"Çöp kutusuna gider."
. — Erken programlama atasözü
Her makine öğrenimi modelinin altında, her korelasyon hesaplaması ve her veri tabanlı politikası önerisine göre, bir veya daha fazla ham veri kümesi bulunmaktadır. Ne kadar güzel ya da temelde yatan veriler eğer mevcutsa son ürünlerin çarpıcı veya ikna edici olmasını hatalı, kötü toplanmış veya düşük kaliteli olması durumunda ortaya çıkan model, aynı şekilde tahmin, görselleştirme veya sonuç kalitedir. Herhangi bir projede modelleri görselleştiren, analiz eden ve eğiten verilerinin kaynağı hakkında zor sorular sormalıdır.
Veri toplama araçları hatalı çalışabilir veya kötü kalibre edilmiş olabilir. Veri toplayan insanlar yorgun, haylaz, tutarsız veya yetersiz olabilir. yardımcı olur. İnsanlar hata yapabilir ve farklı insanlar da makul ölçüde hemfikir olmayabilir belirsiz sinyallerin sınıflandırmasına kıyasla Sonuç olarak, kalite ve verilerin geçerliliği olumsuz etkilenebilir ve veriler gerçeği yansıtamayabilir. Ben Jones, Understandinging Data (Verilerden Kaçma) kitabının yazarı tuzaklar olarak adlandırılır. veri-gerçekliği boşluğu, okuyucuya şunu hatırlatır: "Bu suç değil, bildirilen bir suç. Bu değil sayısı, kaydedilen meteor saldırısı sayısıdır."
Veri-gerçeklik boşluğuna örnekler:
Jones, zaman ölçümlerindeki sıçramaları 5 dakikalık aralıklarla grafikle gösterir ve 5 lb aralıklarıyla yaptığınız ağırlık ölçümlerini test edin. Bu sıçramaları Ancak insan veri toplayıcıları, araçların aksine, belirli bir veri türünün sayıları en yakın 0 veya 5'e yuvarlamak için kullanılır.1
1985 yılında, Joe Farman, Brian Gardiner ve Jonathan Shanklin, British Antarktika Anketi (BAS), ölçümlerinin Güney Yarıküre üzerinde ozon tabakasında oluşan mevsimsel çukur. Bu gözlemleyen NASA verileriyle çelişiyor. NASA fizikçisi Richard Stolarski araştırdı ve NASA'nın veri işleme yazılımının ozon seviyelerinin hiçbir zaman belirli bir miktarın altına düşmeyeceğini tespit edilen ozon değerinin çok, çok düşük olması ve otomatik olarak anlamsız sapmalar olarak yayınlandı.2
Enstrümanlarda çeşitli hata modları var, veri toplar. Adam Ringler ve diğerleri sismograf galerisi sunma araç arızalarından (ve ilgili hatalardan) kaynaklanan okumalar "Kıraşlarım Neden Komik Görünüyor?"3 başlıklı örnek okumalar gerçek sismik aktiviteye karşılık gelmez.
Makine öğrenimi uzmanları için şunları bilmek çok önemlidir:
- Verileri kimler topladı?
- Verilerin nasıl ve ne zaman toplandığı, hangi koşullarda toplandığı
- Ölçüm araçlarının hassasiyeti ve durumu
- Belirli bir modelde araç arızaları ve insan hatalarının nasıl görünebileceği bağlam
- İnsanların sayıları yuvarlama ve istenen yanıtları verme eğilimleri
Neredeyse her zaman veriler ile gerçeklik arasında en azından küçük bir fark vardır. kesin referans olarak da bilinir. Bu farklılığı hesaba katmak, iyi sonuçlar çıkarmanın ve doğru fikirler üretmenin anahtarıdır. yararlı olabilir. Bu doğrultuda, şunlara karar verilir:
- makine öğrenimi tarafından çözülebilecek ve çözülebilecek sorunlar.
- makine öğrenimi tarafından en iyi şekilde çözülemez.
- makine öğrenimi tarafından çözülecek yeterli miktarda yüksek kaliteli veriye sahip olmayan sorunlar.
Şunu sorun: Veriler en açık ve en gerçek anlamda ne ifade ediyor? En önemlisi, veriler hangi verileri aktarmaz?
Verilerdeki kirlilik
Veri kümesi, veri toplama koşullarını araştırmanın yanı sıra kendisinin kendisinin kaydırıcılar, hatalar ve boş veya geçersiz değerler (örneğin, negatif konsantrasyon ölçümleri). Kitle kaynaklı veriler, karmaşık. Bilinmeyen kalitede bir veri kümesiyle çalışmak yanlış sonuçlara yol açabilir.
Yaygın sorunlar şunlardır:
- Yer, tür veya marka adları gibi dize değerlerinin yanlış yazımı
- Yanlış birim dönüşümleri, birimler veya nesne türleri
- Eksik değerler
- Sürekli yanlış sınıflandırmalar veya yanlış etiketlemeler
- Matematik işlemlerinden kalan ve bir cihazın gerçek hassasiyeti
Veri kümesinin temizlenmesi genellikle boş ve eksik değerlerle ilgili seçenekleri içerir (örneğin, değerleri boş olarak bırakın, bırakın veya 0'ların yerine koyun) dönüşüm sayısını artırır. Daha gelişmiş teknik, eksik değerleri tahmin etmektir. Bu yöntem, Veri özellikleri Kursu'na hoş geldiniz.
Örnekleme, hayatta kalma yanlılığı ve vekil uç nokta sorunu
İstatistikler, belirli bir sorgudan sonuçların geçerli ve doğru bir şekilde tahmin edilmesine daha büyük popülasyona tamamen rastgele örneklemi içerir. İnanılmaz kırılgan dengesiz ve eksik eğitim girdileri ile birlikte bu varsayımın birçok makine öğrenimi uygulamasının yüksek profilli arızalarına ve politikalarla ilgilenmeye devam edebilirsiniz. Ayrıca yoklama hataları ve diğer sorunlar demografik gruplar hakkında hatalı sonuçlar var. Çoğu bağlamda tamamen rastgele örnekler de ve edinmesi çok zor olur. Çeşitli geçici çözümler ve uygun fiyatlı Bunun yerine proxy'ler kullanılır. Bu da, kullanıcıların farklı önyargılar üzerinden paylaşabilirsiniz.
Örneğin, tabakalı örnekleme yöntemini kullanmak için örneklenen her katmanın daha büyük popülasyondaki yaygınlığı. Örneğin olup olmadığını tespit ederseniz sonuçlarınız yanlış olacaktır. Benzer şekilde, online anketler de nadiren ulusal bir nüfusu temsil eder. ancak internete bağlı nüfusun bir örneklemi (genellikle birden fazla ülkeden) gelen aboneler için de geçerlidir. Bu grup büyük olasılıkla gerçek bir rastgele örnekten farklı olacaktır. Bu bölümdeki sorular anket, olası sorular için bir örnektir. Bu anket sorularının yanıtları, katılımcıların rastgele bir örneklemi değil, gerçek görüşler ama bu örneklerden katılımcıların kendilerini rahat hissettiği, onların görüşlerinden farklı olabilecek gerçek görüşler.
Klinik sağlık araştırmacıları, vekil uç nokta sorunu. Bir ilacın etkisini kontrol etmek çok uzun sürer. yaşam döngüsü boyunca daha önce yaşamla alakalı olabilir, ancak olmayabilir. Kolesterol düzeyleri taşıyıcı olarak kullanılır kardiyovasküler sorunlardan kaynaklanan kalp krizi ve ölüm uç noktası: bir ilaç kullanıldığında kolesterol düzeylerini düşürürken kalp sorunları riskini de azalttığı varsayılır. Ancak, bu korelasyon zinciri geçerli olmayabilir veya araştırmacının varsaydığı her şeyden farklı olabilir. Bkz. Weintraub ve diğerleri, "Vekil uç noktalarının tehlikeleri", daha fazla örnek ve ayrıntı bulabilirsiniz. Bunun eşdeğeri makine öğreniminde şöyle olur: proxy etiketleri kullanın.
Matematikçi Abraham Wald, bilinen meşhur veri örnekleme sorununu hayatta kalma yanlılığı olarak nitelendirilir. Savaş uçakları kurşun delikleriyle geri dönüyordu belirli konumlarda gösterilir. ABD ordusu daha fazla zırh eklemek istiyordu 80'den fazla mermi deliği bulunan bölgelerdeki uçaklara bunun yerine zırhın mermi deliği olmayan alanlara eklenmesi önerilir. Uçaklar vurduğu için veri örneklerinin çarpıtıldığı sonucuna varmışlardı. o kadar hasar görmüştü ki üsse geri dönemediler.
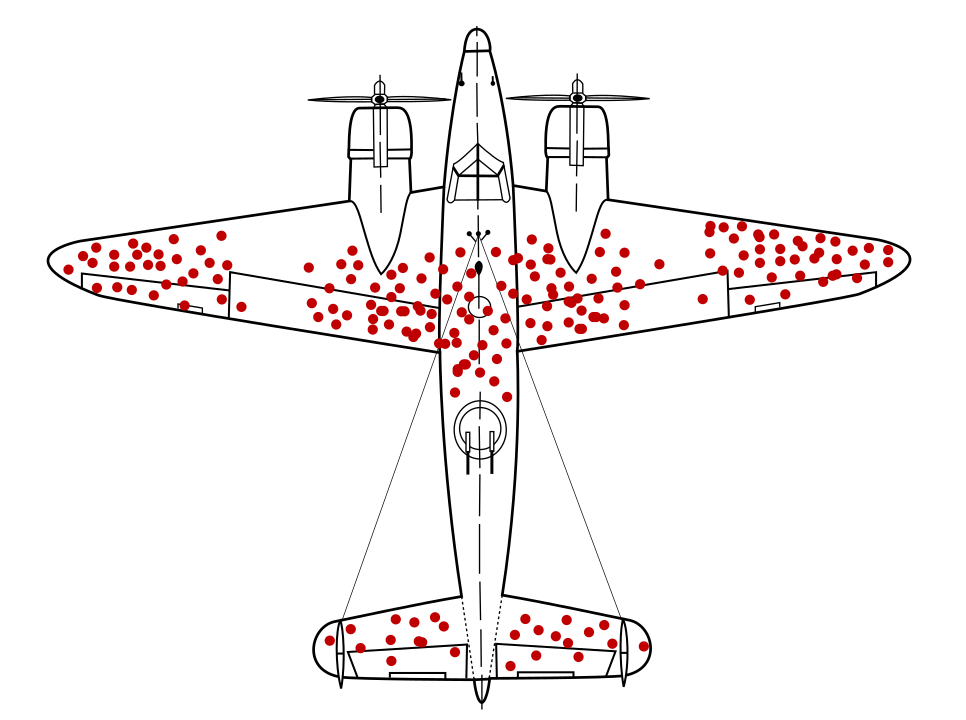
Yalnızca geri dönüş diyagramlarıyla eğitilmiş, zırh öneren bir model verilerde yer alan hayatta kalma önyargıları ne olursa olsun bu model, alanları daha fazla madde deliğiyle güçlendirilmesini önerecektir.
Kendini seçimle ilgili önyargı, bir araştırmaya katılacaksınız. Yeniden mükerrerliği azaltma etkinliğine kaydolmaya motive olan mahkumlar temsil etme olasılığı daha düşük bir nüfusu temsil edebilir mahkumiyetin genel nüfusundan daha fazla suçlama. Bu, sonuçları çarpıtır.4
Daha incelikli bir örnekleme problemi, modelin şekillendirilebilirliğini içeren geri çağırma yanlılığıdır. insan denekleri anılar. 1993'te Edward Giovannucci, yaş grubuna uygun bir gruba soru sordu. bazılarına kanser teşhisi konulan kadınların %71'i, daha önce beslenme şekilleriyle ilgili alışkanlık haline geldi. Aynı kadın hafta önce beslenme alışkanlıklarıyla ilgili bir ankete kanser teşhisi için de kullanılabilecek. Giovannucci, kanseri olmayan kadınların diyetlerini doğru şekilde hatırladığını, ancak meme kanseri olan kadınların daha önce raporladıklarından daha fazla yağ tüketmek, yani bilinçsiz olarak kanser hakkında olası (ama yanlış) bir açıklama sağlar.5
Şu soruyu sorun:
- Veri kümesi örneklemesi aslında nedir?
- Kaç örnekleme düzeyi var?
- Örneklemenin her bir düzeyinde hangi yanlılık ortaya çıkabilir?
- Proxy ölçümü kullanılıyor mu (biyolojik belirteç, online anket veya madde işareti) gerçek korelasyon veya nedenselliği gösteren bir durum mu var?
- Örneklem ve örnekleme yönteminde neler eksik olabilir?
Adalet modülü Makine Öğrenimi Crash Kursu, riskleri ve sorunları demografik veri kümelerinde ön yargıya yol açan ek kaynaklar.
Tanımlar ve sıralamalar
Terimleri açık ve net bir şekilde tanımlayın veya net ve kesin tanımlar sorun. Bu, hangi veri özelliklerinin değerlendirildiğini anlamak için gereklidir ve tam olarak neyin tahmin edildiği veya talep edildiği. Charles Wheelan, Naked İstatistikler çalışmasında "ABD'nin sağlığını imalat" belirsiz bir terim örneği olabilir. ABD'de imalathanenin "sağlıklı" olup olmaması tamamen terimin nasıl tanımlandığına bağlıdır. Greg Ip'nin Mart 2011 tarihli The Economist makalesi bu muğlaklığı gösteriyor. "Sağlık" metriği "üretim" çıktı," Sonra 2011'de ABD'de üretim gitgide daha sağlıklı hale geldi. Öğe "sağlık" metrik “üretim işleri” olarak tanımlanır. Ancak, ABD'de üretim düşüş gösterdi.6
Sıralamalarda çoğu zaman anlaşılmaz veya anlamsız içerikler de dahil olmak üzere benzer sorunlar yer alır sıralamanın çeşitli bileşenlerine verilen ağırlıkları, sıralama sonuçlarını tutarsızlık ve geçersiz seçenekler. The New Yorker'da yazan Malcolm Gladwell, Michigan yüksek mahkeme başkanı Thomas Brennan, yüzlerce avukat, onlardan bazıları ünlü, biri de ünlü ve kaliteli olan on hukuk fakültesini bazıları değildir. Bu avukatlar Penn State'in hukuk fakültesinde yaklaşık beşinci sırada ancak anket sırasında Penn State'te yasa yoktu öğrenin.7 İyi bilinen çoğu sıralamada benzer şekilde öznel bir bakış açısı bulunur. itibar bileşenidir. Sıralamada hangi bileşenlerin yer aldığını ve bu bileşenlerin neden dikkate alındığını sorun bileşenlerine belirli ağırlıklar atanmıştır.
Küçük sayılar ve büyük etkiler
Yazı tura atıyorsanız% 100 kafa veya% 100 kuyruk elde etmeniz şaşırtıcı değildir iki kez. Dört kez yazı tura attıktan sonra% 25'lik tura çıkmamız da şaşırtıcı değildir. %75'i sonraki dört vuruşta oyuna yöneldi. Ancak bu, daha iyi bir oyun çok büyük artış (hatalı bir şekilde, yenen bir sandviçle ilişkilendirilebilecek bir artış) arasındaki farkları belirtir. Ancak elde edilen sayı arasında, örneğin 1.000 veya 2.000'e varan bir çağrı oranı, yüzde 50'nin ise kaybolma olasılığı düşüktür.
Bir çalışmadaki ölçümün veya deneysel deneklerin sayısı genellikle ifade edilir N olarak değiştirin. Şansa bağlı olarak gerçekleşen büyük orantısal değişikliklerin, düşük N değerine sahip veri kümelerinde ve örneklerde ortaya çıkar.
Bir Veri Kartında analiz gerçekleştirirken veya veri kümesini belgelerken N. Böylece diğer kullanıcılar gürültü ve rastgeleliğin etkisini göz önünde bulundurabilir.
Model kalitesi çok sayıda örnekle ölçeklenme eğiliminde olduğundan, düşük N ise modellerin düşük kaliteli olmasına neden olur.
Ortalamaya regresyon
Benzer şekilde, şansın bazı etkisi olan her ölçüm de şu ada sahip efekt ortalama değere regresyonu. Bu, özellikle ekstrem bir ölçümden sonra ölçümün büyük olasılıkla daha az aşırı veya ortalamaya daha yakın olma, tespit edilmesi pek olası değildi. İlgili içeriği oluşturmak için kullanılan özellikle ortalamanın üzerinde veya ortalamanın altında olan gruplarda etki daha fazla olup olmadığını kontrol etmek için, bu grubun dünya genelinde en uzun veya inme riski en yüksek olan sporcuları görebilirsiniz. İlgili içeriği oluşturmak için kullanılan ortalama olarak, en uzun boylu insanların çocuklarının yaş kitlesinden daha kısa olma olasılığı yüksektir. Ebeveynler, en kötü sporcular büyük bir artışın ardından kötü mevsimdir ve inme riski en yüksek olanların riski daha az olma olasılığı yüksektir. nedensel faktörler değil, herhangi bir müdahale veya tedaviden sonra özellikleri ve olasılıkları nedeniyle ortaya çıkar.
İnceleme sırasında, regresyonun ortalama değere olan etkilerini azaltma grubu ortalamanın üzerinde veya altında olan gruplara yönelik müdahale ya da tedavilerin katılımcıları birbirinden ayırmak için bir çalışma grubu ve neden olur. Makine öğrenimi bağlamında bu fenomen, ticari marka kullanımında ekstra aşağıdaki gibi sıra dışı veya aykırı değerleri tahmin eden herhangi bir modele dikkat çekmelidir:
- aşırı hava koşulları veya sıcaklıklar
- en iyi performansı gösteren mağazaları veya sporcular
- bir web sitesindeki en popüler videolar
Bir modelin bu ara hedeflere yönelik zaman içinde ortaya çıkan olağanüstü değerler, gerçekle bir mağaza veya video aracılığıyla başarılı olmaya devam edecektir. hayır, şu soruyu sorun:
- Sorun ortalama değere regresyondan kaynaklanıyor olabilir mi?
- En yüksek ağırlıklara sahip özellikler aslında daha tahmine dayalı mı? daha düşük ağırlıklara sahip özelliklere kıyasla ne kadar önemli?
- Bu özellikler için temel değeri olan verileri topluyor mu, genellikle sıfır (etkili bir şekilde bir kontrol grubu) modelin tahminlerini nasıl değiştirir?
Referanslar
Hımm, Darrell. İstatistikler nasıl yatar? NY: W.W. Norton, 1954.
Cem, Cem. Veri Tuzaklarından Kaçınma. Hoboken, NJ: Wiley, 2020.
O'Connor, Cailin ve James Owen Weatherall. Yanlış Bilgilendirme Çağı. Yeni Liman: Yale UP, 2019.
Ringler, Adam, David Mason, Gabi Laske ve Mary Templeton. "Dalgalarım Neden Komik Görünüyor? Güvenliği İhlal Edilmiş Sismik Sinyaller Galerisi." Sizmolojik Araştırma Mektupları 92 no. 6 (Temmuz 2021). DOI: 10.1785/0220210094
Weintraub, William S, Thomas F. Lüscher ve Stuart Pocock gibi. "Vekil uç noktalarının tehlikeleri." Avrupa Kardiyoloji Dergisi 36 sayı. 33 (Eylül 2015): 2212-2218. DOI: 10.1093/eurHeartj/ehv164
Tekin, Çağrı. Açık İstatistikler: Korkuyu Verilerden Çıkarın. New York: W.W. Norton, 2013
Resim referansı
"Hayatta kalma yanlılığı." Martin Grandjean, McGeddon ve Cameron Moll 2021. CC BY-SA 4.0 Kaynak
{kind=link}
-
Özge 25-29. ↩
-
O'Connor ve Weatherall 22-3 yaş. ↩
-
Ringling ve diğerleri ↩
-
Wheelan 120. ↩
-
Siddhartha Mukherjee, "Cep Telefonları Beyin Kanserine Neden Olur mu?" yayınlanmıştır. The New York Times, 13 Nisan 2011'de yayınlanmıştır. Wheelan 122'de alıntılanmıştır.↩
-
Wheelan 39-40. ↩
-
Malcolm Gladwell, "Nesnelerin Sırası", 14 Şubat 2011'de The New Yorker'da yayınlandı. Wheelan 56'da alıntılanmıştır.↩