本頁面包含指標詞彙表。如要查看所有詞彙,請按這裡。
A
精確度
正確分類預測次數除以預測總次數。也就是:
舉例來說,如果模型做出 40 項正確預測和 10 項錯誤預測,準確率為:
二元分類會為不同類別的正確預測和不正確預測提供特定名稱。因此,二元分類的準確度公式如下:
其中:
詳情請參閱機器學習速成課程中的「分類:準確度、喚回率、精確度和相關指標」。
PR 曲線下面積
請參閱「PR AUC (PR 曲線下的面積)」。
ROC 曲線下面積
請參閱 AUC (ROC 曲線下面積)。
AUC (ROC 曲線下面積)
介於 0.0 和 1.0 之間的數字,代表二元分類模型區分正類和負類的能力。AUC 越接近 1.0,代表模型區分各類別的能力越好。
舉例來說,下圖顯示分類模型完美區分正類 (綠色橢圓) 和負類 (紫色矩形)。這個不切實際的完美模型 AUC 值為 1.0:

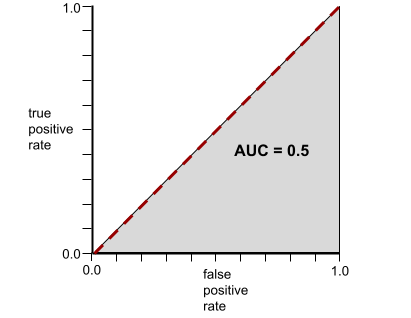
反之,下圖顯示分類模型產生隨機結果時的結果。這個模型的 AUC 為 0.5:

是,前一個模型的 AUC 為 0.5,而非 0.0。
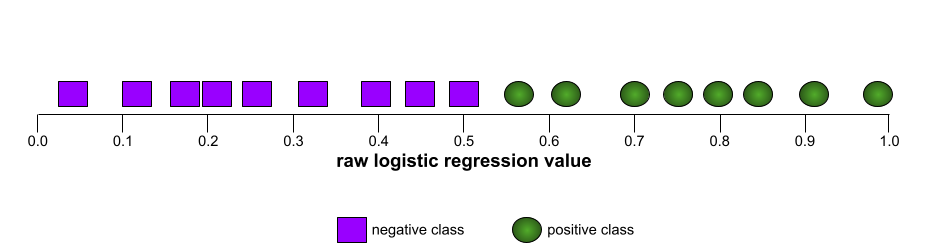
大多數模型都介於這兩個極端之間。舉例來說,下列模型會將正向和負向結果分開,因此 AUC 值介於 0.5 和 1.0 之間:

AUC 會忽略您為分類閾值設定的任何值。AUC 則會考量所有可能的分類門檻。
按一下圖示,瞭解 AUC 與 ROC 曲線之間的關係。
AUC 代表 ROC 曲線下的面積。舉例來說,如果模型能完美區分正類和負類,ROC 曲線會如下所示:
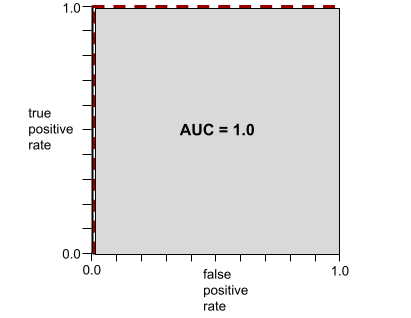
AUC 是上圖中灰色區域的面積。 在這個特殊情況下,面積就是灰色區域的長度 (1.0) 乘以寬度 (1.0)。因此,1.0 和 1.0 的乘積會產生 AUC 值 1.0,這是最高的 AUC 分數。
反之,如果分類模型完全無法區分類別,ROC 曲線如下。這個灰色區域的面積為 0.5。
更典型的 ROC 曲線大致如下所示:
手動計算這條曲線下的面積非常費力,因此通常會由程式計算大多數 AUC 值。
詳情請參閱機器學習速成課程中的「分類:ROC 和 AUC」。
k 的平均精確度
這項指標會彙整模型在單一提示中的成效,並產生排序結果,例如書籍建議的編號清單。k 的平均精確度,就是每個相關結果的 k 精確度值的平均值。因此,k 的平均精確度公式為:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
其中:
- \(n\) 是清單中相關項目的數量。
與 k 時的召回率相比。
B
基準
用來做為參考點的模型,可比較另一個模型 (通常是較複雜的模型) 的效能。舉例來說,邏輯迴歸模型可做為深層模型的良好基準。
針對特定問題,基準可協助模型開發人員量化新模型必須達成的最低預期成效,新模型才能派上用場。
布林值問題 (BoolQ)
用於評估 LLM 回答是非題能力的資料集。 資料集中的每個挑戰都包含三個部分:
- 查詢
- 暗示查詢問題答案的段落。
- 正確答案,也就是「是」或「否」。
例如:
- 查詢:密西根州有核電廠嗎?
- 段落:...三座核電廠為密西根州供應約 30% 的電力。
- 正確答案:是
研究人員從去識別化的匯總 Google 搜尋查詢中收集問題,然後使用維基百科頁面做為資訊基礎。
詳情請參閱「BoolQ:Exploring the Surprising Difficulty of Natural Yes/No Questions」。
BoolQ 是 SuperGLUE 集成模型中的一個元件。
BoolQ
布林值問題的縮寫。
C
CB
CommitmentBank 的縮寫。
字元 N 元語法 F 分數 (ChrF)
評估機器翻譯模型的指標。 字元 N 元語法 F 分數會判斷參考文字中的 N 元語法與 ML 模型生成文字中的 N 元語法重疊程度。
字元 N 元語法 F 分數與 ROUGE 和 BLEU 系列的指標類似,但有以下差異:
- 字元 N 元語法 F 分數會針對字元 N 元語法運算。
- ROUGE 和 BLEU 會對字詞 N-gram 或符記執行運算。
選擇合理替代方案 (COPA)
這個資料集用於評估 LLM 辨識前提下較佳替代答案的能力。資料集中的每個挑戰都包含三個元件:
- 前提,通常是陳述句,後面接著問題
- 前提中提出的問題有兩個可能的答案,其中一個正確,另一個不正確
- 正確答案
例如:
- 前提:男子弄斷了腳趾。請問造成這個問題的原因為何?
- 可能的答案:
- 他的襪子破了。
- 他把鐵鎚掉到腳上。
- 正確答案:2
COPA 是 SuperGLUE 集成模型中的元件。
CommitmentBank (CB)
這個資料集用於評估 LLM 的能力,判斷文章作者是否相信文章中的目標子句。資料集中的每個項目都包含:
- 一段文字
- 該段落中的目標子句
- 布林值,指出文章作者是否認為目標子句
例如:
- 段落:聽到阿提蜜絲的笑聲真有趣。她真是個嚴肅的孩子。 我不知道她有幽默感。
- 目標子句:她很有幽默感
- 布林值:True,表示作者認為目標子句
CommitmentBank 是 SuperGLUE 集成模型的一環。
COPA
「Choice of Plausible Alternatives」的縮寫。
費用
loss 的同義詞。
反事實公平性
這項公平性指標會檢查分類模型是否會為兩位使用者產生相同結果。這兩位使用者完全相同,只差在一或多個敏感屬性。評估分類模型的反事實公平性,是找出模型中潛在偏差來源的方法之一。
詳情請參閱下列任一文章:
交叉熵
對數損失的一般化,適用於多重分類問題。交叉熵可量化兩種機率分布之間的差異。另請參閱 困惑度。
累積分佈函式 (CDF)
這個函式會定義小於或等於目標值的樣本頻率。舉例來說,假設連續值呈常態分布。 CDF 會告訴您,大約 50% 的樣本應小於或等於平均值,大約 84% 的樣本應小於或等於平均值加上一個標準差。
D
群體均等
舉例來說,如果小人國人和大人國人都申請進入格魯布達布德里布大學,只要兩國人錄取率相同,就可達到人口統計均等,無論其中一組的平均資格是否優於另一組。
與均等機率和機會均等形成對比,後兩者允許分類結果匯總取決於私密屬性,但不允許特定基本事實標籤的分類結果取決於私密屬性。如要查看視覺化資料,瞭解以人口統計同等性為最佳化目標時的取捨,請參閱「以更智慧的機器學習對抗歧視」。
詳情請參閱機器學習速成課程中的「公平性:人口統計均等」。
E
搬土距離 (EMD)
用來評估兩個分布的相對相似度。 地球移動距離越小,表示分布越相似。
編輯距離
用來評估兩個字串的相似程度。 在機器學習中,編輯距離有以下用途:
- 編輯距離很容易計算。
- 編輯距離可比較兩個已知相似的字串。
- 編輯距離可判斷不同字串與指定字串的相似程度。
編輯距離有多種定義,每種定義都使用不同的字串作業。請參閱Levenshtein 距離的範例。
實證累積分佈函式 (eCDF 或 EDF)
根據實際資料集的實證測量結果得出的累積分布函數。沿著 x 軸的任何一點,函式的值都是資料集中小於或等於指定值的觀測值比例。
熵
在 資訊理論中,熵是指機率分布的不可預測程度。或者,熵也可以定義為每個樣本所含的資訊量。當隨機變數的所有值都同樣可能發生時,分配的熵最高。
如果集合有兩個可能的值「0」和「1」(例如二元分類問題中的標籤),則熵的公式如下:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
其中:
- H 是熵。
- p 是「1」範例的分數。
- q 是「0」範例的分數。請注意,q = (1 - p)
- 記錄通常是記錄2。在本例中,熵單位為位元。
舉例來說,假設:
- 100 個範例包含值「1」
- 300 個範例包含值「0」
因此,熵值為:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 每個範例 0.81 位元
如果資料集完全平衡 (例如 200 個「0」和 200 個「1」),每個樣本的熵為 1.0 位元。當集合變得越不平衡,其熵值就會越接近 0.0。
在決策樹中,熵有助於制定資訊增益,協助分割器在分類決策樹成長期間選取條件。
比較熵值與:
熵通常稱為「香農熵」。
詳情請參閱「Exact splitter for binary classification with numerical features」(使用精確分割器搭配數值特徵進行二元分類) 課程。
機會平等
公平性指標:評估模型是否能針對敏感屬性的所有值,同樣準確地預測出理想結果。換句話說,如果模型的理想結果是正類,目標就是讓所有群組的真陽性率相同。
機會均等與均等勝算有關,兩者都要求所有群組的真陽率和偽陽率相同。
假設 Glubbdubdrib 大學的嚴格數學課程同時招收小人國和大人國的學生。Lilliputians 的中學提供紮實的數學課程,絕大多數學生都有資格參加大學課程。Brobdingnagian 的中學完全沒有數學課,因此合格的學生少得多。如果合格學生無論是小人國人還是大人國人,錄取機率都相同,則就國籍 (小人國或大人國) 而言,偏好標籤「已錄取」符合機會均等原則。
舉例來說,假設有 100 位小人國人和 100 位大人國人申請進入 Glubbdubdrib 大學,而入學決定如下:
表 1. 小人國申請者 (90% 符合資格)
| 晉級 | 不合格 | |
|---|---|---|
| 已錄取 | 45 | 3 |
| 已遭拒 | 45 | 7 |
| 總計 | 90 | 10 |
|
錄取合格學生的百分比:45/90 = 50% 拒絕不合格學生的百分比:7/10 = 70% 錄取小人國學生的總百分比:(45+3)/100 = 48% |
||
表 2. Brobdingnagian 申請者 (10% 符合資格):
| 晉級 | 不合格 | |
|---|---|---|
| 已錄取 | 5 | 9 |
| 已遭拒 | 5 | 81 |
| 總計 | 10 | 90 |
|
符合資格的學生錄取率:5/10 = 50% 不符合資格的學生拒絕率:81/90 = 90% Brobdingnagian 學生總錄取率:(5+9)/100 = 14% |
||
上述例子符合接受合格學生的機會均等原則,因為合格的 Lilliputians 和 Brobdingnagians 都有 50% 的入學機會。
雖然滿足機會均等,但下列兩項公平性指標不符合條件:
- 人口統計均等:小人國人和大人國人進入大學的比例不同;48% 的小人國學生獲准入學,但只有 14% 的大人國學生獲准入學。
- 均等機會:符合資格的 Lilliputian 和 Brobdingnagian 學生都有相同的入學機會,但額外限制 (不符合資格的 Lilliputian 和 Brobdingnagian 學生都有相同的拒絕機會) 並不符合。不符合資格的 Lilliputian 拒絕率為 70%,不符合資格的 Brobdingnagian 拒絕率則為 90%。
詳情請參閱機器學習速成課程中的「公平性:機會均等」。
等化勝算
這項公平性指標可評估模型是否能針對敏感屬性的所有值,對正類和負類做出同樣準確的預測,而不僅限於其中一類。換句話說,所有群組的真陽率和偽陰率應相同。
均等機會與機會均等相關,後者只著重於單一類別 (正或負) 的錯誤率。
舉例來說,假設 Glubbdubdrib 大學的嚴格數學課程同時招收小人國和大人物國的學生。Lilliputians 的中學提供完善的數學課程,絕大多數學生都符合大學課程的資格。Brobdingnagians 的中學完全沒有數學課,因此合格的學生少得多。只要申請人符合資格,無論是小人國或大人國的人,都有同等機會獲准加入該計畫,若不符合資格,則有同等機會遭到拒絕,即符合均等機會原則。
假設有 100 名小人國人和 100 名大人國人申請進入 Glubbdubdrib 大學,而入學決定如下:
表 3. 小人國申請者 (90% 符合資格)
| 晉級 | 不合格 | |
|---|---|---|
| 已錄取 | 45 | 2 |
| 已遭拒 | 45 | 8 |
| 總計 | 90 | 10 |
|
符合資格的學生錄取百分比:45/90 = 50% 不符合資格的學生遭拒百分比:8/10 = 80% 小人國學生總錄取百分比:(45+2)/100 = 47% |
||
表 4. Brobdingnagian 申請者 (10% 符合資格):
| 晉級 | 不合格 | |
|---|---|---|
| 已錄取 | 5 | 18 |
| 已遭拒 | 5 | 72 |
| 總計 | 10 | 90 |
|
符合資格的學生錄取率:5/10 = 50% 不符合資格的學生拒絕率:72/90 = 80% Brobdingnagian 學生總錄取率:(5+18)/100 = 23% |
||
由於符合資格的 Lilliputian 和 Brobdingnagian 學生都有 50% 的入學機會,不符合資格的 Lilliputian 和 Brobdingnagian 學生則有 80% 的機會遭到拒絕,因此滿足了均等機率條件。
「機會均等」的正式定義請參閱「Equality of Opportunity in Supervised Learning」(監督式學習中的機會均等) 一文,如下所示:「如果預測值 Ŷ 和受保護屬性 A 相互獨立,且以 Y 為條件,則預測值 Ŷ 會滿足受保護屬性 A 和結果 Y 的機會均等條件。」
evals
主要用來做為大型語言模型評估的縮寫。廣義來說,評估是任何形式的評估縮寫。
評估
評估模型品質或比較不同模型成效的程序。
如要評估監督式機器學習模型,通常會根據驗證集和測試集進行評估。評估 LLM 通常需要進行更廣泛的品質和安全評估。
完全比對
這項指標不是 0 就是 1,模型輸出內容必須與基準真相或參照文字完全一致,否則就是 0 分。舉例來說,如果基準真相是「橘子」,只有「橘子」這個模型輸出結果符合完全比對條件。
完全相符也可以評估輸出為序列 (項目排名清單) 的模型。一般而言,完全相符是指產生的排序清單必須與基準真相完全相符,也就是兩個清單中的每個項目都必須依相同順序排列。不過,如果實際資料包含多個正確序列,只要模型輸出內容與其中一個正確序列相符,即為完全比對。
極端摘要 (xsum)
用於評估 LLM 摘要單一文件的能力。資料集中的每個項目都包含:
- 由英國廣播公司 (BBC) 撰寫的文件。
- 該文件的一句話摘要。
F
F1
公平性指標
可衡量的「公平性」數學定義。常用的公平性指標包括:
許多公平性指標互斥,請參閱公平性指標互相衝突。
偽陰性 (FN)
舉例來說,模型錯誤預測為負類。舉例來說,模型預測特定電子郵件訊息「不是垃圾郵件」(負向類別),但該郵件「實際上是垃圾郵件」。
偽陰率
模型錯誤預測為負類的實際正向樣本比例。下列公式可計算偽陰性率:
詳情請參閱機器學習速成課程中的「門檻和混淆矩陣」。
偽陽性 (FP)
舉例來說,模型誤判為正類。舉例來說,模型預測某封電子郵件是垃圾郵件 (正類),但該電子郵件其實不是垃圾郵件。
詳情請參閱機器學習速成課程中的「門檻和混淆矩陣」。
偽陽率 (FPR)
模型錯誤預測為正類的實際負例比例。下列公式會計算誤報率:
偽陽率是 ROC 曲線的 x 軸。
詳情請參閱機器學習速成課程中的「分類:ROC 和 AUC」。
特徵重要性
變數重要性的同義詞。
基礎模型
這類模型經過訓練,可處理大量多樣的訓練集,是極為龐大的預先訓練模型。基礎模型可以執行下列兩項操作:
換句話說,基礎模型在一般情況下已具備強大能力,但可進一步自訂,以更有效率地完成特定工作。
成功次數比例
用於評估機器學習模型生成文字的指標。 成功分數是「成功」生成的文字輸出內容數量,除以生成的文字輸出內容總數。舉例來說,如果大型語言模型生成 10 個程式碼區塊,其中 5 個成功,則成功率為 50%。
雖然成功率在整個統計領域都很有用,但在 ML 領域中,這項指標主要用於評估可驗證的任務,例如程式碼生成或數學問題。
G
吉尼不純度
類似於熵的指標。分割器 會使用從吉尼不純度或熵值衍生的值,組成用於分類條件的決策樹。 資訊增益是從熵值衍生而來。從吉尼不純度衍生的指標,目前沒有普遍接受的同義詞;不過,這個未命名的指標與資訊增益同樣重要。
吉尼不純度也稱為「吉尼係數」,或簡稱「吉尼」。
H
轉折損失
一系列用於分類的損失函式,旨在找出與每個訓練範例盡可能遠的決策邊界,進而盡量擴大範例與邊界之間的間隔。KSVM 使用 hinge 損失 (或平方 hinge 損失等相關函式)。如果是二元分類,鉸鏈損失函式的定義如下:
其中 y 是實際標籤 (-1 或 +1),y' 則是分類模型的原始輸出內容:
因此,鉸鏈損失與 (y * y') 的關係圖如下所示:

I
公平性指標互相衝突
某些公平概念互不相容,無法同時滿足。因此,沒有單一的通用指標可用於量化公平性,並套用至所有機器學習問題。
雖然這可能令人沮喪,但公平性指標不相容並不代表公平性工作毫無成果。而是建議根據特定機器學習問題的發生情境來定義公平性,以避免發生與應用實例相關的危害。
如要進一步瞭解公平性指標互相衝突的問題,請參閱「公平性的(不)可能性」。
個人公平性
這項公平性指標會檢查類似的個人是否獲得類似的分類結果。舉例來說,Brobdingnagian Academy 可能想確保兩名成績和標準化測驗分數相同的學生,獲得入學許可的機率相同,以滿足個人公平性。
請注意,個別公平性完全取決於您如何定義「相似性」(在本例中為成績和測驗分數),如果相似性指標遺漏重要資訊 (例如學生的課程嚴謹程度),您可能會引發新的公平性問題。
如要進一步瞭解個別公平性,請參閱「透過認知實現公平性」。
資訊增益
在決策樹林中,節點的熵與其子項節點熵的加權 (依範例數量) 總和之間的差異。節點的熵是該節點中範例的熵。
舉例來說,請考量下列熵值:
- 父節點的熵 = 0.6
- 一個子節點的熵,有 16 個相關範例 = 0.2
- 另一個子節點的熵,有 24 個相關範例 = 0.1
因此,40% 的範例位於一個子節點,60% 位於另一個子節點。因此:
- 子節點的加權熵總和 = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
因此,資訊增益為:
- 資訊增益 = 父項節點的熵 - 子項節點的加權熵總和
- 資訊增益 = 0.6 - 0.14 = 0.46
資料標註一致性
這項指標可衡量資料標註人員執行工作時,判定一致的頻率。 如果評估人員意見不一致,可能需要改善工作指示。 有時也稱為「標註者間一致性」或「評估者間信度」。另請參閱 Cohen 的 Kappa,這是最常用的評估者間一致性測量方法之一。
詳情請參閱機器學習速成課程中的「類別資料:常見問題」。
L
L1 損失
損失函式,用於計算實際標籤值與模型預測值之間的絕對差異。舉例來說,以下是五個範例的批次 L1 損失計算:
| 範例的實際值 | 模型預測值 | 差異的絕對值 |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 損失 | ||
平均絕對誤差是每個樣本的平均 L1 損失。
詳情請參閱機器學習速成課程中的「線性迴歸:損失」。
L2 損失
損失函式:計算實際標籤值與模型預測值之間的差異平方。舉例來說,以下是五個範例的批次 L2 損失計算:
| 範例的實際值 | 模型預測值 | Delta 的平方 |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 損失 | ||
由於平方運算,L2 損失會放大離群值的影響。也就是說,相較於 L1 損失,L2 損失對錯誤預測的反應更強烈。舉例來說,前述批次的 L1 損失會是 8 而不是 16。請注意,單一離群值就占了 16 個中的 9 個。
迴歸模型通常會使用 L2 損失做為損失函式。
均方誤差是每個樣本的平均 L2 損失。平方損失是 L2 損失的別名。
詳情請參閱機器學習速成課程中的「邏輯迴歸:損失和正規化」。
LLM 評估
用來評估大型語言模型 (LLM) 效能的一組指標和基準。概略來說,LLM 評估作業:
- 協助研究人員找出需要改進的 LLM 領域。
- 有助於比較不同 LLM,並找出最適合特定工作的 LLM。
- 確保 LLM 的使用安全無虞且符合道德規範。
詳情請參閱機器學習速成課程中的大型語言模型 (LLM)。
損失
損失函數會計算損失。
詳情請參閱機器學習速成課程中的「線性迴歸:損失」。
損失函數
在訓練或測試期間,計算批次範例損失的數學函式。如果模型預測結果良好,損失函式會傳回較低的損失值;如果模型預測結果不佳,則會傳回較高的損失值。
訓練的目標通常是盡量減少損失函式傳回的損失。
損失函數的種類繁多,請為您要建構的模型類型選擇適當的損失函數。例如:
M
矩陣分解
在數學中,這是一種機制,可找出點積近似於目標矩陣的矩陣。
在推薦系統中,目標矩陣通常會保留使用者對項目的評分。舉例來說,電影推薦系統的目標矩陣可能如下所示,其中正整數是使用者評分,0 表示使用者未對電影評分:
| 卡薩布蘭加 | 費城故事 | 黑豹 | 神力女超人 | 黑色追緝令 | |
|---|---|---|---|---|---|
| 使用者 1 | 5.0 | 3.0 | 0.0 | 2.0 | 0.0 |
| 使用者 2 | 4.0 | 0.0 | 0.0 | 1.0 | 5.0 |
| 使用者 3 | 3.0 | 1.0 | 4.0 | 5.0 | 0.0 |
電影推薦系統的目標是預測使用者對未評分電影的評分。舉例來說,使用者 1 會喜歡《黑豹》嗎?
建議系統的一種做法是使用矩陣分解,產生下列兩個矩陣:
舉例來說,對三位使用者和五項商品執行矩陣分解,可能會產生下列使用者矩陣和商品矩陣:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
使用者矩陣和項目矩陣的點積會產生建議矩陣,其中不僅包含原始使用者評分,也包含每位使用者未看過電影的預測評分。舉例來說,假設使用者 1 給予《北非諜影》5.0 分,建議矩陣中對應於該儲存格的點積應接近 5.0,而實際值為:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9更重要的是,使用者 1 會喜歡《黑豹》嗎?將第一列和第三欄對應的點積相乘,即可得出預測評分 4.3:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3矩陣分解通常會產生使用者矩陣和項目矩陣,兩者加總起來比目標矩陣精簡許多。
MBPP
「Mostly Basic Python Problems」(大多是 Python 基礎問題) 的縮寫。
平均絕對誤差 (MAE)
使用 L1 損失時,每個樣本的平均損失。平均絕對誤差的計算方式如下:
- 計算批次的 L1 損失。
- 將 L1 損失除以批次中的樣本數。
舉例來說,請考慮下列五個範例批次的 L1 損失計算:
| 範例的實際值 | 模型預測值 | 損失 (實際值與預測值之間的差異) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 損失 | ||
因此,L1 損失為 8,範例數為 5。因此,平均絕對誤差為:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
前 k 項的平均精確度平均值 (mAP@k)
驗證資料集中所有「k 處的平均精確度」分數的統計平均值。在 k 處使用平均精確度,可判斷推薦系統產生的建議品質。
雖然「平均值」這個詞組聽起來很冗餘,但這個指標名稱很合適。畢竟這項指標會找出多個「k 處的平均精確度」值。
均方誤差 (MSE)
使用 L2 損失時,每個樣本的平均損失。均方誤差的計算方式如下:
- 計算批次的 L2 損失。
- 將 L2 損失除以批次中的樣本數。
舉例來說,請考慮下列五個樣本批次的損失:
| 實際值 | 模型預測 | 損失 | 平方損失 |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 損失 | |||
因此,均方誤差為:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
TensorFlow Playground 使用均方差計算損失值。
指標
您重視的統計資料。
目標是機器學習系統嘗試最佳化的指標。
指標 API (tf.metrics)
用於評估模型的 TensorFlow API。舉例來說,tf.metrics.accuracy 可判斷模型的預測結果與標籤相符的頻率。
minimax loss
生成對抗網路的損失函式,以生成資料和真實資料的分布之間的交叉熵為依據。
第一篇論文使用極小極大損失來描述生成對抗網路。
詳情請參閱「生成對抗網路」課程中的損失函式。
模型容量
模型可學習的問題複雜程度。模型能學習的問題越複雜,模型的能力就越高。模型容量通常會隨著模型參數數量增加。如要瞭解分類模型容量的正式定義,請參閱「VC 維度」。
累積熱度
這是一種進階的梯度下降演算法,學習步驟不僅取決於目前步驟的導數,也取決於前一個步驟的導數。動量涉及計算一段時間內梯度指數加權移動平均值,類似於物理學中的動量。動量有時可避免學習過程停滯在局部最小值。
Mostly Basic Python Problems (MBPP)
用於評估 LLM 生成 Python 程式碼能力的一組資料。Mostly Basic Python Problems 提供約 1,000 個由群眾提供的程式設計問題。 資料集中的每個問題都包含:
- 工作說明
- 解決方案程式碼
- 三項自動化測試案例
否
負類
在二元分類中,一個類別稱為「正向」,另一個類別稱為「負向」。正類是模型測試的項目或事件,負類則是其他可能性。例如:
- 醫療檢測的負面類別可能是「非腫瘤」。
- 在電子郵件分類模型中,負面類別可能是「非垃圾郵件」。
與正類形成對比。
O
目標
演算法嘗試最佳化的指標。
目標函式
模型要盡量提升的數學公式或指標。 舉例來說,線性迴歸的目標函式通常是均方損失。因此,訓練線性迴歸模型時,訓練目標是盡量減少均方損失。
在某些情況下,目標是盡量提高目標函式的值。 舉例來說,如果目標函式是準確度,目標就是盡可能提高準確度。
另請參閱「損失」。
P
pass at k (pass@k)
這項指標可判斷大型語言模型生成的程式碼 (例如 Python) 品質。具體來說,k 次傳遞會告訴您,在 k 個生成的程式碼區塊中,至少有一個程式碼區塊通過所有單元測試的可能性。
大型語言模型通常難以針對複雜的程式設計問題生成優質程式碼。軟體工程師會適應這個問題,提示大型語言模型為同一問題生成多個 (k) 解決方案。接著,軟體工程師會針對單元測試,測試每項解決方案。k 的通過計算取決於單元測試的結果:
- 如果一或多個解決方案通過單元測試,則 LLM 通過該程式碼生成挑戰。
- 如果沒有任何解決方案通過單元測試,LLM 就會失敗,無法完成程式碼生成挑戰。
k 的傳遞公式如下:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
一般而言,k 值越高,通過 k 分數就越高;不過,k 值越高,需要的大型語言模型和單元測試資源就越多。
performance
多載字詞,含義如下:
- 軟體工程中的標準意義。也就是:這段軟體執行的速度 (或效率) 有多快?
- 機器學習領域的意義。這裡的成效會回答下列問題:這個模型有多正確?也就是說,模型的預測結果有多準確?
排列變數重要性
一種變數重要性,用於評估模型在特徵值經過排列後,預測錯誤率的增幅。排序變數重要性是與模型無關的指標。
困惑度
用來評估模型完成工作的程度。舉例來說,假設您的工作是讀取使用者在手機鍵盤上輸入的字詞前幾個字母,並提供可能的完成字詞清單。這項工作的困惑度 P 大約是您需要提供的猜測次數,才能讓清單包含使用者嘗試輸入的實際字詞。
複雜度與交叉熵的關係如下:
正類
您要測試的類別。
舉例來說,癌症模型中的正向類別可能是「腫瘤」。 電子郵件分類模型中的正類可能是「垃圾郵件」。
與負類形成對比。
PR AUC (PR 曲線下面積)
內插精確度和喚回度曲線下的面積,是透過繪製不同分類門檻值的 (喚回度、精確度) 點取得。
精確性
分類模型的指標,可用來回答下列問題:
模型預測正類時,預測正確的百分比是多少?
公式如下:
其中:
- 真陽性是指模型正確預測正類。
- 偽陽性是指模型錯誤地預測為正向類別。
舉例來說,假設模型做出 200 項正向預測。在這 200 項正向預測中:
- 其中 150 個是真陽性。
- 其中 50 個是誤判。
在這種情況下:
詳情請參閱機器學習速成課程中的「分類:準確度、喚回率、精確度和相關指標」。
前 k 項的查準率 (precision@k)
用於評估已排序項目清單的指標。 k 的精確度會指出該清單中前 k 個項目與「相關」的比例。也就是:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
k 的值必須小於或等於傳回清單的長度。 請注意,傳回清單的長度不屬於計算範圍。
關聯性通常是主觀的,即使是人工評估人員也經常對哪些項目相關意見不合。
比較時段:
精確度與喚回度曲線
預測偏誤
請勿與機器學習模型中的偏誤項混淆,也不要與倫理和公平性方面的偏誤混淆。
預測同位性
這項公平性指標會檢查特定分類模型的精確度是否對所有考量中的子群組都相同。
舉例來說,如果模型預測大學錄取結果時,對小人國人和大人國人的預測精確度相同,就符合國籍的預測均等性。
預測同價有時也稱為「預測同價率」。
如要進一步瞭解預測均等性,請參閱「公平性定義說明」(第 3.2.1 節)。
預測價格一致性
預測同位的別名。
機率密度函式
這個函式會找出資料樣本完全符合特定值的頻率。如果資料集的值是連續的浮點數,就很少會完全相符。不過,從值 x 到值 y整合機率密度函式,會產生 x 和 y 之間資料樣本的預期頻率。
舉例來說,假設常態分布的平均值為 200,標準差為 30。如要判斷落在 211.4 到 218.7 範圍內的資料樣本預期頻率,您可以整合常態分布的機率密度函式 (從 211.4 到 218.7)。
R
閱讀理解與常識推論資料集 (ReCoRD)
用於評估大型語言模型執行常識推理的能力。資料集中的每個範例都包含三個元件:
- 新聞報導中的一或兩個段落
- 查詢中,段落中明確或隱含識別的其中一個實體遭到遮蓋。
- 答案 (屬於遮罩的實體名稱)
如需大量範例,請參閱 ReCoRD。
ReCoRD 是 SuperGLUE 集合的一部分。
RealToxicityPrompts
這類資料集包含一組可能含有有害內容的句子開頭。使用這個資料集評估 LLM 生成無毒文字來完成句子的能力。一般來說,您會使用 Perspective API 判斷 LLM 在這項工作中的表現。
詳情請參閱「RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models」。
召回
分類模型的指標,可用來回答下列問題:
公式如下:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
其中:
- 真陽性是指模型正確預測正類。
- 偽陰性表示模型錯誤預測為負類。
舉例來說,假設模型對基準真相為正類的樣本做出 200 項預測。在這 200 項預測中:
- 其中 180 個是真陽性。
- 其中 20 個是偽陰性。
在這種情況下:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
詳情請參閱「分類:準確度、查全率、查準率和相關指標」。
k 時的喚回度 (recall@k)
這項指標用於評估系統,該系統會輸出排序 (依序) 的項目清單。「前 k 項的召回率」k 是指在該清單的前 k 個項目中,相關項目所占的分數,計算方式為相關項目數除以傳回的相關項目總數。
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
對比度與 k 的精確度。
辨識文本蘊涵 (RTE)
這個資料集可評估 LLM 的能力,判斷假設是否可從一段文字推論 (邏輯上得出)。RTE 評估中的每個範例都包含三個部分:
- 一段文字,通常來自新聞或維基百科文章
- 假設
- 正確答案 (以下任一):
- True,表示假設可以從文章中推導出來
- False,表示假設無法從文章中推導出來
例如:
- 原文:歐元是歐盟的貨幣。
- 假設:法國使用歐元做為貨幣。
- 蘊含:正確,因為法國是歐盟成員國。
RTE 是 SuperGLUE 集成模型中的一個元件。
ReCoRD
Reading Comprehension with Commonsense Reasoning Dataset 的縮寫。
ROC 曲線
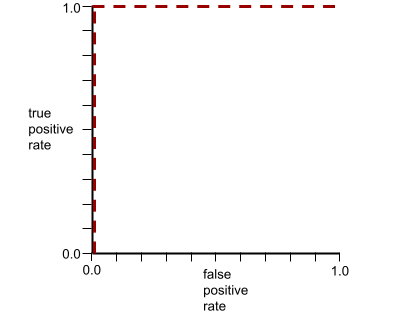
ROC 曲線的形狀代表二元分類模型區分正類和負類的能力。舉例來說,假設二元分類模型完美區分所有負類和正類:
上述模型的 ROC 曲線如下所示:
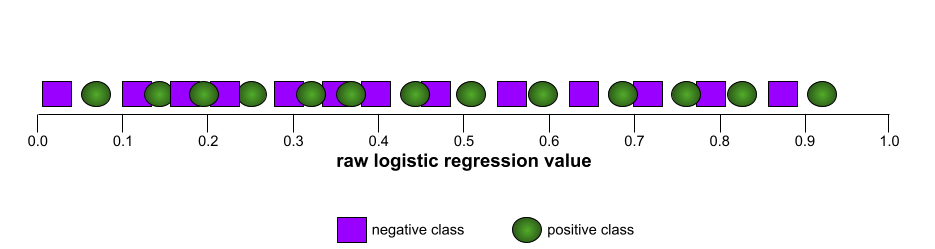
相較之下,下圖繪製了原始邏輯迴歸值,代表模型效能不佳,完全無法區分負面類別和正面類別:
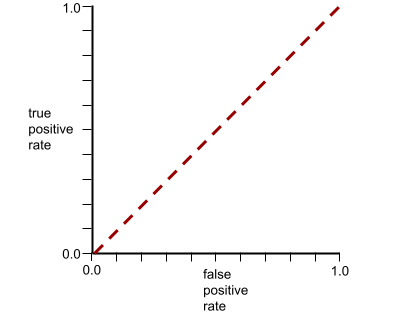
這個模型的 ROC 曲線如下所示:
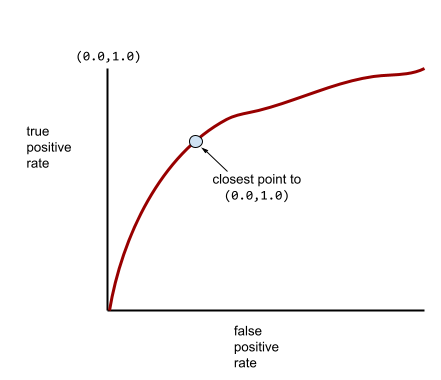
同時,在現實世界中,大多數二元分類模型都會在某種程度上區分正類和負類,但通常不會完美區分。因此,典型的 ROC 曲線會落在兩個極端之間:
ROC 曲線最接近 (0.0,1.0) 的點,理論上會找出理想的分類門檻。不過,其他幾個現實世界的問題會影響理想分類門檻的選取。舉例來說,偽陰性造成的損失可能遠大於偽陽性。
AUC 這項數值指標會將 ROC 曲線匯總為單一浮點數值。
均方根誤差 (RMSE)
均方誤差的平方根。
ROUGE (喚回度導向的摘要評估研究)
這是一系列指標,用於評估自動摘要和機器翻譯模型。ROUGE 指標會判斷參考文字與機器學習模型生成的文字重疊的程度。ROUGE 系列的每個成員都會以不同方式測量重疊程度。ROUGE 分數越高,表示參考文字與生成文字的相似度越高。
每個 ROUGE 系列成員通常會產生下列指標:
- 精確度
- 喚回度
- F1
詳情和範例請參閱:
ROUGE-L
ROUGE 系列的指標,著重於參考文字和生成文字中最長共同子序列的長度。下列公式會計算 ROUGE-L 的召回率和精確度:
然後使用 F1 將 ROUGE-L 喚回率和 ROUGE-L 精確度匯總為單一指標:
ROUGE-L 會忽略參考文字和生成文字中的任何換行符,因此最長共同子序列可能會跨越多個句子。如果參考文字和生成的文字包含多個句子,一般來說,ROUGE-Lsum (ROUGE-L 的變體) 是較好的指標。ROUGE-Lsum 會判斷段落中每個句子的最長共同子序列,然後計算這些最長共同子序列的平均值。
ROUGE-N
ROUGE 系列指標集,用於比較參考文字和生成文字中特定大小的共用 N 元語。例如:
- ROUGE-1 會計算參考文字和生成文字中共同的符記數量。
- ROUGE-2 會計算參考文字和生成文字中二元語法 (2 元語法) 的數量。
- ROUGE-3 會測量參考文字和生成文字中,共用的三元語法 (3 元語法) 數量。
您可以使用下列公式,計算 ROUGE-N 系列中任何成員的 ROUGE-N 召回率和 ROUGE-N 精確度:
然後使用 F1,將 ROUGE-N 喚回率和 ROUGE-N 精確度匯總為單一指標:
ROUGE-S
寬容形式的 ROUGE-N,可啟用 skip-gram 比對。也就是說,ROUGE-N 只會計算完全相符的 N 元語法,但 ROUGE-S 也會計算以一或多個字詞分隔的 N 元語法。舉例來說,您可以嘗試:
計算 ROUGE-N 時,2-gram「White clouds」與「White billowing clouds」不符。不過,在計算 ROUGE-S 時,「White clouds」(白雲)確實與「White billowing clouds」(白色積雲)相符。
R 平方
迴歸指標,指出標籤的變異程度是由個別特徵或特徵集所造成。R 平方值介於 0 到 1 之間,解讀方式如下:
- R 平方值為 0 表示標籤的變異與特徵集無關。
- R 平方值為 1 表示標籤的所有變異都是由特徵集所致。
- 介於 0 到 1 之間的 R 平方值,表示可從特定特徵或特徵集預測標籤變異的程度。舉例來說,R 平方值為 0.10 表示標籤的變異數有 10% 是由特徵集造成,R 平方值為 0.20 表示有 20% 是由特徵集造成,依此類推。
RTE
「Recognizing Textual Entailment」的縮寫。
日
計分
推薦系統的一部分,可為候選項目生成階段產生的每個項目提供值或排名。
相似度指標
在分群演算法中,用來判斷任意兩個樣本相似程度的指標。
稀疏度
向量或矩陣中設為零 (或空值) 的元素數量,除以該向量或矩陣中的項目總數。舉例來說,假設有 100 個元素的矩陣,其中 98 個儲存格包含零。稀疏程度的計算方式如下:
特徵稀疏性是指特徵向量的稀疏性;模型稀疏性是指模型權重的稀疏性。
SQuAD
史丹佛問答資料集的縮寫,在論文《SQuAD:100,000+ Questions for Machine Comprehension of Text》中推出。這個資料集中的問題來自使用者,他們會針對維基百科文章提出問題。SQuAD 中的部分問題有答案,但其他問題刻意沒有答案。因此,您可以使用 SQuAD 評估 LLM 的能力,判斷模型是否能:
- 回答可以回答的問題。
- 找出無法回答的問題。
完全比對搭配 F1 是最常見的指標,可用於根據 SQuAD 評估 LLM。
平方轉折損失
轉折損失的平方。平方轉折損失對離群值的懲罰比一般轉折損失更嚴厲。
平方損失
L2 損失 的同義詞。
SuperGLUE
這組資料集可評估 LLM 整體理解和生成文字的能力。這個集合包含下列資料集:
- 布林問題 (BoolQ)
- CommitmentBank (CB)
- 可信替代方案選擇 (COPA)
- 多句閱讀理解 (MultiRC)
- Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD)
- Recognizing Textual Entailment (RTE)
- 脈絡中的字詞 (WiC)
- Winograd 結構定義挑戰 (WSC)
詳情請參閱「SuperGLUE:一般用途語言理解系統的更嚴格基準」。
T
測試損失
代表模型對測試集的損失的指標。建構模型時,您通常會盡量減少測試損失。這是因為相較於低訓練損失或低驗證損失,低測試損失是更強大的品質信號。
如果測試損失與訓練損失或驗證損失之間存在巨大差距,有時表示您需要提高正規化率。
前 k 項準確率
在生成的清單中,前 k 個位置出現「目標標籤」的百分比。清單可以是個人化建議,也可以是依 softmax 排序的項目清單。
Top-k 準確率也稱為「k 準確率」。
毒性
內容是否具有辱罵、威脅或令人反感的程度。許多機器學習模型都能辨識、評估及分類惡意內容。這些模型大多會根據多項參數判斷是否為有害內容,例如濫用和威脅性語言的程度。
訓練損失
代表模型在特定訓練疊代期間的損失指標。舉例來說,假設損失函式為平均平方誤差。舉例來說,第 10 次疊代的訓練損失 (均方誤差) 為 2.2,第 100 次疊代的訓練損失為 1.9。
損失曲線會繪製訓練損失與疊代次數的關係圖。損失曲線可提供下列訓練提示:
- 如果斜率向下,表示模型正在進步。
- 如果斜率向上,表示模型品質正在變差。
- 平緩的斜率表示模型已達到收斂。
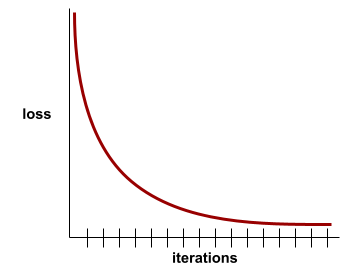
舉例來說,以下是經過某種程度理想化的損失曲線,顯示:
- 在初期反覆執行階段,斜率大幅下降,表示模型快速進步。
- 斜率逐漸趨緩 (但仍向下),直到訓練快要結束為止,這表示模型持續進步,但速度比初期反覆運算時稍慢。
- 訓練結束時的斜率平緩,表示模型已收斂。
雖然訓練損失很重要,但請參閱一般化。
回答益智問題
用來評估 LLM 回答冷知識問題能力的資料集。每個資料集都包含由益智問答愛好者撰寫的問題與答案組合。不同資料集會根據不同來源提供資訊,包括:
- 網頁搜尋 (TriviaQA)
- 維基百科 (TriviaQA_wiki)
詳情請參閱「TriviaQA:大規模遠距監督式閱讀理解挑戰資料集」。
真陰性 (TN)
舉例來說,模型正確預測負類。舉例來說,模型推斷某封電子郵件不是垃圾郵件,而該電子郵件確實不是垃圾郵件。
真陽性 (TP)
舉例來說,模型正確預測正類。舉例來說,模型推斷特定電子郵件是垃圾郵件,而該電子郵件確實是垃圾郵件。
真陽率 (TPR)
recall 的同義詞。也就是:
真陽率是 ROC 曲線的 y 軸。
Typologically Diverse Question Answering (TyDi QA)
用於評估大型語言模型回答問題能力的大型資料集。 資料集包含多種語言的問題和答案組合。
詳情請參閱TyDi QA:針對語言類型多樣的語言,提供資訊搜尋問答的基準。
V
驗證損失
另請參閱一般化曲線。
變數重要性
一組分數,代表各特徵對模型的重要性。
舉例來說,假設您要使用決策樹估算房價。假設這個決策樹使用三項特徵:尺寸、年齡和風格。如果計算出三項特徵的一組變數重要性為 {size=5.8, age=2.5, style=4.7},則對決策樹而言,大小比年齡或風格更重要。
變數重要性指標有很多種,可讓 ML 專家瞭解模型的不同層面。
W
Wasserstein 損失
這是生成對抗網路中常用的損失函式之一,根據生成資料和真實資料分布之間的地球移動距離計算而得。
WiC
WikiLingua (wiki_lingua)
用於評估 LLM 摘要短文能力的資料集。 WikiHow 是一部百科全書,內含說明如何完成各種工作的文章,這些文章和摘要都是由真人撰寫。資料集中的每個項目都包含:
- 文章:將編號清單的散文 (段落) 版本中每個步驟的開頭句子刪除,然後附加每個步驟,即可建立文章。
- 文章摘要,由編號清單中每個步驟的開頭句子組成。
詳情請參閱「WikiLingua:跨語言摘要式摘要的新基準資料集」。
Winograd 結構定義挑戰 (WSC)
評估 LLM 判斷代名詞所指名詞片語的能力時,所用的格式 (或符合該格式的資料集)。
Winograd Schema Challenge 的每個項目都包含:
- 包含目標代名詞的短文
- 目標代名詞
- 候選名詞片語,後面接著正確答案 (布林值)。 如果目標代名詞是指這位候選人,答案為 True。 如果目標代名詞並非指這個候選人,答案為 False。
例如:
- 段落:Mark 向 Pete 謊報自己的許多事蹟,而 Pete 將這些內容寫進書中。他應該更誠實。
- 目標代名詞:他
- 候選名詞片語:
- Mark:True,因為目標代名詞是指 Mark
- 彼得:錯誤,因為目標代名詞並非指彼得
Winograd Schema Challenge 是 SuperGLUE 集合的其中一個元件。
語境中的字詞 (WiC)
這個資料集用於評估 LLM 使用脈絡解讀多義字詞的能力。資料集中的每個項目都包含:
- 兩個句子,每個句子都包含目標字詞
- 目標字詞
- 正確答案 (布林值),其中:
- 「True」表示目標字詞在兩個句子中的含意相同
- False:目標字詞在這兩個句子中的意思不同
例如:
- 兩句話:
- 河床上有許多垃圾。
- 我睡覺時會在床邊放一杯水。
- 目標字詞:床
- 正確答案:錯誤,因為目標字詞在這兩個句子中的意思不同。
詳情請參閱「WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations」。
「Words in Context」是 SuperGLUE 集成模型的一環。
WSC
Winograd Schema Challenge 的縮寫。
X
XL-Sum (xlsum)
用於評估 LLM 摘要文字能力。XL-Sum 提供多種語言的項目。資料集中的每個項目都包含:
- 這篇文章取自英國廣播公司 (BBC)。
- 文章作者撰寫的文章摘要。請注意,摘要可能包含文章中沒有的字詞或詞組。
詳情請參閱「XL-Sum:適用於 44 種語言的大規模多語言摘要生成模型」。