“进来的都没有垃圾。”
- 早期编程流行语
每个机器学习模型之下、每一次相关性计算以及每个基于数据的计算, 政策建议存在于一个或多个原始数据集。无论多么美丽或 最终结果令人印象深刻或令人信服(如果基础数据是 错误、收集不当或质量低劣, 或结论的准确性, 质量。在以下环境中直观呈现、分析和训练模型的 数据集应提出有关其数据源的难题。
数据收集仪器可能出现故障或校准不当。 收集数据的人可能很疲倦、调皮、不稳定或生活欠佳 训练。人难免会犯错,而不同的人也可能有合理的不同意见 对模糊信号进行分类。因此, 可能会受到影响,数据可能无法反映现实。 Ben Jones,《Avoiding Data》一书的作者 误区,将这种情况称为 数据-现实存在差距, 提醒读者:“这并不是犯罪,而是举报的犯罪。这不是 流星撞击次数,即记录的流星撞击次数。”
数据与现实数据缺口的示例:
Jones 绘制了以 5 分钟为间隔的时间测量峰值,并且 而不是因为美国的 但因为与工具不同,人类数据收集者倾向于 将其四舍五入为最接近的 0 或 5。1
1985 年,乔·法曼、布莱恩·加德纳和乔纳森·桑克林,就职于 英国南极勘探局 (BAS) 的测量结果表明 南半球臭氧层中的季节性空洞。这个 与美国国家航空航天局记录的数据相悖,但这些数据没有记录此类空洞。美国国家航空航天局物理学家 Richard 斯托拉斯基在研究后发现,美国国家航空航天局的数据处理软件 设计时假设臭氧含量永远不会低于 而且检测到的臭氧读数非常非常低 被自动丢弃为无意义的离群值。2
乐器会经历多种故障模式,有时 收集数据。Adam Ringler 等。提供地震图图库 仪器故障(以及相应的故障)导致的读数 2021 年论文《Why Do My Squiggles Look Funny?》(为什么我的波浪线看起来很有趣?)3 示例读数与实际地震活动不符。
对于机器学习从业者来说,了解以下要点至关重要:
- 数据由谁收集
- 数据的方式和时间以及条件
- 测量仪器的灵敏度和状态
- 在特定情况下,仪器故障和人为错误可能是什么样子 上下文
- 人类倾向于对数字进行四舍五入并给出理想答案
数据与现实之间至少存在微小的差异 也称为“标准答案”。 考虑到这种差异,是得出良好的结论并 明智的决策。这包括决定:
- 哪些问题可以并且应该由机器学习解决。
- 哪些问题无法通过机器学习得到很好的解决。
- 哪些问题尚未获得通过机器学习解决的足够高质量数据。
问:就最严格、最字面意义而言,数据传达了什么? 同样重要的是,数据不能传达什么?
数据中的脏话
除了调查数据收集条件之外,数据集 本身可能包含错误、错误以及 null 或无效值(例如 浓度测量结果为负值)。众包数据在 使用质量未知的数据集可能会导致结果不准确。
常见问题包括:
- 字符串值拼写错误,例如地点、品种或品牌名称
- 单位转换、单位或对象类型不正确
- 缺失值
- 反复出现分类错误或标记错误
- 超过 乐器的实际灵敏度
清理数据集通常涉及到 null 值和缺失值(无论是 保留为 null、将其删除或替换 0),将拼写更正为 修正单位和换算等。更高级的 使用估计值估计缺失值,详见 数据特征 机器学习速成课程。
抽样、幸存者偏差和代理端点问题
利用统计信息可以有效且准确地推断出 进行随机采样。未经检查的脆度 这种假设,再加上不平衡和不完整的训练输入, 许多机器学习应用的高调故障,包括用于 继续审查和监管。这还导致轮询失败和其他 并做出关于受众特征群体的错误结论。在大多数情况下, 使用计算机生成的人工数据、纯随机样本也 并且太难获得多种解决方案,经济实惠 而是改用其他来源 偏差。
例如,要使用分层采样方法,您必须知道 每个抽样层在总体中的普遍性。假设 出现率实际上不正确,您得到的结果将会不准确。 同样,在线投票也很少是随机抽取的全国人口样本, 但来自互联网用户的样本 (通常来自多个国家/地区)。 该组很可能与真实的随机样本不同。“Google Analytics 4 媒体资源” 对可能会出现的问题进行示例。这些意见调查问题的回答如下: 而不是随机抽取的受访者您的想法, 可能不同于自己的观点, 意见。
临床健康研究人员遇到了一个类似的问题,称为替代疗法 端点问题。因为检查某药物对 研究人员可以使用替代生物标记,这些标记被认为是 与寿命有关联,但也可能并不是胆固醇水平可作为替代品 心血管问题导致的心脏病发作和死亡的终结点:如果药物 降低胆固醇水平,但人们认为它还可以降低心脏问题的风险。 但是,该关联链可能无效,或者 原因可能并非研究人员的假设。请参见 Weintraub 等, 代理端点的风险 了解更多示例和详情。在机器学习中的等效情况是 代理标签。
数学家亚伯拉罕·沃尔德发现了一个著名的数据抽样问题 作为幸存者偏差。战斗机正在返回,弹孔中 而不是在其他地理位置。美军想要增加装甲 也就是弹孔最多的地区的飞机 建议将盔甲添加到没有弹孔的区域。 他们正确地推断,他们的数据样本之所以出现偏差,是因为飞机在 这些区域严重受损,无法回到基地。
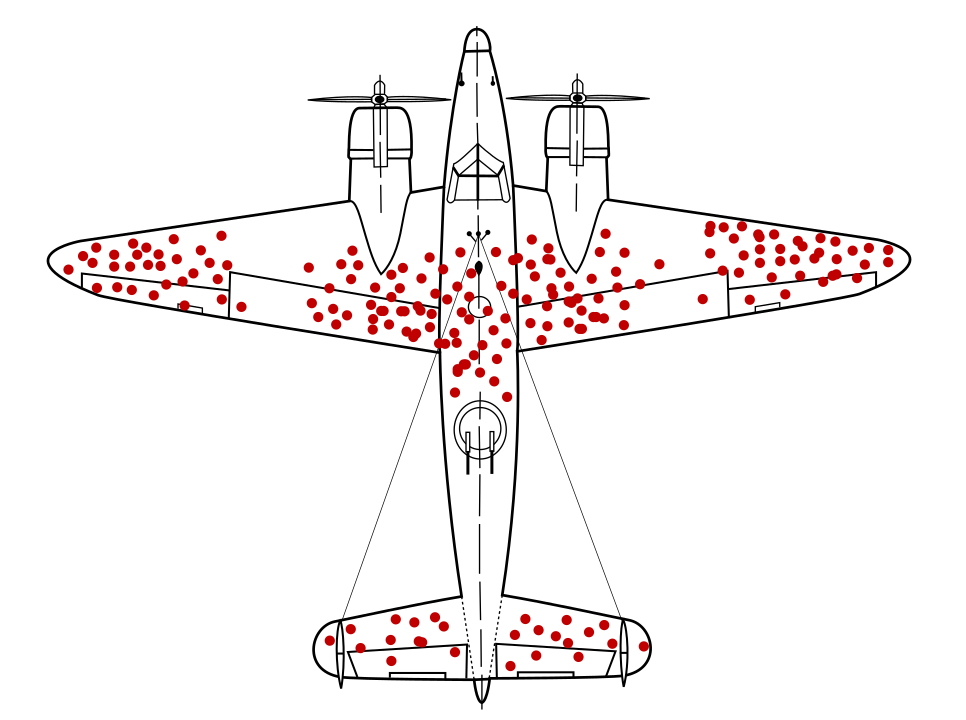
曾仅根据回归图进行训练 而不了解数据中存在的生存偏差, 该模型会建议用更多子弹孔加固这些区域。
自我选择偏差可能源于自愿提供搜索服务的人体 参与研究。监狱囚犯积极报名 计划可以代表不太可能投入的人群 罪行比一般囚犯更多这会导致结果出现偏差。4
更微妙的采样问题是召回率偏差,涉及 人类受试者的回忆。1993 年,Edward Giovannucci 针对年龄匹配的群体 曾诊断出患有癌症的女性比例,以及她们过去的饮食习惯 习惯。这些女性在进入 Google 之前接受了一项饮食习惯调查。 癌症诊断Giovannucci 发现,未患癌的女性 的诊断结果准确补充了自己的饮食,但患有乳腺癌的女性却报告了 他们无意识地摄入了比以前报告更多的脂肪 能够针对其癌症提供可能(但不准确)的解释。5
问题:
- 什么是实际采样的数据集?
- 存在多少个抽样级别?
- 在每个抽样级别,都可能会引入哪些偏差?
- 是否使用了替代测量方法(无论是生物标记物、在线投票还是项目列表) 缺口)显示实际的相关性或因果关系?
- 样本和抽样方法可能缺少什么?
公平性模块 机器学习速成课程介绍了 人口统计数据集中的其他偏见来源。
定义和排名
清楚、准确地定义术语,或询问清晰准确的定义。 您必须这样做,才能了解哪些数据功能正处于考虑范围 以及被预测或声明的确切内容。 Charles Wheelan 在裸体统计信息中介绍了“美国的卫生状况”问题, 制造业”作为含歧义术语的示例。美国制造业是否 “健康”完全取决于该字词的定义方式。Greg Ip 的 2011 年 3 月的《经济学人》一文 解释了这种不明确之处。如果“运行状况”指标是“制造业” 输出”2011 年,美国制造业变得更加健康。如果 “健康”定义为“制造业作业”然而,美国制造业 遭拒。6
排名经常会出现类似问题,包括模糊不清或无意义 为排名的各个组成部分赋予的权重、不一致性 无效选项。马尔科姆·格拉德威尔 (Malcolm Gladwell) 在《纽约客》(The New Yorker) 一书中提到了 密歇根最高法院首席法官托马斯·布伦南 (Thomas Brennan) 数百名律师要求他们按质量对 10 所法律院校进行排名,其中有些院校很有名, 有些则没有。这些律师将宾夕法尼亚州立大学的法学院排名约为第五 不过,在开展调查时,宾夕法尼亚州立大学尚未制定法律 7 许多知名排名都会包含类似的主观判断。 信誉组成部分。询问影响排名的要素,以及这些要素 为其分配了特定权重。
小数值和大效应
抛硬币时,100% 正面或 100% 反面都不足为奇 两次。抛硬币四次后得到 25% 的正面朝上也不足为奇。 接下来四次翻转的次数为 75% (该数字可能以错误的方式归因于吃过三明治 或任何其他虚假因素)。但随着 增加到 1,000 或 2,000, 那么预期 50% 的可能性就绝不复存在了
一项研究中的测量值或实验对象数量通常指的是 设为 N。由偶然因素导致的较大比例变化更有可能 出现在低 N 的数据集和样本中。
在对数据卡片中的数据集进行分析或记录时,请指定 N,这样其他人就可以考虑噪声和随机性的影响。
由于模型质量往往会随着样本的增多而变化, 低 N 往往会导致模型质量不佳。
回归到平均值
同样,任何受偶然影响的衡量结果都受到 这种效应称为 回归平均值。 这说明了在进行特别极端衡量之后如何进行衡量 一般来说, 不太可能会不太极端或更接近平均值,这是因为 不可能一开始就进行极端的衡量。通过 如果某个群体明显高于平均水平或低于平均水平,则更加明显 用于观察,看看这组人是不是世界上最高的人 人数、团队中最差的运动员或中风风险最高的运动员。通过 身高最高的孩子平均可能比身高 父母,最差的运动员可能表现得更好 坏季节,最容易中风的人群的风险可能降低 经任何干预或治疗后,并非基于病因因素,而是 随机应变。
在探索回归模型时, 针对高于平均水平或低于平均水平的群体采取的干预措施或治疗方式, 将受试者分为学习组和对照组, 因果效应。在机器学习环境中,这种现象表明,支付额外的费用 注意任何预测异常值或离群值的模型,例如:
- 极端天气或温度
- 业绩最好的商店或运动员
- 网站上最热门的视频
如果模型持续预测这些变量, 与实际情况不符。 实际上,成功的店铺或视频将会继续获得成功 不是,请问:
- 回归到平均值是否是问题所在?
- 实际上,权重最高的特征的预测性是否更高? 与权重较低的特征相比呢?
- 是否收集具有这些特征的基准值的数据? 通常为零 (实际上是对照组)更改模型的预测结果?
参考
呼哈,达雷尔。如何从统计学说谎。NY:W.W.1954 年,诺顿。
Jones、Ben。避免数据误区。新泽西州霍博肯:威利,2020 年。
O'Connor、Cailin 和 James Owen Weatherall。虚假信息时代。纽黑文: Yale UP,2019 年。
Ringler、Adam、David Mason、Gabi Laske 和 Mary Dieton。 “为什么我的曲线看起来很有趣?A Gallery of Compromised Seismic Signals" 地震研究信函 92 号6(2021 年 7 月)。DOI:10.1785/0220210094
Weintraub、William S、Thomas F.Lüscher 和 Stuart Pocock。 “代理端点的风险。” European Heart Journal 第 36 期33(2015 年 9 月):2212–2218。DOI: 10.1093/eurheartj/ehv164
Wheelan、Charles。裸体统计信息:去除数据中的恐惧。纽约: W.W.诺顿,2013 年
图片参考
“幸存者偏差”。Martin Grandjean、McGeddon 和 Cameron Moll,2021 年。 CC BY-SA 4.0。来源
{kind=link}