"Si entra basura, sale basura".
— proverbio de programación temprana
Detrás de cada modelo de AA, cada cálculo de correlación y cada cálculo son uno o más conjuntos de datos sin procesar. No importa cuán hermosa o el producto final sea impactante o persuasivo, si los datos subyacentes se erróneo, mal recopilado o de baja calidad, el modelo resultante, predicción, visualización o conclusión también tendrán un bajo calidad. Cualquier persona que visualice, analice y entrena modelos en conjuntos de datos deben hacer preguntas difíciles sobre la fuente de sus datos.
Los instrumentos de recopilación de datos pueden fallar o estar mal calibrados. Los seres humanos que recopilan datos pueden estar cansados, traviesos, inconsistentes o deficientes. capacitado. Las personas cometen errores y es posible que diferentes personas estén en desacuerdo razonablemente sobre la clasificación de señales ambiguas. Como resultado, la calidad y la validez de los datos puede verse afectada y los datos pueden no reflejar la realidad. Ben Jones, autor de Cómo evitar los datos errores, se denomina a esto la brecha de realidad de datos, recordar al lector: "No es un crimen, sino que se denuncia. No es el la cantidad de golpes de meteoritos registrados".
Ejemplos de la brecha entre los datos y la realidad:
Jones grafos aumenta las alzas en las mediciones de tiempo en intervalos de 5 minutos, y medidas de peso a intervalos de 5 lb, no porque tales picos existan en la pero debido a que los recolectores humanos, a diferencia de los instrumentos, para redondear sus números al 0 o al 5 más cercano.1
En 1985, Joe Farman, Brian Gardiner y Jonathan Shanklin, trabajaron para la Británico Antártico Survey (BAS), descubrió que sus mediciones indicaban un agujero estacional en la capa de ozono, sobre el hemisferio sur. Esta contradice los datos de la NASA, que no registraban tal agujero. Richard, físico de la NASA Stolarski investigó y descubrió que el software de procesamiento de datos de la NASA diseñado bajo el supuesto de que los niveles de ozono nunca podrían caer por debajo de y las lecturas muy bajas de ozono que se detectaron se descartaron automáticamente como valores atípicos sin sentido.2
Los instrumentos experimentan una diversidad de modos de falla, a veces mientras están quietos recopilando datos. Adam Ringler et al. proporcionar una galería de sismografía como resultado de fallas de instrumentos (y las fallas correspondientes) en el artículo de 2021 “¿Por qué mis garabatos se ven graciosos?”.3 La actividad de la las lecturas de ejemplo no corresponden a la actividad sísmica real.
Para los profesionales del AA, es fundamental comprender lo siguiente:
- Quién recopiló los datos
- Cómo y cuándo se recopilaron los datos y en qué condiciones
- La sensibilidad y el estado de los instrumentos de medición
- Cómo se verían las fallas de instrumentos y los errores humanos en un contexto
- Tendencias humanas a redondear los números y proporcionar respuestas deseables
Casi siempre, hay al menos una pequeña diferencia entre los datos y la realidad también conocido como verdad fundamental. Tener en cuenta esa diferencia es clave para sacar buenas conclusiones y tomar buenas decisiones decisiones acertadas. Esto incluye decidir:
- qué problemas puede y debe resolverse con el AA.
- qué problemas no se resuelven mejor con el AA.
- problemas que aún no tienen suficientes datos de alta calidad para que el AA los resuelva.
Pregunta: ¿Qué, en el sentido más estricto y literal, comunica los datos? Lo que es igual de importante, ¿qué no comunican los datos?
Suciedad en los datos
Además de investigar las condiciones de recopilación de datos, el conjunto de datos puede contener errores, valores nulos o no válidos (como mediciones negativas de concentración). Los datos de participación colectiva pueden ser muy desordenado. Trabajar con un conjunto de datos de calidad desconocida puede generar resultados imprecisos.
Algunos problemas comunes son los siguientes:
- Errores ortográficos en los valores de cadena, como lugares, especies o nombres de marcas
- Conversión de unidades, unidades o tipos de objetos incorrectos
- Valores faltantes
- Clasificaciones erróneas o etiquetas incorrectas coherentes
- Dígitos significativos que quedan de las operaciones matemáticas que superan la sensibilidad real de un instrumento
Limpiar un conjunto de datos a menudo implica elegir valores nulos y faltantes (si para mantenerlas como nulas, descartarlas o sustituirlas por 0), corrigiendo la ortografía a un una sola versión, corregir unidades y conversiones, etcétera. Un enfoque más avanzado técnica es imputar valores faltantes, lo cual se describe en Características de los datos del Curso intensivo de aprendizaje automático.
Muestreo, sesgo de supervivencia y problema del endpoint subrogado
Las estadísticas permiten la extrapolación válida y precisa de los resultados a partir de un puramente aleatoria a la población más grande. La fragilidad no examinada de esta suposición, junto con entradas de entrenamiento incompletas y desequilibradas, hasta fallas de alto perfil de muchas aplicaciones de AA, incluidos los modelos usados para y control del currículum. También ha provocado fallas en los sondeos y otras conclusiones erróneas sobre grupos demográficos. En la mayoría de los contextos, fuera de datos artificiales generados por computadora, las muestras puramente aleatorias son demasiado son costosas y demasiado difíciles de adquirir. Varias soluciones alternativas y precios se usan proxies, que introducen diferentes fuentes de sesgo.
Para utilizar el método de muestreo estratificado, por ejemplo, debes conocer la de cada estrato muestreado en la población más grande. Si supones que una prevalencia realmente incorrecta, los resultados serán inexactos. Asimismo, los sondeos en línea rara vez son una muestra aleatoria de la población nacional, pero una muestra de la población conectada a Internet (suele ser de varios países) que ve la encuesta y está dispuesta a responderla. Es probable que este grupo difiera de una muestra aleatoria verdadera. Las preguntas en la encuesta son una muestra de posibles preguntas. Las respuestas a esas preguntas de la encuesta son: de nuevo, no una muestra aleatoria de las" opiniones reales, pero una muestra de opiniones que los encuestados se sienten cómodas proporcionando, y que pueden diferir de sus opiniones reales.
Los investigadores clínicos de salud enfrentan un problema similar conocido como subrogado extremo. Debido a que lleva demasiado tiempo verificar el efecto de un medicamento en la esperanza de vida de los pacientes, los investigadores usan biomarcadores de proxy que se supone que están relacionados con la esperanza de vida, pero es posible que no lo estén. Los niveles de colesterol se usan como un valor subrogado. punto final por ataques al corazón y muertes causadas por problemas cardiovasculares: si se trata de un medicamento reduce los niveles de colesterol, se supone que también reduce el riesgo de sufrir problemas cardíacos. Sin embargo, esa cadena de correlación puede no ser válida, o bien el orden de causalidad puede ser diferente de lo que supone el investigador. Consultar Weintraub et al., “The perils of subrogate endpoints”, para obtener más detalles y ejemplos. La situación equivalente en el AA es la de etiquetas de proxy.
El matemático Abraham Wald identificó un problema con el muestreo de datos que ahora se conoce como sesgo de supervivencia. Aviones de guerra regresaban con agujeros de bala ubicaciones particulares y no en otras. El ejército de EE.UU. quería agregar más armadura a los aviones en las zonas con más agujeros de bala, pero el grupo de investigación de Wald Se recomienda agregar la armadura en áreas sin orificios de bala. Infirieron de forma correcta que su muestra de datos estaba sesgada porque los aviones dispararon en las zonas estaban tan dañadas que no pudieron volver a la base.
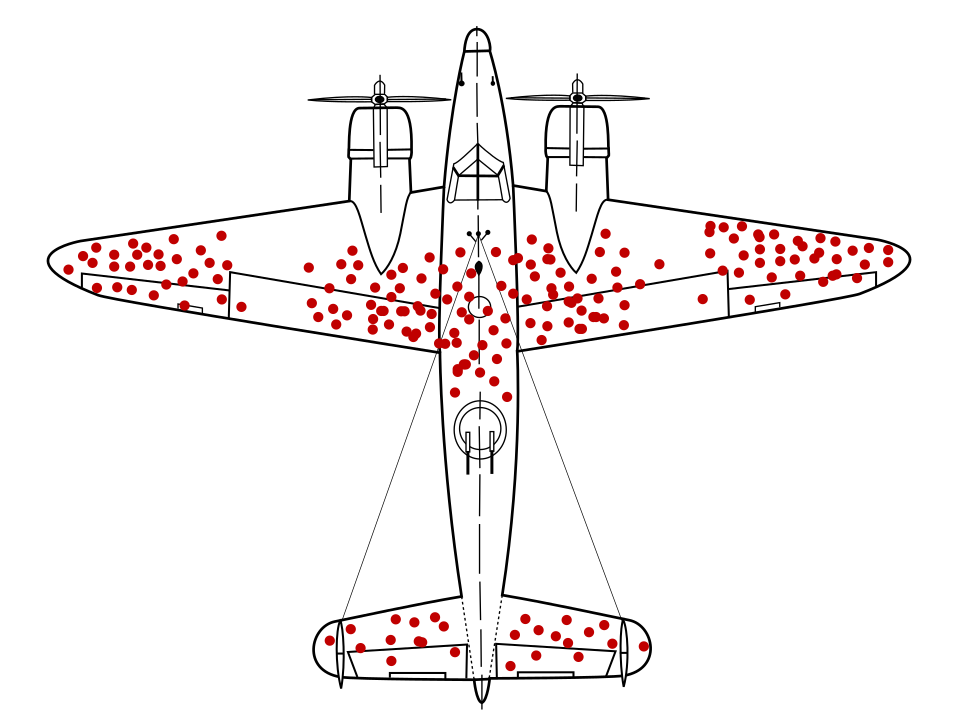
¿Tener un modelo que recomienda una armadura se entrenó solo con diagramas de retorno en aviones de guerra, sin entender el sesgo de supervivencia presente en los datos, hubiera recomendado reforzar las áreas con más orificios de bala.
El sesgo de autoselección puede surgir de sujetos humanos que se ofrezcan participar en un estudio. Los reclusos motivados a inscribirse para solicitar una reducción del recidivismo programa, por ejemplo, podría representar a una población con menos probabilidades de comprometerse delitos futuros que la población general de reclusos. Esto sesgaría los resultados.4
Un problema de muestreo más sutil es el sesgo de recuperación, que implica la maleabilidad de seres humanos los recuerdos. En 1993, Edward Giovannucci le pidió a un grupo de edad similar. de las mujeres, algunas de las cuales habían sido diagnosticadas con cáncer, sobre su dieta anterior de los consumidores. Las mismas mujeres habían respondido una encuesta sobre hábitos alimentarios antes de de cáncer. Giovannucci descubrió que las mujeres sin cáncer recuerda su dieta con precisión, pero las mujeres con cáncer de mama informaron consumiendo más grasas de las que habían informado anteriormente, inconscientemente proporcionando una posible explicación (aunque imprecisa) sobre su cáncer5
Pregunta:
- ¿Qué es lo que realmente muestrea un conjunto de datos?
- ¿Cuántos niveles de muestreo hay?
- ¿Qué sesgo podría introducirse en cada nivel de muestreo?
- ¿Se utiliza la medición sustituta (ya sea un biomarcador, una encuesta o viñeta en línea) agujero) mostrando la correlación o la causalidad real?
- ¿Qué podría faltar en la muestra y en el método de muestreo?
El módulo Equidad del Curso intensivo de aprendizaje automático abarca formas de evaluar y mitigar fuentes adicionales de sesgo en los conjuntos de datos demográficos.
Definiciones y clasificaciones
Define términos de forma clara y precisa, o pregunta sobre definiciones claras y precisas. Esto es necesario para comprender qué atributos de datos se están considerando y qué se predice o reclama exactamente. Charles Wheelan, en Naked Statistics, ofrece "la salud de EE.UU. manufactura" como ejemplo de un término ambiguo. Si la fabricación de EE.UU. es "saludable" depende completamente de cómo se define el término. El artículo de Greg Ip de marzo de 2011 en The Economist ilustra esta ambigüedad. Si la métrica para "estado" es "fabricar de salida", luego, en 2011, la fabricación de EE.UU. era cada vez más saludable. Si el botón "salud" se define como “trabajos de fabricación”, pero la industria manufacturera de EE.UU. tuvo una disminución.6
Las clasificaciones a menudo traen problemas similares, que incluyen puntos ocultos o sin sentido ponderaciones otorgadas a diversos componentes de la clasificación, las tasas de la incoherencia y opciones no válidas. Malcolm Gladwell, escribiendo en The New Yorker, menciona una El presidente de la Corte Suprema de Michigan, Thomas Brennan, quien una vez envió una encuesta a a cien abogados pidiéndoles que clasificaran diez facultades de derecho por calidad, algunos famosas, otras, no. Esos abogados clasificaron a la facultad de Derecho de Penn State en aproximadamente el quinto lugar. aunque al momento de la encuesta, Penn State no tenía una ley en la escuela.7 Muchas clasificaciones conocidas incluyen un modelo subjetivo similar y la reputación. Pregunta qué componentes se incluyen en una clasificación y por qué a los componentes se asignaron pesos particulares.
Números pequeños y efectos grandes
No es de extrañar que obtengas el 100% de cara o de cruz si lanzas una moneda dos veces. Tampoco es sorprendente obtener un 25% de cara luego de lanzar una moneda cuatro veces, Luego, el 75% se dirige a los próximos cuatro giros, aunque eso demuestra un un gran aumento (que podría atribuirse erróneamente a un sándwich ingerido) entre los conjuntos de tiradas de monedas o cualquier otro factor espurio). Pero como el número de lanzamiento de monedas aumenta, digamos a 1,000 o 2,000, grandes desviaciones porcentuales de el 50% esperado se vuelve muy improbable.
El número de mediciones o sujetos experimentales en un estudio a menudo se denomina N. Los cambios proporcionales grandes debidos al azar son mucho más propensos se producen en conjuntos de datos y muestras con una N baja.
Cuando realices un análisis o documentes un conjunto de datos en una tarjeta de datos, especifica N para que otras personas puedan considerar la influencia del ruido y la aleatoriedad.
Debido a que la calidad del modelo tiende a escalar con el número de ejemplos, un conjunto de datos con un valor bajo de N tiende a generar modelos de baja calidad.
Regresión a la media
Asimismo, cualquier medición que tenga algún tipo de influencia en el azar está sujeta a efecto conocido como regresión a la media. Esto describe cómo la medición después de una medición particularmente extrema es, en promedio, probable que sea menos extrema o más cercana a la media, debido a lo poco probable que era que se produjera la medición extrema en primer lugar. El efecto es más pronunciado si un grupo particularmente superior o inferior al promedio se seleccionó para la observación, ya sea que ese grupo esté formado por las personas más altas de un la población general, los peores atletas de un equipo o los que tienen más riesgo de sufrir un accidente cerebrovascular. El los niños de las personas más altas tienen en promedio probabilidades de ser más bajos que sus padres, los peores atletas podrían tener un mejor rendimiento luego de temporada baja y las personas con más riesgo de sufrir un accidente cerebrovascular tienen probabilidades de mostrar un riesgo menor después de cualquier intervención o tratamiento, no por factores causales, sino debido a las propiedades y probabilidades de la aleatorización.
Una mitigación para los efectos de la regresión a la media, cuando se explora intervenciones o tratamientos para un grupo con un nivel superior o inferior al promedio es dividir a los sujetos en un grupo de estudio y uno de control para aislar y los efectos causantes. En el contexto del AA, este fenómeno sugiere pagar más atención a cualquier modelo que prediga valores excepcionales o atípicos, como:
- condiciones meteorológicas o temperaturas extremas
- las tiendas con mejor rendimiento o los atletas
- videos más populares de un sitio web
Si las predicciones en curso de estos valores excepcionales a lo largo del tiempo no coinciden con la realidad, por ejemplo, predecir que un la tienda o el video más exitosos seguirán funcionando cuando pregunta:
- ¿La regresión a la media podría ser el problema?
- ¿Los atributos con las ponderaciones más altas son de hecho más predictivos? que los atributos con pesos más bajos?
- ¿Recopilar datos que tienen el valor de referencia para esos atributos? suele ser cero (efectivamente un grupo de control) cambiar las predicciones del modelo?
Referencias
Huff, Darrell. Cómo lidiar con las estadísticas. NY: W.W. Norton, 1954.
Jones, Ben. Evita errores de datos. Hoboken, NJ: Wiley, 2020.
O'Connor, Cailin y James Owen Weatherall. La era de la información errónea. New Haven: Yale UP, 2019.
Ringler, Adam, David Mason, Gabi Laske y Mary Templeton "¿Por qué mis garabatos se ven graciosos? A Gallery of Compromised Seismic Signals". Seismological Research Letters 92, núm. 6 (julio de 2021). Número de identificación fiscal: 10.1785/0220210094
Weintraub, William S., Thomas F. Lüscher y Stuart Pocock. “Los peligros de los extremos subrogados”. Europe Heart Journal, 36 n. 33 (septiembre de 2015): 2212–2218. DOI: 10.1093/eurheartj/ehv164
Wheelan, Charles. Estadísticas sin datos: Quita el temor de los datos. Nueva York: W.W. Norton, 2013
Referencia de imagen
"Sesgo de supervivencia". Martin Grandjean, McGeddon y Cameron Moll, 2021. CC BY-SA 4.0 Origen
{kind=link}
-
Jones 25-29. ↩
-
O'Connor y Weatherall 22-3. ↩
-
Ringling et al. ↩
-
Wheelan 120 ↩
-
Siddhartha Mukherjee, “¿Los teléfonos celulares causan cáncer cerebral?” en The New York Times 13 de abril de 2011. Cita de Wheelan 122. ↩
-
Wheelan 39-40 ↩
-
Malcolm Gladwell, "El orden de las cosas", en The New Yorker el 14 de febrero de 2011. Citado en Wheelan 56. ↩