“模型皆有误,或由建奇功”。- George Box,1978 年
虽然统计技术很强大,但也有局限性。了解这些限制有助于研究人员避免出现错误和不准确的断言,例如 BF Skinner 断言莎士比亚的押韵使用频率并不高于随机预测的频率。(Skinner 的研究缺乏效力。1)
不确定性和误差条
请务必在分析中指明不确定性。同样重要的是,要量化他人分析中的不确定性。如果数据点似乎在图表上绘制出趋势,但误差条重叠,则可能根本不存在任何规律。不确定性也可能过高,无法根据特定研究或统计测试得出有用的结论。如果研究需要地块级准确性,则不确定性为 +/- 500 米的地理空间数据集的不确定性过大,无法使用。
或者,在决策过程中,不确定性水平可能很有用。如果数据支持采用某种水处理方法,但结果的不确定性为 20%,则系统可能会建议实施该水处理方法,并持续监控该计划以解决这种不确定性。
贝叶斯神经网络可以通过预测值的分布(而非单个值)来量化不确定性。
无关
如前言所述,数据与现实之间始终存在至少一小段差距。精明的机器学习从业者应确定数据集是否与所问问题相关。
Huff 描述了一项早期民意调查,该调查发现,美国白人对“美国黑人能否轻松过上好日子”这一问题的回答与他们对美国黑人的同情程度成正比和反比关系。随着种族仇恨情绪的加剧,人们对预期经济机会的回答越来越乐观。这可能会被误解为进展顺利。 不过,该研究无法说明当时美国黑人可获得的实际经济机会,也不适合据此得出关于就业市场现实情况的结论,只能反映调查对象的观点。收集的数据实际上与就业市场状况无关。2
您可以使用上述调查数据训练模型,其中输出实际上衡量的是乐观程度,而不是机会。但是,由于预测的机会与实际机会无关,因此如果您声称模型在预测实际机会,则会误导用户。
混杂因素
混杂变量、混杂或协变量是指未纳入研究范围但会影响研究对象的变量,可能会导致结果失真。例如,假设有一个机器学习模型,该模型根据公共卫生政策特征预测输入国家/地区的死亡率。假设中位数年龄不是特征。假设某些国家/地区的人口年龄结构比其他国家/地区高。由于忽略了年龄中位数这一混杂变量,此模型可能会预测出错误的死亡率。
在美国,种族通常与社会经济阶层密切相关,但死亡数据中只记录种族,而非阶层。与阶层相关的混杂因素(例如获得医疗保健、营养、从事危险工作和安全住房的机会)对死亡率的影响可能比种族更大,但由于这些因素未包含在数据集中,因此被忽略了。3 识别和控制这些混杂因素对于构建实用模型和得出有意义且准确的结论至关重要。
如果模型是根据包含种族但不包含阶级的现有死亡率数据训练的,则可能会根据种族预测死亡率,即使阶级是更强的死亡率预测因子也是如此。这可能会导致关于因果关系的假设不准确,以及关于患者死亡率的预测不准确。ML 从业者应考虑其数据中是否存在混杂因素,以及其数据集中可能缺少哪些有意义的变量。
1985 年,哈佛医学院和哈佛公共卫生学院开展了一项观察性队列研究“护士健康研究”,结果发现,与从未服用雌激素的队列成员相比,服用雌激素替代疗法的队列成员发生心脏病的几率较低。因此,医生数十年来一直为绝经期和绝经期后患者开具雌激素处方,直到 2002 年的一项临床研究发现长期雌激素疗法会造成健康风险。这种向绝经女性开具雌激素处方的情况已停止,但在此之前,估计已造成数万人过早死亡。
多种混杂因素都可能导致这种关联。流行病学家发现,与不接受激素替代疗法的女性相比,接受激素替代疗法的女性往往体重较轻、受教育程度较高、收入较高、更注重健康,并且更有可能进行锻炼。不同的研究发现,受教育程度和财富水平越高,患心脏病的风险就越低。这些影响会混淆雌激素疗法与心脏病发作之间的明显关联。4
包含负数的百分比
避免在存在负数时使用百分比5,因为这可能会掩盖各种有意义的增益和损失。为了简化计算,假设餐饮行业有 200 万个工作岗位。如果该行业在 2020 年 3 月底失去 100 万个此类工作岗位,在接下来的 10 个月内没有出现净变化,并在 2021 年 2 月初重新获得 90 万个工作岗位,那么在 2021 年 3 月初进行同比比较时,餐厅工作岗位只会减少 5%。假设没有其他变化,那么在 2021 年 4 月底进行同比比较,就会发现餐厅工作岗位增加了 90%,这与现实情况截然不同。
请优先使用经过适当标准化的实际数字。如需了解详情,请参阅处理数值数据。
事后归因谬误和无效的相关性
归因错误是指,因为事件 A 发生在事件 B 之前,因此事件 A 导致了事件 B。更简单地说,就是假定不存在因果关系。更简单地说:相关性不能证明因果关系。
除了明确的因果关系之外,相关性还可能源于:
- 纯粹是巧合(如需查看示例,请参阅 Tyler Vigen 的虚假相关性,其中包括缅因州离婚率与人均食用人造黄油量之间存在很强的相关性)。
- 两个变量之间的真实关系,但仍不清楚哪个变量是致因变量,哪个变量是受影响变量。
- 第三种情况是,存在一个单独的原因会影响这两个变量,但相关变量彼此之间没有关系。例如,全球通胀可能会导致游艇和芹菜的价格上涨。6
此外,根据现有数据推断出相关性也存在风险。Huff 指出,适当的降雨量有助于提高作物产量,但过多的降雨会破坏作物;降雨量与作物产量之间的关系是非线性的。7(如需详细了解非线性关系,请参阅接下来的两个部分。)Jones 指出,世界充满了不可预测的事件(例如战争和饥荒),这会导致时间序列数据的未来预测存在大量的不确定性。8
此外,即使是基于因果关系的真实相关性,也可能对决策没有帮助。举例来说,Huff 指出了 1950 年代结婚机会与大学教育之间的相关性。上过大学的女性结婚的可能性较低,但也可能是上过大学的女性一开始就不太倾向于结婚。如果是这样,大学教育不会改变他们结婚的可能性。9
如果分析检测到数据集中两个变量之间存在相关性,请问自己:
- 这是一种什么类型的相关性:因果关系、虚假关系、未知关系,还是由第三个变量造成的?
- 从数据中推断的风险有多大?对训练数据集中不存在的数据进行的每项模型预测,实际上都是对数据的插值或外推。
- 这种相关性能否用于做出有用决策?例如,乐观情绪可能与工资上调之间存在很强的相关性,但对某些大型文本数据集(例如特定国家/地区用户的社交媒体帖子)进行情感分析,对预测该国家/地区的工资上调没有帮助。
在训练模型时,机器学习从业者通常会寻找与标签高度相关的特征。如果不了解特征与标签之间的关系,就可能会导致本部分中所述的问题,包括基于虚假相关性的模型,以及假定历史趋势将在未来继续存在(但实际上并非如此)的模型。
线性偏差
在“非线性世界中的线性思维”一文中,Bart de Langhe、Stefano Puntoni 和 Richard Larrick 将线性偏差描述为人类大脑倾向于预期和寻找线性关系,尽管许多现象都是非线性的。例如,人类态度与行为之间的关系是凸曲线,而不是直线。在 de Langhe 等人引用的 2007 年 Journal of Consumer Policy 论文中,Jenny van Doorn 等人对调查对象对环境的关注程度与调查对象购买有机产品之间的关系进行了建模。对环境最为担忧的受访者购买的有机产品更多,但所有其他受访者之间的差异很小。
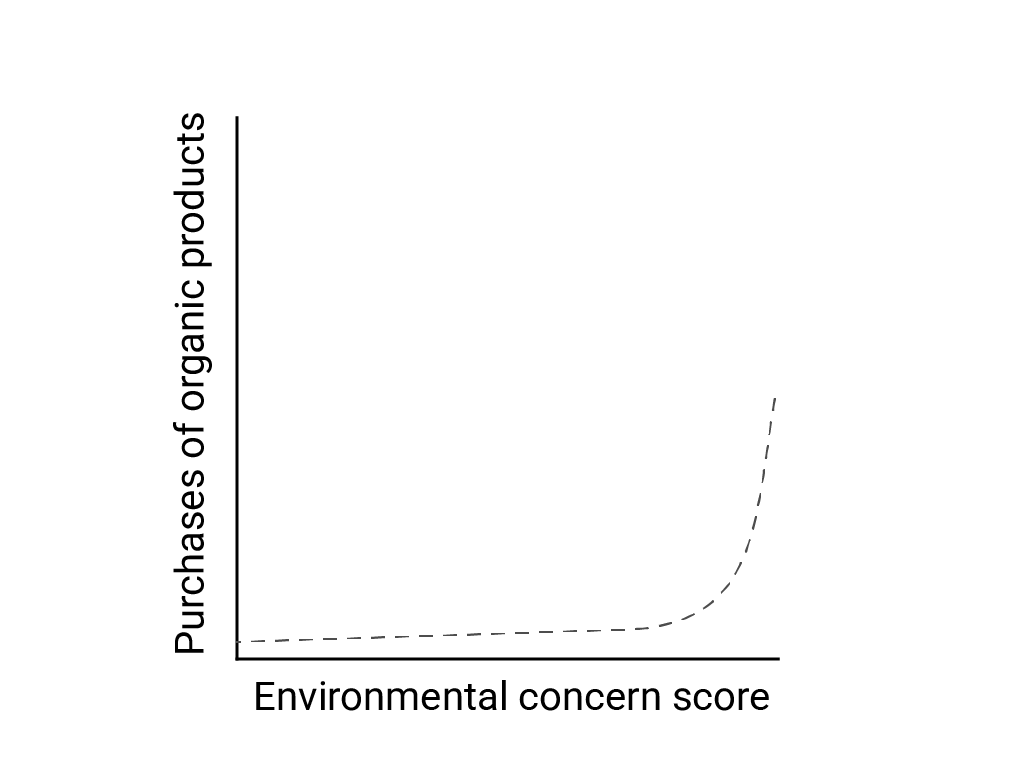
在设计模型或研究时,请考虑非线性关系的可能性。由于A/B 测试可能会遗漏非线性关系,因此不妨考虑再测试第三种中间条件 C。此外,还应考虑看似线性的初始行为是否会继续保持线性,或者未来的数据是否可能会显示更接近对数或其他非线性行为。
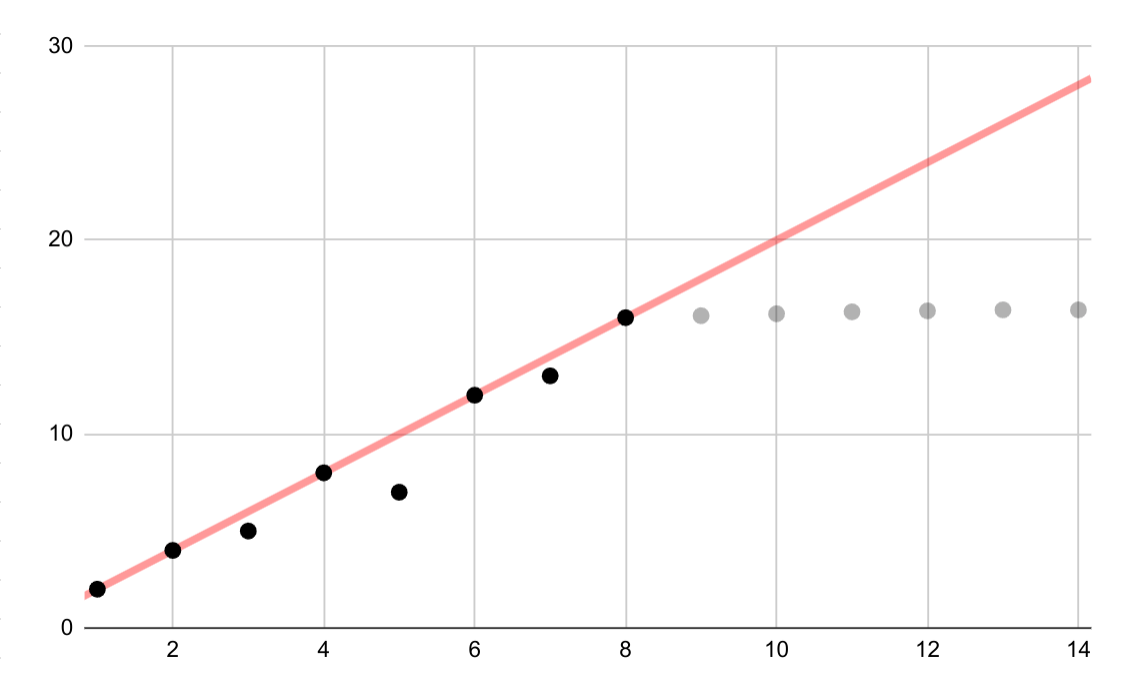
此假设示例展示了对对数数据的线性拟合错误。如果只有前几个数据点可用,假设变量之间存在持续的线性关系既很诱人,又不正确。
线性插值
检查数据点之间的任何插值,因为插值会引入虚构的数据点,而实际测量值之间的间隔可能包含有意义的波动。例如,请考虑以下通过线性插值连接的四个数据点的可视化结果:

然后,请考虑以下示例,其中数据点之间的波动会被线性插值抹去:
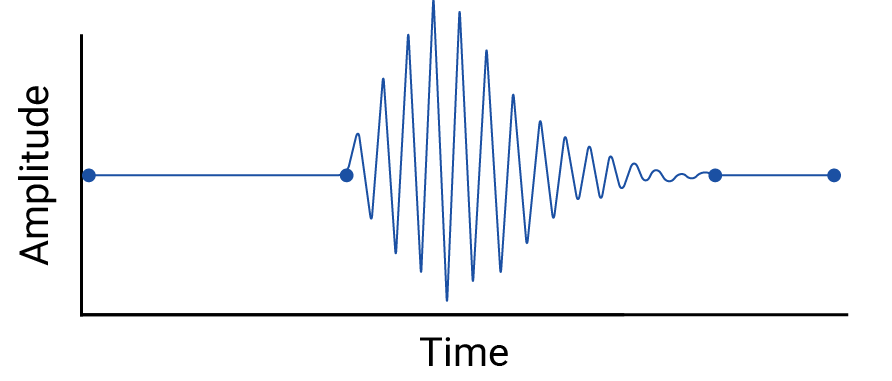
这个示例是人为构造的,因为地震仪会收集连续数据,因此不会错过这场地震。但它有助于说明插值所做的假设,以及数据从业者可能会错过的真实现象。
Runge 现象
朗格现象(也称为“多项式摆动”)与线性插值和线性偏差相反,是另一种极端问题。对数据进行多项式插值拟合时,可能会使用多项式次数过高(次数是指多项式方程中的最高指数)。这会在边缘产生奇怪的振荡。例如,对大致线性数据应用 11 次方多项式插值(即多项式方程中最高次数项为 \(x^{11}\)),会导致数据范围的开头和结尾处的预测结果非常糟糕:
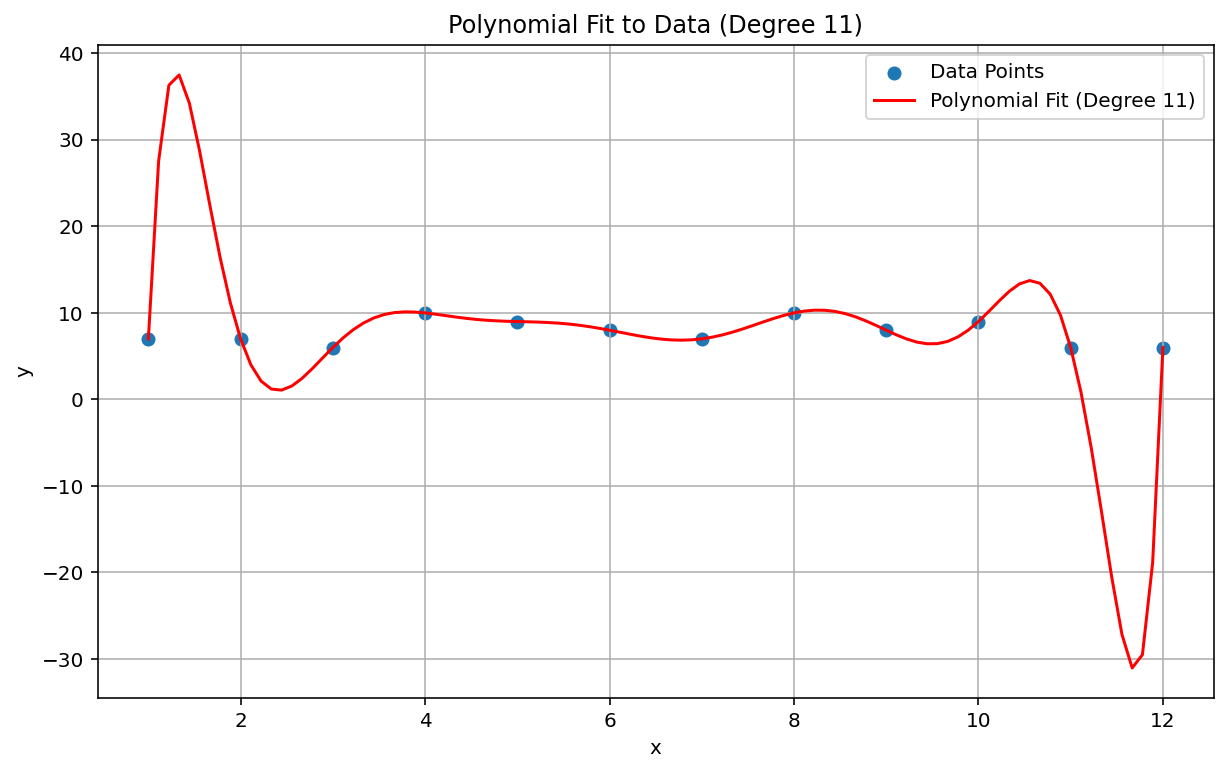
在机器学习环境中,类似的现象是过拟合。
统计检测失败
有时,统计测试的统计效力可能不足以检测到小效应。统计分析的效力较低意味着正确识别真实事件的几率较低,因此误判为假阴性的几率较高。Katherine Button 等人在 Nature 上撰文指出:“如果在某个特定领域开展的研究的设计效力为 20%,则意味着,如果该领域有 100 个真实的非零效应待发现,这些研究预计只会发现其中 20 个。”增加样本规模有时会有帮助,仔细设计研究方案也有助于提高准确性。
在机器学习中,类似的情况是分类问题和分类阈值的选择。选择较高的阈值会导致假正例减少而假负例增多,而选择较低的阈值则会导致假正例增多而假负例减少。
除了统计效力问题之外,由于相关性旨在检测线性关系,因此可能会错过变量之间的非线性相关性。同样,变量之间可以存在关联,但不一定存在统计相关性。变量也可能呈负相关,但完全没有关联,这称为 Berkson 的悖论或 Berkson 的谬论。贝克森谬误的经典示例是,在观察医院住院患者群体(与普通人群相比)时,任何风险因素与严重疾病之间存在虚假的负相关关系,这种关系源于选择过程(病情严重到需要住院)。
考虑您是否符合以下某种情况。
过时模型和无效假设
即使是优秀的模型,也可能会随着时间的推移而出现性能下降,因为行为(以及世界)可能会发生变化。随着 Netflix 的客户群从精通技术的年轻用户转变为普通用户,其早期的预测模型不得不被弃用。10
模型还可能包含静默且不准确的假设,这些假设可能会一直隐藏起来,直到模型发生灾难性故障(如 2008 年的市场崩盘)。金融行业的风险价值 (VaR) 模型声称可以准确估算任何交易者的投资组合的最大损失,例如,99% 的时间预计最大损失为 10 万美元。但在崩溃的异常情况下,预计最大损失为 10 万美元的投资组合有时会损失 100 万美元或更多。
VaR 模型基于错误的假设,包括:
- 过去的市场变化有助于预测未来的市场变化。
- 预测的回报率基于正态分布(尾部较小,因此可预测)。
事实上,基础分布是肥尾分布、“狂野”分布或分形分布,这意味着,与正态分布预测的相比,长尾、极端和假定为罕见事件的风险要高得多。真实分布的肥尾特性众所周知,但没有采取行动。人们不太了解的是,各种现象(包括采用自动抛售功能的计算机交易)是多么复杂且紧密耦合。11
汇总问题
汇总数据(包括大多数受众特征数据和流行病学数据)会受到一组特定陷阱的影响。辛普森悖论(也称为合并悖论)会出现在汇总数据中,当数据在不同级别汇总时,明显的趋势会消失或反转,这是由于混杂因素和误解的因果关系所致。
生态学谬误是指错误地将一个汇总级别的群体信息推广到另一个汇总级别,而该推断可能并不适用。某个省份有 40% 的农民工患有某种疾病,但在更广泛的人口中,该疾病的患病率可能并不相同。该省内也可能有个别农场或农业城镇没有出现该疾病的类似高发病率。假设这些受影响较小的地区的患病率也为 40% 是错误的。
可修改区域单位问题 (MAUP) 是地理空间数据中的一个众所周知的问题,由 Stan Openshaw 于 1984 年在 CATMOG 38 中描述。地理空间数据从业者可以根据用于汇总数据的区域的形状和大小,在数据中的变量之间建立几乎任何相关性。划分有利于某个政党的选区就是 MAUP 的一个例子。
所有这些情况都涉及从一个汇总级别到另一个汇总级别的不当外推。不同级别的分析可能需要不同的汇总,甚至完全不同的数据集。12
请注意,出于隐私保护方面的考虑,普查数据、受众特征数据和流行病学数据通常按区域汇总,而这些区域通常是任意的,也就是说,并非基于有意义的现实边界。在处理此类数据时,机器学习从业者应检查模型性能和预测结果是否会因所选区域的大小和形状或汇总级别而发生变化,如果会,则检查模型预测结果是否会受到其中某个汇总问题的影响。
参考
Button, Katharine et al. "Power failure: why small sample size undermines the reliability of neuroscience." Nature Reviews Neuroscience, vol 14 (2013), 365–376. DOI:https://doi.org/10.1038/nrn3475
Alberto Cairo,How Charts Lie: Getting Smarter about Visual Information(图表如何欺骗:如何更明智地看待视觉信息)。NY: W.W. Norton, 2019.
Davenport, Thomas H. “A Predictive Analytics Primer”(预测分析入门)。见 HBR Guide to Data Analytics Basics for Managers(《面向经理人的 HBR 数据分析基础指南》)(波士顿:HBR Press,2018 年),81-86 页。
De Langhe, Bart, Stefano Puntoni, and Richard Larrick。 “Linear Thinking in a Nonlinear World”(非线性世界中的线性思维)。 《HBR 经理人数据分析基础指南》(波士顿:HBR Press,2018 年),131-154 页。
Ellenberg, Jordan. How Not to Be Wrong: The Power of Mathematical Thinking(如何避免错误:数学思维的力量)。New York: Penguin, 2014.
Huff, Darrell. 如何用统计数据说谎。NY: W.W. Norton, 1954.
Jones, Ben. 避免数据误区。Hoboken, NJ: Wiley, 2020.
Openshaw, Stan. “The Modifiable Areal Unit Problem”(可修改的面积单位问题),CATMOG 38(诺里奇,英格兰:Geo Books,1984 年)37。
The Risks of Financial Modeling: VaR and the Economic Meltdown,第 111 届国会(2009 年)(Nassim N. Taleb 和 Richard Bookstaber)。
Ritter, David. “何时根据相关性采取行动,何时不采取行动”。HBR Guide to Managers 的数据分析基础知识(波士顿:HBR Press,2018 年),第 103-109 页。
Tulchinsky, Theodore H. and Elena A. Varavikova。 新公共卫生(第 3 版),第 3 章“衡量、监测和评估人群健康状况”,San Diego:Academic Press,2014 年,第 91-147 页。 DOI:https://doi.org/10.1016/B978-0-12-415766-8.00003-3。
Van Doorn, Jenny, Peter C. Verhoef, and Tammo H. A. Bijmolt。“政策研究中态度与行为之间非线性关系的重要性。” Journal of Consumer Policy 30 (2007) 75–90. DOI:https://doi.org/10.1007/s10603-007-9028-3
图片引用
基于“Von Mises Distribution”。Rainald62,2018 年。来源
{kind=link}
-
Ellenberg 125. ↩
-
Huff 77-79. Huff 引用了普林斯顿大学的公共舆论研究办公室,但他可能指的是丹佛大学国家舆论研究中心的1944 年 4 月报告。 ↩
-
Tulchinsky 和 Varavikova。 ↩
-
Gary Taubes,《纽约时报》杂志,2007 年 9 月 16 日,我们真的知道什么有助于健康吗? ↩
-
Ellenberg 78. ↩
-
Huff 91-92. ↩
-
Huff 93. ↩
-
Jones 157-167。 ↩
-
Huff 95. ↩
-
Davenport 84. ↩
-
请参阅 Nassim N. Taleb 和 Richard Bookstaber,The Risks of Financial Modeling: VaR and the Economic Meltdown,第 111 届国会 (2009) 11-67。 ↩
-
开罗 155、162。 ↩