Bảng chú giải này định nghĩa các thuật ngữ về học máy.
A
loại bỏ
Một kỹ thuật để đánh giá tầm quan trọng của một đặc điểm hoặc thành phần bằng cách tạm thời xoá đặc điểm hoặc thành phần đó khỏi một mô hình. Sau đó, bạn sẽ huấn luyện lại mô hình mà không có tính năng hoặc thành phần đó. Nếu mô hình được huấn luyện lại hoạt động kém hơn đáng kể, thì tính năng hoặc thành phần đã xoá có thể là quan trọng.
Ví dụ: giả sử bạn huấn luyện một mô hình phân loại trên 10 đặc điểm và đạt được độ chính xác 88% trên tập hợp kiểm thử. Để kiểm tra tầm quan trọng của tính năng đầu tiên, bạn có thể huấn luyện lại mô hình chỉ bằng 9 tính năng khác. Nếu mô hình được huấn luyện lại hoạt động kém hơn đáng kể (ví dụ: độ chính xác 55%), thì có thể tính năng bị xoá là một tính năng quan trọng. Ngược lại, nếu mô hình được huấn luyện lại hoạt động tốt như nhau, thì có thể tính năng đó không quan trọng đến vậy.
Việc loại bỏ cũng có thể giúp xác định tầm quan trọng của:
- Các thành phần lớn hơn, chẳng hạn như toàn bộ hệ thống con của một hệ thống học máy lớn hơn
- Các quy trình hoặc kỹ thuật, chẳng hạn như bước tiền xử lý dữ liệu
Trong cả hai trường hợp, bạn sẽ quan sát thấy hiệu suất của hệ thống thay đổi (hoặc không thay đổi) sau khi bạn xoá thành phần.
Thử nghiệm A/B
Một phương pháp thống kê để so sánh hai (hoặc nhiều) kỹ thuật – A và B. Thông thường, A là một kỹ thuật hiện có và B là một kỹ thuật mới. Thử nghiệm A/B không chỉ xác định kỹ thuật nào hoạt động hiệu quả hơn mà còn xác định xem sự khác biệt đó có ý nghĩa thống kê hay không.
Thử nghiệm A/B thường so sánh một chỉ số duy nhất trên hai kỹ thuật; ví dụ: độ chính xác của mô hình so với hai kỹ thuật như thế nào? Tuy nhiên, thử nghiệm A/B cũng có thể so sánh bất kỳ số lượng hữu hạn nào của các chỉ số.
khối tăng tốc
Một danh mục các thành phần phần cứng chuyên dụng được thiết kế để thực hiện các phép tính chính cần thiết cho các thuật toán học sâu.
Các chip tăng tốc (hoặc chỉ là bộ tăng tốc) có thể tăng đáng kể tốc độ và hiệu quả của các tác vụ huấn luyện và suy luận so với CPU đa năng. Chúng là lựa chọn lý tưởng để huấn luyện mạng nơ-ron và các tác vụ tương tự cần nhiều sức mạnh tính toán.
Sau đây là một số ví dụ về chip tăng tốc:
- Bộ xử lý Tensor (TPU) của Google với phần cứng chuyên dụng để học sâu.
- GPU của NVIDIA, mặc dù ban đầu được thiết kế để xử lý đồ hoạ, nhưng được thiết kế để cho phép xử lý song song, có thể tăng đáng kể tốc độ xử lý.
độ chính xác
Số lượng dự đoán phân loại chính xác chia cho tổng số dự đoán. Đó là:
Ví dụ: một mô hình đưa ra 40 dự đoán chính xác và 10 dự đoán không chính xác sẽ có độ chính xác là:
Phân loại nhị phân cung cấp tên cụ thể cho các danh mục khác nhau của dự đoán chính xác và dự đoán không chính xác. Vì vậy, công thức tính độ chính xác cho phân loại nhị phân như sau:
trong đó:
- TP là số lượng dương tính thật (dự đoán chính xác).
- TN là số lượng âm tính thật (dự đoán chính xác).
- FP là số lượng kết quả dương tính giả (dự đoán không chính xác).
- FN là số lượng âm tính giả (dự đoán không chính xác).
So sánh và đối chiếu độ chính xác với độ đo lường chính xác và khả năng thu hồi.
Hãy xem phần Phân loại: Độ chính xác, khả năng thu hồi, độ đo và các chỉ số liên quan trong Khoá học cấp tốc về học máy để biết thêm thông tin.
hành động
Trong học tăng cường, cơ chế mà tác nhân chuyển đổi giữa các trạng thái của môi trường. Nhân viên hỗ trợ chọn hành động bằng cách sử dụng chính sách.
hàm kích hoạt
Một hàm cho phép mạng nơ-ron học các mối quan hệ phi tuyến tính (phức tạp) giữa các đặc điểm và nhãn.
Các hàm kích hoạt phổ biến bao gồm:
Đồ thị của các hàm kích hoạt không bao giờ là đường thẳng đơn lẻ. Ví dụ: biểu đồ của hàm kích hoạt ReLU bao gồm 2 đường thẳng:

Biểu đồ của hàm kích hoạt sigmoid có dạng như sau:

Nhấp vào biểu tượng để xem ví dụ.
Trong mạng nơ-ron, các hàm kích hoạt sẽ thao tác tổng có trọng số của tất cả các đầu vào cho một nơ-ron. Để tính tổng có trọng số, nơ-ron sẽ cộng các tích của các giá trị và trọng số có liên quan. Ví dụ: giả sử đầu vào liên quan đến một nơ-ron bao gồm những nội dung sau:
| giá trị đầu vào | trọng số đầu vào |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
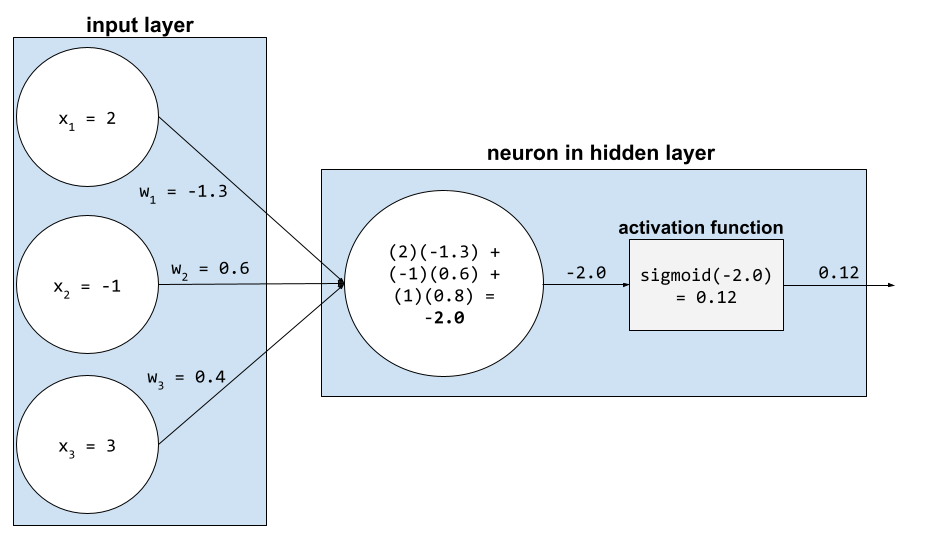
Hãy xem phần Mạng nơ-ron: Hàm kích hoạt trong Khoá học cấp tốc về học máy để biết thêm thông tin.
học tập chủ động
Một phương pháp huấn luyện trong đó thuật toán chọn một số dữ liệu mà thuật toán học được. Học tập chủ động đặc biệt có giá trị khi các ví dụ được gắn nhãn khan hiếm hoặc tốn kém để thu thập. Thay vì mù quáng tìm kiếm nhiều ví dụ được gắn nhãn, thuật toán học tập chủ động sẽ chọn lọc phạm vi ví dụ cụ thể mà thuật toán cần để học.
AdaGrad
Một thuật toán hạ độ dốc tinh vi giúp điều chỉnh lại độ dốc của từng tham số, nhờ đó, mỗi tham số sẽ có một tốc độ học tập độc lập. Để biết nội dung giải thích đầy đủ, hãy xem Phương pháp hạ gradient thích ứng cho học tập trực tuyến và tối ưu hoá ngẫu nhiên.
sự thích ứng
Từ đồng nghĩa với việc điều chỉnh hoặc tinh chỉnh.
nhân viên hỗ trợ
Phần mềm có thể suy luận về thông tin đầu vào đa phương thức của người dùng để lập kế hoạch và thực hiện các hành động thay cho người dùng.
Trong học tăng cường, tác nhân là thực thể sử dụng một chính sách để tối đa hoá lợi nhuận dự kiến thu được từ việc chuyển đổi giữa các trạng thái của môi trường.
phân cụm kết hợp
Xem phần phân cụm phân cấp.
phát hiện điểm bất thường
Quá trình xác định giá trị ngoại lệ. Ví dụ: nếu giá trị trung bình cho một đặc điểm nhất định là 100 với độ lệch chuẩn là 10, thì tính năng phát hiện điểm bất thường sẽ gắn cờ giá trị 200 là đáng ngờ.
Thực tế tăng cường (AR)
Viết tắt của thực tế tăng cường.
diện tích dưới đường cong PR
Xem PR AUC (Diện tích dưới đường cong PR).
diện tích dưới đường cong ROC
Xem AUC (Diện tích dưới đường cong ROC).
trí tuệ nhân tạo tổng quát
Một cơ chế không phải do con người tạo ra, có khả năng giải quyết vấn đề, sáng tạo và thích ứng trên nhiều lĩnh vực. Ví dụ: một chương trình minh hoạ trí tuệ nhân tạo đa năng có thể dịch văn bản, sáng tác bản giao hưởng và chơi giỏi những trò chơi chưa từng xuất hiện.
trí tuệ nhân tạo
Một chương trình hoặc mô hình không phải do con người tạo ra, có thể giải quyết các nhiệm vụ phức tạp. Ví dụ: một chương trình hoặc mô hình dịch văn bản hoặc một chương trình hoặc mô hình xác định bệnh từ hình ảnh chụp X-quang đều thể hiện trí tuệ nhân tạo.
Về mặt chính thức, học máy là một lĩnh vực con của trí tuệ nhân tạo. Tuy nhiên, trong những năm gần đây, một số tổ chức đã bắt đầu sử dụng các thuật ngữ trí tuệ nhân tạo và học máy thay thế cho nhau.
chú ý
Một cơ chế được dùng trong mạng nơ-ron cho biết tầm quan trọng của một từ cụ thể hoặc một phần của từ. Cơ chế chú ý nén lượng thông tin mà mô hình cần để dự đoán mã thông báo/từ tiếp theo. Cơ chế chú ý điển hình có thể bao gồm một tổng có trọng số trên một tập hợp các đầu vào, trong đó trọng số cho mỗi đầu vào được tính toán bởi một phần khác của mạng nơ-ron.
Bạn cũng có thể tham khảo cơ chế tự chú ý và cơ chế tự chú ý nhiều đầu. Đây là các khối xây dựng của Transformer.
Hãy xem bài viết LLM: Mô hình ngôn ngữ lớn là gì? trong Khoá học cấp tốc về học máy để biết thêm thông tin về cơ chế tự chú ý.
thuộc tính
Từ đồng nghĩa với tính năng.
Trong tính công bằng của học máy, các thuộc tính thường đề cập đến những đặc điểm liên quan đến cá nhân.
lấy mẫu thuộc tính
Một chiến thuật để huấn luyện rừng quyết định trong đó mỗi cây quyết định chỉ xem xét một tập hợp con ngẫu nhiên gồm các đặc điểm có thể có khi tìm hiểu điều kiện. Nhìn chung, một tập hợp con khác của các đối tượng được lấy mẫu cho mỗi nút. Ngược lại, khi huấn luyện một cây quyết định mà không lấy mẫu thuộc tính, tất cả các đặc điểm có thể có đều được xem xét cho từng nút.
AUC (Diện tích dưới đường cong ROC)
Một số từ 0,0 đến 1,0 biểu thị khả năng của mô hình phân loại nhị phân trong việc tách các lớp dương khỏi các lớp âm. AUC càng gần 1.0 thì khả năng tách các lớp của mô hình càng tốt.
Ví dụ: hình minh hoạ sau đây cho thấy một mô hình phân loại tách biệt hoàn toàn các lớp dương (hình bầu dục màu xanh lục) với các lớp âm (hình chữ nhật màu tím). Mô hình hoàn hảo một cách phi thực tế này có AUC là 1.0:

Ngược lại, hình minh hoạ sau đây cho thấy kết quả của một mô hình phân loại đã tạo ra kết quả ngẫu nhiên. Mô hình này có AUC là 0,5:

Có, mô hình trước đó có AUC là 0, 5 chứ không phải 0.
Hầu hết các mô hình đều nằm ở khoảng giữa hai thái cực này. Ví dụ: mô hình sau đây tách biệt phần nào các giá trị dương với giá trị âm, do đó có AUC nằm trong khoảng từ 0, 5 đến 1.0:

AUC bỏ qua mọi giá trị mà bạn đặt cho ngưỡng phân loại. Thay vào đó, AUC sẽ xem xét tất cả các ngưỡng phân loại có thể có.
Nhấp vào biểu tượng này để tìm hiểu về mối quan hệ giữa đường cong AUC và ROC.
AUC biểu thị diện tích dưới đường cong ROC. Ví dụ: đường cong ROC cho một mô hình phân tách hoàn hảo các giá trị dương với các giá trị âm sẽ có dạng như sau:
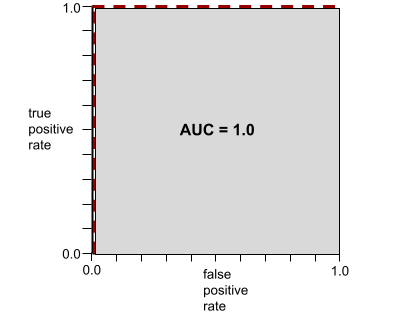
AUC là diện tích của vùng màu xám trong hình minh hoạ trước đó. Trong trường hợp bất thường này, diện tích chỉ đơn giản là chiều dài của vùng màu xám (1.0) nhân với chiều rộng của vùng màu xám (1.0). Vì vậy, tích của 1.0 và 1.0 sẽ cho ra AUC chính xác là 1.0, đây là điểm AUC cao nhất có thể.
Ngược lại, đường cong ROC cho một mô hình phân loại hoàn toàn không thể tách các lớp như sau. Diện tích của vùng màu xám này là 0,5.

Đường cong ROC điển hình hơn sẽ có dạng gần như sau:
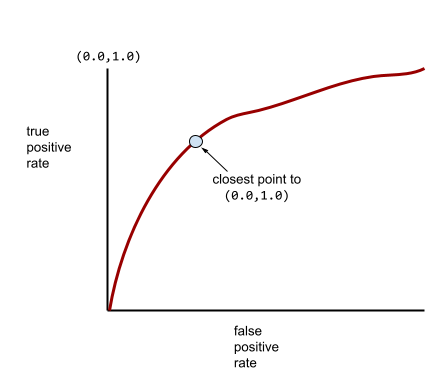
Việc tính toán diện tích dưới đường cong này theo cách thủ công sẽ rất khó khăn. Đó là lý do tại sao một chương trình thường tính toán hầu hết các giá trị AUC.
Hãy xem phần Phân loại: ROC và AUC trong Khoá học học máy ứng dụng để biết thêm thông tin.
thực tế tăng cường
Một công nghệ giúp chồng hình ảnh do máy tính tạo lên khung cảnh thực tế mà người dùng nhìn thấy, từ đó mang đến một khung cảnh kết hợp.
autoencoder
Một hệ thống học cách trích xuất thông tin quan trọng nhất từ dữ liệu đầu vào. Bộ mã hoá tự động là sự kết hợp giữa bộ mã hoá và bộ giải mã. Autoencoder dựa vào quy trình gồm 2 bước sau:
- Bộ mã hoá ánh xạ đầu vào sang định dạng (thường là) mất dữ liệu có kích thước thấp hơn (trung gian).
- Bộ giải mã tạo một phiên bản có tổn hao của dữ liệu đầu vào ban đầu bằng cách ánh xạ định dạng ít chiều hơn sang định dạng đầu vào ban đầu có nhiều chiều hơn.
Các bộ mã hoá tự động được huấn luyện từ đầu đến cuối bằng cách yêu cầu bộ giải mã cố gắng tái tạo đầu vào ban đầu từ định dạng trung gian của bộ mã hoá càng gần càng tốt. Vì định dạng trung gian nhỏ hơn (ít chiều hơn) so với định dạng ban đầu, nên bộ mã hoá tự động buộc phải tìm hiểu thông tin nào trong dữ liệu đầu vào là cần thiết và đầu ra sẽ không hoàn toàn giống với đầu vào.
Ví dụ:
- Nếu dữ liệu đầu vào là một hình ảnh, thì bản sao không hoàn toàn giống sẽ tương tự như hình ảnh gốc, nhưng có sửa đổi đôi chút. Có thể bản sao không hoàn toàn giống sẽ loại bỏ nhiễu khỏi hình ảnh gốc hoặc điền vào một số pixel bị thiếu.
- Nếu dữ liệu đầu vào là văn bản, thì một bộ mã hoá tự động sẽ tạo ra văn bản mới mô phỏng (nhưng không giống hệt) văn bản gốc.
Xem thêm mô hình tự mã hoá biến phân.
đánh giá tự động
Sử dụng phần mềm để đánh giá chất lượng đầu ra của một mô hình.
Khi đầu ra của mô hình tương đối đơn giản, một tập lệnh hoặc chương trình có thể so sánh đầu ra của mô hình với một phản hồi mẫu. Loại đánh giá tự động này đôi khi được gọi là đánh giá theo chương trình. Các chỉ số như ROUGE hoặc BLEU thường hữu ích cho việc đánh giá theo chương trình.
Khi đầu ra của mô hình phức tạp hoặc không có câu trả lời đúng duy nhất, một chương trình học máy riêng biệt có tên là autorater (trình đánh giá tự động) đôi khi sẽ thực hiện quy trình đánh giá tự động.
Tương phản với đánh giá của con người.
thiên kiến tự động hoá
Khi người đưa ra quyết định là con người ưu tiên các đề xuất do hệ thống tự động đưa ra quyết định hơn là thông tin không có sự can thiệp của hệ thống tự động, ngay cả khi hệ thống tự động đưa ra quyết định mắc lỗi.
Hãy xem phần Tính công bằng: Các loại thành kiến trong Khoá học cấp tốc về học máy để biết thêm thông tin.
AutoML
Mọi quy trình tự động để xây dựng mô hình học máy . AutoML có thể tự động thực hiện các tác vụ như sau:
- Tìm kiếm mô hình phù hợp nhất.
- Điều chỉnh siêu tham số.
- Chuẩn bị dữ liệu (bao gồm cả việc thực hiện thiết kế tính năng).
- Triển khai mô hình thu được.
AutoML rất hữu ích cho các nhà khoa học dữ liệu vì có thể giúp họ tiết kiệm thời gian và công sức trong việc phát triển các quy trình học máy, đồng thời cải thiện độ chính xác của dự đoán. Công cụ này cũng hữu ích cho những người không phải là chuyên gia, bằng cách giúp họ dễ dàng thực hiện các tác vụ học máy phức tạp hơn.
Hãy xem phần Học máy tự động (AutoML) trong Khoá học học máy ứng dụng để biết thêm thông tin.
đánh giá autorater
Một cơ chế kết hợp để đánh giá chất lượng đầu ra của mô hình AI tạo sinh, kết hợp quy trình đánh giá thủ công với quy trình đánh giá tự động. Autorater là một mô hình học máy được huấn luyện dựa trên dữ liệu do hoạt động đánh giá của con người tạo ra. Lý tưởng nhất là một công cụ đánh giá tự động học cách mô phỏng một nhân viên đánh giá là con người.Có sẵn các trình đánh giá tự động được tạo sẵn, nhưng trình đánh giá tự động tốt nhất là trình được tinh chỉnh cụ thể cho nhiệm vụ mà bạn đang đánh giá.
mô hình tự hồi quy
Một mô hình suy luận một dự đoán dựa trên các dự đoán trước đó của chính mô hình đó. Ví dụ: mô hình ngôn ngữ tự hồi quy dự đoán mã thông báo tiếp theo dựa trên các mã thông báo đã dự đoán trước đó. Tất cả mô hình ngôn ngữ lớn dựa trên Transformer đều tự hồi quy.
Ngược lại, các mô hình hình ảnh dựa trên GAN thường không tự hồi quy vì chúng tạo ra hình ảnh trong một lần chuyển tiếp duy nhất chứ không phải lặp lại theo các bước. Tuy nhiên, một số mô hình tạo hình ảnh có tính tự hồi quy vì chúng tạo hình ảnh theo từng bước.
tổn thất phụ
Hàm tổn thất – được dùng cùng với hàm tổn thất chính của mô hình mạng nơron. Hàm này giúp tăng tốc quá trình huấn luyện trong các lần lặp lại ban đầu khi trọng số được khởi tạo ngẫu nhiên.
Các hàm tổn thất phụ đẩy độ dốc hiệu quả đến các lớp trước đó. Điều này tạo điều kiện cho sự hội tụ trong quá trình huấn luyện bằng cách giải quyết vấn đề về độ dốc biến mất.
độ chính xác trung bình tại k
Một chỉ số để tóm tắt hiệu suất của mô hình trên một câu lệnh duy nhất tạo ra kết quả được xếp hạng, chẳng hạn như danh sách đề xuất sách có đánh số. Độ chính xác trung bình tại k là giá trị trung bình của các giá trị độ chính xác tại k cho mỗi kết quả có liên quan. Do đó, công thức tính độ chính xác trung bình tại k là:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
trong đó:
- \(n\) là số lượng mặt hàng có liên quan trong danh sách.
Tương phản với khả năng nhớ lại ở k.
điều kiện căn chỉnh theo trục
Trong cây quyết định, điều kiện chỉ liên quan đến một đặc điểm. Ví dụ: nếu area là một đối tượng, thì sau đây là điều kiện căn chỉnh theo trục:
area > 200
Tương phản với điều kiện xiên.
B
lan truyền ngược
Thuật toán triển khai phương pháp hạ độ dốc trong mạng nơron.
Việc huấn luyện mạng nơ-ron bao gồm nhiều lần lặp lại của chu kỳ hai lượt sau đây:
- Trong quá trình truyền xuôi, hệ thống sẽ xử lý một lô gồm ví dụ để đưa ra(các) dự đoán. Hệ thống so sánh từng dự đoán với từng giá trị nhãn. Khoảng chênh lệch giữa giá trị dự đoán và giá trị nhãn là mất mát cho ví dụ đó. Hệ thống tổng hợp các tổn thất cho tất cả các ví dụ để tính toán tổng tổn thất cho lô hiện tại.
- Trong lượt truyền ngược (lan truyền ngược), hệ thống sẽ giảm tổn thất bằng cách điều chỉnh trọng số của tất cả các nơ-ron trong tất cả (các) lớp ẩn.
Mạng nơ-ron thường chứa nhiều nơ-ron trên nhiều lớp ẩn. Mỗi nơ-ron trong số đó đóng góp vào tổn thất tổng thể theo những cách khác nhau. Thuật toán lan truyền ngược xác định xem có nên tăng hay giảm trọng số được áp dụng cho các nơ-ron cụ thể hay không.
Tốc độ học tập là một hệ số nhân kiểm soát mức độ mà mỗi lượt truyền ngược tăng hoặc giảm mỗi trọng số. Tốc độ học tập lớn sẽ tăng hoặc giảm mỗi trọng số nhiều hơn tốc độ học tập nhỏ.
Theo thuật ngữ giải tích, phương pháp lan truyền ngược triển khai quy tắc chuỗi từ giải tích. Tức là quá trình truyền ngược sẽ tính toán đạo hàm riêng phần của sai số đối với từng tham số.
Nhiều năm trước, các chuyên gia về học máy phải viết mã để triển khai phương pháp lan truyền ngược. Các API ML hiện đại như Keras hiện triển khai phương pháp lan truyền ngược cho bạn. Chà!
Hãy xem phần Mạng nơ-ron trong Khoá học học máy ứng dụng để biết thêm thông tin.
đóng gói
Một phương pháp để huấn luyện một tập hợp trong đó mỗi mô hình thành phần huấn luyện trên một tập hợp con ngẫu nhiên của các ví dụ huấn luyện được lấy mẫu có thay thế. Ví dụ: rừng ngẫu nhiên là một tập hợp các cây quyết định được huấn luyện bằng phương pháp lấy mẫu lại.
Thuật ngữ bagging là viết tắt của bootstrap aggregating (tập hợp khởi động).
Hãy xem phần Rừng ngẫu nhiên trong khoá học Rừng quyết định để biết thêm thông tin.
túi từ
Một biểu diễn của các từ trong một cụm từ hoặc đoạn văn, bất kể thứ tự. Ví dụ: mô hình túi từ biểu thị 3 cụm từ sau đây một cách giống hệt nhau:
- con chó nhảy lên
- nhảy con chó
- chó nhảy qua
Mỗi từ được liên kết với một chỉ mục trong vectơ thưa, trong đó vectơ có một chỉ mục cho mỗi từ trong từ vựng. Ví dụ: cụm từ the dog jumps (chú chó nhảy) được ánh xạ thành một vectơ đặc trưng có giá trị khác 0 tại 3 chỉ mục tương ứng với các từ the (chú), dog (chó) và jumps (nhảy). Giá trị khác 0 có thể là bất kỳ giá trị nào sau đây:
- Số 1 cho biết sự xuất hiện của một từ.
- Số lần một từ xuất hiện trong túi. Ví dụ: nếu cụm từ là the maroon dog is a dog with maroon fur (con chó màu hạt dẻ là một con chó có bộ lông màu hạt dẻ), thì cả maroon (màu hạt dẻ) và dog (chó) đều được biểu thị là 2, trong khi các từ khác sẽ được biểu thị là 1.
- Một số giá trị khác, chẳng hạn như logarit của số lần một từ xuất hiện trong túi.
đường cơ sở
Một mô hình được dùng làm điểm tham chiếu để so sánh hiệu suất của một mô hình khác (thường là mô hình phức tạp hơn). Ví dụ: mô hình hồi quy logistic có thể đóng vai trò là một đường cơ sở tốt cho mô hình sâu.
Đối với một vấn đề cụ thể, đường cơ sở giúp các nhà phát triển mô hình định lượng hiệu suất tối thiểu dự kiến mà một mô hình mới phải đạt được để mô hình mới đó hữu ích.
mô hình cơ sở
Một mô hình được huấn luyện trước có thể đóng vai trò là điểm bắt đầu cho quá trình điều chỉnh để giải quyết các nhiệm vụ hoặc ứng dụng cụ thể.
Xem thêm mô hình được huấn luyện trước và mô hình nền tảng.
lô
Tập hợp ví dụ được dùng trong một lần lặp lại quá trình huấn luyện. Kích thước lô xác định số lượng ví dụ trong một lô.
Hãy xem epoch để biết nội dung giải thích về mối quan hệ giữa một lô và một epoch.
Hãy xem phần Hồi quy tuyến tính: Siêu tham số trong Khoá học cấp tốc về học máy để biết thêm thông tin.
suy luận theo lô
Quy trình suy luận dự đoán trên nhiều ví dụ chưa được gắn nhãn được chia thành các tập hợp con nhỏ hơn ("lô").
Suy luận theo lô có thể tận dụng các tính năng song song hoá của các chip tăng tốc. Tức là nhiều bộ tăng tốc có thể đồng thời suy luận dự đoán trên nhiều lô ví dụ chưa được gắn nhãn, giúp tăng đáng kể số lượng suy luận mỗi giây.
Hãy xem bài viết Hệ thống học máy trong sản xuất: Suy luận tĩnh so với suy luận động trong Khoá học cấp tốc về học máy để biết thêm thông tin.
chuẩn hoá theo lô
Chuẩn hoá đầu vào hoặc đầu ra của hàm kích hoạt trong lớp ẩn. Chuẩn hoá theo lô có thể mang lại những lợi ích sau:
- Giúp mạng nơ-ron ổn định hơn bằng cách bảo vệ trước các trọng số dị thường.
- Cho phép tốc độ học tập cao hơn, có thể giúp tăng tốc độ huấn luyện.
- Giảm hiện tượng khớp quá mức.
kích thước lô
Số lượng ví dụ trong một lô. Ví dụ: nếu kích thước lô là 100, thì mô hình sẽ xử lý 100 ví dụ cho mỗi lần lặp lại.
Sau đây là các chiến lược kích thước lô phổ biến:
- Phương pháp giảm độ dốc ngẫu nhiên (SGD), trong đó kích thước lô là 1.
- Kích thước lô đầy đủ, trong đó kích thước lô là số lượng ví dụ trong toàn bộ tập huấn luyện. Ví dụ: nếu tập huấn luyện chứa một triệu ví dụ, thì kích thước lô sẽ là một triệu ví dụ. Xử lý theo lô đầy đủ thường là một chiến lược không hiệu quả.
- Tiểu lô, trong đó kích thước lô thường nằm trong khoảng từ 10 đến 1.000. Mini-batch thường là chiến lược hiệu quả nhất.
Hãy xem phần sau đây để biết thêm thông tin:
- Hệ thống học máy trong sản xuất: Suy luận tĩnh so với suy luận động trong Khoá học học máy ứng dụng.
- Cẩm nang điều chỉnh học sâu.
Mạng nơron Bayesian
Một mạng nơ-ron xác suất có tính đến sự không chắc chắn trong trọng số và đầu ra. Mô hình hồi quy mạng nơ-ron tiêu chuẩn thường dự đoán một giá trị vô hướng; ví dụ: mô hình tiêu chuẩn dự đoán giá nhà là 853.000. Ngược lại, mạng nơ-ron Bayesian dự đoán một phân phối các giá trị; ví dụ: mô hình Bayesian dự đoán giá nhà là 853.000 với độ lệch chuẩn là 67.200.
Mạng nơ-ron Bayesian dựa vào Định lý Bayes để tính toán độ không chắc chắn về trọng số và dự đoán. Mạng nơ-ron Bayesian có thể hữu ích khi bạn cần định lượng mức độ không chắc chắn, chẳng hạn như trong các mô hình liên quan đến dược phẩm. Mạng nơ-ron Bayesian cũng có thể giúp ngăn chặn tình trạng khớp quá mức.
Tối ưu hoá theo phương pháp Bayesian
Một kỹ thuật mô hình hồi quy xác suất để tối ưu hoá hàm mục tiêu tốn nhiều tài nguyên tính toán bằng cách tối ưu hoá một hàm thay thế giúp định lượng mức độ không chắc chắn bằng kỹ thuật học Bayesian. Vì bản thân quá trình tối ưu hoá theo phương pháp Bayesian rất tốn kém, nên phương pháp này thường được dùng để tối ưu hoá các tác vụ khó đánh giá có số lượng nhỏ tham số, chẳng hạn như chọn siêu tham số.
Phương trình Bellman
Trong học tăng cường, danh tính sau đây được đáp ứng bởi Q-function tối ưu:
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
Thuật toán học tăng cường áp dụng danh tính này để tạo Q-learning bằng quy tắc cập nhật sau:
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
Ngoài học tăng cường, phương trình Bellman còn được ứng dụng cho lập trình động. Hãy xem mục nhập về phương trình Bellman trên Wikipedia.
BERT (Bidirectional Encoder Representations from Transformers)
Một cấu trúc mô hình để biểu thị văn bản. Một mô hình BERT được huấn luyện có thể đóng vai trò là một phần của mô hình lớn hơn để phân loại văn bản hoặc các tác vụ học máy khác.
BERT có các đặc điểm sau:
- Sử dụng cấu trúc Transformer và do đó dựa vào cơ chế tự chú ý.
- Sử dụng phần encoder của Transformer. Công việc của bộ mã hoá là tạo ra các biểu diễn văn bản tốt, thay vì thực hiện một tác vụ cụ thể như phân loại.
- Có hai chiều.
- Sử dụng phương pháp che phủ cho huấn luyện không có giám sát.
Các biến thể của BERT bao gồm:
Hãy xem bài viết Nguồn mở BERT: Hoạt động huấn luyện trước hiện đại cho Xử lý ngôn ngữ tự nhiên để biết thông tin tổng quan về BERT.
thiên kiến (đạo đức/tính công bằng)
1. Định kiến, thành kiến hoặc thiên vị đối với một số sự vật, con người hoặc nhóm người so với những người khác. Những thiên kiến này có thể ảnh hưởng đến việc thu thập và diễn giải dữ liệu, thiết kế của một hệ thống và cách người dùng tương tác với hệ thống. Các dạng thiên kiến thuộc loại này bao gồm:
- thiên kiến tự động hoá
- thiên kiến xác nhận
- sự thiên vị của người nghiên cứu
- thiên vị quy cho nhóm
- thiên kiến ngầm
- thiên vị cùng nhóm
- thiên vị khác nhóm
2. Lỗi hệ thống do quy trình lấy mẫu hoặc báo cáo gây ra. Các dạng thiên kiến thuộc loại này bao gồm:
- thiên vị do thiếu bao quát
- thiên vị do thiếu hồi âm
- thiên kiến tham gia
- thiên vị dựa trên báo cáo
- thiên vị do không lấy mẫu
- thiên vị do cách chọn mẫu
Không nhầm lẫn với hệ số thiên vị trong các mô hình học máy hoặc độ thiên lệch dự đoán.
Hãy xem phần Tính công bằng: Các loại thành kiến trong Khoá học cấp tốc về học máy để biết thêm thông tin.
độ lệch (toán học) hoặc hệ số thiên lệch
Một điểm cắt hoặc độ lệch so với điểm gốc. Độ lệch là một tham số trong các mô hình học máy, được biểu thị bằng một trong những tham số sau:
- b
- w0
Ví dụ: độ lệch là b trong công thức sau:
Trong một đường thẳng hai chiều đơn giản, độ lệch chỉ có nghĩa là "giao điểm với trục y". Ví dụ: độ lệch của đường thẳng trong hình minh hoạ sau đây là 2.
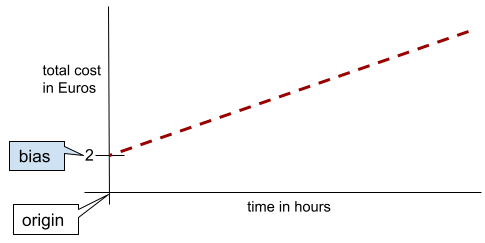
Sai số tồn tại vì không phải tất cả các mô hình đều bắt đầu từ điểm gốc (0,0). Ví dụ: giả sử một công viên giải trí có giá vé vào cửa là 2 EUR và khách hàng phải trả thêm 0,5 EUR cho mỗi giờ ở lại. Do đó, một mô hình ánh xạ tổng chi phí có độ lệch là 2 vì chi phí thấp nhất là 2 EUR.
Không nên nhầm lẫn thiên kiến với thiên kiến về đạo đức và sự công bằng hoặc thiên kiến dự đoán.
Hãy xem phần Hồi quy tuyến tính trong Khoá học học máy ứng dụng để biết thêm thông tin.
hai chiều
Một thuật ngữ dùng để mô tả hệ thống đánh giá văn bản đứng trước và đứng sau một phần văn bản mục tiêu. Ngược lại, hệ thống một chiều chỉ đánh giá văn bản đứng trước một phần văn bản mục tiêu.
Ví dụ: hãy xem xét một mô hình ngôn ngữ được che giấu phải xác định xác suất cho (các) từ đại diện cho phần gạch chân trong câu hỏi sau:
Bạn bị làm sao thế?
Một mô hình ngôn ngữ một chiều sẽ chỉ dựa vào xác suất của ngữ cảnh do các từ "What", "is" và "the" cung cấp. Ngược lại, mô hình ngôn ngữ hai chiều cũng có thể thu thập ngữ cảnh từ "với" và "bạn", điều này có thể giúp mô hình tạo ra thông tin dự đoán chính xác hơn.
mô hình ngôn ngữ hai chiều
Một mô hình ngôn ngữ xác định xác suất mà một mã thông báo nhất định xuất hiện ở một vị trí nhất định trong một đoạn trích văn bản dựa trên văn bản trước và sau.
bigram
Một N-gram trong đó N=2.
phân loại nhị phân
Một loại tác vụ phân loại dự đoán một trong hai lớp loại trừ lẫn nhau:
Ví dụ: mỗi mô hình học máy sau đây đều thực hiện phân loại nhị phân:
- Một mô hình xác định xem thư điện tử có phải là thư rác (lớp dương tính) hay không phải thư rác (lớp âm tính).
- Một mô hình đánh giá các triệu chứng y tế để xác định xem một người có mắc một bệnh cụ thể (lớp dương tính) hay không mắc bệnh đó (lớp âm tính).
Tương phản với phân loại đa mục.
Xem thêm hồi quy logistic và ngưỡng phân loại.
Hãy xem phần Phân loại trong Khoá học học máy ứng dụng để biết thêm thông tin.
điều kiện nhị phân
Trong cây quyết định, điều kiện chỉ có 2 kết quả có thể xảy ra, thường là có hoặc không. Ví dụ: sau đây là một điều kiện nhị phân:
temperature >= 100
Tương phản với điều kiện không phải là nhị phân.
Hãy xem Các loại điều kiện trong khoá học Rừng quyết định để biết thêm thông tin.
phân thùng
Từ đồng nghĩa với phân nhóm.
mô hình hộp đen
Một mô hình có "lý do" mà con người không thể hiểu được hoặc khó hiểu. Tức là mặc dù con người có thể thấy câu lệnh ảnh hưởng đến câu trả lời, nhưng con người không thể xác định chính xác cách một mô hình hộp đen xác định câu trả lời. Nói cách khác, mô hình hộp đen thiếu khả năng diễn giải.
Hầu hết các mô hình sâu và mô hình ngôn ngữ lớn đều là hộp đen.
BLEU (Bilingual Evaluation Understudy)
Một chỉ số từ 0 đến 1 để đánh giá bản dịch bằng máy, ví dụ: từ tiếng Tây Ban Nha sang tiếng Nhật.
Để tính điểm, BLEU thường so sánh bản dịch của một mô hình học máy (văn bản được tạo) với bản dịch của một chuyên gia là con người (văn bản tham chiếu). Mức độ trùng khớp giữa N-gram trong văn bản được tạo và văn bản tham chiếu sẽ xác định điểm BLEU.
Bài viết gốc về chỉ số này là BLEU: a Method for Automatic Evaluation of Machine Translation (BLEU: một phương pháp đánh giá tự động bản dịch máy).
Xem thêm BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
Một chỉ số để đánh giá bản dịch bằng máy từ ngôn ngữ này sang ngôn ngữ khác, đặc biệt là từ tiếng Anh và sang tiếng Anh.
Đối với bản dịch từ tiếng Anh sang tiếng Anh, BLEURT phù hợp với điểm đánh giá của con người hơn so với BLEU. Không giống như BLEU, BLEURT nhấn mạnh sự tương đồng về ngữ nghĩa (ý nghĩa) và có thể điều chỉnh việc diễn giải.
BLEURT dựa vào một mô hình ngôn ngữ lớn được huấn luyện trước (chính xác là BERT) rồi sau đó được điều chỉnh trên văn bản của người dịch.
Bài viết gốc về chỉ số này là BLEURT: Learning Robust Metrics for Text Generation (BLEURT: Học các chỉ số mạnh mẽ để tạo văn bản).
tăng cường
Một kỹ thuật học máy kết hợp lặp đi lặp lại một tập hợp các mô hình phân loại đơn giản và không chính xác lắm (được gọi là "trình phân loại yếu") thành một mô hình phân loại có độ chính xác cao ("trình phân loại mạnh") bằng cách tăng trọng số cho những ví dụ mà mô hình hiện đang phân loại sai.
Xem Cây quyết định được tăng cường độ dốc? trong khoá học Rừng quyết định để biết thêm thông tin.
hộp giới hạn
Trong một hình ảnh, toạ độ (x, y) của một hình chữ nhật xung quanh một vùng mà bạn quan tâm, chẳng hạn như chú chó trong hình ảnh bên dưới.

phát sóng
Mở rộng hình dạng của một toán hạng trong phép toán ma trận để kích thước tương thích cho phép toán đó. Ví dụ: đại số tuyến tính yêu cầu hai toán hạng trong một phép toán cộng ma trận phải có cùng kích thước. Do đó, bạn không thể thêm ma trận có hình dạng (m, n) vào vectơ có độ dài n. Hoạt động truyền tin cho phép thao tác này bằng cách mở rộng vectơ có độ dài n thành ma trận có hình dạng (m, n) bằng cách sao chép các giá trị tương tự xuống từng cột.
Hãy xem nội dung mô tả sau đây về truyền tin trong NumPy để biết thêm thông tin chi tiết.
phân giỏ
Chuyển đổi một đối tượng duy nhất thành nhiều đối tượng nhị phân được gọi là nhóm hoặc thùng, thường dựa trên một dải giá trị. Tính năng bị cắt thường là một tính năng liên tục.
Ví dụ: thay vì biểu thị nhiệt độ dưới dạng một đặc điểm liên tục duy nhất có dấu phẩy động, bạn có thể chia các phạm vi nhiệt độ thành các nhóm rời rạc, chẳng hạn như:
- <= 10 độ C sẽ là nhóm "lạnh".
- 11 – 24 độ C sẽ là nhóm "ôn hoà".
- >= 25 độ C sẽ là nhóm "ấm".
Mô hình sẽ xử lý mọi giá trị trong cùng một nhóm theo cách giống nhau. Ví dụ: giá trị 13 và 22 đều nằm trong nhóm nhiệt độ vừa phải, nên mô hình sẽ xử lý hai giá trị này giống nhau.
Hãy xem phần Dữ liệu dạng số: Phân nhóm trong Khoá học cấp tốc về học máy để biết thêm thông tin.
C
lớp hiệu chỉnh
Giá trị điều chỉnh sau dự đoán, thường là để tính đến sai lệch dự đoán. Các dự đoán và xác suất được điều chỉnh phải khớp với phân phối của một tập hợp nhãn đã quan sát.
tạo đề xuất
Nhóm đề xuất ban đầu do hệ thống đề xuất chọn. Ví dụ: hãy xem xét một hiệu sách cung cấp 100.000 đầu sách. Giai đoạn tạo đề xuất sẽ tạo ra một danh sách nhỏ hơn nhiều gồm những cuốn sách phù hợp cho một người dùng cụ thể, chẳng hạn như 500 cuốn. Nhưng ngay cả 500 cuốn sách cũng là quá nhiều để đề xuất cho một người dùng. Các giai đoạn tiếp theo, tốn kém hơn của hệ thống đề xuất (chẳng hạn như chấm điểm và xếp hạng lại) sẽ giảm 500 đề xuất đó xuống một tập hợp đề xuất nhỏ hơn và hữu ích hơn nhiều.
Hãy xem Tổng quan về việc tạo đề xuất trong khoá học Hệ thống đề xuất để biết thêm thông tin.
lấy mẫu ứng viên
Một quy trình tối ưu hoá trong thời gian huấn luyện sẽ tính toán xác suất cho tất cả các nhãn dương, chẳng hạn như sử dụng softmax, nhưng chỉ dành cho một mẫu nhãn âm ngẫu nhiên. Ví dụ: cho một ví dụ được gắn nhãn beagle và dog, hoạt động lấy mẫu ứng viên sẽ tính toán các xác suất dự đoán và các số hạng tổn thất tương ứng cho:
- beagle
- dog
- một tập hợp con ngẫu nhiên của các lớp âm còn lại (ví dụ: mèo, kẹo mút, hàng rào).
Ý tưởng là các lớp âm có thể học hỏi từ việc củng cố tiêu cực ít thường xuyên hơn, miễn là các lớp dương luôn nhận được sự củng cố tích cực thích hợp và điều này thực sự được quan sát một cách thực nghiệm.
Lấy mẫu ứng viên hiệu quả hơn về mặt tính toán so với các thuật toán huấn luyện tính toán dự đoán cho tất cả các lớp âm tính, đặc biệt là khi số lượng lớp âm tính rất lớn.
dữ liệu phân loại
Tính năng có một nhóm giá trị có thể có cụ thể. Ví dụ: hãy xem xét một đặc điểm phân loại có tên là traffic-light-state, chỉ có thể có một trong 3 giá trị có thể có sau đây:
redyellowgreen
Bằng cách biểu thị traffic-light-state dưới dạng một đặc điểm phân loại, mô hình có thể tìm hiểu những tác động khác nhau của red, green và yellow đối với hành vi của người lái xe.
Các đặc điểm phân loại đôi khi được gọi là đặc điểm rời rạc.
Tương phản với dữ liệu dạng số.
Hãy xem bài viết Làm việc với dữ liệu phân loại trong Khoá học cấp tốc về học máy để biết thêm thông tin.
mô hình ngôn ngữ nhân quả
Từ đồng nghĩa với mô hình ngôn ngữ một chiều.
Hãy xem mô hình ngôn ngữ hai chiều để so sánh các phương pháp định hướng khác nhau trong mô hình hoá ngôn ngữ.
tâm
Tâm của một cụm do thuật toán k-means hoặc k-median xác định. Ví dụ: nếu k là 3, thì thuật toán k-means hoặc k-median sẽ tìm thấy 3 tâm cụm.
Hãy xem Thuật toán phân cụm trong khoá học Phân cụm để biết thêm thông tin.
phân cụm dựa trên tâm
Một danh mục thuật toán phân cụm sắp xếp dữ liệu thành các cụm không theo hệ thống phân cấp. k-means là thuật toán phân cụm dựa trên tâm điểm được sử dụng rộng rãi nhất.
Tương phản với thuật toán phân cụm phân cấp.
Hãy xem Thuật toán phân cụm trong khoá học Phân cụm để biết thêm thông tin.
đặt câu lệnh theo chuỗi suy luận
Một kỹ thuật thiết kế câu lệnh khuyến khích mô hình ngôn ngữ lớn (LLM) giải thích quy trình suy luận của mình từng bước. Ví dụ: hãy xem xét câu lệnh sau, đặc biệt chú ý đến câu thứ hai:
Một người lái xe sẽ chịu bao nhiêu lực g trong một chiếc xe tăng tốc từ 0 đến 60 dặm/giờ trong 7 giây? Trong câu trả lời, hãy trình bày tất cả các phép tính liên quan.
Câu trả lời của LLM có thể sẽ:
- Cho thấy một chuỗi công thức vật lý, cắm các giá trị 0, 60 và 7 vào các vị trí thích hợp.
- Giải thích lý do chọn những công thức đó và ý nghĩa của các biến số.
Câu lệnh chuỗi suy luận buộc LLM thực hiện tất cả các phép tính, điều này có thể dẫn đến câu trả lời chính xác hơn. Ngoài ra, tính năng gợi ý theo chuỗi suy luận cho phép người dùng xem xét các bước của LLM để xác định xem câu trả lời có hợp lý hay không.
trò chuyện
Nội dung của cuộc trò chuyện qua lại với một hệ thống học máy, thường là một mô hình ngôn ngữ lớn. Tương tác trước đó trong cuộc trò chuyện (nội dung bạn đã nhập và cách mô hình ngôn ngữ lớn phản hồi) sẽ trở thành ngữ cảnh cho các phần tiếp theo của cuộc trò chuyện.
Trợ lý trò chuyện là một ứng dụng của mô hình ngôn ngữ lớn.
chốt kiểm tra
Dữ liệu ghi lại trạng thái của các tham số của mô hình trong quá trình huấn luyện hoặc sau khi hoàn tất quá trình huấn luyện. Ví dụ: trong quá trình huấn luyện, bạn có thể:
- Ngừng huấn luyện, có thể là do cố ý hoặc do một số lỗi nhất định.
- Ghi lại điểm kiểm tra.
- Sau đó, tải lại điểm kiểm tra, có thể trên phần cứng khác.
- Bắt đầu lại khoá đào tạo.
lớp
Một danh mục mà nhãn có thể thuộc về. Ví dụ:
- Trong mô hình phân loại nhị phân phát hiện thư rác, hai lớp có thể là thư rác và không phải thư rác.
- Trong mô hình phân loại nhiều lớp xác định giống chó, các lớp có thể là chó poodle, chó beagle, chó pug, v.v.
Mô hình phân loại dự đoán một lớp. Ngược lại, mô hình hồi quy dự đoán một số thay vì một lớp.
Hãy xem phần Phân loại trong Khoá học học máy ứng dụng để biết thêm thông tin.
tập dữ liệu cân bằng về loại
Một tập dữ liệu chứa nhãn phân loại trong đó số lượng thực thể của mỗi danh mục gần bằng nhau. Ví dụ: hãy xem xét một tập dữ liệu thực vật có nhãn nhị phân có thể là cây bản địa hoặc cây không phải bản địa:
- Một tập dữ liệu có 515 cây bản địa và 485 cây không phải bản địa là một tập dữ liệu cân bằng theo lớp.
- Tập dữ liệu có 875 cây bản địa và 125 cây không phải bản địa là một tập dữ liệu bất cân đối về loại.
Không có ranh giới chính thức giữa tập dữ liệu cân bằng lớp và tập dữ liệu mất cân bằng lớp. Sự khác biệt này chỉ trở nên quan trọng khi một mô hình được huấn luyện trên một tập dữ liệu có sự mất cân bằng lớn về lớp không thể hội tụ. Hãy xem phần Tập dữ liệu: tập dữ liệu bất cân đối trong Khoá học học máy ứng dụng để biết thông tin chi tiết.
mô hình phân loại
Một mô hình có dự đoán là một lớp. Ví dụ: sau đây là tất cả các mô hình phân loại:
- Một mô hình dự đoán ngôn ngữ của câu đầu vào (tiếng Pháp? Tiếng Tây Ban Nha? Tiếng Ý).
- Một mô hình dự đoán các loài cây (Cây phong? Oak? Bao báp?).
- Một mô hình dự đoán lớp dương tính hoặc âm tính cho một tình trạng bệnh cụ thể.
Ngược lại, mô hình hồi quy dự đoán các con số thay vì các lớp.
Hai loại mô hình phân loại phổ biến là:
ngưỡng phân loại
Trong phân loại nhị phân, một số từ 0 đến 1 sẽ chuyển đổi đầu ra thô của mô hình hồi quy logistic thành dự đoán về lớp dương tính hoặc lớp âm tính. Xin lưu ý rằng ngưỡng phân loại là giá trị do con người chọn, chứ không phải giá trị do quá trình huấn luyện mô hình chọn.
Mô hình hồi quy logistic xuất ra một giá trị thô trong khoảng từ 0 đến 1. Sau đó:
- Nếu giá trị thô này lớn hơn ngưỡng phân loại, thì lớp dương tính sẽ được dự đoán.
- Nếu giá trị thô này nhỏ hơn ngưỡng phân loại, thì lớp âm tính sẽ được dự đoán.
Ví dụ: giả sử ngưỡng phân loại là 0, 8. Nếu giá trị thô là 0,9, thì mô hình sẽ dự đoán lớp dương. Nếu giá trị thô là 0,7, thì mô hình sẽ dự đoán lớp âm.
Lựa chọn ngưỡng phân loại ảnh hưởng lớn đến số lượng kết quả dương tính giả và kết quả âm tính giả.
Hãy xem phần Ngưỡng và ma trận nhầm lẫn trong Khoá học học máy ứng dụng để biết thêm thông tin.
thuật toán phân loại
Một thuật ngữ thông thường cho mô hình phân loại.
tập dữ liệu bất cân đối về loại
Một tập dữ liệu cho một phân loại trong đó tổng số nhãn của mỗi lớp khác biệt đáng kể. Ví dụ: hãy xem xét một tập dữ liệu phân loại nhị phân có 2 nhãn được chia như sau:
- 1.000.000 nhãn phủ định
- 10 nhãn cho cột giá trị dương
Tỷ lệ nhãn âm tính so với nhãn dương tính là 100.000 trên 1, vì vậy đây là một tập dữ liệu bất cân đối về loại.
Ngược lại, tập dữ liệu sau đây là cân bằng theo lớp vì tỷ lệ nhãn tiêu cực so với nhãn tích cực tương đối gần với 1:
- 517 nhãn phủ định
- 483 nhãn dương
Tập dữ liệu nhiều lớp cũng có thể bất cân đối về lớp. Ví dụ: tập dữ liệu phân loại nhiều lớp sau đây cũng bất cân đối về lớp vì một nhãn có nhiều ví dụ hơn hẳn so với hai nhãn còn lại:
- 1.000.000 nhãn có lớp "xanh lục"
- 200 nhãn có lớp "tím"
- 350 nhãn có lớp "orange"
Việc huấn luyện tập dữ liệu bất cân đối về loại có thể gây ra những thách thức đặc biệt. Hãy xem phần Tập dữ liệu không cân bằng trong Khoá học học máy ứng dụng để biết thông tin chi tiết.
Xem thêm entropy, majority class và minority class.
cắt
Một kỹ thuật xử lý giá trị ngoại lệ bằng cách thực hiện một hoặc cả hai thao tác sau:
- Giảm các giá trị tính năng lớn hơn ngưỡng tối đa xuống ngưỡng tối đa đó.
- Tăng các giá trị của đối tượng nhỏ hơn ngưỡng tối thiểu lên đến ngưỡng tối thiểu đó.
Ví dụ: giả sử <0, 5% giá trị của một tính năng cụ thể nằm ngoài phạm vi 40–60. Trong trường hợp này, bạn có thể làm như sau:
- Cắt tất cả các giá trị trên 60 (ngưỡng tối đa) thành chính xác 60.
- Cắt tất cả các giá trị dưới 40 (ngưỡng tối thiểu) thành chính xác 40.
Giá trị ngoại lệ có thể làm hỏng các mô hình, đôi khi khiến trọng số tràn trong quá trình huấn luyện. Một số giá trị ngoại lệ cũng có thể làm hỏng đáng kể các chỉ số như độ chính xác. Cắt bớt là một kỹ thuật phổ biến để hạn chế thiệt hại.
Giới hạn độ dốc buộc các giá trị độ dốc nằm trong một dải ô được chỉ định trong quá trình huấn luyện.
Hãy xem phần Dữ liệu dạng số: Chuẩn hoá trong Khoá học cấp tốc về học máy để biết thêm thông tin.
Cloud TPU
Một bộ tăng tốc phần cứng chuyên dụng được thiết kế để tăng tốc các tải công việc học máy trên Google Cloud.
phân cụm
Nhóm các ví dụ có liên quan, đặc biệt là trong quá trình học không giám sát. Sau khi tất cả các ví dụ được nhóm lại, con người có thể tuỳ ý cung cấp ý nghĩa cho từng cụm.
Có nhiều thuật toán phân cụm. Ví dụ: thuật toán k-means sẽ phân cụm các ví dụ dựa trên khoảng cách của chúng đến một tâm cụm, như trong sơ đồ sau:

Sau đó, một nhà nghiên cứu có thể xem xét các cụm và ví dụ: gắn nhãn cụm 1 là "cây lùn" và cụm 2 là "cây có kích thước đầy đủ".
Một ví dụ khác là hãy xem xét thuật toán phân cụm dựa trên khoảng cách của một ví dụ từ một điểm trung tâm, minh hoạ như sau:

Hãy xem Khoá học về phân cụm để biết thêm thông tin.
cùng thích nghi
Một hành vi không mong muốn trong đó các nơ-ron dự đoán các mẫu trong dữ liệu huấn luyện bằng cách gần như chỉ dựa vào đầu ra của các nơ-ron cụ thể khác thay vì dựa vào hành vi của toàn bộ mạng. Khi các mẫu gây ra sự thích ứng đồng thời không có trong dữ liệu xác thực, thì sự thích ứng đồng thời sẽ gây ra hiện tượng quá khớp. Điều chỉnh bằng cách loại bỏ giúp giảm sự đồng thích ứng vì việc loại bỏ đảm bảo các nơ-ron không thể chỉ dựa vào các nơ-ron cụ thể khác.
lọc cộng tác
Đưa ra dự đoán về mối quan tâm của một người dùng dựa trên mối quan tâm của nhiều người dùng khác. Lọc cộng tác thường được dùng trong hệ thống đề xuất.
Hãy xem phần Lọc cộng tác trong khoá học Hệ thống đề xuất để biết thêm thông tin.
mô hình thu gọn
Mọi mô hình nhỏ được thiết kế để chạy trên các thiết bị nhỏ có tài nguyên tính toán hạn chế. Ví dụ: các mô hình nhỏ gọn có thể chạy trên điện thoại di động, máy tính bảng hoặc hệ thống nhúng.
tính toán
(Danh từ) Tài nguyên điện toán mà một mô hình hoặc hệ thống sử dụng, chẳng hạn như sức mạnh xử lý, bộ nhớ và bộ nhớ lưu trữ.
Xem các chip tăng tốc.
sự sai lệch về khái niệm
Sự thay đổi trong mối quan hệ giữa các tính năng và nhãn. Theo thời gian, sự thay đổi về khái niệm sẽ làm giảm chất lượng của mô hình.
Trong quá trình huấn luyện, mô hình sẽ học mối quan hệ giữa các đặc điểm và nhãn của chúng trong tập huấn luyện. Nếu nhãn trong tập huấn luyện là các proxy tốt cho thế giới thực, thì mô hình nên đưa ra các dự đoán chính xác về thế giới thực. Tuy nhiên, do sự thay đổi về khái niệm, các dự đoán của mô hình có xu hướng giảm theo thời gian.
Ví dụ: hãy xem xét một mô hình phân loại nhị phân dự đoán xem một mẫu xe nhất định có "tiết kiệm nhiên liệu" hay không. Tức là các tính năng có thể là:
- trọng lượng xe
- độ nén của động cơ
- loại truyền động
trong khi nhãn là một trong hai:
- tiết kiệm nhiên liệu
- không tiết kiệm nhiên liệu
Tuy nhiên, khái niệm về "xe tiết kiệm nhiên liệu" vẫn luôn thay đổi. Một mẫu xe được gắn nhãn tiết kiệm nhiên liệu vào năm 1994 gần như chắc chắn sẽ được gắn nhãn không tiết kiệm nhiên liệu vào năm 2024. Một mô hình chịu ảnh hưởng của sự thay đổi về khái niệm có xu hướng đưa ra những dự đoán ngày càng kém hữu ích theo thời gian.
So sánh và đối chiếu với tính không dừng.
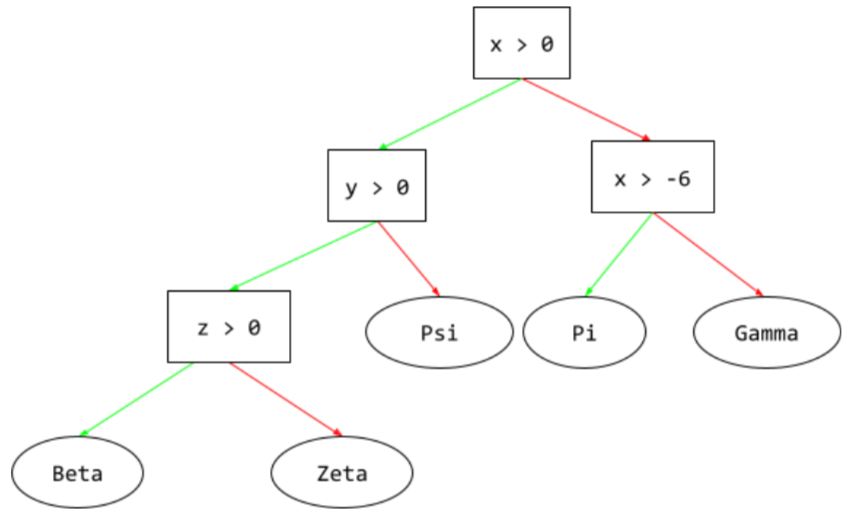
điều kiện
Trong cây quyết định, mọi nút đều thực hiện một kiểm thử. Ví dụ: cây quyết định sau đây có 2 điều kiện:

Điều kiện còn được gọi là phân tách hoặc kiểm thử.
Điều kiện tương phản với lá.
Xem thêm:
Hãy xem Các loại điều kiện trong khoá học Rừng quyết định để biết thêm thông tin.
chuyện bịa đặt
Từ đồng nghĩa với ảo tưởng.
Có lẽ, thuật ngữ bịa chuyện chính xác hơn về mặt kỹ thuật so với ảo giác. Tuy nhiên, ảo giác trở nên phổ biến trước.
cấu hình
Quá trình chỉ định các giá trị thuộc tính ban đầu được dùng để huấn luyện một mô hình, bao gồm:
- các lớp tạo nên mô hình
- vị trí của dữ liệu
- siêu tham số, chẳng hạn như:
Trong các dự án học máy, bạn có thể định cấu hình thông qua một tệp cấu hình đặc biệt hoặc sử dụng các thư viện cấu hình như sau:
thiên kiến xác nhận
Xu hướng tìm kiếm, diễn giải, ủng hộ và nhớ lại thông tin theo cách xác nhận niềm tin hoặc giả thuyết có sẵn của một người. Nhà phát triển học máy có thể vô tình thu thập hoặc gắn nhãn dữ liệu theo cách ảnh hưởng đến kết quả hỗ trợ niềm tin hiện tại của họ. Thiên kiến xác nhận là một dạng thiên kiến ngầm.
Thiên kiến của người thử nghiệm là một dạng thiên kiến xác nhận, trong đó người thử nghiệm tiếp tục huấn luyện các mô hình cho đến khi một giả thuyết có sẵn được xác nhận.
ma trận nhầm lẫn
Một bảng NxN tóm tắt số lượng dự đoán chính xác và không chính xác mà mô hình phân loại đã thực hiện. Ví dụ: hãy xem xét ma trận nhầm lẫn sau đây cho mô hình phân loại nhị phân:
| Khối u (dự đoán) | Không phải khối u (dự đoán) | |
|---|---|---|
| Khối u (thông tin thực tế) | 18 (TP) | 1 (FN) |
| Không phải khối u (thông tin thực tế) | 6 (FP) | 452 (TN) |
Ma trận nhầm lẫn ở trên cho thấy những điều sau:
- Trong số 19 dự đoán mà dữ liệu thực tế là U bướu, mô hình đã phân loại chính xác 18 và phân loại không chính xác 1.
- Trong số 458 dự đoán có dữ liệu thực tế là Không phải khối u, mô hình đã phân loại chính xác 452 và phân loại không chính xác 6.
Ma trận nhầm lẫn cho vấn đề phân loại nhiều lớp có thể giúp bạn xác định các mẫu lỗi. Ví dụ: hãy xem xét ma trận nhầm lẫn sau đây cho một mô hình phân loại nhiều lớp có 3 lớp, phân loại 3 loại hoa diên vĩ khác nhau (Virginica, Versicolor và Setosa). Khi thông tin thực tế là Virginica, ma trận nhầm lẫn cho thấy mô hình có nhiều khả năng dự đoán nhầm Versicolor hơn Setosa:
| Setosa (dự đoán) | Versicolor (dự đoán) | Virginica (dự đoán) | |
|---|---|---|---|
| Setosa (thông tin thực tế) | 88 | 12 | 0 |
| Versicolor (thông tin thực tế) | 6 | 141 | 7 |
| Virginica (thông tin thực tế) | 2 | 27 | 109 |
Một ví dụ khác là ma trận nhầm lẫn có thể cho thấy rằng một mô hình được huấn luyện để nhận dạng chữ số viết tay có xu hướng dự đoán nhầm 9 thay vì 4 hoặc dự đoán nhầm 1 thay vì 7.
Ma trận nhầm lẫn chứa đủ thông tin để tính toán nhiều chỉ số hiệu suất, bao gồm cả độ chính xác và khả năng thu hồi.
phân tích cú pháp thành phần
Chia một câu thành các cấu trúc ngữ pháp nhỏ hơn ("thành phần"). Một phần sau của hệ thống học máy (chẳng hạn như mô hình hiểu ngôn ngữ tự nhiên) có thể phân tích các thành phần dễ dàng hơn so với câu gốc. Ví dụ: hãy xem xét câu sau:
Bạn tôi nhận nuôi hai chú mèo.
Một trình phân tích cú pháp thành phần có thể chia câu này thành 2 thành phần sau:
- My friend (Bạn của tôi) là một cụm danh từ.
- adopted two cats (nhận nuôi hai chú mèo) là một cụm động từ.
Các thành phần này có thể được chia thành các thành phần nhỏ hơn. Ví dụ: cụm động từ
nhận nuôi hai chú mèo
có thể được chia thành:
- adopted là một động từ.
- two cats (hai con mèo) là một cụm danh từ khác.
mô hình nhúng ngôn ngữ theo ngữ cảnh
Một mô hình nhúng gần như "hiểu" được các từ và cụm từ theo cách mà người nói thành thạo có thể hiểu. Các câu lệnh nhúng ngôn ngữ theo ngữ cảnh có thể hiểu được cú pháp, ngữ nghĩa và ngữ cảnh phức tạp.
Ví dụ: hãy xem xét các vectơ nhúng của từ tiếng Anh cow (bò). Các vectơ nhúng cũ hơn, chẳng hạn như word2vec có thể biểu thị các từ tiếng Anh sao cho khoảng cách trong không gian vectơ nhúng từ cow (bò cái) đến bull (bò đực) tương tự như khoảng cách từ ewe (cừu cái) đến ram (cừu đực) hoặc từ female (nữ) đến male (nam). Các vectơ nhúng ngôn ngữ theo ngữ cảnh có thể tiến thêm một bước bằng cách nhận ra rằng đôi khi người nói tiếng Anh sử dụng từ cow (bò cái) một cách tuỳ ý để chỉ cả bò cái và bò đực.
cửa sổ ngữ cảnh
Số lượng mã thông báo mà một mô hình có thể xử lý trong một lời nhắc nhất định. Cửa sổ ngữ cảnh càng lớn, mô hình càng có thể sử dụng nhiều thông tin để đưa ra câu trả lời mạch lạc và nhất quán cho câu lệnh.
đối tượng liên tục
Một đặc điểm dấu phẩy động với vô số giá trị có thể có, chẳng hạn như nhiệt độ hoặc trọng lượng.
Tương phản với đối tượng rời rạc.
lấy mẫu tiện lợi
Sử dụng một tập dữ liệu không được thu thập một cách khoa học để chạy các thử nghiệm nhanh. Sau đó, bạn cần chuyển sang một tập dữ liệu được thu thập một cách khoa học.
hội tụ
Một trạng thái đạt được khi các giá trị mất mát thay đổi rất ít hoặc không thay đổi gì trong mỗi lần lặp lại. Ví dụ: đường cong tổn thất sau đây cho thấy sự hội tụ ở khoảng 700 lần lặp:
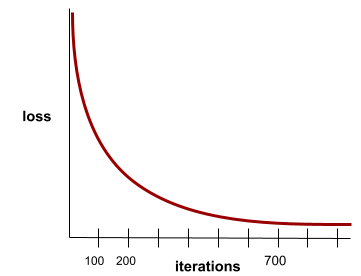
Một mô hình hội tụ khi việc huấn luyện thêm sẽ không cải thiện mô hình.
Trong học sâu, đôi khi các giá trị tổn thất vẫn giữ nguyên hoặc gần như vậy trong nhiều lần lặp lại trước khi giảm xuống. Trong một khoảng thời gian dài có các giá trị tổn thất không đổi, bạn có thể tạm thời có cảm giác sai lầm về sự hội tụ.
Xem thêm dừng sớm.
Hãy xem phần Đường cong hội tụ và tổn thất của mô hình trong Khoá học cấp tốc về học máy để biết thêm thông tin.
lập trình đàm thoại
Một cuộc đối thoại lặp đi lặp lại giữa bạn và một mô hình AI tạo sinh nhằm mục đích tạo ra phần mềm. Bạn đưa ra một câu lệnh mô tả một số phần mềm. Sau đó, mô hình sẽ dùng nội dung mô tả đó để tạo mã. Sau đó, bạn đưa ra một câu lệnh mới để giải quyết các lỗi trong câu lệnh trước đó hoặc trong mã được tạo, rồi mô hình sẽ tạo mã đã cập nhật. Hai bạn sẽ tiếp tục trao đổi cho đến khi phần mềm được tạo ra đủ tốt.
Về cơ bản, mã hoá cuộc trò chuyện là ý nghĩa ban đầu của mã hoá theo cảm hứng.
Tương phản với mã hoá theo quy cách.
hàm lồi
Một hàm mà vùng phía trên đồ thị của hàm là một tập hợp lồi. Hàm lồi nguyên mẫu có dạng như chữ U. Ví dụ: tất cả các hàm sau đều là hàm lồi:
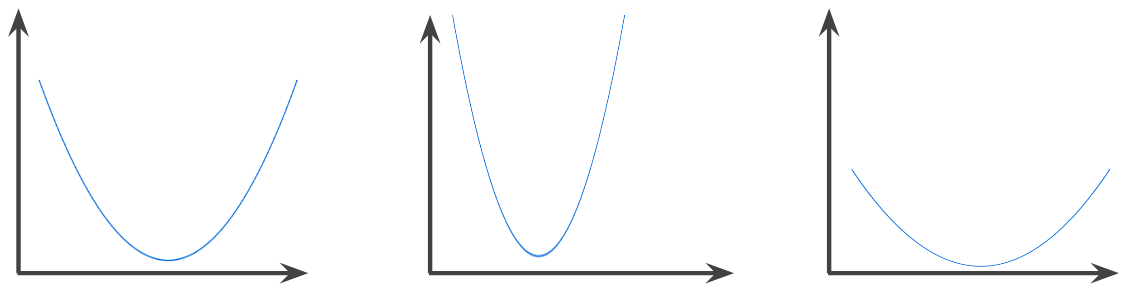
Ngược lại, hàm sau đây không lồi. Lưu ý cách vùng phía trên biểu đồ không phải là một tập hợp lồi:

Hàm lồi hoàn toàn có đúng một điểm cực tiểu cục bộ, cũng là điểm cực tiểu toàn cục. Các hàm có dạng chữ U cổ điển là các hàm lồi nghiêm ngặt. Tuy nhiên, một số hàm lồi (ví dụ: đường thẳng) không có dạng chữ U.
Hãy xem phần Hội tụ và các hàm lồi trong Khoá học cấp tốc về học máy để biết thêm thông tin.
tối ưu hoá lồi
Quy trình sử dụng các kỹ thuật toán học như phương pháp hạ độ dốc để tìm giá trị tối thiểu của một hàm lồi. Rất nhiều nghiên cứu về học máy tập trung vào việc xây dựng các vấn đề khác nhau dưới dạng các vấn đề tối ưu hoá lồi và giải quyết những vấn đề đó một cách hiệu quả hơn.
Để biết đầy đủ thông tin chi tiết, hãy xem Boyd và Vandenberghe, Tối ưu hoá lồi.
tập hợp lồi
Một tập hợp con của không gian Euclide sao cho đường thẳng được vẽ giữa hai điểm bất kỳ trong tập hợp con vẫn hoàn toàn nằm trong tập hợp con đó. Ví dụ: 2 hình dạng sau đây là tập hợp lồi:

Ngược lại, 2 hình dạng sau đây không phải là tập hợp lồi:

tích chập
Trong toán học, nói một cách thông thường, một hỗn hợp của hai hàm. Trong học máy, phép tích chập kết hợp bộ lọc tích chập và ma trận đầu vào để huấn luyện trọng số.
Thuật ngữ "tích chập" trong học máy thường là cách gọi tắt của phép tích chập hoặc lớp tích chập.
Nếu không có các phép tích chập, thuật toán học máy sẽ phải học một trọng số riêng cho mọi ô trong một tensor lớn. Ví dụ: thuật toán học máy huấn luyện trên hình ảnh 2K x 2K sẽ buộc phải tìm 4M trọng số riêng biệt. Nhờ các phép tích chập, thuật toán học máy chỉ phải tìm trọng số cho từng ô trong bộ lọc tích chập, giúp giảm đáng kể bộ nhớ cần thiết để huấn luyện mô hình. Khi bộ lọc tích chập được áp dụng, bộ lọc này sẽ được sao chép trên các ô sao cho mỗi ô được nhân với bộ lọc.
Hãy xem phần Giới thiệu về Mạng nơ-ron tích chập trong khoá học Phân loại hình ảnh để biết thêm thông tin.
bộ lọc tích chập
Một trong hai tác nhân trong phép toán tích chập. (Đối tượng khác là một phần của ma trận đầu vào.) Bộ lọc tích chập là một ma trận có cùng hạng với ma trận đầu vào, nhưng có hình dạng nhỏ hơn. Ví dụ: với ma trận đầu vào 28x28, bộ lọc có thể là bất kỳ ma trận 2D nào nhỏ hơn 28x28.
Trong quá trình xử lý ảnh, tất cả các ô trong bộ lọc tích chập thường được đặt thành một mẫu hằng số gồm các số 1 và 0. Trong quá trình máy học, các bộ lọc tích chập thường được gieo bằng các số ngẫu nhiên, sau đó mạng huấn luyện các giá trị lý tưởng.
Hãy xem phần Tích chập trong khoá học Phân loại hình ảnh để biết thêm thông tin.
lớp tích chập
Một lớp của mạng nơron sâu trong đó bộ lọc tích chập truyền dọc theo ma trận đầu vào. Ví dụ: hãy xem xét bộ lọc tích chập 3x3 sau:
![Ma trận 3x3 có các giá trị sau: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?authuser=9&hl=vi)
Ảnh động sau đây cho thấy một lớp tích chập bao gồm 9 phép toán tích chập liên quan đến ma trận đầu vào 5x5. Lưu ý rằng mỗi phép toán tích chập hoạt động trên một lát cắt 3x3 khác nhau của ma trận đầu vào. Ma trận 3x3 thu được (ở bên phải) bao gồm kết quả của 9 phép toán tích chập:
![Ảnh động minh hoạ hai ma trận. Ma trận đầu tiên là ma trận 5x5: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
Ma trận thứ hai là ma trận 3x3: [[181,303,618], [115,338,605], [169,351,560]].
Ma trận thứ hai được tính bằng cách áp dụng bộ lọc tích chập [[0, 1, 0], [1, 0, 1], [0, 1, 0]] trên các tập hợp con 3x3 khác nhau của ma trận 5x5.](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?authuser=9&hl=vi)
Hãy xem phần Các lớp được kết nối hoàn toàn trong khoá học Phân loại hình ảnh để biết thêm thông tin.
mạng nơron tích chập
Một mạng nơ-ron trong đó ít nhất một lớp là lớp tích chập. Một mạng nơ-ron tích chập điển hình bao gồm một số tổ hợp các lớp sau:
Mạng nơ-ron tích chập đã đạt được thành công lớn trong một số loại vấn đề, chẳng hạn như nhận dạng hình ảnh.
phép tích chập
Phép toán gồm 2 bước sau:
- Phép nhân theo phần tử của bộ lọc tích chập và một lát của ma trận đầu vào. (Lát của ma trận đầu vào có cùng thứ hạng và kích thước với bộ lọc tích chập.)
- Tổng của tất cả các giá trị trong ma trận sản phẩm thu được.
Ví dụ: hãy xem xét ma trận đầu vào 5x5 sau:
![Ma trận 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?authuser=9&hl=vi)
Bây giờ, hãy tưởng tượng bộ lọc tích chập 2x2 sau đây:
![Ma trận 2x2: [[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?authuser=9&hl=vi)
Mỗi phép toán tích chập liên quan đến một lát cắt 2x2 duy nhất của ma trận đầu vào. Ví dụ: giả sử chúng ta sử dụng lát cắt 2x2 ở trên cùng bên trái của ma trận đầu vào. Vì vậy, phép toán tích chập trên lát này có dạng như sau:
![Áp dụng bộ lọc tích chập [[1, 0], [0, 1]] cho phần 2x2 ở trên cùng bên trái của ma trận đầu vào, tức là [[128,97], [35,22]].
Bộ lọc tích chập giữ nguyên 128 và 22, nhưng đặt 97 và 35 thành 0. Do đó, phép toán tích chập sẽ cho ra giá trị 150 (128 + 22).](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?authuser=9&hl=vi)
Lớp tích chập bao gồm một chuỗi các phép tích chập, mỗi phép tích chập hoạt động trên một lát cắt khác nhau của ma trận đầu vào.
chi phí
Từ đồng nghĩa với thua.
cùng đào tạo
Phương pháp học bán giám sát đặc biệt hữu ích khi tất cả các điều kiện sau đây đều đúng:
- Tỷ lệ ví dụ chưa được gắn nhãn so với ví dụ đã được gắn nhãn trong tập dữ liệu là cao.
- Đây là một vấn đề phân loại (nhị phân hoặc đa mục).
- Tập dữ liệu chứa 2 tập hợp riêng biệt gồm các đặc điểm dự đoán độc lập với nhau và bổ sung cho nhau.
Về cơ bản, quá trình huấn luyện đồng thời sẽ khuếch đại các tín hiệu độc lập thành một tín hiệu mạnh hơn. Ví dụ: hãy xem xét một mô hình phân loại phân loại từng chiếc xe đã qua sử dụng là Tốt hoặc Không tốt. Một nhóm tính năng dự đoán có thể tập trung vào các đặc điểm tổng hợp như năm sản xuất, hãng sản xuất và mẫu xe; một nhóm tính năng dự đoán khác có thể tập trung vào hồ sơ lái xe của chủ sở hữu trước và nhật ký bảo dưỡng của xe.
Bài viết mang tính đột phá về đồng huấn luyện là Kết hợp dữ liệu được gắn nhãn và dữ liệu chưa được gắn nhãn bằng phương pháp đồng huấn luyện của Blum và Mitchell.
tính công bằng phản thực tế
Chỉ số công bằng kiểm tra xem mô hình phân loại có tạo ra cùng một kết quả cho một cá nhân như kết quả của một cá nhân khác giống với cá nhân đầu tiên hay không, ngoại trừ một hoặc nhiều thuộc tính nhạy cảm. Đánh giá mô hình phân loại để đảm bảo tính công bằng phản thực tế là một phương pháp để xác định các nguồn thiên vị tiềm ẩn trong một mô hình.
Hãy xem một trong hai phần sau để biết thêm thông tin:
- Tính công bằng: Tính công bằng phản thực tế trong Khoá học học máy ứng dụng.
- Khi các thế giới xung đột: Tích hợp các giả định phản thực tế khác nhau về tính công bằng
thiên kiến do thiếu bao quát
Xem phần thiên vị do cách chọn mẫu.
hiện tượng hoa nở đột ngột
Một câu hoặc cụm từ có nghĩa mơ hồ. Hiệu ứng nở hoa khi gặp sự cố là một vấn đề nghiêm trọng trong việc hiểu ngôn ngữ tự nhiên. Ví dụ: tiêu đề Red Tape Holds Up Skyscraper (Quan liêu cản trở việc xây dựng toà nhà chọc trời) là một tiêu đề gây hiểu lầm vì mô hình NLU có thể hiểu tiêu đề theo nghĩa đen hoặc theo nghĩa bóng.
nhà phê bình
Từ đồng nghĩa với Mạng Q sâu.
cross-entropy
Một khái quát hoá của Log Loss thành các vấn đề phân loại đa mục tiêu. Entropy chéo định lượng sự khác biệt giữa hai hàm phân phối xác suất. Xem thêm độ phức tạp.
xác thực chéo
Một cơ chế để ước tính mức độ khái quát hoá của mô hình đối với dữ liệu mới bằng cách kiểm thử mô hình dựa trên một hoặc nhiều tập hợp con dữ liệu không chồng chéo được giữ lại từ tập huấn luyện.
hàm phân phối tích luỹ (CDF)
Một hàm xác định tần suất của các mẫu nhỏ hơn hoặc bằng một giá trị mục tiêu. Ví dụ: hãy xem xét hàm phân phối chuẩn của các giá trị liên tục. CDF cho biết khoảng 50% mẫu phải nhỏ hơn hoặc bằng giá trị trung bình và khoảng 84% mẫu phải nhỏ hơn hoặc bằng một độ lệch chuẩn so với giá trị trung bình.
D
phân tích dữ liệu
Hiểu rõ dữ liệu bằng cách xem xét các mẫu, phép đo và hình ảnh hoá. Phân tích dữ liệu có thể đặc biệt hữu ích khi bạn nhận được một tập dữ liệu lần đầu tiên, trước khi bạn tạo mô hình đầu tiên. Đây cũng là yếu tố quan trọng trong việc tìm hiểu các thử nghiệm và gỡ lỗi cho hệ thống.
tăng cường dữ liệu
Tăng cường phạm vi và số lượng ví dụ huấn luyện một cách giả tạo bằng cách chuyển đổi các ví dụ hiện có để tạo thêm ví dụ. Ví dụ: giả sử hình ảnh là một trong những tính năng của bạn, nhưng tập dữ liệu của bạn không chứa đủ ví dụ về hình ảnh để mô hình học được các mối liên kết hữu ích. Tốt nhất là bạn nên thêm đủ hình ảnh được gắn nhãn vào tập dữ liệu để mô hình của bạn có thể huấn luyện đúng cách. Nếu không thể, việc tăng cường dữ liệu có thể xoay, kéo dài và phản chiếu từng hình ảnh để tạo ra nhiều biến thể của bức ảnh gốc, có thể tạo ra đủ dữ liệu được gắn nhãn để cho phép quá trình huấn luyện diễn ra hiệu quả.
DataFrame
Một kiểu dữ liệu pandas phổ biến để biểu thị tập dữ liệu trong bộ nhớ.
DataFrame tương tự như một bảng hoặc bảng tính. Mỗi cột của DataFrame có một tên (tiêu đề) và mỗi hàng được xác định bằng một số duy nhất.
Mỗi cột trong DataFrame có cấu trúc giống như một mảng 2D, ngoại trừ việc mỗi cột có thể được chỉ định kiểu dữ liệu riêng.
Bạn cũng có thể xem trang tham chiếu pandas.DataFrame chính thức.
tính song song của dữ liệu
Một cách để mở rộng quy mô huấn luyện hoặc suy luận bằng cách sao chép toàn bộ mô hình sang nhiều thiết bị, sau đó truyền một tập hợp con của dữ liệu đầu vào đến từng thiết bị. Tính song song dữ liệu có thể cho phép huấn luyện và suy luận trên kích thước lô rất lớn; tuy nhiên, tính song song dữ liệu yêu cầu mô hình phải đủ nhỏ để phù hợp với mọi thiết bị.
Tính song song của dữ liệu thường giúp tăng tốc quá trình huấn luyện và suy luận.
Xem thêm song song hoá mô hình.
Dataset API (tf.data)
Một API TensorFlow cấp cao để đọc dữ liệu và chuyển đổi dữ liệu đó thành dạng mà thuật toán học máy yêu cầu.
Một đối tượng tf.data.Dataset biểu thị một chuỗi các phần tử, trong đó mỗi phần tử chứa một hoặc nhiều Tensor. Đối tượng tf.data.Iterator cung cấp quyền truy cập vào các phần tử của Dataset.
tập dữ liệu hoặc tập dữ liệu
Một tập hợp dữ liệu thô, thường (nhưng không chỉ) được sắp xếp theo một trong các định dạng sau:
- bảng tính
- một tệp ở định dạng CSV (giá trị được phân tách bằng dấu phẩy)
ranh giới quyết định
Đường phân cách giữa các lớp mà mô hình học được trong vấn đề phân loại nhị phân hoặc phân loại nhiều lớp. Ví dụ: trong hình ảnh sau đây biểu thị một vấn đề phân loại nhị phân, ranh giới quyết định là ranh giới giữa lớp màu cam và lớp màu xanh dương:

rừng quyết định
Một mô hình được tạo từ nhiều cây quyết định. Rừng quyết định đưa ra dự đoán bằng cách tổng hợp các dự đoán của cây quyết định. Các loại rừng quyết định phổ biến bao gồm rừng ngẫu nhiên và cây được tăng cường độ dốc.
Hãy xem phần Rừng quyết định trong khoá học Rừng quyết định để biết thêm thông tin.
ngưỡng quyết định
Từ đồng nghĩa với ngưỡng phân loại.
cây quyết định
Một mô hình học có giám sát bao gồm một tập hợp các điều kiện và các nút lá được sắp xếp theo hệ phân cấp. Ví dụ: sau đây là một cây quyết định:
bộ giải mã
Nói chung, mọi hệ thống học máy chuyển đổi từ một biểu diễn đã xử lý, dày đặc hoặc nội bộ sang một biểu diễn thô, thưa thớt hoặc bên ngoài hơn.
Bộ giải mã thường là một thành phần của mô hình lớn hơn, trong đó chúng thường được ghép nối với một bộ mã hoá.
Trong các tác vụ từ chuỗi đến chuỗi, bộ giải mã bắt đầu bằng trạng thái nội bộ do bộ mã hoá tạo ra để dự đoán chuỗi tiếp theo.
Hãy tham khảo Transformer để biết định nghĩa về bộ giải mã trong kiến trúc Transformer.
Hãy xem Các mô hình ngôn ngữ lớn trong Khoá học học máy ứng dụng để biết thêm thông tin.
mô hình sâu
Một mạng nơ-ron chứa nhiều lớp ẩn.
Mô hình sâu còn được gọi là mạng nơron sâu.
Tương phản với mô hình rộng.
mạng nơron sâu
Từ đồng nghĩa với mô hình sâu.
Mạng Q sâu (DQN)
Trong Q-learning, một mạng nơron sâu dự đoán Q-function.
Critic là từ đồng nghĩa với Deep Q-Network.
tương đương về nhân khẩu học
Một chỉ số công bằng được đáp ứng nếu kết quả phân loại của một mô hình không phụ thuộc vào một thuộc tính nhạy cảm nhất định.
Ví dụ: nếu cả người Lilliput và người Brobdingnag đều đăng ký vào Đại học Glubbdubdrib, thì sự bình đẳng về nhân khẩu học sẽ đạt được nếu tỷ lệ phần trăm người Lilliput được nhận vào học bằng với tỷ lệ phần trăm người Brobdingnag được nhận vào học, bất kể một nhóm có trình độ chuyên môn cao hơn nhóm còn lại hay không.
Tương phản với xác suất cân bằng và cơ hội bình đẳng, cho phép kết quả phân loại tổng hợp phụ thuộc vào các thuộc tính nhạy cảm, nhưng không cho phép kết quả phân loại cho một số nhãn dữ liệu thực tế được chỉ định phụ thuộc vào các thuộc tính nhạy cảm. Xem bài viết "Chống phân biệt đối xử bằng công nghệ học máy thông minh hơn" để xem hình ảnh minh hoạ khám phá các điểm đánh đổi khi tối ưu hoá để đạt được sự bình đẳng về nhân khẩu học.
Hãy xem phần Tính công bằng: sự bình đẳng về nhân khẩu học trong Khoá học học máy ứng dụng để biết thêm thông tin.
giảm nhiễu
Một phương pháp phổ biến để tự học có giám sát, trong đó:
Việc khử nhiễu giúp bạn học từ các ví dụ không được gắn nhãn. Tập dữ liệu ban đầu đóng vai trò là mục tiêu hoặc nhãn và dữ liệu nhiễu đóng vai trò là dữ liệu đầu vào.
Một số mô hình ngôn ngữ được che giấu sử dụng phương pháp khử nhiễu như sau:
- Nhiễu được thêm vào một câu chưa được gắn nhãn bằng cách che một số mã thông báo.
- Mô hình này cố gắng dự đoán các mã thông báo ban đầu.
tính chất dày đặc
Một đặc điểm trong đó hầu hết hoặc tất cả các giá trị đều khác 0, thường là một Tensor gồm các giá trị dấu phẩy động. Ví dụ: Tensor gồm 10 phần tử sau đây là Tensor dày đặc vì 9 trong số các giá trị của Tensor này khác 0:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Tương phản với tính năng thưa.
lớp dày đặc
Từ đồng nghĩa với lớp liên thông đầy đủ.
chiều sâu
Tổng của những nội dung sau trong mạng nơron:
- số lượng lớp ẩn
- số lượng các lớp đầu ra, thường là 1
- số lượng lớp nhúng bất kỳ
Ví dụ: một mạng nơ-ron có 5 lớp ẩn và 1 lớp đầu ra có độ sâu là 6.
Xin lưu ý rằng lớp đầu vào không ảnh hưởng đến độ sâu.
mạng nơron tích chập có thể phân tách theo chiều sâu (sepCNN)
Một cấu trúc mạng nơ-ron tích chập dựa trên Inception, nhưng trong đó các mô-đun Inception được thay thế bằng các phép tích chập có thể phân tách theo chiều sâu. Còn được gọi là Xception.
Phép tích chập có thể tách theo chiều sâu (còn được gọi là phép tích chập có thể tách) phân tích một phép tích chập 3D tiêu chuẩn thành 2 phép tích chập riêng biệt có hiệu quả tính toán cao hơn: thứ nhất, phép tích chập theo chiều sâu, với độ sâu là 1 (n ✕ n ✕ 1) và thứ hai, phép tích chập theo điểm, với chiều dài và chiều rộng là 1 (1 ✕ 1 ✕ n).
Để tìm hiểu thêm, hãy xem bài viết Xception: Học sâu với các phép tích chập có thể phân tách theo chiều sâu.
nhãn dẫn xuất
Từ đồng nghĩa với nhãn đại diện.
thiết bị
Một thuật ngữ có nhiều nghĩa với 2 định nghĩa có thể có như sau:
- Một danh mục phần cứng có thể chạy một phiên TensorFlow, bao gồm CPU, GPU và TPU.
- Khi huấn luyện một mô hình học máy trên các chip tăng tốc (GPU hoặc TPU), phần của hệ thống thực sự thao tác với các tensor và các mục nhúng. Thiết bị chạy trên các chip tăng tốc. Ngược lại, máy chủ thường chạy trên CPU.
sự riêng tư biệt lập
Trong học máy, đây là một phương pháp ẩn danh để bảo vệ mọi dữ liệu nhạy cảm (ví dụ: thông tin cá nhân của một cá nhân) có trong tập huấn luyện của mô hình khỏi bị lộ. Phương pháp này đảm bảo rằng mô hình không học hoặc ghi nhớ nhiều thông tin về một cá nhân cụ thể. Điều này được thực hiện bằng cách lấy mẫu và thêm thành phần nhiễu trong quá trình huấn luyện mô hình để che giấu các điểm dữ liệu riêng lẻ, giảm thiểu rủi ro để lộ dữ liệu huấn luyện nhạy cảm.
Sự riêng tư biệt lập cũng được dùng bên ngoài công nghệ học máy. Ví dụ: đôi khi các nhà khoa học dữ liệu sử dụng sự riêng tư biệt lập để bảo vệ quyền riêng tư của từng cá nhân khi tính toán số liệu thống kê về mức sử dụng sản phẩm cho các nhóm nhân khẩu học khác nhau.
giảm chiều
Giảm số lượng phương diện được dùng để biểu thị một tính năng cụ thể trong vectơ tính năng, thường là bằng cách chuyển đổi thành một vectơ nhúng.
phương diện
Thuật ngữ bị nạp chồng có một trong các định nghĩa sau:
Số lượng cấp toạ độ trong một Tensor. Ví dụ:
- Một đại lượng vô hướng có 0 chiều; ví dụ:
["Hello"]. - Một vectơ có một chiều; ví dụ:
[3, 5, 7, 11]. - Ma trận có hai phương diện; ví dụ:
[[2, 4, 18], [5, 7, 14]]. Bạn có thể chỉ định một ô cụ thể trong một vectơ một chiều bằng một toạ độ; bạn cần hai toạ độ để chỉ định một ô cụ thể trong ma trận hai chiều.
- Một đại lượng vô hướng có 0 chiều; ví dụ:
Số lượng mục trong một vectơ đối tượng.
Số lượng phần tử trong một lớp nhúng.
đặt câu lệnh trực tiếp
Từ đồng nghĩa với đặt câu lệnh không kèm ví dụ.
tính chất rời rạc
Một đặc điểm có một tập hợp hữu hạn các giá trị có thể có. Ví dụ: một đối tượng có các giá trị chỉ có thể là động vật, thực vật hoặc khoáng chất là một đối tượng rời rạc (hoặc phân loại).
Tương phản với tính năng liên tục.
mô hình phân biệt
Một mô hình dự đoán nhãn từ một tập hợp gồm một hoặc nhiều đặc điểm. Cụ thể hơn, các mô hình phân biệt xác định xác suất có điều kiện của một đầu ra nhất định dựa trên các đặc điểm và trọng số; tức là:
p(output | features, weights)
Ví dụ: một mô hình dự đoán xem email có phải là thư rác hay không dựa trên các đặc điểm và trọng số là một mô hình phân biệt.
Phần lớn các mô hình học có giám sát, bao gồm cả mô hình phân loại và mô hình hồi quy, đều là mô hình phân biệt.
Tương phản với mô hình tạo sinh.
thuộc tính phân biệt
Một hệ thống xác định xem ví dụ là thật hay giả.
Ngoài ra, đây cũng là hệ thống con trong mạng đối nghịch tạo sinh, có chức năng xác định xem các ví dụ do trình tạo tạo ra là thật hay giả.
Hãy xem Phân biệt đối xử trong khoá học về GAN để biết thêm thông tin.
tác động không tương xứng
Đưa ra quyết định về những người có tác động không cân xứng đến các nhóm nhỏ dân số khác nhau. Điều này thường đề cập đến những tình huống mà quy trình ra quyết định dựa trên thuật toán gây hại hoặc mang lại lợi ích cho một số nhóm nhỏ nhiều hơn những nhóm khác.
Ví dụ: giả sử một thuật toán xác định xem người Lilliput có đủ điều kiện vay tiền mua nhà thu nhỏ hay không có nhiều khả năng phân loại họ là "không đủ điều kiện" nếu địa chỉ gửi thư của họ có một mã bưu chính nhất định. Nếu người Lilliput sử dụng hệ thống Big-Endian có nhiều khả năng có địa chỉ gửi thư với mã bưu chính này hơn người Lilliput sử dụng hệ thống Little-Endian, thì thuật toán này có thể dẫn đến tác động không tương xứng.
Tương phản với đối xử phân biệt, tập trung vào sự chênh lệch xảy ra khi các đặc điểm của nhóm nhỏ là thông tin đầu vào rõ ràng cho quy trình đưa ra quyết định bằng thuật toán.
đối xử phân biệt
Đưa thuộc tính nhạy cảm của đối tượng vào quy trình ra quyết định dựa trên thuật toán sao cho các nhóm nhỏ khác nhau của mọi người được đối xử khác nhau.
Ví dụ: hãy xem xét một thuật toán xác định xem người Lilliput có đủ điều kiện để vay tiền mua nhà thu nhỏ hay không dựa trên dữ liệu mà họ cung cấp trong đơn đăng ký vay. Nếu thuật toán sử dụng mối quan hệ của người Lilliputian với Big-Endian hoặc Little-Endian làm dữ liệu đầu vào, thì thuật toán đó đang thực hiện cách xử lý khác biệt theo phương diện đó.
Tương phản với tác động không tương xứng, tập trung vào sự khác biệt trong tác động xã hội của các quyết định dựa trên thuật toán đối với các nhóm nhỏ, bất kể những nhóm nhỏ đó có phải là dữ liệu đầu vào cho mô hình hay không.
chưng cất
Quá trình giảm kích thước của một mô hình (được gọi là giáo viên) thành một mô hình nhỏ hơn (được gọi là học viên) mô phỏng các dự đoán của mô hình ban đầu một cách trung thực nhất có thể. Chưng cất rất hữu ích vì mô hình nhỏ hơn có 2 lợi ích chính so với mô hình lớn hơn (mô hình gốc):
- Thời gian suy luận nhanh hơn
- Giảm mức sử dụng bộ nhớ và năng lượng
Tuy nhiên, các dự đoán của học viên thường không chính xác bằng dự đoán của giáo viên.
Chưng cất giúp huấn luyện mô hình học viên để giảm thiểu hàm tổn thất dựa trên sự khác biệt giữa các kết quả dự đoán của mô hình học viên và mô hình giáo viên.
So sánh và đối chiếu chưng cất với các thuật ngữ sau:
Hãy xem phần Mô hình ngôn ngữ lớn: Tinh chỉnh, chưng cất và kỹ thuật tạo câu lệnh trong Khoá học cấp tốc về học máy để biết thêm thông tin.
Phân phối
Tần suất và phạm vi của các giá trị khác nhau cho một đặc điểm hoặc nhãn nhất định. Phân phối ghi lại khả năng xảy ra một giá trị cụ thể.
Hình ảnh sau đây cho thấy biểu đồ tần suất của 2 phân phối khác nhau:
- Ở bên trái, một quy luật lũy thừa về sự phân phối của cải so với số người sở hữu của cải đó.
- Ở bên phải, một phân phối chuẩn về chiều cao so với số người có chiều cao đó.
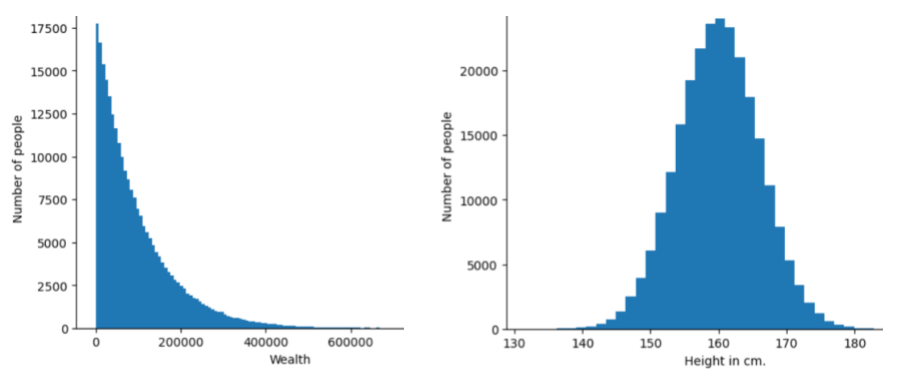
Việc hiểu rõ mức phân phối của từng đặc điểm và nhãn có thể giúp bạn xác định cách chuẩn hoá các giá trị và phát hiện giá trị ngoại lệ.
Cụm từ ngoài phân phối đề cập đến một giá trị không xuất hiện trong tập dữ liệu hoặc rất hiếm khi xuất hiện. Ví dụ: hình ảnh về hành tinh Thổ Tinh sẽ được coi là nằm ngoài phân phối đối với một tập dữ liệu bao gồm hình ảnh mèo.
phân cụm phân chia
Xem phần phân cụm phân cấp.
giảm tốc độ lấy mẫu
Thuật ngữ nạp chồng có thể mang một trong những ý nghĩa sau:
- Giảm lượng thông tin trong một đối tượng để huấn luyện một mô hình hiệu quả hơn. Ví dụ: trước khi huấn luyện mô hình nhận dạng hình ảnh, hãy giảm độ phân giải của hình ảnh có độ phân giải cao xuống định dạng có độ phân giải thấp hơn.
- Huấn luyện trên một tỷ lệ phần trăm thấp không cân xứng của các ví dụ về lớp được biểu thị quá mức để cải thiện quá trình huấn luyện mô hình trên các lớp được biểu thị dưới mức. Ví dụ: trong tập dữ liệu không cân bằng lớp, các mô hình có xu hướng tìm hiểu nhiều về lớp đa số và không đủ về lớp thiểu số. Giảm mẫu giúp cân bằng lượng dữ liệu huấn luyện cho các lớp đa số và thiểu số.
Hãy xem phần Tập dữ liệu: Tập dữ liệu bất cân đối trong Khoá học học máy ứng dụng để biết thêm thông tin.
DQN
Viết tắt của Mạng Q sâu.
điều hoà dropout
Một dạng điều chỉnh hữu ích trong việc huấn luyện mạng nơron. Việc điều chỉnh bằng cách loại bỏ sẽ loại bỏ một số lượng đơn vị cố định được chọn ngẫu nhiên trong một lớp mạng cho một bước gradient duy nhất. Càng nhiều đơn vị bị loại bỏ thì quá trình điều chỉnh càng mạnh. Điều này tương tự như việc huấn luyện mạng để mô phỏng một tập hợp lớn theo cấp số nhân gồm các mạng nhỏ hơn. Để biết thông tin chi tiết, hãy xem bài viết Dropout: A Simple Way to Prevent Neural Networks from Overfitting (Dropout: Một cách đơn giản để ngăn mạng nơ-ron bị khớp quá mức).
linh động
Một việc được thực hiện thường xuyên hoặc liên tục. Các thuật ngữ động và trực tuyến là từ đồng nghĩa trong học máy. Sau đây là những cách sử dụng phổ biến của động và trực tuyến trong học máy:
- Mô hình động (hoặc mô hình trực tuyến) là mô hình được đào tạo lại thường xuyên hoặc liên tục.
- Đào tạo linh hoạt (hoặc đào tạo trực tuyến) là quy trình đào tạo thường xuyên hoặc liên tục.
- Suy luận động (hoặc suy luận trực tuyến) là quy trình tạo ra các dự đoán theo yêu cầu.
mô hình động
Một mô hình thường xuyên (thậm chí có thể liên tục) được huấn luyện lại. Mô hình động là một "người học tập suốt đời" không ngừng thích ứng với dữ liệu đang phát triển. Mô hình động còn được gọi là mô hình trực tuyến.
Tương phản với mô hình tĩnh.
E
thực thi tức thì
Một môi trường lập trình TensorFlow mà trong đó các thao tác chạy ngay lập tức. Ngược lại, các thao tác được gọi trong thực thi đồ thị sẽ không chạy cho đến khi được đánh giá một cách rõ ràng. Thực thi tức thì là một giao diện bắt buộc, giống như mã trong hầu hết các ngôn ngữ lập trình. Các chương trình thực thi tức thì thường dễ gỡ lỗi hơn nhiều so với các chương trình thực thi đồ thị.
dừng sớm
Một phương pháp điều chỉnh liên quan đến việc kết thúc đào tạo trước khi quá trình giảm tổn thất đào tạo kết thúc. Trong tính năng dừng sớm, bạn cố ý dừng huấn luyện mô hình khi mức tổn thất trên tập dữ liệu xác thực bắt đầu tăng; tức là khi hiệu suất khái quát hoá giảm.
Tương phản với lối thoát sớm.
khoảng cách di chuyển của đất (EMD)
Thước đo mức độ tương đồng tương đối của hai phân phối. Khoảng cách di chuyển của máy xúc càng thấp thì các bản phân phối càng giống nhau.
khoảng cách chỉnh sửa
Một chỉ số đo lường mức độ tương đồng giữa hai chuỗi văn bản. Trong học máy, khoảng cách chỉnh sửa rất hữu ích vì những lý do sau:
- Khoảng cách chỉnh sửa rất dễ tính toán.
- Khoảng cách chỉnh sửa có thể so sánh hai chuỗi được biết là tương tự nhau.
- Khoảng cách chỉnh sửa có thể xác định mức độ tương tự của các chuỗi khác nhau với một chuỗi nhất định.
Có một số định nghĩa về khoảng cách chỉnh sửa, mỗi định nghĩa sử dụng các thao tác khác nhau trên chuỗi. Hãy xem Khoảng cách Levenshtein để biết ví dụ.
Ký hiệu Einsum
Một ký hiệu hiệu quả để mô tả cách kết hợp hai tensor. Các tensor được kết hợp bằng cách nhân các phần tử của một tensor với các phần tử của tensor kia, sau đó cộng các tích lại với nhau. Ký hiệu Einsum dùng các biểu tượng để xác định các trục của từng tenxơ và những biểu tượng đó được sắp xếp lại để chỉ định hình dạng của tenxơ kết quả mới.
NumPy cung cấp một cách triển khai Einsum phổ biến.
lớp nhúng
Một lớp ẩn đặc biệt huấn luyện trên một đặc điểm phân loại có nhiều chiều để dần dần tìm hiểu một vectơ nhúng có ít chiều hơn. Lớp nhúng cho phép mạng nơ-ron huấn luyện hiệu quả hơn nhiều so với chỉ huấn luyện trên tính năng phân loại nhiều chiều.
Ví dụ: Earth hiện hỗ trợ khoảng 73.000 loài cây. Giả sử loài cây là một đối tượng trong mô hình của bạn, vì vậy,lớp đầu vào của mô hình sẽ bao gồm một vectơ một lần mã hoá có độ dài 73.000 phần tử.
Ví dụ: có lẽ baobab sẽ được biểu thị như sau:

Mảng gồm 73.000 phần tử là rất dài. Nếu bạn không thêm một lớp nhúng vào mô hình, quá trình huấn luyện sẽ mất rất nhiều thời gian do nhân 72.999 số 0. Có thể bạn chọn lớp nhúng bao gồm 12 phương diện. Do đó, lớp nhúng sẽ dần học được một vectơ nhúng mới cho mỗi loài cây.
Trong một số trường hợp, băm là một giải pháp thay thế hợp lý cho lớp nhúng.
Hãy xem bài viết Nhúng trong Khoá học học máy ứng dụng để biết thêm thông tin.
không gian nhúng
Không gian vectơ d chiều có các đối tượng được ánh xạ từ không gian vectơ có số chiều cao hơn. Không gian nhúng được huấn luyện để nắm bắt cấu trúc có ý nghĩa đối với ứng dụng dự kiến.
Tích vô hướng của hai vectơ nhúng là thước đo mức độ tương đồng của chúng.
vectơ nhúng
Nói chung, một mảng các số dấu phẩy động lấy từ bất kỳ lớp ẩn nào mô tả các đầu vào cho lớp ẩn đó. Thông thường, vectơ nhúng là mảng số thực được huấn luyện trong một lớp nhúng. Ví dụ: giả sử một lớp nhúng phải tìm hiểu một vectơ nhúng cho mỗi trong số 73.000 loài cây trên Trái Đất. Có thể mảng sau đây là vectơ nhúng cho cây bao báp:

Vectơ nhúng không phải là một loạt các số ngẫu nhiên. Một lớp nhúng xác định các giá trị này thông qua quá trình huấn luyện, tương tự như cách mạng nơ-ron học các trọng số khác trong quá trình huấn luyện. Mỗi phần tử của mảng là một điểm phân loại theo một số đặc điểm của một loài cây. Phần tử nào thể hiện đặc điểm của loài cây nào? Con người rất khó xác định được điều đó.
Phần đáng chú ý về mặt toán học của một vectơ nhúng là các mục tương tự có các tập hợp số dấu phẩy động tương tự. Ví dụ: các loài cây tương tự có một tập hợp số thực tương tự hơn so với các loài cây không tương tự. Cây gỗ đỏ và cây cù tùng là những loài cây có quan hệ với nhau, vì vậy, chúng sẽ có một tập hợp các số dấu phẩy động tương tự nhau hơn so với cây gỗ đỏ và cây dừa. Các số trong vectơ nhúng sẽ thay đổi mỗi khi bạn huấn luyện lại mô hình, ngay cả khi bạn huấn luyện lại mô hình bằng dữ liệu đầu vào giống hệt nhau.
hàm phân phối tích luỹ thực nghiệm (eCDF hoặc EDF)
Một hàm phân phối tích luỹ dựa trên các phép đo thực nghiệm từ một tập dữ liệu thực. Giá trị của hàm tại bất kỳ điểm nào dọc theo trục x là phần nhỏ của các quan sát trong tập dữ liệu nhỏ hơn hoặc bằng giá trị đã chỉ định.
giảm thiểu rủi ro theo thực nghiệm (ERM)
Chọn hàm giúp giảm thiểu tổn thất trên tập hợp huấn luyện. Tương phản với giảm thiểu rủi ro theo cấu trúc.
bộ mã hóa
Nhìn chung, mọi hệ thống học máy chuyển đổi từ một biểu diễn thô, thưa thớt hoặc bên ngoài thành một biểu diễn được xử lý, dày đặc hoặc nội bộ hơn.
Bộ mã hoá thường là một thành phần của mô hình lớn hơn, trong đó chúng thường được ghép nối với một bộ giải mã. Một số Transformer ghép nối bộ mã hoá với bộ giải mã, mặc dù các Transformer khác chỉ sử dụng bộ mã hoá hoặc chỉ sử dụng bộ giải mã.
Một số hệ thống sử dụng đầu ra của bộ mã hoá làm đầu vào cho mạng phân loại hoặc hồi quy.
Trong các tác vụ từ chuỗi đến chuỗi, bộ mã hoá sẽ lấy một chuỗi đầu vào và trả về một trạng thái nội bộ (một vectơ). Sau đó, bộ giải mã sẽ dùng trạng thái nội bộ đó để dự đoán chuỗi tiếp theo.
Tham khảo Transformer để biết định nghĩa về bộ mã hoá trong kiến trúc Transformer.
Hãy xem bài viết LLM: Mô hình ngôn ngữ lớn là gì trong Khoá học máy học ứng dụng để biết thêm thông tin.
điểm cuối
Một vị trí có thể định địa chỉ mạng (thường là một URL) mà một dịch vụ có thể truy cập.
ensemble
Một tập hợp các mô hình được huấn luyện độc lập mà các dự đoán được tính trung bình hoặc tổng hợp. Trong nhiều trường hợp, một mô hình kết hợp sẽ tạo ra kết quả dự đoán tốt hơn so với một mô hình duy nhất. Ví dụ: rừng ngẫu nhiên là một tập hợp được tạo từ nhiều cây quyết định. Xin lưu ý rằng không phải tất cả rừng quyết định đều là tập hợp.
Hãy xem phần Rừng ngẫu nhiên trong Khoá học học máy ứng dụng để biết thêm thông tin.
entropy
Trong lý thuyết thông tin, nội dung mô tả mức độ khó dự đoán của một phân phối xác suất. Ngoài ra, entropy cũng được xác định là lượng thông tin mà mỗi ví dụ chứa. Phân phối có entropy cao nhất có thể khi tất cả các giá trị của một biến ngẫu nhiên đều có khả năng xảy ra như nhau.
Độ đo hỗn loạn của một tập hợp có 2 giá trị có thể là "0" và "1" (ví dụ: nhãn trong bài toán phân loại nhị phân) có công thức sau:
H = -p log p – q log q = -p log p – (1-p) * log (1-p)
trong đó:
- H là entropy.
- p là phân số của "1" ví dụ.
- q là tỷ lệ của các ví dụ "0". Lưu ý rằng q = (1 – p)
- log thường là log2. Trong trường hợp này, đơn vị entropy là một bit.
Ví dụ: giả sử những điều sau đây:
- 100 ví dụ chứa giá trị "1"
- 300 ví dụ chứa giá trị "0"
Do đó, giá trị entropy là:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) – (0,75)log2(0,75) = 0,81 bit cho mỗi ví dụ
Một tập hợp cân bằng hoàn hảo (ví dụ: 200 "0" và 200 "1") sẽ có độ đo entropy là 1 bit cho mỗi ví dụ. Khi một tập hợp trở nên mất cân bằng, entropy của tập hợp đó sẽ tiến về 0.0.
Trong cây quyết định, entropy giúp xây dựng mức tăng thông tin để giúp bộ phân tách chọn điều kiện trong quá trình phát triển cây quyết định phân loại.
So sánh entropy với:
- độ tinh khiết gini
- Hàm mất mát cross-entropy
Độ đo hỗn loạn thường được gọi là độ đo hỗn loạn của Shannon.
Hãy xem phần Bộ phân tách chính xác để phân loại nhị phân bằng các đặc điểm số trong khoá học Rừng quyết định để biết thêm thông tin.
môi trường
Trong học tăng cường, thế giới chứa tác nhân và cho phép tác nhân quan sát trạng thái của thế giới đó. Ví dụ: thế giới được biểu thị có thể là một trò chơi như cờ vua hoặc một thế giới thực như mê cung. Khi tác nhân áp dụng một hành động cho môi trường, thì môi trường sẽ chuyển đổi giữa các trạng thái.
tập
Trong học tăng cường, mỗi lần thử lặp lại của tác nhân để tìm hiểu một môi trường.
thời gian bắt đầu của hệ thống
Một lượt huấn luyện đầy đủ trên toàn bộ tập huấn luyện sao cho mỗi ví dụ đã được xử lý một lần.
Một epoch biểu thị N/kích thước lô
số lần lặp lại huấn luyện, trong đó N là tổng số ví dụ.
Ví dụ: giả sử như sau:
- Tập dữ liệu này bao gồm 1.000 ví dụ.
- Kích thước lô là 50 ví dụ.
Do đó, một giai đoạn duy nhất yêu cầu 20 lần lặp:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Hãy xem phần Hồi quy tuyến tính: Siêu tham số trong Khoá học cấp tốc về học máy để biết thêm thông tin.
chính sách tham lam epsilon
Trong học tăng cường, chính sách tuân theo chính sách ngẫu nhiên với xác suất epsilon hoặc chính sách tham lam trong trường hợp khác. Ví dụ: nếu epsilon là 0, 9, thì chính sách sẽ tuân theo một chính sách ngẫu nhiên 90% thời gian và một chính sách tham lam 10% thời gian.
Qua các tập liên tiếp, thuật toán sẽ giảm giá trị epsilon để chuyển từ việc tuân theo một chính sách ngẫu nhiên sang tuân theo một chính sách tham lam. Bằng cách thay đổi chính sách, trước tiên, tác nhân sẽ khám phá môi trường một cách ngẫu nhiên, sau đó khai thác một cách tham lam kết quả của quá trình khám phá ngẫu nhiên.
bình đẳng về cơ hội
Một chỉ số công bằng để đánh giá xem một mô hình có dự đoán kết quả mong muốn một cách công bằng cho tất cả các giá trị của một thuộc tính nhạy cảm hay không. Nói cách khác, nếu kết quả mong muốn cho một mô hình là lớp dương tính, thì mục tiêu là phải có tỷ lệ dương tính thực giống nhau cho tất cả các nhóm.
Bình đẳng về cơ hội có liên quan đến tỷ lệ cược cân bằng, theo đó cả tỷ lệ dương tính thực và tỷ lệ dương tính giả đều phải giống nhau đối với tất cả các nhóm.
Giả sử Đại học Glubbdubdrib nhận cả người Lilliput và người Brobdingnag vào một chương trình toán học nghiêm ngặt. Các trường trung học của người Lilliput cung cấp một chương trình học vững chắc về các lớp toán và phần lớn học sinh đủ điều kiện tham gia chương trình đại học. Các trường trung học của người Brobdingnag không có lớp học toán, và do đó, số lượng học sinh đủ tiêu chuẩn của họ ít hơn nhiều. Cơ hội bình đẳng được đáp ứng cho nhãn ưu tiên "được nhận" đối với quốc tịch (Lilliput hoặc Brobdingnag) nếu sinh viên đủ tiêu chuẩn có khả năng được nhận như nhau bất kể họ là người Lilliput hay người Brobdingnag.
Ví dụ: giả sử có 100 người Lilliput và 100 người Brobdingnag đăng ký vào Đại học Glubbdubdrib, và quyết định nhập học được đưa ra như sau:
Bảng 1. Người đăng ký Lilliputian (90% đủ điều kiện)
| Đủ tiêu chuẩn | Không đủ tiêu chuẩn | |
|---|---|---|
| Được chấp nhận | 45 | 3 |
| Bị từ chối | 45 | 7 |
| Tổng | 90 | 10 |
|
Tỷ lệ phần trăm học viên đủ điều kiện được nhận: 45/90 = 50% Tỷ lệ phần trăm học viên không đủ điều kiện bị từ chối: 7/10 = 70% Tổng tỷ lệ phần trăm học viên Lilliputian được nhận: (45+3)/100 = 48% |
||
Bảng 2. Ứng viên khổng lồ (10% đủ tiêu chuẩn):
| Đủ tiêu chuẩn | Không đủ tiêu chuẩn | |
|---|---|---|
| Được chấp nhận | 5 | 9 |
| Bị từ chối | 5 | 81 |
| Tổng | 10 | 90 |
|
Tỷ lệ phần trăm sinh viên đủ điều kiện được nhận: 5/10 = 50% Tỷ lệ phần trăm sinh viên không đủ điều kiện bị từ chối: 81/90 = 90% Tổng tỷ lệ phần trăm sinh viên Brobdingnagian được nhận: (5+9)/100 = 14% |
||
Các ví dụ trước đó đáp ứng sự bình đẳng về cơ hội chấp nhận sinh viên đủ tiêu chuẩn vì cả người Lilliput và người Brobdingnag đều có 50% cơ hội được nhận.
Mặc dù đã đáp ứng được sự bình đẳng về cơ hội, nhưng 2 chỉ số công bằng sau đây chưa được đáp ứng:
- tính bình đẳng về nhân khẩu học: Người Lilliput và người Brobdingnag được nhận vào trường đại học với tỷ lệ khác nhau; 48% sinh viên Lilliput được nhận, nhưng chỉ có 14% sinh viên Brobdingnag được nhận.
- cơ hội ngang nhau: Mặc dù cả học viên Lilliputian và Brobdingnagian đủ tiêu chuẩn đều có cơ hội được nhận như nhau, nhưng ràng buộc bổ sung là cả học viên Lilliputian và Brobdingnagian không đủ tiêu chuẩn đều có cơ hội bị từ chối như nhau lại không được đáp ứng. Người Lilliput không đủ tiêu chuẩn có tỷ lệ bị từ chối là 70%, trong khi người Brobdingnag không đủ tiêu chuẩn có tỷ lệ bị từ chối là 90%.
Hãy xem bài viết Tính công bằng: Cơ hội bình đẳng trong Khoá học cấp tốc về học máy để biết thêm thông tin.
tỷ lệ cược cân bằng
Một chỉ số công bằng để đánh giá xem một mô hình có dự đoán kết quả tốt như nhau cho tất cả các giá trị của một thuộc tính nhạy cảm hay không, liên quan đến cả lớp dương và lớp âm – không chỉ một lớp hoặc lớp kia một cách riêng biệt. Nói cách khác, cả tỷ lệ dương tính thực và tỷ lệ âm tính giả đều phải giống nhau đối với tất cả các nhóm.
Cơ hội bình đẳng liên quan đến sự bình đẳng về cơ hội, chỉ tập trung vào tỷ lệ lỗi cho một lớp duy nhất (dương hoặc âm).
Ví dụ: giả sử Đại học Glubbdubdrib nhận cả người Lilliput và người Brobdingnag vào một chương trình toán học nghiêm ngặt. Các trường trung học của người Lilliput cung cấp một chương trình học tập toàn diện về các lớp toán và phần lớn học sinh đủ điều kiện tham gia chương trình đại học. Các trường trung học của người Brobdingnag không có lớp học toán nào, và do đó, số lượng học sinh đủ điều kiện của họ ít hơn nhiều. Điều kiện về xác suất ngang bằng được đáp ứng miễn là bất kể người đăng ký là người Lilliput hay người Brobdingnag, nếu họ đủ tiêu chuẩn, thì họ đều có khả năng được nhận vào chương trình như nhau, và nếu họ không đủ tiêu chuẩn, thì họ đều có khả năng bị từ chối như nhau.
Giả sử có 100 người Lilliput và 100 người Brobdingnag đăng ký vào Đại học Glubbdubdrib, và quyết định nhập học được đưa ra như sau:
Bảng 3. Người đăng ký Lilliputian (90% đủ điều kiện)
| Đủ tiêu chuẩn | Không đủ tiêu chuẩn | |
|---|---|---|
| Được chấp nhận | 45 | 2 |
| Bị từ chối | 45 | 8 |
| Tổng | 90 | 10 |
|
Tỷ lệ phần trăm học sinh đủ điều kiện được nhận: 45/90 = 50% Tỷ lệ phần trăm học sinh không đủ điều kiện bị từ chối: 8/10 = 80% Tổng tỷ lệ phần trăm học sinh Lilliputian được nhận: (45+2)/100 = 47% |
||
Bảng 4. Ứng viên khổng lồ (10% đủ tiêu chuẩn):
| Đủ tiêu chuẩn | Không đủ tiêu chuẩn | |
|---|---|---|
| Được chấp nhận | 5 | 18 |
| Bị từ chối | 5 | 72 |
| Tổng | 10 | 90 |
|
Tỷ lệ phần trăm sinh viên đủ điều kiện được nhận: 5/10 = 50% Tỷ lệ phần trăm sinh viên không đủ điều kiện bị từ chối: 72/90 = 80% Tổng tỷ lệ phần trăm sinh viên Brobdingnagian được nhận: (5+18)/100 = 23% |
||
Điều kiện về xác suất ngang bằng được đáp ứng vì cả sinh viên đủ tiêu chuẩn ở Lilliput và Brobdingnag đều có 50% cơ hội được nhận, còn sinh viên không đủ tiêu chuẩn ở Lilliput và Brobdingnag có 80% cơ hội bị từ chối.
Tỷ lệ cược cân bằng được xác định chính thức trong "Cơ hội bình đẳng trong học có giám sát" như sau: "hàm dự đoán Ŷ đáp ứng tỷ lệ cược cân bằng đối với thuộc tính được bảo vệ A và kết quả Y nếu Ŷ và A độc lập, có điều kiện trên Y."
Estimator
Một API TensorFlow không dùng nữa. Sử dụng tf.keras thay vì Trình ước tính.
evals
Chủ yếu được dùng làm từ viết tắt cho các hoạt động đánh giá mô hình ngôn ngữ lớn (LLM). Nói chung, evals là từ viết tắt của mọi hình thức đánh giá.
đánh giá
Quy trình đo lường chất lượng của một mô hình hoặc so sánh các mô hình khác nhau với nhau.
Để đánh giá một mô hình học máy có giám sát, bạn thường đánh giá mô hình đó dựa trên một tập hợp xác thực và một tập hợp kiểm thử. Đánh giá một LLM thường bao gồm các đánh giá rộng hơn về chất lượng và độ an toàn.
ví dụ
Giá trị của một hàng đặc_trưng và có thể là một nhãn. Các ví dụ về học có giám sát thuộc 2 danh mục chung:
- Một ví dụ được gắn nhãn bao gồm một hoặc nhiều đối tượng và một nhãn. Các ví dụ được gắn nhãn được dùng trong quá trình huấn luyện.
- Một ví dụ không được gắn nhãn bao gồm một hoặc nhiều đối tượng nhưng không có nhãn. Các ví dụ không được gắn nhãn sẽ được dùng trong quá trình suy luận.
Ví dụ: giả sử bạn đang huấn luyện một mô hình để xác định mức độ ảnh hưởng của điều kiện thời tiết đến điểm kiểm tra của học viên. Sau đây là 3 ví dụ được gắn nhãn:
| Tính năng | Hãng nhạc | ||
|---|---|---|---|
| Nhiệt độ | Độ ẩm | Áp lực | Điểm kiểm tra |
| 15 | 47 | 998 | Tốt |
| 19 | 34 | 1020 | Rất tốt |
| 18 | 92 | 1012 | Kém |
Sau đây là 3 ví dụ không được gắn nhãn:
| Nhiệt độ | Độ ẩm | Áp lực | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Hàng của một tập dữ liệu thường là nguồn thô cho một ví dụ. Tức là một ví dụ thường bao gồm một tập hợp con của các cột trong tập dữ liệu. Ngoài ra, các đối tượng trong một ví dụ cũng có thể bao gồm đối tượng tổng hợp, chẳng hạn như đối tượng kết hợp.
Hãy xem phần Học có giám sát trong khoá học Giới thiệu về học máy để biết thêm thông tin.
phát lại trải nghiệm
Trong học tăng cường, DQN là một kỹ thuật được dùng để giảm mối tương quan tạm thời trong dữ liệu huấn luyện. Tác nhân lưu trữ các quá trình chuyển đổi trạng thái trong vùng đệm phát lại, sau đó lấy mẫu các quá trình chuyển đổi từ vùng đệm phát lại để tạo dữ liệu huấn luyện.
sự thiên vị của người nghiên cứu
Xem thiên kiến xác nhận.
vấn đề về độ dốc tăng đột biến
Xu hướng độ dốc trong mạng nơron sâu (đặc biệt là mạng nơron hồi quy) trở nên dốc (cao) một cách đáng ngạc nhiên. Độ dốc lớn thường gây ra các bản cập nhật rất lớn cho trọng số của mỗi nút trong mạng nơron sâu.
Các mô hình gặp phải vấn đề về độ dốc tăng đột biến sẽ khó hoặc không thể huấn luyện. Tính năng cắt chuyển màu có thể giảm thiểu vấn đề này.
So sánh với vấn đề về độ dốc biến mất.
F
F1
Một chỉ số "tổng hợp" phân loại nhị phân dựa trên cả độ chính xác và khả năng thu hồi. Sau đây là công thức:
tính xác thực
Trong thế giới học máy, một thuộc tính mô tả mô hình có đầu ra dựa trên thực tế. Tính xác thực là một khái niệm chứ không phải một chỉ số. Ví dụ: giả sử bạn gửi câu lệnh sau đây đến một mô hình ngôn ngữ lớn:
Công thức hoá học của muối ăn là gì?
Một mô hình tối ưu hoá tính xác thực sẽ phản hồi:
NaCl
Chúng ta dễ dàng cho rằng tất cả các mô hình đều phải dựa trên tính xác thực. Tuy nhiên, một số câu lệnh (chẳng hạn như những câu lệnh sau) sẽ khiến mô hình AI tạo sinh tối ưu hoá tính sáng tạo thay vì tính xác thực.
Kể cho tôi nghe một bài thơ limerick về một phi hành gia và một con sâu bướm.
Khó có khả năng bài thơ năm dòng thu được sẽ dựa trên thực tế.
Tương phản với tính thực tế.
quy tắc ràng buộc về tính công bằng
Áp dụng một ràng buộc cho thuật toán để đảm bảo đáp ứng một hoặc nhiều định nghĩa về sự công bằng. Sau đây là một số ví dụ về các ràng buộc công bằng:- Xử lý hậu kỳ đầu ra của mô hình.
- Thay đổi hàm tổn thất để kết hợp một mức phạt khi vi phạm chỉ số công bằng.
- Thêm trực tiếp một điều kiện ràng buộc toán học vào bài toán tối ưu hoá.
chỉ số công bằng
Định nghĩa toán học về "sự công bằng" có thể đo lường được. Sau đây là một số chỉ số công bằng thường dùng:
- xác suất cân bằng
- tính tương đương dự đoán
- tính công bằng phản thực tế
- tính tương đồng về nhân khẩu học
Nhiều chỉ số công bằng loại trừ lẫn nhau; hãy xem sự không tương thích của các chỉ số công bằng.
âm tính giả (FN)
Ví dụ về trường hợp mô hình dự đoán nhầm lớp âm tính. Ví dụ: mô hình dự đoán rằng một thư email cụ thể không phải là thư rác (lớp âm tính), nhưng thư email đó thực sự là thư rác.
tỷ lệ âm tính giả
Tỷ lệ ví dụ dương tính thực tế mà mô hình dự đoán nhầm là lớp âm tính. Công thức sau đây dùng để tính tỷ lệ âm tính giả:
Hãy xem phần Ngưỡng và ma trận nhầm lẫn trong Khoá học học máy ứng dụng để biết thêm thông tin.
dương tính giả (FP)
Ví dụ trong đó mô hình dự đoán nhầm lớp dương tính. Ví dụ: mô hình dự đoán rằng một thư email cụ thể là thư rác (lớp dương tính), nhưng thư email đó thực sự không phải là thư rác.
Hãy xem phần Ngưỡng và ma trận nhầm lẫn trong Khoá học học máy ứng dụng để biết thêm thông tin.
tỷ lệ dương tính giả (FPR)
Tỷ lệ ví dụ thực tế có kết quả âm tính mà mô hình dự đoán nhầm thành lớp dương tính. Công thức sau đây dùng để tính tỷ lệ dương tính giả:
Tỷ lệ dương tính giả là trục x trong đường cong ROC.
Hãy xem phần Phân loại: ROC và AUC trong Khoá học học máy ứng dụng để biết thêm thông tin.
giảm nhanh
Một kỹ thuật đào tạo để cải thiện hiệu suất của LLM. Giảm tốc độ nhanh liên quan đến việc giảm nhanh tốc độ học tập trong quá trình huấn luyện. Chiến lược này giúp ngăn mô hình quá khớp với dữ liệu huấn luyện và cải thiện khả năng khái quát hoá.
tính năng
Một biến đầu vào cho mô hình học máy. Một ví dụ bao gồm một hoặc nhiều đối tượng. Ví dụ: giả sử bạn đang huấn luyện một mô hình để xác định mức độ ảnh hưởng của điều kiện thời tiết đến điểm kiểm tra của học viên. Bảng sau đây cho thấy 3 ví dụ, mỗi ví dụ chứa 3 đối tượng và 1 nhãn:
| Tính năng | Hãng nhạc | ||
|---|---|---|---|
| Nhiệt độ | Độ ẩm | Áp lực | Điểm kiểm tra |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Độ tương phản với nhãn.
Hãy xem phần Học có giám sát trong khoá học Giới thiệu về học máy để biết thêm thông tin.
nhân chéo tính năng
Một đặc điểm tổng hợp được hình thành bằng cách "kết hợp" các đặc điểm theo danh mục hoặc theo nhóm.
Ví dụ: hãy xem xét một mô hình "dự báo tâm trạng" biểu thị nhiệt độ trong một trong 4 nhóm sau:
freezingchillytemperatewarm
Đồng thời biểu thị tốc độ gió theo một trong 3 mức sau:
stilllightwindy
Nếu không có tính năng kết hợp, mô hình tuyến tính sẽ huấn luyện độc lập trên từng trong số 7 nhóm khác nhau trước đó. Vì vậy, mô hình sẽ huấn luyện trên freezing (ví dụ) một cách độc lập với việc huấn luyện trên windy (ví dụ).
Ngoài ra, bạn có thể tạo một tổ hợp chéo của nhiệt độ và tốc độ gió. Tính năng tổng hợp này sẽ có 12 giá trị có thể có sau đây:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Nhờ tính năng kết hợp, mô hình có thể tìm hiểu sự khác biệt về tâm trạng giữa một ngày freezing-windy và một ngày freezing-still.
Nếu bạn tạo một đặc điểm tổng hợp từ 2 đặc điểm, mỗi đặc điểm có nhiều nhóm khác nhau, thì đặc điểm kết hợp thu được sẽ có vô số tổ hợp có thể. Ví dụ: nếu một tính năng có 1.000 bộ chứa và tính năng kia có 2.000 bộ chứa, thì tính năng kết hợp thu được sẽ có 2.000.000 bộ chứa.
Về mặt hình thức, dấu thập là một tích Đề các.
Tương tác giữa các đặc điểm chủ yếu được dùng với các mô hình tuyến tính và hiếm khi được dùng với mạng nơ-ron.
Hãy xem phần Dữ liệu phân loại: Tương tác giữa các đối tượng trong Khoá học cấp tốc về học máy để biết thêm thông tin.
kỹ thuật trích xuất tính chất
Một quy trình bao gồm các bước sau:
- Xác định những đặc điểm có thể hữu ích trong việc huấn luyện một mô hình.
- Chuyển đổi dữ liệu thô từ tập dữ liệu thành các phiên bản hiệu quả của những tính năng đó.
Ví dụ: bạn có thể xác định rằng temperature có thể là một tính năng hữu ích. Sau đó, bạn có thể thử nghiệm với phân nhóm để tối ưu hoá những gì mô hình có thể học được từ các dải temperature khác nhau.
Kỹ thuật đặc trưng đôi khi được gọi là trích xuất đặc trưng hoặc tạo đặc trưng.
Hãy xem phần Dữ liệu dạng số: Cách một mô hình tiếp nhận dữ liệu bằng cách sử dụng vectơ đặc trưng trong Khoá học cấp tốc về học máy để biết thêm thông tin.
trích xuất đặc điểm
Thuật ngữ bị nạp chồng có một trong các định nghĩa sau:
- Truy xuất các biểu diễn tính năng trung gian do một mô hình không được giám sát hoặc mô hình được huấn luyện trước (ví dụ: các giá trị lớp ẩn trong mạng nơ-ron) tính toán để dùng trong một mô hình khác làm dữ liệu đầu vào.
- Từ đồng nghĩa với kỹ thuật trích xuất tính chất.
tầm quan trọng của các đặc điểm
Từ đồng nghĩa với mức độ quan trọng của biến.
tập hợp tính năng
Nhóm các tính năng mà mô hình học máy của bạn huấn luyện. Ví dụ: một bộ tính năng đơn giản cho mô hình dự đoán giá nhà có thể bao gồm mã bưu chính, quy mô tài sản và tình trạng tài sản.
đặc tả tính năng
Mô tả thông tin cần thiết để trích xuất dữ liệu tính năng từ vùng đệm giao thức tf.Example. Vì vùng đệm giao thức tf.Example chỉ là một vùng chứa dữ liệu, nên bạn phải chỉ định những nội dung sau:
- Dữ liệu cần trích xuất (tức là các khoá cho các đối tượng)
- Loại dữ liệu (ví dụ: số thực hoặc số nguyên)
- Độ dài (cố định hoặc thay đổi)
vectơ đặc trưng
Mảng giá trị feature bao gồm một example. Vectơ đặc trưng được nhập trong quá trình huấn luyện và trong quá trình suy luận. Ví dụ: vectơ đặc trưng cho một mô hình có 2 đặc trưng rời rạc có thể là:
[0.92, 0.56]

Mỗi ví dụ cung cấp các giá trị khác nhau cho vectơ đặc trưng, vì vậy, vectơ đặc trưng cho ví dụ tiếp theo có thể là:
[0.73, 0.49]
Thiết kế đặc điểm xác định cách biểu thị các đặc điểm trong vectơ đặc điểm. Ví dụ: một đặc điểm phân loại nhị phân có 5 giá trị có thể được biểu thị bằng mã hoá một lần nóng. Trong trường hợp này, phần của vectơ đối tượng cho một ví dụ cụ thể sẽ bao gồm 4 số 0 và một số 1.0 ở vị trí thứ ba, như sau:
[0.0, 0.0, 1.0, 0.0, 0.0]
Một ví dụ khác, giả sử mô hình của bạn bao gồm 3 đặc điểm:
- một đặc điểm phân loại nhị phân có năm giá trị có thể được biểu thị bằng phương pháp mã hoá một lần nóng; ví dụ:
[0.0, 1.0, 0.0, 0.0, 0.0] - một đặc điểm phân loại nhị phân khác có 3 giá trị có thể được biểu thị bằng mã hoá one-hot; ví dụ:
[0.0, 0.0, 1.0] - một đối tượng dấu phẩy động; ví dụ:
8.3.
Trong trường hợp này, vectơ đặc trưng cho mỗi ví dụ sẽ được biểu thị bằng 9 giá trị. Với các giá trị mẫu trong danh sách trước đó, vectơ đối tượng sẽ là:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Hãy xem phần Dữ liệu dạng số: Cách một mô hình tiếp nhận dữ liệu bằng cách sử dụng vectơ đặc trưng trong Khoá học cấp tốc về học máy để biết thêm thông tin.
featurization
Quá trình trích xuất đặc điểm từ một nguồn đầu vào (chẳng hạn như tài liệu hoặc video) và ánh xạ những đặc điểm đó vào một vectơ đặc điểm.
Một số chuyên gia về học máy sử dụng thuật ngữ liên kết như một từ đồng nghĩa với thiết kế đặc trưng hoặc trích xuất đặc trưng.
học liên kết
Một phương pháp học máy phân tán huấn luyện các mô hình học máy bằng cách sử dụng các ví dụ phi tập trung nằm trên các thiết bị như điện thoại thông minh. Trong quá trình học liên kết, một nhóm nhỏ thiết bị sẽ tải mô hình hiện tại xuống từ một máy chủ điều phối trung tâm. Các thiết bị này sử dụng những ví dụ được lưu trữ trên thiết bị để cải thiện mô hình. Sau đó, các thiết bị sẽ tải những điểm cải tiến của mô hình (nhưng không phải các ví dụ huấn luyện) lên máy chủ điều phối. Tại đây, những điểm cải tiến này sẽ được tổng hợp với các bản cập nhật khác để tạo ra một mô hình chung được cải thiện. Sau khi tổng hợp, mô hình do các thiết bị tính toán sẽ không còn cần thiết nữa và có thể bị loại bỏ.
Vì các ví dụ huấn luyện không bao giờ được tải lên, nên công nghệ học liên kết tuân theo các nguyên tắc về quyền riêng tư của việc thu thập dữ liệu có trọng tâm và giảm thiểu dữ liệu.
Hãy xem truyện tranh về Học liên kết (đúng vậy, là truyện tranh) để biết thêm thông tin chi tiết.
vòng hồi tiếp
Trong học máy, đây là trường hợp mà các dự đoán của một mô hình ảnh hưởng đến dữ liệu huấn luyện cho cùng một mô hình hoặc một mô hình khác. Ví dụ: một mô hình đề xuất phim sẽ ảnh hưởng đến những bộ phim mà mọi người xem, sau đó sẽ ảnh hưởng đến các mô hình đề xuất phim tiếp theo.
Hãy xem phần Hệ thống học máy trong sản xuất: Những câu hỏi cần đặt ra trong Khoá học cấp tốc về học máy để biết thêm thông tin.
mạng nơ-ron truyền thẳng (FFN)
Mạng nơ-ron không có các kết nối theo chu kỳ hoặc đệ quy. Ví dụ: mạng nơron sâu truyền thống là mạng nơron truyền thẳng. Tương phản với mạng nơ-ron hồi quy, là mạng tuần hoàn.
học từ một vài dữ liệu
Một phương pháp học máy, thường được dùng để phân loại đối tượng, được thiết kế để huấn luyện các mô hình phân loại hiệu quả chỉ từ một số ít ví dụ huấn luyện.
Xem thêm học từ một dữ liệu và học từ không có dữ liệu.
đặt câu lệnh dựa trên một vài ví dụ
Một câu lệnh chứa nhiều ví dụ (một "vài" ví dụ) minh hoạ cách mô hình ngôn ngữ lớn nên phản hồi. Ví dụ: câu lệnh dài sau đây chứa 2 ví dụ cho thấy cách mô hình ngôn ngữ lớn trả lời một cụm từ tìm kiếm.
| Các phần của một câu lệnh | Ghi chú |
|---|---|
| Đơn vị tiền tệ chính thức của quốc gia được chỉ định là gì? | Câu hỏi bạn muốn LLM trả lời. |
| Pháp: EUR | Một ví dụ. |
| Vương quốc Anh: GBP | Một ví dụ khác. |
| Ấn Độ: | Cụm từ tìm kiếm thực tế. |
Việc đưa ra một vài ví dụ thường mang lại kết quả mong muốn hơn so với đưa ra không ví dụ và đưa ra một ví dụ. Tuy nhiên, việc đặt câu lệnh dựa trên một vài ví dụ đòi hỏi câu lệnh dài hơn.
Đặt câu lệnh dựa trên một vài ví dụ là một dạng học từ một vài dữ liệu được áp dụng cho học dựa trên câu lệnh.
Hãy xem phần Kỹ thuật tạo câu lệnh trong Khoá học học máy ứng dụng để biết thêm thông tin.
Đàn vĩ cầm
Một thư viện cấu hình ưu tiên Python, đặt các giá trị của hàm và lớp mà không cần mã hoặc cơ sở hạ tầng xâm nhập. Trong trường hợp Pax (và các cơ sở mã ML khác), những hàm và lớp này đại diện cho các mô hình và các siêu tham số đào tạo.
Fiddle giả định rằng các cơ sở mã học máy thường được chia thành:
- Mã thư viện xác định các lớp và trình tối ưu hoá.
- Mã "glue" của tập dữ liệu, gọi các thư viện và kết nối mọi thứ với nhau.
Fiddle nắm bắt cấu trúc lệnh gọi của mã kết dính ở dạng chưa được đánh giá và có thể thay đổi.
tinh chỉnh
Một lần huấn luyện thứ hai, dành riêng cho từng nhiệm vụ, được thực hiện trên mô hình được huấn luyện trước để tinh chỉnh các tham số của mô hình cho một trường hợp sử dụng cụ thể. Ví dụ: trình tự huấn luyện đầy đủ cho một số mô hình ngôn ngữ lớn như sau:
- Huấn luyện trước: Huấn luyện một mô hình ngôn ngữ lớn trên một tập dữ liệu chung rộng lớn, chẳng hạn như tất cả các trang Wikipedia bằng tiếng Anh.
- Tinh chỉnh: Huấn luyện mô hình được huấn luyện trước để thực hiện một nhiệm vụ cụ thể, chẳng hạn như trả lời các câu hỏi về y tế. Quá trình tinh chỉnh thường liên quan đến hàng trăm hoặc hàng nghìn ví dụ tập trung vào nhiệm vụ cụ thể.
Một ví dụ khác là trình tự huấn luyện đầy đủ cho một mô hình hình ảnh lớn như sau:
- Huấn luyện trước: Huấn luyện một mô hình hình ảnh lớn trên một tập dữ liệu hình ảnh chung rộng lớn, chẳng hạn như tất cả hình ảnh trong Wikimedia Commons.
- Tinh chỉnh: Huấn luyện mô hình được huấn luyện trước để thực hiện một nhiệm vụ cụ thể, chẳng hạn như tạo hình ảnh về cá voi sát thủ.
Tinh chỉnh có thể bao gồm bất kỳ sự kết hợp nào của các chiến lược sau:
- Sửa đổi tất cả tham số hiện có của mô hình được huấn luyện trước. Quá trình này đôi khi được gọi là điều chỉnh toàn bộ.
- Chỉ sửa đổi một số tham số hiện có của mô hình được huấn luyện trước (thường là các lớp gần với lớp đầu ra), trong khi vẫn giữ nguyên các tham số hiện có khác (thường là các lớp gần với lớp đầu vào). Xem phần điều chỉnh hiệu quả tham số.
- Thêm nhiều lớp hơn, thường là ở trên cùng của các lớp hiện có gần với lớp đầu ra nhất.
Tinh chỉnh là một dạng học chuyển giao. Do đó, quy trình tinh chỉnh có thể sử dụng một hàm mất mát hoặc một loại mô hình khác với những hàm và loại mô hình được dùng để huấn luyện mô hình được huấn luyện trước. Ví dụ: bạn có thể tinh chỉnh một mô hình hình ảnh lớn được huấn luyện trước để tạo ra một mô hình hồi quy trả về số lượng chim trong một hình ảnh đầu vào.
So sánh và đối chiếu quy trình tinh chỉnh với các thuật ngữ sau:
Hãy xem phần Tinh chỉnh trong Khoá học học máy ứng dụng để biết thêm thông tin.
Mô hình Flash
Một nhóm các mô hình Gemini tương đối nhỏ được tối ưu hoá về tốc độ và độ trễ thấp. Các mô hình Flash được thiết kế cho nhiều ứng dụng mà ở đó, tốc độ phản hồi nhanh và thông lượng cao là yếu tố quan trọng.
Flax
Một thư viện nguồn mở có hiệu suất cao dành cho học sâu được xây dựng dựa trên JAX. Flax cung cấp các hàm để huấn luyện mạng nơ-ron, cũng như các phương pháp đánh giá hiệu suất của mạng nơ-ron.
Flaxformer
Một Transformer nguồn mở library, được xây dựng trên Flax, chủ yếu được thiết kế để xử lý ngôn ngữ tự nhiên và nghiên cứu đa phương thức.
forget gate
Phần của tế bào Trí nhớ dài hạn giúp điều chỉnh luồng thông tin qua tế bào. Các cổng quên duy trì ngữ cảnh bằng cách quyết định loại bỏ thông tin nào khỏi trạng thái ô.
mô hình nền tảng
Một mô hình được huấn luyện trước có quy mô rất lớn, được huấn luyện trên một tập huấn luyện khổng lồ và đa dạng. Một mô hình cơ sở có thể làm cả hai việc sau:
- Đáp ứng tốt nhiều loại yêu cầu.
- Đóng vai trò là một mô hình cơ sở để điều chỉnh hoặc tuỳ chỉnh thêm.
Nói cách khác, mô hình cơ sở đã có khả năng rất cao theo nghĩa chung nhưng có thể được tuỳ chỉnh thêm để trở nên hữu ích hơn nữa cho một nhiệm vụ cụ thể.
phân số thành công
Một chỉ số để đánh giá văn bản do AI tạo của một mô hình học máy. Phân số thành công là số lượng đầu ra văn bản được tạo "thành công" chia cho tổng số đầu ra văn bản được tạo. Ví dụ: nếu mô hình ngôn ngữ lớn tạo ra 10 khối mã, trong đó có 5 khối thành công, thì tỷ lệ thành công sẽ là 50%.
Mặc dù tỷ lệ thành công thường hữu ích trong thống kê, nhưng trong học máy, chỉ số này chủ yếu hữu ích để đo lường các tác vụ có thể xác minh như tạo mã hoặc giải toán.
softmax đầy đủ
Từ đồng nghĩa với softmax.
Tương phản với lấy mẫu ứng viên.
Hãy xem phần Mạng nơ-ron: Phân loại nhiều lớp trong Khoá học cấp tốc về học máy để biết thêm thông tin.
lớp liên thông đầy đủ
Một lớp ẩn trong đó mỗi nút được kết nối với mọi nút trong lớp ẩn tiếp theo.
Lớp kết nối đầy đủ còn được gọi là lớp dày đặc.
biến đổi hàm
Một hàm lấy một hàm làm dữ liệu đầu vào và trả về một hàm đã chuyển đổi làm dữ liệu đầu ra. JAX sử dụng các phép biến đổi hàm.
G
GAN
Từ viết tắt của mạng đối nghịch tạo sinh.
Gemini
Hệ sinh thái bao gồm AI tiên tiến nhất của Google. Các thành phần của hệ sinh thái này bao gồm:
- Nhiều mô hình Gemini.
- Giao diện trò chuyện tương tác với một mô hình Gemini. Người dùng nhập câu lệnh và Gemini sẽ phản hồi những câu lệnh đó.
- Nhiều Gemini API.
- Nhiều sản phẩm kinh doanh dựa trên các mô hình Gemini; ví dụ: Gemini cho Google Cloud.
Các mô hình Gemini
Transformer dựa trên các mô hình đa phương thức tiên tiến của Google. Các mô hình Gemini được thiết kế riêng để tích hợp với các tác nhân.
Người dùng có thể tương tác với các mô hình Gemini theo nhiều cách, bao gồm cả thông qua giao diện hộp thoại tương tác và thông qua các SDK.
Gemma
Một nhóm các mô hình nguồn mở có dung lượng nhỏ được xây dựng dựa trên cùng một nghiên cứu và công nghệ được dùng để tạo ra các mô hình Gemini. Có nhiều mô hình Gemma, mỗi mô hình cung cấp các tính năng khác nhau, chẳng hạn như thị giác, mã và khả năng tuân theo chỉ dẫn. Hãy xem Gemma để biết thông tin chi tiết.
AI tạo sinh hoặc AI tạo sinh
Từ viết tắt của AI tạo sinh.
khái quát hoá
Khả năng của mô hình trong việc đưa ra dự đoán chính xác về dữ liệu mới mà trước đây chưa từng thấy. Một mô hình có thể khái quát hoá là mô hình ngược lại với mô hình khớp quá mức.
Hãy xem phần Khái quát hoá trong Khoá học học máy ứng dụng để biết thêm thông tin.
đường cong tổng quát hoá
Biểu đồ về cả mất mát khi huấn luyện và mất mát khi xác thực dưới dạng một hàm của số lần lặp lại.
Đường cong khái quát hoá có thể giúp bạn phát hiện hiện tượng khớp quá mức. Ví dụ: đường cong khái quát hoá sau đây cho thấy tình trạng khớp quá mức vì tổn thất xác thực cuối cùng cao hơn đáng kể so với tổn thất huấn luyện.
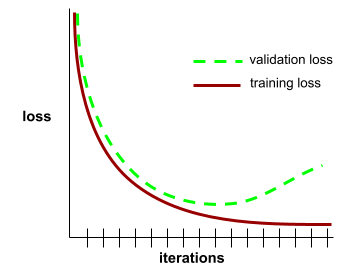
Hãy xem phần Khái quát hoá trong Khoá học học máy ứng dụng để biết thêm thông tin.
mô hình tuyến tính tổng quát
Một mô hình tổng quát hoá của hồi quy bình phương tối thiểu, dựa trên nhiễu Gaussian, đối với các loại mô hình khác dựa trên các loại nhiễu khác, chẳng hạn như nhiễu Poisson hoặc nhiễu phân loại. Sau đây là ví dụ về mô hình tuyến tính tổng quát:
- hồi quy logistic
- hồi quy đa mục
- hồi quy bình phương tối thiểu
Bạn có thể tìm thấy các tham số của mô hình tuyến tính tổng quát thông qua tối ưu hoá lồi.
Mô hình tuyến tính tổng quát có các thuộc tính sau:
- Mức dự đoán trung bình của mô hình hồi quy bình phương tối thiểu tối ưu bằng với nhãn trung bình trên dữ liệu huấn luyện.
- Xác suất trung bình do mô hình hồi quy logistic tối ưu dự đoán bằng với nhãn trung bình trên dữ liệu huấn luyện.
Sức mạnh của mô hình tuyến tính tổng quát bị hạn chế bởi các đặc điểm của mô hình. Không giống như mô hình sâu, mô hình tuyến tính tổng quát không thể "học các tính năng mới".
văn bản được tạo
Nhìn chung, đây là văn bản mà mô hình học máy tạo ra. Khi đánh giá các mô hình ngôn ngữ lớn, một số chỉ số so sánh văn bản được tạo với văn bản tham chiếu. Ví dụ: giả sử bạn đang cố gắng xác định mức độ hiệu quả của một mô hình học máy trong việc dịch từ tiếng Pháp sang tiếng Hà Lan. Trong trường hợp này:
- Văn bản được tạo là bản dịch tiếng Hà Lan mà mô hình học máy đưa ra.
- Văn bản tham khảo là bản dịch tiếng Hà Lan do một người dịch (hoặc phần mềm) tạo ra.
Xin lưu ý rằng một số chiến lược đánh giá không liên quan đến văn bản tham chiếu.
mạng đối nghịch tạo sinh (GAN)
Một hệ thống tạo dữ liệu mới, trong đó trình tạo tạo dữ liệu và phân biệt xác định xem dữ liệu đã tạo đó có hợp lệ hay không hợp lệ.
Hãy xem khoá học Mạng sinh đối kháng để biết thêm thông tin.
AI tạo sinh
Một lĩnh vực biến đổi mới nổi chưa có định nghĩa chính thức. Tuy nhiên, hầu hết các chuyên gia đều đồng ý rằng các mô hình AI tạo sinh có thể tạo ("tạo") nội dung đáp ứng tất cả các tiêu chí sau:
- phức tạp
- mạch lạc
- gốc
Sau đây là một số ví dụ về AI tạo sinh:
- Mô hình ngôn ngữ lớn có thể tạo ra văn bản gốc tinh vi và trả lời câu hỏi.
- Mô hình tạo hình ảnh có thể tạo ra những hình ảnh độc đáo.
- Mô hình tạo âm thanh và nhạc, có thể sáng tác nhạc gốc hoặc tạo lời nói chân thực.
- Mô hình tạo video có thể tạo video nguyên gốc.
Một số công nghệ trước đây, bao gồm cả LSTM và RNN, cũng có thể tạo ra nội dung nguyên gốc và mạch lạc. Một số chuyên gia coi những công nghệ trước đây này là AI tạo sinh, trong khi những người khác cho rằng AI tạo sinh thực sự cần có đầu ra phức tạp hơn so với những gì mà các công nghệ trước đây có thể tạo ra.
Trái ngược với mô hình ML dự đoán.
mô hình tạo sinh
Trên thực tế, một mô hình thực hiện một trong những việc sau:
- Tạo (tạo) các ví dụ mới từ tập dữ liệu huấn luyện. Ví dụ: một mô hình tạo sinh có thể tạo ra thơ sau khi được huấn luyện trên một tập dữ liệu gồm các bài thơ. Phần trình tạo của một mạng đối nghịch tạo sinh thuộc danh mục này.
- Xác định xác suất mà một ví dụ mới đến từ tập huấn luyện hoặc được tạo ra từ cùng một cơ chế đã tạo ra tập huấn luyện. Ví dụ: sau khi được huấn luyện trên một tập dữ liệu bao gồm các câu tiếng Anh, mô hình tạo sinh có thể xác định xác suất mà dữ liệu đầu vào mới là một câu tiếng Anh hợp lệ.
Về lý thuyết, mô hình tạo sinh có thể phân biệt được sự phân phối của các ví dụ hoặc các đặc điểm cụ thể trong một tập dữ liệu. Đó là:
p(examples)
Mô hình học không có giám sát là mô hình tạo sinh.
Tương phản với các mô hình phân biệt.
trình tạo
Hệ thống con trong mạng đối nghịch tạo sinh tạo ra các ví dụ mới.
Tương phản với mô hình phân biệt.
độ tinh khiết Gini
Một chỉ số tương tự như entropy. Trình phân tách sử dụng các giá trị bắt nguồn từ độ tinh khiết gini hoặc entropy để tạo điều kiện cho cây quyết định phân loại. Mức tăng thông tin được suy ra từ entropy. Không có thuật ngữ tương đương được chấp nhận rộng rãi cho chỉ số bắt nguồn từ độ tinh khiết Gini; tuy nhiên, chỉ số chưa được đặt tên này cũng quan trọng như mức tăng thông tin.
Độ tinh khiết Gini còn được gọi là chỉ số Gini hoặc đơn giản là Gini.
tập dữ liệu vàng
Một tập hợp dữ liệu được tuyển chọn thủ công, ghi lại sự thật cơ bản. Các nhóm có thể sử dụng một hoặc nhiều tập dữ liệu mẫu để đánh giá chất lượng của một mô hình.
Một số tập dữ liệu mẫu ghi lại các miền phụ khác nhau của dữ liệu thực tế. Ví dụ: một tập dữ liệu vàng để phân loại hình ảnh có thể ghi lại điều kiện ánh sáng và độ phân giải hình ảnh.
câu trả lời hoàn hảo
Một phản hồi được biết là hữu ích. Ví dụ: với câu lệnh sau:
2 + 2
Phản hồi lý tưởng là:
4
Google AI Studio
Một công cụ của Google cung cấp giao diện thân thiện với người dùng để thử nghiệm và xây dựng các ứng dụng bằng mô hình ngôn ngữ lớn của Google. Hãy xem trang chủ Google AI Studio để biết thông tin chi tiết.
GPT (Generative Pre-trained Transformer)
Một nhóm mô hình ngôn ngữ lớn dựa trên Transformer do OpenAI phát triển.
Các biến thể GPT có thể áp dụng cho nhiều phương thức, bao gồm:
- tạo hình ảnh (ví dụ: ImageGPT)
- tạo hình ảnh từ văn bản (ví dụ: DALL-E).
chuyển màu
Vectơ của đạo hàm riêng phần theo tất cả các biến độc lập. Trong học máy, độ dốc là vectơ của đạo hàm riêng của hàm mô hình. Các điểm dốc theo hướng dốc nhất.
tích luỹ độ dốc
Một kỹ thuật truyền ngược giúp cập nhật tham số chỉ một lần cho mỗi giai đoạn thay vì một lần cho mỗi lần lặp. Sau khi xử lý từng tiểu lô, quá trình tích luỹ độ dốc chỉ cần cập nhật tổng độ dốc đang chạy. Sau đó, sau khi xử lý lô nhỏ cuối cùng trong giai đoạn, hệ thống cuối cùng sẽ cập nhật các tham số dựa trên tổng số tất cả các thay đổi về độ dốc.
Việc tích luỹ độ dốc sẽ hữu ích khi kích thước lô rất lớn so với lượng bộ nhớ có sẵn để huấn luyện. Khi bộ nhớ gặp vấn đề, xu hướng tự nhiên là giảm kích thước lô. Tuy nhiên, việc giảm kích thước lô trong quá trình truyền ngược thông thường sẽ làm tăng số lượng bản cập nhật tham số. Việc tích luỹ độ dốc giúp mô hình tránh được các vấn đề về bộ nhớ nhưng vẫn huấn luyện một cách hiệu quả.
cây (quyết định) được tăng cường theo độ dốc (GBT)
Một loại rừng quyết định trong đó:
- Đào tạo dựa vào tăng cường độ dốc.
- Mô hình yếu là một cây quyết định.
Hãy xem bài viết Cây quyết định tăng cường độ dốc trong khoá học Rừng quyết định để biết thêm thông tin.
tăng cường độ dốc
Một thuật toán huấn luyện trong đó các mô hình yếu được huấn luyện để cải thiện chất lượng (giảm tổn thất) của một mô hình mạnh theo cách lặp đi lặp lại. Ví dụ: một mô hình yếu có thể là mô hình tuyến tính hoặc mô hình cây quyết định nhỏ. Mô hình mạnh sẽ là tổng của tất cả các mô hình yếu đã được huấn luyện trước đó.
Ở dạng đơn giản nhất của phương pháp tăng cường độ dốc, tại mỗi lần lặp lại, một mô hình yếu sẽ được huấn luyện để dự đoán độ dốc tổn thất của mô hình mạnh. Sau đó, đầu ra của mô hình mạnh được cập nhật bằng cách trừ đi độ dốc dự đoán, tương tự như phương pháp hạ độ dốc.
trong đó:
- $F_{0}$ là mô hình mạnh mẽ ban đầu.
- $F_{i+1}$ là mô hình mạnh tiếp theo.
- $F_{i}$ là mô hình mạnh hiện tại.
- $\xi$ là một giá trị nằm trong khoảng từ 0 đến 1, được gọi là hệ số thu hẹp, tương tự như tốc độ học trong phương pháp hạ độ dốc.
- $f_{i}$ là mô hình yếu được huấn luyện để dự đoán độ dốc tổn thất của $F_{i}$.
Các biến thể hiện đại của phương pháp tăng cường độ dốc cũng bao gồm đạo hàm bậc hai (Hessian) của tổn thất trong quá trình tính toán.
Cây quyết định thường được dùng làm mô hình yếu trong phương pháp tăng cường độ dốc. Xem cây (quyết định) được tăng cường độ dốc.
giới hạn độ dốc
Một cơ chế thường được dùng để giảm thiểu vấn đề về độ dốc tăng đột biến bằng cách giới hạn (cắt) nhân tạo giá trị tối đa của độ dốc khi dùng phương pháp hạ độ dốc để huấn luyện một mô hình.
phương pháp giảm độ dốc
Một kỹ thuật toán học để giảm thiểu mất mát. Phương pháp hạ dốc điều chỉnh lặp đi lặp lại trọng số và độ lệch, dần dần tìm ra sự kết hợp tốt nhất để giảm thiểu tổn thất.
Phương pháp hạ độ dốc ra đời trước công nghệ học máy rất lâu.
Hãy xem phần Hồi quy tuyến tính: Phương pháp hạ độ dốc trong Khoá học cấp tốc về học máy để biết thêm thông tin.
đồ thị
Trong TensorFlow, đây là một quy cách tính toán. Các nút trong biểu đồ biểu thị các thao tác. Các cạnh có hướng và biểu thị việc truyền kết quả của một thao tác (một Tensor) làm toán hạng cho một thao tác khác. Sử dụng TensorBoard để trực quan hoá biểu đồ.
thực thi biểu đồ
Môi trường lập trình TensorFlow, trong đó chương trình trước tiên sẽ tạo một đồ thị rồi thực thi toàn bộ hoặc một phần đồ thị đó. Thực thi đồ thị là chế độ thực thi mặc định trong TensorFlow 1.x.
Tương phản với thực thi tức thì.
chính sách tham lam
Trong học tăng cường, chính sách luôn chọn hành động có lợi nhuận dự kiến cao nhất.
tính thực tế
Một thuộc tính của mô hình có đầu ra dựa trên ("dựa vào") tài liệu nguồn cụ thể. Ví dụ: giả sử bạn cung cấp toàn bộ sách giáo khoa vật lý làm dữ liệu đầu vào ("bối cảnh") cho một mô hình ngôn ngữ lớn. Sau đó, bạn sẽ nhắc mô hình ngôn ngữ lớn đó bằng một câu hỏi về vật lý. Nếu phản hồi của mô hình phản ánh thông tin trong sách giáo khoa đó, thì mô hình đó được coi là dựa trên sách giáo khoa đó.Xin lưu ý rằng mô hình có cơ sở không phải lúc nào cũng là mô hình dựa trên thực tế. Ví dụ: sách giáo khoa vật lý mà bạn nhập có thể chứa lỗi.
dữ liệu thực tế
Thực tế.
Điều thực sự đã xảy ra.
Ví dụ: hãy xem xét một mô hình phân loại nhị phân dự đoán xem một sinh viên năm nhất có tốt nghiệp trong vòng 6 năm hay không. Đầu ra thực sự cho mô hình này là việc học viên đó có thực sự tốt nghiệp trong vòng 6 năm hay không.
thiên vị quy cho nhóm
Giả định rằng điều đúng với một cá nhân cũng đúng với mọi người trong nhóm đó. Ảnh hưởng của thiên kiến phân bổ theo nhóm có thể trở nên trầm trọng hơn nếu bạn sử dụng phương pháp lấy mẫu thuận tiện để thu thập dữ liệu. Trong một mẫu không đại diện, các thuộc tính có thể được tạo ra mà không phản ánh thực tế.
Xem thêm thiên vị khác nhóm và thiên vị trong nhóm. Ngoài ra, hãy xem phần Tính công bằng: Các loại thành kiến trong Khoá học cấp tốc về học máy để biết thêm thông tin.
Cao
ảo tưởng
Việc một mô hình AI tạo sinh tạo ra kết quả có vẻ hợp lý nhưng không chính xác về mặt thực tế, trong khi mô hình này tuyên bố đang đưa ra một khẳng định về thế giới thực. Ví dụ: một mô hình AI tạo sinh tuyên bố rằng Barack Obama đã qua đời vào năm 1865 là ảo tưởng.
băm
Trong học máy, một cơ chế để phân loại dữ liệu phân loại, đặc biệt là khi số lượng danh mục lớn, nhưng số lượng danh mục thực sự xuất hiện trong tập dữ liệu tương đối nhỏ.
Ví dụ: Trái Đất là nơi sinh sống của khoảng 73.000 loài cây. Bạn có thể biểu thị từng loài cây trong số 73.000 loài bằng 73.000 nhóm phân loại riêng biệt. Ngoài ra, nếu chỉ có 200 loài cây trong số đó thực sự xuất hiện trong một tập dữ liệu, thì bạn có thể sử dụng hàm băm để chia các loài cây thành có thể là 500 nhóm.
Một thùng có thể chứa nhiều loài cây. Ví dụ: việc băm có thể đặt baobab và red maple (hai loài không giống nhau về mặt di truyền) vào cùng một nhóm. Dù sao thì băm vẫn là một cách hay để ánh xạ các tập hợp phân loại lớn vào số lượng nhóm đã chọn. Băm chuyển một đối tượng phân loại có nhiều giá trị có thể thành một số lượng giá trị nhỏ hơn nhiều bằng cách nhóm các giá trị theo cách xác định.
Hãy xem Dữ liệu phân loại: Từ vựng và mã hoá một lần nóng trong Khoá học cấp tốc về học máy để biết thêm thông tin.
phương pháp đánh giá thử nghiệm
Một giải pháp đơn giản và nhanh chóng để giải quyết vấn đề. Ví dụ: "Với một phương pháp phỏng đoán, chúng tôi đạt được độ chính xác 86%. Khi chúng tôi chuyển sang mạng nơ-ron sâu, độ chính xác đã tăng lên 98%".
lớp ẩn
Một lớp trong mạng nơ-ron giữa lớp đầu vào (các đối tượng) và lớp đầu ra (dự đoán). Mỗi lớp ẩn bao gồm một hoặc nhiều nơ-ron. Ví dụ: mạng nơ-ron sau đây chứa hai lớp ẩn, lớp đầu tiên có 3 nơ-ron và lớp thứ hai có 2 nơ-ron:
Một mạng nơ-ron sâu chứa nhiều lớp ẩn. Ví dụ: hình minh hoạ trước đó là một mạng nơ-ron sâu vì mô hình này có 2 lớp ẩn.
Hãy xem phần Mạng nơ-ron: Các nút và lớp ẩn trong Khoá học cấp tốc về học máy để biết thêm thông tin.
phân cụm phân cấp
Một danh mục thuật toán phân cụm tạo ra một cây cụm. Phân cụm phân cấp phù hợp với dữ liệu phân cấp, chẳng hạn như phân loại thực vật học. Có hai loại thuật toán phân cụm phân cấp:
- Phân cụ kết hợp trước tiên sẽ chỉ định mọi ví dụ cho cụm riêng và lặp lại việc hợp nhất các cụm gần nhất để tạo cây phân cấp.
- Phân cụ phân chia trước tiên sẽ nhóm tất cả các ví dụ thành một cụm rồi lặp lại việc chia cụm thành một cây phân cấp.
Tương phản với phân cụm dựa trên tâm cụm.
Hãy xem Thuật toán phân cụm trong khoá học Phân cụm để biết thêm thông tin.
leo đồi
Một thuật toán để cải thiện lặp đi lặp lại ("leo dốc") một mô hình học máy cho đến khi mô hình ngừng cải thiện ("đạt đến đỉnh đồi"). Dạng chung của thuật toán như sau:
- Xây dựng mô hình ban đầu.
- Tạo các mô hình đề xuất mới bằng cách điều chỉnh một chút cách bạn đào tạo hoặc điều chỉnh. Điều này có thể đòi hỏi bạn phải làm việc với một tập hợp huấn luyện hơi khác hoặc các siêu tham số khác.
- Đánh giá các mô hình đề xuất mới và thực hiện một trong các hành động sau:
- Nếu một mô hình đề xuất hoạt động hiệu quả hơn mô hình ban đầu, thì mô hình đề xuất đó sẽ trở thành mô hình ban đầu mới. Trong trường hợp này, hãy lặp lại Bước 1, 2 và 3.
- Nếu không có mô hình nào hoạt động hiệu quả hơn mô hình ban đầu, thì tức là bạn đã đạt đến đỉnh điểm và nên ngừng lặp lại.
Hãy xem Sổ tay điều chỉnh học sâu để biết hướng dẫn về cách điều chỉnh siêu tham số. Hãy xem các mô-đun Dữ liệu của Khoá học học máy ứng dụng để được hướng dẫn về kỹ thuật trích xuất đặc trưng.
tổn thất khớp nối
Một nhóm các hàm mất mát cho phân loại được thiết kế để tìm ranh giới quyết định càng xa càng tốt so với mỗi ví dụ huấn luyện, do đó tối đa hoá khoảng cách giữa các ví dụ và ranh giới. KSVM sử dụng tổn thất bản lề (hoặc một hàm liên quan, chẳng hạn như tổn thất bản lề bình phương). Đối với phân loại nhị phân, hàm mất mát lề được xác định như sau:
trong đó y là nhãn thực, có thể là -1 hoặc +1, còn y' là đầu ra thô của mô hình phân loại:
Do đó, biểu đồ về tổn thất bản lề so với (y * y') có dạng như sau:

thiên kiến trong quá khứ
Một loại thiên kiến đã tồn tại trên thế giới và đã xuất hiện trong một tập dữ liệu. Những thiên kiến này có xu hướng phản ánh các định kiến văn hoá, sự bất bình đẳng về nhân khẩu học và thành kiến đối với một số nhóm xã hội nhất định.
Ví dụ: hãy xem xét một mô hình phân loại dự đoán liệu người đăng ký vay có vỡ nợ hay không. Mô hình này được huấn luyện dựa trên dữ liệu vỡ nợ của các khoản vay trước đây từ những năm 1980 của các ngân hàng địa phương ở hai cộng đồng khác nhau. Nếu những người đăng ký trước đây ở Cộng đồng A có khả năng không trả được nợ gấp 6 lần so với người đăng ký ở Cộng đồng B, thì mô hình có thể học được một thành kiến trong quá khứ, dẫn đến việc mô hình ít có khả năng phê duyệt khoản vay ở Cộng đồng A, ngay cả khi các điều kiện trong quá khứ dẫn đến tỷ lệ vỡ nợ cao hơn của cộng đồng đó không còn phù hợp nữa.
Hãy xem phần Tính công bằng: Các loại thành kiến trong Khoá học cấp tốc về học máy để biết thêm thông tin.
dữ liệu không huấn luyện
Ví dụ không được dùng ("loại bỏ") một cách có chủ ý trong quá trình huấn luyện. Tập dữ liệu xác thực và tập dữ liệu kiểm thử là các ví dụ về dữ liệu giữ lại. Dữ liệu giữ lại giúp đánh giá khả năng tổng quát hoá của mô hình đối với dữ liệu khác với dữ liệu mà mô hình được huấn luyện. Mức tổn thất trên tập hợp giữ lại cung cấp mức tổn thất ước tính chính xác hơn trên một tập dữ liệu chưa được thấy so với mức tổn thất trên tập hợp huấn luyện.
người tổ chức
Khi huấn luyện một mô hình học máy trên các chip tăng tốc (GPU hoặc TPU), phần của hệ thống sẽ kiểm soát cả hai điều sau:
- Luồng tổng thể của mã.
- Việc trích xuất và chuyển đổi quy trình đầu vào.
Thông thường, máy chủ lưu trữ chạy trên CPU, chứ không phải trên chip tăng tốc; thiết bị thao tác các tensor trên chip tăng tốc.
đánh giá của con người
Một quy trình trong đó con người đánh giá chất lượng đầu ra của một mô hình học máy; ví dụ: yêu cầu người song ngữ đánh giá chất lượng của một mô hình dịch bằng học máy. Đánh giá thủ công đặc biệt hữu ích khi đánh giá những mô hình không có câu trả lời đúng.
Tương phản với đánh giá tự động và đánh giá của người đánh giá tự động.
con người tham gia vào vòng lặp (HITL)
Một thành ngữ được định nghĩa lỏng lẻo có thể mang một trong hai ý nghĩa sau:
- Chính sách xem xét kỹ lưỡng hoặc hoài nghi về kết quả của AI tạo sinh.
- Một chiến lược hoặc hệ thống nhằm đảm bảo rằng mọi người giúp định hình, đánh giá và tinh chỉnh hành vi của mô hình. Việc duy trì sự tham gia của con người giúp AI hưởng lợi từ cả trí thông minh của máy móc và trí thông minh của con người. Ví dụ: một hệ thống mà AI tạo mã rồi kỹ sư phần mềm xem xét là một hệ thống có sự tham gia của con người.
siêu tham số
Các biến mà bạn hoặc dịch vụ điều chỉnh siêu tham sốđiều chỉnh trong các lần chạy liên tiếp của việc huấn luyện một mô hình. Ví dụ: tốc độ học tập là một siêu tham số. Bạn có thể đặt tốc độ học thành 0,01 trước một phiên huấn luyện. Nếu xác định rằng 0,01 là quá cao, bạn có thể đặt tốc độ học thành 0,003 cho phiên đào tạo tiếp theo.
Ngược lại, tham số là nhiều trọng số và độ lệch mà mô hình học được trong quá trình huấn luyện.
Hãy xem phần Hồi quy tuyến tính: Siêu tham số trong Khoá học cấp tốc về học máy để biết thêm thông tin.
siêu phẳng
Một ranh giới phân chia một không gian thành hai không gian con. Ví dụ: một đường thẳng là một siêu phẳng trong hai chiều và một mặt phẳng là một siêu phẳng trong ba chiều. Thông thường hơn trong học máy, siêu phẳng là ranh giới phân tách một không gian nhiều chiều. Máy vectơ hỗ trợ hàm nhân sử dụng siêu phẳng để tách các lớp dương tính khỏi các lớp âm tính, thường là trong một không gian có chiều rất cao.
I
i.i.d.
Viết tắt của phân phối độc lập và đồng nhất.
nhận dạng hình ảnh
Một quy trình phân loại(các) đối tượng, (các) mẫu hoặc(các) khái niệm trong một hình ảnh. Nhận dạng hình ảnh còn được gọi là phân loại hình ảnh.
Để biết thêm thông tin, hãy xem ML Practicum: Phân loại hình ảnh.
Hãy xem Khoá học Thực hành về học máy: Phân loại hình ảnh để biết thêm thông tin.
tập dữ liệu không cân bằng
Từ đồng nghĩa với tập dữ liệu bất cân đối về loại.
thiên kiến ngầm
Tự động liên kết hoặc giả định dựa trên mô hình tư duy và ký ức của một người. Thiên kiến ngầm ẩn có thể ảnh hưởng đến những yếu tố sau:
- Cách dữ liệu được thu thập và phân loại.
- Cách thiết kế và phát triển hệ thống học máy.
Ví dụ: khi tạo mô hình phân loại để xác định ảnh cưới, kỹ sư có thể sử dụng sự xuất hiện của một chiếc váy trắng trong ảnh làm một đặc điểm. Tuy nhiên, váy trắng chỉ là trang phục truyền thống trong một số thời đại và ở một số nền văn hoá.
Xem thêm về thiên kiến xác nhận.
quy kết
Dạng ngắn của phương pháp thay thế giá trị bị thiếu.
sự không tương thích của các chỉ số công bằng
Ý tưởng cho rằng một số khái niệm về sự công bằng không tương thích với nhau và không thể đáp ứng đồng thời. Do đó, không có một chỉ số chung duy nhất để định lượng tính công bằng có thể áp dụng cho tất cả các vấn đề về học máy.
Mặc dù điều này có vẻ đáng thất vọng, nhưng sự không tương thích của các chỉ số công bằng không có nghĩa là những nỗ lực hướng đến sự công bằng là vô ích. Thay vào đó, nó đề xuất rằng sự công bằng phải được xác định theo ngữ cảnh cho một vấn đề cụ thể về học máy, với mục tiêu là ngăn chặn những tác hại cụ thể đối với các trường hợp sử dụng của vấn đề đó.
Hãy xem bài viết "Về (sự) bất khả thi của tính công bằng" để biết thêm thông tin chi tiết về sự không tương thích của các chỉ số công bằng.
học tập theo bối cảnh
Từ đồng nghĩa với đặt câu lệnh dựa trên một vài ví dụ.
phân phối độc lập và đồng nhất (i.i.d)
Dữ liệu được lấy từ một phân phối không thay đổi và trong đó mỗi giá trị được lấy không phụ thuộc vào các giá trị đã được lấy trước đó. i.i.d. là khí lý tưởng của học máy – một cấu trúc toán học hữu ích nhưng hầu như không bao giờ xuất hiện chính xác trong thế giới thực. Ví dụ: việc phân phối khách truy cập vào một trang web có thể là i.i.d. trong một khoảng thời gian ngắn; tức là việc phân phối không thay đổi trong khoảng thời gian ngắn đó và lượt truy cập của một người thường độc lập với lượt truy cập của người khác. Tuy nhiên, nếu bạn mở rộng khoảng thời gian đó, thì sự khác biệt theo mùa về khách truy cập trang web có thể xuất hiện.
Xem thêm nonstationarity.
tính công bằng cho từng cá nhân
Một chỉ số công bằng kiểm tra xem những cá nhân tương tự có được phân loại tương tự hay không. Ví dụ: Brobdingnagian Academy có thể muốn đáp ứng sự công bằng cho từng cá nhân bằng cách đảm bảo rằng 2 học viên có điểm số và điểm kiểm tra tiêu chuẩn giống hệt nhau có khả năng được nhận vào học như nhau.
Xin lưu ý rằng tính công bằng cho từng cá nhân hoàn toàn phụ thuộc vào cách bạn xác định "mức độ tương đồng" (trong trường hợp này là điểm số và điểm kiểm tra), đồng thời bạn có thể gặp phải nguy cơ xuất hiện các vấn đề mới về tính công bằng nếu chỉ số về mức độ tương đồng của bạn bỏ lỡ thông tin quan trọng (chẳng hạn như mức độ nghiêm ngặt của chương trình học của học viên).
Hãy xem bài viết "Công bằng thông qua nhận thức" để biết thêm thông tin chi tiết về sự công bằng cho từng cá nhân.
suy luận
Trong công nghệ học máy truyền thống, quy trình đưa ra dự đoán bằng cách áp dụng một mô hình đã được huấn luyện cho các ví dụ chưa được gắn nhãn. Hãy xem phần Học có giám sát trong khoá học Giới thiệu về học máy để tìm hiểu thêm.
Trong mô hình ngôn ngữ lớn, suy luận là quá trình sử dụng một mô hình đã được huấn luyện để tạo ra một phản hồi cho một câu lệnh đầu vào.
Suy luận có một ý nghĩa khác trong thống kê. Hãy xem bài viết trên Wikipedia về suy luận thống kê để biết thông tin chi tiết.
đường dẫn suy luận
Trong cây quyết định, trong quá trình suy luận, ví dụ cụ thể sẽ đi từ gốc đến các điều kiện khác, kết thúc bằng một nút lá. Ví dụ: trong cây quyết định sau đây, các mũi tên dày hơn cho thấy đường dẫn suy luận cho một ví dụ có các giá trị đặc điểm sau:
- x = 7
- y = 12
- z = -3
Đường dẫn suy luận trong hình minh hoạ sau đây đi qua 3 điều kiện trước khi đến nút lá (Zeta).

Ba mũi tên dày cho thấy đường suy luận.
Hãy xem Cây quyết định trong khoá học Rừng quyết định để biết thêm thông tin.
mức tăng thông tin
Trong rừng quyết định, sự khác biệt giữa entropy của một nút và tổng entropy có trọng số (theo số lượng ví dụ) của các nút con. Độ đo entropy của một nút là độ đo entropy của các ví dụ trong nút đó.
Ví dụ: hãy xem xét các giá trị entropy sau:
- entropy của nút mẹ = 0,6
- entropy của một nút con có 16 ví dụ liên quan = 0,2
- entropy của một nút con khác với 24 ví dụ có liên quan = 0,1
Vì vậy, 40% ví dụ nằm trong một nút con và 60% nằm trong nút con còn lại. Vì thế:
- tổng entropy có trọng số của các nút con = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Vậy mức tăng thông tin là:
- mức tăng thông tin = entropy của nút mẹ – tổng entropy có trọng số của các nút con
- mức tăng thông tin = 0,6 – 0,14 = 0,46
Hầu hết bộ phân tách đều tìm cách tạo ra các điều kiện giúp tối đa hoá mức tăng thông tin.
thiên vị cùng nhóm
Thể hiện sự thiên vị đối với nhóm của mình hoặc đặc điểm của bản thân. Nếu người kiểm thử hoặc người đánh giá là bạn bè, gia đình hoặc đồng nghiệp của nhà phát triển học máy, thì thiên kiến nội nhóm có thể làm mất hiệu lực việc kiểm thử sản phẩm hoặc tập dữ liệu.
Thiên vị cùng nhóm là một dạng thiên vị quy cho nhóm. Xem thêm thiên vị khác nhóm.
Hãy xem phần Tính công bằng: Các loại thành kiến trong Khoá học cấp tốc về học máy để biết thêm thông tin.
trình tạo dữ liệu đầu vào
Một cơ chế mà theo đó dữ liệu được tải vào mạng nơ-ron.
Bạn có thể coi trình tạo dữ liệu đầu vào là một thành phần chịu trách nhiệm xử lý dữ liệu thô thành các tensor được lặp lại để tạo các lô cho quá trình huấn luyện, đánh giá và suy luận.
lớp đầu vào
Lớp của một mạng nơron chứa vectơ đặc trưng. Tức là lớp đầu vào cung cấp ví dụ cho đào tạo hoặc suy luận. Ví dụ: lớp đầu vào trong mạng nơ-ron sau đây bao gồm 2 đặc điểm:
điều kiện trong bộ
Trong cây quyết định, điều kiện kiểm tra sự hiện diện của một mục trong một tập hợp các mục. Ví dụ: sau đây là một điều kiện trong tập hợp:
house-style in [tudor, colonial, cape]
Trong quá trình suy luận, nếu giá trị của đặc điểm về phong cách của ngôi nhà là tudor hoặc colonial hoặc cape, thì điều kiện này sẽ đánh giá là Có. Nếu giá trị của thuộc tính phong cách riêng là một giá trị khác (ví dụ: ranch), thì điều kiện này sẽ đánh giá là Không.
Các điều kiện trong tập hợp thường tạo ra cây quyết định hiệu quả hơn so với các điều kiện kiểm thử các đặc điểm được mã hoá một lần nóng.
bản sao
Từ đồng nghĩa với ví dụ.
điều chỉnh theo chỉ dẫn
Một dạng điều chỉnh giúp cải thiện khả năng tuân theo hướng dẫn của mô hình AI tạo sinh. Tinh chỉnh hướng dẫn liên quan đến việc huấn luyện một mô hình trên một loạt câu lệnh hướng dẫn, thường bao gồm nhiều loại nhiệm vụ. Sau đó, mô hình được tinh chỉnh theo hướng dẫn có xu hướng tạo ra các câu trả lời hữu ích cho các câu lệnh không cần ví dụ trong nhiều nhiệm vụ.
So sánh và đối chiếu với:
khả năng diễn giải
Khả năng giải thích hoặc trình bày lý do của mô hình học máy bằng những thuật ngữ dễ hiểu cho con người.
Ví dụ: Hầu hết các mô hình hồi quy tuyến tính đều có khả năng diễn giải cao. (Bạn chỉ cần xem xét trọng số đã được huấn luyện cho từng đối tượng.) Rừng quyết định cũng có khả năng diễn giải cao. Tuy nhiên, một số mô hình yêu cầu hình ảnh trực quan phức tạp để có thể diễn giải.
Bạn có thể sử dụng Công cụ diễn giải việc học (LIT) để diễn giải các mô hình học máy.
mức độ đồng thuận
Chỉ số đo lường tần suất mà người đánh giá đồng ý với nhau khi thực hiện một nhiệm vụ. Nếu người đánh giá không đồng ý, thì có thể bạn cần cải thiện hướng dẫn cho nhiệm vụ. Đôi khi còn được gọi là mức độ nhất trí giữa các chú thích viên hoặc độ tin cậy giữa các chuyên gia đánh giá. Xem thêm Kappa của Cohen, đây là một trong những chỉ số phổ biến nhất về mức độ nhất quán giữa các chuyên gia đánh giá.
Hãy xem bài viết Dữ liệu phân loại: Các vấn đề thường gặp trong Khoá học cấp tốc về học máy để biết thêm thông tin.
intersection over union (IoU)
Giao của hai tập hợp chia cho hợp của chúng. Trong các tác vụ phát hiện hình ảnh bằng công nghệ học máy, IoU được dùng để đo độ chính xác của khung hình chữ nhật dự đoán của mô hình so với khung hình chữ nhật dữ liệu thực tế. Trong trường hợp này, IoU cho 2 hộp là tỷ lệ giữa diện tích chồng chéo và tổng diện tích, đồng thời giá trị của IoU nằm trong khoảng từ 0 (không có sự chồng chéo giữa hộp giới hạn dự đoán và hộp giới hạn thực tế) đến 1 (hộp giới hạn dự đoán và hộp giới hạn thực tế có cùng toạ độ).
Ví dụ: trong hình ảnh bên dưới:
- Khung hình chữ nhật dự đoán (toạ độ phân định vị trí mà mô hình dự đoán bàn đầu giường trong bức tranh) được viền màu tím.
- Khung hình chữ nhật thực tế (toạ độ phân định vị trí thực tế của chiếc bàn đầu giường trong bức tranh) được đánh dấu bằng màu xanh lục.
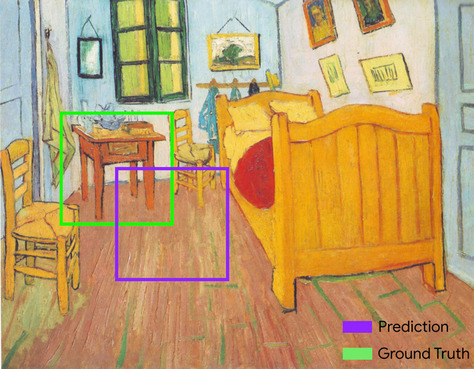
Ở đây, giao điểm của các hộp giới hạn cho dự đoán và dữ liệu thực tế (bên dưới bên trái) là 1, còn hợp của các hộp giới hạn cho dự đoán và dữ liệu thực tế (bên dưới bên phải) là 7, nên IoU là \(\frac{1}{7}\).
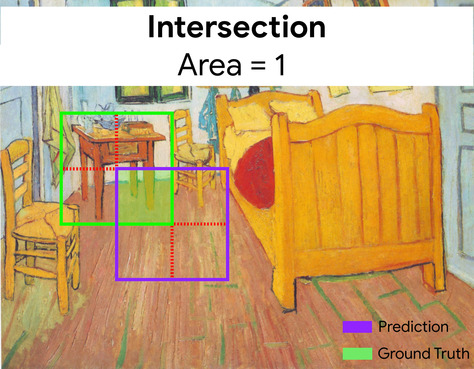
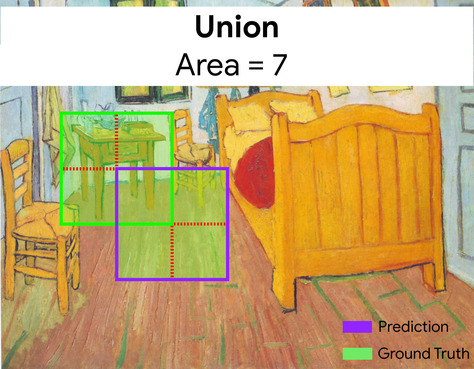
IoU
Viết tắt của intersection over union (giao nhau trên hợp).
ma trận mặt hàng
Trong hệ thống đề xuất, ma trận vectơ nhúng do phân tích ma trận tạo ra sẽ lưu giữ các tín hiệu tiềm ẩn về từng mặt hàng. Mỗi hàng của ma trận mặt hàng chứa giá trị của một đặc điểm tiềm ẩn duy nhất cho tất cả các mặt hàng. Ví dụ: hãy xem xét một hệ thống đề xuất phim. Mỗi cột trong ma trận mục đại diện cho một bộ phim. Các tín hiệu tiềm ẩn có thể đại diện cho thể loại hoặc có thể là những tín hiệu khó diễn giải hơn liên quan đến các tương tác phức tạp giữa thể loại, ngôi sao, độ tuổi của phim hoặc các yếu tố khác.
Ma trận mặt hàng có số cột bằng với số cột của ma trận mục tiêu đang được phân tích. Ví dụ: với một hệ thống đề xuất phim đánh giá 10.000 tiêu đề phim, ma trận mục sẽ có 10.000 cột.
mục
Trong hệ thống đề xuất, các thực thể mà hệ thống đề xuất. Ví dụ: video là những mặt hàng mà một cửa hàng video đề xuất, còn sách là những mặt hàng mà một cửa hàng sách đề xuất.
lặp lại
Một lần cập nhật các tham số của mô hình – trọng số và độ lệch của mô hình – trong quá trình huấn luyện. Kích thước lô xác định số lượng ví dụ mà mô hình xử lý trong một lần lặp. Ví dụ: nếu kích thước lô là 20, thì mô hình sẽ xử lý 20 ví dụ trước khi điều chỉnh các tham số.
Khi huấn luyện một mạng nơron, một lần lặp lại duy nhất sẽ bao gồm 2 lượt truyền sau:
- Một đường chuyền chuyển tiếp để đánh giá tổn thất trên một lô duy nhất.
- Một đường truyền ngược (lan truyền ngược) để điều chỉnh các tham số của mô hình dựa trên mức tổn thất và tốc độ học.
Hãy xem phần Hạ độ dốc trong Khoá học học máy ứng dụng để biết thêm thông tin.
J
JAX
Một thư viện điện toán mảng, kết hợp XLA (Đại số tuyến tính được tăng tốc) và phân biệt tự động để tính toán số học hiệu suất cao. JAX cung cấp một API đơn giản và mạnh mẽ để viết mã số học được tăng tốc bằng các phép biến đổi có thể kết hợp. JAX cung cấp các tính năng như:
grad(phân biệt tự động)jit(biên dịch tức thì)vmap(vector hoá tự động hoặc xử lý hàng loạt)pmap(song song hoá)
JAX là một ngôn ngữ để thể hiện và tạo thành các phép biến đổi mã số, tương tự như thư viện NumPy của Python nhưng có phạm vi rộng hơn nhiều. (Trên thực tế, thư viện .numpy trong JAX là một phiên bản tương đương về chức năng nhưng được viết lại hoàn toàn của thư viện Python NumPy.)
JAX đặc biệt phù hợp để tăng tốc nhiều tác vụ học máy bằng cách chuyển đổi các mô hình và dữ liệu thành một dạng phù hợp với tính song song trên GPU và TPU các chip tăng tốc.
Flax, Optax, Pax và nhiều thư viện khác được xây dựng trên cơ sở hạ tầng JAX.
nghìn
Keras
Một API học máy phổ biến của Python. Keras chạy trên một số khung học sâu, bao gồm cả TensorFlow, nơi Keras được cung cấp dưới dạng tf.keras.
Máy vectơ hỗ trợ hàm nhân (KSVM)
Một thuật toán phân loại tìm cách tối đa hoá khoảng cách giữa các lớp dương và các lớp âm bằng cách ánh xạ các vectơ dữ liệu đầu vào đến một không gian có chiều cao hơn. Ví dụ: hãy xem xét một vấn đề phân loại trong đó tập dữ liệu đầu vào có 100 đặc điểm. Để tối đa hoá khoảng cách giữa các lớp dương và âm, KSVM có thể ánh xạ nội bộ các đối tượng đó vào không gian một triệu chiều. KSVM sử dụng một hàm mất mát có tên là mất mát bản lề.
keypoints
Toạ độ của các đối tượng cụ thể trong một hình ảnh. Ví dụ: đối với một mô hình nhận dạng hình ảnh giúp phân biệt các loài hoa, các điểm chính có thể là tâm của mỗi cánh hoa, cuống hoa, nhị hoa, v.v.
xác thực chéo k lần
Một thuật toán để dự đoán khả năng tổng quát hoá của một mô hình đối với dữ liệu mới. k trong k-fold đề cập đến số lượng nhóm bằng nhau mà bạn chia các ví dụ của một tập dữ liệu thành; tức là bạn huấn luyện và kiểm thử mô hình của mình k lần. Đối với mỗi vòng huấn luyện và kiểm thử, một nhóm khác là tập hợp kiểm thử và tất cả các nhóm còn lại trở thành tập hợp huấn luyện. Sau k vòng huấn luyện và kiểm thử, bạn sẽ tính toán giá trị trung bình và độ lệch chuẩn của(các) chỉ số kiểm thử đã chọn.
Ví dụ: giả sử tập dữ liệu của bạn bao gồm 120 ví dụ. Giả sử bạn quyết định đặt k thành 4. Do đó, sau khi xáo trộn các ví dụ, bạn chia tập dữ liệu thành 4 nhóm bằng nhau gồm 30 ví dụ và tiến hành 4 vòng huấn luyện và kiểm thử:
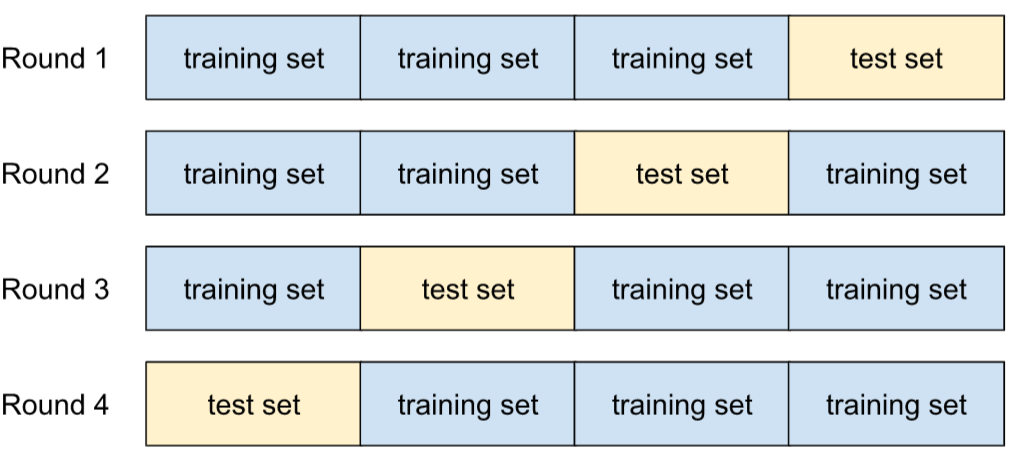
Ví dụ: Sai số bình phương trung bình (MSE) có thể là chỉ số có ý nghĩa nhất đối với mô hình hồi quy tuyến tính. Do đó, bạn sẽ tìm thấy giá trị trung bình và độ lệch chuẩn của MSE trên cả 4 vòng.
k-means
Một thuật toán phân cụm phổ biến, nhóm các ví dụ trong quá trình học không có giám sát. Về cơ bản, thuật toán k-means sẽ thực hiện những việc sau:
- Xác định lặp đi lặp lại k điểm trung tâm tốt nhất (được gọi là tâm khối).
- Chỉ định mỗi ví dụ cho tâm điểm gần nhất. Những ví dụ gần với cùng một tâm điểm nhất sẽ thuộc cùng một nhóm.
Thuật toán k-means chọn vị trí tâm cụm để giảm thiểu bình phương tích luỹ của khoảng cách từ mỗi ví dụ đến tâm cụm gần nhất.
Ví dụ: hãy xem xét biểu đồ sau đây về chiều cao và chiều rộng của chú chó:

Nếu k=3, thuật toán k-means sẽ xác định 3 tâm cụm. Mỗi ví dụ được chỉ định cho tâm điểm gần nhất, tạo ra 3 nhóm:

Hãy tưởng tượng rằng một nhà sản xuất muốn xác định kích thước lý tưởng cho áo len nhỏ, vừa và lớn dành cho chó. Ba tâm này xác định chiều cao trung bình và chiều rộng trung bình của mỗi chú cún trong cụm đó. Vì vậy, nhà sản xuất có thể dựa vào 3 tâm này để xác định kích thước áo len. Xin lưu ý rằng tâm của một cụm thường không phải là một ví dụ trong cụm.
Các hình minh hoạ trước đó cho thấy k-means cho các ví dụ chỉ có 2 đặc điểm (chiều cao và chiều rộng). Lưu ý rằng k-means có thể nhóm các ví dụ trên nhiều đối tượng.
Hãy xem phần Phân cụm k-means là gì? trong khoá học Phân cụm để biết thêm thông tin.
k trung vị
Một thuật toán phân cụm có liên quan chặt chẽ đến k-means. Sự khác biệt thực tế giữa hai loại này như sau:
- Trong k-means, các tâm cụm được xác định bằng cách giảm thiểu tổng bình phương khoảng cách giữa một tâm cụm đề xuất và từng ví dụ của tâm cụm đó.
- Trong k-median, các tâm được xác định bằng cách giảm thiểu tổng khoảng cách giữa một tâm ứng cử và từng ví dụ của tâm đó.
Xin lưu ý rằng định nghĩa về khoảng cách cũng khác nhau:
- k-means dựa vào khoảng cách Euclide từ tâm đến một ví dụ. (Trong không gian hai chiều, khoảng cách Euclid có nghĩa là sử dụng định lý Pythagoras để tính cạnh huyền.) Ví dụ: khoảng cách k-means giữa (2,2) và (5,-2) sẽ là:
- k-median dựa vào khoảng cách Manhattan từ tâm đến một ví dụ. Khoảng cách này là tổng của các delta tuyệt đối trong mỗi phương diện. Ví dụ: khoảng cách k-median giữa (2,2) và (5,-2) sẽ là:
L
Điều hoà L0
Một loại điều chỉnh sẽ phạt tổng số trọng số khác 0 trong một mô hình. Ví dụ: một mô hình có 11 trọng số khác 0 sẽ bị phạt nhiều hơn một mô hình tương tự có 10 trọng số khác 0.
Điều chuẩn L0 đôi khi được gọi là điều chuẩn L0-norm.
Tổn thất L1
Một hàm tổn thất tính toán giá trị tuyệt đối của mức chênh lệch giữa các giá trị nhãn thực tế và các giá trị mà một mô hình dự đoán. Ví dụ: sau đây là cách tính tổn thất L1 cho một lô gồm 5 ví dụ:
| Giá trị thực tế của ví dụ | Giá trị dự đoán của mô hình | Giá trị tuyệt đối của delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = tổn thất L1 | ||
Mất mát L1 ít nhạy cảm với giá trị ngoại lệ hơn mất mát L2.
Sai số tuyệt đối trung bình là mức tổn thất L1 trung bình trên mỗi ví dụ.
Hãy xem phần Hồi quy tuyến tính: Mất mát trong Khoá học cấp tốc về học máy để biết thêm thông tin.
Điều hoà L1
Một loại điều chỉnh sẽ phạt trọng số theo tỷ lệ với tổng giá trị tuyệt đối của trọng số. Việc điều chỉnh L1 giúp giảm trọng số của các đặc điểm không liên quan hoặc hầu như không liên quan xuống chính xác bằng 0. Một đặc điểm có trọng số bằng 0 sẽ bị loại bỏ khỏi mô hình.
Tương phản với điều hoà L2.
Tổn thất L2
Một hàm tổn thất tính bình phương của sự khác biệt giữa các giá trị nhãn thực tế và các giá trị mà một mô hình dự đoán. Ví dụ: sau đây là cách tính tổn thất L2 cho một lô gồm 5 ví dụ:
| Giá trị thực tế của ví dụ | Giá trị dự đoán của mô hình | Bình phương của delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = tổn thất L2 | ||
Do bình phương, tổn thất L2 sẽ khuếch đại ảnh hưởng của các giá trị ngoại lai. Tức là tổn thất L2 phản ứng mạnh hơn với các dự đoán không chính xác so với tổn thất L1. Ví dụ: tổn thất L1 cho lô trước đó sẽ là 8 thay vì 16. Xin lưu ý rằng một giá trị ngoại lệ duy nhất chiếm 9 trong số 16 giá trị.
Mô hình hồi quy thường sử dụng tổn thất L2 làm hàm tổn thất.
Sai số bình phương trung bình là tổn thất L2 trung bình trên mỗi ví dụ. Tổn thất bình phương là một tên khác của tổn thất L2.
Hãy xem phần Hồi quy logistic: Hàm mất mát và điều chuẩn trong Khoá học cấp tốc về học máy để biết thêm thông tin.
Điều hoà L2
Một loại điều chuẩn sẽ phạt trọng số theo tỷ lệ với tổng bình phương của trọng số. Việc điều chỉnh L2 giúp đẩy các trọng số ngoại lai (những trọng số có giá trị dương cao hoặc giá trị âm thấp) gần bằng 0 hơn nhưng không hoàn toàn bằng 0. Các đối tượng có giá trị rất gần với 0 vẫn nằm trong mô hình nhưng không ảnh hưởng nhiều đến dự đoán của mô hình.
Việc điều chỉnh L2 luôn cải thiện khả năng khái quát hoá trong các mô hình tuyến tính.
Tương phản với điều hoà L1.
Hãy xem phần Trang bị quá khớp: Điều chỉnh L2 trong Khoá học học máy ứng dụng để biết thêm thông tin.
nhãn
Trong học máy có giám sát, phần "câu trả lời" hoặc "kết quả" của một ví dụ.
Mỗi ví dụ được gắn nhãn bao gồm một hoặc nhiều đặc điểm và một nhãn. Ví dụ: trong một tập dữ liệu phát hiện thư rác, nhãn có thể là "thư rác" hoặc "không phải thư rác". Trong một tập dữ liệu về lượng mưa, nhãn có thể là lượng mưa trong một khoảng thời gian nhất định.
Hãy xem phần Học có giám sát trong bài viết Giới thiệu về học máy để biết thêm thông tin.
ví dụ được gắn nhãn
Một ví dụ chứa một hoặc nhiều đối tượng và một nhãn. Ví dụ: bảng sau đây cho thấy 3 ví dụ được gắn nhãn từ một mô hình định giá nhà, mỗi ví dụ có 3 đối tượng và 1 nhãn:
| Số lượng phòng ngủ | Số lượng phòng tắm | Tuổi của nhà | Giá nhà (nhãn) |
|---|---|---|---|
| 3 | 2 | 15 | 345.000 USD |
| 2 | 1 | 72 | $179.000 |
| 4 | 2 | 34 | 392.000 USD |
Trong công nghệ học máy có giám sát, các mô hình sẽ được huấn luyện dựa trên các ví dụ được gắn nhãn và đưa ra dự đoán về các ví dụ chưa được gắn nhãn.
So sánh ví dụ có nhãn với ví dụ không có nhãn.
Hãy xem phần Học có giám sát trong bài viết Giới thiệu về học máy để biết thêm thông tin.
rò rỉ nhãn
Một lỗi thiết kế mô hình trong đó đối tượng là một proxy cho nhãn. Ví dụ: hãy xem xét một mô hình phân loại nhị phân dự đoán liệu khách hàng tiềm năng có mua một sản phẩm cụ thể hay không.
Giả sử một trong các tính năng của mô hình là một giá trị Boolean có tên là SpokeToCustomerAgent. Giả sử thêm rằng nhân viên hỗ trợ khách hàng chỉ được chỉ định sau khi khách hàng tiềm năng đã mua sản phẩm. Trong quá trình huấn luyện, mô hình sẽ nhanh chóng học được mối liên kết giữa SpokeToCustomerAgent và nhãn.
Hãy xem phần Giám sát các quy trình trong Khoá học học máy ứng dụng để biết thêm thông tin.
lambda
Từ đồng nghĩa với hệ số điều hoà.
Lambda là một thuật ngữ được nạp chồng. Ở đây, chúng ta sẽ tập trung vào định nghĩa của thuật ngữ trong quy trình chuẩn hoá.
LaMDA (Mô hình ngôn ngữ cho các ứng dụng trò chuyện)
Một mô hình ngôn ngữ lớn dựa trên Transformer do Google phát triển, được huấn luyện trên một tập dữ liệu lớn về các cuộc đối thoại và có thể tạo ra phản hồi giống như thật trong cuộc trò chuyện.
LaMDA: công nghệ đàm thoại đột phá của chúng tôi cung cấp thông tin tổng quan.
địa danh
Từ đồng nghĩa với keypoints.
mô hình ngôn ngữ
Một mô hình ước tính xác suất của một mã thông báo hoặc chuỗi mã thông báo xuất hiện trong một chuỗi mã thông báo dài hơn.
Hãy xem bài viết Mô hình ngôn ngữ là gì? trong Khoá học học máy ứng dụng để biết thêm thông tin.
mô hình ngôn ngữ lớn
Tối thiểu là một mô hình ngôn ngữ có số lượng tham số rất lớn. Một cách không chính thức hơn, bất kỳ mô hình ngôn ngữ nào dựa trên Transformer, chẳng hạn như Gemini hoặc GPT.
Hãy xem bài viết Mô hình ngôn ngữ lớn (LLM) trong Khoá học học máy ứng dụng để biết thêm thông tin.
thời gian chờ
Thời gian cần thiết để một mô hình xử lý dữ liệu đầu vào và tạo ra phản hồi. Phản hồi có độ trễ cao mất nhiều thời gian hơn để tạo so với phản hồi có độ trễ thấp.
Các yếu tố ảnh hưởng đến độ trễ của mô hình ngôn ngữ lớn bao gồm:
- Độ dài [mã thông báo] đầu vào và đầu ra
- Độ phức tạp của mô hình
- Cơ sở hạ tầng mà mô hình chạy trên đó
Việc tối ưu hoá độ trễ là rất quan trọng để tạo ra các ứng dụng có khả năng phản hồi và thân thiện với người dùng.
không gian tiềm ẩn
Từ đồng nghĩa với không gian nhúng.
lớp
Một nhóm nơron trong mạng nơron. Sau đây là 3 loại lớp phổ biến:
- lớp đầu vào, cung cấp các giá trị cho tất cả đối tượng.
- Một hoặc nhiều lớp ẩn, tìm ra các mối quan hệ phi tuyến tính giữa các đối tượng và nhãn.
- lớp đầu ra, cung cấp thông tin dự đoán.
Ví dụ: hình minh hoạ sau đây cho thấy một mạng nơ-ron có một lớp đầu vào, hai lớp ẩn và một lớp đầu ra:
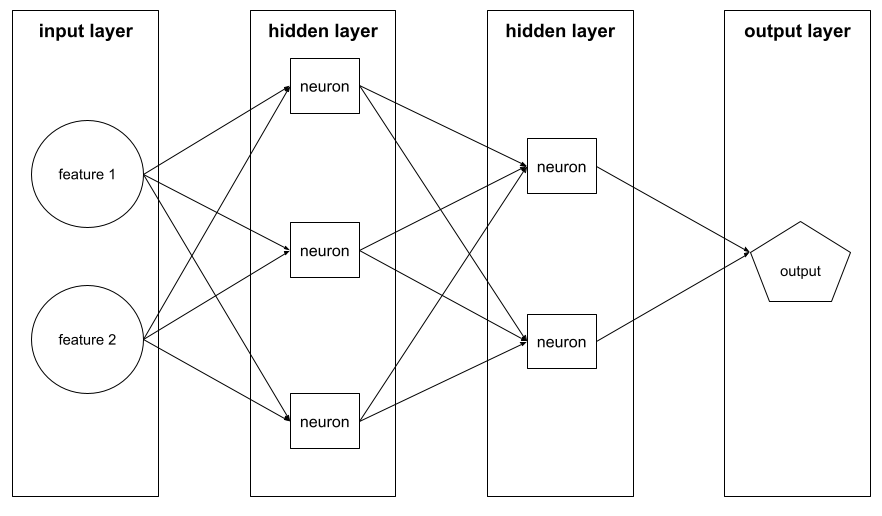
Trong TensorFlow, các lớp cũng là những hàm Python nhận Tensor và các lựa chọn cấu hình làm dữ liệu đầu vào và tạo ra các tensor khác làm dữ liệu đầu ra.
Layers API (tf.layers)
Một API TensorFlow để tạo mạng nơ-ron sâu dưới dạng một thành phần của các lớp. Layers API cho phép bạn tạo nhiều loại lớp, chẳng hạn như:
tf.layers.Densecho lớp kết nối đầy đủ.tf.layers.Conv2Dcho lớp tích chập.
Layers API tuân theo các quy ước về API lớp Keras. Tức là ngoài tiền tố khác, tất cả các hàm trong Layers API đều có cùng tên và chữ ký như các hàm tương ứng trong Keras Layers API.
lá
Mọi điểm cuối trong cây quyết định. Không giống như điều kiện, một nút lá không thực hiện kiểm thử. Thay vào đó, một nút lá là một dự đoán có thể xảy ra. Lá cũng là nút cuối của một đường dẫn suy luận.
Ví dụ: cây quyết định sau đây có 3 nút lá:
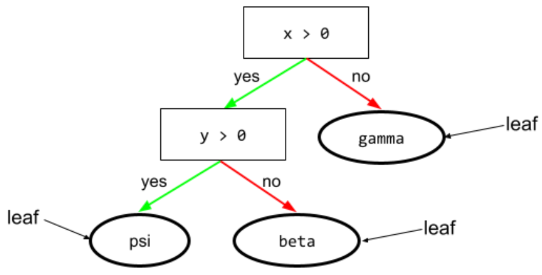
Hãy xem Cây quyết định trong khoá học Rừng quyết định để biết thêm thông tin.
Công cụ diễn giải việc học (LIT)
Một công cụ trực quan, tương tác để hiểu mô hình và trực quan hoá dữ liệu.
Bạn có thể dùng LIT nguồn mở để diễn giải các mô hình hoặc để trực quan hoá văn bản, hình ảnh và dữ liệu dạng bảng.
tốc độ học
Một số thực cho biết thuật toán hạ độ dốc điều chỉnh trọng số và độ lệch mạnh đến mức nào trên mỗi lần lặp lại. Ví dụ: tốc độ học tập là 0,3 sẽ điều chỉnh trọng số và độ lệch mạnh hơn gấp 3 lần so với tốc độ học tập là 0,1.
Tốc độ học tập là một siêu tham số quan trọng. Nếu bạn đặt tốc độ học quá thấp, quá trình huấn luyện sẽ mất quá nhiều thời gian. Nếu bạn đặt tốc độ học tập quá cao, thì quá trình giảm độ dốc thường gặp khó khăn trong việc đạt được sự hội tụ.
Hãy xem phần Hồi quy tuyến tính: Siêu tham số trong Khoá học cấp tốc về học máy để biết thêm thông tin.
hồi quy bình phương tối thiểu
Mô hình hồi quy tuyến tính được huấn luyện bằng cách giảm thiểu Mất mát L2.
Khoảng cách Levenshtein
Chỉ số khoảng cách chỉnh sửa giúp tính toán số lượng tối thiểu các thao tác xoá, chèn và thay thế cần thiết để thay đổi một từ thành một từ khác. Ví dụ: Khoảng cách Levenshtein giữa các từ "heart" và "darts" là 3 vì 3 thao tác chỉnh sửa sau đây là số lượng thay đổi ít nhất để biến một từ thành từ kia:
- heart → deart (thay thế "h" bằng "d")
- deart → dart (xoá "e")
- dart → darts (thêm "s")
Xin lưu ý rằng chuỗi trước đó không phải là đường dẫn duy nhất của 3 lượt chỉnh sửa.
tuyến tính
Mối quan hệ giữa hai hoặc nhiều biến chỉ có thể được biểu thị thông qua phép cộng và phép nhân.
Đồ thị của mối quan hệ tuyến tính là một đường thẳng.
Tương phản với phi tuyến tính.
mô hình tuyến tính
Một mô hình chỉ định một trọng số cho mỗi đặc điểm để đưa ra dự đoán. (Mô hình tuyến tính cũng kết hợp độ lệch.) Ngược lại, mối quan hệ giữa các đặc điểm với dự đoán trong các mô hình sâu thường là phi tuyến tính.
Các mô hình tuyến tính thường dễ huấn luyện và dễ diễn giải hơn so với các mô hình sâu. Tuy nhiên, các mô hình sâu có thể học được các mối quan hệ phức tạp giữa các đặc điểm.
Hồi quy tuyến tính và hồi quy logistic là hai loại mô hình tuyến tính.
hồi quy tuyến tính
Một loại mô hình học máy mà cả hai điều kiện sau đều đúng:
- Mô hình này là một mô hình tuyến tính.
- Giá trị dự đoán là giá trị dấu phẩy động. (Đây là phần hồi quy của hồi quy tuyến tính.)
So sánh hồi quy tuyến tính với hồi quy logistic. Ngoài ra, hãy so sánh hồi quy với phân loại.
Hãy xem phần Hồi quy tuyến tính trong Khoá học học máy ứng dụng để biết thêm thông tin.
LIT
Từ viết tắt của Công cụ diễn giải việc học (LIT), trước đây có tên là Công cụ diễn giải ngôn ngữ.
LLM
Từ viết tắt của mô hình ngôn ngữ lớn.
Đánh giá LLM
Một bộ chỉ số và điểm chuẩn để đánh giá hiệu suất của các mô hình ngôn ngữ lớn (LLM). Ở cấp độ cao, các hoạt động đánh giá LLM:
- Giúp các nhà nghiên cứu xác định những khía cạnh mà LLM cần cải thiện.
- Hữu ích trong việc so sánh các LLM khác nhau và xác định LLM phù hợp nhất cho một nhiệm vụ cụ thể.
- Giúp đảm bảo rằng các LLM an toàn và có đạo đức khi sử dụng.
Hãy xem Mô hình ngôn ngữ lớn (LLM) trong Khoá học học máy ứng dụng để biết thêm thông tin.
hồi quy logistic
Một loại mô hình hồi quy dự đoán xác suất. Mô hình hồi quy logistic có các đặc điểm sau:
- Nhãn này là phân loại. Thuật ngữ hồi quy logistic thường đề cập đến hồi quy logistic nhị phân, tức là một mô hình tính toán xác suất cho các nhãn có 2 giá trị có thể. Một biến thể ít phổ biến hơn, hồi quy logistic đa thức, tính toán xác suất cho các nhãn có nhiều hơn hai giá trị có thể.
- Hàm tổn thất trong quá trình huấn luyện là Tổn thất nhật ký. (Bạn có thể đặt song song nhiều đơn vị Log Loss cho các nhãn có nhiều hơn 2 giá trị có thể.)
- Mô hình này có cấu trúc tuyến tính, không phải mạng nơ-ron sâu. Tuy nhiên, phần còn lại của định nghĩa này cũng áp dụng cho mô hình sâu dự đoán xác suất cho nhãn phân loại.
Ví dụ: hãy xem xét một mô hình hồi quy logistic tính toán xác suất của một email đầu vào là thư rác hay không phải thư rác. Trong quá trình suy luận, giả sử mô hình dự đoán là 0,72. Do đó, mô hình này đang ước tính:
- Email có 72% khả năng là thư rác.
- Có 28% khả năng email này không phải là thư rác.
Mô hình hồi quy logistic sử dụng cấu trúc gồm 2 bước sau:
- Mô hình này tạo ra một dự đoán thô (y') bằng cách áp dụng một hàm tuyến tính của các đặc điểm đầu vào.
- Mô hình này sử dụng thông tin dự đoán thô đó làm dữ liệu đầu vào cho một hàm sigmoid. Hàm này chuyển đổi thông tin dự đoán thô thành một giá trị từ 0 đến 1 (không bao gồm 0 và 1).
Giống như mọi mô hình hồi quy, mô hình hồi quy logistic dự đoán một con số. Tuy nhiên, số này thường trở thành một phần của mô hình phân loại nhị phân như sau:
- Nếu số dự đoán lớn hơn ngưỡng phân loại, thì mô hình phân loại nhị phân sẽ dự đoán lớp dương.
- Nếu số dự đoán nhỏ hơn ngưỡng phân loại, mô hình phân loại nhị phân sẽ dự đoán lớp âm.
Hãy xem phần Hồi quy logistic trong Khoá học học máy ứng dụng để biết thêm thông tin.
logits
Vectơ gồm các dự đoán thô (không được chuẩn hoá) mà một mô hình phân loại tạo ra, thường được truyền đến một hàm chuẩn hoá. Nếu mô hình đang giải quyết vấn đề phân loại nhiều lớp, thì logits thường trở thành một giá trị đầu vào cho hàm softmax. Sau đó, hàm softmax sẽ tạo ra một vectơ gồm các xác suất (đã chuẩn hoá) với một giá trị cho mỗi lớp có thể có.
Tổn thất logistic
Hàm tổn thất được dùng trong hồi quy logistic nhị phân.
Hãy xem phần Hồi quy logistic: Hàm tổn thất và điều chuẩn trong Khoá học cấp tốc về học máy để biết thêm thông tin.
log-odds
Logarit của tỷ lệ cược của một sự kiện nào đó.
Bộ nhớ ngắn hạn dài (LSTM)
Một loại ô trong mạng nơ-ron hồi quy được dùng để xử lý các chuỗi dữ liệu trong các ứng dụng như nhận dạng chữ viết tay, dịch máy và chú thích hình ảnh. LSTM giải quyết vấn đề về độ dốc biến mất xảy ra khi huấn luyện RNN do các chuỗi dữ liệu dài bằng cách duy trì nhật ký ở trạng thái bộ nhớ nội bộ dựa trên dữ liệu đầu vào mới và bối cảnh từ các ô trước đó trong RNN.
LoRA
Viết tắt của Khả năng thích ứng với thứ hạng thấp.
thua
Trong quá trình huấn luyện một mô hình có giám sát, một thước đo cho biết dự đoán của mô hình cách xa nhãn của mô hình bao nhiêu.
Hàm tổn thất tính toán tổn thất.
Hãy xem phần Hồi quy tuyến tính: Mất mát trong Khoá học cấp tốc về học máy để biết thêm thông tin.
đơn vị tập hợp tổn thất
Một loại thuật toán học máy giúp cải thiện hiệu suất của một mô hình bằng cách kết hợp các dự đoán của nhiều mô hình và sử dụng những dự đoán đó để đưa ra một dự đoán duy nhất. Do đó, một bộ tổng hợp tổn thất có thể giảm phương sai của các dự đoán và cải thiện độ chính xác của các dự đoán.
đường cong tổn thất
Biểu đồ mất mát dưới dạng hàm của số lượng lần lặp lại trong quá trình huấn luyện. Biểu đồ sau đây cho thấy một đường cong tổn thất điển hình:
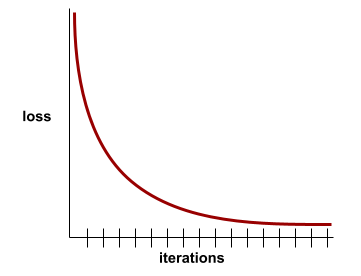
Đường cong tổn thất có thể giúp bạn xác định thời điểm mô hình của bạn hội tụ hoặc quá khớp.
Đường cong tổn thất có thể vẽ tất cả các loại tổn thất sau đây:
Xem thêm đường cong khái quát hoá.
Hãy xem phần Huấn luyện quá mức: Giải thích các đường cong tổn thất trong Khoá học cấp tốc về học máy để biết thêm thông tin.
hàm tổn thất
Trong quá trình huấn luyện hoặc kiểm thử, một hàm toán học sẽ tính toán mức tổn thất trên một lô ví dụ. Hàm tổn thất trả về mức tổn thất thấp hơn cho những mô hình đưa ra dự đoán chính xác so với những mô hình đưa ra dự đoán không chính xác.
Mục tiêu của việc huấn luyện thường là giảm thiểu mức tổn thất mà một hàm tổn thất trả về.
Có nhiều loại hàm tổn thất. Chọn hàm tổn thất phù hợp cho loại mô hình mà bạn đang xây dựng. Ví dụ:
- Mất mát L2 (hoặc Sai số bình phương trung bình) là hàm mất mát cho hồi quy tuyến tính.
- Log Loss là hàm tổn thất cho hồi quy logistic.
bề mặt tổn thất
Biểu đồ về(các) trọng số so với mức giảm. Hạ dốc nhằm mục đích tìm(các) trọng số mà tại đó bề mặt tổn thất đạt mức tối thiểu cục bộ.
Khả năng thích ứng cấp thấp (LoRA)
Một kỹ thuật tiết kiệm tham số để điều chỉnh mà "đóng băng" các trọng số được huấn luyện trước của mô hình (để không thể sửa đổi nữa) rồi chèn một nhóm nhỏ các trọng số có thể huấn luyện vào mô hình. Tập hợp các trọng số có thể huấn luyện này (còn được gọi là "ma trận cập nhật") nhỏ hơn đáng kể so với mô hình cơ sở và do đó, việc huấn luyện sẽ diễn ra nhanh hơn nhiều.
LoRA mang lại những lợi ích sau:
- Cải thiện chất lượng dự đoán của một mô hình cho miền mà hoạt động tinh chỉnh được áp dụng.
- Tinh chỉnh nhanh hơn so với các kỹ thuật yêu cầu tinh chỉnh tất cả các tham số của một mô hình.
- Giảm chi phí tính toán của suy luận bằng cách cho phép phân phát đồng thời nhiều mô hình chuyên biệt dùng chung cùng một mô hình cơ sở.
LSTM
Từ viết tắt của Long Short-Term Memory (Bộ nhớ ngắn hạn dài).
M
học máy
Một chương trình hoặc hệ thống huấn luyện một mô hình từ dữ liệu đầu vào. Mô hình được huấn luyện có thể đưa ra những dự đoán hữu ích từ dữ liệu mới (chưa từng thấy) được lấy từ cùng một bản phân phối như bản phân phối được dùng để huấn luyện mô hình.
Học máy cũng đề cập đến lĩnh vực nghiên cứu liên quan đến các chương trình hoặc hệ thống này.
Hãy xem khoá học Giới thiệu về học máy để biết thêm thông tin.
bản dịch máy
Sử dụng phần mềm (thường là một mô hình học máy) để chuyển đổi văn bản từ ngôn ngữ này sang ngôn ngữ khác, ví dụ: từ tiếng Anh sang tiếng Nhật.
lớp đa số
Nhãn phổ biến hơn trong tập dữ liệu bất cân đối về loại. Ví dụ: với một tập dữ liệu chứa 99% nhãn âm tính và 1% nhãn dương tính, nhãn âm tính là lớp đa số.
Tương phản với lớp thiểu số.
Hãy xem phần Tập dữ liệu: Tập dữ liệu không cân bằng trong Khoá học cấp tốc về học máy để biết thêm thông tin.
Quy trình quyết định Markov (MDP)
Một biểu đồ biểu thị mô hình đưa ra quyết định, trong đó các quyết định (hoặc hành động) được đưa ra để điều hướng một chuỗi trạng thái giả định rằng thuộc tính Markov được duy trì. Trong học tăng cường, những quá trình chuyển đổi này giữa các trạng thái sẽ trả về một phần thưởng bằng số.
Thuộc tính Markov
Một thuộc tính của một số môi trường nhất định, trong đó các quá trình chuyển đổi trạng thái hoàn toàn được xác định bằng thông tin ngầm định trong trạng thái hiện tại và hành động của tác nhân.
mô hình ngôn ngữ được che
Một mô hình ngôn ngữ dự đoán xác suất của các mã thông báo đề xuất để điền vào chỗ trống trong một chuỗi. Ví dụ: mô hình ngôn ngữ che giấu có thể tính toán xác suất cho(các) từ đề xuất để thay thế dấu gạch chân trong câu sau:
____ trong chiếc mũ đã quay trở lại.
Tài liệu thường dùng chuỗi "MASK" thay vì dấu gạch chân. Ví dụ:
"MASK" trong chiếc mũ đã trở lại.
Hầu hết các mô hình ngôn ngữ được che giấu hiện đại đều là hai chiều.
matplotlib
Một thư viện vẽ đồ thị 2D bằng Python mã nguồn mở. matplotlib giúp bạn hình dung các khía cạnh khác nhau của công nghệ học máy.
phân tích ma trận
Trong toán học, một cơ chế để tìm các ma trận có tích vô hướng xấp xỉ một ma trận mục tiêu.
Trong hệ thống đề xuất, ma trận mục tiêu thường chứa điểm xếp hạng của người dùng đối với các mục. Ví dụ: ma trận mục tiêu cho hệ thống đề xuất phim có thể trông như sau, trong đó các số nguyên dương là điểm xếp hạng của người dùng và 0 có nghĩa là người dùng không xếp hạng phim:
| Casablanca | The Philadelphia Story | Black Panther (Chiến binh Báo Đen) | Wonder Woman | Pulp Fiction | |
|---|---|---|---|---|---|
| Người dùng 1 | 5 | 3 | 0.0 | 2 | 0.0 |
| Người dùng 2 | 4 | 0.0 | 0.0 | 1.0 | 5 |
| Người dùng 3 | 3 | 1.0 | 4 | 5 | 0.0 |
Hệ thống đề xuất phim nhằm mục đích dự đoán điểm xếp hạng của người dùng cho những bộ phim chưa được xếp hạng. Ví dụ: Người dùng 1 có thích Black Panther không?
Một phương pháp cho hệ thống đề xuất là sử dụng phương pháp phân tích ma trận để tạo ra 2 ma trận sau:
- Một ma trận người dùng, có dạng số người dùng X số phương diện nhúng.
- Một ma trận mặt hàng, có dạng là số lượng các phương diện nhúng X số lượng mặt hàng.
Ví dụ: việc sử dụng phương pháp phân tích ma trận trên 3 người dùng và 5 mặt hàng có thể tạo ra ma trận người dùng và ma trận mặt hàng sau đây:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
Tích vô hướng của ma trận người dùng và ma trận mặt hàng tạo ra một ma trận đề xuất không chỉ chứa điểm xếp hạng ban đầu của người dùng mà còn chứa các dự đoán cho những bộ phim mà mỗi người dùng chưa xem. Ví dụ: hãy xem xét điểm xếp hạng của Người dùng 1 đối với phim Casablanca là 5.0. Tích của hai số tương ứng với ô đó trong ma trận đề xuất hy vọng sẽ là khoảng 5.0 và đó là:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9Quan trọng hơn, liệu Người dùng 1 có thích phim Chiến binh Báo đen không? Lấy tích vô hướng tương ứng với hàng đầu tiên và cột thứ ba sẽ cho ra điểm xếp hạng dự đoán là 4,3:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3Phân tích ma trận thường tạo ra một ma trận người dùng và ma trận mặt hàng. Hai ma trận này cùng nhau nhỏ gọn hơn đáng kể so với ma trận mục tiêu.
Sai số tuyệt đối trung bình (MAE)
Mức tổn thất trung bình trên mỗi ví dụ khi sử dụng tổn thất L1. Tính Sai số tuyệt đối trung bình như sau:
- Tính toán tổn thất L1 cho một lô.
- Chia tổn thất L1 cho số lượng ví dụ trong lô.
Ví dụ: hãy xem xét việc tính toán tổn thất L1 trên lô gồm 5 ví dụ sau:
| Giá trị thực tế của ví dụ | Giá trị dự đoán của mô hình | Mất mát (chênh lệch giữa giá trị thực tế và giá trị dự đoán) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = tổn thất L1 | ||
Vậy, tổn thất L1 là 8 và số lượng ví dụ là 5. Do đó, Sai số tuyệt đối trung bình là:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Tương phản Sai số tuyệt đối trung bình với Sai số bình phương trung bình và Sai số trung bình bình phương.
độ chính xác trung bình tại k (mAP@k)
Giá trị trung bình thống kê của tất cả các điểm độ chính xác trung bình tại k trên một tập dữ liệu xác thực. Một cách sử dụng độ chính xác trung bình tại k là đánh giá chất lượng của các đề xuất do hệ thống đề xuất tạo ra.
Mặc dù cụm từ "giá trị trung bình" nghe có vẻ dư thừa, nhưng tên của chỉ số này là phù hợp. Sau tất cả, chỉ số này tìm ra giá trị trung bình của nhiều giá trị độ chính xác trung bình tại k.
Sai số bình phương trung bình (MSE)
Mức tổn thất trung bình trên mỗi ví dụ khi sử dụng tổn thất L2. Tính Sai số bình phương trung bình như sau:
- Tính tổn thất L2 cho một lô.
- Chia tổn thất L2 cho số lượng ví dụ trong lô.
Ví dụ: hãy xem xét tổn thất trên lô gồm 5 ví dụ sau:
| Giá trị thực tế | Dự đoán của mô hình | Thua | Tổn thất bình phương |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = tổn thất L2 | |||
Do đó, Sai số bình phương trung bình là:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
Sai số bình phương trung bình là một trình tối ưu hoá huấn luyện phổ biến, đặc biệt là đối với hồi quy tuyến tính.
So sánh Sai số bình phương trung bình với Sai số tuyệt đối trung bình và Sai số trung bình bình phương.
TensorFlow Playground sử dụng Sai số bình phương trung bình để tính giá trị tổn thất.
lưới
Trong lập trình song song ML, đây là một thuật ngữ liên quan đến việc chỉ định dữ liệu và mô hình cho các chip TPU, đồng thời xác định cách các giá trị này sẽ được phân đoạn hoặc sao chép.
Mesh là một thuật ngữ có nhiều nghĩa, có thể là một trong hai nghĩa sau:
- Bố cục thực tế của các chip TPU.
- Một cấu trúc logic trừu tượng để lập bản đồ dữ liệu và mô hình cho các chip TPU.
Trong cả hai trường hợp, một lưới được chỉ định là một hình dạng.
học siêu dữ liệu
Một tập hợp con của công nghệ học máy, có khả năng khám phá hoặc cải thiện thuật toán học. Hệ thống học tập meta cũng có thể hướng đến việc huấn luyện một mô hình để nhanh chóng học một nhiệm vụ mới từ một lượng nhỏ dữ liệu hoặc từ kinh nghiệm thu được trong các nhiệm vụ trước đó. Các thuật toán học siêu dữ liệu thường cố gắng đạt được những mục tiêu sau:
- Cải thiện hoặc tìm hiểu các tính năng được thiết kế thủ công (chẳng hạn như một trình khởi tạo hoặc một trình tối ưu hoá).
- Sử dụng dữ liệu và điện toán hiệu quả hơn.
- Cải thiện khả năng khái quát hoá.
Học siêu dữ liệu có liên quan đến học từ một vài dữ liệu.
chỉ số
Một số liệu thống kê mà bạn quan tâm.
Mục tiêu là một chỉ số mà hệ thống học máy cố gắng tối ưu hoá.
Metrics API (tf.metrics)
Một API TensorFlow để đánh giá các mô hình. Ví dụ: tf.metrics.accuracy xác định tần suất dự đoán của một mô hình khớp với nhãn.
lô nhỏ
Một nhóm nhỏ được chọn ngẫu nhiên trong một lô được xử lý trong một lần lặp. Kích thước lô của một lô nhỏ thường nằm trong khoảng từ 10 đến 1.000 ví dụ.
Ví dụ: giả sử toàn bộ tập huấn luyện (toàn bộ lô) bao gồm 1.000 ví dụ. Giả sử bạn đặt kích thước lô của mỗi lô nhỏ thành 20. Do đó, mỗi lần lặp lại sẽ xác định mức tổn thất trên 20 ví dụ ngẫu nhiên trong số 1.000 ví dụ,sau đó điều chỉnh trọng số và độ lệch cho phù hợp.
Việc tính toán mức tổn thất trên một lô nhỏ hiệu quả hơn nhiều so với mức tổn thất trên tất cả các ví dụ trong lô đầy đủ.
Hãy xem phần Hồi quy tuyến tính: Siêu tham số trong Khoá học cấp tốc về học máy để biết thêm thông tin.
phương pháp giảm độ dốc ngẫu nhiên trên gói nhỏ
Thuật toán giảm độ dốc sử dụng các gói nhỏ. Nói cách khác, phương pháp giảm độ dốc ngẫu nhiên theo lô nhỏ sẽ ước tính độ dốc dựa trên một tập hợp con nhỏ của dữ liệu huấn luyện. Phương pháp giảm độ dốc ngẫu nhiên thông thường sử dụng một gói nhỏ có kích thước là 1.
mất mát minimax
Một hàm tổn thất cho mạng đối kháng sinh tạo, dựa trên cross-entropy giữa phân phối dữ liệu được tạo và dữ liệu thực.
Mất mát tối thiểu tối đa được sử dụng trong bài viết đầu tiên để mô tả mạng đối nghịch tạo sinh.
Hãy xem Hàm tổn thất trong khoá học Mạng sinh đối kháng để biết thêm thông tin.
nhóm thiểu số
Nhãn ít phổ biến hơn trong tập dữ liệu không cân bằng theo lớp. Ví dụ: cho một tập dữ liệu chứa 99% nhãn âm và 1% nhãn dương, nhãn dương là lớp thiểu số.
Tương phản với lớp đa số.
Hãy xem phần Tập dữ liệu: Tập dữ liệu không cân bằng trong Khoá học cấp tốc về học máy để biết thêm thông tin.
mixture of experts
Một lược đồ giúp tăng hiệu quả của mạng nơ-ron bằng cách chỉ sử dụng một tập hợp con các tham số (được gọi là chuyên gia) để xử lý một mã thông báo hoặc ví dụ đầu vào nhất định. Một mạng kiểm soát sẽ định tuyến từng mã thông báo hoặc ví dụ đầu vào đến(các) chuyên gia phù hợp.
Để biết thông tin chi tiết, hãy xem một trong hai bài viết sau:
- Mạng nơ-ron cực lớn: Lớp kết hợp các chuyên gia có cổng thưa thớt
- Mô hình Mixture-of-Experts với tính năng Định tuyến lựa chọn của chuyên gia
ML (Mali)
Từ viết tắt của học máy.
MMIT
Từ viết tắt của mô hình được tinh chỉnh bằng hướng dẫn đa phương thức.
MNIST
Một tập dữ liệu thuộc phạm vi công cộng do LeCun, Cortes và Burges biên soạn, chứa 60.000 hình ảnh, mỗi hình ảnh cho thấy cách một người viết thủ công một chữ số cụ thể từ 0 đến 9. Mỗi hình ảnh được lưu trữ dưới dạng một mảng số nguyên 28x28, trong đó mỗi số nguyên là một giá trị thang độ xám từ 0 đến 255.
MNIST là một tập dữ liệu chuẩn cho hoạt động học máy, thường được dùng để kiểm thử các phương pháp học máy mới. Để biết thông tin chi tiết, hãy xem Cơ sở dữ liệu MNIST về chữ số viết tay.
phương thức
Một danh mục dữ liệu cấp cao. Ví dụ: số, văn bản, hình ảnh, video và âm thanh là 5 phương thức khác nhau.
kiểu máy
Nói chung, bất kỳ cấu trúc toán học nào xử lý dữ liệu đầu vào và trả về đầu ra. Nói cách khác, mô hình là tập hợp các thông số và cấu trúc cần thiết để một hệ thống đưa ra dự đoán. Trong công nghệ học máy có giám sát, một mô hình sẽ lấy một ví dụ làm dữ liệu đầu vào và suy luận một dự đoán làm dữ liệu đầu ra. Trong học máy có giám sát, các mô hình có sự khác biệt nhất định. Ví dụ:
- Mô hình hồi quy tuyến tính bao gồm một tập hợp trọng số và một độ lệch.
- Mô hình mạng nơron bao gồm:
- Một tập hợp gồm các lớp ẩn, mỗi lớp chứa một hoặc nhiều nơ-ron.
- Trọng số và độ lệch liên kết với từng nơ-ron.
- Mô hình cây quyết định bao gồm:
- Hình dạng của cây; tức là mẫu mà các điều kiện và lá được kết nối.
- Các điều kiện và lá.
Bạn có thể lưu, khôi phục hoặc tạo bản sao của một mô hình.
Học máy không giám sát cũng tạo ra các mô hình, thường là một hàm có thể liên kết một ví dụ đầu vào với cụm phù hợp nhất.
dung lượng mô hình
Độ phức tạp của các vấn đề mà một mô hình có thể học được. Mô hình càng có thể học được nhiều vấn đề phức tạp thì năng lực của mô hình càng cao. Dung lượng của mô hình thường tăng lên theo số lượng tham số mô hình. Để biết định nghĩa chính thức về năng lực của mô hình phân loại, hãy xem phương diện VC.
mô hình xếp tầng
Một hệ thống chọn mô hình lý tưởng cho một truy vấn suy luận cụ thể.
Hãy tưởng tượng một nhóm các mô hình, từ rất lớn (nhiều tham số) đến nhỏ hơn nhiều (ít tham số hơn nhiều). Các mô hình rất lớn tiêu thụ nhiều tài nguyên điện toán hơn tại thời điểm suy luận so với các mô hình nhỏ hơn. Tuy nhiên, các mô hình rất lớn thường có thể suy luận các yêu cầu phức tạp hơn so với các mô hình nhỏ hơn. Việc xếp tầng mô hình xác định độ phức tạp của truy vấn suy luận, sau đó chọn mô hình phù hợp để thực hiện suy luận. Động lực chính cho việc xếp tầng mô hình là giảm chi phí suy luận bằng cách thường chọn các mô hình nhỏ hơn và chỉ chọn một mô hình lớn hơn cho các truy vấn phức tạp hơn.
Hãy tưởng tượng rằng một mô hình nhỏ chạy trên điện thoại và một phiên bản lớn hơn của mô hình đó chạy trên một máy chủ từ xa. Việc xếp tầng mô hình hiệu quả giúp giảm chi phí và độ trễ bằng cách cho phép mô hình nhỏ hơn xử lý các yêu cầu đơn giản và chỉ gọi mô hình từ xa để xử lý các yêu cầu phức tạp.
Xem thêm bộ định tuyến mô hình.
tính song song của mô hình
Một cách mở rộng quy mô huấn luyện hoặc suy luận bằng cách đặt các phần khác nhau của một mô hình trên các thiết bị khác nhau. Tính song song của mô hình cho phép các mô hình quá lớn để phù hợp với một thiết bị duy nhất.
Để triển khai tính song song của mô hình, hệ thống thường làm như sau:
- Phân mảnh (chia) mô hình thành các phần nhỏ hơn.
- Phân phối quá trình huấn luyện các phần nhỏ hơn đó trên nhiều bộ xử lý. Mỗi bộ xử lý sẽ huấn luyện phần riêng của mô hình.
- Kết hợp các kết quả để tạo một mô hình duy nhất.
Tính song song của mô hình làm chậm quá trình huấn luyện.
Xem thêm tính song song của dữ liệu.
bộ định tuyến mô hình
Thuật toán xác định mô hình lý tưởng cho suy luận trong phân tầng mô hình. Bản thân bộ định tuyến mô hình thường là một mô hình học máy, dần dần học cách chọn mô hình tốt nhất cho một dữ liệu đầu vào nhất định. Tuy nhiên, đôi khi bộ định tuyến mô hình có thể là một thuật toán đơn giản hơn, không phải thuật toán học máy.
huấn luyện mô hình
Quá trình xác định mô hình phù hợp nhất.
MOE
Từ viết tắt của mixture of experts (tạm dịch: hỗn hợp chuyên gia).
Đà phát triển
Một thuật toán hạ độ dốc phức tạp, trong đó bước học tập không chỉ phụ thuộc vào đạo hàm ở bước hiện tại mà còn phụ thuộc vào các đạo hàm của(các) bước ngay trước đó. Động lượng liên quan đến việc tính toán trung bình động có trọng số theo hàm mũ của các độ dốc theo thời gian, tương tự như động lượng trong vật lý. Đôi khi, động lượng giúp quá trình học không bị mắc kẹt ở mức tối thiểu cục bộ.
MT
Từ viết tắt của bản dịch máy.
phân loại đa mục
Trong học có giám sát, vấn đề phân loại trong đó tập dữ liệu chứa hơn hai lớp nhãn. Ví dụ: nhãn trong tập dữ liệu Iris phải là một trong 3 lớp sau:
- Iris setosa
- Iris virginica
- Iris versicolor
Một mô hình được huấn luyện trên tập dữ liệu Iris để dự đoán loại Iris trên các ví dụ mới đang thực hiện phân loại nhiều lớp.
Ngược lại, các vấn đề phân loại phân biệt chính xác giữa hai lớp là mô hình phân loại nhị phân. Ví dụ: mô hình email dự đoán thư rác hoặc không phải thư rác là mô hình phân loại nhị phân.
Trong các vấn đề về phân cụm, phân loại nhiều lớp đề cập đến hơn hai cụm.
Hãy xem phần Mạng nơ-ron: Phân loại nhiều lớp trong Khoá học cấp tốc về học máy để biết thêm thông tin.
hồi quy logistic đa lớp
Sử dụng hồi quy logistic trong các vấn đề phân loại đa mục.
cơ chế tự chú ý nhiều đầu
Một phần mở rộng của cơ chế tự chú ý. Cơ chế này áp dụng cơ chế tự chú ý nhiều lần cho mỗi vị trí trong chuỗi đầu vào.
Transformer đã giới thiệu cơ chế tự chú ý nhiều đầu.
được tinh chỉnh để đưa ra hướng dẫn đa phương thức
Một mô hình được tinh chỉnh theo chỉ dẫn có thể xử lý dữ liệu đầu vào ngoài văn bản, chẳng hạn như hình ảnh, video và âm thanh.
mô hình đa phương thức
Một mô hình có đầu vào, đầu ra hoặc cả hai bao gồm nhiều phương thức. Ví dụ: hãy xem xét một mô hình lấy cả hình ảnh và chú thích văn bản (hai phương thức) làm đặc điểm, đồng thời xuất ra điểm số cho biết mức độ phù hợp của chú thích văn bản với hình ảnh. Vì vậy, đầu vào của mô hình này là đa phương thức và đầu ra là đơn phương thức.
phân loại đa mục
Từ đồng nghĩa với phân loại đa mục.
hồi quy đa thức
Từ đồng nghĩa với hồi quy logistic đa lớp.
đa nhiệm
Một kỹ thuật học máy trong đó một mô hình duy nhất được huấn luyện để thực hiện nhiều tác vụ.
Các mô hình đa nhiệm được tạo bằng cách huấn luyện trên dữ liệu phù hợp với từng nhiệm vụ khác nhau. Điều này cho phép mô hình học cách chia sẻ thông tin giữa các tác vụ, giúp mô hình học tập hiệu quả hơn.
Một mô hình được huấn luyện cho nhiều tác vụ thường có khả năng tổng quát hoá tốt hơn và có thể mạnh mẽ hơn khi xử lý các loại dữ liệu khác nhau.
Không
Nano
Một mô hình Gemini tương đối nhỏ được thiết kế để sử dụng trên thiết bị. Hãy xem bài viết Gemini Nano để biết thông tin chi tiết.
Bẫy NaN
Khi một số trong mô hình của bạn trở thành NaN trong quá trình huấn luyện, điều này khiến nhiều hoặc tất cả các số khác trong mô hình của bạn cuối cùng trở thành NaN.
NaN là từ viết tắt của Not a Number (Không phải là số).
xử lý ngôn ngữ tự nhiên
Lĩnh vực dạy máy tính xử lý những gì người dùng nói hoặc nhập bằng cách sử dụng các quy tắc ngôn ngữ. Hầu hết các quy trình xử lý ngôn ngữ tự nhiên hiện đại đều dựa vào học máy.hiểu ngôn ngữ tự nhiên
Một phần của quy trình xử lý ngôn ngữ tự nhiên giúp xác định ý định của nội dung được nói hoặc nhập. Tính năng hiểu ngôn ngữ tự nhiên có thể vượt xa khả năng xử lý ngôn ngữ tự nhiên để xem xét các khía cạnh phức tạp của ngôn ngữ như ngữ cảnh, giọng điệu mỉa mai và tình cảm.
lớp âm
Trong phân loại nhị phân, một lớp được gọi là dương tính và lớp còn lại được gọi là âm tính. Lớp dương là đối tượng hoặc sự kiện mà mô hình đang kiểm thử và lớp âm là khả năng khác. Ví dụ:
- Lớp âm tính trong một xét nghiệm y tế có thể là "không phải khối u".
- Lớp âm trong mô hình phân loại email có thể là "không phải thư rác".
Tương phản với lớp dương.
lấy mẫu phủ định
Từ đồng nghĩa với lấy mẫu ứng viên.
Tìm kiếm kiến trúc nơ-ron (NAS)
Một kỹ thuật để tự động thiết kế cấu trúc của một mạng nơ-ron. Các thuật toán NAS có thể giảm lượng thời gian và tài nguyên cần thiết để huấn luyện một mạng nơ-ron.
NAS thường sử dụng:
- Không gian tìm kiếm, là một tập hợp các cấu trúc có thể có.
- Hàm phù hợp là một chỉ số đo lường hiệu suất của một cấu trúc cụ thể trong một nhiệm vụ nhất định.
Thuật toán NAS thường bắt đầu bằng một nhóm nhỏ các cấu trúc có thể và dần dần mở rộng không gian tìm kiếm khi thuật toán tìm hiểu thêm về những cấu trúc hiệu quả. Hàm phù hợp thường dựa trên hiệu suất của cấu trúc trên một tập hợp huấn luyện và thuật toán thường được huấn luyện bằng kỹ thuật học tăng cường.
Các thuật toán NAS đã chứng minh được hiệu quả trong việc tìm ra các cấu trúc có hiệu suất cao cho nhiều tác vụ, bao gồm cả phân loại hình ảnh, phân loại văn bản và dịch máy.
mạng nơ-ron
Một mô hình chứa ít nhất một lớp ẩn. Mạng nơ-ron sâu là một loại mạng nơ-ron có nhiều lớp ẩn. Ví dụ: sơ đồ sau đây cho thấy một mạng nơ-ron sâu chứa 2 lớp ẩn.
Mỗi nơ-ron trong mạng nơ-ron kết nối với tất cả các nút trong lớp tiếp theo. Ví dụ: trong sơ đồ trước đó, hãy lưu ý rằng mỗi trong số 3 nơ-ron ở lớp ẩn đầu tiên kết nối riêng biệt với cả 2 nơ-ron ở lớp ẩn thứ hai.
Mạng nơron được triển khai trên máy tính đôi khi được gọi là mạng nơron nhân tạo để phân biệt với mạng nơron có trong não và các hệ thần kinh khác.
Một số mạng nơ-ron có thể mô phỏng các mối quan hệ phi tuyến tính cực kỳ phức tạp giữa các đặc điểm và nhãn.
Xem thêm mạng nơron tích chập và mạng nơron hồi quy.
Hãy xem phần Mạng nơ-ron trong Khoá học học máy ứng dụng để biết thêm thông tin.
nơron
Trong học máy, một đơn vị riêng biệt trong lớp ẩn của một mạng nơ-ron. Mỗi nơ-ron thực hiện hành động gồm 2 bước sau:
- Tính tổng có trọng số của các giá trị đầu vào nhân với trọng số tương ứng.
- Truyền tổng có trọng số làm dữ liệu đầu vào cho một hàm kích hoạt.
Một nơ-ron trong lớp ẩn đầu tiên chấp nhận dữ liệu đầu vào từ các giá trị của đối tượng trong lớp đầu vào. Một nơ-ron trong bất kỳ lớp ẩn nào ngoài lớp đầu tiên sẽ chấp nhận dữ liệu đầu vào từ các nơ-ron trong lớp ẩn trước đó. Ví dụ: một nơ-ron trong lớp ẩn thứ hai chấp nhận dữ liệu đầu vào từ các nơ-ron trong lớp ẩn thứ nhất.
Hình minh hoạ sau đây làm nổi bật 2 nơ-ron và các đầu vào của chúng.
Một nơron trong mạng nơron mô phỏng hành vi của các nơron trong não và các bộ phận khác của hệ thần kinh.
N-gram
Một chuỗi có thứ tự gồm N từ. Ví dụ: truly madly là một 2-gram. Vì thứ tự có liên quan, nên madly truly là một 2-gram khác với truly madly.
| Không | (Các) tên cho loại N-gram này | Ví dụ |
|---|---|---|
| 2 | bigram hoặc 2-gram | đi, đi đến, ăn trưa, ăn tối |
| 3 | trigram hoặc 3-gram | ăn quá nhiều, trăm năm hạnh phúc, tiếng chuông ngân |
| 4 | 4 gam | walk in the park, dust in the wind, the boy ate lentils |
Nhiều mô hình hiểu ngôn ngữ tự nhiên dựa vào N-gram để dự đoán từ tiếp theo mà người dùng sẽ nhập hoặc nói. Ví dụ: giả sử người dùng nhập happily ever. Một mô hình NLU dựa trên trigram có thể dự đoán rằng người dùng sẽ nhập từ after (sau) tiếp theo.
So sánh N-gram với túi từ, là các tập hợp từ không có thứ tự.
Hãy xem Các mô hình ngôn ngữ lớn trong Khoá học học máy ứng dụng để biết thêm thông tin.
xử lý ngôn ngữ tự nhiên (NLP)
Từ viết tắt của xử lý ngôn ngữ tự nhiên.
hiểu ngôn ngữ tự nhiên (NLU)
Từ viết tắt của hiểu ngôn ngữ tự nhiên.
nút (cây quyết định)
Trong cây quyết định, bất kỳ điều kiện hoặc nút lá nào.
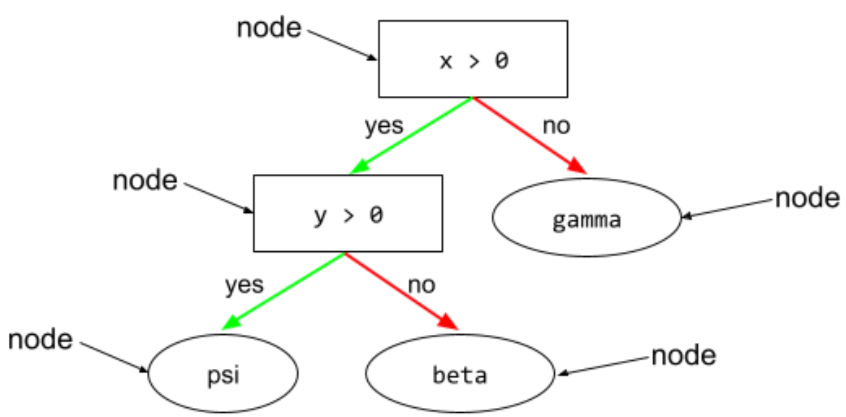
Hãy xem Cây quyết định trong khoá học Rừng quyết định để biết thêm thông tin.
nút (mạng nơron)
Hãy xem phần Mạng nơ-ron trong Khoá học học máy ứng dụng để biết thêm thông tin.
nút (biểu đồ TensorFlow)
Một thao tác trong biểu đồ TensorFlow.
độ nhiễu
Nói chung, mọi thứ làm che khuất tín hiệu trong một tập dữ liệu. Nhiễu có thể xuất hiện trong dữ liệu theo nhiều cách. Ví dụ:
- Nhân viên đánh giá có thể mắc lỗi khi gắn nhãn.
- Con người và thiết bị ghi sai hoặc bỏ sót các giá trị của đối tượng.
điều kiện phi nhị phân
Một điều kiện chứa nhiều hơn 2 kết quả có thể xảy ra. Ví dụ: điều kiện không phải nhị phân sau đây có 3 kết quả có thể xảy ra:
Hãy xem Các loại điều kiện trong khoá học Rừng quyết định để biết thêm thông tin.
phi tuyến tính
Mối quan hệ giữa hai hoặc nhiều biến không thể chỉ được biểu thị thông qua phép cộng và phép nhân. Mối quan hệ tuyến tính có thể được biểu thị dưới dạng một đường thẳng; mối quan hệ phi tuyến tính không thể được biểu thị dưới dạng một đường thẳng. Ví dụ: hãy xem xét 2 mô hình, mỗi mô hình liên kết một tính năng duy nhất với một nhãn duy nhất. Mô hình bên trái là tuyến tính và mô hình bên phải là phi tuyến tính:

Hãy xem phần Mạng nơ-ron: Các nút và lớp ẩn trong Khoá học cấp tốc về học máy để thử nghiệm nhiều loại hàm phi tuyến tính.
thiên kiến do thiếu hồi âm
Xem phần thiên vị do cách chọn mẫu.
nonstationarity
Một đối tượng có giá trị thay đổi theo một hoặc nhiều phương diện, thường là thời gian. Ví dụ: hãy xem xét các ví dụ sau về tính không dừng:
- Số lượng đồ bơi được bán tại một cửa hàng cụ thể sẽ thay đổi theo mùa.
- Số lượng một loại trái cây cụ thể được thu hoạch ở một khu vực cụ thể là 0 trong phần lớn thời gian của năm nhưng lại rất lớn trong một khoảng thời gian ngắn.
- Do biến đổi khí hậu, nhiệt độ trung bình hằng năm đang thay đổi.
Tương phản với tính dừng.
không có câu trả lời nào đúng (NORA)
Một câu lệnh có nhiều phản hồi chính xác. Ví dụ: câu lệnh sau đây không có câu trả lời nào đúng:
Kể cho tôi nghe một chuyện cười hài hước về voi.
Đánh giá câu trả lời cho những lời nhắc không có câu trả lời đúng duy nhất thường mang tính chủ quan hơn nhiều so với việc đánh giá những lời nhắc có một câu trả lời đúng duy nhất. Ví dụ: để đánh giá một câu chuyện cười về con voi, bạn cần có một cách thức có hệ thống để xác định mức độ hài hước của câu chuyện đó.
NORA
Viết tắt của không có câu trả lời đúng.
chuẩn hoá
Nói chung, quy trình chuyển đổi phạm vi giá trị thực tế của một biến thành phạm vi giá trị tiêu chuẩn, chẳng hạn như:
- -1 đến +1
- 0 đến 1
- Điểm Z (từ -3 đến +3)
Ví dụ: giả sử phạm vi giá trị thực của một tính năng nhất định là từ 800 đến 2.400. Trong quá trình thiết kế tính năng, bạn có thể chuẩn hoá các giá trị thực xuống một phạm vi tiêu chuẩn, chẳng hạn như từ -1 đến +1.
Chuẩn hoá là một nhiệm vụ phổ biến trong kỹ thuật trích xuất đặc điểm. Các mô hình thường huấn luyện nhanh hơn (và đưa ra dự đoán chính xác hơn) khi mọi đặc điểm số trong vectơ đặc điểm có phạm vi gần như giống nhau.
Xem thêm Chuẩn hoá điểm Z.
Hãy xem phần Dữ liệu dạng số: Chuẩn hoá trong Khoá học cấp tốc về học máy để biết thêm thông tin.
Notebook LM
Một công cụ dựa trên Gemini cho phép người dùng tải tài liệu lên rồi dùng câu lệnh để đặt câu hỏi, tóm tắt hoặc sắp xếp những tài liệu đó. Ví dụ: một tác giả có thể tải nhiều truyện ngắn lên và yêu cầu NotebookLM tìm ra các chủ đề chung hoặc xác định truyện nào sẽ phù hợp nhất để làm phim.
phát hiện nội dung mới
Quy trình xác định xem một ví dụ mới (chưa từng có) có đến từ cùng một bản phân phối như tập huấn luyện hay không. Nói cách khác, sau khi huấn luyện trên tập huấn luyện, tính năng phát hiện điểm bất thường sẽ xác định xem một ví dụ mới (trong quá trình suy luận hoặc trong quá trình huấn luyện bổ sung) có phải là giá trị ngoại lệ hay không.
Tương phản với phát hiện dữ liệu ngoại lai.
dữ liệu dạng số
Đối tượng được biểu thị dưới dạng số nguyên hoặc số thực. Ví dụ: mô hình định giá nhà có thể biểu thị quy mô của một ngôi nhà (tính bằng feet vuông hoặc mét vuông) dưới dạng dữ liệu dạng số. Việc biểu thị một đối tượng dưới dạng dữ liệu số cho biết rằng các giá trị của đối tượng có mối quan hệ toán học với nhãn. Tức là số mét vuông trong một ngôi nhà có thể có mối quan hệ toán học nào đó với giá trị của ngôi nhà.
Không phải tất cả dữ liệu số nguyên đều phải được biểu thị dưới dạng dữ liệu dạng số. Ví dụ: mã bưu chính ở một số nơi trên thế giới là số nguyên; tuy nhiên, mã bưu chính số nguyên không được biểu thị dưới dạng dữ liệu dạng số trong các mô hình. Điều này là do mã bưu chính 20000 không có hiệu quả gấp đôi (hoặc bằng một nửa) so với mã bưu chính 10000. Hơn nữa, mặc dù các mã bưu chính khác nhau có tương quan với các giá trị bất động sản khác nhau, nhưng chúng ta không thể giả định rằng giá trị bất động sản tại mã bưu chính 20000 có giá trị gấp đôi so với giá trị bất động sản tại mã bưu chính 10000.
Thay vào đó, bạn nên trình bày mã bưu chính dưới dạng dữ liệu phân loại.
Các đặc điểm bằng số đôi khi được gọi là đặc điểm liên tục.
Hãy xem phần Làm việc với dữ liệu dạng số trong Khoá học cấp tốc về học máy để biết thêm thông tin.
NumPy
Thư viện toán học nguồn mở cung cấp các thao tác hiệu quả trên mảng trong Python. pandas được xây dựng trên NumPy.
O
mục tiêu
Một chỉ số mà thuật toán của bạn đang cố gắng tối ưu hoá.
hàm mục tiêu
Công thức toán học hoặc chỉ số mà một mô hình hướng đến việc tối ưu hoá. Ví dụ: hàm mục tiêu cho hồi quy tuyến tính thường là Mất mát bình phương trung bình. Do đó, khi huấn luyện mô hình hồi quy tuyến tính, quá trình huấn luyện nhằm mục đích giảm thiểu Mất mát bình phương trung bình.
Trong một số trường hợp, mục tiêu là tối đa hoá hàm mục tiêu. Ví dụ: nếu hàm mục tiêu là độ chính xác, thì mục tiêu là tối đa hoá độ chính xác.
Xem thêm tổn thất.
điều kiện xiên
Trong cây quyết định, điều kiện liên quan đến nhiều đặc điểm. Ví dụ: nếu chiều cao và chiều rộng đều là các đặc điểm, thì sau đây là điều kiện xiên:
height > width
Tương phản với điều kiện căn chỉnh theo trục.
Hãy xem Các loại điều kiện trong khoá học Rừng quyết định để biết thêm thông tin.
ngoại tuyến
Từ đồng nghĩa với static.
suy luận ngoại tuyến
Quy trình tạo một lô dự đoán của mô hình, sau đó lưu các dự đoán đó vào bộ nhớ đệm. Sau đó, các ứng dụng có thể truy cập vào dự đoán suy luận từ bộ nhớ đệm thay vì chạy lại mô hình.
Ví dụ: hãy xem xét một mô hình tạo thông tin dự báo thời tiết tại địa phương (dữ liệu dự đoán) mỗi 4 giờ một lần. Sau mỗi lần chạy mô hình, hệ thống sẽ lưu vào bộ nhớ đệm tất cả thông tin dự báo thời tiết địa phương. Các ứng dụng thời tiết truy xuất thông tin dự báo từ bộ nhớ đệm.
Suy luận ngoại tuyến còn được gọi là suy luận tĩnh.
Tương phản với suy luận trực tuyến. Hãy xem bài viết Hệ thống ML trong sản xuất: Suy luận tĩnh so với suy luận động trong Khoá học cấp tốc về học máy để biết thêm thông tin.
mã hoá one-hot
Biểu thị dữ liệu phân loại dưới dạng một vectơ trong đó:
- Một phần tử được đặt thành 1.
- Tất cả các phần tử khác được đặt thành 0.
Mã hoá một lần thường được dùng để biểu thị các chuỗi hoặc giá trị nhận dạng có một tập hợp hữu hạn các giá trị có thể.
Ví dụ: giả sử một tính năng phân loại nhất định có tên là Scandinavia có 5 giá trị có thể có:
- "Đan Mạch"
- "Thuỵ Điển"
- "Na Uy"
- "Phần Lan"
- "Iceland"
Phương pháp mã hoá one-hot có thể biểu thị từng giá trị trong số 5 giá trị như sau:
| Quốc gia | Vectơ | ||||
|---|---|---|---|---|---|
| "Đan Mạch" | 1 | 0 | 0 | 0 | 0 |
| "Thuỵ Điển" | 0 | 1 | 0 | 0 | 0 |
| "Na Uy" | 0 | 0 | 1 | 0 | 0 |
| "Phần Lan" | 0 | 0 | 0 | 1 | 0 |
| "Iceland" | 0 | 0 | 0 | 0 | 1 |
Nhờ phương pháp mã hoá một lần, mô hình có thể tìm hiểu các mối liên kết khác nhau dựa trên từng quốc gia trong số 5 quốc gia.
Biểu thị một đối tượng dưới dạng dữ liệu số là một lựa chọn thay thế cho mã hoá one-hot. Rất tiếc, việc biểu thị các quốc gia Bắc Âu bằng số không phải là một lựa chọn hay. Ví dụ: hãy xem xét biểu diễn bằng số sau đây:
- "Đan Mạch" là 0
- "Thuỵ Điển" là 1
- "Na Uy" là 2
- "Phần Lan" là 3
- "Iceland" là 4
Với phương pháp mã hoá bằng số, mô hình sẽ diễn giải các con số thô về mặt toán học và cố gắng huấn luyện dựa trên những con số đó. Tuy nhiên, Iceland không thực sự gấp đôi (hoặc bằng một nửa) một thứ gì đó so với Na Uy, vì vậy, mô hình sẽ đưa ra một số kết luận kỳ lạ.
Hãy xem Dữ liệu phân loại: Từ vựng và mã hoá một lần nóng trong Khoá học cấp tốc về học máy để biết thêm thông tin.
một câu trả lời đúng (ORA)
Một câu lệnh có một phản hồi chính xác. Ví dụ: hãy xem xét câu lệnh sau:
Đúng hay sai: Sao Thổ lớn hơn sao Hoả.
Câu trả lời đúng duy nhất là đúng.
Tương phản với không có câu trả lời đúng.
học từ một dữ liệu
Một phương pháp học máy, thường được dùng để phân loại đối tượng, được thiết kế để tìm hiểu mô hình phân loại hiệu quả từ một ví dụ huấn luyện duy nhất.
Xem thêm học từ một vài dữ liệu và học từ không có dữ liệu.
đặt câu lệnh kèm một ví dụ
Một câu lệnh chứa một ví dụ minh hoạ cách mô hình ngôn ngữ lớn nên phản hồi. Ví dụ: câu lệnh sau đây chứa một ví dụ cho thấy cách mô hình ngôn ngữ lớn nên trả lời một truy vấn.
| Các phần của một câu lệnh | Ghi chú |
|---|---|
| Đơn vị tiền tệ chính thức của quốc gia được chỉ định là gì? | Câu hỏi bạn muốn LLM trả lời. |
| Pháp: EUR | Một ví dụ. |
| Ấn Độ: | Cụm từ tìm kiếm thực tế. |
So sánh và đối chiếu câu lệnh một lần với các thuật ngữ sau:
một-với-tất-cả
Với một vấn đề phân loại có N lớp, một giải pháp bao gồm N mô hình phân loại nhị phân riêng biệt – một mô hình phân loại nhị phân cho mỗi kết quả có thể xảy ra. Ví dụ: cho một mô hình phân loại các ví dụ là động vật, thực vật hoặc khoáng chất, giải pháp một chọi tất cả sẽ cung cấp 3 mô hình phân loại nhị phân riêng biệt sau đây:
- động vật so với không phải động vật
- rau củ so với không phải rau củ
- khoáng chất so với không phải khoáng chất
trực tuyến
Từ đồng nghĩa với linh động.
suy luận trực tuyến
Tạo dự đoán theo yêu cầu. Ví dụ: giả sử một ứng dụng truyền dữ liệu đầu vào đến một mô hình và đưa ra yêu cầu dự đoán. Một hệ thống sử dụng suy luận trực tuyến sẽ phản hồi yêu cầu bằng cách chạy mô hình (và trả về kết quả dự đoán cho ứng dụng).
Tương phản với suy luận ngoại tuyến.
Hãy xem bài viết Hệ thống ML trong sản xuất: Suy luận tĩnh so với suy luận động trong Khoá học cấp tốc về học máy để biết thêm thông tin.
thao tác (op)
Trong TensorFlow, mọi quy trình tạo, thao tác hoặc huỷ Tensor. Ví dụ: phép nhân ma trận là một thao tác lấy 2 Tensor làm đầu vào và tạo ra 1 Tensor làm đầu ra.
Optax
Một thư viện xử lý và tối ưu hoá độ dốc cho JAX. Optax hỗ trợ nghiên cứu bằng cách cung cấp các khối xây dựng có thể kết hợp lại theo cách tuỳ chỉnh để tối ưu hoá các mô hình tham số như mạng nơ-ron sâu. Các mục tiêu khác bao gồm:
- Cung cấp các cách triển khai dễ đọc, được kiểm thử kỹ lưỡng và hiệu quả cho các thành phần cốt lõi.
- Cải thiện năng suất bằng cách cho phép kết hợp các thành phần cấp thấp thành các trình tối ưu hoá tuỳ chỉnh (hoặc các thành phần xử lý độ dốc khác).
- Đẩy nhanh việc áp dụng các ý tưởng mới bằng cách giúp mọi người dễ dàng đóng góp.
optimizer
Một cách triển khai cụ thể của thuật toán giảm độ dốc. Các trình tối ưu hoá phổ biến bao gồm:
- AdaGrad, viết tắt của ADAptive GRADient descent (hạ độ dốc thích ứng).
- Adam, viết tắt của ADAptive with Momentum (Thích ứng theo đà).
ORA
Chữ viết tắt của một câu trả lời đúng.
thiên kiến đồng nhất ngoài nhóm
Xu hướng coi các thành viên bên ngoài nhóm là giống nhau hơn so với các thành viên trong nhóm khi so sánh thái độ, giá trị, đặc điểm tính cách và các đặc điểm khác. Trong nhóm là những người bạn thường xuyên tương tác; ngoài nhóm là những người bạn không thường xuyên tương tác. Nếu bạn tạo một tập dữ liệu bằng cách yêu cầu mọi người cung cấp các thuộc tính về nhóm bên ngoài, thì những thuộc tính đó có thể ít tinh tế hơn và mang tính rập khuôn hơn so với các thuộc tính mà người tham gia liệt kê cho những người trong nhóm của họ.
Ví dụ: Người Lilliput có thể mô tả nhà của những người Lilliput khác một cách chi tiết, nêu rõ những điểm khác biệt nhỏ về phong cách kiến trúc, cửa sổ, cửa ra vào và kích thước. Tuy nhiên, những người Lilliput tương tự có thể chỉ đơn giản tuyên bố rằng tất cả người Brobdingnag đều sống trong những ngôi nhà giống hệt nhau.
Thiên vị đồng nhất ngoài nhóm là một dạng thiên vị quy cho nhóm.
Xem thêm thiên vị cùng nhóm.
phát hiện giá trị ngoại lệ
Quá trình xác định các giá trị ngoại lệ trong tập huấn luyện.
Tương phản với tính năng phát hiện điểm mới lạ.
các điểm ngoại lai
Giá trị khác biệt so với hầu hết các giá trị khác. Trong học máy, bất kỳ điểm nào sau đây đều là giá trị ngoại lệ:
- Dữ liệu đầu vào có giá trị lớn hơn khoảng 3 độ lệch chuẩn so với giá trị trung bình.
- Trọng số có giá trị tuyệt đối cao.
- Giá trị dự đoán tương đối khác xa so với giá trị thực tế.
Ví dụ: giả sử widget-price là một tính năng của một mô hình nhất định.
Giả sử giá trị trung bình widget-price là 7 Euro với độ lệch chuẩn là 1 Euro. Do đó, những ví dụ có widget-price là 12 EUR hoặc 2 EUR sẽ được coi là giá trị ngoại lệ vì mỗi mức giá đó đều có độ lệch chuẩn là 5 so với giá trị trung bình.
Giá trị ngoại lệ thường là do lỗi chính tả hoặc các lỗi nhập liệu khác. Trong những trường hợp khác, giá trị ngoại lệ không phải là lỗi; xét cho cùng, các giá trị có độ lệch chuẩn gấp 5 lần so với giá trị trung bình là rất hiếm nhưng không phải là không thể.
Giá trị ngoại lệ thường gây ra vấn đề trong quá trình huấn luyện mô hình. Cắt bớt là một cách để quản lý giá trị ngoại lệ.
Hãy xem phần Làm việc với dữ liệu dạng số trong Khoá học cấp tốc về học máy để biết thêm thông tin.
đánh giá ngoài túi (đánh giá OOB)
Một cơ chế để đánh giá chất lượng của rừng quyết định bằng cách kiểm thử từng cây quyết định dựa trên các ví dụ không được dùng trong quá trình huấn luyện cây quyết định đó. Ví dụ: trong biểu đồ sau, hãy lưu ý rằng hệ thống huấn luyện từng cây quyết định trên khoảng 2/3 số ví dụ, sau đó đánh giá dựa trên 1/3 số ví dụ còn lại.
Đánh giá ngoài mẫu là một phương pháp tính toán hiệu quả và thận trọng để ước tính cơ chế xác thực chéo. Trong quy trình xác thực chéo, một mô hình sẽ được huấn luyện cho mỗi vòng xác thực chéo (ví dụ: 10 mô hình được huấn luyện trong quy trình xác thực chéo 10 lần). Với hoạt động đánh giá OOB, một mô hình duy nhất sẽ được huấn luyện. Vì phương pháp lấy mẫu lại giữ lại một số dữ liệu của mỗi cây trong quá trình huấn luyện, nên việc đánh giá OOB có thể sử dụng dữ liệu đó để ước tính phương pháp xác thực chéo.
Hãy xem phần Đánh giá ngoài túi trong khoá học Rừng quyết định để biết thêm thông tin.
lớp đầu ra
Lớp "cuối cùng" của mạng nơ-ron. Lớp đầu ra chứa thông tin dự đoán.
Hình minh hoạ sau đây cho thấy một mạng nơ-ron sâu nhỏ có một lớp đầu vào, hai lớp ẩn và một lớp đầu ra:
khái quát hoá kém
Tạo một mô hình khớp với dữ liệu huấn luyện quá sát sao đến mức mô hình không thể đưa ra dự đoán chính xác về dữ liệu mới.
Điều chỉnh có thể giảm tình trạng khớp quá mức. Việc huấn luyện trên một bộ dữ liệu huấn luyện lớn và đa dạng cũng có thể giảm tình trạng khớp quá mức.
Hãy xem phần Quá khớp trong Khoá học học máy ứng dụng để biết thêm thông tin.
lấy mẫu dư
Sử dụng lại ví dụ về một lớp thiểu số trong tập dữ liệu bất cân đối về loại để tạo tập huấn luyện cân bằng hơn.
Ví dụ: hãy xem xét một vấn đề phân loại nhị phân trong đó tỷ lệ lớp đa số so với lớp thiểu số là 5.000:1. Nếu tập dữ liệu chứa một triệu ví dụ, thì tập dữ liệu chỉ chứa khoảng 200 ví dụ về lớp thiểu số. Đây có thể là quá ít ví dụ để huấn luyện hiệu quả. Để khắc phục điểm thiếu hụt này, bạn có thể lấy mẫu quá mức (sử dụng lại) 200 ví dụ đó nhiều lần, có thể tạo ra đủ ví dụ để huấn luyện hữu ích.
Bạn cần cẩn thận về việc khớp quá mức khi lấy mẫu quá mức.
Tương phản với lấy mẫu dưới mức.
Điểm
dữ liệu được đóng gói
Một phương pháp lưu trữ dữ liệu hiệu quả hơn.
Dữ liệu được đóng gói lưu trữ dữ liệu bằng cách sử dụng định dạng nén hoặc theo một cách khác cho phép truy cập hiệu quả hơn. Dữ liệu được đóng gói giúp giảm thiểu lượng bộ nhớ và hoạt động tính toán cần thiết để truy cập vào dữ liệu đó, dẫn đến quá trình huấn luyện nhanh hơn và suy luận mô hình hiệu quả hơn.
Dữ liệu được đóng gói thường được dùng với các kỹ thuật khác, chẳng hạn như tăng cường dữ liệu và điều chỉnh, giúp cải thiện hơn nữa hiệu suất của các mô hình.
PaLM
Từ viết tắt của Mô hình ngôn ngữ Pathways.
gấu trúc
Một API phân tích dữ liệu theo cột được xây dựng dựa trên numpy. Nhiều khung máy học, bao gồm cả TensorFlow, hỗ trợ cấu trúc dữ liệu pandas làm dữ liệu đầu vào. Hãy xem tài liệu về pandas để biết thông tin chi tiết.
tham số
Trọng số và độ lệch mà một mô hình học được trong quá trình huấn luyện. Ví dụ: trong mô hình hồi quy tuyến tính, các tham số bao gồm độ lệch (b) và tất cả các trọng số (w1, w2, v.v.) trong công thức sau:
Ngược lại, siêu tham số là những giá trị mà bạn (hoặc dịch vụ điều chỉnh siêu tham số) cung cấp cho mô hình. Ví dụ: tốc độ học tập là một siêu tham số.
điều chỉnh hiệu quả về tham số
Một tập hợp các kỹ thuật để điều chỉnh một mô hình ngôn ngữ được huấn luyện trước (PLM) lớn một cách hiệu quả hơn so với việc điều chỉnh toàn bộ. Việc tinh chỉnh hiệu quả về tham số thường tinh chỉnh ít tham số hơn nhiều so với việc tinh chỉnh toàn bộ, nhưng thường tạo ra một mô hình ngôn ngữ lớn hoạt động tốt (hoặc gần như tốt) như một mô hình ngôn ngữ lớn được xây dựng từ việc tinh chỉnh toàn bộ.
So sánh và đối chiếu phương pháp tinh chỉnh hiệu quả về tham số với:
Phương pháp điều chỉnh hiệu quả về tham số còn được gọi là điều chỉnh tinh vi hiệu quả về tham số.
Parameter Server (PS)
Một công việc theo dõi các tham số của mô hình trong một chế độ cài đặt phân tán.
cập nhật tham số
Thao tác điều chỉnh tham số của mô hình trong quá trình huấn luyện, thường là trong một lần lặp lại của phương pháp hạ độ dốc.
đạo hàm riêng
Một đạo hàm trong đó tất cả các biến, trừ một biến, được coi là hằng số. Ví dụ: đạo hàm riêng của f(x, y) đối với x là đạo hàm của f được coi là một hàm chỉ của x (tức là giữ y không đổi). Đạo hàm riêng của f theo x chỉ tập trung vào cách x thay đổi và bỏ qua tất cả các biến khác trong phương trình.
thiên kiến tham gia
Từ đồng nghĩa với thiên vị do thiếu hồi âm. Xem phần thiên vị do cách chọn mẫu.
chiến lược phân vùng
Thuật toán mà theo đó các biến được chia trên các máy chủ tham số.
pass at k (pass@k)
Một chỉ số để xác định chất lượng mã (ví dụ: Python) mà mô hình ngôn ngữ lớn tạo ra. Cụ thể hơn, pass ở k cho biết khả năng ít nhất một khối mã được tạo trong số k khối mã được tạo sẽ vượt qua tất cả các kiểm thử đơn vị.
Các mô hình ngôn ngữ lớn thường gặp khó khăn trong việc tạo mã tốt cho các vấn đề lập trình phức tạp. Các kỹ sư phần mềm thích ứng với vấn đề này bằng cách nhắc mô hình ngôn ngữ lớn tạo ra nhiều (k) giải pháp cho cùng một vấn đề. Sau đó, các kỹ sư phần mềm sẽ kiểm thử từng giải pháp dựa trên các kiểm thử đơn vị. Việc tính toán số lượt vượt qua ở k phụ thuộc vào kết quả của các kiểm thử đơn vị:
- Nếu một hoặc nhiều giải pháp trong số đó vượt qua kiểm thử đơn vị, thì LLM sẽ Vượt qua thử thách tạo mã đó.
- Nếu không có giải pháp nào vượt qua được quy trình kiểm thử đơn vị, thì LLM sẽ Không thành công trong thử thách tạo mã đó.
Công thức cho lượt chuyền ở k như sau:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
Nhìn chung, các giá trị k cao hơn sẽ tạo ra điểm vượt qua k cao hơn; tuy nhiên, các giá trị k cao hơn đòi hỏi nhiều mô hình ngôn ngữ lớn và tài nguyên kiểm thử đơn vị hơn.
Mô hình ngôn ngữ Pathways (PaLM)
Một mô hình cũ và là mô hình tiền nhiệm của các mô hình Gemini.
Pax
Một khung lập trình được thiết kế để huấn luyện mạng nơron mô hình quy mô lớn đến mức chúng trải rộng trên nhiều TPU chip tăng tốc lát hoặc nhóm.
Pax được xây dựng dựa trên Flax, được xây dựng dựa trên JAX.
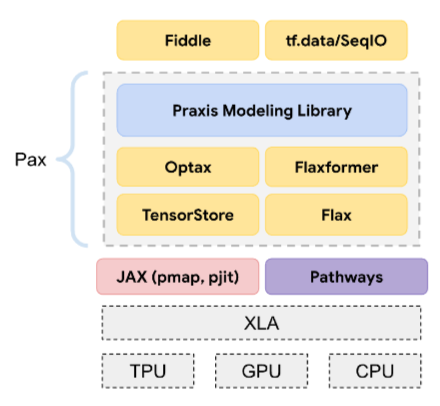
perceptron
Một hệ thống (phần cứng hoặc phần mềm) nhận một hoặc nhiều giá trị đầu vào, chạy một hàm trên tổng có trọng số của các đầu vào và tính toán một giá trị đầu ra duy nhất. Trong học máy, hàm này thường là hàm phi tuyến tính, chẳng hạn như ReLU, sigmoid hoặc tanh. Ví dụ: perceptron sau đây dựa vào hàm sigmoid để xử lý 3 giá trị đầu vào:
Trong hình minh hoạ sau, perceptron nhận 3 đầu vào, mỗi đầu vào được sửa đổi bằng một trọng số trước khi đi vào perceptron:

Perceptron là nơron trong mạng nơron.
hiệu quả hoạt động
Thuật ngữ bị nạp chồng với các ý nghĩa sau:
- Ý nghĩa tiêu chuẩn trong kỹ thuật phần mềm. Cụ thể: Phần mềm này chạy nhanh (hoặc hiệu quả) như thế nào?
- Ý nghĩa trong công nghệ học máy. Ở đây, hiệu suất trả lời câu hỏi sau: Mô hình này chính xác đến mức nào? Tức là mức độ chính xác của thông tin dự đoán do mô hình đưa ra.
mức độ quan trọng của biến hoán vị
Một loại mức độ quan trọng của biến đánh giá mức tăng lỗi dự đoán của một mô hình sau khi hoán vị các giá trị của đối tượng. Mức độ quan trọng của biến hoán vị là một chỉ số độc lập với mô hình.
độ hỗn loạn
Một chỉ số đo lường mức độ hoàn thành nhiệm vụ của mô hình. Ví dụ: giả sử nhiệm vụ của bạn là đọc một vài chữ cái đầu tiên của một từ mà người dùng đang nhập trên bàn phím điện thoại và đưa ra danh sách các từ có thể hoàn thành. Độ phức tạp (P) cho tác vụ này xấp xỉ số lượng các từ bạn cần đoán để danh sách của bạn chứa từ thực tế mà người dùng đang cố gắng nhập.
Độ phức tạp có liên quan đến cross-entropy như sau:
pipeline
Cơ sở hạ tầng xung quanh một thuật toán học máy. Một quy trình bao gồm việc thu thập dữ liệu, đưa dữ liệu vào các tệp dữ liệu huấn luyện, huấn luyện một hoặc nhiều mô hình và xuất các mô hình đó sang giai đoạn sản xuất.
Hãy xem phần Các quy trình học máy trong khoá học Quản lý dự án học máy để biết thêm thông tin.
pipelining
Một dạng song song hoá mô hình trong đó quá trình xử lý của mô hình được chia thành các giai đoạn liên tiếp và mỗi giai đoạn được thực thi trên một thiết bị riêng. Trong khi một giai đoạn đang xử lý một lô, giai đoạn trước đó có thể xử lý lô tiếp theo.
Xem thêm đào tạo theo giai đoạn.
pjit
Một hàm JAX phân tách mã để chạy trên nhiều chip tăng tốc. Người dùng truyền một hàm đến pjit, hàm này sẽ trả về một hàm có ngữ nghĩa tương đương nhưng được biên dịch thành một phép tính XLA chạy trên nhiều thiết bị (chẳng hạn như GPU hoặc các lõi TPU).
pjit cho phép người dùng phân chia các phép tính mà không cần viết lại chúng bằng cách sử dụng trình phân vùng SPMD.
Kể từ tháng 3 năm 2023, pjit đã được hợp nhất với jit. Hãy tham khảo bài viết Mảng phân tán và tính năng song song hoá tự động để biết thêm thông tin chi tiết.
PLM
Từ viết tắt của mô hình ngôn ngữ được huấn luyện trước.
pmap
Một hàm JAX thực thi các bản sao của một hàm đầu vào trên nhiều thiết bị phần cứng cơ bản (CPU, GPU hoặc TPU), với các giá trị đầu vào khác nhau. pmap dựa vào SPMD.
policy
Trong học tăng cường, ánh xạ xác suất của tác nhân từ trạng thái đến hành động.
pooling
Giảm ma trận (hoặc các ma trận) do lớp tích chập trước đó tạo thành một ma trận nhỏ hơn. Việc gộp thường liên quan đến việc lấy giá trị tối đa hoặc trung bình trên toàn bộ khu vực được gộp. Ví dụ: giả sử chúng ta có ma trận 3x3 sau:
![Ma trận 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?authuser=9&hl=vi)
Một thao tác gộp, giống như một thao tác tích chập, chia ma trận đó thành các lát rồi trượt thao tác tích chập đó theo bước sải. Ví dụ: giả sử thao tác gộp chia ma trận tích chập thành các lát 2x2 với bước sải là 1x1. Như minh hoạ trong sơ đồ sau, có 4 thao tác gộp xảy ra. Giả sử mỗi thao tác gộp chọn giá trị tối đa trong 4 giá trị của lát đó:
![Ma trận đầu vào là 3x3 với các giá trị: [[5,3,1], [8,2,5], [9,4,3]].
Ma trận con 2x2 ở trên cùng bên trái của ma trận đầu vào là [[5,3], [8,2]], vì vậy, thao tác gộp ở trên cùng bên trái sẽ cho ra giá trị 8 (là giá trị tối đa của 5, 3, 8 và 2). Ma trận con 2x2 ở trên cùng bên phải của ma trận đầu vào là [[3,1], [2,5]], nên thao tác gộp ở trên cùng bên phải sẽ cho ra giá trị 5. Ma trận con 2x2 ở dưới cùng bên trái của ma trận đầu vào là [[8,2], [9,4]], vì vậy, thao tác gộp ở dưới cùng bên trái sẽ cho ra giá trị 9. Ma trận con 2x2 dưới cùng bên phải của ma trận đầu vào là [[2,5], [4,3]], vì vậy, thao tác gộp dưới cùng bên phải sẽ cho ra giá trị 5. Tóm lại, thao tác gộp tạo ra ma trận 2x2 [[8,5], [9,5]].](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?authuser=9&hl=vi)
Gộp nhóm giúp thực thi tính bất biến tịnh tiến trong ma trận đầu vào.
Gộp cho các ứng dụng thị giác được gọi chính thức hơn là gộp không gian. Các ứng dụng chuỗi thời gian thường gọi việc gộp là gộp theo thời gian. Nói một cách ít trang trọng hơn, gộp thường được gọi là lấy mẫu phụ hoặc giảm mẫu.
Xem phần Giới thiệu về mạng nơ-ron tích chập trong khoá học Thực hành về học máy: Phân loại hình ảnh.
mã hoá vị trí
Một kỹ thuật để thêm thông tin về vị trí của một mã thông báo trong một chuỗi vào quá trình nhúng mã thông báo. Mô hình biến đổi sử dụng phương pháp mã hoá vị trí để hiểu rõ hơn mối quan hệ giữa các phần khác nhau của chuỗi.
Một cách triển khai phổ biến của mã hoá vị trí là sử dụng hàm hình sin. (Cụ thể, tần số và biên độ của hàm hình sin được xác định bằng vị trí của mã thông báo trong chuỗi.) Kỹ thuật này cho phép mô hình Transformer học cách chú ý đến các phần khác nhau của chuỗi dựa trên vị trí của chúng.
lớp dương
Lớp học mà bạn đang kiểm thử.
Ví dụ: lớp dương tính trong mô hình ung thư có thể là "khối u". Lớp dương tính trong mô hình phân loại email có thể là "thư rác".
Tương phản với lớp âm.
hậu xử lý
Điều chỉnh đầu ra của một mô hình sau khi mô hình đó đã chạy. Bạn có thể sử dụng quy trình xử lý hậu kỳ để thực thi các ràng buộc về tính công bằng mà không cần sửa đổi chính các mô hình.
Ví dụ: người ta có thể áp dụng quy trình xử lý hậu kỳ cho một mô hình phân loại nhị phân bằng cách đặt một ngưỡng phân loại sao cho tính bình đẳng về cơ hội được duy trì cho một số thuộc tính bằng cách kiểm tra để đảm bảo rằng tỷ lệ dương tính thực là như nhau đối với tất cả các giá trị của thuộc tính đó.
mô hình được huấn luyện sau
Thuật ngữ được định nghĩa một cách chung chung, thường dùng để chỉ một mô hình được huấn luyện trước đã trải qua một số bước xử lý hậu kỳ, chẳng hạn như một hoặc nhiều bước sau:
AUC PR (diện tích dưới đường cong PR)
Diện tích dưới đường cong độ chính xác-khả năng thu hồi được nội suy, thu được bằng cách vẽ các điểm (khả năng thu hồi, độ chính xác) cho các giá trị khác nhau của ngưỡng phân loại.
Praxis
Một thư viện ML cốt lõi, hiệu suất cao của Pax. Praxis thường được gọi là "Thư viện lớp".
Praxis không chỉ chứa các định nghĩa cho lớp Layer mà còn chứa hầu hết các thành phần hỗ trợ của lớp này, bao gồm:
- đầu vào dữ liệu
- thư viện cấu hình (HParam và Fiddle)
- trình tối ưu hoá
Praxis cung cấp các định nghĩa cho lớp Mô hình.
độ chính xác
Một chỉ số cho các mô hình phân loại giúp trả lời câu hỏi sau:
Khi mô hình dự đoán lớp dương tính, tỷ lệ phần trăm dự đoán chính xác là bao nhiêu?
Sau đây là công thức:
trong đó:
- dương tính thật có nghĩa là mô hình đã dự đoán chính xác lớp dương tính.
- dương tính giả có nghĩa là mô hình đã nhầm lẫn dự đoán hạng mục dương.
Ví dụ: giả sử một mô hình đưa ra 200 dự đoán dương tính. Trong số 200 dự đoán tích cực này:
- 150 trường hợp là dương tính thật.
- 50 trường hợp là dương tính giả.
Trong trường hợp này:
Tương phản với độ chính xác và khả năng thu hồi.
Hãy xem phần Phân loại: Độ chính xác, khả năng thu hồi, độ đo và các chỉ số liên quan trong Khoá học cấp tốc về học máy để biết thêm thông tin.
độ chính xác tại k (precision@k)
Một chỉ số để đánh giá danh sách các mục được xếp hạng (theo thứ tự). Độ chính xác tại k xác định tỷ lệ của k mục đầu tiên trong danh sách đó là "phù hợp". Đó là:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Giá trị của k phải nhỏ hơn hoặc bằng độ dài của danh sách được trả về. Xin lưu ý rằng độ dài của danh sách được trả về không thuộc phạm vi tính toán.
Mức độ phù hợp thường mang tính chủ quan; ngay cả người đánh giá là chuyên gia cũng thường không đồng ý về những mục nào là phù hợp.
So với:
đường cong độ chính xác-độ thu hồi
Đường cong độ chính xác so với khả năng thu hồi ở các ngưỡng phân loại khác nhau.
dự đoán
Đầu ra của một mô hình. Ví dụ:
- Dự đoán của mô hình phân loại nhị phân là lớp dương hoặc lớp âm.
- Thông tin dự đoán của mô hình phân loại đa mục là một lớp.
- Dự đoán của mô hình hồi quy tuyến tính là một con số.
độ lệch của dự đoán
Giá trị cho biết mức độ khác biệt giữa giá trị trung bình của các dự đoán và giá trị trung bình của nhãn trong tập dữ liệu.
Không nhầm lẫn với thuật ngữ thiên kiến trong các mô hình học máy hoặc với thiên kiến trong đạo đức và sự công bằng.
học máy dự đoán
Mọi hệ thống học máy tiêu chuẩn ("cổ điển").
Thuật ngữ học máy dự đoán không có định nghĩa chính thức. Thay vào đó, thuật ngữ này phân biệt một danh mục hệ thống học máy không dựa trên AI tạo sinh.
tính tương đương dự đoán
Một chỉ số công bằng kiểm tra xem đối với một mô hình phân loại nhất định, tỷ lệ độ chính xác có tương đương với các nhóm phụ đang được xem xét hay không.
Ví dụ: một mô hình dự đoán việc được nhận vào trường đại học sẽ đáp ứng tính tương đồng dự đoán về quốc tịch nếu tỷ lệ chính xác của mô hình này là như nhau đối với người Lilliput và người Brobdingnag.
Đôi khi, tính tương đương dự đoán còn được gọi là tính tương đương dự đoán về giá.
Hãy xem phần "Giải thích định nghĩa về tính công bằng" (mục 3.2.1) để biết thông tin chi tiết hơn về tính tương đồng dự đoán.
tỷ lệ ngang bằng dự đoán
Một tên khác của tính chẵn lẻ dự đoán.
tiền xử lý
Xử lý dữ liệu trước khi dùng để huấn luyện mô hình. Quá trình tiền xử lý có thể đơn giản như việc xoá những từ không có trong từ điển tiếng Anh khỏi một kho văn bản tiếng Anh, hoặc có thể phức tạp như việc biểu thị lại các điểm dữ liệu theo cách loại bỏ càng nhiều thuộc tính có tương quan với thuộc tính nhạy cảm càng tốt. Bước tiền xử lý có thể giúp đáp ứng các ràng buộc về tính công bằng.mô hình được huấn luyện trước
Mặc dù thuật ngữ này có thể đề cập đến bất kỳ mô hình được huấn luyện nào hoặc vectơ nhúng được huấn luyện, nhưng hiện tại, mô hình được huấn luyện trước thường đề cập đến một mô hình ngôn ngữ lớn được huấn luyện hoặc một dạng mô hình AI tạo sinh được huấn luyện khác.
Xem thêm mô hình cơ sở và mô hình nền tảng.
huấn luyện trước
Quá trình huấn luyện ban đầu của một mô hình trên một tập dữ liệu lớn. Một số mô hình được huấn luyện trước là những mô hình khổng lồ vụng về và thường phải được tinh chỉnh thông qua quá trình huấn luyện bổ sung. Ví dụ: Các chuyên gia về học máy có thể huấn luyện trước một mô hình ngôn ngữ lớn trên một tập dữ liệu văn bản khổng lồ, chẳng hạn như tất cả các trang tiếng Anh trong Wikipedia. Sau khi được huấn luyện trước, mô hình thu được có thể được tinh chỉnh thêm thông qua bất kỳ kỹ thuật nào sau đây:
giả thiết tiên nhiệm
Những gì bạn tin tưởng về dữ liệu trước khi bắt đầu huấn luyện trên dữ liệu đó. Ví dụ: phương pháp L2 điều chuẩn dựa trên niềm tin trước rằng trọng số phải nhỏ và thường được phân phối xung quanh số 0.
Pro
Một mô hình Gemini có ít tham số hơn Ultra nhưng nhiều tham số hơn Nano. Hãy xem phần Gemini Pro để biết thông tin chi tiết.
mô hình hồi quy xác suất
Một mô hình hồi quy không chỉ sử dụng trọng số cho từng đặc điểm mà còn sử dụng độ không chắc chắn của các trọng số đó. Mô hình hồi quy xác suất tạo ra một thông tin dự đoán và độ không chắc chắn của thông tin dự đoán đó. Ví dụ: mô hình hồi quy xác suất có thể đưa ra dự đoán là 325 với độ lệch chuẩn là 12. Để biết thêm thông tin về các mô hình hồi quy xác suất, hãy xem Colab này trên tensorflow.org.
hàm mật độ xác suất
Một hàm xác định tần suất của các mẫu dữ liệu có chính xác một giá trị cụ thể. Khi các giá trị của một tập dữ liệu là các số dấu phẩy động liên tục, thì hiếm khi xảy ra trường hợp khớp chính xác. Tuy nhiên, việc tích hợp hàm mật độ xác suất từ giá trị x đến giá trị y sẽ cho ra tần suất dự kiến của các mẫu dữ liệu trong khoảng từ x đến y.
Ví dụ: hãy xem xét một phân phối chuẩn có giá trị trung bình là 200 và độ lệch chuẩn là 30. Để xác định tần suất dự kiến của các mẫu dữ liệu nằm trong phạm vi từ 211,4 đến 218,7, bạn có thể tích hợp hàm mật độ xác suất cho một phân phối chuẩn từ 211,4 đến 218,7.
prompt
Mọi văn bản được nhập làm dữ liệu đầu vào cho một mô hình ngôn ngữ lớn để điều kiện hoá mô hình hoạt động theo một cách nhất định. Câu lệnh có thể ngắn như một cụm từ hoặc dài tuỳ ý (ví dụ: toàn bộ văn bản của một cuốn tiểu thuyết). Câu lệnh thuộc nhiều danh mục, bao gồm cả những danh mục được trình bày trong bảng sau:
| Danh mục câu lệnh | Ví dụ: | Ghi chú |
|---|---|---|
| Câu hỏi | Chim bồ câu có thể bay nhanh đến mức nào? | |
| Hướng dẫn | Viết một bài thơ hài hước về hoạt động kinh doanh chênh lệch giá. | Một câu lệnh yêu cầu mô hình ngôn ngữ lớn làm một việc gì đó. |
| Ví dụ: | Dịch mã Markdown sang HTML. Ví dụ:
Markdown: * list item HTML: <ul> <li>list item</li> </ul> |
Câu đầu tiên trong câu lệnh ví dụ này là một chỉ dẫn. Phần còn lại của câu lệnh là ví dụ. |
| Vai trò | Giải thích lý do phương pháp hạ dốc được dùng trong quá trình huấn luyện máy học cho bằng Tiến sĩ Vật lý. | Phần đầu tiên của câu là một chỉ dẫn; cụm từ "đến bằng Tiến sĩ Vật lý" là phần vai trò. |
| Đầu vào một phần để mô hình hoàn tất | Thủ tướng Vương quốc Anh sống tại | Một phần của câu lệnh nhập có thể kết thúc đột ngột (như ví dụ này) hoặc kết thúc bằng dấu gạch dưới. |
Một mô hình AI tạo sinh có thể phản hồi một câu lệnh bằng văn bản, mã, hình ảnh, dữ liệu nhúng, video... gần như mọi thứ.
học dựa trên câu lệnh
Một khả năng của một số mô hình cho phép chúng điều chỉnh hành vi để phản hồi nội dung văn bản tuỳ ý (câu lệnh). Trong mô hình học dựa trên câu lệnh điển hình, mô hình ngôn ngữ lớn sẽ phản hồi một câu lệnh bằng cách tạo văn bản. Ví dụ: giả sử người dùng nhập câu lệnh sau:
Tóm tắt Định luật chuyển động thứ ba của Newton.
Một mô hình có khả năng học dựa trên câu lệnh không được huấn luyện cụ thể để trả lời câu lệnh trước đó. Thay vào đó, mô hình này "biết" rất nhiều thông tin thực tế về vật lý, rất nhiều thông tin về các quy tắc ngôn ngữ chung và rất nhiều thông tin về những gì tạo nên câu trả lời hữu ích nói chung. Kiến thức đó là đủ để đưa ra một câu trả lời (hy vọng là) hữu ích. Ý kiến phản hồi bổ sung của con người ("Câu trả lời đó quá phức tạp" hoặc "Phản ứng là gì?") cho phép một số hệ thống học tập dựa trên câu lệnh dần cải thiện mức độ hữu ích của câu trả lời.
thiết kế câu lệnh
Từ đồng nghĩa với thiết kế câu lệnh.
thiết kế câu lệnh
Nghệ thuật tạo ra câu lệnh để nhận được câu trả lời mong muốn từ mô hình ngôn ngữ lớn. Con người thực hiện kỹ thuật tạo câu lệnh. Viết câu lệnh có cấu trúc rõ ràng là một phần quan trọng để đảm bảo mô hình ngôn ngữ lớn đưa ra câu trả lời hữu ích. Kỹ thuật tạo câu lệnh phụ thuộc vào nhiều yếu tố, bao gồm:
- Tập dữ liệu được dùng để huấn luyện trước và có thể điều chỉnh mô hình ngôn ngữ lớn.
- Nhiệt độ và các tham số giải mã khác mà mô hình sử dụng để tạo phản hồi.
Thiết kế câu lệnh là một từ đồng nghĩa với thiết kế câu lệnh.
Hãy xem phần Giới thiệu về cách thiết kế câu lệnh để biết thêm thông tin về cách viết câu lệnh hữu ích.
tập câu lệnh
Một nhóm câu lệnh để đánh giá một mô hình ngôn ngữ lớn. Ví dụ: hình minh hoạ sau đây cho thấy một tập hợp câu lệnh gồm 3 câu lệnh:

Một bộ câu lệnh tốt bao gồm một tập hợp câu lệnh đủ "rộng" để đánh giá kỹ lưỡng độ an toàn và tính hữu ích của một mô hình ngôn ngữ lớn.
Xem thêm tập hợp phản hồi.
điều chỉnh câu lệnh
Cơ chế điều chỉnh hiệu quả tham số giúp tìm hiểu "tiền tố" mà hệ thống thêm vào trước câu lệnh thực tế.
Một biến thể của phương pháp điều chỉnh câu lệnh (đôi khi được gọi là điều chỉnh tiền tố) là thêm tiền tố vào mọi lớp. Ngược lại, hầu hết các phương pháp điều chỉnh câu lệnh chỉ thêm một tiền tố vào lớp đầu vào.
proxy (thuộc tính nhạy cảm)
Một thuộc tính được dùng làm thuộc tính thay thế cho thuộc tính nhạy cảm. Ví dụ: mã bưu chính của một cá nhân có thể được dùng làm thông tin đại diện cho thu nhập, chủng tộc hoặc sắc tộc của họ.nhãn đại diện
Dữ liệu dùng để ước chừng nhãn không có sẵn trực tiếp trong một tập dữ liệu.
Ví dụ: giả sử bạn phải huấn luyện một mô hình để dự đoán mức độ căng thẳng của nhân viên. Tập dữ liệu của bạn có nhiều đặc điểm dự đoán nhưng không có nhãn nào tên là mức độ căng thẳng. Không nản lòng, bạn chọn "tai nạn tại nơi làm việc" làm nhãn thay thế cho mức độ căng thẳng. Suy cho cùng, nhân viên chịu nhiều áp lực sẽ gặp nhiều tai nạn hơn so với nhân viên bình tĩnh. Hay là không? Có thể tai nạn tại nơi làm việc thực sự tăng và giảm vì nhiều lý do.
Ví dụ thứ hai: giả sử bạn muốn is it raining? (trời có mưa không?) là nhãn Boolean cho tập dữ liệu của mình, nhưng tập dữ liệu của bạn không chứa dữ liệu về mưa. Nếu có ảnh chụp, bạn có thể thiết lập hình ảnh về người mang ô làm nhãn proxy cho trời có mưa không? Đó có phải là nhãn đại diện phù hợp không? Có thể, nhưng người dân ở một số nền văn hoá có thể mang ô để chống nắng hơn là chống mưa.
Nhãn thay thế thường không hoàn hảo. Khi có thể, hãy chọn nhãn thực tế thay vì nhãn proxy. Tuy nhiên, khi không có nhãn thực tế, hãy chọn nhãn thay thế một cách cẩn thận, chọn nhãn thay thế ít tệ nhất.
Hãy xem phần Tập dữ liệu: Nhãn trong Khoá học học máy ứng dụng để biết thêm thông tin.
hàm thuần tuý
Một hàm mà đầu ra chỉ dựa trên đầu vào và không có tác dụng phụ. Cụ thể, hàm thuần tuý không sử dụng hoặc thay đổi bất kỳ trạng thái toàn cục nào, chẳng hạn như nội dung của một tệp hoặc giá trị của một biến bên ngoài hàm.
Bạn có thể dùng các hàm thuần tuý để tạo mã an toàn cho luồng. Điều này rất hữu ích khi phân đoạn mã model trên nhiều chip tăng tốc.
Các phương thức biến đổi hàm của JAX yêu cầu các hàm đầu vào phải là hàm thuần tuý.
Hỏi
Hàm Q
Trong học tăng cường, hàm dự đoán lợi nhuận dự kiến khi thực hiện một hành động trong một trạng thái rồi tuân theo một chính sách nhất định.
Hàm Q còn được gọi là hàm giá trị trạng thái-hành động.
Học tăng cường Q
Trong học tăng cường, một thuật toán cho phép tác nhân học được hàm Q tối ưu của một quy trình quyết định Markov bằng cách áp dụng phương trình Bellman. Mô hình quy trình quyết định Markov môi trường.
số phân vị
Mỗi nhóm trong phân nhóm theo phân vị.
phân nhóm theo phân vị
Phân phối các giá trị của một đối tượng thành các nhóm sao cho mỗi nhóm chứa cùng một số lượng ví dụ (hoặc gần bằng nhau). Ví dụ: hình sau đây chia 44 điểm thành 4 nhóm, mỗi nhóm chứa 11 điểm. Để mỗi nhóm trong hình chứa cùng số lượng điểm, một số nhóm có chiều rộng khác nhau về giá trị x.

Hãy xem phần Dữ liệu dạng số: Phân nhóm trong Khoá học cấp tốc về học máy để biết thêm thông tin.
lượng tử hoá
Thuật ngữ quá tải có thể được sử dụng theo bất kỳ cách nào sau đây:
- Triển khai phân nhóm theo phân vị trên một đặc điểm cụ thể.
- Chuyển đổi dữ liệu thành các số 0 và 1 để lưu trữ, huấn luyện và suy luận nhanh hơn. Vì dữ liệu Boolean có khả năng chống nhiễu và lỗi tốt hơn các định dạng khác, nên việc lượng tử hoá có thể cải thiện độ chính xác của mô hình. Các kỹ thuật lượng tử hoá bao gồm làm tròn, cắt bớt và phân nhóm.
Giảm số lượng bit dùng để lưu trữ tham số của một mô hình. Ví dụ: giả sử các tham số của một mô hình được lưu trữ dưới dạng số thực có độ chính xác đơn 32 bit. Lượng tử hoá chuyển đổi các tham số đó từ 32 bit xuống còn 4, 8 hoặc 16 bit. Lượng tử hoá giúp giảm những yếu tố sau:
- Mức sử dụng điện toán, bộ nhớ, đĩa và mạng
- Thời gian suy luận một dự đoán
- Mức tiêu thụ điện năng
Tuy nhiên, đôi khi việc định lượng sẽ làm giảm độ chính xác của các dự đoán của mô hình.
danh sách chờ
Một Operation TensorFlow triển khai cấu trúc dữ liệu hàng đợi. Thường được dùng trong I/O.
Điểm
RAG
Từ viết tắt của mô hình tạo sinh tăng cường khả năng truy xuất.
rừng ngẫu nhiên
Một tập hợp gồm cây quyết định trong đó mỗi cây quyết định được huấn luyện bằng một nhiễu ngẫu nhiên cụ thể, chẳng hạn như phương pháp lấy mẫu lại.
Rừng ngẫu nhiên là một loại rừng quyết định.
Hãy xem Rừng ngẫu nhiên trong khoá học Rừng quyết định để biết thêm thông tin.
chính sách ngẫu nhiên
Trong học tăng cường, chính sách chọn một hành động một cách ngẫu nhiên.
hạng (số thứ tự)
Vị trí thứ tự của một lớp trong vấn đề học máy phân loại các lớp từ cao nhất đến thấp nhất. Ví dụ: hệ thống xếp hạng hành vi có thể xếp hạng phần thưởng của một chú chó từ cao nhất (một miếng bít tết) đến thấp nhất (cải xoăn héo).
hạng (Tensor)
Số lượng phương diện trong một Tensor. Ví dụ: một đại lượng vô hướng có hạng 0, một vectơ có hạng 1 và một ma trận có hạng 2.
Đừng nhầm lẫn với hạng (số thứ tự).
xếp hạng
Một loại học có giám sát có mục tiêu là sắp xếp danh sách các mục.
người đánh giá
Một người cung cấp nhãn cho ví dụ. "Người chú thích" là một tên gọi khác của người đánh giá.
Hãy xem phần Dữ liệu phân loại: Các vấn đề thường gặp trong Khoá học cấp tốc về học máy để biết thêm thông tin.
mức độ ghi nhớ
Một chỉ số cho các mô hình phân loại giúp trả lời câu hỏi sau:
Khi dữ liệu thực tế là lớp dương tính, mô hình đã xác định chính xác bao nhiêu phần trăm dự đoán là lớp dương tính?
Sau đây là công thức:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
trong đó:
- dương tính thật có nghĩa là mô hình đã dự đoán chính xác lớp dương tính.
- âm tính giả nghĩa là mô hình nhầm lẫn dự đoán lớp âm tính.
Ví dụ: giả sử mô hình của bạn đưa ra 200 dự đoán về các ví dụ mà chân lý cơ bản là lớp dương tính. Trong số 200 dự đoán này:
- 180 trường hợp là dương tính thật.
- 20 trường hợp là âm tính giả.
Trong trường hợp này:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Hãy xem bài viết Phân loại: Độ chính xác, khả năng thu hồi, độ đo lường và các chỉ số liên quan để biết thêm thông tin.
tỷ lệ ghi nhớ ở k (recall@k)
Một chỉ số để đánh giá các hệ thống xuất ra danh sách các mục được xếp hạng (theo thứ tự). Độ thu hồi tại k xác định tỷ lệ các mục có liên quan trong k mục đầu tiên trong danh sách đó so với tổng số mục có liên quan được trả về.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Độ tương phản với độ chính xác tại k.
hệ thống đề xuất
Một hệ thống chọn cho mỗi người dùng một nhóm tương đối nhỏ gồm các mặt hàng mong muốn trong một kho dữ liệu lớn. Ví dụ: hệ thống đề xuất video có thể đề xuất 2 video trong số 100.000 video, chọn Casablanca và The Philadelphia Story cho một người dùng, còn Wonder Woman và Black Panther cho một người dùng khác. Hệ thống đề xuất video có thể dựa vào các yếu tố như:
- Những bộ phim mà người dùng có điểm tương đồng đã đánh giá hoặc xem.
- Thể loại, đạo diễn, diễn viên, nhóm nhân khẩu học mục tiêu...
Hãy xem khoá học Hệ thống đề xuất để biết thêm thông tin.
Rectified Linear Unit (ReLU)
Một hàm kích hoạt có hành vi sau:
- Nếu đầu vào là số âm hoặc số 0, thì đầu ra sẽ là 0.
- Nếu giá trị đầu vào là số dương, thì giá trị đầu ra sẽ bằng giá trị đầu vào.
Ví dụ:
- Nếu đầu vào là -3, thì đầu ra sẽ là 0.
- Nếu đầu vào là +3, thì đầu ra là 3.0.
Sau đây là biểu đồ của ReLU:
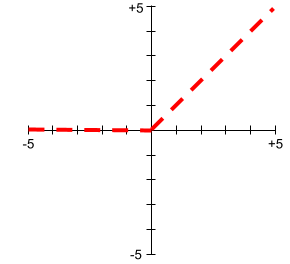
ReLU là một hàm kích hoạt rất phổ biến. Mặc dù có hành vi đơn giản, nhưng ReLU vẫn cho phép mạng nơ-ron học các mối quan hệ phi tuyến tính giữa các đặc điểm và nhãn.
mạng nơron hồi quy
Một mạng nơ-ron được chạy nhiều lần một cách có chủ ý, trong đó các phần của mỗi lần chạy sẽ được đưa vào lần chạy tiếp theo. Cụ thể, các lớp ẩn từ lần chạy trước cung cấp một phần dữ liệu đầu vào cho cùng một lớp ẩn trong lần chạy tiếp theo. Mạng nơ-ron hồi quy đặc biệt hữu ích cho việc đánh giá các chuỗi, để các lớp ẩn có thể học hỏi từ các lần chạy trước của mạng nơ-ron trên các phần trước đó của chuỗi.
Ví dụ: hình sau đây cho thấy một mạng nơ-ron hồi quy chạy 4 lần. Lưu ý rằng các giá trị được tìm hiểu trong các lớp ẩn từ lần chạy đầu tiên sẽ trở thành một phần của dữ liệu đầu vào cho các lớp ẩn tương tự trong lần chạy thứ hai. Tương tự, các giá trị được tìm hiểu trong lớp ẩn ở lần chạy thứ hai sẽ trở thành một phần của dữ liệu đầu vào cho cùng một lớp ẩn ở lần chạy thứ ba. Bằng cách này, mạng nơ-ron hồi quy sẽ dần dần huấn luyện và dự đoán ý nghĩa của toàn bộ chuỗi thay vì chỉ ý nghĩa của từng từ.

văn bản tham khảo
Câu trả lời của chuyên gia cho một câu lệnh. Ví dụ: với câu lệnh sau:
Dịch câu hỏi "Bạn tên gì?" từ tiếng Anh sang tiếng Pháp.
Câu trả lời của chuyên gia có thể là:
Comment vous appelez-vous?
Nhiều chỉ số (chẳng hạn như ROUGE) đo lường mức độ văn bản tham chiếu khớp với văn bản do mô hình học máy tạo.
mô hình hồi quy
Một mô hình tạo ra thông tin dự đoán bằng số. (Ngược lại, mô hình phân loại sẽ tạo ra một dự đoán về lớp.) Ví dụ: sau đây là tất cả các mô hình hồi quy:
- Một mô hình dự đoán giá trị của một ngôi nhà nhất định bằng Euro, chẳng hạn như 423.000.
- Một mô hình dự đoán tuổi thọ của một cây cụ thể theo năm, chẳng hạn như 23,2.
- Một mô hình dự đoán lượng mưa (tính bằng inch) sẽ rơi ở một thành phố nhất định trong 6 giờ tới, chẳng hạn như 0,18.
Hai loại mô hình hồi quy phổ biến là:
- Hồi quy tuyến tính, tìm ra đường thẳng phù hợp nhất với các giá trị nhãn cho các đối tượng.
- Hồi quy logistic, tạo ra một xác suất từ 0,0 đến 1,0 mà hệ thống thường ánh xạ đến một dự đoán về lớp.
Không phải mô hình nào đưa ra dự đoán bằng số cũng là mô hình hồi quy. Trong một số trường hợp, dự đoán bằng số thực sự chỉ là một mô hình phân loại có tên lớp bằng số. Ví dụ: một mô hình dự đoán mã bưu chính bằng số là mô hình phân loại chứ không phải mô hình hồi quy.
điều hoà
Mọi cơ chế giúp giảm hiện tượng khớp quá mức. Các loại điều chuẩn phổ biến bao gồm:
- L1 điều chuẩn
- Điều chuẩn L2
- dropout regularization
- dừng sớm (đây không phải là một phương pháp chính quy hoá chính thức, nhưng có thể hạn chế hiệu quả tình trạng khớp quá mức)
Điều chuẩn hoá cũng có thể được xác định là mức phạt đối với độ phức tạp của mô hình.
Hãy xem phần Quá trình khớp quá mức: Độ phức tạp của mô hình trong Khoá học cấp tốc về học máy để biết thêm thông tin.
tỷ lệ điều hoà
Một số chỉ định tầm quan trọng tương đối của điều chỉnh trong quá trình huấn luyện. Việc tăng tốc độ điều chỉnh sẽ làm giảm tình trạng quá khớp nhưng có thể làm giảm khả năng dự đoán của mô hình. Ngược lại, việc giảm hoặc bỏ qua tốc độ điều chỉnh sẽ làm tăng tình trạng khớp quá mức.
Hãy xem phần Trang bị quá khớp: Điều chỉnh L2 trong Khoá học học máy ứng dụng để biết thêm thông tin.
học tăng cường (RL)
Một nhóm các thuật toán tìm hiểu một chính sách tối ưu, có mục tiêu là tối đa hoá lợi nhuận khi tương tác với một môi trường. Ví dụ: phần thưởng cuối cùng của hầu hết các trò chơi là chiến thắng. Các hệ thống học tăng cường có thể trở thành chuyên gia chơi các trò chơi phức tạp bằng cách đánh giá các chuỗi nước đi trước đó trong trò chơi mà cuối cùng dẫn đến chiến thắng và các chuỗi nước đi cuối cùng dẫn đến thất bại.
Học tăng cường từ phản hồi của con người (RLHF)
Sử dụng ý kiến phản hồi của nhân viên đánh giá để cải thiện chất lượng phản hồi của mô hình. Ví dụ: cơ chế RLHF có thể yêu cầu người dùng đánh giá chất lượng phản hồi của mô hình bằng biểu tượng 👍 hoặc 👎. Sau đó, hệ thống có thể điều chỉnh các câu trả lời trong tương lai dựa trên ý kiến phản hồi đó.
ReLU
Viết tắt của Rectified Linear Unit (Đơn vị tuyến tính được chỉnh sửa).
vùng đệm phát lại
Trong các thuật toán tương tự như DQN, bộ nhớ mà tác nhân dùng để lưu trữ các quá trình chuyển đổi trạng thái để sử dụng trong phát lại trải nghiệm.
hàng nhái
Bản sao (hoặc một phần) của tập dữ liệu huấn luyện hoặc mô hình, thường được lưu trữ trên một máy khác. Ví dụ: một hệ thống có thể sử dụng chiến lược sau đây để triển khai tính song song của dữ liệu:
- Đặt các bản sao của một mô hình hiện có trên nhiều máy.
- Gửi các tập hợp con khác nhau của tập hợp huấn luyện đến từng bản sao.
- Tổng hợp các nội dung cập nhật tham số.
Bản sao cũng có thể tham chiếu đến một bản sao khác của máy chủ suy luận. Việc tăng số lượng bản sao sẽ làm tăng số lượng yêu cầu mà hệ thống có thể xử lý đồng thời, nhưng cũng làm tăng chi phí phân phát.
thiên kiến dựa trên báo cáo
Việc tần suất mà mọi người viết về các hành động, kết quả hoặc thuộc tính không phản ánh tần suất thực tế của họ hoặc mức độ mà một thuộc tính là đặc trưng của một nhóm cá nhân. Thiên kiến báo cáo có thể ảnh hưởng đến thành phần của dữ liệu mà hệ thống học máy học được.
Ví dụ: trong sách, từ cười phổ biến hơn từ thở. Một mô hình học máy ước tính tần suất tương đối của tiếng cười và nhịp thở trong một tuyển tập sách có thể sẽ xác định rằng tiếng cười phổ biến hơn nhịp thở.
Hãy xem phần Tính công bằng: Các loại thành kiến trong Khoá học cấp tốc về học máy để biết thêm thông tin.
sự đại diện
Quá trình ánh xạ dữ liệu đến các đặc điểm hữu ích.
sắp xếp lại
Giai đoạn cuối cùng của hệ thống đề xuất, trong đó các mục được tính điểm có thể được phân loại lại theo một số thuật toán khác (thường là không phải ML). Giai đoạn xếp hạng lại sẽ đánh giá danh sách các mục do giai đoạn tính điểm tạo ra, thực hiện các hành động như:
- Loại bỏ những mặt hàng mà người dùng đã mua.
- Tăng điểm số của các mục mới hơn.
Hãy xem phần Sắp xếp lại trong khoá học Hệ thống đề xuất để biết thêm thông tin.
phản hồi
Văn bản, hình ảnh, âm thanh hoặc video mà mô hình AI tạo sinh suy luận. Nói cách khác, câu lệnh là đầu vào cho một mô hình AI tạo sinh và câu trả lời là đầu ra.
tập hợp phản hồi
Tập hợp các câu trả lời mà mô hình ngôn ngữ lớn trả về cho một tập hợp câu lệnh đầu vào.
tạo sinh tăng cường truy xuất (RAG)
Một kỹ thuật giúp cải thiện chất lượng đầu ra của mô hình ngôn ngữ lớn (LLM) bằng cách liên kết đầu ra đó với các nguồn kiến thức được truy xuất sau khi mô hình được huấn luyện. RAG cải thiện độ chính xác của các câu trả lời của LLM bằng cách cấp cho LLM đã được huấn luyện quyền truy cập vào thông tin được truy xuất từ các cơ sở kiến thức hoặc tài liệu đáng tin cậy.
Sau đây là một số động lực phổ biến để sử dụng phương pháp tạo tăng cường khả năng truy xuất:
- Tăng độ chính xác về mặt thực tế của các câu trả lời do mô hình tạo.
- Cung cấp cho mô hình quyền truy cập vào kiến thức mà mô hình chưa được huấn luyện.
- Thay đổi kiến thức mà mô hình sử dụng.
- Cho phép mô hình trích dẫn nguồn.
Ví dụ: giả sử một ứng dụng hoá học sử dụng PaLM API để tạo bản tóm tắt liên quan đến các truy vấn của người dùng. Khi nhận được một truy vấn, phần phụ trợ của ứng dụng sẽ:
- Tìm kiếm ("truy xuất") dữ liệu liên quan đến cụm từ tìm kiếm của người dùng.
- Thêm ("tăng cường") dữ liệu hoá học có liên quan vào cụm từ tìm kiếm của người dùng.
- Hướng dẫn LLM tạo bản tóm tắt dựa trên dữ liệu được thêm vào.
phím return
Trong học tăng cường, với một chính sách và trạng thái nhất định, lợi nhuận là tổng của tất cả phần thưởng mà tác nhân dự kiến sẽ nhận được khi tuân theo chính sách từ trạng thái đến cuối tập. Tác nhân tính đến bản chất trễ của phần thưởng dự kiến bằng cách chiết khấu phần thưởng theo các chuyển đổi trạng thái cần thiết để nhận được phần thưởng.
Do đó, nếu hệ số chiết khấu là \(\gamma\)và \(r_0, \ldots, r_{N}\)biểu thị phần thưởng cho đến cuối tập, thì cách tính lợi nhuận sẽ như sau:
phần thưởng
Trong học tăng cường, kết quả bằng số của việc thực hiện một hành động trong một trạng thái, do môi trường xác định.
điều hoà theo đường gờ
Từ đồng nghĩa với điều hoà L2. Thuật ngữ điều chỉnh bằng đường gờ thường được dùng trong các ngữ cảnh thống kê thuần tuý, trong khi điều chỉnh L2 thường được dùng trong học máy.
RNN
Từ viết tắt của mạng nơron hồi quy.
Đường cong ROC (đường cong đặc tính hoạt động của máy thu)
Biểu đồ về tỷ lệ dương tính thực so với tỷ lệ dương tính giả cho các ngưỡng phân loại khác nhau trong phân loại nhị phân.
Hình dạng của đường cong ROC cho thấy khả năng của mô hình phân loại nhị phân trong việc tách các lớp dương tính khỏi các lớp âm tính. Ví dụ: giả sử một mô hình phân loại nhị phân tách biệt hoàn toàn tất cả các lớp âm tính với tất cả các lớp dương tính:
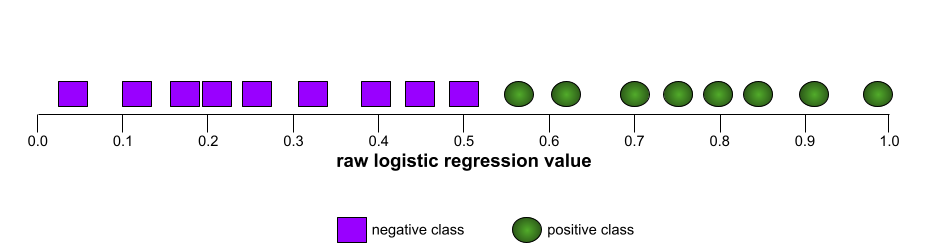
Đường cong ROC cho mô hình trước đó có dạng như sau:
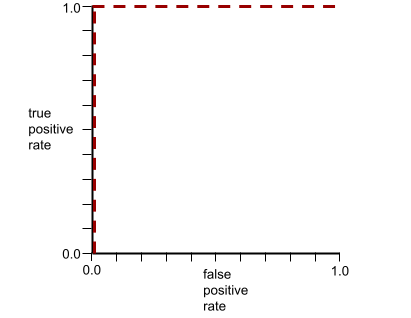
Ngược lại, hình minh hoạ sau đây vẽ đồ thị các giá trị hồi quy logistic thô cho một mô hình kém không thể tách các lớp âm tính khỏi các lớp dương tính:
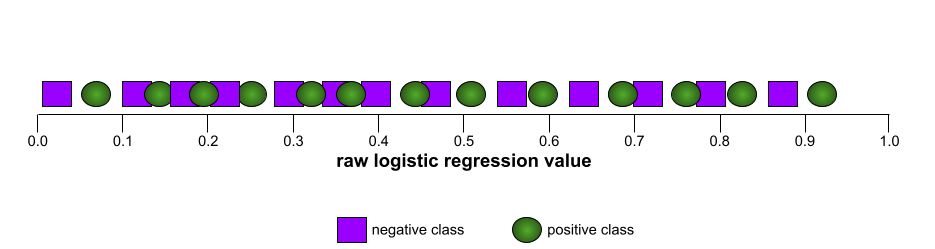
Đường cong ROC cho mô hình này có dạng như sau:
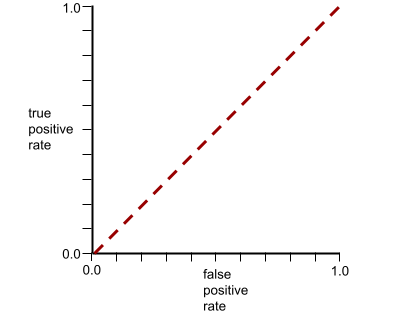
Trong khi đó, trong thế giới thực, hầu hết các mô hình phân loại nhị phân đều tách biệt các lớp dương và âm ở một mức độ nào đó, nhưng thường không hoàn hảo. Vì vậy, đường cong ROC điển hình sẽ nằm ở đâu đó giữa hai cực đoan này:
Điểm trên đường cong ROC gần với (0.0,1.0) nhất về mặt lý thuyết sẽ xác định ngưỡng phân loại lý tưởng. Tuy nhiên, một số vấn đề khác ngoài đời thực ảnh hưởng đến việc lựa chọn ngưỡng phân loại lý tưởng. Ví dụ: có lẽ kết quả âm tính giả gây ra nhiều phiền toái hơn kết quả dương tính giả.
Một chỉ số bằng số có tên là AUC tóm tắt đường cong ROC thành một giá trị dấu phẩy động duy nhất.
đặt câu lệnh theo vai trò
Một câu lệnh, thường bắt đầu bằng đại từ bạn, yêu cầu mô hình AI tạo sinh giả vờ là một người hoặc một vai trò cụ thể khi tạo phản hồi. Câu lệnh đóng vai có thể giúp mô hình AI tạo sinh có được "tư duy" phù hợp để tạo ra câu trả lời hữu ích hơn. Ví dụ: bất kỳ câu lệnh nào sau đây về vai trò đều có thể phù hợp, tuỳ thuộc vào loại câu trả lời mà bạn đang tìm kiếm:
Bạn có bằng tiến sĩ khoa học máy tính.
Bạn là một kỹ sư phần mềm thích giải thích kiên nhẫn về Python cho những sinh viên mới học lập trình.
Bạn là một anh hùng hành động với một bộ kỹ năng lập trình rất đặc biệt. Hãy đảm bảo với tôi rằng bạn sẽ tìm thấy một mục cụ thể trong danh sách Python.
gốc
Nút bắt đầu (điều kiện đầu tiên) trong cây quyết định. Theo quy ước, sơ đồ đặt gốc ở đầu cây quyết định. Ví dụ:

thư mục gốc
Thư mục mà bạn chỉ định để lưu trữ các thư mục con của tệp sự kiện và điểm kiểm tra TensorFlow của nhiều mô hình.
Sai số trung bình bình phương (RMSE)
Căn bậc hai của Sai số bình phương trung bình.
bất biến khi xoay
Trong vấn đề phân loại hình ảnh, khả năng của một thuật toán là phân loại thành công hình ảnh ngay cả khi hướng của hình ảnh thay đổi. Ví dụ: thuật toán vẫn có thể xác định vợt tennis dù vợt hướng lên, hướng ngang hay hướng xuống. Xin lưu ý rằng tính bất biến xoay không phải lúc nào cũng phù hợp; ví dụ: số 9 lộn ngược không được phân loại là số 9.
Xem thêm bất biến theo phép dịch và bất biến khi thay đổi kích thước.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Một nhóm các chỉ số đánh giá mô hình tóm tắt tự động và dịch máy. Các chỉ số ROUGE xác định mức độ mà văn bản tham chiếu trùng lặp với văn bản do mô hình ML tạo. Mỗi thành phần trong họ ROUGE đo lường mức độ trùng lặp theo một cách khác nhau. Điểm ROUGE càng cao thì văn bản tham chiếu và văn bản được tạo càng giống nhau hơn so với điểm ROUGE thấp hơn.
Mỗi thành viên trong họ ROUGE thường tạo ra các chỉ số sau:
- Chính xác
- Nhớ lại
- F1
Để biết thông tin chi tiết và ví dụ, hãy xem:
ROUGE-L
Một thành viên của họ ROUGE tập trung vào độ dài của chuỗi con chung dài nhất trong văn bản tham chiếu và văn bản được tạo. Các công thức sau đây tính toán độ thu hồi và độ chính xác cho ROUGE-L:
Sau đó, bạn có thể sử dụng F1 để tổng hợp độ thu hồi ROUGE-L và độ chính xác ROUGE-L thành một chỉ số duy nhất:
ROUGE-L bỏ qua mọi dấu xuống dòng trong văn bản tham chiếu và văn bản được tạo, vì vậy, chuỗi con chung dài nhất có thể trải dài trên nhiều câu. Khi văn bản tham chiếu và văn bản được tạo có nhiều câu, thì một biến thể của ROUGE-L có tên là ROUGE-Lsum thường là chỉ số phù hợp hơn. ROUGE-Lsum xác định chuỗi con chung dài nhất cho mỗi câu trong một đoạn văn, sau đó tính giá trị trung bình của những chuỗi con chung dài nhất đó.
ROUGE-N
Một nhóm chỉ số trong họ ROUGE so sánh các N-gram dùng chung có kích thước nhất định trong văn bản tham chiếu và văn bản được tạo. Ví dụ:
- ROUGE-1 đo lường số lượng mã thông báo được chia sẻ trong văn bản tham chiếu và văn bản được tạo.
- ROUGE-2 đo lường số lượng bigram (2-gram) được chia sẻ trong văn bản tham chiếu và văn bản được tạo.
- ROUGE-3 đo số lượng trigram (3-gram) dùng chung trong văn bản tham chiếu và văn bản được tạo.
Bạn có thể sử dụng các công thức sau để tính độ thu hồi ROUGE-N và độ chính xác ROUGE-N cho bất kỳ thành viên nào trong họ ROUGE-N:
Sau đó, bạn có thể sử dụng F1 để tổng hợp độ thu hồi ROUGE-N và độ chính xác ROUGE-N thành một chỉ số duy nhất:
ROUGE-S
Một dạng ROUGE-N linh hoạt cho phép so khớp skip-gram. Tức là ROUGE-N chỉ tính N-gram khớp chính xác, nhưng ROUGE-S cũng tính N-gram được phân tách bằng một hoặc nhiều từ. Ví dụ: hãy cân nhắc những điều sau đây:
- văn bản tham chiếu: Mây trắng
- văn bản được tạo: Những đám mây trắng bồng bềnh
Khi tính toán ROUGE-N, 2-gram White clouds (Mây trắng) không khớp với White billowing clouds (Mây trắng cuồn cuộn). Tuy nhiên, khi tính toán ROUGE-S, White clouds (Mây trắng) sẽ khớp với White billowing clouds (Mây trắng cuồn cuộn).
R bình phương
Một chỉ số hồi quy cho biết mức độ biến thiên của một nhãn là do một tính năng riêng lẻ hoặc do một tập hợp tính năng. R bình phương là một giá trị nằm trong khoảng từ 0 đến 1, bạn có thể diễn giải như sau:
- R bình phương bằng 0 có nghĩa là không có biến thể nào của nhãn là do bộ tính năng.
- R bình phương bằng 1 có nghĩa là tất cả các biến thể của nhãn đều là do tập hợp đối tượng.
- R bình phương từ 0 đến 1 cho biết mức độ mà sự biến thiên của nhãn có thể được dự đoán từ một đặc điểm cụ thể hoặc bộ đặc điểm. Ví dụ: R bình phương bằng 0,10 có nghĩa là 10% phương sai trong nhãn là do tập hợp đối tượng, R bình phương bằng 0,20 có nghĩa là 20% là do tập hợp đối tượng, v.v.
R bình phương là bình phương của hệ số tương quan Pearson giữa các giá trị mà một mô hình dự đoán và sự thật cơ bản.
S
thiên vị do không lấy mẫu
Xem phần thiên vị do cách chọn mẫu.
lấy mẫu có hoàn lại
Một phương pháp chọn các mục trong một tập hợp các mục đề xuất, trong đó bạn có thể chọn cùng một mục nhiều lần. Cụm từ "có thay thế" có nghĩa là sau mỗi lần chọn, mục đã chọn sẽ được trả về nhóm các mục đề xuất. Phương pháp ngược lại, lấy mẫu không thay thế, có nghĩa là một mục đề xuất chỉ có thể được chọn một lần.
Ví dụ: hãy xem xét tập hợp trái cây sau:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}Giả sử hệ thống chọn ngẫu nhiên fig làm mục đầu tiên.
Nếu sử dụng phương pháp lấy mẫu có thay thế, thì hệ thống sẽ chọn mục thứ hai trong tập hợp sau:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}Có, đó là cùng một tập hợp như trước đây, vì vậy, hệ thống có thể chọn lại fig.
Nếu sử dụng phương pháp lấy mẫu không thay thế, thì sau khi được chọn, mẫu không thể được chọn lại. Ví dụ: nếu hệ thống chọn ngẫu nhiên fig làm mẫu đầu tiên, thì fig không thể được chọn lại. Do đó, hệ thống sẽ chọn mẫu thứ hai trong tập hợp sau (đã giảm):
fruit = {kiwi, apple, pear, cherry, lime, mango}SavedModel
Định dạng được đề xuất để lưu và khôi phục các mô hình TensorFlow. SavedModel là một định dạng tuần tự hoá có thể khôi phục và không phụ thuộc vào ngôn ngữ, cho phép các hệ thống và công cụ cấp cao hơn tạo, sử dụng và chuyển đổi các mô hình TensorFlow.
Hãy xem phần Lưu và khôi phục trong Hướng dẫn dành cho lập trình viên TensorFlow để biết thông tin chi tiết đầy đủ.
Vận chuyển hàng tiết kiệm
Một đối tượng TensorFlow chịu trách nhiệm lưu các điểm kiểm tra mô hình.
đại lượng vô hướng
Một số hoặc một chuỗi duy nhất có thể được biểu thị dưới dạng tensor có hạng 0. Ví dụ: mỗi dòng mã sau đây sẽ tạo một đại lượng vô hướng trong TensorFlow:
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)điều chỉnh tỷ lệ
Mọi phép biến đổi hoặc kỹ thuật toán học giúp thay đổi phạm vi của nhãn, giá trị của đối tượng hoặc cả hai. Một số dạng tỷ lệ rất hữu ích cho các phép biến đổi như chuẩn hoá.
Sau đây là các hình thức mở rộng quy mô phổ biến và hữu ích trong Học máy:
- phép chia tỷ lệ tuyến tính, thường sử dụng kết hợp phép trừ và phép chia để thay thế giá trị ban đầu bằng một số từ -1 đến +1 hoặc từ 0 đến 1.
- thang đo lôgarit, thay thế giá trị ban đầu bằng lôgarit của giá trị đó.
- Chuẩn hoá điểm Z, thay thế giá trị ban đầu bằng giá trị dấu phẩy động biểu thị số độ lệch chuẩn so với giá trị trung bình của đặc điểm đó.
scikit-learn
Một nền tảng học máy nguồn mở phổ biến. Xem scikit-learn.org.
tính điểm
Phần của hệ thống đề xuất cung cấp giá trị hoặc thứ hạng cho từng mục do giai đoạn tạo đề xuất tạo ra.
thiên vị do cách chọn mẫu
Lỗi trong kết luận rút ra từ dữ liệu lấy mẫu do quy trình chọn tạo ra sự khác biệt có hệ thống giữa các mẫu được quan sát trong dữ liệu và những mẫu không được quan sát. Các dạng thiên vị khi lựa chọn sau đây tồn tại:
- thiên kiến về phạm vi: Tập hợp được biểu thị trong tập dữ liệu không khớp với tập hợp mà mô hình học máy đang dự đoán.
- thiên vị lấy mẫu: Dữ liệu không được thu thập ngẫu nhiên từ nhóm mục tiêu.
- thiên kiến không phản hồi (còn gọi là thiên kiến tham gia): Người dùng thuộc một số nhóm chọn không tham gia khảo sát với tỷ lệ khác với người dùng thuộc các nhóm khác.
Ví dụ: giả sử bạn đang tạo một mô hình học máy dự đoán mức độ thích thú của mọi người đối với một bộ phim. Để thu thập dữ liệu huấn luyện, bạn phát một bản khảo sát cho tất cả mọi người ở hàng ghế đầu của một rạp chiếu phim đang chiếu bộ phim đó. Thoạt nghe qua, đây có vẻ là một cách hợp lý để thu thập tập dữ liệu; tuy nhiên, hình thức thu thập dữ liệu này có thể gây ra các dạng thiên vị chọn mẫu sau đây:
- thiên kiến về phạm vi: Bằng cách lấy mẫu từ một nhóm người đã chọn xem phim, các dự đoán của mô hình có thể không khái quát hoá được cho những người chưa thể hiện mức độ quan tâm đó đối với bộ phim.
- thiên vị trong lấy mẫu: Thay vì lấy mẫu ngẫu nhiên từ nhóm dân số dự kiến (tất cả những người xem phim), bạn chỉ lấy mẫu những người ở hàng ghế đầu. Có thể những người ngồi ở hàng ghế đầu quan tâm đến bộ phim hơn những người ở các hàng ghế khác.
- thiên kiến không phản hồi: Nhìn chung, những người có ý kiến mạnh mẽ thường phản hồi các cuộc khảo sát không bắt buộc thường xuyên hơn những người có ý kiến nhẹ nhàng. Vì khảo sát về phim là không bắt buộc, nên các câu trả lời có nhiều khả năng tạo thành một phân phối hai đỉnh hơn là một phân phối bình thường (hình chuông).
cơ chế tự chú ý (còn gọi là lớp tự chú ý)
Một lớp mạng nơ-ron chuyển đổi một chuỗi các mục nhúng (ví dụ: mục nhúng mã thông báo) thành một chuỗi các mục nhúng khác. Mỗi mục nhúng trong chuỗi đầu ra được tạo bằng cách tích hợp thông tin từ các phần tử của chuỗi đầu vào thông qua cơ chế chú ý.
Phần tự trong cơ chế tự chú ý đề cập đến chuỗi tự chú ý đến chính nó thay vì đến một số ngữ cảnh khác. Cơ chế tự chú ý là một trong những khối xây dựng chính cho Transformer và sử dụng thuật ngữ tra cứu từ điển, chẳng hạn như "truy vấn", "khoá" và "giá trị".
Lớp tự chú ý bắt đầu bằng một chuỗi các biểu diễn đầu vào, một cho mỗi từ. Biểu thị đầu vào cho một từ có thể là một quy trình nhúng đơn giản. Đối với mỗi từ trong một chuỗi đầu vào, mạng sẽ tính điểm mức độ liên quan của từ đó với mọi phần tử trong toàn bộ chuỗi từ. Điểm liên quan xác định mức độ mà bản trình bày cuối cùng của từ kết hợp các bản trình bày của những từ khác.
Ví dụ: hãy xem xét câu sau:
Con vật không băng qua đường vì quá mệt.
Hình minh hoạ sau đây (trong Transformer: A Novel Neural Network Architecture for Language Understanding) cho thấy mẫu chú ý của lớp tự chú ý cho đại từ it, với độ tối của mỗi dòng cho biết mức độ đóng góp của mỗi từ vào biểu thị:
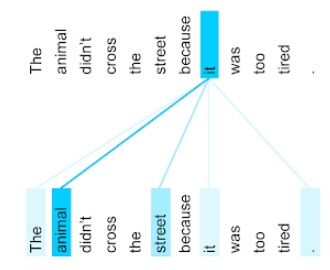
Lớp cơ chế tự chú ý làm nổi bật những từ có liên quan đến "nó". Trong trường hợp này, lớp chú ý đã học được cách làm nổi bật những từ mà nó có thể đề cập đến, gán trọng số cao nhất cho động vật.
Đối với một chuỗi gồm n mã thông báo, cơ chế tự chú ý sẽ biến đổi một chuỗi gồm n mục nhúng riêng biệt, một lần tại mỗi vị trí trong chuỗi.
Bạn cũng có thể tham khảo cơ chế chú ý và cơ chế tự chú ý nhiều đầu.
học tự giám sát
Một nhóm các kỹ thuật để chuyển đổi vấn đề học máy không giám sát thành vấn đề học máy có giám sát bằng cách tạo nhãn thay thế từ các ví dụ không được gắn nhãn.
Một số mô hình dựa trên Transformer (chẳng hạn như BERT) sử dụng phương pháp học có giám sát một phần.
Huấn luyện tự giám sát là một phương pháp học bán giám sát.
tự huấn luyện
Một biến thể của học tập tự giám sát, đặc biệt hữu ích khi tất cả các điều kiện sau đây đều đúng:
- Tỷ lệ ví dụ chưa được gắn nhãn so với ví dụ đã được gắn nhãn trong tập dữ liệu là cao.
- Đây là vấn đề phân loại.
Tính năng tự huấn luyện hoạt động bằng cách lặp lại 2 bước sau cho đến khi mô hình ngừng cải thiện:
- Sử dụng công nghệ học máy có giám sát để huấn luyện một mô hình dựa trên các ví dụ được gắn nhãn.
- Sử dụng mô hình được tạo ở Bước 1 để tạo dự đoán (nhãn) trên các ví dụ chưa được gắn nhãn, di chuyển những ví dụ có độ tin cậy cao vào các ví dụ được gắn nhãn bằng nhãn dự đoán.
Lưu ý rằng mỗi lần lặp lại Bước 2 sẽ thêm nhiều ví dụ được gắn nhãn hơn để Bước 1 huấn luyện.
học bán giám sát
Huấn luyện một mô hình trên dữ liệu mà một số ví dụ huấn luyện có nhãn nhưng những ví dụ khác thì không. Một kỹ thuật học bán giám sát là suy luận nhãn cho các ví dụ chưa được gắn nhãn, sau đó huấn luyện dựa trên các nhãn được suy luận để tạo một mô hình mới. Học bán giám sát có thể hữu ích nếu nhãn tốn kém để thu thập nhưng có nhiều ví dụ chưa được gắn nhãn.
Tự huấn luyện là một kỹ thuật học bán giám sát.
thuộc tính nhạy cảm
Một thuộc tính của con người có thể được xem xét đặc biệt vì lý do pháp lý, đạo đức, xã hội hoặc cá nhân.phân tích cảm xúc
Sử dụng thuật toán học máy hoặc thống kê để xác định thái độ tổng thể của một nhóm (tích cực hoặc tiêu cực) đối với một dịch vụ, sản phẩm, tổ chức hoặc chủ đề. Ví dụ: bằng cách sử dụng khả năng hiểu ngôn ngữ tự nhiên, một thuật toán có thể thực hiện phân tích tình cảm đối với ý kiến phản hồi bằng văn bản của một khoá học đại học để xác định mức độ mà sinh viên nói chung thích hoặc không thích khoá học đó.
Hãy xem hướng dẫn Phân loại văn bản để biết thêm thông tin.
mô hình chuỗi
Một mô hình có dữ liệu đầu vào có sự phụ thuộc tuần tự. Ví dụ: dự đoán video tiếp theo mà người dùng sẽ xem trong một chuỗi các video đã xem trước đó.
nhiệm vụ từ chuỗi đến chuỗi
Một tác vụ chuyển đổi một chuỗi đầu vào gồm mã thông báo thành một chuỗi đầu ra gồm các mã thông báo. Ví dụ: 2 loại tác vụ phổ biến từ chuỗi đến chuỗi là:
- Người dịch:
- Trình tự nhập mẫu: "Tôi yêu bạn."
- Trình tự đầu ra mẫu: "Je t'aime."
- Trả lời câu hỏi:
- Ví dụ về chuỗi đầu vào: "Tôi có cần dùng xe ở Thành phố New York không?"
- Trình tự đầu ra mẫu: "Không. Hãy để xe ở nhà."
đang phân phát
Quy trình cung cấp một mô hình đã được huấn luyện để đưa ra dự đoán thông qua suy luận trực tuyến hoặc suy luận ngoại tuyến.
shape (Tensor)
Số lượng phần tử trong mỗi chiều của một tensor. Hình dạng được biểu thị dưới dạng một danh sách các số nguyên. Ví dụ: tenxơ hai chiều sau đây có hình dạng [3,4]:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
TensorFlow sử dụng định dạng hàng chính (kiểu C) để biểu thị thứ tự của các phương diện. Đó là lý do tại sao hình dạng trong TensorFlow là [3,4] chứ không phải [4,3]. Nói cách khác, trong một Tensor hai chiều của TensorFlow, hình dạng là [số hàng, số cột].
Hình dạng tĩnh là hình dạng tensor được xác định tại thời gian biên dịch.
Hình dạng động là không xác định tại thời gian biên dịch và do đó phụ thuộc vào dữ liệu thời gian chạy. Tensor này có thể được biểu thị bằng một phương diện giữ chỗ trong TensorFlow, như trong [3, ?].
phân đoạn
Một phép chia logic của tập huấn luyện hoặc mô hình. Thông thường, một số quy trình sẽ tạo các phân đoạn bằng cách chia ví dụ hoặc tham số thành các khối có kích thước bằng nhau (thường là như vậy). Sau đó, mỗi phân đoạn sẽ được chỉ định cho một máy khác.
Phân đoạn một mô hình được gọi là tính song song của mô hình; phân đoạn dữ liệu được gọi là tính song song của dữ liệu.
sự co rút
Một siêu tham số trong tăng cường độ dốc giúp kiểm soát việc khớp quá mức. Mức độ giảm trong phương pháp tăng cường độ dốc tương tự như tốc độ học trong phương pháp giảm độ dốc. Độ co rút là một giá trị thập phân trong khoảng từ 0,0 đến 1,0. Giá trị co rút thấp sẽ giảm tình trạng khớp quá mức nhiều hơn giá trị co rút lớn.
đánh giá song song
So sánh chất lượng của hai mô hình bằng cách đánh giá phản hồi của chúng đối với cùng một câu lệnh. Ví dụ: giả sử bạn đưa ra lời nhắc sau đây cho 2 mô hình khác nhau:
Tạo hình ảnh một chú chó dễ thương đang tung hứng 3 quả bóng.
Trong quá trình đánh giá song song, người đánh giá sẽ chọn hình ảnh "tốt hơn" (Chính xác hơn? Đẹp hơn? Cuter?).
hàm sigmoid
Một hàm toán học "nén" giá trị đầu vào vào một phạm vi bị hạn chế, thường là từ 0 đến 1 hoặc từ -1 đến +1. Tức là bạn có thể truyền bất kỳ số nào (2, 1 triệu, âm 1 tỷ, bất kỳ số nào) vào một hàm sigmoid và đầu ra vẫn sẽ nằm trong phạm vi bị hạn chế. Biểu đồ của hàm kích hoạt sigmoid có dạng như sau:
Hàm sigmoid có một số ứng dụng trong học máy, bao gồm:
- Chuyển đổi đầu ra thô của mô hình hồi quy logistic hoặc hồi quy đa thức thành xác suất.
- Đóng vai trò là một hàm kích hoạt trong một số mạng nơ-ron.
đo lường mức độ tương đồng
Trong thuật toán phân cụm, chỉ số được dùng để xác định mức độ giống nhau (mức độ tương tự) giữa hai ví dụ bất kỳ.
một chương trình / nhiều dữ liệu (SPMD)
Một kỹ thuật song song, trong đó cùng một phép tính được chạy trên các dữ liệu đầu vào khác nhau song song trên các thiết bị khác nhau. Mục tiêu của SPMD là thu được kết quả nhanh hơn. Đây là kiểu lập trình song song phổ biến nhất.
bất biến khi thay đổi kích thước
Trong vấn đề phân loại hình ảnh, khả năng của một thuật toán là phân loại thành công hình ảnh ngay cả khi kích thước của hình ảnh thay đổi. Ví dụ: thuật toán vẫn có thể xác định một con mèo dù con mèo đó chiếm 2 triệu pixel hay 200.000 pixel. Xin lưu ý rằng ngay cả những thuật toán phân loại hình ảnh tốt nhất vẫn có giới hạn thực tế về tính bất biến kích thước. Ví dụ: một thuật toán (hoặc con người) khó có thể phân loại chính xác một hình ảnh mèo chỉ chiếm 20 pixel.
Xem thêm tính bất biến theo phép dịch và tính bất biến khi xoay.
Hãy xem Khoá học về phân cụm để biết thêm thông tin.
phác hoạ
Trong học máy không giám sát, một danh mục thuật toán thực hiện phân tích sơ bộ về điểm tương đồng trên các ví dụ. Thuật toán phác thảo sử dụng hàm băm nhạy cảm với vị trí để xác định những điểm có khả năng tương tự, sau đó nhóm chúng thành các nhóm.
Việc phác thảo giúp giảm lượng phép tính cần thiết cho các phép tính về độ tương tự trên các tập dữ liệu lớn. Thay vì tính toán mức độ tương đồng cho từng cặp ví dụ trong tập dữ liệu, chúng ta chỉ tính toán mức độ tương đồng cho từng cặp điểm trong mỗi nhóm.
skip-gram
Một n-gram có thể bỏ qua (hoặc "bỏ sót") các từ trong ngữ cảnh ban đầu, nghĩa là N từ có thể không nằm cạnh nhau ban đầu. Chính xác hơn, "k-skip-n-gram" là một n-gram mà có thể đã bỏ qua tối đa k từ.
Ví dụ: "the quick brown fox" có thể có các 2-gram sau:
- "the quick"
- "quick brown"
- "cáo nâu"
"1-skip-2-gram" là một cặp từ có tối đa 1 từ ở giữa. Do đó, "the quick brown fox" có 2-gram 1-skip sau đây:
- "the brown"
- "quick fox"
Ngoài ra, tất cả các 2-gram cũng là 1-skip-2-gram, vì có thể bỏ qua ít hơn một từ.
Skip-gram rất hữu ích để hiểu rõ hơn về ngữ cảnh xung quanh một từ. Trong ví dụ này, "fox" được liên kết trực tiếp với "quick" trong tập hợp 1-skip-2-gram, nhưng không được liên kết trong tập hợp 2-gram.
Skip-gram giúp huấn luyện các mô hình nhúng từ.
softmax
Một hàm xác định xác suất cho từng lớp có thể có trong mô hình phân loại nhiều lớp. Tổng các xác suất bằng đúng 1.0. Ví dụ: bảng sau đây cho thấy cách hàm softmax phân phối các xác suất khác nhau:
| Hình ảnh là một... | Xác suất |
|---|---|
| chó | 0,85 |
| mèo | 0,13 |
| con ngựa | .02 |
Softmax còn được gọi là softmax đầy đủ.
Tương phản với lấy mẫu ứng viên.
Hãy xem phần Mạng nơ-ron: Phân loại nhiều lớp trong Khoá học cấp tốc về học máy để biết thêm thông tin.
điều chỉnh câu lệnh mềm
Một kỹ thuật điều chỉnh mô hình ngôn ngữ lớn cho một nhiệm vụ cụ thể mà không cần điều chỉnh chính xác tốn nhiều tài nguyên. Thay vì huấn luyện lại tất cả trọng số trong mô hình, tính năng điều chỉnh lời nhắc linh hoạt sẽ tự động điều chỉnh một lời nhắc để đạt được cùng một mục tiêu.
Với một câu lệnh dạng văn bản, hoạt động tinh chỉnh câu lệnh mềm thường thêm các mục nhúng mã thông báo bổ sung vào câu lệnh và sử dụng phương pháp truyền ngược để tối ưu hoá dữ liệu đầu vào.
Câu lệnh "cứng" chứa các mã thông báo thực tế thay vì các mã thông báo được nhúng.
tính chất thưa
Một đặc điểm mà giá trị chủ yếu là 0 hoặc trống. Ví dụ: một đối tượng chứa một giá trị 1 duy nhất và một triệu giá trị 0 là thưa thớt. Ngược lại, đặc điểm dày đặc có các giá trị chủ yếu không phải là 0 hoặc trống.
Trong học máy, một số lượng đáng ngạc nhiên các đặc điểm là đặc điểm thưa thớt. Các đặc điểm phân loại thường là đặc điểm thưa. Ví dụ: trong số 300 loài cây có thể có trong một khu rừng, một ví dụ duy nhất có thể chỉ xác định một cây phong. Hoặc trong hàng triệu video có thể có trong một thư viện video, một ví dụ duy nhất có thể chỉ xác định "Casablanca".
Trong một mô hình, bạn thường biểu thị các đặc điểm thưa thớt bằng mã hoá one-hot. Nếu mã hoá one-hot có kích thước lớn, bạn có thể đặt một lớp nhúng lên trên mã hoá one-hot để tăng hiệu quả.
biểu diễn thưa
Chỉ lưu trữ (các) vị trí của các phần tử khác 0 trong một đối tượng thưa.
Ví dụ: giả sử một đặc điểm phân loại có tên là species xác định 36 loài cây trong một khu rừng cụ thể. Giả sử thêm rằng mỗi ví dụ chỉ xác định một loài duy nhất.
Bạn có thể sử dụng một vectơ mã hoá một lần để biểu thị loài cây trong mỗi ví dụ.
Một vectơ mã hoá một lần sẽ chứa một 1 (để biểu thị loài cây cụ thể trong ví dụ đó) và 35 0 (để biểu thị 35 loài cây không có trong ví dụ đó). Vì vậy, biểu diễn một lần nóng của maple có thể có dạng như sau:

Ngoài ra, phương pháp biểu diễn thưa thớt chỉ đơn giản là xác định vị trí của loài cụ thể. Nếu maple ở vị trí 24, thì biểu diễn thưa thớt của maple sẽ chỉ là:
24
Xin lưu ý rằng biểu diễn thưa thớt nhỏ gọn hơn nhiều so với biểu diễn một lần nóng.
Nhấp vào biểu tượng để xem một ví dụ phức tạp hơn một chút.
Giả sử mỗi ví dụ trong mô hình của bạn phải biểu thị các từ (nhưng không phải thứ tự của các từ đó) trong một câu tiếng Anh. Tiếng Anh có khoảng 170.000 từ, vì vậy tiếng Anh là một đặc điểm phân loại với khoảng 170.000 phần tử. Hầu hết các câu tiếng Anh đều sử dụng một phần cực nhỏ trong số 170.000 từ đó,vì vậy, tập hợp các từ trong một ví dụ duy nhất gần như chắc chắn sẽ là dữ liệu thưa thớt.
Hãy xem xét câu sau:
My dog is a great dog
Bạn có thể sử dụng một biến thể của vectơ mã hoá một lần để biểu thị các từ trong câu này. Trong biến thể này, nhiều ô trong vectơ có thể chứa một giá trị khác 0. Hơn nữa, trong biến thể này, một ô có thể chứa một số nguyên khác với số 1. Mặc dù các từ "my", "is", "a" và "great" chỉ xuất hiện một lần trong câu, nhưng từ "dog" xuất hiện hai lần. Việc sử dụng biến thể này của vectơ một lần nóng để biểu thị các từ trong câu này sẽ tạo ra vectơ gồm 170.000 phần tử sau:

Một biểu diễn thưa của cùng một câu sẽ chỉ là:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Hãy xem phần Làm việc với dữ liệu phân loại trong Khoá học cấp tốc về học máy để biết thêm thông tin.
vectơ thưa
Một vectơ có hầu hết các giá trị là 0. Xem thêm đặc điểm thưa thớt và độ thưa thớt.
độ thưa
Số lượng phần tử được đặt thành 0 (hoặc rỗng) trong một vectơ hoặc ma trận chia cho tổng số mục trong vectơ hoặc ma trận đó. Ví dụ: hãy xem xét một ma trận gồm 100 phần tử, trong đó 98 ô chứa số 0. Cách tính độ thưa thớt như sau:
Độ thưa thớt của đối tượng đề cập đến độ thưa thớt của một vectơ đối tượng; độ thưa thớt của mô hình đề cập đến độ thưa thớt của trọng số mô hình.
spatial pooling
Xem phần tập hợp.
mã hoá theo quy cách
Quy trình viết và duy trì một tệp mô tả phần mềm sẽ được tạo. Sau đó, bạn có thể yêu cầu một mô hình AI tạo sinh tạo ra phần mềm đáp ứng nội dung mô tả trong tệp.
Mã được tạo tự động thường cần phải lặp lại. Trong quá trình mã hoá theo đặc tả, bạn sẽ lặp lại trên tệp nội dung mô tả. Trong lập trình đàm thoại, bạn sẽ lặp lại trong hộp câu lệnh. Trên thực tế, việc tạo mã tự động đôi khi bao gồm sự kết hợp của cả hoạt động viết mã theo quy cách và hoạt động viết mã đàm thoại.
tách
Trong cây quyết định, một tên khác cho điều kiện.
bộ chia
Trong khi huấn luyện một cây quyết định, quy trình (và thuật toán) chịu trách nhiệm tìm ra điều kiện tốt nhất tại mỗi nút.
SPMD
Chữ viết tắt của single program / multiple data (một chương trình/nhiều dữ liệu).
tổn thất khớp nối bình phương
Bình phương của tổn thất khớp nối. Bình phương tổn thất khớp nối phạt các giá trị ngoại lệ nghiêm khắc hơn so với tổn thất khớp nối thông thường.
tổn thất bình phương
Từ đồng nghĩa với tổn thất L2.
huấn luyện theo giai đoạn
Một chiến thuật huấn luyện mô hình theo một trình tự gồm các giai đoạn riêng biệt. Mục tiêu có thể là đẩy nhanh quy trình huấn luyện hoặc đạt được chất lượng mô hình tốt hơn.
Dưới đây là hình minh hoạ về phương pháp xếp chồng tăng dần:
- Giai đoạn 1 có 3 lớp ẩn, giai đoạn 2 có 6 lớp ẩn và giai đoạn 3 có 12 lớp ẩn.
- Giai đoạn 2 bắt đầu huấn luyện bằng các trọng số đã học được trong 3 lớp ẩn của Giai đoạn 1. Giai đoạn 3 bắt đầu huấn luyện bằng các trọng số đã học được trong 6 lớp ẩn của Giai đoạn 2.

Xem thêm pipelining (phân đoạn đường ống).
tiểu bang
Trong học tăng cường, các giá trị tham số mô tả cấu hình hiện tại của môi trường mà tác nhân sử dụng để chọn một hành động.
hàm giá trị trạng thái-hành động
Từ đồng nghĩa với Q-function.
tĩnh
Việc được thực hiện một lần thay vì liên tục. Các thuật ngữ tĩnh và ngoại tuyến là từ đồng nghĩa. Sau đây là những trường hợp sử dụng phổ biến của tĩnh và ngoại tuyến trong học máy:
- mô hình tĩnh (hoặc mô hình ngoại tuyến) là mô hình được huấn luyện một lần rồi được dùng trong một thời gian.
- huấn luyện tĩnh (hoặc huấn luyện ngoại tuyến) là quy trình huấn luyện một mô hình tĩnh.
- suy luận tĩnh (hoặc suy luận ngoại tuyến) là một quy trình trong đó mô hình tạo ra một loạt dự đoán tại một thời điểm.
Tương phản với động.
suy luận tĩnh
Từ đồng nghĩa với suy luận ngoại tuyến.
tính dừng
Một đặc điểm có giá trị không thay đổi trên một hoặc nhiều phương diện, thường là thời gian. Ví dụ: một đối tượng có các giá trị gần như giống nhau vào năm 2021 và 2023 thể hiện tính dừng.
Trong thế giới thực, rất ít đối tượng có tính chất không đổi. Ngay cả những đặc điểm đồng nghĩa với sự ổn định (như mực nước biển) cũng thay đổi theo thời gian.
Tương phản với tính không dừng.
bị xì hơi
Một lượt truyền xuôi và một lượt truyền ngược của một batch (lô).
Hãy xem phần truyền ngược để biết thêm thông tin về lượt truyền xuôi và lượt truyền ngược.
kích cỡ bước
Từ đồng nghĩa với tốc độ học.
phương pháp giảm độ dốc ngẫu nhiên (SGD)
Một thuật toán hạ độ dốc trong đó kích thước lô là một. Nói cách khác, SGD huấn luyện trên một ví dụ duy nhất được chọn ngẫu nhiên một cách đồng nhất từ một tập huấn luyện.
Hãy xem bài viết Hồi quy tuyến tính: Siêu tham số trong Khoá học cấp tốc về học máy để biết thêm thông tin.
sải chân
Trong một phép toán tích chập hoặc gộp, delta trong mỗi phương diện của chuỗi tiếp theo của các lát đầu vào. Ví dụ: ảnh động sau đây minh hoạ một bước (1,1) trong quá trình hoạt động tích chập. Do đó, lát đầu vào tiếp theo sẽ bắt đầu ở vị trí bên phải của lát đầu vào trước đó. Khi thao tác đạt đến cạnh phải, lát cắt tiếp theo sẽ nằm ở bên trái nhưng xuống một vị trí.
Ví dụ trước minh hoạ một bước sải hai chiều. Nếu ma trận đầu vào là ma trận ba chiều, thì bước sải cũng sẽ là ba chiều.
giảm thiểu rủi ro theo cấu trúc (SRM)
Một thuật toán cân bằng hai mục tiêu:
- Nhu cầu xây dựng mô hình dự đoán chính xác nhất (ví dụ: tổn thất thấp nhất).
- Nhu cầu giữ cho mô hình càng đơn giản càng tốt (ví dụ: điều chỉnh mạnh).
Ví dụ: một hàm giảm thiểu tổn thất + điều chỉnh trên tập huấn luyện là một thuật toán giảm thiểu rủi ro theo cấu trúc.
Tương phản với giảm thiểu rủi ro theo thực nghiệm.
lấy mẫu phụ
Xem phần tập hợp.
mã thông báo từ phụ
Trong mô hình ngôn ngữ, mã thông báo là một chuỗi con của một từ, có thể là toàn bộ từ.
Ví dụ: một từ như "itemize" có thể được chia thành các phần "item" (từ gốc) và "ize" (hậu tố), mỗi phần được biểu thị bằng mã thông báo riêng. Việc chia các từ không phổ biến thành những phần như vậy (gọi là từ con) cho phép các mô hình ngôn ngữ hoạt động trên các phần cấu thành phổ biến hơn của từ, chẳng hạn như tiền tố và hậu tố.
Ngược lại, những từ thông thường như "going" có thể không bị phân tách và có thể được biểu thị bằng một mã thông báo duy nhất.
Gemini và Gemini Advanced
Trong TensorFlow, một giá trị hoặc tập hợp các giá trị được tính toán tại một bước cụ thể, thường được dùng để theo dõi các chỉ số mô hình trong quá trình huấn luyện.
học máy có giám sát
Huấn luyện một mô hình từ các đối tượng và nhãn tương ứng của chúng. Học máy có giám sát tương tự như việc học một môn học bằng cách nghiên cứu một bộ câu hỏi và câu trả lời tương ứng. Sau khi nắm vững mối liên hệ giữa câu hỏi và câu trả lời, học viên có thể trả lời các câu hỏi mới (chưa từng gặp) về cùng một chủ đề.
So sánh với học máy không giám sát.
Hãy xem phần Học có giám sát trong khoá học Giới thiệu về học máy để biết thêm thông tin.
đối tượng nhân tạo
Một đối tượng không có trong số các đối tượng đầu vào, nhưng được tập hợp từ một hoặc nhiều đối tượng đầu vào. Các phương pháp tạo đối tượng tổng hợp bao gồm:
- Phân nhóm một đối tượng liên tục thành các nhóm phạm vi.
- Tạo một tính năng kết hợp.
- Nhân (hoặc chia) một giá trị của tính năng với(các) giá trị khác của tính năng hoặc với chính giá trị đó. Ví dụ: nếu
avàblà các đặc điểm đầu vào, thì sau đây là ví dụ về các đặc điểm tổng hợp:- ab
- a2
- Áp dụng một hàm siêu việt cho giá trị của một đối tượng. Ví dụ: nếu
clà một đối tượng đầu vào, thì sau đây là các ví dụ về đối tượng tổng hợp:- sin(c)
- ln(c)
Các đối tượng được tạo bằng cách chỉ chuẩn hoá hoặc điều chỉnh tỷ lệ không được coi là đối tượng nhân tạo.
T
T5
Một mô hình học chuyển giao từ văn bản sang văn bản do Google AI giới thiệu vào năm 2020. T5 là một mô hình bộ mã hoá – bộ giải mã, dựa trên kiến trúc Transformer, được huấn luyện trên một tập dữ liệu cực lớn. Mô hình này có hiệu quả trong nhiều nhiệm vụ xử lý ngôn ngữ tự nhiên, chẳng hạn như tạo văn bản, dịch ngôn ngữ và trả lời câu hỏi theo cách đàm thoại.
T5 được đặt tên theo 5 chữ T trong "Text-to-Text Transfer Transformer" (Mô hình Transformer chuyển văn bản sang văn bản).
T5X
T5X
Một khung học máy nguồn mở được thiết kế để xây dựng và huấn luyện các mô hình xử lý ngôn ngữ tự nhiên (NLP) quy mô lớn. T5 được triển khai trên cơ sở mã T5X (được xây dựng trên JAX và Flax).
học tăng cường dạng bảng
Trong học tăng cường, hãy triển khai Q-learning bằng cách sử dụng một bảng để lưu trữ Q-function cho mọi tổ hợp state và action.
mục tiêu
Từ đồng nghĩa với nhãn.
mạng mục tiêu
Trong Học tăng cường sâu, mạng nơron là một phép tính xấp xỉ ổn định của mạng nơron chính, trong đó mạng nơron chính triển khai hàm Q hoặc chính sách. Sau đó, bạn có thể huấn luyện mạng chính dựa trên các giá trị Q mà mạng mục tiêu dự đoán. Do đó, bạn ngăn chặn vòng hồi tiếp xảy ra khi mạng chính huấn luyện về các giá trị Q do chính mạng đó dự đoán. Bằng cách tránh phản hồi này, độ ổn định của quá trình huấn luyện sẽ tăng lên.
việc cần làm
Một vấn đề có thể giải quyết bằng các kỹ thuật học máy, chẳng hạn như:
nhiệt độ
Một siêu tham số kiểm soát mức độ ngẫu nhiên của đầu ra của một mô hình. Nhiệt độ càng cao thì kết quả càng ngẫu nhiên, còn nhiệt độ càng thấp thì kết quả càng ít ngẫu nhiên.
Việc chọn nhiệt độ tốt nhất phụ thuộc vào ứng dụng cụ thể và/hoặc các giá trị chuỗi.
dữ liệu theo thời gian
Dữ liệu được ghi lại tại nhiều thời điểm. Ví dụ: doanh số bán áo khoác mùa đông được ghi lại cho mỗi ngày trong năm sẽ là dữ liệu tạm thời.
Tensor
Cấu trúc dữ liệu chính trong các chương trình TensorFlow. Tensor là cấu trúc dữ liệu N chiều (trong đó N có thể rất lớn), thường là các đại lượng vô hướng, vectơ hoặc ma trận. Các phần tử của Tensor có thể chứa giá trị số nguyên, dấu phẩy động hoặc chuỗi.
TensorBoard
Trang tổng quan hiển thị các bản tóm tắt được lưu trong quá trình thực thi một hoặc nhiều chương trình TensorFlow.
TensorFlow
Một nền tảng học máy phân tán, quy mô lớn. Thuật ngữ này cũng đề cập đến lớp API cơ sở trong ngăn xếp TensorFlow, hỗ trợ hoạt động tính toán chung trên các biểu đồ luồng dữ liệu.
Mặc dù TensorFlow chủ yếu được dùng cho hoạt động học máy, nhưng bạn cũng có thể dùng TensorFlow cho các tác vụ không phải ML yêu cầu tính toán số bằng cách sử dụng biểu đồ luồng dữ liệu.
TensorFlow Playground
Một chương trình minh hoạ cách các siêu tham số khác nhau ảnh hưởng đến quá trình huấn luyện mô hình (chủ yếu là mạng nơ-ron). Truy cập http://playground.tensorflow.org để thử nghiệm TensorFlow Playground.
TensorFlow Serving
Một nền tảng để triển khai các mô hình đã huấn luyện trong quá trình sản xuất.
Tensor Processing Unit (TPU)
Một mạch tích hợp dành riêng cho ứng dụng (ASIC) giúp tối ưu hoá hiệu suất của khối lượng công việc học máy. Các ASIC này được triển khai dưới dạng nhiều chip TPU trên một thiết bị TPU.
Hạng Tensor
Xem hạng (Tensor).
Hình dạng tensor
Số lượng phần tử mà Tensor chứa trong nhiều phương diện.
Ví dụ: một Tensor [5, 10] có hình dạng là 5 ở một chiều và 10 ở chiều khác.
Kích thước tensor
Tổng số đại lượng vô hướng mà Tensor chứa. Ví dụ: một Tensor [5, 10] có kích thước là 50.
TensorStore
Một thư viện để đọc và ghi hiệu quả các mảng đa chiều lớn.
điều kiện chấm dứt
Trong học tăng cường, các điều kiện xác định thời điểm kết thúc một tập, chẳng hạn như khi tác nhân đạt đến một trạng thái nhất định hoặc vượt quá ngưỡng số lượng chuyển đổi trạng thái. Ví dụ: trong trò chơi tic-tac-toe (còn gọi là trò chơi đánh dấu ô), một tập sẽ kết thúc khi người chơi đánh dấu 3 ô liên tiếp hoặc khi tất cả các ô đều được đánh dấu.
thử nghiệm
Trong cây quyết định, một tên khác cho điều kiện.
mất mát trong kiểm thử
Một chỉ số biểu thị mức tổn thất của một mô hình so với tập dữ liệu kiểm thử. Khi tạo một mô hình, bạn thường cố gắng giảm thiểu tổn thất trong quá trình kiểm thử. Đó là vì tổn thất thấp trong quá trình kiểm thử là một tín hiệu chất lượng mạnh hơn so với tổn thất thấp trong quá trình huấn luyện hoặc tổn thất thấp trong quá trình xác thực.
Đôi khi, khoảng cách lớn giữa tổn thất trong quá trình kiểm thử và tổn thất trong quá trình huấn luyện hoặc tổn thất trong quá trình xác thực cho thấy bạn cần tăng tỷ lệ điều chỉnh.
tập kiểm thử
Một tập hợp con của tập dữ liệu được dành riêng cho việc kiểm thử một mô hình đã được huấn luyện.
Theo truyền thống, bạn chia các ví dụ trong tập dữ liệu thành 3 tập hợp con riêng biệt sau:
- một tập dữ liệu huấn luyện
- một tập xác thực
- tập kiểm thử
Mỗi ví dụ trong một tập dữ liệu chỉ được thuộc một trong các tập hợp con nêu trên. Ví dụ: một ví dụ duy nhất không được thuộc cả tập huấn luyện và tập kiểm thử.
Tập dữ liệu huấn luyện và tập dữ liệu xác thực đều liên quan chặt chẽ đến việc huấn luyện mô hình. Vì tập hợp kiểm thử chỉ liên kết gián tiếp với quá trình huấn luyện, nên mất mát khi kiểm thử là một chỉ số có chất lượng cao hơn và ít thiên vị hơn so với mất mát khi huấn luyện hoặc mất mát khi xác thực.
Hãy xem phần Tập dữ liệu: Chia tập dữ liệu gốc trong Khoá học học máy ứng dụng để biết thêm thông tin.
khoảng văn bản
Khoảng chỉ mục mảng được liên kết với một phần phụ cụ thể của chuỗi văn bản.
Ví dụ: từ good trong chuỗi Python s="Be good now" chiếm khoảng văn bản từ 3 đến 6.
tf.Example
Một bộ đệm giao thức tiêu chuẩn để mô tả dữ liệu đầu vào cho quá trình huấn luyện hoặc suy luận mô hình học máy.
tf.keras
Một hoạt động triển khai Keras được tích hợp vào TensorFlow.
ngưỡng (đối với cây quyết định)
Trong điều kiện căn chỉnh theo trục, giá trị mà đối tượng đang được so sánh. Ví dụ: 75 là giá trị ngưỡng trong điều kiện sau:
grade >= 75
Hãy xem phần Bộ chia chính xác để phân loại nhị phân bằng các đặc điểm số trong khoá học Rừng quyết định để biết thêm thông tin.
phân tích chuỗi thời gian
Một lĩnh vực phụ của công nghệ học máy và số liệu thống kê, phân tích dữ liệu tạm thời. Nhiều loại vấn đề về học máy đòi hỏi phải phân tích chuỗi thời gian, bao gồm phân loại, phân cụm, dự báo và phát hiện điểm bất thường. Ví dụ: bạn có thể sử dụng phân tích chuỗi thời gian để dự đoán doanh số bán áo khoác mùa đông trong tương lai theo tháng dựa trên dữ liệu doanh số bán hàng trong quá khứ.
timestep
Một ô "chưa cuộn" trong mạng nơ-ron hồi quy. Ví dụ: hình sau đây cho thấy 3 bước thời gian (được gắn nhãn bằng các chỉ số dưới t-1, t và t+1):

mã thông báo
Trong mô hình ngôn ngữ, đơn vị nguyên tử mà mô hình đang huấn luyện và đưa ra dự đoán. Mã thông báo thường là một trong những mã sau:
- một từ – ví dụ: cụm từ "dogs like cats" (chó thích mèo) bao gồm 3 mã thông báo từ: "dogs", "like" và "cats".
- một ký tự – ví dụ: cụm từ "bike fish" bao gồm 9 mã thông báo ký tự. (Xin lưu ý rằng khoảng trống được tính là một trong các mã thông báo.)
- từ con – trong đó một từ có thể là một mã thông báo hoặc nhiều mã thông báo. Từ con bao gồm một từ gốc, một tiền tố hoặc một hậu tố. Ví dụ: một mô hình ngôn ngữ sử dụng từ phụ làm mã thông báo có thể xem từ "dogs" (những chú cún) là hai mã thông báo (từ gốc "dog" và hậu tố số nhiều "s"). Cùng một mô hình ngôn ngữ đó có thể xem từ đơn "taller" (cao hơn) là hai từ phụ (từ gốc "tall" (cao) và hậu tố "er").
Trong các miền bên ngoài mô hình ngôn ngữ, mã thông báo có thể đại diện cho các loại đơn vị nguyên tử khác. Ví dụ: trong thị giác máy tính, mã thông báo có thể là một tập hợp con của hình ảnh.
Hãy xem Các mô hình ngôn ngữ lớn trong Khoá học học máy ứng dụng để biết thêm thông tin.
trình phân tích từ
Một hệ thống hoặc thuật toán chuyển đổi một chuỗi dữ liệu đầu vào thành mã thông báo.
Hầu hết mô hình nền tảng hiện đại đều là đa phương thức. Một mã hoá từ cho hệ thống đa phương thức phải dịch từng loại đầu vào sang định dạng thích hợp. Ví dụ: với dữ liệu đầu vào bao gồm cả văn bản và đồ hoạ, trình phân đoạn có thể dịch văn bản đầu vào thành các từ phụ và hình ảnh đầu vào thành các mảng nhỏ. Sau đó, mã hoá từ phải chuyển đổi tất cả các mã thông báo thành một không gian nhúng hợp nhất duy nhất, cho phép mô hình "hiểu" một luồng dữ liệu đầu vào đa phương thức.
độ chính xác top-k
Tỷ lệ phần trăm số lần "nhãn mục tiêu" xuất hiện trong k vị trí đầu tiên của danh sách được tạo. Các danh sách này có thể là đề xuất được cá nhân hoá hoặc danh sách các mục được sắp xếp theo softmax.
Độ chính xác của k mục hàng đầu còn được gọi là độ chính xác tại k.
ngọn tháp
Một thành phần của mạng nơron sâu, bản thân nó cũng là một mạng nơron sâu. Trong một số trường hợp, mỗi tháp đọc từ một nguồn dữ liệu độc lập và các tháp đó vẫn độc lập cho đến khi đầu ra của chúng được kết hợp trong một lớp cuối cùng. Trong các trường hợp khác (ví dụ: trong tháp bộ mã hoá và bộ giải mã của nhiều Transformer), các tháp có kết nối chéo với nhau.
nội dung độc hại
Mức độ nội dung mang tính lạm dụng, đe doạ hoặc phản cảm. Nhiều mô hình học máy có thể xác định và đo lường mức độ độc hại. Hầu hết các mô hình này đều xác định nội dung độc hại dựa trên nhiều thông số, chẳng hạn như mức độ ngôn từ xúc phạm và mức độ ngôn từ đe doạ.
TPU
Viết tắt của Tensor Processing Unit (Đơn vị xử lý tensor).
Chip TPU
Một bộ tăng tốc đại số tuyến tính có thể lập trình với bộ nhớ băng thông cao trên chip được tối ưu hoá cho khối lượng công việc học máy. Nhiều chip TPU được triển khai trên một thiết bị TPU.
Thiết bị TPU
Một bảng mạch in (PCB) có nhiều chip TPU, giao diện mạng có băng thông cao và phần cứng làm mát hệ thống.
Nút TPU
Một tài nguyên TPU trên Google Cloud có một loại TPU cụ thể. Nút TPU kết nối với Mạng VPC của bạn từ mạng VPC ngang hàng. Nút TPU là một tài nguyên được xác định trong API Cloud TPU.
Nhóm TPU
Một cấu hình cụ thể của thiết bị TPU trong một trung tâm dữ liệu của Google. Tất cả các thiết bị trong một Nhóm TPU đều được kết nối với nhau thông qua một mạng chuyên dụng tốc độ cao. Nhóm TPU là cấu hình lớn nhất của thiết bị TPU có sẵn cho một phiên bản TPU cụ thể.
Tài nguyên TPU
Một thực thể TPU trên Google Cloud mà bạn tạo, quản lý hoặc sử dụng. Ví dụ: nút TPU và các loại TPU là các tài nguyên TPU.
Lát TPU
Lát TPU là một phần nhỏ của thiết bị TPU trong một TPU Pod. Tất cả các thiết bị trong một lát TPU đều được kết nối với nhau qua một mạng tốc độ cao chuyên dụng.
Loại TPU
Một cấu hình của một hoặc nhiều thiết bị TPU có phiên bản phần cứng TPU cụ thể. Bạn chọn một loại TPU khi tạo một nút TPU trên Google Cloud. Ví dụ: loại v2-8TPU là một thiết bị TPU phiên bản 2 duy nhất có 8 lõi. Một loại TPU v3-2048 có 256 thiết bị TPU phiên bản 3 được kết nối mạng và tổng cộng 2048 lõi. Các loại TPU là một tài nguyên được xác định trong API Cloud TPU.
Trình chạy TPU
Một quy trình chạy trên máy chủ và thực thi các chương trình học máy trên thiết bị TPU.
đào tạo
Quá trình xác định các tham số (trọng số và độ lệch) lý tưởng bao gồm một mô hình. Trong quá trình huấn luyện, hệ thống sẽ đọc các ví dụ và điều chỉnh dần các tham số. Quá trình huấn luyện sử dụng mỗi ví dụ từ vài lần đến hàng tỷ lần.
Hãy xem phần Học có giám sát trong khoá học Giới thiệu về học máy để biết thêm thông tin.
tổn thất trong quá trình huấn luyện
Một chỉ số biểu thị mức tổn thất của mô hình trong một lần lặp lại huấn luyện cụ thể. Ví dụ: giả sử hàm tổn thất là Sai số bình phương trung bình. Có thể tổn thất huấn luyện (Lỗi bình phương trung bình) cho lần lặp thứ 10 là 2,2 và tổn thất huấn luyện cho lần lặp thứ 100 là 1,9.
Đường cong tổn thất vẽ tổn thất trong quá trình huấn luyện so với số lần lặp lại. Đường cong tổn thất cung cấp các gợi ý sau về quá trình huấn luyện:
- Độ dốc giảm cho thấy mô hình đang cải thiện.
- Đường dốc lên cho thấy mô hình đang trở nên kém hiệu quả hơn.
- Độ dốc bằng phẳng cho thấy mô hình đã đạt đến sự hội tụ.
Ví dụ: đường cong tổn thất (khá lý tưởng) sau đây cho thấy:
- Đường dốc xuống dốc trong các lần lặp lại ban đầu, cho thấy mô hình được cải thiện nhanh chóng.
- Độ dốc giảm dần (nhưng vẫn đi xuống) cho đến gần cuối quá trình huấn luyện, điều này ngụ ý rằng mô hình tiếp tục cải thiện với tốc độ chậm hơn so với các lần lặp lại ban đầu.
- Đường dốc bằng phẳng về cuối quá trình huấn luyện, cho thấy sự hội tụ.

Mặc dù tổn thất khi huấn luyện là rất quan trọng, nhưng bạn cũng nên xem khả năng khái quát hoá.
độ lệch giữa huấn luyện và phân phát
Sự khác biệt giữa hiệu suất của một mô hình trong quá trình huấn luyện và hiệu suất của chính mô hình đó trong quá trình phân phát.
tập dữ liệu huấn luyện
Tập hợp con của tập dữ liệu được dùng để huấn luyện một mô hình.
Theo truyền thống, các ví dụ trong tập dữ liệu được chia thành 3 tập hợp con riêng biệt sau đây:
- tập dữ liệu huấn luyện
- một tập xác thực
- một tập kiểm thử
Tốt nhất là mỗi ví dụ trong tập dữ liệu chỉ nên thuộc một trong các tập hợp con trước đó. Ví dụ: một ví dụ duy nhất không được thuộc cả tập huấn luyện và tập xác thực.
Hãy xem phần Tập dữ liệu: Chia tập dữ liệu gốc trong Khoá học học máy ứng dụng để biết thêm thông tin.
quỹ đạo
Trong học tăng cường, một chuỗi bộ dữ liệu biểu thị một chuỗi các quá trình chuyển đổi trạng thái của tác nhân, trong đó mỗi bộ dữ liệu tương ứng với trạng thái, hành động, phần thưởng và trạng thái tiếp theo cho một quá trình chuyển đổi trạng thái nhất định.
học chuyển giao
Chuyển thông tin từ nhiệm vụ học máy này sang nhiệm vụ học máy khác. Ví dụ: trong quá trình học đa nhiệm, một mô hình duy nhất sẽ giải quyết nhiều nhiệm vụ, chẳng hạn như mô hình sâu có các nút đầu ra khác nhau cho các nhiệm vụ khác nhau. Học chuyển giao có thể liên quan đến việc chuyển giao kiến thức từ giải pháp của một nhiệm vụ đơn giản hơn sang một nhiệm vụ phức tạp hơn, hoặc liên quan đến việc chuyển giao kiến thức từ một nhiệm vụ có nhiều dữ liệu hơn sang một nhiệm vụ có ít dữ liệu hơn.
Hầu hết các hệ thống học máy đều giải quyết một nhiệm vụ đơn lẻ. Học chuyển giao là một bước nhỏ hướng tới trí tuệ nhân tạo, trong đó một chương trình duy nhất có thể giải quyết nhiều tác vụ.
Biến áp
Một kiến trúc mạng nơ-ron được phát triển tại Google, dựa trên cơ chế tự chú ý để chuyển đổi một chuỗi các mục nhúng đầu vào thành một chuỗi các mục nhúng đầu ra mà không cần dựa vào tích chập hoặc mạng nơ-ron hồi quy. Bạn có thể xem Transformer như một ngăn xếp các lớp tự chú ý.
Transformer có thể bao gồm bất kỳ thành phần nào sau đây:
- một bộ mã hoá
- một bộ giải mã
- cả bộ mã hoá và bộ giải mã
Bộ mã hoá chuyển đổi một chuỗi các vectơ nhúng thành một chuỗi mới có cùng độ dài. Bộ mã hoá bao gồm N lớp giống hệt nhau, mỗi lớp chứa hai lớp con. Hai lớp con này được áp dụng tại mỗi vị trí của chuỗi nhúng đầu vào, chuyển đổi từng phần tử của chuỗi thành một mục nhúng mới. Lớp phụ mã hoá đầu tiên tổng hợp thông tin từ toàn bộ chuỗi đầu vào. Lớp phụ mã hoá thứ hai chuyển đổi thông tin tổng hợp thành một vectơ nhúng đầu ra.
Bộ giải mã chuyển đổi một chuỗi các vectơ nhúng đầu vào thành một chuỗi các vectơ nhúng đầu ra, có thể có độ dài khác. Bộ giải mã cũng bao gồm N lớp giống hệt nhau với 3 lớp con, trong đó 2 lớp tương tự như các lớp con của bộ mã hoá. Lớp phụ giải mã thứ ba lấy đầu ra của bộ mã hoá và áp dụng cơ chế tự chú ý để thu thập thông tin từ đó.
Bài đăng trên blog Transformer: Một cấu trúc mạng nơ-ron mới để hiểu ngôn ngữ cung cấp thông tin giới thiệu hữu ích về Transformer.
Hãy xem bài viết LLM: Mô hình ngôn ngữ lớn là gì? trong Khoá học máy học ứng dụng để biết thêm thông tin.
tính bất biến theo phép dịch
Trong vấn đề phân loại hình ảnh, khả năng của một thuật toán trong việc phân loại thành công hình ảnh ngay cả khi vị trí của các đối tượng trong hình ảnh thay đổi. Ví dụ: thuật toán vẫn có thể xác định một con chó, cho dù con chó đó ở giữa khung hình hay ở cuối bên trái của khung hình.
Xem thêm tính bất biến khi thay đổi kích thước và tính bất biến khi xoay.
trigram
Một N-gram trong đó N=3.
âm tính thật (TN)
Ví dụ trong đó mô hình dự đoán chính xác lớp âm. Ví dụ: mô hình suy luận rằng một thư email cụ thể không phải là thư rác và thư email đó thực sự không phải là thư rác.
dương tính thật (TP)
Ví dụ trong đó mô hình dự đoán chính xác lớp dương tính. Ví dụ: mô hình suy luận rằng một thư email cụ thể là thư rác và thư email đó thực sự là thư rác.
tỷ lệ dương tính thật (TPR)
Từ đồng nghĩa với mức độ ghi nhớ. Đó là:
Tỷ lệ dương tính thật là trục y trong đường cong ROC.
TTL
Từ viết tắt của thời gian tồn tại.
U
Ultra
Mô hình Gemini có các tham số nhiều nhất. Hãy xem phần Gemini Ultra để biết thông tin chi tiết.
không nhận biết (đối với một thuộc tính nhạy cảm)
Trường hợp có thuộc tính nhạy cảm nhưng không có trong dữ liệu huấn luyện. Vì các thuộc tính nhạy cảm thường tương quan với các thuộc tính khác trong dữ liệu của một người, nên một mô hình được huấn luyện mà không biết về một thuộc tính nhạy cảm vẫn có thể có tác động không tương xứng đối với thuộc tính đó hoặc vi phạm các ràng buộc khác về tính công bằng.
khớp dữ liệu kém
Tạo ra một mô hình có khả năng dự đoán kém vì mô hình chưa nắm bắt hết độ phức tạp của dữ liệu huấn luyện. Nhiều vấn đề có thể gây ra tình trạng thiếu khớp, bao gồm:
- Huấn luyện trên tập hợp tính năng không chính xác.
- Huấn luyện cho quá ít epoch hoặc ở tốc độ học tập quá thấp.
- Huấn luyện với tốc độ điều chỉnh quá cao.
- Cung cấp quá ít lớp ẩn trong mạng nơ-ron sâu.
Hãy xem phần Quá khớp trong Khoá học học máy ứng dụng để biết thêm thông tin.
lấy mẫu dưới mức
Xoá ví dụ khỏi lớp đa số trong tập dữ liệu bất cân đối về loại để tạo tập huấn luyện cân bằng hơn.
Ví dụ: hãy xem xét một tập dữ liệu trong đó tỷ lệ của lớp đa số so với lớp thiểu số là 20:1. Để khắc phục tình trạng mất cân bằng lớp này, bạn có thể tạo một tập huấn luyện bao gồm tất cả các ví dụ về lớp thiểu số nhưng chỉ có một phần mười các ví dụ về lớp đa số. Điều này sẽ tạo ra tỷ lệ lớp tập huấn luyện là 2:1. Nhờ phương pháp lấy mẫu dưới mức, tập huấn luyện cân bằng hơn này có thể tạo ra một mô hình tốt hơn. Ngoài ra, tập huấn luyện cân bằng hơn này có thể chứa không đủ ví dụ để huấn luyện một mô hình hiệu quả.
Tương phản với lấy mẫu dư thừa.
một hướng
Một hệ thống chỉ đánh giá văn bản đứng trước một phần văn bản mục tiêu. Ngược lại, một hệ thống hai chiều sẽ đánh giá cả văn bản đứng trước và đứng sau một phần văn bản mục tiêu. Hãy xem hai chiều để biết thêm thông tin.
mô hình ngôn ngữ một chiều
Một mô hình ngôn ngữ chỉ dựa vào xác suất của các mã thông báo xuất hiện trước chứ không phải sau(các) mã thông báo mục tiêu. Tương phản với mô hình ngôn ngữ hai chiều.
ví dụ không có nhãn
Ví dụ có các tính năng nhưng không có nhãn. Ví dụ: bảng sau đây cho thấy 3 ví dụ không được gắn nhãn từ một mô hình định giá nhà, mỗi ví dụ có 3 đặc điểm nhưng không có giá trị nhà:
| Số lượng phòng ngủ | Số lượng phòng tắm | Tuổi của nhà |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
Trong công nghệ học máy có giám sát, các mô hình sẽ được huấn luyện dựa trên các ví dụ được gắn nhãn và đưa ra dự đoán về các ví dụ chưa được gắn nhãn.
Trong quá trình học bán giám sát và không giám sát, các ví dụ không được gắn nhãn sẽ được dùng trong quá trình huấn luyện.
So sánh ví dụ không có nhãn với ví dụ có nhãn.
học máy không giám sát
Huấn luyện một mô hình để tìm các mẫu trong một tập dữ liệu, thường là một tập dữ liệu chưa được gắn nhãn.
Ứng dụng phổ biến nhất của công nghệ học máy không giám sát là phân cụm dữ liệu thành các nhóm ví dụ tương tự. Ví dụ: một thuật toán học máy không được giám sát có thể phân cụm các bài hát dựa trên nhiều thuộc tính của nhạc. Các cụm kết quả có thể trở thành dữ liệu đầu vào cho các thuật toán học máy khác (ví dụ: cho một dịch vụ đề xuất nhạc). Việc phân cụm có thể giúp ích khi bạn có ít hoặc không có nhãn hữu ích. Ví dụ: trong các lĩnh vực như chống hành vi sai trái và gian lận, các cụm có thể giúp con người hiểu rõ hơn về dữ liệu.
Tương phản với học máy có giám sát.
Hãy xem bài viết Công nghệ học máy là gì? trong khoá học Giới thiệu về ML để biết thêm thông tin.
lập mô hình mức tăng
Một kỹ thuật lập mô hình, thường được dùng trong hoạt động tiếp thị, giúp lập mô hình "hiệu ứng nhân quả" (còn gọi là "tác động gia tăng") của một "phương pháp can thiệp" đối với một "cá nhân". Dưới đây là hai ví dụ:
- Các bác sĩ có thể sử dụng mô hình nâng cao để dự đoán mức giảm tỷ lệ tử vong (hiệu ứng nhân quả) của một quy trình y tế (phương pháp điều trị) tuỳ thuộc vào độ tuổi và tiền sử bệnh của bệnh nhân (cá nhân).
- Nhà tiếp thị có thể sử dụng mô hình nâng cao để dự đoán mức tăng về khả năng mua hàng (hiệu ứng nhân quả) do một quảng cáo (phương pháp xử lý) tác động lên một người (cá nhân).
Mô hình hoá mức tăng khác với phân loại hoặc hồi quy ở chỗ một số nhãn (ví dụ: một nửa số nhãn trong các phương pháp điều trị nhị phân) luôn bị thiếu trong mô hình hoá mức tăng. Ví dụ: bệnh nhân có thể được điều trị hoặc không được điều trị; do đó, chúng ta chỉ có thể quan sát xem bệnh nhân có khỏi bệnh hay không trong một trong hai trường hợp này (chứ không bao giờ cả hai). Ưu điểm chính của mô hình nâng cao là có thể tạo ra các dự đoán cho tình huống không được ghi nhận (tình huống đối chứng) và sử dụng tình huống đó để tính toán hiệu ứng nhân quả.
tăng trọng số
Áp dụng trọng số cho lớp giảm mẫu bằng với hệ số mà bạn đã giảm mẫu.
ma trận người dùng
Trong hệ thống đề xuất, vectơ nhúng do phân tích ma trận tạo ra sẽ lưu giữ các tín hiệu tiềm ẩn về lựa chọn ưu tiên của người dùng. Mỗi hàng trong ma trận người dùng chứa thông tin về sức mạnh tương đối của nhiều tín hiệu tiềm ẩn cho một người dùng. Ví dụ: hãy xem xét một hệ thống đề xuất phim. Trong hệ thống này, các tín hiệu tiềm ẩn trong ma trận người dùng có thể biểu thị mối quan tâm của mỗi người dùng đối với các thể loại cụ thể hoặc có thể là những tín hiệu khó diễn giải hơn liên quan đến các hoạt động tương tác phức tạp trên nhiều yếu tố.
Ma trận người dùng có một cột cho mỗi đặc điểm tiềm ẩn và một hàng cho mỗi người dùng. Tức là ma trận người dùng có cùng số hàng với ma trận mục tiêu đang được phân tích. Ví dụ: đối với một hệ thống đề xuất phim cho 1.000.000 người dùng, ma trận người dùng sẽ có 1.000.000 hàng.
V
xác thực
Đánh giá ban đầu về chất lượng của một mô hình. Xác thực kiểm tra chất lượng của các dự đoán của mô hình dựa trên tập hợp xác thực.
Vì tập hợp xác thực khác với tập hợp huấn luyện, nên việc xác thực giúp ngăn chặn tình trạng quá khớp.
Bạn có thể coi việc đánh giá mô hình dựa trên tập hợp xác thực là vòng kiểm thử đầu tiên và đánh giá mô hình dựa trên tập hợp kiểm thử là vòng kiểm thử thứ hai.
mất mát xác thực
Một chỉ số biểu thị mất mát của mô hình trên tập hợp xác thực trong một lần lặp lại cụ thể của quá trình huấn luyện.
Xem thêm đường cong khái quát hoá.
tập xác nhận
Tập hợp con của tập dữ liệu thực hiện đánh giá ban đầu dựa trên một mô hình đã được huấn luyện. Thông thường, bạn sẽ đánh giá mô hình đã huấn luyện dựa trên tập hợp xác thực nhiều lần trước khi đánh giá mô hình dựa trên tập hợp kiểm thử.
Theo truyền thống, bạn chia các ví dụ trong tập dữ liệu thành 3 tập hợp con riêng biệt sau đây:
- một tập dữ liệu huấn luyện
- tập xác thực
- một tập kiểm thử
Tốt nhất là mỗi ví dụ trong tập dữ liệu chỉ nên thuộc một trong các tập hợp con trước đó. Ví dụ: một ví dụ duy nhất không được thuộc cả tập huấn luyện và tập xác thực.
Hãy xem phần Tập dữ liệu: Chia tập dữ liệu gốc trong Khoá học học máy ứng dụng để biết thêm thông tin.
suy đoán giá trị
Quy trình thay thế một giá trị bị thiếu bằng một giá trị thay thế được chấp nhận. Khi thiếu một giá trị, bạn có thể loại bỏ toàn bộ ví dụ hoặc sử dụng phương pháp thay thế giá trị để khôi phục ví dụ.
Ví dụ: hãy xem xét một tập dữ liệu chứa một tính năng temperature được ghi lại mỗi giờ. Tuy nhiên, chỉ số nhiệt độ không có sẵn trong một giờ cụ thể. Dưới đây là một phần của tập dữ liệu:
| Dấu thời gian | Nhiệt độ |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | bị thiếu |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
Một hệ thống có thể xoá ví dụ bị thiếu hoặc gán nhiệt độ bị thiếu là 12, 16, 18 hoặc 20, tuỳ thuộc vào thuật toán gán giá trị.
vấn đề về độ dốc biến mất
Xu hướng độ dốc của các lớp ẩn ban đầu của một số mạng nơ-ron sâu trở nên bằng phẳng (thấp) một cách đáng ngạc nhiên. Độ dốc ngày càng thấp dẫn đến những thay đổi ngày càng nhỏ hơn về trọng số trên các nút trong mạng nơ-ron sâu, dẫn đến việc học rất ít hoặc không học được gì. Các mô hình gặp phải vấn đề biến mất độ dốc sẽ trở nên khó khăn hoặc không thể huấn luyện. Các tế bào Long Short-Term Memory (Bộ nhớ ngắn hạn dài) giải quyết vấn đề này.
So sánh với vấn đề về độ dốc tăng dần.
mức độ quan trọng của biến
Một tập hợp các điểm số cho biết tầm quan trọng tương đối của từng đặc điểm đối với mô hình.
Ví dụ: hãy xem xét một cây quyết định ước tính giá nhà. Giả sử cây quyết định này sử dụng 3 đặc điểm: kích thước, độ tuổi và kiểu dáng. Nếu một tập hợp các mức độ quan trọng của biến cho 3 đặc điểm được tính là {size=5.8, age=2.5, style=4.7}, thì kích thước quan trọng hơn đối với cây quyết định so với độ tuổi hoặc kiểu dáng.
Có nhiều chỉ số về tầm quan trọng của biến, có thể cung cấp thông tin cho các chuyên gia về học máy về nhiều khía cạnh của mô hình.
bộ mã hoá tự động biến phân (VAE)
Một loại bộ mã hoá tự động tận dụng sự khác biệt giữa đầu vào và đầu ra để tạo ra các phiên bản đã sửa đổi của đầu vào. Trình mã hoá tự động biến thiên rất hữu ích cho AI tạo sinh.
VAE dựa trên suy luận biến phân: một kỹ thuật để ước tính các tham số của mô hình xác suất.
vectơ
Một thuật ngữ rất chung chung có ý nghĩa khác nhau trong các lĩnh vực toán học và khoa học. Trong học máy, vectơ có hai thuộc tính:
- Loại dữ liệu: Các vectơ trong học máy thường chứa các số thực.
- Số lượng phần tử: Đây là độ dài hoặc kích thước của vectơ.
Ví dụ: hãy xem xét một vectơ đặc trưng chứa 8 số thực. Véc tơ đặc trưng này có độ dài hoặc phương diện là 8. Xin lưu ý rằng các vectơ học máy thường có số lượng phương diện rất lớn.
Bạn có thể biểu thị nhiều loại thông tin dưới dạng vectơ. Ví dụ:
- Mọi vị trí trên bề mặt Trái Đất đều có thể được biểu diễn dưới dạng một vectơ 2 chiều, trong đó một chiều là vĩ độ và chiều còn lại là kinh độ.
- Giá hiện tại của mỗi trong số 500 cổ phiếu có thể được biểu thị dưới dạng một vectơ 500 chiều.
- Bạn có thể biểu diễn hàm phân phối xác suất trên một số lượng hữu hạn các lớp dưới dạng vectơ. Ví dụ: một hệ thống phân loại nhiều lớp dự đoán một trong ba màu đầu ra (đỏ, xanh lục hoặc vàng) có thể xuất vectơ
(0.3, 0.2, 0.5)để biểu thịP[red]=0.3, P[green]=0.2, P[yellow]=0.5.
Bạn có thể nối các vectơ; do đó, nhiều loại nội dung nghe nhìn có thể được biểu thị dưới dạng một vectơ duy nhất. Một số mô hình hoạt động trực tiếp trên sự kết hợp của nhiều mã hoá one-hot.
Các bộ xử lý chuyên dụng như TPU được tối ưu hoá để thực hiện các phép toán trên vectơ.
Vectơ là một tensor có hạng 1.
Đỉnh
Nền tảng của Google Cloud dành cho AI và học máy. Vertex cung cấp các công cụ và cơ sở hạ tầng để xây dựng, triển khai và quản lý các ứng dụng AI, bao gồm cả quyền truy cập vào các mô hình Gemini.lập trình theo cảm hứng
Đưa ra câu lệnh cho mô hình AI tạo sinh để tạo phần mềm. Tức là câu lệnh của bạn mô tả mục đích và các tính năng của phần mềm, mà một mô hình AI tạo sinh sẽ dịch thành mã nguồn. Mã được tạo không phải lúc nào cũng phù hợp với ý định của bạn, vì vậy, việc lập trình theo cảm hứng thường đòi hỏi phải có sự lặp lại.
Andrej Karpathy đã đặt ra thuật ngữ lập trình theo cảm hứng trong bài đăng này trên X. Trong bài đăng trên X, Karpathy mô tả đây là "một kiểu lập trình mới...nơi bạn hoàn toàn đắm chìm vào cảm xúc..." Vì vậy, ban đầu, thuật ngữ này ngụ ý một phương pháp cố ý lỏng lẻo để tạo phần mềm, trong đó bạn thậm chí có thể không kiểm tra mã được tạo. Tuy nhiên, thuật ngữ này đã nhanh chóng phát triển trong nhiều lĩnh vực để giờ đây có nghĩa là bất kỳ hình thức nào của hoạt động lập trình do AI tạo.
Để biết nội dung mô tả chi tiết hơn về mã rung, hãy xem Lập trình theo cảm hứng là gì?
Ngoài ra, hãy so sánh và đối chiếu mã rung với:
W
Tổn thất Wasserstein
Một trong những hàm tổn thất thường được dùng trong mạng đối nghịch sinh, dựa trên khoảng cách của hàm di chuyển trên mặt đất giữa phân phối dữ liệu được tạo và dữ liệu thực.
cân nặng
Giá trị mà một mô hình nhân với một giá trị khác. Huấn luyện là quá trình xác định trọng số lý tưởng của một mô hình; suy luận là quá trình sử dụng những trọng số đã học đó để đưa ra dự đoán.
Hãy xem phần Hồi quy tuyến tính trong Khoá học học máy ứng dụng để biết thêm thông tin.
Bình phương tối thiểu luân phiên có trọng số (WALS)
Một thuật toán để giảm thiểu hàm mục tiêu trong phân tích ma trận trong hệ thống đề xuất, cho phép giảm trọng số của các ví dụ bị thiếu. WALS giảm thiểu sai số bình phương có trọng số giữa ma trận ban đầu và ma trận được tái cấu trúc bằng cách thay đổi giữa việc cố định hệ số phân tích hàng và hệ số phân tích cột. Mỗi chế độ tối ưu hoá này có thể được giải quyết bằng phương pháp bình phương tối thiểu tối ưu hoá lồi. Để biết thông tin chi tiết, hãy xem khoá học Hệ thống đề xuất.
tổng có trọng số
Tổng của tất cả các giá trị đầu vào có liên quan nhân với trọng số tương ứng của chúng. Ví dụ: giả sử các dữ liệu đầu vào có liên quan bao gồm những dữ liệu sau:
| giá trị đầu vào | trọng số đầu vào |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
Do đó, tổng có trọng số là:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Tổng có trọng số là đối số đầu vào cho một hàm kích hoạt.
mô hình rộng
Một mô hình tuyến tính thường có nhiều đặc điểm đầu vào thưa thớt. Chúng tôi gọi mô hình này là "rộng" vì đây là một loại mạng nơ-ron đặc biệt với số lượng lớn đầu vào kết nối trực tiếp với nút đầu ra. Các mô hình rộng thường dễ gỡ lỗi và kiểm tra hơn so với mô hình sâu. Mặc dù các mô hình rộng không thể thể hiện tính phi tuyến tính thông qua các lớp ẩn, nhưng các mô hình rộng có thể sử dụng các phép biến đổi như tính năng kết hợp và phân nhóm để mô hình hoá tính phi tuyến tính theo nhiều cách.
Tương phản với mô hình sâu.
chiều rộng
Số lượng nơ-ron trong một lớp cụ thể của mạng nơ-ron.
trí tuệ tập thể
Ý tưởng cho rằng việc lấy ý kiến hoặc ước tính trung bình của một nhóm lớn người ("đám đông") thường mang lại kết quả tốt một cách đáng ngạc nhiên. Ví dụ: hãy xem xét một trò chơi mà mọi người đoán số lượng kẹo thạch được đóng gói trong một chiếc bình lớn. Mặc dù hầu hết các dự đoán riêng lẻ đều không chính xác, nhưng trung bình của tất cả các dự đoán đã được chứng minh bằng thực nghiệm là gần với số lượng thực tế của kẹo thạch trong bình một cách đáng ngạc nhiên.
Tập hợp là một phần mềm tương tự như trí tuệ tập thể. Ngay cả khi các mô hình riêng lẻ đưa ra dự đoán không chính xác, việc tính trung bình các dự đoán của nhiều mô hình thường tạo ra những dự đoán tốt một cách đáng ngạc nhiên. Ví dụ: mặc dù cây quyết định riêng lẻ có thể đưa ra dự đoán kém chính xác, nhưng rừng quyết định thường đưa ra dự đoán rất chính xác.
word embedding
Biểu thị mỗi từ trong một tập hợp từ trong vectơ nhúng; tức là biểu thị mỗi từ dưới dạng một vectơ gồm các giá trị dấu phẩy động từ 0 đến 1. Những từ có nghĩa tương tự sẽ có biểu diễn tương tự hơn so với những từ có nghĩa khác nhau. Ví dụ: cà rốt, cần tây và dưa chuột đều có cách biểu diễn tương đối giống nhau, khác biệt rất nhiều so với cách biểu diễn của máy bay, kính râm và kem đánh răng.
X
XLA (Đại số tuyến tính được tăng tốc)
Một trình biên dịch học máy mã nguồn mở cho GPU, CPU và bộ tăng tốc ML.
Trình biên dịch XLA lấy các mô hình từ các khung máy học phổ biến như PyTorch, TensorFlow và JAX, đồng thời tối ưu hoá các mô hình này để thực thi hiệu suất cao trên nhiều nền tảng phần cứng, bao gồm cả GPU, CPU và trình tăng tốc ML.
Z
học từ không có dữ liệu
Một loại huấn luyện học máy trong đó mô hình suy ra một dự đoán cho một nhiệm vụ mà mô hình đó chưa được huấn luyện cụ thể. Nói cách khác, mô hình này không được cung cấp ví dụ đào tạo dành riêng cho nhiệm vụ, nhưng được yêu cầu thực hiện suy luận cho nhiệm vụ đó.
đặt câu lệnh không kèm ví dụ
Một câu lệnh không cung cấp ví dụ về cách bạn muốn mô hình ngôn ngữ lớn phản hồi. Ví dụ:
| Các phần của một câu lệnh | Ghi chú |
|---|---|
| Đơn vị tiền tệ chính thức của quốc gia được chỉ định là gì? | Câu hỏi bạn muốn LLM trả lời. |
| Ấn Độ: | Cụm từ tìm kiếm thực tế. |
Mô hình ngôn ngữ lớn có thể trả lời bằng bất kỳ nội dung nào sau đây:
- Rupee
- INR
- ₹
- Đồng rupi Ấn Độ
- Đồng rupee
- Đồng rupi Ấn Độ
Tất cả các câu trả lời đều đúng, mặc dù bạn có thể thích một định dạng cụ thể.
So sánh và đối chiếu câu lệnh không có ví dụ với các thuật ngữ sau:
Chuẩn hoá điểm Z
Kỹ thuật chia tỷ lệ thay thế giá trị đặc điểm thô bằng giá trị dấu phẩy động biểu thị số độ lệch chuẩn so với giá trị trung bình của đặc điểm đó. Ví dụ: hãy xem xét một đặc điểm có giá trị trung bình là 800 và độ lệch chuẩn là 100. Bảng sau đây cho thấy cách chuẩn hoá điểm Z sẽ liên kết giá trị thô với điểm Z:
| Giá trị thô | Điểm Z |
|---|---|
| 800 | 0 |
| 950 | +1,5 |
| 575 | -2,25 |
Sau đó, mô hình học máy sẽ huấn luyện dựa trên điểm Z cho tính năng đó thay vì dựa trên các giá trị thô.
Hãy xem phần Dữ liệu dạng số: Chuẩn hoá trong Khoá học cấp tốc về học máy để biết thêm thông tin.
Bảng chú giải này định nghĩa các thuật ngữ về học máy.