"আবর্জনা ভিতরে, আবর্জনা আউট।"
- প্রারম্ভিক প্রোগ্রামিং প্রবাদ
প্রতিটি ML মডেলের নীচে, পারস্পরিক সম্পর্কের প্রতিটি গণনা এবং প্রতিটি ডেটা-ভিত্তিক নীতি সুপারিশ এক বা একাধিক কাঁচা ডেটাসেট রয়েছে৷ শেষ পণ্যগুলি যতই সুন্দর বা আকর্ষণীয় বা প্ররোচিত হোক না কেন, যদি অন্তর্নিহিত ডেটা ভুল, খারাপভাবে সংগ্রহ করা বা নিম্ন-মানের হয়, ফলাফল মডেল, ভবিষ্যদ্বাণী, ভিজ্যুয়ালাইজেশন বা উপসংহার একইভাবে নিম্নমানের হবে। যে কেউ ডেটাসেটের মডেলগুলিকে ভিজ্যুয়ালাইজ করে, বিশ্লেষণ করে এবং প্রশিক্ষণ দেয় তাদের ডেটার উত্স সম্পর্কে কঠিন প্রশ্ন জিজ্ঞাসা করা উচিত।
ডেটা-সংগ্রহকারী যন্ত্রগুলি ত্রুটিপূর্ণ হতে পারে বা খারাপভাবে ক্রমাঙ্কিত হতে পারে। ডেটা-সংগ্রহকারী মানুষ ক্লান্ত, দুষ্টু, অসংলগ্ন বা দুর্বল প্রশিক্ষিত হতে পারে। লোকেরা ভুল করে, এবং বিভিন্ন লোক অস্পষ্ট সংকেতের শ্রেণীবিভাগ নিয়ে যুক্তিসঙ্গতভাবে দ্বিমত পোষণ করতে পারে। ফলস্বরূপ, ডেটার গুণমান এবং বৈধতা ক্ষতিগ্রস্থ হতে পারে এবং ডেটা বাস্তবতা প্রতিফলিত করতে ব্যর্থ হতে পারে। বেন জোনস, এভয়েডিং ডেটা পিটফলস এর লেখক, এটিকে ডেটা-রিয়েলিটি গ্যাপ বলেছেন, পাঠককে মনে করিয়ে দিয়েছেন: "এটি অপরাধ নয়, এটি অপরাধের প্রতিবেদন করা হয়েছে । এটি উল্কা আঘাতের সংখ্যা নয়, এটি রেকর্ড করা উল্কা আঘাতের সংখ্যা।"
ডেটা-বাস্তবতার ব্যবধানের উদাহরণ:
জোন্স গ্রাফ 5-মিনিটের ব্যবধানে সময়ের পরিমাপ এবং 5-পাউন্ডের ব্যবধানে ওজন পরিমাপ করে, এই কারণে নয় যে এই ধরনের স্পাইক ডেটাতে বিদ্যমান, কিন্তু কারণ মানুষের ডেটা সংগ্রাহক, যন্ত্রগুলির বিপরীতে, তাদের সংখ্যাকে শূন্যের কাছাকাছি পূর্ণ করার প্রবণতা রয়েছে। অথবা 5. 1
1985 সালে, জো ফরমান, ব্রায়ান গার্ডিনার এবং জোনাথন শ্যাঙ্কলিন, ব্রিটিশ অ্যান্টার্কটিক সার্ভে (BAS) এর জন্য কাজ করে দেখেন যে তাদের পরিমাপ দক্ষিণ গোলার্ধের ওজোন স্তরে একটি মৌসুমী গর্ত নির্দেশ করে। এটি NASA ডেটার বিরোধিতা করেছে, যা এমন কোনও গর্ত রেকর্ড করেনি। NASA পদার্থবিজ্ঞানী রিচার্ড স্টোলারস্কি তদন্ত করে দেখেছেন যে NASA-এর ডেটা-প্রসেসিং সফ্টওয়্যারটি এই ধারণার অধীনে ডিজাইন করা হয়েছিল যে ওজোনের মাত্রা কখনই একটি নির্দিষ্ট পরিমাণের নিচে নামতে পারে না এবং ওজোনের খুব কম রিডিং যেগুলি সনাক্ত করা হয়েছিল তা স্বয়ংক্রিয়ভাবে অযৌক্তিক বহিঃপ্রকাশকারী হিসাবে ফেলে দেওয়া হয়েছিল। 2
যন্ত্রগুলি ব্যর্থতার মোডের বৈচিত্র্য অনুভব করে, কখনও কখনও ডেটা সংগ্রহ করার সময়ও। অ্যাডাম রিংলার এবং অন্যান্য। 2021 কাগজ "কেন আমার স্কুইগলগুলি মজার দেখাচ্ছে?" যন্ত্রের ব্যর্থতার (এবং সংশ্লিষ্ট ব্যর্থতার) ফলে সিসমোগ্রাফ রিডিংয়ের একটি গ্যালারি সরবরাহ করুন। 3 উদাহরণ রিডআউটের কার্যকলাপ প্রকৃত ভূমিকম্পের কার্যকলাপের সাথে সঙ্গতিপূর্ণ নয়।
এমএল অনুশীলনকারীদের জন্য, এটি বোঝা গুরুত্বপূর্ণ:
- যারা তথ্য সংগ্রহ করেছে
- কিভাবে এবং কখন তথ্য সংগ্রহ করা হয়েছিল এবং কোন পরিস্থিতিতে
- সংবেদনশীলতা এবং পরিমাপ যন্ত্রের অবস্থা
- কোন বিশেষ প্রেক্ষাপটে যন্ত্রের ব্যর্থতা এবং মানুষের ত্রুটি কেমন হতে পারে
- বৃত্তাকার সংখ্যার প্রতি মানুষের প্রবণতা এবং পছন্দসই উত্তর প্রদান করে
প্রায় সবসময়, ডেটা এবং বাস্তবতার মধ্যে অন্তত একটি ছোট পার্থক্য থাকে, যা স্থল সত্য নামেও পরিচিত। সেই পার্থক্যের জন্য অ্যাকাউন্টিং ভাল সিদ্ধান্তে আঁকতে এবং সঠিক সিদ্ধান্ত নেওয়ার চাবিকাঠি। এর মধ্যে রয়েছে সিদ্ধান্ত নেওয়া:
- কোন সমস্যাগুলি এমএল দ্বারা সমাধান করা উচিত এবং করা উচিত।
- কোন সমস্যা ML দ্বারা ভাল সমাধান করা হয় না.
- যে সমস্যাগুলির এখনও ML দ্বারা সমাধান করার জন্য যথেষ্ট উচ্চ-মানের ডেটা নেই।
জিজ্ঞাসা করুন: কি, সবচেয়ে কঠোর এবং সবচেয়ে আক্ষরিক অর্থে, ডেটা দ্বারা যোগাযোগ করা হয়? ঠিক যেমন গুরুত্বপূর্ণ, ডেটা দ্বারা কী যোগাযোগ করা হয় না ?
ডেটাতে ময়লা
ডেটা সংগ্রহের শর্তগুলি তদন্ত করার পাশাপাশি, ডেটাসেটে নিজেই ভুল, ত্রুটি এবং শূন্য বা অবৈধ মান থাকতে পারে (যেমন ঘনত্বের নেতিবাচক পরিমাপ)। ক্রাউড-সোর্সড ডেটা বিশেষ করে অগোছালো হতে পারে। অজানা মানের ডেটাসেটের সাথে কাজ করলে ভুল ফলাফল হতে পারে।
সাধারণ সমস্যা অন্তর্ভুক্ত:
- স্থান, প্রজাতি বা ব্র্যান্ডের নামগুলির মতো স্ট্রিং মানগুলির ভুল বানান৷
- ভুল ইউনিট রূপান্তর, ইউনিট, বা বস্তুর ধরন
- অনুপস্থিত মান
- ধারাবাহিক ভুল শ্রেণীবিভাগ বা ভুল লেবেলিং
- গাণিতিক ক্রিয়াকলাপ থেকে অবশিষ্ট উল্লেখযোগ্য সংখ্যা যা একটি যন্ত্রের প্রকৃত সংবেদনশীলতা অতিক্রম করে
একটি ডেটাসেট পরিষ্কার করার ক্ষেত্রে প্রায়শই নাল এবং অনুপস্থিত মানগুলির পছন্দ অন্তর্ভুক্ত থাকে (সেগুলিকে শূন্য হিসাবে রাখতে হবে, সেগুলি বাদ দিতে হবে বা 0s প্রতিস্থাপন করতে হবে), একটি একক সংস্করণে বানান সংশোধন করা, ইউনিট এবং রূপান্তরগুলি ঠিক করা ইত্যাদি। একটি আরও উন্নত কৌশল হল অনুপস্থিত মানগুলিকে দায়ী করা, যা মেশিন লার্নিং ক্র্যাশ কোর্সের ডেটা বৈশিষ্ট্যগুলিতে বর্ণিত হয়েছে।
স্যাম্পলিং, সারভাইভারশিপ বায়াস এবং সারোগেট এন্ডপয়েন্ট সমস্যা
পরিসংখ্যান একটি বিশুদ্ধভাবে এলোমেলো নমুনা থেকে বৃহত্তর জনসংখ্যার ফলাফলের বৈধ এবং নির্ভুল এক্সট্রাপোলেশনের অনুমতি দেয়। ভারসাম্যহীন এবং অসম্পূর্ণ প্রশিক্ষণ ইনপুট সহ এই অনুমানের অপরীক্ষিত ভঙ্গুরতা অনেক ML অ্যাপ্লিকেশনগুলির উচ্চ-প্রোফাইল ব্যর্থতার দিকে পরিচালিত করেছে, যার মধ্যে রয়েছে পুনঃসূচনা পর্যালোচনা এবং পুলিশিং এর জন্য ব্যবহৃত মডেলগুলি। এটি জনসংখ্যাগত গোষ্ঠী সম্পর্কে পোলিং ব্যর্থতা এবং অন্যান্য ভুল সিদ্ধান্তের দিকে পরিচালিত করেছে। কৃত্রিম কম্পিউটার-উত্পাদিত ডেটার বাইরে বেশিরভাগ প্রসঙ্গে, বিশুদ্ধভাবে এলোমেলো নমুনাগুলি খুব ব্যয়বহুল এবং অর্জন করা খুব কঠিন। পরিবর্তে বিভিন্ন সমাধান এবং সাশ্রয়ী মূল্যের প্রক্সি ব্যবহার করা হয়, যা পক্ষপাতের বিভিন্ন উত্সের পরিচয় দেয়।
স্তরিত নমুনা পদ্ধতি ব্যবহার করার জন্য, উদাহরণস্বরূপ, আপনাকে বৃহত্তর জনসংখ্যার প্রতিটি নমুনাযুক্ত স্তরের ব্যাপকতা জানতে হবে। আপনি যদি এমন একটি প্রচলন অনুমান করেন যা আসলে ভুল, আপনার ফলাফলগুলি ভুল হবে। একইভাবে, অনলাইন পোলিং খুব কমই একটি জাতীয় জনসংখ্যার র্যান্ডম নমুনা, কিন্তু ইন্টারনেট-সংযুক্ত জনসংখ্যার একটি নমুনা (প্রায়শই একাধিক দেশ থেকে) যে জরিপটি দেখে এবং নিতে ইচ্ছুক। এই গোষ্ঠীটি সত্যিকারের র্যান্ডম নমুনা থেকে আলাদা হতে পারে। ভোটের প্রশ্নগুলি সম্ভাব্য প্রশ্নের একটি নমুনা। সেই পোল প্রশ্নের উত্তরগুলি আবার, উত্তরদাতাদের প্রকৃত মতামতের একটি এলোমেলো নমুনা নয়, কিন্তু মতামতের একটি নমুনা যা উত্তরদাতারা প্রদান করতে স্বাচ্ছন্দ্যবোধ করেন, যা তাদের প্রকৃত মতামত থেকে ভিন্ন হতে পারে।
ক্লিনিকাল স্বাস্থ্য গবেষকরা সারোগেট এন্ডপয়েন্ট সমস্যা নামে পরিচিত একটি অনুরূপ সমস্যার সম্মুখীন হন। যেহেতু রোগীর জীবনকালের উপর ওষুধের প্রভাব পরীক্ষা করতে অনেক বেশি সময় লাগে, তাই গবেষকরা প্রক্সি বায়োমার্কার ব্যবহার করেন যা জীবনকালের সাথে সম্পর্কিত বলে ধরে নেওয়া হয় কিন্তু নাও হতে পারে। কোলেস্টেরলের মাত্রাগুলি হার্ট অ্যাটাক এবং কার্ডিওভাসকুলার সমস্যাগুলির কারণে মৃত্যুর জন্য একটি সারোগেট এন্ডপয়েন্ট হিসাবে ব্যবহৃত হয়: যদি কোনও ওষুধ কোলেস্টেরলের মাত্রা কমিয়ে দেয় তবে এটি কার্ডিয়াক সমস্যাগুলির ঝুঁকিও কম বলে ধরে নেওয়া হয়। যাইহোক, পারস্পরিক সম্পর্কের সেই শৃঙ্খলটি বৈধ নাও হতে পারে, অন্যথায় কারণের ক্রম গবেষকের অনুমান ছাড়া অন্য হতে পারে। আরও উদাহরণ এবং বিশদ বিবরণের জন্য Weintraub et al., "সারোগেট এন্ডপয়েন্টের বিপদ" দেখুন। ML-এর সমতুল্য পরিস্থিতি হল প্রক্সি লেবেলগুলির ।
গণিতবিদ আব্রাহাম ওয়াল্ড বিখ্যাতভাবে একটি ডেটা স্যাম্পলিং সমস্যা চিহ্নিত করেছেন যা বর্তমানে সারভাইভারশিপ বায়াস নামে পরিচিত। যুদ্ধবিমানগুলি নির্দিষ্ট স্থানে বুলেটের ছিদ্র নিয়ে ফিরে আসছিল, অন্য জায়গায় নয়। মার্কিন সামরিক বাহিনী সবচেয়ে বেশি বুলেটের ছিদ্রযুক্ত অঞ্চলে প্লেনে আরও বর্ম যোগ করতে চেয়েছিল, কিন্তু ওয়াল্ডের গবেষণা গোষ্ঠী পরিবর্তে বুলেটের ছিদ্রবিহীন অঞ্চলে বর্ম যুক্ত করার সুপারিশ করেছে। তারা সঠিকভাবে অনুমান করেছে যে তাদের ডেটা নমুনা তির্যক ছিল কারণ সেই এলাকায় গুলি করা প্লেনগুলি এতটাই খারাপভাবে ক্ষতিগ্রস্ত হয়েছিল যে তারা বেসে ফিরে আসতে সক্ষম হয়নি।
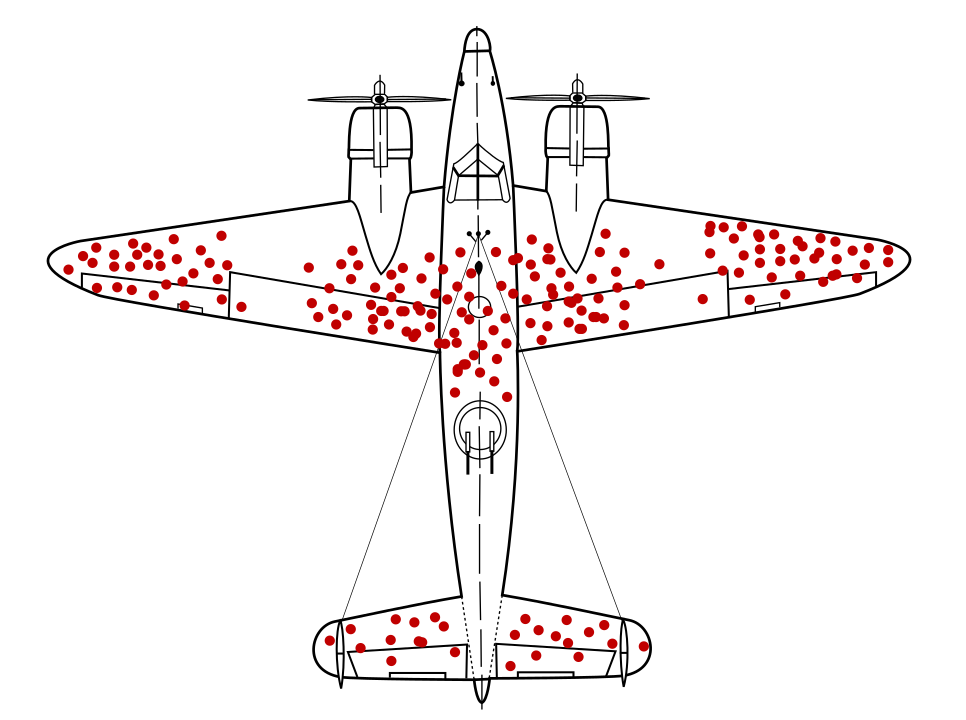
যদি একটি বর্ম-প্রস্তাবিত মডেলকে শুধুমাত্র ফিরে আসা যুদ্ধবিমানগুলির চিত্রের উপর প্রশিক্ষণ দেওয়া হত, ডেটাতে উপস্থিত বেঁচে থাকার পক্ষপাতের অন্তর্দৃষ্টি ছাড়াই, সেই মডেলটি আরও বুলেট ছিদ্রযুক্ত অঞ্চলগুলিকে শক্তিশালী করার সুপারিশ করত।
একটি গবেষণায় অংশগ্রহণের জন্য স্বেচ্ছাসেবী মানব বিষয় থেকে স্ব-নির্বাচনের পক্ষপাতিত্ব দেখা দিতে পারে। বন্দিরা একটি পুনর্বিবেচনা-হ্রাসকারী প্রোগ্রামের জন্য সাইন আপ করতে অনুপ্রাণিত, উদাহরণস্বরূপ, সাধারণ বন্দি জনসংখ্যার তুলনায় ভবিষ্যতে অপরাধ করার সম্ভাবনা কম জনসংখ্যার প্রতিনিধিত্ব করতে পারে। এই ফলাফল তির্যক হবে. 4
একটি আরও সূক্ষ্ম নমুনা সমস্যা হল প্রত্যাহার পক্ষপাত , মানুষের বিষয়ের স্মৃতির নমনীয়তা জড়িত। 1993 সালে, এডওয়ার্ড জিওভানুচি একটি বয়সের সাথে মিলে যাওয়া মহিলাদেরকে জিজ্ঞাসা করেছিলেন, যাদের মধ্যে কিছু ক্যান্সার ধরা পড়েছে, তাদের অতীতের খাদ্যাভ্যাস সম্পর্কে। একই মহিলারা তাদের ক্যান্সার নির্ণয়ের আগে খাদ্যাভ্যাসের উপর একটি সমীক্ষা করেছিলেন। জিওভানুচ্চি যা আবিষ্কার করেছিলেন তা হল যে ক্যান্সার নির্ণয়বিহীন মহিলারা তাদের ডায়েট সঠিকভাবে স্মরণ করে, কিন্তু স্তন ক্যান্সারে আক্রান্ত মহিলারা পূর্বে রিপোর্টের চেয়ে বেশি চর্বি খাওয়ার কথা জানিয়েছেন-অজ্ঞাতসারে তাদের ক্যান্সারের সম্ভাব্য (যদিও ভুল) ব্যাখ্যা প্রদান করে। 5
জিজ্ঞাসা করুন:
- একটি ডেটাসেট আসলে নমুনা কি?
- স্যাম্পলিং এর কয়টি স্তর রয়েছে?
- নমুনার প্রতিটি স্তরে কি পক্ষপাত চালু করা যেতে পারে?
- ব্যবহৃত প্রক্সি পরিমাপ (বায়োমার্কার বা অনলাইন পোল বা বুলেট হোল) কি প্রকৃত পারস্পরিক সম্পর্ক বা কার্যকারণ দেখাচ্ছে?
- নমুনা এবং নমুনা পদ্ধতি থেকে কি অনুপস্থিত হতে পারে?
মেশিন লার্নিং ক্র্যাশ কোর্সের ফেয়ারনেস মডিউল জনসংখ্যাগত ডেটাসেটে পক্ষপাতের অতিরিক্ত উত্সগুলির জন্য মূল্যায়ন এবং প্রশমিত করার উপায়গুলি কভার করে৷
সংজ্ঞা এবং র্যাঙ্কিং
পরিভাষাগুলি স্পষ্টভাবে এবং সুনির্দিষ্টভাবে সংজ্ঞায়িত করুন, অথবা স্পষ্ট এবং সুনির্দিষ্ট সংজ্ঞা সম্পর্কে জিজ্ঞাসা করুন। কোন ডেটা বৈশিষ্ট্যগুলি বিবেচনাধীন রয়েছে এবং ঠিক কী ভবিষ্যদ্বাণী বা দাবি করা হচ্ছে তা বোঝার জন্য এটি প্রয়োজনীয়। চার্লস হুইলান, নেকেড স্ট্যাটিস্টিকসে , একটি অস্পষ্ট শব্দের উদাহরণ হিসেবে "ইউএস ম্যানুফ্যাকচারিং এর স্বাস্থ্য" প্রদান করেন। ইউএস ম্যানুফ্যাকচারিং "স্বাস্থ্যকর" কিনা তা সম্পূর্ণভাবে নির্ভর করে কিভাবে শব্দটি সংজ্ঞায়িত করা হয় তার উপর। দ্য ইকোনমিস্টে গ্রেগ আইপের মার্চ 2011 নিবন্ধটি এই অস্পষ্টতাকে চিত্রিত করে। যদি "স্বাস্থ্য" এর মেট্রিক হয় "উৎপাদন আউটপুট", তাহলে 2011 সালে, ইউএস ম্যানুফ্যাকচারিং ক্রমবর্ধমান স্বাস্থ্যকর ছিল। যদি "স্বাস্থ্য" মেট্রিককে "উৎপাদনমূলক কাজ" হিসাবে সংজ্ঞায়িত করা হয়, তবে, মার্কিন উত্পাদন পতনের দিকে ছিল। 6
র্যাঙ্কিং প্রায়শই একই ধরনের সমস্যায় ভোগে, যার মধ্যে রয়েছে র্যাঙ্কিংয়ের বিভিন্ন উপাদানে দেওয়া অস্পষ্ট বা অযৌক্তিক ওজন, র্যাঙ্কারের অসঙ্গতি এবং অবৈধ বিকল্প। ম্যালকম গ্ল্যাডওয়েল, দ্য নিউ ইয়র্কার- এ লিখেছেন, মিশিগান সুপ্রিম কোর্টের একজন প্রধান বিচারপতি টমাস ব্রেনানকে উল্লেখ করেছেন, যিনি একবার একশত আইনজীবীদের কাছে একটি সমীক্ষা পাঠিয়েছিলেন যাতে তারা গুণমানের ভিত্তিতে দশটি আইন স্কুলের র্যাঙ্কিং করতে বলে, কিছু বিখ্যাত, কিছু নয়। এই আইনজীবীরা পেন স্টেটের আইন স্কুলকে প্রায় পঞ্চম স্থানে স্থান দিয়েছেন, যদিও জরিপের সময়, পেন স্টেটের একটি আইন স্কুল ছিল না। 7 অনেক সুপরিচিত র্যাঙ্কিং-এ একইভাবে বিষয়গত খ্যাতিমূলক উপাদান অন্তর্ভুক্ত। জিজ্ঞাসা করুন কোন উপাদানগুলি একটি র্যাঙ্কিংয়ে যায় এবং কেন সেই উপাদানগুলিকে তাদের নির্দিষ্ট ওজন নির্ধারণ করা হয়েছিল।
ছোট সংখ্যা এবং বড় প্রভাব
আপনি যদি একটি মুদ্রা দুবার ফ্লিপ করেন তবে 100% মাথা বা 100% লেজ পাওয়া আশ্চর্যজনক নয়। একটি কয়েন চারবার ফ্লিপ করার পর 25% হেড পাওয়াও আশ্চর্যজনক নয়, তারপরে পরবর্তী চারটি ফ্লিপের জন্য 75% হেড পাওয়া যায়, যদিও এটি একটি আপাতদৃষ্টিতে প্রচুর বৃদ্ধি দেখায় (যা ভুলভাবে কয়েন ফ্লিপের সেটের মধ্যে খাওয়া একটি স্যান্ডউইচকে দায়ী করা যেতে পারে, বা অন্য কোন জাল ফ্যাক্টর)। কিন্তু মুদ্রা উল্টানোর সংখ্যা বাড়ার সাথে সাথে, 1,000 বা 2,000 বলুন, প্রত্যাশিত 50% থেকে বড় শতাংশ বিচ্যুতি অসম্ভাব্যভাবে অদৃশ্য হয়ে যায়।
একটি গবেষণায় পরিমাপ বা পরীক্ষামূলক বিষয়ের সংখ্যা প্রায়শই N হিসাবে উল্লেখ করা হয়। সম্ভাবনার কারণে বড় আনুপাতিক পরিবর্তনগুলি কম N সহ ডেটাসেট এবং নমুনাগুলিতে হওয়ার সম্ভাবনা অনেক বেশি।
একটি ডেটা কার্ডে একটি বিশ্লেষণ পরিচালনা বা একটি ডেটাসেট নথিভুক্ত করার সময়, N উল্লেখ করুন, যাতে অন্য লোকেরা গোলমাল এবং এলোমেলোতার প্রভাব বিবেচনা করতে পারে।
যেহেতু মডেলের গুণমান উদাহরণের সংখ্যার সাথে স্কেল করার প্রবণতা রাখে, কম এন সহ একটি ডেটাসেট নিম্নমানের মডেলে পরিণত হয়।
গড় প্রতি রিগ্রেশন
একইভাবে, সুযোগ থেকে কিছু প্রভাব ফেলে এমন কোনো পরিমাপ একটি প্রভাবের সাপেক্ষে যা গড়কে রিগ্রেশন বলে পরিচিত। এটি বর্ণনা করে যে কীভাবে একটি বিশেষভাবে চরম পরিমাপের পরে পরিমাপটি গড়ে, কম চরম বা গড়টির কাছাকাছি হওয়ার সম্ভাবনা রয়েছে, কারণ প্রথম স্থানে চরম পরিমাপ হওয়ার সম্ভাবনা কতটা অসম্ভব ছিল। প্রভাবটি আরও স্পষ্ট হয় যদি একটি বিশেষ করে গড়ের উপরে বা গড় থেকে নীচের গোষ্ঠীকে পর্যবেক্ষণের জন্য নির্বাচিত করা হয়, সেই দলটি জনসংখ্যার সবচেয়ে লম্বা লোক, একটি দলের সবচেয়ে খারাপ ক্রীড়াবিদ, বা যারা স্ট্রোকের ঝুঁকিতে সবচেয়ে বেশি। সবচেয়ে লম্বা মানুষদের বাচ্চারা তাদের বাবা-মায়ের থেকে গড়পড়তা খাটো হওয়ার সম্ভাবনা থাকে, সবচেয়ে খারাপ অ্যাথলিটরা ব্যতিক্রমীভাবে খারাপ মৌসুমের পরে আরও ভালো পারফর্ম করতে পারে, এবং যাদের স্ট্রোকের ঝুঁকি সবচেয়ে বেশি তারা কোনো হস্তক্ষেপ বা চিকিত্সার পরে ঝুঁকি কম দেখাতে পারে, কার্যকারক কারণের কারণে নয় বরং এলোমেলোতার বৈশিষ্ট্য এবং সম্ভাবনার কারণে।
গড় প্রতি রিগ্রেশনের প্রভাবগুলির জন্য একটি প্রশমন, যখন একটি উপরে-গড় বা কম-গড় গোষ্ঠীর জন্য হস্তক্ষেপ বা চিকিত্সা অন্বেষণ করা হয়, তখন কার্যকারক প্রভাবগুলিকে বিচ্ছিন্ন করার জন্য বিষয়গুলিকে একটি অধ্যয়ন গ্রুপ এবং একটি নিয়ন্ত্রণ গোষ্ঠীতে ভাগ করা হয়। এমএল প্রেক্ষাপটে, এই ঘটনাটি এমন কোনো মডেলের প্রতি অতিরিক্ত মনোযোগ দেওয়ার পরামর্শ দেয় যা ব্যতিক্রমী বা বাইরের মানগুলির পূর্বাভাস দেয়, যেমন:
- চরম আবহাওয়া বা তাপমাত্রা
- সেরা-পারফর্মিং স্টোর বা ক্রীড়াবিদ
- একটি ওয়েবসাইটে সবচেয়ে জনপ্রিয় ভিডিও
যদি সময়ের সাথে সাথে এই ব্যতিক্রমী মানগুলির একটি মডেলের চলমান ভবিষ্যদ্বাণী বাস্তবতার সাথে মেলে না, উদাহরণস্বরূপ ভবিষ্যদ্বাণী করা যে একটি অত্যন্ত সফল স্টোর বা ভিডিও সফল হতে থাকবে যখন বাস্তবে তা না হয়, জিজ্ঞাসা করুন:
- গড় রিগ্রেশন সমস্যা হতে পারে?
- সবচেয়ে বেশি ওজনের বৈশিষ্ট্যগুলি কি প্রকৃতপক্ষে কম ওজনের বৈশিষ্ট্যগুলির চেয়ে বেশি ভবিষ্যদ্বাণীমূলক?
- এই বৈশিষ্ট্যগুলির জন্য বেসলাইন মান আছে এমন ডেটা সংগ্রহ করা কি প্রায়শই শূন্য (কার্যকরভাবে একটি নিয়ন্ত্রণ গোষ্ঠী) মডেলের ভবিষ্যদ্বাণীগুলিকে পরিবর্তন করে?
তথ্যসূত্র
হাফ, ড্যারেল। পরিসংখ্যানের সাথে কীভাবে মিথ্যা বলা যায়। NY: WW Norton, 1954।
জোন্স, বেন। ডেটা পিটফল এড়ানো। হোবোকেন, এনজে: উইলি, 2020।
ও'কনর, কেলিন এবং জেমস ওয়েন ওয়েদারল। ভুল তথ্যের যুগ। নিউ হ্যাভেন: ইয়েল ইউপি, 2019।
রিংলার, অ্যাডাম, ডেভিড ম্যাসন, গাবি লাস্ক এবং মেরি টেম্পলটন। "কেন আমার স্কুইগলগুলি মজার দেখাচ্ছে? আপোসকৃত সিসমিক সিগন্যালের গ্যালারি।" সিসমোলজিক্যাল রিসার্চ লেটার 92 নং। 6 (জুলাই 2021)। DOI: 10.1785/0220210094
Weintraub, William S, Thomas F. Luscher, এবং Stuart Pocock. "সারোগেট এন্ডপয়েন্টের বিপদ।" ইউরোপীয় হার্ট জার্নাল 36 নং. 33 (সেপ্টেম্বর 2015): 2212–2218। DOI: 10.1093/eurheartj/ehv164
হুইলান, চার্লস। নগ্ন পরিসংখ্যান: ডেটা থেকে ভীতি দূর করা। NY: WW Norton, 2013
ইমেজ রেফারেন্স
"সারভাইভারশিপ পক্ষপাত।" মার্টিন গ্র্যান্ডজিন, ম্যাকগেডন এবং ক্যামেরন মোল 2021। CC BY-SA 4.0। উৎস
{kind=link}
জোন্স 25-29। ↩
O'Connor এবং Weatherall 22-3. ↩
রিংলিং এট আল। ↩
হুইলান 120. ↩
সিদ্ধার্থ মুখোপাধ্যায়, "সেলফোন কি ব্রেন ক্যান্সার সৃষ্টি করে?" নিউ ইয়র্ক টাইমস-এ, এপ্রিল 13, 2011। হুইলান 122-এ উদ্ধৃত। ↩
হুইলান 39-40। ↩
ম্যালকম গ্ল্যাডওয়েল, "দ্য অর্ডার অফ থিংস" , দ্য নিউ ইয়র্কার ফেব্রুয়ারী 14, 2011-এ। হুইলান 56-এ উদ্ধৃত । ↩
"আবর্জনা ভিতরে, আবর্জনা আউট।"
- প্রারম্ভিক প্রোগ্রামিং প্রবাদ
প্রতিটি ML মডেলের নীচে, পারস্পরিক সম্পর্কের প্রতিটি গণনা এবং প্রতিটি ডেটা-ভিত্তিক নীতি সুপারিশ এক বা একাধিক কাঁচা ডেটাসেট রয়েছে৷ শেষ পণ্যগুলি যতই সুন্দর বা আকর্ষণীয় বা প্ররোচিত হোক না কেন, যদি অন্তর্নিহিত ডেটা ভুল, খারাপভাবে সংগ্রহ করা বা নিম্ন-মানের হয়, ফলাফল মডেল, ভবিষ্যদ্বাণী, ভিজ্যুয়ালাইজেশন বা উপসংহার একইভাবে নিম্নমানের হবে। যে কেউ ডেটাসেটের মডেলগুলিকে ভিজ্যুয়ালাইজ করে, বিশ্লেষণ করে এবং প্রশিক্ষণ দেয় তাদের ডেটার উত্স সম্পর্কে কঠিন প্রশ্ন জিজ্ঞাসা করা উচিত।
ডেটা-সংগ্রহকারী যন্ত্রগুলি ত্রুটিপূর্ণ হতে পারে বা খারাপভাবে ক্রমাঙ্কিত হতে পারে। ডেটা-সংগ্রহকারী মানুষ ক্লান্ত, দুষ্টু, অসংলগ্ন বা দুর্বল প্রশিক্ষিত হতে পারে। লোকেরা ভুল করে, এবং বিভিন্ন লোক অস্পষ্ট সংকেতের শ্রেণীবিভাগ নিয়ে যুক্তিসঙ্গতভাবে দ্বিমত পোষণ করতে পারে। ফলস্বরূপ, ডেটার গুণমান এবং বৈধতা ক্ষতিগ্রস্থ হতে পারে এবং ডেটা বাস্তবতা প্রতিফলিত করতে ব্যর্থ হতে পারে। বেন জোনস, এভয়েডিং ডেটা পিটফলস এর লেখক, এটিকে ডেটা-রিয়েলিটি গ্যাপ বলেছেন, পাঠককে মনে করিয়ে দিয়েছেন: "এটি অপরাধ নয়, এটি অপরাধের প্রতিবেদন করা হয়েছে । এটি উল্কা আঘাতের সংখ্যা নয়, এটি রেকর্ড করা উল্কা আঘাতের সংখ্যা।"
ডেটা-বাস্তবতার ব্যবধানের উদাহরণ:
জোন্স গ্রাফ 5-মিনিটের ব্যবধানে সময়ের পরিমাপ এবং 5-পাউন্ডের ব্যবধানে ওজন পরিমাপ করে, এই কারণে নয় যে এই ধরনের স্পাইক ডেটাতে বিদ্যমান, কিন্তু কারণ মানুষের ডেটা সংগ্রাহক, যন্ত্রগুলির বিপরীতে, তাদের সংখ্যাকে শূন্যের কাছাকাছি পূর্ণ করার প্রবণতা রয়েছে। অথবা 5. 1
1985 সালে, জো ফরমান, ব্রায়ান গার্ডিনার এবং জোনাথন শ্যাঙ্কলিন, ব্রিটিশ অ্যান্টার্কটিক সার্ভে (BAS) এর জন্য কাজ করে দেখেন যে তাদের পরিমাপ দক্ষিণ গোলার্ধের ওজোন স্তরে একটি মৌসুমী গর্ত নির্দেশ করে। এটি NASA ডেটার বিরোধিতা করেছে, যা এমন কোনও গর্ত রেকর্ড করেনি। NASA পদার্থবিজ্ঞানী রিচার্ড স্টোলারস্কি তদন্ত করে দেখেছেন যে NASA-এর ডেটা-প্রসেসিং সফ্টওয়্যারটি এই ধারণার অধীনে ডিজাইন করা হয়েছিল যে ওজোনের মাত্রা কখনই একটি নির্দিষ্ট পরিমাণের নিচে নামতে পারে না এবং ওজোনের খুব কম রিডিং যেগুলি সনাক্ত করা হয়েছিল তা স্বয়ংক্রিয়ভাবে অযৌক্তিক বহিঃপ্রকাশকারী হিসাবে ফেলে দেওয়া হয়েছিল। 2
যন্ত্রগুলি ব্যর্থতার মোডের বৈচিত্র্য অনুভব করে, কখনও কখনও ডেটা সংগ্রহ করার সময়ও। অ্যাডাম রিংলার এবং অন্যান্য। 2021 কাগজ "কেন আমার স্কুইগলগুলি মজার দেখাচ্ছে?" যন্ত্রের ব্যর্থতার (এবং সংশ্লিষ্ট ব্যর্থতার) ফলে সিসমোগ্রাফ রিডিংয়ের একটি গ্যালারি সরবরাহ করুন। 3 উদাহরণ রিডআউটের কার্যকলাপ প্রকৃত ভূমিকম্পের কার্যকলাপের সাথে সঙ্গতিপূর্ণ নয়।
এমএল অনুশীলনকারীদের জন্য, এটি বোঝা গুরুত্বপূর্ণ:
- যারা তথ্য সংগ্রহ করেছে
- কিভাবে এবং কখন তথ্য সংগ্রহ করা হয়েছিল এবং কোন পরিস্থিতিতে
- সংবেদনশীলতা এবং পরিমাপ যন্ত্রের অবস্থা
- কোন বিশেষ প্রেক্ষাপটে যন্ত্রের ব্যর্থতা এবং মানুষের ত্রুটি কেমন হতে পারে
- বৃত্তাকার সংখ্যার প্রতি মানুষের প্রবণতা এবং পছন্দসই উত্তর প্রদান করে
প্রায় সবসময়, ডেটা এবং বাস্তবতার মধ্যে অন্তত একটি ছোট পার্থক্য থাকে, যা স্থল সত্য নামেও পরিচিত। সেই পার্থক্যের জন্য অ্যাকাউন্টিং ভাল সিদ্ধান্তে আঁকতে এবং সঠিক সিদ্ধান্ত নেওয়ার চাবিকাঠি। এর মধ্যে রয়েছে সিদ্ধান্ত নেওয়া:
- কোন সমস্যাগুলি এমএল দ্বারা সমাধান করা উচিত এবং করা উচিত।
- কোন সমস্যা ML দ্বারা ভাল সমাধান করা হয় না.
- যে সমস্যাগুলির এখনও ML দ্বারা সমাধান করার জন্য যথেষ্ট উচ্চ-মানের ডেটা নেই।
জিজ্ঞাসা করুন: কি, সবচেয়ে কঠোর এবং সবচেয়ে আক্ষরিক অর্থে, ডেটা দ্বারা যোগাযোগ করা হয়? ঠিক যেমন গুরুত্বপূর্ণ, ডেটা দ্বারা কী যোগাযোগ করা হয় না ?
ডেটাতে ময়লা
ডেটা সংগ্রহের শর্তগুলি তদন্ত করার পাশাপাশি, ডেটাসেটে নিজেই ভুল, ত্রুটি এবং শূন্য বা অবৈধ মান থাকতে পারে (যেমন ঘনত্বের নেতিবাচক পরিমাপ)। ক্রাউড-সোর্সড ডেটা বিশেষ করে অগোছালো হতে পারে। অজানা মানের ডেটাসেটের সাথে কাজ করলে ভুল ফলাফল হতে পারে।
সাধারণ সমস্যা অন্তর্ভুক্ত:
- স্থান, প্রজাতি বা ব্র্যান্ডের নামগুলির মতো স্ট্রিং মানগুলির ভুল বানান৷
- ভুল ইউনিট রূপান্তর, ইউনিট, বা বস্তুর ধরন
- অনুপস্থিত মান
- ধারাবাহিক ভুল শ্রেণীবিভাগ বা ভুল লেবেলিং
- গাণিতিক ক্রিয়াকলাপ থেকে অবশিষ্ট উল্লেখযোগ্য সংখ্যা যা একটি যন্ত্রের প্রকৃত সংবেদনশীলতা অতিক্রম করে
একটি ডেটাসেট পরিষ্কার করার ক্ষেত্রে প্রায়শই নাল এবং অনুপস্থিত মানগুলির পছন্দ অন্তর্ভুক্ত থাকে (সেগুলিকে শূন্য হিসাবে রাখতে হবে, সেগুলি বাদ দিতে হবে বা 0s প্রতিস্থাপন করতে হবে), একটি একক সংস্করণে বানান সংশোধন করা, ইউনিট এবং রূপান্তরগুলি ঠিক করা ইত্যাদি। একটি আরও উন্নত কৌশল হল অনুপস্থিত মানগুলিকে দায়ী করা, যা মেশিন লার্নিং ক্র্যাশ কোর্সের ডেটা বৈশিষ্ট্যগুলিতে বর্ণিত হয়েছে।
স্যাম্পলিং, সারভাইভারশিপ বায়াস এবং সারোগেট এন্ডপয়েন্ট সমস্যা
পরিসংখ্যান একটি বিশুদ্ধভাবে এলোমেলো নমুনা থেকে বৃহত্তর জনসংখ্যার ফলাফলের বৈধ এবং সঠিক এক্সট্রাপোলেশনের অনুমতি দেয়। ভারসাম্যহীন এবং অসম্পূর্ণ প্রশিক্ষণ ইনপুট সহ এই অনুমানের অপরীক্ষিত ভঙ্গুরতা অনেক ML অ্যাপ্লিকেশনগুলির উচ্চ-প্রোফাইল ব্যর্থতার দিকে পরিচালিত করেছে, যার মধ্যে রয়েছে পুনঃসূচনা পর্যালোচনা এবং পুলিশিং এর জন্য ব্যবহৃত মডেলগুলি। এটি জনসংখ্যাগত গোষ্ঠী সম্পর্কে পোলিং ব্যর্থতা এবং অন্যান্য ভুল সিদ্ধান্তের দিকে পরিচালিত করেছে। কৃত্রিম কম্পিউটার-উত্পাদিত ডেটার বাইরে বেশিরভাগ প্রসঙ্গে, বিশুদ্ধভাবে এলোমেলো নমুনাগুলি খুব ব্যয়বহুল এবং অর্জন করা খুব কঠিন। পরিবর্তে বিভিন্ন সমাধান এবং সাশ্রয়ী মূল্যের প্রক্সি ব্যবহার করা হয়, যা পক্ষপাতের বিভিন্ন উত্সের পরিচয় দেয়।
স্তরিত নমুনা পদ্ধতি ব্যবহার করার জন্য, উদাহরণস্বরূপ, আপনাকে বৃহত্তর জনসংখ্যার প্রতিটি নমুনাযুক্ত স্তরের ব্যাপকতা জানতে হবে। আপনি যদি এমন একটি প্রচলন অনুমান করেন যা আসলে ভুল, আপনার ফলাফলগুলি ভুল হবে। একইভাবে, অনলাইন পোলিং খুব কমই একটি জাতীয় জনসংখ্যার র্যান্ডম নমুনা, কিন্তু ইন্টারনেট-সংযুক্ত জনসংখ্যার একটি নমুনা (প্রায়শই একাধিক দেশ থেকে) যে জরিপটি দেখে এবং নিতে ইচ্ছুক। এই গোষ্ঠীটি সত্যিকারের র্যান্ডম নমুনা থেকে আলাদা হতে পারে। ভোটের প্রশ্নগুলি সম্ভাব্য প্রশ্নের একটি নমুনা। সেই পোল প্রশ্নের উত্তরগুলি আবার, উত্তরদাতাদের প্রকৃত মতামতের একটি এলোমেলো নমুনা নয়, কিন্তু মতামতের একটি নমুনা যা উত্তরদাতারা প্রদান করতে স্বাচ্ছন্দ্যবোধ করেন, যা তাদের প্রকৃত মতামত থেকে ভিন্ন হতে পারে।
ক্লিনিকাল স্বাস্থ্য গবেষকরা সারোগেট এন্ডপয়েন্ট সমস্যা নামে পরিচিত একটি অনুরূপ সমস্যার সম্মুখীন হন। যেহেতু রোগীর জীবনকালের উপর ওষুধের প্রভাব পরীক্ষা করতে অনেক বেশি সময় লাগে, তাই গবেষকরা প্রক্সি বায়োমার্কার ব্যবহার করেন যা জীবনকালের সাথে সম্পর্কিত বলে ধরে নেওয়া হয় কিন্তু নাও হতে পারে। কোলেস্টেরলের মাত্রাগুলি হার্ট অ্যাটাক এবং কার্ডিওভাসকুলার সমস্যাগুলির কারণে মৃত্যুর জন্য একটি সারোগেট এন্ডপয়েন্ট হিসাবে ব্যবহৃত হয়: যদি কোনও ওষুধ কোলেস্টেরলের মাত্রা কমিয়ে দেয় তবে এটি কার্ডিয়াক সমস্যাগুলির ঝুঁকিও কম বলে ধরে নেওয়া হয়। যাইহোক, পারস্পরিক সম্পর্কের সেই শৃঙ্খলটি বৈধ নাও হতে পারে, অন্যথায় কারণের ক্রম গবেষকের অনুমান ছাড়া অন্য হতে পারে। আরও উদাহরণ এবং বিশদ বিবরণের জন্য Weintraub et al., "সারোগেট এন্ডপয়েন্টের বিপদ" দেখুন। ML-এর সমতুল্য পরিস্থিতি হল প্রক্সি লেবেলগুলির ।
গণিতবিদ আব্রাহাম ওয়াল্ড বিখ্যাতভাবে একটি ডেটা স্যাম্পলিং সমস্যা চিহ্নিত করেছেন যা বর্তমানে সারভাইভারশিপ বায়াস নামে পরিচিত। যুদ্ধবিমানগুলি নির্দিষ্ট স্থানে বুলেটের ছিদ্র নিয়ে ফিরে আসছিল, অন্য জায়গায় নয়। মার্কিন সামরিক বাহিনী সবচেয়ে বেশি বুলেটের ছিদ্রযুক্ত অঞ্চলে প্লেনে আরও বর্ম যোগ করতে চেয়েছিল, কিন্তু ওয়াল্ডের গবেষণা গোষ্ঠী পরিবর্তে বুলেটের ছিদ্রবিহীন অঞ্চলে বর্ম যুক্ত করার সুপারিশ করেছে। তারা সঠিকভাবে অনুমান করেছে যে তাদের ডেটা নমুনা তির্যক ছিল কারণ সেই এলাকায় গুলি করা প্লেনগুলি এতটাই খারাপভাবে ক্ষতিগ্রস্ত হয়েছিল যে তারা বেসে ফিরে আসতে সক্ষম হয়নি।
যদি একটি বর্ম-প্রস্তাবিত মডেলকে শুধুমাত্র ফিরে আসা যুদ্ধবিমানগুলির চিত্রের উপর প্রশিক্ষণ দেওয়া হত, ডেটাতে উপস্থিত বেঁচে থাকার পক্ষপাতের অন্তর্দৃষ্টি ছাড়াই, সেই মডেলটি আরও বুলেট ছিদ্রযুক্ত অঞ্চলগুলিকে শক্তিশালী করার সুপারিশ করত।
একটি গবেষণায় অংশগ্রহণের জন্য স্বেচ্ছাসেবী মানব বিষয় থেকে স্ব-নির্বাচনের পক্ষপাতিত্ব দেখা দিতে পারে। বন্দিরা একটি পুনর্বিবেচনা-হ্রাসকারী প্রোগ্রামের জন্য সাইন আপ করতে অনুপ্রাণিত, উদাহরণস্বরূপ, সাধারণ বন্দি জনসংখ্যার তুলনায় ভবিষ্যতে অপরাধ করার সম্ভাবনা কম জনসংখ্যার প্রতিনিধিত্ব করতে পারে। এই ফলাফল তির্যক হবে. 4
একটি আরও সূক্ষ্ম নমুনা সমস্যা হল প্রত্যাহার পক্ষপাত , মানুষের বিষয়ের স্মৃতির নমনীয়তা জড়িত। 1993 সালে, এডওয়ার্ড জিওভানুচি একটি বয়সের সাথে মিলে যাওয়া মহিলাদেরকে জিজ্ঞাসা করেছিলেন, যাদের মধ্যে কিছু ক্যান্সার ধরা পড়েছে, তাদের অতীতের খাদ্যাভ্যাস সম্পর্কে। একই মহিলারা তাদের ক্যান্সার নির্ণয়ের আগে খাদ্যাভ্যাসের উপর একটি সমীক্ষা করেছিলেন। জিওভানুচ্চি যা আবিষ্কার করেছিলেন তা হল যে ক্যান্সার নির্ণয়বিহীন মহিলারা তাদের ডায়েট সঠিকভাবে স্মরণ করে, কিন্তু স্তন ক্যান্সারে আক্রান্ত মহিলারা পূর্বে রিপোর্টের চেয়ে বেশি চর্বি খাওয়ার কথা জানিয়েছেন-অজ্ঞাতসারে তাদের ক্যান্সারের সম্ভাব্য (যদিও ভুল) ব্যাখ্যা প্রদান করে। 5
জিজ্ঞাসা করুন:
- একটি ডেটাসেট আসলে নমুনা কি?
- স্যাম্পলিং এর কয়টি স্তর রয়েছে?
- নমুনার প্রতিটি স্তরে কি পক্ষপাত চালু করা যেতে পারে?
- ব্যবহৃত প্রক্সি পরিমাপ (বায়োমার্কার বা অনলাইন পোল বা বুলেট হোল) কি প্রকৃত পারস্পরিক সম্পর্ক বা কার্যকারণ দেখাচ্ছে?
- নমুনা এবং নমুনা পদ্ধতি থেকে কি অনুপস্থিত হতে পারে?
মেশিন লার্নিং ক্র্যাশ কোর্সের ফেয়ারনেস মডিউল জনসংখ্যাগত ডেটাসেটে পক্ষপাতের অতিরিক্ত উত্সগুলির জন্য মূল্যায়ন এবং প্রশমিত করার উপায়গুলি কভার করে৷
সংজ্ঞা এবং র্যাঙ্কিং
পরিভাষাগুলি স্পষ্টভাবে এবং সুনির্দিষ্টভাবে সংজ্ঞায়িত করুন, অথবা স্পষ্ট এবং সুনির্দিষ্ট সংজ্ঞা সম্পর্কে জিজ্ঞাসা করুন। কোন ডেটা বৈশিষ্ট্যগুলি বিবেচনাধীন রয়েছে এবং ঠিক কী ভবিষ্যদ্বাণী বা দাবি করা হচ্ছে তা বোঝার জন্য এটি প্রয়োজনীয়। চার্লস হুইলান, নেকেড স্ট্যাটিস্টিকসে , একটি অস্পষ্ট শব্দের উদাহরণ হিসেবে "ইউএস ম্যানুফ্যাকচারিং এর স্বাস্থ্য" প্রদান করেন। ইউএস ম্যানুফ্যাকচারিং "স্বাস্থ্যকর" কিনা তা সম্পূর্ণভাবে নির্ভর করে কিভাবে শব্দটি সংজ্ঞায়িত করা হয় তার উপর। দ্য ইকোনমিস্টে গ্রেগ আইপের মার্চ 2011 নিবন্ধটি এই অস্পষ্টতাকে চিত্রিত করে। যদি "স্বাস্থ্য" এর মেট্রিক হয় "উৎপাদন আউটপুট", তাহলে 2011 সালে, ইউএস ম্যানুফ্যাকচারিং ক্রমবর্ধমান স্বাস্থ্যকর ছিল। যদি "স্বাস্থ্য" মেট্রিককে "উৎপাদনমূলক কাজ" হিসাবে সংজ্ঞায়িত করা হয়, তবে, মার্কিন উত্পাদন পতনের দিকে ছিল। 6
র্যাঙ্কিং প্রায়শই একই ধরনের সমস্যায় ভোগে, যার মধ্যে রয়েছে র্যাঙ্কিংয়ের বিভিন্ন উপাদানে দেওয়া অস্পষ্ট বা অযৌক্তিক ওজন, র্যাঙ্কারের অসঙ্গতি এবং অবৈধ বিকল্প। ম্যালকম গ্ল্যাডওয়েল, দ্য নিউ ইয়র্কার- এ লিখেছেন, মিশিগান সুপ্রিম কোর্টের একজন প্রধান বিচারপতি টমাস ব্রেনানকে উল্লেখ করেছেন, যিনি একবার একশত আইনজীবীদের কাছে একটি সমীক্ষা পাঠিয়েছিলেন যাতে তারা গুণমানের ভিত্তিতে দশটি আইন স্কুলের র্যাঙ্কিং করতে বলে, কিছু বিখ্যাত, কিছু নয়। এই আইনজীবীরা পেন স্টেটের আইন স্কুলকে প্রায় পঞ্চম স্থানে স্থান দিয়েছেন, যদিও জরিপের সময়, পেন স্টেটের একটি আইন স্কুল ছিল না। 7 অনেক সুপরিচিত র্যাঙ্কিং-এ একইভাবে বিষয়গত খ্যাতিমূলক উপাদান অন্তর্ভুক্ত। জিজ্ঞাসা করুন কোন উপাদানগুলি একটি র্যাঙ্কিংয়ে যায় এবং কেন সেই উপাদানগুলিকে তাদের নির্দিষ্ট ওজন নির্ধারণ করা হয়েছিল।
ছোট সংখ্যা এবং বড় প্রভাব
আপনি যদি একটি মুদ্রা দুবার ফ্লিপ করেন তবে 100% মাথা বা 100% লেজ পাওয়া আশ্চর্যজনক নয়। একটি কয়েন চারবার ফ্লিপ করার পর 25% হেড পাওয়াও আশ্চর্যজনক নয়, তারপরে পরবর্তী চারটি ফ্লিপের জন্য 75% হেড পাওয়া যায়, যদিও এটি একটি আপাতদৃষ্টিতে প্রচুর বৃদ্ধি দেখায় (যা ভুলভাবে কয়েন ফ্লিপের সেটের মধ্যে খাওয়া একটি স্যান্ডউইচকে দায়ী করা যেতে পারে, বা অন্য কোন জাল ফ্যাক্টর)। কিন্তু মুদ্রা উল্টানোর সংখ্যা বাড়ার সাথে সাথে, 1,000 বা 2,000 বলুন, প্রত্যাশিত 50% থেকে বড় শতাংশ বিচ্যুতি অসম্ভাব্যভাবে অদৃশ্য হয়ে যায়।
একটি গবেষণায় পরিমাপ বা পরীক্ষামূলক বিষয়ের সংখ্যা প্রায়শই N হিসাবে উল্লেখ করা হয়। সম্ভাবনার কারণে বড় আনুপাতিক পরিবর্তনগুলি কম N সহ ডেটাসেট এবং নমুনাগুলিতে হওয়ার সম্ভাবনা অনেক বেশি।
একটি ডেটা কার্ডে একটি বিশ্লেষণ পরিচালনা বা একটি ডেটাসেট নথিভুক্ত করার সময়, N উল্লেখ করুন, যাতে অন্য লোকেরা গোলমাল এবং এলোমেলোতার প্রভাব বিবেচনা করতে পারে।
যেহেতু মডেলের গুণমান উদাহরণের সংখ্যার সাথে স্কেল করার প্রবণতা রাখে, কম এন সহ একটি ডেটাসেট নিম্নমানের মডেলে পরিণত হয়।
গড় প্রতি রিগ্রেশন
একইভাবে, সুযোগ থেকে কিছু প্রভাব ফেলে এমন কোনো পরিমাপ একটি প্রভাবের সাপেক্ষে যা গড়কে রিগ্রেশন বলে পরিচিত। এটি বর্ণনা করে যে কীভাবে একটি বিশেষভাবে চরম পরিমাপের পরে পরিমাপটি গড়ে, কম চরম বা গড়টির কাছাকাছি হওয়ার সম্ভাবনা রয়েছে, কারণ প্রথম স্থানে চরম পরিমাপ হওয়ার সম্ভাবনা কতটা অসম্ভব ছিল। প্রভাবটি আরও স্পষ্ট হয় যদি একটি বিশেষ করে গড়ের উপরে বা গড় থেকে নীচের গোষ্ঠীকে পর্যবেক্ষণের জন্য নির্বাচিত করা হয়, সেই দলটি জনসংখ্যার সবচেয়ে লম্বা লোক, একটি দলের সবচেয়ে খারাপ ক্রীড়াবিদ, বা যারা স্ট্রোকের ঝুঁকিতে সবচেয়ে বেশি। সবচেয়ে লম্বা মানুষদের বাচ্চারা তাদের বাবা-মায়ের থেকে গড়পড়তা খাটো হওয়ার সম্ভাবনা থাকে, সবচেয়ে খারাপ অ্যাথলিটরা ব্যতিক্রমীভাবে খারাপ মৌসুমের পরে আরও ভালো পারফর্ম করতে পারে, এবং যাদের স্ট্রোকের ঝুঁকি সবচেয়ে বেশি তারা কোনো হস্তক্ষেপ বা চিকিত্সার পরে ঝুঁকি কম দেখাতে পারে, কার্যকারক কারণের কারণে নয় বরং এলোমেলোতার বৈশিষ্ট্য এবং সম্ভাবনার কারণে।
গড় প্রতি রিগ্রেশনের প্রভাবগুলির জন্য একটি প্রশমন, যখন একটি উপরে-গড় বা কম-গড় গোষ্ঠীর জন্য হস্তক্ষেপ বা চিকিত্সা অন্বেষণ করা হয়, তখন কার্যকারক প্রভাবগুলিকে বিচ্ছিন্ন করার জন্য বিষয়গুলিকে একটি অধ্যয়ন গ্রুপ এবং একটি নিয়ন্ত্রণ গোষ্ঠীতে ভাগ করা হয়। এমএল প্রেক্ষাপটে, এই ঘটনাটি এমন কোনো মডেলের প্রতি অতিরিক্ত মনোযোগ দেওয়ার পরামর্শ দেয় যা ব্যতিক্রমী বা বাইরের মানগুলির পূর্বাভাস দেয়, যেমন:
- চরম আবহাওয়া বা তাপমাত্রা
- সেরা-পারফর্মিং স্টোর বা ক্রীড়াবিদ
- একটি ওয়েবসাইটে সবচেয়ে জনপ্রিয় ভিডিও
যদি সময়ের সাথে সাথে এই ব্যতিক্রমী মানগুলির একটি মডেলের চলমান ভবিষ্যদ্বাণী বাস্তবতার সাথে মেলে না, উদাহরণস্বরূপ ভবিষ্যদ্বাণী করা যে একটি অত্যন্ত সফল স্টোর বা ভিডিও সফল হতে থাকবে যখন বাস্তবে তা না হয়, জিজ্ঞাসা করুন:
- গড় রিগ্রেশন সমস্যা হতে পারে?
- সবচেয়ে বেশি ওজনের বৈশিষ্ট্যগুলি কি প্রকৃতপক্ষে কম ওজনের বৈশিষ্ট্যগুলির চেয়ে বেশি ভবিষ্যদ্বাণীমূলক?
- এই বৈশিষ্ট্যগুলির জন্য বেসলাইন মান আছে এমন ডেটা সংগ্রহ করা কি প্রায়শই শূন্য (কার্যকরভাবে একটি নিয়ন্ত্রণ গোষ্ঠী) মডেলের ভবিষ্যদ্বাণীগুলিকে পরিবর্তন করে?
তথ্যসূত্র
হাফ, ড্যারেল। পরিসংখ্যানের সাথে কীভাবে মিথ্যা বলা যায়। NY: WW Norton, 1954।
জোন্স, বেন। ডেটা পিটফল এড়ানো। হোবোকেন, এনজে: উইলি, 2020।
ও'কনর, কেলিন এবং জেমস ওয়েন ওয়েদারল। ভুল তথ্যের যুগ। নিউ হ্যাভেন: ইয়েল ইউপি, 2019।
রিংলার, অ্যাডাম, ডেভিড ম্যাসন, গাবি লাস্ক এবং মেরি টেম্পলটন। "কেন আমার স্কুইগলগুলি মজার দেখাচ্ছে? আপোসকৃত সিসমিক সিগন্যালের গ্যালারি।" সিসমোলজিক্যাল রিসার্চ লেটার 92 নং। 6 (জুলাই 2021)। DOI: 10.1785/0220210094
Weintraub, William S, Thomas F. Luscher, এবং Stuart Pocock. "সারোগেট এন্ডপয়েন্টের বিপদ।" ইউরোপীয় হার্ট জার্নাল 36 নং. 33 (সেপ্টেম্বর 2015): 2212–2218। DOI: 10.1093/eurheartj/ehv164
হুইলান, চার্লস। নগ্ন পরিসংখ্যান: ডেটা থেকে ভীতি দূর করা। NY: WW Norton, 2013
ইমেজ রেফারেন্স
"সারভাইভারশিপ পক্ষপাত।" মার্টিন গ্র্যান্ডজিন, ম্যাকগেডন এবং ক্যামেরন মোল 2021। CC BY-SA 4.0। উৎস
জোন্স 25-29। ↩
O'Connor এবং Weatherall 22-3. ↩
রিংলিং এট আল। ↩
হুইলান 120. ↩
সিদ্ধার্থ মুখোপাধ্যায়, "সেলফোন কি ব্রেন ক্যান্সার সৃষ্টি করে?" নিউ ইয়র্ক টাইমস-এ, এপ্রিল 13, 2011। হুইলান 122-এ উদ্ধৃত। ↩
হুইলান 39-40। ↩
ম্যালকম গ্ল্যাডওয়েল, "দ্য অর্ডার অফ থিংস" , দ্য নিউ ইয়র্কার ফেব্রুয়ারী 14, 2011-এ। হুইলান 56-এ উদ্ধৃত । ↩
"আবর্জনা ভিতরে, আবর্জনা আউট।"
- প্রারম্ভিক প্রোগ্রামিং প্রবাদ
প্রতিটি ML মডেলের নীচে, পারস্পরিক সম্পর্কের প্রতিটি গণনা এবং প্রতিটি ডেটা-ভিত্তিক নীতি সুপারিশ এক বা একাধিক কাঁচা ডেটাসেট রয়েছে৷ শেষ পণ্যগুলি যতই সুন্দর বা আকর্ষণীয় বা প্ররোচিত হোক না কেন, যদি অন্তর্নিহিত ডেটা ভুল, খারাপভাবে সংগ্রহ করা বা নিম্ন-মানের হয়, ফলাফল মডেল, ভবিষ্যদ্বাণী, ভিজ্যুয়ালাইজেশন বা উপসংহার একইভাবে নিম্নমানের হবে। যে কেউ ডেটাসেটের মডেলগুলিকে ভিজ্যুয়ালাইজ করে, বিশ্লেষণ করে এবং প্রশিক্ষণ দেয় তাদের ডেটার উত্স সম্পর্কে কঠিন প্রশ্ন জিজ্ঞাসা করা উচিত।
ডেটা-সংগ্রহকারী যন্ত্রগুলি ত্রুটিপূর্ণ হতে পারে বা খারাপভাবে ক্রমাঙ্কিত হতে পারে। ডেটা-সংগ্রহকারী মানুষ ক্লান্ত, দুষ্টু, অসংলগ্ন বা দুর্বল প্রশিক্ষিত হতে পারে। লোকেরা ভুল করে, এবং বিভিন্ন লোক অস্পষ্ট সংকেতের শ্রেণীবিভাগ নিয়ে যুক্তিসঙ্গতভাবে দ্বিমত পোষণ করতে পারে। ফলস্বরূপ, ডেটার গুণমান এবং বৈধতা ক্ষতিগ্রস্থ হতে পারে এবং ডেটা বাস্তবতা প্রতিফলিত করতে ব্যর্থ হতে পারে। বেন জোনস, এভয়েডিং ডেটা পিটফলস এর লেখক, এটিকে ডেটা-রিয়েলিটি গ্যাপ বলেছেন, পাঠককে মনে করিয়ে দিয়েছেন: "এটি অপরাধ নয়, এটি অপরাধের প্রতিবেদন করা হয়েছে । এটি উল্কা আঘাতের সংখ্যা নয়, এটি রেকর্ড করা উল্কা আঘাতের সংখ্যা।"
ডেটা-বাস্তবতার ব্যবধানের উদাহরণ:
জোন্স গ্রাফ 5-মিনিটের ব্যবধানে সময়ের পরিমাপ এবং 5-পাউন্ডের ব্যবধানে ওজন পরিমাপ করে, এই কারণে নয় যে এই ধরনের স্পাইক ডেটাতে বিদ্যমান, কিন্তু কারণ মানুষের ডেটা সংগ্রাহক, যন্ত্রগুলির বিপরীতে, তাদের সংখ্যাকে শূন্যের কাছাকাছি পূর্ণ করার প্রবণতা রয়েছে। অথবা 5. 1
1985 সালে, জো ফারম্যান, ব্রায়ান গার্ডিনার এবং জোনাথন শ্যাঙ্কলিন, ব্রিটিশ অ্যান্টার্কটিক জরিপ (বিএএস) এর জন্য কাজ করছেন, তারা আবিষ্কার করেছেন যে তাদের পরিমাপগুলি দক্ষিণ গোলার্ধের উপরে ওজোন স্তরে একটি মৌসুমী গর্ত নির্দেশ করেছে। এই নাসার ডেটা বিরোধী, যা এ জাতীয় কোনও গর্ত রেকর্ড করে নি। নাসার পদার্থবিজ্ঞানী রিচার্ড স্টোলারস্কি তদন্ত করেছেন এবং দেখেছেন যে নাসার ডেটা-প্রসেসিং সফ্টওয়্যারটি এই ধারণার অধীনে ডিজাইন করা হয়েছিল যে ওজোন স্তরগুলি কোনও নির্দিষ্ট পরিমাণের নিচে কখনও পড়তে পারে না, এবং সনাক্ত করা ওজোনটির খুব কম, খুব কম রিডিংগুলি স্বয়ংক্রিয়ভাবে অযৌক্তিক বহিরাগতদের হিসাবে টস করা হয়েছিল। 2
যন্ত্রগুলি ব্যর্থতার মোডগুলির বৈচিত্র্য অনুভব করে, কখনও কখনও ডেটা সংগ্রহ করার সময়। অ্যাডাম রিংলার এট আল। 2021 পেপারে "আমার স্কুইগলগুলি মজার লাগে কেন?" 3 উদাহরণ রিডআউটগুলির ক্রিয়াকলাপটি প্রকৃত ভূমিকম্পের ক্রিয়াকলাপের সাথে মিলে যায় না।
এমএল অনুশীলনকারীদের জন্য, এটি বোঝা সমালোচনা:
- যারা ডেটা সংগ্রহ করেছেন
- কীভাবে এবং কখন ডেটা সংগ্রহ করা হয়েছিল এবং কোন অবস্থার অধীনে
- সংবেদনশীলতা এবং পরিমাপ যন্ত্রের অবস্থা
- কোন উপকরণ ব্যর্থতা এবং মানুষের ত্রুটি কোনও নির্দিষ্ট প্রসঙ্গে দেখতে পারে
- গোলাকার সংখ্যা এবং পছন্দসই উত্তর সরবরাহ করার জন্য মানুষের প্রবণতা
প্রায় সর্বদা, ডেটা এবং বাস্তবতার মধ্যে কমপক্ষে একটি ছোট পার্থক্য রয়েছে, যা স্থল সত্য হিসাবেও পরিচিত। এই পার্থক্যের জন্য অ্যাকাউন্টিং ভাল সিদ্ধান্তগুলি আঁকতে এবং শব্দ সিদ্ধান্ত নেওয়ার মূল চাবিকাঠি। এর মধ্যে সিদ্ধান্ত নেওয়া অন্তর্ভুক্ত:
- কোন সমস্যাগুলি এমএল দ্বারা সমাধান করা উচিত এবং করা উচিত।
- কোন সমস্যাগুলি এমএল দ্বারা সবচেয়ে ভাল সমাধান করা হয় না।
- কোন সমস্যাগুলি এখনও এমএল দ্বারা সমাধান করার জন্য পর্যাপ্ত উচ্চ মানের ডেটা নেই।
জিজ্ঞাসা করুন: কঠোর এবং সবচেয়ে আক্ষরিক অর্থে কী ডেটা দ্বারা জানানো হয়? ঠিক তেমনি গুরুত্বপূর্ণ, ডেটা দ্বারা কী যোগাযোগ করা হয় না ?
ডেটা ময়লা
ডেটা সংগ্রহের শর্তগুলি তদন্ত করার পাশাপাশি, ডেটাসেট নিজেই ত্রুটি, ত্রুটি এবং নাল বা অবৈধ মান (যেমন ঘনত্বের নেতিবাচক পরিমাপ) থাকতে পারে। ভিড়-উত্সাহিত ডেটা বিশেষত অগোছালো হতে পারে। অজানা মানের একটি ডেটাসেটের সাথে কাজ করা ভুল ফলাফলের দিকে নিয়ে যেতে পারে।
সাধারণ সমস্যা অন্তর্ভুক্ত:
- স্থান, প্রজাতি বা ব্র্যান্ডের নামগুলির মতো স্ট্রিং মানগুলির ভুল বানান
- ভুল ইউনিট রূপান্তর, ইউনিট বা অবজেক্টের ধরণ
- অনুপস্থিত মান
- ধারাবাহিক ভুল শ্রেণিবিন্যাস বা বিভ্রান্তি
- গাণিতিক ক্রিয়াকলাপগুলি থেকে গুরুত্বপূর্ণ অঙ্কগুলি যা কোনও যন্ত্রের প্রকৃত সংবেদনশীলতা ছাড়িয়ে যায়
একটি ডেটাসেট পরিষ্কার করা প্রায়শই নাল এবং অনুপস্থিত মানগুলি সম্পর্কে পছন্দগুলি জড়িত করে (এগুলি নাল হিসাবে রাখবেন, তাদের ফেলে দিন, বা 0s বিকল্প করুন), একটি একক সংস্করণে বানান সংশোধন করা, ইউনিট এবং রূপান্তরগুলি ঠিক করা ইত্যাদি। আরও উন্নত কৌশল হ'ল নিখোঁজ মানগুলি বোঝানো, যা মেশিন লার্নিং ক্র্যাশ কোর্সে ডেটা বৈশিষ্ট্যগুলিতে বর্ণিত।
স্যাম্পলিং, বেঁচে থাকার পক্ষপাত এবং সারোগেট এন্ডপয়েন্ট পয়েন্ট সমস্যা
পরিসংখ্যানগুলি বিশুদ্ধভাবে এলোমেলো নমুনা থেকে বৃহত্তর জনসংখ্যার ফলাফলগুলির বৈধ এবং সঠিক এক্সট্রাপোলেশন জন্য অনুমতি দেয়। ভারসাম্যহীন এবং অসম্পূর্ণ প্রশিক্ষণ ইনপুটগুলির সাথে এই অনুমানের অব্যক্ত ব্রিটলেন্সি, পুনঃসূচনা পর্যালোচনা এবং পুলিশিংয়ের জন্য ব্যবহৃত মডেলগুলি সহ অনেক এমএল অ্যাপ্লিকেশনগুলির উচ্চ-প্রোফাইল ব্যর্থতার দিকে পরিচালিত করেছে। এটি পোলিং ব্যর্থতা এবং জনসংখ্যার গোষ্ঠী সম্পর্কে অন্যান্য ভ্রান্ত সিদ্ধান্তের দিকে পরিচালিত করেছে। কৃত্রিম কম্পিউটার-উত্পাদিত ডেটার বাইরে বেশিরভাগ প্রসঙ্গে, খাঁটি এলোমেলো নমুনাগুলি খুব ব্যয়বহুল এবং অর্জন করা খুব কঠিন। পরিবর্তে বিভিন্ন কার্যকারিতা এবং সাশ্রয়ী মূল্যের প্রক্সি ব্যবহার করা হয়, যা পক্ষপাতের বিভিন্ন উত্স প্রবর্তন করে।
স্তরিত স্যাম্পলিং পদ্ধতিটি ব্যবহার করতে, উদাহরণস্বরূপ, আপনাকে বৃহত্তর জনসংখ্যার প্রতিটি নমুনাযুক্ত স্তরগুলির প্রসারটি জানতে হবে। আপনি যদি এমন একটি প্রসার ধরে নেন যা আসলে ভুল, তবে আপনার ফলাফলগুলি ভুল হবে। তেমনি, অনলাইন পোলিং খুব কমই একটি জাতীয় জনগোষ্ঠীর এলোমেলো নমুনা, তবে ইন্টারনেট-সংযুক্ত জনসংখ্যার একটি নমুনা (প্রায়শই একাধিক দেশ থেকে) যা সমীক্ষাটি দেখতে এবং ইচ্ছুক হতে ইচ্ছুক। এই গোষ্ঠীটি সত্যিকারের এলোমেলো নমুনা থেকে পৃথক হতে পারে। জরিপে থাকা প্রশ্নগুলি সম্ভাব্য প্রশ্নের একটি নমুনা। এই জরিপের প্রশ্নের উত্তরগুলি আবার, উত্তরদাতাদের প্রকৃত মতামতের একটি এলোমেলো নমুনা নয়, তবে মতামতের একটি নমুনা যা উত্তরদাতারা সরবরাহ করতে স্বাচ্ছন্দ্য বোধ করে, যা তাদের প্রকৃত মতামত থেকে পৃথক হতে পারে।
ক্লিনিকাল স্বাস্থ্য গবেষকরা সারোগেট এন্ডপয়েন্ট সমস্যা হিসাবে পরিচিত একটি অনুরূপ সমস্যার মুখোমুখি হন। যেহেতু রোগীর জীবনকালগুলিতে ড্রাগের প্রভাব পরীক্ষা করতে অনেক বেশি সময় লাগে, গবেষকরা প্রক্সি বায়োমারকার ব্যবহার করেন যা জীবনকাল সম্পর্কিত বলে ধরে নেওয়া হয় তবে এটি নাও হতে পারে। কার্ডিওভাসকুলার ইস্যুগুলির কারণে হার্ট অ্যাটাক এবং মৃত্যুর জন্য কোলেস্টেরলের স্তরগুলি সারোগেট এন্ডপয়েন্ট হিসাবে ব্যবহৃত হয়: যদি কোনও ড্রাগ কোলেস্টেরলের মাত্রা হ্রাস করে, তবে এটি কার্ডিয়াক সমস্যার ঝুঁকিও কম বলে ধরে নেওয়া হয়। তবে, এই সম্পর্কের শৃঙ্খলাটি বৈধ নাও হতে পারে, অন্যথায় কার্যকারণের ক্রমটি গবেষক যা ধরে নেন তা ছাড়া অন্য হতে পারে। আরও উদাহরণ এবং বিশদগুলির জন্য ওয়েইনট্রাব এট আল।, "সারোগেট এন্ডপয়েন্টগুলির বিপদ" দেখুন। এমএল এর সমতুল্য পরিস্থিতি হ'ল প্রক্সি লেবেল ।
গণিতবিদ আব্রাহাম ওয়াল্ড বিখ্যাতভাবে একটি ডেটা স্যাম্পলিং ইস্যু চিহ্নিত করেছেন যা এখন বেঁচে থাকার পক্ষপাত হিসাবে পরিচিত। যুদ্ধবিমানগুলি নির্দিষ্ট স্থানে বুলেট গর্ত নিয়ে ফিরে আসছিল, অন্যদের মধ্যে নয়। মার্কিন সামরিক বাহিনী সর্বাধিক বুলেট গর্তযুক্ত অঞ্চলগুলিতে আরও বেশি বর্ম যুক্ত করতে চেয়েছিল, তবে ওয়াল্ডের গবেষণা গোষ্ঠীটি পরিবর্তে বুলেট গর্ত ছাড়াই অঞ্চলে বর্ম যুক্ত করার পরামর্শ দিয়েছে। তারা সঠিকভাবে অনুমান করেছিল যে তাদের ডেটা নমুনাটি স্কিউড ছিল কারণ সেই অঞ্চলগুলিতে গুলি করা প্লেনগুলি এত খারাপভাবে ক্ষতিগ্রস্থ হয়েছিল যে তারা বেসে ফিরে আসতে সক্ষম হয় নি।
যদি কোনও বর্ম-রিকমেন্ডিং মডেলটি কেবলমাত্র প্রত্যাবর্তনকারী যুদ্ধবিমানগুলির চিত্রগুলিতে প্রশিক্ষণ দেওয়া হত, তবে তথ্যগুলিতে উপস্থিত বেঁচে থাকা পক্ষপাতিত্ব সম্পর্কে অন্তর্দৃষ্টি ছাড়াই, সেই মডেলটি আরও বুলেট গর্তযুক্ত অঞ্চলগুলিকে শক্তিশালী করার পরামর্শ দিত।
একটি গবেষণায় অংশ নিতে স্বেচ্ছাসেবক মানব বিষয়গুলি থেকে স্ব-নির্বাচন পক্ষপাত দেখা দিতে পারে। পুনর্বিবেচনা-হ্রাসকারী কর্মসূচির জন্য সাইন আপ করতে অনুপ্রাণিত বন্দীরা উদাহরণস্বরূপ, সাধারণ বন্দী জনসংখ্যার তুলনায় ভবিষ্যতের অপরাধ করার সম্ভাবনা কম জনসংখ্যার প্রতিনিধিত্ব করতে পারে। এটি ফলাফল স্কু করবে। 4
আরও একটি সূক্ষ্ম নমুনা সমস্যা হ'ল মানব বিষয়গুলির স্মৃতিগুলির ম্যালেবিলিটি জড়িত পক্ষপাতিত্বকে স্মরণ করুন । 1993 সালে, এডওয়ার্ড জিওভান্নুচি একটি বয়সের সাথে মিলে যাওয়া মহিলাদের জিজ্ঞাসা করেছিলেন, যাদের মধ্যে কয়েকজন ক্যান্সারে আক্রান্ত হয়েছিলেন, তাদের অতীতের ডায়েটরি অভ্যাস সম্পর্কে। একই মহিলারা তাদের ক্যান্সার নির্ণয়ের আগে ডায়েটরি অভ্যাস সম্পর্কে একটি সমীক্ষা নিয়েছিলেন। জিওভান্নুচি যা আবিষ্কার করেছিলেন তা হ'ল ক্যান্সারবিহীন মহিলারা তাদের ডায়েটকে সঠিকভাবে স্মরণ করিয়ে দিয়েছিলেন, তবে স্তন ক্যান্সারে আক্রান্ত মহিলারা তাদের ক্যান্সারের জন্য সম্ভবত একটি সম্ভাব্য (যদিও ভুল) ব্যাখ্যা সরবরাহ করেছেন তার চেয়ে বেশি চর্বি গ্রহণ করছেন বলে জানিয়েছেন। 5
জিজ্ঞাসা করুন:
- একটি ডেটাসেট আসলে নমুনা কি?
- স্যাম্পলিংয়ের কত স্তর উপস্থিত রয়েছে?
- নমুনার প্রতিটি স্তরে কোন পক্ষপাত চালু করা যেতে পারে?
- প্রক্সি পরিমাপটি কি ব্যবহৃত হয় (বায়োমার্কার বা অনলাইন পোল বা বুলেট গর্ত) প্রকৃত সম্পর্ক বা কার্যকারিতা দেখায়?
- নমুনা এবং নমুনা পদ্ধতি থেকে কী অনুপস্থিত হতে পারে?
মেশিন লার্নিং ক্র্যাশ কোর্সে ফেয়ারনেস মডিউলটি ডেমোগ্রাফিক ডেটাসেটগুলিতে পক্ষপাতের অতিরিক্ত উত্সগুলির জন্য মূল্যায়ন এবং প্রশমিত করার উপায়গুলি কভার করে।
সংজ্ঞা এবং র্যাঙ্কিং
শর্তাবলী পরিষ্কার এবং সুনির্দিষ্টভাবে সংজ্ঞায়িত করুন, বা পরিষ্কার এবং সুনির্দিষ্ট সংজ্ঞা সম্পর্কে জিজ্ঞাসা করুন। কোন ডেটা বৈশিষ্ট্যগুলি বিবেচনাধীন রয়েছে এবং কী ঠিক পূর্বাভাস দেওয়া বা দাবি করা হচ্ছে তা বোঝার জন্য এটি প্রয়োজনীয়। চার্লস হুইলান, নগ্ন পরিসংখ্যানগুলিতে , একটি অস্পষ্ট শব্দটির উদাহরণ হিসাবে "মার্কিন যুক্তরাষ্ট্রের স্বাস্থ্য" সরবরাহ করে। মার্কিন উত্পাদন "স্বাস্থ্যকর" কিনা তা পুরোপুরি নির্ভর করে যে শব্দটি কীভাবে সংজ্ঞায়িত করা হয়। দ্য ইকোনমিস্টে গ্রেগ আইপি'র মার্চ ২০১১ নিবন্ধটি এই অস্পষ্টতার চিত্র তুলে ধরেছে। যদি "স্বাস্থ্য" এর মেট্রিকটি "উত্পাদন আউটপুট" হয় তবে ২০১১ সালে মার্কিন উত্পাদন ক্রমবর্ধমান স্বাস্থ্যকর ছিল। যদি "স্বাস্থ্য" মেট্রিককে "উত্পাদন কাজ" হিসাবে সংজ্ঞায়িত করা হয় তবে তবে মার্কিন উত্পাদন হ্রাস পাচ্ছিল। 6
র্যাঙ্কিং, র্যাঙ্কিংয়ের অসঙ্গতি এবং অবৈধ বিকল্পগুলির বিভিন্ন উপাদানকে দেওয়া অস্পষ্ট বা অযৌক্তিক ওজন সহ প্রায়শই অনুরূপ ইস্যুতে ভোগে। নিউইয়র্কের লেখায় ম্যালকম গ্ল্যাডওয়েল মিশিগান সুপ্রিম কোর্টের প্রধান বিচারপতি টমাস ব্রেনানকে উল্লেখ করেছেন, যিনি একবার একশো আইনজীবীদের কাছে একটি সমীক্ষা পাঠিয়েছিলেন তাদের গুণগতভাবে দশটি আইন স্কুলকে র্যাঙ্ক করতে বলেছিলেন, কিছু বিখ্যাত, কিছু না। এই আইনজীবীরা পেন স্টেটের আইন স্কুলকে প্রায় পঞ্চম স্থানে স্থান দিয়েছিল, যদিও জরিপের সময়, পেন স্টেটের কোনও আইন স্কুল ছিল না। 7 অনেক সুপরিচিত র্যাঙ্কিংয়ে একইভাবে সাবজেক্টিভ নামী উপাদান অন্তর্ভুক্ত রয়েছে। কোন উপাদানগুলি একটি র্যাঙ্কিংয়ে যায় এবং কেন সেই উপাদানগুলি তাদের বিশেষ ওজন বরাদ্দ করা হয়েছিল তা জিজ্ঞাসা করুন।
ছোট সংখ্যা এবং বড় প্রভাব
আপনি যদি দু'বার মুদ্রা উল্টিয়ে দিচ্ছেন তবে 100% হেড বা 100% লেজ পাওয়া অবাক হওয়ার কিছু নেই। না কোনও মুদ্রা চারবার উল্টানোর পরে 25% মাথা পাওয়া অবাক হওয়ার মতো নয়, তারপরে পরবর্তী চারটি ফ্লিপগুলির জন্য 75% মাথা, যদিও এটি একটি স্পষ্টতই প্রচুর পরিমাণে বৃদ্ধি দেখায় (এটি মুদ্রা ফ্লিপগুলির সেটগুলির মধ্যে খাওয়া স্যান্ডউইচকে ভুলভাবে দায়ী করা যেতে পারে, বা অন্য কোনও উদ্দীপনা ফ্যাক্টর)। তবে মুদ্রা ফ্লিপের সংখ্যা বাড়ার সাথে সাথে এক হাজার বা ২,০০০ বলুন, প্রত্যাশিত ৫০% থেকে বড় শতাংশ বিচ্যুতি অদৃশ্যভাবে অসম্ভব হয়ে যায়।
একটি গবেষণায় পরিমাপ বা পরীক্ষামূলক বিষয়গুলির সংখ্যা প্রায়শই এন হিসাবে উল্লেখ করা হয়। সুযোগের কারণে বৃহত আনুপাতিক পরিবর্তনগুলি কম এন সহ ডেটাসেট এবং নমুনায় হওয়ার সম্ভাবনা অনেক বেশি।
কোনও বিশ্লেষণ পরিচালনা করার সময় বা কোনও ডেটা কার্ডে কোনও ডেটাসেট ডকুমেন্ট করার সময়, এন নির্দিষ্ট করুন, যাতে অন্যান্য লোকেরা শব্দ এবং এলোমেলোতার প্রভাব বিবেচনা করতে পারে।
যেহেতু মডেল মানের উদাহরণগুলির সংখ্যার সাথে স্কেল করে, কম এন সহ একটি ডেটাসেট নিম্ন মানের মডেলগুলির ফলস্বরূপ।
গড় প্রতি রিগ্রেশন
একইভাবে, সুযোগ থেকে কিছুটা প্রভাব রয়েছে এমন কোনও পরিমাপের প্রভাবের সাপেক্ষে যা গড়ের রিগ্রেশন হিসাবে পরিচিত। এটি বর্ণনা করে যে কীভাবে বিশেষত চরম পরিমাপের পরে পরিমাপটি গড়ে কম চরম বা গড়ের কাছাকাছি হওয়ার সম্ভাবনা রয়েছে, কারণ চরম পরিমাপটি প্রথম স্থানে হওয়ার পক্ষে কতটা অসম্ভব ছিল। প্রভাবটি আরও স্পষ্ট হয় যদি বিশেষত উচ্চ-গড় বা নীচের গড় গোষ্ঠী পর্যবেক্ষণের জন্য নির্বাচিত হয়, তবে সেই গোষ্ঠীটি কোনও জনগোষ্ঠীর সবচেয়ে উঁচু মানুষ, কোনও দলের সবচেয়ে খারাপ অ্যাথলিট বা স্ট্রোকের ঝুঁকির মধ্যে সবচেয়ে বেশি ঝুঁকির মধ্যে রয়েছে কিনা। সবচেয়ে উঁচু মানুষের বাচ্চারা গড়ে তাদের পিতামাতার চেয়ে কম হওয়ার সম্ভাবনা রয়েছে, সবচেয়ে খারাপ অ্যাথলিটরা ব্যতিক্রমী খারাপ মৌসুমের পরে আরও ভাল পারফর্ম করতে পারে এবং স্ট্রোকের জন্য সবচেয়ে বেশি ঝুঁকির মধ্যে থাকা কোনও হস্তক্ষেপ বা চিকিত্সার পরে ঝুঁকি হ্রাস করতে পারে বলে মনে হয়, কার্যকারক কারণগুলির কারণে নয় তবে এলোমেলোতার বৈশিষ্ট্য এবং সম্ভাবনার কারণে।
উপরের গড় বা নিম্ন-গড় গোষ্ঠীর জন্য হস্তক্ষেপ বা চিকিত্সা অন্বেষণ করার সময়, গড়ের সাথে রিগ্রেশন এর প্রভাবগুলির জন্য একটি প্রশমন হ'ল কার্যকারক প্রভাবগুলি বিচ্ছিন্ন করার জন্য বিষয়গুলি একটি অধ্যয়ন গোষ্ঠী এবং একটি নিয়ন্ত্রণ গোষ্ঠীতে বিভক্ত করা। এমএল প্রসঙ্গে, এই ঘটনাটি ব্যতিক্রমী বা বহিরাগত মানগুলির পূর্বাভাস দেয় এমন কোনও মডেলকে অতিরিক্ত মনোযোগ দেওয়ার পরামর্শ দেয়, যেমন:
- চরম আবহাওয়া বা তাপমাত্রা
- সেরা পারফরম্যান্স স্টোর বা অ্যাথলেটরা
- একটি ওয়েবসাইটে সর্বাধিক জনপ্রিয় ভিডিও
যদি সময়ের সাথে সাথে এই ব্যতিক্রমী মানগুলির কোনও মডেলের চলমান ভবিষ্যদ্বাণীগুলি বাস্তবতার সাথে মেলে না, উদাহরণস্বরূপ ভবিষ্যদ্বাণী করে যে একটি অত্যন্ত সফল স্টোর বা ভিডিও সফল হতে থাকবে যখন বাস্তবে এটি না হয়, জিজ্ঞাসা করুন:
- গড়ের রিগ্রেশন ইস্যুটি হতে পারে?
- সর্বোচ্চ ওজনযুক্ত বৈশিষ্ট্যগুলি কি কম ওজনের বৈশিষ্ট্যগুলির চেয়ে বেশি ভবিষ্যদ্বাণীমূলক?
- এই বৈশিষ্ট্যগুলির জন্য বেসলাইন মান রয়েছে এমন ডেটা সংগ্রহ করা কি প্রায়শই শূন্য (কার্যকরভাবে একটি নিয়ন্ত্রণ গোষ্ঠী) মডেলের ভবিষ্যদ্বাণীগুলি পরিবর্তন করে?
তথ্যসূত্র
হাফ, ড্যারেল পরিসংখ্যানের সাথে কীভাবে মিথ্যা বলা যায়। এনওয়াই: ডাব্লুডাব্লু নরটন, 1954।
জোন্স, বেন। ডেটা সমস্যাগুলি এড়ানো। হোবোকেন, এনজে: উইলি, 2020।
ও'কনর, কাইলিন এবং জেমস ওভেন ওয়েদারাল। ভুল তথ্য বয়স। নিউ হ্যাভেন: ইয়েল আপ, 2019।
রিংলার, অ্যাডাম, ডেভিড ম্যাসন, গ্যাবি লাস্কে এবং মেরি টেম্পলটন। "আমার স্কুইগলগুলি কেন মজাদার দেখাচ্ছে? আপোস করা ভূমিকম্পের সংকেতের একটি গ্যালারী" " সিসমোলজিকাল রিসার্চ লেটারস 92 নং। 6 (জুলাই 2021)। Doi: 10.1785/0220210094
ওয়েইনট্রাব, উইলিয়াম এস, টমাস এফ ল্যাসচার এবং স্টুয়ার্ট পোকক। "সারোগেট এন্ডপয়েন্টগুলির বিপদগুলি" " ইউরোপীয় হার্ট জার্নাল 36 নং। 33 (সেপ্টেম্বর 2015): 2212–2218। Doi: 10.1093/EUREARTJ/EHV164
হুইলান, চার্লস নগ্ন পরিসংখ্যান: ডেটা থেকে ভয় ছিনিয়ে নেওয়া। এনওয়াই: ডাব্লুডাব্লু নরটন, 2013
ইমেজ রেফারেন্স
"বেঁচে থাকার পক্ষপাত।" মার্টিন গ্র্যান্ডজিয়ান, ম্যাকজেডডন এবং ক্যামেরন মোল 2021. সিসি বাই-এসএ 4.0। উৎস
জোন্স 25-29। ↩
ও'কনর এবং ওয়েদারাল 22-3। ↩
রিংলিং এট আল। ↩
হুইলান 120. ↩
সিদ্ধার্থ মুখার্জি, "সেলফোনগুলি কি মস্তিষ্কের ক্যান্সারের কারণ হয়?" নিউইয়র্ক টাইমসে, এপ্রিল 13, 2011. হুইলান 122 এ উদ্ধৃত। ↩
হুইলান 39-40। ↩
ম্যালকম গ্ল্যাডওয়েল, "দ্য অর্ডার অফ থিংস" , নিউ ইয়র্কারে 14 ফেব্রুয়ারী, 2011. হুইলানে উদ্ধৃত 56. ↩
"আবর্জনা, আবর্জনা আউট।"
- প্রারম্ভিক প্রোগ্রামিং প্রবাদ
প্রতিটি এমএল মডেলের নীচে, পারস্পরিক সম্পর্কের প্রতিটি গণনা এবং প্রতিটি ডেটা-ভিত্তিক নীতিমালার সুপারিশে এক বা একাধিক কাঁচা ডেটাসেট রয়েছে। শেষ পণ্যগুলি কত সুন্দর বা আকর্ষণীয় বা প্ররোচিত হোক না কেন, যদি অন্তর্নিহিত ডেটা ভ্রান্ত, খারাপভাবে সংগ্রহ করা বা নিম্নমানের হয় তবে ফলস্বরূপ মডেল, ভবিষ্যদ্বাণী, ভিজ্যুয়ালাইজেশন বা উপসংহার একইভাবে নিম্নমানের হবে। যে কেউ ডেটাসেটগুলিতে মডেলগুলি কল্পনা করে, বিশ্লেষণ করে এবং প্রশিক্ষণ দেয় তাদের ডেটাগুলির উত্স সম্পর্কে কঠোর প্রশ্ন জিজ্ঞাসা করা উচিত।
ডেটা সংগ্রহকারী যন্ত্রগুলি ত্রুটিযুক্ত হতে পারে বা খারাপভাবে ক্যালিব্রেট করা যায়। ডেটা সংগ্রহকারী মানুষ ক্লান্ত, দুষ্টু, বেমানান বা খারাপ প্রশিক্ষিত হতে পারে। লোকেরা ভুল করে এবং বিভিন্ন ব্যক্তি অস্পষ্ট সংকেতগুলির শ্রেণিবিন্যাসের বিষয়েও যুক্তিসঙ্গতভাবে একমত হতে পারে। ফলস্বরূপ, ডেটার গুণমান এবং বৈধতা ক্ষতিগ্রস্থ হতে পারে এবং ডেটা বাস্তবতা প্রতিফলিত করতে ব্যর্থ হতে পারে। ডেটা সমস্যাগুলি এড়ানোর লেখক বেন জোন্স এটিকে ডেটা-রিয়েলিটি গ্যাপ বলেছেন, পাঠককে স্মরণ করিয়ে দিয়েছিলেন: "এটি অপরাধ নয়, এটি অপরাধের খবর পাওয়া যায় । এটি উল্কা স্ট্রাইকগুলির সংখ্যা নয়, এটি রেকর্ড করা উল্কা স্ট্রাইকগুলির সংখ্যা।"
ডেটা-রিয়েলিটি গ্যাপের উদাহরণ:
জোন্স গ্রাফগুলি 5 মিনিটের ব্যবধানে সময় পরিমাপে এবং 5-পাউন্ডের বিরতিতে ওজন পরিমাপের ক্ষেত্রে স্পাইক করে, এই জাতীয় স্পাইকগুলি ডেটাতে বিদ্যমান বলে নয়, কারণ মানব ডেটা সংগ্রহকারীদের, যন্ত্রগুলির বিপরীতে, তাদের সংখ্যাগুলি নিকটতম 0 এ গোল করার প্রবণতা রয়েছে বা 5. 1
1985 সালে, জো ফারম্যান, ব্রায়ান গার্ডিনার এবং জোনাথন শ্যাঙ্কলিন, ব্রিটিশ অ্যান্টার্কটিক জরিপ (বিএএস) এর জন্য কাজ করছেন, তারা আবিষ্কার করেছেন যে তাদের পরিমাপগুলি দক্ষিণ গোলার্ধের উপরে ওজোন স্তরে একটি মৌসুমী গর্ত নির্দেশ করেছে। এই নাসার ডেটা বিরোধী, যা এ জাতীয় কোনও গর্ত রেকর্ড করে নি। নাসার পদার্থবিজ্ঞানী রিচার্ড স্টোলারস্কি তদন্ত করেছেন এবং দেখেছেন যে নাসার ডেটা-প্রসেসিং সফ্টওয়্যারটি এই ধারণার অধীনে ডিজাইন করা হয়েছিল যে ওজোন স্তরগুলি কোনও নির্দিষ্ট পরিমাণের নিচে কখনও পড়তে পারে না, এবং সনাক্ত করা ওজোনটির খুব কম, খুব কম রিডিংগুলি স্বয়ংক্রিয়ভাবে অযৌক্তিক বহিরাগতদের হিসাবে টস করা হয়েছিল। 2
যন্ত্রগুলি ব্যর্থতার মোডগুলির বৈচিত্র্য অনুভব করে, কখনও কখনও ডেটা সংগ্রহ করার সময়। অ্যাডাম রিংলার এট আল। 2021 পেপারে "আমার স্কুইগলগুলি মজার লাগে কেন?" 3 উদাহরণ রিডআউটগুলির ক্রিয়াকলাপটি প্রকৃত ভূমিকম্পের ক্রিয়াকলাপের সাথে মিলে যায় না।
এমএল অনুশীলনকারীদের জন্য, এটি বোঝা সমালোচনা:
- যারা ডেটা সংগ্রহ করেছেন
- কীভাবে এবং কখন ডেটা সংগ্রহ করা হয়েছিল এবং কোন অবস্থার অধীনে
- সংবেদনশীলতা এবং পরিমাপ যন্ত্রের অবস্থা
- কোন উপকরণ ব্যর্থতা এবং মানুষের ত্রুটি কোনও নির্দিষ্ট প্রসঙ্গে দেখতে পারে
- গোলাকার সংখ্যা এবং পছন্দসই উত্তর সরবরাহ করার জন্য মানুষের প্রবণতা
প্রায় সর্বদা, ডেটা এবং বাস্তবতার মধ্যে কমপক্ষে একটি ছোট পার্থক্য রয়েছে, যা স্থল সত্য হিসাবেও পরিচিত। এই পার্থক্যের জন্য অ্যাকাউন্টিং ভাল সিদ্ধান্তগুলি আঁকতে এবং শব্দ সিদ্ধান্ত নেওয়ার মূল চাবিকাঠি। এর মধ্যে সিদ্ধান্ত নেওয়া অন্তর্ভুক্ত:
- কোন সমস্যাগুলি এমএল দ্বারা সমাধান করা উচিত এবং করা উচিত।
- কোন সমস্যাগুলি এমএল দ্বারা সবচেয়ে ভাল সমাধান করা হয় না।
- কোন সমস্যাগুলি এখনও এমএল দ্বারা সমাধান করার জন্য পর্যাপ্ত উচ্চ মানের ডেটা নেই।
জিজ্ঞাসা করুন: কঠোর এবং সবচেয়ে আক্ষরিক অর্থে কী ডেটা দ্বারা জানানো হয়? ঠিক তেমনি গুরুত্বপূর্ণ, ডেটা দ্বারা কী যোগাযোগ করা হয় না ?
ডেটা ময়লা
ডেটা সংগ্রহের শর্তগুলি তদন্ত করার পাশাপাশি, ডেটাসেট নিজেই ত্রুটি, ত্রুটি এবং নাল বা অবৈধ মান (যেমন ঘনত্বের নেতিবাচক পরিমাপ) থাকতে পারে। ভিড়-উত্সাহিত ডেটা বিশেষত অগোছালো হতে পারে। অজানা মানের একটি ডেটাসেটের সাথে কাজ করা ভুল ফলাফলের দিকে নিয়ে যেতে পারে।
সাধারণ সমস্যা অন্তর্ভুক্ত:
- স্থান, প্রজাতি বা ব্র্যান্ডের নামগুলির মতো স্ট্রিং মানগুলির ভুল বানান
- ভুল ইউনিট রূপান্তর, ইউনিট বা অবজেক্টের ধরণ
- অনুপস্থিত মান
- ধারাবাহিক ভুল শ্রেণিবিন্যাস বা বিভ্রান্তি
- গাণিতিক ক্রিয়াকলাপগুলি থেকে গুরুত্বপূর্ণ অঙ্কগুলি যা কোনও যন্ত্রের প্রকৃত সংবেদনশীলতা ছাড়িয়ে যায়
একটি ডেটাসেট পরিষ্কার করা প্রায়শই নাল এবং অনুপস্থিত মানগুলি সম্পর্কে পছন্দগুলি জড়িত করে (এগুলি নাল হিসাবে রাখবেন, তাদের ফেলে দিন, বা 0s বিকল্প করুন), একটি একক সংস্করণে বানান সংশোধন করা, ইউনিট এবং রূপান্তরগুলি ঠিক করা ইত্যাদি। আরও উন্নত কৌশল হ'ল নিখোঁজ মানগুলি বোঝানো, যা মেশিন লার্নিং ক্র্যাশ কোর্সে ডেটা বৈশিষ্ট্যগুলিতে বর্ণিত।
স্যাম্পলিং, বেঁচে থাকার পক্ষপাত এবং সারোগেট এন্ডপয়েন্ট পয়েন্ট সমস্যা
পরিসংখ্যানগুলি বিশুদ্ধভাবে এলোমেলো নমুনা থেকে বৃহত্তর জনসংখ্যার ফলাফলগুলির বৈধ এবং সঠিক এক্সট্রাপোলেশন জন্য অনুমতি দেয়। ভারসাম্যহীন এবং অসম্পূর্ণ প্রশিক্ষণ ইনপুটগুলির সাথে এই অনুমানের অব্যক্ত ব্রিটলেন্সি, পুনঃসূচনা পর্যালোচনা এবং পুলিশিংয়ের জন্য ব্যবহৃত মডেলগুলি সহ অনেক এমএল অ্যাপ্লিকেশনগুলির উচ্চ-প্রোফাইল ব্যর্থতার দিকে পরিচালিত করেছে। এটি পোলিং ব্যর্থতা এবং জনসংখ্যার গোষ্ঠী সম্পর্কে অন্যান্য ভ্রান্ত সিদ্ধান্তের দিকে পরিচালিত করেছে। কৃত্রিম কম্পিউটার-উত্পাদিত ডেটার বাইরে বেশিরভাগ প্রসঙ্গে, খাঁটি এলোমেলো নমুনাগুলি খুব ব্যয়বহুল এবং অর্জন করা খুব কঠিন। পরিবর্তে বিভিন্ন কার্যকারিতা এবং সাশ্রয়ী মূল্যের প্রক্সি ব্যবহার করা হয়, যা পক্ষপাতের বিভিন্ন উত্স প্রবর্তন করে।
স্তরিত স্যাম্পলিং পদ্ধতিটি ব্যবহার করতে, উদাহরণস্বরূপ, আপনাকে বৃহত্তর জনসংখ্যার প্রতিটি নমুনাযুক্ত স্তরগুলির প্রসারটি জানতে হবে। আপনি যদি এমন একটি প্রসার ধরে নেন যা আসলে ভুল, তবে আপনার ফলাফলগুলি ভুল হবে। তেমনি, অনলাইন পোলিং খুব কমই একটি জাতীয় জনগোষ্ঠীর এলোমেলো নমুনা, তবে ইন্টারনেট-সংযুক্ত জনসংখ্যার একটি নমুনা (প্রায়শই একাধিক দেশ থেকে) যা সমীক্ষাটি দেখতে এবং ইচ্ছুক হতে ইচ্ছুক। এই গোষ্ঠীটি সত্যিকারের এলোমেলো নমুনা থেকে পৃথক হতে পারে। জরিপে থাকা প্রশ্নগুলি সম্ভাব্য প্রশ্নের একটি নমুনা। এই জরিপের প্রশ্নের উত্তরগুলি আবার, উত্তরদাতাদের প্রকৃত মতামতের একটি এলোমেলো নমুনা নয়, তবে মতামতের একটি নমুনা যা উত্তরদাতারা সরবরাহ করতে স্বাচ্ছন্দ্য বোধ করে, যা তাদের প্রকৃত মতামত থেকে পৃথক হতে পারে।
ক্লিনিকাল স্বাস্থ্য গবেষকরা সারোগেট এন্ডপয়েন্ট সমস্যা হিসাবে পরিচিত একটি অনুরূপ সমস্যার মুখোমুখি হন। যেহেতু রোগীর জীবনকালগুলিতে ড্রাগের প্রভাব পরীক্ষা করতে অনেক বেশি সময় লাগে, গবেষকরা প্রক্সি বায়োমারকার ব্যবহার করেন যা জীবনকাল সম্পর্কিত বলে ধরে নেওয়া হয় তবে এটি নাও হতে পারে। কার্ডিওভাসকুলার ইস্যুগুলির কারণে হার্ট অ্যাটাক এবং মৃত্যুর জন্য কোলেস্টেরলের স্তরগুলি সারোগেট এন্ডপয়েন্ট হিসাবে ব্যবহৃত হয়: যদি কোনও ড্রাগ কোলেস্টেরলের মাত্রা হ্রাস করে, তবে এটি কার্ডিয়াক সমস্যার ঝুঁকিও কম বলে ধরে নেওয়া হয়। তবে, এই সম্পর্কের শৃঙ্খলাটি বৈধ নাও হতে পারে, অন্যথায় কার্যকারণের ক্রমটি গবেষক যা ধরে নেন তা ছাড়া অন্য হতে পারে। আরও উদাহরণ এবং বিশদগুলির জন্য ওয়েইনট্রাব এট আল।, "সারোগেট এন্ডপয়েন্টগুলির বিপদ" দেখুন। এমএল এর সমতুল্য পরিস্থিতি হ'ল প্রক্সি লেবেল ।
গণিতবিদ আব্রাহাম ওয়াল্ড বিখ্যাতভাবে একটি ডেটা স্যাম্পলিং ইস্যু চিহ্নিত করেছেন যা এখন বেঁচে থাকার পক্ষপাত হিসাবে পরিচিত। যুদ্ধবিমানগুলি নির্দিষ্ট স্থানে বুলেট গর্ত নিয়ে ফিরে আসছিল, অন্যদের মধ্যে নয়। মার্কিন সামরিক বাহিনী সর্বাধিক বুলেট গর্তযুক্ত অঞ্চলগুলিতে আরও বেশি বর্ম যুক্ত করতে চেয়েছিল, তবে ওয়াল্ডের গবেষণা গোষ্ঠীটি পরিবর্তে বুলেট গর্ত ছাড়াই অঞ্চলে বর্ম যুক্ত করার পরামর্শ দিয়েছে। তারা সঠিকভাবে অনুমান করেছিল যে তাদের ডেটা নমুনাটি স্কিউড ছিল কারণ সেই অঞ্চলগুলিতে গুলি করা প্লেনগুলি এত খারাপভাবে ক্ষতিগ্রস্থ হয়েছিল যে তারা বেসে ফিরে আসতে সক্ষম হয় নি।
যদি কোনও বর্ম-রিকমেন্ডিং মডেলটি কেবলমাত্র প্রত্যাবর্তনকারী যুদ্ধবিমানগুলির চিত্রগুলিতে প্রশিক্ষণ দেওয়া হত, তবে তথ্যগুলিতে উপস্থিত বেঁচে থাকা পক্ষপাতিত্ব সম্পর্কে অন্তর্দৃষ্টি ছাড়াই, সেই মডেলটি আরও বুলেট গর্তযুক্ত অঞ্চলগুলিকে শক্তিশালী করার পরামর্শ দিত।
একটি গবেষণায় অংশ নিতে স্বেচ্ছাসেবক মানব বিষয়গুলি থেকে স্ব-নির্বাচন পক্ষপাত দেখা দিতে পারে। পুনর্বিবেচনা-হ্রাসকারী কর্মসূচির জন্য সাইন আপ করতে অনুপ্রাণিত বন্দীরা উদাহরণস্বরূপ, সাধারণ বন্দী জনসংখ্যার তুলনায় ভবিষ্যতের অপরাধ করার সম্ভাবনা কম জনসংখ্যার প্রতিনিধিত্ব করতে পারে। এটি ফলাফল স্কু করবে। 4
আরও একটি সূক্ষ্ম নমুনা সমস্যা হ'ল মানব বিষয়গুলির স্মৃতিগুলির ম্যালেবিলিটি জড়িত পক্ষপাতিত্বকে স্মরণ করুন । 1993 সালে, এডওয়ার্ড জিওভান্নুচি একটি বয়সের সাথে মিলে যাওয়া মহিলাদের জিজ্ঞাসা করেছিলেন, যাদের মধ্যে কয়েকজন ক্যান্সারে আক্রান্ত হয়েছিলেন, তাদের অতীতের ডায়েটরি অভ্যাস সম্পর্কে। একই মহিলারা তাদের ক্যান্সার নির্ণয়ের আগে ডায়েটরি অভ্যাস সম্পর্কে একটি সমীক্ষা নিয়েছিলেন। জিওভান্নুচি যা আবিষ্কার করেছিলেন তা হ'ল ক্যান্সারবিহীন মহিলারা তাদের ডায়েটকে সঠিকভাবে স্মরণ করিয়ে দিয়েছিলেন, তবে স্তন ক্যান্সারে আক্রান্ত মহিলারা তাদের ক্যান্সারের জন্য সম্ভবত একটি সম্ভাব্য (যদিও ভুল) ব্যাখ্যা সরবরাহ করেছেন তার চেয়ে বেশি চর্বি গ্রহণ করছেন বলে জানিয়েছেন। 5
জিজ্ঞাসা করুন:
- একটি ডেটাসেট আসলে নমুনা কি?
- স্যাম্পলিংয়ের কত স্তর উপস্থিত রয়েছে?
- নমুনার প্রতিটি স্তরে কোন পক্ষপাত চালু করা যেতে পারে?
- প্রক্সি পরিমাপটি কি ব্যবহৃত হয় (বায়োমার্কার বা অনলাইন পোল বা বুলেট গর্ত) প্রকৃত সম্পর্ক বা কার্যকারিতা দেখায়?
- নমুনা এবং নমুনা পদ্ধতি থেকে কী অনুপস্থিত হতে পারে?
মেশিন লার্নিং ক্র্যাশ কোর্সে ফেয়ারনেস মডিউলটি ডেমোগ্রাফিক ডেটাসেটগুলিতে পক্ষপাতের অতিরিক্ত উত্সগুলির জন্য মূল্যায়ন এবং প্রশমিত করার উপায়গুলি কভার করে।
সংজ্ঞা এবং র্যাঙ্কিং
শর্তাবলী পরিষ্কার এবং সুনির্দিষ্টভাবে সংজ্ঞায়িত করুন, বা পরিষ্কার এবং সুনির্দিষ্ট সংজ্ঞা সম্পর্কে জিজ্ঞাসা করুন। কোন ডেটা বৈশিষ্ট্যগুলি বিবেচনাধীন রয়েছে এবং কী ঠিক পূর্বাভাস দেওয়া বা দাবি করা হচ্ছে তা বোঝার জন্য এটি প্রয়োজনীয়। চার্লস হুইলান, নগ্ন পরিসংখ্যানগুলিতে , একটি অস্পষ্ট শব্দটির উদাহরণ হিসাবে "মার্কিন যুক্তরাষ্ট্রের স্বাস্থ্য" সরবরাহ করে। মার্কিন উত্পাদন "স্বাস্থ্যকর" কিনা তা পুরোপুরি নির্ভর করে যে শব্দটি কীভাবে সংজ্ঞায়িত করা হয়। দ্য ইকোনমিস্টে গ্রেগ আইপি'র মার্চ ২০১১ নিবন্ধটি এই অস্পষ্টতার চিত্র তুলে ধরেছে। যদি "স্বাস্থ্য" এর মেট্রিকটি "উত্পাদন আউটপুট" হয় তবে ২০১১ সালে মার্কিন উত্পাদন ক্রমবর্ধমান স্বাস্থ্যকর ছিল। যদি "স্বাস্থ্য" মেট্রিককে "উত্পাদন কাজ" হিসাবে সংজ্ঞায়িত করা হয় তবে তবে মার্কিন উত্পাদন হ্রাস পাচ্ছিল। 6
র্যাঙ্কিং, র্যাঙ্কিংয়ের অসঙ্গতি এবং অবৈধ বিকল্পগুলির বিভিন্ন উপাদানকে দেওয়া অস্পষ্ট বা অযৌক্তিক ওজন সহ প্রায়শই অনুরূপ ইস্যুতে ভোগে। নিউইয়র্কের লেখায় ম্যালকম গ্ল্যাডওয়েল মিশিগান সুপ্রিম কোর্টের প্রধান বিচারপতি টমাস ব্রেনানকে উল্লেখ করেছেন, যিনি একবার একশো আইনজীবীদের কাছে একটি সমীক্ষা পাঠিয়েছিলেন তাদের গুণগতভাবে দশটি আইন স্কুলকে র্যাঙ্ক করতে বলেছিলেন, কিছু বিখ্যাত, কিছু না। এই আইনজীবীরা পেন স্টেটের আইন স্কুলকে প্রায় পঞ্চম স্থানে স্থান দিয়েছিল, যদিও জরিপের সময়, পেন স্টেটের কোনও আইন স্কুল ছিল না। 7 অনেক সুপরিচিত র্যাঙ্কিংয়ে একইভাবে সাবজেক্টিভ নামী উপাদান অন্তর্ভুক্ত রয়েছে। কোন উপাদানগুলি একটি র্যাঙ্কিংয়ে যায় এবং কেন সেই উপাদানগুলি তাদের বিশেষ ওজন বরাদ্দ করা হয়েছিল তা জিজ্ঞাসা করুন।
ছোট সংখ্যা এবং বড় প্রভাব
আপনি যদি দু'বার মুদ্রা উল্টিয়ে দিচ্ছেন তবে 100% হেড বা 100% লেজ পাওয়া অবাক হওয়ার কিছু নেই। না কোনও মুদ্রা চারবার উল্টানোর পরে 25% মাথা পাওয়া অবাক হওয়ার মতো নয়, তারপরে পরবর্তী চারটি ফ্লিপগুলির জন্য 75% মাথা, যদিও এটি একটি স্পষ্টতই প্রচুর পরিমাণে বৃদ্ধি দেখায় (এটি মুদ্রা ফ্লিপগুলির সেটগুলির মধ্যে খাওয়া স্যান্ডউইচকে ভুলভাবে দায়ী করা যেতে পারে, বা অন্য কোনও উদ্দীপনা ফ্যাক্টর)। তবে মুদ্রা ফ্লিপের সংখ্যা বাড়ার সাথে সাথে এক হাজার বা ২,০০০ বলুন, প্রত্যাশিত ৫০% থেকে বড় শতাংশ বিচ্যুতি অদৃশ্যভাবে অসম্ভব হয়ে যায়।
একটি গবেষণায় পরিমাপ বা পরীক্ষামূলক বিষয়গুলির সংখ্যা প্রায়শই এন হিসাবে উল্লেখ করা হয়। সুযোগের কারণে বৃহত আনুপাতিক পরিবর্তনগুলি কম এন সহ ডেটাসেট এবং নমুনায় হওয়ার সম্ভাবনা অনেক বেশি।
কোনও বিশ্লেষণ পরিচালনা করার সময় বা কোনও ডেটা কার্ডে কোনও ডেটাসেট ডকুমেন্ট করার সময়, এন নির্দিষ্ট করুন, যাতে অন্যান্য লোকেরা শব্দ এবং এলোমেলোতার প্রভাব বিবেচনা করতে পারে।
যেহেতু মডেল মানের উদাহরণগুলির সংখ্যার সাথে স্কেল করে, কম এন সহ একটি ডেটাসেট নিম্ন মানের মডেলগুলির ফলস্বরূপ।
গড় প্রতি রিগ্রেশন
একইভাবে, সুযোগ থেকে কিছুটা প্রভাব রয়েছে এমন কোনও পরিমাপের প্রভাবের সাপেক্ষে যা গড়ের রিগ্রেশন হিসাবে পরিচিত। এটি বর্ণনা করে যে কীভাবে বিশেষত চরম পরিমাপের পরে পরিমাপটি গড়ে কম চরম বা গড়ের কাছাকাছি হওয়ার সম্ভাবনা রয়েছে, কারণ চরম পরিমাপটি প্রথম স্থানে হওয়ার পক্ষে কতটা অসম্ভব ছিল। প্রভাবটি আরও স্পষ্ট হয় যদি বিশেষত উচ্চ-গড় বা নীচের গড় গোষ্ঠী পর্যবেক্ষণের জন্য নির্বাচিত হয়, তবে সেই গোষ্ঠীটি কোনও জনগোষ্ঠীর সবচেয়ে উঁচু মানুষ, কোনও দলের সবচেয়ে খারাপ অ্যাথলিট বা স্ট্রোকের ঝুঁকির মধ্যে সবচেয়ে বেশি ঝুঁকির মধ্যে রয়েছে কিনা। সবচেয়ে উঁচু মানুষের বাচ্চারা গড়ে তাদের পিতামাতার চেয়ে কম হওয়ার সম্ভাবনা রয়েছে, সবচেয়ে খারাপ অ্যাথলিটরা ব্যতিক্রমী খারাপ মৌসুমের পরে আরও ভাল পারফর্ম করতে পারে এবং স্ট্রোকের জন্য সবচেয়ে বেশি ঝুঁকির মধ্যে থাকা কোনও হস্তক্ষেপ বা চিকিত্সার পরে ঝুঁকি হ্রাস করতে পারে বলে মনে হয়, কার্যকারক কারণগুলির কারণে নয় তবে এলোমেলোতার বৈশিষ্ট্য এবং সম্ভাবনার কারণে।
উপরের গড় বা নিম্ন-গড় গোষ্ঠীর জন্য হস্তক্ষেপ বা চিকিত্সা অন্বেষণ করার সময়, গড়ের সাথে রিগ্রেশন এর প্রভাবগুলির জন্য একটি প্রশমন হ'ল কার্যকারক প্রভাবগুলি বিচ্ছিন্ন করার জন্য বিষয়গুলি একটি অধ্যয়ন গোষ্ঠী এবং একটি নিয়ন্ত্রণ গোষ্ঠীতে বিভক্ত করা। এমএল প্রসঙ্গে, এই ঘটনাটি ব্যতিক্রমী বা বহিরাগত মানগুলির পূর্বাভাস দেয় এমন কোনও মডেলকে অতিরিক্ত মনোযোগ দেওয়ার পরামর্শ দেয়, যেমন:
- চরম আবহাওয়া বা তাপমাত্রা
- সেরা পারফরম্যান্স স্টোর বা অ্যাথলেটরা
- একটি ওয়েবসাইটে সর্বাধিক জনপ্রিয় ভিডিও
যদি সময়ের সাথে সাথে এই ব্যতিক্রমী মানগুলির কোনও মডেলের চলমান ভবিষ্যদ্বাণীগুলি বাস্তবতার সাথে মেলে না, উদাহরণস্বরূপ ভবিষ্যদ্বাণী করে যে একটি অত্যন্ত সফল স্টোর বা ভিডিও সফল হতে থাকবে যখন বাস্তবে এটি না হয়, জিজ্ঞাসা করুন:
- গড়ের রিগ্রেশন ইস্যুটি হতে পারে?
- সর্বোচ্চ ওজনযুক্ত বৈশিষ্ট্যগুলি কি কম ওজনের বৈশিষ্ট্যগুলির চেয়ে বেশি ভবিষ্যদ্বাণীমূলক?
- এই বৈশিষ্ট্যগুলির জন্য বেসলাইন মান রয়েছে এমন ডেটা সংগ্রহ করা কি প্রায়শই শূন্য (কার্যকরভাবে একটি নিয়ন্ত্রণ গোষ্ঠী) মডেলের ভবিষ্যদ্বাণীগুলি পরিবর্তন করে?
তথ্যসূত্র
হাফ, ড্যারেল পরিসংখ্যানের সাথে কীভাবে মিথ্যা বলা যায়। এনওয়াই: ডাব্লুডাব্লু নরটন, 1954।
জোন্স, বেন। ডেটা সমস্যাগুলি এড়ানো। হোবোকেন, এনজে: উইলি, 2020।
ও'কনর, কাইলিন এবং জেমস ওভেন ওয়েদারাল। ভুল তথ্য বয়স। নিউ হ্যাভেন: ইয়েল আপ, 2019।
রিংলার, অ্যাডাম, ডেভিড ম্যাসন, গ্যাবি লাস্কে এবং মেরি টেম্পলটন। "আমার স্কুইগলগুলি কেন মজাদার দেখাচ্ছে? আপোস করা ভূমিকম্পের সংকেতের একটি গ্যালারী" " সিসমোলজিকাল রিসার্চ লেটারস 92 নং। 6 (জুলাই 2021)। Doi: 10.1785/0220210094
ওয়েইনট্রাব, উইলিয়াম এস, টমাস এফ ল্যাসচার এবং স্টুয়ার্ট পোকক। "সারোগেট এন্ডপয়েন্টগুলির বিপদগুলি" " ইউরোপীয় হার্ট জার্নাল 36 নং। 33 (সেপ্টেম্বর 2015): 2212–2218। Doi: 10.1093/EUREARTJ/EHV164
হুইলান, চার্লস নগ্ন পরিসংখ্যান: ডেটা থেকে ভয় ছিনিয়ে নেওয়া। এনওয়াই: ডাব্লুডাব্লু নরটন, 2013
ইমেজ রেফারেন্স
"বেঁচে থাকার পক্ষপাত।" মার্টিন গ্র্যান্ডজিয়ান, ম্যাকজেডডন এবং ক্যামেরন মোল 2021. সিসি বাই-এসএ 4.0। উৎস
জোন্স 25-29। ↩
ও'কনর এবং ওয়েদারাল 22-3। ↩
রিংলিং এট আল। ↩
হুইলান 120. ↩
সিদ্ধার্থ মুখার্জি, "সেলফোনগুলি কি মস্তিষ্কের ক্যান্সারের কারণ হয়?" নিউইয়র্ক টাইমসে, এপ্রিল 13, 2011. হুইলান 122 এ উদ্ধৃত। ↩
হুইলান 39-40। ↩
ম্যালকম গ্ল্যাডওয়েল, "দ্য অর্ডার অফ থিংস" , নিউ ইয়র্কারে 14 ফেব্রুয়ারী, 2011. হুইলানে উদ্ধৃত 56. ↩