「種什麼就得什麼。」
— 早期程式設計實證
在每個機器學習模型下,每次計算相關性、以資料為基礎 政策建議會提供一或多個原始資料集。無論多美觀 能凸顯或強調的最終產品,前提是基礎資料 錯誤、收集錯誤或結果品質不佳 預測、資料圖表或結論 品質以視覺化方式呈現、分析及訓練模型的人員 資料集都應該詢問資料來源的棘手問題。
資料收集工具可能故障或校正不當。 收集資料的人類可能很疲累、頑皮、不一致或不太穩定 人會犯錯,而不同人員也可以合理不同意 會著重在模稜兩可的信號分類因此,品質和 會影響資料的有效性,並可能無法反映實際情況。 Ben Jones,《Avoiding Data》作者 Pitfalls 所稱的 資料取得差距、 提醒讀者:「這不是犯罪,而是遭到檢舉犯罪。這不是 流星警告數,但已記錄的流星警告數。」
資料實際情況落差範例:
Jones 圖中的時間測量在 5 分鐘內的高峰,以及 測量體重的間隔是 5 磅,並不是因為這一波激增的 然而,由於人類的資料收集器與儀器不同,因此收集者資料 四捨五入為最接近的 0 或 51。
1985 年,Joe Farman、Brian Gardiner 和 Jonathan Shanklin 任職於 英國南極調查 (BAS) 的測量結果指出 南半球上臭氧層的季節性洞。這個 但 NASA 資料卻未記錄到這個漏洞NASA 物理學家理查 Stolarski 進行調查後發現 NASA 的資料處理軟體 我們假設臭氧濃度永遠無法低於 而偵測到的臭氧濃度極低 自動脫離無感測離群值2。
樂器會有各式各樣的故障模式,有時仍會出現 收集資料Adam Ringler 等人提供一系列拼貼 檢測失敗後 (以及相應的失敗) 讀取回合數 。」3 讀數範例與實際的地震活動不相關。
對機器學習從業人員而言,瞭解以下內容至關重要:
- 資料收集的使用者
- 收集資料的方式和時間,以及收集的條件
- 測量儀器的靈敏度和狀態
- 檢測失敗與人為錯誤在某種情況下可能出現的錯誤 情境
- 人類傾向於將數字四捨五入,提供理想答案
一般來說,資料與實際情況之間 有些微差異 也稱為「真值」。 考量這項差異是做出好結論並做出正確的決定 打造健全的決策包括決定:
- 哪些問題可以透過機器學習解決
- 機器學習無法解決哪些問題
- 哪些問題還沒有足夠的高品質資料,無法透過機器學習解決。
問:如何以最最嚴格且最直觀的方式傳遞資料? 同樣重要的,哪些資料「無法」透過資料傳達?
資料有髒污
除了調查資料收集的條件外 本身可能包含 blunders、錯誤,以及空值或無效值 (例如 負重度測量值)。群眾外包的資料尤其適合 看起來很混亂使用品質不明的資料集可能導致結果不準確。
常見問題包括:
- 字串值拼寫錯誤,例如地點、物種或品牌名稱
- 單位換算、單位或物件類型不正確
- 遺漏值
- 持續分類錯誤或標示錯誤
- 數學運算超出 樂器的實際靈敏度
清理資料集通常涉及空值和遺漏值 (無論 以保留空值或取代 0),請將拼字更正為 以及修正單元和轉換次數等等更進階 計算方法是大量缺少值 資料特性 「機器學習密集」課程
,瞭解如何調查及移除這項存取權。取樣、生存偏見和代理端點問題
統計資料能夠有效地推算 完全隨機抽樣無敵生物 加上不平衡和不完整的訓練輸入內容 以及許多機器學習應用程式可能遭遇的嚴重故障狀況,包括用於 或繼續審查及協調這也會導致輪詢失敗及其他 客層群體做出錯誤的結論。除了 純粹隨機產生的樣本 成本高昂且難以取得多種解決方法,而且經濟實惠 改用 Proxy 來提供不同來源的 bias。
舉例來說,如要使用分層抽樣方法,您必須知道 。如果您認為自己是以下做法: 不正確的盛行,結果就會不正確。 同樣地,線上投票很少是來自全國人口的隨機抽樣結果 而是會由一群網際網路連線人口樣本 (通常是來自多個國家/地區) 的受訪者,且願意參與問卷調查。 此群組可能與真正的隨機樣本不同。「 意見調查也是可能的問題範例意見調查問題的答案如下: 這個模型提供具體意見 表示作答者願意表達的看法,但可能與 他們的看法
臨床健康研究人員面臨的類似問題,稱為 surrogate 端點問題。因為檢查藥物 研究人員使用替代生物標記,以判斷 但不一定使用膽固醇濃度做為代理值 心血管問題造成的心臟病發作與死亡事件的端點:如果藥物 還能降低膽固醇濃度,這麼做也能降低心血管問題的風險。 然而,關聯鏈結可能無效 原因可能與研究人員的假設不同。詳見 Weintraub 等人, "代理端點的安全機制", ,取得更多示例和詳細資料。機器學習的同等情況是 Proxy 標籤。
數學家 Abraham Wald 發現了一個現在已知的資料取樣問題 「生存偏見」。戰士回歸,並於 而非其他位置美國軍隊想新增更多盔甲 但威爾德研究團隊 建議將盔甲新增到「沒有」項目符號的區域。 他們正確地推斷出資料樣本出現偏差,因為飛機是 這些區域的破壞力太強,無法回到基地。
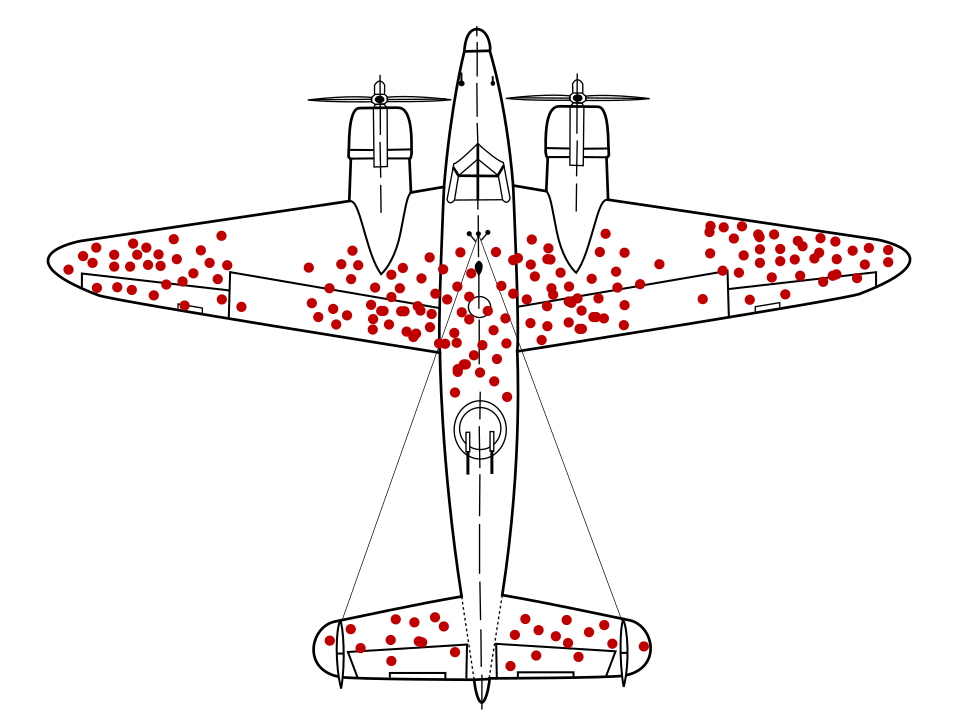
我們只訓練一個裝甲師建議模型,訓練方式僅限於傳回 在無法深入瞭解資料中存在的生存偏見的情況下, 我們的模型建議加重,增加更多項目符號
自我選擇偏見可能源自於人類志工、 參與研究誘使退休人士註冊成為退伍軍人 代表較不可能接受研究的群體 而不是一般民眾的犯罪行為。這會導致結果出現偏差4。
更細微的取樣問題是「喚回度偏見」,其中提及的「可能性」 人體實驗對象回憶1993 年,Edward Giovannucci 要求一位年齡配對的團體 女性,一些確診罹患癌症的女性,認識自己過去的飲食 習慣該女性在研究前接受過自己的飲食習慣問卷調查 癌症診斷Giovannucci 發現沒有癌症的女性 診斷結果準確喚回自己的飲食,但報告顯示患有乳癌的女性 攝取的脂肪數量比之前回報的資訊還多 - 無意識地 提供可能 (但不正確) 的癌症解釋5。
提問:
- 什麼是資料集取樣?
- 取樣分為幾個層級?
- 每個取樣層級都可能會產生哪些偏誤?
- 是否使用代理測量資料 (無論是生物標記還是線上意見調查或項目符號) 缺口) 顯示實際的關聯或因果關係?
- 樣本和取樣方法中可能會缺少什麼?
公平性模組 「機器學習密集課程」中,包含評估和緩解 客層資料集中的其他偏誤來源。
定義和排名
字詞的定義明確且精確,或詢問清楚明確的定義。 因為這是開發人員考慮考慮採用的資料功能 以及預測或聲明的內容 透過《Naked Stats》(統計統計資料) 的 Charles Wheelan,我們提供「美國健康」 製造業」做為混淆字詞的例子。美國製造業是否 「healthy」(健康狀態良好)或不完全取決於字詞的定義。葛雷格伊普 2011 年 3 月《經濟學人》文章 呈現出這種不確定性如果「健康狀態」的指標是「製造業中」 輸出」則在 2011 年,美國製造業的健康越來越健康。如果 「健康」指標的定義為「製造業工作機會」但美國製造業 等待拒絕。6
排名通常發生於類似問題,包括模糊或無意義 獲得排名和排名「排名者」各項元件的權重不一致和 選項無效。Malcolm Gladwell 在「紐約」寫字時提到 密西根最高法院首席法官 Thomas Brennan,他曾經傳送問卷調查給 數百名律師要求他們根據品質 (部分知名 有些則不是。這些律師將賓州法學院 (Penn State) 的法學院排名大約為五 但賓州在調查期間並沒有法律 校方7。許多知名排名皆包含相似主觀的排名 聲譽元件詢問系統排名要納入哪些要素,以及這些要素的顯示原因 每個元件都有專屬的權重
小數字和大型效果
想用 100% 和 100% 的尾巴並不意外 兩次。就算翻到硬幣四次後有機會拿到 25% 的人,也沒料到 接下來 4 次翻轉的頭則有 75% 的頭緒,不過這樣顯然 大幅增加 (可能誤以為食用三明治 或是其他任何虛假因素的比率但身為 的金幣翻轉數增加 30%,例如 1,000 或 2,000,大幅偏差 預估有 50% 的機率就會降低
研究中的測量或實驗科目數量通常是指 變更為 N。比例因為機率變化較高 表示在 N 較低的資料集和樣本中發生。
執行分析或記錄資料集中的資料集時,請指定 N,方便其他人考慮雜訊和隨機程度的影響。
由於模型品質通常會隨著樣本數量而調整,因此如果資料集含有 如果 N 值偏低,通常就會產生低品質模型。
以迴歸方式計算平均值
同樣地,任何因機率影響的測量指標, 稱為 。 這說明瞭在特別極端評估「之後」的評估方式 平均來說,可能出於 它不太可能一開始就進行極端測量。 如果群組的成效特別高於平均值或低於平均值,則更加清楚 獲選為觀察結果 無論該群體是否是 隊伍中最糟的運動員,或是最有中風風險的運動員。 身高最高的兒童在睡眠時通常會比 最糟糕的運動員,表現出的 季節不好,可能中風的風險最有可能降低 任何介入或治療後,並非基於果實因素,但 而是依據隨機性的屬性和機率
使用其中一個緩解措施,即可在探索階段時,迴歸對平均值的影響 對於高於平均值或低於平均值的族群, 藉此區分學習者和控制組 因果關係而造成的傷害在機器學習領域中,這種現象表示需要額外付費 並留意任何預測出例外狀況或離群值的模型,例如:
- 極端天氣或溫度
- 成效最佳商店或運動員
- 網站上最熱門的影片
如果模型持續針對這些預測結果 但長期下來的例外狀況值並不符合實際情況 非常成功的商店或影片 會問:
- 問題是否出在迴歸?
- 事實上,權重最高的特徵是否屬於更預測的 較權重較低的功能?
- 收集的資料包含那些特徵的基準值 通常為零 (實際上是控制組) 會變更模型的預測結果?
參考資料
啊,戴瑞。如何善用統計資料NY:W.W.Norton,1954。
Jones、Ben。避免資料陷入困境。Hoboken,NJ:Wiley,2020 年。
O'Connor、Cailin 和 James Owen Weatherall。不實資訊時代。紐哈芬: Yale UP,2019 年。
Ringler、Adam、David Mason、Gabi Laske 和 Mary Templeton。 「為什麼我的髮絲看起來很有趣?外洩的地震信號庫。" 生態學研究信函:92 號。6 (2021 年 7 月)。DOI:10.1785/0220210094
Weintraub、William S、Thomas F.Lüscher 和 Stuart Pocock 「代理端點的危險。」 歐洲心臟期刊,第 36 號。第 33 期 (2015 年 9 月):2212 至 2218。DOI: 10.1093/eurheartj/ehv164
Charles、Charles。雜訊統計資料:去除資料中的模糊背景紐約: W.W.Norton,2013 年
圖片參照
「存活偏見。」Martin Grandjean、McGeddon 和 Cameron Moll 2021。 CC BY-SA 4.0。資料來源
{kind=link}