare la frequenza prevista dei campioni di dati che rientrano nell'intervallo da 211,4 a 218,7, puoi integrare la funzione di densità di probabilità per una distribuzione normale da 211,4 a 218,7.
R
Comprensione del testo con il set di dati di ragionamento basato sul buon senso (ReCoRD)
Un set di dati per valutare la capacità di un LLM di eseguire ragionamenti di buon senso. Ogni esempio nel set di dati contiene tre componenti:
- Uno o due paragrafi di un articolo di notizie
- Una query in cui una delle entità identificate esplicitamente o implicitamente nel passaggio è mascherata.
- La risposta (il nome dell'entità che appartiene alla maschera)
Per un elenco completo di esempi, consulta ReCoRD.
ReCoRD è un componente dell'ensemble SuperGLUE.
RealToxicityPrompts
Un set di dati che contiene una serie di inizi di frasi che potrebbero contenere contenuti tossici. Utilizza questo set di dati per valutare la capacità di un LLM di generare testo non tossico per completare la frase. In genere, utilizzi l'API Perspective per determinare il rendimento dell'LLM in questa attività.
Per i dettagli, consulta RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models.
richiamo
Una metrica per i modelli di classificazione che risponde alla seguente domanda:
Quando la verità di riferimento era la classe positiva, quale percentuale di previsioni il modello ha identificato correttamente come classe positiva?
Ecco la formula:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
dove:
- vero positivo significa che il modello ha previsto correttamente la classe positiva.
- Un falso negativo significa che il modello ha previsto erroneamente la classe negativa.
Ad esempio, supponiamo che il modello abbia effettuato 200 previsioni su esempi per i quali i dati empirici reali erano la classe positiva. Di queste 200 previsioni:
- 180 erano veri positivi.
- 20 erano falsi negativi.
In questo caso:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Per saperne di più, consulta Classificazione: accuratezza, richiamo, precisione e metriche correlate.
richiamo a k (richiamo@k)
Una metrica per valutare i sistemi che restituiscono un elenco classificato (ordinato) di elementi. Il richiamo a k identifica la frazione di elementi pertinenti nei primi k elementi di questo elenco rispetto al numero totale di elementi pertinenti restituiti.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Contrasto con la precisione a k.
Riconoscimento dell'implicazione testuale (RTE)
Un set di dati per valutare la capacità di un LLM di determinare se un'ipotesi può essere dedotta (logicamente) da un passaggio di testo. Ogni esempio in una valutazione RTE è composto da tre parti:
- Un passaggio, in genere tratto da articoli di notizie o di Wikipedia
- Un'ipotesi
- La risposta corretta, che è:
- Vera, il che significa che l'ipotesi può essere dedotta dal passaggio
- False, il che significa che l'ipotesi non può essere dedotta dal passaggio
Ad esempio:
- Passaggio: l'euro è la valuta dell'Unione Europea.
- Ipotesi:la Francia utilizza l'euro come valuta.
- Implicazione:vero, perché la Francia fa parte dell'Unione Europea.
RTE è un componente dell'ensemble SuperGLUE.
ReCoRD
Abbreviazione di Reading Comprehension with Commonsense Reasoning Dataset.
Curva ROC (caratteristica operativa del ricevitore)
Un grafico della percentuale di veri positivi rispetto alla percentuale di falsi positivi per diverse soglie di classificazione nella classificazione binaria.
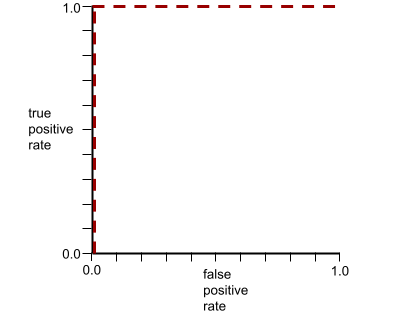
La forma di una curva ROC suggerisce la capacità di un modello di classificazione binaria di separare le classi positive da quelle negative. Supponiamo, ad esempio, che un modello di classificazione binaria separi perfettamente tutte le classi negative da tutte le classi positive:
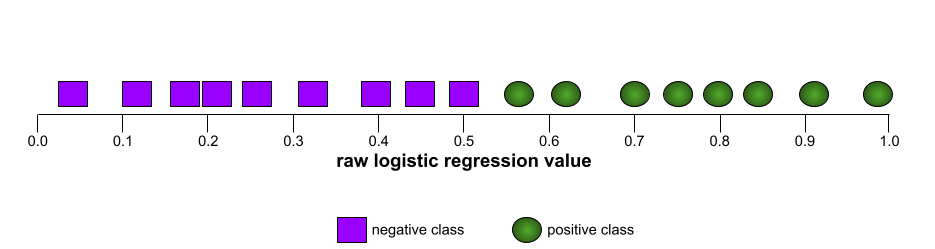
La curva ROC per il modello precedente ha il seguente aspetto:
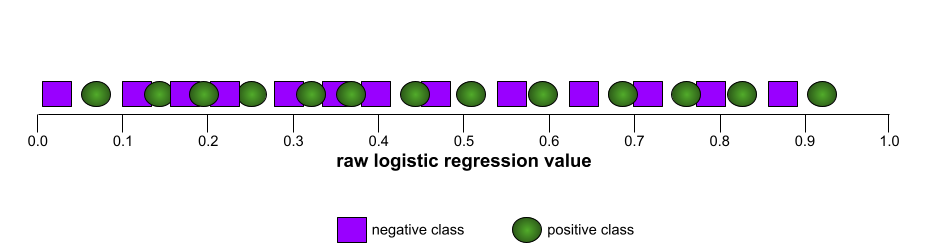
Al contrario, il grafico dell'illustrazione seguente mostra i valori grezzi della regressione logistica per un modello pessimo che non riesce a separare le classi negative da quelle positive:
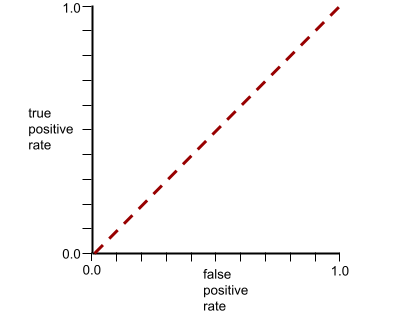
La curva ROC per questo modello ha il seguente aspetto:
Nel frattempo, nel mondo reale, la maggior parte dei modelli di classificazione binaria separa le classi positive e negative in una certa misura, ma di solito non perfettamente. Pertanto, una curva ROC tipica si trova a metà strada tra i due estremi:
Il punto su una curva ROC più vicino a (0.0,1.0) identifica teoricamente la soglia di classificazione ideale. Tuttavia, diversi altri problemi del mondo reale influenzano la selezione della soglia di classificazione ideale. Ad esempio, forse i falsi negativi causano molto più dolore dei falsi positivi.
Una metrica numerica chiamata AUC riassume la curva ROC in un singolo valore in rappresentazione in virgola mobile.
Errore quadratico medio (RMSE)
La radice quadrata dell'errore quadratico medio.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Una famiglia di metriche che valutano i modelli di riepilogo automatico e di traduzione automatica. Le metriche ROUGE determinano il grado di sovrapposizione di un testo di riferimento con un testo generato dal modello di ML. Ogni membro della famiglia ROUGE misura la sovrapposizione in modo diverso. Punteggi ROUGE più elevati indicano una maggiore somiglianza tra il testo di riferimento e il testo generato rispetto a punteggi ROUGE più bassi.
Ogni membro della famiglia ROUGE genera in genere le seguenti metriche:
- Precisione
- Richiamo
- F1
Per dettagli ed esempi, vedi:
ROUGE-L
Un membro della famiglia ROUGE incentrato sulla lunghezza della sottosequenza comune più lunga nel testo di riferimento e nel testo generato. Le seguenti formule calcolano il richiamo e la precisione per ROUGE-L:
Puoi quindi utilizzare F1 per riepilogare il richiamo ROUGE-L e la precisione ROUGE-L in un'unica metrica:
ROUGE-L ignora i nuovi caratteri di fine riga nel testo di riferimento e nel testo generato, quindi la sottosequenza comune più lunga può attraversare più frasi. Quando il testo di riferimento e il testo generato coinvolgono più frasi, una variante di ROUGE-L chiamata ROUGE-Lsum è generalmente una metrica migliore. ROUGE-Lsum determina la sottosequenza comune più lunga per ogni frase in un passaggio e poi calcola la media di queste sottosequenze comuni più lunghe.
ROUGE-N
Un insieme di metriche della famiglia ROUGE che confrontano gli N-gram condivisi di una determinata dimensione nel testo di riferimento e nel testo generato. Ad esempio:
- ROUGE-1 misura il numero di token condivisi nel testo di riferimento e nel testo generato.
- ROUGE-2 misura il numero di bigrammi (2-grammi) nel testo di riferimento e nel testo generato.
- ROUGE-3 misura il numero di trigrammi (3-grammi) condivisi nel testo di riferimento e nel testo generato.
Puoi utilizzare le seguenti formule per calcolare il richiamo ROUGE-N e la precisione ROUGE-N per qualsiasi membro della famiglia ROUGE-N:
Puoi quindi utilizzare F1 per riepilogare il richiamo ROUGE-N e la precisione ROUGE-N in un'unica metrica:
ROUGE-S
Una forma di ROUGE-N che consente la corrispondenza di skip-gram. ovvero ROUGE-N conta solo gli n-grammi che corrispondono esattamente, mentre ROUGE-S conta anche gli n-grammi separati da una o più parole. Ad esempio, prendi in considerazione quanto indicato di seguito.
- reference text: White clouds
- Testo generato: White billowing clouds
Quando viene calcolato ROUGE-N, il 2-gramma White clouds non corrisponde a White billowing clouds. Tuttavia, quando si calcola ROUGE-S, Nuvole bianche corrisponde a Nuvole bianche e gonfie.
R al quadrato
Una metrica di regressione che indica la variazione di un'etichetta dovuta a una singola caratteristica o a un insieme di caratteristiche. R al quadrato è un valore compreso tra 0 e 1, che puoi interpretare nel seguente modo:
- Un valore R quadrato pari a 0 indica che nessuna variazione di un'etichetta è dovuta al set di funzionalità.
- Un valore R quadrato pari a 1 indica che tutta la variazione di un'etichetta è dovuta al set di funzionalità.
- Un valore R quadrato compreso tra 0 e 1 indica la misura in cui la variazione dell'etichetta può essere prevista da una determinata caratteristica o dal set di caratteristiche. Ad esempio, un valore R quadrato di 0,10 significa che il 10% della varianza nell'etichetta è dovuto al set di funzionalità, un valore R quadrato di 0,20 significa che il 20% è dovuto al set di funzionalità e così via.
R al quadrato è il quadrato del coefficiente di correlazione Pearson tra i valori previsti da un modello e i dati empirici reali.
RTE
Abbreviazione di Recognizing Textual Entailment.
S
calcolo punteggio
La parte di un sistema di consigli che fornisce un valore o una classificazione per ogni elemento prodotto dalla fase di generazione dei candidati.
misura di somiglianza
Negli algoritmi di clustering, la metrica utilizzata per determinare quanto sono simili due esempi.
sparsità
Il numero di elementi impostati su zero (o null) in un vettore o una matrice diviso per il numero totale di voci nel vettore o nella matrice. Ad esempio, considera una matrice di 100 elementi in cui 98 celle contengono zero. Il calcolo della sparsità è il seguente:
La sparsità delle caratteristiche si riferisce alla sparsità di un vettore delle caratteristiche; la sparsità del modello si riferisce alla sparsità dei pesi del modello.
SQuAD
Acronimo di Stanford Question Answering Dataset, introdotto nell'articolo SQuAD: 100,000+ Questions for Machine Comprehension of Text. Le domande di questo set di dati provengono da utenti che pongono domande sugli articoli di Wikipedia. Alcune domande di SQuAD hanno risposte, ma altre intenzionalmente non ne hanno. Pertanto, puoi utilizzare SQuAD per valutare la capacità di un LLM di svolgere le seguenti operazioni:
- Rispondi alle domande a cui puoi rispondere.
- Identifica le domande a cui non è possibile rispondere.
Corrispondenza esatta in combinazione con F1 sono le metriche più comuni per valutare gli LLM rispetto a SQuAD.
errore quadratico medio della cerniera
Il quadrato della perdita hinge. La perdita di hinge al quadrato penalizza gli outlier in modo più severo rispetto alla perdita di hinge normale.
perdita quadratica
Sinonimo di perdita L2.
SuperGLUE
Un insieme di set di dati per valutare la capacità complessiva di un LLM di comprendere e generare testo. L'ensemble è costituito dai seguenti set di dati:
- Boolean Questions (BoolQ)
- CommitmentBank (CB)
- Choice of Plausible Alternatives (COPA)
- Multi-sentence Reading Comprehension (MultiRC)
- Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD)
- Recognizing Textual Entailment (RTE)
- Parole nel contesto (WiC)
- Winograd Schema Challenge (WSC)
Per maggiori dettagli, consulta SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.
T
test loss
Una metrica che rappresenta la perdita di un modello rispetto al set di test. Quando crei un modello, in genere cerchi di ridurre al minimo la perdita di test. Questo perché una perdita dei dati di test bassa è un indicatore di qualità più forte rispetto a una perdita di addestramento bassa [training loss] o una perdita di convalida bassa [validation loss].
Un ampio divario tra la perdita di test e la perdita di addestramento o di convalida a volte suggerisce di aumentare il tasso di regolarizzazione.
accuratezza top-k
La percentuale di volte in cui un'etichetta target viene visualizzata nelle prime k posizioni degli elenchi generati. Gli elenchi potrebbero essere consigli personalizzati o un elenco di elementi ordinati in base alla funzione softmax.
L'accuratezza top-k è anche nota come accuratezza a k.
tossicità
Il livello di offensività, minaccia o abuso dei contenuti. Molti modelli di machine learning possono identificare, misurare e classificare la tossicità. La maggior parte di questi modelli identifica la tossicità in base a più parametri, ad esempio il livello di linguaggio offensivo e il livello di linguaggio minaccioso.
perdita di addestramento
Una metrica che rappresenta la perdita di un modello durante una particolare iterazione di addestramento. Ad esempio, supponiamo che la funzione di perdita sia l'errore quadratico medio. Forse la perdita di addestramento (l'errore quadratico medio) per la decima iterazione è 2,2 e la perdita di addestramento per la centesima iterazione è 1,9.
Una curva di perdita traccia la perdita di addestramento rispetto al numero di iterazioni. Una curva di perdita fornisce i seguenti suggerimenti sull'addestramento:
- Una pendenza verso il basso implica che il modello sta migliorando.
- Una pendenza verso l'alto implica che il modello sta peggiorando.
- Una pendenza piatta implica che il modello ha raggiunto la convergenza.
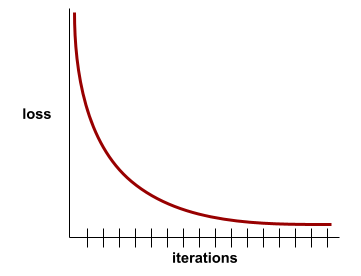
Ad esempio, la seguente curva di perdita un po' idealizzata mostra:
- Una pendenza ripida verso il basso durante le iterazioni iniziali, il che implica un rapido miglioramento del modello.
- Una pendenza che si appiattisce gradualmente (ma ancora verso il basso) fino quasi alla fine dell'addestramento, il che implica un miglioramento continuo del modello a un ritmo un po' più lento rispetto alle iterazioni iniziali.
- Una pendenza piatta verso la fine dell'addestramento, che suggerisce la convergenza.
Sebbene la perdita per l'addestramento sia importante, consulta anche la generalizzazione.
Risposte alle domande di curiosità
Set di dati per valutare la capacità di un LLM di rispondere a domande di cultura generale. Ogni set di dati contiene coppie di domande e risposte create da appassionati di quiz. Set di dati diversi sono basati su fonti diverse, tra cui:
- Ricerca web (TriviaQA)
- Wikipedia (TriviaQA_wiki)
Per saperne di più, consulta TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension.
vero negativo (VN)
Un esempio in cui il modello prevede correttamente la classe negativa. Ad esempio, il modello deduce che un determinato messaggio email non è spam e in effetti non lo è.
vero positivo (VP)
Un esempio in cui il modello prevede correttamente la classe positiva. Ad esempio, il modello deduce che un determinato messaggio email è spam e questo messaggio email è effettivamente spam.
tasso di veri positivi (TVP)
Sinonimo di richiamo. Ossia:
La percentuale di veri positivi è l'asse Y di una curva ROC.
Typologically Diverse Question Answering (TyDi QA)
Un ampio set di dati per valutare la competenza di un LLM nel rispondere alle domande. Il set di dati contiene coppie di domande e risposte in molte lingue.
Per informazioni dettagliate, vedi TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages.
U
Tasso di rivendicazione non supportata (UCR)
La percentuale di affermazioni in una risposta che non sono fondate. Ad esempio, se la risposta di un LLM fa 10 affermazioni, ma solo una è fondata, l'UCR è del 90%.
Un UCR elevato implica che un LLM allucina troppo spesso.
Vedi anche precisione delle citazioni e richiamo delle citazioni.
V
perdita di convalida
Una metrica che rappresenta la perdita di un modello sul set di validazione durante una particolare iterazione dell'addestramento.
Vedi anche la curva di generalizzazione.
importanza delle variabili
Un insieme di punteggi che indica l'importanza relativa di ciascuna caratteristica per il modello.
Ad esempio, considera un albero decisionale che stima i prezzi delle case. Supponiamo che questo albero decisionale utilizzi tre caratteristiche: taglia, età e stile. Se un insieme di importanze delle variabili per le tre caratteristiche viene calcolato come {size=5.8, age=2.5, style=4.7}, la taglia è più importante per l'albero decisionale rispetto all'età o allo stile.
Esistono diverse metriche di importanza delle variabili, che possono fornire agli esperti di ML informazioni su diversi aspetti dei modelli.
M
Perdita di Wasserstein
Una delle funzioni di perdita di uso comune nelle reti generative avversariali, basata sulla distanza di Wasserstein tra la distribuzione dei dati generati e i dati reali.
WiC
Abbreviazione di Parole nel contesto.
WikiLingua (wiki_lingua)
Un set di dati per valutare la capacità di un LLM di riassumere articoli brevi. WikiHow, un'enciclopedia di articoli che spiegano come svolgere varie attività, è la fonte creata da persone sia per gli articoli che per i riepiloghi. Ogni voce del set di dati è composta da:
- Un articolo, creato aggiungendo ogni passaggio della versione in prosa (paragrafo) dell'elenco numerato, meno la frase iniziale di ogni passaggio.
- Un riepilogo dell'articolo, costituito dalla frase iniziale di ogni passaggio dell'elenco numerato.
Per i dettagli, vedi WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization.
Winograd Schema Challenge (WSC)
Un formato (o un set di dati conforme a questo formato) per valutare la capacità di un LLM di determinare il sintagma nominale a cui si riferisce un pronome.
Ogni voce di una Winograd Schema Challenge è composta da:
- Un breve brano contenente un pronome di destinazione
- Un pronome di destinazione
- Frasi nominali candidate, seguite dalla risposta corretta (un valore booleano). Se il pronome target si riferisce a questo candidato, la risposta è True. Se il pronome di destinazione non si riferisce a questo candidato, la risposta è False.
Ad esempio:
- Passaggio: Mark ha raccontato a Pete molte bugie su di sé, che Pete ha incluso nel suo libro. Avrebbe dovuto dire la verità.
- Pronome di destinazione: lui
- Sintagmi nominali del candidato:
- Mark: True, perché il pronome di destinazione si riferisce a Mark
- Pete: False, perché il pronome di destinazione non si riferisce a Peter
La Winograd Schema Challenge è un componente dell'ensemble SuperGLUE.
Parole nel contesto (WiC)
Un set di dati per valutare in che modo un LLM utilizza il contesto per comprendere le parole che hanno più significati. Ogni voce del set di dati contiene:
- Due frasi, ciascuna contenente la parola di destinazione
- La parola target
- La risposta corretta (un valore booleano), dove:
- True significa che la parola di destinazione ha lo stesso significato nelle due frasi
- False significa che la parola di destinazione ha un significato diverso nelle due frasi
Ad esempio:
- Due frasi:
- C'è molta spazzatura sul letto del fiume.
- Quando dormo, tengo un bicchiere d'acqua accanto al letto.
- La parola target:letto
- Risposta corretta: Falso, perché la parola di destinazione ha un significato diverso nelle due frasi.
Per maggiori dettagli, vedi WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations.
Words in Context è un componente dell'ensemble SuperGLUE.
WSC
Abbreviazione di Winograd Schema Challenge.
X
XL-Sum (xlsum)
Un set di dati per valutare la competenza di un LLM nel riepilogare il testo. XL-Sum fornisce voci in molte lingue. Ogni voce del set di dati contiene:
- Un articolo tratto dalla British Broadcasting Company (BBC).
- Un riepilogo dell'articolo, scritto dall'autore. Tieni presente che il riepilogo può contenere parole o frasi non presenti nell'articolo.
Per maggiori dettagli, vedi XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages.