Cet article porte sur la recherche quasi-aléatoire.
Pourquoi utiliser la recherche quasi-aléatoire ?
Nous préférons la recherche quasi-aléatoire (basée sur des séquences à faible divergence) aux outils d'optimisation de boîte noire plus sophistiqués lorsqu'elle est utilisée dans le cadre d'un processus de réglage itératif visant à maximiser les insights sur le problème de réglage (ce que nous appelons la "phase d'exploration"). L'optimisation bayésienne et les outils similaires sont plus adaptés à la phase d'exploitation. La recherche quasi-aléatoire basée sur des séquences à faible écart aléatoire peut être considérée comme une "recherche par grille mélangée et tronquée", car elle explore de manière uniforme, mais aléatoire, un espace de recherche donné et répartit les points de recherche plus que la recherche aléatoire.
Les avantages de la recherche quasi-aléatoire par rapport aux outils d'optimisation en boîte noire plus sophistiqués (par exemple, l'optimisation bayésienne, les algorithmes évolutionnaires) sont les suivants:
- L'échantillonnage non adaptatif de l'espace de recherche permet de modifier l'objectif de réglage dans l'analyse post-hoc sans avoir à réexécuter les tests. Par exemple, nous souhaitons généralement trouver le meilleur essai en termes d'erreur de validation obtenue à tout moment de l'entraînement. Toutefois, la nature non adaptative de la recherche quasi-aléatoire permet de trouver le meilleur essai en fonction de l'erreur de validation finale, de l'erreur d'entraînement ou d'une autre métrique d'évaluation sans réexécuter les tests.
- La recherche quasi-aléatoire se comporte de manière cohérente et statistiquement reproductible. Il devrait être possible de reproduire une étude datant de six mois, même si l'implémentation de l'algorithme de recherche change, à condition qu'elle conserve les mêmes propriétés d'uniformité. Si vous utilisez un logiciel d'optimisation bayésienne sophistiqué, l'implémentation peut changer de manière importante d'une version à l'autre, ce qui rend la reproduction d'une ancienne recherche beaucoup plus difficile. Il n'est pas toujours possible de revenir à une ancienne implémentation (par exemple, si l'outil d'optimisation est exécuté en tant que service).
- Son exploration uniforme de l'espace de recherche permet de raisonner plus facilement sur les résultats et sur ce qu'ils peuvent suggérer sur l'espace de recherche. Par exemple, si le meilleur point de la traversée de la recherche quasi-aléatoire se trouve à la limite de l'espace de recherche, c'est un bon signal (mais pas infaillible) que les limites de l'espace de recherche doivent être modifiées. Toutefois, un algorithme d'optimisation adaptative en boîte noire peut avoir négligé le milieu de l'espace de recherche en raison de quelques essais infructueux au début, même s'il contient des points tout aussi intéressants. En effet, c'est exactement ce type d'inhomogénéité qu'un bon algorithme d'optimisation doit utiliser pour accélérer la recherche.
- Exécuter différents nombres d'essais en parallèle ou de manière séquentielle ne produit pas de résultats statistiquement différents lorsque vous utilisez une recherche quasi-aléatoire (ou d'autres algorithmes de recherche non adaptatifs), contrairement aux algorithmes adaptatifs.
- Les algorithmes de recherche plus sophistiqués ne gèrent pas toujours correctement les points non réalisables, en particulier s'ils ne sont pas conçus pour le réglage des hyperparamètres de réseau de neurones.
- La recherche quasi-aléatoire est simple et fonctionne particulièrement bien lorsque de nombreux essais de réglage sont exécutés en parallèle. De manière anecdotique1, il est très difficile pour un algorithme adaptatif de battre une recherche quasi aléatoire dont le budget est deux fois supérieur, en particulier lorsque de nombreux essais doivent être exécutés en parallèle (et qu'il y a donc très peu de chances d'utiliser les résultats des essais précédents lors du lancement de nouveaux essais). Sans expertise en optimisation bayésienne et dans d'autres méthodes d'optimisation avancées de boîte noire, vous risquez de ne pas bénéficier des avantages qu'elles sont, en principe, capables de fournir. Il est difficile de comparer des algorithmes d'optimisation avancés en boîte noire dans des conditions de réglage du deep learning réalistes. Il s'agit d'un domaine de recherche très actif, et les algorithmes les plus sophistiqués comportent leurs propres écueils pour les utilisateurs inexpérimentés. Les experts de ces méthodes peuvent obtenir de bons résultats, mais dans des conditions de parallélisme élevé, l'espace de recherche et le budget ont tendance à avoir beaucoup plus d'importance.
Toutefois, si vos ressources de calcul ne permettent d'exécuter qu'un petit nombre d'essais en parallèle et que vous pouvez vous permettre d'exécuter de nombreux essais en séquence, l'optimisation bayésienne devient beaucoup plus attrayante, même si elle rend les résultats de votre réglage plus difficiles à interpréter.
Où puis-je trouver une implémentation de la recherche quasi-aléatoire ?
Vizier Open Source propose une implémentation de la recherche quasi-aléatoire.
Définissez algorithm="QUASI_RANDOM_SEARCH" dans cet exemple d'utilisation de Vizier.
Une autre implémentation existe dans cet exemple de balayage des hyperparamètres.
Ces deux implémentations génèrent une séquence Halton pour un espace de recherche donné (destiné à implémenter une séquence Halton décalée et brouillée, comme recommandé dans Critical Hyper-Parameters: No Random, No Cry).
Si un algorithme de recherche quasi-aléatoire basé sur une séquence à faible écart n'est pas disponible, il est possible de remplacer la recherche uniforme pseudo-aléatoire, bien que cela soit probablement un peu moins efficace. En une ou deux dimensions, la recherche par grille est également acceptable, mais pas dans des dimensions supérieures. (voir Bergstra et Bengio, 2012).
Combien d'essais sont nécessaires pour obtenir de bons résultats avec la recherche quasi-aléatoire ?
Il n'est pas possible de déterminer le nombre d'essais nécessaires pour obtenir des résultats avec une recherche quasi-aléatoire en général, mais vous pouvez examiner des exemples spécifiques. Comme le montre la figure 3, le nombre d'essais dans une étude peut avoir un impact important sur les résultats:
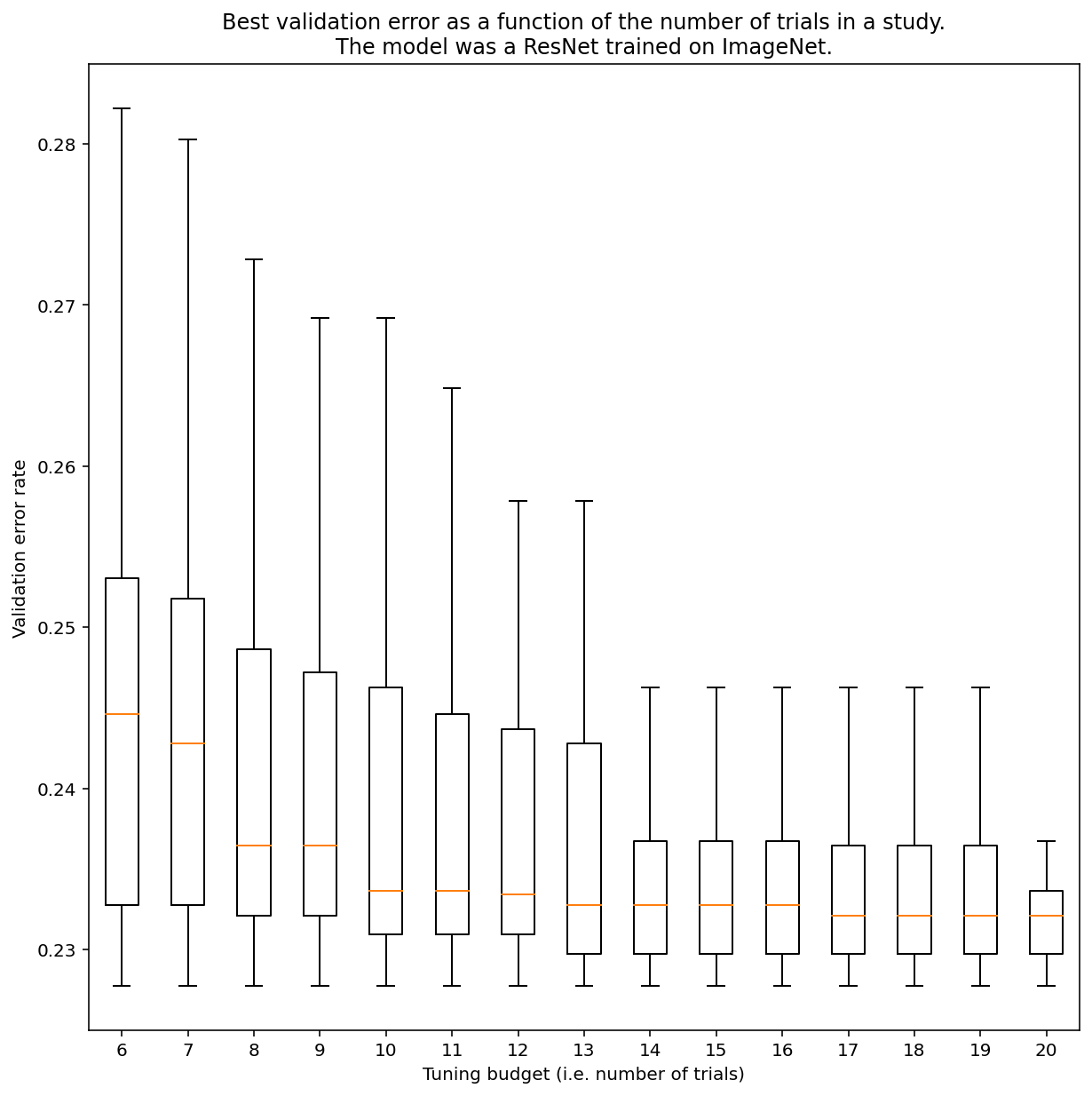
Figure 3:ResNet-50 affiné sur ImageNet avec 100 essais. À l'aide du bootstrapping, différentes quantités de budget de réglage ont été simulées. Les boîtes à moustaches des meilleures performances pour chaque budget d'essai sont représentées.
Notez les points suivants concernant la figure 3:
- Les intervalles interquartiles lorsque six essais ont été échantillonnés sont beaucoup plus importants que lorsque 20 essais ont été échantillonnés.
- Même avec 20 essais, la différence entre les études particulièrement chanceuses et celles qui ne le sont pas est probablement plus importante que la variation typique entre les réentraînements de ce modèle sur différents nombres aléatoires, avec des hyperparamètres fixes, qui pour cette charge de travail peut être d'environ +/- 0,1% pour un taux d'erreur de validation d'environ 23%.
-
Ben Recht et Kevin Jamieson ont fait remarquer que la recherche aléatoire avec un budget multiplié par deux est très efficace comme référence (l'article Hyperband présente des arguments similaires), mais il est certainement possible de trouver des espaces de recherche et des problèmes où les techniques d'optimisation bayésienne de pointe écrasent la recherche aléatoire avec un budget multiplié par deux. Toutefois, d'après notre expérience, il est beaucoup plus difficile de battre la recherche aléatoire à double budget dans le régime de parallélisme élevé, car l'optimisation bayésienne n'a pas la possibilité d'observer les résultats des essais précédents. ↩