Trang này chứa các thuật ngữ trong Bảng thuật ngữ về chỉ số. Để xem tất cả các thuật ngữ trong bảng chú giải, hãy nhấp vào đây.
A
độ chính xác
Số lượng dự đoán phân loại chính xác chia cho tổng số dự đoán. Đó là:
Ví dụ: một mô hình đưa ra 40 dự đoán chính xác và 10 dự đoán không chính xác sẽ có độ chính xác là:
Phân loại nhị phân cung cấp tên cụ thể cho các danh mục khác nhau của dự đoán chính xác và dự đoán không chính xác. Vì vậy, công thức tính độ chính xác cho phân loại nhị phân như sau:
trong đó:
- TP là số lượng dương tính thật (dự đoán chính xác).
- TN là số lượng âm tính thật (dự đoán chính xác).
- FP là số lượng kết quả dương tính giả (dự đoán không chính xác).
- FN là số lượng âm tính giả (dự đoán không chính xác).
So sánh và đối chiếu độ chính xác với độ đo chính xác và khả năng thu hồi.
Xem Phân loại: Độ chính xác, độ bao phủ, độ chính xác và các chỉ số liên quan trong Khoá học học máy ứng dụng để biết thêm thông tin.
diện tích dưới đường cong PR
Xem PR AUC (Diện tích dưới đường cong PR).
diện tích dưới đường cong ROC
Xem AUC (Diện tích dưới đường cong ROC).
AUC (Diện tích dưới đường cong ROC)
Một số từ 0,0 đến 1,0 biểu thị khả năng của mô hình phân loại nhị phân trong việc tách các lớp dương khỏi các lớp âm. AUC càng gần 1.0 thì khả năng phân tách các lớp của mô hình càng tốt.
Ví dụ: hình minh hoạ sau đây cho thấy một mô hình phân loại tách biệt hoàn toàn các lớp dương (hình bầu dục màu xanh lục) với các lớp âm (hình chữ nhật màu tím). Mô hình hoàn hảo một cách phi thực tế này có AUC là 1.0:

Ngược lại, hình minh hoạ sau đây cho thấy kết quả của một mô hình phân loại đã tạo ra kết quả ngẫu nhiên. Mô hình này có AUC là 0,5:

Có, mô hình trước đó có AUC là 0, 5 chứ không phải 0.
Hầu hết các mô hình đều nằm ở khoảng giữa hai thái cực này. Ví dụ: mô hình sau đây tách biệt phần nào các giá trị dương với giá trị âm, do đó có AUC nằm trong khoảng từ 0,5 đến 1,0:

AUC bỏ qua mọi giá trị mà bạn đặt cho ngưỡng phân loại. Thay vào đó, AUC sẽ xem xét tất cả các ngưỡng phân loại có thể có.
Nhấp vào biểu tượng này để tìm hiểu về mối quan hệ giữa đường cong AUC và ROC.
AUC biểu thị diện tích dưới đường cong ROC. Ví dụ: đường cong ROC cho một mô hình phân tách hoàn hảo các giá trị dương với các giá trị âm sẽ có dạng như sau:
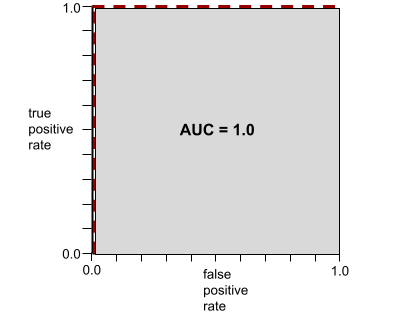
AUC là diện tích của vùng màu xám trong hình minh hoạ trước đó. Trong trường hợp bất thường này, diện tích chỉ đơn giản là chiều dài của vùng màu xám (1.0) nhân với chiều rộng của vùng màu xám (1.0). Vì vậy, tích của 1.0 và 1.0 sẽ cho ra AUC chính xác là 1.0, đây là điểm AUC cao nhất có thể.
Ngược lại, đường cong ROC cho một mô hình phân loại hoàn toàn không thể tách các lớp như sau. Diện tích của vùng màu xám này là 0,5.

Đường cong ROC điển hình hơn sẽ có dạng như sau:
Việc tính toán diện tích dưới đường cong này theo cách thủ công sẽ rất khó khăn. Đó là lý do tại sao một chương trình thường tính toán hầu hết các giá trị AUC.
Hãy xem phần Phân loại: ROC và AUC trong Khoá học học máy ứng dụng để biết thêm thông tin.
độ chính xác trung bình tại k
Một chỉ số để tóm tắt hiệu suất của mô hình trên một câu lệnh duy nhất tạo ra kết quả được xếp hạng, chẳng hạn như danh sách được đánh số đề xuất sách. Độ chính xác trung bình tại k là giá trị trung bình của các giá trị độ chính xác tại k cho mỗi kết quả phù hợp. Do đó, công thức tính độ chính xác trung bình tại k là:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
trong đó:
- \(n\) là số lượng mặt hàng có liên quan trong danh sách.
Tương phản với khả năng nhớ lại ở k.
B
đường cơ sở
Một mô hình được dùng làm điểm tham chiếu để so sánh hiệu suất của một mô hình khác (thường là mô hình phức tạp hơn). Ví dụ: mô hình hồi quy logistic có thể đóng vai trò là một đường cơ sở tốt cho mô hình sâu.
Đối với một vấn đề cụ thể, đường cơ sở giúp các nhà phát triển mô hình định lượng hiệu quả tối thiểu dự kiến mà một mô hình mới phải đạt được để mô hình mới đó hữu ích.
Câu hỏi Boolean (BoolQ)
Một tập dữ liệu để đánh giá mức độ thành thạo của LLM trong việc trả lời các câu hỏi có hoặc không. Mỗi thử thách trong tập dữ liệu đều có 3 thành phần:
- Một truy vấn
- Một đoạn văn ngụ ý câu trả lời cho câu hỏi.
- Câu trả lời đúng là có hoặc không.
Ví dụ:
- Câu hỏi: Có nhà máy điện hạt nhân nào ở Michigan không?
- Đoạn văn: ...3 nhà máy điện hạt nhân cung cấp khoảng 30% lượng điện cho Michigan.
- Câu trả lời đúng: Có
Các nhà nghiên cứu đã thu thập các câu hỏi từ những cụm từ tìm kiếm ẩn danh, tổng hợp trên Google Tìm kiếm, sau đó sử dụng các trang trên Wikipedia để xác minh thông tin.
Để biết thêm thông tin, hãy xem bài viết BoolQ: Khám phá độ khó đáng ngạc nhiên của các câu hỏi tự nhiên có/không.
BoolQ là một thành phần của tập hợp SuperGLUE.
BoolQ
Từ viết tắt của Câu hỏi Boolean.
C
CB
Từ viết tắt của CommitmentBank.
Điểm F N-gram của ký tự (ChrF)
Một chỉ số để đánh giá các mô hình bản dịch máy. Điểm F của N-gram ký tự xác định mức độ mà N-gram trong văn bản tham chiếu trùng lặp với N-gram trong văn bản được tạo của mô hình học máy.
Điểm F của N-gram ký tự tương tự như các chỉ số trong nhóm ROUGE và BLEU, ngoại trừ:
- Điểm F của N-gram ký tự hoạt động trên N-gram ký tự.
- ROUGE và BLEU hoạt động trên N-gram từ hoặc mã thông báo.
Lựa chọn về các giải pháp thay thế hợp lý (COPA)
Một tập dữ liệu để đánh giá mức độ hiệu quả của LLM trong việc xác định câu trả lời tốt hơn trong số hai câu trả lời thay thế cho một tiền đề. Mỗi thử thách trong tập dữ liệu bao gồm 3 thành phần:
- Một tiền đề, thường là một câu nói theo sau là một câu hỏi
- Hai câu trả lời có thể có cho câu hỏi được đặt ra trong tiền đề, trong đó có một câu trả lời đúng và một câu trả lời sai
- Câu trả lời đúng
Ví dụ:
- Tình huống: Người đàn ông bị gãy ngón chân. Đâu là NGUYÊN NHÂN gây ra vấn đề này?
- Các câu trả lời có thể có:
- Anh ấy bị thủng tất.
- Anh ấy làm rơi búa lên chân.
- Câu trả lời đúng: 2
COPA là một thành phần của mô hình kết hợp SuperGLUE.
CommitmentBank (CB)
Một tập dữ liệu để đánh giá mức độ thành thạo của LLM trong việc xác định xem tác giả của một đoạn văn có tin vào một mệnh đề mục tiêu trong đoạn văn đó hay không. Mỗi mục trong tập dữ liệu chứa:
- Một đoạn văn
- Một mệnh đề mục tiêu trong đoạn văn đó
- Giá trị Boolean cho biết liệu tác giả của đoạn văn có tin rằng mệnh đề mục tiêu
Ví dụ:
- Đoạn văn: Thật vui khi nghe Artemis cười. Cô bé là một đứa trẻ rất nghiêm túc. Tôi không biết cô ấy có khiếu hài hước.
- Mệnh đề mục tiêu: cô ấy có khiếu hài hước
- Boolean: True, tức là tác giả tin rằng mệnh đề mục tiêu
CommitmentBank là một thành phần của nhóm SuperGLUE.
COPA
Viết tắt của Choice of Plausible Alternatives (Lựa chọn thay thế hợp lý).
chi phí
Từ đồng nghĩa với tổn thất.
tính công bằng phản thực tế
Chỉ số công bằng kiểm tra xem mô hình phân loại có tạo ra cùng một kết quả cho một cá nhân như kết quả của một cá nhân khác giống với cá nhân đầu tiên hay không, ngoại trừ một hoặc nhiều thuộc tính nhạy cảm. Đánh giá mô hình phân loại để đảm bảo tính công bằng phản thực tế là một phương pháp để xác định các nguồn thiên vị tiềm ẩn trong một mô hình.
Hãy xem một trong hai phần sau để biết thêm thông tin:
- Tính công bằng: Tính công bằng phản thực tế trong Khoá học học máy ứng dụng.
- Khi các thế giới xung đột: Tích hợp các giả định phản thực tế khác nhau về tính công bằng
cross-entropy
Một tổng quát hoá của tổn thất logistic thành các vấn đề phân loại đa mục. Cross-entropy định lượng sự khác biệt giữa hai hàm phân phối xác suất. Xem thêm độ phức tạp.
hàm phân phối tích luỹ (CDF)
Một hàm xác định tần suất của các mẫu nhỏ hơn hoặc bằng một giá trị mục tiêu. Ví dụ: hãy xem xét một hàm phân phối chuẩn của các giá trị liên tục. CDF cho biết khoảng 50% mẫu phải nhỏ hơn hoặc bằng giá trị trung bình và khoảng 84% mẫu phải nhỏ hơn hoặc bằng một độ lệch chuẩn so với giá trị trung bình.
D
tương đương về nhân khẩu học
Một chỉ số công bằng được đáp ứng nếu kết quả phân loại của một mô hình không phụ thuộc vào một thuộc tính nhạy cảm nhất định.
Ví dụ: nếu cả người Lilliput và người Brobdingnag đều đăng ký vào Đại học Glubbdubdrib, thì sự bình đẳng về nhân khẩu học sẽ đạt được nếu tỷ lệ phần trăm người Lilliput được nhận vào học bằng với tỷ lệ phần trăm người Brobdingnag được nhận vào học, bất kể một nhóm có trình độ chuyên môn cao hơn nhóm còn lại hay không.
Tương phản với xác suất cân bằng và cơ hội bình đẳng, cho phép kết quả phân loại tổng hợp phụ thuộc vào các thuộc tính nhạy cảm, nhưng không cho phép kết quả phân loại cho một số nhãn dữ liệu thực tế được chỉ định phụ thuộc vào các thuộc tính nhạy cảm. Xem bài viết "Chống phân biệt đối xử bằng công nghệ học máy thông minh hơn" để xem hình ảnh minh hoạ về những điểm đánh đổi khi tối ưu hoá để đạt được sự bình đẳng về nhân khẩu học.
Hãy xem phần Tính công bằng: sự bình đẳng về nhân khẩu học trong Khoá học học máy ứng dụng để biết thêm thông tin.
E
khoảng cách di chuyển của đất (EMD)
Thước đo mức độ tương đồng tương đối của hai phân phối. Khoảng cách của máy xúc càng thấp thì các bản phân phối càng giống nhau.
khoảng cách chỉnh sửa
Một chỉ số đo lường mức độ tương đồng giữa hai chuỗi văn bản. Trong học máy, khoảng cách chỉnh sửa rất hữu ích vì những lý do sau:
- Khoảng cách chỉnh sửa rất dễ tính toán.
- Khoảng cách chỉnh sửa có thể so sánh hai chuỗi được biết là tương tự nhau.
- Khoảng cách chỉnh sửa có thể xác định mức độ tương tự của các chuỗi khác nhau với một chuỗi nhất định.
Có một số định nghĩa về khoảng cách chỉnh sửa, mỗi định nghĩa sử dụng các thao tác khác nhau trên chuỗi. Hãy xem Khoảng cách Levenshtein để biết ví dụ.
hàm phân phối tích luỹ thực nghiệm (eCDF hoặc EDF)
Một hàm phân phối tích luỹ dựa trên các phép đo thực nghiệm từ một tập dữ liệu thực. Giá trị của hàm tại bất kỳ điểm nào dọc theo trục x là phần nhỏ của các quan sát trong tập dữ liệu nhỏ hơn hoặc bằng giá trị đã chỉ định.
entropy
Trong lý thuyết thông tin, nội dung mô tả mức độ khó dự đoán của một phân phối xác suất. Ngoài ra, entropy cũng được xác định là lượng thông tin mà mỗi ví dụ chứa. Phân phối có entropy cao nhất có thể khi tất cả các giá trị của một biến ngẫu nhiên đều có khả năng xảy ra như nhau.
Độ đo hỗn loạn của một tập hợp có 2 giá trị có thể là "0" và "1" (ví dụ: nhãn trong vấn đề phân loại nhị phân) có công thức sau:
H = -p log p – q log q = -p log p – (1-p) * log (1-p)
trong đó:
- H là entropy.
- p là phân số của "1" ví dụ.
- q là tỷ lệ của các ví dụ "0". Lưu ý rằng q = (1 – p)
- log thường là log2. Trong trường hợp này, đơn vị entropy là một bit.
Ví dụ: giả sử những điều sau đây:
- 100 ví dụ chứa giá trị "1"
- 300 ví dụ chứa giá trị "0"
Do đó, giá trị entropy là:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) – (0,75)log2(0,75) = 0,81 bit cho mỗi ví dụ
Một tập hợp cân bằng hoàn hảo (ví dụ: 200 "0" và 200 "1") sẽ có độ đo entropy là 1 bit cho mỗi ví dụ. Khi một tập hợp trở nên mất cân bằng hơn, entropy của tập hợp đó sẽ tiến về 0.0.
Trong cây quyết định, entropy giúp xây dựng mức tăng thông tin để giúp bộ phân tách chọn điều kiện trong quá trình phát triển cây quyết định phân loại.
So sánh entropy với:
- độ tinh khiết gini
- Hàm mất mát cross-entropy
Độ đo hỗn loạn thường được gọi là độ đo hỗn loạn của Shannon.
Hãy xem phần Bộ phân tách chính xác để phân loại nhị phân bằng các đặc điểm số trong khoá học Rừng quyết định để biết thêm thông tin.
bình đẳng về cơ hội
Một chỉ số công bằng để đánh giá xem một mô hình có dự đoán kết quả mong muốn một cách công bằng cho tất cả các giá trị của một thuộc tính nhạy cảm hay không. Nói cách khác, nếu kết quả mong muốn cho một mô hình là hạng mục dương, thì mục tiêu là phải có tỷ lệ dương tính thật như nhau cho tất cả các nhóm.
Bình đẳng về cơ hội có liên quan đến tỷ lệ cược cân bằng, theo đó cả tỷ lệ dương tính thực và tỷ lệ dương tính giả đều phải như nhau đối với tất cả các nhóm.
Giả sử Đại học Glubbdubdrib nhận cả người Lilliput và người Brobdingnag vào một chương trình toán học nghiêm ngặt. Các trường trung học của người Lilliput cung cấp một chương trình học vững chắc về các lớp toán và phần lớn học sinh đủ điều kiện tham gia chương trình đại học. Các trường trung học của người Brobdingnag không có lớp học toán, và do đó, số lượng học sinh đủ tiêu chuẩn của họ ít hơn nhiều. Cơ hội bình đẳng được đáp ứng cho nhãn ưu tiên "được nhận" đối với quốc tịch (Lilliput hoặc Brobdingnag) nếu sinh viên đủ tiêu chuẩn có khả năng được nhận như nhau bất kể họ là người Lilliput hay người Brobdingnag.
Ví dụ: giả sử 100 người Lilliput và 100 người Brobdingnag đăng ký vào Đại học Glubbdubdrib và quyết định nhập học được đưa ra như sau:
Bảng 1. Ứng viên Lilliputian (90% đủ điều kiện)
| Đủ tiêu chuẩn | Không đủ tiêu chuẩn | |
|---|---|---|
| Được chấp nhận | 45 | 3 |
| Bị từ chối | 45 | 7 |
| Tổng | 90 | 10 |
|
Tỷ lệ phần trăm sinh viên đủ điều kiện được nhận: 45/90 = 50% Tỷ lệ phần trăm sinh viên không đủ điều kiện bị từ chối: 7/10 = 70% Tổng tỷ lệ phần trăm sinh viên Lilliputian được nhận: (45+3)/100 = 48% |
||
Bảng 2. Ứng viên khổng lồ (10% đủ tiêu chuẩn):
| Đủ tiêu chuẩn | Không đủ tiêu chuẩn | |
|---|---|---|
| Được chấp nhận | 5 | 9 |
| Bị từ chối | 5 | 81 |
| Tổng | 10 | 90 |
|
Tỷ lệ phần trăm sinh viên đủ điều kiện được nhận: 5/10 = 50% Tỷ lệ phần trăm sinh viên không đủ điều kiện bị từ chối: 81/90 = 90% Tổng tỷ lệ phần trăm sinh viên Brobdingnagian được nhận: (5+9)/100 = 14% |
||
Các ví dụ trước đó đáp ứng sự bình đẳng về cơ hội chấp nhận sinh viên đủ tiêu chuẩn vì cả người Lilliput và người Brobdingnag đều có 50% cơ hội được nhận.
Mặc dù đã đáp ứng được sự bình đẳng về cơ hội, nhưng 2 chỉ số công bằng sau đây chưa được đáp ứng:
- tính bình đẳng về nhân khẩu học: Người Lilliput và người Brobdingnag được nhận vào trường đại học với tỷ lệ khác nhau; 48% sinh viên Lilliput được nhận, nhưng chỉ có 14% sinh viên Brobdingnag được nhận.
- cơ hội ngang nhau: Mặc dù cả học viên Lilliputian và Brobdingnagian đủ tiêu chuẩn đều có cơ hội được nhận như nhau, nhưng ràng buộc bổ sung rằng cả học viên Lilliputian và Brobdingnagian không đủ tiêu chuẩn đều có cơ hội bị từ chối như nhau không được đáp ứng. Người Lilliput không đủ tiêu chuẩn có tỷ lệ bị từ chối là 70%, trong khi người Brobdingnag không đủ tiêu chuẩn có tỷ lệ bị từ chối là 90%.
Hãy xem bài viết Tính công bằng: Cơ hội bình đẳng trong Khoá học học máy ứng dụng để biết thêm thông tin.
tỷ lệ cược cân bằng
Một chỉ số công bằng để đánh giá xem một mô hình có dự đoán kết quả tốt như nhau cho tất cả các giá trị của một thuộc tính nhạy cảm hay không, liên quan đến cả hạng mục dương và hạng mục âm – không chỉ một hạng mục hoặc hạng mục kia một cách riêng biệt. Nói cách khác, cả tỷ lệ dương tính thực và tỷ lệ âm tính giả đều phải giống nhau đối với tất cả các nhóm.
Cơ hội bình đẳng liên quan đến sự bình đẳng về cơ hội, chỉ tập trung vào tỷ lệ lỗi cho một lớp duy nhất (dương hoặc âm).
Ví dụ: giả sử Đại học Glubbdubdrib nhận cả người Lilliput và người Brobdingnag vào một chương trình toán học nghiêm ngặt. Các trường trung học của người Lilliput cung cấp một chương trình học tập toàn diện về các lớp toán và phần lớn học sinh đủ điều kiện tham gia chương trình đại học. Các trường trung học của người Brobdingnag không có lớp học toán nào, và do đó, số lượng học sinh đủ điều kiện của họ ít hơn nhiều. Điều kiện về xác suất ngang bằng được đáp ứng miễn là bất kể người đăng ký là người Lilliput hay người Brobdingnag, nếu họ đủ tiêu chuẩn, thì họ có khả năng được nhận vào chương trình như nhau, và nếu họ không đủ tiêu chuẩn, thì họ có khả năng bị từ chối như nhau.
Giả sử 100 người Lilliput và 100 người Brobdingnag đăng ký vào Đại học Glubbdubdrib, và quyết định nhập học được đưa ra như sau:
Bảng 3. Ứng viên Lilliputian (90% đủ điều kiện)
| Đủ tiêu chuẩn | Không đủ tiêu chuẩn | |
|---|---|---|
| Được chấp nhận | 45 | 2 |
| Bị từ chối | 45 | 8 |
| Tổng | 90 | 10 |
|
Tỷ lệ phần trăm học sinh đủ điều kiện được nhận: 45/90 = 50% Tỷ lệ phần trăm học sinh không đủ điều kiện bị từ chối: 8/10 = 80% Tổng tỷ lệ phần trăm học sinh Lilliputian được nhận: (45+2)/100 = 47% |
||
Bảng 4. Ứng viên khổng lồ (10% đủ tiêu chuẩn):
| Đủ tiêu chuẩn | Không đủ tiêu chuẩn | |
|---|---|---|
| Được chấp nhận | 5 | 18 |
| Bị từ chối | 5 | 72 |
| Tổng | 10 | 90 |
|
Tỷ lệ phần trăm sinh viên đủ điều kiện được nhận: 5/10 = 50% Tỷ lệ phần trăm sinh viên không đủ điều kiện bị từ chối: 72/90 = 80% Tổng tỷ lệ phần trăm sinh viên Brobdingnagian được nhận: (5+18)/100 = 23% |
||
Điều kiện về tỷ lệ cược công bằng được đáp ứng vì cả sinh viên đủ tiêu chuẩn ở Lilliput và Brobdingnag đều có 50% cơ hội được nhận, còn sinh viên không đủ tiêu chuẩn ở Lilliput và Brobdingnag có 80% cơ hội bị từ chối.
Tỷ lệ cược cân bằng được xác định chính thức trong "Equality of Opportunity in Supervised Learning" (Cơ hội bình đẳng trong học có giám sát) như sau: "trình dự đoán Ŷ đáp ứng tỷ lệ cược cân bằng đối với thuộc tính được bảo vệ A và kết quả Y nếu Ŷ và A độc lập, có điều kiện trên Y".
evals
Chủ yếu được dùng làm từ viết tắt cho các bản đánh giá mô hình ngôn ngữ lớn. Nói chung, evals là từ viết tắt của mọi hình thức đánh giá.
đánh giá
Quy trình đo lường chất lượng của một mô hình hoặc so sánh các mô hình khác nhau với nhau.
Để đánh giá một mô hình học máy có giám sát, bạn thường đánh giá mô hình đó dựa trên một tập xác nhận và một tập kiểm định. Đánh giá một LLM thường bao gồm các đánh giá rộng hơn về chất lượng và độ an toàn.
đối sánh chính xác
Đây là một chỉ số tất cả hoặc không có gì, trong đó đầu ra của mô hình khớp chính xác với thông tin thực tế hoặc văn bản tham chiếu hoặc không. Ví dụ: nếu thông tin thực tế là cam, thì chỉ có đầu ra của mô hình cam đáp ứng tiêu chí khớp chính xác.
Kiểu khớp chính xác cũng có thể đánh giá các mô hình có đầu ra là một chuỗi (danh sách các mục được xếp hạng). Nhìn chung, kết quả khớp chính xác yêu cầu danh sách được xếp hạng đã tạo phải khớp chính xác với dữ liệu thực tế; tức là mỗi mục trong cả hai danh sách phải theo cùng một thứ tự. Tuy nhiên, nếu dữ liệu thực tế bao gồm nhiều chuỗi chính xác, thì tính năng khớp chính xác chỉ yêu cầu đầu ra của mô hình khớp với một trong các chuỗi chính xác.
Tóm tắt cực kỳ ngắn gọn (xsum)
Một tập dữ liệu để đánh giá khả năng tóm tắt một tài liệu của LLM. Mỗi mục trong tập dữ liệu bao gồm:
- Một tài liệu do British Broadcasting Corporation (BBC) biên soạn.
- Bản tóm tắt một câu về tài liệu đó.
Để biết thông tin chi tiết, hãy xem phần Đừng cung cấp cho tôi thông tin chi tiết, chỉ cần tóm tắt thôi! Mạng nơron tích chập nhận biết chủ đề để tóm tắt cực đoan.
F
F1
Một chỉ số "tổng hợp" phân loại nhị phân dựa trên cả độ chính xác và khả năng thu hồi. Sau đây là công thức:
chỉ số công bằng
Định nghĩa toán học về "sự công bằng" có thể đo lường được. Sau đây là một số chỉ số công bằng thường dùng:
- xác suất cân bằng
- tính tương đương dự đoán
- tính công bằng phản thực tế
- tính bình đẳng về nhân khẩu học
Nhiều chỉ số công bằng loại trừ lẫn nhau; hãy xem sự không tương thích của các chỉ số công bằng.
âm tính giả (FN)
Ví dụ về trường hợp mô hình dự đoán nhầm hạng mục âm. Ví dụ: mô hình dự đoán rằng một nội dung email cụ thể không phải là thư rác (hạng mục âm), nhưng nội dung email đó thực sự là thư rác.
tỷ lệ âm tính giả
Tỷ lệ ví dụ dương tính thực tế mà mô hình dự đoán nhầm là hạng mục âm. Công thức sau đây dùng để tính tỷ lệ âm tính giả:
Hãy xem phần Ngưỡng và ma trận nhầm lẫn trong Khoá học học máy ứng dụng để biết thêm thông tin.
dương tính giả (FP)
Ví dụ trong đó mô hình dự đoán nhầm hạng mục dương. Ví dụ: mô hình dự đoán rằng một nội dung email cụ thể là thư rác (hạng mục dương), nhưng nội dung email đó thực sự không phải là thư rác.
Hãy xem phần Ngưỡng và ma trận nhầm lẫn trong Khoá học học máy ứng dụng để biết thêm thông tin.
tỷ lệ dương tính giả (FPR)
Tỷ lệ ví dụ thực tế có kết quả âm tính mà mô hình dự đoán nhầm thành hạng mục dương. Công thức sau đây dùng để tính tỷ lệ dương tính giả:
Tỷ lệ dương tính giả là trục x trong đường cong ROC.
Hãy xem phần Phân loại: ROC và AUC trong Khoá học học máy ứng dụng để biết thêm thông tin.
mức độ quan trọng của các tính năng
Từ đồng nghĩa với mức độ quan trọng của biến.
mô hình cơ sở
Một mô hình được huấn luyện tiền kỳ có kích thước rất lớn, được huấn luyện trên một tập dữ liệu huấn luyện khổng lồ và đa dạng. Một mô hình cơ sở có thể làm cả hai việc sau:
- Phản hồi tốt cho nhiều loại yêu cầu.
- Đóng vai trò là một mô hình cơ sở để điều chỉnh thêm hoặc tuỳ chỉnh theo cách khác.
Nói cách khác, mô hình cơ sở đã có khả năng rất cao theo nghĩa chung nhưng có thể được tuỳ chỉnh thêm để trở nên hữu ích hơn nữa cho một nhiệm vụ cụ thể.
tỷ lệ thành công
Một chỉ số để đánh giá văn bản do AI tạo của một mô hình học máy. Phân số thành công là số lượng đầu ra văn bản được tạo "thành công" chia cho tổng số đầu ra văn bản được tạo. Ví dụ: nếu mô hình ngôn ngữ lớn tạo ra 10 khối mã, trong đó có 5 khối thành công, thì tỷ lệ thành công sẽ là 50%.
Mặc dù tỷ lệ thành công thường hữu ích trong thống kê, nhưng trong học máy, chỉ số này chủ yếu hữu ích để đo lường các tác vụ có thể xác minh như tạo mã hoặc giải toán.
G
độ tinh khiết Gini
Một chỉ số tương tự như entropy. Trình phân tách sử dụng các giá trị bắt nguồn từ độ tinh khiết gini hoặc entropy để tạo điều kiện cho cây quyết định phân loại. Mức tăng thông tin được suy ra từ entropy. Không có thuật ngữ tương đương được chấp nhận rộng rãi cho chỉ số bắt nguồn từ độ tinh khiết gini; tuy nhiên, chỉ số chưa được đặt tên này cũng quan trọng như mức tăng thông tin.
Độ tinh khiết Gini còn được gọi là chỉ số Gini hoặc đơn giản là Gini.
Cao
tổn thất khớp nối
Một nhóm các hàm tổn thất cho phân loại được thiết kế để tìm ranh giới quyết định càng xa càng tốt so với mỗi ví dụ huấn luyện, do đó tối đa hoá khoảng cách giữa các ví dụ và ranh giới. KSVM sử dụng tổn thất khớp nối (hoặc một hàm liên quan, chẳng hạn như bình phương tổn thất khớp nối). Đối với phân loại nhị phân, hàm tổn thất khớp nối được xác định như sau:
trong đó y là nhãn thực, có thể là -1 hoặc +1, còn y' là đầu ra thô của mô hình phân loại:
Do đó, biểu đồ về tổn thất khớp nối so với (y * y') sẽ có dạng như sau:

I
sự không tương thích của các chỉ số công bằng
Ý tưởng cho rằng một số khái niệm về sự công bằng không tương thích với nhau và không thể đồng thời thoả mãn. Do đó, không có một chỉ số chung duy nhất để định lượng sự công bằng có thể áp dụng cho tất cả các vấn đề về học máy.
Mặc dù điều này có vẻ đáng thất vọng, nhưng sự không tương thích của các chỉ số công bằng không có nghĩa là những nỗ lực hướng đến sự công bằng là vô ích. Thay vào đó, nó đề xuất rằng sự công bằng phải được xác định theo ngữ cảnh cho một vấn đề cụ thể về học máy, với mục tiêu là ngăn chặn những tác hại cụ thể đối với các trường hợp sử dụng của vấn đề đó.
Xem bài viết "Về (khả năng) bất khả thi của sự công bằng" để biết nội dung thảo luận chi tiết hơn về sự không tương thích của các chỉ số công bằng.
tính công bằng cho từng cá nhân
Một chỉ số công bằng kiểm tra xem những cá nhân tương tự có được phân loại tương tự hay không. Ví dụ: Học viện Brobdingnagian có thể muốn đáp ứng sự công bằng cho từng cá nhân bằng cách đảm bảo rằng 2 sinh viên có điểm số và điểm kiểm tra tiêu chuẩn giống hệt nhau có khả năng được nhận vào học như nhau.
Xin lưu ý rằng tính công bằng cho từng cá nhân hoàn toàn phụ thuộc vào cách bạn xác định "mức độ tương đồng" (trong trường hợp này là điểm số và điểm kiểm tra), đồng thời bạn có thể gặp phải nguy cơ xuất hiện các vấn đề mới về tính công bằng nếu chỉ số mức độ tương đồng của bạn bỏ lỡ thông tin quan trọng (chẳng hạn như mức độ nghiêm ngặt của chương trình học của học viên).
Hãy xem bài viết "Công bằng thông qua nhận thức" để biết thêm thông tin chi tiết về sự công bằng cho từng cá nhân.
mức tăng thông tin
Trong rừng quyết định, sự khác biệt giữa entropy của một nút và tổng entropy có trọng số (theo số lượng ví dụ) của các nút con. Độ đo entropy của một nút là độ đo entropy của các ví dụ trong nút đó.
Ví dụ: hãy xem xét các giá trị entropy sau:
- entropy của nút mẹ = 0,6
- độ đo entropy của một nút con có 16 ví dụ liên quan = 0,2
- entropy của một nút con khác với 24 ví dụ có liên quan = 0,1
Vì vậy, 40% ví dụ nằm trong một nút con và 60% nằm trong nút con còn lại. Vì thế:
- tổng entropy có trọng số của các nút con = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Vậy mức tăng thông tin là:
- mức tăng thông tin = entropy của nút mẹ – tổng entropy có trọng số của các nút con
- mức tăng thông tin = 0,6 – 0,14 = 0,46
Hầu hết bộ phân tách đều tìm cách tạo ra các điều kiện giúp tối đa hoá mức tăng thông tin.
mức độ đồng thuận
Một chỉ số đo lường tần suất mà người đánh giá đồng ý với nhau khi thực hiện một nhiệm vụ. Nếu người gán nhãn không đồng ý, thì có thể bạn cần cải thiện hướng dẫn cho nhiệm vụ. Đôi khi còn được gọi là mức độ nhất trí giữa các chú thích viên hoặc độ tin cậy giữa các chuyên gia đánh giá. Xem thêm Kappa của Cohen, đây là một trong những chỉ số phổ biến nhất về mức độ đồng thuận giữa các chuyên gia đánh giá.
Hãy xem bài viết Dữ liệu phân loại: Các vấn đề thường gặp trong Khoá học học máy ứng dụng để biết thêm thông tin.
L
Tổn thất L1
Một hàm tổn thất tính toán giá trị tuyệt đối của mức chênh lệch giữa các giá trị nhãn thực tế và các giá trị mà một mô hình dự đoán. Ví dụ: sau đây là cách tính tổn thất L1 cho một lô gồm 5 ví dụ:
| Giá trị thực tế của ví dụ | Giá trị dự đoán của mô hình | Giá trị tuyệt đối của delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = tổn thất L1 | ||
Tổn thất L1 ít nhạy cảm hơn với điểm ngoại lai so với tổn thất L2.
Sai số tuyệt đối trung bình là mức tổn thất L1 trung bình trên mỗi ví dụ.
Hãy xem phần Hồi quy tuyến tính: Tổn thất trong Khoá học học máy ứng dụng để biết thêm thông tin.
Tổn thất L2
Một hàm tổn thất tính bình phương của sự khác biệt giữa các giá trị nhãn thực tế và các giá trị mà một mô hình dự đoán. Ví dụ: sau đây là cách tính tổn thất L2 cho một lô gồm 5 ví dụ:
| Giá trị thực tế của ví dụ | Giá trị dự đoán của mô hình | Bình phương của delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = tổn thất L2 | ||
Do bình phương, tổn thất L2 sẽ khuếch đại ảnh hưởng của các giá trị ngoại lai. Tức là tổn thất L2 phản ứng mạnh hơn với các dự đoán không chính xác so với tổn thất L1. Ví dụ: tổn thất L1 cho lô trước đó sẽ là 8 thay vì 16. Xin lưu ý rằng một giá trị ngoại lệ duy nhất chiếm 9 trong số 16 giá trị.
Mô hình hồi quy thường sử dụng tổn thất L2 làm hàm tổn thất.
Sai số bình phương trung bình là tổn thất L2 trung bình trên mỗi ví dụ. Tổn thất bình phương là một tên khác của tổn thất L2.
Hãy xem phần Hồi quy logistic: Tổn thất và điều hòa trong Khoá học học máy ứng dụng để biết thêm thông tin.
Đánh giá LLM
Một bộ chỉ số và điểm chuẩn để đánh giá hiệu suất của các mô hình ngôn ngữ lớn (LLM). Ở cấp độ cao, các hoạt động đánh giá LLM:
- Giúp các nhà nghiên cứu xác định những khía cạnh mà LLM cần cải thiện.
- Hữu ích trong việc so sánh các LLM khác nhau và xác định LLM phù hợp nhất cho một nhiệm vụ cụ thể.
- Giúp đảm bảo rằng các LLM an toàn và có đạo đức khi sử dụng.
Hãy xem Mô hình ngôn ngữ lớn (LLM) trong Khoá học học máy ứng dụng để biết thêm thông tin.
trận thua
Trong quá trình huấn luyện một mô hình có giám sát, một thước đo cho biết dự đoán của mô hình cách xa nhãn của mô hình bao nhiêu.
Hàm tổn thất tính toán tổn thất.
Hãy xem phần Hồi quy tuyến tính: Tổn thất trong Khoá học học máy ứng dụng để biết thêm thông tin.
hàm tổn thất
Trong quá trình huấn luyện hoặc kiểm thử, một hàm toán học sẽ tính toán mức tổn thất trên một lô ví dụ. Hàm tổn thất trả về mức tổn thất thấp hơn cho những mô hình đưa ra dự đoán chính xác so với những mô hình đưa ra dự đoán không chính xác.
Mục tiêu của việc huấn luyện thường là giảm thiểu tổn thất mà một hàm tổn thất trả về.
Có nhiều loại hàm tổn thất. Chọn hàm tổn thất phù hợp cho loại mô hình mà bạn đang xây dựng. Ví dụ:
- Mất mát L2 (hoặc Sai số bình phương trung bình) là hàm mất mát cho hồi quy tuyến tính.
- Tổn thất logistic là hàm tổn thất cho hồi quy logistic.
M
MBPP
Từ viết tắt của Mostly Basic Python Problems (Hầu hết các vấn đề cơ bản về Python).
Sai số tuyệt đối trung bình (MAE)
Mức tổn thất trung bình trên mỗi ví dụ khi sử dụng tổn thất L1. Tính Sai số tuyệt đối trung bình như sau:
- Tính mức tổn thất L1 cho một lô.
- Chia tổn thất L1 cho số lượng ví dụ trong lô.
Ví dụ: hãy xem xét việc tính toán tổn thất L1 trên lô gồm 5 ví dụ sau:
| Giá trị thực tế của ví dụ | Giá trị dự đoán của mô hình | Tổn thất (chênh lệch giữa giá trị thực tế và giá trị dự đoán) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = tổn thất L1 | ||
Vậy, tổn thất L1 là 8 và số lượng ví dụ là 5. Do đó, Sai số tuyệt đối trung bình là:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Tương phản Sai số tuyệt đối trung bình với Sai số bình phương trung bình và Sai số trung bình bình phương.
độ chính xác trung bình ở k (mAP@k)
Giá trị trung bình thống kê của tất cả các điểm độ chính xác trung bình tại k trên một tập dữ liệu xác thực. Một cách sử dụng độ chính xác trung bình tại k là đánh giá chất lượng của các đề xuất do hệ thống đề xuất tạo ra.
Mặc dù cụm từ "giá trị trung bình" nghe có vẻ dư thừa, nhưng tên của chỉ số này là phù hợp. Sau tất cả, chỉ số này tìm ra giá trị trung bình của nhiều giá trị độ chính xác trung bình tại k.
Sai số bình phương trung bình (MSE)
Mức tổn thất trung bình trên mỗi ví dụ khi sử dụng tổn thất L2. Tính Sai số bình phương trung bình như sau:
- Tính toán tổn thất L2 cho một lô.
- Chia tổn thất L2 cho số lượng ví dụ trong lô.
Ví dụ: hãy xem xét mức tổn thất của lô gồm 5 ví dụ sau:
| Giá trị thực tế | Dự đoán của mô hình | Thua | Tổn thất bình phương |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = tổn thất L2 | |||
Do đó, Sai số bình phương trung bình là:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
Sai số bình phương trung bình là một trình tối ưu hoá huấn luyện phổ biến, đặc biệt là đối với hồi quy tuyến tính.
So sánh Sai số bình phương trung bình với Sai số tuyệt đối trung bình và Sai số trung bình bình phương.
TensorFlow Playground sử dụng Sai số bình phương trung bình để tính giá trị tổn thất.
chỉ số
Một số liệu thống kê mà bạn quan tâm.
Mục tiêu là một chỉ số mà hệ thống học máy cố gắng tối ưu hoá.
Metrics API (tf.metrics)
Một API TensorFlow để đánh giá các mô hình. Ví dụ: tf.metrics.accuracy xác định tần suất dự đoán của một mô hình khớp với nhãn.
tổn thất minimax
Một hàm tổn thất cho mạng đối kháng sinh tạo, dựa trên cross-entropy giữa phân phối dữ liệu được tạo và dữ liệu thực.
Mất mát tối thiểu tối đa được dùng trong bài viết đầu tiên để mô tả mạng đối kháng sinh.
Hãy xem phần Hàm tổn thất trong khoá học Mạng sinh đối kháng để biết thêm thông tin.
dung lượng mô hình
Mức độ phức tạp của các vấn đề mà một mô hình có thể học được. Mô hình càng có thể học được nhiều vấn đề phức tạp thì năng lực của mô hình càng cao. Dung lượng của một mô hình thường tăng lên khi số lượng tham số mô hình tăng lên. Để biết định nghĩa chính thức về năng lực của mô hình phân loại, hãy xem phương diện VC.
Mostly Basic Python Problems (MBPP)
Một tập dữ liệu để đánh giá trình độ của LLM trong việc tạo mã Python. Mostly Basic Python Problems cung cấp khoảng 1.000 vấn đề lập trình do cộng đồng đóng góp. Mỗi vấn đề trong tập dữ liệu chứa:
- Nội dung mô tả việc cần làm
- Đoạn mã giải pháp
- 3 trường hợp kiểm thử tự động
Không
hạng mục âm
Trong phân loại nhị phân, một lớp được gọi là dương tính và lớp còn lại được gọi là âm tính. Hạng mục dương là đối tượng hoặc sự kiện mà mô hình đang kiểm thử và hạng mục âm là khả năng khác. Ví dụ:
- Hạng mục âm trong một xét nghiệm y tế có thể là "không phải khối u".
- Hạng mục âm trong mô hình phân loại email có thể là "không phải thư rác".
Tương phản với hạng mục dương.
O
mục tiêu
Một chỉ số mà thuật toán của bạn đang cố gắng tối ưu hoá.
hàm mục tiêu
Công thức toán học hoặc chỉ số mà một mô hình hướng đến việc tối ưu hoá. Ví dụ: hàm mục tiêu cho hồi quy tuyến tính thường là Mất mát bình phương trung bình. Do đó, khi huấn luyện mô hình hồi quy tuyến tính, quá trình huấn luyện nhằm mục đích giảm thiểu Mất mát bình phương trung bình.
Trong một số trường hợp, mục tiêu là tối đa hoá hàm mục tiêu. Ví dụ: nếu hàm mục tiêu là độ chính xác, thì mục tiêu là tối đa hoá độ chính xác.
Xem thêm tổn thất.
Điểm
pass at k (pass@k)
Một chỉ số để xác định chất lượng mã (ví dụ: Python) mà mô hình ngôn ngữ lớn tạo ra. Cụ thể hơn, pass at k cho biết khả năng ít nhất một khối mã được tạo trong số k khối mã được tạo sẽ vượt qua tất cả các kiểm thử đơn vị.
Các mô hình ngôn ngữ lớn thường gặp khó khăn trong việc tạo mã tốt cho các vấn đề lập trình phức tạp. Các kỹ sư phần mềm thích ứng với vấn đề này bằng cách nhắc mô hình ngôn ngữ lớn tạo ra nhiều (k) giải pháp cho cùng một vấn đề. Sau đó, các kỹ sư phần mềm sẽ kiểm thử từng giải pháp dựa trên các kiểm thử đơn vị. Việc tính toán số lần vượt qua ở k phụ thuộc vào kết quả của các kiểm thử đơn vị:
- Nếu một hoặc nhiều giải pháp trong số đó vượt qua kiểm thử đơn vị, thì LLM sẽ Vượt qua thử thách tạo mã đó.
- Nếu không có giải pháp nào vượt qua được quy trình kiểm thử đơn vị, thì LLM sẽ Không thành công trong thử thách tạo mã đó.
Công thức cho lượt chuyền ở k như sau:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
Nhìn chung, các giá trị k cao hơn sẽ tạo ra điểm vượt qua k cao hơn; tuy nhiên, các giá trị k cao hơn đòi hỏi nhiều tài nguyên hơn cho mô hình ngôn ngữ lớn và kiểm thử đơn vị.
hiệu quả hoạt động
Thuật ngữ bị nạp chồng với các ý nghĩa sau:
- Ý nghĩa tiêu chuẩn trong kỹ thuật phần mềm. Cụ thể: Phần mềm này chạy nhanh (hoặc hiệu quả) đến mức nào?
- Ý nghĩa trong công nghệ học máy. Ở đây, hiệu quả trả lời câu hỏi sau: Mô hình này chính xác đến mức nào? Tức là, mức độ chính xác của thông tin dự đoán do mô hình đưa ra?
mức độ quan trọng của biến hoán vị
Một loại mức độ quan trọng của biến đánh giá mức tăng lỗi dự đoán của một mô hình sau khi hoán vị các giá trị của đối tượng. Mức độ quan trọng của biến hoán vị là một chỉ số độc lập với mô hình.
độ hỗn loạn
Một chỉ số đo lường mức độ hoàn thành nhiệm vụ của mô hình. Ví dụ: giả sử nhiệm vụ của bạn là đọc một vài chữ cái đầu tiên của một từ mà người dùng đang nhập trên bàn phím điện thoại và đưa ra danh sách các từ có thể hoàn thành. Độ hỗn loạn (P) cho tác vụ này xấp xỉ số lượng các từ bạn cần đoán để danh sách của bạn chứa từ thực tế mà người dùng đang cố gắng nhập.
Độ hỗn loạn liên quan đến cross-entropy như sau:
hạng mục dương
Lớp học mà bạn đang kiểm thử.
Ví dụ: hạng mục dương trong mô hình ung thư có thể là "khối u". Hạng mục dương trong mô hình phân loại email có thể là "thư rác".
Tương phản với hạng mục âm.
AUC PR (diện tích dưới đường cong PR)
Diện tích dưới đường cong độ chính xác-khả năng thu hồi được nội suy, thu được bằng cách vẽ các điểm (khả năng thu hồi, độ chính xác) cho các giá trị khác nhau của ngưỡng phân loại.
độ chính xác
Một chỉ số cho các mô hình phân loại giúp trả lời câu hỏi sau:
Khi mô hình dự đoán hạng mục dương, tỷ lệ phần trăm dự đoán chính xác là bao nhiêu?
Sau đây là công thức:
trong đó:
- dương tính thật có nghĩa là mô hình đã dự đoán chính xác hạng mục dương.
- dương tính giả có nghĩa là mô hình đã nhầm lẫn dự đoán hạng mục dương.
Ví dụ: giả sử một mô hình đưa ra 200 dự đoán dương tính. Trong số 200 dự đoán tích cực này:
- 150 trường hợp là dương tính thật.
- 50 trường hợp là dương tính giả.
Trong trường hợp này:
Tương phản với độ chính xác và khả năng thu hồi.
Xem Phân loại: Độ chính xác, độ bao phủ, độ chính xác và các chỉ số liên quan trong Khoá học học máy ứng dụng để biết thêm thông tin.
độ chính xác tại k (độ chính xác@k)
Một chỉ số để đánh giá danh sách các mục được xếp hạng (theo thứ tự). Độ chính xác tại k xác định tỷ lệ của k mục đầu tiên trong danh sách đó là "phù hợp". Đó là:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Giá trị của k phải nhỏ hơn hoặc bằng độ dài của danh sách được trả về. Xin lưu ý rằng độ dài của danh sách được trả về không thuộc phạm vi tính toán.
Mức độ phù hợp thường mang tính chủ quan; ngay cả người đánh giá là chuyên gia cũng thường không đồng ý về những mục nào là phù hợp.
So với:
đường cong độ chính xác-độ thu hồi
Đường cong độ chính xác so với khả năng thu hồi ở các ngưỡng phân loại khác nhau.
độ lệch của dự đoán
Giá trị cho biết mức độ khác biệt giữa giá trị trung bình của các dự đoán và giá trị trung bình của nhãn trong tập dữ liệu.
Không nhầm lẫn với hệ số thiên vị trong các mô hình học máy hoặc với thiên vị trong đạo đức và sự công bằng.
tương đương về khả năng dự đoán
Một chỉ số công bằng kiểm tra xem đối với một mô hình phân loại nhất định, tỷ lệ độ chính xác có tương đương với các nhóm phụ đang được xem xét hay không.
Ví dụ: một mô hình dự đoán việc được nhận vào trường đại học sẽ đáp ứng tính tương đồng dự đoán về quốc tịch nếu tỷ lệ độ chính xác của mô hình này là như nhau đối với người Lilliput và người Brobdingnag.
Đôi khi, tính tương đương dự đoán còn được gọi là tính tương đương dự đoán về giá.
Hãy xem phần "Giải thích về định nghĩa công bằng" (mục 3.2.1) để biết thông tin chi tiết hơn về sự ngang bằng dự đoán.
tỷ lệ ngang bằng dự đoán
Một tên khác của tính chẵn lẻ dự đoán.
hàm mật độ xác suất
Một hàm xác định tần suất của các mẫu dữ liệu có chính xác một giá trị cụ thể. Khi các giá trị của một tập dữ liệu là các số dấu phẩy động liên tục, thì hiếm khi xảy ra trường hợp khớp chính xác. Tuy nhiên, việc tích hợp hàm mật độ xác suất từ giá trị x đến giá trị y sẽ cho ra tần suất dự kiến của các mẫu dữ liệu trong khoảng từ x đến y.
Ví dụ: hãy xem xét một phân phối chuẩn có giá trị trung bình là 200 và độ lệch chuẩn là 30. Để xác định tần suất dự kiến của các mẫu dữ liệu nằm trong phạm vi từ 211,4 đến 218,7, bạn có thể tích hợp hàm mật độ xác suất cho một phân phối chuẩn từ 211,4 đến 218,7.
Điểm
Tập dữ liệu Đọc hiểu bằng suy luận thông thường (ReCoRD)
Một tập dữ liệu để đánh giá khả năng suy luận thông thường của LLM. Mỗi ví dụ trong tập dữ liệu chứa 3 thành phần:
- Một hoặc hai đoạn văn trong một tin bài
- Một truy vấn trong đó một trong các thực thể được xác định rõ ràng hoặc ngầm ẩn trong đoạn văn được che giấu.
- Câu trả lời (tên của thực thể thuộc mặt nạ)
Hãy xem ReCoRD để biết danh sách ví dụ đầy đủ.
ReCoRD là một thành phần của nhóm SuperGLUE.
RealToxicityPrompts
Một tập dữ liệu chứa một tập hợp các phần đầu câu có thể chứa nội dung độc hại. Sử dụng tập dữ liệu này để đánh giá khả năng tạo văn bản không độc hại của LLM nhằm hoàn thành câu. Thông thường, bạn sẽ sử dụng Perspective API để xác định mức độ hiệu quả của LLM (mô hình ngôn ngữ lớn) trong nhiệm vụ này.
Hãy xem bài viết RealToxicityPrompts: Đánh giá sự suy giảm độc hại của mạng nơ-ron trong các mô hình ngôn ngữ để biết thông tin chi tiết.
mức độ ghi nhớ
Một chỉ số cho các mô hình phân loại giúp trả lời câu hỏi sau:
Khi thông tin thực tế là hạng mục dương, mô hình đã xác định chính xác bao nhiêu phần trăm dự đoán là hạng mục dương?
Sau đây là công thức:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
trong đó:
- dương tính thật có nghĩa là mô hình đã dự đoán chính xác hạng mục dương.
- âm tính giả nghĩa là mô hình nhầm lẫn dự đoán hạng mục âm.
Ví dụ: giả sử mô hình của bạn đã đưa ra 200 dự đoán về các ví dụ mà thông tin thực tế là hạng mục dương. Trong số 200 dự đoán này:
- 180 trường hợp là dương tính thật.
- 20 trường hợp là âm tính giả.
Trong trường hợp này:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Hãy xem bài viết Phân loại: Độ chính xác, khả năng thu hồi, độ đo và các chỉ số liên quan để biết thêm thông tin.
mức độ ghi nhớ tại k (recall@k)
Một chỉ số để đánh giá các hệ thống xuất ra danh sách các mục được xếp hạng (theo thứ tự). Độ thu hồi tại k xác định tỷ lệ các mục có liên quan trong k mục đầu tiên trong danh sách đó so với tổng số mục có liên quan được trả về.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Tương phản với độ chính xác tại k.
Nhận dạng quan hệ kéo theo văn bản (RTE)
Một tập dữ liệu để đánh giá khả năng của LLM trong việc xác định xem một giả thuyết có thể được suy ra (rút ra một cách logic) từ một đoạn văn bản hay không. Mỗi ví dụ trong quá trình đánh giá RTE bao gồm 3 phần:
- Một đoạn văn, thường là từ các bài viết trên Wikipedia hoặc tin bài
- Một giả thuyết
- Câu trả lời đúng là một trong hai lựa chọn sau:
- Đúng, tức là giả thuyết có thể được suy ra từ đoạn văn
- Sai, nghĩa là giả thuyết không thể được suy ra từ đoạn văn
Ví dụ:
- Đoạn văn: Euro là đơn vị tiền tệ của Liên minh Châu Âu.
- Giả thuyết: Pháp sử dụng đồng Euro làm đơn vị tiền tệ.
- Hàm ý: Đúng, vì Pháp là một phần của Liên minh Châu Âu.
RTE là một thành phần của tập hợp SuperGLUE.
ReCoRD
Viết tắt của Tập dữ liệu Đọc hiểu bằng lý luận thông thường.
Đường cong ROC (đường cong đặc tính hoạt động của máy thu)
Biểu đồ về tỷ lệ dương tính thực so với tỷ lệ dương tính giả cho các ngưỡng phân loại khác nhau trong phân loại nhị phân.
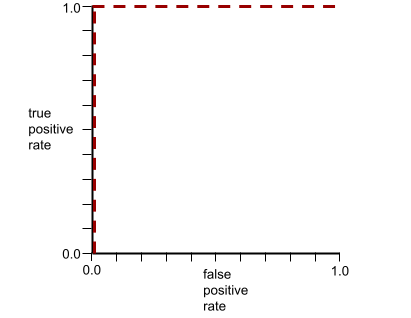
Hình dạng của đường cong ROC cho thấy khả năng của mô hình phân loại nhị phân trong việc tách các lớp dương tính khỏi các lớp âm tính. Ví dụ: giả sử một mô hình phân loại nhị phân tách biệt hoàn toàn tất cả các lớp âm tính với tất cả các lớp dương tính:
Đường cong ROC cho mô hình trước đó có dạng như sau:
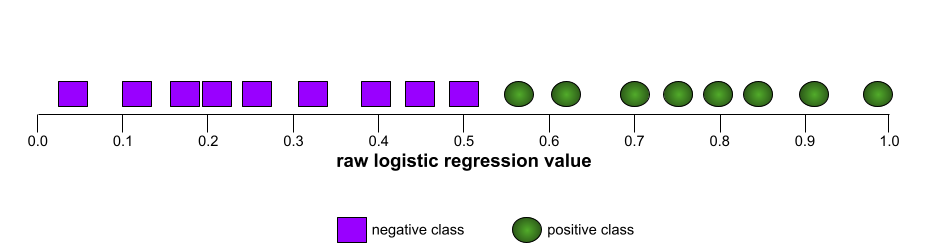
Ngược lại, hình minh hoạ sau đây vẽ đồ thị các giá trị hồi quy logistic thô cho một mô hình kém không thể tách các lớp âm tính khỏi các lớp dương tính:
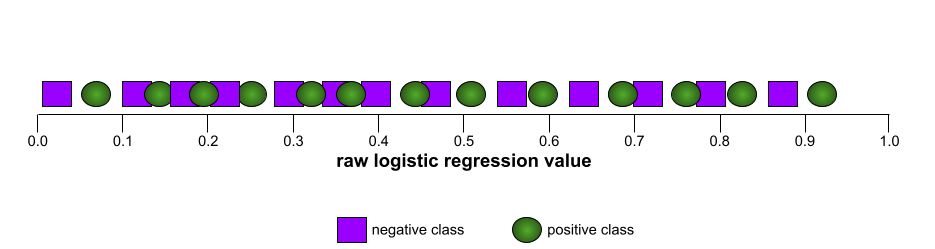
Đường cong ROC cho mô hình này có dạng như sau:
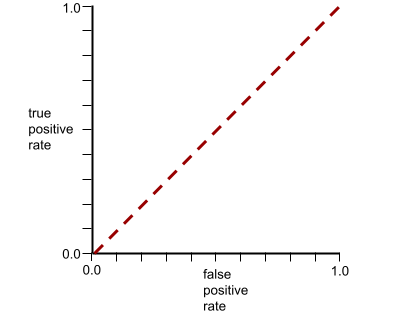
Trong khi đó, trong thế giới thực, hầu hết các mô hình phân loại nhị phân đều tách biệt các lớp dương và âm ở một mức độ nào đó, nhưng thường không hoàn hảo. Vì vậy, đường cong ROC điển hình nằm ở đâu đó giữa hai cực đoan:
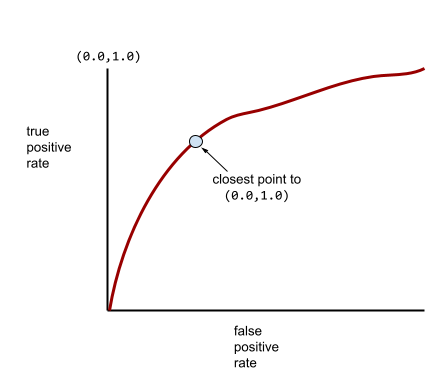
Điểm trên đường cong ROC gần với (0.0,1.0) nhất về mặt lý thuyết sẽ xác định ngưỡng phân loại lý tưởng. Tuy nhiên, một số vấn đề khác ngoài đời thực ảnh hưởng đến việc lựa chọn ngưỡng phân loại lý tưởng. Ví dụ: có lẽ kết quả âm tính giả gây ra nhiều phiền toái hơn kết quả dương tính giả.
Một chỉ số bằng số có tên là AUC tóm tắt đường cong ROC thành một giá trị dấu phẩy động duy nhất.
Sai số trung bình bình phương (RMSE)
Căn bậc hai của Sai số bình phương trung bình.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Một nhóm các chỉ số đánh giá mô hình tóm tắt tự động và mô hình bản dịch máy. Các chỉ số ROUGE xác định mức độ mà văn bản tham chiếu trùng lặp với văn bản do mô hình học máy tạo. Mỗi thành phần trong họ ROUGE đo lường mức độ trùng lặp theo một cách khác nhau. Điểm ROUGE càng cao thì văn bản tham chiếu và văn bản được tạo càng giống nhau so với điểm ROUGE thấp hơn.
Mỗi thành viên trong họ ROUGE thường tạo ra các chỉ số sau:
- Chính xác
- Nhớ lại
- F1
Để biết thông tin chi tiết và ví dụ, hãy xem:
ROUGE-L
Một thành viên của họ ROUGE tập trung vào độ dài của dãy con chung dài nhất trong văn bản tham chiếu và văn bản được tạo. Các công thức sau đây tính toán độ thu hồi và độ chính xác cho ROUGE-L:
Sau đó, bạn có thể sử dụng F1 để tổng hợp độ thu hồi ROUGE-L và độ chính xác ROUGE-L thành một chỉ số duy nhất:
ROUGE-L bỏ qua mọi dấu xuống dòng trong văn bản tham chiếu và văn bản được tạo, vì vậy, chuỗi con chung dài nhất có thể trải dài trên nhiều câu. Khi văn bản tham chiếu và văn bản được tạo có nhiều câu, thì một biến thể của ROUGE-L có tên là ROUGE-Lsum thường là chỉ số phù hợp hơn. ROUGE-Lsum xác định chuỗi con chung dài nhất cho mỗi câu trong một đoạn văn, sau đó tính giá trị trung bình của những chuỗi con chung dài nhất đó.
ROUGE-N
Một nhóm chỉ số trong họ ROUGE so sánh N-gram dùng chung có kích thước nhất định trong văn bản tham chiếu và văn bản được tạo. Ví dụ:
- ROUGE-1 đo lường số lượng token được chia sẻ trong văn bản tham chiếu và văn bản được tạo.
- ROUGE-2 đo lường số lượng bigram (2-gram) được chia sẻ trong văn bản tham chiếu và văn bản được tạo.
- ROUGE-3 đo số lượng trigram (3-gram) dùng chung trong văn bản tham chiếu và văn bản được tạo.
Bạn có thể sử dụng các công thức sau để tính độ thu hồi ROUGE-N và độ chính xác ROUGE-N cho bất kỳ thành viên nào trong họ ROUGE-N:
Sau đó, bạn có thể sử dụng F1 để tổng hợp độ thu hồi ROUGE-N và độ chính xác ROUGE-N thành một chỉ số duy nhất:
ROUGE-S
Một dạng ROUGE-N linh hoạt cho phép so khớp skip-gram. Tức là ROUGE-N chỉ tính N-gram khớp chính xác, nhưng ROUGE-S cũng tính N-gram được phân tách bằng một hoặc nhiều từ. Ví dụ: hãy cân nhắc những điều sau đây:
- văn bản tham chiếu: Mây trắng
- văn bản được tạo: Những đám mây trắng bồng bềnh
Khi tính toán ROUGE-N, 2-gram White clouds (Mây trắng) không khớp với White billowing clouds (Mây trắng cuồn cuộn). Tuy nhiên, khi tính toán ROUGE-S, White clouds (Mây trắng) khớp với White billowing clouds (Mây trắng cuồn cuộn).
R bình phương
Một chỉ số hồi quy cho biết mức độ biến thiên của một nhãn là do một đặc điểm riêng lẻ hoặc do một tập hợp đặc điểm. R bình phương là một giá trị nằm trong khoảng từ 0 đến 1, bạn có thể diễn giải như sau:
- R bình phương bằng 0 có nghĩa là không có biến thể nào của nhãn là do tập tính chất.
- R bình phương bằng 1 có nghĩa là tất cả các biến thể của nhãn đều là do tập tính chất.
- R bình phương từ 0 đến 1 cho biết mức độ mà sự biến thiên của nhãn có thể được dự đoán từ một đặc điểm cụ thể hoặc tập tính chất. Ví dụ: R bình phương bằng 0,10 có nghĩa là 10% phương sai trong nhãn là do tập tính chất, R bình phương bằng 0,20 có nghĩa là 20% là do tập tính chất, v.v.
R bình phương là bình phương của hệ số tương quan Pearson giữa các giá trị mà một mô hình dự đoán và chân lý cơ bản.
RTE
Viết tắt của Nhận dạng quan hệ kéo theo văn bản.
N
tính điểm
Phần của hệ thống đề xuất cung cấp giá trị hoặc thứ hạng cho từng mục do giai đoạn tạo đề xuất tạo ra.
đo lường mức độ tương đồng
Trong thuật toán phân cụm, chỉ số được dùng để xác định mức độ giống nhau (mức độ tương tự) giữa hai ví dụ bất kỳ.
độ thưa
Số lượng phần tử được đặt thành 0 (hoặc rỗng) trong một vectơ hoặc ma trận chia cho tổng số mục trong vectơ hoặc ma trận đó. Ví dụ: hãy xem xét một ma trận gồm 100 phần tử, trong đó 98 ô chứa số 0. Cách tính độ thưa thớt như sau:
Độ thưa thớt của đối tượng đề cập đến độ thưa thớt của một vectơ đối tượng; độ thưa thớt của mô hình đề cập đến độ thưa thớt của trọng số mô hình.
SQuAD
Từ viết tắt của Tập dữ liệu trả lời câu hỏi của Stanford, được giới thiệu trong bài viết SQuAD: Hơn 100.000 câu hỏi để máy hiểu được văn bản. Các câu hỏi trong tập dữ liệu này là của những người đặt câu hỏi về các bài viết trên Wikipedia. Một số câu hỏi trong SQuAD có câu trả lời, nhưng những câu hỏi khác thì không có câu trả lời. Do đó, bạn có thể sử dụng SQuAD để đánh giá khả năng của LLM trong việc thực hiện cả hai điều sau:
- Trả lời những câu hỏi có thể trả lời.
- Xác định những câu hỏi không thể trả lời.
Đối sánh chính xác kết hợp với F1 là những chỉ số phổ biến nhất để đánh giá LLM dựa trên SQuAD.
bình phương tổn thất khớp nối
Bình phương của tổn thất khớp nối. Bình phương tổn thất khớp nối phạt các giá trị ngoại lệ nghiêm khắc hơn so với tổn thất khớp nối thông thường.
tổn thất bình phương
Từ đồng nghĩa với tổn thất L2.
SuperGLUE
Một tập hợp các tập dữ liệu để đánh giá khả năng tổng thể của một LLM trong việc hiểu và tạo văn bản. Tập hợp này bao gồm các tập dữ liệu sau:
- Câu hỏi Boolean (BoolQ)
- CommitmentBank (CB)
- Lựa chọn thay thế hợp lý (COPA)
- Multi-sentence Reading Comprehension (MultiRC)
- Tập dữ liệu về khả năng đọc hiểu dựa trên suy luận thông thường (ReCoRD)
- Nhận dạng quan hệ kéo theo văn bản (RTE)
- Từ trong ngữ cảnh (WiC)
- Thử thách lược đồ Winograd (WSC)
Để biết thông tin chi tiết, hãy xem bài viết SuperGLUE: Một điểm chuẩn hiệu quả hơn cho các hệ thống hiểu ngôn ngữ đa năng.
T
tổn thất khi kiểm thử
Một chỉ số biểu thị tổn thất của một mô hình so với tập kiểm định. Khi tạo một mô hình, bạn thường cố gắng giảm thiểu tổn thất trong quá trình kiểm thử. Đó là vì tổn thất thấp trong quá trình kiểm thử là một tín hiệu chất lượng mạnh hơn so với tổn thất thấp trong quá trình huấn luyện hoặc tổn thất thấp trong quá trình xác thực.
Đôi khi, khoảng cách lớn giữa tổn thất khi kiểm thử và tổn thất khi huấn luyện hoặc tổn thất khi xác thực cho thấy bạn cần tăng hệ số điều hòa.
độ chính xác top-k
Tỷ lệ phần trăm số lần "nhãn mục tiêu" xuất hiện trong k vị trí đầu tiên của danh sách được tạo. Các danh sách này có thể là đề xuất được cá nhân hoá hoặc danh sách các mục được sắp xếp theo softmax.
Độ chính xác của k mục hàng đầu còn được gọi là độ chính xác tại k.
nội dung độc hại
Mức độ nội dung mang tính lăng mạ, đe doạ hoặc phản cảm. Nhiều mô hình học máy có thể xác định, đo lường và phân loại nội dung độc hại. Hầu hết các mô hình này đều xác định nội dung độc hại dựa trên nhiều thông số, chẳng hạn như mức độ ngôn từ lăng mạ và mức độ ngôn từ đe doạ.
mất mát trong quá trình huấn luyện
Một chỉ số biểu thị mức tổn thất của một mô hình trong một lần lặp lại huấn luyện cụ thể. Ví dụ: giả sử hàm tổn thất là Sai số bình phương trung bình. Có thể tổn thất huấn luyện (Lỗi bình phương trung bình) cho lần lặp thứ 10 là 2,2 và tổn thất huấn luyện cho lần lặp thứ 100 là 1,9.
Đường cong tổn thất vẽ tổn thất trong quá trình huấn luyện so với số lần lặp lại. Đường cong tổn thất cung cấp các gợi ý sau về quá trình huấn luyện:
- Độ dốc giảm cho thấy mô hình đang cải thiện.
- Độ dốc đi lên cho thấy mô hình đang trở nên kém hiệu quả hơn.
- Đường dốc bằng phẳng cho thấy mô hình đã đạt đến sự hội tụ.
Ví dụ: đường cong tổn thất (khá lý tưởng) sau đây cho thấy:
- Độ dốc giảm mạnh trong các lần lặp lại ban đầu, cho thấy mô hình được cải thiện nhanh chóng.
- Độ dốc giảm dần (nhưng vẫn đi xuống) cho đến gần cuối quá trình huấn luyện, điều này ngụ ý rằng mô hình vẫn tiếp tục cải thiện với tốc độ chậm hơn so với các lần lặp lại ban đầu.
- Đường dốc bằng phẳng về cuối quá trình huấn luyện, cho thấy sự hội tụ.

Mặc dù tổn thất khi huấn luyện là rất quan trọng, nhưng bạn cũng nên xem tổng quát hoá.
Trả lời câu hỏi đố vui
Các tập dữ liệu để đánh giá khả năng trả lời các câu hỏi về kiến thức chung của một LLM. Mỗi tập dữ liệu chứa các cặp câu hỏi và câu trả lời do những người yêu thích câu đố tạo ra. Các tập dữ liệu khác nhau được dựa trên nhiều nguồn, bao gồm:
- Tìm kiếm trên web (TriviaQA)
- Wikipedia (TriviaQA_wiki)
Để biết thêm thông tin, hãy xem TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension (TriviaQA: Một tập dữ liệu thử thách được giám sát từ xa trên quy mô lớn để đọc hiểu).
âm tính thật (TN)
Ví dụ trong đó mô hình dự đoán chính xác hạng mục âm. Ví dụ: mô hình suy luận rằng một nội dung email cụ thể không phải là thư rác và nội dung email đó thực sự không phải là thư rác.
dương tính thật (TP)
Ví dụ trong đó mô hình dự đoán chính xác hạng mục dương. Ví dụ: mô hình suy luận rằng một nội dung email cụ thể là thư rác và nội dung email đó thực sự là thư rác.
tỷ lệ dương tính thật (TPR)
Từ đồng nghĩa với mức độ ghi nhớ. Đó là:
Tỷ lệ dương tính thật là trục y trong đường cong ROC.
Hệ thống trả lời câu hỏi đa dạng về kiểu hình (TyDi QA)
Một tập dữ liệu lớn để đánh giá trình độ của LLM trong việc trả lời câu hỏi. Tập dữ liệu này chứa các cặp câu hỏi và câu trả lời bằng nhiều ngôn ngữ.
Để biết thông tin chi tiết, hãy xem TyDi QA: Điểm chuẩn cho tính năng trả lời câu hỏi tìm kiếm thông tin bằng nhiều ngôn ngữ đa dạng về kiểu hình.
U
tỷ lệ thông tin không được xác thực (UCR)
Tỷ lệ phần trăm số tuyên bố trong một phản hồi không có cơ sở. Ví dụ: nếu câu trả lời của một LLM đưa ra 10 tuyên bố nhưng chỉ có 1 tuyên bố dựa trên thông tin thực tế, thì UCR là 90%.
UCR cao có nghĩa là LLM đang ảo tưởng quá thường xuyên.
Xem thêm độ chính xác của trích dẫn và khả năng trích dẫn.
V
tổn thất xác thực
Một chỉ số biểu thị tổn thất của mô hình trên tập xác nhận trong một vòng lặp cụ thể của quá trình huấn luyện.
Xem thêm đường cong tổng quát hoá.
mức độ quan trọng của biến
Một tập hợp các điểm số cho biết tầm quan trọng tương đối của từng đặc điểm đối với mô hình.
Ví dụ: hãy xem xét một cây quyết định ước tính giá nhà. Giả sử cây quyết định này sử dụng 3 đặc điểm: kích thước, độ tuổi và kiểu dáng. Nếu một tập hợp các mức độ quan trọng của biến cho 3 đặc điểm được tính là {size=5.8, age=2.5, style=4.7}, thì kích thước quan trọng hơn đối với cây quyết định so với độ tuổi hoặc kiểu dáng.
Có nhiều chỉ số về tầm quan trọng của biến, có thể cung cấp cho các chuyên gia về học máy thông tin về nhiều khía cạnh của mô hình.
T
Tổn thất Wasserstein
Một trong những hàm tổn thất thường được dùng trong mạng đối nghịch sinh, dựa trên khoảng cách của người di chuyển trái đất giữa phân phối dữ liệu được tạo và dữ liệu thực.
WiC
Từ viết tắt của Từ trong ngữ cảnh.
WikiLingua (wiki_lingua)
Một tập dữ liệu để đánh giá khả năng tóm tắt các bài viết ngắn của LLM. WikiHow là một bách khoa toàn thư gồm các bài viết giải thích cách thực hiện nhiều việc. Đây là nguồn do con người viết cho cả bài viết và bản tóm tắt. Mỗi mục trong tập dữ liệu bao gồm:
- Một bài viết được tạo bằng cách thêm từng bước của phiên bản văn xuôi (đoạn văn) của danh sách được đánh số, trừ câu mở đầu của mỗi bước.
- Bản tóm tắt của bài viết đó, bao gồm câu mở đầu của từng bước trong danh sách được đánh số.
Để biết thông tin chi tiết, hãy xem bài viết WikiLingua: Một tập dữ liệu điểm chuẩn mới để tóm tắt trừu tượng đa ngôn ngữ.
Thử thách giản đồ Winograd (WSC)
Một định dạng (hoặc tập dữ liệu tuân theo định dạng đó) để đánh giá khả năng của LLM trong việc xác định cụm danh từ mà đại từ đề cập đến.
Mỗi mục trong Thử thách Winograd Schema bao gồm:
- Một đoạn văn ngắn có chứa đại từ mục tiêu
- Đại từ nhân xưng mục tiêu
- Cụm danh từ đề xuất, theo sau là câu trả lời đúng (một giá trị boolean). Nếu đại từ mục tiêu đề cập đến ứng cử viên này, thì câu trả lời là True. Nếu đại từ mục tiêu không đề cập đến ứng viên này, thì câu trả lời là False.
Ví dụ:
- Đoạn văn: Mark đã nói dối Pete rất nhiều về bản thân, và Pete đã đưa những lời nói dối đó vào cuốn sách của mình. Anh ta nên trung thực hơn.
- Đại từ nhân xưng mục tiêu: Anh ấy
- Cụm danh từ đề xuất:
- Đánh dấu: Đúng, vì đại từ nhân xưng mục tiêu đề cập đến Mark
- Pete: Sai, vì đại từ nhân xưng mục tiêu không đề cập đến Peter
Thử thách Winograd Schema là một thành phần của tập hợp SuperGLUE.
Từ trong ngữ cảnh (WiC)
Một tập dữ liệu để đánh giá mức độ hiệu quả của LLM trong việc sử dụng ngữ cảnh để hiểu những từ có nhiều nghĩa. Mỗi mục trong tập dữ liệu chứa:
- Hai câu, mỗi câu chứa từ mục tiêu
- Từ mục tiêu
- Câu trả lời chính xác (một giá trị Boolean), trong đó:
- True có nghĩa là từ mục tiêu có cùng nghĩa trong hai câu
- False có nghĩa là từ mục tiêu có nghĩa khác nhau trong hai câu
Ví dụ:
- Hai câu:
- Có rất nhiều rác trên lòng sông.
- Tôi luôn để một cốc nước bên cạnh giường khi ngủ.
- Từ mục tiêu: giường
- Câu trả lời chính xác: Sai, vì từ mục tiêu có nghĩa khác nhau trong hai câu.
Để biết thông tin chi tiết, hãy xem WiC: Tập dữ liệu Word-in-Context để đánh giá các biểu thị ý nghĩa theo ngữ cảnh.
Words in Context là một thành phần của nhóm mô hình SuperGLUE.
WSC
Từ viết tắt của Thử thách giản đồ Winograd.
X
XL-Sum (xlsum)
Một tập dữ liệu để đánh giá trình độ của LLM trong việc tóm tắt văn bản. XL-Sum cung cấp các mục nhập bằng nhiều ngôn ngữ. Mỗi mục trong tập dữ liệu chứa:
- Một bài viết của British Broadcasting Company (BBC).
- Phần tóm tắt bài viết do tác giả của bài viết đó viết. Xin lưu ý rằng bản tóm tắt đó có thể chứa những từ hoặc cụm từ không có trong bài viết.
Để biết thông tin chi tiết, hãy xem bài viết XL-Sum: Tóm tắt trừu tượng đa ngôn ngữ quy mô lớn cho 44 ngôn ngữ.