'잘못된 데이터를 입력하면 잘못된 결과가 표시됩니다.'
— 초기 프로그래밍 속담
모든 ML 모델, 모든 상관관계 계산, 모든 데이터 기반 정책 추천에는 하나 이상의 원시 데이터 세트가 있습니다. 아무리 아름답거나 타당하거나 설득력 있게 보이도록 해야 합니다. 품질이 낮거나, 오류가 있거나, 잘못 수집되거나, 예측, 시각화 또는 결론도 있습니다. 모델을 시각화, 분석, 학습시키는 모든 사용자 데이터 세트는 데이터 소스에 대해 어려운 질문을 해야 합니다.
데이터 수집 도구는 오작동하거나 잘못 보정될 수 있습니다. 데이터를 수집하는 사람이 피곤하거나, 장난스럽거나, 일관성이 없거나, 형편없이 인코더로 전달합니다. 사람들은 실수를 하며, 다른 사람도 합리적으로 동의하지 않을 수 있습니다. 분류에 대한 편법입니다. 결과적으로 품질과 데이터의 유효성이 저하될 수 있고 데이터가 현실을 반영하지 못할 수 있습니다. 벤 존스, 데이터 회피 저자 함정에서는 이를 데이터 현실 격차, '이건 범죄가 아니라 범죄로 신고되었습니다. 그것은 유성우타격 횟수는 기록된 유성우 위반 횟수입니다."
데이터 현실 격차의 예는 다음과 같습니다.
Jones는 5분 간격으로 시간 측정이 급증합니다. 5lb 간격으로 체중 측정이 그러나 인간 데이터 수집자는 도구와 달리 숫자를 가장 가까운 0 또는 5로 반올림합니다.1
1985년 Joe Farman, Brian Gardiner, Jonathan Shanklin은 영국 남극 서베이 (BAS)의 연구 결과 남반구의 오존층에 생긴 구멍입니다. 이 은 NASA 데이터와 모순되었는데, 이 구멍은 기록되지 않았습니다. NASA 물리학자 리처드 조사 결과 NASA의 데이터 처리 소프트웨어가 오존 수치가 고농도 최저 농도보다 낮아질 수 없다는 가정하에 오존 수치가 매우 낮다는 것을 발견했습니다. 자동으로 제외되었습니다.2
계측기가 다양한 장애 모드를 경험하지만 데이터를 수집하는 것입니다. 아담 링글러 외 지진계 갤러리 제공 계기 고장 및 해당 고장에서 비롯된 판독값 2021년 논문 'Why Do My Squiggles Look Funny?'3에서 예시 판독 값이 실제 지진 활동과 일치하지 않습니다.
ML 실무자가 이해하는 것은 중요합니다.
- 데이터를 수집한 사람
- 데이터를 수집한 방법 및 시기와 조건
- 측정 도구의 민감도 및 상태
- 특정 사례에서 발생할 수 있는 계측 고장 및 사람의 실수 컨텍스트
- 숫자를 반올림하고 원하는 답변을 제공하는 인간의 경향
거의 항상, 데이터와 현실 사이에는 최소한 약간의 차이가 있습니다. 정답이라고도 합니다. 그 차이를 설명하는 것이 좋은 결론을 내리고 결정을 내릴 수 있습니다. 여기에는 다음과 같은 결정이 포함됩니다.
- ML로 해결할 수 있고 해결해야 하는 문제를 살펴봤습니다
- ML로 가장 잘 해결할 수 없는 문제를 파악하는 데 도움이 될 수 있습니다
- 아직 ML로 해결할 수 있는 고품질 데이터가 충분하지 않은 문제를 해결할 수 있습니다
질문: 가장 엄격하고 가장 문자 그대로의 의미에서, 데이터가 전달하는 것은 무엇인가? 중요한 것은 데이터를 통해 전달되지 않는 것이라는 것입니다.
데이터의 먼지
데이터 수집 조건을 조사하는 것 외에도 데이터 세트는 자체에 실수, 오류 및 null 또는 잘못된 값 (예: 농도의 음수 측정값). 크라우드소싱된 데이터는 지저분할 수 있습니다. 알 수 없는 품질의 데이터 세트로 작업하면 부정확한 결과가 나올 수 있습니다.
일반적인 문제는 다음과 같습니다.
- 장소, 종, 브랜드 이름과 같은 문자열 값의 맞춤법 오류
- 잘못된 단위 변환, 단위 또는 객체 유형
- 결측치
- 일관된 잘못된 분류 또는 잘못된 라벨 지정
- 다음 숫자를 초과하는 수학적 연산에서 남은 자릿수 악기의 실제 감도
데이터 세트를 정리할 때는 종종 null 및 누락된 값에 관한 선택사항(null로 유지, 삭제 또는 0으로 대체 여부), 단일 버전으로 맞춤법 수정, 단위 및 변환 수정 등이 필요합니다. 고급 누락된 값을 귀속하는 것으로 데이터 특성 머신러닝 단기집중과정을 마칩니다.
<ph type="x-smartling-placeholder">를 통해 개인정보처리방침을 정의할 수 있습니다.샘플링, 생존 편향, 서로게이트 엔드포인트 문제
통계를 사용하면 2014년 12월 11일부터 샘플링합니다. 검사되지 않은 민감함은 이러한 가정은 불균형하고 불완전한 학습 입력과 함께 많은 ML 애플리케이션의 주목할 만한 장애에 대처할 수 있는 검토 및 감시를 재개할 수 있습니다 또한 이로 인해 폴링 실패 및 기타 잘못된 결론을 내릴 수 있다는 것을 보여 주었다. 외부 대부분의 컨텍스트에서 무작위 샘플도 있으며 비싸고 구하기가 너무 어렵습니다. 다양한 해결 방법 및 저렴한 비용 프록시가 대신 사용되어 편향.
예를 들어 계층화된 샘플링 방법을 사용하려면 샘플링된 각 계층의 보급률 을 나타냅니다. 가정의 결과가 정확하지 않을 수 있습니다. 마찬가지로 온라인 설문조사는 전국을 대상으로 한 무작위 표본이 아니기 때문에 인터넷에 연결된 인구 중 샘플이 응답자(종종 여러 나라에서 응답함)입니다. 이 그룹은 실제 무작위 표본과 다를 가능성이 높습니다. 이 설문조사는 가능한 질문의 샘플입니다. 이러한 설문조사 질문에 대한 답변은 설문조사 응답자 중 무작위 표본이 아니라 실제 의견도 있지만 이는 응답자가 편안하게 제공할 수 있는 의견으로, 실제 설문조사와 도움이 될 수 있습니다
임상 보건 연구원은 서로게이트(surrogate)'로 알려진 유사한 문제를 접하게 됩니다. 엔드포인트 문제에 대해 자세히 알아보세요. 약물의 효과를 확인하는 데 너무 오래 걸리기 때문에 환자 수명, 연구자들은 생물학적 지능적 지표인 생물지표 또는 관련이 없을 수도 있습니다. 콜레스테롤 수치는 서로게이트로 사용됨 심장마비 및 심혈관 문제로 인한 사망에 대한 엔드포인트: 약물이 콜레스테롤 수치가 감소한다는 사실을 알게 되면 심장 질환의 발생 위험도 낮아진다고 알려져 있습니다. 그러나 그 상관관계 체인이 유효하지 않을 수도 있고, 그렇지 않으면 인과관계가 연구원이 추측한 것과 다를 수 있습니다. Weintraub 외, "서로게이트 엔드포인트의 위험", 더 많은 예와 세부정보를 확인하세요. 이와 동등한 ML의 상황은 프록시 라벨을 사용하여 문제를 해결할 수 있습니다.
수학자 에이브러햄 월드는 오늘날 알려진 데이터 샘플링 문제를 식별했습니다. 생존 편향으로 간주됩니다. 총알 구멍이 뚫린 상태로 돌아오고 있던 전투기 다른 위치에는 포함되지 않습니다. 미군은 갑옷을 더 많이 추가하려고 탄탄한 구멍이 가장 많이 뚫린 비행기에 착륙할 수 있었지만 발트의 연구 그룹은 대신 총알 구멍이 없는 영역에 갑옷을 추가하는 것이 좋습니다. 그들은 국제적으로 날아가는 비행기의 발사로 인해 데이터 표본이 왜곡되었다는 것을 기지로 돌아갈 수 없을 정도로 심하게 손상되었습니다.
<ph type="x-smartling-placeholder">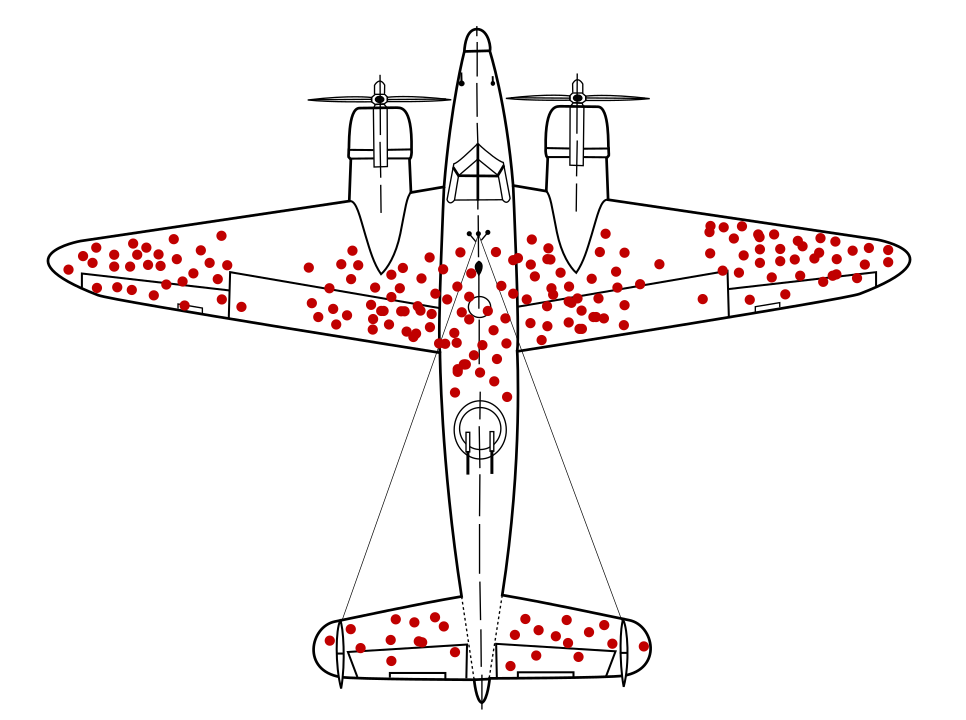
갑옷 추천 모델이 복귀 다이어그램으로만 학습됨 데이터에 존재하는 생존 편향에 대한 통찰력 없이 구멍이 더 많은 부분을 보강할 것을 권장했을 것입니다.
자기 선택 편향은 실험 대상자가 자발적으로 참여할 수 없습니다. 재범 퇴치를 신청하려는 수감자들 예를 들어 이 프로그램은 헌신할 가능성이 낮은 인구를 나타낼 수 있습니다. 더 높은 범죄를 저지르는 것입니다. 이 경우 결과가 왜곡됩니다.4
보다 미묘한 샘플링 문제는 재현율 편향으로, 인간 실험 있습니다. 1993년 Edward Giovannucci는 나이가 일치하는 사람들에게 암 진단을 받은 여성 중 이전 식단에 대해 이야기하는 비율 도움이 됩니다 동일한 여성들이 식생활을 시작하기 전에 식이 습관에 대한 설문조사를 암 진단을 주로 담당합니다. 조반누치가 발견한 것은 암이 없는 여성들이 식단을 정확하게 회상했지만, 유방암을 앓고 있는 여성들은 이전에 보고한 것보다 더 많은 지방을 섭취한다는 사실을 암에 대해 정확하지는 않지만 가능한 설명을 제공합니다.5
질문:
- 데이터 세트가 실제로 샘플링하는 것은 무엇인가요?
- 몇 가지 수준의 샘플링이 있나요?
- 각 샘플링 수준에서 발생할 수 있는 편향은 무엇인가요?
- 프록시 측정이 사용되나요 (생물지표, 온라인 설문 또는 글머리기호 등) 실제 상관관계 또는 인과관계를 보여주나요?
- 샘플 및 샘플링 방법에서 누락된 것은 무엇인가요?
공정성 모듈 '머신러닝 단기집중과정'은 이러한 문제를 해결하고 인구 통계 데이터 세트에서 추가 편향의 원인이 될 수 있습니다.
정의 및 순위
용어를 분명하고 정확하게 정의하거나, 명확하고 정확한 정의를 물어보십시오. 이는 고려 중인 데이터 기능을 이해하는 데 필요합니다. 예측 또는 주장되는 것이 무엇인지 정확히 파악할 수 있습니다 Naked Statistics의 Charles Wheelan은 '미국의 건강'을 제공합니다. 제조업" 를 모호한 용어의 예로 들 수 있습니다. 미국의 제조업이 "건강함" 용어가 정의되는 방식에 전적으로 의존하지 않을 수 있습니다. Greg Ip의 The Economist의 2011년 3월 기사 은 이러한 모호성을 보여줍니다. '건강' 측정항목이 "제조업 출력" 2011년에는 미국 제조업 건전성이 높아졌습니다. 만약 '건강' 측정항목은 '제조업 일자리'로 정의되며 미국의 제조업은 감소세를 보였습니다.6
모호하거나 무의미한 등 유사한 문제가 순위에 영향을 미치는 경우가 많습니다. 다양한 순위의 구성요소에 부여되는 가중치, 불일치 및 잘못된 옵션입니다. Malcolm Gladwell은 The New Yorker에서 미시간 대법원장인 토마스 브레넌은 100명의 변호사가 품질에 따라 10개의 로스쿨을 선정해 달라고 요청했습니다. 일부는 그렇지 않습니다. 이들은 펜실베이니아주립대학교 법학전문대학원에서 약 5위로 설문 조사 당시 펜실베이니아 주립대학교는 법이 없는 7 잘 알려진 순위는 비슷한 주관적이면서도 영향을 줄 수 있습니다 어떤 구성요소가 순위에 포함되는지, 그 이유가 무엇인지 질문합니다. 각 구성요소에 특정 가중치가 부여되었습니다.
작은 숫자와 큰 효과
동전을 던져도 앞면이 100%, 뒷면이 100% 나오는 것은 놀라운 일이 아닙니다. 두 번입니다. 동전을 네 번 던진 후에 앞면이 25% 나오는 것도 놀랍지 않습니다. 75% 가 다음 네 번의 반전에 대비합니다. 엄청난 증가분 (사이즈를 먹은 것이 잘못되었을 수 있음) 부정적 요인으로 인해 발생할 수 있습니다. 하지만 숫자는 1,000, 2,000이면 동전 던지기의 비율이 예상 50% 의 가능성은 거의 사라지게 됩니다
연구에서 측정치 또는 실험 대상의 수를 자주 언급함 N으로 변환합니다. 우연에 의한 비례 변화가 크면 N이 낮은 데이터 세트 및 샘플에서 발생합니다.
<ph type="x-smartling-placeholder">데이터 카드에서 분석을 수행하거나 데이터 세트를 문서화할 때 다음을 지정합니다. N: 다른 사람들이 노이즈와 무작위성의 영향을 고려할 수 있도록 합니다.
모델 품질은 예시의 수에 따라 조정되는 경향이 있기 때문에 N이 낮으면 모델의 품질이 낮아지는 경향이 있습니다.
평균값으로 회귀
마찬가지로 우연히도 어느 정도의 영향을 미치는 측정은 효과 회귀입니다. 특히 극단적인 측정 후의 측정이 어떻게 이루어지는지 설명합니다. 평균값은 덜 극단적이거나 평균에 가깝습니다 애초에 극단적인 측정이 이루어진 것은 아니었습니다. 이 특히 평균 이상 또는 평균 미만의 그룹이 있는 경우 효과가 더 두드러집니다. 10억 명이 넘는 인구가 팀원 중 최악의 운동선수, 뇌졸중 발병 위험이 가장 높은 선수 등이 여기에 해당합니다. 이 키가 가장 큰 아이의 평균은 최악의 운동선수는 굉장히 좋은 성적을 거두고 비수기이며 뇌졸중 발병 위험이 가장 높은 사람들은 인과적 요인 때문이 아니라 어떤 개입이나 치료를 받은 후 왜냐하면 무작위성의 속성과 확률 때문입니다.
탐색 시 회귀가 평균값에 미치는 영향을 완화하는 방법 평균 이상 또는 평균 이하 집단에 대한 개입이나 치료는 분리하기 위해 실험 대상을 스터디 그룹과 통제 그룹으로 나눕니다. 발생할 수 있습니다. ML 맥락에서 이 현상은 추가 비용을 지불할 다음과 같이 예외 또는 이상점 값을 예측하는 모든 모델에 주의를 기울입니다.
- 기상 이변 또는 기온
- 실적이 가장 우수한 매장 또는 운동선수
- 웹사이트에서 가장 인기 있는 동영상
모델이 이러한 데이터에 대해 지속적으로 예측한다면 시간 경과에 따른 예외적인 값이 현실과 일치하지 않는데, 예를 들어 스토어 또는 동영상은 앞으로도 계속 성공할 것입니다. 문제가 해결되지 않으면 다음과 같이 질문하세요.
- 평균값으로의 회귀가 문제일 수 있나요?
- 가중치가 가장 높은 특성의 예측 가능성이 가중치가 낮은 특성보다 어떻게 해야 할까요?
- 해당 특성의 기준 가치가 있는 데이터를 수집하는가 보통 0 모델의 예측을 변경하나요?
참조
허프, 대럴. 통계적으로 거짓말하는 방법. 뉴욕: W.W. 노턴, 1954년.
존스, 벤. 데이터 문제 방지. Hoboken, NJ: Wiley, 2020년.
오코너, 캐일린, 제임스 오언 웨더올입니다. 잘못된 정보의 시대 뉴헤이번: Yale UP, 2019년
링러, 아담, 데이비드 메이슨, 가비 라스케, 메리 템플턴 '구불구불한 모양이 재미있는 이유는 무엇인가요? A Gallery of Compromised Seismic Signals." Seismological Research Letters 92 호. 6 (2021년 7월). DOI: 10.1785/0220210094
웨인트라웁, 윌리엄 S, 토마스 F. Lüscher, Stuart Pocock이 있습니다. "서로게이트 엔드포인트의 위험." European Heart Journal 36호 33 (2015년 9월): 2212–2218. DOI: 10.1093/eurheartj/ehv164
윌란, 찰스. Naked Statistics: Stripping the Dread from the Data 뉴욕: W.W. Norton, 2013년
이미지 참조
"생존 편향." 2021년 Martin Grandjean, McGeddon, Cameron Moll CC BY-SA 4.0 소스
{kind=link}