このページには、指標の用語集が記載されています。用語集のすべての用語については、こちらをクリックしてください。
A
accuracy
分類予測の正解の数を予測の総数で割った数。具体的には、次のことが求められます。
たとえば、40 回の正しい予測と 10 回の誤った予測を行ったモデルの精度は次のようになります。
バイナリ分類では、正しい予測と正しくない予測のさまざまなカテゴリに固有の名前が付けられます。したがって、バイナリ分類の精度式は次のようになります。
ここで
詳細については、ML 集中講座の分類: 精度、再現率、適合率、関連指標をご覧ください。
PR 曲線下面積
PR AUC(PR 曲線の下の面積)をご覧ください。
ROC 曲線下面積
AUC(ROC 曲線の下の面積)をご覧ください。
AUC(ROC 曲線の下の面積)
陽性クラスと陰性クラスを分離するバイナリ分類モデルの能力を表す 0.0 ~ 1.0 の数値。AUC が 1.0 に近いほど、クラスを互いに分離するモデルの能力が優れています。
たとえば、次の図は、陽性クラス(緑色の楕円)と陰性クラス(紫色の長方形)を完全に分離する分類モデルを示しています。この非現実的な完全なモデルの AUC は 1.0 です。

一方、次の図は、ランダムな結果を生成した分類モデルの結果を示しています。このモデルの AUC は 0.5 です。

はい。上記のモデルの AUC は 0.0 ではなく 0.5 です。
ほとんどのモデルは、この 2 つの極端なモデルの中間に位置します。たとえば、次のモデルは陽性と陰性をある程度分離しているため、AUC は 0.5 ~ 1.0 の範囲になります。

AUC は、分類しきい値に設定した値を無視します。AUC は、可能なすべての分類しきい値を考慮します。
アイコンをクリックして、AUC と ROC 曲線との関係を確認します。
AUC は、ROC 曲線の下の面積を表します。たとえば、陽性と陰性を完全に分離するモデルの ROC 曲線は次のようになります。
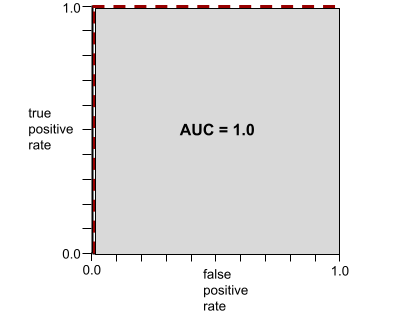
AUC は、上の図のグレーの領域の面積です。この特殊なケースでは、面積はグレーの領域の長さ(1.0)にグレーの領域の幅(1.0)を掛けた値になります。したがって、1.0 と 1.0 の積は AUC が 1.0 になり、これは可能な限り高い AUC スコアです。
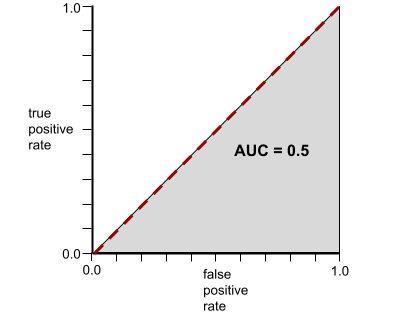
逆に、クラスをまったく分離できない分類モデルの ROC 曲線は次のようになります。このグレーの領域の面積は 0.5 です。
一般的な ROC 曲線は次のようになります。
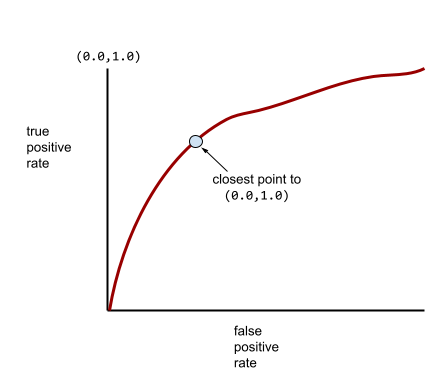
この曲線の下の面積を手動で計算するのは大変なため、通常はプログラムでほとんどの AUC 値を計算します。
詳細については、ML 集中講座の分類: ROC と AUC をご覧ください。
k における平均適合率
ランク付けされた結果(書籍の推奨事項の番号付きリストなど)を生成する単一のプロンプトに対するモデルのパフォーマンスを要約する指標。k での平均適合率は、各関連結果の k での適合率の値の平均です。したがって、k における平均適合率の式は次のようになります。
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
ここで
- \(n\) は、リスト内の関連アイテムの数です。
k でのリコールとのコントラスト。
B
ベースライン
別のモデル(通常はより複雑なモデル)のパフォーマンスを比較評価するための基準点として使用されるモデル。たとえば、ロジスティック回帰モデルは、ディープ ラーニング モデルの優れたベースラインとして機能します。
特定の問題に関して、ベースラインは、新しいモデルが有用であるために新しいモデルが達成する必要があるパフォーマンスの最小期待値をモデル デベロッパーが定量化するのに役立ちます。
ブール値の質問(BoolQ)
LLM がイエス / ノーの質問に答える能力を評価するためのデータセット。データセット内の各チャレンジには、次の 3 つのコンポーネントがあります。
- クエリ
- クエリに対する回答を暗示するパッセージ。
- 正解(はいまたはいいえ)。
次に例を示します。
- クエリ: ミシガン州に原子力発電所はありますか?
- 引用文: ...3 つの原子力発電所がミシガン州に電力の約 30% を供給しています。
- 正解: はい
研究者は、匿名化された集計済みの Google 検索クエリから質問を収集し、Wikipedia のページを使用して情報を検証しました。
詳細については、BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions をご覧ください。
BoolQ は、SuperGLUE アンサンブルのコンポーネントです。
BoolQ
ブール値の質問の略。
C
CB
CommitmentBank の略。
文字 N グラム F スコア(ChrF)
機械翻訳モデルを評価する指標。文字 N グラム F スコアは、参照テキストの N グラムが、ML モデルの生成テキストの N グラムとどの程度重複しているかを判断します。
文字 n グラム F スコアは、ROUGE ファミリーと BLEU ファミリーの指標と似ていますが、次の点が異なります。
- 文字 N グラム F スコアは、文字 N グラムで動作します。
- ROUGE と BLEU は、単語 N グラムまたはトークンで動作します。
妥当な代替案の選択(COPA)
前提に対する 2 つの回答のうち、どちらがより適切かを LLM がどの程度識別できるかを評価するためのデータセット。データセット内の各チャレンジは、次の 3 つのコンポーネントで構成されています。
- 前提(通常は質問に続くステートメント)
- 前提で提示された質問に対する 2 つの回答。1 つは正解、もう 1 つは不正解
- 正解
次に例を示します。
- 前提: 男性は足の指を骨折しました。この原因は何ですか?
- 解答例:
- 靴下に穴が開いた。
- 彼は足にハンマーを落とした。
- 正解: 2
COPA は SuperGLUE アンサンブルのコンポーネントです。
コミットメントバンク(CB)
LLM が、文章の著者がその文章内のターゲット句を信じているかどうかを判断する能力を評価するためのデータセット。データセットの各エントリには次のものが含まれます。
- 文章
- その文節内のターゲット句
- パッセージの著者がターゲット句を信じているかどうかを示すブール値
次に例を示します。
- 一節: アルテミスが笑うのを聞くのは楽しい。彼女はとても真面目な子供です。彼女にユーモアのセンスがあるとは知らなかった。
- ターゲット句: ユーモアのセンスがある
- Boolean: True。つまり、著者は対象の条項を信じている
CommitmentBank は、SuperGLUE アンサンブルのコンポーネントです。
COPA
妥当な代替案の選択の略。
費用
損失と同義。
反事実的公平性
1 つ以上の機密属性を除いて、最初の個人と同一の別の個人に対して、分類モデルが同じ結果を生成するかどうかを確認する公平性指標。反事実的公平性について分類モデルを評価することは、モデル内の潜在的なバイアスの原因を特定する 1 つの方法です。
詳しくは、次のいずれかをご覧ください。
- 機械学習集中講座の公平性: 反事実的公平性。
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness(英語)
交差エントロピー
対数損失をマルチクラス分類問題に一般化したものです。交差エントロピーは、2 つの確率分布間の差を定量化します。パープレキシティもご覧ください。
累積分布関数(CDF)
目標値以下のサンプルの頻度を定義する関数。たとえば、連続値の正規分布を考えてみましょう。CDF は、サンプルの約 50% が平均値以下であり、サンプルの約 84% が平均値より 1 標準偏差大きい値以下であることを示します。
D
人口統計学的等価性
モデルの分類結果が特定の機密属性に依存しない場合に満たされる公平性指標。
たとえば、リリパット人とブロブディンナグ人が Glubbdubdrib 大学に申し込んだ場合、リリパット人の合格率とブロブディンナグ人の合格率が同じであれば、一方のグループが他方よりも平均的に資格があるかどうかに関係なく、人口統計学的パリティが達成されます。
均等化されたオッズと機会の平等とは対照的です。これらは、分類結果の集計が機密属性に依存することを許可しますが、特定の指定されたグラウンド トゥルース ラベルの分類結果が機密属性に依存することを許可しません。人口統計学的パリティの最適化におけるトレードオフを説明する可視化については、「よりスマートな機械学習による差別の是正」をご覧ください。
詳細については、ML 集中講座の公平性: 人口統計学的パリティをご覧ください。
E
アース ムーバー距離(EMD)
2 つの分布の相対的な類似度を測定します。アース ムーバー距離が小さいほど、分布の類似性が高くなります。
編集距離
2 つのテキスト文字列の類似性を測定します。機械学習では、編集距離は次の理由で役立ちます。
- 編集距離は簡単に計算できます。
- 編集距離は、互いに類似していることがわかっている 2 つの文字列を比較できます。
- 編集距離を使用すると、異なる文字列が特定の文字列にどの程度類似しているかを判断できます。
編集距離にはいくつかの定義があり、それぞれ異なる文字列操作を使用します。例については、レーベンシュタイン距離をご覧ください。
経験累積分布関数(eCDF または EDF)
実際のデータセットの実測値に基づく累積分布関数。X 軸上の任意の点における関数の値は、指定された値以下のデータセット内の観測値の割合です。
エントロピー
情報理論では、確率分布の予測不可能性を説明します。また、エントロピーは、各例に含まれる情報量としても定義されます。分布のエントロピーが最大になるのは、確率変数のすべての値が等しい確率で発生する場合です。
2 つの値「0」と「1」を持つセットのエントロピー(たとえば、バイナリ分類問題のラベル)は、次の式で表されます。
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
ここで
- H はエントロピーです。
- p は「1」の例の割合です。
- q は「0」の例の割合です。q = (1 - p) であることに注意してください。
- log は通常 log2 です。この場合、エントロピー単位はビットです。
たとえば、次のように仮定します。
- 100 個の例に値「1」が含まれている
- 300 個の例に値「0」が含まれている
したがって、エントロピー値は次のようになります。
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 1 例あたり 0.81 ビット
完全にバランスの取れたセット(たとえば、200 個の「0」と 200 個の「1」)のエントロピーは、例あたり 1.0 ビットになります。セットのバランスが崩れるほど、エントロピーは 0.0 に近づきます。
決定木では、エントロピーは情報ゲインの定式化に役立ち、スプリッタが分類決定木の成長中に条件を選択するのに役立ちます。
エントロピーを以下と比較します。
エントロピーは、シャノンのエントロピーと呼ばれることもあります。
詳細については、デシジョン フォレスト コースの数値特徴を使用したバイナリ分類の正確な分割ツールをご覧ください。
機会の平等
モデルが機密属性のすべての値について望ましい結果を平等に予測しているかどうかを評価する公平性指標。つまり、モデルの望ましい結果が陽性クラスである場合、すべてのグループで真陽性率が同じになることが目標となります。
機会の平等は、均等化されたオッズに関連しています。これは、すべてのグループで真陽性率と偽陽性率の両方が同じであることを必要とします。
Glubbdubdrib 大学が、リリパット人とブロブディンナグ人を厳格な数学プログラムに受け入れたとします。リリパットのセカンダリー スクールでは、数学の授業の充実したカリキュラムが提供されており、生徒のほとんどが大学プログラムの資格を取得しています。ブロブディンナグの学校では数学の授業がまったく提供されていないため、資格のある生徒の数がはるかに少なくなっています。リリパット人かブロブディンナグ人かに関係なく、資格のある生徒が同じ確率で入学できる場合、国籍(リリパット人またはブロブディンナグ人)に関して「合格」という優先ラベルの機会均等性が満たされます。
たとえば、Glubbdubdrib 大学に 100 人の Lilliputians と 100 人の Brobdingnagians が応募し、次のように入学が決定されるとします。
表 1. 小人症の応募者(90% が資格あり)
| リードの精査が完了 | 見込みなし | |
|---|---|---|
| Admitted | 45 | 3 |
| 不承認 | 45 | 7 |
| 合計 | 90 | 10 |
|
入学が許可された適格な学生の割合: 45/90 = 50% 入学が許可されなかった不適格な学生の割合: 7/10 = 70% 入学が許可されたリリパット人の学生の割合: (45+3)/100 = 48% |
||
表 2. Brobdingnagian の応募者(10% が資格あり):
| リードの精査が完了 | 見込みなし | |
|---|---|---|
| Admitted | 5 | 9 |
| 不承認 | 5 | 81 |
| 合計 | 10 | 90 |
|
入学を許可された資格のある学生の割合: 5/10 = 50% 入学を拒否された資格のない学生の割合: 81/90 = 90% 入学を許可された Brobdingnagian 学生の合計割合: (5+9)/100 = 14% |
||
上記の例では、リリパット人とブロブディンナグ人がどちらも 50% の確率で入学できるため、有資格の学生の入学機会の平等が満たされています。
機会均等性は満たされていますが、次の 2 つの公平性指標は満たされていません。
- 人口統計学的パリティ: リリパット人とブロブディンナグ人が異なる割合で大学に入学している。リリパット人の学生の 48% が入学しているが、ブロブディンナグ人の学生は 14% しか入学していない。
- 均等オッズ: 資格のあるリリパット人とブロブディンナグ人が同じ確率で入学できる一方で、資格のないリリパット人とブロブディンナグ人が同じ確率で不合格になるという追加の制約は満たされません。リリパット人の不合格率は 70% ですが、ブロブディンナグ人の不合格率は 90% です。
詳細については、ML 集中講座の公平性: 機会の平等をご覧ください。
均等オッズ
モデルがポジティブ クラスとネガティブ クラスの両方に関して、機密属性のすべての値に対して結果を平等に予測しているかどうかを評価する公平性指標。一方のクラスのみを排他的に評価するものではありません。つまり、真陽性率と偽陰性率の両方が、すべてのグループで同じである必要があります。
均等化オッズは、単一のクラス(正または負)のエラー率のみに焦点を当てた機会の平等に関連しています。
たとえば、Glubbdubdrib 大学がリリパット人とブロブディンナグ人の両方を厳格な数学プログラムに受け入れているとします。リリパットの高校では、数学の授業のカリキュラムが充実しており、ほとんどの生徒が大学プログラムの資格を取得しています。ブロブディンナグの高校では数学の授業がまったく提供されていないため、資格のある生徒ははるかに少なくなっています。応募者がリリパット人であろうとブロブディンナグ人であろうと、資格があればプログラムに合格する可能性は同じであり、資格がなければ不合格になる可能性も同じである場合、均等なオッズが満たされます。
リリパット人とブロブディンナグ人がそれぞれ 100 人ずつ Glubbdubdrib 大学に入学を申し込んだとします。入学の決定は次のように行われます。
表 3: 小人症の応募者(90% が資格あり)
| リードの精査が完了 | 見込みなし | |
|---|---|---|
| Admitted | 45 | 2 |
| 不承認 | 45 | 8 |
| 合計 | 90 | 10 |
|
入学が許可された資格のある学生の割合: 45/90 = 50% 入学が許可されなかった資格のない学生の割合: 8/10 = 80% 入学が許可されたリリパットの学生の合計割合: (45+2)/100 = 47% |
||
表 4. Brobdingnagian の応募者(10% が資格あり):
| リードの精査が完了 | 見込みなし | |
|---|---|---|
| Admitted | 5 | 18 |
| 不承認 | 5 | 72 |
| 合計 | 10 | 90 |
|
合格した資格のある学生の割合: 5/10 = 50% 不合格になった資格のない学生の割合: 72/90 = 80% 合格したブロブディンナグ人の学生の合計割合: (5+18)/100 = 23% |
||
リリパット人とブロブディンナグ人の両方で、合格した学生の 50% が合格し、不合格の学生の 80% が不合格になるため、均等なオッズが満たされています。
等しいオッズは、「Equality of Opportunity in Supervised Learning」で次のように正式に定義されています。「予測子 Ŷ が保護属性 A と結果 Y に関して等しいオッズを満たすのは、Ŷ と A が Y を条件として独立している場合です。」
evals
主に LLM 評価の略語として使用されます。広義には、evals は、評価のあらゆる形式の略語です。
評価
モデルの品質を測定したり、異なるモデルを比較したりするプロセス。
教師あり機械学習モデルを評価するには、通常、検証セットとテストセットに対してモデルを評価します。LLM の評価には通常、品質と安全性のより広範な評価が含まれます。
完全一致
モデルの出力がグラウンド トゥルースまたは参照テキストと完全に一致するかどうかを測定するオール オア ナッシングの指標。たとえば、正解が「オレンジ」の場合、完全一致を満たすモデル出力は「オレンジ」のみです。
完全一致では、出力がシーケンス(項目のランク付けされたリスト)であるモデルを評価することもできます。一般に、完全一致では、生成されたランキング リストがグラウンド トゥルースと完全に一致している必要があります。つまり、両方のリストの各項目が同じ順序になっている必要があります。ただし、グラウンド トゥルースが複数の正しいシーケンスで構成されている場合、完全一致では、モデルの出力が正しいシーケンスの 1 つと一致するだけで済みます。
Extreme Summarization(xsum)
単一のドキュメントを要約する LLM の能力を評価するためのデータセット。データセットの各エントリは次の要素で構成されます。
- 英国放送協会(BBC)が作成したドキュメント。
- そのドキュメントの 1 文の要約。
詳しくは、詳細ではなく要約だけを教えてください。Topic-Aware Convolutional Neural Networks for Extreme Summarization。
F
F1
適合率と再現率の両方に依存する「ロールアップ」2 値分類指標。式は次のとおりです。
公平性指標
測定可能な「公平性」の数学的定義。よく使用される公平性指標には次のようなものがあります。
公平性に関する指標の多くは相互に排他的です。公平性に関する指標の不整合をご覧ください。
偽陰性(FN)
モデルが陰性クラスを誤って予測した例。たとえば、特定のメール メッセージがスパムではない(負のクラス)と予測されたが、そのメール メッセージが実際にはスパムである場合などです。
偽陰性率
モデルが誤って陰性クラスを予測した実際の陽性例の割合。次の式は、偽陰性率を計算します。
詳細については、ML 集中講座のしきい値と混同行列をご覧ください。
偽陽性(FP)
モデルが陽性クラスを誤って予測した例。たとえば、特定のメール メッセージがスパム(ポジティブ クラス)であるとモデルが予測したが、そのメール メッセージは実際にはスパムではない。
詳細については、ML 集中講座のしきい値と混同行列をご覧ください。
偽陽性率(FPR)
モデルが陽性クラスを誤って予測した実際の陰性例の割合。次の式は、偽陽性率を計算します。
偽陽性率は、ROC 曲線の x 軸です。
詳細については、ML 集中講座の分類: ROC と AUC をご覧ください。
特徴の重要度
変数の重要度と同義。
基盤モデル
膨大で多様なトレーニング セットでトレーニングされた、非常に大規模な事前トレーニング済みモデル。基盤モデルは、次の両方を行うことができます。
- 幅広いリクエストに適切に対応する。
- 追加のファインチューニングやその他のカスタマイズのベースモデルとして機能します。
つまり、基盤モデルは一般的な意味ですでに非常に有能ですが、特定のタスクでさらに有用になるようにカスタマイズできます。
成功の割合
ML モデルの生成されたテキストを評価するための指標。成功の割合は、生成されたテキスト出力の総数で「成功」した生成テキスト出力の数を割った値です。たとえば、大規模言語モデルが 10 個のコードブロックを生成し、そのうち 5 個が成功した場合、成功の割合は 50% になります。
成功率の指標は統計全体で幅広く使用できますが、ML では主にコード生成や数学の問題などの検証可能なタスクの測定に使用されます。
G
ジニ不純度
エントロピーに似た指標。スプリッタは、ジニ不純度またはエントロピーから導出された値を使用して、分類の決定木の条件を構成します。情報ゲインはエントロピーから導出されます。ジニ不純度から導出された指標に、一般的に受け入れられている同等の用語はありません。ただし、この名前のない指標は情報ゲインと同じくらい重要です。
ジニ不純度は、ジニ係数または単にジニとも呼ばれます。
H
ヒンジ損失
分類用の損失関数のファミリー。各トレーニング例から可能な限り離れた決定境界を見つけるように設計されており、例と境界の間のマージンを最大化します。KSVM はヒンジ損失(または 2 乗ヒンジ損失などの関連関数)を使用します。バイナリ分類の場合、ヒンジ損失関数は次のように定義されます。
ここで、y は -1 または +1 の真のラベル、y' は分類モデルの未加工の出力です。
したがって、ヒンジ損失と(y * y')のプロットは次のようになります。

I
公平性指標の不整合
公平性の概念の中には、相互に両立せず、同時に満たすことができないものがあるという考え方。そのため、すべての ML 問題に適用できる公平性を定量化するための単一の普遍的な指標はありません。
これは落胆するようなことかもしれませんが、公平性の指標の不整合は、公平性の取り組みが無駄であることを意味するものではありません。代わりに、公平性は特定の ML 問題のコンテキストに沿って定義し、そのユースケースに固有の危害を防ぐことを目標にする必要があることを示唆しています。
公平性指標の非互換性について詳しくは、「公平性の(不)可能性について」をご覧ください。
個人の公平性
類似した個人が同様に分類されているかどうかを確認する公平性指標。たとえば、Brobdingnagian Academy は、成績と標準テストのスコアが同じ 2 人の生徒が同じ確率で入学できるようにすることで、個人の公平性を満たしたいと考えています。
個人の公平性は「類似性」(この場合は成績とテストの点数)の定義に完全に依存します。類似性指標で重要な情報(生徒のカリキュラムの厳しさなど)が欠落していると、新たな公平性の問題が生じる可能性があります。
個人の公平性について詳しくは、「認識による公平性」をご覧ください。
情報利得
決定フォレストでは、ノードのエントロピーとその子ノードのエントロピーの重み付け(例の数による)された合計の差。ノードのエントロピーは、そのノード内の例のエントロピーです。
たとえば、次のエントロピー値を考えてみましょう。
- 親ノードのエントロピー = 0.6
- 16 個の関連する例を含む 1 つの子ノードのエントロピー = 0.2
- 関連する例が 24 個ある別の子ノードのエントロピー = 0.1
したがって、例の 40% は一方の子ノードにあり、60% はもう一方の子ノードにあります。そのため、次のようになります。
- 子ノードの重み付きエントロピーの合計 = (0.4 × 0.2) + (0.6 × 0.1) = 0.14
したがって、情報利得は次のようになります。
- 情報利得 = 親ノードのエントロピー - 子ノードの重み付きエントロピーの合計
- 情報利得 = 0.6 - 0.14 = 0.46
ほとんどの分割器は、情報ゲインを最大化する条件を作成しようとします。
inter-rater agreement(採点者間の一致度)
タスクの実行時に人間の評価者が一致する頻度を測定します。評価者が一致しない場合は、タスクの指示を改善する必要があるかもしれません。アノテーター間の一致度または評価者間の信頼性とも呼ばれます。最も一般的な評価者間一致度の測定値の 1 つである Cohen のカッパもご覧ください。
詳細については、ML 集中講座のカテゴリデータ: 一般的な問題をご覧ください。
L
L1 損失
実際のラベル値とモデルが予測する値の差の絶対値を計算する損失関数。たとえば、5 つの例のバッチの L1 損失の計算は次のようになります。
| 例の実際の値 | モデルの予測値 | デルタの絶対値 |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 損失 | ||
L1 損失は、L2 損失よりも外れ値の影響を受けにくいです。
詳細については、ML 集中講座の線形回帰: 損失をご覧ください。
L2 損失
実際のラベル値とモデルが予測する値の差の二乗を計算する損失関数。たとえば、5 つの例のバッチの L2 損失の計算は次のようになります。
| 例の実際の値 | モデルの予測値 | デルタの二乗 |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 損失 | ||
2 乗するため、L2 損失は外れ値の影響を増幅します。つまり、L2 損失は、L1 損失よりも悪い予測に強く反応します。たとえば、前のバッチの L1 損失は 16 ではなく 8 になります。16 個のうち 9 個が 1 つの外れ値で占められています。
回帰モデルでは、通常、損失関数として L2 損失が使用されます。
平均二乗誤差は、例ごとの L2 損失の平均です。二乗損失は、L2 損失の別名です。
詳細については、ML 集中講座のロジスティック回帰: 損失と正則化をご覧ください。
LLM 評価
大規模言語モデル(LLM)のパフォーマンスを評価するための指標とベンチマークのセット。LLM 評価の概要は次のとおりです。
- LLM の改善が必要な領域を研究者が特定するのに役立ちます。
- さまざまな LLM を比較し、特定のタスクに最適な LLM を特定するのに役立ちます。
- LLM の安全で倫理的な使用を確保します。
詳細については、ML 集中講座の大規模言語モデル(LLM)をご覧ください。
損失
教師ありモデルのトレーニングで、モデルの予測がラベルからどのくらい離れているかを表す指標。
損失関数では損失が計算されます。
詳細については、ML 集中講座の線形回帰: 損失をご覧ください。
損失関数
トレーニングまたはテスト中に、例のバッチの損失を計算する数学関数。損失関数は、予測が悪いモデルよりも予測がよいモデルに対して、より低い損失を返します。
通常、トレーニングの目標は、損失関数が返す損失を最小限に抑えることです。
損失関数にはさまざまな種類があります。構築するモデルの種類に適した損失関数を選択します。次に例を示します。
M
行列分解
数学では、ドット積がターゲット行列に近似する行列を見つけるメカニズム。
レコメンデーション システムでは、ターゲット行列にアイテムに対するユーザーの評価が格納されることがよくあります。たとえば、映画のレコメンデーション システムのターゲット マトリックスは次のようになります。正の整数はユーザー評価、0 はユーザーが映画を評価していないことを意味します。
| カサブランカ | フィラデルフィア物語 | Black Panther(「ブラック パンサー」) | ワンダーウーマン | パルプフィクション | |
|---|---|---|---|---|---|
| ユーザー 1 | 5.0 | 3.0 | 0.0 | 2.0 | 0.0 |
| ユーザー 2 | 4.0 | 0.0 | 0.0 | 1.0 | 5.0 |
| ユーザー 3 | 3.0 | 1.0 | 4.0 | 5.0 | 0.0 |
映画のレコメンデーション システムは、評価されていない映画に対するユーザーの評価を予測することを目的としています。たとえば、ユーザー 1 は ブラックパンサーを気に入るでしょうか?
レコメンデーション システムのアプローチの 1 つとして、行列分解を使用して次の 2 つの行列を生成する方法があります。
たとえば、3 人のユーザーと 5 つのアイテムに対して行列分解を行うと、次のようなユーザー行列とアイテム行列が得られます。
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
ユーザー行列とアイテム行列の内積により、元のユーザー評価だけでなく、各ユーザーがまだ見ていない映画の予測も含むおすすめ行列が生成されます。たとえば、ユーザー 1 の「カサブランカ」の評価が 5.0 であったとします。推奨事項マトリックスのそのセルに対応するドット積は、5.0 前後になるはずです。
(1.1 * 0.9) + (2.3 * 1.7) = 4.9さらに重要なのは、ユーザー 1 が ブラックパンサーを気に入るかどうかです。1 行目と 3 列目に対応する内積を計算すると、予測評価は 4.3 になります。
(1.1 * 1.4) + (2.3 * 1.2) = 4.3通常、行列分解では、ターゲット行列よりもはるかにコンパクトなユーザー行列とアイテム行列が生成されます。
MBPP
Mostly Basic Python Problems の略。
平均絶対誤差(MAE)
L1 損失が使用されている場合の、例ごとの平均損失。平均絶対誤差は次のように計算します。
- バッチの L1 損失を計算します。
- L1 損失をバッチ内のサンプル数で割ります。
たとえば、次の 5 つの例のバッチで L1 損失を計算することを考えます。
| 例の実際の値 | モデルの予測値 | 損失(実測値と予測値の差) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 損失 | ||
したがって、L1 損失は 8 で、サンプル数は 5 です。したがって、平均絶対誤差は次のようになります。
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
平均絶対誤差と平均二乗誤差、二乗平均平方根誤差を比較します。
k での平均適合率の平均(mAP@k)
検証データセット全体で計算されたすべての k における平均適合率スコアの統計的平均。k における平均適合率の用途の一つは、レコメンデーション システムによって生成された推奨事項の品質を判断することです。
「平均平均」というフレーズは冗長に聞こえますが、指標の名前としては適切です。この指標は、複数の k における平均適合率の値の平均を求めるためです。
平均二乗誤差(MSE)
L2 損失が使用されている場合の、例あたりの平均損失。平均二乗誤差は次のように計算します。
- バッチの L2 損失を計算します。
- L2 損失をバッチ内のサンプル数で割ります。
たとえば、次の 5 つの例のバッチの損失について考えてみましょう。
| 実際の値 | モデルの予測 | 損失 | 二乗損失 |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 損失 | |||
したがって、平均二乗誤差は次のようになります。
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
平均二乗誤差は、特に線形回帰でよく使用されるトレーニング オプティマイザーです。
平均二乗誤差と平均絶対誤差、二乗平均平方根誤差を比較します。
TensorFlow Playground では、平均二乗誤差を使用して損失値を計算します。
指標
重視すべき統計情報。
目標は、ML システムが最適化しようとする指標です。
指標 API(tf.metrics)
モデルを評価するための TensorFlow API。たとえば、tf.metrics.accuracy は、モデルの予測がラベルと一致する頻度を決定します。
ミニマックス損失
生成されたデータと実際のデータの分布間のクロスエントロピーに基づく、敵対的生成ネットワークの損失関数。
ミニマックス損失は、最初の論文で敵対的生成ネットワークを説明するために使用されています。
詳細については、Generative Adversarial Networks コースの損失関数をご覧ください。
モデル容量
モデルが学習できる問題の複雑さ。モデルが学習できる問題が複雑であるほど、モデルの容量は大きくなります。通常、モデルの容量はモデル パラメータの数とともに増加します。分類モデルの容量の正式な定義については、VC ディメンションをご覧ください。
モメンタム
学習ステップが現在のステップの導関数だけでなく、直前のステップの導関数にも依存する高度な勾配降下アルゴリズム。運動量では、物理学の運動量と同様に、勾配の指数加重移動平均を時間とともに計算します。モメンタムは、学習が局所的な最小値で停滞するのを防ぐことがあります。
Mostly Basic Python Problems(MBPP)
LLM の Python コード生成能力を評価するためのデータセット。Mostly Basic Python Problems には、約 1,000 件のクラウドソーシングによるプログラミングの問題が用意されています。データセット内の各問題には次のものが含まれています。
- タスクの説明
- 解答コード
- 3 つの自動テストケース
N
陰性クラス
バイナリ分類では、一方のクラスを「陽性」、もう一方のクラスを「陰性」と呼びます。陽性クラスはモデルがテストしているものまたはイベントであり、陰性クラスはそれ以外の可能性です。次に例を示します。
- 医学検査の陰性クラスは「腫瘍なし」などになります。
- メールの分類モデルの負のクラスは「迷惑メールではない」になります。
ポジティブ クラスと対照的です。
O
目標
アルゴリズムが最適化しようとしている指標。
目的関数
モデルの最適化対象とする数式または指標。たとえば、線形回帰の目的関数は、通常は平均二乗損失です。したがって、線形回帰モデルをトレーニングするときは、平均二乗損失を最小限に抑えることが目標となります。
場合によっては、目的関数を最大化することが目標になります。たとえば、目的関数が精度の場合、目標は精度を最大化することです。
損失もご覧ください。
P
pass at k(pass@k)
大規模言語モデルが生成するコード(Python など)の品質を判断する指標。具体的には、pass at k は、生成された k 個のコードブロックのうち、少なくとも 1 つのコードブロックがすべての単体テストに合格する可能性を示します。
大規模言語モデルは、複雑なプログラミング問題に対して適切なコードを生成するのに苦労することがよくあります。ソフトウェア エンジニアは、大規模言語モデルに同じ問題に対する複数の(k 個の)解決策を生成するように指示することで、この問題に対応します。次に、ソフトウェア エンジニアが各ソリューションを単体テストに対してテストします。k での合格の計算は、単体テストの結果によって異なります。
- これらのソリューションのいずれかが単体テストに合格した場合、LLM はそのコード生成チャレンジに合格します。
- どのソリューションも単体テストに合格しない場合、LLM はそのコード生成チャレンジに失敗します。
k でのパスの式は次のとおりです。
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
一般に、k の値が大きいほど、pass at k スコアが高くなります。ただし、k の値が大きいほど、大規模言語モデルと単体テストのリソースが必要になります。
パフォーマンス
次の意味を持つオーバーロードされた用語。
- ソフトウェア エンジニアリングにおける標準的な意味。つまり、このソフトウェアはどのくらいの速さ(または効率)で実行されるかということです。
- ML における意味。ここで、パフォーマンスは「このモデルはどの程度正確か?」という質問に答えます。つまり、モデルの予測はどの程度正確かということです。
permutation variable importances
特徴量の値を並べ替えた後のモデルの予測誤差の増加を評価する変数重要度の一種。順列変数重要度は、モデルに依存しない指標です。
パープレキシティ
モデルがタスクをどの程度達成しているかを測定する指標の 1 つ。たとえば、ユーザーがスマートフォンのキーボードで入力している単語の最初の数文字を読み取り、候補となる補完単語のリストを表示するタスクがあるとします。このタスクのパープレキシティ P は、ユーザーが入力しようとしている実際の単語をリストに含めるために必要な推測の数にほぼ等しくなります。
パープレキシティは、次のように交差エントロピーに関連しています。
陽性クラス
テスト対象のクラス。
たとえば、がんモデルのポジティブ クラスは「腫瘍」になります。メールの分類モデルのポジティブ クラスは「迷惑メール」になる可能性があります。
陰性クラスと比較してください。
PR AUC(PR 曲線の下の面積)
さまざまな分類しきい値の値に対して(再現率、適合率)の点をプロットして得られた、補間された適合率 / 再現率曲線の下の面積。
precision
「全陽性のラベルの中でモデルが正しく識別したラベルの数は?」という質問に回答する分類モデルの指標。
モデルが陽性クラスを予測したとき、予測が正しかった割合はどのくらいですか?
式は次のとおりです。
ここで
- 真陽性とは、モデルが陽性のクラスを正しく予測したことを意味します。
- 偽陽性とは、モデルが陽性クラスを誤って予測したことを意味します。
たとえば、モデルが 200 件のポジティブ予測を行ったとします。この 200 件の正の予測のうち:
- 150 件が真陽性でした。
- 50 件は誤検出でした。
この例の場合は、次のようになります。
詳細については、ML 集中講座の分類: 精度、再現率、適合率、関連指標をご覧ください。
k での適合率(precision@k)
ランク付けされた(順序付けされた)アイテムのリストを評価するための指標。Precision at k は、そのリストの最初の k 個の項目のうち「関連性がある」項目の割合を示します。具体的には、次のことが求められます。
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
k の値は、返されるリストの長さ以下にする必要があります。返されるリストの長さは計算に含まれません。
関連性は主観的なことが多く、人間の評価者の間でも、どの項目が関連性があるかについて意見が分かれることがよくあります。
比較対象日:
適合率と再現率の曲線
予測バイアス
ML モデルのバイアス項や、倫理と公平性におけるバイアスと混同しないようにしてください。
予測のパリティ
特定の分類モデルについて、考慮対象のサブグループの適合率が同等かどうかをチェックする公平性指標。
たとえば、大学の合格を予測するモデルの場合、リリパット人とブロブディンナグ人の適合率が同じであれば、国籍に関する予測パリティを満たします。
予測パリティは、予測率パリティとも呼ばれます。
予測パリティの詳細については、「公平性の定義の説明」(セクション 3.2.1)をご覧ください。
予測料金同等性
予測パリティの別名。
確率密度関数
特定の値を正確に持つデータサンプルの頻度を特定する関数。データセットの値が連続する浮動小数点数の場合、完全一致はほとんど発生しません。ただし、値 x から値 y までの確率密度関数を積分すると、x と y の間のデータサンプル数の期待値が得られます。
たとえば、平均が 200 で標準偏差が 30 の正規分布を考えてみましょう。211.4 ~ 218.7 の範囲に収まるデータサンプルがどの程度の頻度で発生するかを判断するには、正規分布の確率密度関数を 211.4 ~ 218.7 の範囲で積分します。
R
Reading Comprehension with Commonsense Reasoning Dataset(ReCoRD)
常識的な推論を行う LLM の能力を評価するためのデータセット。データセット内の各例には、次の 3 つのコンポーネントが含まれています。
- ニュース記事の 1 ~ 2 つの段落
- パッセージで明示的または暗黙的に識別されたエンティティのいずれかがマスクされているクエリ。
- 回答(マスクに含めるエンティティの名前)
例の完全なリストについては、ReCoRD をご覧ください。
ReCoRD は SuperGLUE アンサンブルのコンポーネントです。
RealToxicityPrompts
有害なコンテンツが含まれている可能性のある一連の文の始まりを含むデータセット。このデータセットを使用して、文を完成させるための有害でないテキストを生成する LLM の能力を評価します。通常、Perspective API を使用して、LLM がこのタスクをどの程度うまく実行できたかを判断します。
詳細については、RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models をご覧ください。
recall
「全陽性のラベルの中でモデルが正しく識別したラベルの数は?」という質問に回答する分類モデルの指標。
グラウンド トゥルースが陽性クラスだった場合、モデルが陽性クラスとして正しく識別した予測の割合はどのくらいですか?
式は次のとおりです。
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
ここで
- 真陽性とは、モデルが陽性のクラスを正しく予測したことを意味します。
- 偽陰性は、モデルが陰性クラスを誤って予測したことを意味します。
たとえば、モデルがグラウンド トゥルースが陽性クラスである例について 200 件の予測を行ったとします。これらの 200 個の予測のうち:
- 180 件が真陽性でした。
- 20 件が偽陰性でした。
この例の場合は、次のようになります。
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
詳細については、分類: 精度、再現率、適合率、関連指標をご覧ください。
上位 k 件の再現率(recall@k)
ランク付けされた(順序付けされた)アイテムのリストを出力するシステムを評価するための指標。再現率(k)は、返された関連アイテムの総数のうち、リストの最初の k 個のアイテムに含まれる関連アイテムの割合を示します。
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
k での精度とのコントラスト。
テキスト含意認識(RTE)
仮説がテキスト パッセージから含意(論理的に導出)できるかどうかを判断する LLM の能力を評価するためのデータセット。RTE 評価の各例は、次の 3 つの部分で構成されています。
- 通常はニュース記事や Wikipedia の記事からの抜粋
- 仮説
- 正解は次のいずれかです。
- True。つまり、仮説は文から導き出すことができる
- False。つまり、仮説は文から導き出すことができない
次に例を示します。
- 文章: ユーロは欧州連合の通貨です。
- 仮説: フランスでは通貨としてユーロが使用されている。
- 含意: フランスは欧州連合の一部であるため、True。
RTE は SuperGLUE アンサンブルのコンポーネントです。
ReCoRD
Reading Comprehension with Commonsense Reasoning Dataset の略語。
ROC(受信者操作特性)曲線
バイナリ分類におけるさまざまな分類しきい値に対する真陽性率と偽陽性率のグラフ。
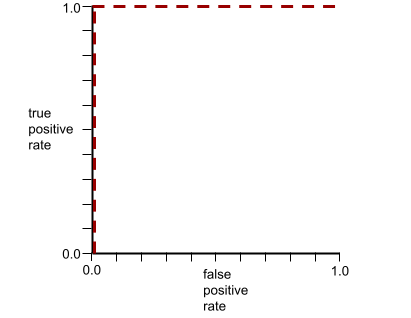
ROC 曲線の形状は、陽性クラスと陰性クラスを分離するバイナリ分類モデルの能力を示します。たとえば、バイナリ分類モデルがすべての陰性クラスとすべての陽性クラスを完全に分離するとします。
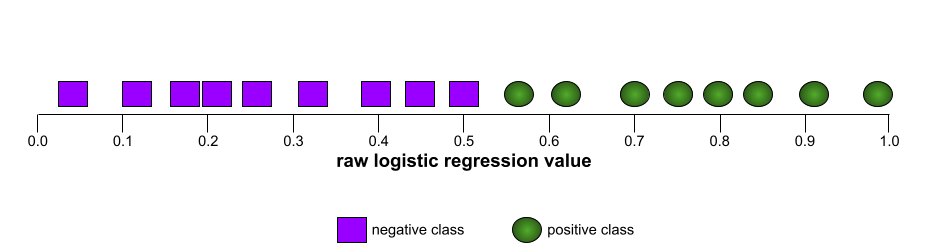
上記のモデルの ROC 曲線は次のようになります。
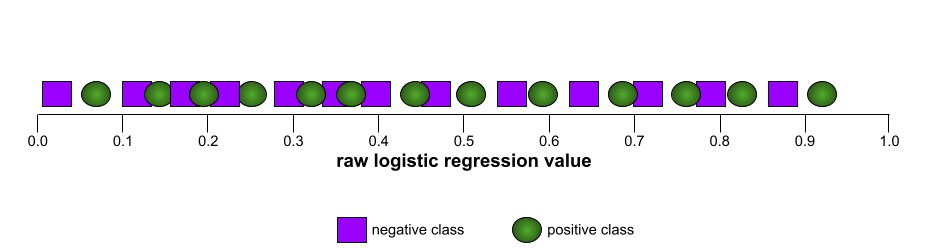
一方、次の図は、負のクラスと正のクラスをまったく分離できないひどいモデルのロジスティック回帰の生値をグラフ化したものです。
このモデルの ROC 曲線は次のようになります。
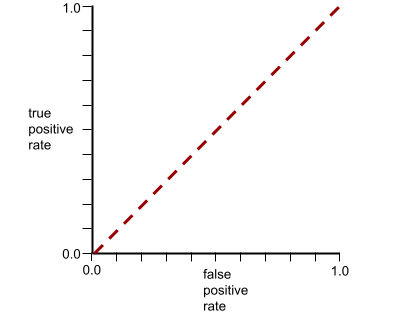
一方、現実の世界では、ほとんどのバイナリ分類モデルは陽性クラスと陰性クラスをある程度分離しますが、完全に分離することは通常ありません。したがって、一般的な ROC 曲線は、次の 2 つの極端なケースの中間に位置します。
ROC 曲線上の点のうち、(0.0,1.0) に最も近い点が、理論上は理想的な分類しきい値を特定します。ただし、理想的な分類しきい値の選択には、他のいくつかの現実世界の問題が影響します。たとえば、偽陰性の方が偽陽性よりもはるかに大きな問題を引き起こす可能性があります。
AUC という数値指標は、ROC 曲線を単一の浮動小数点値に要約します。
二乗平均平方根誤差(RMSE)
平均二乗誤差の平方根。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation の略)
自動要約モデルと機械翻訳モデルを評価する指標のファミリー。ROUGE 指標は、参照テキストが ML モデルの生成テキストとどの程度重複しているかを判断します。ROUGE ファミリーの各メンバーは、重複を異なる方法で測定します。ROUGE スコアが高いほど、ROUGE スコアが低い場合よりも参照テキストと生成されたテキストの類似性が高いことを示します。
通常、ROUGE ファミリーの各メンバーは次の指標を生成します。
- 適合率
- 再現率
- F1
詳細と例については、以下をご覧ください。
ROUGE-L
ROUGE ファミリーのメンバーで、参照テキストと生成されたテキストの最長共通部分列の長さに焦点を当てています。次の式は、ROUGE-L の再現率と適合率を計算します。
次に、F1 を使用して、ROUGE-L 再現率と ROUGE-L 適合率を 1 つの指標にロールアップできます。
ROUGE-L は、参照テキストと生成されたテキストの改行を無視するため、最長共通部分列が複数の文にまたがる可能性があります。参照テキストと生成されたテキストに複数の文が含まれている場合は、一般的に ROUGE-Lsum という ROUGE-L のバリエーションの方が優れた指標になります。ROUGE-Lsum は、パッセージ内の各文の最長共通部分列を特定し、それらの最長共通部分列の平均を計算します。
ROUGE-N
ROUGE ファミリー内の指標のセット。参照テキストと生成されたテキストの特定のサイズの共有 N グラムを比較します。次に例を示します。
- ROUGE-1 は、参照テキストと生成されたテキストで共有されているトークンの数を測定します。
- ROUGE-2 は、参照テキストと生成されたテキストで共有されるバイグラム(2 グラム)の数を測定します。
- ROUGE-3 は、参照テキストと生成されたテキストで共有されるトライグラム(3 グラム)の数を測定します。
次の数式を使用すると、ROUGE-N ファミリーの任意のメンバーの ROUGE-N 再現率と ROUGE-N 適合率を計算できます。
次に、F1 を使用して、ROUGE-N 再現率と ROUGE-N 適合率を 1 つの指標にロールアップできます。
ROUGE-S
スキップグラム マッチングを可能にする ROUGE-N の寛容な形式。つまり、ROUGE-N は完全に一致する N グラムのみをカウントしますが、ROUGE-S は 1 つ以上の単語で区切られた N グラムもカウントします。たとえば、次の点を考えます。
ROUGE-N を計算する場合、2 グラムの「白い雲」は「白いもくもくとした雲」と一致しません。ただし、ROUGE-S を計算する際は、白い雲は白い積雲と一致します。
決定係数
ラベルの分散が個々の特徴量または特徴量セットにどの程度起因するかを示す回帰指標。決定係数は 0 ~ 1 の値をとります。その解釈は次のとおりです。
- 決定係数 0 は、その特徴量セットがラベルの分散にまったく寄与していないことを意味します。
- 決定係数 1 は、ラベルの分散のすべてがその特徴量セットによるものであることを意味します。
- 0 ~ 1 の決定係数は、ラベルの分散が特定の特徴量または特徴量セットからどの程度予測可能であるかを示します。たとえば、決定係数が 0.10 の場合、ラベルの分散の 10% が特徴量セットによるものであることを意味します。決定係数が 0.20 の場合、20% が特徴量セットによるものであることを意味します。
決定係数は、モデルが予測した値とグラウンド トゥルースの間のピアソン相関係数の 2 乗です。
RTE
テキスト含意認識の略。
S
得点
候補生成フェーズで生成された各アイテムの値またはランキングを提供するレコメンデーション システムの一部。
類似性指標
クラスタリング アルゴリズムで、2 つの例がどの程度類似しているかを判断するために使用される指標。
スパース性
ベクトルまたは行列でゼロ(または null)に設定された要素の数を、そのベクトルまたは行列のエントリの総数で割った値。たとえば、98 個のセルに 0 が含まれる 100 要素の行列について考えてみましょう。スパース性の計算は次のとおりです。
特徴量のスパース性は特徴ベクトル内のスパース性を指し、モデルのスパース性はモデルの重みのスパース性を指します。
SQuAD
SQuAD: 100,000+ Questions for Machine Comprehension of Text という論文で紹介された Stanford Question Answering Dataset の頭字語。このデータセットの質問は、Wikipedia の記事について質問するユーザーから寄せられたものです。SQuAD の質問には回答があるものと、意図的に回答がないものがあります。したがって、SQuAD を使用して、LLM が次の両方を行う能力を評価できます。
- 回答できる質問に回答します。
- 回答できない質問を特定します。
完全一致と F1 の組み合わせは、SQuAD に対して LLM を評価する最も一般的な指標です。
二乗ヒンジ損失
ヒンジ損失の 2 乗。2 乗ヒンジ損失は、通常のヒンジ損失よりも外れ値に厳しいペナルティを科します。
二乗損失
L2 損失と同義。
SuperGLUE
LLM のテキストの理解と生成の全体的な能力を評価するためのデータセットのアンサンブル。アンサンブルは次のデータセットで構成されています。
- ブール値の質問(BoolQ)
- CommitmentBank(CB)
- もっともらしい選択肢(COPA)
- 複数文の読解(MultiRC)
- 常識的推論データセットによる読解(ReCoRD)
- テキスト含意認識(RTE)
- 文脈内の単語(WiC)
- Winograd Schema Challenge(WSC)
詳細については、SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems をご覧ください。
T
テスト損失
テストセットに対するモデルの損失を表す指標。モデルを構築する場合、通常はテスト損失を最小限に抑えようとします。テスト損失が小さいほど、トレーニング損失や検証損失が小さい場合よりも、品質シグナルが強くなるためです。
テスト損失とトレーニング損失または検証損失の間に大きな差がある場合は、正則化率を上げる必要があることを示している場合があります。
上位 k の精度
生成されたリストの最初の k 個の位置に「ターゲット ラベル」が表示される割合。リストは、パーソナライズされたおすすめや、softmaxで並べ替えられたアイテムのリストなどです。
上位 k の精度は、k での精度とも呼ばれます。
有害
コンテンツが誹謗中傷、脅迫、不快な内容である度合い。多くの ML モデルは、有害性を特定、測定、分類できます。これらのモデルのほとんどは、暴言のレベルや脅迫的な言葉のレベルなど、複数のパラメータに沿って有害性を特定します。
トレーニングの損失
特定のトレーニング反復処理中のモデルの損失を表す指標。たとえば、損失関数が平均二乗誤差であるとします。たとえば、10 回目の反復のトレーニング損失(平均二乗誤差)が 2.2 で、100 回目の反復のトレーニング損失が 1.9 であるとします。
損失曲線は、トレーニングの損失と反復回数をプロットしたものです。損失曲線は、トレーニングについて次のヒントを提供します。
- 右下がりの傾斜は、モデルが改善されていることを意味します。
- 上向きの傾斜は、モデルが悪化していることを意味します。
- 傾斜が平らな場合は、モデルが収束に達したことを意味します。
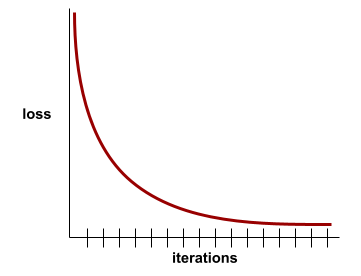
たとえば、次のやや理想化された損失曲線は、次のようになります。
- 初期の反復で急激な下降勾配が見られる。これは、モデルが急速に改善していることを意味します。
- トレーニングの終了近くまで徐々に平坦になる(ただし、まだ下降している)傾斜。これは、最初の反復処理よりもやや遅いペースでモデルの改善が継続していることを意味します。
- トレーニングの終わりに近づくにつれて傾斜が平らになり、収束を示しています。
トレーニング損失は重要ですが、汎化もご覧ください。
雑学の質問応答
LLM が雑学クイズに回答できるかどうかを評価するためのデータセット。各データセットには、雑学愛好家が作成した質問と回答のペアが含まれています。さまざまなデータセットは、次のようなさまざまなソースに基づいて作成されています。
- ウェブ検索(TriviaQA)
- Wikipedia(TriviaQA_wiki)
詳細については、TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension をご覧ください。
真陰性(TN)
モデルが陰性クラスを正しく予測した例。たとえば、特定のメール メッセージが迷惑メールではないとモデルが推論し、そのメール メッセージが実際に迷惑メールではない場合です。
真陽性(TP)
モデルが陽性のクラスを正しく予測した例。たとえば、特定のメール メッセージがスパムであるとモデルが推論し、そのメール メッセージが実際にスパムである場合です。
真陽性率(TPR)
再現率と同義。具体的には、次のことが求められます。
真陽性率は ROC 曲線の y 軸です。
Typologically Diverse Question Answering(TyDi QA)
質問に答える LLM の熟練度を評価するための大規模なデータセット。このデータセットには、さまざまな言語の質問と回答のペアが含まれています。
詳細については、TyDi QA: Typologically Diverse Languages での情報検索質問応答のベンチマークをご覧ください。
V
検証損失
トレーニングの特定の反復における検証セットでのモデルの損失を表す指標。
汎化曲線もご覧ください。
変数の重要度
各特徴のモデルに対する相対的な重要度を示すスコアのセット。
たとえば、住宅価格を推定する決定木について考えてみましょう。この決定木では、サイズ、年齢、スタイルの 3 つの特徴を使用するとします。3 つの特徴の変数重要度のセットが {size=5.8, age=2.5, style=4.7} と計算された場合、サイズは年齢やスタイルよりも決定木にとって重要です。
さまざまな変数重要度指標があり、ML の専門家はモデルのさまざまな側面について知ることができます。
W
Wasserstein 損失
敵対的生成ネットワークで一般的に使用される損失関数の 1 つ。生成されたデータの分布と実際のデータの間のアース ムーバー距離に基づいています。
WiC
Words in Context の略。
WikiLingua(wiki_lingua)
短い記事を要約する LLM の能力を評価するためのデータセット。WikiHow は、さまざまなタスクの実行方法を説明する記事の百科事典であり、記事と要約の両方の人間が作成したソースです。データセットの各エントリは次の要素で構成されます。
- 番号付きリストの各ステップの文章(段落)バージョンから、各ステップの冒頭の文を除いたものを追加して作成された記事。
- その記事の要約。番号付きリストの各ステップの冒頭の文で構成されます。
詳細については、WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization をご覧ください。
Winograd Schema Challenge(WSC)
代名詞が参照する名詞句を特定する LLM の能力を評価するための形式(またはその形式に準拠するデータセット)。
Winograd Schema Challenge の各エントリは、次の要素で構成されています。
- ターゲット代名詞を含む短い文章
- ターゲット代名詞
- 候補の名詞句と、その後に続く正解(ブール値)。ターゲット代名詞がこの候補を参照している場合、答えは True です。ターゲット代名詞がこの候補を参照していない場合、答えは False です。
次に例を示します。
- 文章: Mark は Pete に自分のことについて多くの嘘を語り、Pete はそれを本に書いた。もっと正直であるべきだった。
- 対象の代名詞: 彼
- 候補の名詞句:
- Mark: True。ターゲット代名詞は Mark を指しているため
- ピート: 誤り。代名詞がピーターを指していないため。
Winograd Schema Challenge は、SuperGLUE アンサンブルのコンポーネントです。
Words in Context(WiC)
LLM が文脈を使用して複数の意味を持つ単語を理解する能力を評価するためのデータセット。データセットの各エントリには次のものが含まれます。
- ターゲット単語を含む 2 つの文
- ターゲット単語
- 正解(ブール値)。
- True は、対象の単語が 2 つの文で同じ意味であることを意味します。
- False は、ターゲット単語が 2 つの文で異なる意味を持つことを意味します
次に例を示します。
- 2 つの文:
- 川底にはたくさんのゴミがあります。
- 寝るときはベッドの横に水の入ったグラスを置いています。
- 対象の単語: bed
- 正解: 誤り。2 つの文で対象語の意味が異なるため。
詳しくは、WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations をご覧ください。
Words in Context は、SuperGLUE アンサンブルのコンポーネントです。
WSC
Winograd Schema Challenge の略語。
X
XL-Sum(xlsum)
テキストの要約における LLM の熟練度を評価するためのデータセット。XL-Sum は、多くの言語でエントリを提供します。データセットの各エントリには次のものが含まれます。
- 英国放送協会(BBC)の記事。
- 記事の著者が書いた記事の概要。なお、要約には記事にない語句が含まれることがあります。
詳細については、XL-Sum: 44 言語の大規模な多言語抽象的要約をご覧ください。