Como os erros de otimização podem ser depurados e mitigados?
Resumo: se o modelo estiver com dificuldades de otimização, é importante corrigir isso antes de tentar outras coisas. Diagnosticar e corrigir falhas de treinamento é uma área de pesquisa ativa.
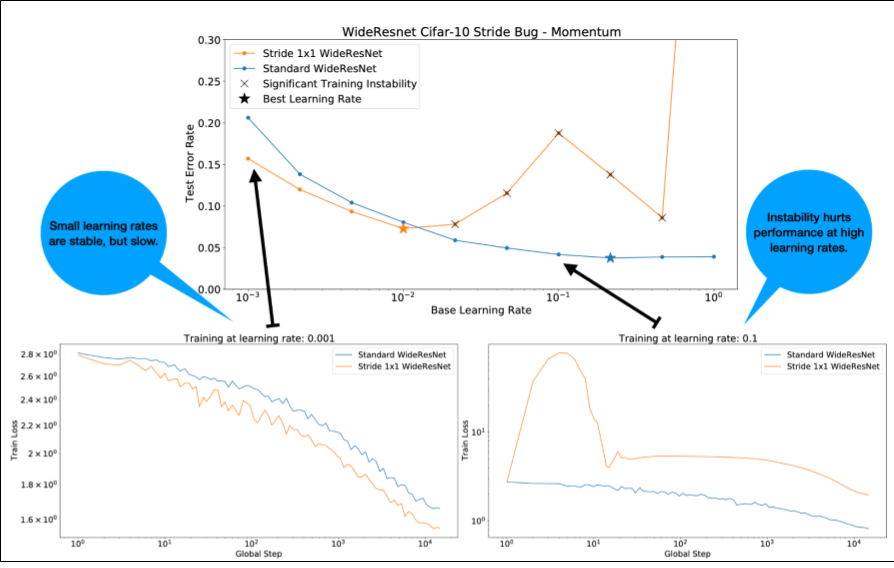
Observe o seguinte sobre a Figura 4:
- Mudar os strides não prejudica a performance com taxas de aprendizado baixas.
- As altas taxas de aprendizado não treinam mais bem devido à instabilidade.
- Aplicar 1.000 etapas de aquecimento da taxa de aprendizado resolve essa instância específica de instabilidade, permitindo um treinamento estável com uma taxa de aprendizado máxima de 0,1.
Como identificar cargas de trabalho instáveis
Qualquer carga de trabalho fica instável se a taxa de aprendizado for muito alta. A instabilidade só é um problema quando força você a usar uma taxa de aprendizado muito pequena. Vale a pena distinguir pelo menos dois tipos de instabilidade de treinamento:
- Instabilidade na inicialização ou no início do treinamento.
- Instabilidade repentina no meio do treinamento.
Para identificar problemas de estabilidade na sua carga de trabalho, faça o seguinte:
- Faça uma varredura da taxa de aprendizado e encontre a melhor taxa lr*.
- Trace curvas de perda de treinamento para taxas de aprendizado logo acima de lr*.
- Se as taxas de aprendizado > lr* mostrarem instabilidade de perda (a perda aumenta e não diminui durante os períodos de treinamento), corrigir a instabilidade geralmente melhora o treinamento.
Registre a norma L2 do gradiente de perda total durante o treinamento, já que valores discrepantes podem causar instabilidade espúria no meio do treinamento. Isso pode informar o nível de agressividade do corte de gradientes ou atualizações de peso.
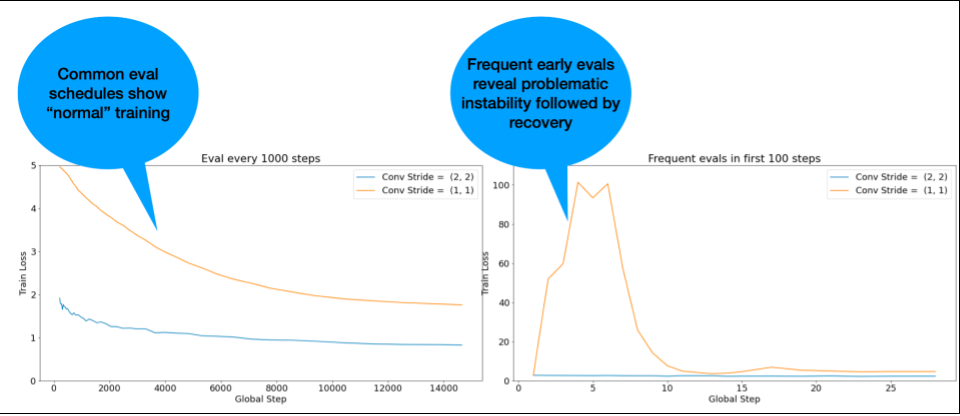
OBSERVAÇÃO: alguns modelos mostram instabilidade muito precoce seguida de uma recuperação que resulta em treinamento lento, mas estável. Os cronogramas de avaliação comuns podem perder esses problemas por não avaliarem com frequência suficiente.
Para verificar isso, treine uma execução abreviada de apenas 500 etapas usando lr = 2 * current best, mas avalie todas as etapas.
Possíveis correções para padrões comuns de instabilidade
Considere as seguintes correções possíveis para padrões comuns de instabilidade:
- Aplicar o aquecimento da taxa de aprendizado. Isso é melhor para instabilidade no início do treinamento.
- Aplique o truncamento de gradiente. Isso é bom para instabilidade no início e no meio do treinamento, e pode corrigir algumas inicializações ruins que o warmup não consegue.
- Tente usar outro otimizador. Às vezes, o Adam consegue lidar com instabilidades que o Momentum não consegue. Essa é uma área de pesquisa ativa.
- Use as práticas recomendadas e as melhores inicializações para a arquitetura do modelo (confira exemplos a seguir). Adicione conexões residuais e normalização se o modelo ainda não as tiver.
- Normalizar como a última operação antes do residual. Por exemplo:
x + Norm(f(x)). ONorm(x + f(x))pode causar problemas. - Tente inicializar ramificações residuais como 0. Consulte ReZero is All You Need: Fast Convergence at Large Depth.
- Diminua a taxa de aprendizado. Essa é uma medida de último recurso.
Aumento gradual da taxa de aprendizado
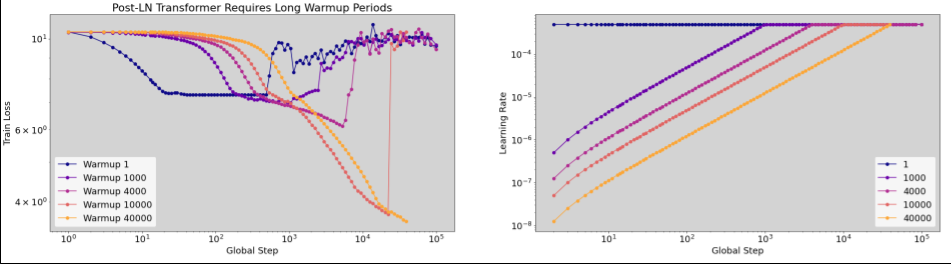
Quando aplicar o aumento gradual da taxa de aprendizado
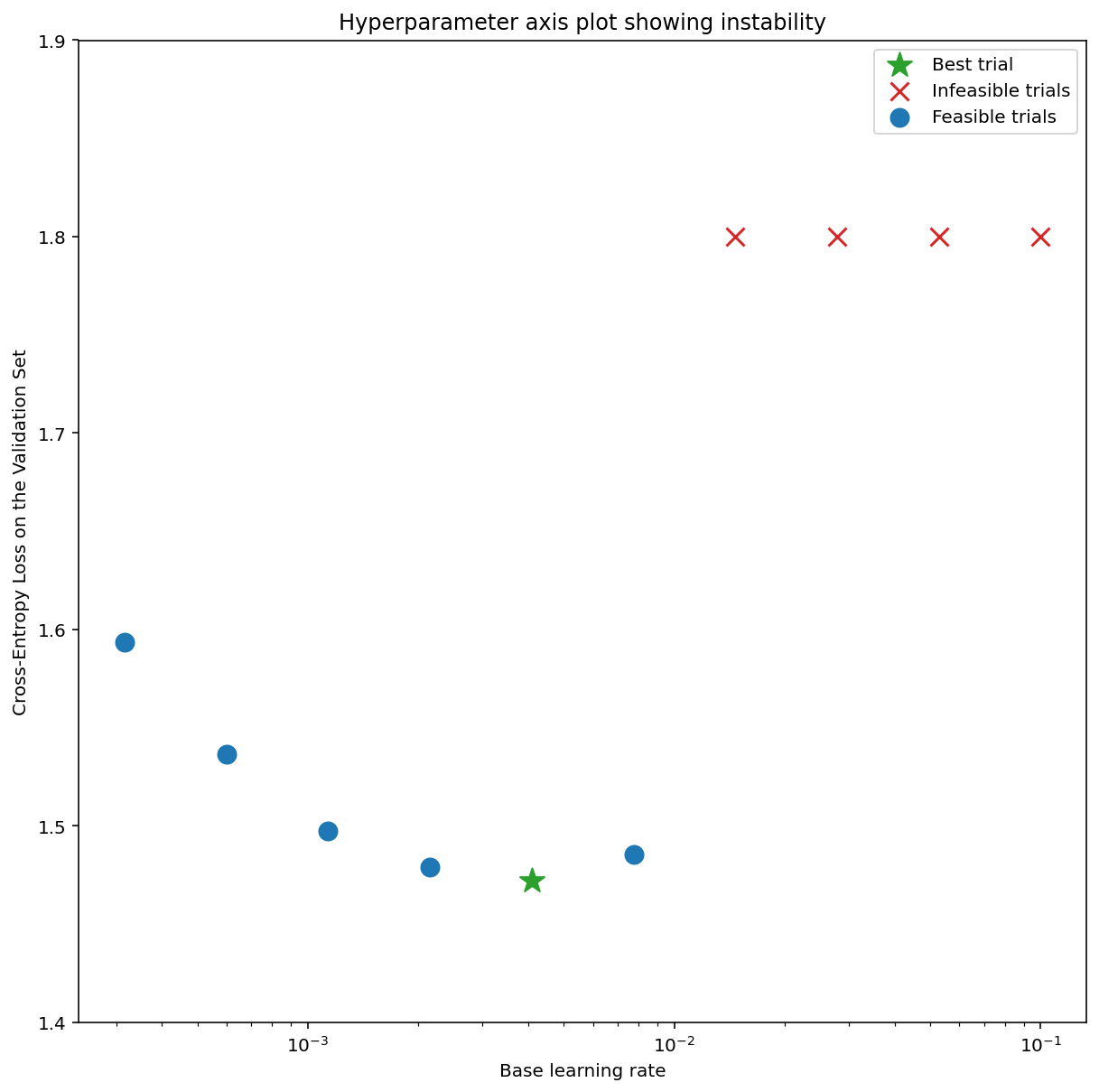
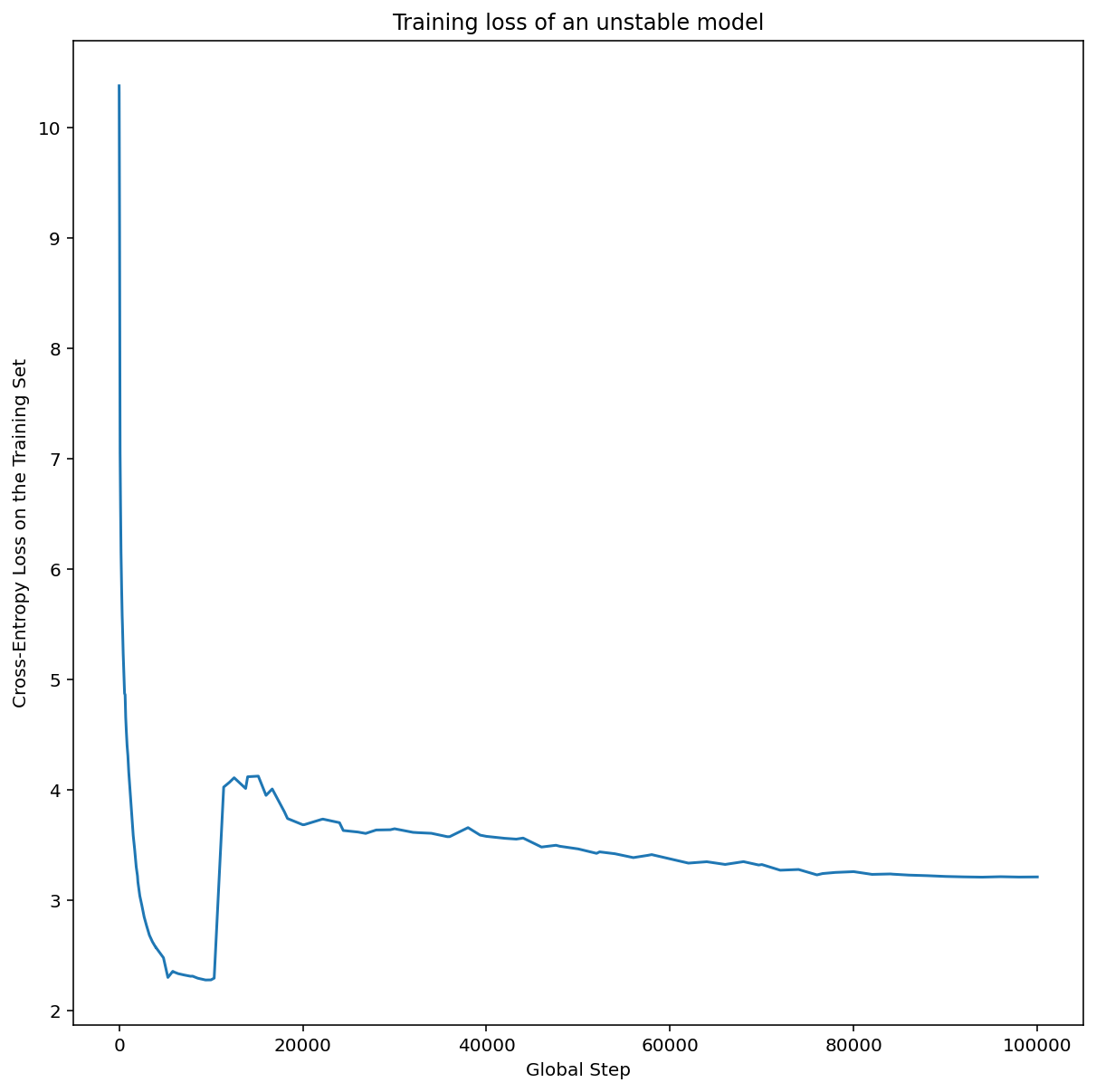
A Figura 7a mostra um gráfico de eixo de hiperparâmetros que indica um modelo com instabilidades de otimização, porque a melhor taxa de aprendizado está bem na borda da instabilidade.
A Figura 7b mostra como isso pode ser verificado examinando a perda de treinamento de um modelo treinado com uma taxa de aprendizado 5 ou 10 vezes maior que esse pico. Se esse gráfico mostrar um aumento repentino na perda após um declínio constante (por exemplo, na etapa ~10k na figura acima), é provável que o modelo sofra de instabilidade de otimização.
Como aplicar o aprendizado gradual da taxa de aprendizado
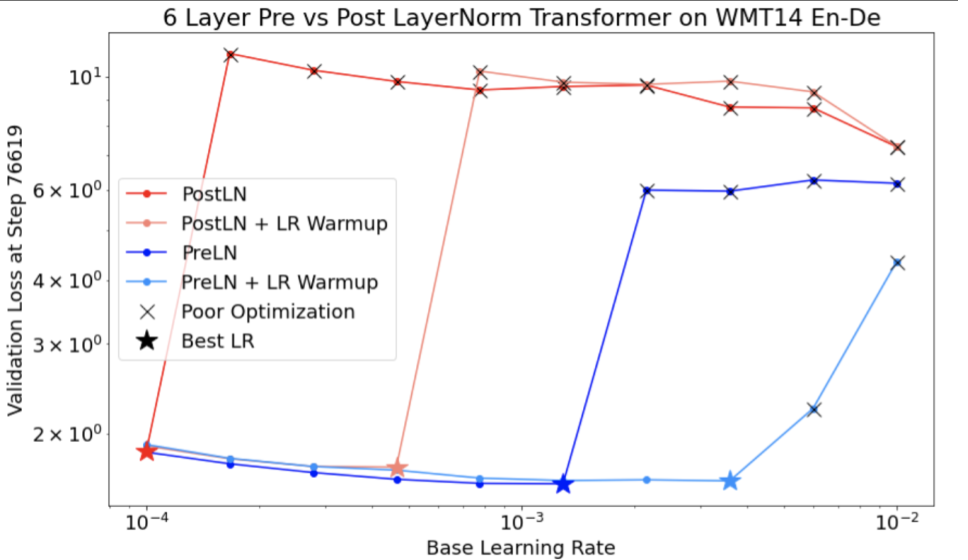
Seja unstable_base_learning_rate a taxa de aprendizado em que o modelo fica instável, usando o procedimento anterior.
O warmup envolve adicionar uma programação de taxa de aprendizado que aumenta a taxa de aprendizado de 0 para algum base_learning_rate estável, que é pelo menos uma ordem de magnitude maior que unstable_base_learning_rate.
O padrão seria tentar um base_learning_rate 10 vezes unstable_base_learning_rate. No entanto, é possível executar todo esse procedimento novamente para algo como 100x unstable_base_learning_rate. O cronograma específico é:
- Aumenta de 0 para base_learning_rate em warmup_steps.
- Treine a uma taxa constante para post_warmup_steps.
Seu objetivo é encontrar o menor número de warmup_steps que permite acessar taxas de aprendizado máximas muito maiores que unstable_base_learning_rate.
Portanto, para cada base_learning_rate, é necessário ajustar warmup_steps e post_warmup_steps. Geralmente, é bom definir post_warmup_steps como 2*warmup_steps.
O ajuste de taxa de aprendizado pode ser feito de forma independente de uma programação de decaimento. warmup_steps precisa ser varrido em algumas ordens de magnitude diferentes. Por exemplo, um estudo de caso pode tentar [10, 1000, 10,000, 100,000]. O maior ponto possível não pode ser mais de 10% de max_train_steps.
Depois que um warmup_steps que não prejudica o treinamento em base_learning_rate é estabelecido, ele precisa ser aplicado ao modelo de referência.
Basicamente, adicione essa programação à programação atual e use a seleção de checkpoint ideal discutida acima para comparar esse experimento com a linha de base. Por exemplo, se originalmente tínhamos 10.000 max_train_steps e fizemos warmup_steps por 1.000 etapas, o novo procedimento de treinamento deve ser executado por um total de 11.000 etapas.
Se forem necessários warmup_steps longos para um treinamento estável (>5% de max_train_steps), talvez seja necessário aumentar max_train_steps para considerar isso.
Não há um valor "típico" em toda a variedade de cargas de trabalho. Alguns modelos precisam de apenas 100 etapas, enquanto outros (principalmente transformadores) podem precisar de mais de 40 mil.
Truncamento de gradiente
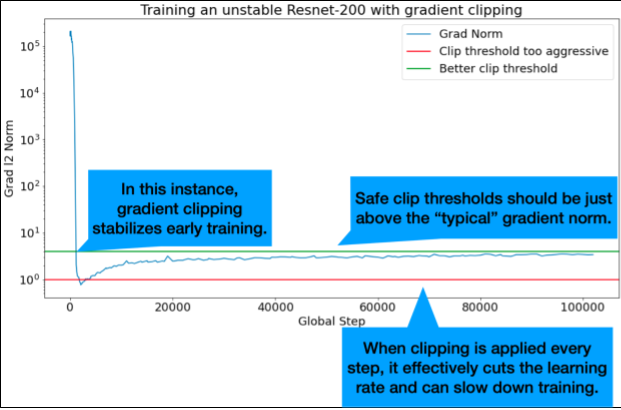
O corte de gradiente é mais útil quando ocorrem problemas de gradiente grandes ou outliers. O corte de gradiente pode corrigir qualquer um dos seguintes problemas:
- Instabilidade inicial do treinamento (norma de gradiente grande no início)
- Instabilidades durante o treinamento (picos repentinos de gradiente durante o treinamento).
Às vezes, períodos de aquecimento mais longos podem corrigir instabilidades que o corte não corrige. Para mais detalhes, consulte Aquecimento da taxa de aprendizado.
🤖 E o corte durante a introdução?
Os limites ideais de corte estão logo acima da norma de gradiente "típica".
Confira um exemplo de como o corte de gradiente pode ser feito:
- Se a norma do gradiente $\left | g \right |$ for maior que o limite de corte do gradiente $\lambda$, faça ${g}'= \lambda \times \frac{g}{\left | g \right |}$, em que ${g}'$ é o novo gradiente.
Registre a norma do gradiente sem corte durante o treinamento. Por padrão, gere:
- Um gráfico da norma do gradiente em relação à etapa
- Um histograma de normas de gradiente agregadas em todas as etapas
Escolha um limite de corte de gradiente com base no percentil 90 das normas de gradiente. O limite depende da carga de trabalho, mas 90% é um bom ponto de partida. Se 90% não funcionar, ajuste esse limite.
🤖 E uma estratégia adaptativa?
Se você tentar o corte de gradiente e os problemas de instabilidade persistirem, tente com mais intensidade, ou seja, diminua o limite.
Um truncamento de gradiente extremamente agressivo (ou seja, mais de 50% das atualizações sendo truncadas) é, na verdade, uma maneira estranha de reduzir a taxa de aprendizado. Se você estiver usando um corte muito agressivo, provavelmente é melhor reduzir a taxa de aprendizado.
Por que você chama a taxa de aprendizado e outros parâmetros de otimização de hiperparâmetros? Eles não são parâmetros de nenhuma distribuição a priori.
O termo "hiperparâmetro" tem um significado preciso no aprendizado de máquina bayesiano. Portanto, referir-se à taxa de aprendizado e à maioria dos outros parâmetros ajustáveis de aprendizado profundo como "hiperparâmetros" é, sem dúvida, um abuso da terminologia. Preferimos usar o termo "metaparâmetro" para taxas de aprendizado, parâmetros arquitetônicos e todas as outras coisas ajustáveis do aprendizado profundo. Isso porque o metaparâmetro evita a possível confusão que surge do uso incorreto da palavra "hiperparâmetro". Essa confusão é especialmente provável ao discutir a otimização bayesiana, em que os modelos de superfície de resposta probabilística têm hiperparâmetros verdadeiros próprios.
Infelizmente, embora possa ser confuso, o termo "hiperparâmetro" se tornou extremamente comum na comunidade de aprendizado profundo. Portanto, para este documento, destinado a um público amplo que inclui muitas pessoas que provavelmente não conhecem essa tecnicidade, optamos por contribuir para uma fonte de confusão no campo na esperança de evitar outra. No entanto, podemos fazer uma escolha diferente ao publicar um artigo de pesquisa, e recomendamos que outras pessoas usem "metaparâmetro" na maioria dos contextos.
Por que o tamanho do lote não deve ser ajustado para melhorar diretamente a performance do conjunto de validação?
Mudar o tamanho do lote sem alterar outros detalhes do pipeline de treinamento geralmente afeta a performance do conjunto de validação. No entanto, a diferença no desempenho do conjunto de validação entre dois tamanhos de lote geralmente desaparece se o pipeline de treinamento for otimizado de forma independente para cada tamanho de lote.
Os hiperparâmetros que interagem mais fortemente com o tamanho do lote e, portanto, são mais importantes para ajustar separadamente para cada tamanho de lote são os hiperparâmetros do otimizador (por exemplo, taxa de aprendizado, momentum) e os hiperparâmetros de regularização. Tamanhos de lote menores introduzem mais ruído no algoritmo de treinamento devido à variância da amostra. Esse ruído pode ter um efeito de regularização. Assim, tamanhos de lote maiores podem ser mais propensos a overfitting e exigir uma regularização mais forte e/ou técnicas de regularização adicionais. Além disso, talvez seja necessário ajustar o número de etapas de treinamento ao mudar o tamanho do lote.
Depois que todos esses efeitos são considerados, não há evidências convincentes de que o tamanho do lote afeta o desempenho máximo de validação possível. Para mais detalhes, consulte Shallue et al. 2018.
Quais são as regras de atualização para todos os algoritmos de otimização mais usados?
Esta seção fornece regras de atualização para vários algoritmos de otimização conhecidos.
Gradiente descendente estocástico (GDE)
\[\theta_{t+1} = \theta_{t} - \eta_t \nabla \mathcal{l}(\theta_t)\]
Em que $\eta_t$ é a taxa de aprendizado na etapa $t$.
Momentum
\[v_0 = 0\]
\[v_{t+1} = \gamma v_{t} + \nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - \eta_t v_{t+1}\]
Em que $\eta_t$ é a taxa de aprendizado na etapa $t$, e $\gamma$ é o coeficiente de momento.
Nesterov
\[v_0 = 0\]
\[v_{t+1} = \gamma v_{t} + \nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - \eta_t ( \gamma v_{t+1} + \nabla \mathcal{l}(\theta_{t}) )\]
Em que $\eta_t$ é a taxa de aprendizado na etapa $t$, e $\gamma$ é o coeficiente de momento.
RMSProp
\[v_0 = 1 \text{, } m_0 = 0\]
\[v_{t+1} = \rho v_{t} + (1 - \rho) \nabla \mathcal{l}(\theta_t)^2\]
\[m_{t+1} = \gamma m_{t} + \frac{\eta_t}{\sqrt{v_{t+1} + \epsilon}}\nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - m_{t+1}\]
ADAM
\[m_0 = 0 \text{, } v_0 = 0\]
\[m_{t+1} = \beta_1 m_{t} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)\]
\[v_{t+1} = \beta_2 v_{t} + (1 - \beta_2) \nabla \mathcal{l}(\theta_t)^2\]
\[b_{t+1} = \frac{\sqrt{1 - \beta_2^{t+1}}}{1 - \beta_1^{t+1}}\]
\[\theta_{t+1} = \theta_{t} - \alpha_t \frac{m_{t+1}}{\sqrt{v_{t+1}} + \epsilon} b_{t+1}\]
NADAM
\[m_0 = 0 \text{, } v_0 = 0\]
\[m_{t+1} = \beta_1 m_{t} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)\]
\[v_{t+1} = \beta_2 v_{t} + (1 - \beta_2) \nabla \mathcal{l} (\theta_t)^2\]
\[b_{t+1} = \frac{\sqrt{1 - \beta_2^{t+1}}}{1 - \beta_1^{t+1}}\]
\[\theta_{t+1} = \theta_{t} - \alpha_t \frac{\beta_1 m_{t+1} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)}{\sqrt{v_{t+1}} + \epsilon} b_{t+1}\]