¿Cómo se pueden depurar y mitigar las fallas de optimización?
Resumen: Si el modelo tiene dificultades para optimizarse, es importante corregirlas antes de probar otras opciones. El diagnóstico y la corrección de errores de entrenamiento son un área activa de investigación.

Ten en cuenta lo siguiente sobre la figura 4:
- Cambiar los pasos no degrada el rendimiento con tasas de aprendizaje bajas.
- Las tasas de aprendizaje altas ya no se entrenan bien debido a la inestabilidad.
- Aplicar 1,000 pasos de aumento gradual de la tasa de aprendizaje resuelve esta instancia particular de inestabilidad, lo que permite un entrenamiento estable con una tasa de aprendizaje máxima de 0.1.
Cómo identificar cargas de trabajo inestables
Cualquier carga de trabajo se vuelve inestable si la tasa de aprendizaje es demasiado alta. La inestabilidad solo es un problema cuando te obliga a usar una tasa de aprendizaje demasiado baja. Vale la pena distinguir al menos dos tipos de inestabilidad del entrenamiento:
- Inestabilidad en la inicialización o al principio del entrenamiento
- Inestabilidad repentina en el medio del entrenamiento
Para identificar los problemas de estabilidad en tu carga de trabajo de forma sistemática, haz lo siguiente:
- Realiza un análisis de la tasa de aprendizaje y encuentra la mejor tasa de aprendizaje lr*.
- Traza las curvas de pérdida del entrenamiento para las tasas de aprendizaje justo por encima de lr*.
- Si las tasas de aprendizaje > lr* muestran inestabilidad en la pérdida (la pérdida aumenta y no disminuye durante los períodos de entrenamiento), corregir la inestabilidad suele mejorar el entrenamiento.
Registra la norma L2 del gradiente de pérdida completo durante el entrenamiento, ya que los valores atípicos pueden causar inestabilidad espuria en el medio del entrenamiento. Esto puede informar qué tan agresivamente se deben recortar los gradientes o las actualizaciones de pesos.
NOTA: Algunos modelos muestran inestabilidad muy temprana, seguida de una recuperación que genera un entrenamiento lento, pero estable. Los programas de evaluación comunes pueden pasar por alto estos problemas si no evalúan con la frecuencia suficiente.
Para verificar esto, puedes entrenar para una ejecución abreviada de solo 500 pasos con lr = 2 * current best, pero evalúa cada paso.

Posibles correcciones para patrones de inestabilidad comunes
Considera las siguientes posibles soluciones para los patrones de inestabilidad comunes:
- Aplica el aumento gradual de la tasa de aprendizaje. Esta opción es mejor para la inestabilidad del entrenamiento inicial.
- Aplica el recorte de gradientes. Esto es útil para la inestabilidad tanto al principio como a la mitad del entrenamiento, y puede corregir algunas inicializaciones incorrectas que el calentamiento no puede.
- Prueba un nuevo optimizador. A veces, Adam puede controlar las inestabilidades que Momentum no puede. Esta es un área de investigación activa.
- Asegúrate de usar las prácticas recomendadas y las mejores inicializaciones para la arquitectura de tu modelo (se proporcionarán ejemplos más adelante). Agrega conexiones residuales y normalización si el modelo aún no las contiene.
- Normaliza como la última operación antes del residuo. Por ejemplo:
x + Norm(f(x))Ten en cuenta queNorm(x + f(x))puede causar problemas. - Intenta inicializar las ramas residuales en 0. (Consulta ReZero is All You Need: Fast Convergence at Large Depth).
- Reduce la tasa de aprendizaje. Esta es la última opción.
Aumento gradual de la tasa de aprendizaje

Cuándo aplicar el calentamiento de la tasa de aprendizaje

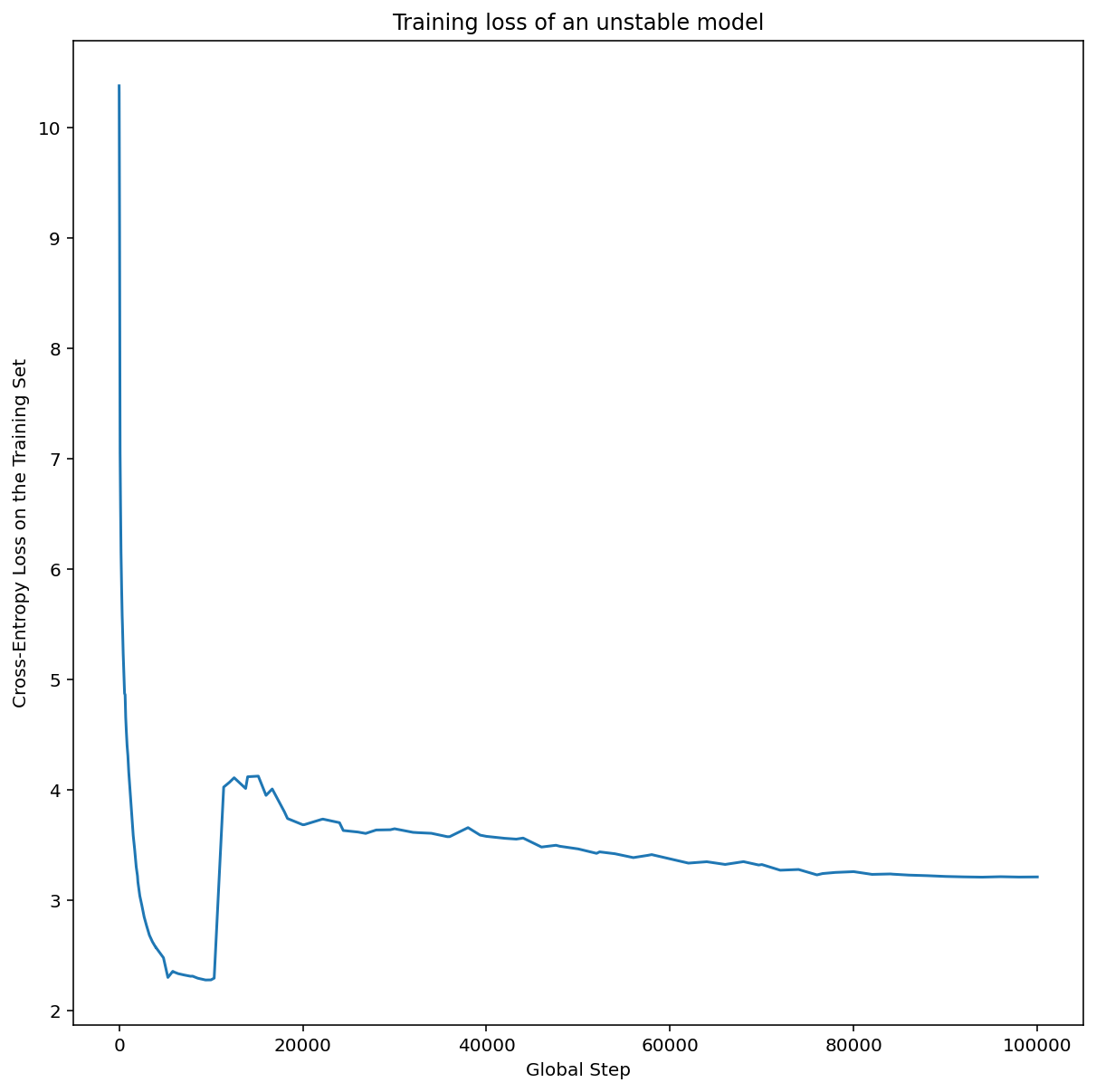
En la figura 7a, se muestra un gráfico de ejes de hiperparámetros que indica que un modelo experimenta inestabilidades de optimización, ya que la mejor tasa de aprendizaje se encuentra justo en el límite de la inestabilidad.
En la figura 7b, se muestra cómo se puede verificar esto examinando la pérdida del entrenamiento de un modelo entrenado con una tasa de aprendizaje 5 o 10 veces mayor que este pico. Si ese gráfico muestra un aumento repentino en la pérdida después de una disminución constante (p.ej., en el paso ~10 000 de la figura anterior), es probable que el modelo sufra inestabilidad en la optimización.
Cómo aplicar el calentamiento de la tasa de aprendizaje

Sea unstable_base_learning_rate la tasa de aprendizaje con la que el modelo se vuelve inestable, según el procedimiento anterior.
El calentamiento implica anteponer un programa de la tasa de aprendizaje que aumenta la tasa de aprendizaje de 0 a un valor base_learning_rate estable que es, al menos, un orden de magnitud mayor que unstable_base_learning_rate.
La opción predeterminada sería probar un base_learning_rate que sea 10 veces unstable_base_learning_rate. Sin embargo, ten en cuenta que sería posible volver a ejecutar todo este procedimiento para algo como 100 veces unstable_base_learning_rate. El programa específico es el siguiente:
- Aumenta de 0 a base_learning_rate durante warmup_steps.
- Entrena a una tasa constante para post_warmup_steps.
Tu objetivo es encontrar la menor cantidad de warmup_steps que te permita acceder a tasas de aprendizaje máximas mucho más altas que unstable_base_learning_rate.
Por lo tanto, para cada base_learning_rate, debes ajustar warmup_steps y post_warmup_steps. Por lo general, no hay problemas en establecer post_warmup_steps como 2*warmup_steps.
El período de calentamiento se puede ajustar de forma independiente a un programa de decaimiento existente. warmup_stepsdebe variar en diferentes órdenes de magnitud. Por ejemplo, un estudio de ejemplo podría probar [10, 1000, 10,000, 100,000]. El punto factible más grande no debe superar el 10% de max_train_steps.
Una vez que se establece un warmup_steps que no hace que el entrenamiento explote en base_learning_rate, se debe aplicar al modelo de referencia.
Básicamente, antepone este programa al programa existente y usa la selección óptima de puntos de control que se analizó anteriormente para comparar este experimento con el modelo de referencia. Por ejemplo, si originalmente teníamos 10,000 max_train_steps y realizamos warmup_steps durante 1,000 pasos, el nuevo procedimiento de entrenamiento debería ejecutarse durante 11,000 pasos en total.
Si se requieren warmup_steps largos para un entrenamiento estable (más del 5% de max_train_steps), es posible que debas aumentar max_train_steps para tener esto en cuenta.
En realidad, no hay un valor "típico" en todo el rango de cargas de trabajo. Algunos modelos solo necesitan 100 pasos, mientras que otros (en particular, los transformadores) pueden necesitar más de 40,000.
Recorte de gradientes

El recorte de gradiente es más útil cuando se producen problemas de gradiente grandes o atípicos. El recorte de gradiente puede solucionar cualquiera de los siguientes problemas:
- Inestabilidad en el entrenamiento inicial (norma de gradiente grande al principio)
- Inestabilidades durante el entrenamiento (aumentos repentinos del gradiente durante el entrenamiento)
En ocasiones, los períodos de entrenamiento más largos pueden corregir las inestabilidades que no corrige el recorte. Para obtener más detalles, consulta Aumento gradual de la tasa de aprendizaje.
🤖 ¿Qué sucede con el recorte durante la preparación?
Los umbrales de recorte ideales se encuentran justo por encima de la norma del gradiente “típica”.
A continuación, se muestra un ejemplo de cómo se podría realizar el recorte de gradiente:
- Si la norma del gradiente $\left | g \right |$ es mayor que el umbral de recorte del gradiente $\lambda$, entonces haz ${g}'= \lambda \times \frac{g}{\left | g \right |}$, donde ${g}'$ es el nuevo gradiente.
Registra la norma del gradiente sin recortar durante el entrenamiento. De forma predeterminada, se genera lo siguiente:
- Gráfico de la norma del gradiente en comparación con el paso
- Histograma de las normas de gradiente agregadas en todos los pasos
Elige un umbral de recorte del gradiente según el percentil 90 de las normas del gradiente. El umbral depende de la carga de trabajo, pero el 90% es un buen punto de partida. Si el 90% no funciona, puedes ajustar este umbral.
🤖 ¿Qué tal una estrategia adaptable?
Si intentas el recorte de gradiente y los problemas de inestabilidad persisten, puedes intentarlo con más fuerza, es decir, puedes reducir el umbral.
El recorte de gradientes extremadamente agresivo (es decir, más del 50% de las actualizaciones se recortan) es, en esencia, una forma extraña de reducir la tasa de aprendizaje. Si te encuentras usando un recorte extremadamente agresivo, probablemente deberías reducir la tasa de aprendizaje.
¿Por qué llamas hiperparámetros a la tasa de aprendizaje y a otros parámetros de optimización? No son parámetros de ninguna distribución a priori.
El término "hiperparámetro" tiene un significado preciso en el aprendizaje automático bayesiano, por lo que referirse a la tasa de aprendizaje y a la mayoría de los otros parámetros ajustables del aprendizaje profundo como "hiperparámetros" es, sin duda, un abuso de la terminología. Preferimos usar el término "parámetro secundario" para las tasas de aprendizaje, los parámetros arquitectónicos y todos los demás elementos ajustables del aprendizaje profundo. Esto se debe a que el metaparámetro evita la posible confusión que surge del uso incorrecto de la palabra "hiperparámetro". Esta confusión es especialmente probable cuando se analiza la optimización bayesiana, en la que los modelos de superficie de respuesta probabilística tienen sus propios hiperparámetros verdaderos.
Lamentablemente, aunque puede ser confuso, el término "hiperparámetro" se ha vuelto muy común en la comunidad del aprendizaje profundo. Por lo tanto, en este documento, que está dirigido a un público amplio que incluye a muchas personas que probablemente no conozcan este tecnicismo, decidimos contribuir a una fuente de confusión en el campo con la esperanza de evitar otra. Dicho esto, es posible que tomemos una decisión diferente cuando publiquemos un documento de investigación, y alentamos a otros a usar "parámetro secundario" en la mayoría de los contextos.
¿Por qué no se debe ajustar el tamaño del lote para mejorar directamente el rendimiento del conjunto de validación?
Cambiar el tamaño del lote sin cambiar ningún otro detalle de la canalización de entrenamiento suele afectar el rendimiento del conjunto de validación. Sin embargo, la diferencia en el rendimiento del conjunto de validación entre dos tamaños de lote suele desaparecer si la canalización de entrenamiento se optimiza de forma independiente para cada tamaño de lote.
Los hiperparámetros que interactúan con mayor intensidad con el tamaño del lote y, por lo tanto, son más importantes para ajustar por separado para cada tamaño del lote son los hiperparámetros del optimizador (por ejemplo, la tasa de aprendizaje y el momento) y los hiperparámetros de regularización. Los tamaños de lotes más pequeños introducen más ruido en el algoritmo de entrenamiento debido a la varianza de la muestra. Este ruido puede tener un efecto regularizador. Por lo tanto, los tamaños de lotes más grandes pueden ser más propensos al sobreajuste y pueden requerir una regularización más sólida o técnicas de regularización adicionales. Además, es posible que debas ajustar la cantidad de pasos de entrenamiento cuando cambies el tamaño del lote.
Una vez que se tienen en cuenta todos estos efectos, no hay evidencia convincente de que el tamaño del lote afecte el rendimiento máximo de validación alcanzable. Para obtener más detalles, consulta Shallue et al., 2018.
¿Cuáles son las reglas de actualización para todos los algoritmos de optimización populares?
En esta sección, se proporcionan reglas de actualización para varios algoritmos de optimización populares.
Descenso de gradientes estocástico (SGD)
\[\theta_{t+1} = \theta_{t} - \eta_t \nabla \mathcal{l}(\theta_t)\]
Aquí $\eta_t$ es la tasa de aprendizaje en el paso $t$.
Momentum
\[v_0 = 0\]
\[v_{t+1} = \gamma v_{t} + \nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - \eta_t v_{t+1}\]
Aquí, $\eta_t$ es la tasa de aprendizaje en el paso $t$, y $\gamma$ es el coeficiente de momentum.
Nesterov
\[v_0 = 0\]
\[v_{t+1} = \gamma v_{t} + \nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - \eta_t ( \gamma v_{t+1} + \nabla \mathcal{l}(\theta_{t}) )\]
Aquí, $\eta_t$ es la tasa de aprendizaje en el paso $t$, y $\gamma$ es el coeficiente de momentum.
RMSProp
\[v_0 = 1 \text{, } m_0 = 0\]
\[v_{t+1} = \rho v_{t} + (1 - \rho) \nabla \mathcal{l}(\theta_t)^2\]
\[m_{t+1} = \gamma m_{t} + \frac{\eta_t}{\sqrt{v_{t+1} + \epsilon}}\nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - m_{t+1}\]
ADAM
\[m_0 = 0 \text{, } v_0 = 0\]
\[m_{t+1} = \beta_1 m_{t} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)\]
\[v_{t+1} = \beta_2 v_{t} + (1 - \beta_2) \nabla \mathcal{l}(\theta_t)^2\]
\[b_{t+1} = \frac{\sqrt{1 - \beta_2^{t+1}}}{1 - \beta_1^{t+1}}\]
\[\theta_{t+1} = \theta_{t} - \alpha_t \frac{m_{t+1}}{\sqrt{v_{t+1}} + \epsilon} b_{t+1}\]
NADAM
\[m_0 = 0 \text{, } v_0 = 0\]
\[m_{t+1} = \beta_1 m_{t} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)\]
\[v_{t+1} = \beta_2 v_{t} + (1 - \beta_2) \nabla \mathcal{l} (\theta_t)^2\]
\[b_{t+1} = \frac{\sqrt{1 - \beta_2^{t+1}}}{1 - \beta_1^{t+1}}\]
\[\theta_{t+1} = \theta_{t} - \alpha_t \frac{\beta_1 m_{t+1} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)}{\sqrt{v_{t+1}} + \epsilon} b_{t+1}\]