如何调试和缓解优化失败问题?
总结:如果模型遇到优化困难,请务必先解决这些问题,然后再尝试其他方法。诊断和纠正训练失败是一个活跃的研究领域。
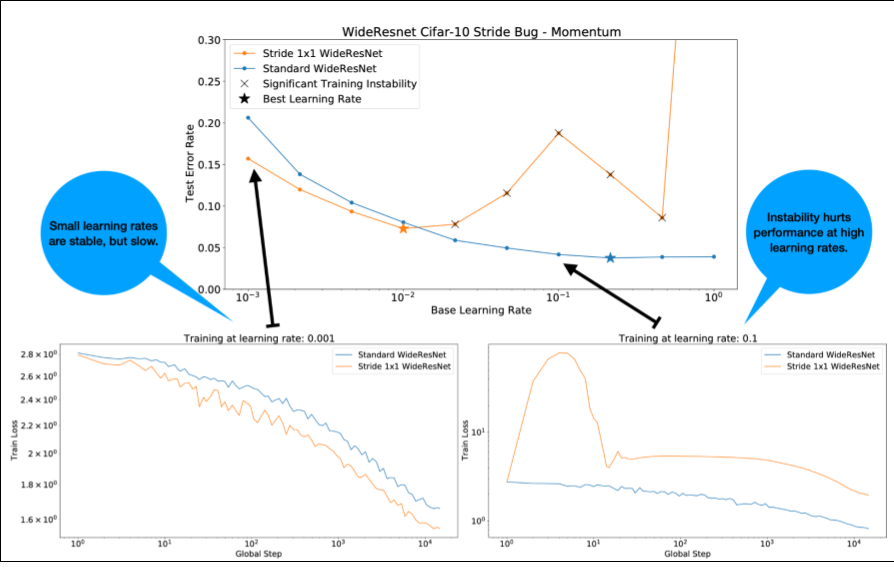
关于图 4,请注意以下几点:
- 在学习速率较低的情况下,更改步幅不会降低性能。
- 由于不稳定,高学习率不再能很好地进行训练。
- 应用 1, 000 步的学习速率预热可解决此特定不稳定实例,从而以 0.1 的最大学习速率实现稳定训练。
识别不稳定的工作负载
如果学习率过大,任何工作负载都会变得不稳定。只有当不稳定性迫使您使用过小的学习率时,它才会成为问题。至少有两种类型的训练不稳定值得区分:
- 初始化时或训练早期阶段的不稳定性。
- 训练过程中突然出现不稳定情况。
您可以采取系统性方法来识别工作负载中的稳定性问题,具体做法如下:
- 进行学习速率扫描,找到最佳学习速率 lr*。
- 绘制略高于 lr* 的学习速率的训练损失曲线。
- 如果学习率 > lr* 时出现损失不稳定(在训练期间损失不降反升),那么修复不稳定问题通常会改善训练效果。
在训练期间记录完整损失梯度 L2 范数,因为异常值可能会在训练过程中导致虚假的不稳定性。这有助于了解剪裁梯度或权重更新的程度。
注意:有些模型在早期表现出非常不稳定的状态,随后会恢复,但训练速度会变慢,不过会保持稳定。如果评估频率不够高,常见的评估时间表可能会遗漏这些问题!
为了检查是否存在这种情况,您可以使用 lr = 2 * current best 训练大约 500 个步骤,但每一步都要进行评估。
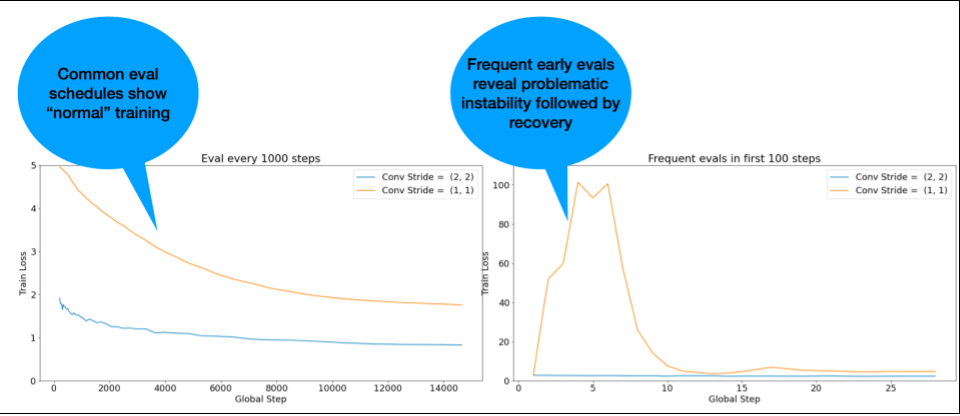
常见不稳定模式的潜在修复
请考虑以下针对常见不稳定模式的可能修复方案:
- 应用学习速率预热。这最适合早期训练不稳定情况。
- 应用梯度裁剪。这有助于解决训练初期和中期的不稳定性问题,并且可以修正预热无法解决的一些不良初始化问题。
- 尝试使用新的优化器。有时,Adam 可以处理 Momentum 无法处理的不稳定性。这是一个热门研究领域。
- 确保您为模型架构使用了最佳实践和最佳初始化(示例如下)。如果模型尚不包含残差连接和归一化,请添加它们。
- 在残差之前作为最后一次操作进行归一化。例如:
x + Norm(f(x))。请注意,Norm(x + f(x))可能会导致问题。 - 尝试将残差分支初始化为 0。(请参阅《ReZero is All You Need: Fast Convergence at Large Depth》一文。)
- 降低学习速率。这是最后的补救措施。
学习速率预热
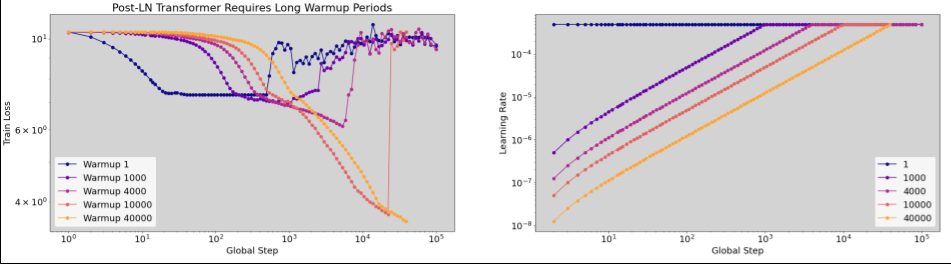
何时应用学习速率预热
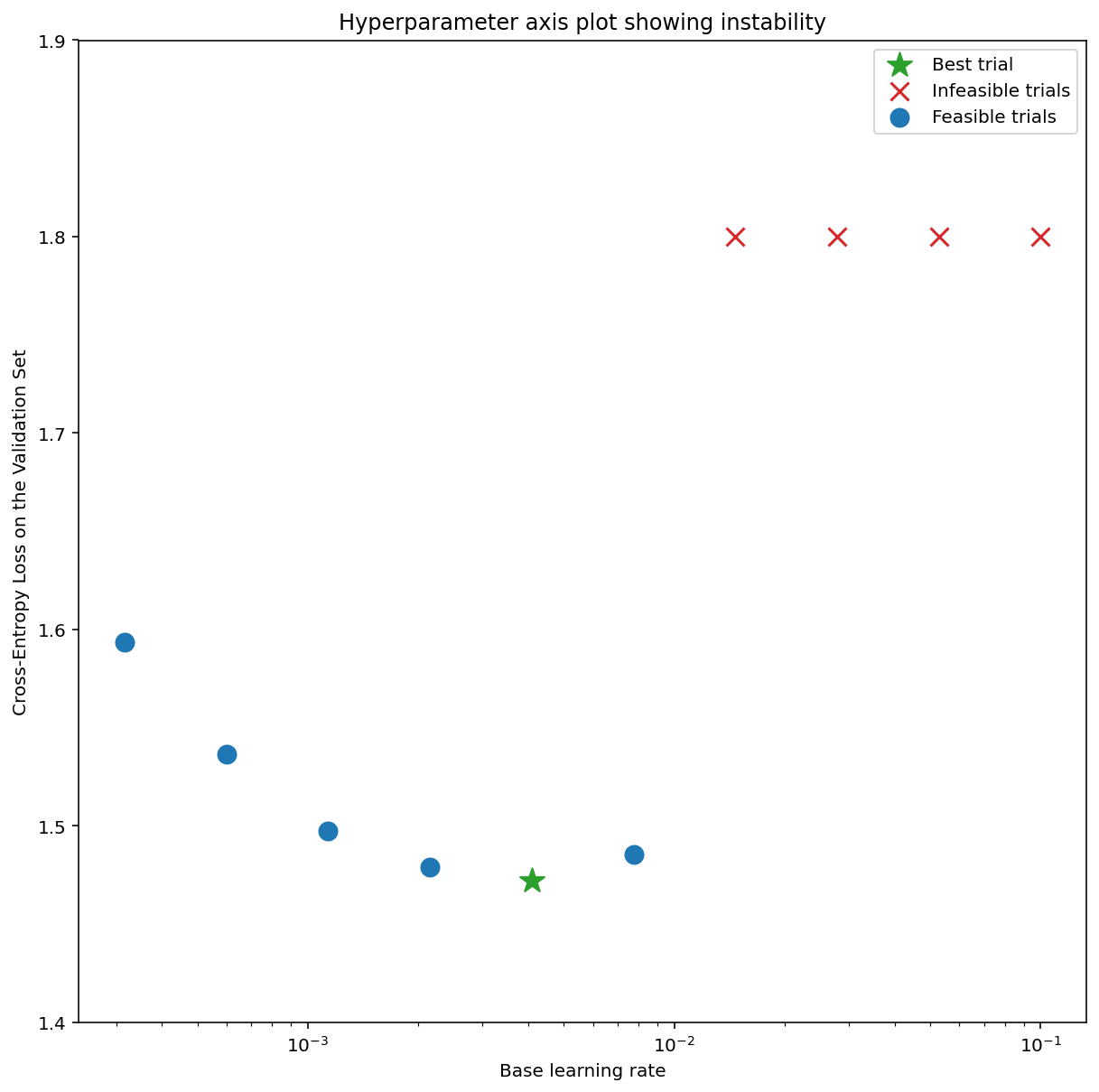
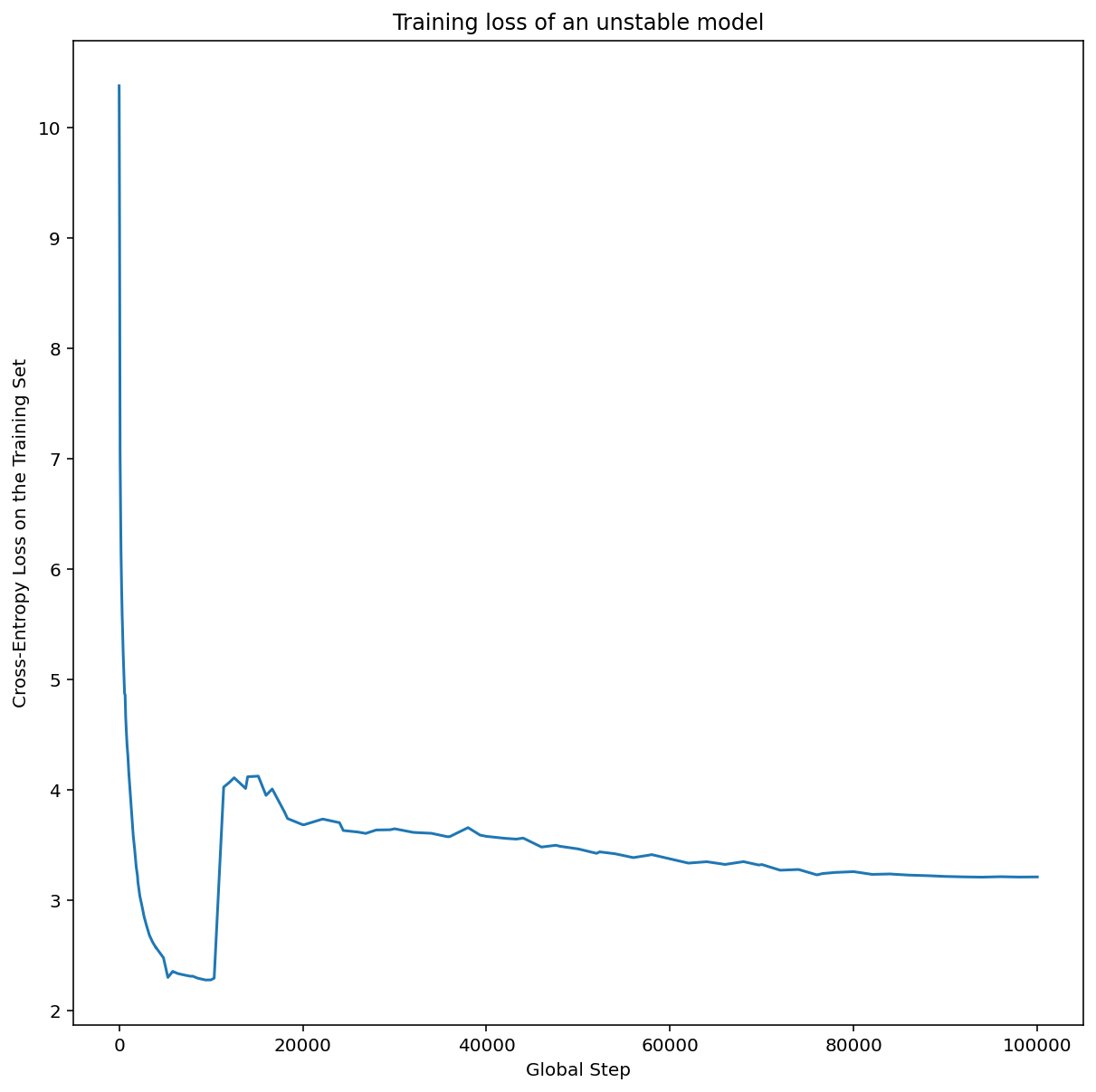
图 7a 显示了一个超参数轴图,该图表明模型遇到了优化不稳定问题,因为最佳学习率正好处于不稳定边缘。
图 7b 显示了如何通过检查以比此峰值大 5 倍或 10 倍的学习速率训练的模型的训练损失来对此进行双重检查。如果该图显示损失在稳步下降后突然上升(例如在上图中的第 1 万步左右),则模型可能存在优化不稳定问题。
如何应用学习速率预热
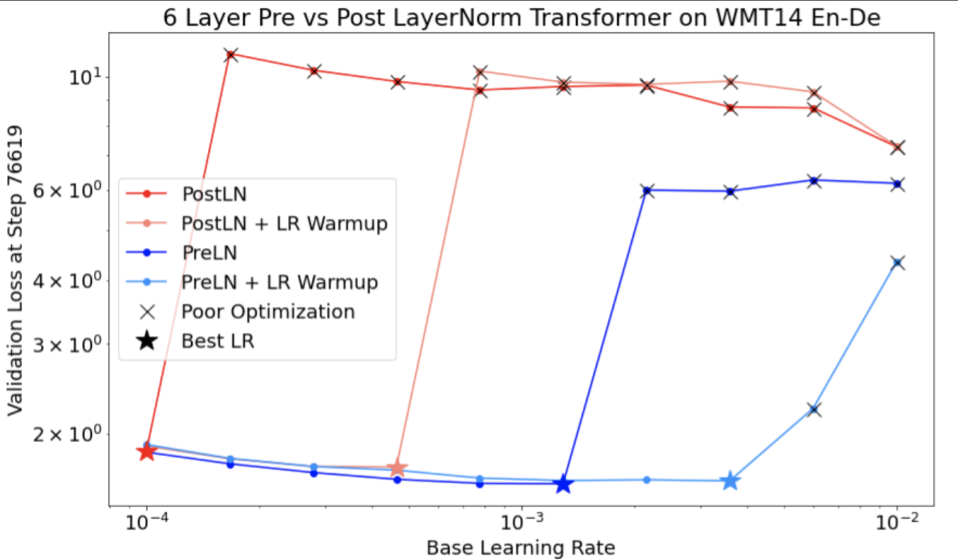
使用上述过程,令 unstable_base_learning_rate 为模型变得不稳定的学习速率。
预热是指在学习速率调度中添加一个学习速率从 0 逐渐增加到某个稳定值 base_learning_rate 的过程,该稳定值至少比 unstable_base_learning_rate 大一个数量级。默认情况下,系统会尝试使用 10 倍于 unstable_base_learning_rate 的 base_learning_rate。不过,请注意,您可以再次运行整个过程,以获得大约 100 倍的 unstable_base_learning_rate。具体时间安排如下:
- 在 warmup_steps 内从 0 线性增加到 base_learning_rate。
- 在 post_warmup_steps 期间以恒定速率进行训练。
您的目标是找到最短的 warmup_steps,以便获得远高于 unstable_base_learning_rate 的峰值学习率。
因此,对于每个 base_learning_rate,您都需要调整 warmup_steps 和 post_warmup_steps。通常情况下,将 post_warmup_steps 设置为 2*warmup_steps 即可。
预热可以独立于现有衰减时间表进行调整。warmup_steps应在几个不同的数量级上进行扫描。例如,一项研究可能会尝试 [10, 1000, 10,000, 100,000]。最大可行点不应超过 max_train_steps 的 10%。
确定不会在 base_learning_rate 时导致训练崩溃的 warmup_steps 后,应将其应用于基准模型。从本质上讲,将此时间表添加到现有时间表的前面,并使用上文讨论的最佳检查点选择方法将此实验与基准进行比较。例如,如果我们最初有 10,000 个 max_train_steps,并进行了 1,000 步的 warmup_steps,则新的训练程序应总共运行 11,000 步。
如果需要较长的 warmup_steps 才能实现稳定的训练(>5% 的 max_train_steps),您可能需要增加 max_train_steps 以解决此问题。
在整个工作负载范围内,没有真正的“典型”值。有些模型只需要 100 步,而另一些模型(尤其是 Transformer)可能需要 4 万步以上。
梯度裁剪
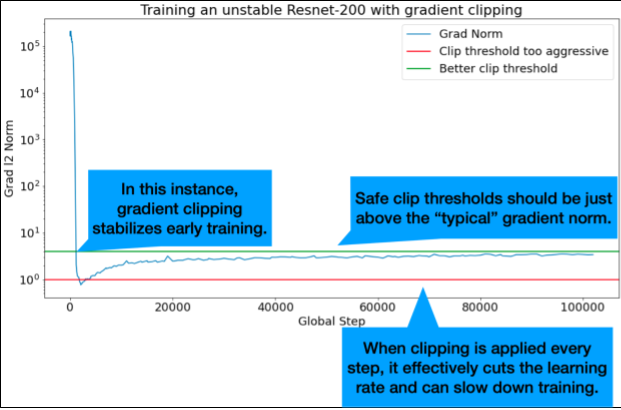
当出现梯度过大或离群梯度问题时,梯度裁剪最为有用。梯度剪裁可以解决以下任一问题:
- 早期训练不稳定(早期梯度范数较大)
- 训练期间的不稳定性(训练期间突然出现梯度峰值)。
有时,较长的预热期可以纠正剪切无法纠正的不稳定性;有关详情,请参阅学习率预热。
🤖 预热期间出现剪辑会怎么样?
理想的剪切阈值略高于“典型”梯度范数。
以下示例展示了如何进行梯度裁剪:
- 如果梯度 $\left | g \right |$ 的范数大于梯度剪裁阈值 $\lambda$,则执行以下操作:${g}'= \lambda \times \frac{g}{\left | g \right |}$,其中 ${g}'$ 是新梯度。
在训练期间记录未剪裁的梯度范数。默认情况下,生成:
- 梯度范数与步长的关系图
- 梯度范数的直方图(汇总了所有步数)
根据梯度范数的第 90 百分位选择梯度剪裁阈值。阈值取决于工作负载,但 90% 是一个不错的起点。如果 90% 不起作用,您可以调整此阈值。
🤖 那么,采用某种自适应策略呢?
如果您尝试了梯度剪裁,但不稳定性问题仍然存在,您可以尝试更严格的剪裁,即减小阈值。
极具侵略性的梯度裁剪(即超过 50% 的更新被裁剪)本质上是一种降低学习速率的奇怪方式。如果您发现自己使用了非常激进的梯度裁剪,可能应该直接降低学习率。
为什么将学习速率和其他优化参数称为超参数?它们不是任何先验分布的形参。
在贝叶斯机器学习中,“超参数”一词具有确切的含义,因此将学习速率和大多数其他可调的深度学习参数称为“超参数”可以说是滥用术语。我们更倾向于使用“元参数”一词来指代学习率、架构参数以及深度学习中所有其他可调的内容。这是因为元参数避免了因误用“超参数”一词而可能造成的混淆。在讨论贝叶斯优化时,这种混淆尤其容易发生,因为概率响应面模型有自己的真实超参数。
遗憾的是,尽管“超参数”一词可能会令人困惑,但在深度学习社区中已变得非常常见。因此,对于本文档(面向广泛的受众群体,其中包括许多不太可能了解此技术细节的人),我们选择增加一个混淆来源,希望借此避免另一个混淆来源。不过,在发表研究论文时,我们可能会做出不同的选择,并且我们建议其他人在大多数情况下使用“元形参”。
为什么不应调整批次大小来直接提升验证集性能?
更改批次大小而不更改训练流水线的任何其他细节通常会影响验证集性能。不过,如果针对每个批次大小分别优化训练流水线,那么两种批次大小之间的验证集性能差异通常会消失。
与批次大小交互最强的超参数(因此对于每个批次大小,单独调整这些超参数最为重要)是优化器超参数(例如,学习速率、动量)和正则化超参数。由于样本方差,较小的批次大小会给训练算法带来更多噪声。这种噪声可以起到正则化作用。因此,较大的批次大小更容易出现过拟合,可能需要更强的正则化和/或其他正则化技术。此外,更改批次大小时,您可能需要调整训练步数。
综合考虑所有这些效应后,没有令人信服的证据表明批次大小会影响可实现的最大验证性能。如需了解详情,请参阅 Shallue 等人的著作(2018 年)。
所有热门优化算法的更新规则是什么?
本部分提供了几种热门优化算法的更新规则。
随机梯度下降法 (SGD)
\[\theta_{t+1} = \theta_{t} - \eta_t \nabla \mathcal{l}(\theta_t)\]
其中,$\eta_t$ 是第 $t$ 步的学习速率。
造势
\[v_0 = 0\]
\[v_{t+1} = \gamma v_{t} + \nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - \eta_t v_{t+1}\]
其中,$\eta_t$ 是第 $t$ 步的学习速率,$\gamma$ 是动量系数。
Nesterov
\[v_0 = 0\]
\[v_{t+1} = \gamma v_{t} + \nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - \eta_t ( \gamma v_{t+1} + \nabla \mathcal{l}(\theta_{t}) )\]
其中,$\eta_t$ 是第 $t$ 步的学习速率,$\gamma$ 是动量系数。
RMSProp
\[v_0 = 1 \text{, } m_0 = 0\]
\[v_{t+1} = \rho v_{t} + (1 - \rho) \nabla \mathcal{l}(\theta_t)^2\]
\[m_{t+1} = \gamma m_{t} + \frac{\eta_t}{\sqrt{v_{t+1} + \epsilon}}\nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - m_{t+1}\]
ADAM
\[m_0 = 0 \text{, } v_0 = 0\]
\[m_{t+1} = \beta_1 m_{t} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)\]
\[v_{t+1} = \beta_2 v_{t} + (1 - \beta_2) \nabla \mathcal{l}(\theta_t)^2\]
\[b_{t+1} = \frac{\sqrt{1 - \beta_2^{t+1}}}{1 - \beta_1^{t+1}}\]
\[\theta_{t+1} = \theta_{t} - \alpha_t \frac{m_{t+1}}{\sqrt{v_{t+1}} + \epsilon} b_{t+1}\]
NADAM
\[m_0 = 0 \text{, } v_0 = 0\]
\[m_{t+1} = \beta_1 m_{t} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)\]
\[v_{t+1} = \beta_2 v_{t} + (1 - \beta_2) \nabla \mathcal{l} (\theta_t)^2\]
\[b_{t+1} = \frac{\sqrt{1 - \beta_2^{t+1}}}{1 - \beta_1^{t+1}}\]
\[\theta_{t+1} = \theta_{t} - \alpha_t \frac{\beta_1 m_{t+1} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)}{\sqrt{v_{t+1}} + \epsilon} b_{t+1}\]