Esta página contém termos do glossário de métricas. Para conferir todos os termos do glossário, clique aqui.
A
precisão
O número de previsões de classificação corretas dividido pelo número total de previsões. Ou seja:
Por exemplo, um modelo que fez 40 previsões corretas e 10 incorretas teria uma acurácia de:
A classificação binária fornece nomes específicos para as diferentes categorias de previsões corretas e incorretas. Assim, a fórmula de acurácia para classificação binária é a seguinte:
em que:
- TP é o número de verdadeiros positivos (previsões corretas).
- TN é o número de verdadeiros negativos (previsões corretas).
- FP é o número de falsos positivos (previsões incorretas).
- FN é o número de falsos negativos (previsões incorretas).
Compare e contraste a acurácia com a precisão e o recall.
Consulte Classificação: acurácia, recall, precisão e métricas relacionadas no Curso intensivo de machine learning para mais informações.
área sob a curva PR
Consulte AUC PR (área sob a curva PR).
área sob a curva ROC
Consulte AUC (área sob a curva ROC).
AUC (área sob a curva ROC)
Um número entre 0,0 e 1,0 que representa a capacidade de um modelo de classificação binária separar classes positivas de classes negativas. Quanto mais perto de 1,0 a AUC estiver, melhor será a capacidade do modelo de distinguir as classes.
Por exemplo, a ilustração a seguir mostra um modelo de classificação que separa perfeitamente as classes positivas (ovais verdes) das negativas (retângulos roxos). Esse modelo irrealisticamente perfeito tem uma AUC de 1,0:

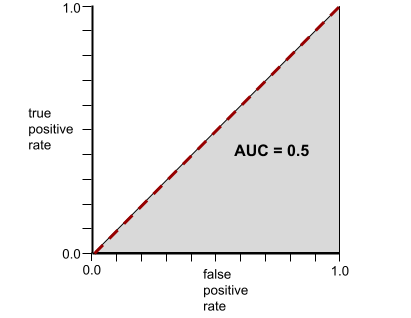
Por outro lado, a ilustração a seguir mostra os resultados de um modelo de classificação que gerou resultados aleatórios. Esse modelo tem uma AUC de 0,5:

Sim, o modelo anterior tem uma AUC de 0,5, não de 0,0.
A maioria dos modelos está em algum lugar entre os dois extremos. Por exemplo, o modelo a seguir separa positivos de negativos de alguma forma e, portanto, tem uma AUC entre 0,5 e 1,0:

A AUC ignora qualquer valor definido para o limiar de classificação. Em vez disso, a AUC considera todos os limiares de classificação possíveis.
Clique no ícone para saber mais sobre a relação entre AUC e curvas ROC.
A AUC representa a área sob uma curva ROC. Por exemplo, a curva ROC de um modelo que separa perfeitamente positivos de negativos tem esta aparência:
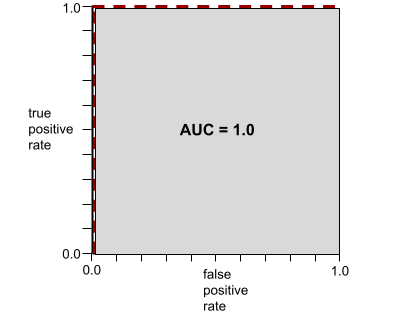
A AUC é a área da região cinza na ilustração anterior. Nesse caso incomum, a área é simplesmente o comprimento da região cinza (1,0) multiplicado pela largura da região cinza (1,0). Portanto, o produto de 1,0 e 1,0 gera uma AUC de exatamente 1,0, que é a pontuação mais alta possível.
Por outro lado, a curva ROC de um modelo de classificação que não consegue separar classes é assim: A área dessa região cinza é 0,5.
Uma curva ROC mais típica tem aproximadamente esta aparência:
Calcular a área abaixo dessa curva manualmente seria trabalhoso. Por isso, um programa geralmente calcula a maioria dos valores de AUC.
Consulte Classificação: ROC e AUC no Curso intensivo de machine learning para mais informações.
Precisão média em k
Uma métrica para resumir a performance de um modelo em um único comando que gera resultados classificados, como uma lista numerada de recomendações de livros. A precisão média em k é, bem, a média dos valores de precisão em k para cada resultado relevante. Portanto, a fórmula para a precisão média em k é:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
em que:
- \(n\) é o número de itens relevantes na lista.
Contraste com o recall em k.
B
baseline
Um modelo usado como ponto de referência para comparar o desempenho de outro modelo (normalmente, um mais complexo). Por exemplo, um modelo de regressão logística pode servir como um bom valor de referência para um modelo profundo.
Para um problema específico, a referência ajuda os desenvolvedores de modelos a quantificar o desempenho mínimo esperado que um novo modelo precisa alcançar para ser útil.
Perguntas booleanas (BoolQ)
Um conjunto de dados para avaliar a proficiência de um LLM em responder a perguntas de sim ou não. Cada um dos desafios no conjunto de dados tem três componentes:
- Uma consulta
- Uma passagem que implica a resposta à consulta.
- A resposta correta, que é sim ou não.
Exemplo:
- Consulta: Há usinas nucleares em Michigan?
- Trecho: ...três usinas nucleares fornecem a Michigan cerca de 30% da eletricidade.
- Resposta correta: sim
Os pesquisadores coletaram as perguntas de consultas anônimas e agregadas da Pesquisa Google e usaram páginas da Wikipédia para fundamentar as informações.
Para mais informações, consulte BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions.
O BoolQ é um componente do conjunto SuperGLUE.
BoolQ
Abreviação de Perguntas booleanas.
C
CB
Abreviação de CommitmentBank.
Pontuação F de n-gramas de caracteres (ChrF)
Uma métrica para avaliar modelos de tradução automática. A pontuação F de n-gramas de caracteres determina o grau em que os n-gramas no texto de referência se sobrepõem aos n-gramas no texto gerado de um modelo de ML.
A pontuação F de n-gramas de caracteres é semelhante às métricas das famílias ROUGE e BLEU, exceto que:
- A pontuação F de N-gramas de caracteres opera em N-gramas de caracteres.
- ROUGE e BLEU operam em N-gramas de palavras ou tokens.
Escolha de alternativas plausíveis (COPA, na sigla em inglês)
Um conjunto de dados para avaliar a capacidade de um LLM de identificar a melhor entre duas respostas alternativas para uma premissa. Cada um dos desafios no conjunto de dados consiste em três componentes:
- Uma premissa, que normalmente é uma declaração seguida de uma pergunta
- Duas respostas possíveis para a pergunta feita na premissa, uma correta e outra incorreta
- A resposta correta
Exemplo:
- Premissa:o homem quebrou o dedo do pé. Qual foi a CAUSA disso?
- Possíveis respostas:
- Ele fez um buraco na meia.
- Ele deixou cair um martelo no pé.
- Resposta correta:2
O COPA é um componente do conjunto SuperGLUE.
CommitmentBank (CB)
Um conjunto de dados para avaliar a proficiência de um LLM em determinar se o autor de uma passagem acredita em uma cláusula de destino dentro dessa passagem. Cada entrada no conjunto de dados contém:
- Um trecho
- Uma cláusula de destino dentro dessa passagem
- Um valor booleano que indica se o autor da passagem acredita que a cláusula de destino
Exemplo:
- Trecho:Que divertido ouvir Artemis rir. Ela é uma criança muito séria. Não sabia que ela tinha senso de humor.
- Cláusula de destino:ela tinha senso de humor
- Booleano: "True", o que significa que o autor acredita que a cláusula de destino
O CommitmentBank é um componente do conjunto SuperGLUE.
COPA
Abreviação de Escolha de alternativas plausíveis.
custo
Sinônimo de perda.
Imparcialidade contrafactual
Uma métrica de justiça que verifica se um modelo de classificação produz o mesmo resultado para um indivíduo e para outro idêntico ao primeiro, exceto em relação a um ou mais atributos sensíveis. A avaliação de um modelo de classificação para imparcialidade contrafactual é um método para identificar possíveis fontes de viés em um modelo.
Para mais informações, consulte:
- Imparcialidade: imparcialidade contrafactual no curso intensivo de machine learning.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness (em inglês)
entropia cruzada
Uma generalização da Log Perda para problemas de classificação multiclasse. A entropia cruzada quantifica a diferença entre duas distribuições de probabilidade. Consulte também perplexidade.
função de distribuição cumulativa (CDF)
Uma função que define a frequência de amostras menores ou iguais a um valor de destino. Por exemplo, considere uma distribuição normal de valores contínuos. Uma CDF informa que aproximadamente 50% das amostras devem ser menores ou iguais à média e que aproximadamente 84% das amostras devem ser menores ou iguais a um desvio padrão acima da média.
D
paridade demográfica
Uma métrica de imparcialidade que é satisfeita se os resultados da classificação de um modelo não dependem de um determinado atributo sensível.
Por exemplo, se os liliputianos e os brobdingnagianos se inscreverem na Universidade de Glubbdubdrib, a paridade demográfica será alcançada se a porcentagem de liliputianos admitidos for a mesma que a de brobdingnagianos, independente de um grupo ser, em média, mais qualificado que o outro.
Contraste com odds equalizadas e igualdade de oportunidades, que permitem que os resultados da classificação no agregado dependam de atributos sensíveis, mas não permitem que os resultados da classificação para determinados rótulos de informações empíricas especificados dependam de atributos sensíveis. Consulte "Como combater a discriminação com um aprendizado de máquina mais inteligente" para ver uma visualização que explora as compensações ao otimizar para a paridade demográfica.
Consulte Imparcialidade: paridade demográfica no Curso intensivo de machine learning para mais informações.
E
Distância de movimentação de terra (EMD, na sigla em inglês)
Uma medida da similaridade relativa de duas distribuições. Quanto menor a distância de movimentação de terra, mais semelhantes serão as distribuições.
distância de edição
Uma medição de como duas strings de texto são semelhantes entre si. No aprendizado de máquina, a distância de edição é útil pelos seguintes motivos:
- A distância de edição é fácil de calcular.
- A distância de edição pode comparar duas strings que se parecem.
- A distância de edição pode determinar o grau de semelhança entre diferentes strings e uma string específica.
Existem várias definições de distância de edição, cada uma usando diferentes operações de string. Consulte Distância de Levenshtein para conferir um exemplo.
função de distribuição cumulativa empírica (eCDF ou EDF)
Uma função de distribuição cumulativa com base em medições empíricas de um conjunto de dados real. O valor da função em qualquer ponto ao longo do eixo x é a fração de observações no conjunto de dados que são menores ou iguais ao valor especificado.
entropia
Na teoria da informação, uma descrição de como uma distribuição de probabilidade é imprevisível. Outra definição de entropia é a quantidade de informações que cada exemplo contém. Uma distribuição tem a maior entropia possível quando todos os valores de uma variável aleatória têm a mesma probabilidade.
A entropia de um conjunto com dois valores possíveis "0" e "1" (por exemplo, os rótulos em um problema de classificação binária) tem a seguinte fórmula:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
em que:
- H é a entropia.
- p é a fração de exemplos "1".
- q é a fração de exemplos "0". q = (1 - p)
- log geralmente é log2. Nesse caso, a unidade de entropia é um bit.
Por exemplo, suponha que:
- 100 exemplos contêm o valor "1"
- 300 exemplos contêm o valor "0"
Portanto, o valor de entropia é:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) - (0,75)log2(0,75) = 0,81 bits por exemplo
Um conjunto perfeitamente equilibrado (por exemplo, 200 "0"s e 200 "1"s) teria uma entropia de 1,0 bit por exemplo. À medida que um conjunto se torna mais desequilibrado, a entropia dele se aproxima de 0,0.
Nas árvores de decisão, a entropia ajuda a formular o ganho de informações para que o divisor selecione as condições durante o crescimento de uma árvore de decisão de classificação.
Compare a entropia com:
- impureza de Gini
- Função de perda de entropia cruzada
A entropia é geralmente chamada de entropia de Shannon.
Consulte Divisor exato para classificação binária com recursos numéricos no curso "Florestas de decisão" para mais informações.
igualdade de oportunidades
Uma métrica de imparcialidade para avaliar se um modelo está prevendo o resultado desejado de forma igualmente boa para todos os valores de um atributo sensível. Em outras palavras, se o resultado desejado para um modelo for a classe positiva, a meta seria ter a taxa de verdadeiro positivo igual para todos os grupos.
A igualdade de oportunidade está relacionada às chances equalizadas, que exigem que ambas as taxas de verdadeiro positivo e falso positivo sejam iguais para todos os grupos.
Suponha que a Universidade Glubbdubdrib admita liliputianos e brobdingnagianos em um programa rigoroso de matemática. As escolas de ensino médio de Lilliput oferecem um currículo robusto de aulas de matemática, e a grande maioria dos estudantes se qualifica para o programa universitário. As escolas secundárias de Brobdingnag não oferecem aulas de matemática, e, como resultado, muito menos estudantes se qualificam. A igualdade de oportunidades é satisfeita para o rótulo preferencial "admitido" em relação à nacionalidade (Lilliputian ou Brobdingnagian) se os estudantes qualificados tiverem a mesma probabilidade de serem admitidos, independentemente de serem Lilliputian ou Brobdingnagian.
Por exemplo, suponha que 100 liliputianos e 100 brobdingnagianos se inscrevam na Universidade de Glubbdubdrib, e as decisões de admissão sejam tomadas da seguinte forma:
Tabela 1. Candidatos liliputianos (90% são qualificados)
| Qualificado | Não qualificado | |
|---|---|---|
| Permitido | 45 | 3 |
| Recusado | 45 | 7 |
| Total | 90 | 10 |
|
Porcentagem de estudantes qualificados admitidos: 45/90 = 50% Porcentagem de estudantes não qualificados rejeitados: 7/10 = 70% Porcentagem total de estudantes de Lilliput admitidos: (45+3)/100 = 48% |
||
Tabela 2. Candidatos de Brobdingnag (10% são qualificados):
| Qualificado | Não qualificado | |
|---|---|---|
| Permitido | 5 | 9 |
| Recusado | 5 | 81 |
| Total | 10 | 90 |
|
Porcentagem de estudantes qualificados admitidos: 5/10 = 50% Porcentagem de estudantes não qualificados rejeitados: 81/90 = 90% Porcentagem total de estudantes de Brobdingnag admitidos: (5+9)/100 = 14% |
||
Os exemplos anteriores atendem à igualdade de oportunidades para a aceitação de estudantes qualificados, porque tanto os liliputianos quanto os brobdingnagianos têm 50% de chance de serem aceitos.
Embora a igualdade de oportunidade seja atendida, as duas métricas de imparcialidade a seguir não são:
- Paridade demográfica: os liliputianos e os brobdingnagianos são admitidos na universidade em taxas diferentes. 48% dos estudantes liliputianos são admitidos, mas apenas 14% dos estudantes brobdingnagianos são admitidos.
- Probabilidades igualadas: embora os estudantes qualificados de Lilliput e Brobdingnag tenham a mesma chance de serem aceitos, a restrição adicional de que os estudantes não qualificados de Lilliput e Brobdingnag tenham a mesma chance de serem rejeitados não é atendida. Os lilliputianos não qualificados têm uma taxa de rejeição de 70%, enquanto os brobdingnagianos não qualificados têm uma taxa de rejeição de 90%.
Consulte Imparcialidade: igualdade de oportunidades no Curso intensivo de machine learning para mais informações.
probabilidades igualadas
Uma métrica de justiça para avaliar se um modelo está prevendo resultados igualmente bem para todos os valores de um atributo sensível em relação à classe positiva e à classe negativa, e não apenas uma classe ou outra exclusivamente. Em outras palavras, tanto a taxa de verdadeiros positivos quanto a taxa de falsos negativos precisam ser iguais para todos os grupos.
A igualdade de chances está relacionada à igualdade de oportunidades, que se concentra apenas nas taxas de erro de uma única classe (positiva ou negativa).
Por exemplo, suponha que a Universidade Glubbdubdrib admita liliputianos e brobdingnagianos em um programa rigoroso de matemática. As escolas de ensino médio de Lilliput oferecem um currículo robusto de aulas de matemática, e a grande maioria dos estudantes se qualifica para o programa universitário. As escolas secundárias de Brobdingnag não oferecem aulas de matemática, e, como resultado, muito menos estudantes se qualificam. A igualdade de chances é satisfeita desde que, não importa se um candidato é um liliputiano ou um brobdingnagiano, se ele for qualificado, terá a mesma probabilidade de ser aceito no programa, e se não for qualificado, terá a mesma probabilidade de ser rejeitado.
Suponha que 100 liliputianos e 100 brobdingnagianos se inscrevam na Universidade de Glubbdubdrib, e as decisões de admissão sejam tomadas da seguinte forma:
Tabela 3. Candidatos liliputianos (90% são qualificados)
| Qualificado | Não qualificado | |
|---|---|---|
| Permitido | 45 | 2 |
| Recusado | 45 | 8 |
| Total | 90 | 10 |
|
Porcentagem de estudantes qualificados admitidos: 45/90 = 50% Porcentagem de estudantes não qualificados rejeitados: 8/10 = 80% Porcentagem total de estudantes de Lilliput admitidos: (45+2)/100 = 47% |
||
Tabela 4. Candidatos de Brobdingnag (10% são qualificados):
| Qualificado | Não qualificado | |
|---|---|---|
| Permitido | 5 | 18 |
| Recusado | 5 | 72 |
| Total | 10 | 90 |
|
Porcentagem de estudantes qualificados admitidos: 5/10 = 50% Porcentagem de estudantes não qualificados rejeitados: 72/90 = 80% Porcentagem total de estudantes de Brobdingnag admitidos: (5+18)/100 = 23% |
||
A condição de chances igualadas é atendida porque os estudantes qualificados de Lilliput e Brobdingnag têm uma chance de 50% de serem aceitos, e os não qualificados têm uma chance de 80% de serem rejeitados.
A probabilidade igualada é formalmente definida em "Equality of Opportunity in Supervised Learning" (em inglês) da seguinte forma: "o preditor Ŷ satisfaz a probabilidade igualada em relação ao atributo protegido A e ao resultado Y se Ŷ e A forem independentes, condicionalmente a Y".
avaliações
Usado principalmente como abreviação de avaliações de LLM. De modo geral, avaliações é uma abreviação de qualquer forma de avaliação.
Avaliação
O processo de medir a qualidade de um modelo ou comparar diferentes modelos entre si.
Para avaliar um modelo de machine learning supervisionado, normalmente você o compara a um conjunto de validação e a um conjunto de teste. Avaliar um LLM normalmente envolve avaliações mais amplas de qualidade e segurança.
correspondência exata
Uma métrica tudo ou nada em que a saída do modelo corresponde exatamente às informações empíricas ou ao texto de referência, ou não corresponde. Por exemplo, se a informação empírica for laranja, a única saída do modelo que atende à correspondência exata é laranja.
A correspondência exata também pode avaliar modelos cuja saída é uma sequência (uma lista classificada de itens). Em geral, a correspondência exata exige que a lista classificada gerada corresponda exatamente à verdade fundamental. Ou seja, cada item nas duas listas precisa estar na mesma ordem. No entanto, se as informações empíricas consistirem em várias sequências corretas, a correspondência exata só vai exigir que a saída do modelo corresponda a uma das sequências corretas.
Resumo extremo (xsum)
Um conjunto de dados para avaliar a capacidade de um LLM de resumir um único documento. Cada entrada no conjunto de dados consiste em:
- Um documento criado pela British Broadcasting Corporation (BBC).
- Um resumo de uma frase desse documento.
Para mais detalhes, consulte Não me dê os detalhes, apenas o resumo! Redes neurais convolucionais com reconhecimento de tema para sumarização extrema.
F
F1
Uma métrica de classificação binária "visualização completa" que depende da precisão e do recall. Esta é a fórmula:
métrica de imparcialidade
Uma definição matemática de "justiça" que pode ser medida. Algumas métricas de imparcialidade usadas com frequência incluem:
Muitas métricas de imparcialidade são mutuamente exclusivas. Consulte incompatibilidade das métricas de imparcialidade.
falso negativo (FN)
Um exemplo em que o modelo prevê incorretamente a classe negativa. Por exemplo, o modelo prevê que uma determinada mensagem de e-mail não é spam (a classe negativa), mas na verdade é spam.
taxa de falso negativo
A proporção de exemplos positivos reais para os quais o modelo previu incorretamente a classe negativa. A fórmula a seguir calcula a taxa de falsos negativos:
Consulte Limiares e a matriz de confusão no Curso intensivo de machine learning para mais informações.
falso positivo (FP)
Um exemplo em que o modelo prevê incorretamente a classe positiva. Por exemplo, o modelo prevê que uma determinada mensagem de e-mail é spam (a classe positiva), mas que essa mensagem não é spam.
Consulte Limiares e a matriz de confusão no Curso intensivo de machine learning para mais informações.
taxa de falso positivo (FPR)
A proporção de exemplos negativos reais para os quais o modelo previu incorretamente a classe positiva. A fórmula a seguir calcula a taxa de falsos positivos:
A taxa de falso positivo é o eixo x em uma curva ROC.
Consulte Classificação: ROC e AUC no Curso intensivo de machine learning para mais informações.
importâncias de atributos
Sinônimo de importâncias de variáveis.
modelo de fundação
Um modelo pré-treinado muito grande treinado em um conjunto de treinamento enorme e diversificado. Um modelo de fundação pode fazer o seguinte:
- Responder bem a uma ampla variedade de solicitações.
- Servir como um modelo de base para outros ajustes refinados ou personalizações.
Em outras palavras, um modelo de fundação já é muito capaz em um sentido geral, mas pode ser ainda mais personalizado para se tornar ainda mais útil para uma tarefa específica.
fração de sucessos
Uma métrica para avaliar o texto gerado de um modelo de ML. A fração de sucessos é o número de saídas de texto geradas "bem-sucedidas" dividido pelo número total de saídas de texto geradas. Por exemplo, se um modelo de linguagem grande gerar 10 blocos de código, cinco dos quais foram bem-sucedidos, a fração de sucessos será de 50%.
Embora a fração de sucessos seja útil em estatísticas, no aprendizado de máquina, essa métrica é usada principalmente para medir tarefas verificáveis, como geração de código ou problemas de matemática.
G
impureza de Gini
Uma métrica semelhante à entropia. Divisores usam valores derivados da impureza de Gini ou da entropia para compor condições para classificação árvores de decisão. O ganho de informação é derivado da entropia. Não existe um termo equivalente universalmente aceito para a métrica derivada da impureza de Gini. No entanto, essa métrica sem nome é tão importante quanto o ganho de informação.
A impureza de Gini também é chamada de índice de Gini ou simplesmente Gini.
H
perda de articulação
Uma família de funções de perda para classificação projetada para encontrar a fronteira de decisão o mais distante possível de cada exemplo de treinamento, maximizando assim a margem entre os exemplos e a fronteira. KSVMs usam perda de articulação (ou uma função relacionada, como perda de articulação quadrática). Para classificação binária, a função de perda de articulação é definida da seguinte forma:
em que y é o rótulo verdadeiro, -1 ou +1, e y' é a saída bruta do modelo de classificação:
Consequentemente, um gráfico de perda de articulação versus (y * y') tem esta aparência:

I
incompatibilidade das métricas de imparcialidade
A ideia de que algumas noções de justiça são mutuamente incompatíveis e não podem ser atendidas simultaneamente. Por isso, não há uma única métrica universal para quantificar a imparcialidade que possa ser aplicada a todos os problemas de ML.
Embora isso possa parecer desencorajador, a incompatibilidade das métricas de imparcialidade não significa que os esforços de imparcialidade são inúteis. Em vez disso, ela sugere que a imparcialidade seja definida dentro do contexto de um determinado problema de ML, com o objetivo de evitar danos específicos aos casos de uso.
Consulte "On the (im)possibility of fairness" (em inglês) para uma discussão mais detalhada sobre a incompatibilidade das métricas de imparcialidade.
justiça individual
Uma métrica de justiça que verifica se indivíduos semelhantes são classificados de maneira semelhante. Por exemplo, a Academia Brobdingnagian pode querer satisfazer a justiça individual garantindo que dois estudantes com notas idênticas e pontuações de testes padronizados tenham a mesma probabilidade de serem aceitos.
A imparcialidade individual depende totalmente de como você define "similaridade" (neste caso, notas e resultados de testes). Você pode correr o risco de introduzir novos problemas de imparcialidade se sua métrica de similaridade não considerar informações importantes, como o rigor do currículo de um estudante.
Consulte "Fairness Through Awareness" (em inglês) para uma discussão mais detalhada sobre a justiça individual.
ganho de informação
Em florestas de decisão, a diferença entre a entropia de um nó e a soma ponderada (pelo número de exemplos) da entropia dos nós filhos. A entropia de um nó é a entropia dos exemplos nesse nó.
Por exemplo, considere os seguintes valores de entropia:
- entropia do nó pai = 0,6
- entropia de um nó filho com 16 exemplos relevantes = 0,2
- entropia de outro nó filho com 24 exemplos relevantes = 0,1
Portanto, 40% dos exemplos estão em um nó filho e 60% estão no outro. Assim:
- Soma ponderada da entropia dos nós filhos = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Portanto, o ganho de informação é:
- Ganho de informação = entropia do nó pai - soma ponderada da entropia dos nós filhos
- ganho de informação = 0,6 - 0,14 = 0,46
A maioria dos divisores tenta criar condições que maximizam o ganho de informações.
concordância entre avaliadores
Uma medida de quantas vezes os avaliadores humanos concordam ao realizar uma tarefa. Se os avaliadores discordarem, talvez seja necessário melhorar as instruções da tarefa. Também chamado de concordância entre rotuladores ou confiabilidade entre avaliadores. Consulte também Kappa de Cohen, uma das medidas de concordância entre avaliadores mais usadas.
Consulte Dados categóricos: problemas comuns no Curso intensivo de machine learning para mais informações.
L
Perda L1
Uma função de perda que calcula o valor absoluto da diferença entre os valores reais de rótulo e os valores previstos por um modelo. Por exemplo, este é o cálculo da perda L1 para um lote de cinco exemplos:
| Valor real do exemplo | Valor previsto do modelo | Valor absoluto de delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = perda L1 | ||
A perda L1 é menos sensível a outliers do que a perda L2.
O erro médio absoluto é a perda média L1 por exemplo.
Consulte Regressão linear: perda no Curso intensivo de machine learning para mais informações.
Perda L2
Uma função de perda que calcula o quadrado da diferença entre os valores reais de rótulo e os valores previstos por um modelo. Por exemplo, este é o cálculo da perda L2 para um lote de cinco exemplos:
| Valor real do exemplo | Valor previsto do modelo | Quadrado de delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = perda L2 | ||
Devido ao uso de quadrados, a perda L2 aumenta a influência de outliers. Ou seja, a perda L2 reage mais fortemente a previsões ruins do que a perda L1. Por exemplo, a perda L1 para o lote anterior seria 8 em vez de 16. Uma única conta atípica representa 9 das 16.
Modelos de regressão geralmente usam a perda L2 como função de perda.
O erro quadrático médio é a perda média de L2 por exemplo. Perda quadrática é outro nome para perda L2.
Consulte Regressão logística: perda e regularização no Curso intensivo de machine learning para mais informações.
Avaliações de LLM
Um conjunto de métricas e comparativos de mercado para avaliar a performance de modelos de linguagem grandes (LLMs). Em um nível alto, as avaliações de LLM:
- Ajudar os pesquisadores a identificar áreas em que os LLMs precisam melhorar.
- São úteis para comparar diferentes LLMs e identificar o melhor para uma tarefa específica.
- Ajudar a garantir que os LLMs sejam seguros e éticos para uso.
Consulte Modelos de linguagem grandes (LLMs) no Curso intensivo de machine learning para mais informações.
perda
Durante o treinamento de um modelo supervisionado, uma medida de quanto uma previsão do modelo se distancia do rótulo.
Uma função de perda calcula a perda.
Consulte Regressão linear: perda no Curso intensivo de machine learning para mais informações.
função de perda
Durante o treinamento ou teste, uma função matemática que calcula a perda em um lote de exemplos. Uma função de perda retorna uma perda menor para modelos que fazem boas previsões do que para modelos que fazem previsões ruins.
O objetivo do treinamento geralmente é minimizar a perda retornada por uma função de perda.
Existem muitos tipos diferentes de funções de perda. Escolha a função de perda adequada para o tipo de modelo que você está criando. Exemplo:
- A perda L2 (ou erro quadrático médio) é a função de perda da regressão linear.
- A Log Perda é a função de perda para regressão logística.
M
MBPP
Abreviação de Mostly Basic Python Problems.
Erro médio absoluto (MAE)
A perda média por exemplo quando a perda L1 é usada. Calcule o erro médio absoluto da seguinte forma:
- Calcula a perda L1 para um lote.
- Divida a perda L1 pelo número de exemplos no lote.
Por exemplo, considere o cálculo da perda L1 no seguinte lote de cinco exemplos:
| Valor real do exemplo | Valor previsto do modelo | Perda (diferença entre o valor real e o previsto) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = perda L1 | ||
Portanto, a perda L1 é 8 e o número de exemplos é 5. Portanto, o erro absoluto médio é:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Compare o erro médio absoluto com o erro quadrático médio e a raiz do erro quadrático médio.
Precisão média em k (mAP@k)
A média estatística de todas as pontuações de precisão média em k em um conjunto de dados de validação. Um uso da precisão média em k é julgar a qualidade das recomendações geradas por um sistema de recomendação.
Embora a frase "média média" pareça redundante, o nome da métrica é adequado. Afinal, essa métrica encontra a média de vários valores de precisão média em k.
Erro quadrático médio (EQM)
A perda média por exemplo quando a perda L2 é usada. Calcule o erro quadrático médio da seguinte forma:
- Calcula a perda L2 de um lote.
- Divida a perda L2 pelo número de exemplos no lote.
Por exemplo, considere a perda no seguinte lote de cinco exemplos:
| Valor real | Previsão do modelo | Perda | Perda quadrática |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = perda L2 | |||
Portanto, o erro quadrático médio é:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
O erro quadrático médio é um otimizador de treinamento popular, principalmente para regressão linear.
Contraste o erro quadrático médio com o erro médio absoluto e a raiz do erro quadrático médio.
O TensorFlow Playground usa o erro quadrático médio para calcular os valores de perda.
métrica
Uma estatística importante para você.
Um objetivo é uma métrica que um sistema de machine learning tenta otimizar.
API Metrics (tf.metrics)
Uma API do TensorFlow para avaliar modelos. Por exemplo, tf.metrics.accuracy determina a frequência com que as previsões de um modelo correspondem aos rótulos.
perda minimax
Uma função de perda para redes adversárias generativas, com base na entropia cruzada entre a distribuição de dados gerados e dados reais.
A perda de minimax é usada no primeiro artigo para descrever redes generativas adversárias.
Consulte Funções de perda no curso de redes adversárias generativas para mais informações.
capacidade do modelo
A complexidade dos problemas que um modelo pode aprender. Quanto mais complexos forem os problemas que um modelo pode aprender, maior será a capacidade dele. A capacidade de um modelo geralmente aumenta com o número de parâmetros. Para uma definição formal da capacidade de um modelo de classificação, consulte Dimensão VC.
Mostly Basic Python Problems (MBPP)
Um conjunto de dados para avaliar a proficiência de um LLM na geração de código Python. O Mostly Basic Python Problems oferece cerca de 1.000 problemas de programação criados por colaboradores. Cada problema no conjunto de dados contém:
- Uma descrição da tarefa
- Código da solução
- Três casos de teste automatizados
N
classe negativa
Na classificação binária, uma classe é chamada de positiva e a outra de negativa. A classe positiva é o objeto ou evento que o modelo está testando, e a classe negativa é a outra possibilidade. Exemplo:
- A classe negativa em um teste médico pode ser "sem tumor".
- A classe negativa em um modelo de classificação de e-mail pode ser "não é spam".
Contraste com a classe positiva.
O
objetivo
Uma métrica que seu algoritmo está tentando otimizar.
função objetiva
A fórmula matemática ou métrica que um modelo visa otimizar. Por exemplo, a função objetiva da regressão linear geralmente é a perda quadrática média. Assim, ao treinar um modelo de regressão linear, o objetivo é minimizar a perda quadrática média.
Em alguns casos, a meta é maximizar a função objetiva. Por exemplo, se a função objetiva for a acurácia, a meta será maximizar a acurácia.
Consulte também perda.
P
pass at k (pass@k)
Uma métrica para determinar a qualidade do código (por exemplo, Python) que um modelo de linguagem grande gera. Mais especificamente, "pass at k" informa a probabilidade de que pelo menos um bloco de código gerado entre k blocos de código gerados passe em todos os testes de unidade.
Os modelos de linguagem grandes geralmente têm dificuldade para gerar um bom código para problemas de programação complexos. Os engenheiros de software se adaptam a esse problema pedindo ao modelo de linguagem grande para gerar várias (k) soluções para o mesmo problema. Em seguida, os engenheiros de software testam cada uma das soluções com testes de unidade. O cálculo da aprovação em k depende do resultado dos testes de unidade:
- Se uma ou mais dessas soluções passarem no teste de unidade, o LLM passará no desafio de geração de código.
- Se nenhuma das soluções passar no teste de unidade, o LLM falhará no desafio de geração de código.
A fórmula para aprovação em k é a seguinte:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
Em geral, valores mais altos de k produzem pontuações mais altas de aprovação em k. No entanto, valores mais altos de k exigem mais recursos de teste de unidade e modelo de linguagem grande.
desempenho
Termo sobrecarregado com os seguintes significados:
- O significado padrão na engenharia de software. Ou seja, qual a velocidade (ou eficiência) de execução desse software?
- O significado no machine learning. Aqui, a performance responde à seguinte pergunta: quão correto é este modelo? Ou seja, quão boas são as previsões do modelo?
Importâncias de variáveis de troca
Um tipo de importância da variável que avalia o aumento no erro de previsão de um modelo após a troca dos valores do atributo. A importância da variável de permutação é uma métrica independente do modelo.
perplexidade
Uma medida de como um modelo está realizando a tarefa. Por exemplo, suponha que sua tarefa seja ler as primeiras letras de uma palavra que um usuário está digitando em um teclado de smartphone e oferecer uma lista de possíveis palavras de conclusão. A perplexidade, P, para essa tarefa é aproximadamente o número de palpites que você precisa oferecer para que sua lista contenha a palavra real que o usuário está tentando digitar.
A perplexidade está relacionada à entropia cruzada da seguinte maneira:
classe positiva
A classe que você está testando.
Por exemplo, a classe positiva em um modelo de câncer pode ser "tumor". A classe positiva em um modelo de classificação de e-mail pode ser "spam".
Contraste com a classe negativa.
AUC PR (área sob a curva PR)
Área sob a curva de precisão-recall interpolada, obtida ao representar pontos (recall, precisão) para diferentes valores do limiar de classificação.
precision
Uma métrica para modelos de classificação que responde à seguinte pergunta:
Quando o modelo previu a classe positiva, qual foi a porcentagem de previsões corretas?
Esta é a fórmula:
em que:
- verdadeiro positivo significa que o modelo previu corretamente a classe positiva.
- falso positivo significa que o modelo previu incorretamente a classe positiva.
Por exemplo, suponha que um modelo tenha feito 200 previsões positivas. Das 200 previsões positivas:
- 150 eram verdadeiros positivos.
- 50 eram falsos positivos.
Neste caso:
Contraste com acurácia e recall.
Consulte Classificação: acurácia, recall, precisão e métricas relacionadas no Curso intensivo de machine learning para mais informações.
precisão em k (precision@k)
Uma métrica para avaliar uma lista classificada (ordenada) de itens. A precisão em k identifica a fração dos primeiros k itens na lista que são "relevantes". Ou seja:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
O valor de k precisa ser menor ou igual ao tamanho da lista retornada. O comprimento da lista retornada não faz parte do cálculo.
A relevância costuma ser subjetiva. Até mesmo avaliadores humanos especializados discordam sobre quais itens são relevantes.
Comparar com:
curva de precisão/recall
Uma curva de precisão versus recall em diferentes limiares de classificação.
viés de previsão
Um valor que indica a distância entre a média das previsões e a média dos rótulos no conjunto de dados.
Não confundir com o termo de viés em modelos de machine learning ou com o viés em ética e imparcialidade.
paridade preditiva
Uma métrica de imparcialidade que verifica se, para um determinado modelo de classificação, as taxas de precisão são equivalentes para os subgrupos em consideração.
Por exemplo, um modelo que prevê a aceitação na faculdade satisfaria a paridade preditiva para nacionalidade se a taxa de precisão fosse a mesma para liliputianos e brobdingnagianos.
Às vezes, a paridade preditiva também é chamada de paridade de taxa preditiva.
Consulte "Explicação das definições de justiça" (seção 3.2.1) para uma discussão mais detalhada sobre a paridade preditiva.
paridade de taxa preditiva
Outro nome para paridade preditiva.
função da densidade de probabilidade
Uma função que identifica a frequência de amostras de dados com exatamente um valor específico. Quando os valores de um conjunto de dados são números de usar pontos flutuantes contínuos, as correspondências exatas raramente ocorrem. No entanto, integrar uma função de densidade de probabilidade do valor x ao valor y gera a frequência esperada de amostras de dados entre x e y.
Por exemplo, considere uma distribuição normal com média de 200 e desvio padrão de 30. Para determinar a frequência esperada de amostras de dados que estão no intervalo de 211,4 a 218,7, é possível integrar a função de densidade de probabilidade de uma distribuição normal de 211,4 a 218,7.
R
Interpretação de texto com o conjunto de dados de raciocínio de senso comum (ReCoRD)
Um conjunto de dados para avaliar a capacidade de um LLM de realizar raciocínio de senso comum. Cada exemplo no conjunto de dados contém três componentes:
- Um ou dois parágrafos de uma matéria
- Uma consulta em que uma das entidades identificadas explícita ou implicitamente na passagem está mascarada.
- A resposta (o nome da entidade que pertence à máscara)
Consulte ReCoRD para ver uma lista extensa de exemplos.
O ReCoRD é um componente do conjunto SuperGLUE.
RealToxicityPrompts
Um conjunto de dados que contém um conjunto de inícios de frases que podem ter conteúdo tóxico. Use esse conjunto de dados para avaliar a capacidade de um LLM de gerar texto não tóxico para completar a frase. Normalmente, você usa a API Perspective para determinar o desempenho do LLM nessa tarefa.
Consulte RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models para mais detalhes.
recall
Uma métrica para modelos de classificação que responde à seguinte pergunta:
Quando a informação empírica era a classe positiva, qual porcentagem de previsões o modelo identificou corretamente como a classe positiva?
Esta é a fórmula:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
em que:
- verdadeiro positivo significa que o modelo previu corretamente a classe positiva.
- Um falso negativo significa que o modelo previu incorretamente a classe negativa.
Por exemplo, suponha que seu modelo tenha feito 200 previsões em exemplos para os quais a verdade fundamental era a classe positiva. Das 200 previsões:
- 180 eram verdadeiros positivos.
- 20 eram falsos negativos.
Neste caso:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Consulte Classificação: acurácia, recall, precisão e métricas relacionadas para mais informações.
recall em k (recall@k)
Uma métrica para avaliar sistemas que geram uma lista classificada (ordenada) de itens. O recall em k identifica a fração de itens relevantes nos primeiros k itens da lista em relação ao número total de itens relevantes retornados.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Contraste com precisão em k.
Reconhecimento de implicação textual (RTE, na sigla em inglês)
Um conjunto de dados para avaliar a capacidade de um LLM de determinar se uma hipótese pode ser deduzida (extraída logicamente) de uma passagem de texto. Cada exemplo em uma avaliação de RTE consiste em três partes:
- Um trecho, geralmente de notícias ou artigos da Wikipédia
- Uma hipótese
- A resposta correta, que é:
- Verdadeiro, ou seja, a hipótese pode ser deduzida da passagem
- Falso, ou seja, a hipótese não pode ser inferida da passagem
Exemplo:
- Trecho:o euro é a moeda da União Europeia.
- Hipótese:a França usa o euro como moeda.
- Entailment:verdadeiro, porque a França faz parte da União Europeia.
O RTE é um componente do conjunto SuperGLUE.
ReCoRD
Abreviação de Reading Comprehension with Commonsense Reasoning Dataset.
Curva ROC
Um gráfico da taxa de verdadeiro positivo em relação à taxa de falso positivo para diferentes limiares de classificação na classificação binária.
O formato de uma curva ROC sugere a capacidade de um modelo de classificação binária de separar classes positivas de negativas. Suponha, por exemplo, que um modelo de classificação binária separe perfeitamente todas as classes negativas de todas as classes positivas:
A curva ROC do modelo anterior é assim:
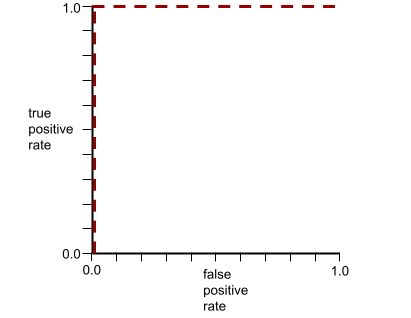
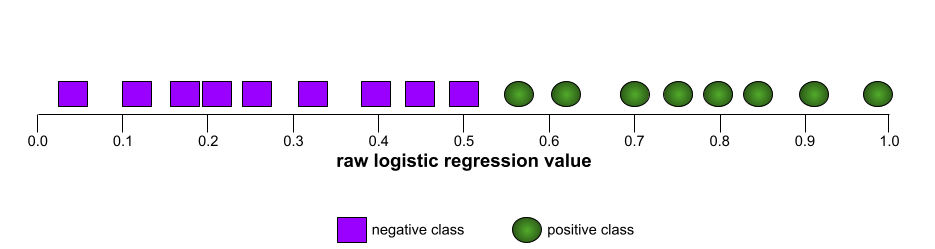
Em contraste, a ilustração a seguir mostra os valores brutos de regressão logística para um modelo ruim que não consegue separar classes negativas de positivas:
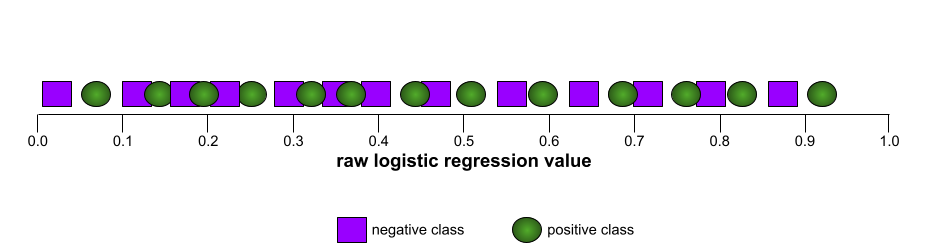
A curva ROC para esse modelo é assim:
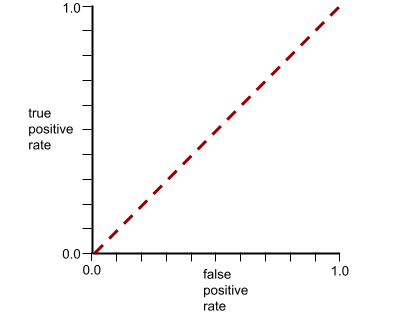
Enquanto isso, no mundo real, a maioria dos modelos de classificação binária separa as classes positivas e negativas até certo ponto, mas geralmente não de forma perfeita. Assim, uma curva ROC típica fica entre os dois extremos:
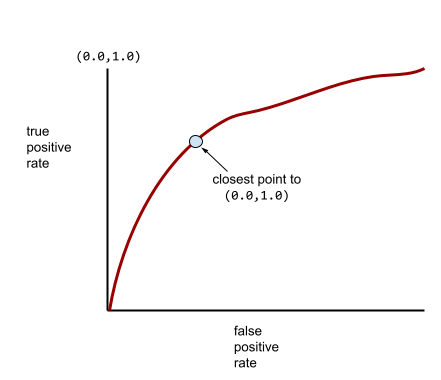
O ponto em uma curva ROC mais próximo de (0,0, 1,0) identifica teoricamente o limite de classificação ideal. No entanto, vários outros problemas do mundo real influenciam a seleção do limite de classificação ideal. Por exemplo, talvez os falsos negativos causem muito mais problemas do que os falsos positivos.
Uma métrica numérica chamada AUC resume a curva ROC em um único valor de ponto flutuante.
Raiz do erro quadrático médio (RMSE)
A raiz quadrada do erro quadrático médio.
Recall-Oriented Understudy for Gisting Evaluation (ROUGE, na sigla em inglês)
Uma família de métricas que avaliam modelos de resumo automático e tradução automática. As métricas ROUGE determinam o grau em que um texto de referência se sobrepõe ao texto gerado de um modelo de ML. Cada membro da família ROUGE mede a sobreposição de uma maneira diferente. Pontuações ROUGE mais altas indicam mais similaridade entre o texto de referência e o texto gerado do que pontuações ROUGE mais baixas.
Cada membro da família ROUGE geralmente gera as seguintes métricas:
- Precisão
- Recall
- F1
Para detalhes e exemplos, consulte:
ROUGE-L
Um membro da família ROUGE (em inglês) focado no comprimento da maior subsequência comum no texto de referência e no texto gerado. As fórmulas a seguir calculam o recall e a precisão para ROUGE-L:
Em seguida, use F1 para resumir o recall e a precisão do ROUGE-L em uma única métrica:
O ROUGE-L ignora todas as novas linhas no texto de referência e no texto gerado. Assim, a maior subsequência comum pode abranger várias frases. Quando o texto de referência e o texto gerado envolvem várias frases, uma variação do ROUGE-L chamada ROUGE-Lsum geralmente é uma métrica melhor. O ROUGE-Lsum determina a maior subsequência comum para cada frase em um trecho e calcula a média dessas maiores subsequências comuns.
ROUGE-N
Um conjunto de métricas da família ROUGE que compara os N-gramas compartilhados de um determinado tamanho no texto de referência e no texto gerado. Exemplo:
- ROUGE-1 mede o número de tokens compartilhados no texto de referência e no texto gerado.
- ROUGE-2 mede o número de bigramas (2-gramas) compartilhados no texto de referência e no texto gerado.
- ROUGE-3 mede o número de trigramas (3-gramas) compartilhados no texto de referência e no texto gerado.
Você pode usar as seguintes fórmulas para calcular o recall e a precisão de ROUGE-N para qualquer membro da família ROUGE-N:
Em seguida, use F1 para agregar o recall e a precisão do ROUGE-N em uma única métrica:
ROUGE-S
Uma forma tolerante de ROUGE-N que permite a correspondência de skip-gram. Ou seja, o ROUGE-N conta apenas N-gramas que correspondem exatamente, mas o ROUGE-S também conta N-gramas separados por uma ou mais palavras. Por exemplo, considere o seguinte:
- texto de referência: Nuvens brancas
- texto gerado: White billowing clouds
Ao calcular o ROUGE-N, o 2-grama Nuvens brancas não corresponde a Nuvens brancas e onduladas. No entanto, ao calcular o ROUGE-S, Nuvens brancas corresponde a Nuvens brancas e onduladas.
R ao quadrado
Uma métrica de regressão que indica o quanto da variação em um rótulo se deve a um atributo individual ou a um conjunto de atributos. O R ao quadrado é um valor entre 0 e 1, que pode ser interpretado da seguinte maneira:
- Um R ao quadrado de 0 significa que nada da variação de um rótulo se deve ao conjunto de atributos.
- Um R ao quadrado de 1 significa que toda a variação de um rótulo se deve ao conjunto de atributos.
- Um R ao quadrado entre 0 e 1 indica o quanto da variação de um rótulo pode ser previsto a partir de um atributo específico ou do conjunto de atributos. Por exemplo, um R ao quadrado de 0,10 significa que 10% da variância no rótulo se deve ao conjunto de atributos, um R ao quadrado de 0,20 significa que 20% se deve ao conjunto de atributos e assim por diante.
R ao quadrado é o quadrado do coeficiente de correlação de Pearson entre os valores previstos por um modelo e a verdade fundamental.
RTE
Abreviação de Recognizing Textual Entailment.
S
em lote
A parte de um sistema de recomendação que fornece um valor ou classificação para cada item produzido pela fase de geração de candidatos.
medida de similaridade
Em algoritmos de clustering, a métrica usada para determinar o grau de semelhança entre dois exemplos.
esparsidade
O número de elementos definidos como zero (ou nulo) em um vetor ou matriz dividido pelo número total de entradas nesse vetor ou matriz. Por exemplo, considere uma matriz de 100 elementos em que 98 células contêm zero. O cálculo da escassez é o seguinte:
A esparsidade de atributos se refere à esparsidade de um vetor de atributos, e a esparsidade de modelo se refere à esparsidade dos pesos do modelo.
SQuAD
Acrônimo de Stanford Question Answering Dataset, apresentado no artigo SQuAD: 100.000+ Questions for Machine Comprehension of Text. As perguntas neste conjunto de dados são de pessoas que fazem perguntas sobre artigos da Wikipédia. Algumas perguntas no SQuAD têm respostas, mas outras não têm intencionalmente. Portanto, é possível usar o SQuAD para avaliar a capacidade de um LLM de fazer o seguinte:
- Responda às perguntas que podem ser respondidas.
- Identifique perguntas que não podem ser respondidas.
Correspondência exata em combinação com F1 são as métricas mais comuns para avaliar LLMs em relação ao SQuAD.
perda de articulação quadrática
O quadrado da perda de articulação. A perda de articulação quadrática penaliza os outliers com mais rigor do que a perda de articulação regular.
perda quadrática
Sinônimo de perda L2.
SuperGLUE
Um conjunto de dados para classificar a capacidade geral de um LLM de entender e gerar texto. O conjunto é composto pelos seguintes conjuntos de dados:
- Perguntas booleanas (BoolQ)
- CommitmentBank (CB)
- Escolha de alternativas plausíveis (COPA)
- Interpretação de texto com várias frases (MultiRC)
- Conjunto de dados de interpretação de texto com raciocínio de senso comum (ReCoRD)
- Reconhecimento de implicação textual (RTE)
- Palavras no contexto (WiC)
- Desafio do esquema de Winograd (WSC)
Para mais detalhes, consulte SuperGLUE: um comparativo de mercado mais consistente para sistemas de compreensão de linguagem de uso geral.
T
perda de teste
Uma métrica que representa a perda de um modelo em relação ao conjunto de teste. Ao criar um modelo, geralmente você tenta minimizar a perda de teste. Isso porque uma perda de teste baixa é um indicador de qualidade mais forte do que uma perda de treinamento ou validação baixa.
Uma grande diferença entre a perda de teste e a perda de treinamento ou validação às vezes sugere que você precisa aumentar a taxa de regularização.
Acurácia Top-K
A porcentagem de vezes que um "rótulo de destino" aparece nas primeiras k posições das listas geradas. As listas podem ser recomendações personalizadas ou uma lista de itens ordenados por softmax.
A acurácia Top-k também é conhecida como acurácia em k.
conteúdo tóxico
O grau em que o conteúdo é abusivo, ameaçador ou ofensivo. Muitos modelos de aprendizado de máquina podem identificar, medir e classificar a toxicidade. A maioria desses modelos identifica a toxicidade em vários parâmetros, como o nível de linguagem abusiva e ameaçadora.
perda de treinamento
Uma métrica que representa a perda de um modelo durante uma iteração de treinamento específica. Por exemplo, suponha que a função de perda seja erro quadrático médio. Talvez a perda de treinamento (o erro quadrático médio) da 10ª iteração seja 2,2, e a perda de treinamento da 100ª iteração seja 1,9.
Uma curva de perda representa a perda de treinamento em relação ao número de iterações. Uma curva de perda fornece as seguintes dicas sobre o treinamento:
- Uma inclinação para baixo significa que o modelo está melhorando.
- Uma inclinação para cima significa que o modelo está piorando.
- Uma inclinação plana significa que o modelo atingiu a convergência.
Por exemplo, a curva de perda um pouco idealizada a seguir mostra:
- Uma inclinação acentuada para baixo durante as iterações iniciais, o que implica uma melhoria rápida do modelo.
- Uma inclinação gradualmente mais plana (mas ainda descendente) até perto do fim do treinamento, o que implica uma melhoria contínua do modelo em um ritmo um pouco mais lento do que durante as iterações iniciais.
- Uma inclinação plana no final do treinamento, o que sugere convergência.

Embora a perda de treinamento seja importante, consulte também a generalização.
Respostas a perguntas de curiosidades
Conjuntos de dados para avaliar a capacidade de um LLM de responder a perguntas sobre curiosidades. Cada conjunto de dados contém pares de perguntas e respostas criados por entusiastas de curiosidades. Diferentes conjuntos de dados são fundamentados por diferentes fontes, incluindo:
- Pesquisa na Web (TriviaQA)
- Wikipedia (TriviaQA_wiki)
Para mais informações, consulte TriviaQA: um conjunto de dados de desafio supervisionado remotamente em grande escala para compreensão de leitura.
verdadeiro negativo (VN)
Um exemplo em que o modelo prevê corretamente a classe negativa. Por exemplo, o modelo deduz que uma determinada mensagem de e-mail não é spam, e essa mensagem realmente não é spam.
verdadeiro positivo (VP)
Um exemplo em que o modelo prevê corretamente a classe positiva. Por exemplo, o modelo infere que uma determinada mensagem de e-mail é spam, e ela realmente é.
taxa de verdadeiro positivo (TVP)
Sinônimo de recall. Ou seja:
A taxa de verdadeiro positivo é o eixo y em uma curva ROC.
Respostas a perguntas tipologicamente diversas (TyDi QA)
Um grande conjunto de dados para avaliar a proficiência de um LLM em responder a perguntas. O conjunto de dados contém pares de perguntas e respostas em vários idiomas.
Para mais detalhes, consulte TyDi QA: um comparativo para resposta a perguntas de busca de informações em idiomas tipologicamente diversos (em inglês).
U
taxa de declarações não aceitas (UCR)
A porcentagem de declarações em uma resposta que não são fundamentadas. Por exemplo, se a resposta de um LLM fizer 10 declarações, mas apenas uma for embasada, a UCR será de 90%.
Uma UCR alta implica que um LLM está alucinando com muita frequência.
Consulte também precisão de citação e recall de citação.
V
perda de validação
Uma métrica que representa a perda de um modelo no conjunto de validação durante uma iteração específica do treinamento.
Consulte também a curva de generalização.
importâncias de variáveis
Um conjunto de pontuações que indica a importância relativa de cada atributo para o modelo.
Por exemplo, considere uma árvore de decisão que estima os preços das casas. Suponha que essa árvore de decisão use três recursos: tamanho, idade e estilo. Se um conjunto de importâncias de variáveis para os três recursos for calculado como {size=5.8, age=2.5, style=4.7}, o tamanho será mais importante para a árvore de decisão do que a idade ou o estilo.
Existem diferentes métricas de importância da variável, que podem informar aos especialistas em ML sobre diferentes aspectos dos modelos.
W
Perda de Wasserstein
Uma das funções de perda usadas com frequência em redes generativas adversárias, com base na distância de transporte de massa entre a distribuição de dados gerados e dados reais.
WiC
Abreviação de Palavras em contexto.
WikiLingua (wiki_lingua)
Um conjunto de dados para avaliar a capacidade de um LLM de resumir artigos curtos. O WikiHow, uma enciclopédia de artigos que explicam como realizar várias tarefas, é a fonte criada por humanos para os artigos e os resumos. Cada entrada no conjunto de dados consiste em:
- Um artigo, que é criado anexando cada etapa da versão em prosa (parágrafo) da lista numerada, menos a frase inicial de cada etapa.
- Um resumo desse artigo, consistindo na frase inicial de cada etapa da lista numerada.
Para mais detalhes, consulte WikiLingua: um novo conjunto de dados de comparativo para resumo abstrativo multilíngue.
Desafio de esquema de Winograd (WSC)
Um formato (ou conjunto de dados em conformidade com esse formato) para avaliar a capacidade de um LLM de determinar a frase nominal a que um pronome se refere.
Cada entrada em um desafio de esquema de Winograd consiste em:
- Um Shorts curto que contém um pronome de destino
- Um pronome de destino
- Frases nominais candidatas, seguidas da resposta correta (um booleano). Se o pronome de destino se referir a esse candidato, a resposta será "True". Se o pronome de destino não se referir a esse candidato, a resposta será "False".
Exemplo:
- Trecho: Mark contou muitas mentiras sobre si mesmo para Pete, que as incluiu no livro. Ele deveria ter sido mais sincero.
- Pronome de destino: ele
- Frases nominais candidatas:
- Mark: True, porque o pronome de destino se refere a Mark
- Pete: falso, porque o pronome de destino não se refere a Peter.
O Winograd Schema Challenge é um componente do conjunto SuperGLUE.
Palavras no contexto (WiC)
Um conjunto de dados para avaliar o desempenho de um LLM ao usar o contexto para entender palavras que têm vários significados. Cada entrada no conjunto de dados contém:
- Duas frases, cada uma contendo a palavra de destino
- A palavra-alvo
- A resposta correta (um booleano), em que:
- "True" significa que a palavra de destino tem o mesmo significado nas duas frases.
- "False" significa que a palavra de destino tem um significado diferente nas duas frases.
Exemplo:
- Duas frases:
- Há muito lixo no leito do rio.
- Eu deixo um copo de água ao lado da minha cama quando durmo.
- A palavra-alvo:cama
- Resposta correta: falso, porque a palavra-alvo tem um significado diferente nas duas frases.
Para mais detalhes, consulte WiC: o conjunto de dados Word-in-Context para avaliar representações de significado sensíveis ao contexto.
O recurso "Palavras no contexto" é um componente do conjunto SuperGLUE.
WSC
Abreviação de Winograd Schema Challenge.
X
XL-Sum (xlsum)
Um conjunto de dados para avaliar a capacidade de um LLM de resumir texto. O XL-Sum fornece entradas em vários idiomas. Cada entrada no conjunto de dados contém:
- Um artigo da British Broadcasting Company (BBC).
- Um resumo do artigo, escrito pelo autor dele. O resumo pode conter palavras ou frases que não estão no artigo.
Para mais detalhes, consulte XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages (em inglês).